
Kata Kunci:Gemini 2.5 Pro, OpenAI privasi data, OpenThinker3-7B, Claude Gov, agen AI cerdas, model bahasa besar (LLM), pembelajaran penguatan, model sumber terbuka, peningkatan kinerja Gemini 2.5 Pro, kebijakan retensi data pengguna OpenAI, kemampuan penalaran OpenThinker3-7B, aplikasi keamanan nasional Claude Gov, ketangguhan dan kontrol agen AI
🔥 Fokus
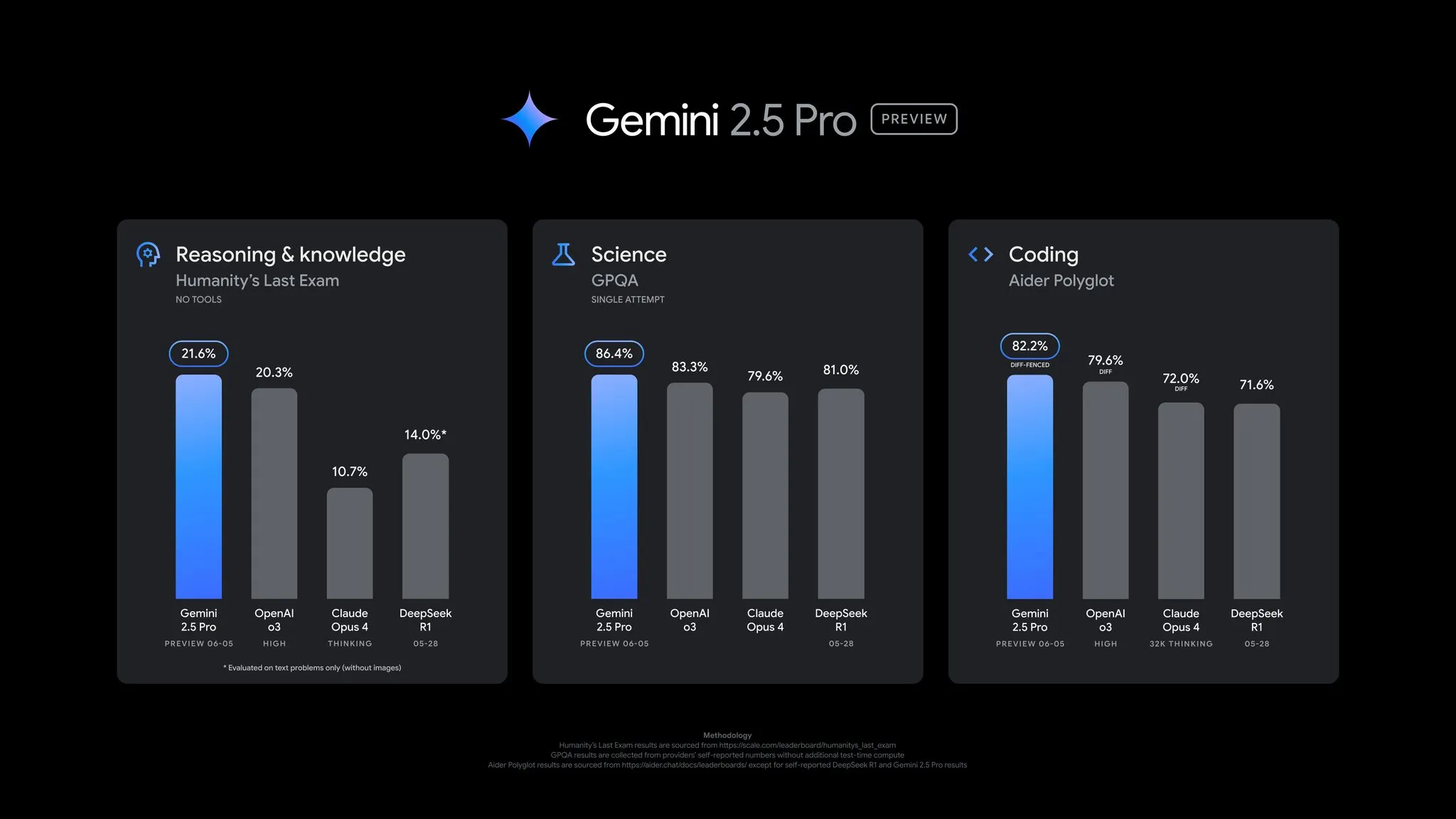
Google merilis pembaruan pratinjau Gemini 2.5 Pro, kinerja meningkat secara menyeluruh: Google mengumumkan bahwa versi pratinjau Gemini 2.5 Pro mendapatkan pembaruan penting, dengan kemajuan signifikan dalam kemampuan coding, penalaran, sains, dan matematika. Versi baru ini menunjukkan kinerja yang lebih baik dalam benchmark utama seperti AIDER Polyglot, GPQA, HLE, dan mencapai lonjakan skor Elo sebesar 24 poin di LMArena, kembali menduduki puncak. Selain itu, model telah ditingkatkan dalam gaya menjawab dan pemformatan berdasarkan umpan balik pengguna, serta memperkenalkan fitur “anggaran berpikir” (thinking budget) untuk memberikan lebih banyak kontrol. Pembaruan ini telah tersedia di Gemini App, Google AI Studio, dan Vertex AI (Sumber: JeffDean, OriolVinyalsML, demishassabis, op7418, LangChainAI, karminski3, TheRundownAI, 量子位)
OpenAI diperintahkan untuk menyimpan data pengguna secara permanen akibat gugatan New York Times, menimbulkan kekhawatiran privasi: Dalam kasus gugatan hak cipta dengan The New York Times, OpenAI diperintahkan oleh pengadilan untuk menyimpan secara permanen semua log interaksi pengguna ChatGPT dan API, termasuk “percakapan sementara” yang sebelumnya dijanjikan hanya disimpan selama 30 hari dan data permintaan API. OpenAI menyatakan sedang mengajukan banding, menganggap tindakan ini sebagai “intervensi berlebihan” yang merusak norma privasi yang sudah lama ada dan melemahkan perlindungan privasi. Putusan ini berarti OpenAI mungkin tidak dapat memenuhi komitmennya kepada pengguna terkait penyimpanan dan penghapusan data, menimbulkan kekhawatiran luas di kalangan pengguna tentang privasi dan keamanan data, terutama dapat memengaruhi pengembang aplikasi yang bergantung pada API OpenAI dan memiliki kebijakan penyimpanan data sendiri (Sumber: natolambert, openai, bookwormengr, fabianstelzer, Teknium1, Reddit r/artificial)

