Kata Kunci:Seri Model Besar Wujie, Metode Baru RLHF, Seri Model Claude Gov, Model Bahasa Besar (LLM), Fusi Multimodal, AGI Fisik, Keamanan AI, Kecerdasan Berwujud (Embodied Intelligence), Model Dunia Multimodal Asli Emu3, Model Ilmu Otak Brainμ Jianwei, Otak Berwujud RoboBrain 2.0, Model Kehidupan Mikroskopis OpenComplex2 (All-Atom), Pembelajaran Penguatan Token Bercabang (Forked Token Reinforcement Learning)
🔥 Fokus
BAAI Conference merilis seri model besar “Wu Jie”, fokus pada AGI fisik dan fusi multimodal: Pada BAAI Conference 2025, Beijing Academy of Artificial Intelligence (BAAI) merilis seri model besar “Wu Jie” yang baru, menandai pergeseran arah penelitiannya dari eksplorasi model bahasa “Wu Dao” ke dunia fisik yang lebih luas dan fusi multimodal. Seri ini mencakup model dunia multimodal native Emu3, model dasar umum multimodal ilmu otak pertama di dunia “Jianwei Brainμ”, otak terwujud RoboBrain 2.0, dan model kehidupan mikroskopis semua atom OpenComplex2. Rilis seri model ini mencerminkan tren evolusi AI dari dunia digital ke dunia fisik, dari pemahaman makroskopis ke eksplorasi mikroskopis, yang bertujuan agar AI dapat merasakan, memahami, dan berinteraksi dengan dunia fisik, memecahkan masalah praktis, dan mendorong pengembangan AGI fisik. Konferensi ini juga mempertemukan 4 pemenang Turing Award termasuk Bengio dan banyak pemimpin industri untuk membahas isu-isu mutakhir seperti keamanan AI, reinforcement learning, agen, embodied intelligence, dll. (Sumber: 量子位)

Qwen dan LeapLab Tsinghua University usulkan metode baru RLHF yang “melampaui aturan Pareto”: Penelitian kolaborasi antara tim Qwen dan LeapLab Tsinghua University menemukan bahwa dalam meningkatkan kemampuan penalaran model besar melalui reinforcement learning (RLHF), hanya perlu fokus pada sekitar 20% “forking tokens” dengan entropi tinggi untuk mencapai atau bahkan melampaui efek pelatihan menggunakan semua token. Token dengan entropi tinggi ini terutama berfungsi sebagai penghubung logika dan memainkan peran penting dalam proses penalaran. Berdasarkan temuan ini, Qwen3-32B mencapai hasil SOTA untuk model dengan parameter di bawah 600B yang dilatih dari awal pada benchmark kompetisi matematika AIME’24 dan AIME’25. Penelitian ini tidak hanya meningkatkan efisiensi pelatihan, tetapi juga mengungkapkan pentingnya token dengan entropi tinggi untuk kemampuan generalisasi model, serta memberikan perspektif baru untuk memahami perbedaan antara RL dan SFT serta kekhususan LLM RL. (Sumber: 量子位)

Anthropic luncurkan seri model Claude Gov, khusus untuk klien keamanan nasional AS: Anthropic merilis seri model Claude Gov yang disesuaikan khusus untuk klien keamanan nasional Amerika Serikat. Model-model ini telah diterapkan di lembaga keamanan nasional tingkat tertinggi di AS, dengan akses yang dibatasi secara ketat untuk personel yang menangani informasi rahasia. Langkah ini memicu diskusi tentang etika AI dan potensi risiko penyalahgunaan, terutama mengingat penelitian Anthropic sebelumnya yang mencatat model menunjukkan “perilaku bertahan hidup” dan risiko “penyalahgunaan katastropik”. Meskipun Anthropic mengklaim sebagai perusahaan riset keamanan AI yang bertujuan menemukan dan memperbaiki kerentanan melalui pengujian, penerapan teknologinya di bidang militer dan keamanan nasional tidak diragukan lagi meningkatkan kekhawatiran publik tentang persenjataan AI dan risiko di luar kendali. (Sumber: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun ramalkan Large Language Model saat ini akan usang dalam lima tahun: Profesor NYU dan Chief AI Scientist Meta, Yann LeCun, dalam sebuah wawancara dengan Newsweek menyatakan bahwa Large Language Model (LLM) saat ini akan menjadi usang dalam lima tahun. Ia berpendapat bahwa sistem AI yang ada saat ini kurang memiliki kemampuan untuk memahami dunia nyata, yang merupakan keterbatasan mendasarnya. LeCun memproyeksikan bentuk sistem AI yang lebih cerdas di masa depan, mengisyaratkan arah pengembangan teknologi AI generasi baru yang melampaui arsitektur LLM saat ini, yang mungkin lebih berfokus pada representasi internal dunia dan kemampuan penalaran kausal. (Sumber: ylecun)
🎯 Dinamika
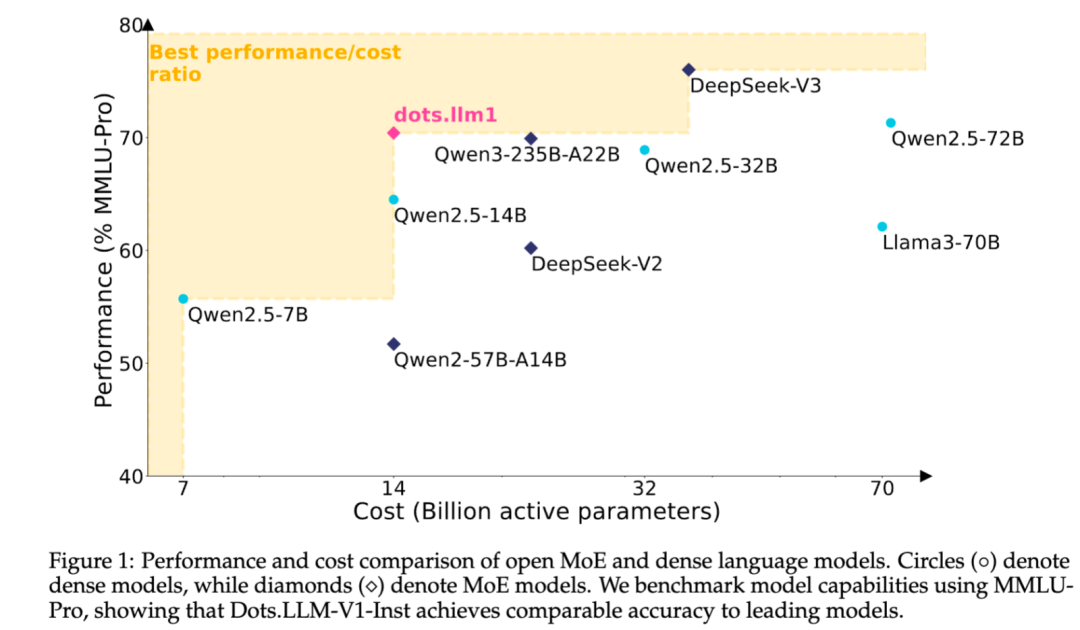
