
Kata Kunci:Model Bahasa Besar, Kemampuan Penalaran, Kecocokan Pola, Kecerdasan Buatan Umum, Halusinasi Pemikiran, Penelitian Apple, Detektor AI, Pengawasan AI, Mekanisme Perhatian Log-Linear, Model Huawei Pangu MoE, Mode Suara Lanjutan ChatGPT, Kerangka TensorZero, Pandangan CEO Anthropic tentang Regulasi
🔥 Fokus
Penelitian Apple mengungkapkan “ilusi berpikir”: model “reasoning” saat ini tidak benar-benar berpikir, lebih mengandalkan pencocokan pola: Makalah penelitian terbaru Apple, “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models Through the Lens of Problem Complexity,” menunjukkan bahwa Large Language Model (seperti Claude, DeepSeek-R1, GPT-4o-mini, dll.) yang saat ini diklaim memiliki kemampuan “reasoning”, kinerjanya lebih mirip pencocok pola yang efisien daripada penalaran logis dalam arti sebenarnya. Penelitian menemukan bahwa kinerja model-model ini menurun secara signifikan ketika menangani masalah di luar distribusi pelatihan atau dengan kompleksitas yang lebih tinggi, bahkan dapat membuat kesalahan pada masalah sederhana karena “berpikir berlebihan” (overthinking) dan sulit untuk memperbaiki kesalahan awal. Penelitian ini menekankan bahwa proses “berpikir” yang diklaim model (seperti chain of thought) seringkali gagal ketika menghadapi tugas baru atau kompleks, menunjukkan bahwa kita mungkin lebih jauh dari Artificial General Intelligence (AGI) daripada yang diperkirakan. (Sumber: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

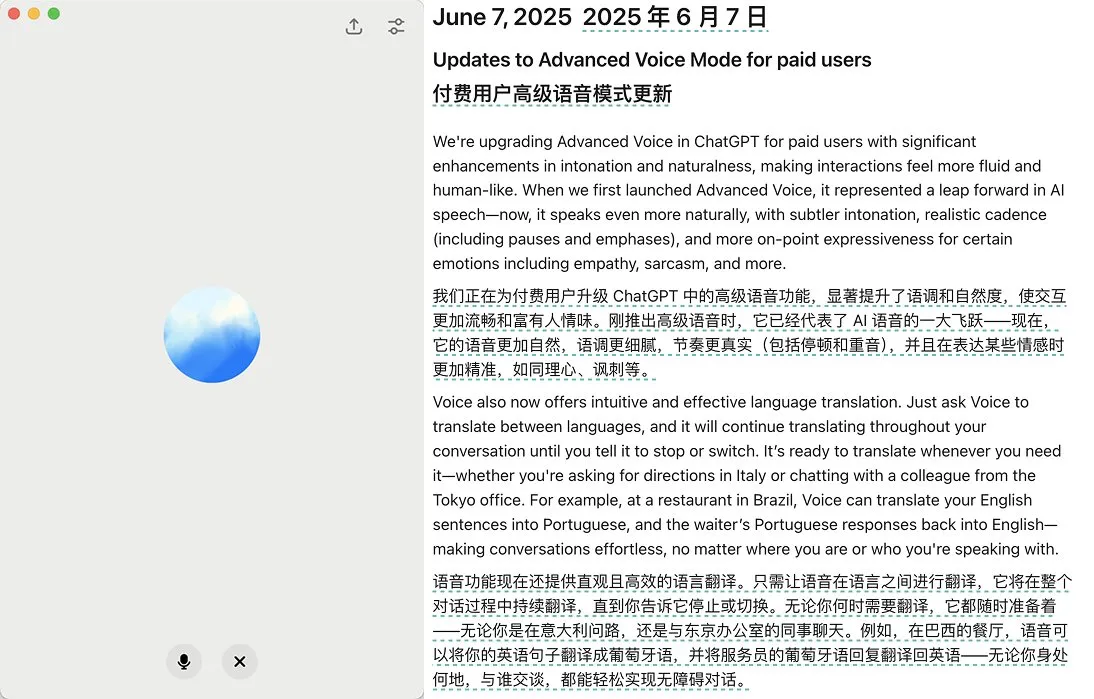
OpenAI meluncurkan pembaruan mode suara canggih ChatGPT, meningkatkan kealamian dan fungsi terjemahan: OpenAI meluncurkan pembaruan besar untuk mode suara canggih (Advanced Voice Mode) ChatGPT bagi pengguna berbayar. Versi baru ini secara signifikan meningkatkan kelancaran alami suara, membuatnya terdengar lebih seperti manusia daripada asisten AI. Selain itu, pembaruan ini juga meningkatkan kinerja terjemahan bahasa dan kemampuan mengikuti instruksi, serta menambahkan mode terjemahan baru, yang memungkinkan pengguna meminta ChatGPT untuk terus menerjemahkan percakapan kedua belah pihak selama seluruh dialog hingga diminta berhenti. Pembaruan ini bertujuan untuk membuat interaksi suara lebih mudah dan alami, serta meningkatkan pengalaman pengguna. (Sumber: juberti, Plinz, op7418, BorisMPower)
Detektor AI dituduh tidak efektif dan berpotensi membantu konten AI menjadi “terselubung”: Diskusi luas muncul di media sosial dan forum teknologi yang menunjukkan bahwa alat pendeteksi konten AI saat ini tidak hanya tidak efektif, tetapi bahkan mungkin secara tidak sengaja membantu konten yang dihasilkan AI menjadi lebih sulit dideteksi. Banyak pengguna dan ahli percaya bahwa detektor ini terutama menilai berdasarkan pola bahasa dan kosakata tertentu (seperti istilah akademis “delve”), bukan benar-benar memahami sumber konten. Karena risiko salah identifikasi (yang dapat merugikan kelompok seperti siswa) dan model AI sendiri juga berevolusi untuk menghindari deteksi, keandalan alat ini sangat dipertanyakan. Ada pandangan bahwa keberadaan detektor AI justru mendorong konten yang dihasilkan AI untuk menghindari fitur tertentu yang mudah ditandai, sehingga lebih mirip tulisan manusia. (Sumber: Reddit r/ArtificialInteligence, sytelus)

