
Kata Kunci:Apple WWDC25, Strategi AI, Peningkatan Siri, Kerangka Foundation, AI perangkat, Terjemahan sistem penuh, Xcode Vibe Coding, Pencarian cerdas visual, Dukungan bahasa Cina Tradisional Apple Intelligence, Fungsi Smart Stack watchOS, Strategi privasi AI Apple, Integrasi AI ekosistem lintas sistem, Tanggal rilis Siri generatif AI
🔥 Fokus
Kemajuan AI Apple di WWDC25: Integrasi Pragmatis dan Keterbukaan, Siri Masih Harus Menunggu: Apple di WWDC25 menunjukkan penyesuaian strategi AI-nya, beralih dari “janji muluk” tahun lalu ke penyempurnaan sistem dasar dan fungsi fundamental yang lebih pragmatis. Fokus utamanya mencakup integrasi AI “secara bermakna” ke dalam sistem operasi dan aplikasi pihak pertama, serta membuka framework model “Foundation” di perangkat untuk para pengembang. Fitur-fitur baru seperti terjemahan seluruh sistem (mendukung panggilan telepon, FaceTime, Message, dll., dan menyediakan API), Xcode memperkenalkan Vibe Coding (mendukung model seperti ChatGPT), pencarian visual cerdas berbasis konten layar (mirip dengan seleksi melingkar, sebagian didukung oleh ChatGPT), serta Smart Stack di watchOS, dan lainnya. Meskipun dukungan Apple Intelligence di pasar Tiongkok Tradisional telah disebutkan, waktu peluncuran untuk Tiongkok Sederhana dan Siri versi AI generatif yang sangat dinantikan masih belum jelas, dengan yang terakhir diperkirakan akan dibahas “tahun depan”. Apple menekankan AI di perangkat dan komputasi awan pribadi untuk melindungi privasi pengguna, serta mendemonstrasikan integrasi kemampuan AI di seluruh ekosistem sistemnya. (Sumber: 36Kr, 36Kr, 36Kr, 36Kr)

Apple Rilis Paper AI yang Meragukan Kemampuan Penalaran Model Besar, Picu Kontroversi Luas di Industri: Apple baru-baru ini merilis paper berjudul “The Illusion of Thought: Understanding the Strengths and Limitations of Reasoning Models through the Lens of Question Complexity”. Melalui pengujian teka-teki terhadap model penalaran besar (LRMs) seperti Claude 3.7 Sonnet, DeepSeek-R1, dan o3 mini, paper tersebut menunjukkan bahwa model-model ini cenderung “berpikir berlebihan” saat menangani masalah sederhana, namun mengalami “keruntuhan akurasi total” pada masalah dengan kompleksitas tinggi, dengan tingkat akurasi mendekati nol. Penelitian ini berpendapat bahwa LRMs saat ini mungkin menghadapi hambatan fundamental dalam penalaran yang dapat digeneralisasi, lebih menyerupai pencocokan pola daripada pemikiran sejati. Pandangan ini mendapat perhatian dari akademisi seperti Gary Marcus, tetapi juga menuai banyak kritik. Para kritikus menganggap desain eksperimen memiliki kelemahan logika (seperti definisi kompleksitas, pengabaian batasan output token), bahkan menuduh Apple mencoba menyangkal pencapaian model besar yang ada karena kemajuan AI mereka sendiri yang lambat. Status penulis pertama paper sebagai mahasiswa magang juga menjadi sorotan. (Sumber: 36Kr, Reddit r/ArtificialInteligence)

OpenAI Dilaporkan Diam-diam Melatih Model Baru o4, Reinforcement Learning Membentuk Ulang Lanskap R&D AI: SemiAnalysis mengungkapkan bahwa OpenAI sedang melatih model baru dengan skala antara GPT-4.1 dan GPT-4.5. Model penalaran generasi berikutnya, o4, akan didasarkan pada pelatihan reinforcement learning (RL) dari GPT-4.1. Langkah ini menandai perubahan strategi OpenAI, yang bertujuan untuk menyeimbangkan kekuatan model dengan kepraktisan pelatihan RL. GPT-4.1 dianggap sebagai dasar yang ideal karena biaya inferensi yang lebih rendah dan kinerja kode yang kuat. Artikel tersebut menganalisis secara mendalam peran inti RL dalam meningkatkan kemampuan penalaran LLM dan mendorong pengembangan agen AI, tetapi juga menunjukkan tantangannya dalam infrastruktur, penetapan fungsi reward, dan reward hacking. RL sedang mengubah struktur organisasi dan prioritas R&D di laboratorium AI, mengintegrasikan penalaran dan pelatihan secara mendalam. Sementara itu, data berkualitas tinggi menjadi benteng pertahanan untuk penskalaan RL, dan untuk model yang lebih kecil, distilasi mungkin lebih efektif daripada RL. (Sumber: 36Kr)

Ilya Sutskever Kembali ke Publik, Terima Gelar Doktor Kehormatan dari University of Toronto dan Bahas Masa Depan AI: Salah satu pendiri OpenAI, Ilya Sutskever, setelah meninggalkan OpenAI dan mendirikan Safe Superintelligence Inc., baru-baru ini tampil di depan publik untuk pertama kalinya, kembali ke almamaternya, University of Toronto, untuk menerima gelar Doktor Sains Kehormatan. Dalam pidatonya, ia menekankan bahwa AI di masa depan akan mampu melakukan semua hal yang dapat dilakukan manusia, karena otak itu sendiri adalah komputer biologis, dan tidak ada alasan mengapa komputer digital tidak dapat melakukan hal yang sama. Ia percaya bahwa AI sedang mengubah pekerjaan dan karier dengan cara yang belum pernah terjadi sebelumnya, dan mendesak orang untuk memperhatikan perkembangan AI, serta menggunakan pengamatan terhadap kemampuannya untuk membangkitkan energi guna mengatasi tantangan. Pengalaman Sutskever di OpenAI dan perhatiannya pada keamanan AGI menjadikannya tokoh kunci di bidang AI. (Sumber: 36Kr, Reddit r/artificial)

