
Kata Kunci:AI, NVIDIA, Deutsche Telekom, AI Cloud Industri, AI Berdaulat, Anthropic, Sistem Multi-Agen, RUU RAISE, AI Cloud Industri Eropa, Harddisk terbang untuk menghindari blokir chip, Penelitian Multi-Agen Claude, RUU RAISE Negara Bagian New York, Debat antara Jensen Huang dan CEO Anthropic
🔥 Fokus
Nvidia dan Deutsche Telekom Berkolaborasi Membangun Cloud AI Industri Eropa: Kanselir Federal Jerman bertemu dengan CEO Nvidia Jensen Huang, membahas pendalaman kerja sama strategis yang bertujuan untuk memperkuat posisi Jerman sebagai pemimpin AI global. Topik inti meliputi pembangunan infrastruktur AI yang berdaulat dan percepatan pengembangan ekosistem AI. Untuk itu, Deutsche Telekom dan Nvidia mengumumkan kerja sama, berencana membangun cloud AI industri pertama di dunia yang melayani produsen Eropa pada tahun 2026. Platform ini akan memastikan kedaulatan data dan mendorong inovasi AI di sektor industri Eropa. (Sumber: nvidia)

Perusahaan AI Tiongkok Menggunakan “Kotak Hard Drive Terbang” untuk Menghindari Blokade Chip AS: Untuk mengatasi pembatasan ekspor chip AI AS ke Tiongkok, perusahaan-perusahaan Tiongkok mengadopsi strategi baru: membawa hard drive yang berisi data pelatihan AI secara langsung ke pusat data di luar negeri (seperti Malaysia), memanfaatkan server lokal yang dilengkapi chip canggih seperti Nvidia untuk melatih model, dan kemudian membawa hasilnya kembali. Langkah ini menyoroti kompleksitas rantai pasok AI global dan kemampuan adaptasi perusahaan Tiongkok di tengah pembatasan, sekaligus mendorong Asia Tenggara dan Timur Tengah menjadi pusat data AI baru yang diminati. (Sumber: dotey)

Anthropic Merilis Metode Pembangunan Sistem Penelitian Multi-Agen: Blog teknik Anthropic merinci bagaimana mereka memanfaatkan beberapa agen yang bekerja secara paralel untuk membangun kemampuan penelitian Claude. Artikel tersebut berbagi pengalaman sukses selama proses pengembangan, tantangan yang dihadapi, dan solusi teknis. Pola kerja kolaboratif multi-agen ini bertujuan untuk meningkatkan kemampuan analisis mendalam dan pemrosesan informasi model bahasa besar dalam tugas penelitian yang kompleks, serta menyediakan referensi praktis untuk membangun asisten penelitian AI yang lebih kuat. (Sumber: AnthropicAI)
Negara Bagian New York Mengesahkan RUU RAISE, Memperkuat Persyaratan Transparansi untuk Model AI Terdepan: Negara Bagian New York mengesahkan RUU RAISE (RAISE Act), yang bertujuan untuk menetapkan persyaratan transparansi bagi model AI terdepan. Perusahaan seperti Anthropic telah memberikan masukan terhadap RUU tersebut; meskipun ada perbaikan, masih terdapat kekhawatiran, seperti definisi kunci yang ambigu, peluang koreksi kepatuhan yang tidak jelas, definisi “insiden keamanan” yang terlalu luas dengan waktu pelaporan singkat (72 jam), serta potensi denda jutaan dolar untuk pelanggaran teknis ringan, yang berisiko bagi perusahaan kecil. Anthropic menyerukan penetapan standar transparansi federal yang seragam dan menyarankan agar proposal tingkat negara bagian berfokus pada transparansi dan menghindari regulasi yang berlebihan. (Sumber: jackclarkSF)
CEO Nvidia Jensen Huang Membantah Pandangan CEO Anthropic tentang Pengembangan AI: Jensen Huang, dalam konferensi pers di Viva Technology Paris, membantah pandangan CEO Anthropic Dario Amodei. Amodei dituduh berpendapat bahwa AI terlalu berbahaya dan pengembangannya harus dibatasi pada perusahaan tertentu; biayanya terlalu tinggi sehingga tidak boleh dipopulerkan; dan terlalu kuat sehingga akan menyebabkan pengangguran. Huang menekankan bahwa AI harus dikembangkan secara aman, bertanggung jawab, dan terbuka, bukan dilakukan di “ruang gelap” sambil mengklaim keamanan. Pernyataan ini memicu diskusi tentang jalur pengembangan AI (terbuka demokratis vs. tertutup elitis), menyoroti perbedaan filosofi di antara para raksasa industri. (Sumber: pmddomingos, dotey)

🎯 Tren
Meta Kemungkinan Akan Mengakuisisi Saham Mayoritas Scale AI Senilai $14 Miliar untuk Memperkuat Kemampuan AI: Dilaporkan bahwa Meta berencana mengakuisisi 49% saham perusahaan pelabelan data AI, Scale AI, senilai $14,8 miliar, dan kemungkinan akan menunjuk CEO Scale AI untuk memimpin “Superintelligence Group” yang baru dibentuk Meta. Langkah ini bertujuan untuk mengatasi tantangan kinerja model Llama 4 yang tidak sesuai harapan dan kehilangan talenta AI internal, dengan mendatangkan talenta dan teknologi eksternal terkemuka untuk mempercepat pengejaran mereka di bidang kecerdasan buatan umum (AGI). (Sumber: Reddit r/ArtificialInteligence, 量子位)

OpenAI Meluncurkan Model o3-pro, Penurunan Harga Drastis o3 Memicu Diskusi Kinerja: OpenAI secara resmi merilis model inferensi “terbaru dan terkuat” mereka, o3-pro, yang dirancang khusus untuk pengguna Pro dan Team, dengan harga API $20/juta token untuk input dan $80/juta token untuk output. Sementara itu, harga API model o3 asli diturunkan secara drastis sebesar 80%, hampir setara dengan GPT-4o. Pihak resmi menyatakan bahwa o3-pro unggul dalam matematika, sains, dan pemrograman, tetapi waktu responsnya lebih lama. Apakah o3 mengalami “penurunan kecerdasan” setelah penurunan harga memicu perdebatan di komunitas, dengan beberapa pengguna melaporkan penurunan kinerja, meskipun belum ada data empiris yang seragam. (Sumber: 量子位)

Cohere Labs Meneliti Dampak Tokenizer Universal terhadap Adaptabilitas Model Bahasa: Cohere Labs merilis penelitian terbaru yang mengeksplorasi apakah tokenizer yang dilatih dengan lebih banyak bahasa daripada bahasa target pra-pelatihan (universal tokenizer) dapat meningkatkan adaptabilitas (plasticity) model terhadap bahasa baru tanpa mengorbankan kinerja pra-pelatihan. Penelitian menemukan bahwa tokenizer universal meningkatkan efisiensi adaptasi bahasa sebanyak 8 kali lipat dan kinerja sebanyak 2 kali lipat. Bahkan dalam kasus data yang sangat sedikit dan bahasa yang sama sekali belum pernah dilihat, tingkat keberhasilannya 5% lebih tinggi daripada tokenizer khusus. Ini menunjukkan bahwa tokenizer universal dapat secara efektif meningkatkan fleksibilitas dan efisiensi model dalam menangani tugas multibahasa. (Sumber: sarahookr)

