
Kata Kunci:OpenAI, o3-pro, Meta, Laboratorium Kecerdasan Super, Mistral AI, Magistral, IBM, Komputer Kuantum, harga o3-pro, investasi Scale AI, Magistral-Small-2506, Komputer Kuantum Starling, uji coba aplikasi militer AI
🔥 Fokus
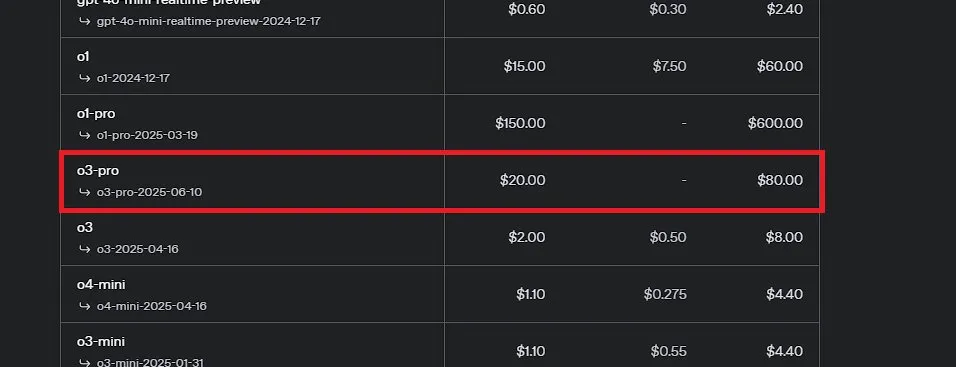
OpenAI merilis o3-pro, diklaim sebagai model terkuat dalam sejarah, dan secara signifikan menurunkan harga o3: OpenAI secara resmi meluncurkan model inferensi terkuatnya hingga saat ini, o3-pro, dan telah membukanya untuk pengguna ChatGPT Pro serta Team, dengan API juga diluncurkan secara bersamaan. o3-pro menunjukkan kinerja yang lebih unggul dari pendahulunya di berbagai bidang seperti sains, pendidikan, pemrograman, bisnis, dan bantuan penulisan, serta mendukung berbagai alat seperti pencarian web, analisis file, input visual, dan pemrograman Python. Harganya ditetapkan sebesar 20 dolar AS per juta token untuk input, dan 80 dolar AS untuk output. Sementara itu, harga model o3 asli diturunkan secara signifikan sebesar 80%, setelah penyesuaian menjadi 2 dolar AS per juta token untuk input, dan 8 dolar AS untuk output, setara dengan GPT-4o. Langkah ini dapat memicu perang harga model AI dan mendorong aplikasi AI yang lebih mendalam di bidang profesional, tetapi o3-pro juga memiliki keterbatasan seperti waktu respons yang lebih lama dan belum mendukung percakapan sementara. (Sumber: OpenAI, sama, OpenAIDevs, scaling01, dotey)
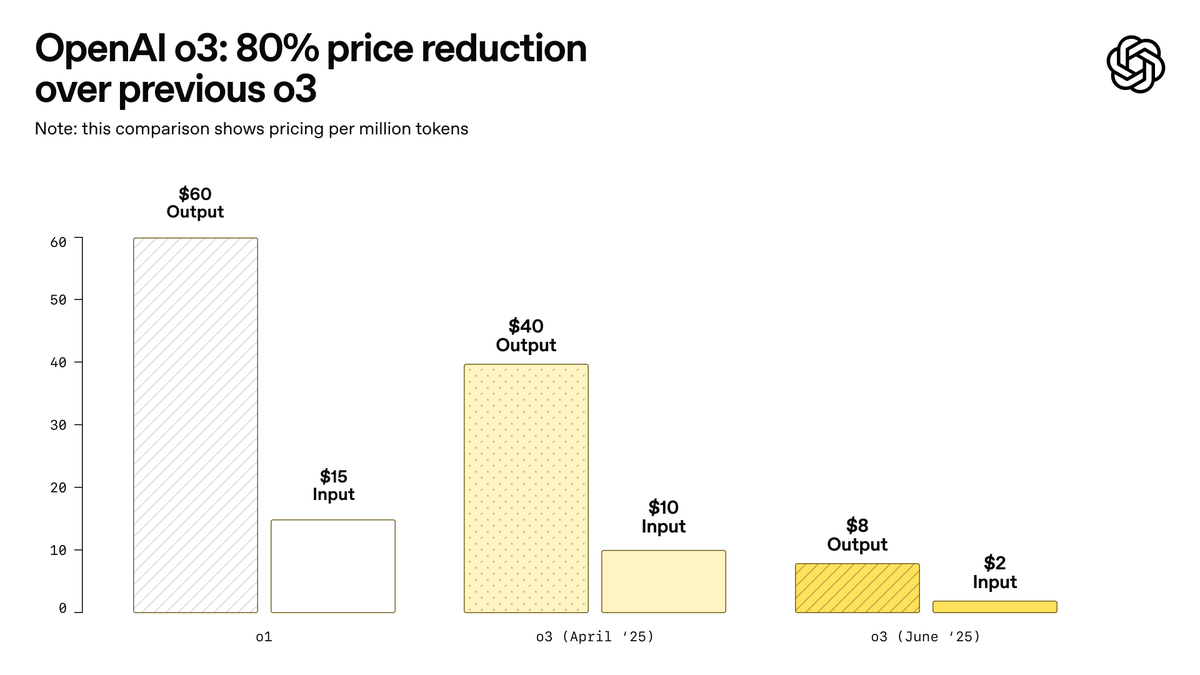
Meta membentuk “Superintelligence Lab” dan berinvestasi besar di Scale AI untuk menghidupkan kembali daya saing AI: Menurut berbagai sumber termasuk New York Times, Meta Platforms sedang merestrukturisasi departemen AI-nya, membentuk “Superintelligence Lab” baru, dan berencana menginvestasikan lebih dari 14 miliar dolar AS untuk mengakuisisi 49% saham perusahaan anotasi data Scale AI. Salah satu pendiri dan CEO Scale AI, Alexandr Wang, akan bergabung dengan Meta dan memimpin laboratorium baru ini. Langkah ini bertujuan untuk mempercepat penelitian dan pengembangan kecerdasan buatan umum (AGI), meningkatkan daya saing Meta secara keseluruhan di bidang AI, terutama dalam pemrosesan data berkualitas tinggi dan perekrutan talenta terbaik. Ini menandai penyesuaian besar dalam strategi AI Meta dan dapat berdampak besar pada lanskap persaingan industri. (Sumber: natolambert, kylebrussell, Yuchenj_UW, steph_palazzolo)

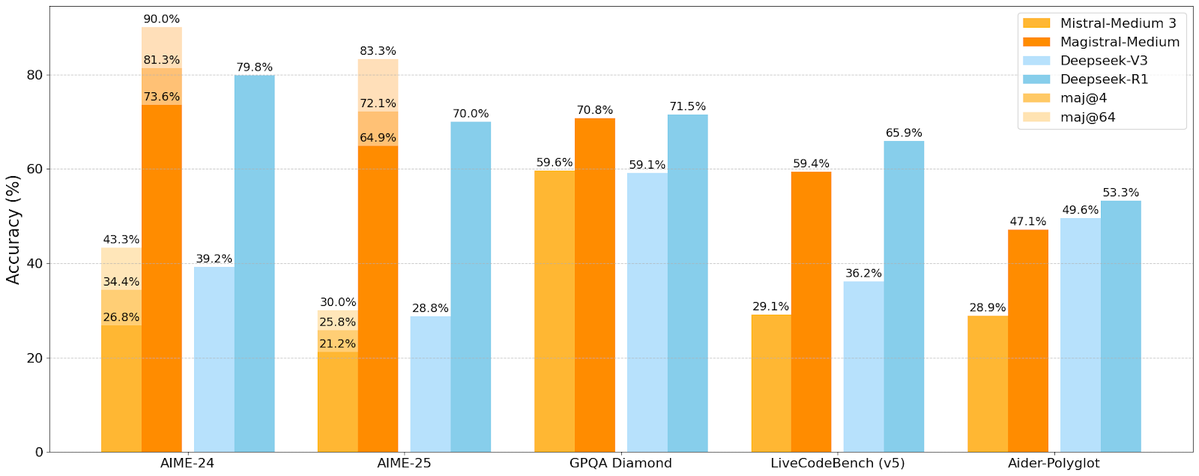
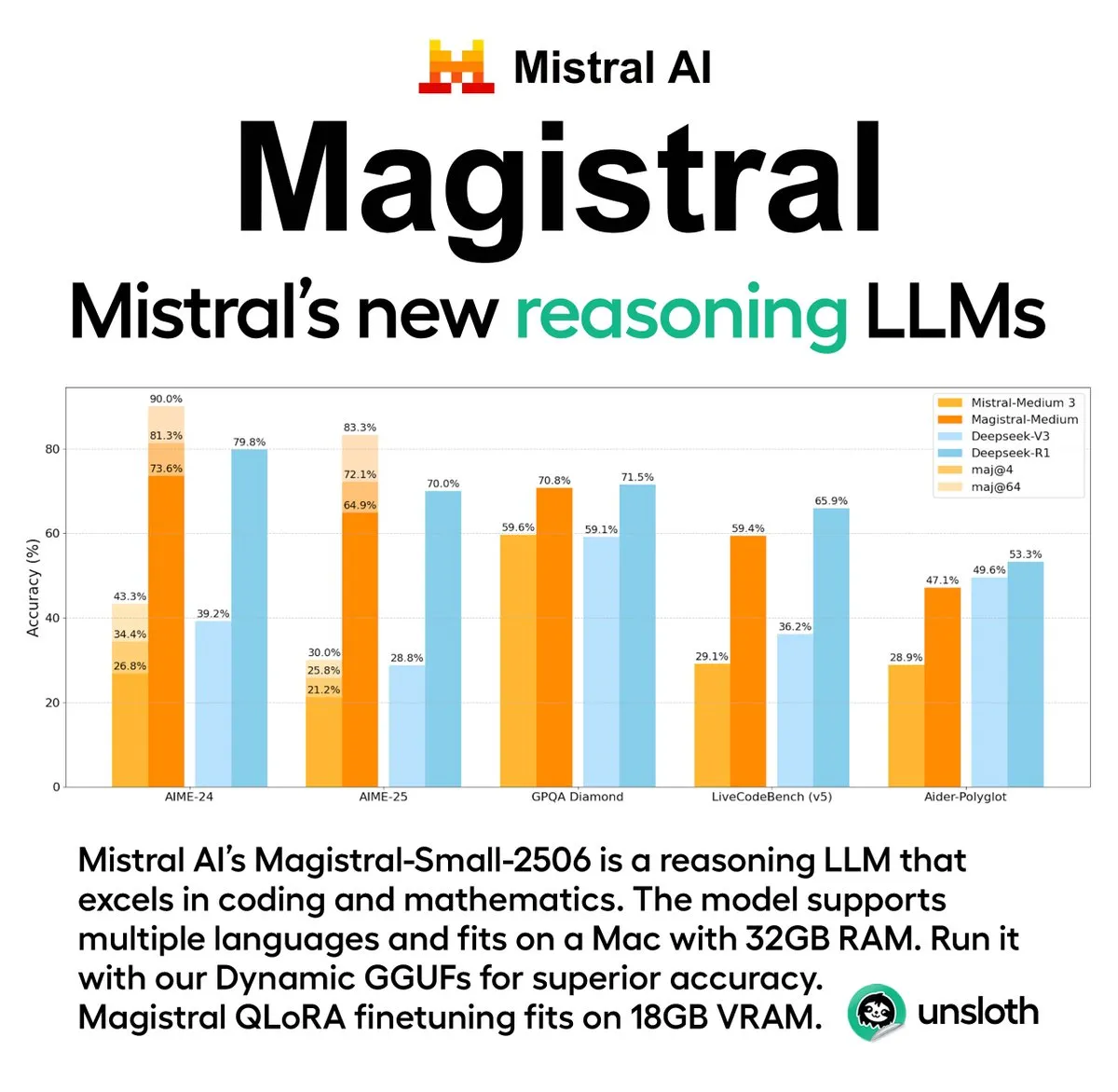
Mistral AI merilis seri model inferensi pertamanya Magistral, termasuk versi open-source: Perusahaan rintisan AI Prancis, Mistral AI, meluncurkan seri model pertamanya yang dirancang khusus untuk inferensi, Magistral. Seri ini mencakup model closed-source kelas perusahaan yang lebih kuat, Magistral Medium, dan model open-source dengan 24 miliar parameter, Magistral Small (Magistral-Small-2506), yang dirilis di bawah lisensi Apache 2.0. Model-model ini menunjukkan kinerja yang sangat baik dalam matematika, pengkodean, dan inferensi multibahasa, yang bertujuan untuk menyediakan kemampuan inferensi yang lebih transparan dan spesifik domain. Kecepatan inferensi Magistral Medium di platform Le Chat diklaim 10 kali lebih cepat dari pesaing, sementara Magistral Small menyediakan opsi yang kuat bagi komunitas untuk dijalankan secara lokal. (Sumber: Mistral AI, jxmnop, karminski3)
IBM berencana membangun komputer kuantum toleran kesalahan skala besar Starling pada tahun 2028: IBM mengumumkan peta jalan pengembangan komputasi kuantumnya, berencana untuk membangun komputer kuantum toleran kesalahan skala besar bernama Starling pada tahun 2028, dan berharap untuk membukanya bagi pengguna melalui layanan cloud pada tahun 2029. Sistem Starling diharapkan akan berisi sekitar 100 modul dan 200 qubit logis, dengan tujuan inti untuk mencapai koreksi kesalahan yang efektif, yang merupakan salah satu tantangan teknis terbesar yang dihadapi bidang komputasi kuantum saat ini. Mesin tersebut akan menggunakan kode paritas-cek densitas rendah (LDPC) IBM untuk koreksi kesalahan dan berkomitmen untuk mencapai diagnosis kesalahan waktu-nyata. Jika berhasil, ini akan menjadi terobosan besar di bidang komputasi kuantum, yang berpotensi mempercepat aplikasinya dalam masalah kompleks seperti ilmu material dan pengembangan obat. (Sumber: MIT Technology Review)

🎯 Tren
Kemajuan terkait AI Apple di WWDC 2025 gagal mengesankan pengembang: Apple merilis beberapa pembaruan di WWDC 2025, termasuk bahasa desain “liquid glass” baru dan integrasi Xcode 26 dengan ChatGPT. Namun, komunitas pengembang secara umum menyatakan bahwa kemajuannya di bidang kecerdasan buatan “tidak sesuai harapan”. Meskipun Apple untuk pertama kalinya membuka model AI sisi perangkatnya untuk pengembang dan meluncurkan kerangka kerja Foundation Models untuk menyederhanakan integrasi fungsi AI, pembaruan Siri versi baru yang sangat dinanti mungkin ditunda hingga tahun depan. Analis Ming-Chi Kuo menunjukkan bahwa strategi AI Apple menempati posisi sentral, tetapi secara teknis tidak ada terobosan besar, dan manajemen ekspektasi pasar menjadi kunci. Apple tampaknya lebih fokus pada peningkatan antarmuka pengguna dan fungsionalitas sistem operasi daripada melakukan inovasi disruptif pada model AI itu sendiri. (Sumber: MIT Technology Review, jonst0kes, rowancheung)