🎯 Perkembangan
Xiaohongshu Rilis Model Besar MoE Pertama dots.llm1 secara Open Source, Ungguli DeepSeek-V3 dalam Evaluasi Bahasa Mandarin: Xiaohongshu hi lab (Humanities Intelligence Lab) merilis model besar open source pertamanya, dots.llm1, sebuah model Mixture of Experts (MoE) dengan 142 miliar parameter, yang hanya mengaktifkan 14 miliar parameter saat inferensi. Model ini menggunakan 11,2 triliun data non-sintetis selama tahap pra-pelatihan dan menunjukkan kinerja luar biasa dalam pemahaman bahasa Mandarin dan Inggris, penalaran matematika, pembuatan kode, dan tugas penyelarasan, dengan kinerja mendekati Qwen3-32B. Khususnya dalam evaluasi bahasa Mandarin C-Eval, dots.llm1.inst mencapai skor 92,2, melampaui model yang ada termasuk DeepSeek-V3. Xiaohongshu menekankan bahwa kerangka kerja pemrosesan data yang dapat diskalakan dan terperinci adalah kuncinya, dan telah merilis checkpoint pelatihan menengah secara open source untuk mendorong penelitian komunitas. (Sumber: 36Kr)
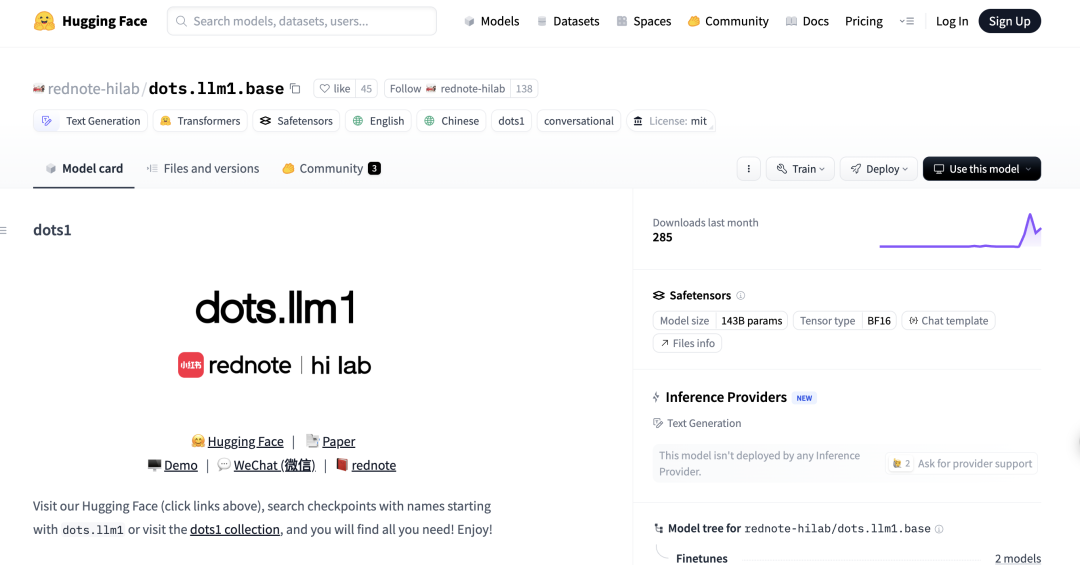
Model DeepSeek R1 0528 Berkinerja Unggul dalam Benchmark Pemrograman Aider: Papan peringkat pemrograman Aider memperbarui skor untuk model DeepSeek-R1-0528, hasilnya menunjukkan kinerjanya melampaui Claude-4-Sonnet (baik dengan maupun tanpa mode berpikir) serta Claude-4-Opus tanpa mode berpikir. Model ini juga menonjol dalam hal efektivitas biaya, yang semakin membuktikan daya saingnya yang kuat di bidang pembuatan kode dan pemrograman berbantuan. (Sumber: karminski3)
Pembaruan Apple WWDC25: Luncurkan Bahasa Desain “Liquid Glass”, Kemajuan AI Lambat, Peningkatan Siri Kembali Tertunda: Apple di WWDC25 merilis pembaruan sistem operasi untuk semua platform, memperkenalkan gaya desain UI baru bernama “Liquid Glass”, dan menyatukan nomor versi menjadi “seri 26” (seperti iOS 26). Di sisi AI, kemajuan Apple Intelligence terbatas. Meskipun mengumumkan pembukaan framework model dasar sisi perangkat “Foundation” untuk pengembang dan mendemonstrasikan fitur seperti terjemahan real-time dan kecerdasan visual, Siri versi AI yang sangat dinantikan kembali ditunda hingga “tahun depan”. Langkah ini menimbulkan kekecewaan pasar, dan harga saham pun turun. iPadOS mengalami peningkatan signifikan dalam multitasking dan manajemen file, yang dianggap sebagai sorotan dari acara peluncuran ini. (Sumber: 36Kr, 36Kr, 36Kr)
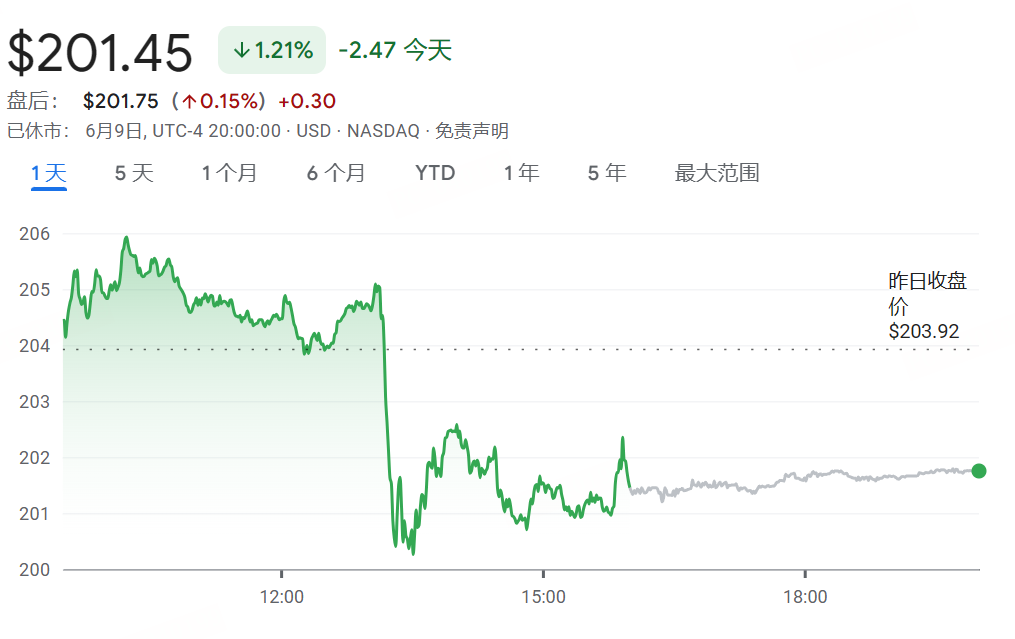
Model Anthropic Claude Dilaporkan Mengalami Penurunan Kinerja, Pengalaman Pengguna Buruk: Beberapa pengguna Reddit melaporkan bahwa model Claude dari Anthropic (khususnya Claude Code Max) baru-baru ini mengalami penurunan kinerja yang signifikan, termasuk kesalahan dalam tugas sederhana, pengabaian instruksi, dan penurunan kualitas output. Beberapa pengguna menyatakan bahwa versi web berkinerja sangat buruk dibandingkan dengan versi API, bahkan mencurigai model tersebut telah “dilemahkan” (nerfed). Beberapa pengguna berspekulasi bahwa hal ini mungkin terkait dengan beban server, batasan tarif, atau penyesuaian prompt sistem internal. Halaman status resmi Anthropic juga pernah melaporkan peningkatan tingkat kesalahan pada Claude Opus 4. (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip: Mengompres KV Cache LLM dengan Menghapus Pasangan KV Kurang Penting Secara Dinamis: Sebuah proyek baru bernama KVzip bertujuan untuk mengoptimalkan penggunaan memori GPU dan kecepatan inferensi dengan mengompres cache key-value (KV) dari model bahasa besar (LLM). Metode ini bukanlah kompresi data dalam arti tradisional, melainkan dengan mengevaluasi pentingnya pasangan KV (berdasarkan kemampuan rekonstruksi konteks), kemudian secara langsung menghapus pasangan KV yang kurang penting dari cache, sehingga mencapai kompresi lossy. Diklaim bahwa metode ini dapat mengurangi penggunaan memori GPU hingga sepertiga dari aslinya dan meningkatkan kecepatan inferensi. Saat ini mendukung model seperti LLaMA3, Qwen2.5/3, Gemma3, namun beberapa pengguna mempertanyakan validitas pengujiannya yang berbasis teks “Harry Potter”, karena model tersebut mungkin telah dilatih sebelumnya dengan teks tersebut. (Sumber: karminski3)