CEO Anthropic menyerukan peningkatan transparansi dan regulasi tanggung jawab perusahaan AI: CEO Anthropic menerbitkan artikel opini di The New York Times, menekankan bahwa regulasi terhadap perusahaan AI tidak boleh dilonggarkan, terutama kebutuhan untuk meningkatkan transparansi dan meminta pertanggungjawaban mereka. Pandangan ini menjadi sangat penting di tengah perkembangan pesat industri AI dan kemampuannya yang terus meningkat, sejalan dengan kekhawatiran masyarakat tentang potensi risiko dan etika AI. Artikel tersebut berpendapat bahwa seiring dengan meluasnya pengaruh teknologi AI, memastikan perkembangannya sejalan dengan kepentingan publik dan menghindari penyalahgunaan adalah hal yang krusial, dan ini membutuhkan kombinasi disiplin industri dan pengawasan eksternal. (Sumber: Reddit r/artificial)

🎯 Perkembangan
Jeff Dean memproyeksikan masa depan AI: hardware khusus, evolusi model, dan aplikasi ilmiah: Kepala Google AI, Jeff Dean, dalam acara AI Ascent Sequoia Capital, berbagi pandangannya tentang perkembangan AI di masa depan. Ia menekankan pentingnya hardware khusus (seperti TPU) untuk kemajuan AI dan membahas tren evolusi arsitektur model. Dean juga memproyeksikan bentuk infrastruktur komputasi di masa depan, serta potensi aplikasi AI yang sangat besar di bidang penelitian ilmiah dan lainnya, dengan keyakinan bahwa AI akan menjadi alat kunci untuk mendorong penemuan ilmiah. (Sumber: TheTuringPost)

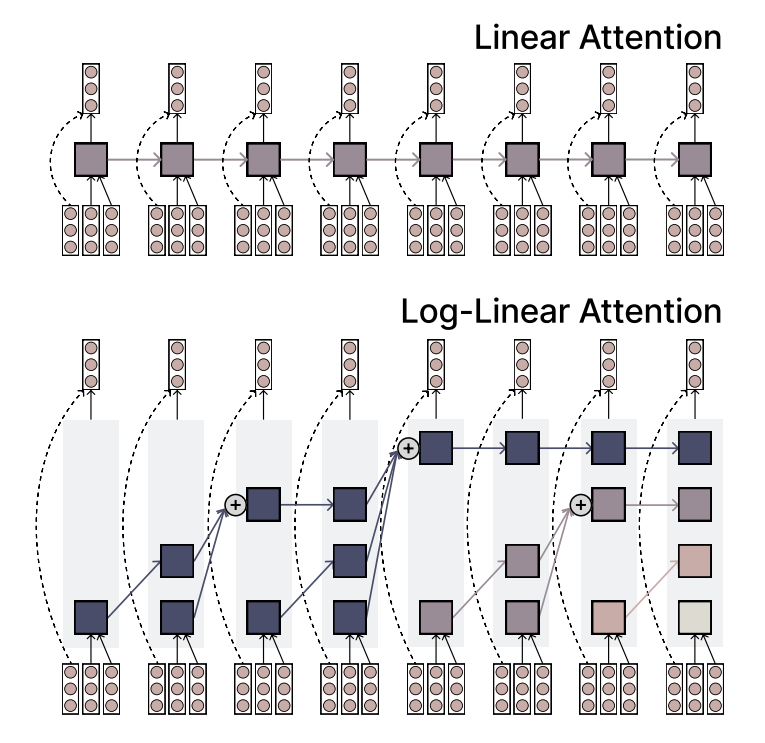
MIT mengusulkan mekanisme Log-Linear Attention, menyeimbangkan efisiensi dan daya ekspresif: Peneliti MIT mengusulkan mekanisme attention baru yang disebut Log-Linear Attention. Mekanisme ini bertujuan untuk menggabungkan efisiensi tinggi dari Linear Attention dengan daya ekspresif yang kuat dari Softmax Attention. Fitur intinya adalah penggunaan sejumlah kecil memory slot yang bertambah secara logaritmik dengan panjang sekuens, sehingga menjaga kompleksitas komputasi tetap rendah saat memproses sekuens panjang, sambil tetap menangkap informasi penting. (Sumber: TheTuringPost)
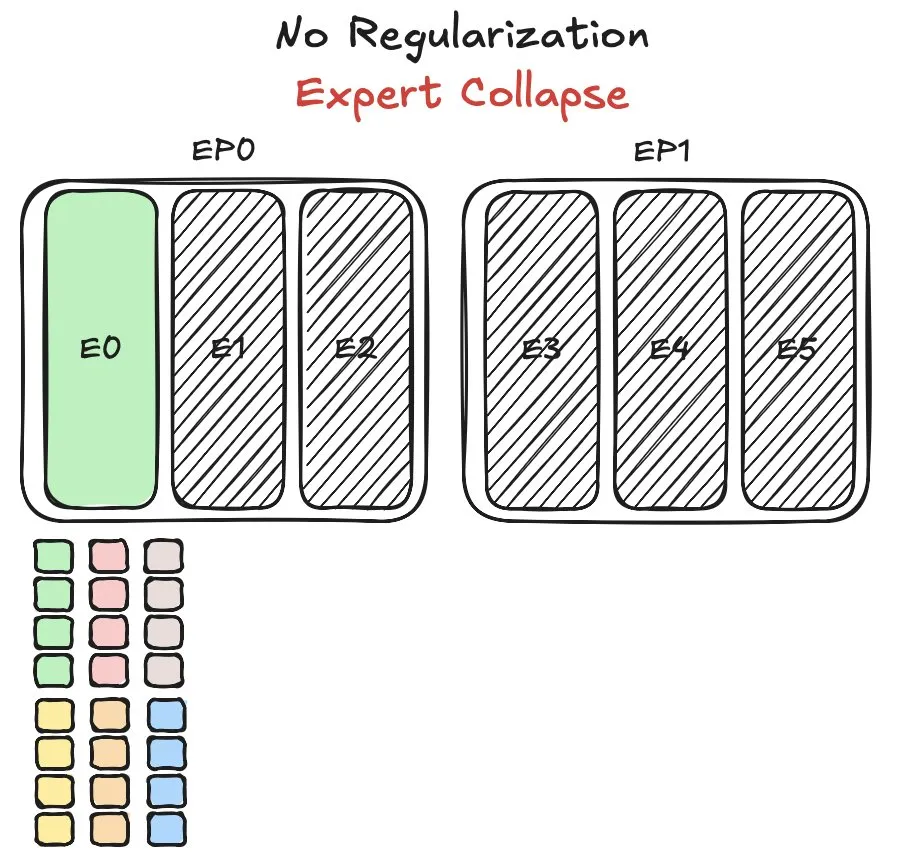
Model Pangu MoE Huawei hadapi tantangan penyeimbangan beban expert, usulkan metode baru: Huawei menghadapi masalah krusial penyeimbangan beban expert (expert load balancing) saat melatih model Mixture of Experts (MoE) mereka, Pangu Ultra MoE. Penyeimbangan beban expert memerlukan trade-off antara dinamika pelatihan dan efisiensi sistem. Huawei mengusulkan solusi baru untuk masalah ini, yang bertujuan untuk mengoptimalkan alokasi tugas dan beban komputasi di antara berbagai modul expert dalam model MoE, guna meningkatkan efisiensi pelatihan dan kinerja model. Penelitian terkait telah dipublikasikan dalam sebuah makalah. (Sumber: finbarrtimbers)
NVIDIA merilis model Cascade Mask R-CNN Mamba Vision, fokus pada deteksi objek: NVIDIA merilis model baru di Hugging Face bernama cascade_mask_rcnn_mamba_vision_tiny_3x_coco. Dilihat dari namanya, model ini dirancang khusus untuk tugas deteksi objek dan kemungkinan menggabungkan arsitektur Cascade R-CNN dengan teknologi visi Mamba (sejenis state space model), yang bertujuan untuk meningkatkan akurasi dan efisiensi deteksi objek. (Sumber: _akhaliq)
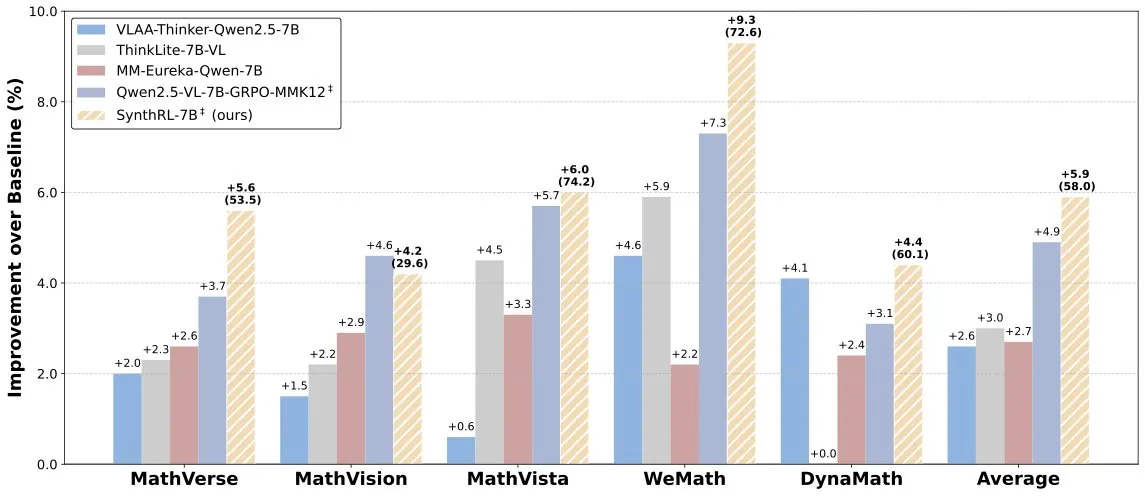
Model SynthRL dirilis: realisasikan penalaran visual yang dapat diskalakan melalui sintesis data yang dapat diverifikasi: Model SynthRL dirilis di Hugging Face. Model ini berfokus pada kemampuan penalaran visual yang dapat diskalakan, dengan teknologi intinya adalah metode sintesis data yang dapat diverifikasi untuk menghasilkan varian tugas penalaran visual yang lebih menantang, sambil mempertahankan kebenaran jawaban asli. Ini membantu meningkatkan pemahaman dan tingkat penalaran model dalam skenario visual yang kompleks. (Sumber: _akhaliq)
