Kata Kunci:Meta V-JEPA 2, NVIDIA AI Cloud Industri, Sakana AI Text-to-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, HistBench Universitas Princeton, Model Dunia Sumber Terbuka Pelatihan Video, Platform AI Cloud Manufaktur Eropa, Adaptor LLM Pembuatan Teks, Penyetelan Halus DPO GPT-4.1, Observabilitas Agen AI
🔥 Fokus
Meta merilis V-JEPA 2: Model dunia gambar/video open source yang dilatih berdasarkan video : Meta meluncurkan model dunia gambar/video open source baru V-JEPA 2, model ini berbasis arsitektur ViT, memiliki versi dengan ukuran (L/G/H) dan resolusi (286/384) yang berbeda, dengan jumlah parameter mencapai 1,2 miliar. V-JEPA 2 menunjukkan kinerja luar biasa dalam pemahaman dan prediksi visual, memungkinkan robot untuk melakukan perencanaan zero-shot dan menjalankan tugas di lingkungan asing. Meta menekankan visinya adalah AI memanfaatkan model dunia untuk beradaptasi dengan lingkungan dinamis dan mempelajari keterampilan baru secara efisien. Sementara itu, Meta juga merilis tiga benchmark baru: MVPBench, IntPhys 2, dan CausalVQA, yang digunakan untuk mengevaluasi kemampuan model yang ada dalam melakukan inferensi dunia fisik dari video. (Sumber: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
Nvidia membangun cloud AI industri pertama di Eropa, mendorong perkembangan manufaktur : Nvidia mengumumkan sedang membangun platform cloud kecerdasan buatan industri pertama di dunia untuk produsen Eropa. Pabrik AI ini bertujuan untuk membantu para pemimpin industri mempercepat aplikasi manufaktur secara menyeluruh, mulai dari desain, simulasi rekayasa, hingga digital factory twin dan teknologi robotika. Langkah ini merupakan salah satu dari serangkaian inisiatif yang diumumkan Nvidia di GTC Paris dan VivaTech 2025, yang bertujuan untuk mempercepat inovasi AI di Eropa dan wilayah lainnya. Jensen Huang menyatakan bahwa daya komputasi AI Eropa diperkirakan akan meningkat sepuluh kali lipat dalam dua tahun, dan menekankan bahwa “semua objek yang bergerak akan menjadi robotik, mobil adalah yang berikutnya.” (Sumber: nvidia, nvidia, 黄仁勋:欧洲AI算力两年翻十倍)

Sakana AI meluncurkan Text-to-LoRA: Menghasilkan adaptor LLM spesifik tugas secara instan dengan deskripsi teks : Sakana AI merilis teknologi Text-to-LoRA, sebuah Hypernetwork yang mampu menghasilkan adaptor LLM (LoRAs) spesifik tugas secara instan berdasarkan deskripsi teks pengguna tentang tugas tersebut. Teknologi ini bertujuan untuk menurunkan hambatan dalam kustomisasi model besar, memungkinkan pengguna non-teknis untuk mengkhususkan model dasar melalui bahasa alami, tanpa memerlukan latar belakang teknis yang mendalam atau sumber daya komputasi yang besar. Text-to-LoRA mampu mengkodekan ratusan adaptor LoRA yang ada dan melakukan generalisasi ke tugas-tugas yang belum pernah dilihat sebelumnya sambil mempertahankan kinerja. Makalah dan kode terkait telah dipublikasikan di arXiv dan GitHub, dan akan dipresentasikan di ICML2025. (Sumber: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
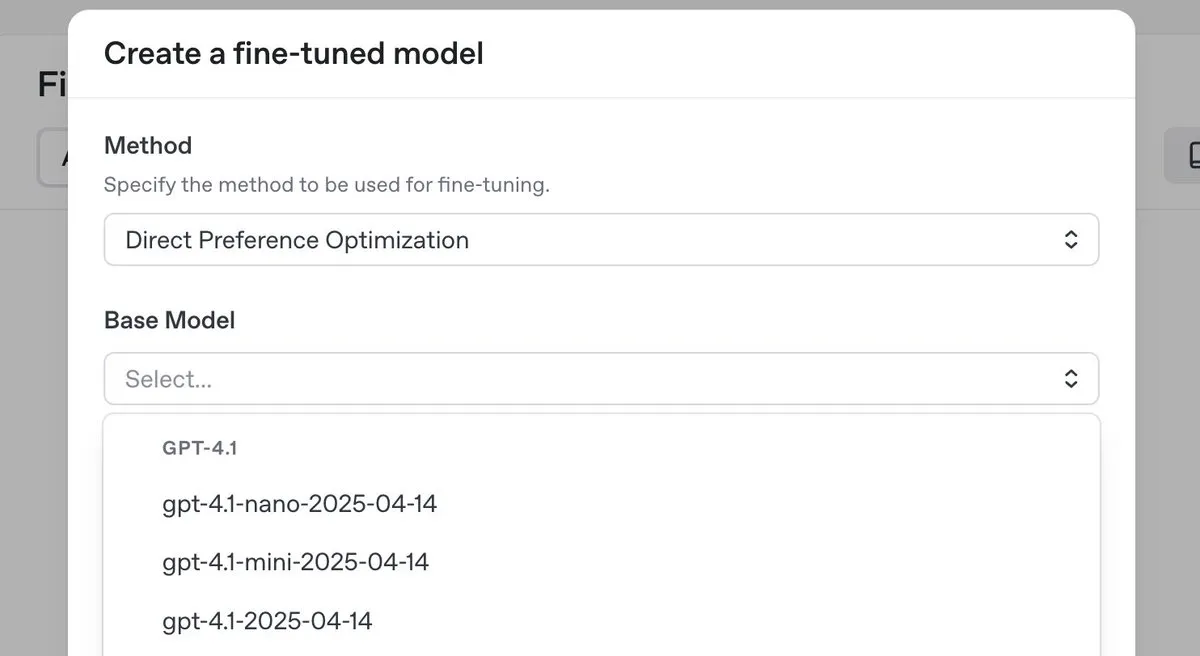
OpenAI merilis model inferensi teratas o3-pro dan menurunkan harga secara signifikan, sekaligus meluncurkan fitur fine-tuning DPO untuk seri GPT-4.1 : OpenAI meluncurkan model inferensi teratas barunya, o3-pro, dan melakukan penurunan harga yang signifikan untuk seri model o3, bertujuan untuk mengurangi biaya penggunaan bagi pengembang. Sementara itu, OpenAI mengumumkan bahwa pengguna sekarang dapat menggunakan Direct Preference Optimization (DPO) untuk melakukan fine-tuning pada keluarga model GPT-4.1 (termasuk 4.1, 4.1-mini, dan 4.1-nano). DPO memungkinkan kustomisasi melalui perbandingan respons model daripada target tetap, yang sangat cocok untuk tugas-tugas dengan persyaratan subjektif terkait nada, gaya, dan kreativitas. ARC Prize melakukan pengujian ulang terhadap o3 setelah penurunan harga, dan hasilnya menunjukkan bahwa kinerjanya di ARC-AGI tidak mengalami perubahan. (Sumber: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 Perkembangan
Databricks meluncurkan Lakebase, versi gratis & Agent Bricks, mempercepat pengembangan aplikasi data & AI : Databricks mengumumkan bahwa Lakebase memasuki tahap pratinjau publik, sebuah database Postgres yang dikelola sepenuhnya yang terintegrasi dengan lakehouse dan dibangun untuk AI, menggabungkan kemudahan penggunaan Postgres, skalabilitas lakehouse, serta teknologi percabangan database Neon. Sementara itu, Databricks meluncurkan platform versi gratis dan banyak materi pelatihan untuk membantu pengembang mempelajari rekayasa data, ilmu data, dan AI. Selain itu, Databricks Apps telah tersedia secara umum (GA), mendukung pelanggan dalam membangun dan menerapkan aplikasi data dan AI interaktif di platform tersebut. Databricks juga meluncurkan Agent Bricks, yang mengadopsi pendekatan deklaratif untuk mengembangkan agen AI, di mana pengguna mendeskripsikan tugas dan sistem secara otomatis menghasilkan evaluasi serta mengoptimalkan agen. (Sumber: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