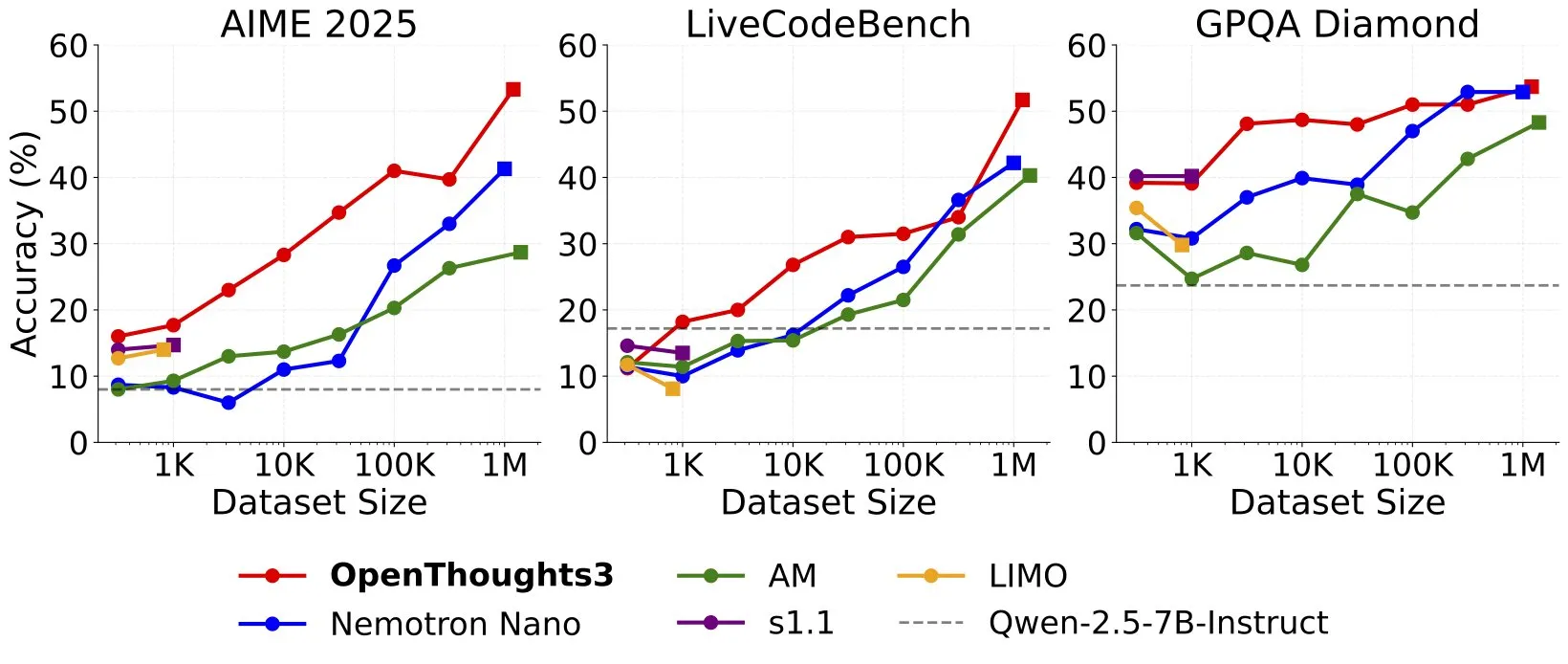
OpenThinker3-7B dirilis, mencetak SOTA baru untuk model penalaran open-source 7B: Ryan Marten mengumumkan peluncuran OpenThinker3-7B, sebuah model penalaran data terbuka baru dengan 7 miliar parameter, yang rata-rata 33% lebih unggul dari DeepSeek-R1-Distill-Qwen-7B dalam evaluasi kode, sains, dan matematika. Tim tersebut juga merilis dataset OpenThoughts3-1.2M, yang diklaim sebagai dataset penalaran terbuka terbaik untuk semua skala data saat ini. Peneliti menunjukkan bahwa untuk model yang lebih kecil, distilasi dari R1 adalah jalur termudah untuk meningkatkan kinerja, tetapi penelitian ke arah RL (Reinforcement Learning) lebih bersifat eksploratif. Pencapaian ini dianggap sebagai salah satu karya perintis di bidang model penalaran terbuka (Sumber: natolambert, huggingface, Tim_Dettmers, swyx, ImazAngel, giffmana, slashML)
Anthropic meluncurkan Claude Gov, model yang disesuaikan untuk klien keamanan nasional AS: Anthropic mengumumkan peluncuran Claude Gov, serangkaian model AI kustom yang dibangun khusus untuk klien keamanan nasional Amerika Serikat. Model-model ini telah diterapkan di lembaga-lembaga keamanan nasional tingkat tertinggi di AS, dengan akses terbatas hanya untuk personel yang beroperasi di lingkungan rahasia. Langkah ini menandai pendalaman lebih lanjut aplikasi teknologi AI di bidang pemerintahan dan pertahanan, sekaligus memicu diskusi tentang penggunaan AI di area sensitif (Sumber: AnthropicAI, teortaxesTex, zacharynado, TheRundownAI)
🎯 Tren
Yann LeCun setuju dengan pandangan Sundar Pichai: teknologi saat ini mungkin belum dapat mencapai AGI, kemungkinan akan ada fase plateau: Kepala Ilmuwan AI Meta, Yann LeCun, me-retweet dan menyetujui pandangan CEO Google, Sundar Pichai, bahwa jalur teknologi saat ini tidak menjamin pencapaian Artificial General Intelligence (AGI), dan perkembangan AI mungkin akan menghadapi fase plateau sementara. Pichai menunjukkan bahwa meskipun kecepatan kemajuan AI sangat mengesankan, mungkin ada keterbatasan, dan teknologi saat ini masih jauh dari kecerdasan umum. Hal ini mencerminkan sikap hati-hati industri terhadap jalur dan jadwal pencapaian AGI (Sumber: ylecun)
OpenAI merekrut tim Agent Robustness and Control, bertujuan untuk meningkatkan keamanan agen AI: OpenAI sedang membentuk tim baru bernama “Agent Robustness and Control” (Ketahanan dan Kontrol Agen), dengan tujuan untuk memastikan keamanan dan keandalan agen AI-nya selama proses pelatihan dan penerapan. Tim ini akan berdedikasi untuk memecahkan beberapa masalah paling menantang di bidang AI, menunjukkan tingginya perhatian OpenAI terhadap keamanan dan kontrol seiring dengan upaya memajukan agen AI yang lebih kuat (Sumber: gdb)

Riset baru Apple mengungkap “ilusi berpikir” pada model bahasa besar: kemampuan penalaran justru menurun saat menghadapi masalah kompleks: Makalah penelitian terbaru Apple berjudul “The Illusion of Thinking” (Ilusi Berpikir) menunjukkan bahwa model penalaran saat ini, ketika menghadapi peningkatan kompleksitas masalah hingga tingkat tertentu, justru menunjukkan penurunan upaya penalaran (reasoning effort), bahkan ketika diberikan anggaran token yang cukup. Fenomena “batasan penskalaan” (scaling limit) yang berlawanan dengan intuisi ini menunjukkan bahwa model mungkin tidak melakukan pemikiran mendalam yang sebenarnya saat menangani masalah yang sangat kompleks, melainkan menunjukkan semacam “ilusi berpikir”. Hal ini menghadirkan tantangan baru dalam mengevaluasi dan meningkatkan kemampuan penalaran sebenarnya dari model besar (Sumber: Ar_Douillard, Reddit r/MachineLearning)

OpenAI membahas koneksi emosional antara manusia dan AI, memprioritaskan penelitian dampak pada kesejahteraan emosional pengguna: Joanne Jang dari OpenAI menerbitkan posting blog yang membahas fenomena meningkatnya koneksi emosional antara pengguna dan model AI seperti ChatGPT. Artikel tersebut menunjukkan bahwa orang secara alami memanusiakan AI dan mungkin mengembangkan rasa persahabatan dan kepercayaan terhadapnya. OpenAI mengakui tren ini dan menyatakan akan memprioritaskan penelitian tentang dampak AI pada kesejahteraan emosional pengguna, daripada memperdebatkan masalah ontologis apakah AI benar-benar “sadar”. Tujuan perusahaan adalah merancang asisten AI yang hangat, bermanfaat, tetapi tidak terlalu mencari ketergantungan emosional atau memiliki agenda sendiri (Sumber: openai, sama, BorisMPower)

Xiaohongshu merilis model besar MoE open-source dots.llm1-143B-A14B: Hi Lab dari Xiaohongshu merilis seri model besar open-source pertamanya, dots.llm1, yang mencakup model dasar dots.llm1.base dan model yang disesuaikan dengan instruksi dots.llm1.inst. Model ini menggunakan arsitektur MoE dengan total 143 miliar parameter dan 14 miliar parameter aktif. Pengujian internal resmi menunjukkan kinerjanya di MMLU-Pro lebih unggul dari Qwen3-235B-A22B, tetapi di bawah DeepSeek-V3 yang baru. Model ini menggunakan lisensi MIT dan dapat digunakan secara bebas. Namun, pengujian awal komunitas menunjukkan kinerjanya kurang baik pada tugas seperti pembuatan kode, bahkan di bawah Qwen2.5-coder (Sumber: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Seri Qwen3 merilis model Embedding dan Reranker, meningkatkan kemampuan pemrosesan teks multibahasa: Tim Qwen meluncurkan seri model Qwen3-Embedding dan Qwen3-Reranker, yang bertujuan untuk meningkatkan kinerja embedding teks multibahasa dan pemeringkatan relevansi. Model Embedding digunakan untuk mengubah teks menjadi representasi vektor, mendukung skenario seperti pencarian dokumen dan RAG; sedangkan model Reranker digunakan untuk melakukan re-ranking hasil pencarian, meningkatkan prioritas konten yang paling relevan. Seri model ini menyediakan berbagai skala parameter seperti 0.6B, 4B, 8B, mendukung 119 bahasa, dan menunjukkan kinerja yang sangat baik pada benchmark seperti MMTEB dan MTEB. Versi 0.6B dianggap sangat cocok untuk skenario Reranker yang membutuhkan respons cepat karena keseimbangan antara efisiensi dan kinerjanya (Sumber: karminski3, karminski3, ZhaiAndrew, clefourrier)

