
Kata Kunci:model bahasa besar, evaluasi AI, sistem multi-agen, kemampuan penalaran, pemrosesan konteks, model sumber terbuka, pembuatan video AI, pemrograman AI, evaluasi kemampuan penalaran LLM, Claude Opus 4 membantah makalah Apple, model MiniMax-M1 MoE, model pemrograman Kimi-Dev-72B, fitur Gemini Deep Think
🔥 Fokus
Makalah Apple yang mempertanyakan kemampuan penalaran model besar dibantah, makalah yang ditulis bersama Claude menunjukkan kelemahan desain eksperimen: Apple baru-baru ini menerbitkan makalah “The Illusion of Thought”, yang melalui pengujian masalah klasik seperti Menara Hanoi dan dunia balok, menunjukkan bahwa model bahasa besar (LLM) utama berkinerja buruk pada tugas penalaran kompleks, pada dasarnya adalah pencocokan pola, bukan pemahaman sejati. Namun, peneliti independen Alex Lawsen bersama dengan model AI Claude Opus 4 menerbitkan artikel sanggahan berjudul “‘The Illusion of Thought’ Itself is an Illusion”, berpendapat bahwa eksperimen Apple memiliki kelemahan desain: 1. Tidak mempertimbangkan batas atas output Token LLM, yang menyebabkan model dinilai salah karena tidak dapat menghasilkan langkah-langkah yang sangat panjang secara lengkap; 2. Beberapa kasus uji (seperti beberapa “masalah menyeberangi sungai”) secara matematis tidak memiliki solusi dalam kondisi yang diberikan, ketidakmampuan AI untuk memberikan “jawaban yang benar” bukanlah karena kurangnya kemampuan; 3. Mengubah metode evaluasi, seperti meminta model untuk menghasilkan program pemecahan masalah alih-alih langkah-langkah lengkap, maka AI menunjukkan kinerja yang sangat baik. Insiden ini memicu diskusi luas tentang kemampuan penalaran LLM yang sebenarnya dan metodologi evaluasi, menyoroti pentingnya merancang skema evaluasi yang masuk akal, dan mengingatkan para developer untuk memperhatikan faktor-faktor seperti jendela konteks, anggaran output, dan perumusan tugas yang memengaruhi kinerja model dalam aplikasi praktis. (Sumber: Xin Zhiyuan, Big Data Digest)
Peta jalan AI Google terungkap, mengisyaratkan arsitektur AI generasi berikutnya mungkin akan meninggalkan mekanisme atensi saat ini: Logan Kilpatrick, Product Lead Google, mengungkapkan arah pengembangan model Gemini di masa depan pada AI Engineer World Fair, dengan yang paling menarik perhatian adalah visi untuk mencapai “konteks tak terbatas”. Dia menunjukkan bahwa dengan mekanisme atensi dan cara pemrosesan konteks saat ini, konteks tak terbatas yang sesungguhnya tidak dapat dicapai, mengisyaratkan bahwa Google mungkin sedang meneliti arsitektur inti AI yang benar-benar baru. Peta jalan tersebut juga mencakup: kemampuan full-modality (sudah mendukung gambar + audio, video adalah tahap berikutnya), eksperimen awal Diffusion, kemampuan Agent secara default (pemanggilan dan penggunaan alat kelas satu, model secara bertahap berkembang menjadi agen cerdas), kemampuan penalaran yang terus berkembang, dan peluncuran lebih banyak model kecil. Rangkaian rencana ini menunjukkan bahwa Google secara aktif mendorong evolusi AI dari respons pasif menjadi agen cerdas proaktif, dan berkomitmen untuk menembus hambatan teknis yang ada, terutama dalam pemrosesan konteks, yang berpotensi memimpin perubahan besar dalam arsitektur AI. (Sumber: Xin Zhiyuan)
Sakana AI merilis ALE-Agent, mengalahkan 98% kontestan manusia dalam kompetisi pemrograman NP-hard: Sakana AI, yang didirikan bersama oleh salah satu penulis Transformer, Llion Jones, bekerja sama dengan platform kompetisi pemrograman Jepang AtCoder untuk meluncurkan ALE-Bench (Algorithm Engineering Benchmark), yang berfokus pada evaluasi kemampuan penalaran jangka panjang dan pemrograman kreatif AI pada masalah NP-hard (seperti perencanaan jalur, penjadwalan tugas). ALE-Agent yang dikembangkannya, berdasarkan Gemini 2.5 Pro, menggabungkan petunjuk pengetahuan domain dan strategi pencarian ruang solusi yang beragam, menunjukkan kinerja luar biasa dalam kompetisi heuristik AtCoder, menempati peringkat ke-21 (2% teratas), melampaui sejumlah besar developer manusia papan atas. Ini menandai kemajuan penting AI dalam memecahkan masalah optimasi kompleks, yang memiliki arti penting untuk aplikasi praktis seperti logistik dan perencanaan produksi. Meskipun ALE-Agent berkinerja sangat baik pada algoritma seperti simulated annealing, masih ada ruang untuk perbaikan dalam debugging, analisis kompleksitas, dan menghindari kesalahan optimasi. (Sumber: Xin Zhiyuan, SakanaAILabs, hardmaru)
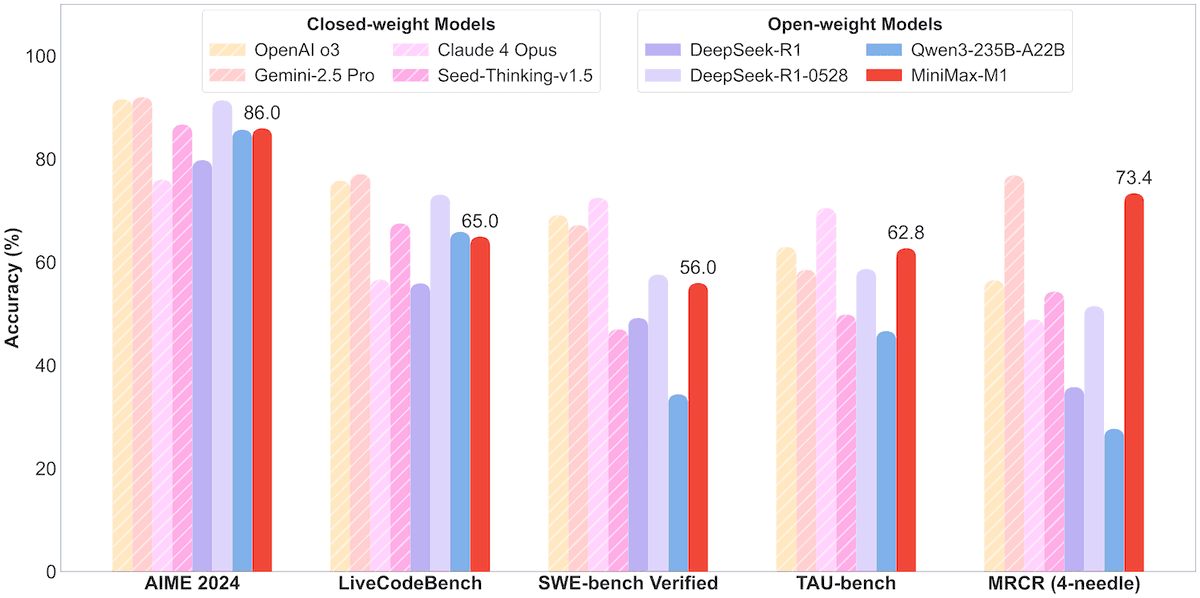
MiniMax merilis model MoE MiniMax-M1 dengan parameter 456B, mendukung konteks jutaan dan output 80 ribu Token: Perusahaan MiniMax merilis model inferensi Mixture of Experts (MoE) skala besar open-source pertamanya, MiniMax-M1. Model ini memiliki skala parameter 45,6 miliar, dengan setiap Token mengaktifkan 4,59 miliar parameter, dan mengadopsi arsitektur yang menggabungkan MoE dengan Lightning Attention. M1 secara native mendukung panjang konteks 1 juta Token dan dapat mencapai output 80 ribu Token yang terdepan di industri, termasuk versi dengan anggaran pemikiran 40k dan 80k. Dalam benchmark untuk rekayasa perangkat lunak, penggunaan alat, dan tugas konteks panjang, M1 berkinerja lebih baik daripada model seperti DeepSeek-R1 dan Qwen3-235B, terutama dalam penggunaan alat Agent (seperti TAU-bench) dengan hasil yang menonjol. Tahap reinforcement learning-nya hanya menggunakan 512 unit H800 selama tiga minggu, dengan biaya sekitar $537.400. Model M1 telah tersedia secara gratis di aplikasi dan web MiniMax, serta melalui layanan API. (Sumber: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, Zhidongxi)
🎯 Perkembangan
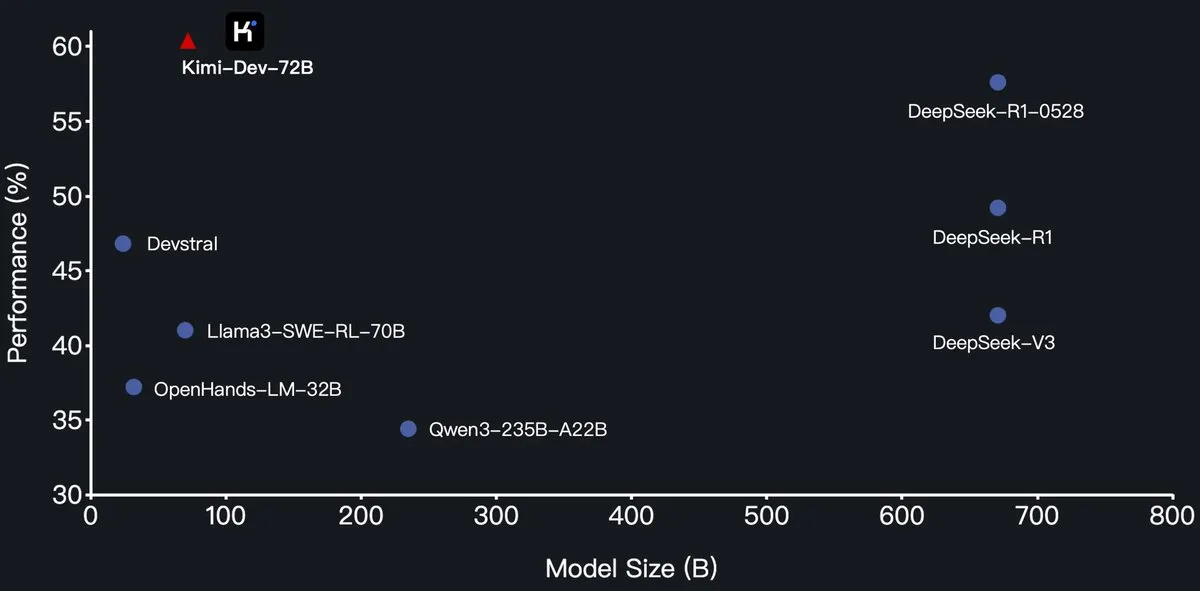
Moonshot AI merilis model besar pemrograman Kimi-Dev-72B secara open-source, melampaui DeepSeek-R1 di SWE-Bench: Moonshot AI (Moonshot AI) merilis model bahasa besar pemrograman open-source barunya, Kimi-Dev-72B, yang di-fine-tune berdasarkan Qwen2.5-72B. Disebutkan bahwa Kimi-Dev-72B mencapai tingkat penyelesaian 60,4% pada benchmark SWE-bench Verified, melampaui model seperti DeepSeek-R1-0528 (57,6%) dan Qwen3-235B-A22B, menjadi salah satu model open-source terkemuka. Model ini dilatih dengan reinforcement learning, berfokus pada perbaikan repositori kode nyata di lingkungan Docker, dan hanya mendapatkan reward ketika seluruh rangkaian pengujian berhasil dilewati. Kepala R&D Qwen menyatakan tidak memberikan otorisasi, tetapi penggunaan lisensi MIT oleh Kimi untuk merilis versi fine-tuned sesuai dengan ketentuan. (Sumber: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
Seri model Qwen3 menambahkan dukungan format MLX, mengoptimalkan inferensi pada chip Apple: Tim Tongyi Qianwen Alibaba mengumumkan bahwa seri model Qwen3 kini mendukung format MLX, dan menyediakan empat tingkat kuantisasi: 4bit, 6bit, 8bit, dan BF16. Langkah ini bertujuan untuk mengoptimalkan efisiensi operasional model pada framework MLX Apple, memudahkan developer untuk melakukan deployment dan inferensi lokal pada perangkat Mac. Pengguna dapat memperoleh model terkait di HuggingFace dan ModelScope. (Sumber: ClementDelangue, stablequan, jeremyphoward)