Nvidia bekerja sama dengan Mistral AI, membangun platform cloud end-to-end di Eropa : Nvidia mengumumkan kerja sama dengan perusahaan startup Prancis, Mistral AI, untuk bersama-sama membangun platform cloud end-to-end. Tahap pertama kerja sama akan melibatkan penempatan 18.000 sistem Nvidia Grace Blackwell, dan direncanakan akan diperluas ke lebih banyak lokasi pada tahun 2026. Kerja sama ini merupakan bagian dari upaya Nvidia dalam mendorong pembangunan infrastruktur AI dan konsep “Sovereign AI” di Eropa, yang bertujuan untuk menyediakan pusat data dan server yang terlokalisasi bagi Eropa. (Sumber: 黄仁勋:欧洲AI算力两年翻十倍)
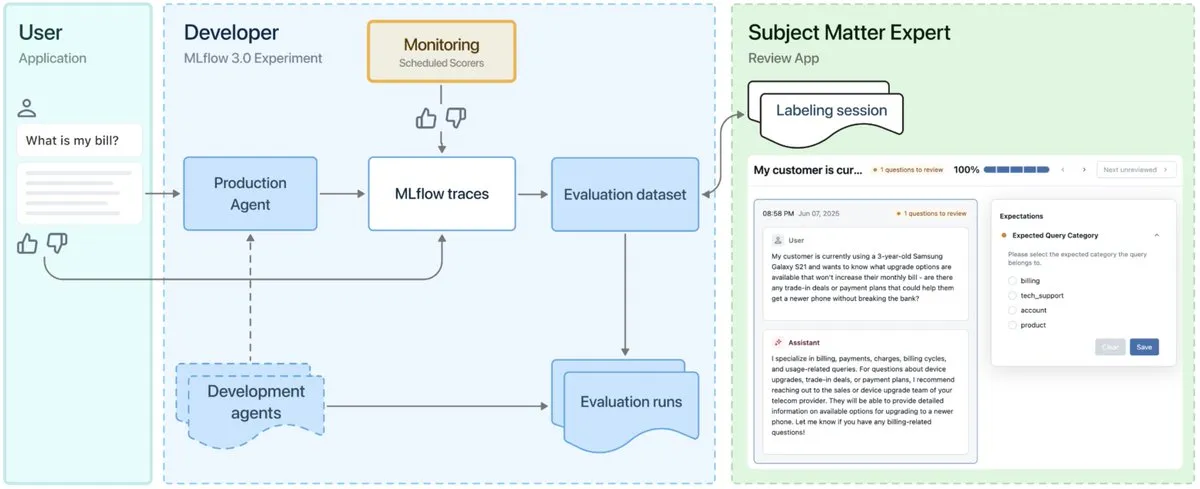
MLflow 3.0 dirilis, dirancang khusus untuk observabilitas dan pengembangan agen AI : MLflow 3.0 resmi dirilis, versi baru ini dirancang ulang khusus untuk observabilitas dan pengembangan agen AI, serta memperbarui fungsionalitas machine learning terstruktur tradisional. MLflow 3.0 bertujuan untuk mencapai peningkatan berkelanjutan sistem AI melalui data, mendukung pelacakan, evaluasi, dan pemantauan sistem AI, serta mempertimbangkan kebutuhan tingkat perusahaan seperti kolaborasi manusia, tata kelola dan keamanan data, serta integrasi dengan ekosistem data Databricks. (Sumber: matei_zaharia, matei_zaharia, lateinteraction)
Universitas Princeton dan Universitas Fudan bersama-sama meluncurkan HistBench dan HistAgent, mendorong aplikasi AI dalam penelitian sejarah : Laboratorium AI Universitas Princeton bekerja sama dengan Departemen Sejarah Universitas Fudan meluncurkan benchmark evaluasi AI pertama di dunia untuk penelitian sejarah, HistBench, dan asisten AI, HistAgent. HistBench mencakup 414 pertanyaan sejarah, meliputi 29 bahasa dan sejarah multi-peradaban, yang bertujuan untuk menguji kemampuan AI dalam memproses materi sejarah yang kompleks dan pemahaman multimodal. HistAgent adalah agen cerdas yang dirancang khusus untuk penelitian sejarah, mengintegrasikan alat-alat seperti pencarian literatur, OCR, dan terjemahan. Pengujian menunjukkan bahwa model besar umum memiliki akurasi kurang dari 20% pada HistBench, sementara HistAgent menunjukkan kinerja yang jauh melampaui model yang ada. (Sumber: 全球首个历史基准,普林复旦打造AI历史助手,AI破圈人文学科)

Microsoft Research dan Universitas Peking bersama-sama merilis kerangka kerja Next-Frame Diffusion (NFD), meningkatkan efisiensi generasi video autoregresif : Microsoft Research dan Universitas Peking bersama-sama meluncurkan kerangka kerja baru Next-Frame Diffusion (NFD), yang melalui pengambilan sampel paralel dalam frame dan cara autoregresif antar frame, mencapai generasi video autoregresif berkualitas tinggi lebih dari 30 frame per detik pada GPU A100 menggunakan model 310M. NFD mengadopsi Transformer dengan mekanisme perhatian kausal blok dan menggabungkan teknik distilasi konsistensi serta pengambilan sampel spekulatif untuk lebih meningkatkan efisiensi, diharapkan dapat diterapkan dalam skenario seperti game interaktif real-time. (Sumber: 每秒生成超30帧视频,支持实时交互,自回归视频生成新框架刷新生成效率)

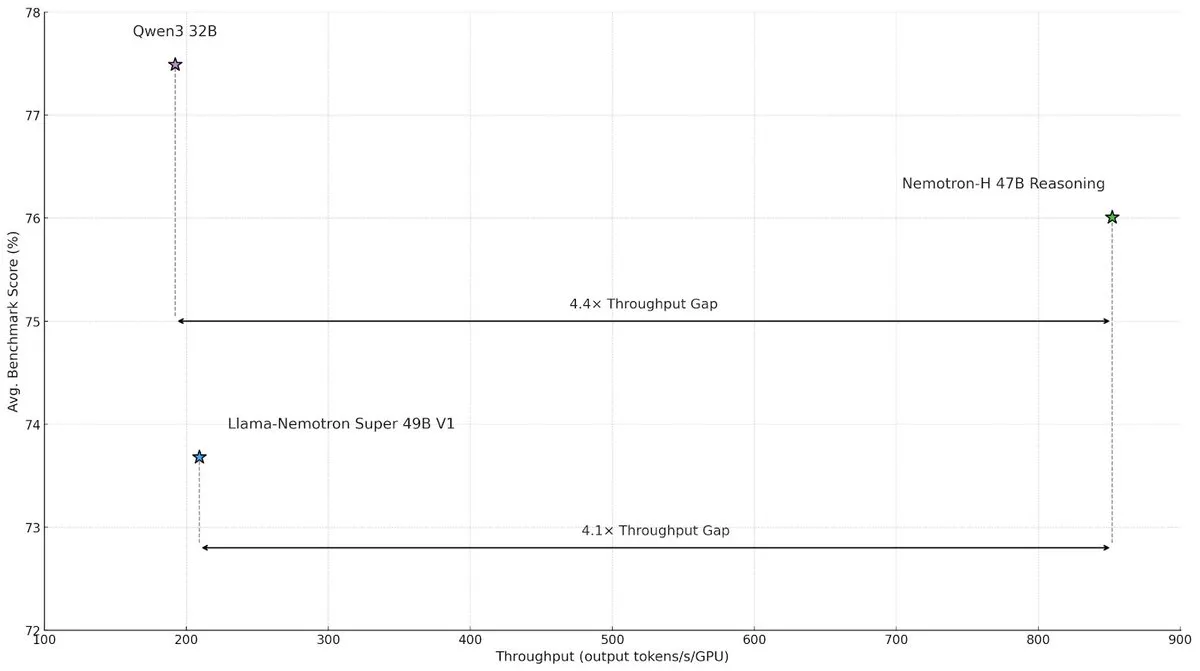
NVIDIA merilis model arsitektur hibrida Nemotron-H, meningkatkan kecepatan dan efisiensi inferensi skala besar : NVIDIA Research meluncurkan model Nemotron-H, yang mengadopsi arsitektur hibrida Mamba dan Transformer, bertujuan untuk mengatasi bottleneck kecepatan dalam tugas inferensi skala besar. Model ini, sambil mempertahankan kemampuan inferensi, mencapai throughput 4 kali lebih tinggi daripada model Transformer sejenis. Penelitian menunjukkan bahwa model hibrida dapat mempertahankan kinerja inferensi bahkan dengan menggunakan lebih sedikit lapisan perhatian, terutama dalam skenario rantai inferensi panjang, keunggulan efisiensi arsitektur linier menjadi signifikan. (Sumber: _albertgu, tri_dao, krandiash)
Peneliti Google DeepMind Jack Rae bergabung dengan grup “Superintelligence” Meta : Peneliti utama Google DeepMind, Jack Rae, telah dikonfirmasi bergabung dengan grup “Superintelligence” yang baru dibentuk Meta. Selama di DeepMind, Rae bertanggung jawab atas kemampuan “berpikir” model Gemini dan merupakan salah satu tokoh perwakilan dari gagasan “kompresi adalah kecerdasan”, serta pernah berpartisipasi dalam pengembangan GPT-4 di OpenAI. CEO Meta, Mark Zuckerberg, secara pribadi merekrut talenta AI terkemuka, menawarkan paket kompensasi puluhan juta dolar untuk tim baru tersebut, bertujuan untuk meningkatkan model Llama dan mengembangkan alat AI yang lebih kuat guna mengejar para pemimpin industri. (Sumber: 小扎“超级智能”小组第一位大佬,谷歌DeepMind首席研究员,“压缩即智能”核心人物, DhruvBatraDB)