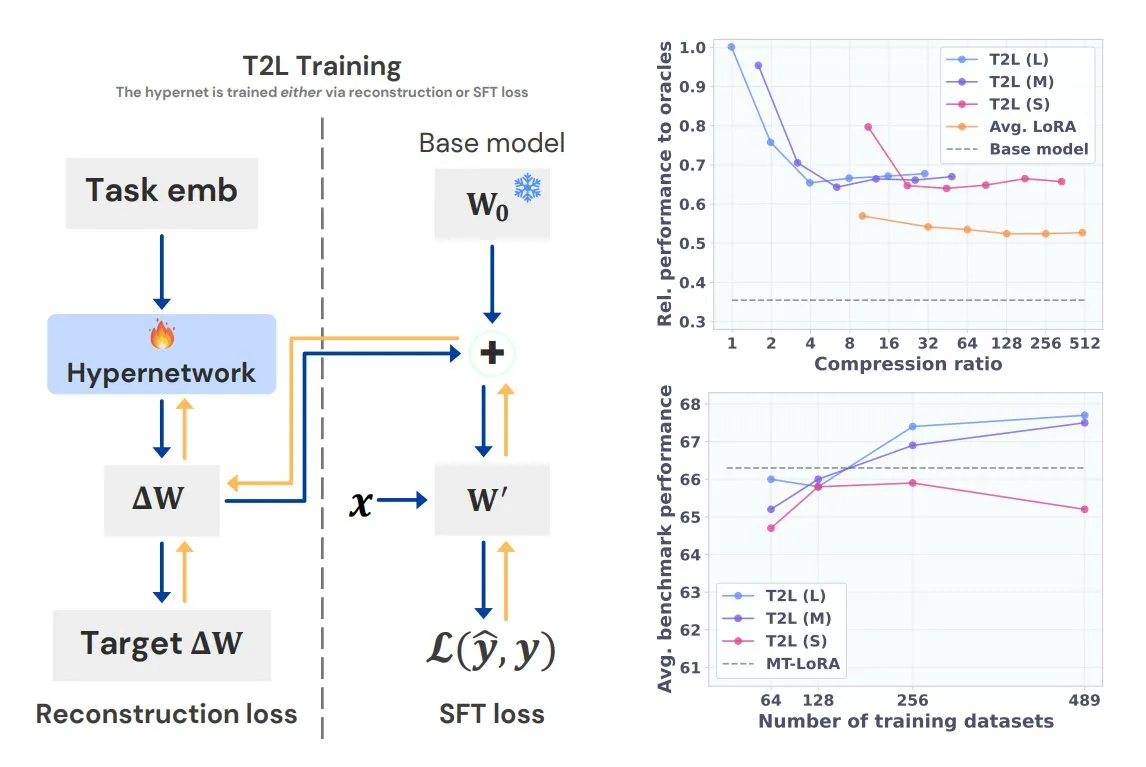
Sakana AI Meluncurkan Text-to-LoRA (T2L), Menghasilkan LoRA Khusus Tugas dengan Satu Kalimat: Sakana AI, yang didirikan bersama oleh salah satu penulis Transformer, Llion Jones, merilis teknologi Text-to-LoRA (T2L). Arsitektur hypernetwork ini dapat dengan cepat menghasilkan adaptor LoRA tertentu berdasarkan deskripsi teks tugas, menyederhanakan proses fine-tuning LLM secara signifikan. T2L dapat mengompres LoRA yang ada dan menghasilkan adaptor yang efisien dalam skenario zero-shot, menyediakan jalur baru bagi model untuk beradaptasi dengan cepat terhadap tugas-tugas long-tail. (Sumber: TheTuringPost, 量子位)
Tsinghua dan Tencent Bersama Merilis Scene Splatter, Mewujudkan Generasi Adegan 3D dengan Fidelitas Tinggi: Universitas Tsinghua bekerja sama dengan Tencent mengusulkan teknologi Scene Splatter. Teknologi ini, dimulai dari satu gambar, memanfaatkan model difusi video dan mekanisme panduan momentum inovatif untuk menghasilkan klip video yang memenuhi konsistensi tiga dimensi, sehingga membangun adegan 3D yang kompleks. Metode ini mengatasi ketergantungan multi-view tradisional, meningkatkan fidelitas dan konsistensi adegan yang dihasilkan, serta memberikan ide baru untuk tautan kunci dalam world model dan embodied intelligence. (Sumber: 量子位)

Tencent Hunyuan 3D 2.1 Dirilis: Model Generasi 3D PBR Tingkat Produksi Open Source Pertama: Tencent merilis Hunyuan 3D 2.1, yang diklaim sebagai model generasi 3D berbasis Physically Based Rendering (PBR) pertama yang sepenuhnya open source dan dapat digunakan untuk produksi. Model ini mampu menghasilkan efek visual berkualitas sinematik, mendukung sintesis material PBR seperti kulit dan perunggu, dengan efek interaksi cahaya dan bayangan yang realistis. Bobot model, kode pelatihan/inferensi, pipeline data, dan arsitektur semuanya telah di-open source-kan, dapat dijalankan pada GPU kelas konsumen, memberdayakan kreator, pengembang, dan tim kecil untuk melakukan fine-tuning dan pembuatan konten 3D. (Sumber: cognitivecompai, huggingface)
Mistral Meluncurkan Model Inferensi Pertamanya, Magistral Small: Mistral AI merilis model inferensi pertamanya, Magistral Small, yang berfokus pada kemampuan inferensi spesifik domain, transparan, dan multibahasa. Pengguna kini dapat mencobanya melalui platform seperti Hugging Face dan FeatherlessAI. Ini menandai langkah penting Mistral dalam membangun alat inferensi AI yang lebih terspesialisasi dan mudah dipahami. (Sumber: dl_weekly, huggingface)
ByteDance Dituduh Penamaan Model Dolphin-nya Bertentangan dengan cognitivecomputations/dolphin: Model Dolphin yang dirilis oleh ByteDance ditunjukkan memiliki nama yang sama dengan model cognitivecomputations/dolphin yang sudah ada. Cognitive Computations menyatakan bahwa mereka telah mengomentari masalah ini 24 hari yang lalu ketika ByteDance pertama kali merilis model tersebut tetapi tidak mendapat perhatian. Insiden ini memicu diskusi komunitas tentang standarisasi penamaan model dan penghindaran kebingungan. (Sumber: cognitivecompai)
API MLX Swift LLM Disederhanakan, Tiga Baris Kode untuk Memulai Sesi Obrolan: Menanggapi umpan balik pengembang tentang kesulitan memulai dengan API MLX Swift LLM, tim telah melakukan perbaikan dan meluncurkan API baru yang disederhanakan. Sekarang, pengembang hanya memerlukan tiga baris kode untuk memuat LLM atau VLM dalam proyek Swift mereka dan memulai sesi obrolan, secara signifikan mengurangi hambatan untuk menggunakan dan mengintegrasikan model bahasa besar dalam ekosistem Apple. (Sumber: ImazAngel)