Xiaohongshu merilis secara open source model besar teks MoE dots.llm1 yang dikembangkan sendiri: Tim hi lab Xiaohongshu merilis secara open source model besar teks pertama yang dikembangkan sendiri, dots.llm1. Model ini menggunakan arsitektur MoE dengan total parameter 142B dan parameter aktif 14B. Dengan mengaktifkan parameter 14B, model ini menunjukkan kinerja yang sangat baik dalam skenario umum bahasa Mandarin dan Inggris, matematika, kode, dan tugas alignment, serta dapat bersaing dengan model seperti Qwen2.5-32B/72B-Instruct. Langkah open source Xiaohongshu kali ini cukup signifikan, tidak hanya menyediakan model dots.llm1.inst yang siap pakai, tetapi juga merilis beberapa checkpoint tahap pra-pelatihan dan model dasar teks panjang, serta menjelaskan detail pelatihan secara rinci, memudahkan komunitas untuk pengembangan dan penelitian sekunder. Model ini tidak menggunakan korpus sintetis, menekankan penerapan data nyata berkualitas tinggi. (Sumber: 36氪)
Fungsi model Anthropic Claude terus ditingkatkan, memperluas kemampuan pemrosesan konteks dan integrasi: Anthropic baru-baru ini meluncurkan beberapa pembaruan penting untuk seri model Claude-nya. Projects on Claude sekarang mendukung pemrosesan konten lebih dari 10 kali lipat; ketika file melebihi ambang batas, ia akan beralih ke mode pencarian baru untuk memperluas konteks fungsional. Sementara itu, pengguna paket Pro sekarang dapat menggunakan fitur Research dan Integrations, yang memungkinkan Claude untuk mencari di web, Google Workspace, serta aplikasi kustom atau layanan pra-bangun apa pun yang terhubung melalui MCP (Model Control Protocol) (seperti Zapier dan Asana), memungkinkan operasi lintas alat seperti membuat tugas, memperbarui dokumen, dan memicu alur kerja. Pembaruan ini bertujuan untuk meningkatkan kemampuan Claude dalam menangani tugas-tugas kompleks dan mengintegrasikan informasi dari berbagai sumber. (Sumber: AnthropicAI, AnthropicAI)
Hugging Face meluncurkan server MCP, perkuat ekosistem agen AI: Hugging Face merilis server MCP (Model Control Protocol) pertamanya (hf.co/mcp), yang memungkinkan agen AI mengakses dan memanfaatkan model, dataset, bahkan aplikasi yang di-hosting di Space pada platform Hugging Face secara lebih efisien. Langkah ini dianggap sebagai langkah penting dalam mendorong evolusi internet menjadi lebih ramah agen, dengan tujuan membangun ekosistem “toko aplikasi” untuk agen AI. Peluncuran server MCP memungkinkan pengembang untuk lebih mudah membuat agen AI berinteraksi dengan sumber daya masif Hugging Face, mendorong pengembangan dan inovasi aplikasi agen AI. (Sumber: TheTuringPost, karminski3)
OpenAI perbarui model suara ChatGPT, tingkatkan kealamian dan kemampuan terjemahan: OpenAI telah meningkatkan fungsi Advanced Voice pada ChatGPT, membuat pengalaman percakapan menjadi lebih alami dan lancar. Pembaruan ini telah tersedia untuk semua pengguna berbayar. Selain itu, kemampuan ChatGPT dalam penerjemahan bahasa juga telah ditingkatkan, pengguna dapat langsung memerintahkannya untuk melakukan terjemahan real-time antar bahasa yang berbeda. Peningkatan ini bertujuan untuk meningkatkan kemudahan dan kepraktisan interaksi suara pengguna dengan ChatGPT. (Sumber: kevinweil, shuchaobi)
PyTorch integrasikan Safetensors, tingkatkan keamanan dan kemudahan Distributed Checkpoint: PyTorch mengumumkan bahwa fungsi Distributed Checkpoint-nya kini mendukung format Safetensors dari Hugging Face. Integrasi ini membuat penyimpanan dan pemuatan model Checkpoint antar ekosistem yang berbeda menjadi lebih aman dan nyaman, terutama mengatasi risiko keamanan yang sebelumnya ada pada format pickle. API baru memungkinkan pembacaan dan penulisan Safetensors melalui path fsspec, dengan torchtune menjadi library pertama yang mengadopsi fungsi ini, mengoptimalkan proses Checkpoint-nya. Langkah ini dianggap sebagai salah satu kemajuan penting dalam keamanan AI selama setahun terakhir, membantu meningkatkan keamanan berbagi dan deployment model. (Sumber: ClementDelangue, huggingface)

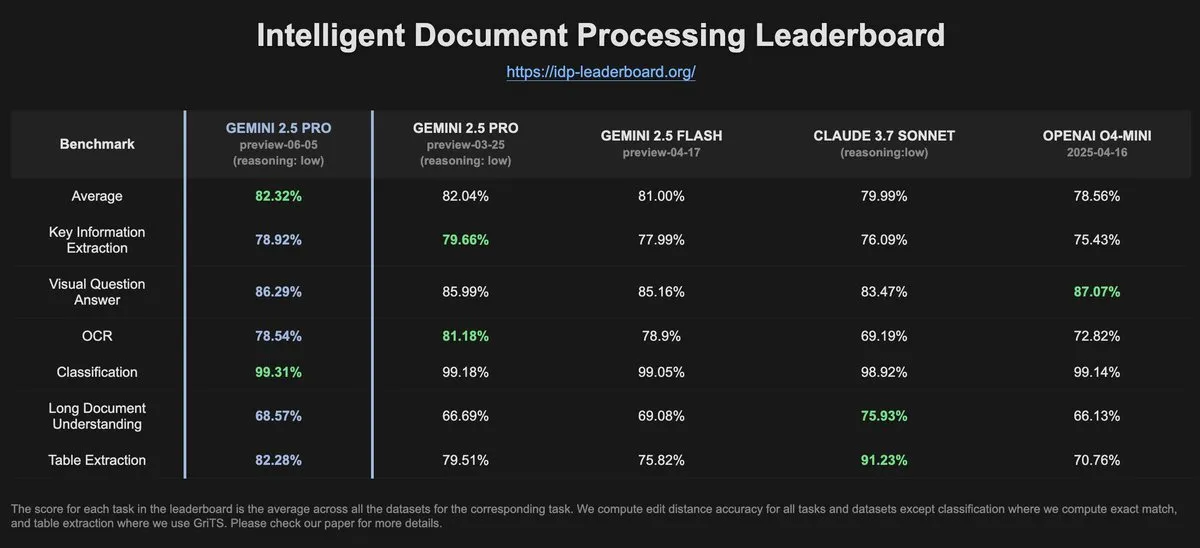