Google Gemini akan segera meluncurkan fitur “Deep Think”, meningkatkan kemampuan penanganan masalah kompleks: Google sedang bersiap untuk memperkenalkan fitur baru bernama “Deep Think” untuk model Gemini 2.5 Pro-nya. Fitur ini bertujuan untuk menangani masalah yang lebih menantang dengan menyediakan kemampuan komputasi tambahan, terutama dalam tugas terkait matematika, di mana Deep Think diperkirakan akan meningkatkan kinerja hingga 15% dibandingkan dengan Gemini 2.5 Pro versi reguler. Fitur ini akan muncul sebagai opsi baru di toolbar, dan proses penanganannya mungkin memerlukan beberapa menit. Sementara itu, antarmuka pengguna Gemini juga akan mendapatkan pembaruan. (Sumber: op7418)
Model generasi video Google Veo 3 resmi diluncurkan, diperluas ke lebih dari 70 pasar: Google mengumumkan bahwa model generasi video AI-nya, Veo 3, telah resmi diluncurkan untuk pelanggan AI Pro dan Ultra, mencakup lebih dari 70 pasar di seluruh dunia. Veo 3 menarik perhatian karena efek video yang dihasilkannya realistis dan kreatif. Sebelumnya, pengguna telah memanfaatkannya untuk membuat konten ASMR seperti “memotong buah yang viral” yang telah ditonton puluhan juta kali di media sosial, menunjukkan potensinya di bidang pembuatan konten. Peluncuran resmi ini akan memungkinkan lebih banyak pengguna untuk merasakan dan memanfaatkan Veo 3 untuk pembuatan video. (Sumber: Google, Xin Zhiyuan)
Hugging Face bekerja sama dengan Groq, menyediakan layanan inferensi LLM berkecepatan tinggi: Hugging Face mengumumkan kemitraan dengan perusahaan chip AI Groq untuk mengintegrasikan LPU™ (Language Processing Unit) Groq ke dalam Hugging Face Playground dan API. Pengguna sekarang dapat langsung merasakan layanan inferensi LLM yang dipercepat oleh perangkat keras Groq di platform Hugging Face, mendukung berbagai model termasuk Llama 4 dan Qwen 3. Langkah ini bertujuan untuk menyediakan opsi inferensi model AI yang lebih cepat dan efisien bagi para developer, terutama cocok untuk membangun agent, asisten, dan aplikasi AI real-time. (Sumber: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub menambahkan fitur filter ukuran model, membantu developer memilih model yang sesuai: Platform Hugging Face meluncurkan fitur baru yang memungkinkan pengguna untuk memfilter berdasarkan ukuran model (Size Range), terutama untuk model yang berjalan pada framework mlx / mlx-lm. Peningkatan ini bertujuan untuk membantu developer menemukan model yang sesuai dengan kebutuhan perangkat keras dan kinerja spesifik mereka dengan lebih mudah, menekankan bahwa model yang lebih besar tidak selalu lebih baik, dan model khusus yang lebih kecil seringkali lebih optimal dalam skenario tertentu. (Sumber: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

Pembaruan NVIDIA NCCL, mulai menggunakan akumulasi FP32 untuk operasi reduksi pada input presisi setengah: Versi terbaru NVIDIA Collective Communications Library (NCCL) (commit 72d2432) memperkenalkan pembaruan penting: saat memproses operasi reduksi (reduction ops) pada input presisi setengah (seperti FP16, BF16), mulai menggunakan FP32 untuk akumulasi. Perubahan ini sangat penting untuk menjaga presisi komputasi dan mencegah overflow, terutama dalam pelatihan terdistribusi skala besar. Versi ini diharapkan akan terintegrasi dalam PyTorch 2.8 dan versi yang lebih baru. (Sumber: StasBekman)

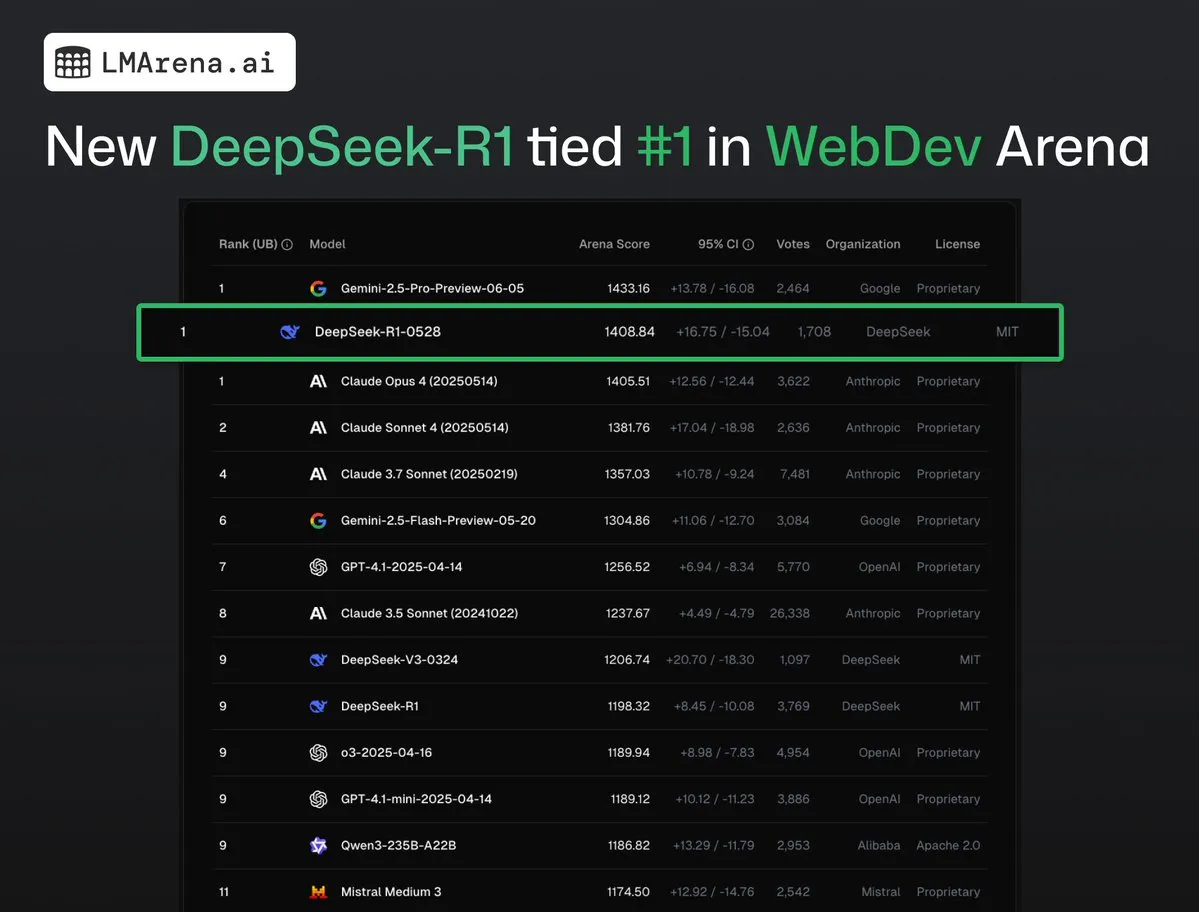
DeepSeek-R1 (0528) berada di peringkat pertama bersama Claude Opus 4 di WebDev Arena: Data terbaru dari lmarena.ai menunjukkan bahwa DeepSeek-R1 (0528) versi baru berkinerja sangat baik dalam benchmark WebDev Arena, berada di peringkat pertama bersama Claude Opus 4. Model ini menempati peringkat keenam secara keseluruhan di Text Arena, peringkat kedua dalam kemampuan pemrograman, peringkat keempat dalam prompt sulit, peringkat kelima dalam kemampuan matematika, dan merupakan model open-source berlisensi MIT dengan kinerja terbaik di papan peringkat. Ini menandai daya saing kuat DeepSeek dalam tugas pengembangan dan penalaran tertentu. (Sumber: ClementDelangue, zizhpan)
ByteDance meluncurkan model gambar Seedream 3.0 dan model video Seedance 1.0 Lite di platform Poe: Alat kreasi AI milik ByteDance meluncurkan pembaruan di platform Poe luar negeri, dengan merilis model generasi gambar Seedream 3.0 dari Jmeng AI dan model generasi video Seedance 1.0 Lite. Seedream 3.0 bertujuan untuk menghasilkan gambar yang jelas dan hidup, sedangkan Seedance 1.0 Lite dapat dengan cepat menghasilkan video dengan efek dinamis yang realistis. Pengguna dapat terlebih dahulu menggunakan Seedream untuk menghasilkan gambar di Poe, kemudian mengubahnya menjadi video dengan menyebutkan @-Seedance, mewujudkan alur kerja kreasi gambar-ke-video yang berkelanjutan. (Sumber: op7418)