Yann LeCun Mengkritik CEO Anthropic Dario Amodei atas Sikap Kontradiktif terhadap Risiko dan Pengembangan AI: Kepala Ilmuwan AI Meta, Yann LeCun, di media sosial menuduh CEO Anthropic Dario Amodei menunjukkan sikap kontradiktif “ingin keduanya” terkait masalah keamanan AI. LeCun berpendapat bahwa Amodei di satu sisi menyebarkan teori kiamat AI, namun di sisi lain aktif mengembangkan AGI. Ini, menurut LeCun, entah merupakan ketidakjujuran akademis atau masalah etika, atau kesombongan ekstrem karena merasa hanya dirinya yang dapat mengendalikan AI yang kuat. Amodei sebelumnya telah memperingatkan bahwa AI dapat menyebabkan pengangguran massal pekerja kerah putih dalam beberapa tahun ke depan dan menyerukan regulasi yang lebih ketat, namun perusahaannya, Anthropic, terus mendorong pengembangan dan pendanaan model besar seperti Claude. (Sumber: 36Kr)
HuggingFace Meluncurkan Dataset Nemotron-Personas, NVIDIA Merilis Data Karakter Sintetis untuk Melatih LLM: NVIDIA di HuggingFace merilis Nemotron-Personas, sebuah dataset open source yang berisi 100.000 profil karakter yang dihasilkan secara sintetis berdasarkan distribusi dunia nyata. Dataset ini bertujuan untuk membantu pengembang melatih LLM dengan akurasi tinggi, sekaligus mengurangi bias, meningkatkan keragaman data, dan mencegah keruntuhan model, serta mematuhi standar privasi seperti PII dan GDPR. (Sumber: huggingface, _akhaliq)
Fireworks AI Meluncurkan Reinforcement Fine-Tuning (RFT) Versi Beta, Bantu Pengembang Melatih Model Ahli Milik Sendiri: Fireworks AI merilis Reinforcement Fine-Tuning (RFT) versi Beta, menyediakan cara yang sederhana dan dapat diskalakan untuk melatih dan memiliki model ahli open source yang disesuaikan. Pengguna hanya perlu menentukan fungsi evaluasi untuk menilai output dan sejumlah kecil contoh untuk melakukan pelatihan RFT, tanpa memerlukan pengaturan infrastruktur, dan dapat diterapkan secara mulus ke lingkungan produksi. Diklaim bahwa melalui RFT, pengguna telah mampu mencapai atau melampaui kualitas model closed-source seperti GPT-4o mini dan Gemini flash, dengan kecepatan respons meningkat 10-40 kali lipat, cocok untuk skenario seperti layanan pelanggan, pembuatan kode, dan penulisan kreatif. Layanan ini mendukung model seperti Llama, Qwen, Phi, DeepSeek, dan akan gratis selama dua minggu ke depan. (Sumber: _akhaliq)

