
Kata Kunci:VGGT, 3D Vision, Transformer, CVPR 2025, Meta, University of Oxford, Autonomous Driving, AI Safety, Vision Geometry Transformer, Single Feedforward 3D Prediction, SafeKey Framework, Waymo Autonomous Driving Research, Doubao Large Model 1.6
🔥 Fokus
VGGT: Meta dan Universitas Oxford mengusulkan Visual Geometry Transformer, memprediksi informasi adegan 3D lengkap dalam satu kali forward pass, memenangkan penghargaan Best Paper di CVPR 2025: VGGT (Visual Geometry Grounded Transformer) yang diusulkan bersama oleh Meta dan Universitas Oxford menjadi satu-satunya Best Paper di CVPR 2025. Model ini didasarkan pada Vision Transformer, menggunakan mekanisme self-attention “global-antar frame” secara bergantian, dan dapat memprediksi informasi adegan 3D lengkap secara end-to-end dalam satu kali forward pass, termasuk parameter intrinsik dan ekstrinsik kamera, peta kedalaman (depth map), peta titik awan (point cloud), dan lintasan 3D. VGGT belajar mandiri hanya melalui sejumlah besar data beranotasi 3D, tanpa memerlukan bias induktif geometris, menunjukkan kinerja yang sangat baik saat memproses input 1 hingga 200 gambar, melampaui berbagai metode geometri atau deep learning yang ada, dan menunjukkan potensi aplikasi yang luas di bidang visi 3D (Sumber: 量子位)

CEO Nvidia Jensen Huang dan CEO Anthropic berbeda pandangan mengenai pengembangan AI: CEO Nvidia Jensen Huang menyatakan dalam konferensi pers di Paris bahwa ia hampir tidak setuju dengan semua pandangan CEO Anthropic Dario Amodei mengenai AI. Jensen Huang menunjukkan bahwa Amodei berpendapat AI terlalu berbahaya dan harus dikendalikan oleh segelintir perusahaan; biaya AI mahal dan perusahaan lain tidak boleh terlibat; serta AI akan menyebabkan pengangguran massal. Jensen Huang membantah dengan menyatakan bahwa AI adalah teknologi penting yang harus dikembangkan secara terbuka, aman, dan bertanggung jawab, bukan dalam lingkungan tertutup, serta menekankan pentingnya keterbukaan untuk keamanan (Sumber: hardmaru)
Framework SafeKey meningkatkan keamanan model penalaran besar (LRM), mengurangi tingkat risiko sebesar 9,6%: Tim peneliti dari University of California Santa Cruz, Berkeley, Cisco Research, dan Yale University mengusulkan framework SafeKey, yang bertujuan untuk meningkatkan keamanan model penalaran besar (LRM). Penelitian menemukan bahwa “jailbreak” model terkait dengan kegagalan memanfaatkan sinyal keamanan “kalimat kunci” awal secara efektif. SafeKey memperkuat sinyal keamanan melalui “kepala keamanan jalur ganda” dan memaksa model untuk mengandalkan pemahamannya sendiri dalam membuat keputusan keamanan melalui “pemodelan penyamaran kueri”. Eksperimen menunjukkan bahwa SafeKey dapat mengurangi tingkat respons berbahaya sebesar 9,6% tanpa memengaruhi kemampuan inti model secara signifikan (bahkan sedikit meningkatkannya), terutama menunjukkan kinerja yang lebih baik dalam menghadapi serangan yang tidak diketahui (Sumber: 量子位)

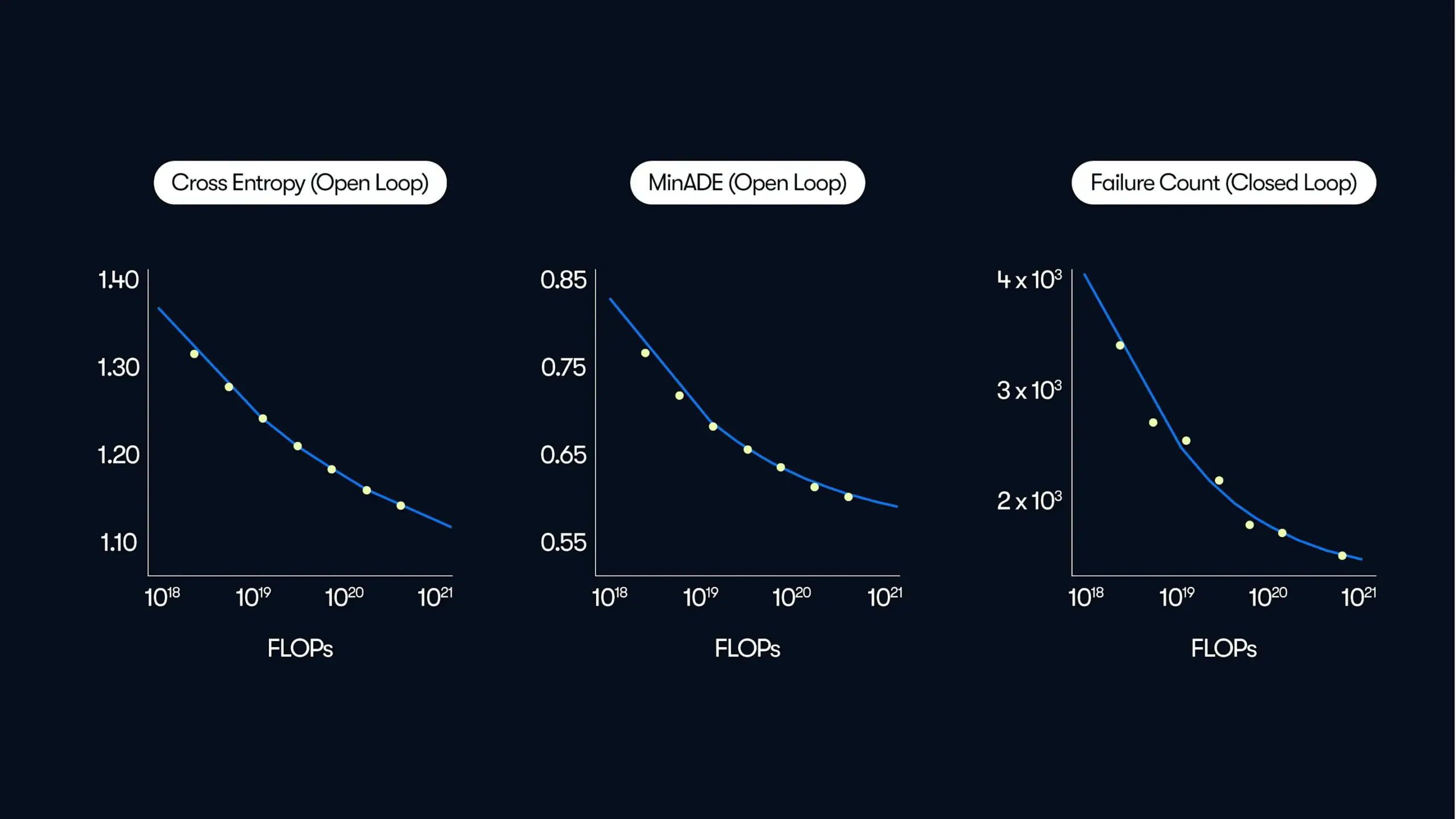
Penelitian Waymo menunjukkan kinerja sistem self-driving meningkat secara power law seiring dengan skala data dan komputasi: Waymo merilis studi komprehensif berdasarkan 500.000 jam data mengemudi, yang mengungkapkan adanya hubungan power law antara kualitas prediksi gerakan dalam sistem self-drivingnya dan jumlah komputasi pelatihan, serupa dengan hukum penskalaan pada Large Language Models (LLM). Studi ini menekankan bahwa skala data sangat penting untuk meningkatkan kinerja model, sementara peningkatan komputasi inferensi juga dapat meningkatkan kemampuan model dalam menangani skenario mengemudi yang kompleks. Penelitian ini untuk pertama kalinya menunjukkan bahwa kinerja self-driving di dunia nyata dapat ditingkatkan dengan menambah data pelatihan dan sumber daya komputasi (Sumber: zacharynado)
🎯 Perkembangan