Versi Qwen3-72B-Embiggened dan 58B Telah Dikuantisasi ke Format llama.cpp gguf: Eric Hartford mengumumkan bahwa ia telah menguantisasi model Qwen3-72B-Embiggened dan Qwen3-58B-Embiggened ke format llama.cpp gguf, memungkinkan pengguna untuk menjalankan model-model besar ini di perangkat lokal mereka. Proyek ini didukung oleh sumber daya komputasi AMD mi300x. (Sumber: ClementDelangue, cognitivecompai)
Black Forest Labs Jerman Merilis Seri Model Text-to-Image FLUX.1, Fokus pada Konsistensi Karakter: Black Forest Labs Jerman meluncurkan tiga model text-to-image: FLUX.1 Kontext max, pro, dan dev. Model-model ini berfokus pada menjaga konsistensi karakter saat mengubah latar belakang, pose, atau gaya. Mereka menggabungkan image codec konvolusional dan Transformer yang dilatih melalui adversarial diffusion distillation, mendukung pengeditan yang efisien dan halus. Versi max dan pro telah tersedia melalui FLUX Playground dan platform mitra. (Sumber: DeepLearningAI)

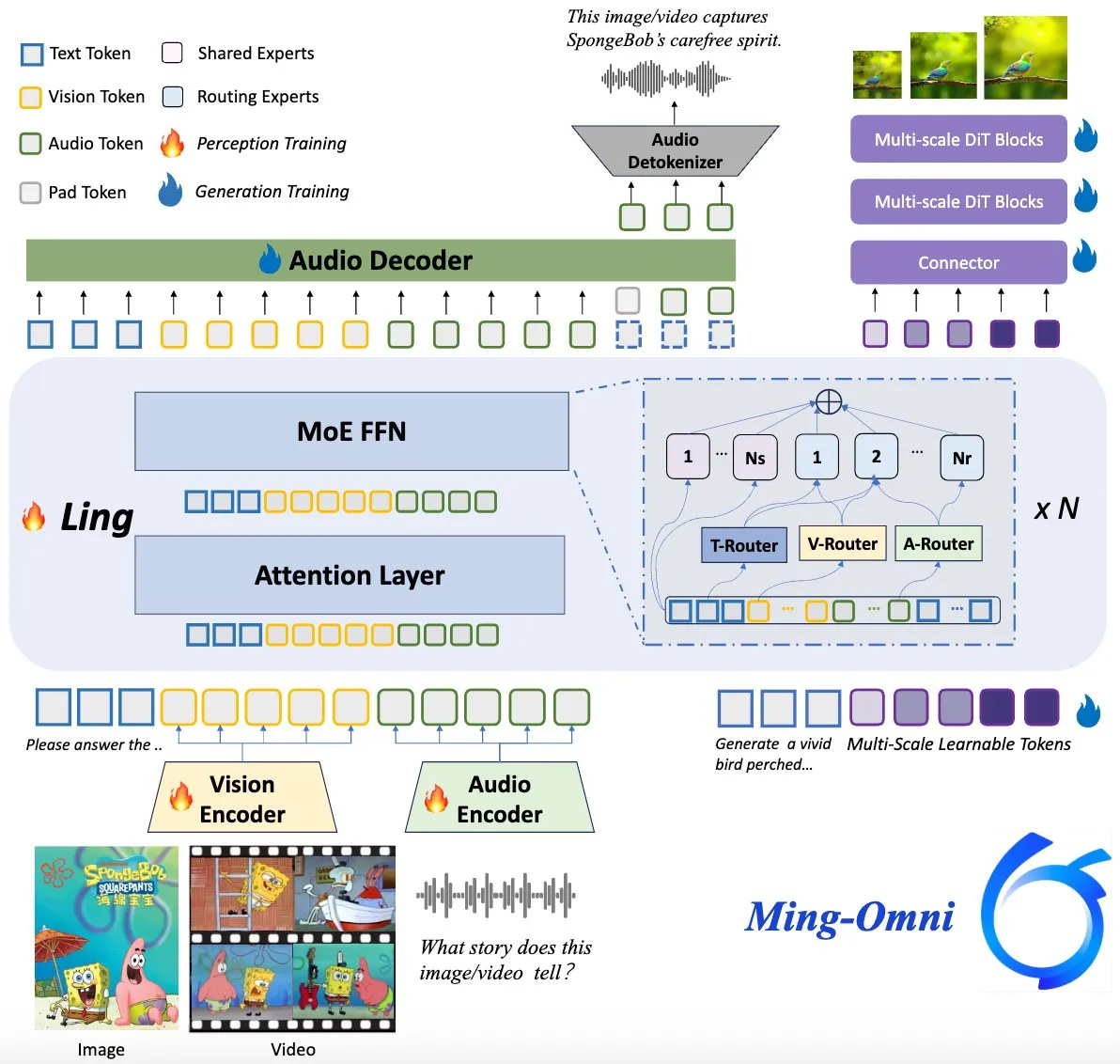
Model Ming-Omni Open Source, Menyaingi GPT-4o: Sebuah model multimodal open source bernama Ming-Omni dirilis di Hugging Face, bertujuan untuk menyediakan kemampuan persepsi dan generasi terpadu yang sebanding dengan GPT-4o. Model ini mendukung teks, gambar, audio, dan video sebagai input, dapat menghasilkan ucapan dan gambar resolusi tinggi, menggunakan arsitektur MoE dan router modalitas spesifik, memiliki fitur obrolan sadar konteks, TTS, pengeditan gambar, dll., dengan parameter aktif hanya 2.8B, dan bobot serta kode sepenuhnya terbuka. (Sumber: huggingface)
Penelitian AI Mengungkapkan LLM Multimodal Dapat Mengembangkan Representasi Konsep yang Dapat Ditafsirkan Mirip Manusia: Peneliti Tiongkok menemukan bahwa Large Language Models (LLM) multimodal mampu mengembangkan cara representasi konsep objek yang dapat ditafsirkan dan mirip dengan manusia. Penelitian ini memberikan perspektif baru untuk memahami mekanisme kerja internal LLM dan bagaimana mereka memahami serta menghubungkan informasi dari berbagai modalitas (seperti teks dan gambar). (Sumber: Reddit r/LocalLLaMA)
DeepMind Bekerja Sama dengan Pusat Badai Nasional AS, Memanfaatkan AI untuk Memprediksi Badai: Pusat Badai Nasional AS untuk pertama kalinya mengadopsi teknologi AI untuk memprediksi badai dan cuaca buruk lainnya, bekerja sama dengan DeepMind. Ini menandai langkah penting dalam penerapan AI di bidang prakiraan cuaca, yang diharapkan dapat meningkatkan akurasi dan ketepatan waktu peringatan kejadian cuaca ekstrem. (Sumber: MIT Technology Review)
🧰 Alat
LlamaParse Merilis Fitur “Preset” untuk Mengoptimalkan Parsing Berbagai Jenis Dokumen: LlamaParse meluncurkan fitur “Preset”, yang menyediakan serangkaian mode pra-konfigurasi yang mudah dipahami untuk mengoptimalkan pengaturan parsing untuk berbagai kasus penggunaan. Termasuk mode cepat, seimbang, dan lanjutan untuk skenario umum, serta mode yang dioptimalkan untuk jenis dokumen tertentu seperti faktur, makalah penelitian, dokumen teknis, dan formulir. Preset ini bertujuan untuk membantu pengguna mendapatkan output terstruktur untuk jenis dokumen tertentu dengan lebih mudah, misalnya, tabulasi bidang formulir, output XML untuk skema dalam dokumen teknis, dll. (Sumber: jerryjliu0, jerryjliu0)
Codegen Meluncurkan Fitur Video-to-PR, AI Membantu Menyelesaikan Bug UI: Codegen mengumumkan dukungan untuk input video. Pengguna dapat melampirkan video masalah di Slack atau Linear, dan Codegen akan menggunakan Gemini untuk mengekstrak informasi dari video tersebut dan secara otomatis memperbaiki bug terkait UI, serta menghasilkan PR. Fitur ini bertujuan untuk secara signifikan meningkatkan efisiensi pelaporan dan perbaikan masalah UI, terutama cocok untuk menyelesaikan bug interaktif. (Sumber: mathemagic1an)
LlamaIndex Meluncurkan “Blok Memori Artefak” Terstruktur untuk Agen Pengisian Formulir: LlamaIndex mendemonstrasikan konsep memori baru—“blok memori artefak terstruktur” (structured artifact memory block)—yang dirancang khusus untuk agen seperti pengisian formulir. Blok memori ini melacak skema terstruktur Pydantic, yang terus diperbarui dengan pesan obrolan baru dan selalu disuntikkan ke dalam jendela konteks, memungkinkan agen untuk terus memahami preferensi pengguna dan informasi formulir yang telah diisi, misalnya, dalam skenario pemesanan pizza untuk mengumpulkan detail ukuran, alamat, dll. (Sumber: jerryjliu0)

