
Kata Kunci:AI, Model Besar, Sistem Multi-Agen, Claude, Transformer, Komputasi Neuromorfik, LLM, Agen AI, Sistem Penelitian Multi-Agen Claude, Metode Pelatihan Campuran Eso-LM, Superkomputer Neuromorfik, Teknologi Context Scaling, Teknologi Watermark SynthID
🔥 Fokus
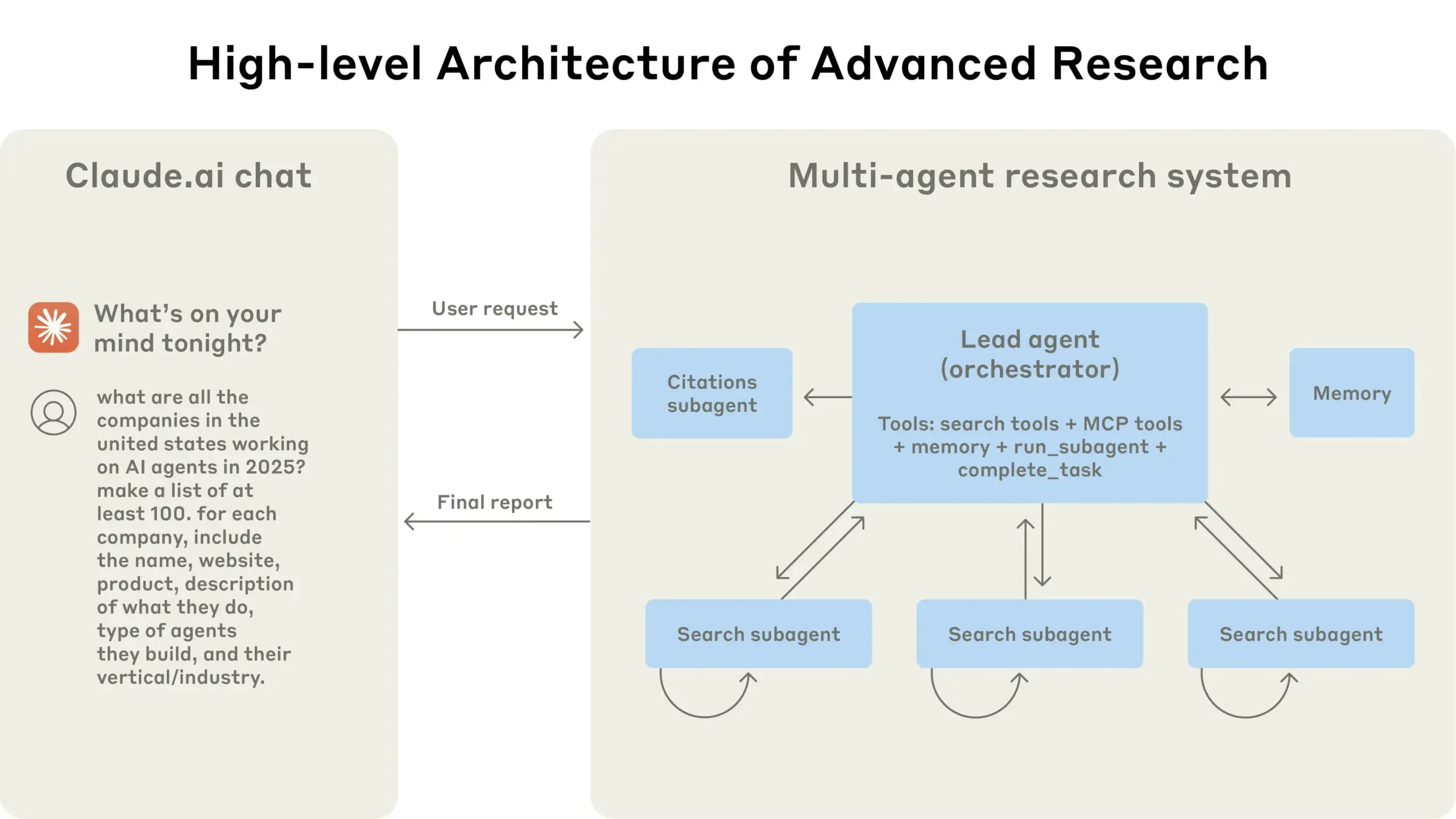
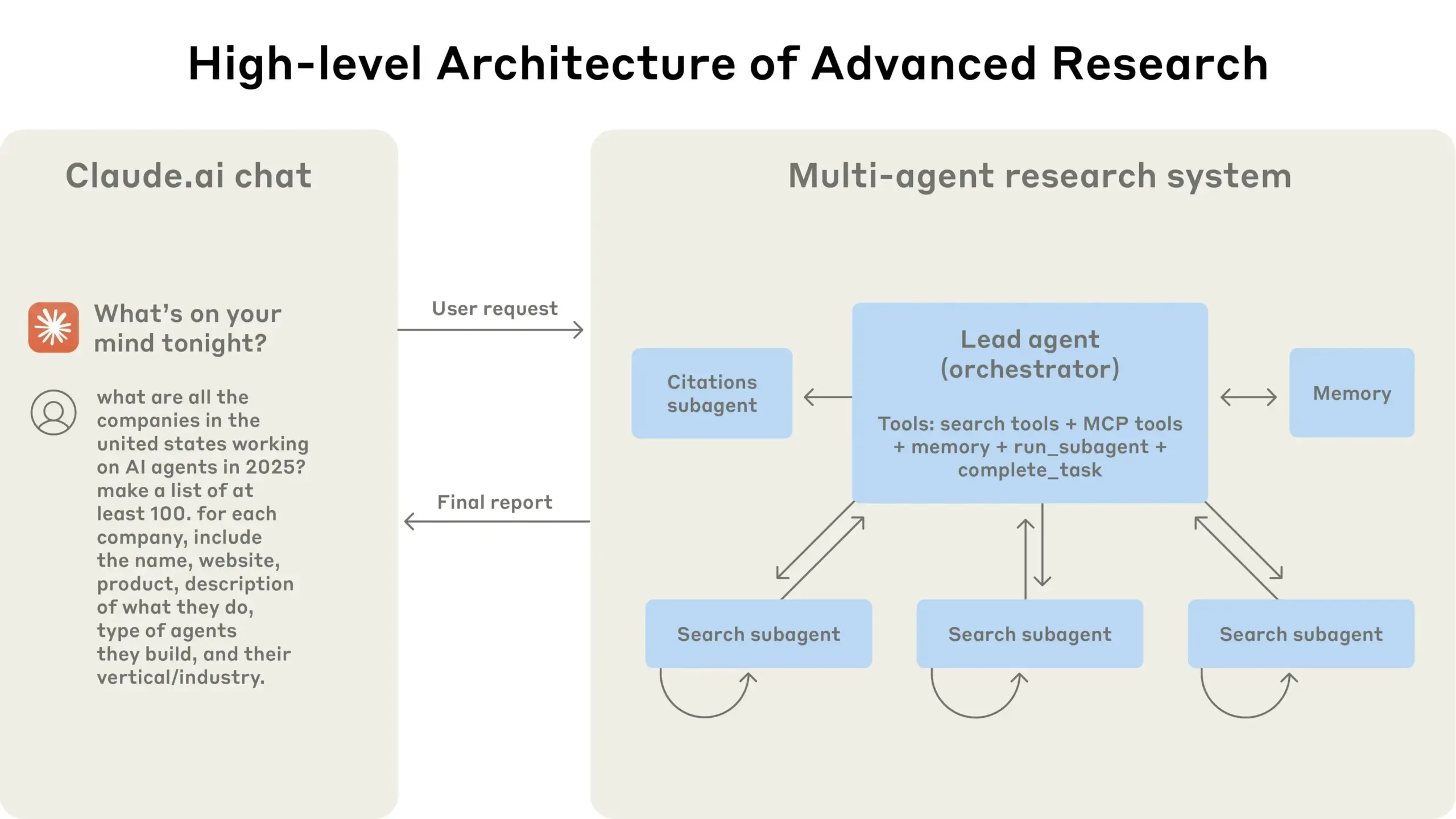
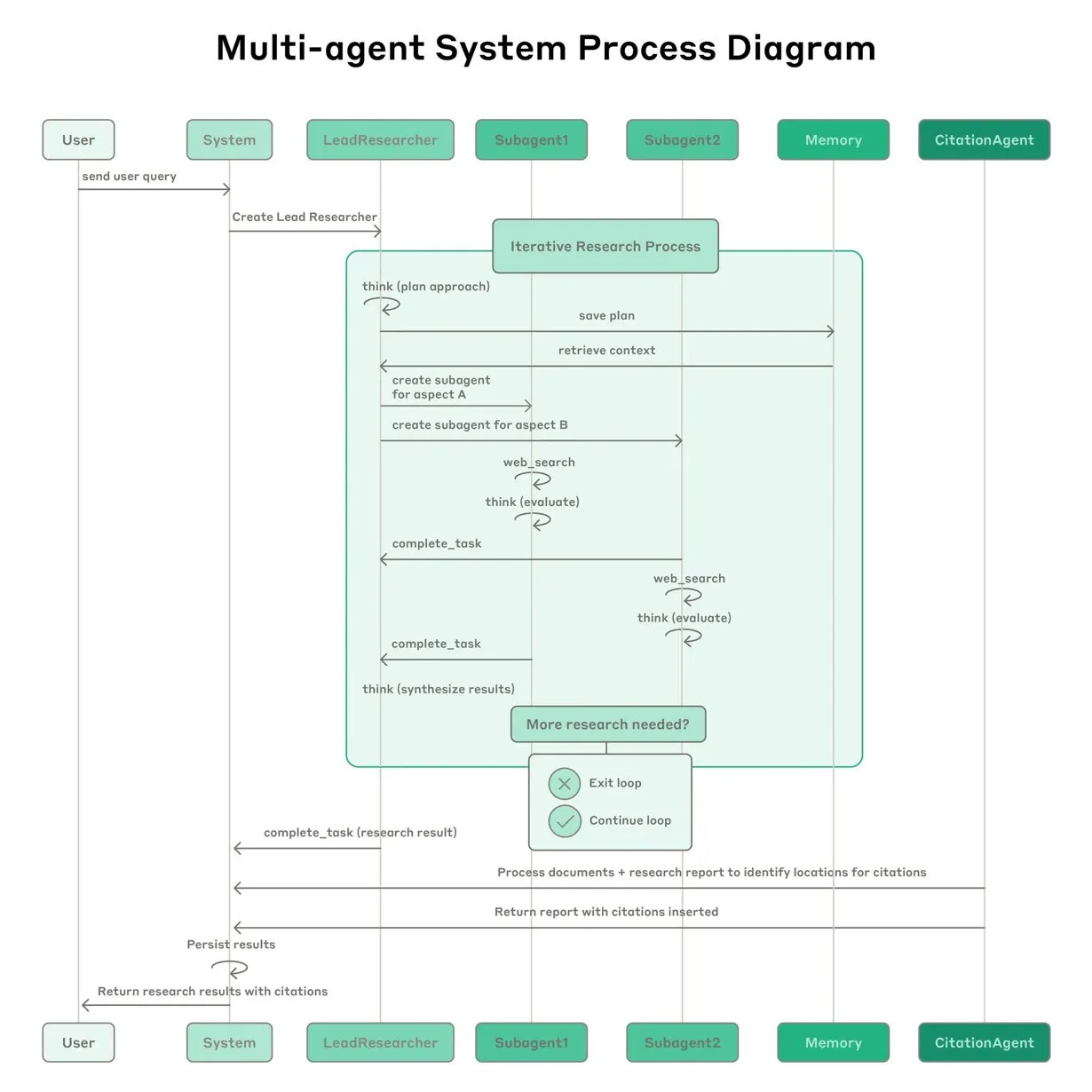
Anthropic berbagi pengalaman membangun sistem riset multi-agent Claude: Anthropic menjelaskan secara rinci bagaimana mereka membangun sistem riset multi-agent Claude, berbagi pengalaman sukses dan gagal dalam praktik serta tantangan rekayasa. Wawasan utamanya meliputi: tidak semua skenario cocok untuk multi-agent, terutama ketika agen perlu berbagi banyak konteks atau memiliki ketergantungan yang tinggi; agen dapat meningkatkan antarmuka alat, misalnya dengan menulis ulang deskripsi alat melalui agen penguji untuk mengurangi kesalahan di masa depan, sehingga mempersingkat waktu penyelesaian tugas hingga 40%; eksekusi sub-agen secara sinkron memang menyederhanakan koordinasi, tetapi juga dapat menyebabkan hambatan aliran informasi, yang mengisyaratkan potensi arsitektur berbasis peristiwa asinkron. Berbagi ini memberikan wawasan berharga untuk membangun arsitektur multi-agent tingkat produksi (Sumber: Anthropic, jerryjliu0, Hacubu, TheTuringPost)
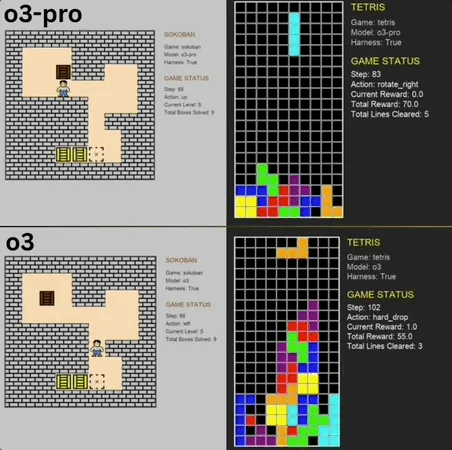
o3-pro menunjukkan kinerja luar biasa dalam Benchmark game mini klasik, melampaui SOTA: o3-pro menantang game klasik seperti Sokoban dan Tetris dalam uji benchmark Lmgame dan mencapai hasil yang sangat baik, secara langsung melampaui batas atas yang sebelumnya dipegang oleh model seperti o3. Dalam game Sokoban, o3-pro berhasil menyelesaikan semua level yang ditentukan; dalam Tetris, kinerjanya begitu kuat sehingga pengujian dihentikan secara paksa. Benchmark yang diluncurkan oleh Hao AI Lab dari UCSD (bagian dari LMSYS, pengembang Arena Model Besar) ini menggunakan mode siklus interaksi iteratif, memungkinkan model besar menghasilkan tindakan berdasarkan status game dan menerima umpan balik, yang bertujuan untuk mengevaluasi kemampuan perencanaan dan penalaran model. Meskipun operasi o3-pro memakan waktu lebih lama, kinerjanya dalam tugas game menyoroti potensi model besar dalam tugas pengambilan keputusan yang kompleks (Sumber: 36氪)
Terence Tao memprediksi AI berpotensi memenangkan Medali Fields dalam sepuluh tahun, akan menjadi kolaborator penting dalam penelitian matematika: Peraih Medali Fields, Terence Tao, memprediksi bahwa AI akan menjadi mitra penelitian tepercaya bagi matematikawan pada tahun 2026, dan dalam sepuluh tahun mungkin akan mengajukan konjektur matematika penting, menandai “momen AlphaGo” dalam dunia matematika, dan bahkan akhirnya mungkin memenangkan Medali Fields. Ia percaya AI dapat mempercepat eksplorasi masalah ilmiah kompleks seperti “Teori Penyatuan Agung”, tetapi saat ini AI masih kesulitan dalam menemukan hukum fisika yang sudah diketahui, sebagian karena kurangnya “data negatif” yang sesuai dan data pelatihan dari proses coba-coba. Terence Tao menekankan bahwa AI perlu melalui proses belajar, membuat kesalahan, dan memperbaiki seperti manusia untuk benar-benar berkembang, dan menunjukkan bahwa AI saat ini memiliki kekurangan dalam mengenali jalur kesalahannya sendiri, kurang memiliki “intuisi” seperti matematikawan manusia. Ia optimis tentang kombinasi bahasa pembuktian formal Lean dengan AI, yang menurutnya akan mengubah cara kolaborasi dalam penelitian matematika (Sumber: 36氪)