Mistral AI merilis model inferensi pertamanya Magistral, mendukung inferensi multibahasa : Mistral AI meluncurkan model inferensi pertamanya, Magistral, termasuk versi open source 24B parameter Magistral Small dan Magistral Medium yang ditujukan untuk perusahaan. Model ini secara khusus di-fine-tuned untuk logika multi-langkah dan interpretabilitas, mendukung inferensi multibahasa, terutama dioptimalkan untuk bahasa-bahasa Eropa, dan dapat menyediakan proses berpikir yang dapat dilacak. Magistral menggunakan algoritma GRPO yang ditingkatkan dan dilatih melalui reinforcement learning murni, tanpa bergantung pada data distilasi dari model inferensi yang ada. Namun, hasil benchmark-nya mendapat beberapa kritik karena tidak menyertakan data dari versi terbaru Qwen dan DeepSeek R1. (Sumber: 新“SOTA”推理模型避战Qwen和R1?欧版OpenAI被喷麻了)

Model Besar Doubao ByteDance 1.6 dirilis dan kembali turun harga secara signifikan, model video Seedance 1.0 pro diluncurkan bersamaan : Volcengine merilis Model Besar Doubao 1.6, yang pertama kali menetapkan harga berdasarkan interval “panjang input”, dengan harga 0,8 yuan/juta token untuk interval input 0-32K, dan output 8 yuan/juta token, biaya turun 63% dibandingkan versi 1.5. Model generasi video Seedance 1.0 pro yang baru dirilis dihargai 1,5 sen per seribu token, menghasilkan video 1080P berdurasi 5 detik dengan biaya sekitar 3,67 yuan. Presiden Volcengine, Tan Dai, menyatakan bahwa penurunan harga kali ini dicapai melalui optimalisasi biaya yang ditargetkan untuk rentang 32K yang umum digunakan perusahaan dan inovasi model bisnis, bertujuan untuk mendorong aplikasi Agent skala besar. (Sumber: 豆包大模型再次大幅降价,火山引擎还在激进争夺市场份额, 「火山」烧向百度云)
Universitas Sains dan Teknologi Hong Kong bersama Huawei mengusulkan kerangka kerja AutoSchemaKG, mewujudkan konstruksi knowledge graph yang sepenuhnya otonom : Laboratorium KnowComp Universitas Sains dan Teknologi Hong Kong bekerja sama dengan Departemen Teori Huawei Hong Kong mengusulkan kerangka kerja AutoSchemaKG, yang dapat membangun knowledge graph secara sepenuhnya otonom tanpa memerlukan skema yang telah ditentukan sebelumnya. Sistem ini memanfaatkan model bahasa besar untuk secara langsung mengekstrak triplet pengetahuan dari teks dan menginduksi skema entitas dan peristiwa. Berdasarkan kerangka kerja ini, tim membangun seri knowledge graph ATLAS yang berisi lebih dari 900 juta node dan 5,9 miliar edge. Eksperimen menunjukkan bahwa metode ini, tanpa intervensi manusia, mencapai keselarasan semantik 95% antara skema yang diinduksi dan skema yang dirancang manusia. (Sumber: 最大的开源GraphRag:知识图谱完全自主构建)

Qujing Technology merilis solusi server 8-kartu terintegrasi perangkat lunak dan keras, meningkatkan efisiensi operasional model besar DeepSeek : Qujing Technology bersama Intel mengadakan salon ekologi, merilis solusi server 8-kartu terintegrasi perangkat lunak dan keras terbaru. Solusi ini dapat menjalankan model besar seperti DeepSeek-R1/V3-671B secara efisien, dengan peningkatan kinerja hingga 7 kali lipat dibandingkan kartu tunggal. Sementara itu, mesin inferensi KLLM yang dikembangkan sendiri, platform manajemen model besar AMaaS, dan suite aplikasi perkantoran “Qujing·Zhiwen” juga mengalami peningkatan penting, bertujuan untuk mengatasi tantangan seperti hambatan awal yang tinggi dan kinerja operasional yang tidak memadai dalam penerapan model besar secara privat. (Sumber: 趋境科技&英特尔生态沙龙举办,硬件、推理引擎、上层应用生态融合,打通大模型私有化“最后一公里”)

Black Forest Labs merilis seri model gambar FLUX.1 Kontext, memperkuat konsistensi karakter dan gaya : Black Forest Labs dari Jerman meluncurkan seri model teks-ke-gambar FLUX.1 Kontext (versi max, pro, dev), yang berfokus pada menjaga konsistensi karakter dan gaya saat mengedit gambar. Seri model ini mendukung modifikasi lokal dan global pada gambar, dan dapat menghasilkan gambar dari input teks dan/atau gambar. Versi FLUX.1 Kontext dev direncanakan akan menjadi open source. Dalam pengujian benchmark eksklusif yang mencakup sekitar 1000 pasang prompt dan gambar referensi, versi FLUX.1 Kontext max dan pro menunjukkan kinerja yang lebih unggul dibandingkan model pesaing seperti OpenAI GPT Image 1 dan Google Gemini 2.0 Flash. (Sumber: DeepLearning.AI Blog)

Nvidia, Universitas Rutgers, dkk. mengusulkan kerangka kerja STORM, mengurangi Token yang dibutuhkan untuk pemahaman video melalui lapisan Mamba : Para peneliti dari Nvidia, Universitas Rutgers, Universitas California Berkeley, dan institusi lainnya membangun sistem teks-video STORM. Sistem ini memperkenalkan lapisan Mamba di antara vision transformer SigLIP dan LLM Qwen2-VL, dengan memperkaya embedding Token satu frame (berisi informasi dari frame lain dalam klip yang sama), sehingga dapat merata-ratakan embedding Token antar frame tanpa kehilangan informasi penting. Hal ini memungkinkan sistem untuk memproses video dengan lebih sedikit Token, menunjukkan kinerja yang lebih unggul daripada GPT-4o dan Qwen2-VL dalam benchmark pemahaman video seperti MVBench dan MLVU, sekaligus meningkatkan kecepatan pemrosesan lebih dari 3 kali lipat. (Sumber: DeepLearning.AI Blog)

Salah satu pendiri Google skeptis terhadap robot humanoid, prospek komersialisasi robot khusus lebih cerah : Salah satu pendiri Google, Sergey Brin, menyatakan kurang antusias terhadap robot humanoid yang meniru bentuk manusia secara ketat, berpendapat bahwa hal tersebut bukanlah syarat mutlak agar robot dapat bekerja secara efektif. Sementara itu, robot khusus mendapatkan perhatian karena karakteristiknya yang “siap pakai” dan jalur komersialisasi yang jelas. Misalnya, robot bawah air dan robot pemotong rumput menunjukkan potensi besar dalam skenario tertentu. Analisis menunjukkan bahwa pada tahap ini, bentuk robot dan produktivitas yang dapat memecahkan masalah nyata adalah kunci, dan robot khusus, dengan model bisnis yang jelas dan kebutuhan yang mendesak, lebih dulu mencapai komersialisasi. (Sumber: 专用机器人拍了拍人形机器人“兄弟让一让,我要上桌吃饭。”)