Pentagon mengurangi skala kantor pengujian dan evaluasi sistem senjata AI: Menteri Pertahanan AS Pete Hegseth mengumumkan pengurangan separuh skala Kantor Direktur Pengujian dan Evaluasi Operasional (DOT&E) Departemen Pertahanan, dengan personel berkurang dari 94 menjadi sekitar 45 orang. Kantor ini bertanggung jawab untuk menguji dan mengevaluasi keamanan dan efektivitas senjata serta sistem AI. Penyesuaian ini bertujuan untuk “mengurangi birokrasi yang membengkak dan pengeluaran yang boros, serta meningkatkan daya bunuh”. Langkah ini menimbulkan kekhawatiran tentang kemungkinan terpengaruhnya pengujian keamanan dan efektivitas aplikasi militer AI, terutama mengingat Pentagon sedang aktif mengintegrasikan teknologi AI (termasuk model bahasa besar) ke dalam berbagai sistem militer. (Sumber: MIT Technology Review)

OpenBMB merilis seri model bahasa besar yang sangat efisien untuk perangkat edge, MiniCPM-4: OpenBMB (Mianbi Intelligence) meluncurkan seri model MiniCPM-4, yang dirancang khusus untuk perangkat edge, bertujuan untuk mencapai operasi dengan efisiensi sangat tinggi. Seri ini mencakup MiniCPM4-0.5B, MiniCPM4-8B (model unggulan), BitCPM4 (model terkuantisasi 1-bit), MiniCPM4-Survey yang khusus untuk pembuatan laporan, dan model khusus MCP, MiniCPM4-MCP. Laporan teknis merinci arsitektur modelnya yang efisien (seperti mekanisme perhatian jarang yang dapat dilatih InfLLM v2), algoritma pembelajaran yang efisien (seperti Model Wind Tunnel 2.0), serta metode pemrosesan data pelatihan berkualitas tinggi. Model-model ini sekarang tersedia untuk diunduh di Hugging Face. (Sumber: _akhaliq, arankomatsuzaki, karminski3)
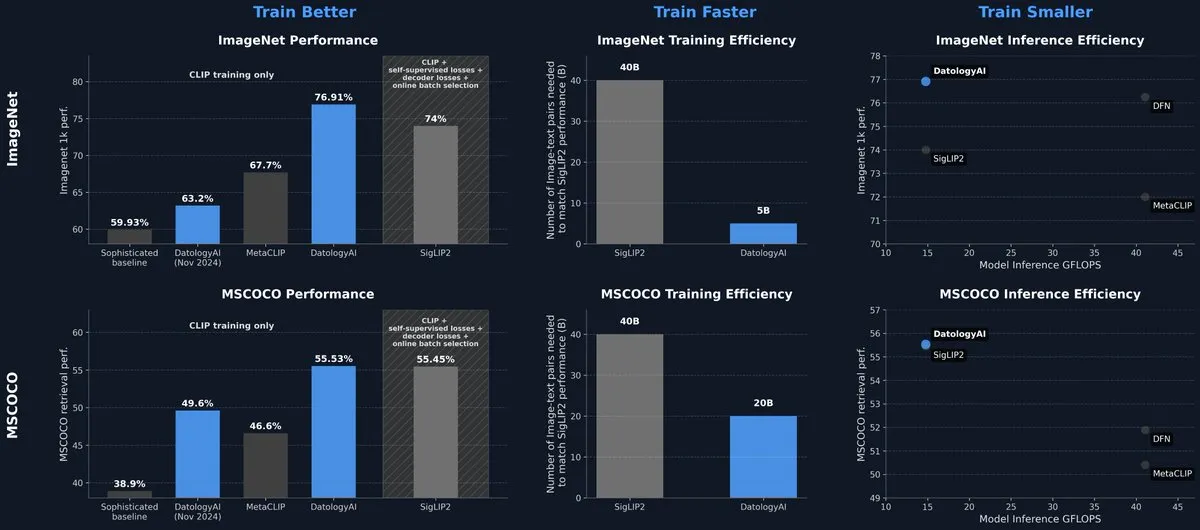
DatologyAI merilis model CLIP yang mencapai level SOTA hanya melalui manajemen data: DatologyAI memamerkan hasil penelitian terbarunya di bidang multimodal, di mana melalui kurasi data yang cermat alih-alih inovasi algoritma atau arsitektur, model CLIP ViT-B/32 miliknya mencapai akurasi 76,9% di ImageNet 1k, melampaui 74% yang dilaporkan oleh SigLIP2. Metode ini juga menghasilkan peningkatan efisiensi pelatihan 8 kali lipat dan peningkatan efisiensi inferensi 2 kali lipat. Model tersebut telah dirilis secara publik, menyoroti potensi besar data berkualitas tinggi dalam meningkatkan kinerja model. (Sumber: code_star, andersonbcdefg)
Krea AI merilis model gambar internal pertamanya, Krea 1: Krea AI meluncurkan model gambar pertamanya, Krea 1, yang menunjukkan kinerja luar biasa dalam kontrol estetika dan kualitas gambar, memiliki cadangan pengetahuan artistik yang luas, serta mendukung referensi gaya dan pelatihan khusus. Krea 1 bertujuan untuk meningkatkan realisme gambar, tekstur halus, dan ekspresi gaya yang kaya. Saat ini, Krea 1 telah membuka pengujian Beta gratis, dan pengguna dapat merasakan kemampuan generasi gambarnya yang kuat. (Sumber: _akhaliq, op7418)
NVIDIA merilis model robot humanoid open-source yang dapat disesuaikan, GR00T N1: NVIDIA meluncurkan GR00T N1, sebuah model robot humanoid open-source yang dapat disesuaikan. Langkah ini bertujuan untuk mendorong penelitian dan pengembangan di bidang robot humanoid, menyediakan platform yang fleksibel bagi pengembang untuk membangun dan bereksperimen dengan berbagai aplikasi robot. Sifat open-source GR00T N1 diharapkan dapat menarik partisipasi komunitas yang lebih luas, mempercepat kemajuan teknologi robot humanoid. (Sumber: Ronald_vanLoon)
RoboBrain 2.0 merilis model robot multimodal 7B dan 32B: RoboBrain 2.0 merilis model robot multimodal dengan parameter 7B dan 32B, yang bertujuan untuk meningkatkan kemampuan robot dalam hal persepsi, pemikiran, dan pelaksanaan tugas. Model baru ini mendukung inferensi interaktif, perencanaan jangka panjang, umpan balik loop tertutup, persepsi spasial yang akurat (prediksi titik dan kotak pembatas), persepsi temporal (estimasi lintasan masa depan), serta inferensi adegan yang dicapai melalui pembangunan dan pembaruan memori terstruktur waktu-nyata. Peningkatan kemampuan ini diharapkan dapat mendorong operasi otonom dan tingkat pengambilan keputusan robot di lingkungan yang kompleks. (Sumber: Reddit r/LocalLLaMA)
Kling AI akan berbagi penelitian terbaru tentang model generasi video di CVPR 2025: Pengfei Wan, kepala model generasi video Kling AI, akan menyampaikan pidato utama berjudul “Pengantar Kling dan Penelitian Kami tentang Model Generasi Video yang Lebih Kuat” di konferensi visi komputer terkemuka CVPR 2025. Dia akan berdiskusi dengan para ahli dari institusi seperti Google DeepMind tentang terobosan terbaru dan kemajuan mutakhir dalam teknologi generasi video. Pembagian ini akan memperkenalkan secara mendalam pencapaian Kling dalam mendorong pengembangan teknologi generasi video. (Sumber: Kling_ai)

