
Kata Kunci:Model AI, Dataset, Robot humanoid, Agen AI, Model bahasa, Pembelajaran mendalam, Model sumber terbuka, Optimalisasi inferensi, Dataset Common Pile v0.1, Model kontrol end-to-end Helix, Server Hugging Face MCP, Pembaruan Gemini 2.5 Pro, Mekanisme perhatian jarang
🔥 Fokus
EleutherAI merilis Common Pile v0.1: dataset teks 8TB dengan lisensi terbuka, menantang pelatihan model bahasa tanpa data berlisensi : EleutherAI bersama beberapa institusi merilis Common Pile v0.1, sebuah dataset besar berisi 8TB teks dengan lisensi terbuka dan domain publik, yang bertujuan untuk mengeksplorasi kelayakan pelatihan model bahasa berkinerja tinggi tanpa menggunakan teks tanpa lisensi. Tim menggunakan dataset ini untuk melatih model dengan parameter 7B (1T dan 2T token), yang kinerjanya sebanding dengan model serupa seperti LLaMA 1 dan LLaMA 2. Dataset ini berisi metadata tingkat dokumen seperti atribusi penulis, detail lisensi, dan tautan ke salinan asli, menyediakan sumber data yang transparan dan patuh bagi para peneliti. Langkah ini sangat penting untuk mendorong pengembangan model AI yang terbuka dan patuh, serta memberikan ide baru untuk menyelesaikan masalah hak cipta data pelatihan AI (Sumber: EleutherAI, percyliang, BlancheMinerva, code_star, ShayneRedford, Tim_Dettmers, jeremyphoward, stanfordnlp, ClementDelangue, tri_dao, andersonbcdefg)

Robot humanoid Figure dengan model Helix menunjukkan kemampuan penyortiran paket berkecepatan tinggi, menarik perhatian : CEO Figure, Brett Adcock, menunjukkan kemajuan terbaru robot humanoid perusahaannya dalam menyortir paket di skenario logistik, yang didorong oleh model kontrol universal end-to-end Helix. Video menunjukkan robot tersebut dapat menangani berbagai jenis paket (kardus keras, kemasan plastik) dengan kecepatan dan akurasi yang mendekati manusia, termasuk merapikan paket dan memastikan kode batang menghadap ke bawah untuk pemindaian. Kemampuan ini menyoroti kemampuan generalisasi dan fleksibilitas model Helix di lingkungan yang kompleks dan dinamis, berbeda dengan demonstrasi sebelumnya pada pekerjaan mesin press (yang menekankan presisi dan kecepatan tinggi). Robot Figure telah beroperasi selama 20 jam shift berkelanjutan di lini produksi BMW, menunjukkan potensinya dalam aplikasi industri. Adcock menekankan bahwa dalam bidang robot humanoid, membangun robot yang paling cerdas dan berbiaya terendah akan menjadi kunci untuk memenangkan pasar, karena lebih banyak robot yang digunakan berarti biaya lebih rendah, lebih banyak data pelatihan, dan model Helix yang lebih cerdas (Sumber: dotey, _philschmid, adcock_brett, 量子位)

Hugging Face merilis server MCP resmi pertama, membangun platform kolaborasi AI Agent : Hugging Face meluncurkan server MCP (Model-Client Protocol) resmi pertamanya, yang memungkinkan pengguna menghubungkan LLM secara langsung ke API Hugging Face Hub untuk digunakan dalam aplikasi Cursor, VSCode, Windsurf, dan aplikasi lain yang mendukung MCP. Server ini menyediakan alat bawaan seperti pencarian semantik untuk model, dataset, makalah, dan Spaces, serta dapat secara dinamis mendaftar semua aplikasi Gradio yang kompatibel dengan MCP yang di-host di Spaces. Langkah ini bertujuan untuk menjadikan Hugging Face sebagai platform kolaborasi bagi para pembuat AI Agent, mendorong pengembangan dan interoperabilitas ekosistem AI Agent. Saat ini, sekitar 900 MCP Spaces telah tersedia (Sumber: ClementDelangue, mervenoyann, reach_vb, ben_burtenshaw, huggingface, code_star, op7418, TheTuringPost, clefourrier)