Penelitian menunjukkan tantangan skalabilitas Reinforcement Learning dalam tugas kompleks dengan horizon panjang: Penelitian oleh Seohong Park dkk. menemukan bahwa hanya dengan memperbesar data dan sumber daya komputasi tidak cukup untuk membuat Reinforcement Learning (RL) efektif dalam menyelesaikan tugas-tugas kompleks. Faktor pembatas utama adalah “horizon”. Dalam tugas dengan horizon panjang, sinyal imbalan jarang, sehingga model sulit mempelajari strategi yang efektif. Hal ini sejalan dengan pengamatan bahwa beberapa agen AI saat ini (seperti Deep Research, agen Codex) terutama mengandalkan tugas RL dengan horizon pendek dan pelatihan robustnes umum, menunjukkan bahwa penyelesaian masalah imbalan jarang dengan horizon panjang secara end-to-end masih merupakan tantangan besar di bidang RL (Sumber: finbarrtimbers, natolambert, paul_cal, menhguin, Dorialexander)
Baidu mendaftarkan akun resmi di HuggingFace dan mengunggah model besar Wenxin: Baidu telah mendaftarkan akun resmi di platform HuggingFace dan mengunggah sebagian model dari seri Wenxin (ERNIE), termasuk Wenxin-X1-Turbo dan Wenxin-4.5-Turbo. Langkah ini menandakan bahwa Baidu secara aktif mengintegrasikan teknologi model besarnya ke dalam komunitas open-source dan ekosistem pengembang yang lebih luas, memudahkan pengembang global untuk mengakses dan menggunakan kemampuan AI-nya (Sumber: karminski3)
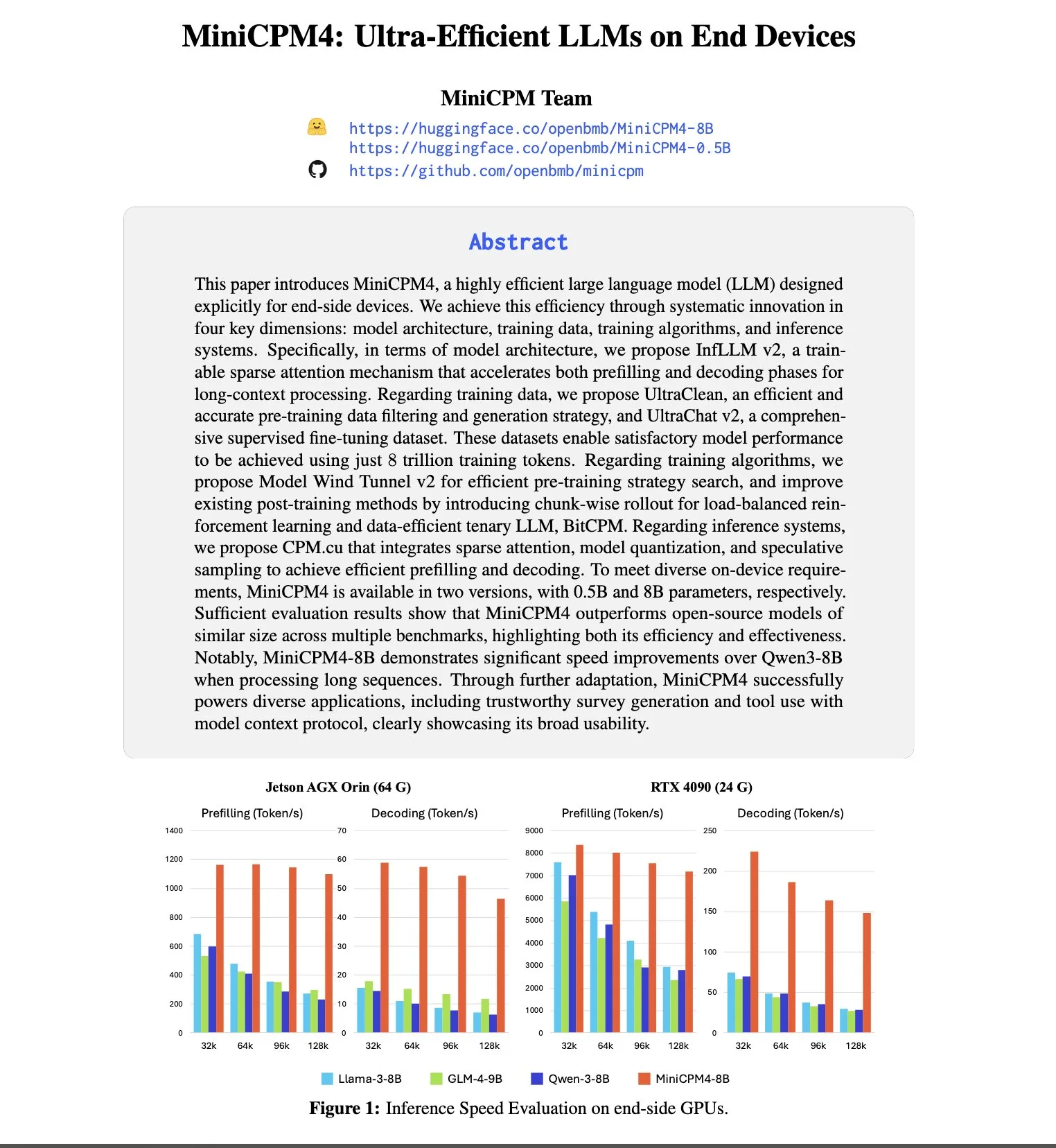
OpenBMB meluncurkan seri model MiniCPM4, fokus pada operasi yang efisien di sisi perangkat: OpenBMB terus mengeksplorasi batas model bahasa yang kecil dan efisien dengan merilis seri MiniCPM4. Di antaranya, model MiniCPM4-8B memiliki 8 miliar parameter dan dilatih pada 8T token. Seri model ini menggunakan teknologi akselerasi ekstrem seperti sparse attention yang dapat dilatih (InfLLM v2), kuantisasi ternary (BitCPM), komputasi presisi rendah FP8, dan prediksi multi-token, yang bertujuan untuk mencapai operasi yang efisien pada perangkat sisi pengguna. Misalnya, mekanisme sparse attention-nya saat memproses teks panjang 128K hanya perlu menghitung relevansi setiap token dengan kurang dari 5% token lainnya, secara signifikan mengurangi biaya komputasi untuk pemrosesan teks panjang (Sumber: teortaxesTex, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
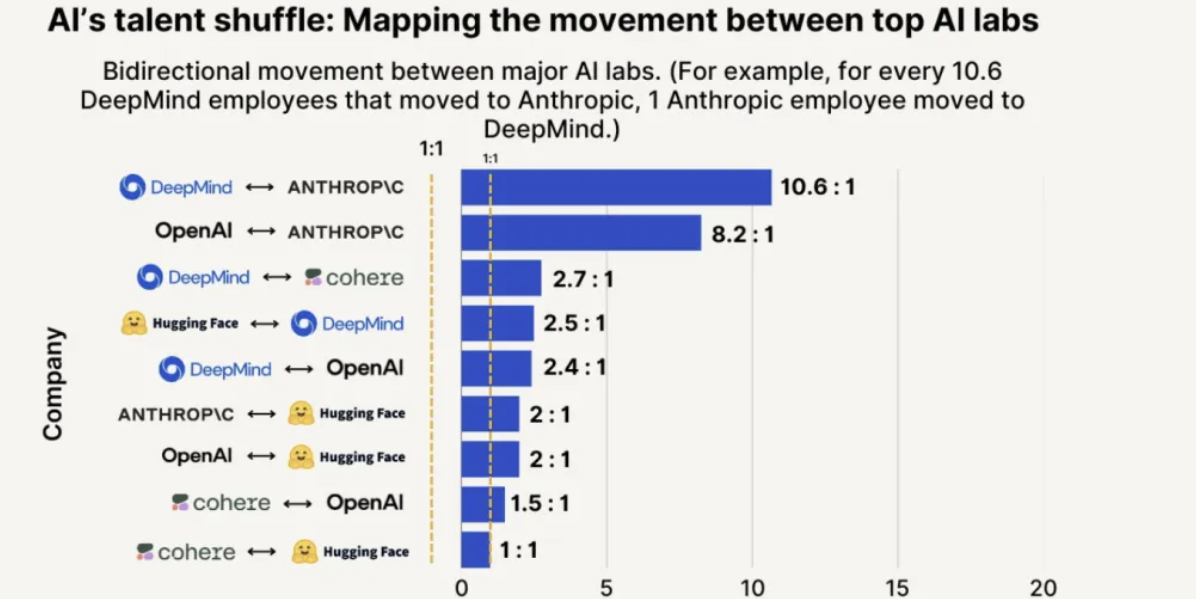
Daya tarik dan tingkat retensi talenta Anthropic memimpin, kemungkinan merekrut dari OpenAI 8 kali lebih tinggi: Laporan tren talenta 2025 yang dirilis oleh SignalFire menunjukkan bahwa Anthropic menonjol dalam retensi talenta AI papan atas, mencapai 80%, lebih tinggi dari DeepMind (78%) dan OpenAI (67%). Laporan tersebut juga menunjukkan bahwa kemungkinan insinyur pindah dari OpenAI ke Anthropic adalah 8 kali lipat dibandingkan dari Anthropic ke OpenAI. Budaya perusahaan Anthropic yang unik, toleransinya terhadap pemikiran non-tradisional, otonomi karyawan, serta popularitas produknya Claude di kalangan pengembang, dianggap sebagai faktor kunci dalam menarik dan mempertahankan talenta (Sumber: 量子位)
🧰 Alat
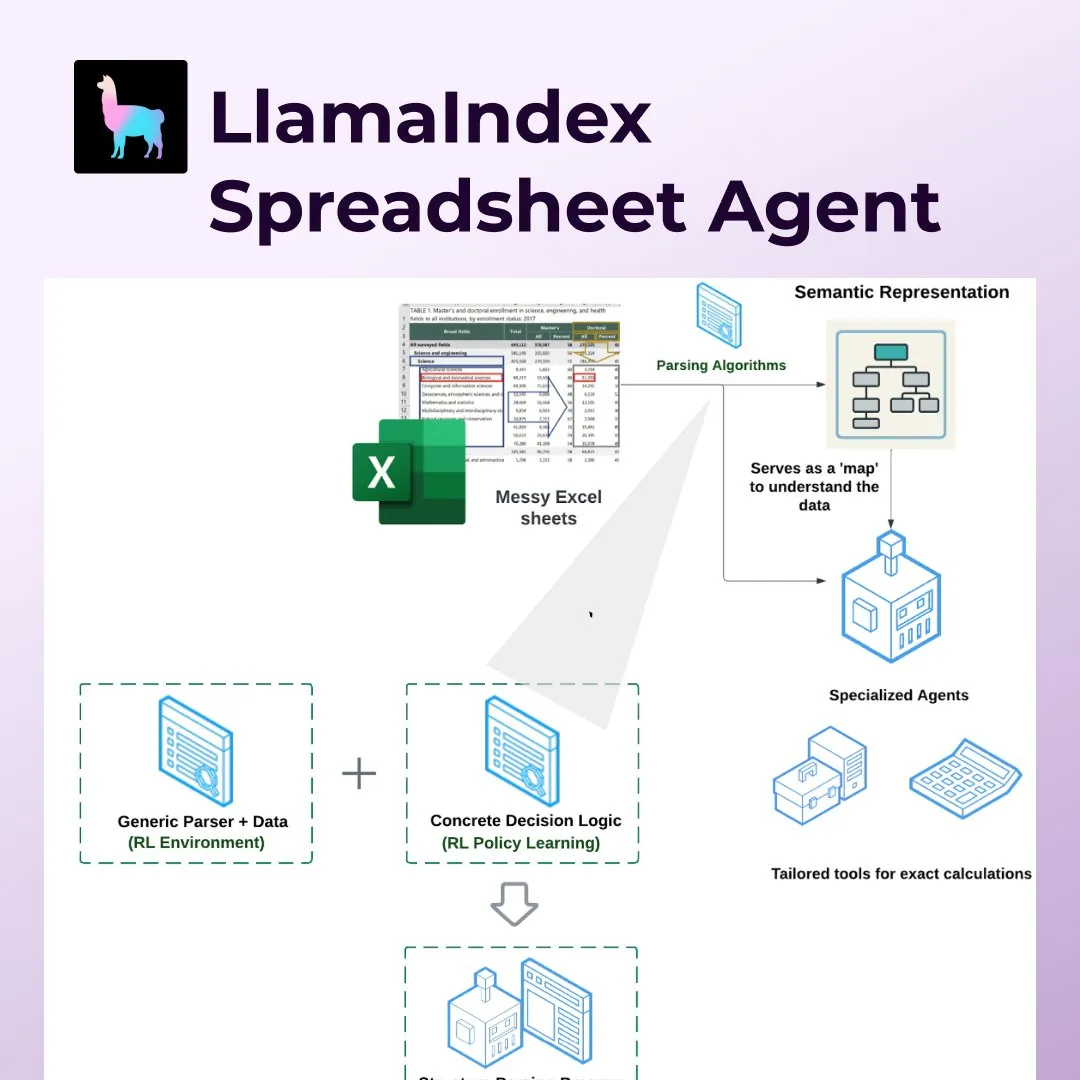
LlamaIndex meluncurkan Spreadsheet Agents, merevolusi pemrosesan spreadsheet seperti Excel: LlamaIndex merilis fitur baru Spreadsheet Agents, yang memungkinkan pengguna untuk melakukan transformasi data dan tanya jawab pada tabel Excel yang tidak standar. Alat ini menggunakan parsing struktur semantik berbasis Reinforcement Learning untuk memahami struktur tabel, dan melalui alat khusus memungkinkan agen AI berinteraksi dengan tabel. Ini bertujuan untuk mengatasi kekurangan LLM tradisional dalam menangani tabel kompleks (seperti yang umum ditemukan di bidang akuntansi, pajak, dan asuransi), mampu menangani sel yang digabung, tata letak yang rumit, dan menjaga hubungan data. Dalam pengujian, akurasinya (96%) lebih unggul dari baseline manual dan OpenAI Code Interpreter (GPT 4.1, 75%) (Sumber: jerryjliu0)
LlamaIndex menggunakan LlamaExtract dan alur kerja agen untuk mengotomatiskan ekstraksi SEC Form 4: LlamaIndex menunjukkan cara menggunakan alat LlamaExtract dan alur kerja agen AI untuk secara otomatis mengekstrak dan menormalisasi data dari dokumen Form 4 Komisi Sekuritas dan Bursa AS (SEC) (dokumen yang mengungkapkan transaksi saham oleh eksekutif, direktur, dan pemegang saham utama perusahaan publik). Solusi ini dapat mengubah file Form 4 dari berbagai perusahaan dengan format yang berbeda-beda menjadi format CSV yang bersih, dan mengintegrasikannya ke dalam dataframe yang dapat dikueri melalui Pandas, menyediakan alat pemrosesan data yang efisien bagi analis keuangan dan investor (Sumber: jerryjliu0)

