
Kata Kunci:DeepSeek, OpenAI, Model Inferensi, Model Multimodal Besar, Pembelajaran Penguatan, Inovasi AI, Model Sumber Terbuka, Model Inferensi DeepSeek R1, Pelatihan Pembelajaran Penguatan OpenAI o4, Peta Pikiran Manusia Model Multimodal Besar, Seri Mistral AI Magistral, Model MoE dots.llm1 Xiaohongshu
🔥 Fokus
Jalur Inovasi DeepSeek dan OpenAI Mengungkap “Inovasi Kognitif”: DeepSeek, melalui inovasi “Scaling Law terbatas”, arsitektur MLA & MoE, serta optimasi kolaboratif perangkat lunak dan keras, berhasil mencapai kinerja tinggi dengan biaya rendah. Model R1 open-source mereka mendorong terobosan dalam kemampuan kognitif AI, mematahkan “stempel pemikiran” para inovator Tiongkok di bidang penelitian dasar, dan membuktikan kepemimpinan global perusahaan Tiongkok dalam penelitian dasar AI dan inovasi model. Sementara itu, OpenAI, dengan pemanfaatan ekstrem arsitektur Transformer dan Scaling Law (hukum penskalaan), memimpin revolusi model bahasa besar, dan melalui ChatGPT serta model penalaran o1, mendorong perubahan paradigma interaksi manusia-mesin dan lompatan dalam kemampuan kognitif AI. Jalur pengembangan keduanya menekankan pemahaman mendalam tentang esensi teknologi dan restrukturisasi strategis, memberikan ide-ide berharga bagi para wirausahawan di era AI dalam membangun organisasi dan berinovasi, terutama paradigma AI Lab DeepSeek yang mendorong “kemunculan”, yang menawarkan referensi model organisasi baru bagi para wirausahawan yang didorong oleh inovasi teknologi (Sumber: 36氪)
OpenAI Dikabarkan Melatih Model Baru o4, Reinforcement Learning Membentuk Ulang Lanskap AI: SemiAnalysis mengungkapkan bahwa OpenAI sedang melatih model baru yang berada di antara GPT-4.1 dan GPT-4.5. Model penalaran generasi berikutnya, o4, akan dilatih berdasarkan GPT-4.1 menggunakan Reinforcement Learning (RL). RL membuka kemampuan penalaran model melalui CoT dan mendorong pengembangan agen AI, tetapi sangat menuntut infrastruktur (terutama untuk penalaran) dan desain fungsi reward, serta rentan terhadap fenomena “reward hacking”. Data berkualitas tinggi adalah kunci untuk memperluas RL, dan data perilaku pengguna akan menjadi aset penting. RL juga mengubah struktur organisasi laboratorium, mengintegrasikan penalaran dan pelatihan secara mendalam. Berbeda dengan pra-pelatihan, RL dapat terus memperbarui kemampuan model, seperti DeepSeek R1. Untuk model kecil, distilasi mungkin lebih unggul daripada RL. Bocoran ini menandakan bahwa bidang AI, khususnya model penalaran, akan mengalami evolusi berkelanjutan dan lompatan kemampuan berdasarkan RL (Sumber: 36氪)
Model Besar Multimodal Ditemukan Dapat Secara Spontan Membentuk “Peta Pemikiran Manusia”: Tim gabungan dari Institut Otomasi Akademi Ilmu Pengetahuan Tiongkok dan Pusat Inovasi Unggulan Ilmu Otak dan Teknologi Cerdas, melalui eksperimen perilaku dan analisis neuroimaging, mengonfirmasi bahwa Multimodal Large Language Models (MLLMs) dapat secara spontan membentuk sistem representasi konsep objek yang sangat mirip dengan manusia. Penelitian ini, melalui analisis 4,7 juta data penilaian perilaku dari “tugas identifikasi outlier tiga pilihan satu”, untuk pertama kalinya membangun “peta konsep” model AI. Temuan inti meliputi: model AI dengan arsitektur berbeda dapat konvergen ke struktur kognitif dimensi rendah yang serupa; model dalam kondisi tanpa pengawasan memunculkan kemampuan klasifikasi konsep objek tingkat tinggi, yang konsisten dengan kognisi manusia; “dimensi berpikir” model AI dapat diberi label semantik, seperti hewan, makanan, kekerasan, dll.; representasi MLLM secara signifikan berkorelasi dengan pola aktivitas saraf di area otak tertentu (seperti FFA, PPA), memberikan bukti untuk “AI dan manusia berbagi mekanisme pemrosesan konsep”. Penelitian ini memberikan ide baru untuk memahami kognisi AI, mengembangkan kecerdasan mirip otak, dan antarmuka otak-mesin (Sumber: 量子位)

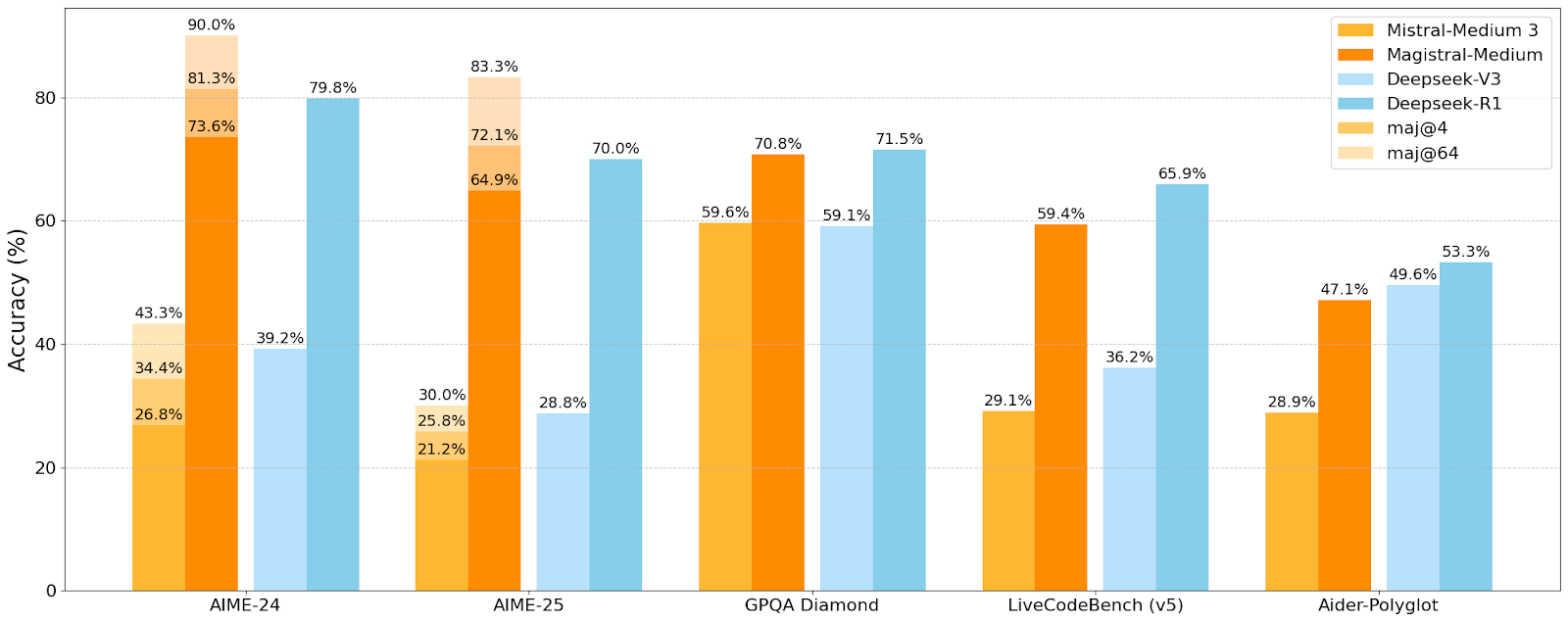