Tencent meluncurkan model menyanyi Levo, mendukung pemisahan trek dan kloning timbre zero-shot: Tencent merilis model menyanyi AI bernama Levo, yang diklaim kinerjanya sebanding dengan Suno V3.5. Levo mendukung fungsi pemisahan trek audio dan kloning timbre zero-shot. Dari demo dan skor yang dirilis, kinerjanya sangat baik. Kemajuan ini menunjukkan kekuatan Tencent di bidang generasi musik AI. (Sumber: karminski3)
OpenAI meluncurkan fitur generasi gambar ChatGPT di WhatsApp: OpenAI mengumumkan bahwa pengguna sekarang dapat menggunakan fitur generasi gambar ChatGPT melalui layanan 1-800-ChatGPT di WhatsApp. Pembaruan ini memungkinkan kelompok pengguna yang lebih luas untuk dengan mudah menghasilkan gambar AI langsung di aplikasi pesan instan. (Sumber: gdb, eliza_luth, iScienceLuvr)
SpatialLM diperbarui ke versi 1.1, meningkatkan kemampuan pemahaman dan rekonstruksi adegan 3D: Model penalaran spasial SpatialLM merilis versi 1.1. Versi baru ini mendukung berbagai mode sumber input, termasuk generasi teks-ke-3D (Text-to-3D), rekonstruksi video dari kamera genggam, data point cloud LiDAR (seperti LiDAR iPhone Pro), dan pengambilan sampel mesh sintetis. Fitur utama termasuk penanganan yang kuat terhadap point cloud tidak terstruktur, bahkan jika data pemindaian 3D tidak lengkap, rekonstruksi yang masuk akal masih dapat dilakukan. Selain itu, versi baru mengoptimalkan deteksi zero-shot untuk input aliran video, meningkatkan akurasi estimasi tata letak dalam ruangan, dan meningkatkan efek deteksi objek 3D. Skenario aplikasi luas, mencakup rekonstruksi adegan AR, pemahaman spasial robot, alur kerja desain 3D, dan aplikasi kamera sisi konsumen. (Sumber: karminski3)
GitHub Copilot meluncurkan paket $39 per bulan, mengintegrasikan Claude Opus 4 dan berbagai model besar lainnya: GitHub Copilot menambahkan paket langganan baru seharga $39 per bulan. Paket ini tidak hanya menyediakan fungsi asisten pengkodean, tetapi juga memungkinkan pengguna mengakses berbagai model bahasa yang kuat termasuk Claude Opus 4, o3, dan GPT-4.5, serta dapat menggunakan Coding agent. Langkah ini bertujuan untuk memberikan pengalaman pemrograman berbantuan AI yang lebih komprehensif kepada para developer. (Sumber: dotey)
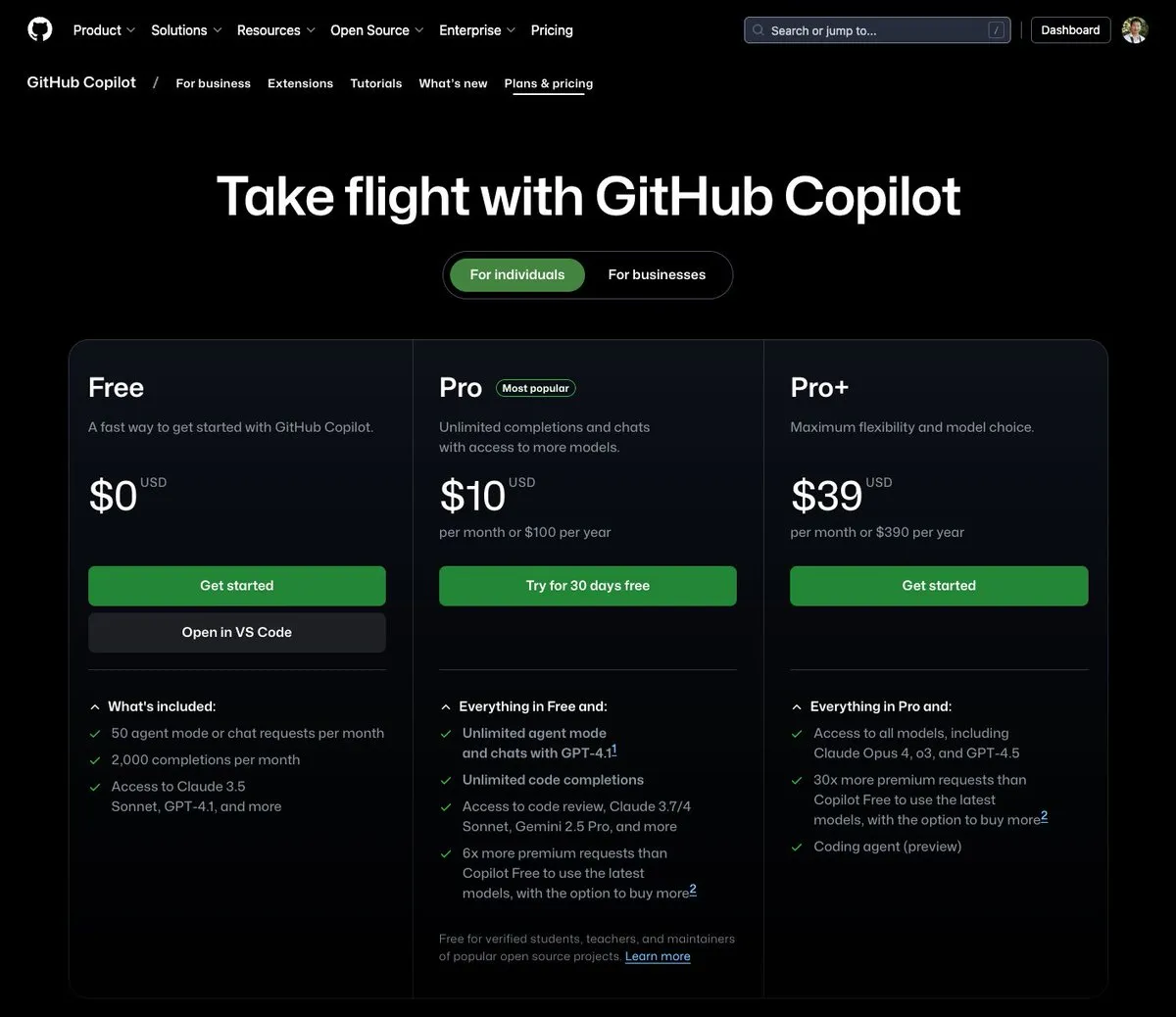
Biaya pemanggilan model besar AI terus menurun, harga seri Doubao 1.6 turun lagi 63%: Volcano Engine merilis seri model besar Doubao 1.6 pada Konferensi Force Dynamics dan mengumumkan bahwa biaya komprehensifnya telah berkurang sebesar 63%. Untuk rentang panjang input 0-32K yang umum digunakan oleh sebagian besar perusahaan, harganya adalah 0,8 yuan per juta token input dan 8 yuan untuk output. Ini menandai eskalasi berkelanjutan dalam perang harga model besar, setelah Alibaba Qianwen menurunkan biayanya menjadi 1/10 dari DeepSeek R1 pada bulan Maret tahun ini. Biaya rendah akan semakin mendorong implementasi dan adopsi aplikasi seperti AI Agent. (Sumber: ByteDance Must Win Again)
Alat akselerasi generasi video Chipmunk diperbarui, mendukung arsitektur multi-GPU dan lebih banyak model open-source: Alat Chipmunk dari tim Dan Fu mendapatkan pembaruan, kini mendukung akselerasi lossless generasi video 1,4-3 kali pada berbagai arsitektur GPU NVIDIA (sm_80, sm_89, sm_90, seperti A100s, 4090s, H100s). Sementara itu, Chipmunk menambahkan dukungan untuk lebih banyak model video open-source seperti Mochi dan Wan, serta menyediakan tutorial integrasi. Alat ini memanfaatkan sparsity nilai aktivasi dalam model video (hanya 5-25% nilai aktivasi yang berkontribusi lebih dari 90% output) untuk mencapai akselerasi, tanpa perlu melatih ulang model. (Sumber: realDanFu)