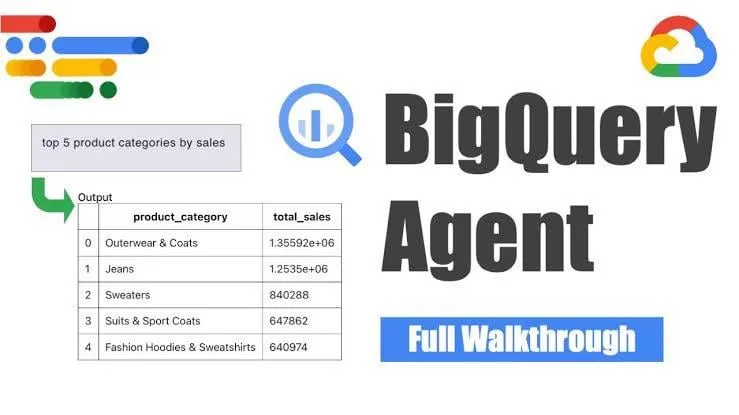
Google meluncurkan agen rekayasa data BigQuery, mewujudkan generasi pipeline cerdas : Google meluncurkan agen rekayasa data BigQuery, alat ini memanfaatkan inferensi sadar konteks untuk secara efisien memperluas generasi pipeline data. Pengguna melalui perintah baris perintah sederhana dapat mendefinisikan kebutuhan pipeline, agen kemudian memanfaatkan prompt khusus domain untuk menghasilkan kode pipeline batch yang disesuaikan dengan lingkungan data pengguna, termasuk konfigurasi penyerapan data, kueri transformasi, logika pembuatan tabel, dan pengaturan penjadwalan melalui Dataform atau Composer. Alat ini bertujuan untuk menyederhanakan pekerjaan berulang yang dihadapi oleh insinyur data dalam menangani berbagai domain data, lingkungan, dan logika transformasi melalui bantuan AI. (Sumber: Reddit r/deeplearning)
Yandex merilis Yambda, dataset publik skala besar yang berisi hampir 5 miliar interaksi pengguna-trek audio : Yandex merilis dataset publik skala besar bernama Yambda, yang dirancang khusus untuk penelitian sistem rekomendasi. Dataset ini berisi hampir 5 miliar data interaksi anonim pengguna dengan trek audio dari Yandex Music, memberikan kesempatan langka bagi para peneliti untuk menangani data skala dunia nyata. (Sumber: _akhaliq)

ByteDance merilis model perbaikan video SeedVR2 di Hugging Face : Tim Seed ByteDance merilis SeedVR2 di Hugging Face, sebuah model Transformer difusi satu langkah untuk perbaikan video. Model ini menggunakan lisensi Apache 2.0, memiliki ciri khas inferensi satu langkah, cepat dan efisien, serta mendukung pemrosesan resolusi apa pun tanpa perlu pembagian blok atau batasan ukuran. (Sumber: huggingface)
Model video besar Doubao ByteDance Seedance 1.0 Pro mendapat pujian dalam uji coba nyata : Model besar gambar-ke-video terbaru dari ByteDance, Seedance 1.0 Pro, menunjukkan kemampuan mengikuti instruksi yang baik dan stabilitas generasi objek dalam uji coba nyata. Umpan balik pengguna menyatakan kualitas generasi videonya tinggi, pergerakan kamera dan penempatan titik akurat, hanya kalah dari Veo 2/3. Salah satu potensi kekurangan adalah, saat menghasilkan gerakan objek murni, model terkadang menambahkan operasi tangan untuk membuat gambar lebih masuk akal, yang dapat dihindari dengan membatasi kemunculan tangan. (Sumber: karminski3, karminski3, karminski3)
Alibaba merilis kerangka kerja digital human Mnn3dAvatar secara open source, mendukung penangkapan wajah real-time dan pembuatan karakter virtual 3D : Alibaba merilis kerangka kerja digital human bernama Mnn3dAvatar di GitHub secara open source. Proyek ini mampu melakukan penangkapan wajah secara real-time dan memetakan ekspresi ke karakter virtual 3D, sekaligus mendukung pengguna untuk membuat karakter virtual 3D mereka sendiri. Kerangka kerja ini cocok untuk skenario sederhana seperti siaran langsung penjualan, presentasi konten, dll. (Sumber: karminski3)
Nvidia merilis model dasar robot humanoid Gr00t N 1.5 3B secara open source, dan menyediakan tutorial fine-tuning : Nvidia merilis model Gr00t N 1.5 3B secara open source, sebuah model dasar terbuka yang dirancang khusus untuk kemampuan inferensi robot humanoid, dengan lisensi komersial. Sementara itu, Nvidia juga merilis tutorial fine-tuning lengkap yang digunakan bersama LeRobotHF SO101, bertujuan untuk mendorong pengembangan dan aplikasi teknologi robot humanoid. (Sumber: ClementDelangue)
Together AI meluncurkan Batch API, menyediakan layanan inferensi LLM skala besar dan menurunkan harga secara signifikan : Together AI meluncurkan Batch API baru, yang dirancang khusus untuk inferensi LLM skala besar, mendukung aplikasi dengan throughput tinggi seperti generasi data sintetis, pengujian benchmark, moderasi dan peringkasan konten, ekstraksi dokumen, dll. API ini memperkenalkan harga awal yang 50% lebih murah daripada API real-time, mendukung pemrosesan batch hingga 50.000 permintaan atau 100MB setiap kali, dan kompatibel dengan 15 model teratas. (Sumber: vipulved)
Google Gemini 2.5 Pro menambahkan fitur generasi seni fraktal interaktif : Google mengumumkan bahwa Gemini 2.5 Pro sekarang mendukung pembuatan seni fraktal interaktif secara instan. Pengguna dapat memberikan prompt seperti “buatkan saya karya seni fraktal yang indah, berbasis partikel, animasi, tak berujung, 3D, simetris, terinspirasi oleh rumus matematika” untuk menghasilkan seni visual yang unik. (Sumber: demishassabis)
Kecepatan generasi video Google Veo3 Fast meningkat dua kali lipat : Laboratorium Google mengumumkan bahwa kecepatan generasi versi Veo3 Fast dalam alat generasi video Flow mereka meningkat lebih dari dua kali lipat, sambil mempertahankan resolusi 720p. Pembaruan ini bertujuan agar pengguna dapat membuat konten video lebih cepat. (Sumber: op7418)
Hugging Face mengintegrasikan Google Colab dan Kaggle, menyederhanakan alur penggunaan model : Hugging Face kini telah terintegrasi dengan Google Colab dan Kaggle. Pengguna dapat langsung meluncurkan notebook Colab dari kartu model mana pun, atau membuka model yang sama di Kaggle Notebook, disertai dengan contoh kode publik yang dapat dijalankan, sehingga menyederhanakan alur penggunaan dan eksperimen model. (Sumber: ClementDelangue, huggingface)
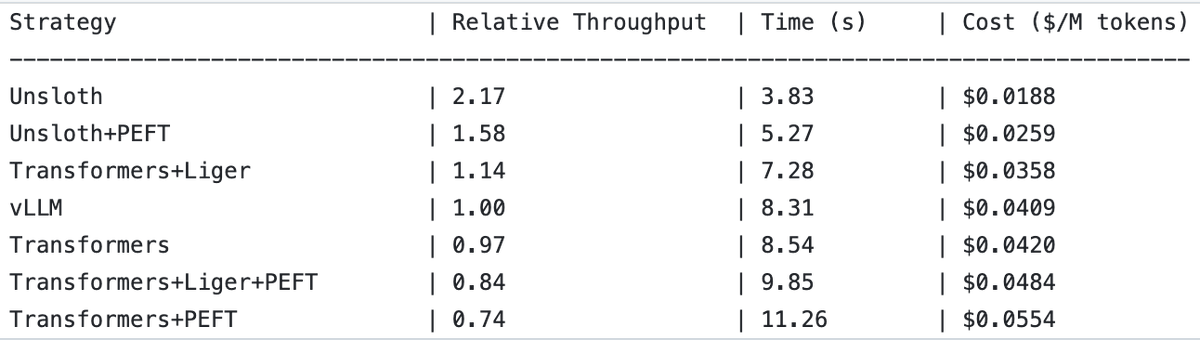
UnslothAI mencapai peningkatan throughput 2x dalam layanan model reward dan inferensi klasifikasi sekuensial : UnslothAI ditemukan dapat digunakan untuk menyediakan layanan model reward (RM), dan dalam inferensi klasifikasi sekuensial, throughput-nya dua kali lipat dari vLLM. Penemuan ini menarik perhatian di komunitas RL (Reinforcement Learning), peningkatan kinerja UnslothAI diharapkan dapat mempercepat penelitian dan aplikasi terkait. (Sumber: natolambert, danielhanchen)
Digua Robot merilis kit pengembangan robot terintegrasi komputasi-kontrol SoC tunggal pertama RDK S100 : Digua Robot meluncurkan kit pengembangan robot terintegrasi komputasi-kontrol SoC tunggal pertama di industri, RDK S100. Kit ini mengadopsi desain arsitektur mirip otak besar-otak kecil manusia, mengintegrasikan CPU+BPU+MCU pada satu SoC, mendukung kolaborasi efisien model besar dan kecil untuk embodied intelligence, dan menghubungkan loop tertutup “persepsi-keputusan-kontrol”. RDK S100 menyediakan berbagai antarmuka dan infrastruktur pengembangan yang terkoordinasi perangkat lunak-keras serta terintegrasi edge-cloud, bertujuan untuk mempercepat pembuatan produk embodied intelligence dan penerapan multi-skenario. Saat ini telah bekerja sama dengan lebih dari 20 pelanggan terkemuka, dengan harga pasar 2799 yuan. (Sumber: 地瓜机器人发布首款单SoC算控一体化机器人开发套件,已同超20家头部客户达成合作|最前线)