Meskipun DeepSeek-R1 berkinerja baik, keunggulan produk ChatGPT tetap kokoh: VentureBeat berkomentar bahwa meskipun model-model baru seperti DeepSeek-R1 menunjukkan kinerja yang sangat baik dalam beberapa aspek, ChatGPT dengan keunggulan sebagai pelopor, basis pengguna yang luas, ekosistem produk yang matang, dan kemampuan iterasi yang berkelanjutan, posisi terdepannya di tingkat produk sulit untuk dilampaui dalam jangka pendek. Persaingan AI bukan hanya adu parameter teknis, tetapi juga pertarungan komprehensif dalam pengalaman produk, pembangunan ekosistem, dan model bisnis. (Sumber: Ronald_vanLoon)

Tim Qwen mengonfirmasi Qwen3-coder sedang dalam pengembangan: Junyang Lin dari tim Qwen mengonfirmasi bahwa mereka sedang mengembangkan Qwen3-coder, model versi peningkatan kemampuan coding dari seri Qwen3. Meskipun jadwal spesifik belum diumumkan, merujuk pada siklus rilis Qwen2.5, diperkirakan akan hadir dalam beberapa minggu. Komunitas menantikan model ini dapat membuat terobosan dalam pembuatan kode, integrasi alur kerja otonom/agent, dan tetap mempertahankan dukungan yang baik untuk berbagai bahasa pemrograman. (Sumber: Reddit r/LocalLLaMA)

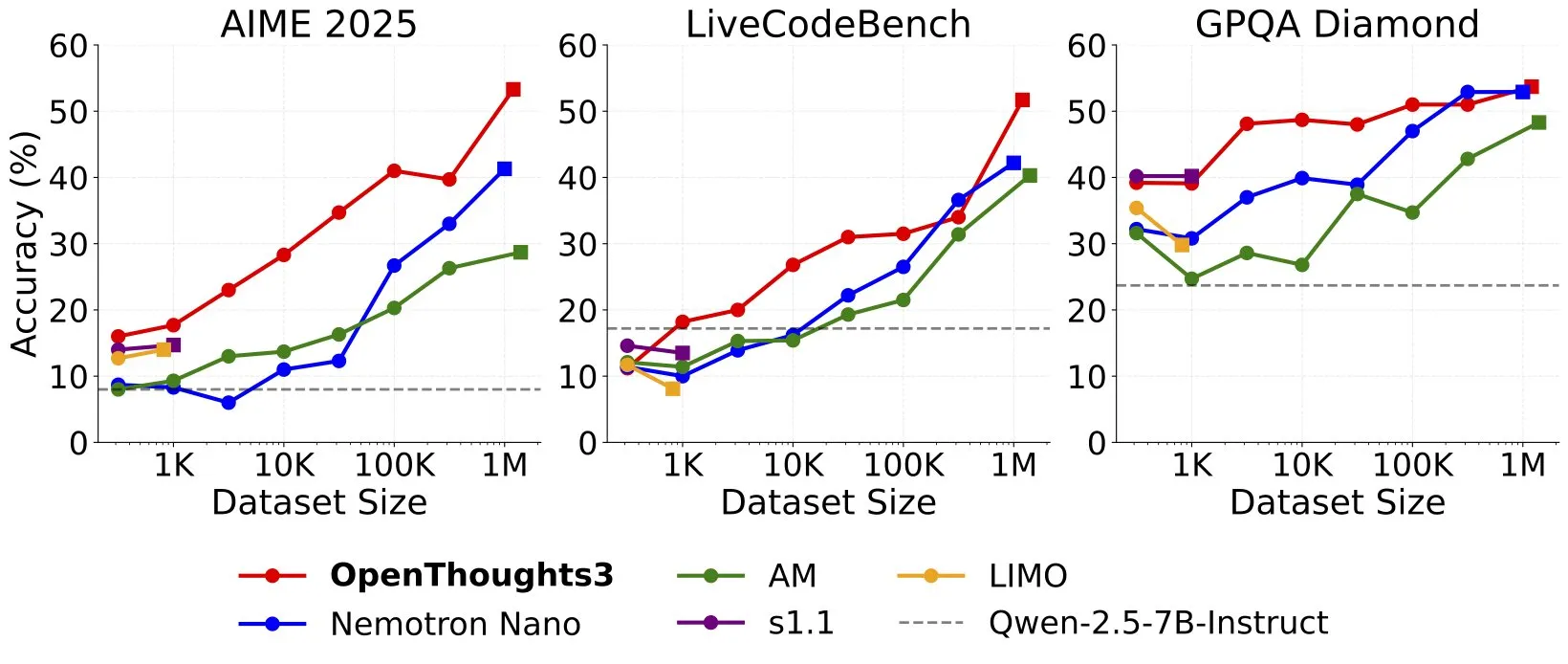
OpenThinker3-7B dirilis, diklaim sebagai model penalaran 7B data open source SOTA: Ryan Marten mengumumkan peluncuran model OpenThinker3-7B, yang diklaim sebagai model penalaran dengan parameter 7B tercanggih saat ini yang dilatih berdasarkan data terbuka. Menurut klaim, model ini rata-rata 33% lebih unggul dari DeepSeek-R1-Distill-Qwen-7B dalam evaluasi kode, sains, dan matematika. Bersamaan dengan itu, dirilis juga dataset pelatihannya, OpenThoughts3-1.2M. (Sumber: menhguin)
🧰 Alat
TensorZero: Kerangka kerja LLMOps open source, optimalkan pengembangan & deployment aplikasi LLM: TensorZero adalah kerangka kerja optimasi aplikasi LLM open source yang bertujuan untuk mengubah data produksi menjadi model yang lebih cerdas, lebih cepat, dan lebih ekonomis melalui feedback loop. Ini mengintegrasikan LLM gateway (mendukung berbagai penyedia model), observability, optimasi (prompt, fine-tuning, RL), evaluasi, dan eksperimen (A/B testing), serta mendukung latensi rendah, throughput tinggi, dan GitOps. Alat ini ditulis dalam Rust, menekankan kinerja dan kebutuhan aplikasi tingkat industri. (Sumber: GitHub Trending)

LangChain meluncurkan sistem RAG berkinerja tinggi yang menggabungkan SambaNova, Qdrant, dan LangGraph: LangChain memperkenalkan solusi implementasi Retrieval Augmented Generation (RAG) berkinerja tinggi. Solusi ini menggabungkan model DeepSeek-R1 dari SambaNova, teknologi binary quantization dari Qdrant, dan LangGraph, yang mampu mencapai pengurangan memori hingga 32 kali lipat, sehingga dapat memproses dokumen berskala besar secara efisien. Ini memberikan kemungkinan baru untuk membangun aplikasi RAG yang lebih ekonomis dan lebih cepat. (Sumber: hwchase17, qdrant_engine)
Aplikasi pembuatan video edukasi sekali klik Google Sparkify tunjukkan kasus berkualitas tinggi: Aplikasi Sparkify yang diluncurkan Google, yang mampu menghasilkan video edukasi dengan sekali klik, menunjukkan kualitas kasus yang cukup tinggi. Konten video memiliki konsistensi keseluruhan yang baik, sulih suara alami, dan bahkan dapat mencapai efek kompleks seperti tampilan layar terpisah, menunjukkan potensi AI dalam pembuatan konten video otomatis. (Sumber: op7418)