Teknologi AI membantu Ujian Masuk Perguruan Tinggi Nasional Tiongkok 2025, beberapa daerah mengaktifkan sistem patroli cerdas: Ujian Masuk Perguruan Tinggi Nasional Tiongkok 2025 secara luas mengadopsi sistem patroli cerdas AI, dengan tempat ujian di Tianjin, Jiangxi, Hubei, Yangjiang di Guangdong, dan daerah lainnya mencapai cakupan penuh pengawasan AI. Sistem ini menggunakan kamera 4K, pelacakan kerangka, pengenalan wajah, pemantauan audio, dan teknologi lainnya untuk mendeteksi perilaku curang siswa secara waktu-nyata, seperti mengerjakan soal sebelum waktunya, memberikan barang, berbicara, dan pandangan mata yang menyimpang secara tidak normal, serta dapat mengeluarkan peringatan. Langkah ini bertujuan untuk meningkatkan keadilan ujian dan memastikan disiplin di tempat ujian. Penerapan sistem pengawasan AI menandai masuknya manajemen ujian ke era cerdas, membawa perubahan pada metode pengawasan tradisional. (Sumber: 36氪)
Model desktop Gemma 3n dirilis, mendukung lintas platform dan perangkat IoT: Google merilis model desktop Gemma 3n, termasuk versi parameter 2 miliar dan 4 miliar, yang dioptimalkan khusus untuk desktop (Mac/Windows/Linux) dan perangkat Internet of Things (IoT). Model ini didukung oleh pustaka LiteRT-LM baru, yang bertujuan untuk menyediakan kemampuan menjalankan lokal yang efisien. Pengembang dapat mengakses pratinjau melalui Hugging Face dan sumber daya terkait di GitHub, lebih lanjut mendorong penerapan model AI ringan pada perangkat edge. (Sumber: ClementDelangue, demishassabis)
🧰 Alat
Yutori AI meluncurkan Scouts: Agen AI pemantauan web waktu-nyata: Yutori AI, yang didirikan oleh mantan peneliti Meta AI, merilis produk agen AI bernama Scouts. Scouts dapat memantau informasi internet secara waktu-nyata berdasarkan topik atau kata kunci yang ditetapkan pengguna, dan memberi tahu pengguna ketika konten yang relevan muncul. Alat ini bertujuan untuk membantu pengguna menyaring konten berharga dari informasi web yang rumit, seperti melacak berita di bidang tertentu, tren pasar, penawaran produk, atau bahkan reservasi langka. Peluncuran Scouts menandai pengembangan lebih lanjut alat perolehan informasi yang dipersonalisasi, menjadikan AI sebagai “pengintai” digital bagi pengguna. (Sumber: DhruvBatraDB, krandiash, saranormous, JeffDean)
Replit meluncurkan fitur baru: mengubah rancangan desain dari Figma dan lainnya menjadi aplikasi fungsional dengan sekali klik: Replit merilis fitur Replit Import, yang memungkinkan pengguna untuk mengimpor rancangan desain dari platform seperti Figma, Lovable, Bolt, dan mengubahnya langsung menjadi aplikasi yang dapat dijalankan. Fitur ini bertujuan untuk menurunkan ambang batas pengembangan, memungkinkan non-programmer untuk dengan cepat mengubah ide desain menjadi kenyataan. Replit Import mendukung pemeliharaan fidelitas desain, dan dilengkapi dengan pemindaian keamanan serta manajemen kunci bawaan, dikombinasikan dengan Replit Agent, basis data, otentikasi, dan layanan hosting, untuk membuat aplikasi full-stack. (Sumber: amasad, pirroh)
Hugging Face merilis AISheets: menggabungkan spreadsheet dengan ribuan model AI: Salah satu pendiri Hugging Face, Thomas Wolf, mengumumkan peluncuran produk eksperimental AISheets, sebuah alat yang menggabungkan kemudahan penggunaan spreadsheet dengan kemampuan kuat ribuan model AI open-source (terutama LLM). Pengguna dapat membangun, menganalisis, dan mengotomatiskan tugas pemrosesan data dalam antarmuka spreadsheet yang sudah dikenal, memanfaatkan model AI untuk wawasan data dan otomatisasi tugas, yang bertujuan untuk menyediakan cara baru analisis data yang cepat, sederhana, dan kuat. (Sumber: _akhaliq, clefourrier, ClementDelangue, huggingface)
LlamaIndex mendukung konversi Agen menjadi server MCP untuk berinteraksi dengan model seperti Claude: LlamaIndex mengumumkan dukungan untuk mengubah Agen mana pun menjadi server Model Context Protocol (MCP). Melalui contoh kode dan video, ditunjukkan cara menerapkan alur kerja FidelityFundExtraction khusus (untuk mengekstraksi data terstruktur dari PDF kompleks) sebagai server MCP dan memanggilnya dari model Claude. Fungsi ini bertujuan untuk meningkatkan tingkat intelijen alat, memfasilitasi integrasi dengan klien MCP seperti Claude Desktop dan Cursor, serta menyederhanakan proses menghubungkan alur kerja yang ada ke ekosistem AI yang lebih luas. (Sumber: jerryjliu0)
GPT Researcher mengintegrasikan Model Context Protocol (MCP) LangChain: GPT Researcher sekarang menggunakan adaptor Model Context Protocol (MCP) LangChain untuk pemilihan alat cerdas dan penelitian. Integrasi ini menggabungkan MCP dengan fungsi pencarian web secara mulus untuk mencapai pengumpulan data yang komprehensif. Pengguna dapat merujuk ke dokumentasi integrasi terkait untuk memahami cara mengkonfigurasi dan menggunakan fitur baru ini, sehingga meningkatkan efisiensi dan kedalaman penelitian. (Sumber: hwchase17)
Tesslate merilis seri model generasi UI UIGEN-T3, mendukung berbagai ukuran: Tim Tesslate meluncurkan seri model generasi UI UIGEN-T3, termasuk skala parameter 32B, 14B, 8B, dan 4B. Model-model ini dirancang khusus untuk menghasilkan komponen UI (seperti breadcrumbs, tombol, kartu) dan kode frontend lengkap (seperti halaman login, dasbor, antarmuka obrolan), serta mendukung Tailwind CSS. Model-model ini tersedia di Hugging Face, bertujuan untuk membantu pengembang membangun antarmuka pengguna dengan cepat. Pengembang memberikan umpan balik bahwa kuantisasi standar akan secara signifikan mengurangi kualitas model, dan menyarankan untuk menjalankannya di bawah BF16 atau FP8 untuk hasil terbaik. (Sumber: Reddit r/LocalLLaMA)