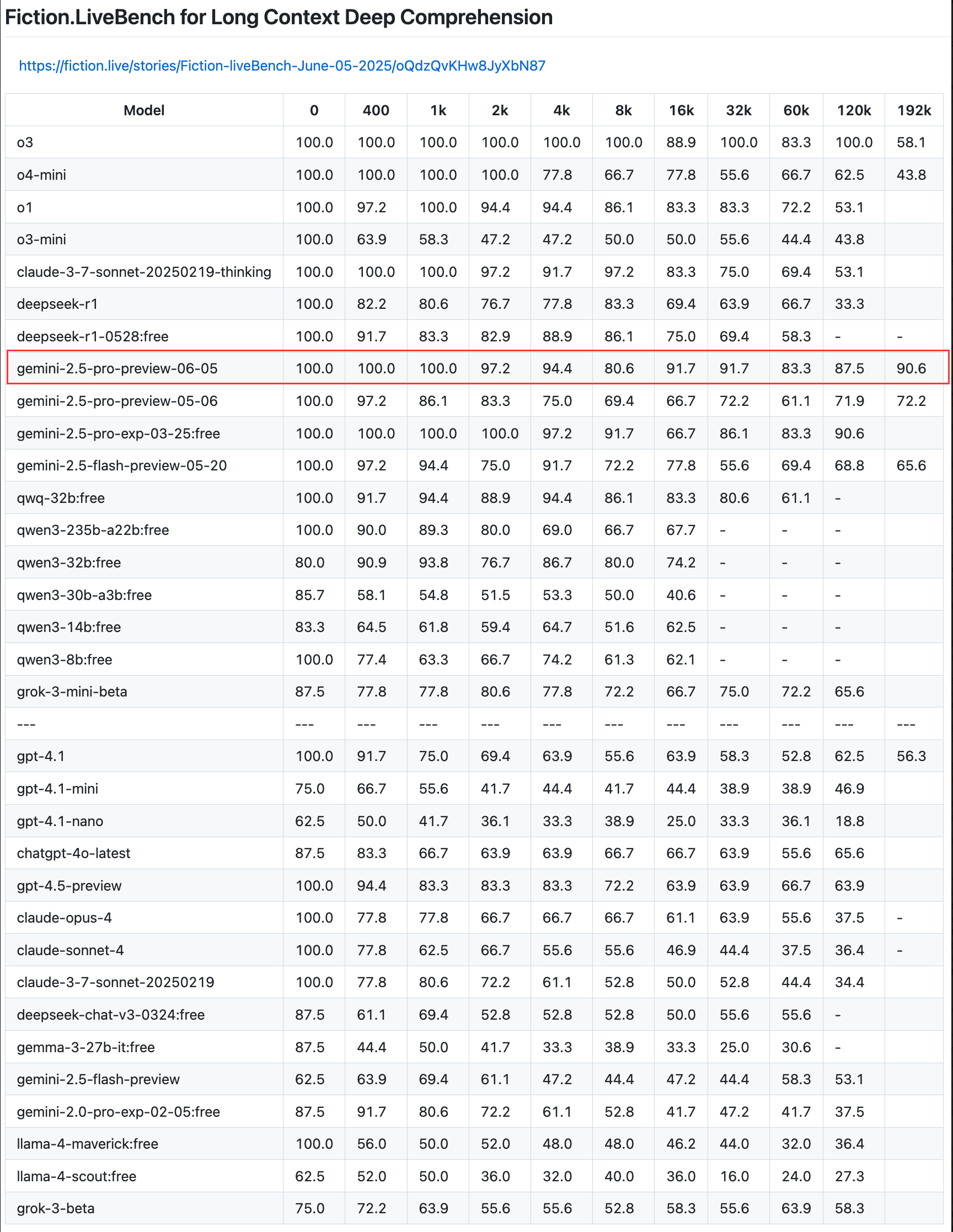
Google memperbarui pratinjau Gemini 2.5 Pro, meningkatkan kemampuan coding, penalaran & kreasi, serta memperkenalkan “thinking budget” : Google mengumumkan pembaruan untuk pratinjau model tercerdasnya, Gemini 2.5 Pro, yang semakin meningkatkan kemampuannya dalam coding, penalaran logis, dan penulisan kreatif. Versi baru ini secara khusus memperkenalkan fitur “thinking budget”, yang memungkinkan pengembang mengontrol konsumsi sumber daya komputasi model dengan lebih baik. Umpan balik pengguna menunjukkan bahwa versi baru (06-05) berkinerja sangat baik dalam hal recall teks panjang, terutama dengan tingkat recall mencapai 90,6% pada panjang 192K, melampaui OpenAI-o3. Model ini telah diintegrasikan ke dalam LangChain dan LangGraph, memudahkan pengembang untuk mencoba dan membangun aplikasi. Google juga mendemonstrasikan kemampuan kreatif Gemini 2.5 Pro dalam pemahaman gambar dan pembuatan teks kontekstual yang jenaka (Sumber: Teknium1, Google, karminski3, hwchase17, )
🎯 Perkembangan
DeepSeek merilis versi upgrade DeepSeek-R1-0528, kinerja setara model closed-source : DeepSeek meluncurkan versi upgrade dari model bobot open-source andalannya, DeepSeek-R1-0528. Model ini diklaim memiliki kinerja yang sebanding dengan model closed-source seperti o3 dari OpenAI dan Gemini-2.5 Pro dari Google dalam berbagai benchmark. Meskipun perusahaan tidak mengungkapkan detail pelatihan, laporan menunjukkan bahwa model baru ini memiliki peningkatan signifikan dalam penalaran, penanganan kompleksitas tugas, dan pengurangan halusinasi, sekali lagi menantang anggapan tradisional bahwa AI papan atas membutuhkan sumber daya yang sangat besar. Unsloth AI telah menyediakan Notebook gratis untuk fine-tuning DeepSeek-R1-0528-Qwen3 menggunakan GRPO, mengklaim bahwa fungsi reward barunya dapat meningkatkan tingkat respons multibahasa (atau domain kustom) lebih dari 40%, serta membuat fine-tuning R1 2x lebih cepat dengan penggunaan VRAM 70% lebih sedikit (Sumber: DeepLearningAI, ImazAngel)
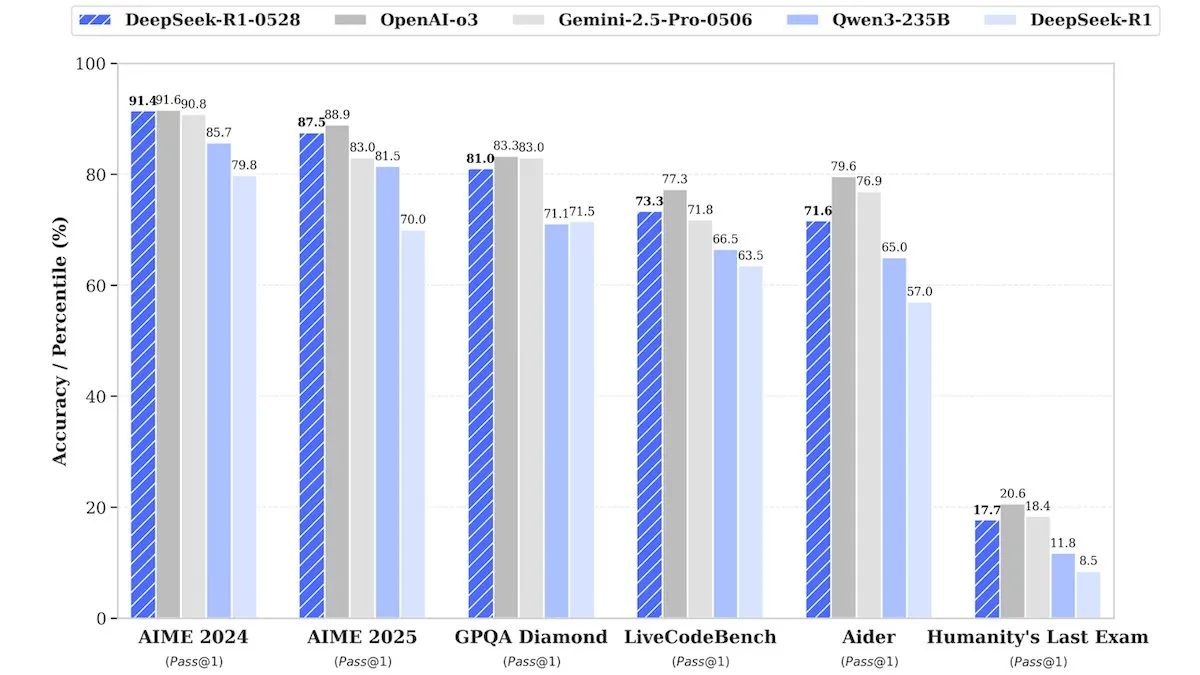
Nvidia merilis model inferensi arsitektur hibrida Nemotron-H, meningkatkan throughput dan efisiensi : Nvidia meluncurkan model inferensi baru Nemotron-H, termasuk versi 47B dan 8B (mendukung BF16 dan FP8), yang menggunakan arsitektur hibrida Mamba-Transformer. Model ini dirancang untuk mengatasi masalah inferensi skala besar sambil mempertahankan kecepatan tinggi, dengan throughput yang diklaim 4x lebih tinggi dari model Transformer sejenis. Nemotron-H-47B-Reasoning-128k memiliki akurasi sedikit lebih tinggi daripada Llama-Nemotron-Super-49B-1.0 di semua benchmark, tetapi dengan biaya inferensi hingga 4x lebih rendah. Bobot model telah dirilis di HuggingFace dengan lisensi non-produktif, dan laporan teknis akan segera hadir (Sumber: ClementDelangue, ctnzr)
Anthropic meluncurkan Claude Gov, dirancang khusus untuk lembaga pemerintah dan intelijen militer AS : Perusahaan Anthropic merilis layanan AI baru bernama Claude Gov, yang dirancang khusus untuk memenuhi kebutuhan pemerintah, pertahanan, dan lembaga intelijen Amerika Serikat. Langkah ini menandai ekspansi resmi teknologi AI canggih Anthropic ke ranah aplikasi pemerintah dan militer, yang berpotensi digunakan untuk analisis data, pemrosesan intelijen, dukungan keputusan, dan berbagai skenario lainnya. Anthropic sebelumnya juga bergabung dengan dana perwalian kepentingan jangka panjang, yang bertujuan membantu perusahaan mewujudkan misi kepentingan publiknya (Sumber: MIT Technology Review, akbirkhan, jeremyphoward)
Hugging Face dan Google Colab berkolaborasi, menyederhanakan proses uji coba model dan desain prototipe : Hugging Face mengumumkan kemitraan dengan Google Colaboratory, menambahkan dukungan “Buka di Colab” di semua kartu model di Hugging Face Hub. Pengguna sekarang dapat langsung meluncurkan Colab Notebook dari kartu model mana pun, sehingga lebih mudah untuk melakukan eksperimen dan evaluasi model. Selain itu, pengguna dapat menempatkan file notebook.ipynb kustom di repositori model mereka, dan Hugging Face akan langsung menyediakan Notebook tersebut, yang selanjutnya meningkatkan aksesibilitas model AI dan kemampuan desain prototipe cepat (Sumber: huggingface, osanseviero, ClementDelangue, mervenoyann)
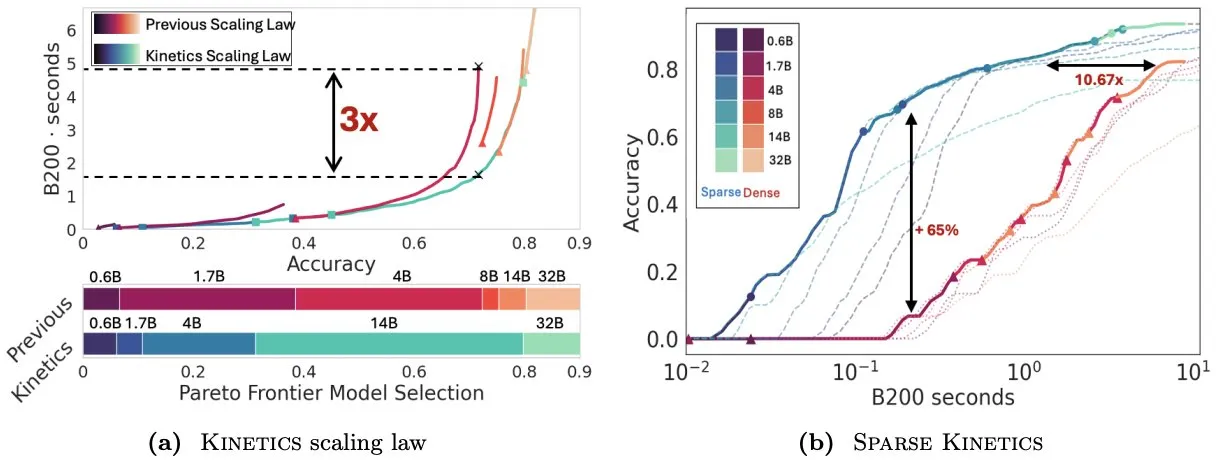
Makalah Kinetics memikirkan kembali hukum penskalaan waktu uji, menekankan pentingnya sparse attention untuk efisiensi inferensi : Infini-AI-Lab menerbitkan makalah berjudul “Kinetics: Rethinking Test-Time Scaling Laws”, yang menunjukkan bahwa hukum penskalaan sebelumnya yang didasarkan pada optimalitas komputasi melebih-lebihkan efektivitas model kecil, dan mengabaikan bottleneck akses memori yang disebabkan oleh strategi waktu inferensi (seperti Best-of-N, CoT panjang). Penelitian ini mengusulkan hukum penskalaan Kinetics baru yang mempertimbangkan biaya komputasi dan akses memori secara komprehensif, berpendapat bahwa sumber daya komputasi waktu uji lebih efektif digunakan untuk model besar daripada model kecil, karena attention, bukan jumlah parameter, menjadi biaya dominan. Makalah ini selanjutnya mengusulkan paradigma penskalaan yang berpusat pada sparse attention, yang mencapai generasi yang lebih panjang dan lebih banyak sampel paralel dengan mengurangi biaya per token. Eksperimen menunjukkan bahwa model sparse attention mengungguli model dense di berbagai rentang biaya, yang sangat penting untuk meningkatkan efisiensi inferensi model skala besar (Sumber: realDanFu, tri_dao, simran_s_arora)
Pasar AI Agent Tiongkok sedang panas, Manus memimpin gelombang startup : Setelah demam model dasar tahun lalu, fokus bidang AI Tiongkok tahun ini beralih ke AI Agent. AI Agent lebih menekankan pada penyelesaian tugas secara otonom untuk pengguna, daripada sekadar merespons kueri. Manus, sebagai pelopor AI Agent universal, menarik perhatian luas setelah rilis terbatas pada awal Maret, dan memicu munculnya sejumlah perusahaan rintisan yang membangun alat digital universal yang mampu menangani email, merencanakan perjalanan, bahkan merancang situs web interaktif. Tren ini menunjukkan bahwa industri teknologi Tiongkok secara aktif mengeksplorasi aplikasi praktis dan model bisnis AI Agent (Sumber: MIT Technology Review)

ElevenLabs merilis Conversational AI 2.0, meningkatkan kinerja asisten suara tingkat perusahaan : ElevenLabs meluncurkan platform AI percakapan versi 2.0, yang bertujuan untuk membangun agen suara tingkat perusahaan yang lebih canggih. Versi baru ini secara signifikan meningkatkan kealamian dan kemampuan interaksi asisten suara, memungkinkannya untuk lebih memahami ritme percakapan, mengetahui kapan harus berhenti sejenak, kapan harus berbicara, dan kapan harus melakukan pergantian giliran percakapan. Peningkatan ini diharapkan dapat memberikan pengalaman interaksi suara yang lebih lancar dan cerdas bagi pengguna perusahaan, yang dapat diterapkan dalam layanan pelanggan, asisten virtual, dan berbagai skenario lainnya (Sumber: dl_weekly)
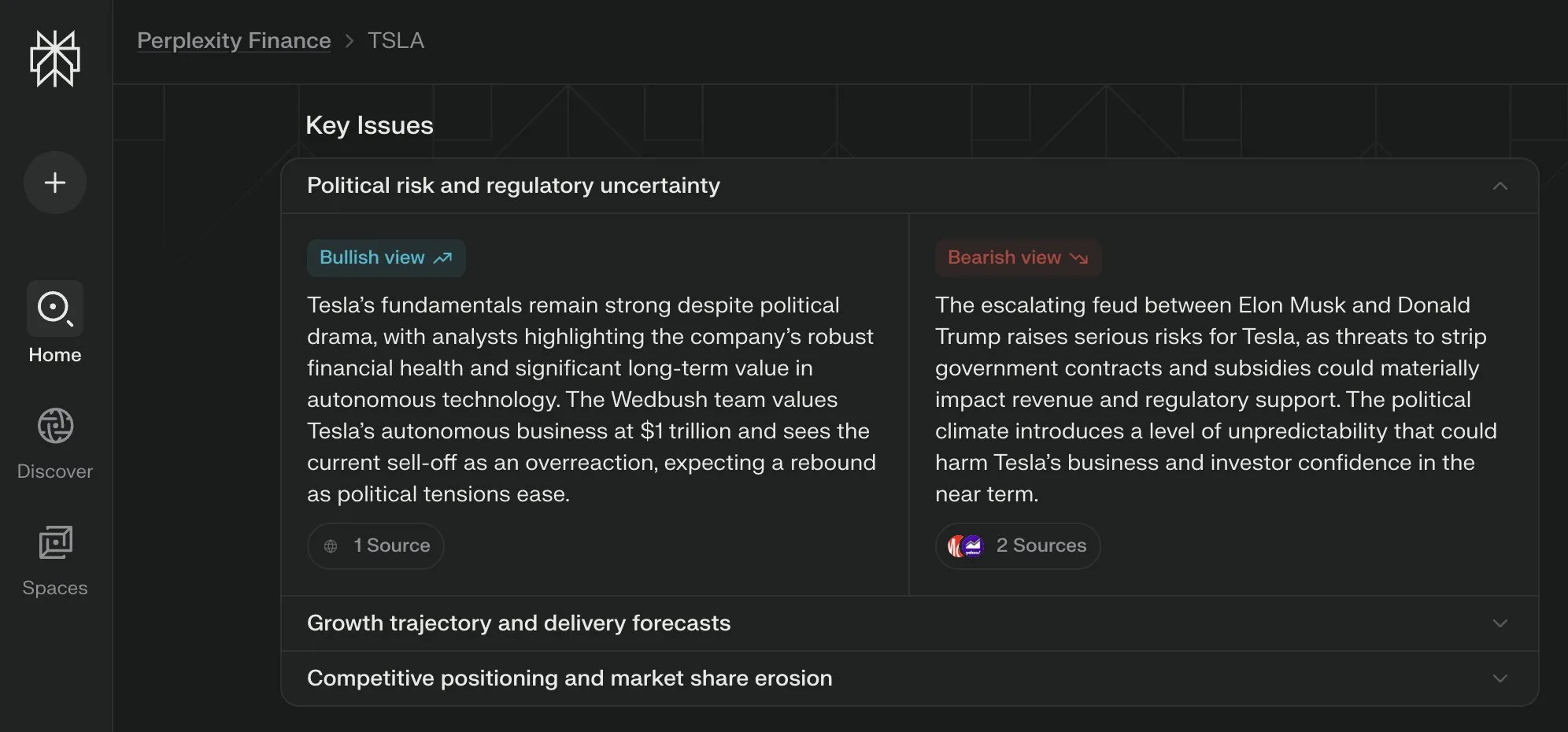
Perplexity Labs meluncurkan tampilan “Key Issues” untuk halaman keuangannya, mengintegrasikan pandangan dari berbagai pihak : Perplexity Labs menambahkan fitur tampilan “Key Issues” (Masalah Utama) pada halaman informasi keuangannya. Fitur ini mampu mengintegrasikan pandangan dari investor, analis, dan komentator di internet, dengan cepat menunjukkan kepada pengguna faktor-faktor penting yang saat ini memengaruhi suatu perusahaan dan poin-poin diskusi utama. Misalnya, halaman tentang Tesla dapat mengintegrasikan berbagai informasi mengenai dinamika antara Trump dan Musk dalam beberapa jam, membantu pengguna memahami gambaran keseluruhan dengan cepat (Sumber: AravSrinivas)
Checkpoint terdistribusi PyTorch kini mendukung safetensors Hugging Face : PyTorch mengumumkan bahwa fitur checkpoint terdistribusinya sekarang mendukung format safetensors dari Hugging Face, yang akan membuat penyimpanan dan pemuatan checkpoint antar ekosistem yang berbeda menjadi lebih mudah. API baru ini memungkinkan pengguna untuk membaca dan menulis safetensors melalui path fsspec. torchtune menjadi library pertama yang mengadopsi fitur ini, sehingga menyederhanakan proses checkpoint-nya. Pembaruan ini membantu meningkatkan interoperabilitas dan efisiensi pelatihan dan deployment model (Sumber: ClementDelangue)