🧰 Alat
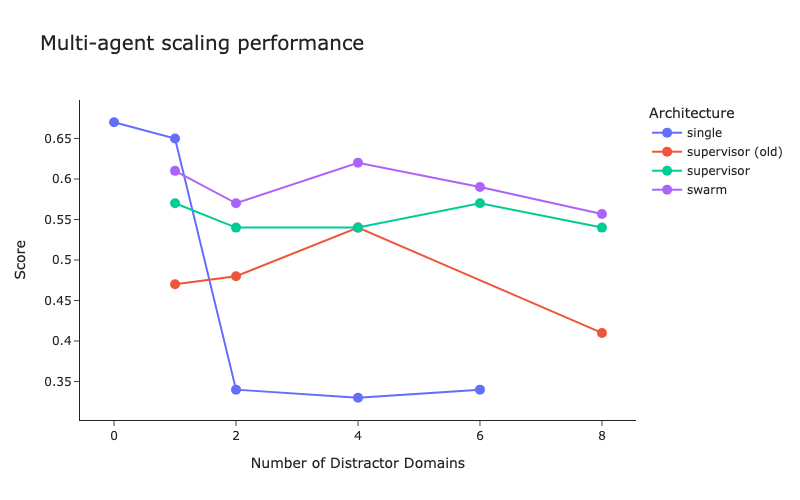
LangChain merilis benchmark arsitektur multi-agen dan perbaikan metode supervisor : LangChain, menanggapi meningkatnya jumlah sistem multi-agen, melakukan pengujian benchmark awal untuk mengeksplorasi cara mengoptimalkan koordinasi antar multi-agen. Sementara itu, LangChain melakukan beberapa perbaikan pada metode supervisornya, dan blog terkait telah dipublikasikan. (Sumber: LangChainAI, hwchase17)
Cartesia meluncurkan Ink-Whisper: Model speech-to-text streaming cepat dan ekonomis yang dirancang untuk agen suara : Cartesia merilis Ink-Whisper, model speech-to-text (STT) streaming berkecepatan tinggi dan berbiaya rendah yang dioptimalkan untuk agen suara. Model ini dirancang khusus untuk akurasi dalam kondisi dunia nyata, dan dapat digunakan bersama dengan model text-to-speech (TTS) Sonic dari Cartesia untuk mewujudkan interaksi AI suara yang cepat. Ink-Whisper mendukung koneksi ke platform seperti VapiAI, PipecatAI, dan Livekit. (Sumber: simran_s_arora, tri_dao, krandiash)

MonkeyOCR: Model parsing dokumen open source yang kecil, cepat : Sebuah model parsing dokumen dengan parameter 3B bernama MonkeyOCR dirilis, menggunakan lisensi Apache 2.0. Model ini mampu mem-parsing berbagai elemen dalam dokumen, termasuk grafik, rumus, tabel, dll., bertujuan untuk menggantikan pipeline parser tradisional dan menyediakan solusi pemrosesan dokumen yang lebih baik. (Sumber: mervenoyann, huggingface)
LlamaIndex terintegrasi dengan Cleanlab, meningkatkan kredibilitas respons asisten AI : LlamaIndex mengumumkan integrasi dengan CleanlabAI. LlamaIndex digunakan untuk membangun asisten pengetahuan AI dan agen tingkat produksi, menghasilkan wawasan dari data perusahaan. Penambahan Cleanlab bertujuan untuk meningkatkan kredibilitas respons asisten AI ini, mampu memberi skor pada setiap respons LLM, menangkap halusinasi atau respons yang salah secara real-time, dan membantu menganalisis penyebab respons yang tidak kredibel (seperti pengambilan yang buruk, masalah data/konteks, kueri yang sulit, atau halusinasi LLM). (Sumber: jerryjliu0)

Claude Code menambahkan “mode rencana”, meningkatkan kontrol atas perubahan kode yang kompleks : Claude Code dari Anthropic memperkenalkan “mode rencana” (Plan mode). Fitur ini memungkinkan pengguna untuk meninjau rencana implementasi sebelum benar-benar mengubah kode, memastikan setiap langkah dipertimbangkan dengan matang, terutama cocok untuk perubahan kode yang kompleks. Pengguna dapat masuk ke mode rencana dengan menekan Shift + Tab dua kali, Claude Code akan memberikan rencana implementasi terperinci dan meminta konfirmasi sebelum eksekusi. Fitur ini telah diluncurkan untuk semua pengguna Claude Code (termasuk pelanggan Pro atau Max). (Sumber: dotey, kylebrussell)
rvn-convert: Alat konversi SafeTensors ke GGUF v3 yang diimplementasikan dengan Rust : Sebuah alat open source bernama rvn-convert dirilis, ditulis dalam bahasa Rust, digunakan untuk mengonversi file model format SafeTensors ke format GGUF v3. Alat ini memiliki fitur dukungan shard tunggal, kecepatan tinggi, tidak memerlukan lingkungan Python, mampu memetakan file safetensors ke memori dan langsung menulis ke file gguf, menghindari puncak RAM dan masalah perputaran disk. Saat ini mendukung upsampling BF16 ke F32, penyematan tokenizer.json, dan fungsi lainnya. (Sumber: Reddit r/LocalLLaMA)
Runway API menambahkan fitur super-resolusi video 4K : Runway mengumumkan bahwa API-nya kini mendukung fitur super-resolusi video 4K. Pengembang dapat mengintegrasikan fitur ini ke dalam aplikasi, produk, platform, dan situs web mereka sendiri untuk meningkatkan kejernihan dan kualitas konten video. (Sumber: c_valenzuelab)
You.com meluncurkan fitur Projects untuk mengatur dan mengelola materi penelitian : You.com merilis alat baru bernama “Projects”, yang bertujuan untuk membantu pengguna mengatur materi penelitian ke dalam folder yang mudah diakses. Fitur ini mendukung pengguna untuk mengontekstualisasikan dan menyusun percakapan, menghindari catatan obrolan yang tersebar dan kehilangan wawasan, sehingga menyederhanakan proses manajemen pengetahuan. (Sumber: RichardSocher)
LlamaIndex meluncurkan layanan ekstraksi dokumen cerdas LlamaExtract : LlamaIndex merilis LlamaExtract, sebuah layanan ekstraksi dokumen yang digerakkan oleh agen, bertujuan untuk mengekstrak data terstruktur dari dokumen kompleks dan pola input. Layanan ini tidak hanya dapat mengekstrak pasangan kunci-nilai, tetapi juga menyediakan inferensi sumber yang akurat, referensi halaman, dan teks yang cocok untuk setiap item yang diekstraksi. LlamaExtract disediakan dalam bentuk API dan dapat dengan mudah diintegrasikan ke dalam alur kerja agen hilir. (Sumber: jerryjliu0)

langchain-google-vertexai merilis pembaruan, meningkatkan caching klien dan dukungan alat : langchain-google-vertexai menyambut rilis versi baru. Pembaruan utama meliputi: caching klien prediksi, membuat instansiasi klien baru 500 kali lebih cepat; dukungan untuk alat eksekusi kode bawaan. (Sumber: LangChainAI, Hacubu)
Perplexity Finance menambahkan fitur unduh langsung model Excel : Perplexity Finance mengumumkan bahwa pengguna sekarang dapat langsung mengunduh model Excel dari halamannya, memberikan titik awal yang lebih cepat untuk pemodelan dan penelitian keuangan. Fitur ini terbuka gratis untuk semua pengguna, sebelumnya hanya mendukung unduhan format CSV. (Sumber: AravSrinivas)
Viwoods merilis tablet layar tinta AI Paper Mini, mengintegrasikan GPT-4o dan fungsi AI lainnya : Produsen layar tinta baru, Viwoods, meluncurkan AI Paper Mini, sebuah tablet layar tinta yang dilengkapi dengan fungsi AI. Perangkat ini mendukung berbagai model AI seperti GPT-4o, DeepSeek, menyediakan mode Chat dan asisten AI prasetel (analisis konten, pembuatan email, AI ke teks). Fitur khasnya termasuk manajemen tugas tampilan kalender, catatan jendela mengambang cepat, dll. Dari segi perangkat keras, Paper Mini menggunakan layar Carta 1000 292 ppi, penyimpanan 4GB+128GB, dilengkapi dengan stylus. Sementara itu, Viwoods juga meluncurkan AI Paper berukuran lebih besar, dengan layar fleksibel Carta 1300 300ppi, dengan kecepatan respons yang lebih cepat. (Sumber: 我花半台 iPhone 的价格,买到了一台带 AI 的「墨水屏平板」……)