Model podcast Doubao dirilis, menghasilkan podcast AI yang dipersonifikasikan dengan sekali klik: Volcengine merilis model podcast Doubao, yang dapat dengan cepat menghasilkan podcast dengan gaya percakapan yang sangat dipersonifikasikan berdasarkan teks yang dimasukkan pengguna (seperti tautan artikel atau Prompt). Audio yang dihasilkan model ini mendekati suara manusia dalam hal nada, jeda, dan ekspresi sehari-hari, bahkan dapat melakukan diskusi berpendapat berdasarkan konten. Teknologi ini didasarkan pada model suara waktu-nyata end-to-end dari tim teknologi suara ByteDance, yang mewujudkan pemahaman dan inferensi langsung pada modalitas suara. Saat ini, fungsi ini telah diluncurkan di Doubao versi PC dan K扣子空间 (Kouzi Space), bertujuan untuk menurunkan ambang batas pembuatan konten audio dan menyediakan cara perolehan informasi yang efisien dan dipersonalisasi. (Sumber: 量子位)

Unsloth AI menyediakan versi terkuantisasi GGUF dari Magistral-Small-2506: Untuk model inferensi Magistral-Small-2506 yang baru dirilis oleh Mistral AI, Unsloth AI menyediakan versi terkuantisasi GGUF. Ini memungkinkan pengguna untuk menjalankan model 24 miliar parameter ini secara lokal, misalnya, pada perangkat dengan RAM hanya 32GB. Langkah ini menurunkan ambang batas perangkat keras untuk model inferensi berkinerja tinggi, memudahkan pengembang dan peneliti yang lebih luas untuk merasakan dan menggunakan model Magistral di lingkungan lokal mereka. (Sumber: ImazAngel)
📚 Pembelajaran
Analisis mendalam teknologi pembangunan asisten visual LLaVA-1.5: LearnOpenCV merilis artikel analisis teknis mendalam tentang arsitektur LLaVA-1.5. Artikel tersebut merinci bagaimana LLaVA-1.5 membangun asisten visual AI canggih, termasuk teknologi terobosannya Visual Instruction Tuning dan dataset open-source yang mengubah bidang AI multimodal. Panduan ini memiliki nilai referensi penting bagi insinyur dan peneliti AI/ML untuk memahami prinsip kerja dan metode pelatihan model bahasa besar multimodal. (Sumber: LearnOpenCV)
Panduan pengantar machine learning protein dirilis: DL Weekly membagikan panduan komprehensif machine learning protein untuk pemula. Panduan ini mencakup tipe data dasar terkait protein, model deep learning, metode komputasi, serta konsep biologi dasar, yang bertujuan untuk membantu peneliti dan pengembang yang tertarik pada bidang interdisipliner ini untuk memulai dengan cepat. (Sumber: dl_weekly)
Qdrant bekerja sama dengan DataTalksClub meluncurkan kursus gratis RAG dan pencarian vektor: Qdrant mengumumkan kerja sama dengan DataTalksClub untuk menyediakan kursus online gratis selama 10 minggu. Materi kursus mencakup Retrieval Augmented Generation (RAG), pencarian vektor, pencarian hibrida, metode evaluasi, dan lain-lain, serta mencakup praktik proyek end-to-end. Pakar Qdrant, Kacper Łukawski dan Daniel Wanderung, akan mengajar secara langsung, bertujuan untuk membantu peserta didik menguasai keterampilan praktis dalam membangun aplikasi AI tingkat lanjut. (Sumber: qdrant_engine)
Podcast Weaviate membahas output terstruktur LLM dan constrained decoding: Episode terbaru podcast Weaviate mengundang Will Kurt dan Cameron Pfiffer dari dottxt.ai, bersama dengan pembawa acara Connor Shorten, untuk membahas masalah output terstruktur dari model bahasa besar (LLM). Acara tersebut membahas secara mendalam bagaimana memastikan LLM menghasilkan hasil yang andal dan dapat diprediksi (seperti JSON, email, tweet yang valid, dll.) melalui teknologi constrained decoding, bukan hanya validasi format JSON sederhana. Mereka juga memperkenalkan alat open-source Outlines dan aplikasinya dalam kasus penggunaan AI praktis, serta memandang ke depan dampak teknologi ini pada sistem AI di masa depan. (Sumber: bobvanluijt)
Makalah ACL2025NLP SynthesizeMe!: Menghasilkan prompt yang dipersonalisasi dari interaksi pengguna: Sebuah makalah konferensi ACL 2025 NLP berjudul “SynthesizeMe!” mengusulkan metode baru untuk membuat model pengguna yang dipersonalisasi dalam bahasa alami dengan menganalisis interaksi pengguna dengan AI (termasuk umpan balik implisit dan eksplisit). Metode ini pertama-tama menghasilkan dan memvalidasi proses penalaran yang menjelaskan preferensi pengguna, kemudian menggeneralisasi potret pengguna sintetis darinya, menyaring interaksi pengguna sebelumnya yang kaya informasi, dan akhirnya membangun prompt yang dipersonalisasi untuk pengguna tertentu, dengan harapan dapat meningkatkan pemodelan hadiah yang dipersonalisasi dan kemampuan respons LLM. DSPy juga me-retweet dan menyebutkan bahwa ini adalah contoh aplikasi yang sangat baik dari dspy.MIPROv2. (Sumber: lateinteraction, stanfordnlp)