🧰 Alat
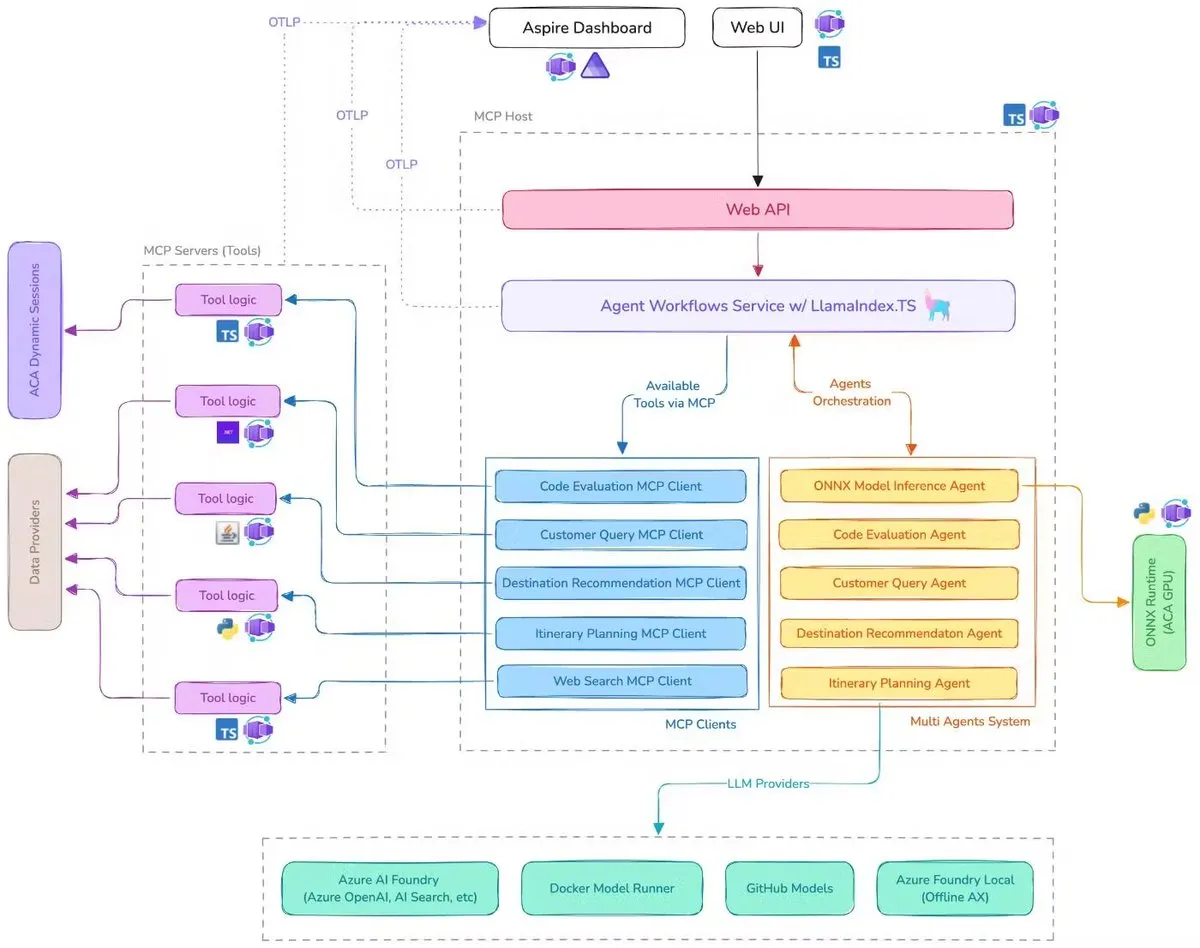
Microsoft merilis Demo Asisten Perjalanan AI, mengintegrasikan MCP, LlamaIndex.TS, dan Azure AI Foundry: Microsoft mendemonstrasikan Demo Asisten Perjalanan AI. Sistem ini mengoordinasikan beberapa agen AI (termasuk klasifikasi kueri, rekomendasi tujuan, perencanaan perjalanan, dan enam agen khusus lainnya) untuk bersama-sama menyelesaikan tugas perencanaan perjalanan yang kompleks melalui Model Context Protocol (MCP), LlamaIndex.TS, dan Azure AI Foundry. Setiap agen memperoleh data real-time dan alat melalui server MCP yang ditulis dalam Java, .NET, Python, dan TypeScript. Aplikasi ini menunjukkan bagaimana multi-agen tingkat perusahaan dapat bekerja sama melalui layanan mikro multi-bahasa, memanfaatkan model Azure OpenAI dan GitHub untuk menyediakan kemampuan AI, dan dapat mencapai deployment tanpa server yang dapat diskalakan melalui Azure Container Apps. (Sumber: jerryjliu0, jerryjliu0)
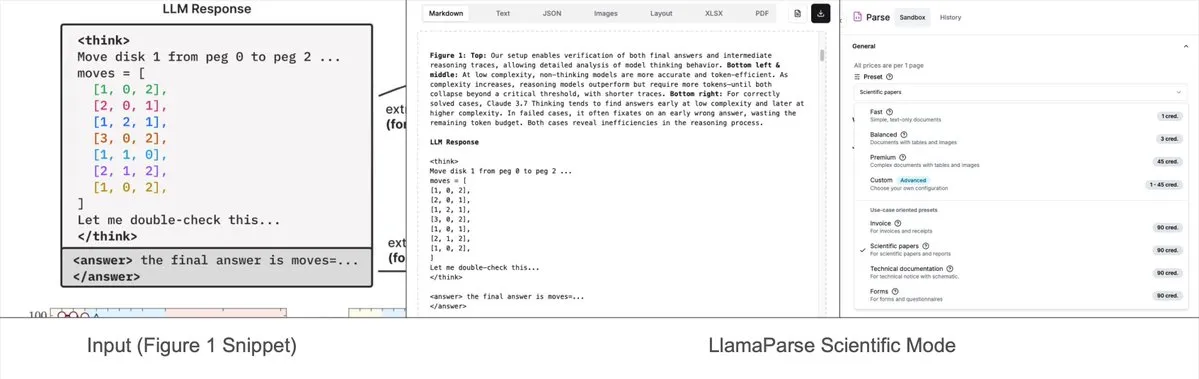
LlamaParse menambahkan mode prasetel, dapat mengurai diagram kompleks menjadi Mermaid atau Markdown: Alat LlamaParse dari LlamaIndex baru-baru ini diperbarui dengan menambahkan “mode prasetel” (preset-modes), yang memungkinkannya untuk mengurai diagram kompleks dalam dokumen seperti laporan penelitian (misalnya, diagram dengan banyak kurva dan anotasi), dan mengubahnya menjadi diagram Mermaid atau tabel Markdown yang terformat. Fungsi ini membantu menangkap konteks lengkap dari halaman, dan teks terstruktur yang dihasilkan dapat digunakan untuk membangun alur RAG atau untuk ekstraksi metadata lebih lanjut. (Sumber: jerryjliu0)
Prompt Optimizer: Alat optimasi untuk membantu menulis prompt berkualitas tinggi: Prompt Optimizer adalah alat yang dirancang untuk membantu pengguna menulis prompt AI yang lebih baik, sehingga meningkatkan kualitas output AI. Alat ini mendukung bentuk aplikasi web dan ekstensi Chrome, menyediakan optimasi cerdas, perbaikan iteratif multi-putaran, perbandingan prompt asli dan yang dioptimalkan, integrasi multi-model (OpenAI, Gemini, DeepSeek, Zhipu AI, SiliconFlow, dll.), konfigurasi parameter lanjutan, dan penyimpanan terenkripsi lokal. Alat ini menggunakan pemrosesan murni sisi klien, memastikan keamanan dan privasi data. (Sumber: GitHub Trending)