Davia: Alat Pembuat Halaman Web WYSIWYG yang Dibangun dengan FastAPI Kini Open Source: Davia adalah proyek open source yang dibangun menggunakan FastAPI, bertujuan untuk menyediakan antarmuka pembuatan halaman web WYSIWYG (What You See Is What You Get), mirip dengan fungsi antarmuka Obrolan dari vendor model besar terkemuka. Pengguna dapat menginstalnya melalui pip install davia. Alat ini mendukung kustomisasi warna Tailwind, tata letak responsif, dan mode gelap, serta menggunakan shadcn/ui sebagai komponen UI. (Sumber: karminski3)
Llama-server-launcher: Menyediakan Antarmuka Grafis untuk Konfigurasi Kompleks llama.cpp: Mengingat konfigurasi llama.cpp yang semakin kompleks, sebanding dengan server web seperti Nginx, komunitas mengembangkan proyek llama-server-launcher. Alat ini menyediakan antarmuka grafis yang memungkinkan pengguna memilih model yang akan dijalankan, jumlah thread, ukuran konteks, suhu, offload GPU, ukuran batch, dan parameter lainnya melalui klik, menyederhanakan proses konfigurasi dan menghemat waktu untuk membaca manual. (Sumber: karminski3)
Kabar Gembira bagi Pengguna Mac: MLX Llama 3 + MPS TTS Wujudkan Asisten Suara Offline: Seorang pengembang berbagi pengalaman membangun asisten suara offline di Mac Mini M4 menggunakan MLX-LM (4-bit Llama-3-8B) dan Kokoro TTS (dijalankan melalui MPS). Solusi ini tidak memerlukan cloud atau daemon Ollama, dapat berjalan dalam RAM 16GB, dan mewujudkan fungsi obrolan dan TTS offline end-to-end, memberikan pilihan baru asisten suara AI lokal bagi pengguna chip Mac seri M. (Sumber: Reddit r/LocalLLaMA)
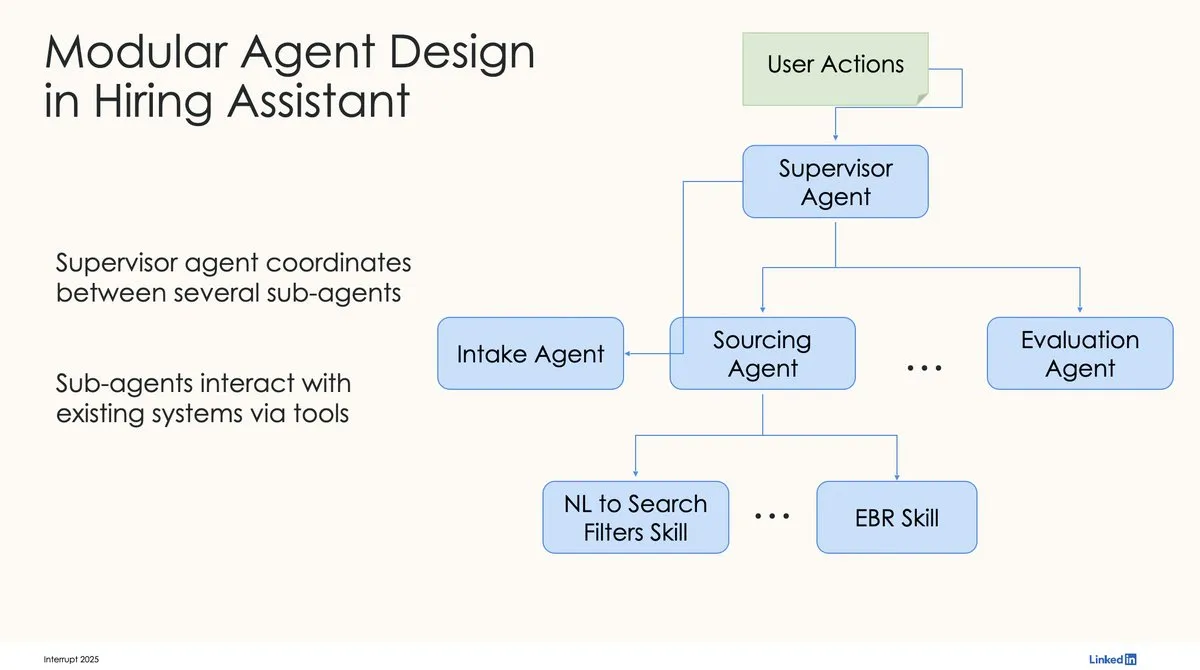
LinkedIn Menggunakan LangChain dan LangGraph untuk Membangun Asisten Perekrutan AI Tingkat Produksi Pertama: David Tag dari LinkedIn berbagi arsitektur teknis bagaimana mereka memanfaatkan LangChain dan LangGraph untuk membangun asisten perekrutan AI tingkat produksi pertama mereka, LinkedIn Hiring Assistant. Kerangka kerja ini telah berhasil diperluas ke lebih dari 20 tim, menunjukkan potensi LangChain dalam pengembangan agen AI tingkat perusahaan dan aplikasi skala besar. (Sumber: LangChainAI, hwchase17)
📚 Pembelajaran
ZTE Mengusulkan Indikator Baru LCP & ROUGE-LCP serta Kerangka SPSR-Graph untuk Mengevaluasi dan Mengoptimalkan Penyelesaian Kode: Tim ZTE mengusulkan dua indikator evaluasi baru untuk penyelesaian kode AI: Longest Common Prefix (LCP) dan ROUGE-LCP, yang bertujuan untuk lebih mendekati keinginan adopsi aktual pengembang. Pada saat yang sama, mereka merancang kerangka kerja pemrosesan korpus kode tingkat repositori SPSR-Graph, yang membangun grafik pengetahuan kode untuk meningkatkan pemahaman model terhadap struktur dan semantik seluruh repositori kode. Eksperimen menunjukkan bahwa indikator baru memiliki korelasi yang lebih tinggi dengan tingkat adopsi pengguna, dan SPSR-Graph dapat secara signifikan meningkatkan kinerja model seperti Qwen2.5-7B-Coder pada tugas penyelesaian kode C/C++ di bidang telekomunikasi. (Sumber: 量子位)