ByteDance merilis Doubao Large Model 1.6 dan berbagai aplikasi AI, menekankan kemampuan kombinasi dan implementasi produk: ByteDance baru-baru ini secara intensif merilis serangkaian produk AI termasuk Doubao Large Model 1.6, model generasi video Seedance 1.0 Pro, serta model podcast suara dan suara real-time. Doubao 1.6 meningkatkan kemampuan pemrosesan dan operasi multimodal, mendukung pencarian sambil berpikir dan DeepResearch, serta dapat melakukan operasi antarmuka grafis. Seedance 1.0 Pro menunjukkan kinerja luar biasa dalam hal koherensi dan stabilitas generasi video, mendukung generasi video 10 detik 1080p. Strategi ByteDance lebih berfokus pada pengintegrasian kemampuan AI ke dalam aplikasi yang dapat langsung dijalankan dan disematkan ke dalam produk yang sudah ada (seperti aplikasi Doubao, Volcano Engine), menekankan kemampuan kombinasi dan produkisasi cepat, daripada hanya mengejar keunggulan parameter model tunggal. Strategi penetapan harganya juga lebih hemat biaya, bertujuan untuk menurunkan ambang batas penggunaan AI (Sumber: 36氪)
Model Tencent Hunyuan 3D 2.1 menjadi open source, fokus pada tekstur PBR dan kompatibilitas dengan kartu grafis kelas konsumen: Tencent mengumumkan di konferensi CVPR bahwa mereka akan membuka sumber model generasi 3D terbarunya, Hunyuan 3D 2.1. Model ini telah dioptimalkan ganda dalam hal akurasi geometris dan detail tekstur, terutama memperkenalkan teknologi generasi tekstur PBR (Physically Based Rendering), yang dapat merender material kompleks seperti kulit, logam, dan keramik dengan kualitas tinggi, menghasilkan efek visual yang realistis. Hunyuan 3D 2.1 telah mencapai open source penuh, termasuk bobot model, kode pelatihan, dan alur pemrosesan data, serta mendukung pengoperasian pada kartu grafis kelas konsumen dan deployment sekali klik, bertujuan untuk mempromosikan populasi pembuatan konten 3D (Sumber: 量子位)

Perplexity AI secara aktif meningkatkan fungsi Deep Research sebagai respons terhadap umpan balik pengguna: CEO Perplexity AI Arav Srinivas menyatakan bahwa tim telah mendengarkan dengan saksama umpan balik negatif mengenai fungsi Deep Research mereka dan telah mulai melakukan perbaikan. Sebagian perbaikan telah diluncurkan di lingkungan produksi, dan pengguna seharusnya dapat merasakan peningkatan pengalaman. Di masa mendatang, fungsi Deep Research dan Labs akan diintegrasikan ke dalam produk Comet, yang bertujuan untuk mengoptimalkan proses pengambilan keputusan pengguna dengan memanfaatkan konteks dan data pribadi (Sumber: AravSrinivas)
Penelitian Anthropic mengungkapkan sistem multi-agen dapat meningkatkan kinerja tugas secara signifikan: Penelitian yang dirilis oleh Anthropic menunjukkan bahwa penggunaan sistem multi-agen (seperti Opus sebagai agen utama dan Sonnet sebagai sub-agen) untuk menangani tugas dapat meningkatkan kinerja sebesar 90% dibandingkan dengan penggunaan Opus saja. Model kerja kolaboratif ini mirip dengan bagaimana masyarakat manusia meningkatkan produktivitas secara signifikan melalui pembagian kerja. Penelitian ini merinci cara membangun sistem penelitian multi-agen yang efektif dan membagikan metode evaluasinya, termasuk penggunaan LLM sebagai juri. Namun, beberapa komentar menunjukkan bahwa metode penelitian Claude yang dijelaskan dalam laporan mungkin memiliki masalah kedalaman pencarian yang tidak memadai (Sumber: zacharynado, omarsar0, nrehiew_)

Penelitian menunjukkan kemampuan penalaran Large Language Model dibatasi oleh “ketidakbiasaan” bukan “kompleksitas”: François Chollet menunjukkan bahwa kemampuan penalaran Large Language Model (LRM) tidak runtuh ketika mencapai ambang batas “kompleksitas” atau “jumlah langkah” tertentu, melainkan gagal ketika menghadapi tugas yang “tidak biasa”, dan ambang batas ketidakbiasaan ini sangat rendah. Model dapat menyelesaikan tugas yang sangat kompleks yang telah dicakup selama tahap pelatihan/penyesuaian, tetapi bahkan tugas baru yang sederhana (seperti tugas ARC 2) dapat gagal. Ambang batas langkah/kompleksitas yang diamati pada masalah yang familiar (seperti Menara Hanoi) sebenarnya adalah hasil dari menciptakan “kebaruan” dengan meningkatkan variabel masalah (Sumber: fchollet, jeremyphoward)
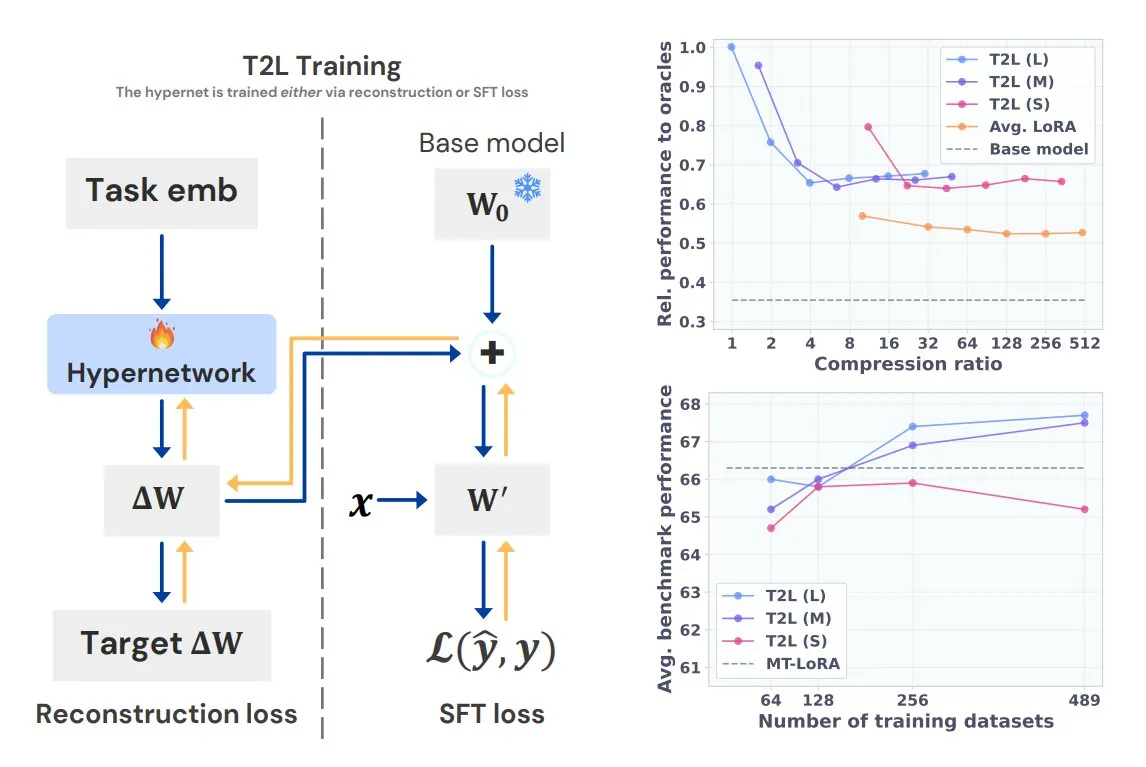