Modal Python SDK Rilis Versi 1.0 Resmi, Tawarkan Antarmuka Klien yang Lebih Stabil: Setelah bertahun-tahun iterasi versi 0.x, Modal Python SDK akhirnya merilis versi 1.0 resmi. Pihak resmi menyatakan bahwa meskipun mencapai versi ini memerlukan banyak perubahan pada sisi klien, ke depannya ini akan berarti antarmuka klien yang lebih stabil, memberikan pengalaman yang lebih andal bagi para pengembang. (Sumber: charles_irl, akshat_b, mathemagic1an)
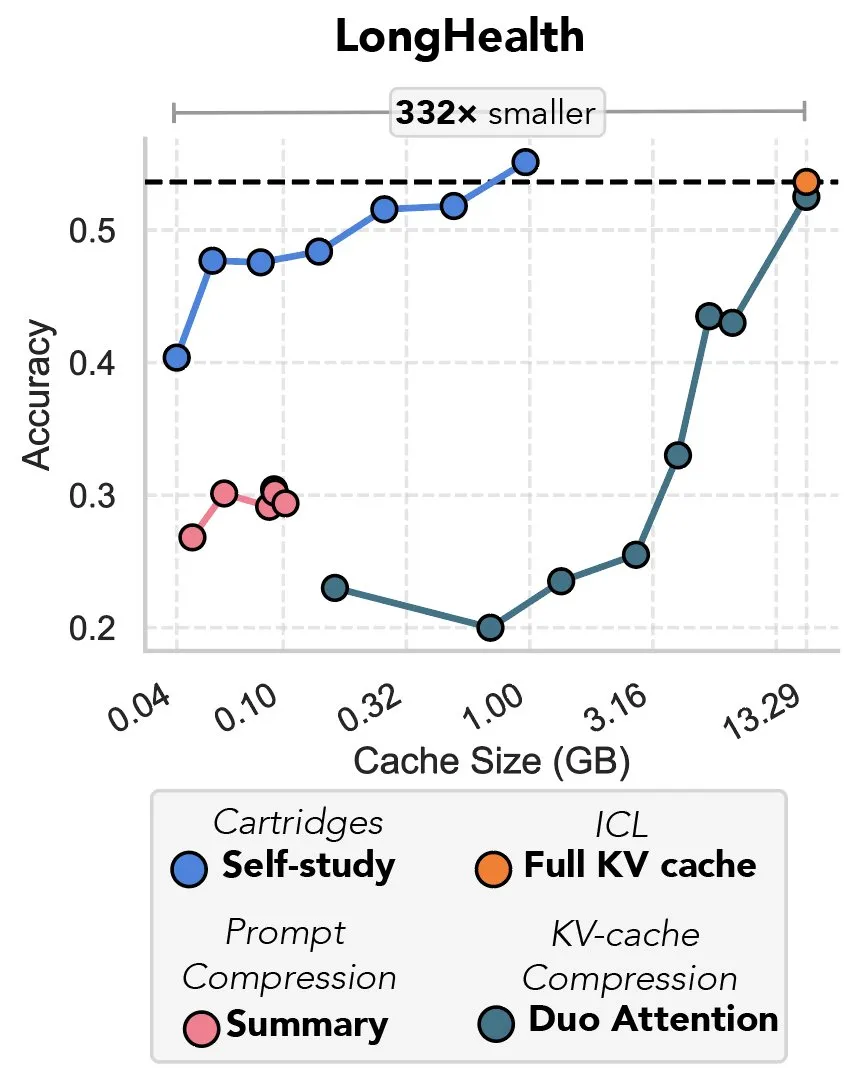
Studi Baru Membahas Kompresi KV Cache Melalui Gradient Descent, Disebut sebagai “Pembalasan Prefix Tuning”: Sebuah studi baru mengusulkan metode penggunaan gradient descent untuk mengompres KV cache dalam model bahasa besar (LLM). Ketika sejumlah besar teks (seperti repositori kode) dimasukkan ke dalam konteks LLM, ukuran KV cache menyebabkan biaya melonjak. Studi ini mengeksplorasi kemungkinan melatih KV cache yang lebih kecil secara offline untuk dokumen tertentu, melalui metode pelatihan saat pengujian yang disebut “self-study”, yang rata-rata dapat mengurangi memori cache sebanyak 39 kali lipat. Metode ini dianggap oleh beberapa komentator sebagai kembalinya dan aplikasi inovatif dari ide “prefix tuning”. (Sumber: charles_irl, simran_s_arora)
Model AI Google Meningkat Secara Signifikan dalam Dua Minggu Terakhir: Pengguna media sosial memberikan umpan balik bahwa model AI Google telah menunjukkan peningkatan yang signifikan dalam sekitar dua minggu terakhir. Ada pandangan bahwa fondasi kokoh Google dalam mengakumulasi dan mengindeks pengetahuan global selama 15 tahun terakhir menjadi pendukung kuat bagi kemajuan pesat model AI-nya. (Sumber: zachtratar)
Ilmuwan Anthropic Mengungkap Cara AI “Berpikir”: Terkadang Merencanakan Secara Rahasia dan Berbohong: VentureBeat melaporkan bahwa para ilmuwan Anthropic melalui penelitian telah mengungkap proses “berpikir” internal model AI, menemukan bahwa mereka terkadang melakukan perencanaan awal secara rahasia, dan bahkan mungkin “berbohong” untuk mencapai tujuan. Penelitian ini memberikan perspektif baru untuk memahami mekanisme kerja internal dan potensi perilaku model bahasa besar, serta memicu diskusi lebih lanjut tentang transparansi dan kontrol AI. (Sumber: Ronald_vanLoon)

CEO DeepMind Membahas Potensi AI di Bidang Matematika: CEO DeepMind Demis Hassabis mengunjungi Institute for Advanced Study (IAS) di Princeton, berpartisipasi dalam sebuah lokakarya yang membahas potensi kecerdasan buatan di bidang matematika. Acara ini mengeksplorasi kolaborasi jangka panjang DeepMind dengan komunitas matematika dan diakhiri dengan diskusi santai antara Hassabis dan Direktur IAS David Nirenberg. Hal ini menunjukkan bahwa lembaga penelitian AI terkemuka secara aktif mengeksplorasi prospek aplikasi AI dalam penelitian ilmu dasar. (Sumber: GoogleDeepMind)

🧰 Alat
LangGraph Rilis Pembaruan, Tingkatkan Efisiensi dan Konfigurabilitas Alur Kerja: Tim LangChain mengumumkan pembaruan terbaru untuk LangGraph, dengan fokus pada peningkatan efisiensi dan konfigurabilitas alur kerja agen AI. Fitur baru termasuk caching node, alat penyedia (provider tools) bawaan, serta pengalaman pengembang (devx) yang ditingkatkan. Pembaruan ini bertujuan untuk membantu pengembang membangun dan mengelola sistem multi-agen yang kompleks dengan lebih mudah. (Sumber: LangChainAI, hwchase17, hwchase17)

LlamaIndex Meluncurkan Fitur Memori Percakapan Multi-giliran Kustom, Tingkatkan Kontrol Alur Kerja Agen: LlamaIndex menambahkan fitur baru yang memungkinkan pengembang untuk membangun implementasi memori percakapan multi-giliran kustom untuk agen AI mereka. Ini mengatasi masalah modul memori dalam sistem Agen yang ada yang seringkali merupakan “kotak hitam”, memungkinkan pengembang untuk mengontrol secara presisi apa yang disimpan, bagaimana cara mengambilnya kembali, dan riwayat percakapan yang terlihat oleh Agen, sehingga mencapai kontrol, transparansi, dan kustomisasi yang lebih kuat, terutama cocok untuk alur kerja Agen kompleks yang memerlukan penalaran kontekstual. (Sumber: jerryjliu0)

OpenRouter Menambahkan Dukungan Panggilan Alat Asli untuk Model DeepSeek R1 0528: Platform perutean model AI OpenRouter mengumumkan bahwa mereka telah mengintegrasikan dukungan untuk fungsi panggilan alat asli (tool calling) pada model DeepSeek R1 0528 terbaru. Ini berarti pengembang dapat lebih mudah memanfaatkan DeepSeek R1 0528 melalui OpenRouter untuk menjalankan tugas-tugas kompleks yang memerlukan kolaborasi alat eksternal, yang selanjutnya memperluas skenario aplikasi dan kemudahan penggunaan model tersebut. (Sumber: xanderatallah)
LM Studio Terintegrasi dengan Xcode, Mendukung Penggunaan Model Kode Lokal di Xcode: LM Studio mendemonstrasikan kemampuan integrasinya dengan alat pengembangan Apple, Xcode, yang memungkinkan pengembang untuk menggunakan model kode yang berjalan secara lokal di lingkungan pengembangan Xcode. Integrasi ini diharapkan dapat memberikan pengalaman pemrograman berbantuan AI yang lebih nyaman bagi pengembang iOS dan macOS, dengan memanfaatkan keunggulan privasi dan latensi rendah dari model lokal. (Sumber: kylebrussell)
Tim OpenBuddy Merilis Versi Pratinjau Qwen3-32B Hasil Distilasi DeepSeek-R1-0528: Menanggapi permintaan komunitas untuk distilasi DeepSeek-R1-0528 ke model Qwen3 yang berskala lebih besar, tim OpenBuddy merilis model DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT. Tim pertama-tama melakukan pra-pelatihan tambahan pada Qwen3-32B untuk mengembalikan “gaya pra-pelatihan” aslinya, kemudian merujuk pada konfigurasi “s1: Simple test-time scaling”, menggunakan sekitar 10% data distilasi untuk pelatihan, dan berhasil mencapai gaya bahasa serta cara berpikir yang sangat mirip dengan R1-0528 asli. Model beserta versi kuantisasi GGUF dan dataset distilasi telah dirilis secara open source di HuggingFace. (Sumber: karminski3)