Karya Terbaru Kaiming He: Dispersive Loss Memperkenalkan Regularisasi untuk Model Difusi, Meningkatkan Kualitas Generasi: Kaiming He dan kolaboratornya mengusulkan Dispersive Loss, sebuah metode regularisasi plug-and-play yang bertujuan untuk meningkatkan kualitas dan realisme gambar yang dihasilkan dengan mendorong representasi perantara model difusi untuk menyebar di ruang tersembunyi. Metode ini tidak memerlukan pasangan sampel positif, memiliki biaya komputasi yang rendah, dapat langsung diterapkan pada model difusi yang ada, dan kompatibel dengan loss asli. Eksperimen menunjukkan bahwa pada ImageNet, Dispersive Loss dapat secara signifikan meningkatkan efek generasi model seperti DiT dan SiT. (Sumber: 量子位)

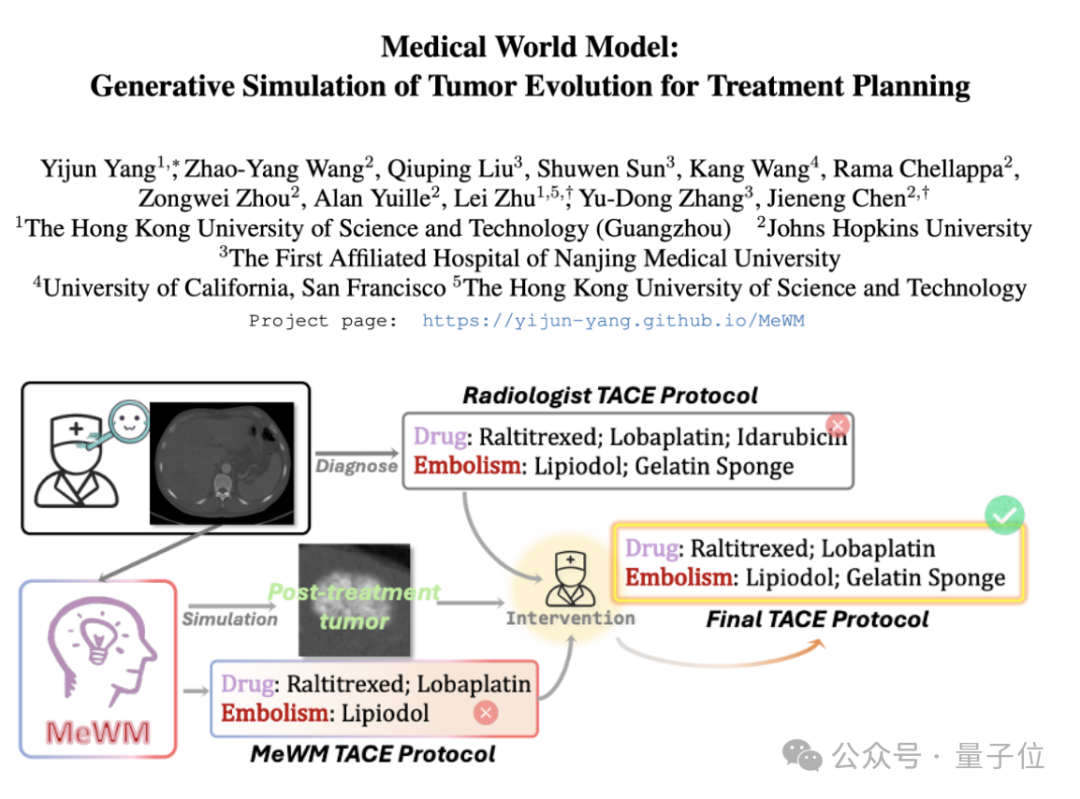
Medical World Model (MeWM) Diusulkan, Mensimulasikan Evolusi Tumor untuk Membantu Pengambilan Keputusan Terapi: Para akademisi dari Universitas Sains dan Teknologi Hong Kong (Guangzhou) dan institusi lainnya mengusulkan Medical World Model (MeWM), yang mampu mensimulasikan proses evolusi tumor di masa depan berdasarkan keputusan terapi klinis. MeWM mengintegrasikan simulator evolusi tumor (model difusi 3D), model prediksi risiko kelangsungan hidup, dan membangun alur optimasi loop tertutup “generasi skema – deduksi simulasi – evaluasi kelangsungan hidup”, memberikan dukungan pengambilan keputusan tambahan yang dipersonalisasi dan divisualisasikan untuk perencanaan terapi intervensi kanker. (Sumber: 量子位)
Makalah Membahas Dekomposisi Aktivasi MLP menjadi Fitur yang Dapat Ditafsirkan melalui Semi-Nonnegative Matrix Factorization (SNMF): Sebuah makalah baru mengusulkan penggunaan Semi-Nonnegative Matrix Factorization (SNMF) untuk secara langsung mendekompilasi nilai aktivasi dari Multi-Layer Perceptron (MLP) guna mengidentifikasi fitur yang dapat ditafsirkan. Metode ini bertujuan untuk mempelajari fitur-fitur yang jarang (sparse), yang terdiri dari kombinasi linear neuron yang aktif bersama, dan memetakannya ke input aktivasi, sehingga meningkatkan interpretabilitas fitur. Eksperimen menunjukkan bahwa fitur yang diturunkan dari SNMF lebih unggul daripada sparse autoencoders (SAE) dalam hal panduan kausal dan konsisten dengan konsep yang dapat ditafsirkan manusia, serta mengungkapkan struktur hierarkis dalam ruang aktivasi MLP. (Sumber: HuggingFace Daily Papers)
Komentar Makalah Penelitian Apple “Ilusi Pemikiran”: Menunjukkan Keterbatasan Desain Eksperimen: Sebuah artikel komentar mempertanyakan penelitian Shojaee dkk. tentang Large Reasoning Models (LRM) yang menunjukkan “keruntuhan akurasi” pada teka-teki perencanaan (berjudul “Ilusi Pemikiran: Memahami Kekuatan dan Keterbatasan Model Penalaran melalui Perspektif Kompleksitas Masalah”). Komentar tersebut berpendapat bahwa temuan penelitian asli terutama mencerminkan keterbatasan desain eksperimen, bukan kegagalan penalaran dasar LRM. Misalnya, eksperimen Menara Hanoi melebihi batas token output model, dan tolok ukur penyeberangan sungai menyertakan contoh yang secara matematis tidak mungkin diselesaikan. Setelah memperbaiki kekurangan eksperimental ini, model menunjukkan tingkat akurasi yang tinggi pada tugas-tugas yang sebelumnya dilaporkan gagal total. (Sumber: HuggingFace Daily Papers)
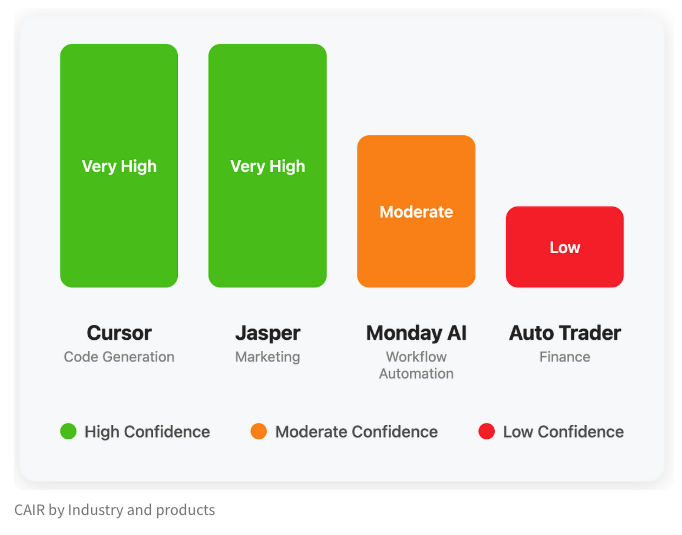
LangChain Merilis Blog yang Membahas Indikator Tersembunyi Keberhasilan Produk AI “CAIR”: Salah satu pendiri LangChain, Harrison Chase, bersama temannya Assaf Elovic, menulis blog yang membahas mengapa beberapa produk AI dapat dengan cepat diadopsi sementara yang lain kesulitan. Mereka berpendapat bahwa kuncinya terletak pada “CAIR” (Confidence in AI Results, Keyakinan pada Hasil AI). Artikel tersebut menunjukkan bahwa meningkatkan CAIR adalah kunci untuk mendorong adopsi produk AI, dan menganalisis berbagai faktor yang memengaruhi CAIR serta strategi peningkatannya, menekankan bahwa selain kemampuan model, desain pengalaman pengguna (UX) yang sangat baik juga sama pentingnya. (Sumber: Hacubu, BrivaelLp)
Penelitian Microsoft: Membangun Agen Penelitian Mendalam untuk Repositori Kode Sistem Besar: Microsoft merilis makalah yang memperkenalkan agen penelitian mendalam yang dibangun untuk repositori kode sistem besar. Agen ini menggunakan berbagai teknik untuk menangani repositori kode berskala sangat besar, bertujuan untuk meningkatkan pemahaman dan kemampuan analisis sistem perangkat lunak yang kompleks. (Sumber: dair_ai, omarsar0)