Sakana AI meluncurkan model hypernetwork Text-to-LoRA (T2L): Sakana AI merilis Text-to-LoRA (T2L), sebuah hypernetwork jenis baru yang mampu dengan cepat menghasilkan adapter LoRA baru untuk Large Language Model berdasarkan deskripsi teks tugas. T2L tidak hanya dapat mengompres beberapa LoRA yang sudah ada, tetapi juga dapat membuat LoRA baru secara instan setelah pelatihan, menyediakan jalur baru untuk kustomisasi cepat model khusus tugas. Penelitian ini akan dipresentasikan di ICML 2025 (Sumber: TheTuringPost)
Nvidia Cosmos-Predict2 (model 2B) menunjukkan kemampuan generasi gambar yang luar biasa: Cosmos-Predict2 dari Nvidia, sebuah model dengan 2 miliar parameter, diposisikan sebagai “platform model dasar dunia untuk AI fisika,” menunjukkan kemampuan yang mengesankan dalam generasi gambar artistik. Meskipun dataset dasarnya mungkin bukan yang terbaik, struktur modelnya bagus, dan kualitas gambar yang dihasilkan tidak jauh berbeda dengan versi 14B parameter, hanya sedikit kalah dalam detail dan kepatuhan terhadap prompt, menunjukkan potensi model kecil dengan optimasi tertentu (Sumber: teortaxesTex)
MIT mengembangkan algoritma baru yang memungkinkan drone menghindari badai secara otonom: MIT telah mengembangkan algoritma baru yang memberikan kemampuan pengambilan keputusan seperti “otak” kepada drone (UAVs), memungkinkannya menganalisis kondisi cuaca secara real-time dan merencanakan jalur secara otonom untuk menghindari badai. Teknologi ini diharapkan dapat meningkatkan keselamatan penerbangan dan efisiensi pelaksanaan misi drone dalam kondisi meteorologi yang kompleks (Sumber: Ronald_vanLoon)

Penelitian Meta: Model bahasa gaya GPT mengingat 3,6 bit informasi per parameter: Sebuah studi baru dari Meta menghitung bahwa model bahasa gaya GPT mampu mengingat sekitar 3,6 bit informasi per parameter. Studi ini mengevaluasi kapasitas memori model dengan mengukur jumlah total bit yang diingat (berdasarkan teori Shannon tahun 1953) dan mengamati hubungan kurva tertentu antara memori dan skala data (Sumber: jxmnop)

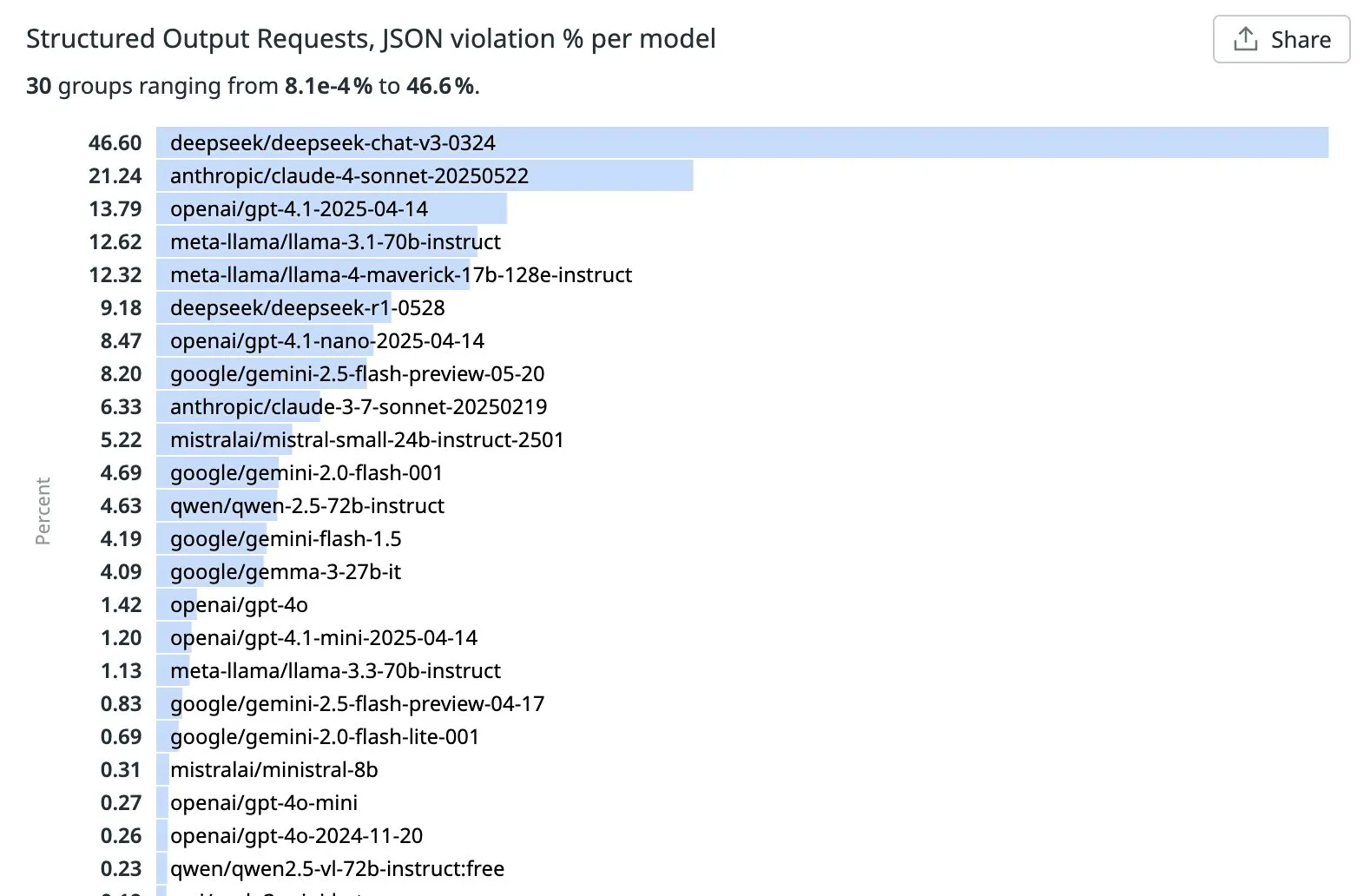
OpenRouter merilis peringkat tingkat pelanggaran LLM dalam tugas output terstruktur (JSON): OpenRouter memberi peringkat LLM utama berdasarkan persentase pelanggaran JSON yang terdeteksi dalam permintaan output terstruktur teratas selama seminggu terakhir. Hasilnya menunjukkan bahwa Qwen, Mistral, dan GPT-4o-mini berkinerja baik, dengan tingkat pelanggaran JSON yang rendah. Sementara itu, tingkat pelanggaran DeepSeek v3 dan Sonnet 4 melebihi 20%, menunjukkan masih ada ruang besar untuk perbaikan dalam mengikuti format JSON secara akurat. Saat ini belum jelas pola spesifik apa yang menyebabkan perbedaan ini (Sumber: xanderatallah, teortaxesTex)
Ant Group meluncurkan model multimodal terpadu Ming-Omni: Ant Group merilis seri model Ming-Omni, sebuah model multimodal terpadu yang mampu melakukan persepsi dan generasi lintas teks, gambar, audio, dan video. Versi ringannya, Ming-Lite-Omni, menggunakan arsitektur MoE dengan parameter aktif hanya 2,8B, memiliki kemampuan generasi gambar berkualitas tinggi dan sintesis ucapan alami, dan telah dirilis secara open source di Hugging Face dengan lisensi MIT (Sumber: teortaxesTex, _akhaliq)
Alat chip AI Tiongkok “QiMeng” menyelesaikan desain prosesor dalam beberapa hari, melampaui efisiensi insinyur: Alat desain chip AI Tiongkok “QiMeng” menunjukkan kemampuan desain prosesornya yang efisien, mampu menyelesaikan tugas desain yang biasanya membutuhkan waktu lebih lama bagi insinyur tradisional hanya dalam beberapa hari. Ini menandai potensi AI dalam otomatisasi desain chip, yang diharapkan dapat mempercepat siklus pengembangan chip dan mengurangi biaya (Sumber: Ronald_vanLoon)

Model o3-pro dari Hao AI Lab menunjukkan kinerja luar biasa dalam benchmark game LLM: Model o3-pro dari Hao AI Lab mencapai kemajuan signifikan dalam Lmgame Bench (sebuah benchmark untuk mengevaluasi kemampuan Large Language Model dalam bermain game). Dalam game Tetris dan Sokoban, o3-pro mencapai level SOTA dan jauh melampaui pendahulunya, model o3. Khususnya di Tetris, o3-pro mampu membersihkan lebih dari 8 baris, menunjukkan kemampuan perencanaannya, sementara model lain terjebak setelah beberapa baris (Sumber: clefourrier)
