
Kata Kunci:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, AI Agent, Gemini 2.5 Pro Mode Deep Think, Kerangka Kecerdasan Embodi Umum VeBrain, Segmentasi Gambar Video SAM 2, Qwen3-Embedding Konteks 32k, Pemahaman Multimodal AI Agent
🔥 Fokus
Google merilis beberapa kemajuan AI baru, mode Deep Think pada Gemini 2.5 Pro meningkatkan kemampuan penalaran yang kompleks: Di konferensi Google I/O, Google mengumumkan mode Deep Think untuk Gemini 2.5 Pro, yang bertujuan untuk secara signifikan meningkatkan kemampuan penalaran AI dalam menangani masalah kompleks (seperti soal matematika tingkat USAMO). Pada saat yang sama, Google juga meluncurkan AlphaEvolve, sebuah agen pengkodean yang didukung oleh Gemini, yang digunakan untuk penemuan algoritma. AlphaEvolve telah mencapai hasil dalam desain algoritma perkalian matriks dan penyelesaian masalah matematika terbuka, serta diterapkan untuk mengoptimalkan pusat data internal Google, desain chip, dan efisiensi pelatihan AI. Selain itu, model video Veo 3, model gambar Imagen 4, dan alat penyuntingan AI FLOW juga dirilis bersamaan, menunjukkan tata letak komprehensif dan kemajuan pesat Google di bidang AI multimodal. (Sumber: OriolVinyalsML, demishassabis, demishassabis, op7418)
Shanghai AI Laboratory bersama-sama merilis kerangka kerja otak kecerdasan buatan yang dapat diwujudkan secara umum VeBrain: Shanghai Artificial Intelligence Laboratory bersama dengan beberapa unit meluncurkan VeBrain (Visual Embodied Brain), sebuah kerangka kerja otak kecerdasan buatan yang dapat diwujudkan secara umum yang bertujuan untuk menyatukan kemampuan persepsi visual, penalaran spasial, dan kontrol robot. Kerangka kerja ini mengubah tugas kontrol robot menjadi tugas teks spasial 2D dalam MLLM (seperti deteksi titik kunci dan pengenalan keterampilan yang diwujudkan), dan memperkenalkan “adaptor robot” untuk mencapai pemetaan yang akurat dan kontrol loop tertutup dari keputusan teks ke tindakan nyata. Untuk mendukung pelatihan model, tim membangun dataset VeBrain-600k, yang berisi 600.000 data instruksi, mencakup tiga jenis tugas: pemahaman multimodal, penalaran visual-spasial, dan operasi robot. Pengujian menunjukkan bahwa VeBrain mencapai tingkat SOTA dalam pemahaman multimodal, penalaran spasial, dan kontrol robot nyata (lengan mekanik dan anjing robot). (Sumber: 量子位)

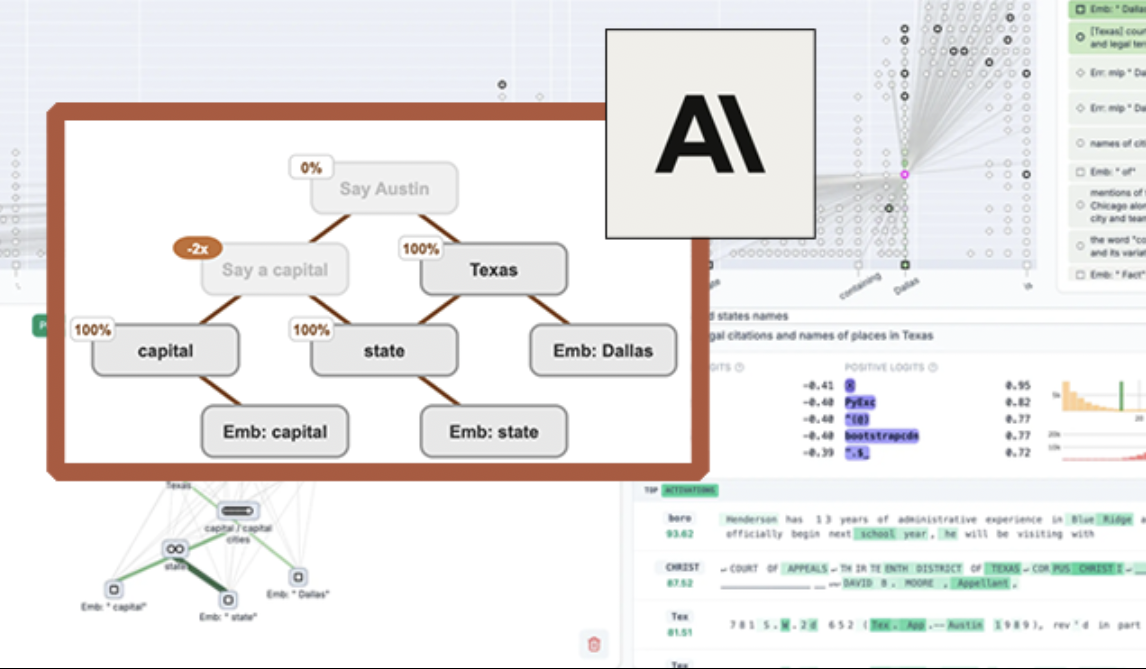