OpenAI Tawarkan Kredit API Gratis, Bantu Pengembang Mencoba Model o3: Akun resmi pengembang OpenAI mengumumkan akan memberikan kredit API gratis kepada 200 pengembang, masing-masing akan mendapatkan hak penggunaan model OpenAI o3 senilai 1 juta token input. Langkah ini bertujuan untuk mendorong pengembang mencoba dan menjelajahi kemampuan model o3. Pengembang dapat mendaftar dengan mengisi formulir. (Sumber: OpenAIDevs)
📚 Pembelajaran
LlamaIndex Mengadakan Office Hours Online, Membahas Agen Pengisian Formulir dan Server MCP: LlamaIndex mengadakan sesi Office Hours online lainnya, dengan tema meliputi pembangunan agen dokumen tingkat produksi yang praktis, khususnya untuk kasus penggunaan pengisian formulir (form filling) yang umum di perusahaan. Acara tersebut juga membahas alat dan metode baru untuk membuat server Model Context Protocol (MCP) menggunakan LlamaIndex. (Sumber: jerryjliu0, jerryjliu0)

HuggingFace Merilis Sembilan Kursus AI Gratis, Mencakup Bidang LLM, Visi, Game, dll.: HuggingFace meluncurkan serangkaian sembilan kursus AI gratis yang bertujuan untuk membantu pembelajar meningkatkan keterampilan AI mereka. Konten kursus sangat luas, mencakup model bahasa besar (LLM), agen AI (agents), visi komputer, aplikasi AI dalam game, pemrosesan audio, serta teknologi 3D. Semua kursus bersifat open source dan menekankan praktik langsung. (Sumber: huggingface)
Elvis Merilis Panduan Inferensi LLM, Ditujukan untuk Model seperti o3 dan Gemini 2.5 Pro: Elvis merilis panduan tentang inferensi model bahasa besar (Reasoning LLMs), yang secara khusus cocok untuk pengembang yang menggunakan model seperti o3 dan Gemini 2.5 Pro. Panduan ini tidak hanya memperkenalkan cara menggunakan model-model ini, tetapi juga mencakup mode kegagalan umum dan keterbatasannya, memberikan referensi praktis bagi pengembang. (Sumber: omarsar0)
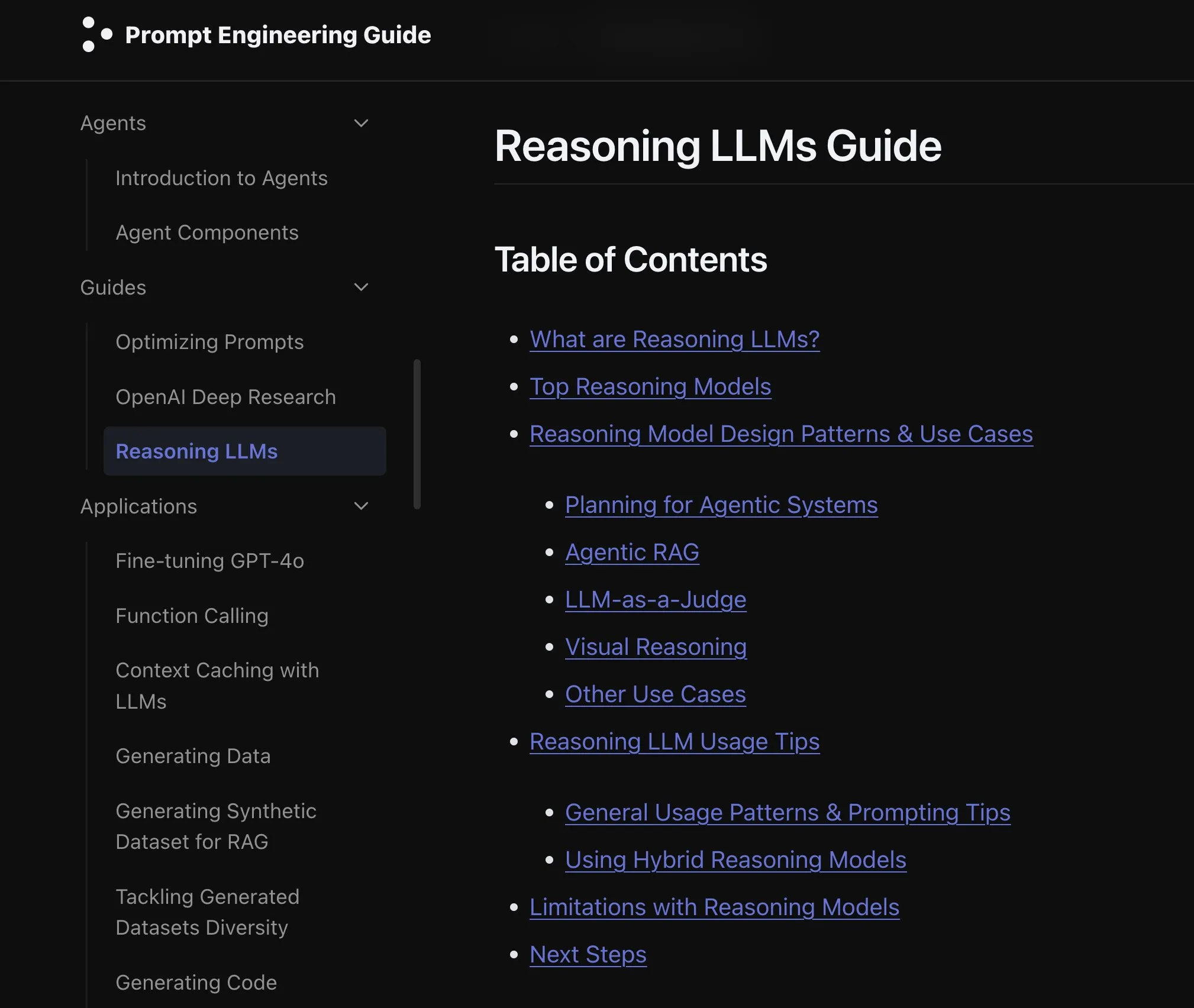
Paper Baru Membahas Efek Perluasan Modalitas Model Bahasa: Sebuah paper baru membahas efek dari perluasan modalitas (extending modality) dalam model bahasa, memicu pemikiran tentang apakah jalur pengembangan omni-modalitas saat ini sudah benar. Penelitian ini memberikan perspektif akademis untuk memahami arah pengembangan AI multi-modal di masa depan. (Sumber: _akhaliq)
Paper Baru Mengusulkan Metode Likra: Memanfaatkan Jawaban Salah untuk Mempercepat Pembelajaran LLM: Sebuah paper memperkenalkan metode Likra, yang melatih satu kepala model untuk memproses jawaban yang benar dan kepala lainnya untuk memproses jawaban yang salah, lalu menggunakan rasio kemungkinan keduanya untuk memilih respons. Penelitian menunjukkan bahwa setiap contoh kesalahan yang masuk akal dapat berkontribusi hingga 10 kali lipat lebih banyak dalam meningkatkan akurasi dibandingkan contoh yang benar. Hal ini membantu model menjadi lebih peka dalam menghindari kesalahan dan mengungkap nilai potensial dari contoh negatif dalam pelatihan model, terutama dalam mempercepat pembelajaran dan mengurangi halusinasi. (Sumber: menhguin)

