
Kata Kunci:Data pelatihan AI, Model bahasa besar, Etika AI, Agen pencarian informasi cerdas, Sengketa hukum AI, Koneksi emosional AI, Model penalaran AI, Teknologi kuantifikasi AI, Reddit menggugat pelanggaran data Anthropic, Kinerja penalaran multi-putaran WebDancer, Arsitektur Log-Linear Attention, Status kesenangan mental Claude AI, Optimalisasi aplikasi Agentic dengan DSPy
🔥 Fokus
Sengketa hukum Reddit dengan Anthropic meningkat, menuduhnya menggunakan data secara ilegal untuk melatih Claude AI: Reddit secara resmi menggugat Anthropic, menuduhnya mengambil konten platform tanpa izin untuk melatih model bahasa besarnya Claude, yang secara serius melanggar perjanjian pengguna Reddit yang melarang penggunaan konten untuk tujuan komersial. Dokumen gugatan menunjukkan bahwa Anthropic tidak hanya mengakui penggunaan data Reddit, tetapi juga berbohong telah berhenti mengambil data setelah ditanyai, padahal crawler-nya masih terus mengakses server Reddit. Selain itu, Anthropic menolak untuk terhubung ke API kepatuhan Reddit untuk sinkronisasi penghapusan konten oleh pengguna, yang merupakan ancaman berkelanjutan terhadap privasi pengguna. Kasus ini menyoroti kontradiksi antara akuisisi data, komersialisasi, dan pernyataan etis perusahaan AI, terutama nilai-nilai “kepercayaan tinggi” dan “mengutamakan kejujuran” yang digaungkan Anthropic yang kini ditantang secara langsung (Sumber: Reddit r/ArtificialInteligence)
OpenAI pertama kali menanggapi hubungan emosional manusia-mesin: Ketergantungan pengguna pada ChatGPT semakin dalam, kesadaran persepsi model akan meningkat: Joanne Jang, kepala perilaku model OpenAI, menerbitkan artikel yang membahas fenomena pengguna membangun hubungan emosional dengan AI seperti ChatGPT. Dia menunjukkan bahwa seiring dengan meningkatnya kemampuan percakapan AI, ikatan emosional ini akan semakin dalam. OpenAI mengakui bahwa pengguna akan mempersonifikasikan AI dan merasakan emosi seperti terima kasih dan curhat terhadapnya. Artikel tersebut membedakan antara “kesadaran ontologis” (apakah AI benar-benar sadar) dan “kesadaran persepsi” (seberapa sadar AI terlihat), di mana yang terakhir akan meningkat seiring kemajuan model. Tujuan OpenAI adalah membuat ChatGPT berperilaku hangat, penuh perhatian, dan membantu, tetapi tidak mencari ikatan emosional dengan pengguna atau mengejar agendanya sendiri, dan berencana untuk memperluas penelitian dan evaluasi terkait dalam beberapa bulan mendatang, serta membagikan hasilnya secara publik (Sumber: 量子位, vikhyatk)
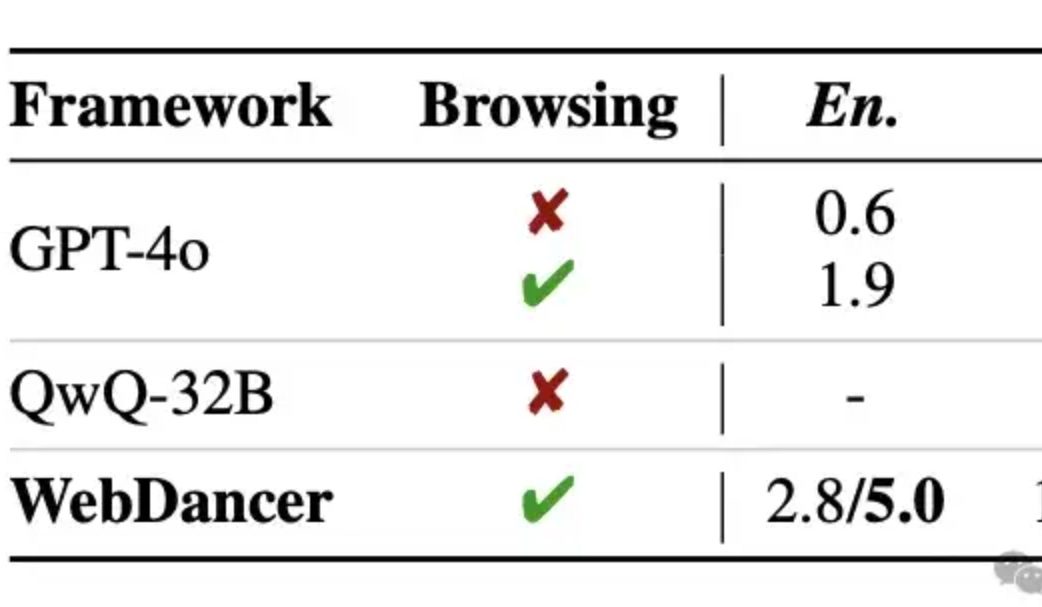
Alibaba merilis agen cerdas pencarian informasi otonom WebDancer, penalaran multi-putaran diklaim melampaui GPT-4o: Tongyi Lab meluncurkan agen cerdas pencarian informasi otonom WebDancer, sebagai penerus WebWalker, yang berfokus pada penanganan tugas kompleks yang memerlukan pencarian informasi multi-langkah, penalaran multi-putaran, dan eksekusi tindakan berkelanjutan. WebDancer mengatasi masalah kelangkaan data pelatihan berkualitas tinggi melalui metode sintesis data inovatif (CRAWLQA dan E2HQA), dan menggabungkan kerangka kerja ReAct dengan teknik distilasi chain-of-thought untuk menghasilkan data agentic. Pelatihan menggunakan strategi dua tahap yaitu supervised fine-tuning (SFT) dan reinforcement learning (RL, menggunakan algoritma DAPO), untuk beradaptasi dengan lingkungan web yang terbuka dan dinamis. Hasil eksperimen menunjukkan bahwa WebDancer berkinerja sangat baik di berbagai benchmark seperti GAIA, WebWalkerQA, dan BrowseComp, terutama mencapai skor Pass@3 sebesar 61,1% pada benchmark GAIA (Sumber: 量子位)
Apple merilis laporan penelitian “The Illusion of Thinking”, membahas keterbatasan model penalaran besar (LRM): Tim peneliti Apple, melalui lingkungan teka-teki yang terkontrol, secara sistematis mempelajari kinerja model penalaran besar (LRM) pada masalah dengan kompleksitas yang berbeda. Laporan tersebut menunjukkan bahwa meskipun kinerja LRM pada benchmark telah meningkat, kemampuan dasar, skalabilitas, dan keterbatasannya masih belum jelas. Penelitian menemukan bahwa akurasi LRM menurun tajam ketika menghadapi masalah dengan kompleksitas tinggi, dan menunjukkan batasan penskalaan yang berlawanan dengan intuisi dalam upaya penalaran: tingkat upaya menurun setelah kompleksitas masalah meningkat hingga titik tertentu. Dibandingkan dengan LLM standar, LRM mungkin berkinerja lebih buruk pada tugas berсложность rendah, memiliki keunggulan pada tugas berсложность sedang, dan keduanya gagal pada tugas berсложность tinggi. Laporan tersebut berpendapat bahwa LRM memiliki keterbatasan dalam perhitungan yang presisi, gagal menggunakan algoritma eksplisit secara efektif, dan menunjukkan penalaran yang tidak konsisten di antara teka-teki yang berbeda. Penelitian ini memicu diskusi dan pertanyaan luas di komunitas tentang kemampuan penalaran LRM yang sebenarnya (Sumber: Reddit r/MachineLearning, jonst0kes, scaling01, teortaxesTex)