Makalah baru membahas pemantauan dan overclocking LLM dengan Test-Time Scaling: Sebuah makalah baru berfokus pada teknik Test-Time Scaling yang diadopsi oleh model seperti o3 dan DeepSeek-R1, yang memungkinkan LLM untuk melakukan lebih banyak penalaran sebelum menjawab, tetapi pengguna seringkali tidak dapat memahami kemajuan internalnya atau mengendalikannya. Peneliti mengusulkan untuk mengekspos “jam” internal LLM dan menunjukkan cara memantau proses penalarannya serta “men-overclock” untuk mempercepatnya. Ini memberikan ide baru untuk memahami dan mengoptimalkan efisiensi model inferensi besar. (Sumber: arankomatsuzaki)

Makalah mengusulkan CARTRIDGES: Mengompres KV cache LLM konteks panjang melalui pembelajaran mandiri offline: Peneliti dari HazyResearch Universitas Stanford mengusulkan metode baru bernama CARTRIDGES, yang bertujuan untuk mengatasi masalah penggunaan memori KV cache yang berlebihan pada LLM konteks panjang. Metode ini menggunakan mekanisme pelatihan saat pengujian “pembelajaran mandiri” untuk melatih KV cache yang lebih kecil (disebut cartridge) secara offline untuk menyimpan informasi dokumen, sehingga mengurangi memori cache rata-rata 39 kali lipat dan meningkatkan throughput puncak 26 kali lipat sambil mempertahankan kinerja tugas. Cartridge ini, setelah dilatih sekali, dapat digunakan kembali oleh permintaan pengguna yang berbeda, memberikan ide optimasi baru untuk pemrosesan konteks panjang. (Sumber: gallabytes, simran_s_arora, stanfordnlp)

Makalah baru Grafting: Mengedit arsitektur Diffusion Transformer pra-terlatih dengan biaya rendah: Peneliti dari Universitas Stanford mengusulkan metode baru bernama Grafting untuk mengedit arsitektur model Diffusion Transformer pra-terlatih. Teknologi ini memungkinkan penggantian mekanisme perhatian dan primitif komputasi lainnya dalam model dengan yang baru, hanya dengan 2% biaya komputasi dari pra-pelatihan, sehingga memungkinkan desain arsitektur model yang disesuaikan dengan anggaran komputasi kecil. Ini memiliki arti penting untuk mengeksplorasi arsitektur model baru dan meningkatkan efisiensi model yang ada. (Sumber: realDanFu, togethercompute)
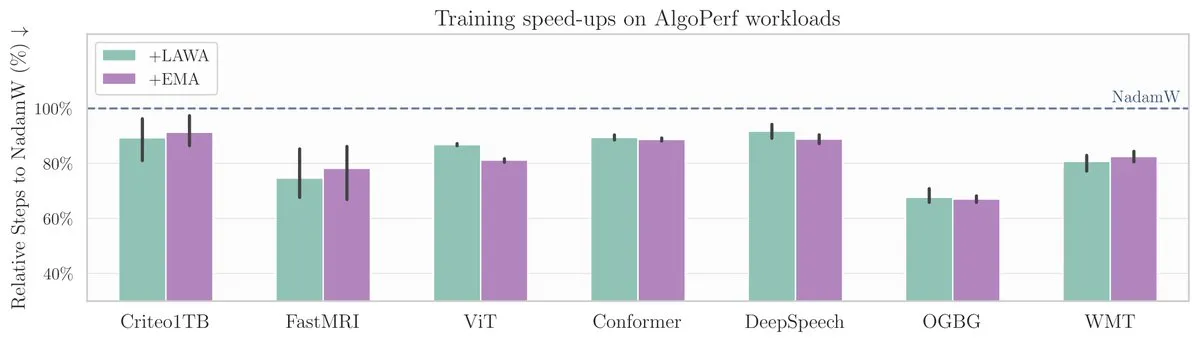
Makalah ICML baru: Metode Averaging Checkpoints mempercepat pelatihan model pada benchmark AlgoPerf: Sebuah makalah ICML baru meneliti penerapan metode klasik Averaging Checkpoints dalam meningkatkan kecepatan dan kinerja pelatihan model machine learning. Para peneliti menguji metode ini pada AlgoPerf, sebuah benchmark algoritma optimasi yang terstruktur dan beragam, untuk mengeksplorasi manfaat praktisnya pada berbagai tugas, memberikan referensi praktis untuk mempercepat pelatihan model. (Sumber: aaron_defazio)
Alat visualisasi penjelasan Transformer open-source: DL Weekly memperkenalkan alat visualisasi interaktif yang bertujuan untuk membantu pengguna memahami cara kerja model berbasis arsitektur Transformer (seperti GPT). Alat ini membedah mekanisme internal model secara visual, membuat konsep kompleks lebih mudah dipahami, cocok untuk pelajar dan peneliti yang tertarik pada model Transformer. Proyek ini telah di-open-source di GitHub. (Sumber: dl_weekly)
Universitas Zhejiang mengusulkan InftyThink: Segmentasi dan peringkasan untuk mencapai inferensi kedalaman tak terbatas: Tim peneliti gabungan dari Universitas Zhejiang dan Universitas Peking mengusulkan paradigma baru inferensi model besar, InftyThink. Metode ini memecah inferensi panjang menjadi beberapa segmen pendek dan memperkenalkan ringkasan di antara segmen untuk menghubungkan konteks, sehingga secara teoritis mencapai inferensi kedalaman tak terbatas sambil mempertahankan throughput generasi yang tinggi. Metode ini tidak bergantung pada penyesuaian struktur model, dan kompatibel dengan alur pra-pelatihan dan fine-tuning yang ada dengan merekonstruksi data pelatihan menjadi format inferensi multi-putaran. Eksperimen menunjukkan bahwa InftyThink dapat secara signifikan meningkatkan kinerja model pada benchmark seperti AIME24 dan meningkatkan throughput generasi. (Sumber: 量子位)

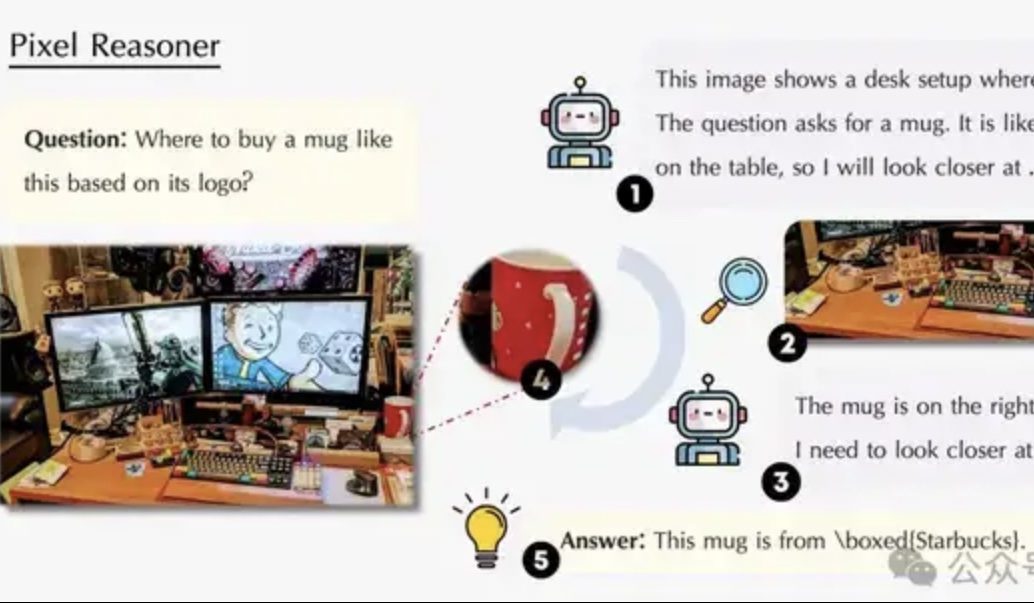
Makalah membahas Pixel-Space Reasoning: Membuat VLM “menggunakan mata dan otak” seperti manusia: Tim peneliti dari Universitas Waterloo, HKUST, dan USTC mengusulkan paradigma “Pixel-Space Reasoning”, yang memungkinkan model bahasa visual (VLM) untuk beroperasi dan bernalar langsung pada tingkat piksel, seperti zoom visual, penandaan spasial-temporal, dll., daripada mengandalkan token teks sebagai perantara. Melalui skema pembelajaran penguatan dengan insentif keingintahuan intrinsik dan insentif kebenaran ekstrinsik, “kemalasan kognitif” model dapat diatasi. Pixel-Reasoner yang dibangun berdasarkan Qwen2.5-VL-7B menunjukkan kinerja yang sangat baik pada beberapa benchmark seperti V*Bench, dengan kinerja model 7B melampaui GPT-4o. (Sumber: 量子位)
DeepLearning.AI meluncurkan kursus kelima sertifikat profesional analisis data: Data Storytelling: DeepLearning.AI merilis kursus kelima dari sertifikat profesional analisis datanya, dengan tema “Data Storytelling”. Kursus ini mengajarkan cara memilih media yang tepat (dasbor, memo, presentasi) untuk menyajikan wawasan, menggunakan Tableau untuk merancang dasbor interaktif, menyelaraskan temuan dengan tujuan bisnis dan mengkomunikasikannya secara efektif, serta panduan mencari kerja. Menekankan pentingnya data storytelling dalam meningkatkan kinerja bisnis dan menyampaikan wawasan secara efektif. (Sumber: DeepLearningAI)