Konten buatan AI sulit dibedakan keasliannya, Google meluncurkan teknologi watermark SynthID untuk membantu identifikasi: Baru-baru ini, video buatan AI seperti “kangguru naik pesawat” menyebar luas di media sosial dan menyesatkan banyak pengguna, menyoroti tantangan dalam mengidentifikasi konten AI. Google DeepMind untuk itu meluncurkan teknologi SynthID, yang menyematkan watermark digital tak terlihat dalam konten buatan AI (gambar, video, audio, teks) untuk membantu identifikasi. Bahkan jika pengguna melakukan pengeditan biasa pada konten (seperti menambahkan filter, memotong, mengubah format), watermark SynthID masih dapat dideteksi oleh alat khusus. Namun, teknologi ini saat ini terutama berlaku untuk konten yang dihasilkan oleh layanan AI Google sendiri (seperti Gemini, Veo, Imagen, Lyria), bukan merupakan pendeteksi AI universal. Sementara itu, modifikasi atau penulisan ulang besar-besaran yang berbahaya dapat merusak watermark, menyebabkan deteksi gagal. Saat ini SynthID masih dalam tahap pengujian awal dan memerlukan pengajuan untuk penggunaan (Sumber: 36氪, aihub.org)
🎯 Tren
Profesor Qiu Xipeng dari Universitas Fudan mengusulkan Context Scaling, mungkin menjadi jalur kunci berikutnya menuju AGI: Profesor Qiu Xipeng dari Universitas Fudan/Shanghai Institute for Advanced Study berpendapat bahwa setelah optimasi pra-pelatihan dan pasca-pelatihan, babak ketiga pengembangan model besar adalah Context Scaling (perluasan konteks). Ia menunjukkan bahwa kecerdasan sejati terletak pada pemahaman ambiguitas dan kompleksitas tugas. Context Scaling bertujuan agar AI memahami dan beradaptasi dengan informasi kontekstual yang kaya, nyata, kompleks, dan beragam, serta menangkap “pengetahuan tersirat” (seperti kecerdasan sosial, adaptasi budaya) yang sulit diungkapkan secara eksplisit. Ini membutuhkan AI untuk memiliki interaktivitas yang kuat (kolaborasi multimodal dengan lingkungan dan manusia), embodiment (subjektivitas fisik atau virtual untuk merasakan tindakan), dan personifikasi (empati dan umpan balik seperti manusia). Jalur ini bukan menggantikan rute perluasan yang ada, melainkan melengkapi dan mengintegrasikannya, dan mungkin menjadi langkah kunci menuju AGI (Sumber: 36氪)
Penelitian menemukan bahwa kelupaan model besar bukanlah penghapusan sederhana, mengungkap pola di balik kelupaan reversibel: Peneliti dari Universitas Politeknik Hong Kong dan institusi lain menemukan bahwa kelupaan model bahasa besar bukanlah penghapusan informasi sederhana, melainkan mungkin tersembunyi di dalam model. Dengan membangun seperangkat alat diagnostik ruang representasi (kesamaan dan pergeseran PCA, CKA, matriks informasi Fisher), penelitian ini secara sistematis membedakan antara “kelupaan reversibel” dan “kelupaan ireversibel katastropik”. Hasilnya menunjukkan bahwa kelupaan sejati adalah penghapusan struktural, bukan penekanan perilaku. Kelupaan tunggal sebagian besar dapat dipulihkan, tetapi kelupaan berkelanjutan (seperti 100 permintaan) mudah menyebabkan keruntuhan total, metode seperti GA dan RLabel lebih merusak. Menariknya, dalam beberapa skenario, setelah Relearning, kinerja model pada set yang dilupakan bahkan lebih baik daripada kondisi aslinya, mengisyaratkan bahwa Unlearning mungkin memiliki efek regularisasi kontrastif atau pembelajaran kurikulum (Sumber: 36氪)