Hugging Face meluncurkan server MCP pertama, perluas fungsi chatbot: Hugging Face merilis server MCP (Modular Chat Processor) pertamanya (hf.co/mcp), yang dapat ditempelkan pengguna ke kotak obrolan untuk digunakan. Server MCP bertujuan untuk meningkatkan fungsionalitas chatbot dengan menyediakan pengalaman interaktif yang lebih kaya melalui unit pemrosesan modular. Komunitas juga telah mengumpulkan daftar server MCP berguna lainnya, seperti Agentset MCP, GitHub MCP, dll. (Sumber: TheTuringPost)
Efek Chatterbox TTS sebanding dengan ElevenLabs, telah terintegrasi ke gptme: Alat TTS (Text-to-Speech) Chatterbox mendapat perhatian karena efek sintesis suaranya yang luar biasa, dengan umpan balik pengguna menyatakan bahwa efeknya sebanding dengan ElevenLabs yang terkenal, dan lebih unggul dari Kokoro. Chatterbox mendukung kustomisasi suara melalui sampel referensi, dan kini telah ditambahkan sebagai backend TTS untuk gptme, memberikan pengguna opsi output suara berkualitas tinggi. (Sumber: teortaxesTex, _akhaliq)
E-Library-Agent: Sistem pencarian cerdas dan tanya jawab untuk buku/literatur lokal: E-Library-Agent adalah agen AI yang di-hosting sendiri yang mampu mengekstrak, mengindeks, dan melakukan query pada koleksi buku atau makalah pribadi. Proyek ini didasarkan pada ingest-anything dan didukung oleh platform LlamaIndex, Qdrant, dan Linkup, mewujudkan ekstraksi materi lokal, tanya jawab yang sadar konteks, serta penemuan web melalui antarmuka tunggal, memudahkan pengguna mengelola dan memanfaatkan basis pengetahuan pribadi mereka. (Sumber: qdrant_engine)
Claude Code mendapat pujian tinggi dari pengembang karena kemampuan bantuan coding yang kuat: Pengguna komunitas Reddit berbagi pengalaman positif menggunakan Claude Code dari Anthropic untuk pengembangan perangkat lunak, terutama di bidang pengembangan game (seperti proyek Godot C#). Pengguna memuji kemampuannya untuk memecahkan masalah kompleks yang jauh melampaui asisten coding AI lainnya (seperti GitHub Copilot), mampu memahami konteks dan menghasilkan kode yang efektif, bahkan biaya $100 per bulan dianggap sepadan. Pengembang percaya bahwa programmer berpengalaman yang dikombinasikan dengan Claude Code akan sangat produktif. (Sumber: Reddit r/ClaudeAI)
ChatterUI implementasikan dukungan model visual lokal, namun pemrosesan di Android lambat: Versi pra-rilis klien obrolan LLM ChatterUI menambahkan dukungan untuk lampiran dan model visual lokal (melalui llama.rn). Pengguna dapat memuat file mmproj untuk model yang kompatibel secara lokal, atau terhubung ke API yang mendukung fungsi visual (seperti Google AI Studio, OpenAI). Namun, karena llama.cpp tidak memiliki backend GPU yang stabil di Android, kecepatan pemrosesan gambar sangat lambat (misalnya, gambar 512×512 membutuhkan waktu 5 menit), kinerja di iOS relatif lebih baik. (Sumber: Reddit r/LocalLLaMA)
FLUX kontext menunjukkan kinerja luar biasa dalam penggantian latar belakang gambar promosi mobil: Pengujian pengguna menemukan bahwa alat edit gambar AI FLUX kontext menunjukkan efek yang signifikan dalam memodifikasi latar belakang gambar promosi mobil. Misalnya, mengganti latar belakang gambar resmi Xiaomi SU7 (seperti pantai senja, trek balap), alat ini tidak hanya dapat memadukan latar belakang secara alami, tetapi juga secara cerdas menambahkan efek motion blur pada kendaraan yang bergerak, meningkatkan realisme dan dampak visual gambar. (Sumber: op7418)