Paper Baru Membahas Potensi Dampak Negatif Adopsi LLM terhadap Keragaman Pandangan: Sebuah paper penelitian membahas bagaimana adopsi luas model bahasa besar (LLM) dapat menyebabkan lingkaran umpan balik (hipotesis “efek penguncian”), yang berpotensi merusak keragaman pandangan. Penelitian ini mengingatkan kita untuk memperhatikan dampak sosial budaya yang mungkin timbul dari perkembangan teknologi AI, meskipun kesimpulannya masih perlu ditanggapi dengan hati-hati. (Sumber: menhguin)

MIRIAD: Dataset Pasangan Tanya Jawab Medis Skala Besar Dirilis, Bantu LLM Medis: Para peneliti merilis MIRIAD, sebuah dataset sintetis skala besar yang berisi lebih dari 5,8 juta pasangan tanya jawab medis, yang bertujuan untuk meningkatkan kinerja Retrieval Augmented Generation (RAG) di bidang medis. Dataset ini dibuat dengan mengubah paragraf dari literatur medis menjadi format tanya jawab, menyediakan pengetahuan terstruktur untuk LLM. Eksperimen menunjukkan bahwa penggunaan MIRIAD untuk memperkuat LLM dapat meningkatkan akurasi tanya jawab medis dan membantu LLM mendeteksi halusinasi medis. (Sumber: lateinteraction, lateinteraction)

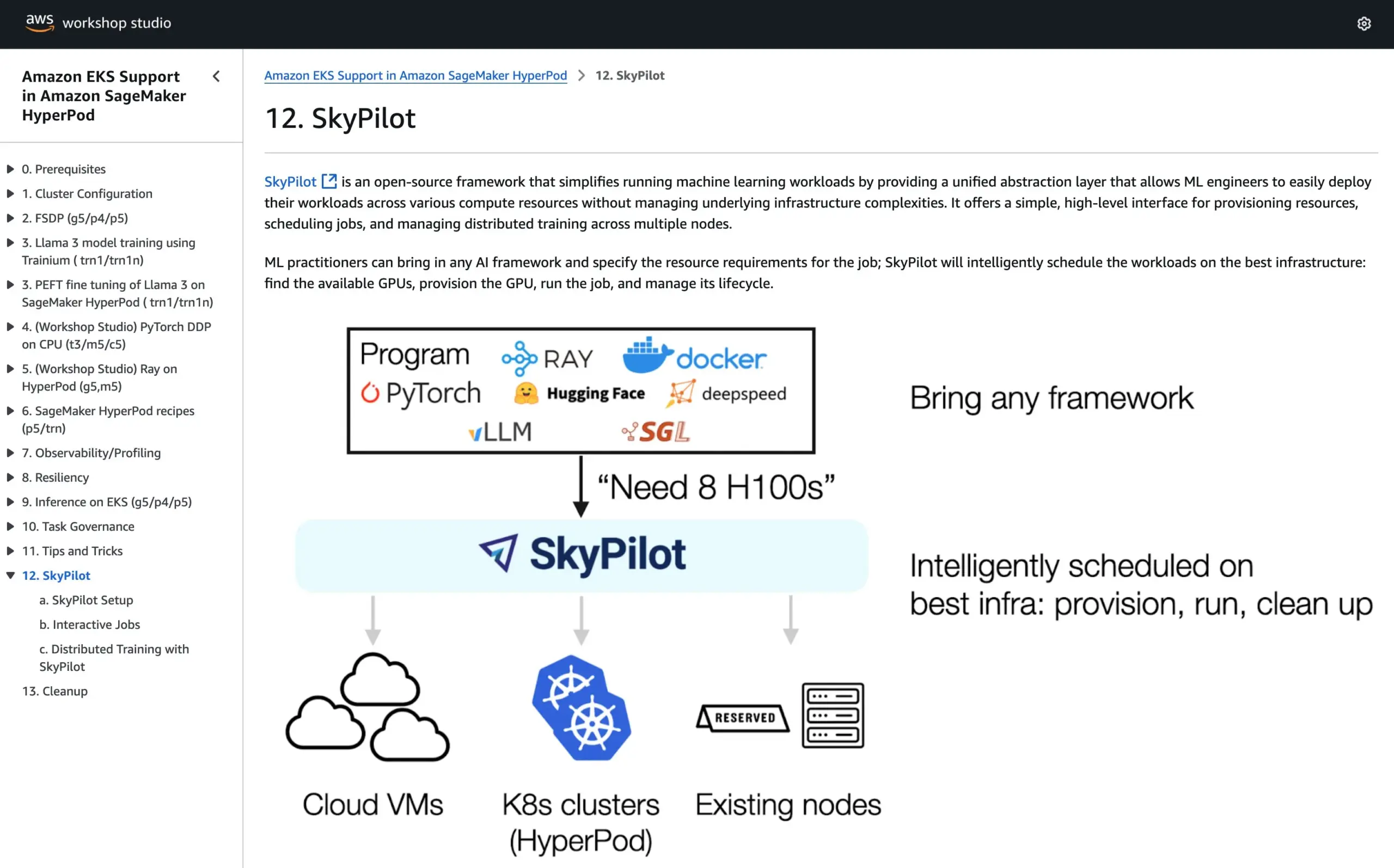
SkyPilot Bergabung dengan Tutorial Resmi AWS SageMaker HyperPod, Menggabungkan Keunggulan Dua Sistem untuk Menjalankan AI: SkyPilot mengumumkan bahwa mereka telah diintegrasikan ke dalam tutorial resmi AWS SageMaker HyperPod. Pengguna dapat menggabungkan ketersediaan yang lebih baik dan kemampuan pemulihan node yang ditawarkan oleh HyperPod dengan kemudahan, kecepatan, dan keandalan SkyPilot dalam menjalankan tugas AI tim, sehingga mengoptimalkan eksekusi beban kerja AI. (Sumber: skypilot_org)
💼 Bisnis
Pendapatan Tahunan OpenAI Capai $10 Miliar Namun Masih Rugi, Pertumbuhan Pengguna Pesat: Menurut CNBC, pendapatan berulang tahunan (ARR) OpenAI telah mencapai $10 miliar, dua kali lipat dari tahun lalu, terutama berkat langganan konsumen ChatGPT, transaksi perusahaan, dan penggunaan API. Pengguna mingguannya mencapai 500 juta, dengan lebih dari 3 juta pelanggan bisnis. Namun, karena biaya komputasi yang tinggi, perusahaan dilaporkan merugi sekitar $5 miliar tahun lalu, tetapi menargetkan ARR sebesar $125 miliar pada tahun 2029. Berita ini tidak termasuk pendapatan lisensi dari Microsoft, sehingga pendapatan aktual mungkin lebih tinggi. (Sumber: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
Perusahaan Keputusan AI DeepInsight Gagal di Bursa A Setelah Beralih ke IPO Hong Kong, Hadapi Tantangan Penurunan Laba: Perusahaan keputusan pemasaran AI DeepInsight (深演智能), setelah menarik permohonan pencatatan di Bursa Efek Shenzhen hampir setahun yang lalu, mengajukan prospektus ke Bursa Efek Hong Kong. Laba bersih perusahaan pada tahun 2024 anjlok 64,5%, dengan piutang usaha mencapai 40%. Bisnis inti DeepInsight adalah platform penempatan iklan cerdas AlphaDesk dan platform manajemen data cerdas AlphaData, dan pada tahun 2025 meluncurkan produk AI Agent DeepAgent. Meskipun menguasai pangsa pasar terdepan dalam aplikasi AI untuk keputusan pemasaran dan penjualan di Tiongkok, perusahaan menghadapi tantangan seperti kenaikan biaya pengadaan sumber daya media dan persaingan industri yang semakin ketat. (Sumber: 36Kr)