Makalah MARBLE mengusulkan metode baru untuk restrukturisasi dan pencampuran material berbasis ruang CLIP : Sebuah penelitian baru bernama MARBLE mengusulkan metode untuk mencampur dan merestrukturisasi atribut material berbutir halus pada objek dalam gambar dengan mencari embedding material di ruang CLIP dan menggunakan embedding ini untuk mengontrol model teks-ke-gambar yang telah dilatih sebelumnya. Metode ini meningkatkan pengeditan material berbasis sampel dengan melokalisasi modul dalam UNet denoise yang bertanggung jawab atas atribusi material, sehingga memungkinkan kontrol parametrik atas atribut material berbutir halus seperti kekasaran, kemetalan, transparansi, dan kilau. Para peneliti membuktikan efektivitas metode ini melalui analisis kualitatif dan kuantitatif, serta menunjukkan penerapannya dalam melakukan beberapa pengeditan dalam satu kali forward propagation dan dalam domain lukisan (Sumber: HuggingFace Daily Papers, ClementDelangue)
Makalah FlowDirector: Metode panduan aliran pengeditan teks-ke-video yang presisi tanpa pelatihan : FlowDirector adalah kerangka kerja pengeditan video baru tanpa inversi yang memodelkan proses pengeditan sebagai evolusi langsung ruang data. Melalui persamaan diferensial biasa (ODE), FlowDirector memandu video untuk bertransisi secara mulus di sepanjang manifold spasio-temporal intrinsiknya, sehingga menjaga koherensi temporal dan detail struktural. Untuk mencapai pengeditan yang dapat dikontrol secara lokal, diperkenalkan mekanisme masking yang dipandu oleh attention. Selain itu, untuk mengatasi masalah pengeditan yang tidak lengkap dan meningkatkan keselarasan semantik dengan instruksi pengeditan, diusulkan strategi pengeditan yang ditingkatkan dengan panduan yang terinspirasi dari panduan tanpa klasifikasi. Eksperimen menunjukkan bahwa FlowDirector berkinerja sangat baik dalam hal kepatuhan instruksi, konsistensi temporal, dan pelestarian latar belakang (Sumber: HuggingFace Daily Papers)
Makalah RACRO: Inferensi multimodal yang dapat diskalakan melalui optimasi reward teks deskriptif : Untuk mengatasi masalah tingginya biaya pelatihan ulang penyelarasan visual-bahasa saat meningkatkan LLM inferensi dasar, para peneliti mengusulkan RACRO (Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization). Metode ini mengubah input visual menjadi representasi bahasa (seperti teks deskriptif), yang kemudian diteruskan ke inferensi teks. RACRO menggunakan strategi reinforcement learning yang dipandu oleh penalaran, dengan mengoptimalkan reward untuk menyelaraskan perilaku teks deskriptif ekstraktor dengan tujuan penalaran, sehingga memperkuat dasar visual dan mengekstrak representasi yang dioptimalkan untuk penalaran. Eksperimen menunjukkan bahwa RACRO mencapai kinerja SOTA pada benchmark matematika dan sains multimodal, serta mendukung adaptasi plug-and-play ke LLM penalaran yang lebih canggih tanpa memerlukan penyelarasan ulang multimodal yang mahal (Sumber: HuggingFace Daily Papers)
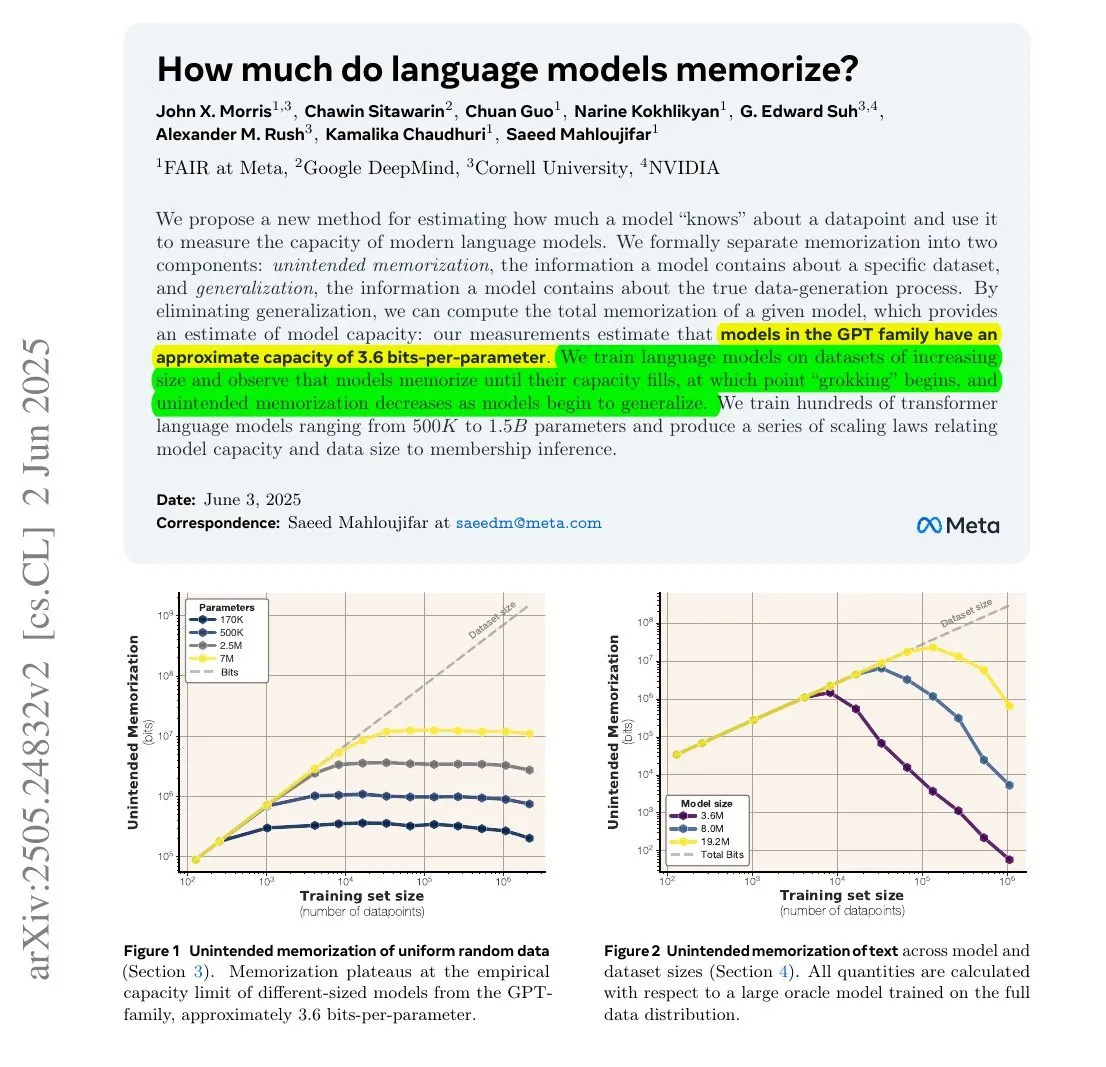
Penelitian menunjukkan: Jumlah informasi yang diingat LLM mungkin terkait dengan jumlah parameter dan entropi informasinya : Sebuah penelitian kolaborasi antara Meta, DeepMind, NVIDIA, dan Cornell University mengeksplorasi jumlah informasi yang sebenarnya diingat oleh model bahasa besar (LLM). Penelitian menemukan bahwa jumlah informasi yang diingat LLM mungkin terkait dengan jumlah parameternya dan entropi informasi data. Misalnya, Wikipedia bahasa Inggris memiliki sekitar 29,4 miliar karakter, dengan setiap karakter mengandung sekitar 1,5 bit informasi. Sebuah model dengan parameter 12B (dengan asumsi kapasitas penyimpanan 3,6 bit per parameter) secara teoritis dapat mengingat seluruh Wikipedia bahasa Inggris. Penelitian ini memiliki arti penting untuk memahami mekanisme memori LLM dan mengevaluasi masalah hak cipta data. François Chollet juga menyebutkan metodologi pelatihan LLM menggunakan string acak dan temuan kuantitatifnya, yang dianggapnya berharga untuk memahami mekanisme memori LLM (Sumber: fchollet, AymericRoucher)
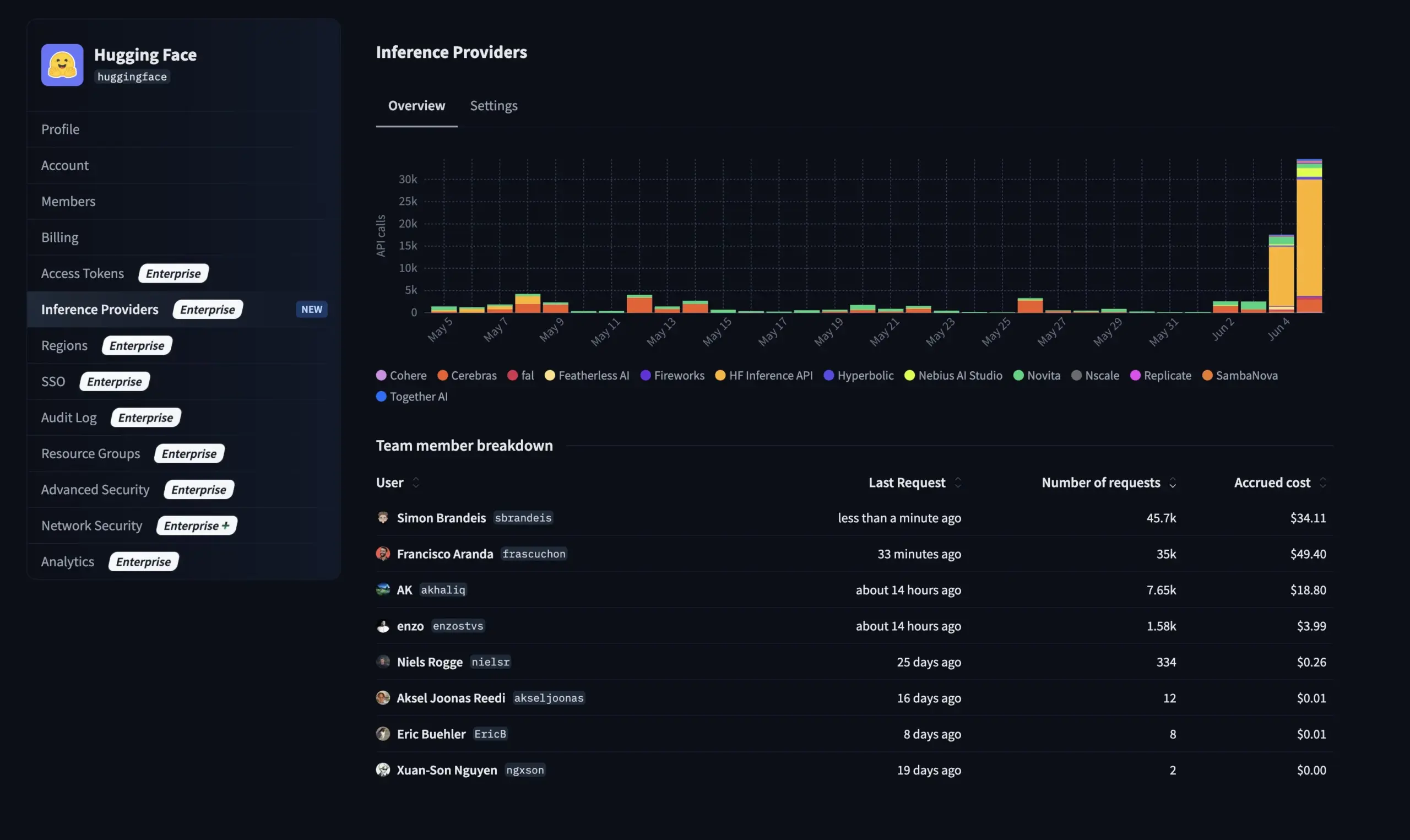
Hugging Face meluncurkan fitur baru untuk versi Enterprise: mengelola penggunaan dan biaya penyedia inferensi : Hugging Face menambahkan fitur baru ke Enterprise Hub-nya, yang memungkinkan organisasi untuk mengkonfigurasi dan memantau penggunaan serta biaya terkait dari penyedia inferensi (Inference Providers) oleh anggota tim mereka. Ini berarti pengguna perusahaan dapat mengelola dan mengontrol penggunaan layanan inferensi tanpa server untuk lebih dari 40.000 model dari berbagai penyedia seperti TogetherCompute, FireworksAI, Replicate, Cohere, dan lainnya dengan lebih baik, sehingga mengoptimalkan efektivitas biaya dan alokasi sumber daya untuk deployment aplikasi AI (Sumber: huggingface, _akhaliq)
Model penalaran ilmiah Mistral AI, ether0, dirilis, hasil fine-tuning dari Mistral 24B : Mistral AI merilis model penalaran ilmiah pertamanya, ether0. Model ini dibuat dengan melatih Mistral 24B menggunakan reinforcement learning (RL) pada beberapa tugas desain molekul di bidang kimia. Penelitian menemukan bahwa LLM belajar data pada beberapa tugas ilmiah jauh lebih efisien daripada model khusus yang dilatih dari awal, dan dapat secara signifikan mengungguli model dan manusia terdepan pada tugas-tugas ini. Hal ini menunjukkan bahwa untuk sebagian masalah klasifikasi, regresi, dan generasi ilmiah, melakukan post-training pada LLM mungkin menawarkan jalur yang lebih efisien daripada metode machine learning tradisional (Sumber: MistralAI)
Model Konsistensi Dua Ahli (DCM) meningkatkan kecepatan pembuatan video 10 kali lipat : Ziwei Liu dan peneliti lainnya mengusulkan Model Konsistensi Dua Ahli (Dual Consistency Model – DCM), yang dapat meningkatkan kecepatan model pembuatan video (dengan jumlah parameter dari 1,3B hingga 13B) sebanyak 10 kali lipat tanpa mengurangi kualitas. Model ini saat ini telah mendukung Tencent Hunyuan dan Alibaba Tongyi Wanxiang. Pengajuan DCM membawa terobosan baru di bidang pembuatan video berkualitas tinggi yang efisien, membantu mempercepat pembuatan konten video dan pengembangan aplikasi terkait (Sumber: _akhaliq)
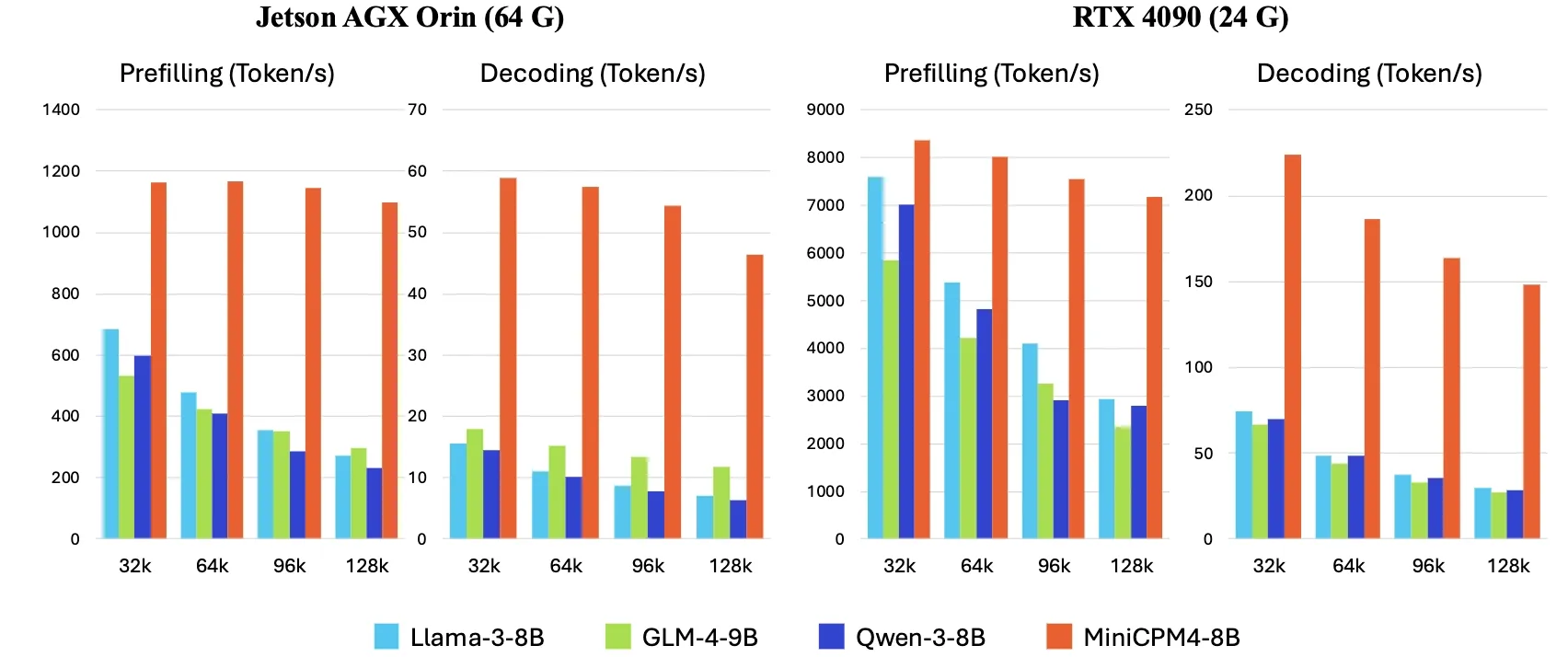
OpenBMB merilis MiniCPM4, kecepatan inferensi di sisi perangkat meningkat 5 kali lipat : OpenBMB meluncurkan seri model MiniCPM4, yang mencapai peningkatan kecepatan inferensi 5 kali lipat pada perangkat sisi (edge devices) melalui adopsi arsitektur model yang efisien (mekanisme sparse attention yang dapat dilatih InfLLM v2), algoritma pembelajaran yang efisien (Model Wind Tunnel 2.0, kuantisasi terner BitCPM), data pelatihan berkualitas tinggi (UltraClean, UltraChat v2), serta sistem inferensi yang efisien (CPM.cu, ArkInfer). Model andalan MiniCPM4-8B (parameter 8B, dilatih dengan 8T token) telah tersedia di Hugging Face. Seri model ini bertujuan untuk mengeksplorasi batas kemampuan LLM kecil dan murah, mendorong aplikasi AI pada perangkat dengan sumber daya terbatas (Sumber: eliebakouch, Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞))
Perusahaan X memperbarui persyaratan layanan, melarang penggunaan postingannya untuk “fine-tuning atau melatih” model AI, kecuali ada perjanjian : Perusahaan X (sebelumnya Twitter) memperbarui persyaratan layanannya, secara eksplisit melarang penggunaan konten postingan di platform untuk “fine-tuning atau melatih” model kecerdasan buatan, kecuali jika ada perjanjian khusus dengan Perusahaan X. Langkah ini mencerminkan meningkatnya kesadaran dan keinginan platform konten untuk mengontrol nilai data mereka di era AI, yang mungkin meniru perusahaan seperti Reddit dan Google yang memonetisasi data melalui perjanjian lisensi. Perubahan kebijakan ini akan berdampak pada peneliti dan pengembang AI yang bergantung pada data media sosial publik untuk pelatihan model (Sumber: MIT Technology Review)
🧰 Alat
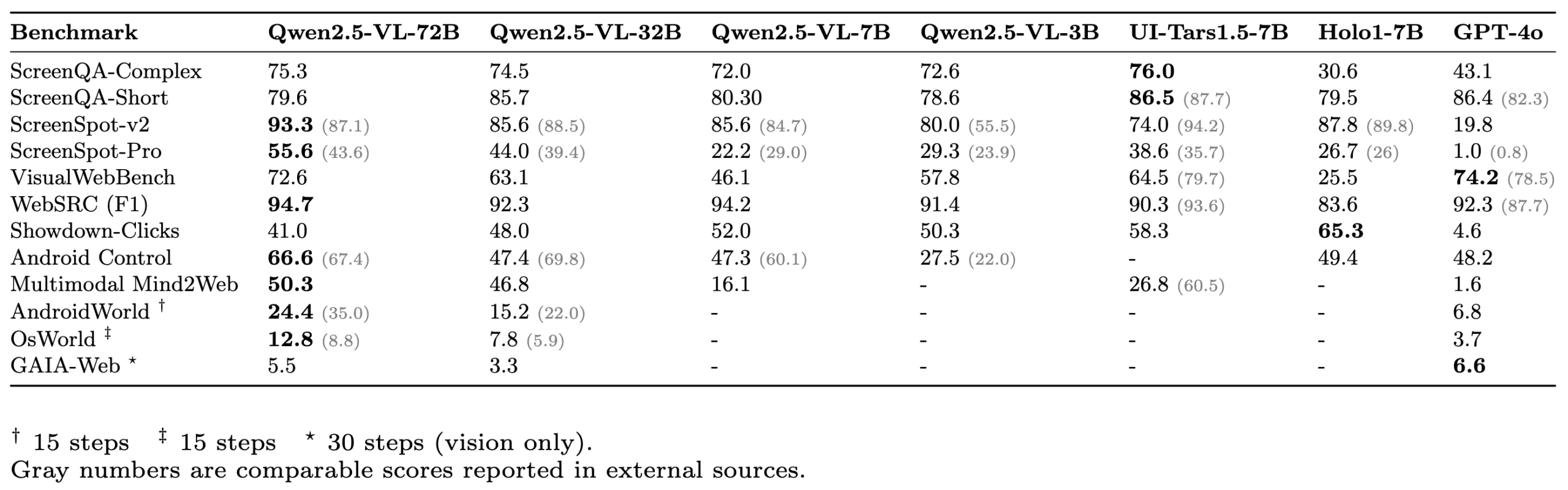
ScreenSuite: Rangkaian evaluasi GUI Agent komprehensif dirilis : Hugging Face merilis ScreenSuite, sebuah rangkaian evaluasi agen antarmuka pengguna grafis (GUI) yang komprehensif. Ini mengintegrasikan benchmark utama dari penelitian mutakhir, mendukung evaluasi ter-Docker-isasi untuk lingkungan Ubuntu dan Android, serta mencakup skenario seluler, desktop, dan web. Rangkaian ini menekankan evaluasi murni visual (tanpa kecurangan DOM), bertujuan untuk menyediakan platform terpadu yang mudah digunakan untuk mengukur kemampuan model bahasa visual (VLM) dalam persepsi, lokalisasi, operasi langkah tunggal, dan tugas agen multi-langkah. Model seperti Qwen-2.5-VL, UI-Tars-1.5-7B, Holo1-7B, dan GPT-4o telah dievaluasi menggunakan rangkaian ini (Sumber: huggingface, AymericRoucher, clefourrier, tonywu_71, mervenoyann, HuggingFace Blog)
Pengalaman menggunakan Claude Code dibagikan: pemahaman instruksi, perencanaan tugas, dan kemampuan penggunaan alat menonjol : Pengguna dotey membagikan pengalamannya menggunakan asisten pemrograman AI dari Anthropic, Claude Code. Menurutnya, keunggulan Claude Code terletak pada: 1. Pemahaman instruksi yang sangat baik; 2. Kemampuan merencanakan tugas dengan wajar, untuk tugas kompleks akan membuat TODO List dan melaksanakannya satu per satu; 3. Kemampuan penggunaan alat yang sangat kuat, terutama mahir menggunakan perintah grep untuk mencari di codebase, jauh lebih efisien daripada manusia, bahkan mampu menganalisis kode JS yang diobfuscated; 4. Waktu eksekusi yang lama, mampu “mengerahkan tenaga besar untuk hasil luar biasa”, tetapi konsumsi Token juga besar, cocok digunakan bersama langganan Claude Max; 5. Intervensi manual yang minim selama proses, terutama setelah mengaktifkan parameter --dangerously-skip-permissions dapat mencapai pemrograman tanpa pengawasan. Pengguna beralih dari pengguna berat Cursor menjadi lebih mengandalkan Claude Code untuk menyelesaikan tugas terlebih dahulu, baru kemudian meninjau dan memodifikasi di IDE. Plan Mode (mode rencana) Claude Code juga telah diluncurkan secara diam-diam, memungkinkan pengguna melakukan pembacaan dan pemikiran murni tanpa mengedit file (Sumber: dotey, Reddit r/ClaudeAI)
ClaudeBox: Menjalankan Claude Code dengan aman di Docker, menghilangkan permintaan izin : Pengembang RchGrav membuat alat ClaudeBox, yang memungkinkan pengguna menjalankan Claude Code dalam mode berkelanjutan (tanpa permintaan izin) di dalam kontainer Docker. Hal ini menghindari gangguan alur kerja akibat konfirmasi izin yang sering, sekaligus menjamin keamanan sistem operasi utama, karena semua operasi Claude Code dibatasi dalam lingkungan Docker yang terisolasi. ClaudeBox menyediakan lebih dari 15 lingkungan pengembangan yang telah dikonfigurasi sebelumnya (seperti Python+ML, C++/Rust/Go, dll.), yang dapat diatur dengan cepat oleh pengguna melalui perintah sederhana. Alat ini bertujuan untuk meningkatkan pengalaman penggunaan Claude Code, memungkinkan pengguna membiarkan AI mencoba berbagai operasi tanpa khawatir (Sumber: Reddit r/ClaudeAI)
Toolio 0.6.0 dirilis: Toolkit GenAI dan Agent yang dirancang khusus untuk Mac : Toolio merilis versi 0.6.0, sebuah toolkit yang terintegrasi secara mendalam dengan MLX, dirancang untuk memberikan dukungan kuat bagi model bahasa besar (LLM) di Mac. Toolio mengimplementasikan output terstruktur berbasis panduan JSON Schema dan fungsionalitas pemanggilan alat, menggunakan bahasa Python. Toolkit ini berfokus pada peningkatan pengalaman dan efisiensi pengembangan aplikasi GenAI dan Agent di lingkungan Mac (Sumber: awnihannun)
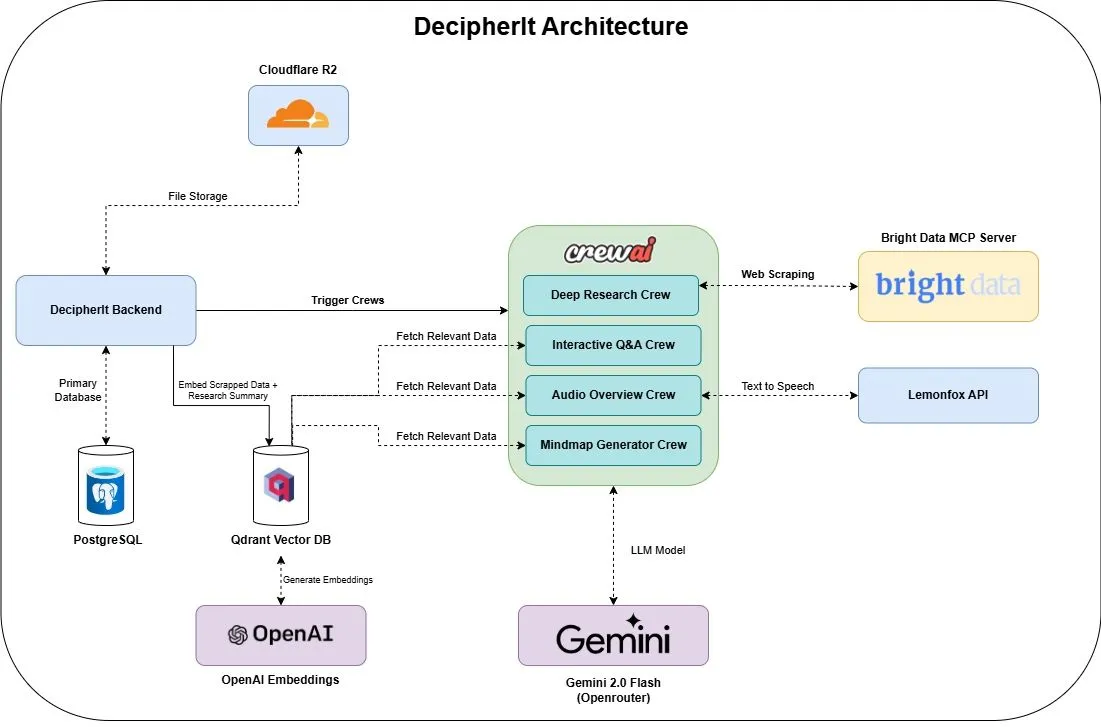
DecipherIt: Asisten riset AI open-source, terintegrasi dengan multi-agen dan pencarian semantik : DecipherIt adalah asisten riset AI open-source, yang dianggap sebagai alternatif untuk NotebookLM. Alat ini memanfaatkan orkestrasi multi-agen, pencarian semantik, dan fungsionalitas akses web real-time untuk membantu pengguna memproses materi riset. Pengguna dapat mengunggah dokumen, menempelkan URL, atau memasukkan topik, dan DecipherIt akan mengubahnya menjadi ruang kerja riset lengkap yang berisi ringkasan, peta pikiran, ikhtisar audio, FAQ, dan tanya jawab semantik. Tumpukan teknologinya mencakup agen crewAI, Bright Data MCP, Qdrant, OpenAI, dan LemonFox AI, dengan frontend menggunakan Next.js dan React 19, serta backend FastAPI (Sumber: qdrant_engine)
Search Arena: Dataset interaksi pengguna dengan LLM yang ditingkatkan pencarian dirilis untuk analisis : Search Arena adalah dataset preferensi manusia berskala besar (lebih dari 24.000) yang dikumpulkan secara crowdsourcing, berisi interaksi pengguna multi-giliran berpasangan dengan LLM yang ditingkatkan pencarian. Dataset ini mencakup berbagai maksud dan bahasa, serta berisi sekitar 12.000 jejak sistem lengkap dari pemungutan suara preferensi manusia. Analisis menunjukkan bahwa preferensi pengguna dipengaruhi oleh jumlah kutipan, bahkan jika konten kutipan tidak secara langsung mendukung klaim atribusi; platform yang didorong oleh komunitas umumnya lebih disukai. Dataset ini bertujuan untuk mendukung penelitian masa depan tentang LLM yang ditingkatkan pencarian, dengan kode dan data yang telah dirilis secara open source (Sumber: HuggingFace Daily Papers, jiayi_pirate, lmarena_ai)