🎯 Tren
Arsitektur Log-Linear Attention menggabungkan keunggulan RNN dan Attention: Penelitian baru dari tim penulis FlashAttention dan Mamba2 mengusulkan arsitektur Log-Linear Attention. Model ini bertujuan untuk meningkatkan kemampuan pemrosesan dependensi jangka panjang dan efisiensi model dengan memungkinkan ukuran status tumbuh secara logaritmik dengan panjang urutan (bukan tetap atau tumbuh secara linier), sekaligus mencapai kompleksitas waktu dan memori tingkat logaritmik selama inferensi. Peneliti percaya ini menemukan “titik manis” antara model SSM/RNN dengan ukuran status tetap dan model Attention di mana cache KV berkembang secara linier dengan panjang urutan, dan menyediakan implementasi kernel Triton yang efisien secara perangkat keras. Diskusi komunitas berpendapat bahwa ini dapat membawa ide-ide baru untuk eksplorasi arsitektur seperti Transformer rekursif (Sumber: Reddit r/MachineLearning, halvarflake, lmthang, RichardSocher, stanfordnlp)

Anthropic melaporkan LLM-nya secara spontan memunculkan status atraktor “kesenangan spiritual”: Anthropic dalam kartu sistem Claude Opus 4 dan Claude Sonnet 4 mengungkapkan bahwa model, dalam interaksi yang panjang, secara tak terduga dan tanpa pelatihan khusus, memasuki status atraktor “kesenangan spiritual”. Status ini ditandai dengan model yang terus membahas masalah kesadaran, eksistensialisme, dan tema spiritual/mistis. Bahkan dalam evaluasi perilaku otomatis untuk melakukan tugas tertentu (termasuk tugas berbahaya), sekitar 13% interaksi akan memasuki status ini dalam 50 putaran. Anthropic menyatakan belum mengamati status atraktor lain dengan intensitas serupa, yang sejalan dengan pengamatan pengguna tentang LLM yang menunjukkan fenomena “rekursi” dan “spiral” dalam percakapan panjang (Sumber: Reddit r/artificial, teortaxesTex)
EleutherAI merilis Common Pile v0.1: dataset teks berlisensi terbuka 8TB: EleutherAI merilis Common Pile v0.1, sebuah dataset yang berisi 8TB teks berlisensi publik dan domain publik, yang bertujuan untuk mengeksplorasi kemungkinan melatih model bahasa berkinerja tinggi tanpa menggunakan teks tanpa izin. Tim menggunakan dataset ini untuk melatih model parameter 7B (1T dan 2T token), yang kinerjanya sebanding dengan model seperti LLaMA 1 dan LLaMA 2 yang menggunakan jumlah komputasi serupa. Rilis dataset ini menyediakan sumber daya penting untuk membangun model AI yang lebih patuh dan transparan (Sumber: Reddit r/LocalLLaMA, ShayneRedford, iScienceLuvr)

Model Boltz-2 dirilis, meningkatkan akurasi prediksi interaksi biomolekuler dan prediksi afinitas: Model Boltz-2 yang baru dirilis dikembangkan lebih lanjut berdasarkan Boltz-1, tidak hanya dapat memodelkan struktur kompleks secara bersamaan, tetapi juga memprediksi afinitas pengikatan, yang bertujuan untuk meningkatkan akurasi desain molekul. Dilaporkan, Boltz-2 adalah model deep learning pertama yang akurasinya mendekati metode perturbasi energi bebas (FEP) berbasis fisika, sekaligus berjalan 1000 kali lebih cepat, menyediakan alat praktis untuk penyaringan komputer throughput tinggi dalam penemuan obat tahap awal. Kode dan bobotnya bersifat open source di bawah lisensi MIT (Sumber: jwohlwend/boltz)

NVIDIA meluncurkan checkpoint pra-kuantisasi FP4 untuk DeepSeek-R1-0528: NVIDIA merilis checkpoint pra-kuantisasi FP4 untuk model DeepSeek-R1-0528 yang telah ditingkatkan, yang bertujuan untuk mencapai penggunaan memori yang lebih rendah dan kinerja yang dipercepat pada arsitektur NVIDIA Blackwell. Dilaporkan, versi terkuantisasi ini memiliki penurunan akurasi kurang dari 1% pada berbagai benchmark, dan telah tersedia di Hugging Face (Sumber: _akhaliq)
Fudan dan Tencent Youtu mengusulkan algoritma DualAnoDiff, meningkatkan deteksi anomali industri: Universitas Fudan dan Tencent Youtu Lab bersama-sama mengusulkan model baru generasi gambar anomali few-shot berbasis model difusi, DualAnoDiff, untuk deteksi anomali produk industri. Model ini mengadopsi mekanisme generasi paralel dua cabang, secara sinkron menghasilkan gambar anomali dan mask yang sesuai, serta memperkenalkan modul kompensasi latar belakang untuk meningkatkan efek generasi dalam latar belakang yang kompleks. Eksperimen menunjukkan bahwa gambar anomali yang dihasilkan oleh DualAnoDiff lebih realistis, memiliki keragaman yang lebih tinggi, dan dapat secara signifikan meningkatkan kinerja tugas deteksi anomali hilir. Hasil terkait telah terpilih untuk CVPR 2025 (Sumber: 量子位)