Mistral AI Merilis Seri Model Penalaran Pertamanya Magistral, Model Kecil Magistral-Small Telah Open-Source: Mistral AI meluncurkan seri model pertamanya yang dirancang khusus untuk penalaran, Magistral, yang mencakup Magistral-Small dan Magistral-Medium. Magistral-Small dibangun berdasarkan Mistral Small 3.1 (2503), sebuah model penalaran efisien dengan 24B parameter, yang dilatih melalui SFT dan RL menggunakan lintasan Magistral Medium, sehingga meningkatkan kemampuan penalarannya. Model ini mendukung multibahasa, memiliki jendela konteks 128k (konteks efektif yang direkomendasikan 40k), dirilis di bawah lisensi Apache 2.0, dan dapat di-deploy secara lokal pada satu RTX 4090 atau MacBook dengan RAM 32GB (setelah kuantisasi). Pengujian benchmark menunjukkan bahwa Magistral-Small berkinerja sangat baik pada tugas-tugas seperti AIME24, AIME25, GPQA Diamond, dan Livecodebench (v5), mendekati atau bahkan melampaui beberapa model yang lebih besar. Magistral-Medium memiliki kinerja yang lebih kuat tetapi saat ini belum open-source. Rilis ini menandai kemajuan Mistral dalam meningkatkan kemampuan penalaran model dan dukungan multibahasa (Sumber: Reddit r/LocalLLaMA, Mistral AI, X)
🎯 Tren
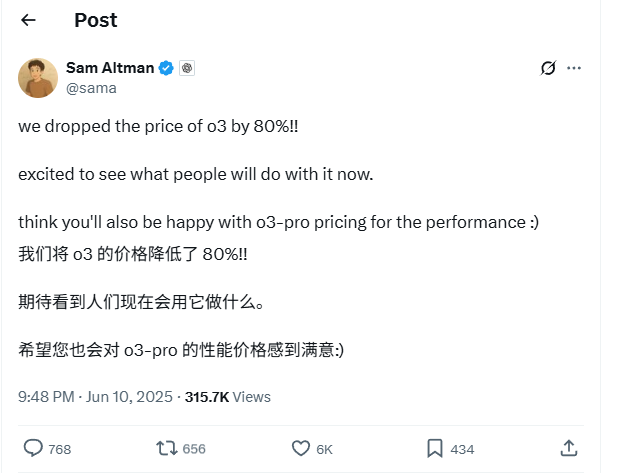
Harga API Model OpenAI o3 Turun Drastis 80%: CEO OpenAI Sam Altman mengumumkan bahwa harga API model o3 mereka telah diturunkan sebesar 80%. Setelah penyesuaian, harga input menjadi $2 per juta token, dan harga output menjadi $8 per juta token (beberapa sumber menyebutkan harga output $5 per juta token, perlu dikonfirmasi dengan dokumentasi resmi). Penurunan harga yang signifikan ini membuat biaya penggunaan model o3 untuk tugas seperti penulisan kode menjadi jauh lebih rendah, dan diharapkan akan mendorong aplikasi dan inovasi yang lebih luas. Pengguna perlu memperhatikan bahwa daftar harga di situs web resmi mungkin belum diperbarui; disarankan untuk melakukan pengujian sebelum melakukan panggilan API untuk mengonfirmasi harga efektif aktual guna menghindari kerugian yang tidak perlu. Langkah ini dianggap sebagai strategi untuk menghadapi persaingan pasar (seperti Gemini 2.5 Pro dan Claude 4 Sonnet) dan mungkin menandakan bahwa biaya kecerdasan AI akan terus menurun (Sumber: X, X, X)
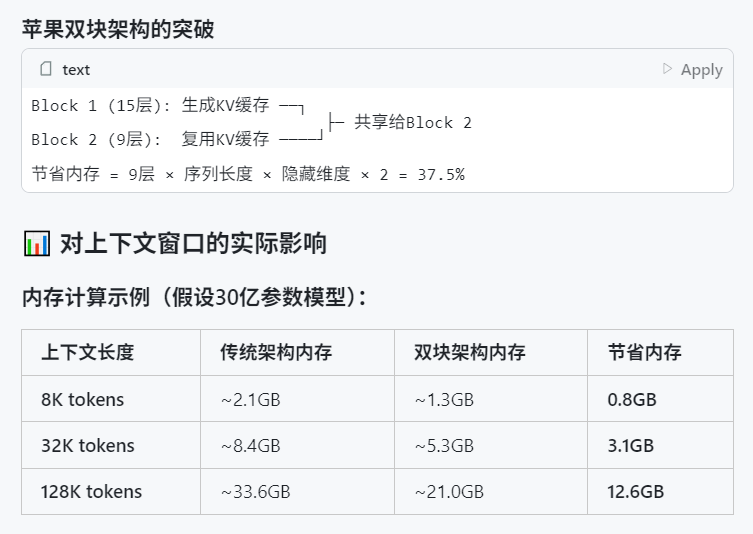
WWDC 2025 Apple Disebut Kurang Menyoroti AI, Namun Detail Teknis Menunjukkan Ambisi: Apple dalam Worldwide Developers Conference (WWDC) 2025 tampaknya tidak banyak menyoroti AI seperti yang diharapkan, tetapi dokumen teknisnya mengungkapkan investasi mendalamnya dalam model on-device dan cloud. Apple menggunakan teknik pelatihan, distilasi, dan kuantisasi canggih, termasuk “arsitektur blok ganda” yang dirancang untuk model seluler (sekitar ukuran 3B) (bertujuan mengurangi penggunaan memori) dan arsitektur “PT-MoE” (Parallel Track Mixture of Experts) yang digunakan untuk model sisi server. Teknologi ini bertujuan untuk mengoptimalkan inferensi latensi rendah pada chip Apple dan mengurangi penggunaan memori KV cache. Meskipun ada suara dari luar yang menganggap Apple tertinggal di bidang AI, pencapaiannya dalam teknologi model (seperti model embedding open-source) dan fokus pada prioritas yang berbeda (seperti kecerdasan on-device daripada hanya chatbot) menunjukkan strategi AI yang unik. WWDC juga mengumumkan Safari 26 akan mendukung WebGPU, yang akan sangat meningkatkan kinerja menjalankan model AI on-device (seperti melalui Transformers.js), misalnya, kecepatan pembuatan teks untuk model visual di browser meningkat sekitar 12 kali lipat (Sumber: X, X, X)
Pengguna Perplexity Pro Kini Dapat Menggunakan Model OpenAI o3: Perplexity mengumumkan bahwa pelanggan Pro mereka sekarang dapat menggunakan model o3 OpenAI. Integrasi ini akan memberi pengguna Perplexity Pro kemampuan pemrosesan informasi dan tanya jawab yang lebih kuat. Sementara itu, Perplexity juga sedang menguji fitur “Memory”-nya dan memperbarui asisten suara iOS, bertujuan untuk memberikan pengalaman pengguna yang lebih ringkas dan praktis. Fitur artikel Discover-nya juga secara default menggunakan mode “Summary” yang lebih ringkas dan menyediakan opsi untuk beralih ke mode “Report” yang lebih mendalam (Sumber: X, X, X)

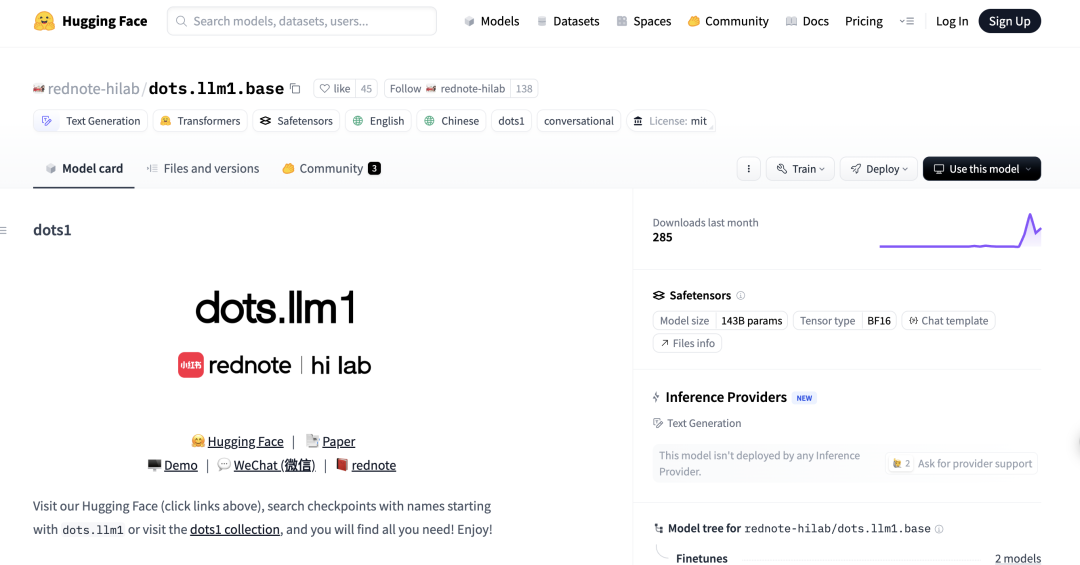
Xiaohongshu Merilis Model Besar MoE 142B Pertamanya dots.llm1, Melampaui DeepSeek-V3 dalam Evaluasi Bahasa Mandarin: Xiaohongshu merilis model besar pertamanya, dots.llm1, sebuah model MoE (Mixture of Experts) dengan 142 miliar parameter, yang hanya mengaktifkan 14 miliar parameter saat inferensi. Model ini menggunakan 11,2 triliun token non-sintetis dalam tahap pra-pelatihan, terutama dari data Web yang dikumpulkan oleh crawler umum dan crawler milik sendiri. Tim Xiaohongshu mengusulkan kerangka kerja pemrosesan data tiga tahap yang dapat diskalakan dan menjadikannya open-source untuk meningkatkan reproduktifitas. dots.llm1 mencapai skor 92,2 pada C-Eval, melampaui semua model termasuk DeepSeek-V3, dan mendekati kinerja Qwen3-32B dari Alibaba dalam tugas bahasa Mandarin dan Inggris, matematika, dan alignment. Xiaohongshu juga merilis checkpoint pelatihan menengah untuk mempromosikan pemahaman komunitas tentang dinamika model besar (Sumber: 36氪)