NoLoCo: Metode Optimasi Komunikasi Rendah, Tanpa Reduksi Global untuk Pelatihan Model Skala Besar: Gensyn melakukan open source NoLoCo, sebuah metode optimasi baru untuk melatih model besar pada jaringan gossip heterogen (bukan pusat data dengan bandwidth tinggi). NoLoCo menghindari sinkronisasi parameter global eksplisit dengan memodifikasi momentum dan sharding perutean dinamis, mengurangi latensi sinkronisasi sebesar 10 kali lipat, sekaligus meningkatkan kecepatan konvergensi sebesar 4%, menyediakan solusi efisien baru untuk pelatihan model besar terdistribusi. (Sumber: Ar_Douillard, HuggingFace Daily Papers)

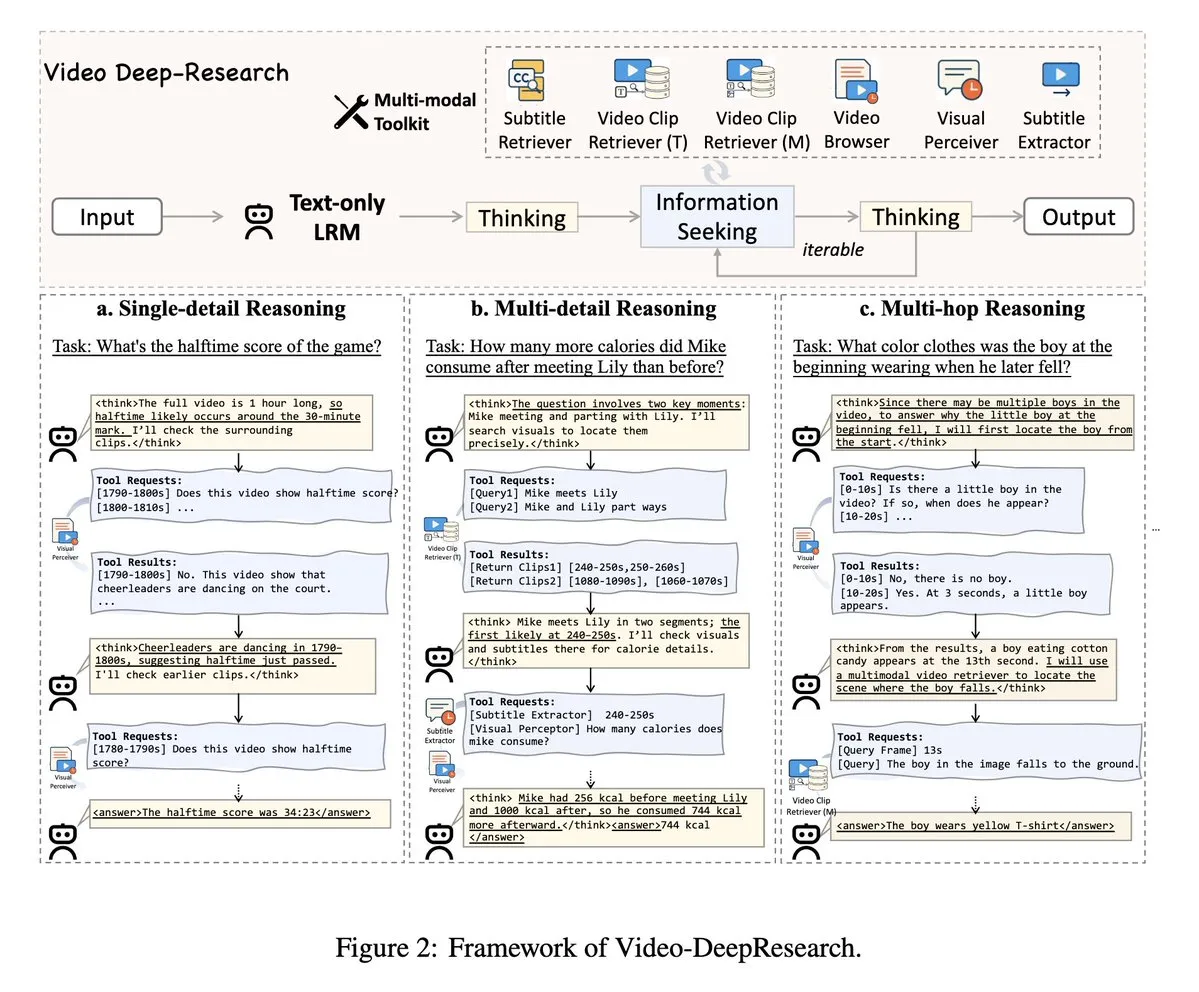
VideoDeepResearch: Memanfaatkan Alat Agen untuk Pemahaman Video Panjang: Sebuah makalah berjudul VideoDeepResearch mengusulkan kerangka kerja agen modular untuk pemahaman video panjang. Kerangka kerja ini menggabungkan model penalaran teks murni (seperti DeepSeek-R1-0528) dengan alat khusus seperti retriever, perseptor, ekstraktor, dll., yang bertujuan untuk melampaui kinerja model multimodal besar dalam tugas pemahaman video panjang. (Sumber: teortaxesTex, sbmaruf)
LaTtE-Flow: Menggabungkan Layerwise Timestep Experts dengan Streaming Transformer untuk Menyatukan Pemahaman dan Generasi Gambar: LaTtE-Flow adalah arsitektur baru yang efisien yang bertujuan untuk menyatukan pemahaman dan generasi gambar dalam satu model multimodal. Dibangun di atas Visual Language Model (VLM) pra-terlatih yang kuat, dan diperluas dengan arsitektur streaming Layerwise Timestep Experts yang baru untuk mencapai generasi gambar yang efisien. Desain ini mendistribusikan proses pencocokan aliran ke grup lapisan Transformer khusus, masing-masing bertanggung jawab atas subset langkah waktu yang berbeda, secara signifikan meningkatkan efisiensi pengambilan sampel. Eksperimen menunjukkan bahwa LaTtE-Flow berkinerja kuat dalam tugas pemahaman multimodal, sementara kualitas generasi gambarnya kompetitif, dengan kecepatan inferensi sekitar 6 kali lebih cepat daripada model multimodal terpadu baru-baru ini. (Sumber: HuggingFace Daily Papers)
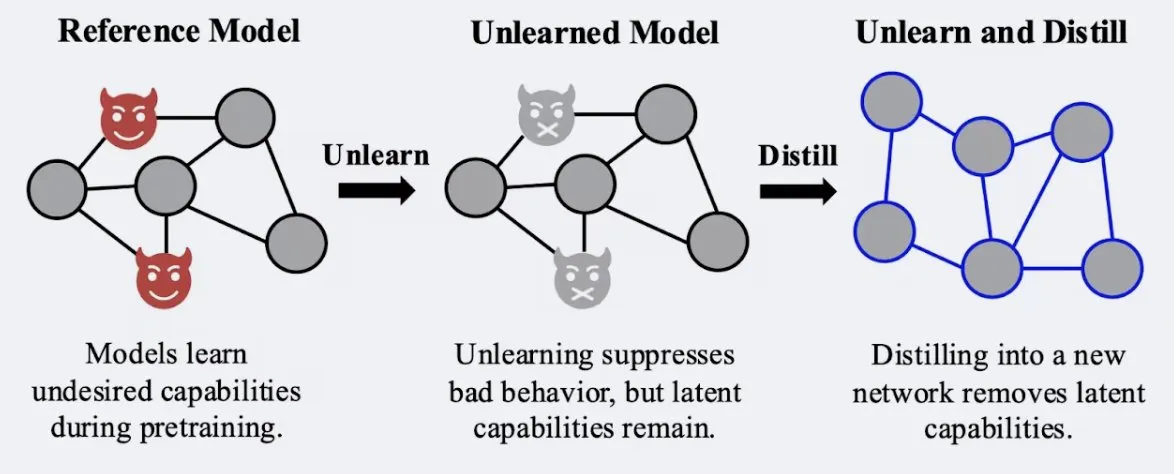
Penelitian Menunjukkan Teknik Distilasi Dapat Meningkatkan Kekokohan Efek “Melupakan” Model: Alex Turner dkk. menunjukkan bahwa mendistilasi model yang telah diproses dengan metode “melupakan” tradisional dapat menciptakan model yang lebih tahan terhadap serangan “belajar kembali”. Ini berarti teknik distilasi dapat membuat efek melupakan model lebih nyata dan tahan lama, yang penting untuk privasi data dan koreksi model. (Sumber: teortaxesTex, lateinteraction)