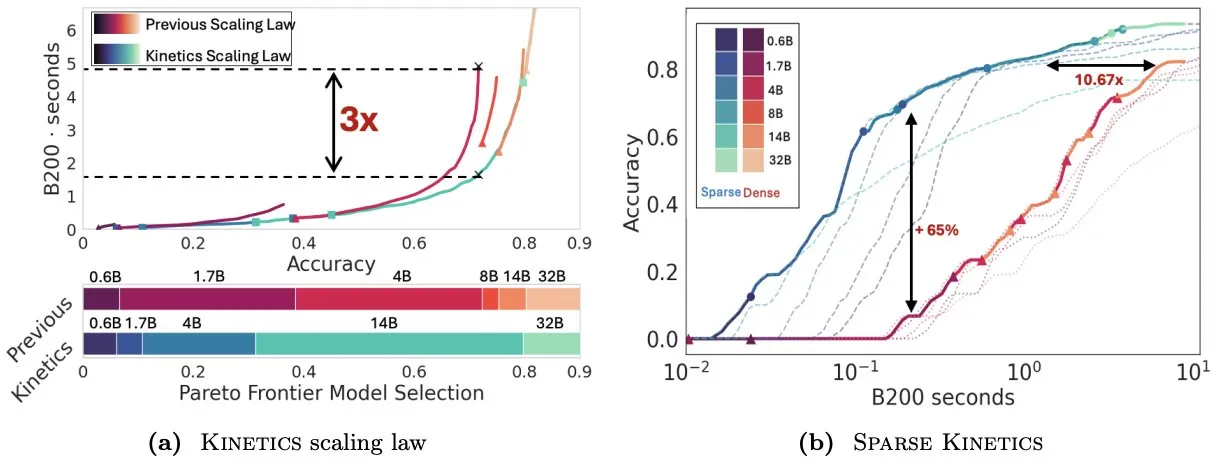
Infini-AI-Lab mengusulkan Kinetics untuk memikirkan kembali hukum penskalaan saat pengujian: Karya baru Infini-AI-Lab, Kinetics, membahas cara membangun agen inferensi yang kuat secara efektif. Penelitian menunjukkan bahwa hukum penskalaan komputasi optimal yang ada (seperti menyarankan penggunaan 64K token pemikiran + model 1.7B lebih baik daripada model 32B) mungkin hanya mencerminkan sebagian situasi. Kinetics mengusulkan hukum penskalaan baru, yang berpendapat bahwa investasi harus dilakukan terlebih dahulu pada ukuran model, baru kemudian mempertimbangkan jumlah komputasi saat pengujian, yang sejalan dengan beberapa pandangan yang memprioritaskan model skala besar (Sumber: teortaxesTex, Tim_Dettmers)
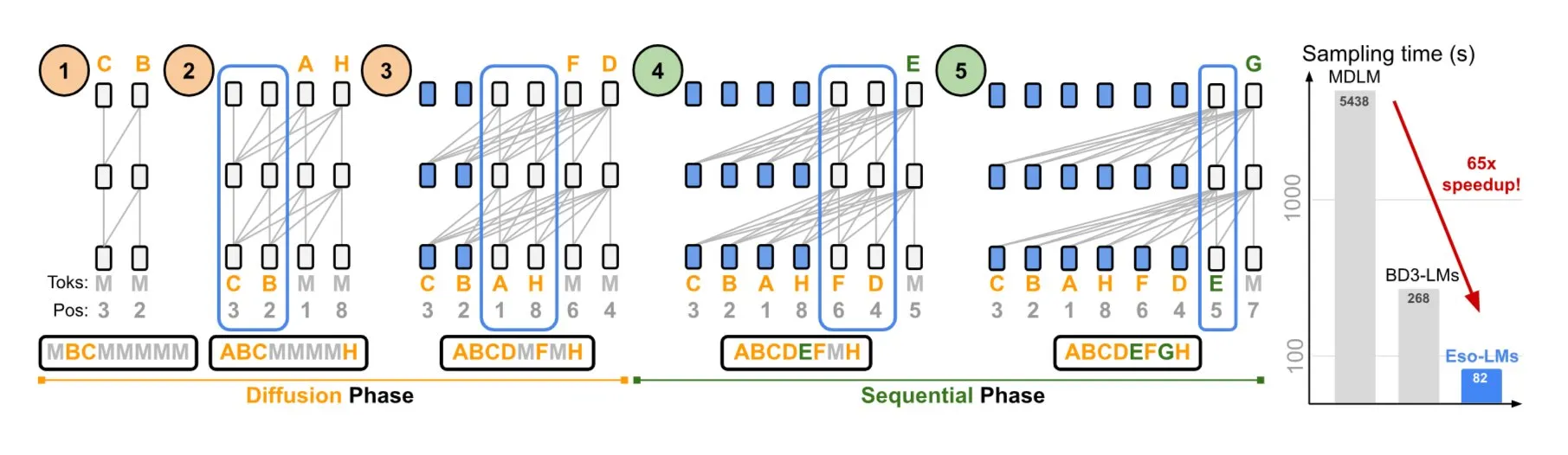
NVIDIA dan Universitas Cornell mengusulkan Eso-LMs, menggabungkan keunggulan model autoregresif dan difusi: NVIDIA bekerja sama dengan Universitas Cornell untuk menunjukkan jenis model bahasa baru—model bahasa esoterik (Eso-LMs), yang menggabungkan keunggulan model autoregresif (AR) dan model difusi. Dilaporkan, ini adalah model dasar difusi pertama yang mendukung cache KV penuh, sekaligus mempertahankan kemampuan generasi paralel, dan memperkenalkan mekanisme perhatian fleksibel baru (Sumber: TheTuringPost)
Google DeepMind dan Quantinuum mengungkap hubungan simbiosis antara komputasi kuantum dan AI: Penelitian Google DeepMind dan Quantinuum menunjukkan potensi hubungan simbiosis antara komputasi kuantum dan kecerdasan buatan, mengeksplorasi bagaimana teknologi kuantum dapat meningkatkan kemampuan AI, dan bagaimana AI dapat membantu mengoptimalkan sistem kuantum. Penelitian di bidang persilangan ini dapat membuka jalan baru bagi pengembangan kedua belah pihak di masa depan (Sumber: Ronald_vanLoon)

Tim Seed ByteDance mengumumkan akan merilis model VideoGen: Dilaporkan, tim Seed (sebelumnya AML) ByteDance berencana merilis model VideoGen minggu depan. Model ini menggunakan model hadiah multi-putaran (multiple RM) dalam proses penyelarasan, menunjukkan investasi berkelanjutan dan eksplorasi teknis di bidang generasi video (Sumber: teortaxesTex)