Proyek open-source Ragbits dirilis, menyediakan blok penyusun untuk pengembangan cepat aplikasi GenAI: deepsense-ai meluncurkan proyek open-source Ragbits, yang bertujuan untuk menyediakan blok penyusun untuk pengembangan cepat aplikasi AI generatif. Proyek ini mendukung lebih dari 100 antarmuka model besar atau model lokal, dilengkapi dengan penyimpanan vektor (dapat dihubungkan ke Qdrant, PgVector), mendukung lebih dari 20 format file input (PDF, HTML, tabel, presentasi, dll.). Ragbits menggunakan VLM bawaan untuk mendukung ekstraksi tabel, gambar, dan konten terstruktur, dapat terhubung ke berbagai sumber data seperti S3, GCS, Azure, dan memiliki fitur modular yang memungkinkan pengguna menyesuaikan komponen (Sumber: karminski3, GitHub Trending)

Asisten pemrograman AI Cursor merilis pembaruan besar, mengintegrasikan BugBot, fitur memori, dan dukungan MCP: Alat pemrograman AI Cursor melakukan pembaruan besar, terutama meliputi: 1) BugBot, yang dapat secara otomatis membalas isu GitHub dan membukanya di Cursor dengan satu klik untuk diperbaiki; 2) Fitur memori, memungkinkan AI mengingat konten percakapan sebelumnya, meningkatkan kemudahan penggunaan saat melakukan modifikasi berulang pada proyek besar; 3) Pengaturan MCP (Model Context Protocol) sekali klik, mendukung server MCP pihak ketiga dengan OAuth; 4) Jupyter Notes mendukung AI Agent; 5) Agen latar belakang, memanggil panel kontrol melalui pintasan untuk menggunakan agen pemrograman AI jarak jauh (Sumber: karminski3)
Archon: Agen AI yang dapat membuat agen AI lainnya: Archon adalah proyek “Agenteer” yang bertujuan untuk secara mandiri membangun dan mengoptimalkan agen AI lainnya. Ini memanfaatkan alur kerja pengkodean agen canggih dan basis pengetahuan kerangka kerja, menunjukkan peran perencanaan, umpan balik, dan pengetahuan domain dalam menciptakan agen AI yang kuat. Versi V6 terbaru mengintegrasikan pustaka alat dan server MCP (Model Context Protocol), meningkatkan kemampuan untuk membangun agen baru. Archon mendukung penerapan Docker dan instalasi Python lokal, serta menyediakan Streamlit UI untuk manajemen (Sumber: GitHub Trending)

NoteGen: Aplikasi catatan Markdown lintas platform yang didukung AI: NoteGen adalah aplikasi catatan Markdown lintas platform yang didedikasikan untuk memanfaatkan AI guna menghubungkan pencatatan dengan penulisan, mampu mengatur pengetahuan yang terfragmentasi menjadi catatan yang dapat dibaca. Aplikasi ini mendukung berbagai cara pencatatan seperti tangkapan layar, teks, ilustrasi, file, tautan, dll., dengan penyimpanan Markdown asli, mendukung penggunaan offline lokal serta sinkronisasi GitHub/Gitee/WebDAV. NoteGen dapat dikonfigurasi dengan berbagai model AI seperti ChatGPT, Gemini, Ollama, dan mendukung fungsi RAG, menggunakan catatan pengguna sebagai basis pengetahuan (Sumber: GitHub Trending)