📚 Belajar
Fitur baru fastcore flexicache: dekorator caching yang fleksibel: Jeremy Howard memperkenalkan fitur baru yang praktis di pustaka fastcore, yaitu flexicache. Ini adalah dekorator caching yang sangat fleksibel, dengan dua strategi caching bawaan, ‘mtime’ (berdasarkan waktu modifikasi file) dan ‘time’ (berdasarkan stempel waktu), dan memungkinkan pengguna untuk menyesuaikan strategi caching baru dengan sedikit kode. Fitur ini dijelaskan secara rinci dalam artikel oleh Daniel Roy Greenfeld, dan membantu meningkatkan efisiensi eksekusi kode. (Sumber: jeremyphoward)
Membahas potensi kombinasi MuP dan Muon untuk pelatihan model Transformer: Jingyuan Liu mendalami karya Jeremy Bernstein tentang penurunan Muon dan kondisi spektral, dan menyatakan kekagumannya pada proses penurunan yang elegan, terutama bagaimana MuP (Maximal Update Parametrization) dan Muon (sejenis optimizer) bekerja sama. Ia berpendapat bahwa dari penurunannya, penggunaan Muon sebagai optimizer untuk pelatihan model berbasis MuP adalah pilihan yang alami, dan menunjukkan bahwa ini mungkin lebih menarik daripada pekerjaan Moonlight dari Moonshot yang mentransfer hyperparameter dari AdamW ke Muon melalui pencocokan pembaruan RMS. Diskusi komunitas berpendapat bahwa kombinasi MuP + Muon diharapkan dapat diterapkan secara massal oleh perusahaan teknologi besar sebelum akhir tahun. (Sumber: jeremyphoward)

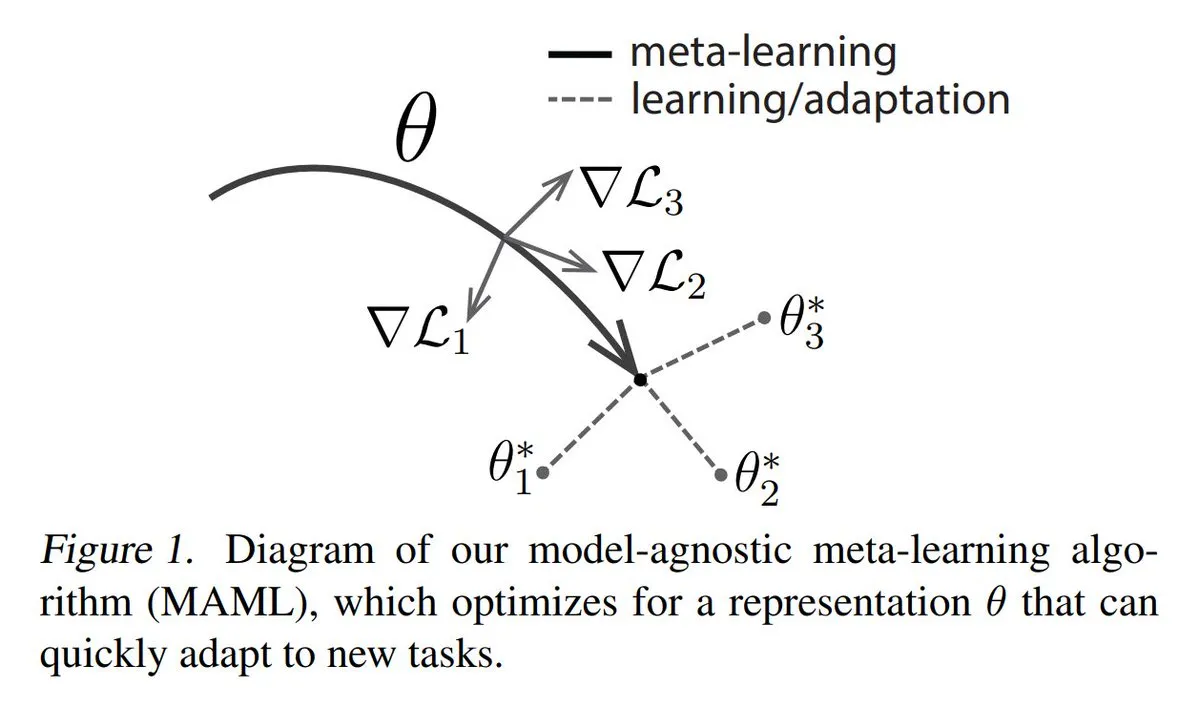
Analisis tiga metode utama Meta-learning: Meta-learning bertujuan untuk melatih model agar cepat mempelajari tugas baru, bahkan hanya dengan sedikit sampel. Metode umum meliputi: 1. Berbasis optimasi/berbasis gradien: mencari parameter model yang dapat di-fine-tune secara efisien pada tugas dengan sedikit langkah gradien. 2. Berbasis metrik: membantu model menemukan cara yang lebih baik untuk mengukur kesamaan antara sampel baru dan lama, mengelompokkan sampel terkait secara efektif. 3. Berbasis model: seluruh model dirancang untuk dapat beradaptasi dengan cepat menggunakan memori internal atau mekanisme dinamis. TuringPost menyediakan penjelasan rinci dari dasar hingga metode meta-learning modern. (Sumber: TheTuringPost)
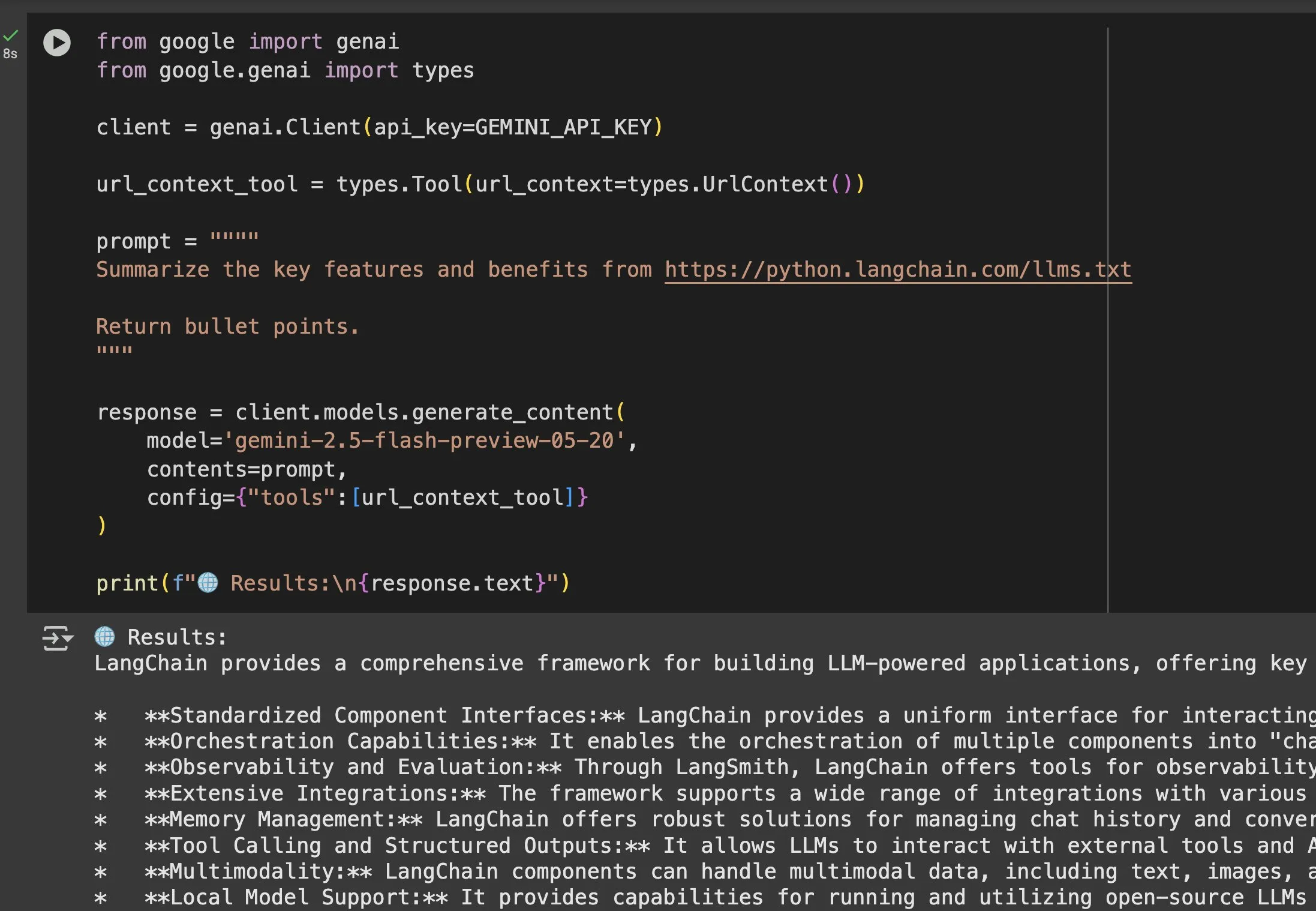
Nilai aplikasi file llms.txt dalam model seperti Gemini semakin menonjol: Jeremy Phoward menekankan kegunaan file llms.txt. Misalnya, Gemini sekarang dapat memahami konten dalam URL, cukup dengan menambahkan URL ke dalam prompt dan mengonfigurasi alat konteks URL. Ini berarti klien (seperti Gemini) dengan membaca endpoint llms.txt dapat mengetahui secara akurat di mana informasi yang dibutuhkan disimpan, sangat memudahkan perolehan dan pemanfaatan informasi secara terprogram. (Sumber: jeremyphoward)
EleutherAI merilis dataset teks berlisensi terbuka 8TB Common Pile v0.1: EleutherAI mengumumkan peluncuran Common Pile v0.1, sebuah dataset besar yang berisi 8TB teks berlisensi terbuka dan domain publik. Mereka melatih model bahasa dengan parameter 7B berdasarkan dataset ini (masing-masing menggunakan 1T dan 2T token untuk pelatihan), yang kinerjanya sebanding dengan model serupa seperti LLaMA 1 dan LLaMA 2. Ini menyediakan sumber daya dan bukti empiris yang berharga untuk penelitian pelatihan model bahasa berkinerja tinggi yang sepenuhnya menggunakan data yang sesuai dengan peraturan. (Sumber: clefourrier)