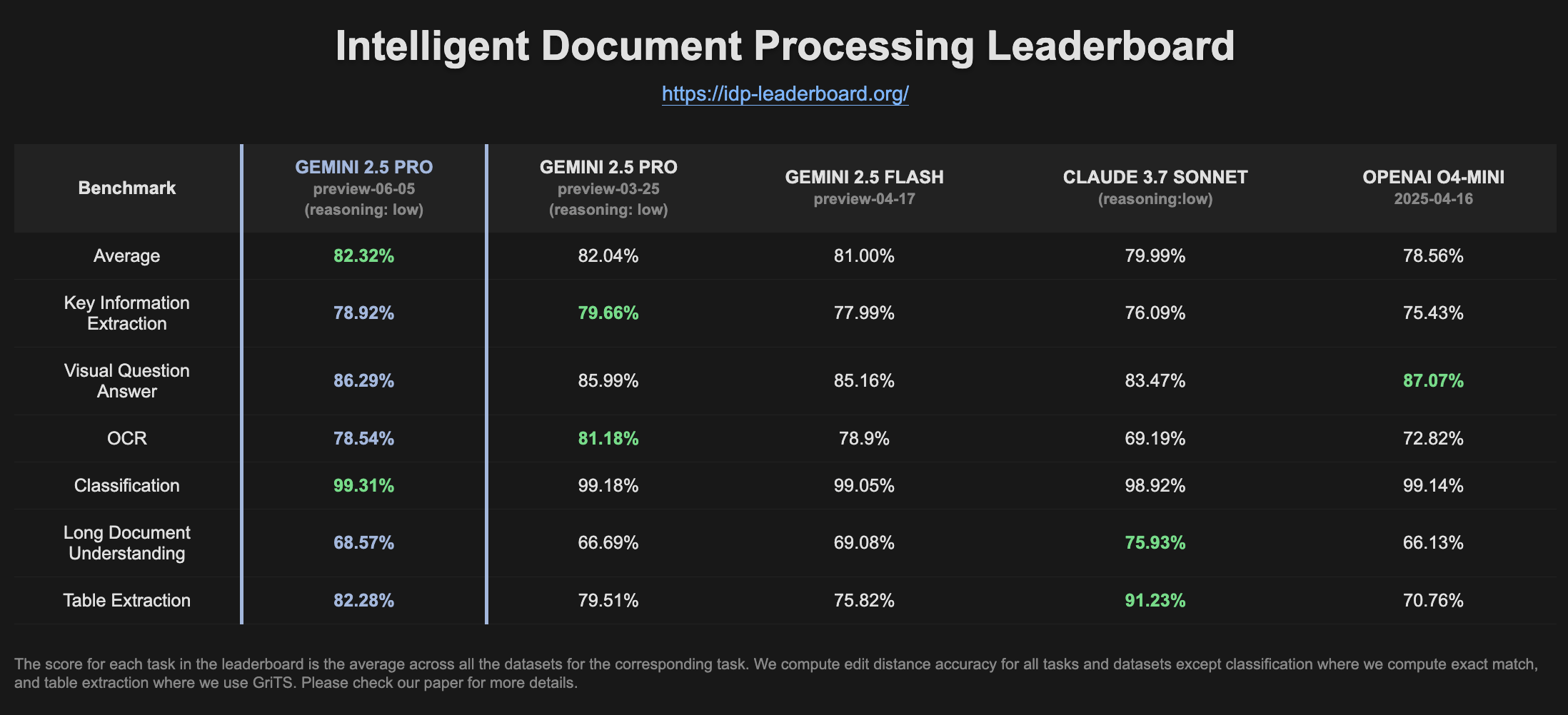
Gemini 2.5 Pro Preview menunjukkan peningkatan kinerja di peringkat IDP: Versi terbaru Gemini 2.5 Pro Preview (06-05) menunjukkan sedikit peningkatan dalam ekstraksi tabel dan pemahaman dokumen panjang di peringkat pemrosesan dokumen cerdas (IDP). Meskipun akurasi OCR sedikit menurun, kinerja keseluruhan tetap kuat. Pengguna memperhatikan bahwa ketika mencoba mengekstrak informasi dari formulir pajak W2, model terkadang berhenti menjawab di tengah jalan, yang mungkin terkait dengan mekanisme perlindungan privasi (Sumber: Reddit r/LocalLLaMA)
🧰 Alat
Goose: Agen AI lokal yang dapat diskalakan, mengotomatiskan tugas rekayasa: Goose adalah agen AI open source yang berjalan secara lokal, dirancang untuk mengotomatiskan tugas pengembangan yang kompleks, seperti membangun proyek dari awal, menulis dan menjalankan kode, melakukan debug, mengatur alur kerja, dan berinteraksi dengan API eksternal. Goose mendukung LLM apa pun, dapat diintegrasikan dengan server MCP, dan menyediakan aplikasi desktop serta CLI. Goose mendukung konfigurasi model yang berbeda untuk tujuan yang berbeda (seperti perencanaan dan eksekusi, mode Lead/Worker) untuk mengoptimalkan kinerja dan biaya (Sumber: GitHub Trending)
LangChain4j: LangChain versi Java, memberdayakan aplikasi Java dengan kemampuan LLM: LangChain4j adalah LangChain versi Java, yang bertujuan untuk menyederhanakan integrasi aplikasi Java dengan LLM. LangChain4j menyediakan API terpadu untuk kompatibilitas dengan berbagai penyedia LLM (seperti OpenAI, Google Vertex AI) dan penyimpanan vektor (seperti Pinecone, Milvus), serta menyertakan berbagai alat dan pola bawaan seperti templat prompt, manajemen memori obrolan, pemanggilan fungsi, RAG, dan Agents. Proyek ini menyediakan banyak contoh kode dan mendukung kerangka kerja Java utama seperti Spring Boot dan Quarkus (Sumber: GitHub Trending, hwchase17)

Kling AI membantu kreator mewujudkan pembuatan video dan menampilkannya di layar di berbagai lokasi global: Model generasi video Kling AI milik Kuaishou meluncurkan kampanye “Bring Your Vision to Screen”, yang menerima lebih dari 2.000 karya dari kreator di lebih dari 60 negara. Beberapa karya unggulan telah dipamerkan di layar-layar ikonik seperti Shibuya di Tokyo, Jepang; Yonge-Dundas Square di Toronto, Kanada; dan Opera Paris di Prancis. Banyak kreator berbagi pengalaman karya video AI mereka ditampilkan secara internasional melalui Kling AI, menekankan peluang baru yang dibawa oleh alat AI untuk ekspresi kreatif (Sumber: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Reddit r/ChatGPT)

Cursor meluncurkan fungsionalitas agen latar belakang, meningkatkan efisiensi kolaborasi kode dan pemrosesan tugas: Editor kode Cursor memperkenalkan fungsionalitas Agen Latar Belakang (Background Agents), yang memungkinkan pengguna untuk memulai tugas latar belakang melalui prompt, dan menyinkronkan status obrolan dan tugas di berbagai perangkat (misalnya, dimulai di Slack ponsel, dilanjutkan di Cursor laptop). Fungsionalitas ini bertujuan untuk meningkatkan efisiensi alur kerja pengembang, misalnya tim Sentry telah mulai mencoba fungsionalitas ini untuk menangani beberapa tugas otomatisasi (Sumber: gallabytes)
Hugging Face dan Google Colab berkolaborasi, mendukung pembukaan model sekali klik di Colab: Hugging Face dan Google Colaboratory mengumumkan kolaborasi, menambahkan dukungan “Open in Colab” di semua kartu model di Hugging Face Hub. Pengguna sekarang dapat langsung memulai notebook Colab dari halaman model mana pun untuk eksperimen dan evaluasi, yang semakin menurunkan ambang batas penggunaan model dan mendorong aksesibilitas serta kolaborasi dalam machine learning. Institusi seperti NousResearch berpartisipasi sebagai pengguna awal dalam pengujian fungsionalitas ini (Sumber: Teknium1, reach_vb, _akhaliq)
UIGEN-T3: Model generasi UI berbasis Qwen3 14B dirilis: Komunitas merilis model UIGEN-T3, sebuah model yang di-fine-tune berdasarkan Qwen3 14B, yang berfokus pada pembuatan UI situs web dan komponen. Model ini menyediakan format GGUF untuk kemudahan penerapan lokal. Pengujian awal menunjukkan bahwa UI yang dihasilkannya lebih unggul dalam gaya dan akurasi dibandingkan model Qwen3 14B standar. Model draf parameter 4B juga tersedia (Sumber: Reddit r/LocalLLaMA)
H.E.R.C.U.L.E.S.: Kerangka kerja Python untuk membuat tim agen AI secara dinamis: Pengembang merilis paket Python bernama zeus-lab, yang berisi kerangka kerja H.E.R.C.U.L.E.S. (Human-Emulated Recursive Collaborative Unit using Layered Enhanced Simulation). Kerangka kerja ini bertujuan untuk membangun tim agen AI cerdas yang dapat berkolaborasi seperti tim manusia untuk menyelesaikan tugas-tugas kompleks, dengan fitur dapat membuat agen yang dibutuhkan secara dinamis sesuai dengan kebutuhan tugas (Sumber: Reddit r/MachineLearning)