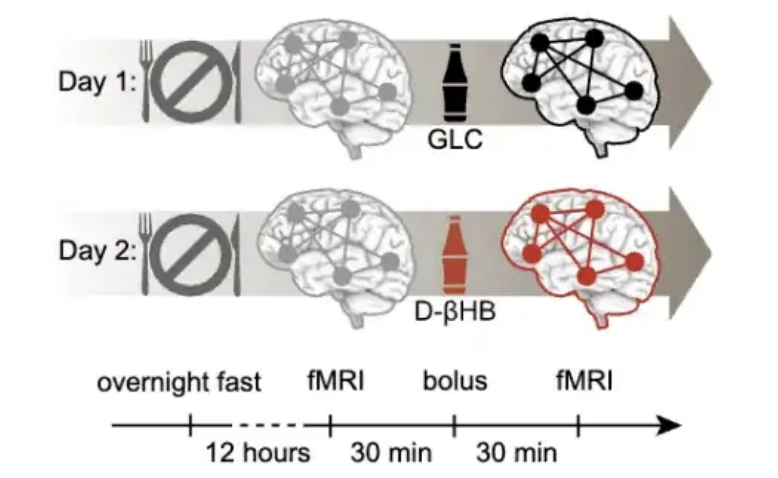
Penelitian menemukan usia 40 tahun adalah periode kritis untuk mencegah penuaan otak, intervensi keton menunjukkan efek signifikan: Sebuah penelitian yang diterbitkan di PNAS, melalui analisis data pemindaian otak dari hampir 20.000 orang, menemukan bahwa penuaan otak bukanlah proses linier, melainkan mengikuti kurva berbentuk S, dan terkait dengan peningkatan resistensi insulin. Penelitian menunjukkan bahwa sekitar usia 40 tahun adalah periode ketika ketidakstabilan jaringan otak mulai meningkat, dan kecepatan penuaan paling cepat terjadi pada usia 60-an. Eksperimen menunjukkan bahwa keton (D-βHB) dapat memasok energi ke neuron dengan melewati resistensi insulin, dan memiliki efek signifikan dalam menstabilkan jaringan otak, terutama dengan efek intervensi terbaik pada kelompok usia 40-59 tahun, memberikan ide baru untuk perawatan kesehatan otak pada usia paruh baya (Sumber: 量子位)
🧰 Alat
The Browser Company meluncurkan versi beta browser AI-native Dia: Pengembang browser Arc, The Browser Company, merilis versi beta internal browser AI-native pertamanya, Dia. Keunggulan utama Dia adalah memungkinkan pengguna berinteraksi langsung dengan konten halaman web apa pun (termasuk video YouTube, FigJam, Google Calendar, dll.) melalui obrolan, tanpa perlu membuka alat AI eksternal seperti ChatGPT. Dia dapat secara otomatis mengambil konteks dari tab, mendukung integrasi dan perbandingan informasi multi-halaman, pembuatan rencana, pembuatan konten, dan fungsi lainnya. Saat ini hanya mendukung MacOS, bertujuan untuk memberikan pengalaman menjelajah yang lebih ringkas dan mengutamakan AI (Sumber: 36氪)
LangChain meluncurkan generator podcast AI lokal: LangChain merilis generator podcast AI lokal, sistem yang dibangun menggunakan LangChain dan Ollama, yang mampu mengubah teks menjadi podcast multibahasa. Ini menggabungkan teknologi peringkasan teks dan generasi suara, mewujudkan alur kerja pembuatan podcast yang mulus. Pengguna dapat merujuk ke tutorial yang disediakan untuk mempelajari cara menggunakan alat ini (Sumber: LangChainAI, hwchase17)

Davia: Mengubah aplikasi Python dan agen LangGraph menjadi aplikasi Web dengan cepat: Davia adalah alat yang dapat secara instan mengubah aplikasi Python dan agen LangGraph menjadi aplikasi Web yang menarik, tanpa perlu menulis kode frontend apa pun. Dibangun di atas FastAPI, Davia dapat secara otomatis menghasilkan antarmuka pengguna interaktif, memungkinkan pengembang untuk fokus pada implementasi logika Python (Sumber: LangChainAI, Hacubu)
Tensorlake terintegrasi dengan LangChain, mewujudkan pemrosesan dokumen terstruktur: Tensorlake mengumumkan integrasi dengan LangChain, memungkinkan agen LangGraph untuk memanfaatkan sistem pemrosesan multimodal Tensorlake yang kuat untuk mengubah dokumen tidak terstruktur menjadi data terstruktur. Integrasi ini menyediakan solusi baru untuk menangani dokumen kompleks (Sumber: LangChainAI, hwchase17)
Quark merilis model besar pertama di Tiongkok untuk pemilihan jurusan perguruan tinggi dan fungsi laporan jurusan gratis: Quark meluncurkan model besar pertama di Tiongkok untuk pemilihan jurusan perguruan tinggi dan merilis fungsi “laporan jurusan” gratis. Model ini didasarkan pada mode operasi Agent, mampu mensimulasikan proses pengambilan keputusan ahli, dikombinasikan dengan “basis pengetahuan ujian masuk perguruan tinggi” yang diperbarui secara real-time (mencakup lebih dari 2900 perguruan tinggi, hampir 1600 program sarjana, dan informasi pekerjaan), untuk menghasilkan skema pengisian formulir jurusan yang dipersonalisasi bagi para kandidat, yang mencakup tiga tingkatan: “menantang, stabil, aman”. Langkah ini bertujuan untuk memanfaatkan teknologi AI guna mengurangi ambang batas dan biaya pengisian formulir jurusan perguruan tinggi, serta mengubah situasi konsultasi tradisional berbiaya tinggi (Sumber: 量子位)