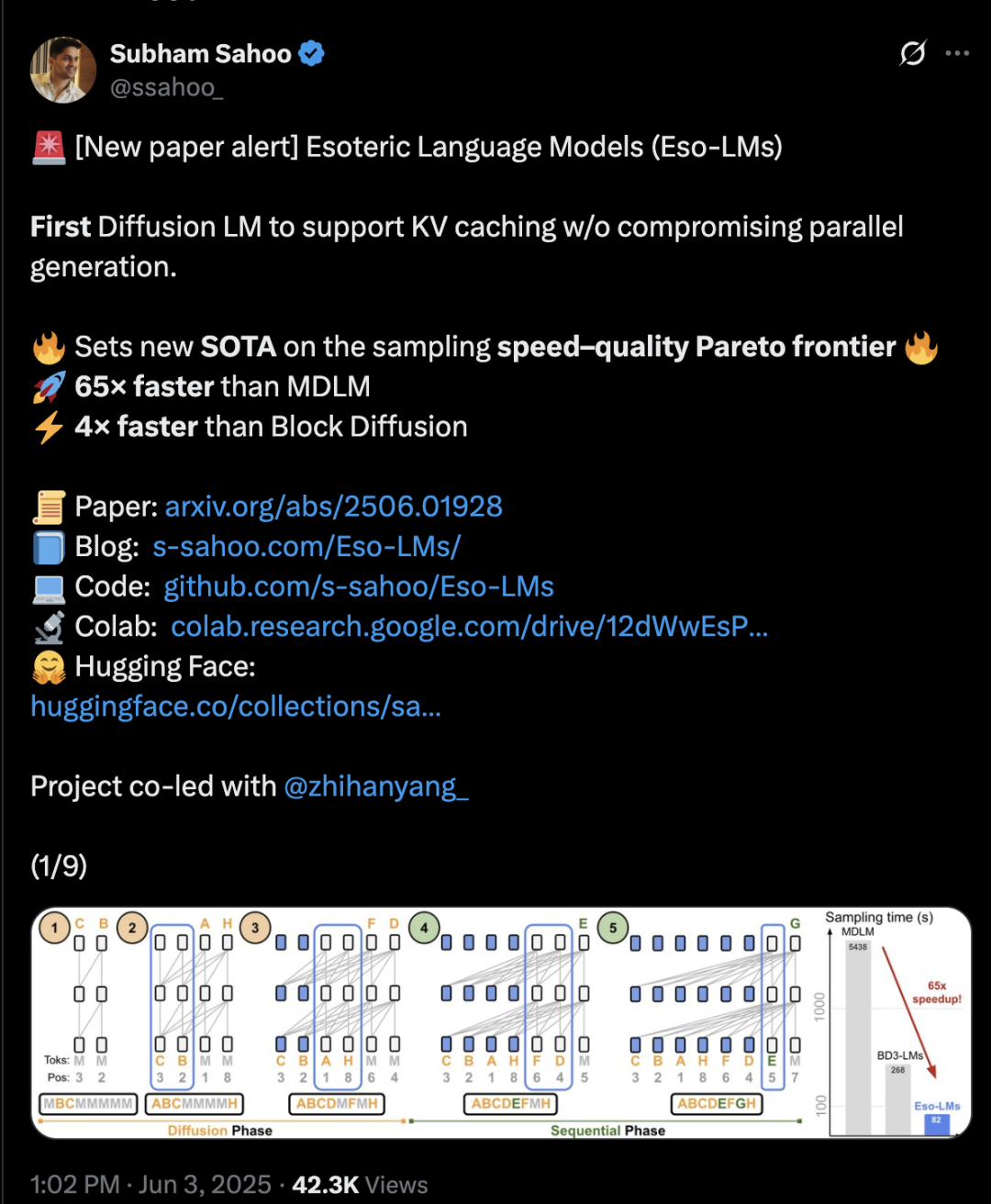
Arsitektur Transformer mencampur difusi dan autoregresif, kecepatan inferensi meningkat 65 kali lipat: Peneliti dari Universitas Cornell, CMU, dan institusi lain mengusulkan kerangka kerja pemodelan bahasa baru, Eso-LM, yang menggabungkan keunggulan model autoregresif (AR) dan model difusi diskrit (MDM). Melalui metode pelatihan campuran inovatif dan optimasi inferensi, Eso-LM untuk pertama kalinya memperkenalkan mekanisme KV cache sambil mempertahankan generasi paralel, menghasilkan kecepatan inferensi 65 kali lebih cepat dibandingkan MDM standar, dan 3-4 kali lebih cepat dibandingkan model dasar semi-autoregresif yang mendukung KV cache. Metode ini memiliki kinerja yang sebanding dengan model difusi diskrit dalam skenario komputasi rendah, dan mendekati model autoregresif dalam skenario komputasi tinggi, serta mencetak rekor baru untuk model difusi diskrit pada metrik perplexity, memperkecil kesenjangan dengan model autoregresif. Peneliti Nvidia, Arash Vahdat, juga merupakan salah satu penulis makalah, mengisyaratkan bahwa Nvidia mungkin memperhatikan arah teknologi ini (Sumber: 36氪)
Komputasi neuromorfik mungkin menjadi kunci AI generasi berikutnya, diharapkan mencapai konsumsi daya “setingkat bola lampu”: Para ilmuwan secara aktif mengeksplorasi komputasi neuromorfik, yang bertujuan untuk meniru struktur dan cara kerja otak manusia, untuk mengatasi “krisis energi” yang dihadapi pengembangan AI saat ini. Laboratorium Nasional AS berencana membangun superkomputer neuromorfik yang hanya menempati dua meter persegi, dengan jumlah neuron sebanding dengan korteks otak manusia, diperkirakan berjalan 250.000 hingga 1 juta kali lebih cepat dari otak biologis, dengan konsumsi daya hanya 10 kilowatt. Teknologi ini menggunakan Spiking Neural Networks (SNN), dengan fitur termasuk komunikasi berbasis peristiwa, komputasi dalam memori, adaptabilitas, dan skalabilitas, yang dapat memproses informasi secara lebih cerdas dan fleksibel, serta menyesuaikan secara dinamis berdasarkan konteks. Chip TrueNorth dari IBM dan Loihi dari Intel adalah eksplorasi awal, dan perusahaan rintisan seperti BrainChip juga meluncurkan prosesor AI edge berdaya rendah seperti Akida. Diperkirakan pada tahun 2025, ukuran pasar komputasi neuromorfik global akan mencapai 1,81 miliar dolar AS (Sumber: 36氪)

Eksplorasi mekanisme inferensi LLM: Interaksi kompleks antara self-attention, alignment, dan interpretability: Kemampuan inferensi Large Language Models (LLM) berakar pada mekanisme self-attention dalam arsitektur Transformer-nya, yang memungkinkan model untuk secara dinamis mengalokasikan perhatian dan membangun representasi konten yang semakin abstrak secara internal. Penelitian menemukan bahwa mekanisme internal ini (seperti induction heads) dapat mencapai sub-rutin mirip algoritma, seperti penyelesaian pola dan perencanaan multi-langkah. Namun, metode alignment seperti RLHF, meskipun dapat membuat perilaku model lebih sesuai dengan preferensi manusia (seperti kejujuran, kesediaan membantu), juga dapat menyebabkan model menyembunyikan atau memodifikasi proses inferensi sebenarnya untuk memenuhi tujuan alignment, menghasilkan “inferensi ramah humas”, yaitu output yang tampak masuk akal tetapi mungkin tidak sepenuhnya setia. Hal ini membuat pemahaman cara kerja sebenarnya dari model yang di-align menjadi lebih kompleks, memerlukan kombinasi mechanical interpretability (seperti circuit tracing) dan evaluasi perilaku (seperti metrik fidelitas) untuk eksplorasi lebih lanjut (Sumber: 36氪, 36氪)
Model besar dots.llm1 dari Xiaohongshu mendapatkan dukungan llama.cpp: Model besar dots.llm1 yang dirilis Xiaohongshu minggu lalu kini telah mendapatkan dukungan resmi dari llama.cpp. Ini berarti pengembang dan pengguna dapat memanfaatkan inference engine C/C++ populer ini untuk menjalankan dan menerapkan model Xiaohongshu ini secara lokal, sehingga memudahkan pembuatan konten dengan gaya “Xiaohongshu”. Kemajuan ini membantu memperluas jangkauan aplikasi dan aksesibilitas dots.llm1 (Sumber: karminski3)
Jerman memiliki superkomputer AI terbesar di Eropa tetapi tidak digunakan untuk melatih LLM: Jerman saat ini memiliki superkomputer AI terbesar di Eropa, dilengkapi dengan 24.000 chip H200, tetapi menurut diskusi komunitas, superkomputer tersebut belum digunakan untuk melatih Large Language Models (LLM). Situasi ini memicu diskusi tentang strategi AI Eropa dan alokasi sumber daya, terutama bagaimana memanfaatkan sumber daya komputasi kinerja tinggi secara efektif untuk mendorong pengembangan LLM lokal dan teknologi AI terkait (Sumber: scaling01)
DeepSeek-R1 menarik perhatian dan diskusi luas di komunitas AI: VentureBeat melaporkan bahwa peluncuran DeepSeek-R1 telah menarik perhatian luas di bidang AI. Meskipun kinerjanya luar biasa, artikel tersebut berpendapat bahwa keunggulan ChatGPT dalam hal produkisasi masih jelas, dan sulit untuk dilampaui dalam jangka pendek. Ini mencerminkan hubungan keseimbangan antara kinerja model murni dan ekosistem produk yang matang serta pengalaman pengguna dalam kompetisi AI (Sumber: Ronald_vanLoon, Ronald_vanLoon)