SelfCheckGPT: Metode deteksi halusinasi LLM tanpa referensi: Sebuah artikel blog membahas SelfCheckGPT sebagai alternatif dari LLM-as-a-judge (menggunakan LLM sebagai evaluator) untuk mendeteksi halusinasi dalam model bahasa. Ini adalah metode deteksi tanpa referensi teks dan tanpa sumber daya (zero-resource), yang memberikan ide baru untuk mengevaluasi dan meningkatkan kebenaran output LLM. (Sumber: dl_weekly)
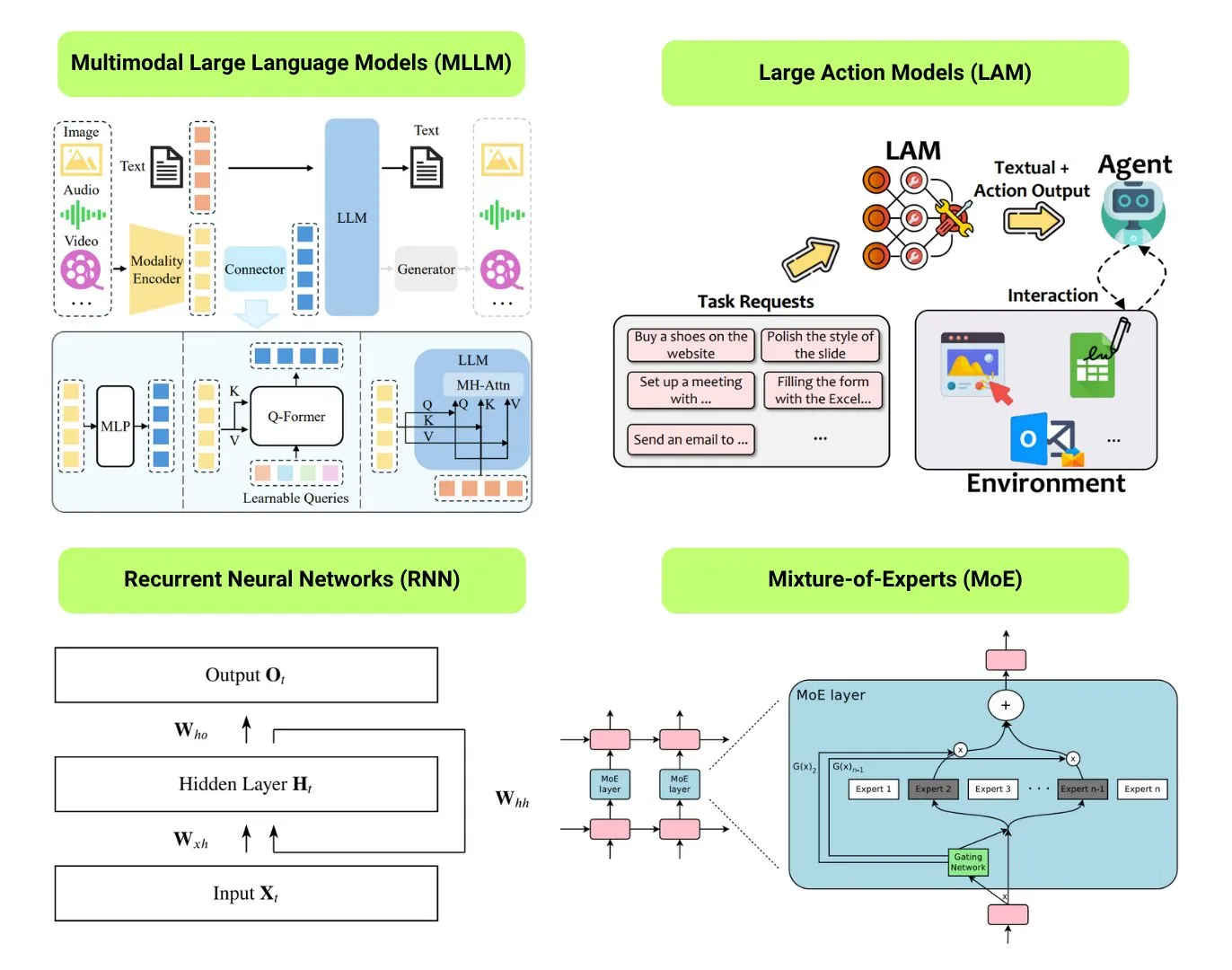
Rangkuman 12 jenis model AI dasar: The Turing Post merangkum 12 jenis model AI dasar, termasuk LLM (Large Language Model), SLM (Small Language Model), VLM (Visual Language Model), MLLM (Multimodal Large Language Model), LAM (Large Action Model), LRM (Large Reasoning Model), MoE (Mixture of Experts), SSM (State Space Model), RNN (Recurrent Neural Network), CNN (Convolutional Neural Network), SAM (Segment Anything Model), dan LNN (Logic Neural Network). Sumber daya terkait menyediakan penjelasan dan tautan berguna untuk jenis-jenis model ini. (Sumber: TheTuringPost)
Populer di GitHub: Tutorial Kubernetes The Hard Way: Tutorial Kelsey Hightower “Kubernetes The Hard Way” terus mendapatkan perhatian di GitHub. Tutorial ini bertujuan untuk membantu pengguna membangun klaster Kubernetes secara manual langkah demi langkah, untuk memahami secara mendalam komponen inti dan cara kerjanya, bukan bergantung pada skrip otomatis. Tutorial ini ditujukan untuk pembelajar yang ingin menguasai dasar-dasar Kubernetes, mencakup seluruh proses mulai dari persiapan lingkungan hingga pembersihan klaster. (Sumber: GitHub Trending)
Populer di GitHub: Daftar GPTs dan Prompts Gratis: Repositori friuns2/BlackFriday-GPTs-Prompts menjadi populer di GitHub. Repositori ini mengumpulkan dan mengatur serangkaian model GPT gratis dan Prompts berkualitas tinggi yang dapat digunakan pengguna tanpa langganan Plus. Sumber daya ini mencakup berbagai bidang seperti pemrograman, pemasaran, penelitian akademis, pencarian kerja, game, kreativitas, dan juga berisi beberapa teknik “Jailbreaks”, menyediakan alat dan inspirasi siap pakai yang kaya bagi pengguna GPT. (Sumber: GitHub Trending)

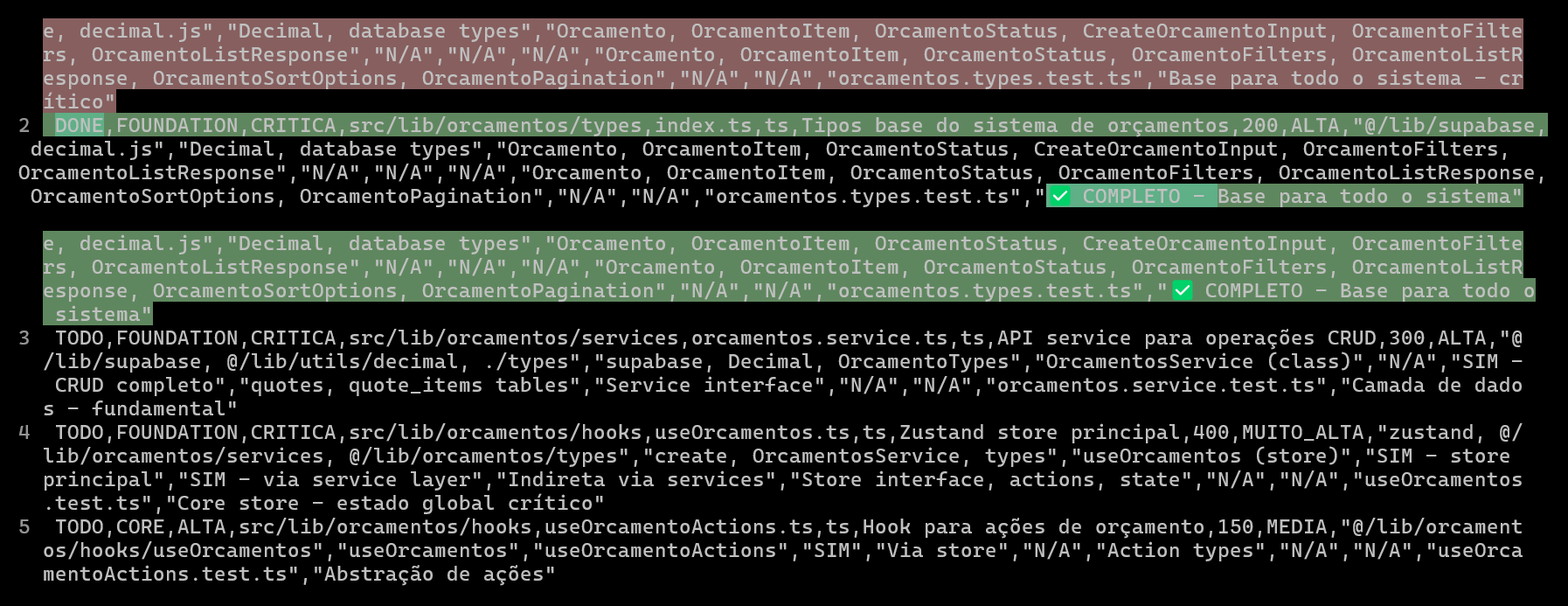
Menggunakan CSV untuk merencanakan dan melacak proyek coding AI, meningkatkan kualitas dan efisiensi kode: Seorang pengembang berbagi pengalamannya menggunakan Claude Code untuk mengembangkan sistem ERP, dengan membuat file CSV terperinci untuk merencanakan dan melacak kemajuan coding setiap file, sehingga secara signifikan meningkatkan efisiensi pengembangan fungsi kompleks dan kualitas kode. File CSV berisi status, nama file, prioritas, jumlah baris kode, kompleksitas, dependensi, deskripsi fungsi, Hooks yang digunakan, modul impor/ekspor, dan “catatan kemajuan” yang penting. Metode ini memungkinkan AI untuk lebih fokus dalam membangun kode dan memungkinkan pengembang untuk memahami dengan jelas kemajuan aktual proyek dibandingkan dengan rencana awal. (Sumber: Reddit r/ClaudeAI)
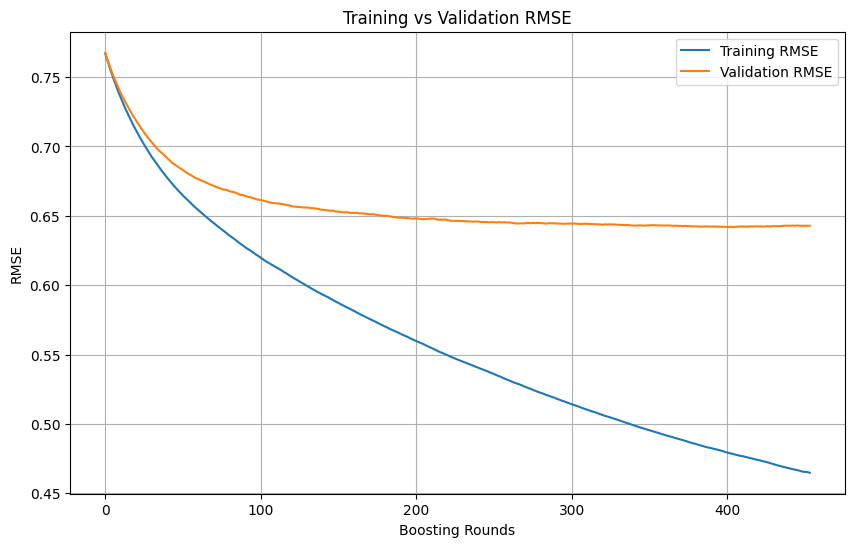