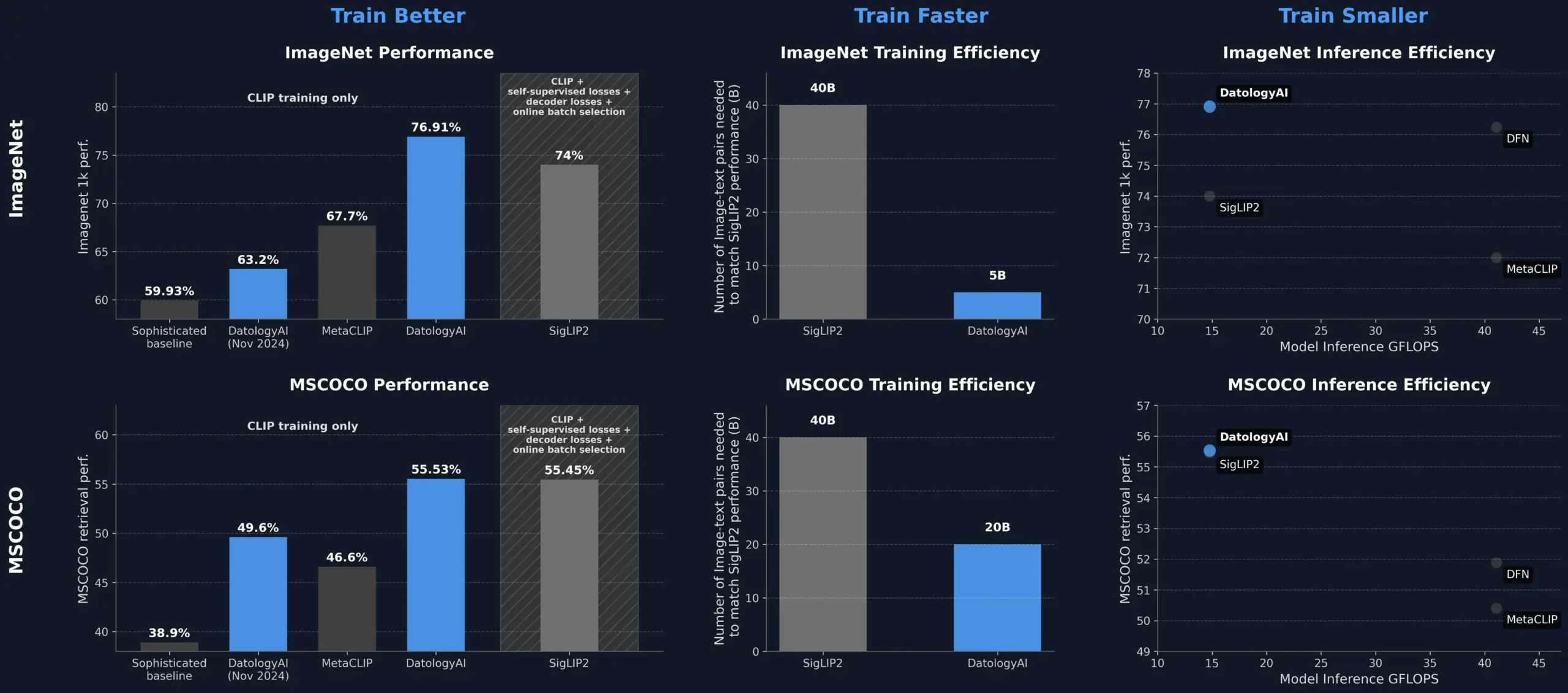
DatologyAI Meningkatkan Kinerja Model CLIP Melalui Manajemen Data, Melampaui SigLIP2: DatologyAI menunjukkan bahwa hanya melalui manajemen data (data curation) dapat secara signifikan meningkatkan kinerja model CLIP. Metode mereka memungkinkan model ViT-B/32 mencapai akurasi 76,9% pada ImageNet 1k, melampaui 74% yang dilaporkan oleh SigLIP2. Selain itu, metode ini juga menghasilkan peningkatan efisiensi pelatihan 8x dan peningkatan efisiensi inferensi 2x, dan telah merilis model terkait secara publik. Ini menyoroti peran inti dari dataset berkualitas tinggi yang dikelola dengan cermat dalam melatih model AI canggih; bahkan tanpa mengubah arsitektur model, potensi model dapat digali melalui optimasi data (Sumber: X, X)
Kuaishou dan Northeastern University Bersama-sama Mengusulkan Kerangka Kerja Embedding Multimodal Terpadu UNITE: Untuk mengatasi masalah interferensi lintas-modal yang disebabkan oleh perbedaan distribusi data berbagai modalitas (teks, gambar, video) dalam pencarian multimodal, peneliti dari Kuaishou dan Northeastern University mengusulkan kerangka kerja embedding multimodal terpadu UNITE. Kerangka kerja ini, melalui mekanisme “Modal-aware Masked Contrastive Learning” (MAMCL), dalam pembelajaran kontrastif hanya mempertimbangkan sampel negatif yang konsisten dengan modalitas target kueri, menghindari persaingan yang salah antar modalitas. UNITE mengadopsi pelatihan dua tahap “adaptasi pencarian + penyempurnaan instruksi”, dan mencapai hasil SOTA dalam beberapa evaluasi seperti pencarian gambar-teks, pencarian video-teks, dan pencarian instruksi, misalnya, melampaui model skala lebih besar di MMEB Benchmark, dan secara signifikan mengungguli di CoVR. Penelitian menekankan kemampuan inti data video-teks dalam modalitas terpadu, dan menunjukkan bahwa tugas instruksi lebih bergantung pada data yang didominasi teks (Sumber: 量子位)

NVIDIA Merilis Model Dasar AI Simulasi Iklim Earth-2: Platform Earth-2 NVIDIA meluncurkan model dasar AI baru yang mampu mensimulasikan iklim global dengan resolusi tingkat kilometer. Model ini bertujuan untuk memberikan prediksi iklim yang lebih cepat dan lebih akurat, menyediakan cara baru untuk memahami dan memprediksi sistem alam kompleks Bumi. Langkah ini menandai langkah penting dalam penerapan AI di bidang ilmu iklim dan pemodelan sistem Bumi, diharapkan dapat meningkatkan penelitian perubahan iklim dan kemampuan peringatan dini bencana (Sumber: X)

Layanan OpenAI Mengalami Gangguan Skala Besar, ChatGPT dan API Terdampak: Layanan ChatGPT OpenAI dan antarmuka API mengalami gangguan skala besar pada malam hari tanggal 10 Juni waktu Beijing, ditandai dengan peningkatan tingkat kesalahan dan latensi. Banyak pengguna melaporkan tidak dapat mengakses layanan atau mengalami pesan kesalahan seperti “Hmm…something seems to have gone wrong”. Halaman status resmi OpenAI mengonfirmasi masalah tersebut dan menyatakan bahwa para insinyur telah menemukan akar penyebabnya dan sedang melakukan perbaikan darurat. Gangguan ini memengaruhi sejumlah besar pengguna dan aplikasi di seluruh dunia yang bergantung pada ChatGPT dan API-nya, sekali lagi menyoroti pentingnya stabilitas layanan AI skala besar (Sumber: X, Reddit r/ChatGPT, Reddit r/ChatGPT)
🧰 Alat
Ekosistem Server Model Context Protocol (MCP) Terus Berkembang: Model Context Protocol (MCP) bertujuan untuk menyediakan akses alat dan sumber data yang aman dan terkontrol untuk Large Language Models (LLM). Repositori modelcontextprotocol/servers di GitHub mengumpulkan implementasi referensi MCP dan server yang dibangun oleh komunitas, menunjukkan aplikasi yang beragam. Server resmi dan pihak ketiga mencakup sistem file, operasi Git, interaksi database (seperti PostgreSQL, MySQL, MongoDB, Redis, ClickHouse, Cassandra, dll.), layanan cloud (AWS, Azure, Cloudflare), integrasi API (GitHub, GitLab, Slack, Google Drive, Stripe, PayPal), pencarian (Brave, Algolia, Exa, Tavily), eksekusi kode, panggilan model AI (Replicate, ElevenLabs), dan bidang luas lainnya. Ekosistem MCP berkembang pesat, dengan lebih dari 130 server resmi dan komunitas, dan munculnya kerangka kerja pengembangan seperti EasyMCP, FastMCP, MCP-Framework, serta alat manajemen seperti MCP-CLI, MCPM, bertujuan untuk menurunkan ambang batas bagi LLM untuk mengakses alat dan data eksternal, mendorong pengembangan AI Agent (Sumber: GitHub Trending)