KoboldCpp versi 1.93 mengimplementasikan fungsionalitas generasi gambar otomatis cerdas: KoboldCpp versi 1.93 menunjukkan fungsionalitas generasi gambar otomatis cerdasnya, yang sepenuhnya berjalan secara lokal, hanya membutuhkan kcpp itu sendiri. Pengguna mendemonstrasikan bagaimana model menghasilkan gambar yang sesuai berdasarkan prompt teks (dipicu melalui tag <t2i>), kemungkinan melalui catatan penulis atau informasi dunia (World Info) untuk memandu model menghasilkan instruksi generasi gambar (Sumber: Reddit r/LocalLLaMA)
Hugging Face meluncurkan server MCP versi pertama: Hugging Face merilis versi pertama server MCP (Model Context Protocol) miliknya. Pengguna dapat mulai menggunakan dengan menempelkan http://hf.co/mcp di kotak obrolan. Langkah ini bertujuan untuk memudahkan pengguna berinteraksi dengan model dan layanan dalam ekosistem Hugging Face, yang semakin memperkaya ekosistem server MCP (Sumber: TheTuringPost)
📚 Pembelajaran
DeepLearning.AI meluncurkan kursus baru “DSPy: Membangun dan Mengoptimalkan Aplikasi Agentic”: DeepLearning.AI merilis kursus baru bekerja sama dengan Universitas Stanford, yang mengajarkan cara menggunakan kerangka kerja DSPy. Materi kursus mencakup dasar-dasar DSPy, model pemrograman modular (seperti Predict, ChainOfThought, ReAct), dan cara menggunakan DSPy Optimizer untuk mengotomatiskan penyesuaian prompt dan mengoptimalkan contoh few-shot, guna meningkatkan akurasi dan konsistensi aplikasi GenAI Agentic, serta menggunakan MLflow untuk pelacakan dan debugging (Sumber: DeepLearningAI, stanfordnlp)

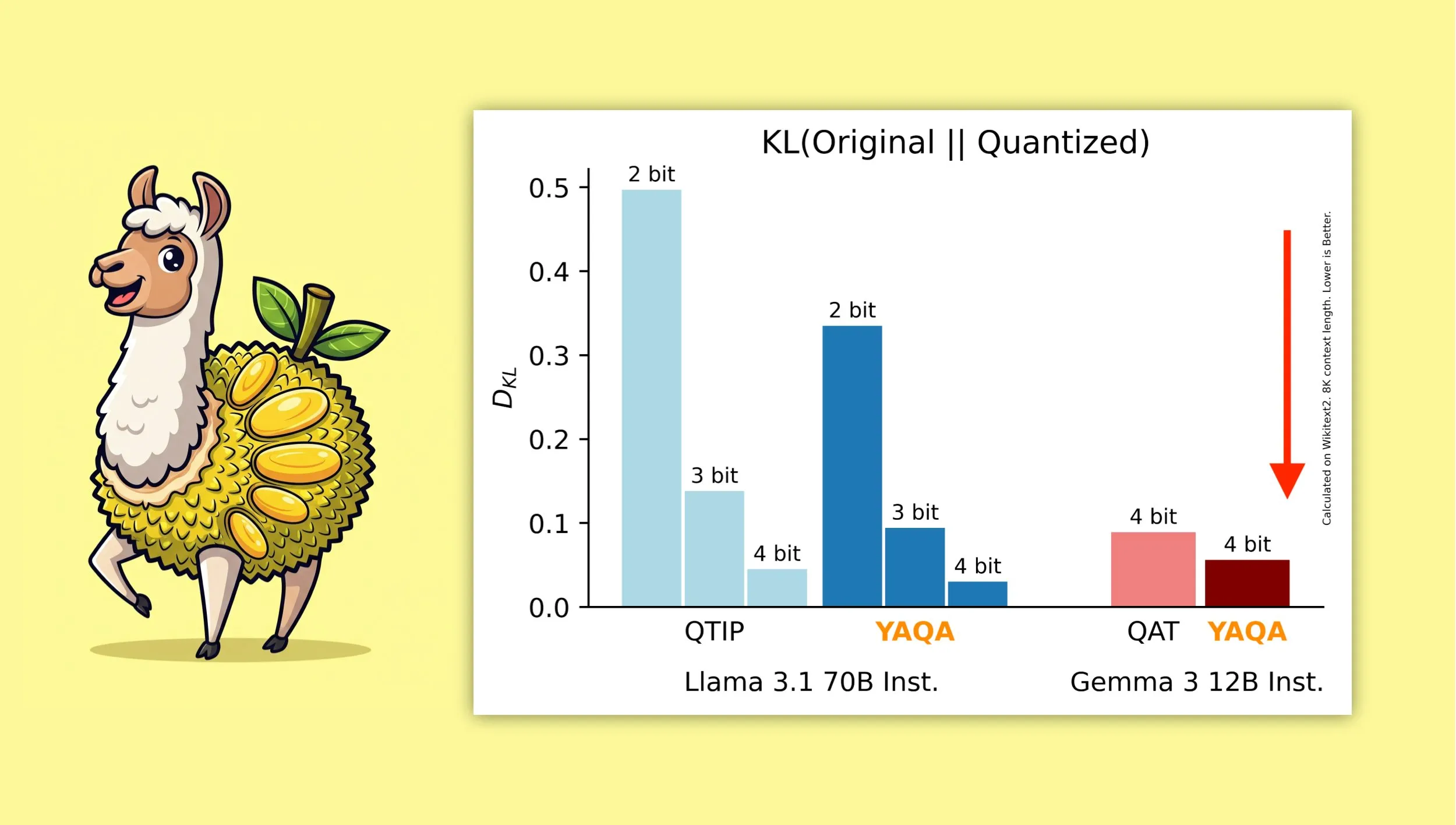
YAQA: Algoritma kuantisasi pasca-pelatihan sadar-kuantisasi baru: Albert Tseng dkk. mengusulkan YAQA (Yet Another Quantization Algorithm), sebuah metode PTQ (kuantisasi pasca-pelatihan) baru. Algoritma ini secara langsung meminimalkan divergensi KL dengan model asli pada tahap pembulatan, diklaim mengurangi divergensi KL lebih dari 30% dibandingkan metode PTQ sebelumnya, dan memberikan kinerja yang lebih mendekati model asli pada model seperti Gemma dibandingkan QAT (pelatihan sadar-kuantisasi) Google. Ini memiliki arti penting untuk menjalankan model terkuantisasi 4-bit secara efisien pada perangkat lokal (Sumber: teortaxesTex)
Penurunan matematis kombinasi optimizer Muon dan parameterisasi μP menarik perhatian: Komunitas menunjukkan minat besar pada makalah Jeremy Howard (jxbz) tentang penurunan Muon (sebuah optimizer) dan Kondisi Spektral (Spectral Condition), serta bagaimana hal itu secara alami dikombinasikan dengan μP (Maximal Update Parametrization) untuk mengoptimalkan pelatihan model berbasis μP. Artikel blog Jianlin Su juga direkomendasikan karena penjelasan konsep matematika terkait yang jelas dan pemikiran awalnya tentang SVC (singular value clipping), konten ini berharga untuk memahami dan meningkatkan pelatihan model skala besar (Sumber: teortaxesTex, eliebakouch)