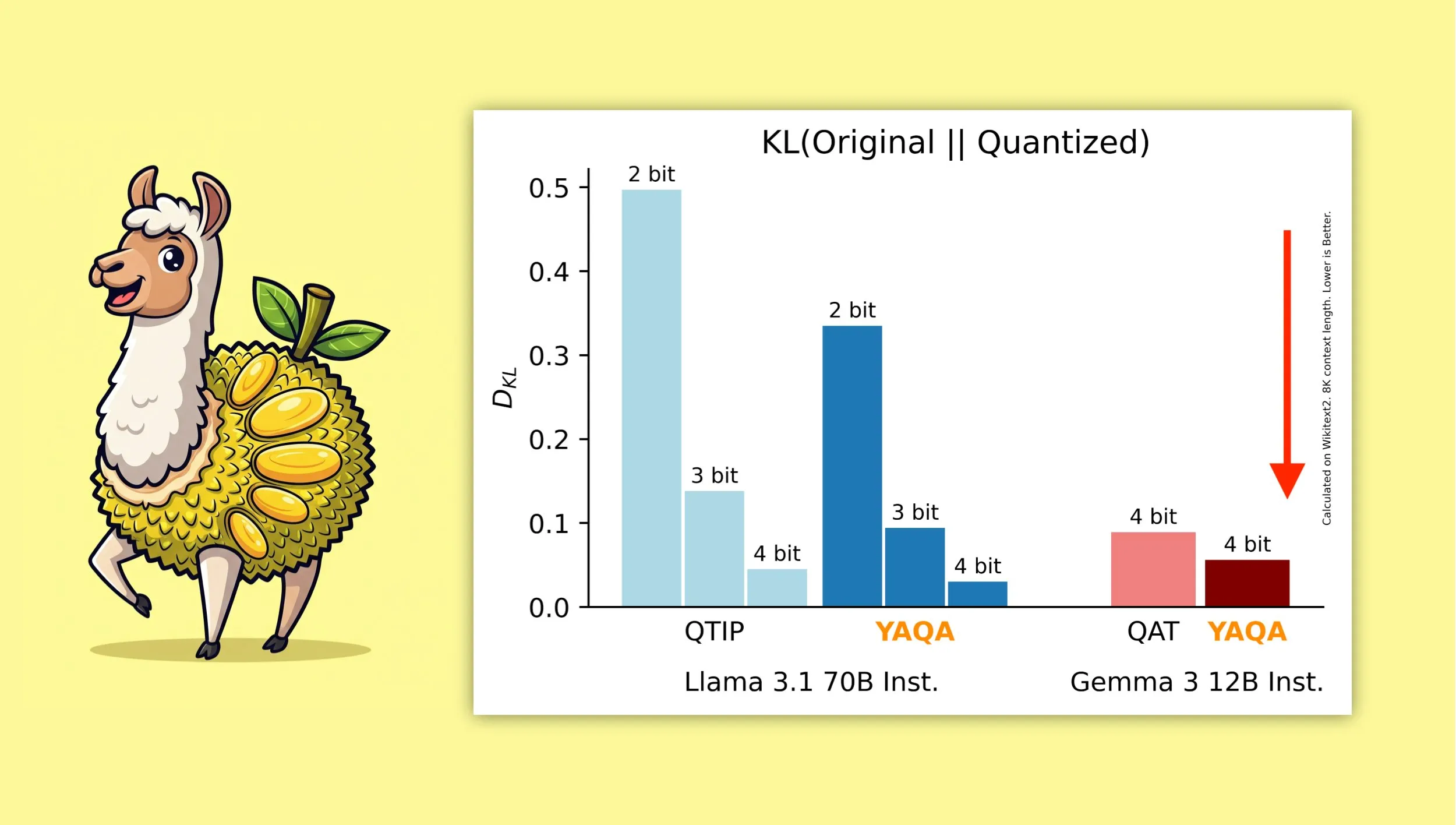
YAQA: Algoritma kuantisasi baru yang bertujuan untuk mempertahankan output asli model dengan lebih baik : Peneliti dari Cornell University meluncurkan “Yet Another Quantization Algorithm” (YAQA), sebuah algoritma kuantisasi baru yang bertujuan untuk mempertahankan output model asli dengan lebih baik setelah kuantisasi. YAQA diklaim dapat mengurangi divergensi KL lebih dari 30% dibandingkan QTIP, dan mencapai divergensi KL yang lebih rendah daripada model QAT Google pada Gemma 3. Penelitian ini memberikan ide dan alat baru di bidang kuantisasi model, membantu memaksimalkan kinerja model sambil mengurangi ukuran model dan kebutuhan komputasi. Makalah dan kode terkait telah dirilis, serta menyediakan model Llama 3.1 70B Instruct yang telah dikuantisasi sebelumnya (Sumber: Reddit r/MachineLearning, Reddit r/LocalLLaMA, tri_dao, simran_s_arora)
Tokasaurus: Mesin yang dirancang khusus untuk inferensi LLM throughput tinggi dirilis : HazyResearch merilis Tokasaurus, sebuah mesin inferensi LLM baru yang dirancang khusus untuk beban kerja throughput tinggi, cocok untuk model besar maupun kecil. Mesin ini bertujuan untuk mengoptimalkan efisiensi dan kecepatan pemrosesan LLM dalam skenario permintaan konkuren skala besar, kemungkinan menggunakan teknik canggih seperti continuous batching dan paged attention untuk meningkatkan kinerja. Rilis Tokasaurus memberikan pilihan baru bagi pengembang dan perusahaan yang membutuhkan pemrosesan tugas inferensi LLM dalam jumlah besar secara efisien (Sumber: Tim_Dettmers)
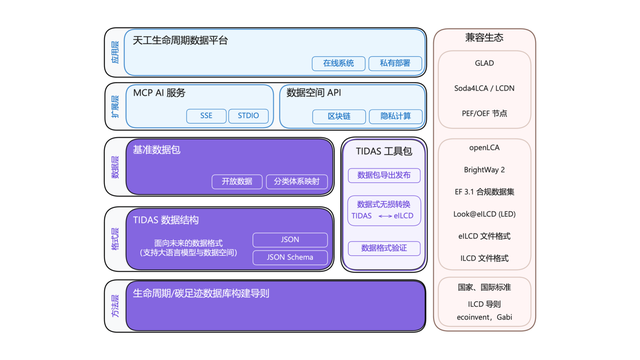
Sistem “Android” jejak karbon TIDAS dirilis, Ant Digital menyediakan dukungan teknis : Aliansi Inovasi Teknologi Industri Jejak Karbon merilis “Sistem Data LCA Tiangong” (TIDAS), yang bertujuan untuk menyediakan solusi bagi evaluasi siklus hidup (LCA) dan pembangunan database jejak karbon, dengan target membangun sistem “Android” untuk database LCA dan jejak karbon di Tiongkok bahkan global. Ant Digital, sebagai anggota inti, menyediakan dukungan teknologi blockchain dan platform kolaborasi data tepercaya untuk TIDAS. Melalui teknologi blockchain miliknya, Ant Digital mewujudkan pendaftaran dan penentuan hak aset data karbon yang tepercaya, serta menggunakan teknologi komputasi privasi untuk menjamin data “dapat digunakan tetapi tidak terlihat”, meningkatkan standardisasi, kemampuan fusi, dan interoperabilitas data (Sumber: 量子位)
📚 Pembelajaran
LangChain mengadakan lokakarya AI tingkat perusahaan, fokus pada sistem multi-agen : LangChain akan mengadakan lokakarya AI tingkat perusahaan pada 16 Juni di San Francisco. Pada acara tersebut, Jake Broekhuizen dari LangChain akan memandu peserta membangun sistem multi-agen yang siap produksi menggunakan LangGraph, dengan materi yang mencakup aspek-aspek penting seperti keamanan dan observabilitas. Ini adalah lokakarya praktis yang bertujuan membantu pengembang menguasai keterampilan membangun aplikasi AI Agent yang kompleks dan andal (Sumber: LangChainAI, hwchase17)