360 merilis agen super search Nano AI, Zhou Hongyi secara pribadi mendukung : Pendiri Grup 360, Zhou Hongyi, memimpin peluncuran agen super search Nano AI. Agen ini bertujuan untuk mewujudkan “satu kalimat, semua bisa dicari”, mampu berpikir secara mandiri, memanggil browser dan alat eksternal untuk menjalankan tugas tanpa intervensi manusia, serta mendukung visualisasi penuh dan penelusuran langkah. Zhou Hongyi menyatakan bahwa konferensi pers ini sendiri juga mencoba menggunakan Nano AI untuk persiapan, dan merilis perangkat keras perekaman suara cerdas AI Nano Note serta kacamata AI hasil kolaborasi dengan Rokid. (Sumber: 周鸿祎要用AI“干掉”市场部,“纳米”做到了吗?)
📚 Pembelajaran
DeepLearning.AI meluncurkan kursus singkat baru: Mengatur alur kerja GenAI menggunakan Apache Airflow : DeepLearning.AI bekerja sama dengan Astronomer meluncurkan kursus singkat baru, mengajarkan cara menggunakan Apache Airflow 3.0 untuk mengubah prototipe RAG menjadi alur kerja yang siap produksi. Materi kursus mencakup pemecahan alur kerja menjadi tugas modular, menggunakan pemicu berbasis waktu dan berbasis peristiwa untuk menjadwalkan pipeline, pemetaan tugas dinamis untuk menjalankan tugas secara paralel, menambahkan percobaan ulang/peringatan/pengisian ulang untuk toleransi kesalahan, serta teknik perluasan pipeline. Kursus ini tidak memerlukan pengalaman Airflow sebelumnya. (Sumber: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain meluncurkan kursus mini optimasi dan evaluasi RAG : Hamel Husain mengumumkan peluncuran kursus mini empat bagian tentang optimasi dan evaluasi RAG (Retrieval Augmented Generation). Bagian pertama dibawakan oleh @bclavie, membahas pandangan “retrieval adalah RAG”, bertujuan untuk menanggapi diskusi sebelumnya tentang RAG sebagai “virus pemikiran yang harus diberantas”. Seri kursus ini gratis, bertujuan untuk membantu praktisi mengatasi kesulitan yang dihadapi dalam evaluasi RAG. (Sumber: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

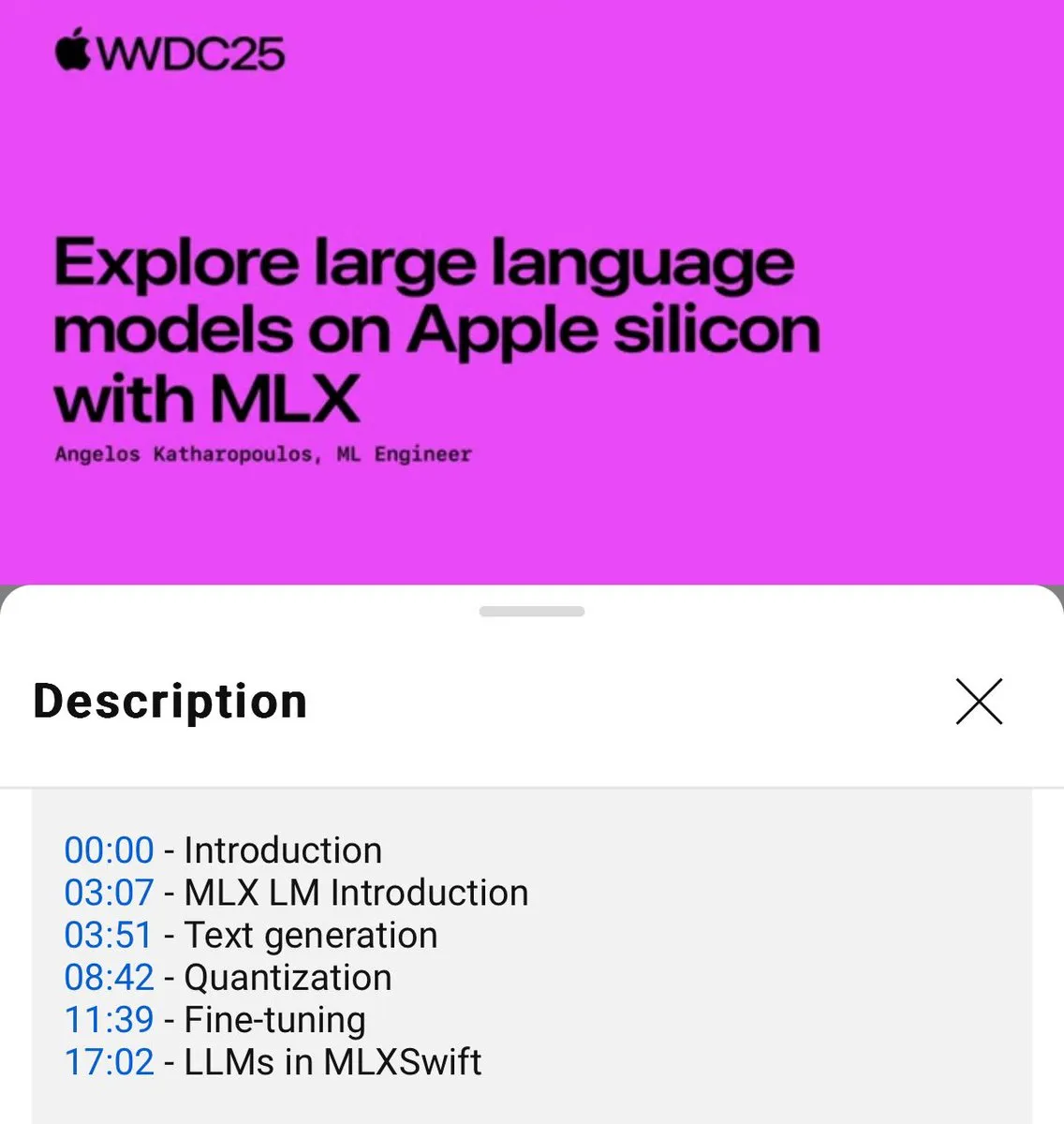
Tutorial penggunaan lokal model bahasa MLX dirilis (WWDC25) : Pada konferensi WWDC25, Angelos Katharopoulos memperkenalkan cara menggunakan MLX untuk memulai dengan cepat model bahasa lokal. Tutorial ini mencakup penggunaan MLXLM CLI untuk operasi baris perintah tunggal, seperti kuantisasi model (mlx_lm.convert), fine-tuning LoRA (mlx_lm.lora), serta penggabungan model dan pengunggahan ke Hugging Face (mlx_lm.fuse). Tutorial Jupyter Notebook lengkap telah tersedia di GitHub. (Sumber: awnihannun)
LangChain berbagi metode Harvey AI dalam membangun agen AI hukum : Ben Liebald dari Harvey AI, dalam acara Interrupt LangChain, berbagi metode matang mereka dalam membangun agen AI hukum. Metode ini menggabungkan evaluasi LangSmith dan strategi “lawyer-in-the-loop”, bertujuan untuk menyediakan alat AI yang dapat dipercaya oleh pengacara untuk pekerjaan hukum yang kompleks. (Sumber: LangChainAI, hwchase17)