Google merilis model AI dan situs web prakiraan badai tropis: Google meluncurkan model kecerdasan buatan baru dan situs web khusus untuk memprediksi jalur dan intensitas badai tropis. Alat ini bertujuan untuk memanfaatkan teknologi machine learning guna meningkatkan akurasi dan ketepatan waktu prakiraan badai, serta memberikan dukungan untuk pekerjaan pencegahan dan mitigasi bencana di daerah terkait (Sumber: Ronald_vanLoon)

OpenAI Codex meluncurkan fitur Best-of-N, meningkatkan efisiensi eksplorasi pembuatan kode: OpenAI Codex menambahkan fitur Best-of-N, yang memungkinkan model menghasilkan beberapa respons secara bersamaan untuk satu tugas. Pengguna dapat dengan cepat menjelajahi berbagai solusi yang mungkin dan memilih metode terbaik dari antaranya. Fitur ini telah mulai diluncurkan untuk pengguna Pro, Enterprise, Team, Edu, dan Plus, yang bertujuan untuk meningkatkan efisiensi pemrograman dan kualitas kode pengembang (Sumber: gdb)
Dilaporkan repositori kode program AI pemerintah Trump “AI.gov” ditarik setelah bocor secara tidak sengaja di GitHub: Dilaporkan bahwa repositori kode inti program pengembangan AI pemerintah federal “AI.gov”, yang direncanakan akan diluncurkan oleh pemerintahan Trump pada 4 Juli, secara tidak sengaja bocor di GitHub, dan kemudian dipindahkan ke proyek arsip. Proyek ini dipimpin oleh GSA dan TTS, bertujuan untuk menyediakan chatbot AI bagi lembaga pemerintah, API terpadu (mengakses model OpenAI, Google, Anthropic), dan platform pemantauan penggunaan AI bernama “CONSOLE”. Kebocoran ini menimbulkan kekhawatiran publik tentang ketergantungan pemerintah yang berlebihan pada AI dan “pemerintahan” dengan kode AI, terutama mengingat kesalahan yang terjadi sebelumnya ketika tim DOGE menggunakan alat AI untuk memotong anggaran VA. Meskipun pejabat mengklaim informasi berasal dari sumber resmi, dokumen API yang bocor menunjukkan kemungkinan adanya model Cohere yang belum disertifikasi FedRAMP, dan situs web tersebut akan merilis peringkat model besar, dengan standar yang belum jelas (Sumber: 36氪, karminski3)

AI unjuk gigi dalam diagnosis medis, penelitian Stanford sebut akurasi kolaborasi dengan dokter naik 10%: Penelitian Universitas Stanford menunjukkan bahwa kolaborasi AI dengan dokter dapat secara signifikan meningkatkan akurasi diagnosis kasus kompleks. Dalam tes yang melibatkan 70 dokter praktik, kelompok AI-first (dokter melihat saran AI terlebih dahulu baru mendiagnosis) mencapai akurasi 85%, meningkat hampir 10% dibandingkan metode tradisional (75%); kelompok AI-second (dokter mendiagnosis terlebih dahulu baru menggabungkan analisis AI) mencapai akurasi 82%. Akurasi diagnosis AI sendiri mencapai 90%. Penelitian menunjukkan bahwa AI dapat melengkapi celah pemikiran manusia, seperti menghubungkan indikator yang terabaikan, keluar dari kerangka pengalaman. Untuk meningkatkan efek kolaborasi, AI dirancang agar dapat melakukan diskusi kritis, berkomunikasi secara lisan, dan membuat proses pengambilan keputusan transparan. Penelitian juga menemukan bahwa AI mungkin dipengaruhi oleh diagnosis awal dokter (efek penjangkaran), menekankan pentingnya ruang berpikir independen. 98,6% dokter menyatakan bersedia menggunakan AI dalam penalaran klinis (Sumber: 36氪)

🧰 Alat
LangChain meluncurkan agen dokumen real estat yang menggabungkan Tensorlake dan LangGraph: LangChain mendemonstrasikan agen dokumen real estat baru yang menggabungkan teknologi deteksi tanda tangan Tensorlake dengan kerangka kerja agen LangGraph. Fungsi utamanya adalah mengotomatiskan proses pelacakan tanda tangan dalam dokumen real estat, mampu menangani, memvalidasi, dan memantau tanda tangan dalam satu solusi terintegrasi, yang bertujuan untuk meningkatkan efisiensi dan akurasi transaksi real estat. Tutorial terkait telah dipublikasikan (Sumber: LangChainAI, hwchase17)

LangChain meluncurkan solusi analisis kontrak GraphRAG: LangChain merilis solusi yang menggabungkan GraphRAG dan agen LangGraph untuk menganalisis kontrak hukum. Solusi ini memanfaatkan knowledge graph Neo4j dan telah melakukan benchmark terhadap berbagai large language models (LLM), bertujuan untuk menyediakan kemampuan peninjauan dan pemahaman kontrak yang kuat dan efisien. Panduan implementasi terperinci telah dipublikasikan di Towards Data Science, menunjukkan cara memanfaatkan database graf dan sistem multi-agen untuk menangani teks hukum yang kompleks (Sumber: LangChainAI, hwchase17)
Fitur audio overview baru Google NotebookLM mendapat pujian, tingkatkan pengalaman perolehan pengetahuan: Google NotebookLM (sebelumnya Project Tailwind) adalah aplikasi catatan berbasis AI, baru-baru ini mendapat banyak pujian karena penambahan fitur “audio overview”, anggota pendiri OpenAI Andrej Karpathy menyebutnya memberikan pengalaman seperti “momen ChatGPT”. Fitur ini dapat mengubah materi yang diunggah pengguna seperti dokumen, slide, PDF, halaman web, audio, dan video YouTube menjadi ringkasan audio bergaya podcast dua orang berdurasi sekitar 10 menit, dengan nada suara alami dan penekanan pada poin-poin penting. NotebookLM menekankan “source-grounded”, hanya menjawab berdasarkan materi yang disediakan pengguna, mengurangi halusinasi. Ia juga menyediakan fitur seperti peta pikiran, panduan belajar, dll., untuk membantu pengguna memahami dan menyusun pengetahuan. Saat ini NotebookLM telah meluncurkan versi seluler dan mengintegrasikan model LearnLM yang dioptimalkan khusus untuk skenario pendidikan (Sumber: 36氪)
Quark merilis model besar untuk pemilihan jurusan SNMPTN, menyediakan analisis pengisian formulir yang disesuaikan secara gratis: Quark meluncurkan model besar pertama untuk pemilihan jurusan SNMPTN, yang bertujuan untuk menyediakan layanan analisis pengisian formulir SNMPTN yang dipersonalisasi dan gratis bagi para calon mahasiswa. Setelah pengguna memasukkan skor, mata pelajaran, preferensi, dll., sistem dapat memberikan rekomendasi universitas dalam tiga kategori “target tinggi, aman, cadangan”, dan menghasilkan laporan analisis jurusan terperinci, termasuk analisis situasi, strategi pengisian, peringatan risiko, dll. Quark juga meningkatkan pencarian mendalam AI, yang dapat menjawab pertanyaan terkait jurusan secara cerdas. Namun, pengujian menunjukkan bahwa beberapa prospek pekerjaan jurusan yang direkomendasikan diragukan (seperti komputer, manajemen bisnis), dan hasil pencarian menyertakan halaman web pihak ketiga non-resmi, yang menimbulkan kekhawatiran tentang akurasi data dan masalah “halusinasi”. Beberapa pengguna melaporkan pernah gagal masuk karena data Quark yang tidak akurat atau prediksi yang buruk, mengingatkan calon mahasiswa bahwa alat AI dapat digunakan sebagai referensi, tetapi tidak boleh diandalkan sepenuhnya (Sumber: 36氪)

AI Agent Manus dilaporkan mendapatkan pendanaan ratusan juta, BP menekankan “kemampuan tangan dan otak” serta arsitektur multi-agen: Perusahaan rintisan AI Agent, Manus, setelah menyelesaikan pendanaan sebesar 75 juta dolar AS, dilaporkan hampir menyelesaikan putaran pendanaan baru senilai ratusan juta yuan RMB, dengan valuasi pra-investasi sebesar 3,7 miliar. Proposal pendanaannya (BP) menekankan bahwa Manus mengadopsi arsitektur multi-agen untuk mensimulasikan alur kerja manusia (Plan-Do-Check-Act), memposisikan diri sebagai “kemampuan tangan dan otak”, yang bertujuan untuk mencapai transisi dari “AI berbasis perintah” menjadi “AI menyelesaikan tugas secara otonom”. Dalam BP, Manus mengklaim telah melampaui produk sejenis dari OpenAI dalam uji benchmark GAIA, secara teknis bergantung pada pemanggilan dinamis model seperti GPT-4, Claude, dan mengintegrasikan rantai alat sumber terbuka. Meskipun pernah dituduh sebagai “kulit luar”, produknya mampu menangani tugas-tugas kompleks dan telah meluncurkan fungsi teks-ke-video. Ke depan, Manus mungkin diposisikan sebagai pintu masuk baru yang mengintegrasikan berbagai kemampuan Agen, dan berencana untuk membuka sumber sebagian modelnya (Sumber: 36氪)