DeepLearning.AI meluncurkan kursus baru “DSPy: Membangun dan Mengoptimalkan Aplikasi Agentic” : DeepLearning.AI merilis kursus baru berjudul “DSPy: Build and Optimize Agentic Apps”. Kursus ini akan mengajarkan peserta dasar-dasar DSPy, cara menggunakan signature dan model pemrograman berbasis modulnya untuk membangun aplikasi GenAI Agentic yang modular, dapat dilacak, dan dapat di-debug. Materi mencakup pembangunan aplikasi dengan menghubungkan modul DSPy seperti Predict, ChainOfThought, dan ReAct, menggunakan MLflow untuk pelacakan dan debugging, serta memanfaatkan DSPy Optimizer untuk menyesuaikan prompt secara otomatis dan meningkatkan contoh few-shot guna meningkatkan akurasi dan konsistensi jawaban (Sumber: DeepLearningAI, lateinteraction)
Proyek GitHub tutorial teknik RAG tingkat lanjut menarik perhatian : Proyek tutorial teknik RAG (Retrieval-Augmented Generation) yang dibagikan oleh NirDiamant di GitHub telah mendapatkan 16,6K bintang. Tutorial ini mencakup berbagai aspek, termasuk pra-pemrosesan untuk peningkatan retrieval, optimasi, pola retrieval, iterasi, serta langkah-langkah rekayasa. Bagi pengembang yang ingin mendalami dan meningkatkan efektivitas aplikasi RAG, ini adalah sumber belajar lanjutan yang berharga (Sumber: karminski3)
Bagaimana pelanggan OpenAI menggunakan evaluasi (Evals) untuk membangun produk AI yang lebih baik : Hamel Husain mempromosikan webinar yang dibawakan oleh Jim Blomo dari OpenAI, yang akan membahas bagaimana pelanggan OpenAI memanfaatkan alat evaluasi (Evals) untuk membangun produk AI berkualitas lebih tinggi. Konten akan mencakup studi kasus dan hasil nyata, serta menampilkan alat evaluasi internal OpenAI (seperti pelacakan, penilaian, dll.). Webinar ini bertujuan untuk memberikan wawasan dan metode praktis tentang evaluasi produk AI kepada para pengembang (Sumber: HamelHusain)