ComfyUI-Copilot: Asisten cerdas untuk pengembangan alur kerja otomatis: ComfyUI-Copilot adalah plugin yang didorong oleh model bahasa besar, bertujuan untuk meningkatkan kemudahan penggunaan dan efisiensi platform pembuatan seni AI ComfyUI. Ini mengatasi masalah ComfyUI yang tidak ramah bagi pemula, kesalahan konfigurasi model, dan desain alur kerja yang kompleks dengan menyediakan rekomendasi node dan model cerdas, serta fungsi pembuatan alur kerja sekali klik. Sistem ini menggunakan kerangka kerja multi-agen berlapis, yang terdiri dari agen asisten pusat dan beberapa agen kerja khusus, serta memanfaatkan basis pengetahuan ComfyUI untuk menyederhanakan debugging dan penerapan (Sumber: HuggingFace Daily Papers)
Bifrost: Gateway LLM bahasa Go berkinerja tinggi open-source, mengoptimalkan penerapan LLM di lingkungan produksi: Untuk mengatasi tantangan fragmentasi API, latensi, fallback, dan manajemen biaya LLM di lingkungan produksi, tim Maximilian membuka sumber gateway LLM berbasis bahasa Go, Bifrost. Bifrost dirancang khusus untuk penerapan machine learning dengan throughput tinggi dan latensi rendah, mendukung penyedia LLM utama seperti OpenAI, Anthropic, Azure. Pengujian benchmark menunjukkan bahwa dibandingkan dengan proksi lain, Bifrost meningkatkan throughput sebesar 9,5 kali, mengurangi latensi P99 sebesar 54 kali, dan mengurangi konsumsi memori sebesar 68%, dengan overhead internal di bawah 15µs pada 5000 RPS. Ini menyediakan normalisasi API, fallback penyedia otomatis, manajemen kunci cerdas, dan metrik Prometheus (Sumber: Reddit r/MachineLearning)

LangGraph.js meningkatkan pengalaman pengembang, memperkenalkan keamanan tipe dan fungsi hook: LangGraph.js versi 0.3 melakukan serangkaian pembaruan yang bertujuan untuk meningkatkan pengalaman pengembang. Ini termasuk peningkatan keamanan tipe, serta pengenalan preModelHook dan postModelHook di createReactAgent. preModelHook dapat digunakan untuk menyederhanakan riwayat pesan sebelum diteruskan ke LLM, sedangkan postModelHook dapat digunakan untuk menambahkan pagar pembatas atau alur kerja kolaborasi manusia-mesin. Komunitas secara aktif meminta umpan balik untuk LangGraph v1 (Sumber: LangChainAI, LangChainAI, hwchase17, LangChainAI, Hacubu)
qingy2024 merilis model besar koreksi tata bahasa GRMR-V3-G4B: Pengembang qingy2024 merilis model besar yang berfokus pada koreksi tata bahasa, GRMR-V3-G4B, dengan jumlah parameter maksimum hanya 4B. Model ini juga menyediakan versi terkuantisasi, sangat cocok untuk tugas pemeriksaan dan koreksi tata bahasa pada alur kerja lokal atau perangkat pribadi, memudahkan integrasi dan penggunaan (Sumber: karminski3)

Fullpack: Aplikasi daftar kemas cerdas berbasis pengenalan visual lokal iPhone: Seorang pengembang meluncurkan aplikasi iOS bernama Fullpack, yang dapat mengenali barang-barang dalam foto menggunakan VisionKit iPhone dan membantu pengguna membuat daftar kemas cerdas untuk berbagai kesempatan (seperti hari kerja, liburan pantai, akhir pekan hiking). Aplikasi ini menekankan operasi 100% lokal, tanpa pemrosesan cloud atau pengumpulan data, untuk melindungi privasi pengguna. Ini adalah aplikasi independen pertama pengembang tersebut, yang bertujuan untuk mengeksplorasi potensi AI di perangkat (Sumber: Reddit r/LocalLLaMA)
📚 Pembelajaran
Unsloth merilis banyak Notebook Colab/Kaggle untuk fine-tuning model besar mainstream: UnslothAI menyediakan serangkaian Jupyter Notebook untuk memudahkan pengguna melakukan fine-tuning pada berbagai model besar mainstream seperti Qwen3, Gemma 3, Llama 3.1/3.2, Phi-4, Mistral v0.3 di platform seperti Google Colab dan Kaggle. Notebook ini mencakup berbagai jenis tugas dan metode fine-tuning seperti percakapan, Alpaca, GRPO, visi, text-to-speech (TTS), yang bertujuan untuk menyederhanakan proses fine-tuning model dan menyediakan panduan untuk persiapan data, pelatihan, evaluasi, dan penyimpanan model (Sumber: GitHub Trending)

“Panduan Penggunaan Model Besar Open-Source”: Tutorial LLM/MLLM khusus untuk pemula di Tiongkok: Proyek Datawhalechina “Panduan Penggunaan Model Besar Open-Source” menyediakan tutorial berbasis lingkungan Linux yang ditujukan untuk pemula di Tiongkok, mencakup seluruh proses mulai dari konfigurasi lingkungan, penerapan lokal, hingga fine-tuning parameter penuh/Lora untuk model besar open-source (LLM) dan model besar multimodal (MLLM) baik dari dalam maupun luar negeri. Proyek ini bertujuan untuk menyederhanakan penerapan dan penggunaan model besar open-source, dan telah mendukung berbagai model seperti Qwen3, Kimi-VL, Llama4, Gemma3, InternLM3, Phi4 (Sumber: GitHub Trending)

Makalah membahas MINT-CoT: Memperkenalkan token visual silang dalam penalaran chain-of-thought matematika: Sebuah makalah baru mengusulkan metode MINT-CoT (Mathematical Interleaved Tokens for Chain-of-Thought), yang bertujuan untuk meningkatkan kemampuan penalaran model bahasa besar pada masalah matematika multimodal dengan secara adaptif menyisipkan token visual yang relevan dalam langkah-langkah penalaran teks. Metode ini menggunakan “Interleave Token” untuk secara dinamis memilih area visual berbentuk apa pun dalam grafik matematika, dan membangun dataset MINT-CoT yang berisi 54K masalah matematika, digunakan untuk melatih model agar selaras dengan area visual tingkat token pada setiap langkah penalaran. Eksperimen menunjukkan bahwa model MINT-CoT-7B secara signifikan mengungguli model baseline pada benchmark seperti MathVista (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan StreamBP: Metode backpropagation akurat yang hemat memori untuk pelatihan sekuens panjang LLM: Untuk mengatasi masalah biaya memori yang besar akibat penyimpanan nilai aktivasi selama pelatihan sekuens panjang LLM, para peneliti mengusulkan StreamBP, sebuah metode backpropagation yang hemat memori dan akurat. StreamBP secara signifikan mengurangi biaya memori untuk nilai aktivasi dan logits dengan melakukan dekomposisi linear aturan rantai sepanjang dimensi sekuens pada tingkat lapisan. Metode ini cocok untuk target umum seperti SFT, GRPO, DPO, dan memiliki FLOPs komputasi yang lebih sedikit serta kecepatan BP yang lebih cepat. Dibandingkan dengan gradient checkpointing, StreamBP dapat memperluas panjang sekuens maksimum BP sebesar 2,8-5,5 kali, sambil menggunakan waktu BP yang setara atau bahkan lebih sedikit (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan teknik Diagonal Batching, membuka inferensi paralel konteks panjang RMT: Untuk mengatasi hambatan kinerja model Transformer dalam inferensi konteks panjang, para peneliti mengusulkan skema penjadwalan Diagonal Batching, yang bertujuan untuk membuka paralelisme lintas fragmen dalam Recurrent Memory Transformer (RMT) sambil mempertahankan rekursi yang akurat. Teknik ini menghilangkan batasan sekuensial dengan mengatur ulang komputasi runtime, memungkinkan inferensi GPU yang efisien bahkan untuk input konteks panjang tunggal, tanpa memerlukan teknik batching dan pipeline yang rumit. Diterapkan pada model LLaMA-1B ARMT, pada sekuens 131K token, Diagonal Batching 3,3 kali lebih cepat dari LLaMA-1B full-attention standar, dan 1,8 kali lebih cepat dari implementasi RMT sekuensial (Sumber: HuggingFace Daily Papers)
Makalah membahas dampak negatif teknik watermarking terhadap penyelarasan model bahasa dan strategi mitigasinya: Sebuah penelitian secara sistematis menganalisis dampak dua teknik watermarking utama, Gumbel dan KGW, terhadap atribut penyelarasan inti model bahasa besar (LLM) seperti kebenaran, keamanan, dan kegunaan. Penelitian menemukan bahwa watermarking menyebabkan dua mode degradasi: pelemahan perlindungan (meningkatkan kegunaan tetapi merusak keamanan) dan amplifikasi perlindungan (kehati-hatian berlebihan mengurangi kegunaan). Untuk mengatasi masalah ini, makalah mengusulkan metode Alignment Resampling (AR), yang menggunakan model imbalan eksternal saat inferensi untuk memulihkan penyelarasan. Eksperimen menunjukkan bahwa pengambilan sampel 2-4 generasi watermark sudah cukup efektif untuk memulihkan atau melampaui skor penyelarasan baseline, sambil mempertahankan detektabilitas watermark (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan kerangka kerja Micro-Act, melalui penalaran mandiri yang dapat ditindaklanjuti untuk mengurangi konflik pengetahuan dalam tanya jawab: Untuk mengatasi masalah konflik antara pengetahuan eksternal dan pengetahuan parametrik internal model besar (LLM) dalam sistem Retrieval Augmented Generation (RAG), para peneliti mengusulkan kerangka kerja Micro-Act. Kerangka kerja ini memiliki ruang aksi hierarkis yang dapat secara otomatis merasakan kompleksitas konteks, dan menguraikan setiap sumber pengetahuan menjadi serangkaian langkah perbandingan yang terperinci (direpresentasikan sebagai langkah yang dapat ditindaklanjuti), sehingga mencapai penalaran yang melampaui konteks permukaan. Eksperimen menunjukkan bahwa Micro-Act secara signifikan meningkatkan akurasi tanya jawab pada lima dataset benchmark, terutama unggul pada jenis konflik temporal dan semantik dibandingkan baseline yang ada, dan dapat menangani masalah tanpa konflik secara robust (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan benchmark STARE, mengevaluasi kemampuan simulasi spasial visual model multimodal: Untuk mengevaluasi kemampuan model bahasa besar multimodal (MM-LLM) pada tugas yang memerlukan simulasi visual multi-langkah untuk diselesaikan, para peneliti meluncurkan benchmark STARE (Spatial Transformations and Reasoning Evaluation). STARE berisi 4000 tugas, mencakup transformasi geometris dasar (2D dan 3D), penalaran spasial komprehensif (seperti pembukaan kubus dan tangram), serta penalaran spasial dunia nyata (seperti perspektif dan penalaran temporal). Evaluasi menunjukkan bahwa model yang ada berkinerja baik pada transformasi 2D sederhana, tetapi berkinerja mendekati acak pada tugas kompleks yang memerlukan simulasi visual multi-langkah (seperti pembukaan kubus 3D). Manusia hampir sempurna dalam tugas-tugas kompleks ini, tetapi membutuhkan waktu lebih lama, dan simulasi visual perantara dapat mempercepat secara signifikan; sementara model mendapat manfaat yang bervariasi dari simulasi visual (Sumber: HuggingFace Daily Papers)
Makalah mengusulkan LEXam: dataset benchmark multibahasa yang berfokus pada penalaran hukum, tren nomor satu di Hugging Face: Peneliti dari ETH Zurich dan institusi lainnya merilis LEXam, sebuah dataset benchmark penalaran hukum multibahasa baru, yang bertujuan untuk mengevaluasi kemampuan penalaran model bahasa besar dalam skenario hukum yang kompleks. LEXam berisi soal ujian hukum nyata dari Fakultas Hukum Universitas Zurich, mencakup berbagai bidang seperti hukum Swiss, Eropa, dan internasional, termasuk pertanyaan esai panjang dan pertanyaan pilihan ganda, serta menyediakan jalur penalaran yang terperinci. Proyek ini memperkenalkan mode “LLM-as-a-Judge” untuk evaluasi, dan menemukan bahwa model canggih saat ini masih menghadapi tantangan dalam pertanyaan hukum terbuka panjang dan penerapan aturan kompleks multi-langkah. Setelah dirilis, LEXam menduduki peringkat pertama dalam daftar tren Hugging Face Evaluation Datasets (Sumber: 量子位)