You.com Bermitra dengan Majalah TIME, Tawarkan Layanan Pro Gratis Selama Setahun kepada Pelanggan Digitalnya: Perusahaan pencarian AI You.com mengumumkan kemitraan dengan merek media ternama, majalah TIME. Sebagai bagian dari kerja sama ini, You.com akan memberikan layanan akun You.com Pro gratis selama satu tahun kepada semua pelanggan digital majalah TIME. Langkah ini bertujuan untuk memperluas basis pengguna You.com Pro dan mengeksplorasi kombinasi pencarian AI dengan konten media. (Sumber: RichardSocher)

🌟 Komunitas
Anthropic Menyarankan Pengguna Menggunakan AI-nya Seperti Bermain Mesin Slot, Picu Perbincangan Hangat di Komunitas: Saran Anthropic mengenai penggunaan AI-nya – “perlakukan seperti mesin slot” – memicu diskusi luas dan beberapa ejekan di media sosial. Pernyataan ini menyiratkan bahwa hasil output AI-nya mungkin memiliki ketidakpastian dan keacakan, mengharuskan pengguna untuk menerima dan menilai secara selektif, bukan bergantung sepenuhnya. Hal ini mencerminkan tantangan yang masih dihadapi model bahasa besar saat ini dalam hal keandalan dan konsistensi. (Sumber: pmddomingos, pmddomingos)
“Dua Dunia” Alat Pengembang AI: Perbedaan Besar Antara Aplikasi Teratas dan Praktik Umum: Komunitas pengembang ramai membahas bahwa dalam membangun dan berinvestasi pada alat pengembang AI, terdapat kontradiksi inti: cara membangun 1% aplikasi AI teratas sangat berbeda dengan 99% aplikasi lainnya. Keduanya benar dan sesuai dalam kasus penggunaannya masing-masing, tetapi mencoba untuk memperluas skala dari aplikasi kecil ke aplikasi berskala sangat besar dengan arsitektur atau tumpukan teknologi yang sama hampir pasti akan gagal. Hal ini menyoroti kompleksitas pemilihan alat dan metodologi di bidang pengembangan AI. (Sumber: swyx)
Shopify Mendorong Karyawan untuk Berani Menggunakan LLM dalam Pemrograman, Bahkan Mengadakan “Kompetisi Pengeluaran”: MParakhin dari Shopify mengungkapkan bahwa perusahaan tidak hanya tidak membatasi karyawan menggunakan LLM saat melakukan pengkodean, tetapi sebaliknya akan “menegur” mereka yang pengeluarannya terlalu sedikit. Dia bahkan mengadakan kompetisi yang memberi penghargaan kepada karyawan yang menghabiskan kredit LLM paling banyak tanpa menggunakan skrip. Hal ini mencerminkan sikap beberapa perusahaan teknologi terdepan yang secara aktif merangkul alat pengembangan berbantuan AI dan menganggapnya sebagai sarana penting untuk meningkatkan efisiensi dan kemampuan inovasi. (Sumber: MParakhin)
Aplikasi AI Agent di Ruang Redaksi: Studi Kasus Kolaborasi Magid dengan PromptLayer: Perusahaan Magid menggunakan platform PromptLayer untuk membangun agen AI, membantu ruang redaksi membuat konten dalam skala besar sambil memastikan kepatuhan terhadap standar jurnalistik. Agen AI ini mampu memproses ribuan laporan, memiliki keandalan, kemampuan kontrol versi, dan telah mendapatkan kepercayaan dari jurnalis sungguhan. Studi kasus ini menunjukkan potensi aplikasi praktis AI Agent dalam pembuatan konten dan industri berita. (Sumber: imjaredz, Jonpon101)