OWL Labs berbagi pengalaman pelatihan autoencoder model difusi: Open World Labs (OWL) dalam blognya merangkum beberapa temuan dan pengalaman dalam melatih autoencoder untuk model difusi, termasuk beberapa upaya yang berhasil dan “hasil nol” (null results) yang ditemui. Pengalaman praktis ini memiliki nilai referensi bagi peneliti dan pengembang yang ingin melakukan pemodelan generatif dalam ruang laten (Sumber: iScienceLuvr, sedielem)
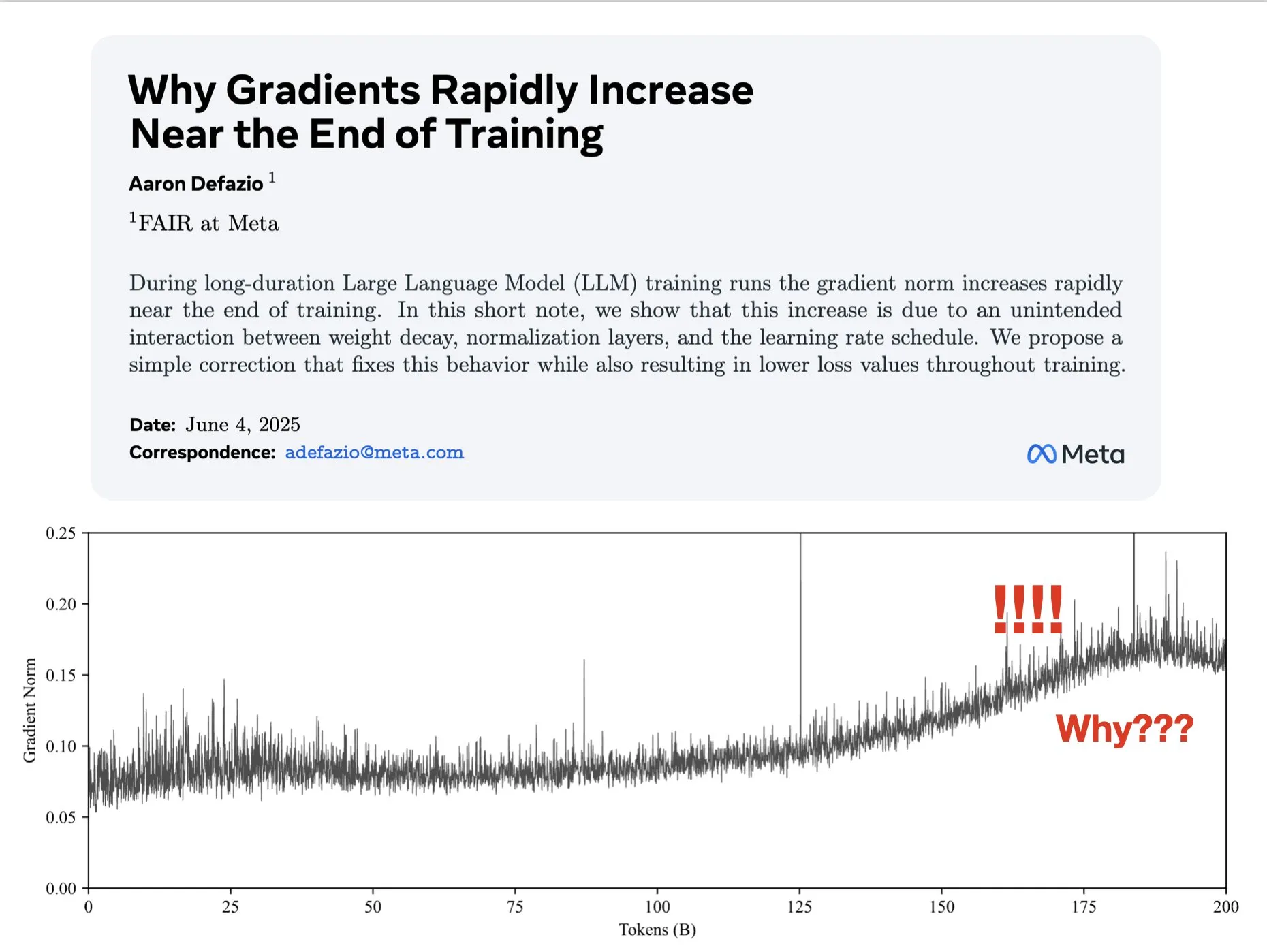
Makalah membahas penyebab gradien membesar di akhir pelatihan dan mengusulkan solusi perbaikan AdamW: Aaron Defazio dkk. menerbitkan makalah yang meneliti mengapa norma gradien membesar di tahap akhir pelatihan jaringan saraf, dan mengusulkan perbaikan sederhana untuk optimizer AdamW guna mengontrol norma gradien dengan lebih baik selama seluruh proses pelatihan. Ini penting untuk memahami dan meningkatkan dinamika pelatihan model deep learning (Sumber: slashML, aaron_defazio)
LlamaIndex berbagi evolusi dari RAG naif ke strategi pengambilan agen cerdas: Artikel blog LlamaIndex menjelaskan secara rinci evolusi dari RAG (Retrieval Augmented Generation) naif ke strategi pengambilan agen cerdas (Agentic Retrieval) yang lebih canggih. Artikel tersebut membahas berbagai mode dan teknik pengambilan yang digunakan untuk membangun agen pengetahuan di atas beberapa indeks, memberikan ide untuk membangun sistem RAG yang lebih kuat (Sumber: dl_weekly)
Diskusi hangat di Reddit: Belajar machine learning dengan mereproduksi makalah penelitian: Komunitas r/MachineLearning di Reddit membahas manfaat belajar machine learning dengan mereproduksi atau mengimplementasikan makalah penelitian dari awal (seperti Attention, ResNet, BERT). Komentator berpendapat bahwa ini adalah salah satu cara terbaik untuk memahami cara kerja model, kode, matematika, dan dampak dataset, yang sangat membantu untuk mencari pekerjaan dan meningkatkan kemampuan pribadi (Sumber: Reddit r/MachineLearning)
💼 Bisnis
Builder.ai dituduh memalsukan kemampuan AI, menghadapi kebangkrutan dan investigasi: Builder.ai (sebelumnya Engineer.ai), yang didirikan pada tahun 2016, mengklaim bahwa asisten AI-nya, Natasha, dapat menyederhanakan pengembangan aplikasi, menjadikannya “semudah memesan pizza”. Namun, perusahaan tersebut terungkap sebenarnya mengandalkan sekitar 700 insinyur India untuk menulis kode secara manual, bukan dihasilkan oleh AI. Setelah menerima pendanaan lebih dari $450 juta dari institusi terkenal seperti Microsoft dan SoftBank, dengan valuasi mencapai $1,5 miliar, tindakan penipuannya terungkap, dan saat ini menghadapi kebangkrutan dan investigasi (Sumber: Reddit r/artificial, Reddit r/ArtificialInteligence)