Makalah membahas dampak konflik pengetahuan pada model bahasa besar: Sebuah makalah baru secara sistematis mengevaluasi perilaku model bahasa besar (LLM) ketika menghadapi konflik antara input kontekstual dan pengetahuan terparameterisasi (yaitu, “memori” internal model). Penelitian menemukan bahwa konflik pengetahuan memiliki dampak kecil pada tugas yang tidak bergantung pada pemanfaatan pengetahuan; ketika konteks konsisten dengan pengetahuan parameter, model berkinerja lebih baik; bahkan ketika diinstruksikan, model tidak dapat sepenuhnya menekan pengetahuan internalnya; memberikan alasan untuk menjelaskan konflik meningkatkan ketergantungan model pada konteks. Temuan ini menimbulkan pertanyaan tentang validitas evaluasi berbasis model dan menekankan perlunya mempertimbangkan masalah konflik pengetahuan saat menerapkan LLM. (Sumber: HuggingFace Daily Papers)
Makalah CyberV: Kerangka kerja sibernetika untuk Test-Time Scaling dalam pemahaman video: Untuk mengatasi masalah kebutuhan komputasi, ketahanan, dan akurasi yang dihadapi oleh model bahasa besar multimodal (MLLM) dalam memproses video panjang atau kompleks, para peneliti mengusulkan kerangka kerja CyberV. Kerangka kerja ini terinspirasi oleh prinsip-prinsip sibernetika, merancang ulang MLLM video sebagai sistem adaptif, yang terdiri dari sistem inferensi MLLM, sensor, dan pengendali. Sensor memantau proses maju model dan mengumpulkan interpretasi perantara (seperti penyimpangan perhatian), pengendali memutuskan kapan dan bagaimana memicu koreksi diri dan menghasilkan umpan balik. Kerangka kerja perluasan adaptif saat pengujian ini dapat meningkatkan MLLM yang ada tanpa pelatihan ulang, dan eksperimen menunjukkan bahwa kerangka kerja ini secara signifikan meningkatkan kinerja model seperti Qwen2.5-VL-7B pada benchmark seperti VideoMMMU. (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan LoRMA: Low-Rank Multiplicative Adaptation untuk Parameter-Efficient Fine-Tuning LLM: Untuk mengatasi masalah keruntuhan representasi dan ketidakseimbangan beban pakar yang ada pada metode Parameter-Efficient Fine-Tuning (PEFT) berbasis LoRA dan MoE, para peneliti mengusulkan Low-Rank Multiplicative Adaptation (LoRMA). Metode ini mengubah cara pembaruan pakar adaptor PEFT dari aditif menjadi transformasi perkalian matriks yang lebih kaya, dengan mengatasi kompleksitas komputasi dan bottleneck peringkat melalui operasi penataan ulang yang efektif dan pengenalan strategi perluasan peringkat. Eksperimen membuktikan bahwa metode heterogen MoA (Mixture-of-Adapters) mengungguli metode MoE-LoRA homogen baik dalam kinerja maupun efisiensi parameter. (Sumber: Reddit r/MachineLearning)
Makalah mengusulkan FlashDMoE: Implementasi Distributed MoE cepat dalam satu kernel: Para peneliti meluncurkan FlashDMoE, sistem pertama yang sepenuhnya menggabungkan propagasi maju Distributed Mixture-of-Experts (MoE) ke dalam satu kernel CUDA. Dengan menulis lapisan fusi dari awal menggunakan CUDA murni, FlashDMoE mencapai peningkatan pemanfaatan GPU hingga 9x, pengurangan latensi 6x, dan peningkatan efisiensi perluasan lemah 4x. Karya ini memberikan ide dan implementasi baru untuk mengoptimalkan efisiensi inferensi model MoE skala besar. (Sumber: Reddit r/MachineLearning)
💼 Bisnis
xAI dan Polymarket bekerja sama, menggabungkan prediksi pasar dengan analisis Grok: xAI, perusahaan kecerdasan buatan milik Elon Musk, mengumumkan kemitraan dengan platform pasar prediksi terdesentralisasi Polymarket. Kerja sama ini bertujuan untuk menggabungkan data prediksi pasar Polymarket dengan data dari X (sebelumnya Twitter) dan kemampuan analisis Grok AI, untuk menciptakan “mesin kebenaran garis keras” guna mengungkap faktor-faktor yang membentuk dunia. xAI menyatakan bahwa ini hanyalah awal dari kerja sama, dan akan ada lebih banyak konten kerja sama di masa depan. (Sumber: xai)
Perusahaan chip inferensi AI Groq mendapatkan komitmen investasi 1,5 miliar dolar AS dari Arab Saudi, fokus pada strategi integrasi vertikal: Perusahaan chip inferensi AI Groq mengumumkan telah menerima komitmen investasi sebesar 1,5 miliar dolar AS dari Arab Saudi untuk memperluas skala pengiriman infrastruktur inferensi AI berbasis LPU (Language Processing Unit) di negara tersebut. Groq, yang didirikan oleh salah satu penemu TPU, Jonathan Ross, berfokus pada komputasi inferensi AI. Chip LPU-nya menggunakan arsitektur pipeline yang dapat diprogram, dengan unit memori dan komputasi terintegrasi pada chip yang sama, yang secara signifikan meningkatkan kecepatan akses data dan efisiensi energi. Groq tidak hanya menjual chip, tetapi juga menyediakan klaster GroqRack (cloud pribadi/pusat komputasi AI) dan platform cloud GroqCloud (Tokens-as-a-Service), serta mendukung model open-source utama seperti Llama, DeepSeek, dan Qwen. Perusahaan ini juga mengembangkan sistem AI komposit Compound untuk meningkatkan nilai cloud inferensi AI. (Sumber: 36氪)