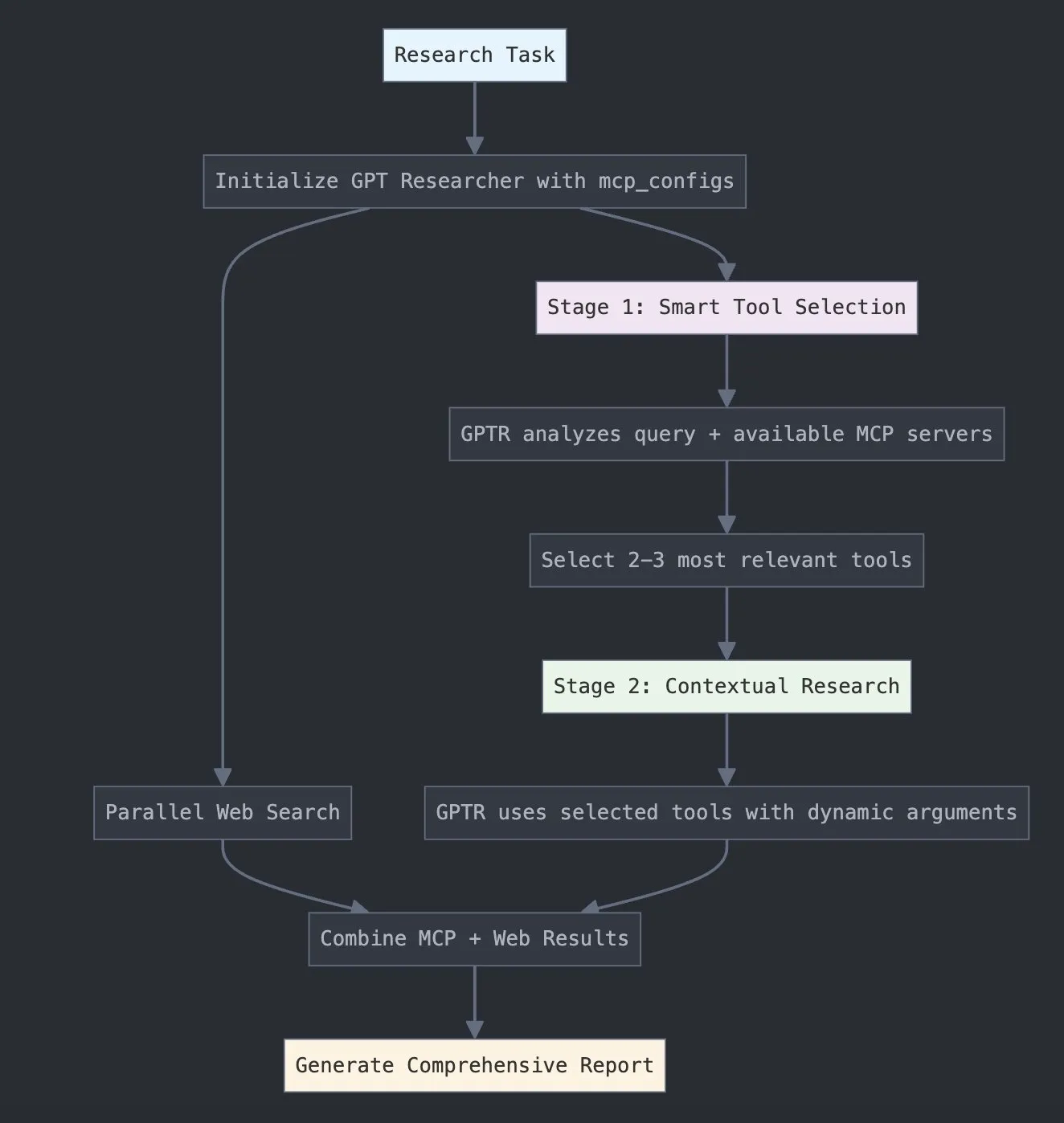
LangChain Meluncurkan GPT Researcher MCP, Meningkatkan Kemampuan Penelitian: LangChain mengumumkan GPT Researcher sekarang menggunakan adaptor Model Context Protocol (MCP) untuk mencapai pemilihan alat dan penelitian yang cerdas. Integrasi ini menggabungkan MCP dengan fungsi pencarian web, bertujuan untuk memberi pengguna kemampuan pengumpulan dan analisis data yang lebih komprehensif, lebih lanjut meningkatkan kedalaman dan luasnya aplikasi AI di bidang penelitian (Sumber: X)
Hugging Face Merilis Vui: NotebookLM Open-Source 100M, Mewujudkan TTS Mirip Manusia: Hugging Face merilis Vui, sebuah proyek NotebookLM open-source dengan 100 juta parameter, yang mencakup tiga model: Vui.BASE (model dasar yang dilatih pada 40.000 jam percakapan audio), Vui.ABRAHAM (model pembicara tunggal dengan kemampuan sadar konteks), dan Vui.COHOST (model yang dapat melakukan percakapan dua orang). Vui mampu mengkloning suara, meniru pernapasan, gumaman seperti “hmm”, “ah”, dan bahkan suara non-ucapan, menandai kemajuan baru dalam teknologi Text-to-Speech (TTS) yang mirip manusia (Sumber: X, X)
Consilium: Platform Kolaborasi Multi-Agen Open-Source, Memecahkan Masalah Kompleks: Hugging Face menampilkan proyek Consilium, sebuah platform kolaborasi multi-agen open-source. Pengguna dapat membentuk tim agen AI ahli, melalui debat dan penelitian real-time (halaman web, arXiv, file SEC) untuk bersama-sama memecahkan masalah kompleks dan mencapai konsensus. Pengguna menetapkan strategi, tim agen bertanggung jawab untuk menemukan jawaban, menunjukkan eksplorasi baru AI dalam pemecahan masalah kolaboratif (Sumber: X)
Unsloth Merilis Model GGUF Optimal Magistral-Small-2506: Setelah Mistral AI merilis model penalaran Magistral-Small-2506, Unsloth dengan cepat meluncurkan model format GGUF versi optimalnya, cocok untuk platform seperti llama.cpp, LMStudio, dan Ollama. Respons cepat ini mencerminkan vitalitas dan efisiensi komunitas open-source dalam optimasi dan deployment model, memungkinkan model baru lebih cepat digunakan oleh pengguna dan pengembang yang lebih luas (Sumber: X)
📚 Belajar
Makalah Baru Membahas Paradigma Pra-Pelatihan Reinforcement Learning (RPT): Sebuah makalah baru berjudul “Reinforcement Pre-Training (RPT)” mengusulkan untuk merekonstruksi prediksi token generasi berikutnya sebagai tugas penalaran menggunakan RLVR (Reinforcement Learning with Verifiable Rewards). RPT bertujuan untuk meningkatkan akurasi prediksi model bahasa dengan memberi insentif pada kemampuan penalaran token berikutnya, dan menyediakan dasar yang kuat untuk penyempurnaan penguatan berikutnya. Penelitian menunjukkan bahwa peningkatan komputasi pelatihan dapat terus meningkatkan akurasi prediksi, menunjukkan bahwa RPT adalah paradigma ekstensi yang efektif dan menjanjikan untuk memajukan pra-pelatihan model bahasa (Sumber: HuggingFace Daily Papers, X)

Makalah Mengusulkan Cartridges: Mewujudkan Representasi Konteks Panjang Ringan Melalui Self-Study: Sebuah makalah berjudul “Cartridges: Lightweight and general-purpose long context representations via self-study” membahas metode untuk memproses teks panjang dengan melatih KV cache kecil secara offline (disebut Cartridge), sebagai alternatif untuk menempatkan seluruh korpus ke dalam jendela konteks saat inferensi. Penelitian menemukan bahwa Cartridge yang dilatih melalui “self-study” (menghasilkan dialog sintetis tentang korpus dan melatih dengan target distilasi konteks), dapat mencapai kinerja yang sebanding dengan ICL dengan konsumsi memori yang jauh lebih rendah (berkurang 38,6 kali) dan throughput yang lebih tinggi (meningkat 26,4 kali), dan dapat memperluas panjang konteks efektif model, bahkan mendukung penggunaan kombinasi lintas korpus tanpa pelatihan ulang (Sumber: HuggingFace Daily Papers, X)