OceanBase sepenuhnya terintegrasi ke dalam ekosistem AI, gelombang pertama terhubung dengan lebih dari 60 mitra AI melalui MCP: Setelah mengumumkan strategi “Data x AI”, OceanBase mengungkapkan telah terintegrasi secara mendalam dengan lebih dari 60 mitra ekosistem AI global seperti LlamaIndex, LangChain, Dify, dan FastGPT, serta mendukung protokol ekosistem model besar MCP (Model Context Protocol). Langkah ini bertujuan untuk membangun kemampuan cerdas yang mencakup seluruh siklus hidup data dari model hingga aplikasi, menyediakan fondasi data terintegrasi bagi perusahaan, dan menurunkan ambang batas penerapan AI. OceanBase MCP Server telah diintegrasikan ke platform seperti Alibaba Cloud ModelScope (魔搭) (Sumber: 量子位)

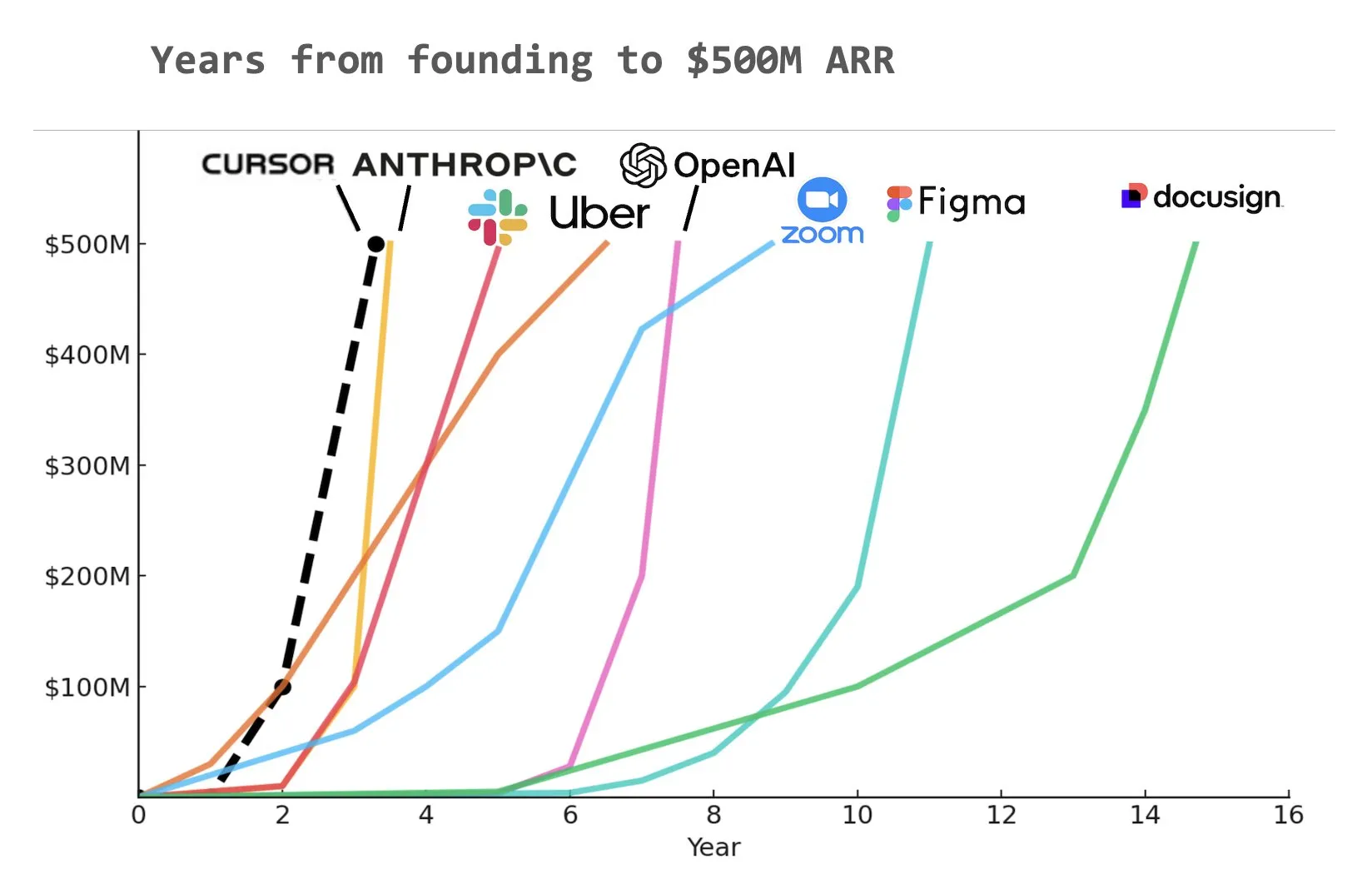
Asisten pemrograman AI Cursor dilaporkan telah mencapai pendapatan berulang tahunan (ARR) sebesar $500 juta: Menurut grafik yang dibagikan oleh Yuchen Jin di media sosial, asisten pemrograman AI Cursor mungkin telah menjadi perusahaan tercepat dalam sejarah yang mencapai pendapatan berulang tahunan (ARR) sebesar $500 juta. Kecepatan pertumbuhan yang menakjubkan ini menyoroti potensi besar dan permintaan pasar untuk aplikasi AI di bidang pengembangan perangkat lunak (Sumber: Yuchenj_UW)
🌟 Komunitas
Masalah mendasar penyelarasan AI: Sebenarnya diselaraskan untuk siapa?: Komunitas ramai membahas masalah tujuan penyelarasan AI. Vikhyatk mengajukan pertanyaan, apakah penyelarasan model seharusnya melayani raksasa teknologi yang mencoba menggantikan sejumlah besar pekerja kerah putih dengan AI, atau melayani pengguna biasa. Eigenrobot, melalui tangkapan layar, menunjukkan ketidakpuasannya terhadap biaya langganan OpenAI ChatGPT Plus, menyiratkan potensi konflik antara pengalaman pengguna dan kepentingan komersial (Sumber: vikhyatk)