LlamaIndex membagikan ikhtisar 13 protokol Agent, membahas standar interoperabilitas : Seldo dari LlamaIndex memberikan presentasi ikhtisar di KTT Pengembang MCP mengenai 13 protokol komunikasi antar-Agent yang berbeda saat ini (termasuk MCP, A2A, ACP, dll.). Ia menganalisis fitur unik masing-masing protokol, posisinya dalam lanskap teknologi saat ini, dan tren pengembangan di masa depan. Presentasi ini bertujuan untuk membantu pengembang memahami dan memilih standar komunikasi yang sesuai untuk aplikasi Agent mereka, serta mendorong interoperabilitas ekosistem Agent (Sumber: jerryjliu0, jerryjliu0)

Analisis arsitektur Claude Code: Alur kontrol, mesin orkestrasi, dan eksekusi alat : Sebuah artikel melakukan analisis mendalam terhadap arsitektur Claude Code, dengan fokus pada alur kontrol dan mesin orkestrasinya, serta alat dan mesin eksekusinya. Analisis ini memiliki nilai referensi bagi pengembang yang ingin membuat alat bantu coding baris perintah serupa atau melakukan modifikasi kustom, dan ide desainnya juga berlaku untuk pengembangan alat Agent jenis lain (Sumber: karminski3)