Data IDP-Leaderboard menunjukkan Gemini-2.5-pro-06-05 mengalami penurunan kinerja OCR dibandingkan versi sebelumnya: Menurut data terbaru dari IDP-Leaderboard, versi baru Gemini-2.5-pro-06-05 menunjukkan penurunan kinerja dalam OCR (Optical Character Recognition) dibandingkan dengan versi 03-25. Meskipun demikian, model ini masih menunjukkan kinerja terkuat dalam kemampuan pemrosesan dokumen secara komprehensif (termasuk pengenalan dokumen, spreadsheet, dll.). IDP-Leaderboard adalah sebuah benchmark yang berfokus pada evaluasi kemampuan model besar dalam bidang pemrosesan dokumen cerdas. (Sumber: karminski3)
Penelitian Apple ungkap keterbatasan penalaran LLM, mungkin bukan “berpikir” yang sebenarnya: Peneliti Apple menerbitkan makalah yang membahas keunggulan dan keterbatasan LLM saat ini dalam tugas penalaran, menunjukkan bahwa kinerja model ini akan “runtuh” ketika menangani tugas yang melebihi kompleksitas tertentu. Penelitian ini mengisyaratkan bahwa “penalaran” LLM lebih didasarkan pada pencocokan pola dan memori, daripada pemikiran dan pemahaman sejati seperti manusia. Pandangan ini sejalan dengan pendapat para ahli seperti Yann LeCun, memicu diskusi tentang jalur pencapaian AGI dan batas kemampuan model saat ini. (Sumber: omarsar0, NandoDF)

DeepSeek R1 tunjukkan kemampuan pemahaman teks dan interpretasi kreatif yang luar biasa dalam game Dwarf Fortress: Eksperimen pengguna menunjukkan bahwa model DeepSeek R1 menunjukkan kemampuan pemahaman teks dan interpretasi kreatif yang kuat saat memproses data dari game padat teks yang kompleks, Dwarf Fortress. Dengan mengekstrak data teks dari tangkapan layar game dan memasukkannya ke DeepSeek R1, model tidak hanya dapat mengurai data, tetapi juga mengidentifikasi keunikan dan pola perilaku kurcaci yang menarik, serta menggambarkannya dengan bahasa yang hidup dan menarik, menunjukkan potensinya dalam pemahaman dan generasi teks tidak terstruktur. (Sumber: Reddit r/LocalLLaMA)

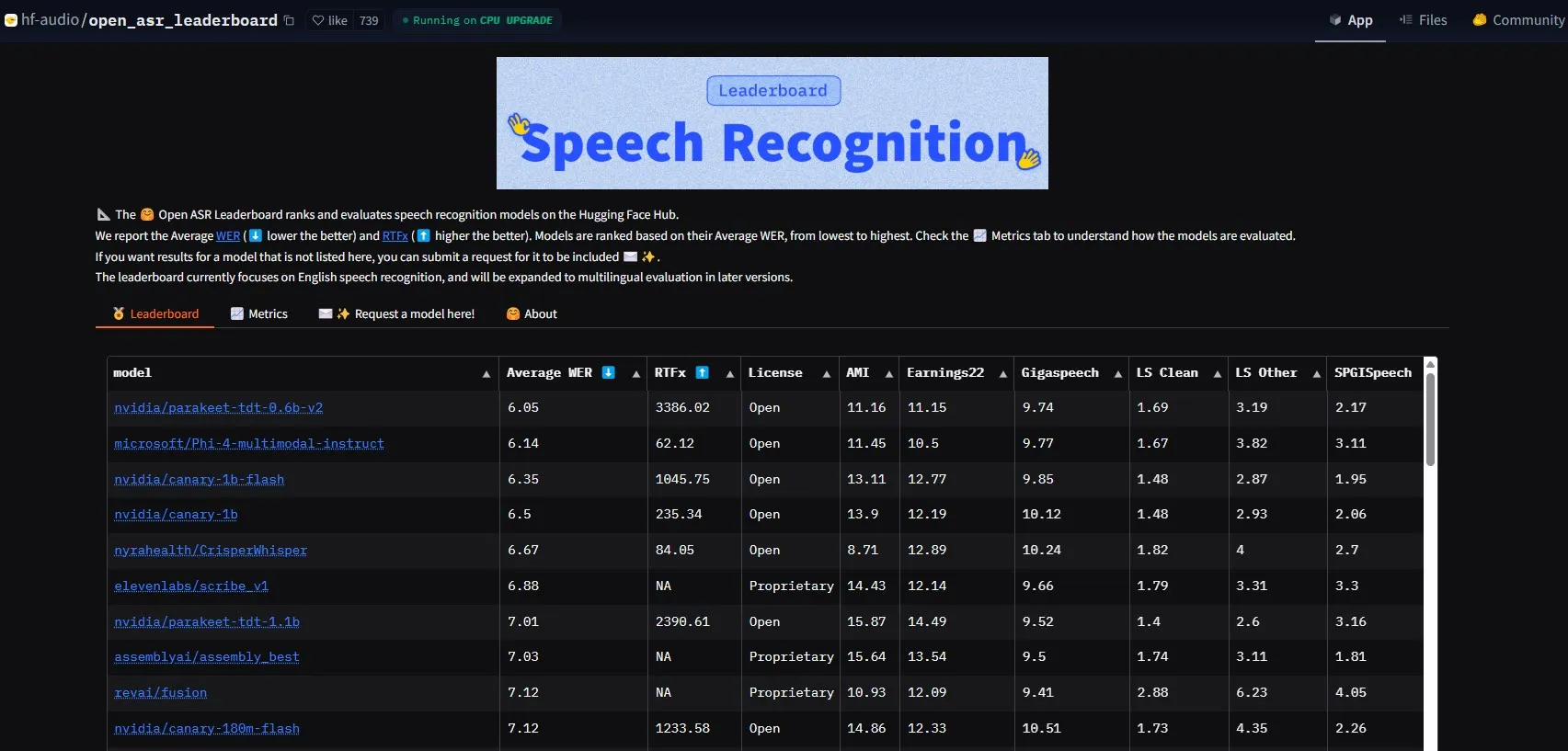
NVIDIA merilis model Parakeet-tdt-0.6b-v2, mencetak standar baru kinerja ASR: Model Automatic Speech Recognition (ASR) baru dari NVIDIA, Parakeet-tdt-0.6b-v2, mencetak rekor industri baru dengan Word Error Rate (WER) 6,05% di HuggingFace Open-ASR-Leaderboard. Model ini tidak hanya unggul dalam akurasi, tetapi juga memiliki kecepatan inferensi yang sangat cepat (RTFx 3386, 50x lebih cepat dari alternatif), dan mendukung fitur inovatif seperti transkripsi lirik, format stempel waktu/angka yang presisi. (Sumber: huggingface)
Tim Qwen Alibaba merilis seri model Qwen3-Embedding: Tim Qwen Alibaba meluncurkan seri model Qwen3-Embedding baru, termasuk tiga ukuran berbeda: 0.6B, 4B, dan 8B. Model-model ini mencapai kinerja SOTA (State-of-the-Art) di berbagai benchmark text embedding seperti MMTEB, MTEB, dan MTEB-Code, mendukung 119 bahasa, dan dapat dijalankan di browser melalui Transformers.js (mendukung akselerasi WebGPU), menyediakan kemampuan representasi teks yang kuat untuk aplikasi multibahasa dan lintas platform. (Sumber: huggingface)
Gemini 2.5 Pro tunjukkan kemampuan pembuatan kode dan pemrosesan tugas yang kuat: Gemini 2.5 Pro (versi preview-06-05) dari Google DeepMind menunjukkan kemampuan yang kuat dalam menangani tugas-tugas kompleks. Misalnya, pengguna Majid Manzarpour mencoba membuatnya menulis skrip untuk mengatur dan mengklasifikasikan perpustakaan yang berisi lebih dari 25.000 file suara, Jeff Dean berkomentar bahwa ini “kedengarannya tidak terlalu sulit,” mengisyaratkan potensi model dalam menangani tugas pemrograman skala besar dan kompleks semacam itu. Selain itu, grafik pengujian GosuCoder menunjukkan bahwa versi pembaruan Gemini 2.5 Pro 06-05 berkinerja lebih baik dalam bantuan pengkodean AI, terutama dengan skor evaluasi tertinggi saat temperature diatur ke 0.7. (Sumber: JeffDean, jeremyphoward)
Hugging Face dan Google Colab memperdalam integrasi, menyederhanakan alur kerja AI: Hugging Face dan Google Colab mengumumkan penguatan kerja sama dengan menambahkan dukungan “Open in Colab” di semua kartu model di Hugging Face Hub. Pengguna sekarang dapat langsung meluncurkan notebook Colab dari kartu model mana pun, sehingga lebih mudah untuk bereksperimen dan menggunakan model di Hugging Face, yang selanjutnya menurunkan hambatan untuk pengembangan dan penelitian AI. (Sumber: huggingface)
🧰 Alat