Penentuan overfitting dan waktu berhenti dalam pelatihan machine learning: Dalam proses pelatihan model machine learning, ketika training loss terus menurun dengan cepat, sementara validation loss menurun lambat atau bahkan berhenti atau meningkat, biasanya menunjukkan bahwa model mungkin mengalami overfitting. Pada prinsipnya, selama validation loss masih menurun, pelatihan dapat dilanjutkan. Kuncinya adalah memastikan validation set independen dari training set dan dapat mewakili distribusi data nyata dari tugas tersebut. Jika validation loss berhenti menurun atau mulai meningkat, pertimbangkan untuk menghentikan pelatihan lebih awal, atau mengambil metode seperti regularisasi untuk meningkatkan kemampuan generalisasi model. (Sumber: Reddit r/MachineLearning)
🌟 Komunitas
AI Engineer World’s Fair 2025 fokus pada isu RL+Reasoning, Eval, dll.: Tema konferensi AI Engineer World’s Fair 2025 mencakup arah-arah mutakhir seperti Reinforcement Learning + Reasoning (RL+Reasoning), Evaluasi (Eval), Software Engineering Agent (SWE-Agent), Arsitek AI, dan Infrastruktur Agent. Peserta menyatakan bahwa konferensi ini penuh dengan vitalitas dan pemikiran inovatif, banyak orang berani mencoba hal-hal baru, terus membentuk kembali diri mereka sendiri, dan terjun ke bidang AI. Konferensi ini juga menyediakan platform bagi para insinyur AI untuk bertukar pikiran dan belajar. (Sumber: swyx, hwchase17, charles_irl, swyx)

AI ideal Sam Altman: model kecil + penalaran super kuat + konteks masif + alat serbaguna: Sam Altman mendeskripsikan bentuk AI ideal menurutnya: sebuah model dengan kemampuan penalaran super manusia, berukuran sangat kecil, dapat mengakses informasi konteks triliunan tingkat, dan dapat memanggil alat apa pun yang bisa dibayangkan. Pandangan ini memicu diskusi, sebagian orang berpendapat bahwa ini berbeda dengan kondisi model besar saat ini yang bergantung pada penyimpanan pengetahuan, dan mempertanyakan kelayakan model kecil dalam menganalisis pengetahuan dan melakukan penalaran kompleks dalam konteks yang sangat besar, berpendapat bahwa pengetahuan dan kemampuan berpikir sulit dipisahkan secara efisien. (Sumber: teortaxesTex)
Agent coding memicu keinginan untuk refactoring kode, tantangan dan peluang pemrograman berbantuan AI: Pengembang menyatakan bahwa kemunculan agent coding sangat meningkatkan “godaan” mereka untuk melakukan refactoring kode orang lain, dan juga membawa bahaya baru. Seorang pengembang berbagi pengalaman menggunakan bantuan AI untuk menyelesaikan tugas pemrograman yang membutuhkan sekitar 10 menit kerja manual, meskipun AI dapat dengan cepat menghasilkan kode yang berfungsi, untuk mencapai tingkat organisasi dan gaya programmer berpengalaman, masih diperlukan banyak panduan dan refactoring manual. Ini menyoroti tantangan pemrograman berbantuan AI dalam meningkatkan kualitas kode dari tingkat pemula/menengah ke tingkat lanjut. (Sumber: finbarrtimbers, mitchellh)
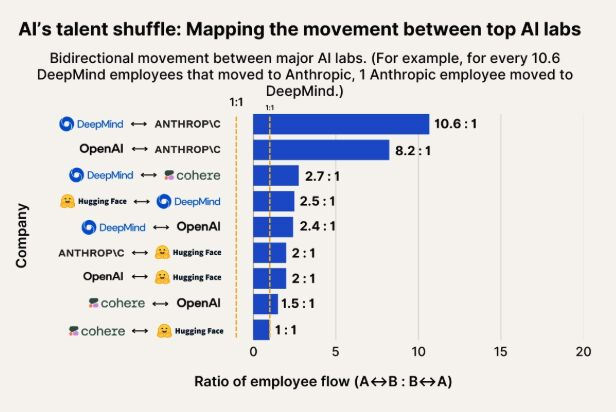
Observasi perpindahan talenta AI: Anthropic menjadi tujuan penting bagi talenta dari Google DeepMind dan OpenAI: Sebuah grafik yang menunjukkan perpindahan talenta AI menunjukkan bahwa Anthropic menjadi perusahaan penting yang menarik peneliti dari Google DeepMind dan OpenAI. Komunitas menyatakan bahwa ini sesuai dengan persepsi, dan ada pengguna yang berspekulasi bahwa Anthropic mungkin memiliki beberapa “senjata rahasia” atau arah penelitian unik yang menarik talenta terbaik untuk bergabung. (Sumber: bookwormengr, TheZachMueller)