Perusahaan robot interaktif humanoid Shenzhen “Digital Huaxia” menyelesaikan putaran pendanaan Angel+ senilai puluhan juta yuan: Digital Huaxia (Shenzhen) Technology Co., Ltd. baru-baru ini menyelesaikan putaran pendanaan Angel+ senilai puluhan juta yuan, dengan investasi eksklusif dari Co-Stone Capital. Perusahaan ini berfokus pada komersialisasi skala besar robot AGI, dengan produk inti termasuk robot bionik “Xia Lan”, robot humanoid serbaguna “Xia Qi”, dan robot seri IP “Xing Xing Xia”. Robot “Xia Lan”, dengan teknologi bionik presisi sebagai intinya, dapat meniru sebagian besar ekspresi manusia dan memiliki kemampuan interaksi multimodal. Perusahaan telah menerima pesanan senilai ratusan juta yuan, dengan pelanggan termasuk vendor ICT terkemuka dan perusahaan listrik daerah. (Sumber: 36氪)

🌟 Komunitas
Sam Altman menerbitkan posting blog “Singularitas yang Lembut”, membahas revolusi AI yang bertahap dan masa depan: CEO OpenAI Sam Altman menerbitkan posting blog, berpendapat bahwa singularitas teknologi terjadi secara diam-diam dengan cara yang lebih landai dan “lembut” daripada yang dibayangkan, merupakan proses bertahap yang berkelanjutan dan dipercepat secara eksponensial. Dia memprediksi bahwa pada tahun 2025, agen AI yang dapat secara mandiri menyelesaikan pekerjaan mental kompleks (seperti pemrograman) akan membentuk kembali industri perangkat lunak, pada tahun 2026 mungkin muncul sistem yang dapat menemukan wawasan ilmiah baru, dan pada tahun 2027 robot yang dapat menyelesaikan tugas di dunia nyata mungkin akan muncul. Altman menekankan bahwa penyelesaian masalah AI alignment dan memastikan aksesibilitas teknologi adalah kunci menuju masa depan yang sejahtera. Dia juga mengungkapkan bahwa model bobot open-source pertama OpenAI akan ditunda hingga akhir musim panas, karena tim peneliti mencapai “hasil luar biasa yang tidak terduga”. (Sumber: dotey, scaling01, sama)
Komunitas ramai membahas OpenAI o3-pro: kinerja kuat tetapi biaya mahal, penurunan harga o3 memicu reaksi berantai: Peluncuran OpenAI o3-pro dan harganya yang mahal (output $80/M token) menjadi fokus diskusi komunitas. Pengguna umumnya mengakui kemampuannya yang kuat dalam tugas penalaran kompleks, pemrograman, dll., tetapi juga menyatakan keprihatinan tentang kecepatan respons dan biayanya, dengan beberapa pengguna bercanda bahwa sapaan sederhana “Hai” bisa menghabiskan biaya 80 dolar. Sementara itu, penurunan harga model o3 secara signifikan sebesar 80% dianggap dapat memicu perang harga model AI, menyaingi GPT-4o dan produk pesaing lainnya. Terdapat perdebatan di komunitas mengenai apakah kinerja o3 “menurun kecerdasannya” setelah penurunan harga. OpenAI kemudian mengumumkan akan menggandakan kuota penggunaan o3 bagi pengguna ChatGPT Plus untuk menanggapi permintaan pengguna. (Sumber: Yuchenj_UW, scaling01, imjaredz, kevinweil, dotey)
Gaji tinggi Meta untuk menarik talenta dan investasi dalam organisasi AI memicu diskusi hangat: Paket gaji tinggi yang ditawarkan Meta untuk peneliti AI (dilaporkan mencapai sembilan digit dolar AS) memicu diskusi komunitas. Nat Lambert berkomentar bahwa gaji seperti itu mungkin dapat mendanai seluruh lembaga penelitian sekelas AI2, menyiratkan tingginya biaya talenta terbaik. Dikombinasikan dengan pembentukan “Superintelligence Lab” oleh Meta dan investasi besar di Scale AI, komunitas umumnya percaya bahwa Meta berusaha keras untuk membentuk kembali daya saing AI-nya, tetapi juga memperhatikan masalah politik dan efisiensi organisasi internalnya. Konten ChinaTalk yang di-retweet oleh Helen Toner menunjukkan bahwa langkah Meta ini adalah untuk memecahkan masalah politik dan keangkuhan internal organisasi. (Sumber: natolambert, natolambert)
Gaya UI baru Apple WWDC “Liquid Glass” memicu diskusi desain dan usabilitas: Gaya desain UI baru Apple “Liquid Glass” yang diluncurkan di WWDC 2025 memicu diskusi luas di kalangan pengembang dan desainer. Beberapa berpendapat bahwa efek visualnya baru dan mencerminkan eksplorasi Apple terhadap desain antarmuka 3D. Namun, tokoh senior seperti ID_AA_Carmack (John Carmack) menunjukkan bahwa UI semi-transparan biasanya memiliki masalah usabilitas, mudah menimbulkan gangguan visual dan kontras rendah, yang memengaruhi keterbacaan dan pengoperasian, serta menyebutkan bahwa Windows dan Mac secara historis juga pernah mencoba desain serupa tetapi akhirnya disesuaikan karena masalah usabilitas. Pengalaman pengguna (UX) harus diprioritaskan di atas efek visual antarmuka pengguna (UI) menjadi inti diskusi. (Sumber: gfodor, ID_AA_Carmack, ReamBraden, dotey)
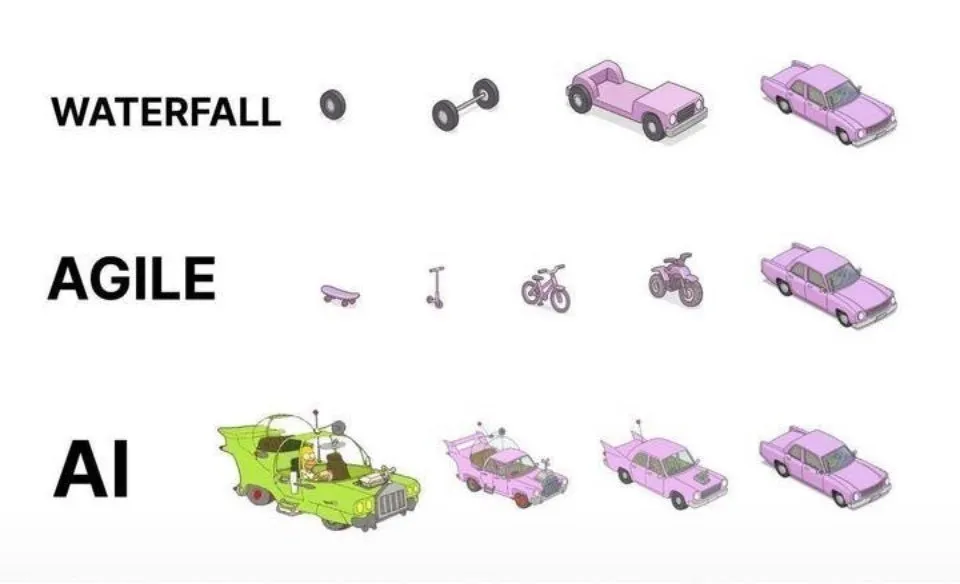
Praktik pemrograman berbantuan AI: Iterasi tangkas lebih baik daripada generasi sekali jadi: Di media sosial, dotey menyampaikan pandangannya tentang praktik terbaik penggunaan AI (seperti Claude Code) untuk pemrograman. Dia berpendapat bahwa tidak seharusnya mengadopsi model pemberian kebutuhan lengkap sekaligus agar AI menghasilkan produk setengah jadi yang besar (model air terjun) atau menghasilkan produk yang tidak sempurna terlebih dahulu lalu dioptimalkan (mirip mode ketiga dalam gambar), karena ini sulit dikendalikan kualitasnya dan sulit dipelihara di kemudian hari. Dia menganjurkan adopsi model iterasi tangkas (mirip mode pertama dalam gambar), memecah proyek besar (seperti sistem ERP) menjadi beberapa versi kecil yang dapat berjalan stabil secara independen, dikembangkan secara bertahap, memastikan kelengkapan fungsional dan keterkendalian setiap versi, yang sejalan dengan praktik terbaik rekayasa perangkat lunak tradisional. (Sumber: dotey)