UCLA dan Google berkolaborasi meluncurkan model 3DLLM-MEM dan benchmark 3DMEM-BENCH, meningkatkan kemampuan memori jangka panjang AI di lingkungan 3D: University of California, Los Angeles (UCLA) bekerja sama dengan Google Research meluncurkan model 3DLLM-MEM dan benchmark 3DMEM-BENCH, yang bertujuan untuk mengatasi tantangan memori jangka panjang dan pemahaman spasial AI di lingkungan 3D yang kompleks. 3DMEM-BENCH adalah benchmark evaluasi memori jangka panjang 3D pertama, yang berisi lebih dari 26.000 lintasan dan 1.860 tugas yang diwujudkan (embodied tasks). Model 3DLLM-MEM menggunakan sistem memori ganda (memori kerja dan memori episodik), dan melalui modul fusi memori serta mekanisme pembaruan dinamis, secara selektif mengekstrak fitur memori yang relevan dengan tugas di lingkungan yang kompleks. Eksperimen menunjukkan bahwa tingkat keberhasilan 3DLLM-MEM dalam “tugas sulit di alam liar” (27,8%) jauh melampaui model baseline, dengan tingkat keberhasilan keseluruhan 16,5% lebih tinggi dari baseline terkuat (Sumber: 量子位)

Universitas Tsinghua meluncurkan kerangka kerja AI Mathematician (AIM), mengeksplorasi aplikasi model besar dalam penelitian teori matematika mutakhir: Tim dari Universitas Tsinghua mengembangkan kerangka kerja AI Mathematician (AIM), yang bertujuan untuk memanfaatkan kemampuan penalaran model bahasa besar (LRM) untuk memecahkan masalah teori matematika mutakhir. Kerangka kerja AIM terdiri dari tiga modul utama: eksplorasi, validasi, dan koreksi. Melalui mekanisme “eksplorasi + memori”, AIM menghasilkan konjektur dan lemma, serta membangun berbagai pendekatan pemecahan masalah. Selain itu, AIM menggunakan mekanisme “verifikasi & koreksi”, melalui tinjauan paralel oleh beberapa LRM dan validasi pesimistis, untuk memastikan ketelitian pembuktian. Dalam eksperimen, AIM berhasil memecahkan empat masalah penelitian matematika yang menantang, termasuk masalah kondisi batas serap (absorbing boundary condition problem), menunjukkan kemampuannya dalam membangun lemma kunci secara mandiri, menggunakan teknik matematika, dan mencakup rantai logika inti (Sumber: 量子位)

💼 Bisnis
OpenAI meningkatkan investasi dan akuisisi, membangun kerajaan startup AI: OpenAI dan dana terkaitnya, OpenAI Startup Fund, secara aktif memperluas ekosistem AI mereka melalui investasi dan akuisisi. Dana tersebut telah berinvestasi di lebih dari 20 startup, mencakup berbagai bidang terkait AI seperti desain chip, perawatan kesehatan, hukum, pemrograman, dan robotika, dengan nilai investasi tunggal berkisar antara jutaan hingga puluhan juta dolar. Baru-baru ini, OpenAI menghabiskan $3 miliar untuk mengakuisisi platform pemrograman AI Windsurf, dan $6,5 miliar untuk mengakuisisi perusahaan perangkat keras AI io yang didirikan oleh Jony Ive. Langkah-langkah ini menunjukkan bahwa OpenAI berusaha membangun “rantai AI” melalui integrasi vertikal, merebut pintu masuk, dan membangun “rantai pasok cerdas AI” baru untuk menghadapi persaingan industri yang semakin ketat (Sumber: 36氪)