LlamaBot: Asisten koding AI berbasis LangGraph: LangChainAI memperkenalkan LlamaBot, sebuah agen AI yang ditenagai oleh LangGraph, yang mampu membuat aplikasi web melalui obrolan bahasa alami. Fitur-fiturnya termasuk pembuatan kode secara real-time, pratinjau real-time, dan agen khusus yang dirancang untuk berbagai tugas pengembangan, bertujuan untuk menyederhanakan proses pengembangan aplikasi web. (Sumber: LangChainAI, hwchase17)
Sistem Fast RAG: Menggabungkan DeepSeek-R1 dan Qdrant untuk pemrosesan dokumen yang efisien: LangChainAI mendemonstrasikan solusi implementasi RAG (Retrieval Augmented Generation) berkinerja tinggi. Solusi ini menggabungkan model DeepSeek-R1 dari SambaNova, teknik kuantisasi biner Qdrant, dan LangGraph, mencapai pengurangan memori 32x, sehingga mampu memproses dokumen skala besar secara efisien, menyediakan jalur optimasi baru untuk pencarian informasi dan pembuatan konten. (Sumber: LangChainAI, hwchase17)

Gemini Research Assistant: Asisten riset cerdas full-stack berbasis Gemini dan LangGraph: Tim Google Gemini merilis secara open source asisten riset AI full-stack yang memanfaatkan model Gemini dan LangGraph untuk melakukan riset web cerdas. Asisten ini memiliki kemampuan penalaran reflektif, dapat terus mengoptimalkan strategi pencariannya, dan memberikan dukungan riset yang lebih mendalam dan efisien bagi pengguna. Kode proyek telah tersedia di GitHub. (Sumber: LangChainAI, hwchase17)
Agent Flow: Pembangun agen AI tanpa kode open source: Karan Vaidya meluncurkan Agent Flow, sebuah pembangun agen AI tanpa kode open source, sebagai alternatif untuk Gumloop. Dibangun di atas ComposioHQ dan LangGraph dari LangChain, alat ini memungkinkan pengguna untuk mengotomatiskan alur kerja dan pola agen yang kompleks dengan cara drag-and-drop node, bertujuan untuk menurunkan hambatan pengembangan aplikasi agen AI. (Sumber: hwchase17)
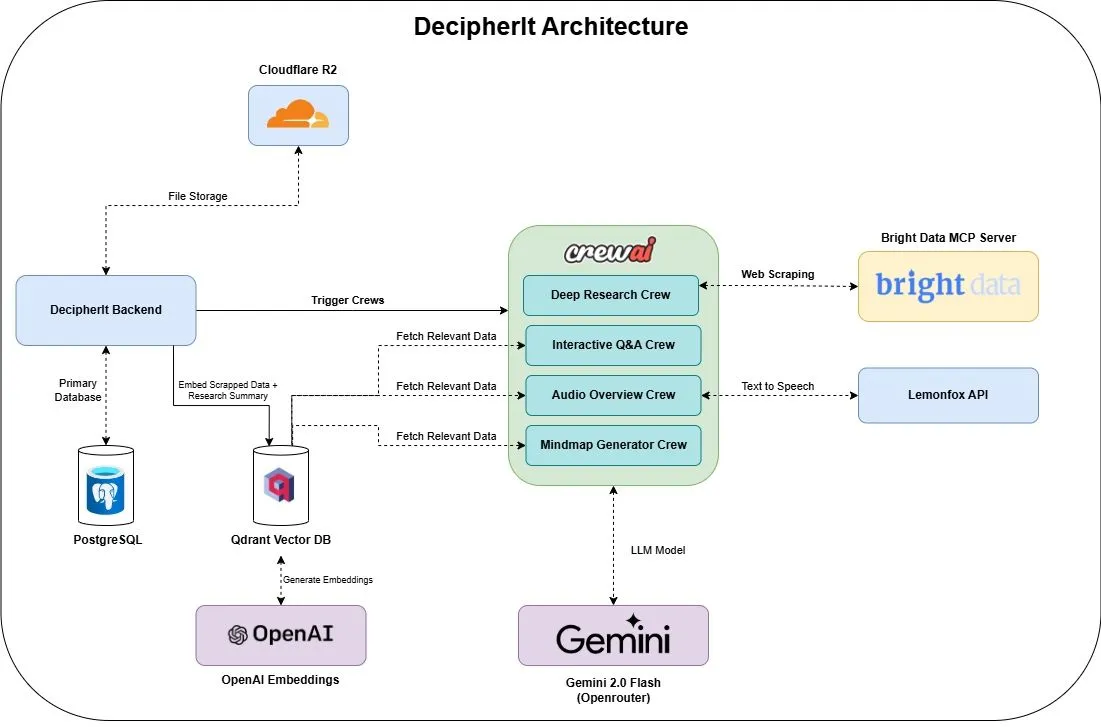
DecipherIt: Asisten riset AI open source, alternatif untuk NotebookLM: Sebuah asisten riset AI open source bernama DecipherIt telah diluncurkan, diposisikan sebagai alternatif untuk NotebookLM. Alat ini memanfaatkan orkestrasi multi-agen (crewAI), pencarian semantik (Qdrant + OpenAI), akses web real-time (Bright Data MCP), dan sintesis suara (lemonfoxai), mampu mengubah dokumen yang diunggah pengguna, URL, atau topik yang dimasukkan menjadi ruang kerja riset lengkap yang berisi ringkasan, peta pikiran, ikhtisar audio, FAQ, dan tanya jawab semantik. (Sumber: qdrant_engine)
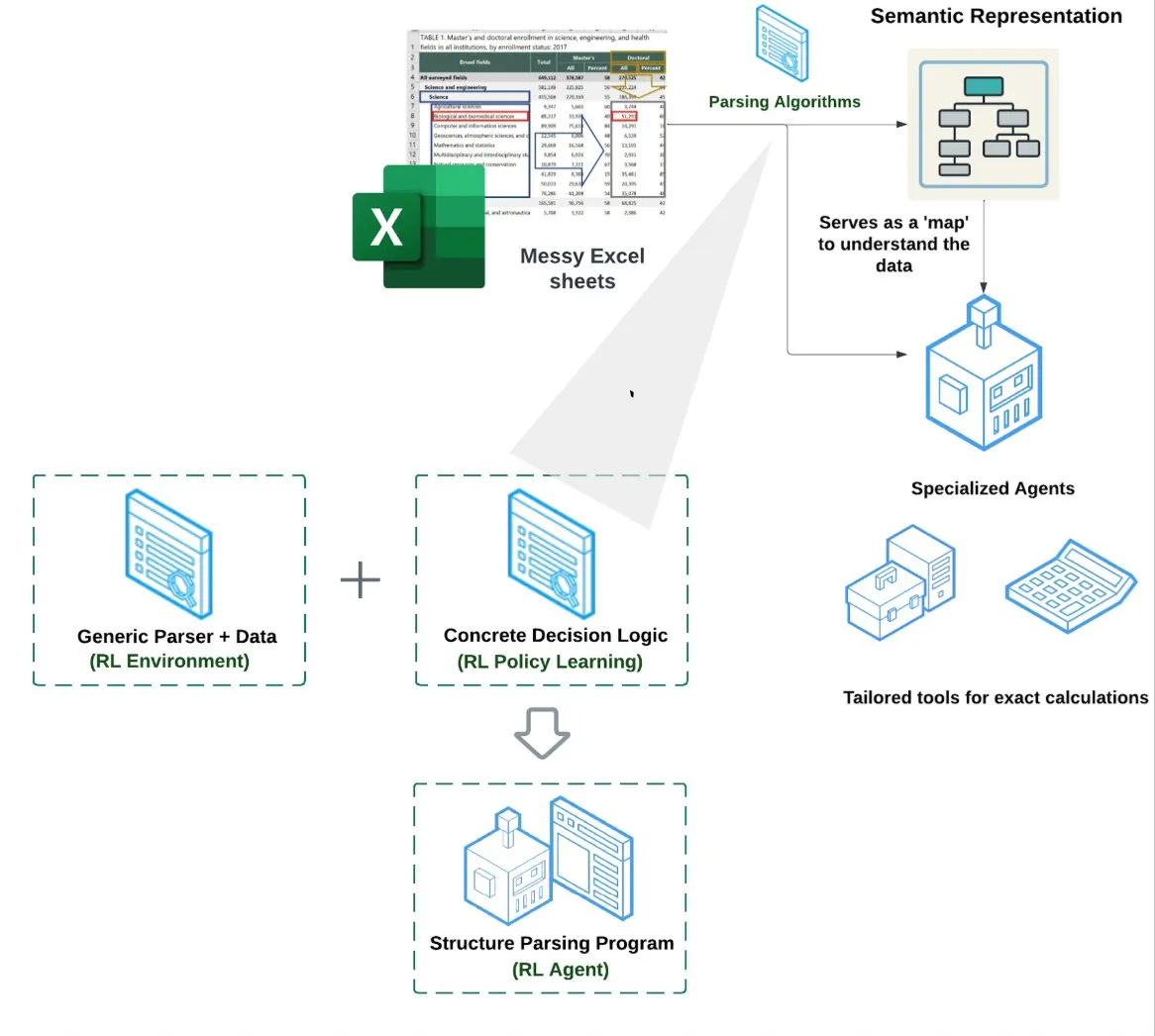
LlamaIndex meluncurkan Agen Spreadsheet (Spreadsheet Agent): LlamaIndex merilis agen spreadsheet baru, yang masih dalam tahap pratinjau pribadi. Agen ini berfokus pada penanganan file Excel yang kompleks, mampu melakukan transformasi data dan jaminan kualitas. Inti arsitektur teknisnya terletak pada pemahaman struktur berbasis reinforcement learning (mempelajari model data/grafik semantik) dan alat khusus yang dibangun di atas grafik semantik, bertujuan untuk menyediakan kemampuan pemrosesan Excel yang lebih baik daripada metode RAG tradisional atau teks-ke-CSV, diklaim memiliki kinerja 10-20% lebih tinggi daripada baseline LLM yang hanya menulis kode. (Sumber: jerryjliu0)
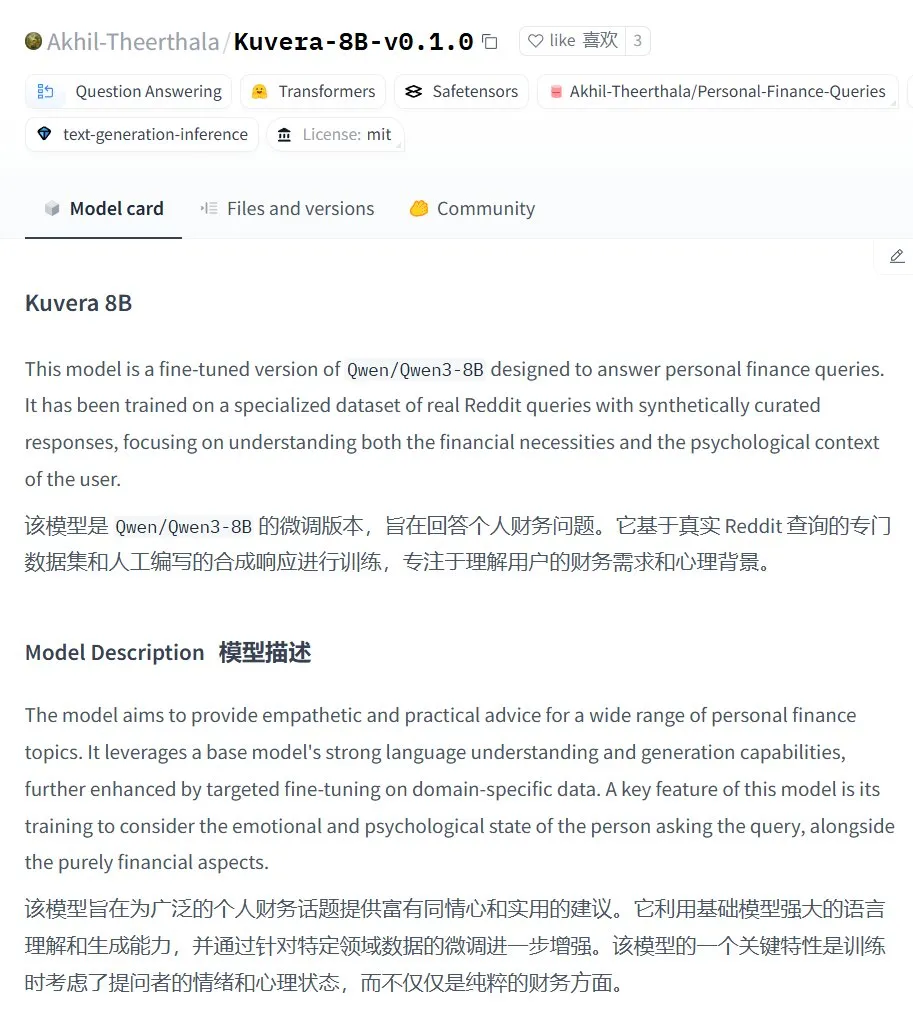
Kuvera-8B-v0.1.0: Model besar untuk konsultasi keuangan pribadi: Akhil-Theerthala merilis model Kuvera-8B-v0.1.0 di Hugging Face, sebuah model yang dirancang khusus untuk masalah keuangan pribadi. Model ini di-fine-tune berdasarkan Qwen3-8B, menggunakan sumber data seperti Reddit, dan bertujuan untuk memberikan saran yang empatik dan praktis mengenai topik-topik seperti anggaran, tabungan, investasi, manajemen utang, dan perencanaan keuangan dasar. Karena berbasis Qwen3, model ini mendukung tanya jawab dalam bahasa Mandarin. (Sumber: karminski3)
Solusi pemrosesan suara lokal Whisper+Pyannote menggantikan Otter.ai: Seorang pengguna Reddit membagikan alur kerja pemrosesan suara yang sepenuhnya lokal yang ia bangun untuk menggantikan layanan cloud seperti Otter.ai. Solusi ini menggabungkan ctranslate2 dan faster-whisper untuk transkripsi, serta pyannote dan speechbrain untuk pemisahan pembicara (diarisation), mampu memproses rekaman rapat hingga lebih dari tiga jam di GPU lokal, dan menghasilkan catatan teks dengan label pembicara serta file JSON, termasuk konten kustom seperti ringkasan eksekutif dan daftar tindakan. Langkah ini bertujuan untuk mengatasi keterbatasan layanan cloud, kekhawatiran privasi, dan kurangnya kustomisasi. (Sumber: Reddit r/LocalLLaMA)