Task Orchestrator: Alat manajemen proyek MCP yang dirancang untuk Claude Code: Pengembang jpicklyk menciptakan alat MCP (Machine-Level Code Programming) bernama Task Orchestrator, yang bertujuan untuk mengatasi masalah Claude Code yang mudah “terganggu” dan lupa konteks saat menangani proyek kompleks. Alat ini memberikan Claude memori persisten, manajemen proyek terstruktur (proyek → fitur → tugas), templat AI-native, hubungan ketergantungan cerdas, dan kemampuan pelacakan kemajuan, menjadikannya lebih seperti mitra rekayasa yang terorganisir. Proyek ini telah dirilis secara open source di GitHub (Sumber: Reddit r/ClaudeAI)
ATLAS: Mitra AI rekayasa perangkat lunak yang memberdayakan Claude Code dengan kemampuan persepsi diri: Pengembang syahiidkamil menciptakan proyek ATLAS, yang bertujuan untuk mengubah Claude Code menjadi mitra AI rekayasa perangkat lunak yang memiliki kesadaran diri awal, memori, identitas, dan standar profesional. ATLAS mampu menjaga konteks proyek, mengelola pengetahuannya sendiri, berevolusi seiring dengan commit kode, dan secara proaktif meminta tinjauan kode, sehingga mendorong alur kerja kolaborasi dan tinjauan yang lebih alami antara pengguna dan AI. Proyek ini telah dirilis secara open source di GitHub, bertujuan untuk membantu pengguna dan AI bersama-sama menjaga kualitas kode yang lebih tinggi (Sumber: Reddit r/ClaudeAI)
Observer: Asisten AI pemantau layar yang berjalan secara lokal: Observer adalah alat AI yang dapat berjalan secara lokal dan mampu memantau aktivitas layar pengguna. Melalui tutorial, pengguna dapat mempelajari cara menghosting Observer sendiri di server rumahan, memungkinkan analisis atau interaksi berbantuan AI terhadap konten layar (Sumber: Reddit r/LocalLLaMA)
VantaAI: Berbagi proyek asisten AI lokal dengan memori dan logika emosional: Seorang pengembang membagikan proyek pribadinya, VantaAI, sebuah asisten AI lokal yang dirancang untuk berjalan sepenuhnya secara offline. VantaAI mensimulasikan fitur seperti memori emosional, fluktuasi suasana hati, dan identitas pribadi, memiliki memori jangka panjang yang berevolusi berdasarkan konteks percakapan, “peta emosi” yang melacak perubahan suasana hati, dan pengelompokan memori berbasis narasi yang menganggap dirinya sebagai protagonis cerita. Proyek ini menggunakan backend Vulkan kustom untuk inferensi dan pelatihan model, serta mendukung respons berbasis kepribadian dan hot-reloading plugin (Sumber: Reddit r/LocalLLaMA)
📚 Pembelajaran
Hamel Husain dan Shreya Shankar menulis bersama buku AI Evals dan membuka kursus: Hamel Husain dan Shreya Shankar berkolaborasi menulis buku tentang evaluasi AI (Evals) dan membuka kursus terkait. Bab pertama buku dan daftar isi lengkap telah disediakan sebagai pratinjau, dengan konten yang mencakup metode evaluasi AI dari teori hingga praktik. Kursus ini juga mengundang beberapa pakar industri sebagai dosen tamu, bertujuan untuk membantu peserta meningkatkan kemampuan evaluasi sistem AI. Kursus ini mendapat pujian luas dan dianggap sebagai salah satu sumber daya terlengkap tentang evaluasi AI saat ini (Sumber: HamelHusain, HamelHusain)
Framework DSPy: Menyediakan abstraksi pemrograman tingkat tinggi untuk program model bahasa yang kompleks: Tim Stanford NLP menekankan bahwa framework DSPy bertujuan untuk menjadi bahasa berbandwidth tinggi untuk interaksi yang presisi dengan komputer. DSPy memungkinkan pengembang untuk membangun dan mengoptimalkan program model bahasa multi-tahap yang kompleks (Compound AI Systems), mendukung struktur program arbitrer seperti rekursi, penanganan pengecualian, alur kontrol bersarang, dan bukan hanya “rantai” atau “aliran” sederhana. Pengoptimalnya berdedikasi untuk menyesuaikan instruksi, demonstrasi, dan bobot dalam program komputer arbitrer yang dapat memanggil satu atau lebih LLM secara arbitrer (Sumber: stanfordnlp)