Manual RLHF v1.1 diperbarui, memperluas konten model RLVR/inferensi : Manual RLHF (rlhfbook.com) telah diperbarui ke versi v1.1, menambahkan konten yang diperluas tentang RLVR (Reinforcement Learning from Video Representations) dan model inferensi. Pembaruan mencakup ringkasan laporan model inferensi utama, praktik/trik yang umum digunakan beserta penggunanya, pekerjaan inferensi terkait sebelum o1, serta perbaikan seperti RL asinkron. (Sumber: menhguin)
Makalah SWE-Flow: Mensintesis data rekayasa perangkat lunak dengan pendekatan berbasis tes : Sebuah makalah baru bernama SWE-Flow mengusulkan kerangka kerja sintesis data baru berdasarkan Test-Driven Development (TDD). Kerangka kerja ini secara otomatis menyimpulkan langkah-langkah pengembangan inkremental dengan menganalisis unit test, membangun runtime dependency graph (RDG) untuk menghasilkan rencana pengembangan terstruktur. Setiap langkah menghasilkan sebagian basis kode, unit test yang sesuai, dan modifikasi kode yang diperlukan, sehingga menciptakan tugas TDD yang dapat diverifikasi. Berdasarkan metode ini, dataset benchmark SWE-Flow-Eval dihasilkan. (Sumber: HuggingFace Daily Papers)
Makalah PlayerOne: Simulator dunia nyata pertama yang dibangun dari perspektif orang pertama : PlayerOne diusulkan sebagai simulator dunia nyata pertama yang dibangun dari perspektif orang pertama (egosentris), mampu melakukan eksplorasi imersif di lingkungan dinamis. Diberikan gambar adegan orang pertama pengguna, PlayerOne dapat membangun dunia yang sesuai dan menghasilkan video orang pertama yang selaras secara ketat dengan gerakan nyata pengguna yang ditangkap oleh kamera eksternal. Model ini mengadopsi alur pelatihan dari kasar ke halus dan merancang skema injeksi gerakan yang memisahkan komponen serta kerangka kerja rekonstruksi bersama. (Sumber: HuggingFace Daily Papers)
Makalah ComfyUI-R1: Mengeksplorasi model inferensi untuk generasi alur kerja : ComfyUI-R1 adalah model inferensi besar pertama untuk generasi alur kerja otomatis. Peneliti pertama-tama membangun dataset yang berisi 4K alur kerja dan menyusun data inferensi Chain-of-Thought (CoT) yang panjang. ComfyUI-R1 dilatih melalui kerangka kerja dua tahap: fine-tuning CoT untuk cold start, dan reinforcement learning untuk mendorong kemampuan inferensi. Eksperimen menunjukkan bahwa model parameter 7B secara signifikan mengungguli metode yang ada dalam hal validitas format, tingkat keberhasilan, serta skor F1 tingkat node/grafik. (Sumber: HuggingFace Daily Papers)
Makalah SeerAttention-R: Kerangka kerja adaptif perhatian jarang untuk inferensi panjang : SeerAttention-R adalah kerangka kerja perhatian jarang yang dirancang khusus untuk dekode panjang model inferensi. Ini mempelajari sparsitas perhatian melalui mekanisme gating self-distillation dan menghilangkan query pooling untuk beradaptasi dengan dekode autoregresif. Kerangka kerja ini dapat diintegrasikan sebagai plugin ringan ke dalam model pra-terlatih yang ada tanpa memodifikasi parameter asli. Dalam pengujian benchmark AIME, SeerAttention-R yang dilatih hanya dengan 0.4B token mempertahankan akurasi inferensi yang mendekati lossless dalam blok perhatian jarang besar (64/128) dengan anggaran 4K token. (Sumber: HuggingFace Daily Papers)
Makalah SAFE: Deteksi kegagalan multi-tugas untuk model visual-bahasa-aksi : Makalah ini mengusulkan SAFE, sebuah detektor kegagalan yang dirancang untuk kebijakan robot universal (seperti VLA). Dengan menganalisis ruang fitur VLA, SAFE belajar memprediksi kemungkinan kegagalan tugas dari fitur internal VLA. Detektor ini dilatih pada penerapan yang berhasil dan gagal, dan dievaluasi pada tugas yang belum pernah dilihat, kompatibel dengan arsitektur kebijakan yang berbeda, bertujuan untuk meningkatkan keamanan VLA saat berinteraksi dengan lingkungan. (Sumber: HuggingFace Daily Papers)
Makalah Branched Schrödinger Bridge Matching: Mempelajari jembatan Schrödinger bercabang : Penelitian ini memperkenalkan kerangka kerja Branched Schrödinger Bridge Matching (BranchSBM) untuk mempelajari jembatan Schrödinger bercabang, guna memprediksi lintasan antara distribusi awal dan distribusi target. Berbeda dengan metode yang ada, BranchSBM mampu memodelkan evolusi bercabang atau divergen dari titik awal bersama ke beberapa hasil yang berbeda, melalui parameterisasi beberapa medan kecepatan yang bergantung waktu dan proses pertumbuhan. (Sumber: HuggingFace Daily Papers)
💼 Bisnis
Meta dilaporkan berencana mengakuisisi perusahaan pelabelan data Scale AI senilai $15 miliar, pendiri kemungkinan bergabung dengan Meta : Menurut laporan, Meta berencana mengakuisisi perusahaan terkemuka di bidang pelabelan data, Scale AI, senilai $15 miliar. Jika transaksi tercapai, pendiri Scale AI keturunan Tionghoa berusia 28 tahun, Alexandr Wang, beserta timnya akan langsung bergabung dengan Meta. Langkah ini dianggap sebagai upaya besar CEO Meta, Mark Zuckerberg, untuk memperkuat kemampuan tim AGI (Artificial General Intelligence) miliknya, guna mengejar pesaing seperti OpenAI dan Google. Meta belakangan ini gencar merekrut talenta AI, menawarkan paket gaji puluhan juta dolar untuk insinyur terkemuka. (Sumber: 小扎“超级智能”小组第一位大佬,谷歌DeepMind首席研究员,“压缩即智能”核心人物, dylan522p, sarahcat21, Dorialexander)
Disney dan Universal Pictures menggugat perusahaan gambar AI Midjourney atas pelanggaran hak cipta : Disney dan Universal Pictures telah mengajukan gugatan terhadap perusahaan generator gambar AI Midjourney, menuduh penggunaan karya IP terkenal seperti “Star Wars” dan “The Simpsons” tanpa izin. Kasus ini menarik perhatian, jika Disney menang, hal ini dapat menimbulkan efek domino bagi perusahaan AI lain yang bergantung pada pelatihan data skala besar, dan semakin memperuncing kontroversi hak cipta di bidang AI. (Sumber: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

Google kembali meluncurkan “program pengunduran diri sukarela” akibat dampak pencarian AI, mempengaruhi beberapa tim penting seperti pencarian dan periklanan : Menghadapi dampak dari pencarian AI, Google kembali menawarkan “program pengunduran diri sukarela” kepada karyawan di beberapa departemen di Amerika Serikat, yang melibatkan tim-tim kunci seperti pencarian, periklanan, dan rekayasa inti, serta memperkuat kebijakan kembali bekerja di kantor. Langkah ini bertujuan untuk merestrukturisasi sumber daya, memfokuskan lebih banyak upaya pada proyek unggulan AI Gemini dan pengembangan pengalaman pencarian “mode AI”. Bisnis pencarian tradisional Google menghadapi tantangan besar akibat kebangkitan AI, sementara perusahaan juga menghadapi tekanan regulasi. (Sumber: AI搜索冲击下谷歌再推“自愿离职方案”,波及多个重要团队, jpt401)
🌟 Komunitas
AI dalam eksperimen deteksi penipuan kesejahteraan di Amsterdam mengungkap bias, proyek dihentikan : Amsterdam mencoba menggunakan sistem AI (Smart Check) untuk mengevaluasi aplikasi kesejahteraan guna mendeteksi penipuan. Meskipun mengikuti praktik terbaik AI yang bertanggung jawab, termasuk pengujian bias dan perlindungan teknis, dalam proyek percontohan, sistem tersebut tetap gagal mencapai keadilan dan efektivitas. Model awal memiliki bias terhadap pemohon non-Belanda dan laki-laki; setelah penyesuaian, model tersebut malah bias terhadap warga Belanda dan perempuan. Akhirnya, karena tidak dapat memastikan tidak adanya diskriminasi, proyek ini dihentikan. Kasus ini memicu diskusi luas tentang keadilan algoritmik, efektivitas praktik AI yang bertanggung jawab, dan penerapan AI dalam pengambilan keputusan layanan publik. (Sumber: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