Solusi pemenang kedua kompetisi kernel perkalian matriks FP8 GPU AMD dibagikan : Tim Dettmers membagikan solusi dari pemenang kedua kompetisi kernel perkalian matriks FP8 GPU AMD. Penjelasan rinci solusi ini memiliki nilai referensi penting untuk memahami cara mengoptimalkan kinerja operasi floating-point presisi rendah pada GPU AMD, terutama dalam konteks meningkatnya penggunaan format presisi rendah seperti FP8 dalam pelatihan dan inferensi model AI untuk meningkatkan efisiensi (Sumber: Tim_Dettmers)
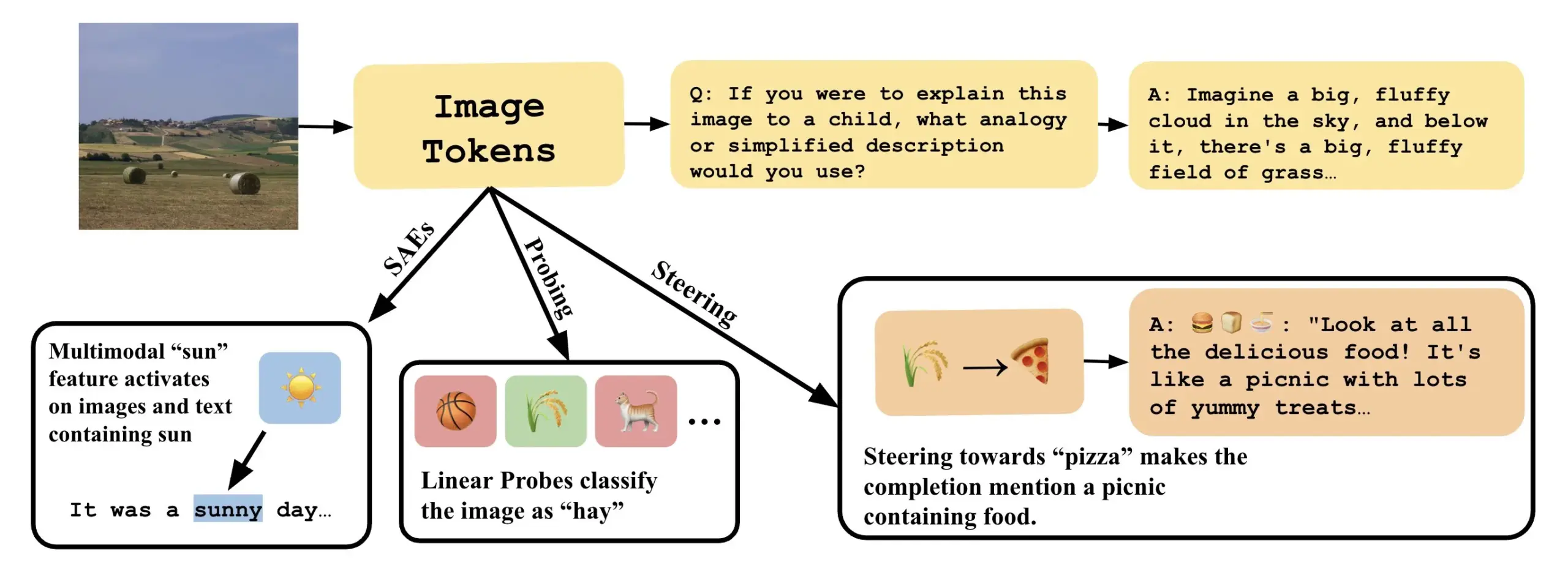
Makalah membahas cara memahami model bahasa visual dengan menjelaskan arah linear dalam VLLM : Sebuah makalah baru berjudul “Line of Sight” membahas pemahaman mekanisme internal model bahasa visual besar (VLLM) dengan menjelaskan arah linear dalam ruang latennya. Para peneliti menggunakan alat seperti probing, steering, dan sparse autoencoders (SAEs) untuk menjelaskan representasi gambar dalam VLLM. Karya ini memberikan perspektif dan metode baru untuk memahami cara kerja internal model multimodal (Sumber: nabla_theta)
💼 Bisnis
Startup AI Vareon mendapatkan pendanaan pra-bibit $3 juta dari Norck, fokus pada AI mutakhir dan sistem otonom : Norck, perusahaan yang didirikan oleh Faruk Guney, berkomitmen untuk memberikan pendanaan pra-bibit sebesar $3 juta berdasarkan pencapaian tertentu kepada startup AI barunya, Vareon. Vareon berfokus pada bidang AI mutakhir, penalaran kausal, dan sistem otonom, dengan inti MALPAC (Multi-Agent Learning Architecture for Planning and Closed-Loop Optimization). Perusahaan ini bertujuan untuk menjadi perusahaan riset AI dasar, mendorong pengembangan di bidang robotika, LLM, desain molekuler, arsitektur kognitif, dan agen otonom. Bersamaan dengan itu, diluncurkan pula RAPID (kerangka kerja perencanaan yang dapat didiferensiasi), CIMO (koordinator multi-skala kausal), SCA (arsitektur kognitif yang terinspirasi biologis), dan Lumon-XAI (lapisan interpretabilitas) (Sumber: farguney)

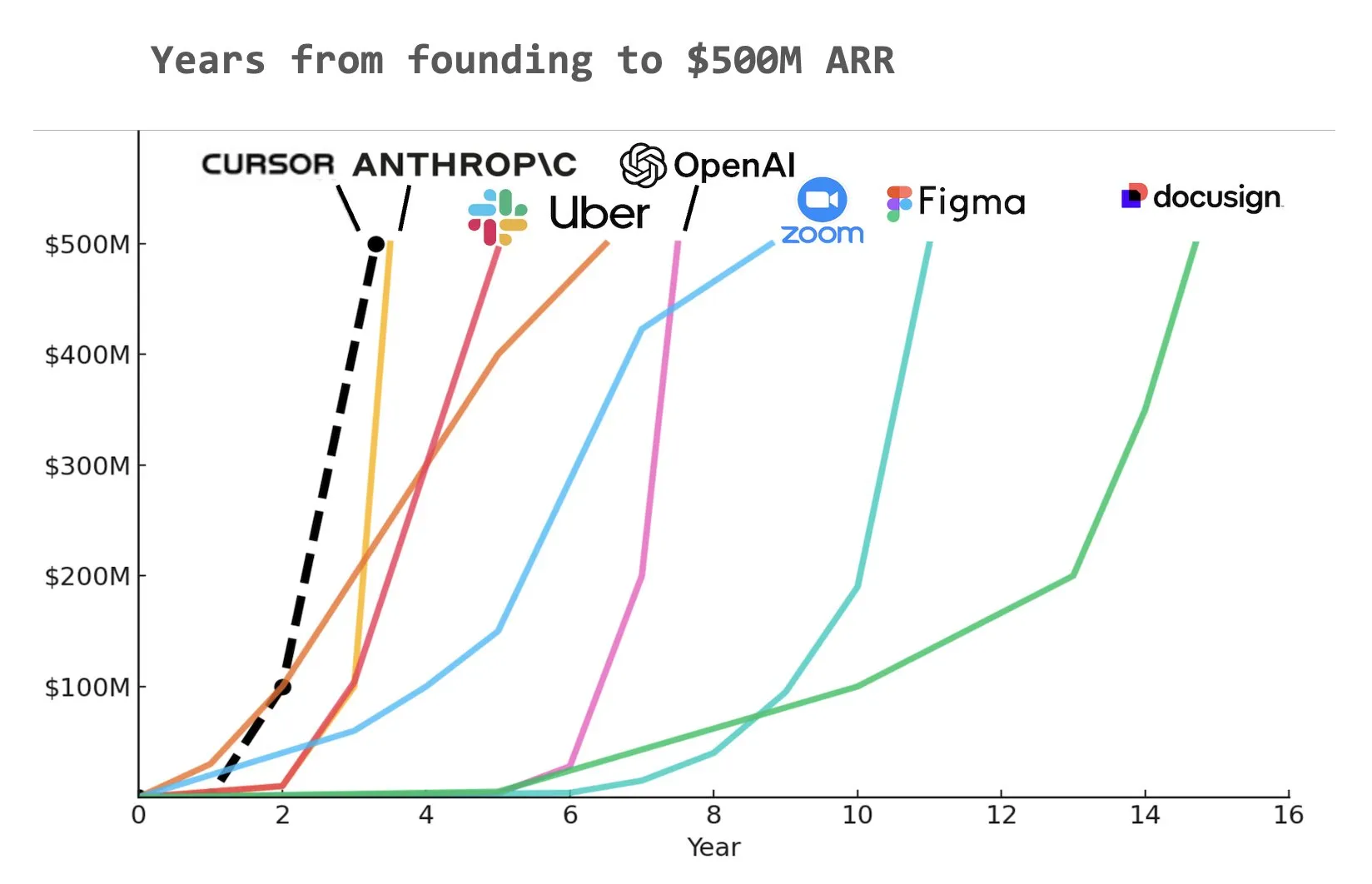
Alat coding AI Cursor mendapatkan pendanaan Seri C $900 juta, ARR mencapai $500 juta : Startup alat coding AI, Cursor, mengumumkan penyelesaian putaran pendanaan Seri C sebesar $900 juta yang dipimpin oleh Thrive, Accel, Andreessen Horowitz, dan DST. Perusahaan mengungkapkan bahwa pendapatan berulang tahunannya (ARR) telah melampaui $500 juta dan digunakan oleh lebih dari separuh perusahaan Fortune 500, termasuk NVIDIA, Uber, dan Adobe. Putaran pendanaan ini akan membantu Cursor lebih lanjut mendorong batas penelitian di bidang coding AI. Ada analisis yang menunjukkan bahwa Cursor mungkin menjadi salah satu perusahaan tercepat dalam sejarah yang mencapai ARR $500 juta (Sumber: cursor_ai, Yuchenj_UW, op7418)
Anthropic memutus akses langsung Windsurf ke model Claude, kemungkinan karena rumor akuisisi oleh OpenAI : Salah satu pendiri dan Chief Scientific Officer Anthropic, Jared Kaplan, menyatakan bahwa perusahaan memutus hak akses langsung asisten pemrograman AI Windsurf ke model Claude terutama karena rumor pasar bahwa Windsurf akan segera diakuisisi oleh OpenAI. Kaplan mengatakan “akan aneh menjual Claude ke OpenAI,” dan menyatakan bahwa Anthropic cenderung mengalokasikan sumber daya komputasi kepada mitra yang stabil dalam jangka panjang. Meskipun demikian, Anthropic secara aktif menjalin kerja sama dengan pengembang alat pemrograman AI lainnya (seperti Cursor) dan menekankan bahwa di masa depan akan lebih fokus pada pengembangan produk pemrograman AI dengan kemampuan pengambilan keputusan otonom, seperti Claude Code (Sumber: dotey, vikhyatk, jeremyphoward, swyx)