Mustafa Suleyman: Teknologi AI sedang berevolusi dari tetap dan seragam menjadi dinamis dan personal: Mustafa Suleyman, salah satu pendiri Inflection AI dan mantan DeepMind, berkomentar bahwa teknologi tradisional biasanya bersifat tetap, seragam, dan “satu untuk semua”, sedangkan teknologi kecerdasan buatan saat ini menunjukkan karakteristik dinamis, personal, dan emergen. Dia berpendapat bahwa ini berarti teknologi sedang bertransisi dari menyediakan hasil tunggal yang berulang menjadi menjelajahi jalur kemungkinan tak terbatas, menekankan potensi besar AI dalam layanan yang dipersonalisasi dan aplikasi kreatif. (Sumber: mustafasuleyman)
Perplexity AI mengalami masalah infrastruktur, CEO menjelaskan: CEO Perplexity AI, Arav Srinivas, menanggapi keluhan pengguna tentang ketidakstabilan layanan di media sosial, menyatakan bahwa karena masalah infrastruktur, mereka terpaksa mengaktifkan pengalaman pengguna yang diturunkan (degraded UX) untuk sebagian lalu lintas. Dia menekankan bahwa data pengguna (seperti library atau threads) tidak hilang, dan semua fungsi akan kembali normal setelah sistem stabil. Ini mencerminkan tantangan stabilitas dan skalabilitas infrastruktur yang dihadapi layanan AI dalam perkembangannya yang pesat. (Sumber: AravSrinivas)
Sergey Levine membahas perbedaan pembelajaran antara model bahasa dan model video: Profesor UC Berkeley Sergey Levine dalam artikelnya “Model Bahasa di Gua Plato” mengajukan pertanyaan mendalam: mengapa model bahasa dapat belajar banyak dari memprediksi kata berikutnya, sedangkan model video belajar relatif sedikit dari memprediksi frame berikutnya? Dia berpendapat bahwa LLM memperoleh kemampuan penalaran yang kuat dengan mempelajari “bayangan” pengetahuan manusia (data teks), yang lebih mirip “rekayasa terbalik” kognisi manusia daripada benar-benar menjelajahi dunia fisik secara mandiri. Model video mengamati dunia fisik secara langsung, tetapi saat ini kalah dari LLM dalam penalaran kompleks. Dia mengusulkan bahwa tujuan jangka panjang AI seharusnya adalah menembus ketergantungan pada “bayangan” pengetahuan manusia, dan berinteraksi langsung dengan dunia fisik melalui sensor untuk mencapai eksplorasi otonom. (Sumber: 36氪)
💡 Lainnya
Diskusi etika dan kesadaran AI: Dapatkah AI memiliki kesadaran sejati?: MIT Technology Review menyoroti isu kompleks kesadaran AI. Artikel tersebut menunjukkan bahwa kesadaran AI bukan hanya teka-teki intelektual, tetapi juga isu dengan bobot moral. Kesalahan dalam menilai kesadaran AI dapat menyebabkan perbudakan AI yang memiliki kemampuan merasa secara tidak sengaja, atau mengorbankan kesejahteraan manusia untuk mesin yang tidak memiliki kemampuan merasa. Komunitas riset telah mencapai kemajuan dalam memahami hakikat kesadaran, dan hasil ini dapat memberikan panduan untuk mengeksplorasi dan menangani kesadaran buatan. Hal ini memicu pemikiran mendalam tentang hak, tanggung jawab AI, serta hubungan manusia-mesin. (Sumber: MIT Technology Review)
Pemenang Turing Award Joseph Sifakis: AI saat ini bukan kecerdasan sejati, perlu waspada terhadap kebingungan antara pengetahuan dan informasi: Pemenang Turing Award Joseph Sifakis dalam karya tulis dan wawancaranya menunjukkan bahwa pemahaman masyarakat saat ini tentang AI terdapat penyimpangan, mencampuradukkan penumpukan informasi dengan penciptaan kebijaksanaan, dan melebih-lebihkan “kecerdasan” mesin. Dia berpendapat bahwa saat ini belum ada sistem cerdas yang sejati, dan dampak aktual AI terhadap industri masih minim. AI kurang memiliki pemahaman akal sehat, “kecerdasannya” adalah produk model statistik, dan sulit untuk menimbang nilai dan risiko dalam situasi sosial yang kompleks. Dia menekankan bahwa inti pendidikan adalah menumbuhkan pemikiran kritis dan kreativitas, bukan transmisi pengetahuan, dan menyerukan pembentukan standar global aplikasi AI, memperjelas batas tanggung jawab, agar AI menjadi mitra yang memperkuat manusia, bukan pengganti. (Sumber: 36氪)
Restrukturisasi industri periklanan di era AI: Perubahan dari generasi kreatif hingga penayangan yang dipersonalisasi: Konferensi Google I/O 2025 menunjukkan bagaimana AI secara mendalam merestrukturisasi industri periklanan. Tren meliputi: 1) Otomatisasi kreatif yang didorong AI, dari gambar hingga skrip video dapat dihasilkan oleh AI, seperti alat Veo 3, Imagen 4, dan Flow yang menurunkan ambang batas pembuatan konten berkualitas tinggi. 2) Paradigma personalisasi berubah dari “ribuan wajah untuk ribuan orang” menjadi “ribuan wajah untuk satu orang”, agen cerdas AI dapat secara proaktif memahami kebutuhan pengguna dan memfasilitasi transaksi. 3) Batas antara iklan dan konten menjadi kabur, iklan langsung diintegrasikan ke dalam hasil pencarian yang dihasilkan AI, menjadi bagian dari informasi. Pemilik merek perlu membangun agen cerdas eksklusif, menyediakan layanan yang berorientasi pada AI, dan berpegang pada strategi jangka panjang “integrasi merek dan kinerja” untuk beradaptasi dengan perubahan. (Sumber: 36氪)