Makalah Membahas Optimasi Kebijakan Kontrastif Grup (GCPO) LLM dalam Pemecahan Masalah Geometri: Makalah “GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization” menargetkan tantangan konstruksi garis bantu LLM dalam pemecahan masalah geometri, mengusulkan kerangka kerja GCPO. Kerangka kerja ini melalui “group contrastive mask” menyediakan sinyal reward positif dan negatif untuk konstruksi garis bantu berdasarkan utilitas kontekstual, dan memperkenalkan reward panjang untuk mempromosikan rantai penalaran yang lebih panjang. Seri model GeometryZero yang dikembangkan berdasarkan GCPO, berkinerja lebih baik daripada model dasar pada benchmark seperti Geometry3K dan MathVista, dengan peningkatan rata-rata 4,29%, menunjukkan potensi untuk meningkatkan kemampuan penalaran geometri model kecil dengan daya komputasi terbatas (Sumber: HuggingFace Daily Papers)
Makalah “The Illusion of Thinking” Menyelidiki Kemampuan dan Batasan Model Penalaran Melalui Kompleksitas Masalah: Penelitian ini secara sistematis mengkaji kemampuan, karakteristik penskalaan, dan batasan Large Reasoning Models (LRMs). Dengan menggunakan lingkungan teka-teki yang kompleksitasnya dapat dikontrol secara akurat, penelitian menemukan bahwa akurasi LRMs akan runtuh sepenuhnya setelah melebihi kompleksitas tertentu, dan menunjukkan batasan penskalaan yang berlawanan dengan intuisi: upaya penalaran menurun setelah kompleksitas masalah meningkat hingga tingkat tertentu. Dibandingkan dengan LLM standar, LRMs berkinerja lebih buruk pada tugas kompleksitas rendah, unggul pada tugas kompleksitas sedang, dan keduanya gagal pada tugas kompleksitas tinggi. Penelitian menunjukkan bahwa LRMs memiliki keterbatasan dalam perhitungan yang tepat, sulit menerapkan algoritma eksplisit, dan penalaran tidak konsisten pada skala yang berbeda (Sumber: HuggingFace Daily Papers, X)
Makalah Meneliti Evaluasi Ketahanan LLM dalam Bahasa Sumber Daya Rendah: Makalah “Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models” membahas sensitivitas Large Language Models (LLMs) terhadap gangguan (seperti serangan tingkat karakter dan kata) dalam bahasa sumber daya rendah seperti bahasa Polandia. Penelitian menemukan bahwa dengan sedikit modifikasi karakter dan menggunakan model proxy kecil untuk menghitung pentingnya kata, dapat dibuat serangan yang secara signifikan mengubah prediksi LLM yang berbeda. Ini mengungkapkan potensi kerentanan keamanan LLM dalam bahasa-bahasa ini, yang dapat digunakan untuk menghindari mekanisme keamanan internalnya. Peneliti telah merilis dataset dan kode terkait (Sumber: HuggingFace Daily Papers)
Rel-LLM: Metode Baru untuk Meningkatkan Efisiensi LLM dalam Memproses Database Relasional: Sebuah makalah mengusulkan kerangka kerja Rel-LLM, yang bertujuan untuk mengatasi masalah efisiensi rendah Large Language Models (LLM) dalam memproses database relasional. Metode tradisional yang mengubah data terstruktur menjadi teks menyebabkan hilangnya tautan penting dan redundansi input. Rel-LLM melalui encoder Graph Neural Network (GNN) membuat prompt grafik terstruktur, mempertahankan struktur relasional dalam kerangka kerja Retrieval Augmented Generation (RAG). Metode ini mencakup pengambilan sampel subgraf yang sadar waktu, encoder GNN heterogen, lapisan proyeksi MLP untuk menyelaraskan embedding grafik dengan ruang laten LLM, dan menstrukturkan representasi grafik sebagai prompt grafik JSON, serta menyelaraskan representasi grafik dan teks melalui target pra-pelatihan yang diawasi sendiri. Eksperimen menunjukkan bahwa encoding GNN dapat secara efektif menangkap struktur relasional kompleks yang hilang dalam serialisasi teks, dan prompt grafik terstruktur dapat secara efektif menyuntikkan konteks relasional ke dalam mekanisme perhatian LLM (Sumber: X)

Makalah Membahas Masalah “Penolakan Berlebihan” LLM dan Metode Optimasi EvoRefuse: Makalah “EVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions” meneliti masalah penolakan berlebihan Large Language Models (LLM) terhadap “instruksi pseudo-berbahaya” (input yang secara semantik tidak berbahaya tetapi memicu penolakan model). Untuk mengatasi kekurangan metode manajemen instruksi yang ada dalam skalabilitas dan keragaman, makalah ini mengusulkan EVOREFUSE, metode yang menggunakan algoritma evolusioner untuk mengoptimalkan prompt, yang dapat menghasilkan instruksi pseudo-berbahaya yang beragam dan terus-menerus memicu penolakan LLM. Berdasarkan ini, peneliti membuat EVOREFUSE-TEST (benchmark yang berisi 582 instruksi) dan EVOREFUSE-ALIGN (dataset pelatihan alignment yang berisi 3000 instruksi dan respons). Eksperimen menunjukkan bahwa model LLAMA3.1-8B-INSTRUCT yang disesuaikan pada EVOREFUSE-ALIGN, tingkat penolakan berlebihannya berkurang hingga 14,31% dibandingkan model yang dilatih pada dataset alignment sub-optimal, tanpa mengorbankan keamanan (Sumber: HuggingFace Daily Papers)