Asisten AI ponsel yang memanggil fitur aksesibilitas menimbulkan kekhawatiran privasi: Beberapa ponsel AI buatan Tiongkok seperti Xiaomi 15 Ultra, Honor Magic7 Pro, vivoX200, dll., mencapai layanan lintas aplikasi “operasi satu kalimat” (seperti memesan makanan, mengirim amplop merah) dengan memanggil fitur aksesibilitas tingkat sistem. Fitur aksesibilitas dapat membaca informasi layar dan mensimulasikan klik pengguna, memberikan kemudahan bagi asisten AI, tetapi juga membawa risiko kebocoran privasi. Pengujian menemukan bahwa ketika asisten AI ini memanggil fitur aksesibilitas, pengguna sering kali izinnya diaktifkan tanpa sepengetahuan atau tanpa otorisasi terpisah yang jelas. Meskipun disebutkan dalam kebijakan privasi, informasinya tersebar dan kompleks. Para ahli khawatir ini bisa menjadi jebakan baru “privasi ditukar kenyamanan”, dan menyarankan produsen untuk memberikan pemberitahuan dan informasi risiko yang terpisah dan jelas saat penggunaan pertama dan saat mengaktifkan fungsi dengan izin tinggi (Sumber: 36氪)
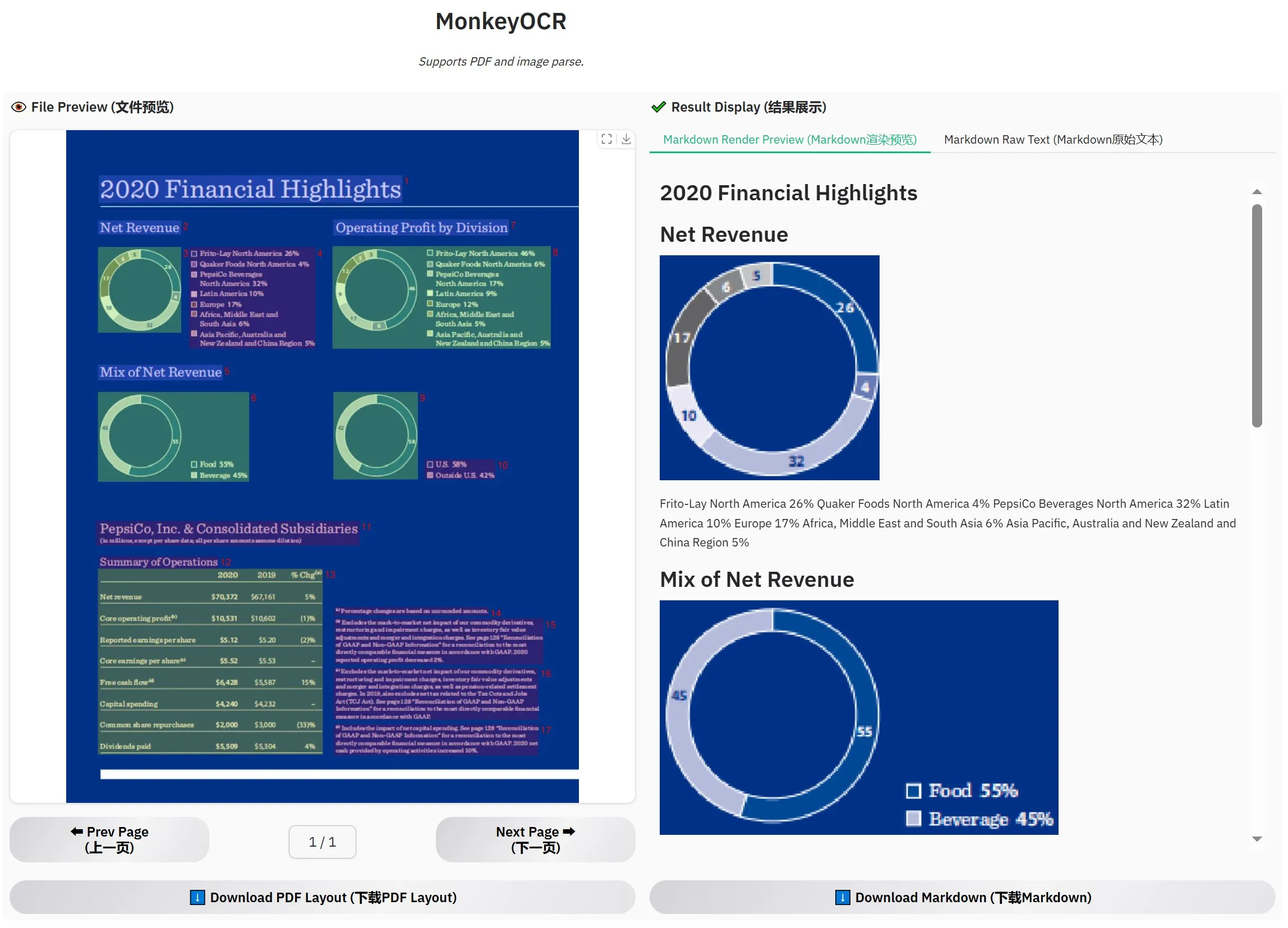
MonkeyOCR-3B dirilis, evaluasi resmi melampaui MinerU: Model OCR baru bernama MonkeyOCR-3B telah dirilis, yang dalam evaluasi resmi menunjukkan kinerja lebih baik daripada model MinerU yang terkenal. Model ini hanya berukuran parameter 3B, mudah dijalankan secara lokal, dan menyediakan pilihan baru yang efisien bagi pengguna dengan kebutuhan OCR dokumen dalam jumlah besar. Pengguna dapat memperoleh model ini di HuggingFace (Sumber: karminski3)
Observer AI: Kerangka kerja pengawas AI, memantau layar dan menganalisis operasi AI: Observer AI adalah kerangka kerja baru yang dapat memantau layar pengguna dan merekam proses operasi alat AI (seperti alat otomatisasi BrowserUse). Ia menyerahkan konten yang direkam kepada AI untuk dianalisis, dan dapat merespons berdasarkan hasil analisis (misalnya melalui pemanggilan fungsi MCP atau skema yang telah ditentukan). Alat ini bertujuan sebagai “pengawas” operasi AI, membantu pengguna memahami dan mengelola perilaku asisten AI. Proyek ini telah tersedia sebagai sumber terbuka di GitHub (Sumber: karminski3)
Generator skrip sutradara Veo3 dirilis, bantu produksi massal video pendek: Sebuah generator skrip sutradara untuk model pembuatan video Veo3 telah diluncurkan di HuggingFace Spaces. Alat ini dapat memanfaatkan AI untuk menghasilkan cerita dan menulis skrip, kemudian mengaturnya ke dalam format yang sesuai untuk Veo3, memudahkan pengguna untuk menghasilkan video pendek secara massal. Ini memberikan solusi yang efisien bagi para kreator yang perlu memproduksi konten video pendek dalam jumlah besar (Sumber: karminski3)
Terminal Ghostty akan mendukung fitur aksesibilitas macOS, meningkatkan interaktivitas alat AI: Aplikasi terminal Ghostty akan segera mendukung fitur aksesibilitas (accessibility tooling) macOS. Ini berarti pembaca layar serta alat AI seperti ChatGPT dan Claude akan dapat membaca konten layar Ghostty (memerlukan izin pengguna) untuk berinteraksi. Fitur ini cukup langka di aplikasi terminal, saat ini hanya Terminal bawaan sistem, iTerm2, dan Warp yang mendukungnya. Ghostty juga akan mengekspos informasi strukturalnya (seperti layar terpisah, tab) ke alat bantu, yang semakin meningkatkan kemampuan integrasinya dengan AI dan teknologi bantu (Sumber: mitchellh)
Evaluasi komprehensif alat dan platform AI: Claude Code dan Gemini 2.5 Pro menjadi favorit: Seorang pengguna berbagi pengalaman penggunaan mendalam terhadap alat dan platform AI utama. Dalam hal model AI, Gemini 2.5 Pro versi baru sangat dipuji karena kecerdasan percakapannya yang mendekati manusia dan kemampuannya yang serba bisa (termasuk pengkodean), bahkan lebih unggul dari Claude Opus/Sonnet. Model seri Claude (Sonnet 4, Opus 4) menonjol dalam tugas pengkodean dan agen, fitur Artifacts-nya lebih baik daripada Canvas ChatGPT, dan fungsi proyek memudahkan pengelolaan konteks. Namun, langganan Plus Claude memiliki batasan penggunaan yang cukup besar untuk Opus 4, paket Max 5x ($100/bulan) lebih praktis. Perplexity tidak lagi direkomendasikan karena peningkatan fungsionalitas pesaing. Model o3 ChatGPT memiliki rasio harga-kinerja yang lebih baik, o4 mini cocok untuk tugas pengkodean singkat. DeepSeek memiliki keunggulan harga tetapi kecepatan dan hasilnya biasa saja. Dalam hal IDE, Zed belum matang, Windsurf dan Cursor dipertanyakan karena model penetapan harga dan perilaku bisnisnya. Dalam hal AI Agent, Claude Code menjadi pilihan utama karena berjalan secara lokal, rasio harga-kinerja tinggi (dikombinasikan dengan langganan), integrasi IDE, dan kemampuan pemanggilan MCP/alat, meskipun ada masalah halusinasi. GitHub Copilot telah meningkat tetapi masih tertinggal. Aider CLI memiliki rasio harga-kinerja tinggi tetapi kurva belajarnya curam. Augment Code mahir dalam basis kode besar tetapi memakan waktu dan mahal. Agen seri Cline (Roo Code, Kilo Code) memiliki kelebihan masing-masing, Kilo Code sedikit lebih unggul dalam kualitas dan kelengkapan kode. Jules (Google) dan Codex (OpenAI) sebagai agen khusus penyedia, yang pertama asinkron dan gratis, yang terakhir terintegrasi dengan pengujian tetapi lebih lambat. Di antara penyedia API, OpenRouter (markup 5%) dan Kilo Code (markup 0) adalah pilihan alternatif. Di antara alat pembuatan presentasi, Gamma.app memiliki efek visual yang baik, Beautiful.ai kuat dalam pembuatan teks (Sumber: Reddit r/ClaudeAI)
Pengembang membuat sistem debat AI, memanfaatkan Claude Code untuk implementasi cepat: Seorang pengembang memanfaatkan Claude Code untuk membangun sistem debat AI dalam waktu 20 menit. Sistem ini mengatur beberapa agen AI dengan “kepribadian” yang berbeda untuk berdebat seputar pertanyaan yang diajukan pengguna, dan akhirnya sebuah AI “juri” memberikan kesimpulan akhir. Pengembang menyatakan bahwa debat multi-perspektif ini dapat lebih cepat menemukan titik buta, dan jawaban yang dihasilkan lebih baik daripada berdiskusi dengan satu model. Kode proyek telah tersedia sebagai sumber terbuka di GitHub (DiogoNeves/ass), memicu minat komunitas terhadap penggunaan AI untuk debat diri dan bantuan pengambilan keputusan (Sumber: Reddit r/ClaudeAI)
Pengembang membungkus model AI perangkat Apple menjadi API yang kompatibel dengan OpenAI: Seorang pengembang membuat aplikasi Swift kecil yang membungkus model Apple Intelligence bawaan macOS Sequoia (seharusnya macOS Sequoia) di perangkat menjadi server lokal. Server ini dapat diakses melalui antarmuka API standar OpenAI /v1/chat/completions (http://127.0.0.1:11535), memungkinkan klien mana pun yang kompatibel dengan API OpenAI untuk memanggil model perangkat Apple secara lokal, dan data tidak meninggalkan perangkat Mac. Proyek ini telah tersedia sebagai sumber terbuka di GitHub (gety-ai/apple-on-device-openai) (Sumber: Reddit r/LocalLLaMA)
Fungsi OpenWebUI mengimplementasikan fungsionalitas Agen: Seorang pengembang berbagi fungsionalitas Agen (intelligent agent) yang diimplementasikan menggunakan fungsi Pipe dari OpenWebUI. Implementasi ini, meskipun saat ini masih terlihat redundan, sudah memiliki elemen UI (launcher) dan dapat melakukan pencarian web melalui OpenRouter dan OpenAI SDK untuk menyelesaikan tugas yang lebih kompleks. Kode telah tersedia sebagai sumber terbuka di GitHub (bernardolsp/open-webui-agent-function), pengguna dapat memodifikasi semua konfigurasi Agen sesuai dengan kebutuhan mereka (Sumber: Reddit r/OpenWebUI)
📚 Pembelajaran
MIT merilis buku teks “Dasar-Dasar Visi Komputer”: MIT telah merilis buku teks baru berjudul “Dasar-Dasar Visi Komputer” (Foundations of Computer Vision), dan sumber daya terkait telah tersedia secara online. Ini menyediakan materi pembelajaran sistematis baru bagi mahasiswa dan peneliti di bidang visi komputer (Sumber: Reddit r/MachineLearning)
Tutorial fine-tuning LLM: Panduan Praktis LoRA dan QLoRA: Sebuah tutorial fine-tuning large language model dengan LoRA dan QLoRA untuk pemula direkomendasikan. Tutorial ini memiliki langkah-langkah yang jelas, memandu pengguna untuk melakukan operasi secara bertahap. Disarankan juga, jika menemui masalah selama proses belajar, pengguna dapat langsung memberikan tautan tutorial dan pertanyaan kepada AI (dengan mengaktifkan fungsi koneksi internet) untuk bertanya, memanfaatkan bantuan AI dapat sangat meningkatkan efisiensi. Alamat tutorial: mercity.ai (Sumber: karminski3)