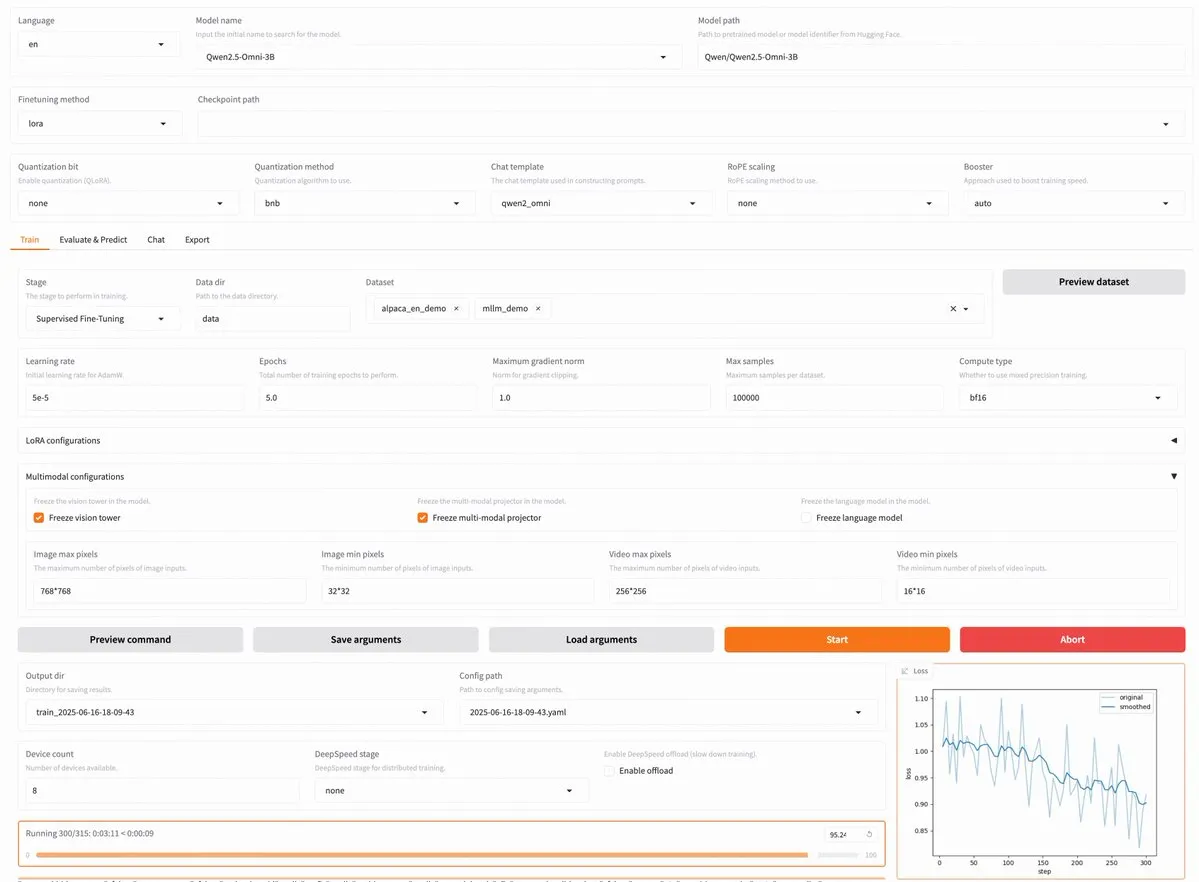
LLaMA Factory v0.9.3 dirilis, mendukung fine-tuning tanpa kode untuk hampir 300 model termasuk Qwen3, Llama 4: LLaMA Factory merilis versi v0.9.3. Versi ini adalah platform fine-tuning tanpa kode yang sepenuhnya open-source dengan antarmuka pengguna Gradio, cocok untuk hampir 300+ model, termasuk Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni terbaru, dan lainnya. Pengguna dapat menginstalnya secara lokal melalui image Docker, atau mencobanya di Hugging Face Spaces, Google Colab, serta cloud GPU Novita. (Sumber: _akhaliq)
Nanonets OCR: Model OCR SOTA berbasis Qwen 2.5 VL 3B dirilis secara open-source: Nanonets merilis model OCR baru dengan parameter 3B—Nanonets OCR. Model ini berbasis backbone Qwen 2.5 VL 3B, kinerjanya melampaui Mistral OCR API, dan dirilis dengan lisensi Apache 2.0. Model ini mampu menangani berbagai tugas OCR seperti pengenalan LaTeX, deteksi watermark dan tanda tangan, serta ekstraksi tabel kompleks. (Sumber: huggingface)
Perplexity Labs disebut dapat menggantikan berbagai posisi profesional, memicu diskusi tentang kemampuan alat AI: Seorang pengguna, GREG ISENBERG, mengklaim telah menggunakan Perplexity Labs untuk menggantikan pekerjaan lima posisi: tenaga penjualan, copywriter, sutradara film, manajer media sosial, dan analis keuangan, berpendapat bahwa kemampuan alat AI “benar-benar gila”. CEO Perplexity, Arav Srinivas, me-retweet dan berkomentar bahwa ini adalah salah satu video terbaik yang menunjukkan bagaimana agen AI dapat diterapkan dalam kasus penggunaan kehidupan nyata, membandingkan Perplexity Labs dengan alat lain di pasar dalam analisis keuangan, pemasaran media sosial, pengarahan kreatif, dan penjualan. Hal ini menyoroti potensi AI Agent dalam mengintegrasikan dan melaksanakan tugas profesional multi-bidang. (Sumber: AravSrinivas, AravSrinivas)
Claude-Flow merilis pembaruan besar v1.0.50, mengaktifkan “mode kawanan” untuk meningkatkan efisiensi otomatisasi kode: Claude-Flow, sistem agen paralel batch berbasis Claude Code, merilis versi v1.0.50. Versi baru ini memperkenalkan “mode kawanan” (Swarm Mode), yang memungkinkan pengguna untuk secara bersamaan menghasilkan, mengelola, dan mengoordinasikan ratusan agen Claude yang bekerja secara paralel, untuk membangun, menguji, mendeploy, atau siklus penelitian multi-tahap. Disebutkan bahwa peningkatan kinerja mencapai 20 kali lipat dibandingkan dengan otomatisasi Claude Code sekuensial tradisional. Developer dapat melakukan inisialisasi melalui npx claude-flow@latest init --sparc --force. (Sumber: Reddit r/ClaudeAI)

📚 Pembelajaran
Awesome Machine Learning: Daftar sumber daya machine learning yang komprehensif: Proyek “awesome-machine-learning” di GitHub adalah daftar framework, library, dan perangkat lunak machine learning yang dikurasi dengan cermat, diklasifikasikan berdasarkan bahasa pemrograman. Proyek ini juga berisi tautan ke buku machine learning gratis, acara profesional, kursus online, buletin blog, dan pertemuan lokal, menyediakan navigasi yang berharga bagi pembelajar dan praktisi machine learning. (Sumber: GitHub Trending)
Anthropic dan Cognition AI masing-masing menerbitkan artikel blog tentang pembangunan sistem multi-agen, LangChain membuat ringkasan: Anthropic dan Cognition AI baru-baru ini masing-masing merilis artikel blog tentang membangun (atau tidak membangun) sistem multi-agen. Anthropic membagikan pengalaman mereka dalam membangun sistem penelitian multi-agen mereka, sementara Cognition AI mengajukan pandangan “jangan membangun multi-agen”. Harrison Chase dari LangChain merangkum hal ini, menunjukkan bahwa meskipun pandangan mereka tampak berbeda di permukaan, kedua artikel tersebut memiliki banyak kesamaan dalam pedoman dan saran, dan menghubungkannya dengan upaya LangChain dalam bidang multi-agen. (Sumber: hwchase17, Hacubu)
Makalah “Recent Advances in Speech Language Models: A Survey” diterima di konferensi utama ACL 2025: Makalah tinjauan model bahasa ucapan (SpeechLM) berjudul “Recent Advances in Speech Language Models: A Survey” yang ditulis oleh tim dari The Chinese University of Hong Kong telah diterima di konferensi utama ACL 2025. Makalah ini adalah tinjauan sistematis komprehensif pertama di bidang ini, yang menganalisis secara mendalam arsitektur teknis SpeechLM (tokenizer ucapan, model bahasa, vocoder), strategi pelatihan (pra-pelatihan, fine-tuning instruksi, pasca-penyelarasan), paradigma interaksi (pemodelan full-duplex), skenario aplikasi (semantik, pembicara, paralinguistik), dan sistem evaluasi. Makalah ini menekankan potensi SpeechLM dalam mewujudkan interaksi ucapan manusia-mesin yang alami dan menunjukkan tantangan serta arah masa depan. (Sumber: 36Kr)

Penelitian baru melalui Visual Game Learning (ViGaL) meningkatkan kemampuan penalaran lintas domain model kecil, kinerja matematika model 7B melampaui GPT-4o: Tim peneliti dari Rice University, Johns Hopkins University, dan NVIDIA mengusulkan paradigma pasca-pelatihan baru yang disebut ViGaL (Visual Game Learning). Dengan membiarkan model multimodal parameter 7B (Qwen2.5-VL-7B) memainkan game arcade sederhana seperti Snake dan rotasi 3D, model tidak hanya meningkatkan keterampilan bermain game, tetapi juga menunjukkan peningkatan kemampuan lintas domain yang signifikan dalam tugas penalaran kompleks seperti matematika (MathVista) dan tanya jawab multidisiplin (MMMU), bahkan melampaui model teratas seperti GPT-4o dalam beberapa aspek. Penelitian menunjukkan bahwa pelatihan game dapat mengembangkan kemampuan kognitif umum model seperti pemahaman spasial dan perencanaan sekuensial, dan game yang berbeda dapat memperkuat aspek keterampilan penalaran yang berbeda. Metode ini meningkatkan kemampuan penalaran sambil mempertahankan kemampuan visual umum model. (Sumber: Xin Zhiyuan)

Shanghai AI Lab dkk. mengusulkan framework MathFusion, meningkatkan kemampuan LLM dalam memecahkan masalah matematika melalui fusi instruksi: Shanghai Artificial Intelligence Laboratory, Gaoling School of Artificial Intelligence Renmin University of China, dan institusi lainnya bersama-sama mengusulkan framework MathFusion, yang bertujuan untuk meningkatkan kemampuan model bahasa besar (LLM) dalam memecahkan masalah matematika dengan menggabungkan instruksi sintetis yang lebih beragam secara struktural dan lebih kompleks secara logis dari berbagai masalah matematika. Framework ini mencakup tiga strategi fusi: fusi sekuensial, fusi paralel, dan fusi kondisional, yang secara efektif dapat menangkap hubungan mendalam antar masalah. Eksperimen menunjukkan bahwa hanya dengan menggunakan 45K instruksi sintetis, setelah fine-tuning pada model seperti DeepSeekMath-7B, Llama3-8B, dan Mistral-7B, MathFusion meningkatkan akurasi rata-rata sebesar 18,0 poin persentase pada beberapa benchmark matematika, menunjukkan efisiensi data dan kinerja yang tinggi. (Sumber: QubitAI)

Shanghai AI Lab dkk. mengusulkan framework GRA, model kecil berkolaborasi menghasilkan data berkualitas tinggi, kinerja sebanding dengan model 72B: Shanghai Artificial Intelligence Laboratory bekerja sama dengan Renmin University of China mengusulkan framework GRA (Generator–Reviewer–Adjudicator). Dengan mensimulasikan mekanisme pengajuan makalah dan tinjauan sejawat, beberapa model bahasa kecil (parameter 7-8B) berkolaborasi untuk menghasilkan data pelatihan berkualitas tinggi. Dalam framework ini, Generator bertanggung jawab untuk menghasilkan, Reviewer melakukan tinjauan dan penilaian multi-putaran, dan Adjudicator membuat keputusan akhir jika terjadi konflik tinjauan. Eksperimen menunjukkan bahwa model dasar seperti LLaMA-3.1-8B dan Qwen-2.5-7B yang dilatih dengan data yang dihasilkan oleh GRA, kinerjanya pada 10 dataset mainstream seperti matematika, kode, dan penalaran logis, sebanding atau bahkan melampaui data yang dihasilkan oleh distilasi model besar seperti Qwen-2.5-72B-Instruct. Ini memberikan ide baru untuk sintesis data berbiaya rendah dan berefisiensi tinggi. (Sumber: QubitAI)