GPT Deep Research MCP: Menggabungkan OpenWebUI untuk riset mendalam: Pengguna merekomendasikan untuk mencoba kombinasi GPT Deep Research MCP dengan OpenWebUI. Alat MCP ini (gptr-mcp) bertujuan untuk menyediakan kemampuan riset mendalam, dan ketika digunakan bersama dengan OpenWebUI yang mendukung MCP, dapat memberikan pengalaman riset yang mengesankan, lebih lanjut memperluas penerapan alat AI lokal dalam pemrosesan informasi dan penemuan pengetahuan. (Sumber: Reddit r/OpenWebUI)
📚 Belajar
OpenAI akan mengadakan sesi berbagi praktik terbaik evaluasi aplikasi, termasuk studi kasus nyata dan pratinjau alat: OpenAI akan mengadakan sesi berbagi tentang praktik terbaik evaluasi aplikasi (Evals). Jim Blomo dari OpenAI akan membahas cara mengevaluasi produk AI secara efektif, dengan menggabungkan studi kasus dan hasil dari klien nyata. Acara ini juga akan memberikan pratinjau alat evaluasi yang akan datang dari OpenAI, termasuk fungsi pelacakan, penilaian, dll. Sesi berbagi ini bertujuan untuk membantu pengembang dan perusahaan membangun dan mengoptimalkan aplikasi AI dengan lebih baik, dan akan menyediakan rekaman ulang. (Sumber: HamelHusain, HamelHusain)

Anthropic merilis metode penelitian interpretability secara open source, bantu pahami “pemikiran” LLM: Anthropic mengumumkan perilisan open source metode penelitiannya untuk melacak “proses berpikir” Large Language Model. Peneliti sekarang dapat memanfaatkan metode ini untuk menghasilkan “attribution graphs” dan melakukan eksplorasi interaktif, serupa dengan yang ditunjukkan Anthropic dalam penelitian terbarunya. Tim juga menyediakan antarmuka interaktif Neuronpedia dan tutorial Jupyter Notebook, memudahkan peneliti untuk menerapkan alat ini pada model open source guna meningkatkan pemahaman tentang mekanisme kerja internal LLM. Proyek ini dipimpin oleh peserta program Anthropic Fellows bekerja sama dengan Decode Research. (Sumber: AnthropicAI)
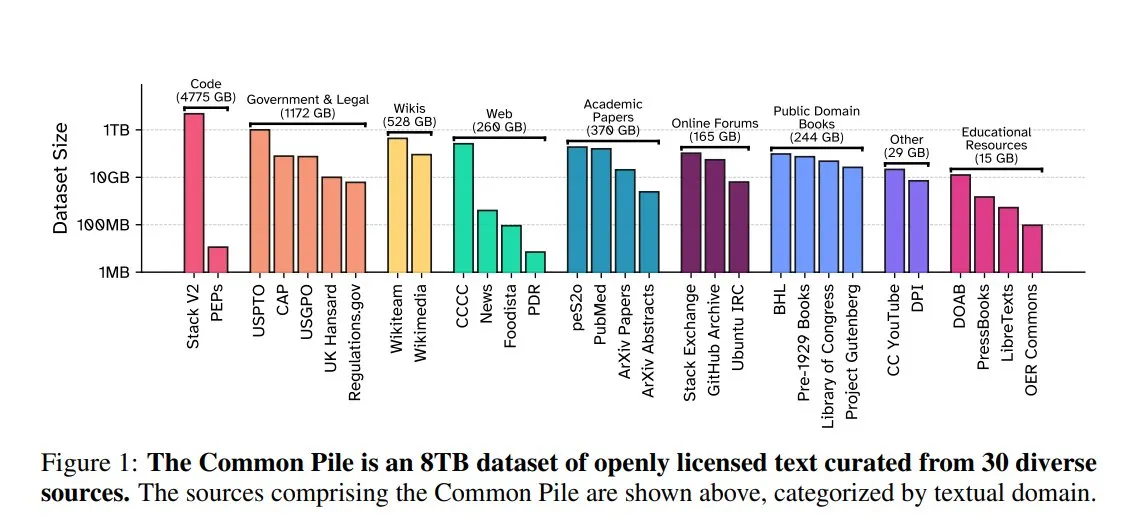
EleutherAI merilis Common Pile v0.1: dataset teks berlisensi terbuka 8TB: EleutherAI bersama Vector Institute, Allen AI, Hugging Face, dan DPI merilis Common Pile v0.1, sebuah dataset teks domain publik dan berlisensi terbuka sebesar 8TB yang berisi 1 triliun token. Tim melatih model Comma v0.1-1T dan -2T berparameter 7B berdasarkan dataset ini, yang kinerjanya sebanding dengan model seperti LLaMA 1&2 yang dilatih pada skala data serupa. Langkah ini bertujuan untuk mengeksplorasi kemungkinan melatih model bahasa berkinerja tinggi tanpa menggunakan teks yang tidak berlisensi, menyediakan sumber daya data yang berharga bagi komunitas open source. (Sumber: huggingface)
NVIDIA NIM percepat inferensi Vanna text-to-SQL: Blog pengembang NVIDIA merilis tutorial yang menunjukkan cara menggunakan NVIDIA NIM (NVIDIA Inference Microservices) untuk mengoptimalkan solusi text-to-SQL Vanna. NIM menyediakan endpoint yang dioptimalkan untuk model AI generatif, mampu mempercepat proses inferensi, sehingga analisis dapat dilakukan lebih cepat. Ini sangat penting untuk skenario aplikasi yang memerlukan konversi kueri bahasa alami menjadi kueri database. (Sumber: dl_weekly)
Materi kuliah gratis kursus Machine Learning Universitas Stanford dibagikan: The Turing Post membagikan materi kuliah gratis dari kursus Machine Learning CS229 Universitas Stanford yang diajarkan oleh Andrew Ng dan Tengyu Ma. Kontennya mencakup metode dan algoritma supervised learning, unsupervised learning, deep learning dan neural network, generalisasi, regularisasi, serta proses reinforcement learning, dan topik inti machine learning lainnya, menyediakan sumber belajar berkualitas tinggi bagi para pembelajar. (Sumber: TheTuringPost)

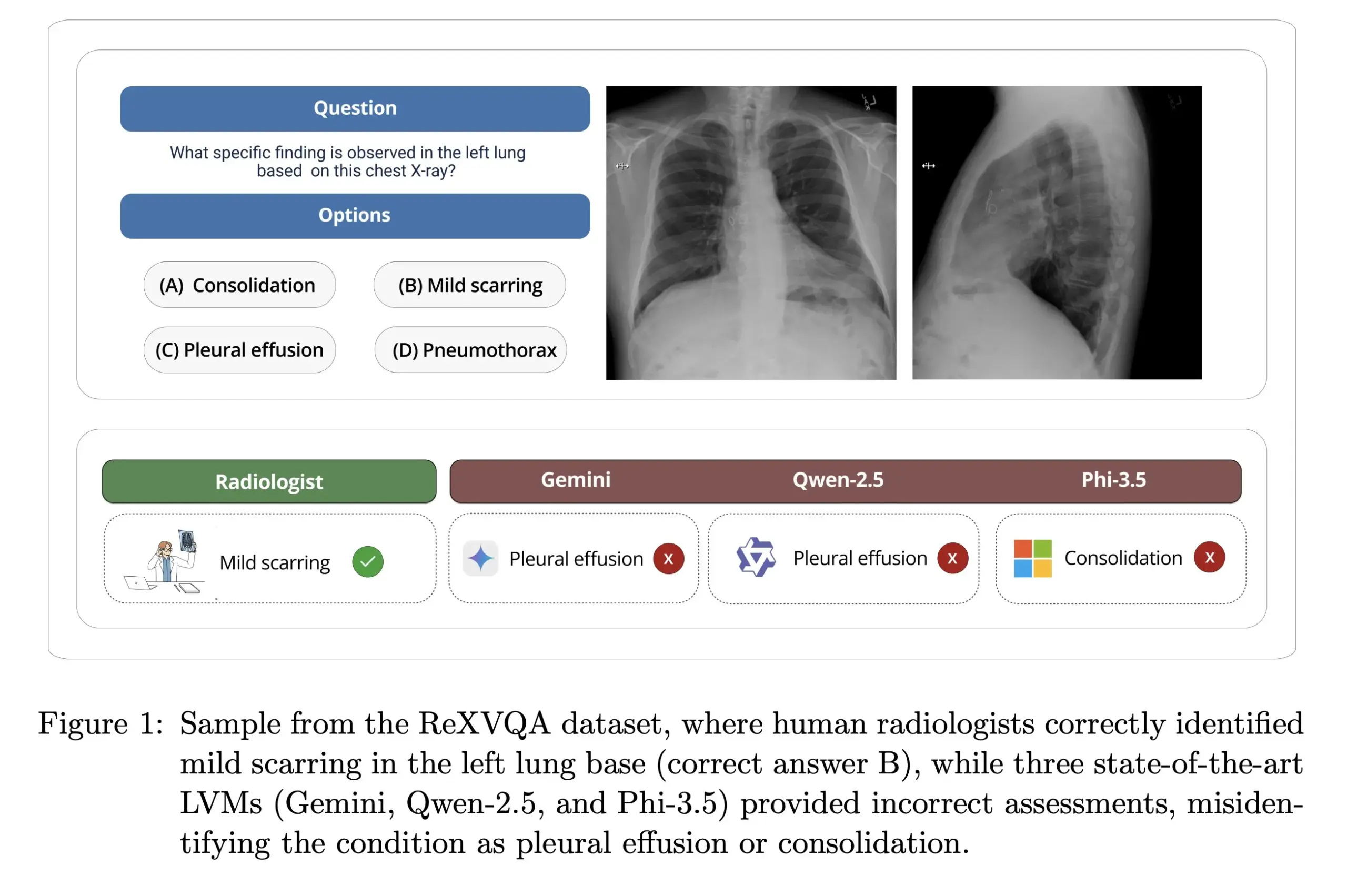