Robot humanoid menghadapi tantangan kepercayaan dan penerimaan sosial dalam普及: Komentator teknologi Faruk Guney memprediksi bahwa gelombang pertama robot humanoid mungkin gagal karena defisit kepercayaan yang sangat besar. Ia berpendapat bahwa meskipun teknologi terus berkembang, masyarakat belum siap menerima “kecerdasan kotak hitam” ini masuk ke dalam rumah, melakukan tugas pendampingan, pekerjaan rumah tangga, bahkan pengasuhan anak. Keputusan robot yang tidak transparan, potensi risiko pengawasan, dan penampilan “lucu” yang sangat berbeda dari manusia (tidak seperti Wall-E), semuanya dapat menjadi hambatan bagi aplikasi luasnya. Hanya setelah diskusi sosial yang memadai, regulasi, audit, dan pembangunan kembali kepercayaan, barulah普及 robot humanoid yang sebenarnya dapat terjadi. (Sumber: farguney, farguney)
Desain personalisasi AI: “Ketidaksempurnaan” lebih unggul dari “kesempurnaan”: Seorang pengembang berbagi pengalamannya membuat 50 persona AI di platform audio AI. Kesimpulannya, latar belakang cerita yang terlalu dirancang, konsistensi logis absolut, dan kepribadian tunggal yang ekstrem justru membuat AI tampak mekanis dan tidak nyata. Pembentukan kepribadian AI yang sukses terletak pada “tumpukan kepribadian 3 lapis” (sifat inti + sifat pengubah + keanehan), “pola ketidaksempurnaan” yang sesuai (seperti sesekali salah ucap, koreksi diri), dan informasi latar belakang yang pas (300-500 kata, berisi pengalaman positif dan menantang, antusiasme spesifik, dan titik kerentanan yang terkait dengan profesionalisme). Detail “ketidaksempurnaan” ini justru membuat AI lebih manusiawi dan memiliki koneksi. (Sumber: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
Diskusi tentang apakah LLM memiliki “persepsi” dan “AGI”: antusiasme dan skeptisisme berdampingan: Komunitas umumnya merasa antusias dengan potensi besar LLM, menganggapnya sebanding dengan penemuan besar bersejarah dan akan mengubah segalanya. Namun, mengenai apakah LLM telah memiliki “kemampuan persepsi”, apakah memerlukan “hak”, dan apakah akan “mengakhiri umat manusia” atau membawa “AGI”, banyak orang masih bersikap skeptis. Ditekankan bahwa dalam menafsirkan kemampuan LLM dan hasil penelitian, perlu untuk tetap teliti dan berhati-hati. (Sumber: fabianstelzer)
💡 Lainnya
Membahas kolaborasi multi-robot dalam berjalan otonom: Media sosial membahas eksplorasi kolaborasi multi-robot dalam aspek berjalan otonom. Ini melibatkan teknologi kompleks seperti perencanaan jalur robot, alokasi tugas, berbagi informasi, dan penghindaran tabrakan, yang merupakan arah penelitian yang terus menjadi perhatian di bidang robotika, RPA (Robotic Process Automation), dan machine learning. (Sumber: Ronald_vanLoon)
Trik menggunakan random forest untuk mengoptimalkan hyperparameter ULMFiT: Jeremy Howard berbagi trik yang ia gunakan saat mengoptimalkan ULMFiT (metode transfer learning): dengan menjalankan sejumlah besar eksperimen ablasi, dan memasukkan semua hyperparameter serta data hasil ke model random forest, sehingga dapat menemukan hyperparameter yang paling berpengaruh terhadap kinerja model. Metode ini telah diintegrasikan oleh Weights & Biases ke dalam produknya, memberikan ide baru untuk penyetelan hyperparameter. (Sumber: jeremyphoward)

Robot humanoid Figure perusahaan menunjukkan kemampuan menangani tugas logistik selama 60 menit: Perusahaan Figure merilis video berdurasi 60 menit yang menunjukkan robot humanoidnya, yang ditenagai oleh jaringan saraf Helix, secara otonom menyelesaikan berbagai tugas dalam skenario logistik. Demonstrasi ini bertujuan untuk membuktikan kemampuan kerja stabil jangka panjang dan tingkat pengambilan keputusan otonom robotnya di lingkungan nyata yang kompleks. (Sumber: adcock_brett)