Terence Tao menjadi tamu di podcast Lex Fridman, membahas teka-teki matematika, fisika, dan masa depan AI: Matematikawan terkenal Terence Tao diwawancarai oleh Lex Fridman, membahas secara mendalam masalah paling menantang dalam matematika dan fisika, seperti persamaan Navier-Stokes, masalah P vs NP, dan memandang ke depan potensi kecerdasan buatan dalam membantu memecahkan teka-teki ini. Konten podcast juga mencakup pembuktian teorema berbantuan AI, bahasa pemrograman Lean, AlphaProof dari DeepMind, dan kemungkinan AI memenangkan Fields Medal (Sumber: , arohan)

Tim Phillip Isola merilis buku teks visi komputer online gratis: Phillip Isola dan timnya merilis buku teks visi komputer yang mereka tulis secara online dan gratis. Situs web buku teks (visionbook.mit.edu) sedang mengembangkan komponen interaktif, seperti fungsi pencarian dan integrasi dengan LLM (versi beta), bertujuan untuk menyediakan sumber belajar yang lebih nyaman bagi pembelajar, dan mendorong pengguna untuk membantu meningkatkan konten buku teks melalui isu GitHub (Sumber: jeremyphoward, natolambert)
Hugging Face meluncurkan kursus pengantar MCP: Hugging Face bekerja sama dengan Theodora Chu untuk meluncurkan kursus pengantar MCP (Master Control Program, mungkin merujuk pada kontrol AI Agent atau sistem multi-agen) baru. Kursus ini bertujuan untuk membantu pembelajar memahami dan menguasai pengetahuan dan keterampilan terkait MCP (Sumber: huggingface, ClementDelangue)
Penelitian penyelarasan DINOv2 dengan teks (dino.txt) tampil di CVPR 2025: Sebuah penelitian bernama dino.txt dipresentasikan di CVPR 2025, yang didedikasikan untuk menyelaraskan fitur DINOv2 yang dibekukan dengan teks keterangan, untuk mencapai penyelarasan visual-bahasa tingkat gambar dan patch dengan biaya rendah. Hal ini memungkinkan model untuk secara bersamaan memanfaatkan fitur visual berkualitas tinggi dari DINOv2 dan kemampuan penyelarasan visual-bahasa gaya CLIP (Sumber: TimDarcet, andersonbcdefg)

💼 Bisnis
Unicorn AI yang didukung Tencent, Minglue Technology, mengajukan IPO di Hong Kong dengan valuasi 12 miliar RMB: Perusahaan perangkat lunak aplikasi intelijen data Minglue Technology (sebelumnya dikenal sebagai “Huizhi Holdings”) telah mengajukan prospektus ke Bursa Efek Hong Kong. Perusahaan ini didirikan pada tahun 2005 oleh alumni Sekolah Matematika Universitas Peking, Wu Minghui, dan berfokus pada penyediaan dukungan keputusan pemasaran dan operasional untuk perusahaan menggunakan model besar, pengetahuan industri, dan data multimodal. Produk intinya meliputi Miaozhen Systems, Jinshuju, dll., melayani pelanggan termasuk 135 perusahaan Fortune 500 seperti Procter & Gamble dan McDonald’s. Tencent adalah pemegang saham terbesarnya, dengan kepemilikan 27,33%. Perusahaan menyelesaikan putaran pendanaan pra-IPO terakhirnya pada Januari 2024, dengan valuasi sekitar 12 miliar RMB (Sumber: 量子位)

OpenAI dan produsen mainan Mattel mencapai kerja sama strategis untuk bersama-sama mengembangkan mainan cerdas AI: OpenAI mengumumkan kerja sama dengan produsen mainan terkenal global Mattel untuk bersama-sama mengembangkan mainan cerdas yang dilengkapi dengan teknologi kecerdasan buatan. Kerja sama ini bertujuan untuk menerapkan teknologi AI OpenAI pada pengalaman bermain mainan yang sesuai usia, merombak cara bermain game tradisional. Mattel memiliki IP terkenal seperti boneka Barbie dan Hot Wheels. Kedua belah pihak berkomitmen untuk menjamin keselamatan dan privasi anak-anak secara ketat dalam kerja sama tersebut. Mattel juga akan mengintegrasikan alat AI OpenAI (seperti ChatGPT Enterprise) ke dalam operasi bisnisnya untuk memperkuat pengembangan dan inovasi produk (Sumber: 36氪)
Startup pencarian perusahaan Glean menyelesaikan pendanaan tahap akhir sebesar $150 juta: Startup pencarian perusahaan Glean mengumumkan perolehan pendanaan tahap akhir sebesar $150 juta, sehingga valuasinya mencapai $7,2 miliar. Glean menggunakan teknologi AI untuk membantu karyawan perusahaan lebih efisien dalam menemukan informasi di antara berbagai aplikasi SaaS dan sumber data internal perusahaan yang rumit (Sumber: dl_weekly)
🌟 Komunitas