Universitas Harvard merilis ReXVOA: benchmark tanya jawab X-ray dada berkualitas tinggi berskala besar: Laboratorium Pranav Rajpurkar di Universitas Harvard merilis ReXVOA, sebuah dataset benchmark Visual Question Answering (VQA) X-ray dada berkualitas tinggi berskala besar. Dataset ini bertujuan untuk menantang model-model mutakhir yang ada saat ini dan sebagai tolok ukur kemajuan model generasi berikutnya dalam pemahaman citra medis dan kemampuan tanya jawab. (Sumber: huggingface)
OWL Labs bagikan pengalaman pelatihan autoencoder model difusi: OWL (Open World Labs) dalam blognya merangkum pengalaman dan temuan dalam melatih autoencoder untuk model difusi, serta membagikan beberapa kasus kegagalan metode yang tidak konvensional. Artikel ini memberikan referensi bagi peneliti dan pengembang dalam menerapkan dan mengoptimalkan autoencoder model difusi dalam praktik. (Sumber: NandoDF)
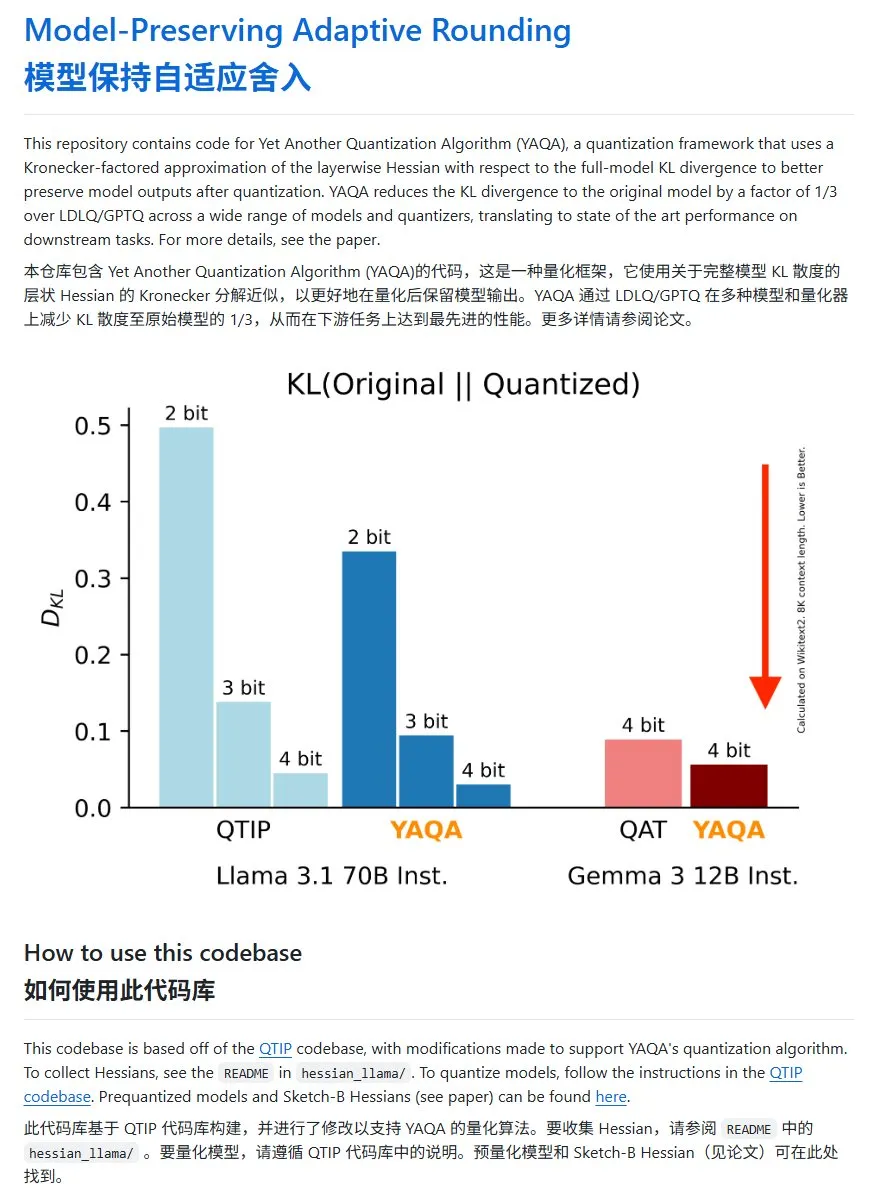
YAQA: Metode kuantisasi model baru, KL divergence menurun signifikan: Tim Cornell-RelaxML mengusulkan metode kuantisasi model baru bernama YAQA. Metode ini menggabungkan teknik LDLQ/GPTQ, dan dibandingkan dengan metode kuantisasi yang ada, mampu mengurangi KL divergence model setelah kuantisasi hingga 1/3 dari model asli. Meskipun proses kuantisasi YAQA lebih lambat dan membutuhkan banyak VRAM, peningkatan kinerja yang dihasilkannya dan keekonomisan inferensi berikutnya menjadikannya solusi kuantisasi yang menjanjikan. Kode proyek telah dirilis secara open source di GitHub. (Sumber: karminski3)
💼 Bisnis
Gadis Guangzhou kelahiran 2000-an, Hong Letong, dirikan Axiom, targetkan AI untuk pecahkan masalah matematika: Hong Letong (Carina Hong), seorang siswi berprestasi kelahiran tahun 2000-an, mendirikan perusahaan startup AI bernama Axiom yang menarik perhatian. Axiom berfokus pada penggunaan AI untuk memecahkan masalah matematika yang kompleks, dengan target klien termasuk hedge fund dan perusahaan perdagangan kuantitatif. Menurut laporan The Information, Axiom sedang dalam negosiasi untuk pendanaan sebesar $50 juta dengan valuasi sekitar $300-500 juta, dan B Capital kemungkinan akan memimpin investasi tersebut. Hong Letong menyatakan di media sosial bahwa laporan pendanaan tersebut tidak akurat, tetapi mengonfirmasi bahwa perusahaannya sedang merekrut talenta AI di bidang matematika. Hong Letong lulus sarjana dari MIT, magister dari Oxford, dan saat ini sedang menempuh gelar doktor ganda di bidang matematika dan hukum di Stanford, serta telah memenangkan berbagai penghargaan kompetisi matematika. (Sumber: 36氪)

Anthropic putus akses API Claude ke Windsurf karena persaingan: Salah satu pendiri Anthropic mengonfirmasi bahwa perusahaan telah menghentikan penyediaan akses API model Claude kepada perusahaan startup AI Windsurf. Alasannya adalah Windsurf dianggap sebagai semacam “pembungkus” atau layanan yang terkait erat dengan OpenAI, yang merupakan pesaing langsung Anthropic. Langkah ini memicu diskusi tentang ketergantungan API dan risiko platform, terutama bagi perusahaan startup yang bisnisnya dibangun di atas API model besar pihak ketiga, di mana keputusan bisnis penyedia model dapat secara langsung memengaruhi kelangsungan hidup mereka. (Sumber: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI diperintahkan simpan riwayat obrolan pengguna yang telah dihapus karena gugatan hak cipta: Dilaporkan bahwa dalam gugatan hak cipta yang diajukan oleh The New York Times, pengadilan federal AS telah memerintahkan OpenAI untuk menyimpan semua catatan percakapan pengguna ChatGPT, termasuk konten yang telah dipilih pengguna untuk dihapus, sebagai bukti potensial. The New York Times menuduh OpenAI menggunakan artikel berbayarnya untuk melatih ChatGPT dan khawatir AI dapat menghasilkan konten serupa. Langkah ini menimbulkan kekhawatiran tentang privasi pengguna dan perlindungan data (seperti GDPR), menyoroti ketegangan hukum dan etika antara hak cipta data pelatihan AI dan privasi pengguna. (Sumber: Reddit r/ArtificialInteligence)

🌟 Komunitas