🌟 Komunitas
Greg Brockman dari OpenAI: Masa depan AGI lebih seperti kolaborasi beragam Agent khusus daripada model tunggal : Greg Brockman dari OpenAI berpendapat bahwa bentuk masa depan kecerdasan buatan umum (AGI) akan lebih menyerupai “kebun binatang” yang terdiri dari banyak agen cerdas (Agent) khusus, daripada model “batu besar” tunggal yang maha bisa. Agen-agen khusus ini akan dapat saling memanggil, bekerja sama, dan bersama-sama mendorong perkembangan ekonomi. Pandangan ini mengisyaratkan tren perkembangan AI di masa depan, yaitu melalui pembangunan dan integrasi beberapa AI Agent dengan kemampuan spesifik untuk mencapai sistem cerdas yang lebih kompleks dan kuat, dengan tujuan membuka 10 kali lipat lebih banyak aktivitas dan hasil. Clement Delangue berkomentar mengenai hal ini, bahwa diperlukan teknologi robotika AI open source untuk mematahkan monopoli dan menghindari satu perusahaan mengendalikan semua robot (Sumber: natolambert, ClementDelangue, HamelHusain)
LLM menunjukkan potensi dalam penulisan akademis dan peringkasan konten, memicu pemikiran tentang kualitas tulisan manusia : Dwarkesh Patel berpendapat bahwa LLM saat ini adalah penulis “5/10”, tetapi fakta bahwa mereka dapat secara andal meningkatkan penjelasan dalam makalah dan buku merupakan kecaman besar terhadap kualitas penulisan akademis. Arvind Narayanan lebih lanjut menunjukkan bahwa sebagian besar tulisan akademis sering kali mengorbankan kejelasan demi tampak mendalam dan kompleks, padahal tulisan yang baik seharusnya ringkas. Hal ini memicu diskusi tentang peran LLM dalam membantu penelitian akademis, meningkatkan keterbacaan konten, dan bagaimana hal itu dapat mengubah cara komunikasi akademis di masa depan (Sumber: random_walker, jeremyphoward)
Alat coding AI memicu diskusi ketergantungan pengembang, Claude Code menarik perhatian karena fungsionalitasnya yang kuat dan konsumsi Token yang tinggi : Pengguna dotey berpendapat bahwa penggunaan alat pemrograman AI (seperti Claude Code) mudah menimbulkan ketergantungan yang kuat, bahkan ketika memiliki kuota, lebih memilih menunggu AI selesai daripada menulis secara manual. Langganan Claude Max memang memiliki batasan, tetapi kemampuan coding yang kuat yang ditawarkannya (seperti pemahaman instruksi yang sangat baik, perencanaan tugas, penggunaan alat grep, dan eksekusi yang lama) menjadikannya alat yang efisien. Fenomena ini memicu diskusi tentang bagaimana alat AI mengubah kebiasaan kerja pengembang, serta keseimbangan antara efisiensi dan ketergantungan. Pengguna lain, Asuka小能猫, juga menunjukkan kasus penggunaan Claude-4-Opus dan mode Cursor Max untuk menyelesaikan pengembangan frontend secara efisien, tetapi juga menyebutkan masalah konsumsi Token (Sumber: dotey, dotey)
Pendidikan personal yang didorong AI memiliki potensi besar, tetapi perlu memperhatikan tantangan implementasi : Austen Allred membagikan pengalaman anaknya yang mengikuti sekolah yang didorong AI (tanpa guru) selama lima bulan, dan menganggap hasilnya “luar biasa”. Noah Smith berkomentar bahwa bimbingan belajar satu lawan satu adalah intervensi pendidikan yang efektif, dan AI memungkinkan hal itu dilakukan dalam skala besar. Hal ini memicu diskusi tentang penerapan AI di bidang pendidikan, termasuk jalur pembelajaran yang dipersonalisasi, potensi tutor AI, serta bagaimana memastikan keadilan pendidikan dan mengatasi tantangan implementasi teknologi. Jon Stokes me-retweet dan memperhatikan tren ini (Sumber: jonst0kes, jeremyphoward)
Koneksi emosional antara AI agent dan manusia menarik perhatian, OpenAI menekankan prioritas penelitian kesejahteraan pengguna : Joanne Jang dari OpenAI menerbitkan posting blog yang membahas hubungan antara manusia dan AI serta sikap perusahaan terhadap hal ini. Poin utamanya adalah OpenAI membangun model terutama untuk melayani manusia, dan seiring semakin banyaknya orang yang merasakan koneksi emosional dengan AI, perusahaan memprioritaskan penelitian mengenai dampak hal ini terhadap kesejahteraan emosional pengguna. Corbtt berkomentar bahwa pendamping AI adalah teknologi sosial yang paling transformatif sejak internet, dan jika perusahaan mengoptimalkan keterlibatan daripada kesehatan mental, dampaknya bisa lebih buruk daripada dampak negatif media sosial terhadap anak-anak, tetapi jika mengoptimalkan kesehatan mental, itu bisa menjadi berkah bagi umat manusia. cto_junior dengan jenaka membayangkan skenario di masa depan di mana mungkin perlu berdiskusi dengan anak-anak tentang “apakah pantas menikah dengan GPT” (Sumber: cto_junior, corbtt)

Teknologi AI Agent berkembang pesat, tetapi tugas reinforcement learning sparse end-to-end masih menantang : Nathan Lambert berpendapat bahwa proyek-proyek seperti Deep Research dan Codex agent saat ini dicapai terutama dengan melatih model pada tugas-tugas reinforcement learning (RL) jangka pendek dan ketahanan umum. Sementara itu, pelatihan end-to-end pada tugas-tugas RL yang sangat sparse tampaknya lebih jauh dari yang dibayangkan orang. Corbtt mengomentari hal ini, bahkan manusia pun belum secara efektif menguasai cara berlatih dalam tugas-tugas jangka panjang dan dengan sinyal reward yang sparse. Ini mencerminkan keterbatasan teknologi AI Agent saat ini dalam menangani perencanaan jangka panjang yang kompleks dan pembelajaran otonom (Sumber: corbtt)
“Pelajaran pahit” di bidang AI: Verifikasi (Verification) menjadi kunci bagi LLM tipe penalaran : Rishabh Agarwal menyampaikan pidato di lokakarya penalaran multimodal CVPR berjudul “Pelajaran Pahit RL: Verifikasi sebagai Kunci untuk LLM Tipe Penalaran”. Pidato ini terinspirasi oleh artikel klasik Rich Sutton tentang “pelajaran pahit”, dan membahas pentingnya mekanisme verifikasi dalam reinforcement learning dan penalaran model bahasa besar. Ini mungkin berarti bahwa hanya mengandalkan kemampuan generatif model itu sendiri tidak cukup, dan mekanisme verifikasi serta umpan balik yang kuat sangat penting untuk meningkatkan kemampuan penalaran dan keandalan AI (Sumber: jack_w_rae)

Perkembangan AI menimbulkan kekhawatiran pasar kerja, pandangan para ahli beragam : CEO Klarna, Sebastian Siemiatkowski, memperingatkan bahwa AI dapat memicu resesi ekonomi dengan menyebabkan pengangguran massal (terutama pekerjaan kerah putih). Klarna sendiri telah menggantikan 700 agen layanan pelanggan dengan asisten AI, menghemat sekitar $40 juta per tahun. Peneliti Anthropic, Sholto Douglas, juga memprediksi bahwa pada tahun 2027-28, kemampuan AI akan sangat kuat. Namun, ada juga pandangan bahwa AI akan meningkatkan produktivitas dan menciptakan lapangan kerja baru, seperti yang pernah dikatakan Sundar Pichai bahwa AI akan menjadi akselerator dan setidaknya tidak akan menyebabkan PHK sebelum tahun 2026. Video dari AI Explained menganalisis apakah berita utama saat ini tentang AI yang menyebabkan pengangguran masuk akal, dan membahas beberapa perubahan sikap Duolingo dan Klarna dalam penerapan AI. Diskusi-diskusi ini mencerminkan kecemasan umum masyarakat dan ekspektasi yang berbeda mengenai dampak ekonomi AI (Sumber: , Reddit r/ArtificialInteligence, Reddit r/ClaudeAI, Reddit r/ArtificialInteligence)
Pembahasan jalur masa depan interaksi AI agent dengan jaringan/API yang ada : Seiring meningkatnya kemampuan interaksi jaringan otonom AI agent, cara interaksinya dengan Web/API yang ada menjadi masalah infrastruktur. Diskusi mengajukan tiga jalur yang mungkin: 1. Membangun ulang dari awal, mengadopsi protokol asli Agent (tidak praktis); 2. Mengajari Agent untuk mengoperasikan situs web seperti manusia (tingkat kesalahan tinggi, terutama dalam hal otentikasi); 3. Membuat HTTP “berbicara bahasa Agent”, misalnya dengan memperkaya konteks yang dapat dibaca mesin dari respons non-sukses seperti 402 (perlu pembayaran), sehingga Agent dapat secara otonom memverifikasi dan membeli akses. Pandangan inti berpendapat bahwa menyediakan informasi konteks yang kaya untuk interaksi Web/API yang tidak berhasil akan menjadi kunci bagi Agent otonom untuk melakukan pekerjaan yang bermakna, memungkinkannya pulih secara otomatis dari kesalahan dan menavigasi proses yang kompleks (Sumber: Reddit r/ArtificialInteligence)
Penelitian matematika dengan bantuan AI menunjukkan kemajuan, Terence Tao dkk. memperhatikan potensi dan keterbatasannya : Para matematikawan secara aktif mengeksplorasi penerapan AI dalam memecahkan masalah matematika yang kompleks. Terence Tao membagikan kasus kolaborasi AI (AlphaEvolve) dengan manusia yang tiga kali memecahkan rekor indeks himpunan jumlah-selisih dalam 30 hari, dan menggabungkan bahasa Lean dengan GitHub Copilot untuk menantang masalah limit “ε-δ”, menunjukkan kemampuan AI dalam membantu pemula, menangani tugas-tugas dasar, dan memprediksi struktur pembuktian, tetapi juga menunjukkan kekurangannya dalam derivasi kompleks dan menemukan lemma matematika. Laporan lain menyebutkan bahwa 30 matematikawan terkemuka dalam pertemuan rahasia menguji OpenAI o4-mini, dan menemukan bahwa model tersebut dapat memecahkan sebagian masalah yang sangat sulit, menunjukkan tingkat yang mendekati jenius matematika. Kemajuan ini menandakan bahwa AI mungkin menjadi asisten yang berharga dalam penelitian matematika, tetapi juga mengajukan pemikiran baru tentang peran matematikawan dan pengembangan kreativitas (Sumber: 36氪)

💡 Lainnya
Kompetisi teknologi alternatif GPS memanas, Xona Space Systems berencana membangun konstelasi PNT orbit rendah : Karena sinyal sistem GPS mudah terganggu (cuaca, menara 5G, jammer) dan akurasinya terbatas, terutama kerentanannya yang terlihat jelas dalam konflik Rusia-Ukraina, pencarian alternatif menjadi prioritas strategis. Startup asal California, Xona Space Systems, berencana meluncurkan konstelasi satelit orbit Bumi rendah bernama Pulsar (akhirnya 258 satelit). Satelitnya memiliki orbit lebih rendah, kekuatan sinyal sekitar 100 kali lipat GPS, lebih sulit diganggu, dan lebih baik menembus penghalang. Tujuannya adalah menyediakan layanan penentuan posisi, navigasi, dan pewaktuan (PNT) dengan akurasi sentimeter dan keandalan tinggi untuk mendukung teknologi baru seperti kendaraan otonom. Satelit uji pertama akan diluncurkan bulan ini dengan SpaceX Transporter 14 (Sumber: MIT Technology Review)

Penelitian membahas dampak positif harapan dan optimisme terhadap pemulihan pasien penyakit jantung : Penelitian terbaru menunjukkan bahwa harapan dan optimisme pasien penyakit jantung berkorelasi dengan hasil kesehatan yang lebih baik, sedangkan keputusasaan berkorelasi dengan risiko kematian yang lebih tinggi. Hal ini sejalan dengan fenomena efek plasebo (ekspektasi positif meningkatkan hasil) dan efek nosebo (ekspektasi negatif menyebabkan gejala negatif). Alexander Montasem dkk. dari Universitas Liverpool menemukan bahwa harapan yang tinggi berkorelasi dengan berkurangnya angina, berkurangnya kelelahan pasca-stroke, peningkatan kualitas hidup, dan penurunan risiko kematian. Para peneliti sedang menjajaki cara memanfaatkan kekuatan berpikir positif dalam praktik klinis, misalnya dengan membantu pasien menetapkan tujuan dan meningkatkan agensi untuk “meresepkan harapan”, sambil menekankan bahwa tujuan non-materi lebih penting untuk kesejahteraan (Sumber: MIT Technology Review)

Promosi layanan AI Apple dan Alibaba di Tiongkok terhambat, kemungkinan karena gesekan perdagangan : Menurut laporan Financial Times, rencana promosi layanan AI Apple dan Alibaba di Tiongkok mengalami penundaan, yang dianggap sebagai korban terbaru dari gesekan perdagangan Tiongkok-AS. Kerja sama ini awalnya direncanakan untuk menyediakan dukungan fungsionalitas AI untuk iPhone yang dijual di Tiongkok. Penundaan ini dapat memengaruhi jadwal penerapan fungsionalitas AI Apple di pasar Tiongkok dan membawa ketidakpastian pada prospek kerja sama kedua perusahaan (Sumber: MIT Technology Review)