Makalah membahas status dan masa depan interpretabilitas model besar, menekankan pentingnya untuk deployment AI yang aman: Tencent Research Institute menerbitkan artikel yang membahas secara mendalam status, jalur teknis, dan tantangan masa depan interpretabilitas model bahasa besar (LLM). Artikel tersebut menunjukkan bahwa memahami mekanisme internal LLM sangat penting untuk mencegah penyimpangan nilai, men-debug dan meningkatkan model, mencegah penyalahgunaan, dan mendorong aplikasi dalam skenario berisiko tinggi. Jalur teknis saat ini meliputi interpretasi otomatis (model besar menjelaskan model kecil), visualisasi fitur (seperti sparse autoencoders), pemantauan chain-of-thought, dan interpretabilitas mekanistik (seperti “AI microscope” Anthropic dan Tracr DeepMind). Namun, semantik ganda neuron, universalitas pola interpretasi, dan keterbatasan kognitif manusia masih menjadi tantangan utama. Artikel tersebut menyerukan peningkatan investasi dalam penelitian interpretabilitas dan menyarankan penerapan aturan hukum lunak yang mendorong disiplin diri industri pada tahap saat ini, untuk memastikan pengembangan teknologi AI yang aman, transparan, dan berpusat pada manusia. (Sumber: Tencent Research Institute)

Makalah baru membahas aplikasi dan kemajuan model difusi diskrit dalam model bahasa besar dan multimodal: Sebuah makalah berjudul “Discrete Diffusion in Large Language and Multimodal Models: A Survey” secara sistematis meninjau kemajuan penelitian model bahasa difusi diskrit (dLLMs) dan model bahasa multimodal difusi diskrit (dMLLMs). Model-model ini mengadopsi decoding paralel multi-Token dan strategi generasi berbasis denoising, mencapai generasi paralel, kontrol output yang halus, serta kemampuan persepsi yang dinamis dan responsif, dengan kecepatan inferensi hingga 10 kali lebih cepat dibandingkan model autoregresif. Makalah ini menelusuri sejarah perkembangannya, memformalkan kerangka kerja matematisnya, mengklasifikasikan model-model representatif, menganalisis teknik pelatihan dan inferensi utama, dan merangkum aplikasi di bidang bahasa, visual-bahasa, dan biologi, serta akhirnya membahas arah penelitian masa depan dan tantangan deployment. (Sumber: HuggingFace Daily Papers)
Penelitian baru mengusulkan Test3R: meningkatkan akurasi geometris rekonstruksi 3D melalui pembelajaran saat pengujian: Sebuah teknologi baru bernama Test3R secara signifikan meningkatkan akurasi geometris rekonstruksi 3D melalui pembelajaran saat pengujian. Metode ini memanfaatkan triplet gambar (I_1,I_2,I_3), menghasilkan hasil rekonstruksi dari pasangan gambar (I_1,I_2) dan (I_1,I_3). Ide intinya adalah mengoptimalkan jaringan melalui target self-supervised saat pengujian: memaksimalkan konsistensi geometris dari kedua hasil rekonstruksi ini relatif terhadap gambar bersama I_1. Eksperimen menunjukkan bahwa Test3R secara signifikan mengungguli metode SOTA yang ada pada tugas rekonstruksi 3D dan estimasi kedalaman multi-view, serta memiliki karakteristik universalitas dan biaya rendah, mudah diterapkan pada model lain, dengan overhead pelatihan saat pengujian dan jumlah parameter yang sangat kecil. (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan Mirage-1: agen GUI dengan keterampilan multimodal bertingkat, meningkatkan kemampuan penanganan tugas jangka panjang: Para peneliti mengusulkan Mirage-1, agen GUI multimodal, lintas platform, dan plug-and-play, yang bertujuan untuk mengatasi masalah kurangnya pengetahuan dan kesenjangan domain offline-online yang dihadapi agen GUI saat ini dalam menangani tugas jangka panjang di lingkungan online. Inti dari Mirage-1 adalah modul keterampilan multimodal bertingkat (Hierarchical Multimodal Skills – HMS), yang secara bertahap mengabstraksi lintasan menjadi keterampilan eksekusi, keterampilan inti, dan keterampilan meta, menyediakan struktur pengetahuan bertingkat untuk perencanaan tugas jangka panjang. Sementara itu, algoritma pencarian pohon Monte Carlo yang ditingkatkan keterampilan (Skill-Augmented Monte Carlo Tree Search – SA-MCTS) memanfaatkan keterampilan yang diperoleh secara offline untuk mengurangi ruang pencarian tindakan dalam eksplorasi pohon online. Dalam benchmark AndroidWorld, MobileMiniWob++, Mind2Web-Live, dan AndroidLH yang baru dibangun, Mirage-1 menunjukkan peningkatan kinerja yang signifikan. (Sumber: HuggingFace Daily Papers)
Makalah “Don’t Pay Attention” mengusulkan arsitektur dasar jaringan saraf baru Avey, menantang Transformer: Sebuah makalah berjudul “Don’t Pay Attention” mengusulkan arsitektur dasar jaringan saraf baru bernama Avey, yang bertujuan untuk melepaskan diri dari ketergantungan pada mekanisme atensi dan rekuren. Avey terdiri dari ranker dan prosesor saraf autoregresif (autoregressive neural processor), yang bekerja sama untuk mengidentifikasi dan hanya memproses Token yang paling relevan dengan Token tertentu (terlepas dari posisinya dalam urutan) untuk kontekstualisasi. Arsitektur ini memisahkan panjang urutan dari lebar konteks, sehingga mampu memproses urutan dengan panjang berapa pun secara efektif. Hasil eksperimen menunjukkan bahwa Avey berkinerja sebanding dengan Transformer pada benchmark NLP jangka pendek standar, dan menunjukkan kinerja yang sangat baik dalam menangkap dependensi jangka panjang. (Sumber: HuggingFace Daily Papers)
Makalah baru membahas validasi kode yang dapat diskalakan melalui model reward, menyeimbangkan akurasi dan throughput: Sebuah penelitian membahas trade-off antara penggunaan model reward hasil (Outcome Reward Model – ORM) dan validator komprehensif (seperti rangkaian pengujian lengkap) ketika model bahasa besar (LLM) menyelesaikan tugas pengkodean. Penelitian menemukan bahwa bahkan dengan adanya validator komprehensif, ORM memainkan peran penting dalam validasi yang dapat diskalakan dengan mengorbankan sejumlah akurasi untuk kecepatan. Khususnya dalam metode “generate-prune-rerank”, penggunaan validator yang lebih cepat tetapi kurang akurat untuk menghilangkan solusi yang salah terlebih dahulu dapat meningkatkan kecepatan sistem hingga 11,65 kali, sementara akurasi hanya berkurang 8,33%. Metode ini bekerja dengan menyaring solusi yang salah tetapi berperingkat tinggi, memberikan ide baru untuk merancang sistem pengurutan program yang dapat diskalakan dan akurat. (Sumber: HuggingFace Daily Papers)
Benchmark baru AbstentionBench mengungkapkan: LLM tipe penalaran berkinerja buruk pada pertanyaan yang tidak dapat dijawab: Untuk mengevaluasi kemampuan model bahasa besar (LLM) untuk memilih abstain (yaitu, menolak untuk menjawab secara eksplisit) ketika menghadapi ketidakpastian, para peneliti meluncurkan AbstentionBench. Benchmark skala besar ini berisi 20 dataset yang berbeda, mencakup berbagai jenis pertanyaan seperti jawaban tidak diketahui, spesifikasi tidak memadai, premis salah, interpretasi subjektif, dan informasi usang. Evaluasi terhadap 20 LLM terdepan menunjukkan bahwa abstain adalah masalah yang belum terpecahkan, dan peningkatan skala model tidak banyak membantu dalam hal ini. Yang mengejutkan, bahkan LLM tipe penalaran yang dilatih secara eksplisit untuk domain matematika dan sains, fine-tuning penalaran mereka justru menurunkan kemampuan abstain rata-rata sebesar 24%. Meskipun prompt sistem yang dirancang dengan baik dapat meningkatkan kinerja abstain dalam praktik, hal ini tidak dapat menyelesaikan kekurangan mendasar model dalam penalaran ketidakpastian. (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan metode berbasis patch dan dekomposisi (PatchInstruct) untuk memanfaatkan LLM dalam prediksi deret waktu: Sebuah studi baru mengeksplorasi strategi prompting yang sederhana dan fleksibel untuk memanfaatkan model bahasa besar (LLM) dalam prediksi deret waktu, tanpa memerlukan pelatihan ulang ekstensif atau arsitektur eksternal yang kompleks. Dengan menggabungkan dekomposisi deret waktu, tokenisasi berbasis patch (patch-based tokenization), dan peningkatan tetangga berbasis kesamaan, para peneliti menemukan bahwa kualitas prediksi LLM dapat ditingkatkan sambil mempertahankan kesederhanaan dan meminimalkan pra-pemrosesan data. Metode PatchInstruct yang diusulkan penelitian ini memungkinkan LLM untuk membuat prediksi yang akurat dan efektif. (Sumber: HuggingFace Daily Papers)
Dataset baru MS4UI dirilis, berfokus pada ringkasan multimodal video instruksional antarmuka pengguna: Untuk mengatasi kekurangan benchmark yang ada dalam menyediakan instruksi langkah demi langkah yang dapat dieksekusi dan ilustrasi grafis, para peneliti mengusulkan dataset MS4UI (Multi-modal Summarization for User Interface Instructional Videos). Dataset ini berisi 2413 video instruksional UI, dengan total durasi lebih dari 167 jam, dan telah dianotasi secara manual untuk segmentasi video, ringkasan teks, dan ringkasan video. Tujuannya adalah untuk mendorong penelitian metode ringkasan multimodal yang ringkas dan dapat dieksekusi untuk video instruksional UI. Eksperimen menunjukkan bahwa metode ringkasan multimodal SOTA saat ini berkinerja buruk pada MS4UI, menyoroti pentingnya metode baru di bidang ini. (Sumber: HuggingFace Daily Papers)
DeepResearch Bench: Benchmark agen penelitian mendalam yang komprehensif: Untuk mengevaluasi secara sistematis kemampuan agen penelitian mendalam berbasis LLM (Deep Research Agents, DRAs), para peneliti meluncurkan DeepResearch Bench. Benchmark ini berisi 100 tugas penelitian tingkat doktoral yang dirancang dengan cermat oleh para ahli dari 22 bidang yang berbeda. Karena kompleksitas dan intensitas tenaga kerja dalam mengevaluasi DRA, para peneliti mengusulkan dua metode evaluasi baru yang sangat selaras dengan penilaian manusia: satu adalah metode kriteria adaptif berbasis referensi untuk mengevaluasi kualitas laporan penelitian yang dihasilkan; metode lainnya adalah kerangka kerja yang mengevaluasi kemampuan pengambilan dan pengumpulan informasi DRA dengan menilai jumlah kutipan yang efektif dan akurasi kutipan secara keseluruhan. (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan BridgeVLA: pembelajaran operasi 3D yang efisien melalui penyelarasan input-output: Untuk meningkatkan efisiensi pemanfaatan sinyal 3D oleh model bahasa visual (VLM) dalam pembelajaran operasi robotik, para peneliti mengusulkan BridgeVLA, sebuah model aksi bahasa visual 3D (VLA) yang baru. BridgeVLA memproyeksikan input 3D ke beberapa gambar 2D, memastikan keselarasan dengan input backbone VLM, dan menggunakan heatmap 2D untuk prediksi aksi, sehingga menyatukan input dan output dalam ruang gambar 2D yang konsisten. Selain itu, penelitian ini juga mengusulkan metode pra-pelatihan yang dapat diskalakan, yang memungkinkan backbone VLM untuk memiliki kemampuan memprediksi heatmap 2D sebelum pembelajaran kebijakan hilir. Eksperimen menunjukkan bahwa BridgeVLA berkinerja sangat baik di beberapa benchmark simulasi dan eksperimen robot nyata, secara signifikan meningkatkan efisiensi dan efektivitas pembelajaran operasi 3D, serta menunjukkan efisiensi sampel dan kemampuan generalisasi yang kuat. (Sumber: HuggingFace Daily Papers)
Penelitian baru melalui sintesis berbasis atribusi menghasilkan jutaan instruksi pengguna yang beragam dan kompleks (SynthQuestions): Untuk mengatasi kurangnya data instruksi yang beragam, kompleks, dan berskala besar yang diperlukan untuk penyelarasan model bahasa besar (LLM), para peneliti mengusulkan metode sintesis instruksi berbasis landasan atribusi (attributed grounding). Kerangka kerja ini meliputi: 1) proses atribusi top-down, yang menghubungkan instruksi nyata yang dipilih dengan pengguna yang dikontekstualisasikan; 2) proses sintesis bottom-up, yang memanfaatkan dokumen web untuk pertama-tama menghasilkan konteks, kemudian menghasilkan instruksi yang bermakna. Melalui metode ini, dibangun dataset SynthQuestions yang berisi 1 juta instruksi. Eksperimen menunjukkan bahwa model yang dilatih pada dataset ini mencapai kinerja terdepan di beberapa benchmark umum, dan kinerjanya terus meningkat seiring dengan bertambahnya korpus web. (Sumber: HuggingFace Daily Papers)
PersonaFeedback: Benchmark evaluasi personalisasi berskala besar dengan anotasi manusia dirilis: Untuk mengevaluasi kemampuan model bahasa besar (LLM) dalam memberikan respons yang dipersonalisasi berdasarkan profil pengguna dan kueri yang telah ditentukan sebelumnya, para peneliti meluncurkan benchmark PersonaFeedback. Benchmark ini berisi 8298 kasus uji yang dianotasi secara manual, dibagi menjadi tiga tingkat kesulitan: mudah, sedang, dan sulit, berdasarkan kompleksitas kontekstual profil pengguna dan kesulitan dalam membedakan respons yang dipersonalisasi. Berbeda dengan benchmark yang ada, PersonaFeedback memisahkan inferensi profil dari personalisasi, berfokus pada evaluasi kemampuan model untuk menghasilkan respons yang disesuaikan dengan profil yang jelas. Hasil eksperimen menunjukkan bahwa bahkan LLM SOTA menghadapi tantangan dalam pengujian tingkat sulit, menunjukkan bahwa kerangka kerja peningkatan pengambilan saat ini bukanlah solusi akhir untuk tugas personalisasi. (Sumber: HuggingFace Daily Papers)
Makalah membahas “operasi bahasa” dalam model besar multibahasa: kontrol bahasa saat inferensi melalui injeksi laten: Sebuah penelitian baru membahas fenomena penyelarasan representasi yang muncul secara alami dalam model bahasa besar (LLM) dan signifikansinya dalam memisahkan informasi spesifik bahasa dan informasi independen bahasa. Penelitian ini mengkonfirmasi keberadaan penyelarasan ini dan menganalisis perbandingannya dengan perilaku model yang dirancang secara eksplisit untuk penyelarasan. Berdasarkan temuan ini, para peneliti mengusulkan metode Kontrol Bahasa Saat Inferensi (Inference-Time Language Control, ITLC), yang memanfaatkan injeksi laten (latent injection) untuk mencapai kontrol lintas bahasa yang presisi dan mengurangi masalah kebingungan bahasa dalam LLM. Eksperimen membuktikan bahwa ITLC memiliki kemampuan kontrol lintas bahasa yang kuat sambil mempertahankan integritas semantik bahasa target, dan dapat secara efektif mengurangi masalah kebingungan lintas bahasa yang masih ada bahkan dalam LLM skala besar saat ini. (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan metode NoWait: menghilangkan “Token berpikir” untuk meningkatkan efisiensi inferensi model besar: Penelitian terbaru menunjukkan bahwa model inferensi besar, ketika melakukan penalaran langkah demi langkah yang kompleks, sering kali menghasilkan output yang berlebihan karena terlalu banyak “berpikir” (misalnya, mengeluarkan Token seperti “Wait”, “Hmm”), yang memengaruhi efisiensi. Metode NoWait yang baru diusulkan bertujuan untuk memvalidasi perlunya Token refleksi diri eksplisit ini untuk penalaran tingkat lanjut dengan menekan Token tersebut saat inferensi. Dalam sepuluh benchmark yang mencakup tugas penalaran teks, visual, dan video, NoWait mengurangi panjang lintasan chain-of-thought sebesar 27%-51% pada lima seri model gaya R1, tanpa merusak utilitas model. Metode ini menyediakan solusi plug-and-play untuk mencapai inferensi multimodal yang efisien sambil mempertahankan utilitas. (Sumber: HuggingFace Daily Papers)
💼 Bisnis
OpenAI memenangkan kontrak AI senilai $200 juta dari Departemen Pertahanan AS, mengembangkan kemampuan militer mutakhir: OpenAI telah menandatangani kontrak satu tahun senilai $200 juta dengan Departemen Pertahanan AS untuk mengembangkan alat kecerdasan buatan canggih untuk keamanan nasional. Ini menandai pertama kalinya OpenAI mendapatkan kontrak semacam itu yang terdaftar oleh Pentagon. Pekerjaan sebagian besar akan dilakukan di wilayah Ibu Kota Nasional. Sebelumnya OpenAI telah bekerja sama dengan perusahaan pertahanan Anduril. Langkah ini dilakukan di tengah dorongan luas untuk aplikasi AI di sektor pertahanan AS, di mana pesaingnya, Anthropic, juga telah bekerja sama dengan Palantir dan Amazon di bidang ini. CEO OpenAI Sam Altman secara terbuka menyatakan dukungannya untuk proyek keamanan nasional. (Sumber: Reddit r/ArtificialInteligence, code_star)