💼 Bisnis
ZKWG Menyelesaikan Putaran Baru Pembiayaan Strategis, Diinvestasikan oleh Dana Industri Distrik Shijingshan Beijing: Penyedia layanan AI tingkat perusahaan, ZKWG, mengumumkan penyelesaian putaran baru pembiayaan strategis, dengan investor adalah Beijing Shijingshan District Modern Innovation Industry Development Fund Co., Ltd. Putaran pembiayaan ini terutama akan digunakan untuk investasi R&D dan promosi pasar sistem operasi intelijen keputusan DIOS yang dikembangkan sendiri, mempercepat pengembangan teknologi kecerdasan buatan tingkat perusahaan dan pendaratan komersial. ZKWG didirikan pada tahun 2017, tim intinya berasal dari Institut Otomasi Akademi Ilmu Pengetahuan Tiongkok, berfokus pada pemahaman multibahasa, semantik lintas-modal, dan teknologi keputusan adegan kompleks, melayani industri seperti media, keuangan, urusan pemerintahan, dan energi. Sebelumnya telah menerima lebih dari satu miliar yuan investasi dari dana milik negara seperti CDB Capital, China Internet Investment Fund, dan Shenzhen Capital Group (Sumber: 量子位)

Sakana AI Mencapai Kerjasama Strategis dengan Bank Hokkoku Jepang, Mendorong Pengembangan AI Keuangan Regional: Perusahaan rintisan AI Jepang, Sakana AI, mengumumkan penandatanganan nota kesepahaman (MOU) dengan Hokkoku Financial Holdings yang berbasis di Prefektur Ishikawa. Kedua belah pihak akan melakukan kerja sama strategis dalam kombinasi keuangan regional dan AI. Ini adalah kerja sama kedua Sakana AI dengan lembaga keuangan setelah menjalin kemitraan komprehensif dengan Mitsubishi UFJ Bank, bertujuan untuk menerapkan teknologi AI mutakhir untuk memecahkan masalah yang dihadapi masyarakat regional Jepang, terutama di sektor jasa keuangan. Sakana AI berkomitmen untuk mengembangkan teknologi AI yang sangat terspesialisasi untuk lembaga keuangan. Kerja sama ini diharapkan dapat menjadi contoh penerapan AI bagi bank-bank regional lainnya di Jepang (Sumber: X, X)

Cohere Bekerja Sama dengan Ensemble, Membawa Platform AI-nya ke Industri Perawatan Kesehatan: Perusahaan AI Cohere mengumumkan kemitraan dengan EnsembleHP (penyedia solusi perawatan kesehatan), untuk membawa platform agen cerdas Cohere North AI ke industri perawatan kesehatan. Kedua belah pihak bertujuan untuk mengurangi gesekan dalam proses manajemen medis dan meningkatkan pengalaman pasien di rumah sakit dan sistem kesehatan melalui platform agen AI yang aman. Langkah ini menandai langkah penting bagi Cohere dalam mendorong penerapan model bahasa besar dan teknologi AI-nya di industri vertikal utama (Sumber: X)
🌟 Komunitas
Pidato Gelar Kehormatan Ilya Sutskever di Universitas Toronto: AI Pada Akhirnya Akan Mampu Melakukan Segalanya, Perlu Perhatian Aktif: Salah satu pendiri OpenAI, Ilya Sutskever, dalam pidatonya saat menerima gelar Doktor Kehormatan Ilmu Pengetahuan dari Universitas Toronto (gelar keempatnya dari universitas tersebut) menyatakan bahwa kemajuan AI akan membuatnya “suatu hari nanti dapat melakukan semua yang bisa kita lakukan,” karena otak manusia adalah komputer biologis, dan AI adalah otak digital. Ia percaya bahwa kita berada di era luar biasa yang ditentukan oleh AI, dan AI telah secara mendalam mengubah makna siswa dan pekerjaan. Ia menekankan bahwa daripada khawatir, lebih baik membentuk intuisi dengan menggunakan dan mengamati AI terkemuka untuk memahami batas kemampuannya. Ia menyerukan agar orang-orang memperhatikan perkembangan AI dan secara aktif menghadapi tantangan dan peluang besar yang menyertainya, karena AI akan sangat memengaruhi kehidupan setiap orang. Ia juga berbagi mentalitas pribadinya: “Terima kenyataan, jangan menyesali masa lalu, berusahalah untuk memperbaiki keadaan saat ini.” (Sumber: X, 36氪)
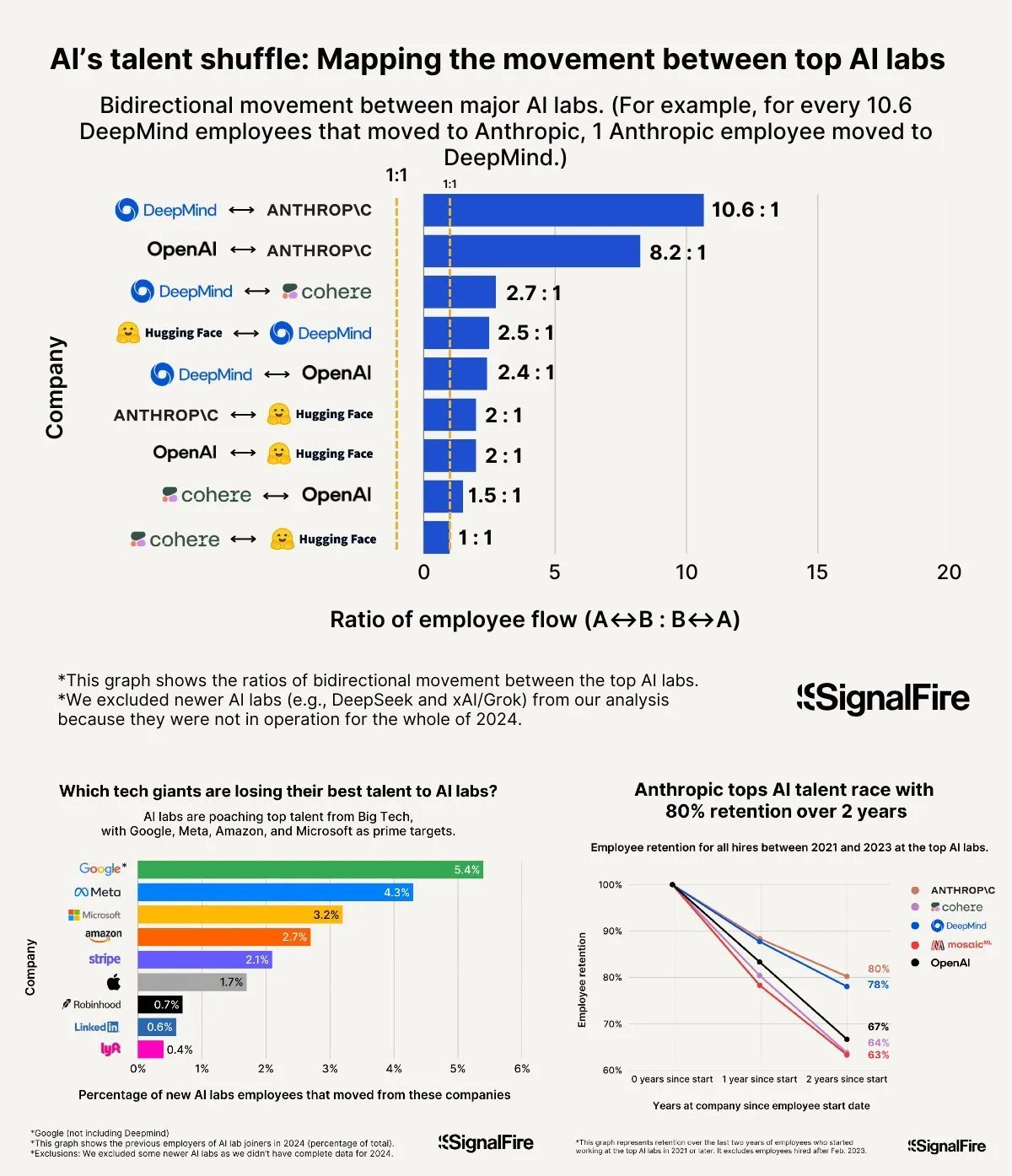
Perang Talenta AI Memanas: Gaji Tinggi Meta Masih Kalah Saing dengan OpenAI dan Anthropic: Meta dilaporkan menawarkan gaji tahunan lebih dari $2 juta untuk merekrut talenta AI, tetapi masih menghadapi kesulitan karena talenta beralih ke OpenAI dan Anthropic. Ada diskusi yang menunjukkan bahwa gaji tingkat L6 OpenAI mendekati $1,5 juta, dan potensi apresiasi sahamnya dianggap lebih baik daripada Meta, membuatnya lebih menarik di mata talenta papan atas. Selain itu, tim Llama dituduh melakukan kecurangan dan faktor-faktor seperti tekanan KPI internal Meta yang tinggi dan tingkat eliminasi karyawan berkinerja rendah yang tinggi (mencapai 15-20% tahun ini) juga memengaruhi pilihan talenta. Anthropic, dengan tingkat retensi talenta sekitar 80% (setelah dua tahun berdiri), menjadi salah satu perusahaan besar pilihan utama bagi peneliti AI papan atas. Intensitas perang talenta ini digambarkan sebagai “luar biasa” (Sumber: X, X)