Sistem penandaan konten yang dihasilkan AI: Diskusi tentang nilai, batasan, dan logika tata kelola : Seiring meningkatnya rumor dan propaganda palsu yang dihasilkan AI, sistem penandaan AI sebagai alat tata kelola mendapat perhatian. Secara teori, penandaan eksplisit dan implisit dapat meningkatkan efisiensi identifikasi dan kewaspadaan pengguna. Namun dalam praktiknya, penandaan mudah dihindari, dipalsukan, dan salah dinilai, serta berbiaya tinggi. Artikel ini berpendapat bahwa penandaan AI harus dimasukkan ke dalam sistem tata kelola konten yang ada, berfokus pada area berisiko tinggi (seperti rumor, propaganda palsu), dan secara wajar mendefinisikan tanggung jawab platform generasi dan penyebaran, sekaligus memperkuat pendidikan literasi informasi publik. (Sumber: 当谣言搭上“AI”的东风)
Alat pengkodean berbantuan AI (seperti Claude Code) secara signifikan meningkatkan efisiensi pengembang dan mengurangi tekanan kerja : Banyak pengembang di komunitas berbagi pengalaman positif menggunakan alat pengkodean berbantuan AI (terutama Claude Code dari Anthropic). Alat-alat ini tidak hanya membantu menulis, menguji, dan men-debug kode, tetapi juga memberikan dukungan dalam perencanaan proyek, penyelesaian masalah kompleks, sehingga secara signifikan meningkatkan efisiensi pengembangan, mengurangi tekanan kerja dan kecemasan tenggat waktu. Beberapa pengguna menyatakan bahwa bantuan AI membuat mereka merasa menjadi “kekuatan yang tak terhentikan”. (Sumber: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Konsumsi energi dan sumber daya air oleh konten yang dihasilkan AI menarik perhatian, Sam Altman menyebut setiap kueri ChatGPT menghabiskan sekitar 1/15 sendok teh air : CEO OpenAI Sam Altman mengungkapkan bahwa setiap kueri ChatGPT menghabiskan sekitar “seperlima belas sendok teh” air. Data ini memicu diskusi tentang dampak lingkungan dari pelatihan dan inferensi model AI. Meskipun metode perhitungan spesifik dan apakah biaya pelatihan disertakan masih belum jelas, jejak energi dan konsumsi sumber daya air AI telah menjadi isu yang menjadi perhatian di dunia teknologi dan bidang lingkungan. (Sumber: MIT Technology Review, Reddit r/ChatGPT)

Diskusi tentang apakah LLM benar-benar memahami pembuktian matematika: Benchmark IneqMath mengungkap kelemahan model : Benchmark IneqMath yang baru dirilis berfokus pada pembuktian ketidaksetaraan matematika tingkat Olimpiade. Penelitian menemukan bahwa meskipun LLM terkadang dapat menemukan jawaban yang benar, terdapat kesenjangan signifikan dalam membangun pembuktian yang ketat dan masuk akal. Hal ini memicu diskusi tentang apakah LLM di bidang seperti matematika benar-benar memahami atau hanya “menebak”. Sathya menunjukkan bahwa fenomena “jawaban benar – penalaran salah” ini juga terlihat dalam benchmark seperti PutnamBench. (Sumber: lupantech, lupantech, _akhaliq, clefourrier)
Aplikasi dan diskusi AI Agent dalam pengembangan perangkat lunak, penelitian, dan tugas sehari-hari : Komunitas secara luas membahas aplikasi AI Agent di berbagai bidang. Misalnya, ada pengguna yang berbagi pengalaman menggunakan n8n dan Claude untuk membangun alur kerja agen penelitian mendalam; LlamaIndex menunjukkan cara mengimplementasikan agen pengisian formulir inkremental melalui Artifact Memory Block; diskusi juga mencakup penggunaan MCP (Model Context Protocol) untuk merancang antarmuka alat yang berorientasi AI, serta aplikasi AI Agent di bidang hukum, otomatisasi infrastruktur (seperti JARVIS dari Cisco), dll. (Sumber: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

Standar keamanan robot humanoid menarik perhatian, perlu mempertimbangkan dampak fisik dan psikologis : Seiring robot humanoid secara bertahap memasuki aplikasi industri dan bertujuan untuk skenario seperti rumah tangga, standar keamanannya menjadi fokus diskusi. Grup penelitian robot humanoid IEEE menunjukkan bahwa robot humanoid memiliki sifat unik seperti stabilitas dinamis, yang memerlukan aturan keamanan baru. Selain keamanan fisik (seperti mencegah jatuh, tabrakan), perlu juga dipertimbangkan tantangan komunikasi dalam interaksi manusia-robot (seperti ekspresi niat, koordinasi multi-robot) dan dampak psikologis (seperti antropomorfisme berlebihan yang menyebabkan harapan terlalu tinggi, keamanan emosional). Penyusunan standar perlu menyeimbangkan inovasi dan keamanan, serta mempertimbangkan kebutuhan skenario aplikasi yang berbeda. (Sumber: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 Lain-lain
Docker mengumumkan docker run --gpus kini mendukung AMD GPU : Docker secara resmi mengumumkan pembaruan bahwa perintah docker run --gpus sekarang juga mendukung penggunaan pada AMD GPU. Peningkatan ini meningkatkan kemudahan penggunaan AMD GPU dalam beban kerja AI/ML yang dikontainerisasi, dan memiliki dampak positif dalam mendorong penerapan AMD dalam ekosistem AI. (Sumber: dylan522p)
Jumlah repositori GitHub melampaui 1 miliar : Jumlah repositori kode di platform GitHub secara resmi telah melampaui angka 1 miliar. Tonggak sejarah ini menandai kemakmuran dan pertumbuhan berkelanjutan dari komunitas open source dan platform hosting kode. (Sumber: karminski3, zacharynado)
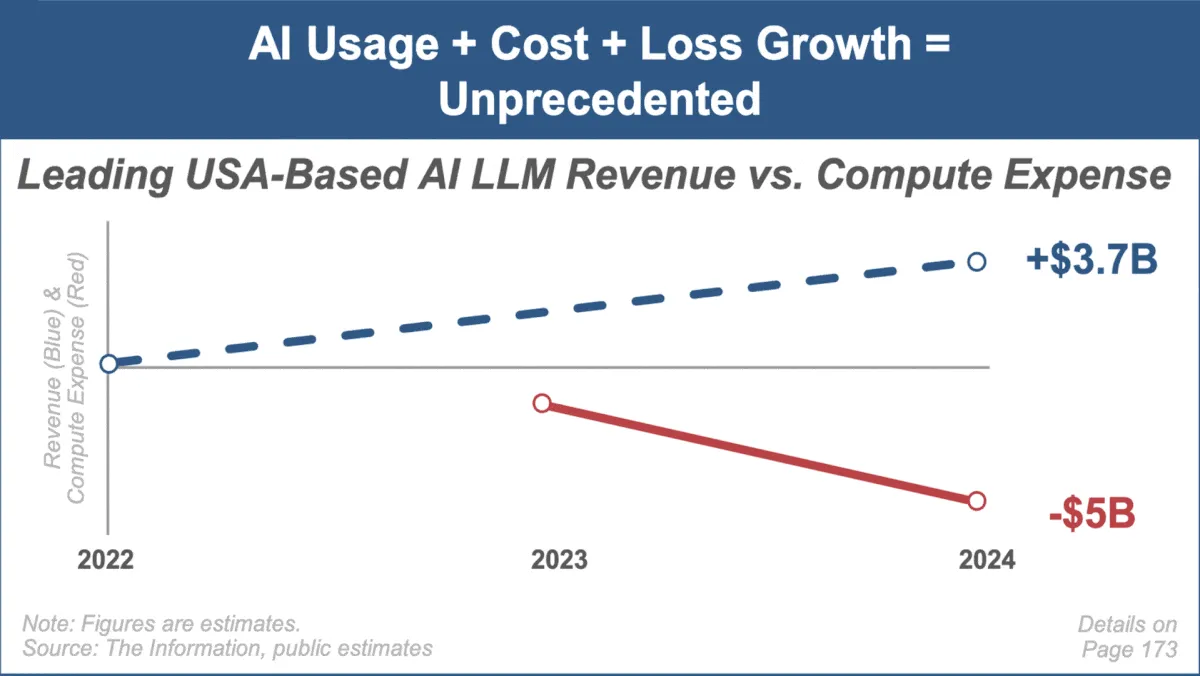
Mary Meeker merilis laporan tren AI terbaru, berfokus pada pertumbuhan pasar yang cepat dan tantangan : Analis investasi terkenal Mary Meeker merilis laporan tren pertamanya tentang pasar kecerdasan buatan berjudul “Trends — Artificial Intelligence (May ‘25)”. Laporan tersebut menyoroti kecepatan pertumbuhan yang belum pernah terjadi sebelumnya di bidang AI, lonjakan jumlah pengguna (seperti pengguna ChatGPT mencapai 800 juta), peningkatan signifikan dalam belanja modal terkait AI, serta terobosan berkelanjutan AI dalam kinerja dan kemampuan baru. Laporan tersebut juga menunjukkan tantangan yang dihadapi model bisnis AI, seperti kenaikan biaya komputasi, iterasi model yang cepat, dan persaingan dari alternatif open source. (Sumber: DeepLearning.AI Blog)