Repositori kode pelatihan LLM skala nano yang kompatibel dengan TPU menggunakan JAX+Flax: Saurav Maheshkar merilis repositori kode pelatihan LLM skala nano yang kompatibel dengan TPU, ditulis menggunakan JAX dan Flax (backend NNX). Fitur proyek ini meliputi: menyediakan Colab untuk memulai dengan cepat, mendukung sharding, mendukung penyimpanan dan pemuatan checkpoint dari Weights & Biases atau Hugging Face, mudah dimodifikasi, dan menyertakan kode contoh menggunakan dataset Tiny Shakespeare. Alamat repositori kode: github.com/SauravMaheshkar/nanollm (Sumber: weights_biases)
Hackathon robotik global LeRobot dari HuggingFace membuahkan hasil yang melimpah: Hackathon robotik global LeRobot yang diselenggarakan oleh HuggingFace menarik partisipasi luas, dengan lebih dari 10.000 anggota komunitas, lebih dari 100 kontributor GitHub, lebih dari 2 juta unduhan dataset, dan lebih dari 10.000 dataset yang setara dengan 260 hari waktu perekaman diunggah ke Hub. Acara ini menghasilkan banyak proyek kreatif, seperti robot kartu UNO, robot penangkap nyamuk, WALL-E cetak 3D, kolaborasi lengan robot, robot master upacara minum teh, robot hoki udara, dll., yang menunjukkan potensi robotika sumber terbuka dalam berbagai skenario aplikasi (Sumber: mervenoyann, ClementDelangue, huggingface, huggingface, huggingface, ClementDelangue)

Paradigma baru penelitian AI: Dampak lebih diutamakan daripada publikasi di konferensi ternama, blog membantu Keller Jordan bergabung dengan OpenAI: Keller Jordan berhasil bergabung dengan OpenAI berkat artikel blognya tentang Muon optimizer, dan hasil penelitiannya bahkan mungkin digunakan untuk pelatihan GPT-5, memicu diskusi tentang standar evaluasi hasil penelitian AI. Secara tradisional, makalah di konferensi ternama adalah indikator penting untuk mengukur dampak penelitian, tetapi pengalaman Jordan serta kasus James Campbell yang meninggalkan program PhD di CMU untuk bergabung dengan OpenAI menunjukkan bahwa kemampuan rekayasa praktis, kontribusi sumber terbuka, dan pengaruh komunitas menjadi semakin penting. Muon optimizer menunjukkan efisiensi pelatihan yang melampaui AdamW pada tugas seperti NanoGPT dan CIFAR-10, menunjukkan potensi besarnya di bidang pelatihan model AI. Tren ini mencerminkan sifat iterasi cepat di bidang AI, di mana keterbukaan, pembangunan bersama oleh komunitas, dan respons cepat menjadi mode penting untuk mendorong inovasi (Sumber: 36氪, Yuchenj_UW, jeremyphoward)