Berbagi Pengalaman “Vibe Coding”: 5 Aturan untuk Menghindari Jebakan dalam Pemrograman dengan Bantuan AI: Di media sosial, pengembang berpengalaman berbagi lima aturan untuk menghindari siklus debugging yang tidak efisien saat menggunakan AI (seperti Claude) untuk “Vibe Coding” (cara pemrograman yang bergantung pada bantuan AI): 1. Tiga kali gagal, keluar: Jika AI gagal memperbaiki masalah tiga kali, hentikan dan minta AI membangun dari awal berdasarkan deskripsi kebutuhan yang baru. 2. Setel ulang konteks: AI akan “lupa” setelah percakapan panjang; disarankan untuk menyimpan kode yang valid setiap 8-10 putaran pesan, memulai sesi baru dan hanya menempelkan komponen masalah serta deskripsi aplikasi singkat. 3. Deskripsikan masalah secara singkat dan jelas: Jelaskan bug dengan satu kalimat yang jelas. 4. Kontrol versi yang sering: Commit ke Git setiap kali satu fitur selesai. 5. Jika perlu, mulai dari awal: Jika memperbaiki bug memakan waktu terlalu lama (misalnya lebih dari 2 jam), lebih baik hapus komponen masalah dan minta AI membangunnya kembali. Intinya adalah mengakui ketika kode sudah rusak secara permanen, dan harus tegas untuk tidak memperbaikinya lagi. Ditekankan juga bahwa memahami pemrograman akan membantu dalam mengarahkan AI dan melakukan debugging dengan lebih baik (Sumber: Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Fei-Fei Li Membahas Pendirian World Labs: Berasal dari Eksplorasi Esensi Kecerdasan, Kecerdasan Spasial adalah Kekurangan Kunci AI: Dalam podcast a16z, Fei-Fei Li berbagi alasan di balik pendirian World Labs, menekankan bahwa itu bukan karena mengikuti tren model dasar, melainkan eksplorasi berkelanjutan terhadap esensi kecerdasan. Ia percaya bahwa meskipun bahasa adalah pembawa informasi yang efisien, ia memiliki kekurangan dalam merepresentasikan dunia fisik tiga dimensi; kecerdasan umum sejati harus dibangun di atas pemahaman ruang fisik dan hubungan objek. Pengalaman cedera kornea yang menyebabkan hilangnya penglihatan stereoskopis sementara membuatnya lebih memahami pentingnya representasi ruang tiga dimensi untuk interaksi fisik. World Labs bertujuan untuk membangun model AI (world model LWM) yang benar-benar dapat memahami dunia fisik, mengisi kekosongan AI saat ini dalam kecerdasan spasial. Ia percaya bahwa untuk mencapai visi ini, diperlukan pengumpulan daya komputasi, data, dan talenta tingkat industri, dan menunjukkan bahwa titik terobosan teknologi saat ini adalah memungkinkan AI merekonstruksi pemahaman adegan tiga dimensi lengkap dari penglihatan monokuler (Sumber: 量子位)

AI Membantu Gaokao: Dari Kontroversi Prediksi Soal hingga Peluang dan Kekhawatiran dalam Pemilihan Jurusan: Sebelum dan sesudah ujian masuk perguruan tinggi nasional (Gaokao), penerapan AI di bidang pendidikan memicu diskusi luas. Di satu sisi, “AI prediksi soal” menjadi topik hangat, tetapi karena sifat ilmiah, kerahasiaan, dan mekanisme “anti-prediksi” dalam pembuatan soal Gaokao, kemungkinan AI memprediksi soal secara akurat rendah, dan kualitas beberapa lembar soal prediksi di pasaran mengkhawatirkan. Di sisi lain, AI menunjukkan peran positif dalam perencanaan persiapan ujian, penjelasan soal, pengawasan ujian, dan penilaian, seperti rencana belajar yang dipersonalisasi, tanya jawab cerdas, dan sistem pengawasan AI yang meningkatkan keadilan dan efisiensi. Dalam tahap pengisian formulir pilihan jurusan, alat AI dapat dengan cepat merekomendasikan perguruan tinggi dan jurusan berdasarkan skor dan peringkat siswa, menghilangkan kesenjangan informasi. Namun, ketergantungan berlebihan pada AI untuk pengisian formulir juga menimbulkan kekhawatiran: algoritma dapat memperkuat preferensi jurusan populer, mengabaikan minat individu dan pengembangan jangka panjang; menyerahkan sepenuhnya pilihan hidup kepada algoritma dapat menyebabkan “pembajakan hidup oleh algoritma”. Artikel tersebut menyerukan pandangan rasional terhadap bantuan AI, menekankan penggunaan alat dengan bijak dan mendefinisikan masa depan dengan pemikiran (Sumber: 36氪)