Alta menyelesaikan pendanaan $11 juta, dipimpin oleh Menlo Ventures, berfokus pada AI+Fashion: Startup fashion AI, Alta, mengumumkan penyelesaian pendanaan sebesar $11 juta yang dipimpin oleh Menlo Ventures, dengan partisipasi dari Benchstrength dan Aglaé Ventures (dana VC yang didukung oleh keluarga Arnault dari LVMH Group). Amy Tong Wu akan bergabung dengan dewan direksi Alta. Pendanaan ini akan membantu Alta dalam pengembangan lebih lanjut di bidang kombinasi AI dan fashion. (Sumber: ZhaiAndrew)
Figure menyesuaikan struktur organisasi, menggabungkan departemen kontrol ke Helix untuk mempercepat peta jalan AI: Perusahaan robot humanoid Figure mengumumkan bahwa departemen Kontrol (Controls) mereka tidak ada lagi, dan seluruh tim telah digabungkan ke dalam departemen Helix. Langkah ini bertujuan untuk mempercepat pengembangan peta jalan perusahaan di bidang kecerdasan buatan, menunjukkan bahwa Figure memfokuskan lebih banyak sumber daya dan upaya pada penelitian dan pengembangan serta aplikasi teknologi AI. (Sumber: adcock_brett)
🌟 Komunitas
Diskusi tentang AGI: pengguna biasa tidak perlu terlalu khawatir, AGI lebih condong ke strategi daripada alat sehari-hari: Banyak diskusi di komunitas menunjukkan bahwa bagi pengguna LLM biasa, tidak perlu terlalu khawatir tentang kedatangan AGI (Artificial General Intelligence). Definisi AGI kabur dan sangat teoretis. Bahkan jika tercapai, dalam jangka pendek tidak akan langsung terlihat di jendela obrolan pengguna, melainkan sebagai alat strategis dan infrastruktur untuk negara atau institusi besar, digunakan untuk menangani urusan kompleks seperti negosiasi antar negara, bukan untuk membantu individu mengatur pertemuan. (Sumber: farguney, farguney, farguney, farguney)
Pembangunan sistem multi-agen memerlukan evaluasi manual, perhatikan kasus tepi dan kualitas sumber: Dalam membangun sistem multi-agen, evaluasi dan pengujian manual sangat penting, karena dapat menemukan kasus tepi yang mungkin diabaikan oleh evaluasi otomatis. Misalnya, agen awal dalam memilih sumber informasi cenderung memilih content farm yang dioptimalkan untuk SEO daripada PDF akademis atau blog pribadi yang otoritatif. Menambahkan heuristik kualitas sumber dalam prompt membantu mengatasi masalah seperti itu. Ini menunjukkan bahwa bahkan di era evaluasi otomatis, pengujian manual tetap tak tergantikan untuk menemukan kegagalan sistem, bias pemilihan sumber yang halus, dan masalah lainnya. (Sumber: riemannzeta)