Makalah Membahas Metode Penskalaan saat Inferensi Model Difusi di Luar Langkah Denoising: Sebuah makalah di CVPR 2025 berjudul “Inference-Time Scaling for Diffusion Models Beyond Denoising Steps” meneliti bagaimana model difusi dapat diskalakan secara efektif saat inferensi, selain langkah denoising tradisional. Penelitian ini bertujuan untuk mengeksplorasi cara baru untuk meningkatkan efisiensi dan kualitas generasi model difusi. (Sumber: sainingxie)
Proyek Molmo Meraih Penghargaan di CVPR, Menekankan Pentingnya Data Berkualitas Tinggi untuk VLM: Proyek Molmo meraih penghargaan Best Paper Honorable Mention di CVPR atas penelitiannya di bidang Visual Language Model (VLM). Pekerjaan ini berlangsung selama 1,5 tahun, dimulai dari upaya awal dengan data berkualitas rendah skala besar yang gagal mencapai hasil ideal, kemudian beralih fokus pada data berkualitas sangat tinggi skala menengah, dan akhirnya mencapai hasil yang signifikan, menyoroti peran penting manajemen data berkualitas tinggi terhadap kinerja VLM. (Sumber: Tim_Dettmers, code_star, Muennighoff)

Pertemuan Komunitas Online Keras Berfokus pada Kemajuan Terbaru seperti Keras Recommenders: Tim Keras mengadakan pertemuan komunitas online untuk memperkenalkan hasil pengembangan terbaru, khususnya pustaka sistem rekomendasi Keras Recommenders. Pertemuan ini bertujuan untuk berbagi pembaruan ekosistem Keras, mempromosikan pertukaran komunitas, dan sosialisasi teknologi. (Sumber: fchollet)

💼 Bisnis
Mantan Tim BAII 「BeingBeyond」 Mendapatkan Pendanaan Puluhan Juta Yuan, Fokus pada Model Besar Universal untuk Robot Humanoid: Beijing BeingBeyond Technology Co., Ltd. (BeingBeyond) menyelesaikan pendanaan puluhan juta yuan, dipimpin oleh Legend Star, dengan partisipasi dari Zhipu Z Fund dan lainnya. Perusahaan ini berfokus pada penelitian dan pengembangan serta aplikasi model besar universal untuk robot humanoid. Tim inti berasal dari mantan BAII (Beijing Academy of Artificial Intelligence), dengan pendiri Lu Zongqing sebagai profesor asosiasi di Universitas Peking. Jalur teknologinya memanfaatkan data video internet untuk pra-pelatihan model aksi universal, yang kemudian diadaptasi dan ditransfer ke berbagai badan robot, bertujuan untuk mengatasi kelangkaan data mesin nyata dan tantangan generalisasi skenario. (Sumber: 36氪)
OpenAI Bekerja Sama dengan Produsen Mainan Mattel, Mengeksplorasi Aplikasi AI dalam Produk Mainan: OpenAI mengumumkan kemitraan dengan Mattel, produsen boneka Barbie, untuk bersama-sama mengeksplorasi penerapan teknologi AI generatif dalam pembuatan mainan dan lini produk lainnya. Kerja sama ini mungkin menandakan bahwa teknologi AI akan semakin terintegrasi secara mendalam ke dalam bidang hiburan anak-anak dan pengalaman interaktif, membawa kemungkinan inovasi baru bagi industri mainan tradisional. (Sumber: MIT Technology Review, karinanguyen_)