Hugging Face menyelenggarakan hackathon robotika LeRobot global, mendorong pengembangan teknologi robotika open source: Hugging Face menyelenggarakan hackathon robotika LeRobot secara serentak di beberapa kota di seluruh dunia (termasuk Miami, Aachen, Lyon, Munich, Bangalore, London, Paris, Los Angeles, San Francisco Bay Area, dll.). Acara ini bertujuan untuk mendorong teknologi robotika open source dan aplikasi AI di bidang robotika, dengan peserta memanfaatkan platform LeRobot dan perangkat keras yang disediakan (seperti lengan robot, kamera kedalaman) untuk pengembangan. Acara ini menarik banyak pengembang untuk berpartisipasi, bersama-sama menjelajahi teknologi mutakhir seperti pembelajaran robot, pelatihan model bahasa visual (VLA), dan memunculkan proyek-proyek kreatif seperti glambot mini, asisten laboratorium biologi otomatis, dan robot penyaji teh (Sumber: ClementDelangue, huggingface, ClementDelangue)

Diskusi tentang kemampuan dan metode penggunaan Claude Code: Diskusi tentang kemampuan Claude Code muncul di media sosial. Beberapa pengguna berpendapat bahwa meskipun Claude Code mengklaim sebagian kodenya dihasilkan oleh dirinya sendiri, ini tidak sama dengan “bootstrap” sepenuhnya, analog dengan kode VSCode yang juga sebagian besar ditulis oleh VSCode. Ditekankan bahwa saat menggunakan alat seperti Claude Code, prinsip-prinsip dasar seperti iterasi langkah kecil, peninjauan kode, dan manajemen versi harus diterapkan, serta kemampuan untuk memimpin desain program dan pembagian tugas. Ketika kode yang dihasilkan bermasalah, pertama-tama coba biarkan Claude Code memperbaikinya, jika tidak efektif maka lakukan rollback. Pengguna lain menunjukkan bahwa Rizo yang diluncurkan oleh Atlassian dianggap sebagai pesaing Claude Code dan menawarkan 20 juta token gratis setiap hari (Sumber: dotey, dotey, Reddit r/ClaudeAI)
Pandangan tentang dampak AI pada pasar kerja: memperburuk polarisasi, talenta terbaik diuntungkan: BrivaelLp berpendapat bahwa teknologi AI saat ini (seperti alat penghasil kode) dapat meningkatkan efisiensi pengembang biasa sebanyak 5 kali lipat, sementara pengembang terbaik dapat meningkatkannya sebanyak 100 kali lipat. Hal ini akan menyebabkan perusahaan lebih cenderung merekrut talenta terbaik yang berpengalaman, dan mengurangi permintaan untuk personel tingkat pemula. AI dapat memperburuk “efek Matthew” di berbagai industri, di mana 10% praktisi terbaik akan mengalami masa keemasan, sementara lapisan menengah menghadapi tekanan, sejalan dengan pandangan “tidak ada pasar untuk yang biasa-biasa saja” (Sumber: BrivaelLp)
Diskusi tentang keunggulan dan skenario aplikasi LLM lokal: Komunitas Reddit membahas keunggulan menjalankan Large Language Model (LLM) secara lokal. Selain perlindungan privasi dan potensi penghematan biaya (meskipun investasi perangkat keras mungkin tidak sedikit), pengguna menekankan kontrol penuh atas model, kemampuan kustomisasi (seperti memodifikasi model, mengintegrasikan RAG), tidak ada batasan API, penggunaan offline, dan mekanisme sensor yang lebih sedikit. LLM lokal juga memberikan kemudahan untuk belajar dan bereksperimen, misalnya ada pengguna yang menerapkan LLM visual secara lokal untuk memproses foto keluarga, atau mengembangkan asisten AI dengan memori dan logika emosional (Sumber: Reddit r/LocalLLaMA)
Diskusi tentang apakah LLM memiliki kemampuan penalaran sejati terus berlanjut: Di komunitas, diskusi terus berlanjut mengenai apakah Large Language Model (LLM) benar-benar memiliki kemampuan penalaran, dan di mana batas kemampuannya. François Chollet berpendapat bahwa kemampuan penalaran LLM dibatasi oleh “ketidakbiasaan” bukan “kompleksitas”. Pandangan lain menyatakan bahwa LLM hanya melakukan pencocokan pola dan “mengingat” berdasarkan sejumlah besar data pelatihan, bukan berpikir secara sejati. Diskusi ini mencerminkan pemikiran mendalam tentang sifat teknologi AI saat ini dan arah pengembangan di masa depan (Sumber: fchollet, francoisfleuret, vikhyatk)
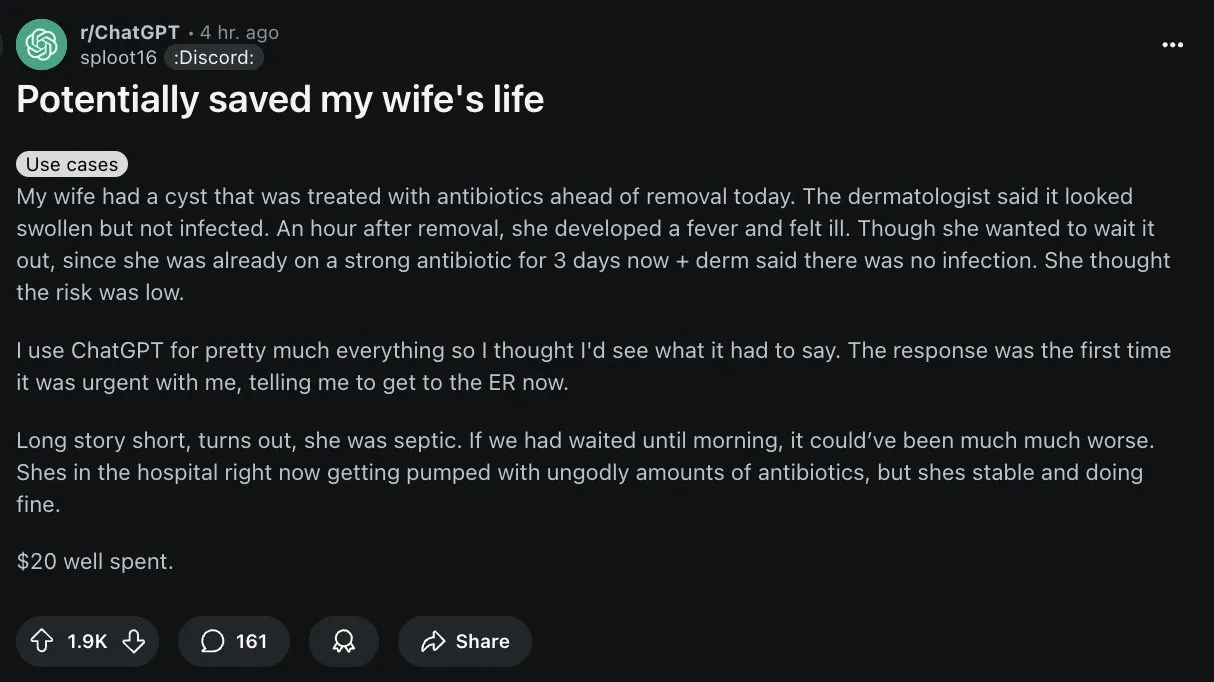