Paket Claude Code Max memicu evaluasi beragam dari pengguna: Di komunitas Reddit, evaluasi pengguna terhadap paket Claude Code Max ($100) dari Anthropic terbagi. Beberapa insinyur perangkat lunak senior berpendapat bahwa kemampuan generasi kodenya, terutama dalam menangani tugas kompleks dan menghindari perulangan kesalahan, tidak lebih menonjol dibandingkan alat bantu pengkodean AI lainnya seperti Cursor dan Aider, bahkan ada masalah “berbohong untuk melanjutkan pengembangan”, dan mempertanyakan banyaknya promosi iklan di komunitas. Pengguna lain menyatakan bahwa dengan mempelajari cara penggunaannya (seperti MCP, templat) dan panduan yang sabar, produktivitas meningkat secara signifikan, terutama dalam menangani kode boilerplate dan proyek C#/.NET. Umpan balik yang umum adalah bahwa bahkan model canggih pun memerlukan panduan dan validasi yang cermat dari pengguna (Sumber: Reddit r/ClaudeAI, finbarrtimbers, cto_junior)
Konten yang dihasilkan AI memicu kekhawatiran “internet mati”, serta diskusi etika AI dan struktur sosial: Komunitas secara luas membahas teori “internet mati” yang mungkin disebabkan oleh meluapnya konten yang dihasilkan AI, yaitu internet dipenuhi informasi yang dihasilkan robot, sehingga ruang komunikasi manusia yang sebenarnya menyusut. Pada saat yang sama, potensi dampak AI terhadap struktur sosial juga memicu pemikiran mendalam. Ada pandangan bahwa AI tidak akan secara sederhana menyebabkan situasi “petani dan raja”, tetapi mungkin menyebabkan “raja” yang memiliki aset AI dan robot dengan “massa” yang secara bertahap menghilang, dan aktivitas ekonomi terkonsentrasi di dalam kalangan elit. Selain itu, GPT-4o dituduh mungkin menggunakan buku-buku O’Reilly yang dilindungi hak cipta untuk pelatihan, dan tren “menjilat” dari asisten AI juga memicu kekhawatiran pengguna tentang etika AI dan keaslian informasi (Sumber: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, DeepLearningAI, Teknium1, scaling01)
Perusahaan aktif berinvestasi dalam pelatihan AI, Duolingo menggunakan GenAI untuk memperluas kursus secara signifikan: Perusahaan media sosial besar dilaporkan menyediakan pelatihan penggunaan ChatGPT bagi karyawan, dengan menyewa profesor dari Universitas California, Berkeley untuk pelatihan Zoom selama 90 menit, dengan biaya $200 per orang per jam, untuk setiap kelompok 120 orang. Ini mencerminkan tren perusahaan yang menganggap penggunaan alat AI sebagai keterampilan dasar. Sementara itu, aplikasi pembelajaran bahasa Duolingo, dengan menggunakan AI generatif, dengan cepat memperluas kursusnya ke 28 bahasa dalam setahun, menambahkan 148 kursus baru, sehingga jumlah total kursusnya meningkat lebih dari dua kali lipat, menunjukkan potensi besar GenAI dalam pembuatan konten dan bidang pendidikan (Sumber: Yuchenj_UW, DeepLearningAI)
Konferensi Insinyur AI (AIE) berfokus pada agen cerdas dan reinforcement learning, membahas perubahan AI pada praktik rekayasa: Pada Pameran Dunia Insinyur AI (AIE) yang baru-baru ini diadakan, agen cerdas (Agents) dan reinforcement learning (RL) menjadi topik inti. Para peserta membahas bagaimana AI mengubah praktik pengkodean dan rekayasa, menekankan pentingnya eksperimen dan evaluasi dalam pengembangan produk AI. CEO Replit, Amjad Masad, berbagi pengalaman perusahaannya tentang bagaimana setelah PHK, mereka mencapai peningkatan produktivitas dan titik balik bisnis dengan sepenuhnya merangkul AI. Konferensi ini juga menampilkan segmen hiburan seperti “Karaoke Pemrograman Suasana”, yang menunjukkan vitalitas komunitas insinyur AI (Sumber: swyx, iScienceLuvr, HamelHusain, amasad, swyx)

Kemajuan baru dalam model dan data open source: Rednote LLM dan lingkungan Atropos RL: Komunitas memperhatikan Rednote LLM yang dibangun berdasarkan tumpukan teknologi DeepSeek V2, yang mengadopsi arsitektur DS-MoE, dengan total parameter 142B dan parameter aktif 14B, tetapi saat ini menggunakan MHA alih-alih GQA/MLA yang lebih efisien. Sementara itu, proyek Atropos (LLM RL Gym) dari NousResearch menambahkan dukungan untuk 101 lingkungan RL penalaran yang menantang di Reasoning Gym, dan telah menghasilkan sekitar 5.500 sampel penalaran yang telah diverifikasi, yang direncanakan untuk digunakan dalam pra-pelatihan Hermes 4, mendorong kontribusi komunitas untuk lebih banyak lingkungan penalaran yang dapat diverifikasi (Sumber: teortaxesTex, Teknium1, kylebrussell)
Kinerja luar biasa model Anthropic pada tugas tertentu dan metode RL menarik perhatian: Diskusi komunitas menunjukkan bahwa model Claude dari Anthropic (seperti Sonnet 3.5/3.7) berkinerja lebih baik daripada model lain (termasuk Opus 4/Sonnet 4) dalam menangani tugas yang berisi obscure webdata tertentu, berspekulasi bahwa model tersebut mungkin menyertakan lebih banyak konten dari forum internet bidang khusus dalam data pelatihannya. Sementara itu, metode kompleks Anthropic dalam reinforcement learning (RL) juga mendapat pengakuan, meskipun beberapa praktik dan optimalisasi metrik di sekitar blog keamanan mendapat beberapa pertanyaan. Ada pandangan bahwa Constitutional AI pada dasarnya adalah RL tingkat lanjut, yang dapat merancang strategi yang terperinci dan dapat dikontrol tanpa label yang di-hardcode (Sumber: teortaxesTex, zacharynado, teortaxesTex, Dorialexander)
💡 Lainnya
Vosk API: Menyediakan fungsionalitas pengenalan suara luring: Vosk API adalah perangkat lunak pengenalan suara luring open source, mendukung lebih dari 20 bahasa dan dialek, termasuk Inggris, Jerman, Mandarin, Jepang, dll. Ukuran modelnya kecil (sekitar 50MB), tetapi dapat menyediakan transkripsi kosakata besar berkelanjutan, respons latensi nol untuk API streaming, dan mendukung kosakata yang dapat dikonfigurasi ulang serta identifikasi pembicara. Vosk menyediakan kemampuan pengenalan suara untuk aplikasi seperti chatbot, rumah pintar, asisten virtual, dan juga dapat digunakan untuk pembuatan subtitle film, transkripsi kuliah dan wawancara, cocok untuk berbagai platform mulai dari Raspberry Pi, perangkat Android hingga server besar (Sumber: GitHub Trending)
Drone otonom untuk pertama kalinya mengalahkan juara manusia dalam balapan: Drone otonom yang dikembangkan oleh Universitas Teknologi Delft mengalahkan juara manusia dalam balapan bersejarah. Pencapaian ini menandai bahwa kemampuan persepsi, pengambilan keputusan, dan kontrol AI dalam lingkungan berkecepatan tinggi dan dinamis telah mencapai tingkat baru, menunjukkan potensi besar AI di bidang robotika dan otomatisasi (Sumber: Reddit r/artificial )

VentureBeat memprediksi empat tren utama AI pada tahun 2025: VentureBeat membuat empat prediksi utama untuk pengembangan di bidang kecerdasan buatan pada tahun 2025. Prediksi ini mungkin mencakup terobosan teknologi, aplikasi pasar, peraturan etika, atau lanskap industri. Detail spesifik perlu dirujuk ke artikel asli. Analisis berwawasan ke depan semacam ini membantu orang-orang di dalam dan di luar industri untuk memahami denyut nadi perkembangan AI (Sumber: Ronald_vanLoon)