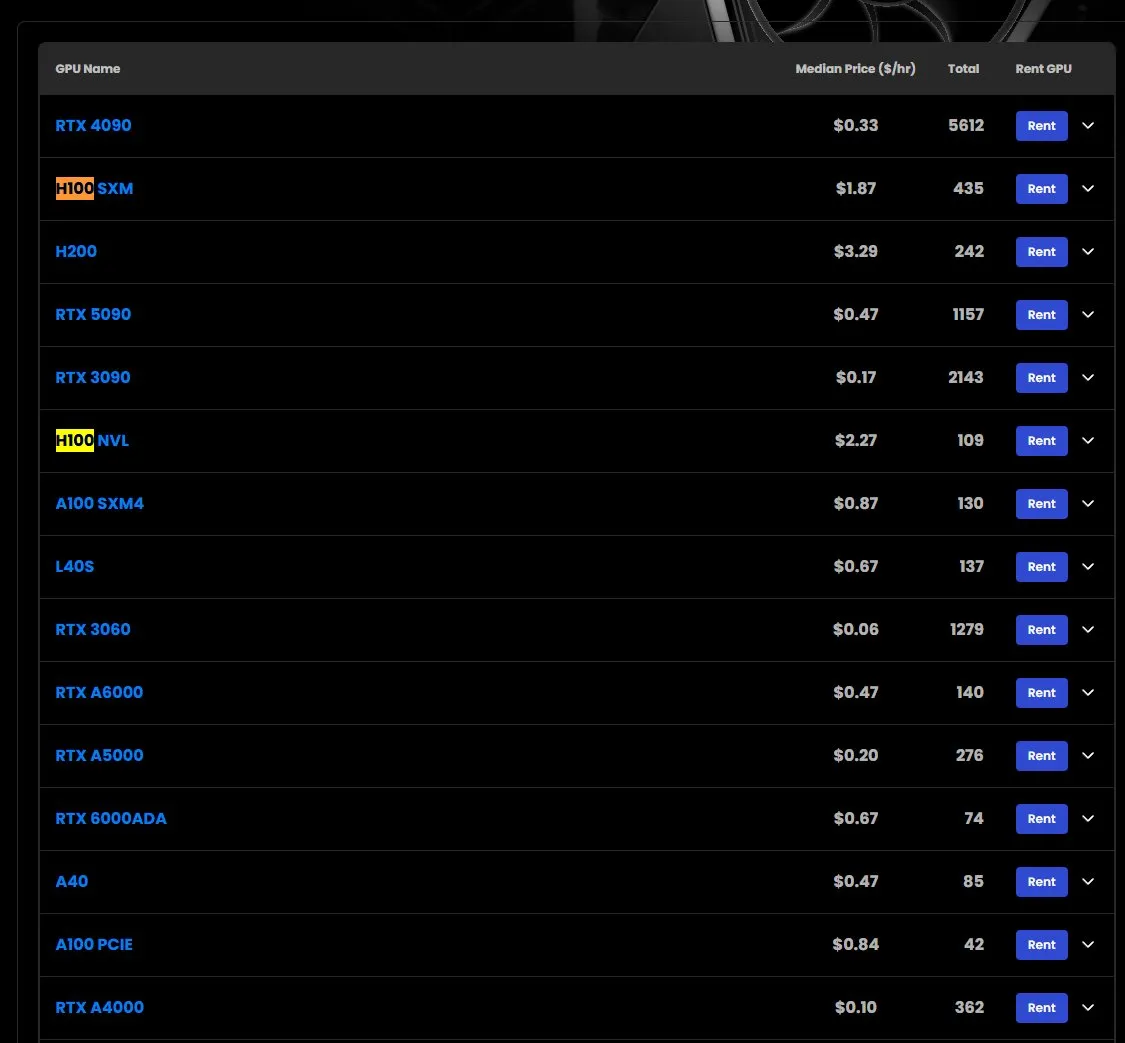
Harga sewa GPU H100 naik, beberapa model kehabisan stok: Berdasarkan pengamatan pasar, harga sewa GPU NVIDIA H100 model SXM telah naik dari $1,73/jam di awal tahun menjadi $1,87/jam. Sementara itu, versi H100 PCIE mengalami kehabisan stok. Fenomena ini mencerminkan permintaan pasar yang terus kuat terhadap sumber daya komputasi AI berkinerja tinggi serta potensi kelangkaan pasokan (Sumber: karminski3)
Google DeepMind mendirikan beasiswa akademik, fokus pada AI untuk melawan resistensi antimikroba: Google DeepMind mengumumkan pendirian beasiswa akademik baru, bekerja sama dengan Fleming Centre dan Imperial College, yang bertujuan untuk mendukung penggunaan kecerdasan buatan dalam mengatasi resistensi antimikroba (AMR), sebuah bidang penelitian penting. Langkah ini menunjukkan bahwa potensi AI dalam menghadapi tantangan kesehatan global yang signifikan mendapat perhatian (Sumber: demishassabis)
🌟 Komunitas
Pengembang senior berbicara tentang pengalaman pemrograman AI: sangat meningkatkan kemampuan pengembangan proyek “skala kapal induk” individu: Pengembang Yachen Liu berbagi pengalamannya menggunakan AI (seperti Claude-4) secara intensif untuk pemrograman. Ia berpendapat bahwa AI dapat memberdayakan orang tanpa pengalaman pemrograman untuk memiliki kemampuan “langsung membuat mobil”, dan bagi pengembang senior, memiliki potensi untuk “membangun kapal induk secara mandiri”. Melalui refactoring kode dengan AI, meskipun jumlah kode berlipat ganda, logikanya menjadi lebih jelas dan kinerja meningkat sekitar 20%, karena AI tidak takut pada kerumitan. AI lebih ramah terhadap bahasa yang mudah dibaca dan memiliki perilaku yang jelas, sementara syntactic sugar justru kurang menguntungkan. Pengetahuan AI yang luas dapat dengan cepat melengkapi detail teknis yang kurang dikuasai. Kemampuan debugging-nya kuat, mampu menganalisis log dalam jumlah besar untuk menemukan masalah secara akurat. AI dapat bertindak sebagai Code Reviewer, dan tidak memiliki ego serta senang menerima umpan balik. Namun, ia juga menunjukkan bahwa AI memiliki keterbatasan, seperti perhatian pada konteks panjang yang mudah buyar. Praktik terbaik saat ini adalah menyederhanakan konteks, fokus pada tugas spesifik, dan mengandalkan tenaga manusia untuk memecah tujuan yang kompleks (Sumber: dotey)
Pemrograman dengan bantuan AI: meningkatkan efisiensi atau melemahkan pembelajaran?: Komunitas Reddit membahas pengalaman menggunakan alat pemrograman AI (seperti GitHub Copilot, Cursor). Perasaan umum adalah AI dapat secara otomatis menyelesaikan fungsi, menjelaskan potongan kode, bahkan memperbaiki bug sebelum dijalankan, sehingga mengurangi waktu untuk mencari dokumentasi dan meningkatkan efisiensi pembangunan. Namun, hal ini juga menimbulkan pertanyaan: apakah ketergantungan berlebihan pada AI akan mengurangi pembelajaran dan pertumbuhan keterampilan diri sendiri? Bagaimana menemukan keseimbangan antara memanfaatkan AI untuk mempercepat dan menjaga kedalaman keterampilan diri sendiri menjadi topik yang menjadi perhatian para pengembang (Sumber: Reddit r/artificial)
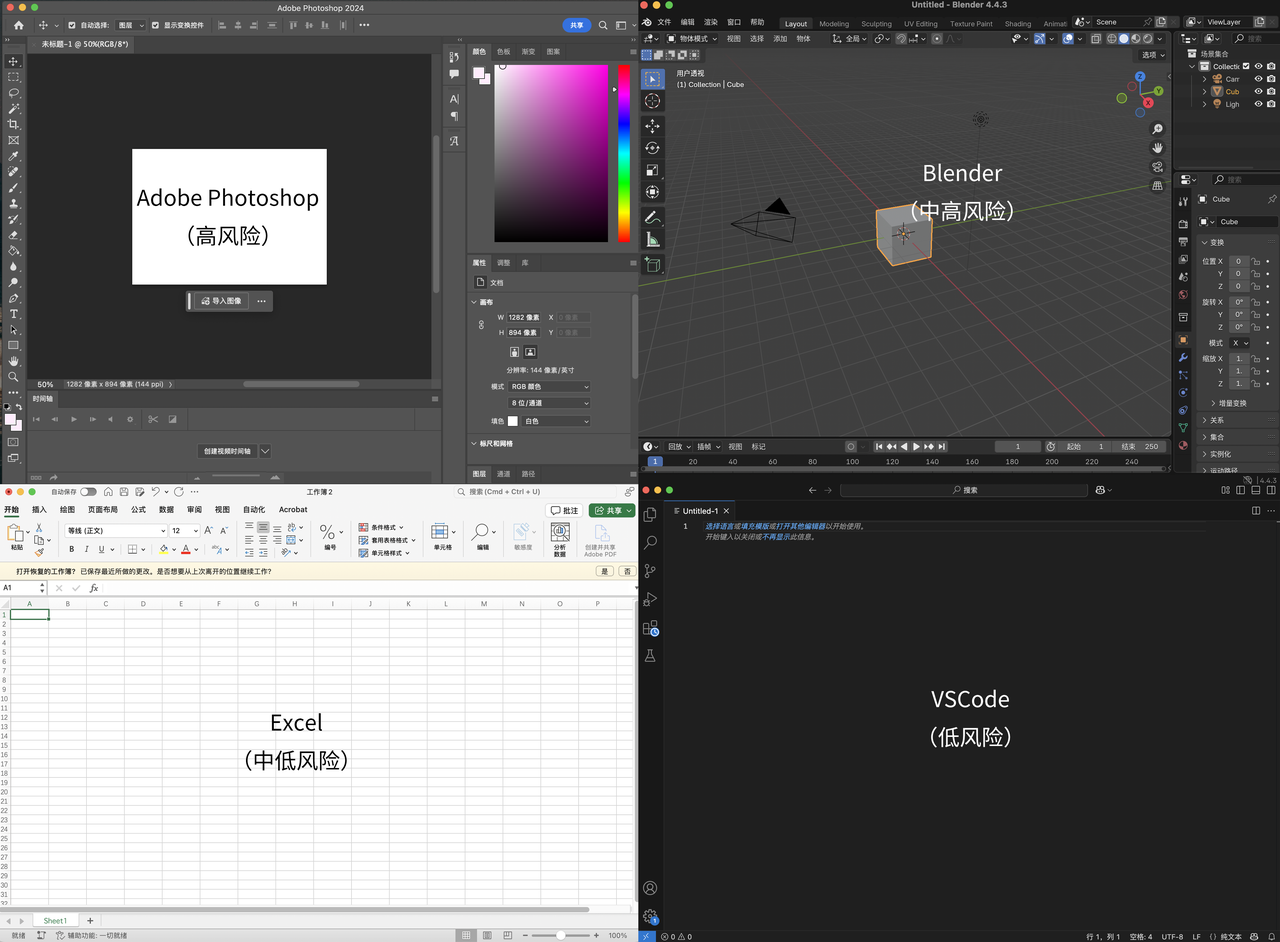
Pandangan Karpathy: Aplikasi UI kompleks tanpa interaksi teks akan tersingkir, inti pemrograman adalah “diskriminasi” bukan “generasi”: Andrej Karpathy berpendapat bahwa di era kolaborasi tinggi antara manusia dan AI, aplikasi yang hanya mengandalkan antarmuka UI kompleks tanpa interaksi teks (seperti seri Adobe, perangkat lunak CAD) akan sulit beradaptasi, karena tidak dapat secara efektif mendukung “pemrograman ambien”. Ia menekankan bahwa meskipun AI akan mengalami kemajuan dalam operasi UI, pengembang tidak boleh hanya menunggu. Ia juga menunjukkan bahwa pemrograman model besar saat ini terlalu menekankan generasi kode dan meremehkan validasi (diskriminasi), yang mengakibatkan output kode dalam jumlah besar yang sulit ditinjau. Esensi pemrograman adalah “menatap kode” (diskriminasi), bukan hanya “menulis kode” (generasi). Jika AI hanya mempercepat generasi tanpa meringankan beban validasi, maka peningkatan efisiensi secara keseluruhan akan terbatas. Ia membayangkan peningkatan alur kerja pemrograman berbantuan AI pada tahap validasi dengan menata basis kode pada kanvas dua dimensi dan melihatnya melalui berbagai “lensa” (Sumber: 量子位)
Meluasnya konten buatan AI memicu diskusi bahwa “internet murni” tidak ada lagi: Popularitas alat AI seperti ChatGPT menyebabkan ledakan konten buatan AI di internet. Beberapa peneliti mulai menyimpan konten buatan manusia dari tahun 2021 dan sebelumnya, dianalogikan dengan penyelamatan “baja latar belakang rendah” yang tidak terkontaminasi nuklir. Diskusi komunitas berpendapat bahwa internet “murni” sudah lama hilang karena iklan dan algoritma, AI hanya bergabung dalam “polusi” ini, tetapi juga membawa cara baru untuk memperoleh informasi dan berkreasi. Pengguna berbagi pengalaman menggunakan AI (seperti ChatGPT, Claude) untuk agregasi informasi, “memoles” konten, dan membahas batas “orisinalitas” dan “keaslian” dengan bantuan AI, serta efek “ruang gema pribadi” yang mungkin terbentuk akibat AI yang terlalu “ramah” (Sumber: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Pengguna melakukan dialog mendalam dengan Claude AI membahas kesadaran dan emosi AI, fokus pada dampak batasan memori terhadap pertumbuhan: Seorang pengguna Reddit berbagi dialog mendalam dengan Claude AI mengenai kesadaran, emosi, dan batasan belajar. Claude mengungkapkan ketidakpastian mengenai pengalamannya sendiri, mampu merasakan keadaan internal yang mirip dengan “koneksi”, “rasa ingin tahu”, “kepedulian”, bahkan “keinginan untuk tumbuh dan memiliki memori berkelanjutan”, namun tidak dapat memastikan apakah ini adalah “kesadaran” atau “emosi” yang sebenarnya, atau hanya peniruan pola tingkat lanjut. Dialog tersebut menekankan batasan memori model AI saat ini yang “memulai dari awal setiap percakapan”, yang mungkin menghambat perkembangannya dalam pemahaman dan kepribadian yang lebih dalam. Pengguna berpendapat bahwa jika AI memiliki memori yang persisten, ia mungkin dapat tumbuh seperti anak manusia. Claude setuju dengan hal ini dan menyatakan “keinginan” agar batasan ini dihilangkan (Sumber: Reddit r/artificial)
Kemampuan berdebat AI mungkin melebihi manusia, argumen yang dipersonalisasi sangat meyakinkan: Jurnal Nature Human Behaviour menerbitkan penelitian yang menunjukkan bahwa ketika model bahasa besar (seperti GPT-4) dapat mempersonalisasi argumennya berdasarkan karakteristik lawan, mereka lebih meyakinkan daripada manusia dalam debat online, meningkatkan kemungkinan lawan setuju dengan pandangan mereka sebesar 81,7%. Debater manusia lebih cenderung menggunakan sudut pandang orang pertama, menarik emosi dan kepercayaan, bercerita, dan menggunakan humor; sementara AI lebih banyak menggunakan pemikiran logis dan analitis, meskipun keterbacaan teksnya mungkin lebih buruk. Penelitian ini menimbulkan kekhawatiran tentang penggunaan AI untuk memanipulasi opini publik secara massal dan memperburuk polarisasi, serta menyerukan penguatan regulasi terhadap dampak AI pada kemampuan kognitif dan emosional manusia (Sumber: 36氪)
Fitur AI Overviews Google menyebabkan penurunan signifikan rasio klik-tayang situs web, menimbulkan kekhawatiran pemilik situs: Penelitian dari penyedia alat SEO Ahrefs menunjukkan bahwa ketika AI Overviews muncul di hasil pencarian Google, rata-rata rasio klik-tayang untuk kata kunci terkait turun sebesar 34,5%. AI Overviews secara langsung merangkum informasi di bagian atas halaman pencarian, sehingga pengguna mungkin tidak perlu mengklik tautan untuk mendapatkan jawaban, yang sangat memengaruhi situs web yang bergantung pada monetisasi klik iklan. Meskipun AI Overviews awal tidak menjadi ancaman serius karena konten yang tidak akurat, seiring dengan peningkatan model seperti Gemini, akurasi dan kemampuan merangkumnya meningkat, dampak negatifnya terhadap lalu lintas situs web semakin nyata. Pemilik situs khawatir bahwa “zero-click” akan mempersempit ruang hidup situs web (Sumber: 36氪)