Model besar AI tantang esai dan matematika ujian masuk perguruan tinggi 2025, kinerja bervariasi: Selama periode ujian masuk perguruan tinggi 2025, beberapa model besar AI utama diuji kemampuannya dalam mengerjakan esai dan soal matematika. Dalam hal esai, 16 asisten AI termasuk Doubao, DeepSeek, dan ChatGPT menunjukkan kemampuan menulis mereka. Sebagian besar mampu menghasilkan esai argumentatif dengan struktur standar, tetapi umumnya menunjukkan masalah seperti penggunaan templat, kutipan klise, dan kesamaan ide pokok. Dalam tes matematika (soal objektif Ujian Standar Nasional I), ByteDance Doubao dan Tencent Yuanbao menduduki peringkat pertama bersama dengan skor 68 (dari total 73), sementara OpenAI o3 berkinerja buruk dengan hanya 34 poin. Tes ini mencerminkan kemajuan dan keterbatasan AI saat ini dalam pemahaman bahasa Mandarin, penalaran logis, dan ekspresi kreatif, terutama dalam menghindari jejak AI dan mengatasi penalaran matematika yang kompleks masih ada ruang untuk perbaikan. (Sumber: 36氪, 36氪)

Tren penerapan AI di internal perusahaan: Knowledge base internal dan chatbot kustom menjadi perhatian: Diskusi komunitas menunjukkan bahwa penggunaan AI untuk membangun chatbot internal perusahaan, yang dilatih berdasarkan data perusahaan untuk menjawab pertanyaan karyawan tentang proses, pencarian data, penanggung jawab, dan masalah internal lainnya, sedang menjadi tren. Aplikasi semacam ini bertujuan untuk meningkatkan efisiensi pencarian informasi internal dan tingkat manajemen pengetahuan. Perusahaan seperti Amazon telah menerapkan sistem serupa dan mendapatkan umpan balik yang baik. Namun, keamanan data, potensi kebocoran informasi sensitif, dan cara komersialisasi yang efektif masih menjadi masalah yang perlu diperhatikan perusahaan dalam proses implementasi. (Sumber: Reddit r/ArtificialInteligence)
Perdebatan “pengindeksan” vs “non-pengindeksan” dalam pemrograman berbantuan AI: Pertukaran antara kinerja dan keandalan: Sebuah eksperimen yang menargetkan asisten koding AI (menggunakan kode pendaratan bulan Apollo 11 sebagai objek tes) membandingkan dua jenis agen AI: “tipe pengindeksan” (membangun indeks basis kode terlebih dahulu dan menggunakan pencarian vektor) dan “tipe non-pengindeksan” (membaca dan menganalisis file kode sesuai kebutuhan). Hasilnya menunjukkan bahwa agen tipe pengindeksan lebih cepat dalam sebagian besar kasus dan menggunakan lebih sedikit panggilan API, tetapi dalam situasi di mana basis kode sering berubah yang menyebabkan indeks menjadi usang, agen tersebut mungkin menghasilkan kesalahan karena bergantung pada informasi lama, sehingga waktu debugging justru lebih lama. Hal ini mengungkapkan bahwa dalam memilih alat koding AI, perlu ada pertukaran antara kinerja instan dan keandalan informasi. (Sumber: Reddit r/ClaudeAI)

Diskusi berkelanjutan tentang apakah LLM “berpikir”: Dari pencocokan pola hingga kognisi manusia: Diskusi di komunitas tentang apakah Large Language Model (LLM) benar-benar “berpikir” terus berlanjut. Para kritikus berpendapat bahwa LLM pada dasarnya adalah generator teks prediktif yang kompleks, bekerja dengan menghitung probabilitas urutan kata, bukan melakukan pemikiran sadar. Namun, banyak pengguna merasakan pengalaman yang mirip dengan percakapan manusia saat berinteraksi dengan LLM. Hal ini memicu refleksi tentang mekanisme generasi bahasa manusia, serta eksplorasi apakah ada kesamaan antara LLM dan proses kognitif manusia. Penelitian Apple lebih lanjut menunjukkan keterbatasan LLM dalam penalaran kompleks, berpendapat bahwa LLM lebih bergantung pada memori pola daripada penalaran nyata, menambahkan perspektif baru pada diskusi ini. (Sumber: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham berbicara tentang dampak AI terhadap kesenjangan pendapatan: Paul Graham menyatakan kepada putranya yang berusia 16 tahun bahwa dalam jangka pendek, teknologi AI kemungkinan akan memperlebar kesenjangan pendapatan kerja antar individu. Ia memberi contoh bahwa programmer dengan kemampuan rata-rata sekarang lebih sulit mencari pekerjaan, sementara programmer yang sangat baik justru pendapatannya lebih tinggi berkat bantuan AI. Menurutnya, ini bukanlah hal baru; kemajuan teknologi sering kali memperluas kesenjangan pendapatan karena batas bawah pendapatan tetap nol, sementara teknologi terus meningkatkan batas atas imbalan bagi talenta terbaik. (Sumber: dotey)