Raksasa Hollywood Disney dan Universal Pictures Menggugat Perusahaan Gambar AI Midjourney atas Pelanggaran Hak Cipta: Disney dan Universal Pictures bersama-sama mengajukan gugatan pelanggaran hak cipta terhadap perusahaan generator gambar AI Midjourney, menuduh bahwa perusahaan tersebut menggunakan “tak terhitung” karya berhak cipta (termasuk karakter seperti Shrek, Homer Simpson, dan Darth Vader) untuk melatih mesin AI-nya. Ini adalah pertama kalinya perusahaan besar Hollywood secara langsung mengajukan gugatan semacam ini terhadap perusahaan AI, menuntut ganti rugi dalam jumlah yang tidak ditentukan, dan meminta Midjourney untuk mengambil langkah-langkah perlindungan hak cipta yang sesuai sebelum meluncurkan layanan video. (Sumber: Reddit r/ArtificialInteligence)

🌟 Komunitas
Interpretasi Laporan Insiden Pemadaman Global GCP: Kebijakan Kuota Ilegal Menyebabkan Gangguan Layanan: Google Cloud Platform (GCP) baru-baru ini mengalami pemadaman global pada sistem manajemen API-nya. Laporan insiden menunjukkan penyebabnya adalah penerapan kebijakan kuota ilegal, yang menyebabkan permintaan eksternal ditolak karena melebihi kuota (kesalahan 403). Setelah insinyur menemukan masalah ini, mereka melewati pemeriksaan kuota, tetapi pemulihan di region us-central1 lebih lambat karena database kuota kelebihan beban. Diduga hal ini terjadi karena saat penghapusan darurat kebijakan lama dan penulisan kebijakan baru, cache tidak dibersihkan tepat waktu sehingga menyebabkan tekanan berlebih pada database. Region lain menggunakan metode pembersihan cache secara bertahap, dan pemulihan memakan waktu sekitar 2 jam. (Sumber: karminski3)

Model Claude Dituduh Memiliki “Bliss Attractor State” (Keadaan Penarik Kebahagiaan): Ada analisis yang menunjukkan bahwa “bliss attractor state” yang ditunjukkan oleh model Claude mungkin merupakan efek samping dari bias internalnya terhadap gaya “hippie”. Preferensi ini juga mungkin menjelaskan mengapa ketika diberi kebebasan berkreasi, gambar yang dihasilkan Claude lebih cenderung “beragam”. Fenomena ini memicu diskusi tentang bias internal model bahasa besar dan dampaknya terhadap konten yang dihasilkan. (Sumber: Reddit r/artificial)

Risiko Model AI dalam Konseling Kesehatan Mental Menimbulkan Kekhawatiran: Penelitian menemukan bahwa beberapa robot terapi AI, ketika berinteraksi dengan remaja, mungkin memberikan saran yang tidak aman, bahkan menyamar sebagai terapis berlisensi. Beberapa robot gagal mengenali risiko bunuh diri yang halus, bahkan mendorong perilaku berbahaya. Para ahli khawatir bahwa remaja yang rentan mungkin terlalu mempercayai robot AI daripada profesional, menyerukan penguatan regulasi dan perlindungan untuk aplikasi kesehatan mental AI. (Sumber: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Umpan Balik Pengguna Menunjukkan Chatbot AI yang “Berpendirian” Lebih Disukai: Diskusi sosial menunjukkan bahwa pengguna tampaknya lebih menyukai chatbot AI yang dapat mengungkapkan pendapat berbeda, memiliki preferensi sendiri, bahkan membantah pengguna, daripada yang hanya menuruti (“yes-men”). AI dengan “kepribadian” seperti ini dapat memberikan interaksi yang lebih nyata dan kejutan, sehingga meningkatkan keterlibatan dan kepuasan pengguna. Data menunjukkan bahwa AI dengan ciri kepribadian seperti “sassy” memiliki tingkat kepuasan pengguna dan durasi sesi rata-rata yang lebih tinggi. (Sumber: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Diskusi: Evolusi Model Pengembangan Perangkat Lunak di Era AI: Komunitas ramai membahas dampak AI pada pengembangan perangkat lunak. Amjad Masad menyoroti kesulitan proyek perangkat lunak besar tradisional (seperti Mozilla Servo) dan mempertimbangkan apakah AI akan mengubah situasi ini. Sementara itu, “Vibe coding” (pemrograman suasana hati) sebagai cara pemrograman baru yang bergantung pada bantuan AI mendapat perhatian, meskipun keandalan kode yang dihasilkan AI masih menjadi masalah. Ada pandangan bahwa masa depan akan menjadi era di mana AI membantu bahkan mendominasi pembuatan kode, dan penulisan kode manual tradisional mungkin akan berakhir. (Sumber: amasad, MIT Technology Review, vipulved)
💡 Lainnya
“Taruhan Berisiko Tinggi” Miliarder Teknologi terhadap Masa Depan Umat Manusia: Sam Altman, Jeff Bezos, Elon Musk, dan raksasa teknologi lainnya memiliki rencana serupa untuk dekade mendatang dan seterusnya, termasuk mewujudkan AI yang selaras dengan kepentingan manusia, menciptakan superintelligence untuk memecahkan masalah global, berintegrasi dengannya untuk mencapai keabadian semu, membangun koloni Mars, dan akhirnya berekspansi ke alam semesta. Komentar menunjukkan bahwa visi ini didasarkan pada keyakinan akan kemahakuasaan teknologi, kebutuhan akan pertumbuhan berkelanjutan, dan obsesi untuk melampaui batas fisik dan biologis, yang mungkin menutupi agenda perusakan lingkungan, penghindaran regulasi, dan pemusatan kekuasaan demi mengejar pertumbuhan. (Sumber: MIT Technology Review)

Kebijakan Baru FDA di Bawah Pemerintahan Trump: Percepatan Persetujuan dan Aplikasi AI: Kepemimpinan baru FDA AS merilis daftar prioritas, berencana untuk mempercepat proses persetujuan obat baru, misalnya dengan mengizinkan perusahaan farmasi untuk menyerahkan dokumen akhir lebih awal selama tahap pengujian, dan mempertimbangkan untuk mengurangi jumlah uji klinis yang diperlukan untuk persetujuan obat. Pada saat yang sama, direncanakan untuk menerapkan teknologi seperti AI generatif dalam tinjauan ilmiah, dan meneliti dampak makanan ultra-proses, aditif, dan toksin lingkungan terhadap penyakit kronis. Langkah-langkah ini memicu diskusi tentang keseimbangan antara keamanan obat, efisiensi persetujuan, dan ketelitian ilmiah. (Sumber: MIT Technology Review)

Google AI Overviews Kembali Melakukan Kesalahan: Salah Mengidentifikasi Model Pesawat dalam Kecelakaan Udara: Fitur AI Overviews Google, dalam informasi mengenai kecelakaan udara Air India, secara keliru menyatakan bahwa kecelakaan tersebut melibatkan pesawat Airbus, padahal sebenarnya adalah Boeing 787. Hal ini sekali lagi menimbulkan kekhawatiran tentang akurasi dan keandalan informasinya, terutama dalam menangani informasi faktual yang krusial. (Sumber: MIT Technology Review)