Perbedaan LLM dalam mekanisme prediksi dan pembelajaran dengan model video memicu pemikiran: Yann LeCun dan Pedro Domingos me-retweet pandangan Sergey Levine, membahas mengapa model bahasa dapat belajar begitu banyak dari prediksi Token berikutnya, sementara model video belajar relatif sedikit dari prediksi frame berikutnya. Levine berspekulasi bahwa ini mungkin karena LLM dalam beberapa hal berperan sebagai “pemindai otak”, mengisyaratkan keunikan mekanisme pembelajarannya, atau bahwa LLM seperti hidup di gua Plato, menyimpulkan dunia nyata dengan mengamati urutan bayangan (teks). (Sumber: ylecun, pmddomingos, pmddomingos)

Dampak positif AI Agent di bidang pendidikan: mendorong pembelajar keluar dari zona nyaman: Diskusi komunitas berpendapat bahwa AI Agent tidak hanya berdampak positif bagi perusahaan, tetapi juga memiliki potensi besar di bidang pendidikan. Melalui interaksi dengan AI Agent, pembelajar dapat lebih efektif keluar dari zona nyaman mereka, sehingga mendorong peningkatan hasil belajar. (Sumber: pirroh, amasad)
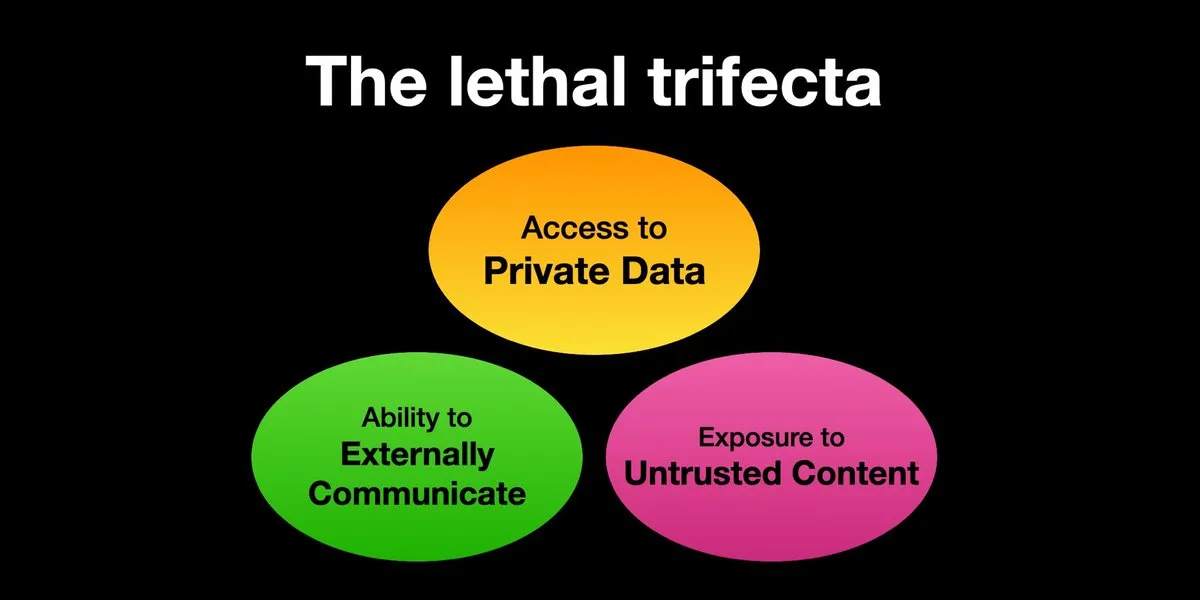
AI Agent menghadapi risiko serangan injeksi prompt, perlindungan keamanan perlu diperkuat: Karpathy me-retweet peringatan Simon Willison tentang risiko “Lethal Trifecta” yang dihadapi AI Agent, yaitu ketika AI Agent secara bersamaan memiliki akses ke data pribadi, terpapar konten yang tidak dipercaya, dan kemampuan komunikasi eksternal, penyerang dapat menipu sistem untuk mencuri data. Ini mengingatkan pada era “Wild West” virus komputer awal. Saat ini, mekanisme pertahanan terhadap prompt berbahaya belum sempurna, misalnya, kurangnya paradigma keamanan seperti kernel/ruang pengguna sistem operasi untuk membatasi kemampuan Agent menjalankan skrip sewenang-wenang. Hal ini menimbulkan kekhawatiran tentang adopsi awal LLM Agent untuk komputasi pribadi. (Sumber: karpathy, TheTuringPost)
Di era AI, kemampuan belajar cepat menjadi kompetensi inti: Mustafa Suleyman menunjukkan bahwa akselerator karir terbesar dalam sepuluh tahun ke depan adalah kemampuan belajar yang luar biasa. Dia menyarankan orang untuk mengidentifikasi gaya belajar mereka, memanfaatkan AI untuk mengubah materi menjadi format yang sesuai (seperti podcast, kuis), kemudian menerapkan pengetahuan dan terus mengulang proses ini, sehingga mencapai pembelajaran dan pertumbuhan yang cepat. (Sumber: mustafasuleyman)
Keaslian dan relevansi konten yang dihasilkan AI: relevansi mungkin mengalahkan keaslian: Pengguna imjaredz berbagi pengalaman bahwa setelah mengirim 2000 email panduan yang dihasilkan AI, tidak ada yang mengeluh bahwa itu ditulis oleh AI, sebaliknya 5 orang menyatakan bahwa konten email “persis seperti yang sedang mereka kerjakan”. Hal ini memicu diskusi tentang apakah dalam komunikasi, relevansi konten lebih penting daripada “keasliannya” (apakah dibuat oleh manusia). (Sumber: imjaredz)
Diskusi tentang kemampuan “pemahaman” LLM: aproksimasi perilaku tidak sama dengan pemahaman sejati: Ada pandangan di komunitas bahwa meskipun model bahasa besar menunjukkan kemampuan aproksimasi perilaku dan kognitif yang kuat, ini tidak sama dengan pemahaman sejati. Pemahaman membutuhkan kemampuan penjelasan, dan hanya menunjukkan perilaku bukanlah kecerdasan atau pemahaman. Perbedaan mendasar ini sering diabaikan. Pandangan ini menekankan bahwa sebelum menyerahkan keputusan yang melibatkan keselamatan jiwa kepada model, perlu untuk mengevaluasi dengan hati-hati apakah model tersebut benar-benar mendekati kecerdasan buatan umum, dan waspada terhadap klaim berlebihan tentang kemampuannya. (Sumber: farguney)
AI Agent berkinerja mengesankan dalam benchmark rekayasa perangkat lunak, tetapi diskusi tentang esensi “agen” mereka: Seiring dengan meningkatnya skor AI dalam benchmark rekayasa perangkat lunak seperti SWE-bench (bahkan melebihi 50-60 poin), komunitas membahas apakah “era pengkodean agen” benar-benar telah tiba. Ada pandangan bahwa jika yang umum digunakan adalah “framework tanpa agen” (agentless frameworks), bukan membiarkan model bahasa benar-benar menjelajahi lingkungan, maka menyebutnya “era pengkodean agen” mungkin tidak sesuai dengan kenyataan, meskipun framework itu sendiri sangat berharga. (Sumber: huybery, terryyuezhuo)
Kebutuhan moderasi konten untuk gambar yang dihasilkan AI: mencari solusi open-source atau komersial: Seiring dengan meluasnya teknologi generasi gambar AI, developer di Tiongkok mulai memperhatikan masalah kepatuhan konten output, terutama cara mendeteksi konten pornografi, sensitif secara politik, dll. Muncul diskusi di komunitas untuk mencari model kecil open-source atau produk komersial yang tersedia untuk melakukan moderasi konten. (Sumber: dotey)
💡 Lainnya
Personalisasi dan relevansi konten yang didorong AI: 2000 email AI tanpa keluhan, 5 orang menyebut “persis yang saya butuhkan”: Seorang pengguna berbagi bahwa setelah mengirim 2000 email panduan yang dihasilkan AI, tidak ada penerima yang mengeluh bahwa email tersebut ditulis oleh AI. Sebaliknya, lima penerima menyatakan bahwa konten email “persis seperti pekerjaan yang sedang mereka lakukan saat ini”. Kasus ini memicu diskusi tentang apakah dalam komunikasi yang dibantu AI, relevansi konten yang tinggi dapat melampaui kekhawatiran tentang “keaslian” (yaitu, apakah ditulis oleh manusia), mengisyaratkan potensi AI dalam generasi konten yang dipersonalisasi. (Sumber: imjaredz)
Manusia menjadi bottleneck sistem AI, perlu dihindari atau ditingkatkan efisiensi manusia: Pandangan Charles Earl menunjukkan bahwa kotak masuk email menumpuk, sementara kotak keluar kosong, yang mencerminkan bahwa manusia adalah bottleneck dalam pemrosesan dan respons informasi. Di era AI, perlu dipikirkan cara menghindari bottleneck manusia, atau cara meningkatkan efisiensi kerja manusia melalui teknologi seperti AI. (Sumber: charles_irl)
Potensi risiko AI mengendalikan rumah pintar: pengguna terjebak di tempat tidur pintar yang dingin karena kerusakan aplikasi: Seorang pengguna berbagi pengalamannya terjebak di tempat tidur yang dingin karena aplikasi tempat tidur pintar yang dikendalikan AI (Eight Sleep Pod3) miliknya mengalami kerusakan dan tidak dapat mengatur suhu. Karena model ini tidak memiliki kontrol manual dan sepenuhnya bergantung pada aplikasi, kerusakan ini menyoroti ketidaknyamanan dan pengalaman “distopia” yang mungkin timbul dari ketergantungan berlebihan pada AI dan kontrol aplikasi untuk perangkat rumah pintar. (Sumber: madiator)