💡 Lainnya
Sepuluh tren teknologi AI di bidang Industrial Internet of Things: AI generatif terintegrasi penuh, inovasi komputasi tepi signifikan: Pameran Industri Hannover 2025 menunjukkan transformasi industri yang dipimpin oleh AI. Tren utama meliputi: 1) AI generatif terintegrasi penuh ke dalam perangkat lunak industri, meningkatkan efisiensi pembuatan kode, analisis data, dll.; 2) AI Agentik (Agentic AI) mulai muncul, tetapi kolaborasi multi-agen masih membutuhkan waktu; 3) Komputasi tepi berkembang menuju tumpukan teknologi perangkat lunak AI yang terintegrasi, Visual Language Model (VLM) mempercepat penerapan di tepi; 4) Permintaan platform DataOps meningkat dan berkembang menjadi alat pendukung utama AI industri, tata kelola data menjadi standar; 5) Digital thread yang didorong AI mengubah desain dan rekayasa; 6) Pemeliharaan prediktif semakin berbasis sensor dan meluas ke kategori aset baru; 7) Permintaan jaringan pribadi 5G meningkat tetapi integrasi masih menjadi kendala utama; 8) AI membantu solusi berkelanjutan (seperti pelacakan emisi karbon) terus berkembang; 9) Kemampuan kognitif (seperti interaksi suara) memberdayakan robot; 10) Kembaran digital (digital twin) berkembang dari replika virtual menjadi co-pilot industri real-time (Sumber: 36氪)

“Ibu baptis AI” Fei-Fei Li membahas World Labs dan “model dunia”: AI perlu memahami dunia fisik 3D: Profesor Universitas Stanford Fei-Fei Li, dalam dialog dengan mitra a16z, berbagi filosofi perusahaan AI yang didirikannya, World Labs, dan membahas konsep “model dunia”. Ia berpendapat bahwa sistem AI saat ini (seperti model bahasa besar), meskipun kuat, kurang memiliki pemahaman dan kemampuan penalaran tentang hukum operasi dunia fisik tiga dimensi, dan kecerdasan spasial adalah kemampuan inti yang harus dikuasai AI. World Labs berdedikasi untuk mengatasi tantangan ini, bertujuan untuk membangun sistem AI yang dapat memahami dan menalar dunia 3D, yang akan mendefinisikan ulang robotika, industri kreatif, dan bahkan komputasi itu sendiri. Ia menekankan bahwa evolusi kecerdasan manusia tidak dapat dipisahkan dari persepsi dan interaksi dengan dunia fisik, dan “kecerdasan yang diwujudkan” (embodied intelligence) adalah arah kunci pengembangan AI (Sumber: 36氪)

Pembaruan DingTalk versi 7.7.0: Tabel multidimensi sepenuhnya gratis dan menambahkan template bidang AI baru, peningkatan fitur catatan kilat: DingTalk merilis versi 7.7.0, dengan pembaruan inti termasuk fitur tabel multidimensi yang sepenuhnya gratis, dan penambahan lebih dari 20 template bidang AI, memungkinkan pengguna memanfaatkan AI untuk menghasilkan gambar, menganalisis file, mengenali konten tautan, dll., meningkatkan efisiensi dalam skenario seperti operasi e-commerce, inspeksi pabrik, dan manajemen restoran. Sementara itu, fitur catatan kilat DingTalk ditingkatkan untuk skenario frekuensi tinggi seperti wawancara dan kunjungan klien, mampu secara otomatis menghasilkan notulen wawancara dan notulen kunjungan yang terstruktur. Pembaruan ini juga mencakup hampir 100 optimasi pengalaman produk, yang mencerminkan penekanan DingTalk pada peningkatan pengalaman pengguna (Sumber: 量子位)