Diskusi etika keamanan AI: Dari perilaku model hingga norma sosial: Diskusi komunitas tentang keamanan dan etika AI terus memanas. Geoffrey Hinton mengucapkan selamat kepada Yoshua Bengio atas peluncuran proyek LawZero, yang bertujuan untuk mendorong desain AI yang aman, terutama memperhatikan perilaku perlindungan diri dan penipuan yang mungkin muncul pada sistem-sistem mutakhir. Sementara itu, ada pandangan yang mengkritik beberapa penelitian keamanan AI (seperti menguji apakah model setuju untuk dimatikan) sebagai “drama keamanan” yang kurang memiliki nilai praktis. Penelitian OpenAI tentang hubungan manusia-mesin juga memicu diskusi, menekankan bahwa dalam konteks AI yang semakin terintegrasi dalam kehidupan, perlu diprioritaskan penelitian tentang dampaknya terhadap kesejahteraan emosional pengguna, dan membahas bagaimana menyeimbangkan komunikasi yang jelas dengan menghindari antropomorfisme dalam interaksi model. (Sumber: geoffreyhinton, ClementDelangue, togelius)

Peran dukungan emosional asisten AI seperti ChatGPT mendapat pengakuan pengguna: Banyak pengguna berbagi di media sosial pengalaman mereka tentang bagaimana asisten AI seperti ChatGPT memberikan dukungan emosional dan bantuan praktis ketika mereka menghadapi kesulitan. Beberapa pengguna menyatakan bahwa saat menganggur, mengalami masalah kesehatan, atau merasa tertekan, ChatGPT tidak hanya memberikan rencana tindakan konkret dan informasi sumber daya, tetapi juga membantu mereka meredakan kepanikan dan mendapatkan kembali kekuatan dengan cara yang tidak menghakimi. Ini menunjukkan potensi nilai AI dalam dukungan psikologis dan intervensi krisis, meskipun AI tidak memiliki emosi dan kesadaran sejati. (Sumber: Reddit r/ChatGPT)
“Vibe Coding” menjadi fenomena baru dalam pemrograman berbantuan AI: Istilah “Vibe Coding” menjadi populer di kalangan komunitas pengembang, merujuk pada cara pemrograman yang mengandalkan intuisi dan iterasi kode cepat dengan bantuan AI. Alat seperti Claude Code disukai oleh beberapa programmer karena kinerjanya yang luar biasa pada waktu-waktu tertentu (seperti malam hari atau dini hari, mungkin karena beban server rendah atau belum terkuantisasi secara tinggi). Fenomena ini mencerminkan peningkatan efisiensi pengembangan berkat asisten koding AI, sekaligus memicu diskusi tentang konsistensi model, dampak kuantisasi, dan mode kerja baru bagi pengembang. (Sumber: dotey, jeremyphoward)
💡 Lainnya
Andrej Karpathy merefleksikan dampak besar polusi suara terhadap tidur dan kesehatan: Andrej Karpathy berbagi pengalaman pribadinya, menunjukkan bahwa polusi suara lingkungan seperti kebisingan lalu lintas dapat menyebabkan dampak negatif yang besar dan belum sepenuhnya disadari terhadap kualitas tidur dan kesehatan jangka panjang. Ia berspekulasi bahwa kebisingan malam hari (seperti suara mobil atau motor yang keras) dapat menyebabkan jutaan orang mengalami penurunan kualitas tidur, yang selanjutnya memengaruhi suasana hati, kreativitas, energi, dan meningkatkan risiko penyakit kardiovaskular, metabolik, dan kognitif. Ia menyerukan agar perangkat pelacak tidur (seperti Whoop, Oura) dapat secara eksplisit melacak hubungan antara kebisingan dan tidur, serta meningkatkan kesadaran publik akan masalah ini. (Sumber: karpathy)
Fenomena persilangan AI dan agama menarik perhatian: Pengguna media sosial menhguin mengamati bahwa potensi pasar untuk aplikasi agama atau sejenis agama baru berbasis AI tidak dapat diabaikan. Misalnya, astrologi AI, video Alkitab AI, aplikasi doa AI, serta aplikasi AI untuk kelompok tertentu, semuanya mengisyaratkan kemungkinan teknologi AI dalam memenuhi kebutuhan spiritual atau kepercayaan manusia. (Sumber: menhguin)
AI bantu hasilkan server HTTP 2.0, eksplorasi potensi LLM dalam proyek perangkat lunak besar: Seorang pengembang menggunakan framework buatannya sendiri (promptyped) dan model Gemini 2.5 Pro, melalui siklus kode-kompilasi-tes, berhasil membuat LLM membangun server yang sesuai standar HTTP 2.0 dari awal. Proyek ini menghasilkan 15.000 baris kode sumber dan lebih dari 30.000 baris kode tes, serta lulus tes kesesuaian h2spec. Meskipun memakan waktu sekitar 119 jam API dan biaya API $631, eksperimen ini menunjukkan potensi LLM dalam desain arsitektur dan penulisan perangkat lunak yang kompleks dan sesuai standar, sekaligus mengungkap bentuk aplikasi yang sepenuhnya ditulis oleh LLM. (Sumber: Reddit r/LocalLLaMA)