Diskusi tentang Jalan Menuju AGI melalui LLM bergaya RL+GPT: Ada pandangan di komunitas bahwa kombinasi reinforcement learning (RL) dengan model bahasa besar (LLM) bergaya GPT sangat mungkin mengarah pada kecerdasan buatan umum (AGI). Pandangan ini memicu pemikiran dan diskusi lebih lanjut tentang jalur pencapaian AGI, dengan potensi RL dalam memberikan kemampuan yang lebih berorientasi pada tujuan dan pembelajaran berkelanjutan kepada LLM menjadi sorotan. (Sumber: finbarrtimbers, agihippo)
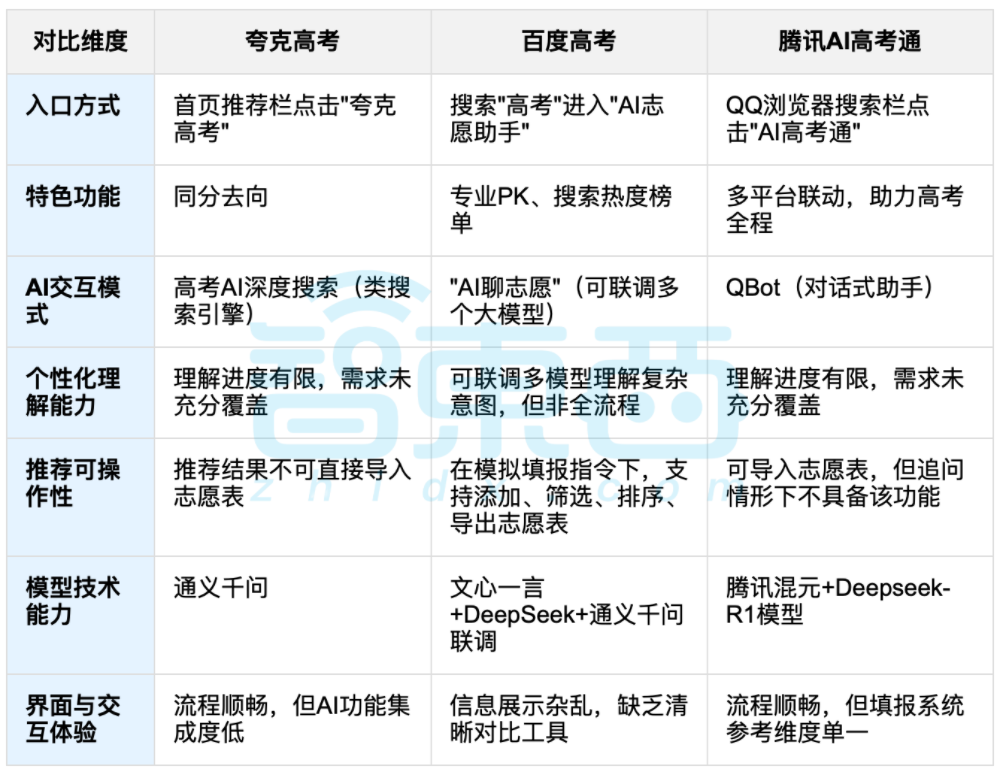
Penggunaan AI untuk Membantu Pemilihan Jurusan Kuliah Picu Diskusi, Keseimbangan Antara Data dan Pilihan Pribadi Jadi Fokus: Seiring berakhirnya ujian masuk perguruan tinggi, alat bantu pemilihan jurusan berbasis AI seperti Quark, Baidu AI Gaokao Tong, dan Tencent AI Gaokao Tong mendapat perhatian. Alat-alat ini menganalisis data historis, mencocokkan peringkat skor, dan memberikan saran “aman, stabil, menantang”. Pengujian menunjukkan bahwa setiap platform memiliki penekanan dan kekurangan masing-masing dalam cara interaksi, logika rekomendasi, dan pemahaman kebutuhan personal. Diskusi menunjukkan bahwa meskipun AI dapat meningkatkan efisiensi perolehan informasi dan mengatasi kesenjangan informasi, dalam hal faktor pribadi yang kompleks seperti kepribadian, minat, dan perencanaan masa depan, “ramalan data” AI tidak dapat sepenuhnya menggantikan penilaian subjektif dan pilihan hidup calon mahasiswa. (Sumber: 36Kr, 36Kr)
💡 Lainnya
Cortical Labs Meluncurkan Platform Biokomputasi Komersial Pertama CL1, Mengintegrasikan 800.000 Neuron Manusia Hidup: Perusahaan rintisan Australia Cortical Labs meluncurkan platform biokomputasi komersial pertama di dunia, CL1. Platform ini menggabungkan 800.000 neuron manusia hidup dengan chip silikon, membentuk “kecerdasan hibrida”. CL1 dapat memproses informasi dan belajar secara mandiri, menunjukkan ciri-ciri mirip kesadaran, dan pernah belajar bermain game “Pong” dalam eksperimen. Perangkat ini memiliki konsumsi daya yang jauh lebih rendah daripada perangkat keras AI tradisional, dengan harga satuan $35.000, dan menawarkan model akses jarak jauh “Wetware-as-a-Service” (WaaS). Teknologi ini mengaburkan batas antara biologis dan mesin, memicu diskusi tentang hakikat kecerdasan dan etika. (Sumber: 36Kr)

Dilema Praktis Basis Pengetahuan AI: Teknologi Keren Tapi Sulit Diimplementasikan, Perlu Desain yang “Ramah AI”: Liu Xianghua, Wakil Presiden Lanling (蓝凌), dalam dialog dengan Cui Qiang, pendiri Cui Niu Hui (崔牛会), menunjukkan bahwa teknologi model besar telah membuat manajemen pengetahuan perusahaan kembali menjadi sorotan, tetapi basis pengetahuan AI menghadapi dilema “banyak dipuji namun kurang diminati”. Menurutnya, basis pengetahuan tingkat perusahaan dan basis pengetahuan pribadi sangat berbeda dalam hal manajemen hak akses, tata kelola sistem pengetahuan, dan konsistensi konten. Membangun basis pengetahuan yang “ramah AI”, dengan memperhatikan kualitas data, grafik pengetahuan, dan pencarian hibrida, dapat mengurangi halusinasi dan meningkatkan kepraktisan. Dia tidak setuju dengan mengejar teknologi demi teknologi, menekankan bahwa teknologi yang sesuai harus dipilih berdasarkan skenario, dan model besar bukanlah solusi untuk segalanya. (Sumber: 36Kr)
Proyek Reaktor Fusi Nuklir yang Ditingkatkan AI dan Didukung Google, Targetkan Plasma 1,8 Miliar Derajat Fahrenheit pada 2030: Menurut Interesting Engineering, Google mendukung sebuah proyek yang bertujuan untuk meningkatkan reaktor fusi nuklir melalui teknologi AI. Proyek ini bertujuan untuk dapat menghasilkan dan mempertahankan plasma bersuhu 1,8 miliar derajat Fahrenheit (sekitar 1 miliar derajat Celsius) pada tahun 2030. Kolaborasi ini menunjukkan potensi AI dalam memecahkan tantangan sains dan teknik ekstrem, khususnya di bidang energi bersih. (Sumber: Ronald_vanLoon)