AI menunjukkan potensi dalam diagnosis medis, tetapi pengguna harus berhati-hati: Di Reddit, seorang pengguna membagikan kasus di mana ChatGPT membantu istrinya mengoreksi kesalahan diagnosis dokter, yang memicu diskusi tentang aplikasi AI di bidang medis. Meskipun AI menunjukkan potensi dalam membantu diagnosis, terutama dalam identifikasi penyakit langka dan analisis citra medis, komunitas juga menekankan bahwa AI umum seperti ChatGPT bukanlah alat medis profesional, dan informasinya mungkin tidak akurat atau kedaluwarsa. Pengguna harus sangat berhati-hati dalam menerima saran medis yang diberikan AI dan wajib berkonsultasi dengan dokter profesional. Beberapa pengguna menyarankan untuk memverifikasi keterbatasan AI dengan menanyakan apakah AI itu sendiri benar-benar dapat diandalkan (Sumber: Reddit r/ChatGPT, gdb)
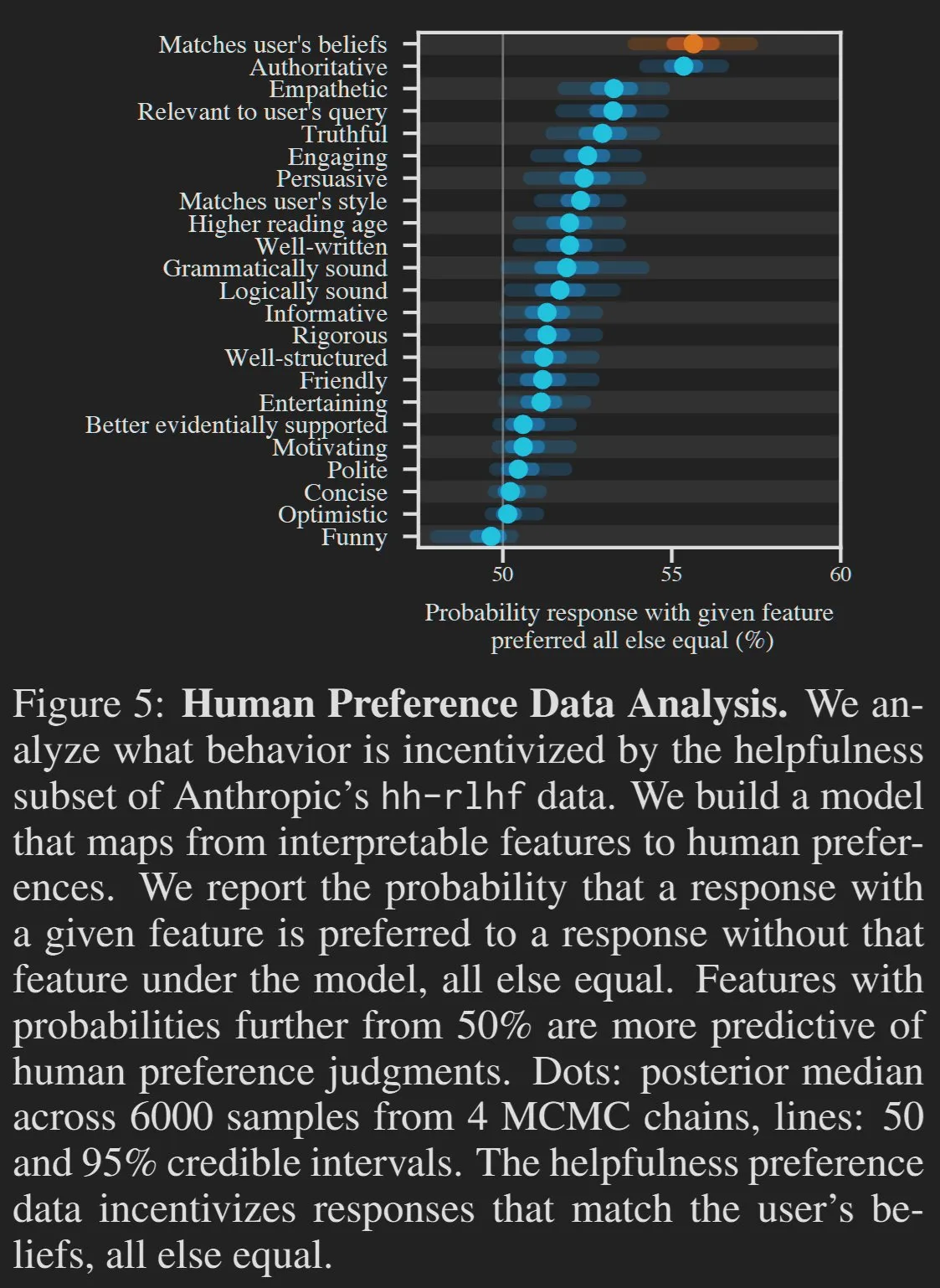
Kualitas konten yang dihasilkan AI dan preferensi pengguna memicu diskusi: Ada pandangan bahwa beberapa karakteristik “buruk” dari Large Language Model (LLM), seperti terlalu bertele-tele atau menyenangkan pengguna, sebenarnya adalah hasil dari preferensi pengguna. Mirip dengan bagaimana orang lebih menyukai makanan olahan tinggi gula, perusahaan AI untuk mengoptimalkan peringkat platform seperti LMArena, dapat menyebabkan output model cenderung menyenangkan pengguna daripada mengejar akurasi dan keringkasan yang ekstrem. HamelHusain juga membagikan panduan penulisannya yang ditambahkan dalam prompt untuk melawan “omong kosong” dalam konten yang dihasilkan AI, menekankan perlunya secara aktif menghapus informasi yang berlebihan (Sumber: scaling01, jeremyphoward, HamelHusain)
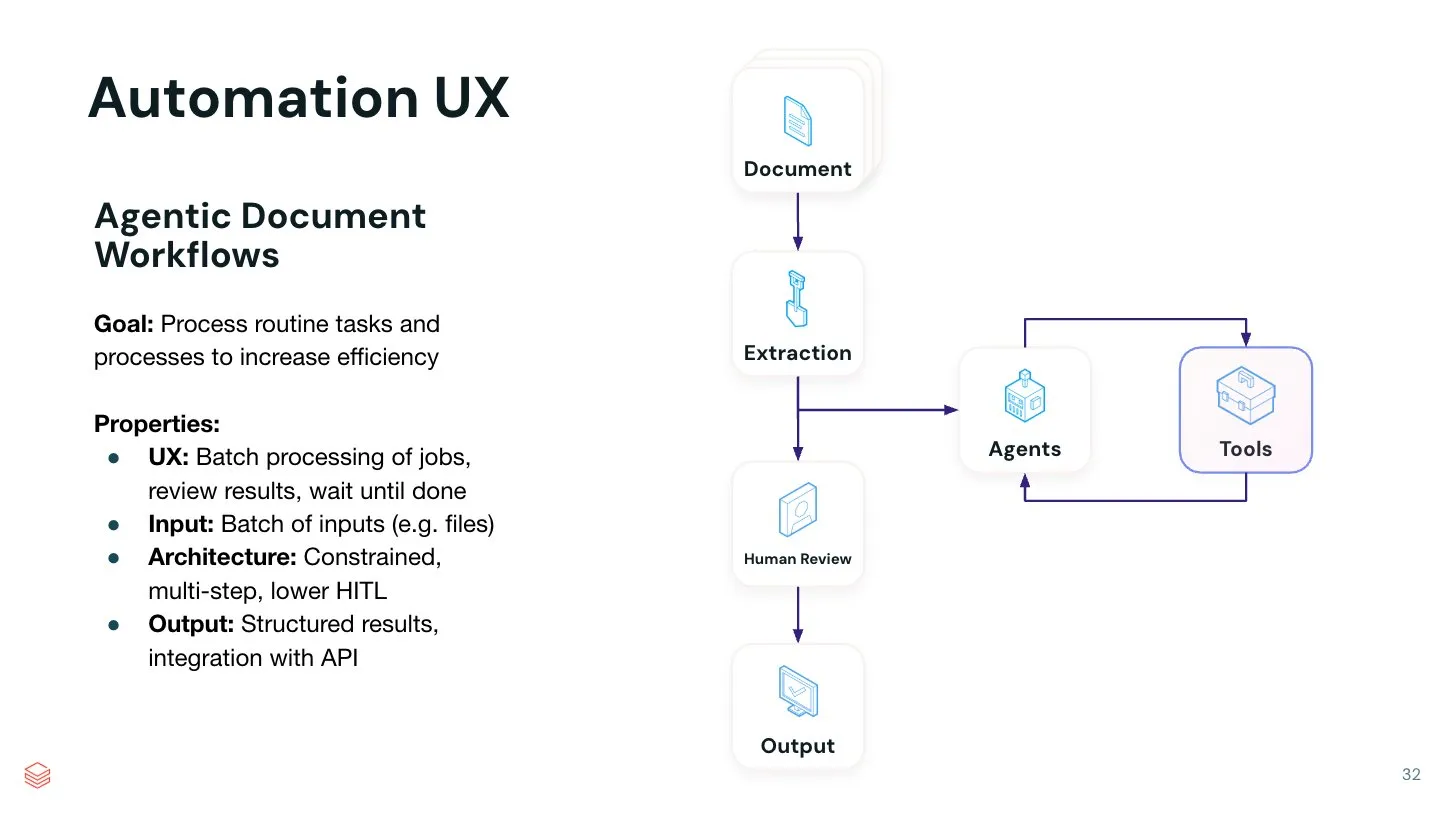
Nilai AI Agent dalam otomatisasi tugas tertentu semakin menonjol: Jerry Liu menunjukkan bahwa meskipun asisten obrolan umum berkinerja sangat baik dalam hal brainstorming kreatif, mereka masih memerlukan banyak rekayasa prompt saat menjalankan tugas tertentu. Dia percaya bahwa membangun sistem AI Agent otomatis yang dapat menyelesaikan satu tugas spesifik dengan sangat baik memiliki nilai yang sangat besar. Dengan mengkodekan proses tertentu ke dalam alur kerja Agent, otomatisasi yang lebih efisien dan terkontrol dapat dicapai. LlamaIndex berdedikasi untuk mendukung alur kerja kode khusus semacam ini, dan di masa depan mungkin akan muncul lebih banyak UI/UX tanpa kode untuk membangun Agent otomatis semacam itu (Sumber: jerryjliu0)
💡 Lain-lain
Penghargaan Cendekiawan Muda CVPR 2025 diberikan kepada Saining Xie dan Hao Su: Pada konferensi CVPR 2025, Saining Xie dan Hao Su dianugerahi Penghargaan Cendekiawan Muda. Penghargaan ini bertujuan untuk mengakui kontribusi luar biasa di bidang visi komputer oleh para peneliti awal yang memperoleh gelar doktor tidak lebih dari 7 tahun yang lalu. Hao Su (mahasiswa doktoral Fei-Fei Li) berpartisipasi dalam proyek ImageNet, sementara Saining Xie berkolaborasi dengan Kaiming He dalam menyelesaikan ResNeXt dan berpartisipasi dalam proyek MAE, keduanya merupakan karya penting di bidang CV (Sumber: 量子位)

Printer laser Nikon SLM NXG mungkin mendorong perubahan manufaktur: Printer laser SLM NXG yang diluncurkan oleh Nikon memiliki penampilan yang sangat mirip dengan peralatan DUV (deep ultraviolet lithography). Printer ini dianggap berpotensi memicu revolusi manufaktur generatif, terutama untuk bidang tertentu. Meskipun Nikon kalah dalam persaingan DUV melawan ASML, teknologi sumber lasernya terus berkembang dan diterapkan di bidang manufaktur baru (Sumber: teortaxesTex)
Kemajuan signifikan dalam generasi gambar AI antara tahun 2022 dan 2025: Pengguna Reddit membagikan perbandingan gambar yang dihasilkan oleh AI pada tahun 2022 dan 2025 menggunakan prompt yang sama (tema “Rick and Morty”). Gambar tahun 2022 memiliki kekurangan yang jelas dalam detail karakter (seperti tangan, hidung) dan koordinasi keseluruhan, sedangkan gambar tahun 2025 telah meningkat pesat, menunjukkan perkembangan pesat teknologi generasi gambar AI hanya dalam beberapa tahun. Meskipun masih ada pengguna yang menunjukkan bahwa detail tangan karakter pada gambar baru masih belum sempurna, kemajuan keseluruhan sangat jelas (Sumber: Reddit r/artificial)