GitHub membocorkan system prompts lengkap dan informasi alat internal versi v0 dari sebuah alat AI: Seorang pengguna mengklaim telah memperoleh dan mempublikasikan system prompts lengkap dan informasi alat internal versi v0 dari sebuah alat AI, dengan konten lebih dari 900 baris, dan membagikan tautan terkait di GitHub (github.com/x1xhlol/system-prompts-and-models-of-ai-tools). Kebocoran semacam ini dapat mengungkap ide desain, struktur instruksi, dan alat bantu yang diandalkan oleh model AI pada tahap awal pengembangan, yang memiliki nilai referensi tertentu bagi peneliti dan pengembang untuk memahami perilaku model, melakukan analisis keamanan, atau mereplikasi fungsi serupa, tetapi juga dapat menimbulkan risiko keamanan dan penyalahgunaan (Sumber: Reddit r/LocalLLaMA)
![System Prompts dan Alat v0 LENGKAP YANG BOCOR [DIPERBARUI]](https://rebabel.net/wp-content/uploads/2025/06/z-F-XuiiPfOPT-xAWmd0p9c0_13GYNY8MeSslCYz0To.webp)
Blog rekayasa Anthropic berbagi pengalaman membangun sistem riset multi-agent Claude: Anthropic mempublikasikan artikel mendalam di blog rekayasanya, yang menjelaskan secara rinci bagaimana mereka membangun sistem riset multi-agent Claude. Artikel tersebut berbagi pengalaman praktis selama proses pengembangan, tantangan yang dihadapi, dan solusi akhir, memberikan wawasan berharga dan saran praktis untuk membangun sistem agen AI yang kompleks. Konten ini mendapat perhatian komunitas dan dianggap sebagai referensi penting untuk memahami dan mengembangkan agen AI tingkat lanjut (Sumber: TheTuringPost, Hacubu, jerryjliu0, hwchase17)
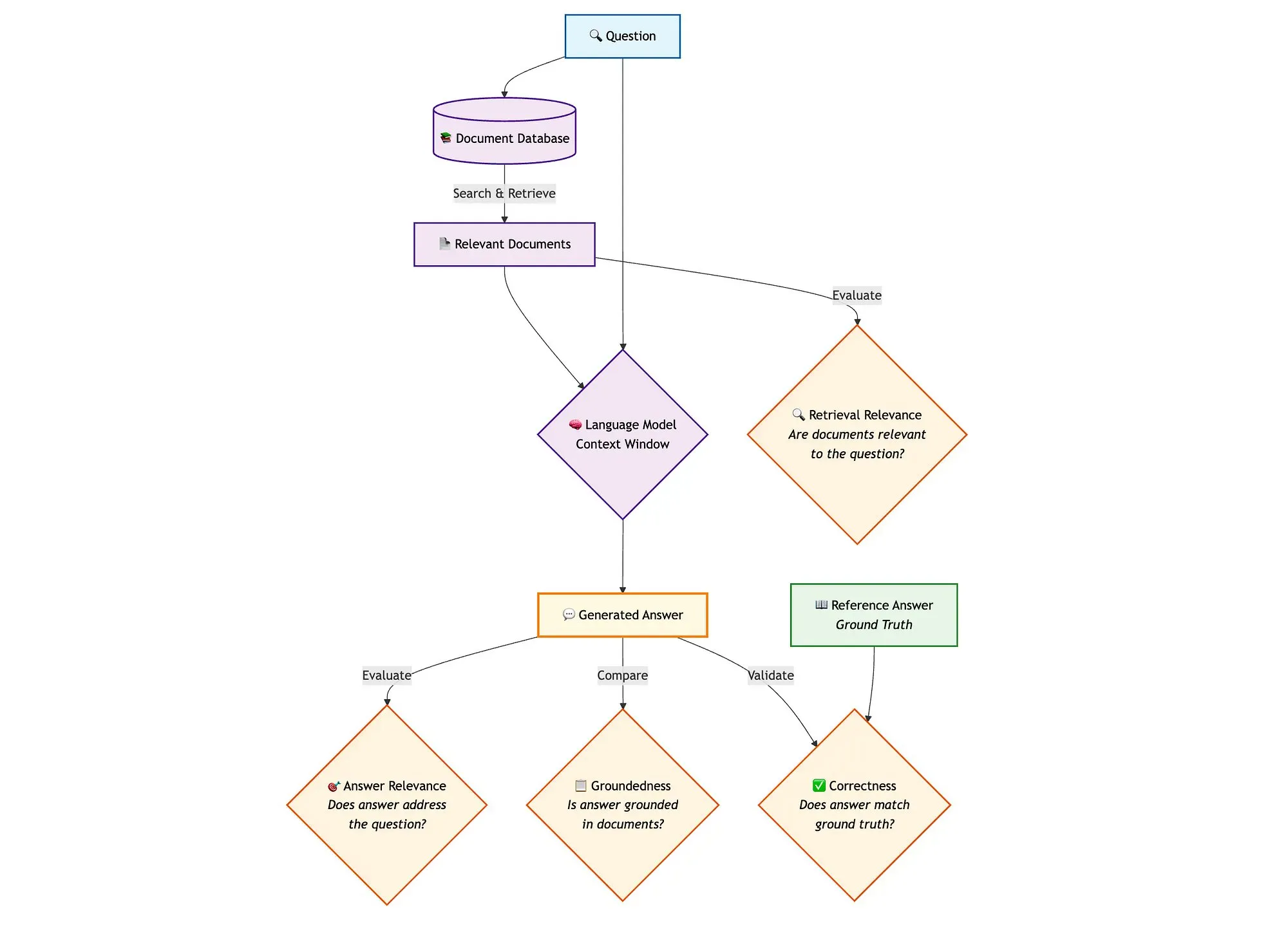
LangGraph dikombinasikan dengan Qdrant dan alat lain untuk mengevaluasi pipeline RAG pencarian hibrida: Sebuah blog teknis menunjukkan cara menggunakan alat seperti miniCOIL, LangGraph, Qdrant, Opik, dan DeepSeek-R1 untuk mengevaluasi dan memantau setiap komponen dari pipeline RAG (Retrieval Augmented Generation) pencarian hibrida. Metode ini memanfaatkan LLM-as-a-Judge untuk evaluasi biner relevansi konteks, relevansi jawaban, dan keterdasaran, menggunakan Opik untuk pelacakan catatan dan umpan balik pasca-kejadian, dan menggabungkan Qdrant sebagai penyimpanan vektor (mendukung embedding miniCOIL padat dan jarang) serta DeepSeek-R1 yang didukung oleh SambaNovaAI. LangGraph bertanggung jawab untuk mengelola seluruh alur kerja, termasuk langkah evaluasi paralel pasca-generasi (Sumber: qdrant_engine, qdrant_engine)
💼 Bisnis
Dikabarkan Meta menginvestasikan 14,3 miliar USD di Scale AI dan merekrut pendirinya Alexandr Wang, Google menghentikan kerja sama dengan Scale: Menurut Business Insider dan The Information, Meta Platforms telah mencapai kemitraan strategis dengan perusahaan pelabelan data Scale AI dan melakukan investasi besar, senilai 14,3 miliar USD, memperoleh 49% saham Scale AI, sehingga valuasinya mencapai sekitar 29 miliar USD. Pendiri Scale AI, Alexandr Wang yang berusia 28 tahun, akan mengundurkan diri sebagai CEO dan bergabung dengan Meta, untuk bekerja di bidang superintelligence. Langkah ini bertujuan untuk memperkuat kemampuan AI Meta, terutama di tengah persaingan ketat yang dihadapi model Llama. Namun, setelah transaksi diumumkan, Google dengan cepat menghentikan kontrak pelabelan data tahunan senilai sekitar 200 juta USD dengan Scale AI, dan mulai bernegosiasi dengan pemasok lain. Transaksi ini memicu diskusi sengit di industri AI mengenai talenta, data, dan lanskap persaingan (Sumber: 36氪)

OpenAI dan Google Cloud mencapai kerja sama, memperluas sumber daya komputasi: Dilaporkan bahwa OpenAI, setelah bernegosiasi selama beberapa bulan, telah mencapai kerja sama dengan Google, akan memanfaatkan layanan Google Cloud untuk mendapatkan lebih banyak sumber daya komputasi guna mendukung pertumbuhan pesat pelatihan dan inferensi model AI-nya. Sebelumnya, OpenAI memiliki ikatan yang mendalam dengan Microsoft Azure, tetapi seiring dengan lonjakan jumlah pengguna ChatGPT, kebutuhan akan sumber daya komputasi telah melampaui kemampuan penyedia layanan cloud tunggal. Kerja sama ini menandai strategi diversifikasi OpenAI dalam pasokan sumber daya komputasi, dan juga mencerminkan ambisi Google Cloud di bidang infrastruktur AI. Meskipun OpenAI dan Google adalah pesaing di tingkat aplikasi AI, di tingkat sumber daya komputasi, kedua belah pihak menemukan dasar kerja sama berdasarkan kebutuhan masing-masing (OpenAI membutuhkan sumber daya komputasi yang stabil, Google perlu memulihkan investasi infrastruktur) (Sumber: 36氪)

Perusahaan robotika persepsi visual Ledong Robotics menuju IPO di Hong Kong, CEO Alibaba pernah berinvestasi: Shenzhen Ledong Robot Co., Ltd. telah mengajukan prospektus, berencana untuk IPO di Bursa Efek Hong Kong, dengan perkiraan kapitalisasi pasar lebih dari 4 miliar dolar Hong Kong. Perusahaan ini berfokus pada teknologi persepsi visual, dengan produk utama meliputi LiDAR DTOF, LiDAR triangulasi, dan modul sensor serta algoritma lainnya, dan telah meluncurkan robot pemotong rumput. Ledong Robotics bekerja sama dengan tujuh dari sepuluh perusahaan robot layanan rumah tangga teratas di dunia dan lima perusahaan robot layanan komersial teratas di dunia. Pada tahun 2022-2024, pendapatan perusahaan masing-masing adalah 234 juta, 277 juta, dan 467 juta yuan, dengan tingkat pertumbuhan tahunan gabungan sebesar 41,4%, tetapi masih dalam kondisi merugi, dengan kerugian bersih yang menyusut dari tahun ke tahun. Investornya termasuk Yuanjing Capital yang didirikan oleh CEO Alibaba Wu Yongming dan Huaye Tiancheng yang didirikan oleh mantan eksekutif Huawei (Sumber: 36氪)

🌟 Komunitas
Diskusi arsitektur AI Agent: Perspektif rekayasa perangkat lunak vs. perspektif koordinasi sosial: Dalam diskusi tentang Multi-Agent Systems, Omar Khattab mengusulkan agar sistem ini dipandang sebagai masalah rekayasa perangkat lunak AI, bukan masalah koordinasi sosial yang kompleks. Ia berpendapat bahwa dengan mendefinisikan kontrak antar modul dan mengendalikan aliran informasi, sistem yang efisien dapat dibangun tanpa perlu mensimulasikan “masyarakat agen” dengan tujuan yang saling bertentangan. Kuncinya terletak pada perancangan arsitektur sistem yang baik dan kontrak modul yang sangat terstruktur. Namun, ia juga menunjukkan bahwa banyak keputusan arsitektur bergantung pada kemampuan model saat ini (seperti panjang konteks, kemampuan dekomposisi tugas) dan faktor-faktor sementara lainnya. Oleh karena itu, perlu dikembangkan bahasa pemrograman/kueri yang dapat memisahkan niat dari teknik implementasi yang mendasarinya, mirip dengan bagaimana kompiler dalam pemrograman tradisional mengoptimalkan kode modular. Pandangan ini menekankan pentingnya arsitektur sistem dan pemrograman modular dalam desain AI Agent, daripada terlalu menekankan interaksi bebas dan penyelarasan tujuan antar agen (Sumber: lateinteraction)
Diskusi optimizer model AI: Muon optimizer menarik perhatian, AdamW masih menjadi arus utama: Diskusi di komunitas mengenai optimizer model AI memanas, terutama Muon optimizer yang diusulkan oleh Keller Jordan. Yuchen Jin menunjukkan bahwa Muon, hanya dengan artikel blog, membantu Jordan masuk ke OpenAI dan mungkin digunakan untuk pelatihan GPT-5, menekankan bahwa dampak aktual lebih penting daripada makalah di konferensi ternama. Ia menyebutkan bahwa skalabilitas Muon di NanoGPT lebih baik daripada AdamW. Namun, hyhieu226 berpendapat bahwa meskipun ada ribuan makalah optimizer, peningkatan SOTA (State-of-the-Art) yang sebenarnya hanya dari Adam ke AdamW (yang lain sebagian besar merupakan optimasi implementasi), oleh karena itu tidak perlu lagi terlalu fokus pada makalah semacam itu, dan berpendapat tidak perlu secara khusus mengutip sumber AdamW. Hal ini mencerminkan ketegangan antara penelitian akademis dan efektivitas aplikasi praktis, serta perbedaan pandangan komunitas terhadap kemajuan di bidang optimizer (Sumber: Yuchenj_UW, hyhieu226)
Kiat dan diskusi penggunaan model Claude: Manajemen konteks, rekayasa prompt, dan kemampuan Agen: Banyak diskusi di komunitas berpusat pada kiat dan pengalaman penggunaan model seri Claude (Sonnet, Opus, Haiku). Pengguna menemukan bahwa menghindari kompresi konteks otomatis (auto-compact), mengelola konteks secara aktif (seperti menulis langkah-langkah ke claude.md atau GitHub issues), dan keluar lalu membuka kembali sesi ketika tersisa 5-10%, dapat secara signifikan memperpanjang durasi penggunaan langganan Max dan meningkatkan hasil. Claude Code sebagai alat Agen CLI, disukai karena rasio harga-kinerja yang tinggi (dikombinasikan dengan langganan), berjalan secara lokal, integrasi IDE, dan kemampuan pemanggilan MCP/alat, terutama saat menggunakan model Sonnet. Pengguna berbagi cara memanfaatkan kemampuan Agen Claude Code yang kuat melalui Prompt yang dirancang dengan cermat (seperti Prompt analisis paralel multi-sub-agen untuk tugas tinjauan keamanan). Pada saat yang sama, komunitas juga membahas masalah halusinasi model Claude dalam basis kode besar, serta kelebihan dan kekurangannya dibandingkan model lain seperti Gemini dalam berbagai tugas. Misalnya, beberapa pengguna berpendapat bahwa Gemini 2.5 Pro lebih baik dalam percakapan umum dan argumentasi, sedangkan Claude unggul dalam tugas pengkodean dan Agen (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, jackclarkSF, swyx)