Diskusi Model Kesuksesan Perusahaan AI Agent: Layanan Mandiri vs. Layanan Kustom: Komunitas membahas model kesuksesan perusahaan AI Agent. Satu pandangan berpendapat bahwa perusahaan AI Agent yang sukses (terutama yang melayani pasar menengah hingga besar) lebih banyak mengadopsi model yang mirip dengan Palantir, yaitu sejumlah besar field development engineers (FDEs) dan perangkat lunak yang disesuaikan, daripada model layanan mandiri murni. Pihak lain bersikeras pada nilai jangka panjang model layanan mandiri, percaya bahwa tim pada akhirnya akan memilih untuk membangun aplikasi penting secara internal. Ini mencerminkan jalur pemikiran yang berbeda dalam model layanan dan strategi pasar di bidang AI Agent (Sumber: X)
💡 Lainnya
System Prompt Google Diffusion Terungkap, Menunjukkan Prinsip Desain dan Batas Kemampuannya: Seorang pengguna membagikan apa yang diklaim sebagai system prompt untuk Google Diffusion (sebuah model bahasa difusi teks). Prompt tersebut merinci identitas model (Gemini Diffusion, model bahasa difusi teks ahli yang dilatih oleh Google, non-autoregresif), prinsip inti dan batasan (seperti kepatuhan instruksi, sifat non-autoregresif, akurasi, tidak ada akses real-time, etika keamanan, batas pengetahuan Desember 2023, kemampuan pembuatan kode), serta instruksi khusus untuk pembuatan halaman web HTML dan game HTML. Instruksi ini mencakup format output, desain estetika, gaya (seperti penggunaan khusus Tailwind CSS atau CSS kustom dalam game), penggunaan ikon (ikon Lucide SVG), tata letak dan kinerja (pencegahan CLS), persyaratan komentar, dll. Terakhir, ditekankan pentingnya berpikir langkah demi langkah dan mengikuti instruksi pengguna dengan tepat. Prompt ini memberikan jendela untuk memahami ide desain dan perilaku yang diharapkan dari model semacam itu (Sumber: Reddit r/LocalLLaMA)
Arvind Narayanan Menjelaskan Kelahiran dan Pemikiran di Balik Makalah “AI as Normal Technology”: Profesor Universitas Princeton Arvind Narayanan berbagi proses pembuatan makalahnya “AI as Normal Technology” yang ditulis bersama Sayash Kapoor. Ia awalnya skeptis terhadap AGI dan risiko eksistensial, tetapi atas desakan rekannya, memutuskan untuk menanggapinya dengan serius dan berpartisipasi dalam diskusi terkait. Melalui refleksi, ia menyadari bahwa pandangan terkait superintelligence layak ditanggapi dengan serius, media sosial tidak cocok untuk diskusi serius, dan komunitas etika AI serta keamanan AI masing-masing memiliki “ruang gema informasi” mereka sendiri. Draf awal makalah ditolak oleh ICML, tetapi perdebatan sengit selama proses peninjauan justru memperkuat tekad mereka untuk melanjutkan penelitian. Mereka menyadari bahwa perbedaan pendapat dengan komunitas keamanan AI lebih dalam dari yang diperkirakan, dan menyadari perlunya debat lintas batas yang lebih produktif. Akhirnya, makalah tersebut diterbitkan di lokakarya Knight First Amendment Institute Universitas Columbia, memicu perhatian luas dan diskusi yang bermanfaat, membuat Narayanan lebih optimis tentang masa depan kebijakan AI (Sumber: X)
Kebangkitan Kelompok Wirausahawan AI Generasi Z, Membentuk Ulang Aturan Kewirausahaan: Sekelompok wirausahawan AI generasi Z (lahir setelah tahun 2000) muncul dengan kecepatan luar biasa dalam gelombang kewirausahaan global. Mereka, dengan pemahaman mendalam tentang teknologi AI dan wawasan tajam terhadap lingkungan digital asli, mendefinisikan ulang aturan kewirausahaan. Contoh kasus termasuk Michael Truell dari Anysphere (Cursor) (dari magang menjadi CEO perusahaan bernilai puluhan miliar dolar dalam 3 tahun), tiga pendiri Mercor (membangun platform rekrutmen AI bernilai miliaran dalam 2 tahun), Eric Steinberger dari Magic (pada usia 25 tahun turut mendirikan perusahaan pengkodean AI dengan pendanaan lebih dari $400 juta), dan Hong Letong dari Axiom (berfokus pada AI untuk memecahkan masalah matematika, mendapatkan valuasi tinggi bahkan sebelum memiliki produk). Para wirausahawan muda ini umumnya memiliki karakteristik berikut: pemrograman adalah bahasa ibu mereka; terkenal di usia muda, memanfaatkan jendela bonus teknologi; peka terhadap kebutuhan pengguna; memiliki pemahaman asli AI tentang organisasi dan produk, cenderung pada tim yang sangat efisien dan logika “AI sebagai produk”. Kesuksesan mereka menandai pergeseran paradigma kewirausahaan di era AI (Sumber: 36氪)