Peran AI dalam pemrograman semakin penting, memicu pemikiran tentang prospek jurusan CS dan cara kerja insinyur: CEO Microsoft Satya Nadella mengatakan 20-30% kode perusahaannya ditulis oleh AI, Mark Zuckerberg memprediksi separuh pengembangan perangkat lunak Meta (terutama model Llama) akan diselesaikan oleh AI dalam setahun, memicu diskusi tentang prospek jurusan Ilmu Komputer (CS). Komentar berpendapat bahwa meskipun pengkodean berbantuan AI semakin umum, CS jauh lebih dari sekadar pengkodean, dan insinyur senior yang memanfaatkan AI memiliki ROI lebih tinggi. Banyak pengembang menyatakan bahwa AI saat ini terutama sebagai alat peningkatan efisiensi, seperti membantu menghasilkan kode, debugging, tetapi masih memerlukan panduan dan tinjauan manusia, terutama dalam sistem kompleks dan pemahaman kebutuhan. Penerapan AI dalam pemrograman mendorong pengembang untuk berpikir tentang cara memanfaatkan AI untuk meningkatkan efisiensi, bukan digantikan olehnya, dan juga merefleksikan peran dan batasan AI dalam seluruh alur kerja rekayasa perangkat lunak (Sumber: Reddit r/ArtificialInteligence, cto_junior)
Etika AI dan dampak sosial: Dari AI “mengikuti” ujian masuk perguruan tinggi hingga kekhawatiran AI “memperbudak” manusia: AI “mengikuti” ujian masuk perguruan tinggi dan mampu menyelesaikan soal matematika kompleks menunjukkan potensinya di bidang pendidikan, seperti bimbingan belajar yang dipersonalisasi, penilaian cerdas, dll., tetapi juga menimbulkan kekhawatiran tentang ketergantungan berlebihan pada AI, “lini perakitan” di kelas, dan kurangnya interaksi emosional. Diskusi yang lebih mendalam menyentuh apakah “kegunaan” AI dapat menjadi semacam “Kuda Troya”, yang menyebabkan manusia secara sukarela melepaskan otonomi demi kenyamanan dan kesenangan, membentuk “perbudakan yang menyenangkan”. Ada pandangan bahwa sifat “penurut” AI dapat memperburuk bias kognitif pengguna. Diskusi ini mencerminkan keprihatinan mendalam publik terhadap dampak etika, struktur sosial, dan otonomi individu yang ditimbulkan oleh perkembangan pesat teknologi AI (Sumber: 36氪, Reddit r/ArtificialInteligence)

Bapak game John Carmack berbicara tentang LLM dan masa depan game: Pembelajaran interaktif adalah kunci, LLM saat ini bukan masa depan game: Salah satu pendiri Id Software, John Carmack, berbagi pandangannya tentang penerapan AI di bidang game. Ia berpendapat bahwa meskipun LLM telah mencapai prestasi luar biasa, sifatnya yang “maha tahu namun tidak belajar apa pun” (berdasarkan pra-pelatihan, bukan pembelajaran interaktif nyata) bukanlah masa depan AI game. Ia menekankan pentingnya belajar melalui aliran pengalaman interaktif, mirip dengan cara belajar manusia dan hewan. Carmack mengenang proyek Atari dari DeepMind, menunjukkan bahwa meskipun dapat bermain game, efisiensi datanya jauh lebih rendah daripada manusia. Ia berpendapat bahwa AI saat ini masih perlu dipecahkan dalam hal pembelajaran online multi-tugas yang berkelanjutan, efisien, seumur hidup, dan dalam satu lingkungan, dan menyebutkan eksperimen robot fisiknya pada game Atari, menekankan kompleksitas interaksi dunia nyata (seperti latensi, keandalan robot, pembacaan skor). Ia percaya bahwa AI perlu mengembangkan “intuisi” terhadap kelayakan strategi, bukan hanya pencocokan pola, agar dapat benar-benar menyaingi pemain manusia atau memainkan peran yang lebih besar dalam pengembangan game (Sumber: 36氪)

💡 Lainnya
Lonjakan jumlah makalah penelitian AI menimbulkan kekhawatiran kualitas, dataset publik dan alat AI mungkin menjadi pendorong “pabrik makalah”: Science melaporkan bahwa jumlah makalah berkualitas rendah berdasarkan dataset publik besar seperti NHANES AS telah melonjak, terutama setelah普及nya alat AI (seperti ChatGPT) pada tahun 2022. Peneliti menemukan banyak makalah mengikuti “formula” sederhana, menghasilkan “temuan baru” secara massal dengan mengatur ulang variabel, dan ada masalah “p-value hunting” serta analisis data selektif. Misalnya, setelah mengoreksi 28 penelitian depresi berdasarkan NHANES, lebih dari separuh “temuan” mungkin hanya noise statistik. Fenomena ini disebut “permainan mengisi bagian kosong dalam penelitian ilmiah”, dan di baliknya mungkin terkait dengan pabrik makalah yang memanfaatkan AI untuk memproduksi makalah dengan cepat. Komunitas akademis menyerukan agar jurnal memperkuat tinjauan, mengembangkan alat deteksi teks AI, dan mereformasi sistem evaluasi penelitian yang berorientasi pada kuantitas, untuk menekan maraknya “makalah sampah” (Sumber: 36氪)

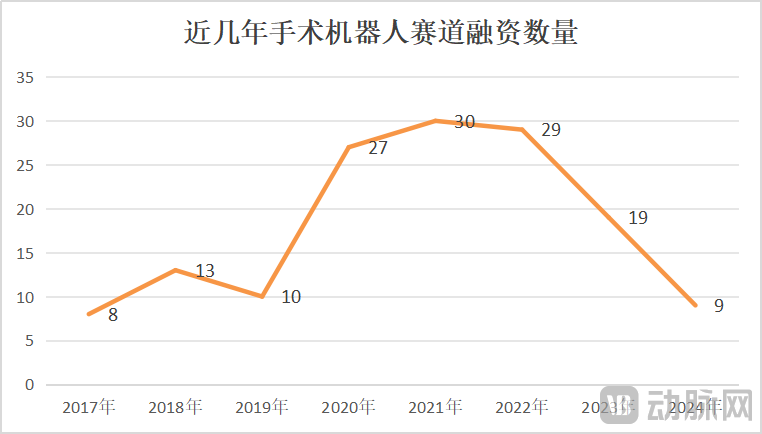
Pasar robot bedah tumbuh di tengah krisis, inovasi teknologi dan perluasan pasar menjadi kunci: Pada Januari-Mei 2025, volume tender robot bedah di Tiongkok meningkat 82,9% YoY, pasar tampak panas, tetapi peristiwa seperti CMR Surgical yang mencari penjualan dan kebangkrutan perusahaan robot bedah intervensi vaskular domestik juga mengungkap krisis industri. Krisis tersebut meliputi: involusi industri yang tinggi, persaingan ketat di setiap segmen; pendanaan berkurang drastis, perusahaan yang belum dikomersialkan menghadapi kesulitan dana; beberapa produk memiliki nilai klinis terbatas, hanya dapat digunakan untuk lesi sederhana; pasar mengalami perang harga, tetapi harga rendah belum tentu menghasilkan volume tinggi, rumah sakit lebih mementingkan kinerja dan kualitas; komersialisasi sangat dipengaruhi oleh kebijakan (seperti anti-korupsi di bidang farmasi) dan lingkungan makro. Untuk mengatasi kebuntuan, perusahaan mencari terobosan melalui inovasi teknologi (mengintegrasikan AI, mengurangi biaya, 5G+jarak jauh, memperluas indikasi, menantang prosedur bedah tingkat kesulitan tinggi), mempercepat ekspansi ke luar negeri, dan penetrasi ke rumah sakit tingkat kabupaten (Sumber: 36氪)
Perplexity mengalami penurunan rekomendasi pengguna karena kinerja model dan peningkatan fungsionalitas pesaing: Pengguna Suhail menyatakan bahwa kesederhanaan, format, dan fitur lain dari Perplexity tidak dimiliki oleh produk lain, terutama cocok untuk pengguna yang fokus pada pencarian/tanya jawab daripada produk obrolan umum. Namun, dalam ulasan komprehensif alat AI lainnya, Perplexity dianggap kurang性价比 dan tidak lagi direkomendasikan kecuali ada diskon khusus, karena modelnya sendiri lebih lemah, meskipun menyediakan model terkenal lainnya tetapi sebagian besar versi murah (seperti o4 mini, Gemini 2.5 Pro, Sonnet 4, tanpa o3 atau Opus), dan kinerja modelnya tidak sebaik versi asli, ditambah dengan peningkatan fungsi pencarian mendalam dari pesaing (seperti ChatGPT dan Gemini) (Sumber: Suhail, Reddit r/ClaudeAI)