Anthropic merilis alat visualisasi LLM sumber terbuka “circuit tracing”, meningkatkan interpretabilitas model: Anthropic meluncurkan alat sumber terbuka “circuit tracing”, yang bertujuan untuk membantu peneliti memahami mekanisme kerja internal model bahasa besar (LLM). Alat ini menghasilkan “attribution graphs”, yang memvisualisasikan super-node internal dan hubungan koneksinya saat model memproses informasi, mirip dengan diagram jaringan saraf. Peneliti dapat memverifikasi fungsi setiap node dengan mengintervensi nilai aktivasi node dan mengamati perubahan perilaku model, untuk mendekode logika keputusan LLM. Alat ini mendukung pembuatan attribution graphs pada model sumber terbuka utama dan menyediakan antarmuka frontend interaktif Neuronpedia untuk visualisasi, anotasi, dan berbagi. Langkah ini bertujuan untuk mendorong penelitian interpretabilitas AI, memungkinkan komunitas yang lebih luas untuk menjelajahi dan memahami perilaku model. (Sumber: 量子位, swyx)
Meta merilis Segment Anything Model 2 (SAM 2), meningkatkan kemampuan segmentasi gambar dan video: Meta AI Research (FAIR) meluncurkan SAM 2, versi terbaru dari Segment Anything Model yang populer. SAM 2 adalah model dasar yang berfokus pada tugas segmentasi visual yang dapat diminta dalam gambar dan video, mampu mengidentifikasi dan mensegmentasi objek atau area tertentu dalam gambar atau video secara akurat berdasarkan petunjuk (seperti titik, kotak, teks). Model ini sekarang bersifat sumber terbuka, mengikuti lisensi Apache, untuk digunakan dan dibangun aplikasi oleh peneliti dan pengembang secara gratis, lebih lanjut mendorong pengembangan di bidang visi komputer. (Sumber: AIatMeta)
🎯 Tren
Beijing Academy of Artificial Intelligence (BAAI) merilis Video-XL-2 sumber terbuka, mencapai pemahaman video puluhan ribu frame dengan satu kartu: BAAI bersama dengan Shanghai Jiao Tong University dan institusi lainnya merilis model pemahaman video ultra-panjang generasi baru, Video-XL-2. Model ini menunjukkan peningkatan signifikan dalam hal efek, panjang pemrosesan, dan kecepatan, mampu memproses input video puluhan ribu frame dengan satu kartu, dan mengkodekan video 2048 frame hanya dalam 12 detik. Video-XL-2 menggunakan encoder visual SigLIP-SO400M, modul sintesis token dinamis (DTS), dan model bahasa besar Qwen2.5-Instruct, serta mencapai kinerja tinggi melalui pelatihan progresif empat tahap dan strategi optimasi efisiensi (seperti pra-pengisian tersegmentasi dan decoding KV dua granularitas). Model ini menunjukkan kinerja yang sangat baik pada benchmark seperti MLVU dan Video-MME, dan bobotnya telah dirilis sebagai sumber terbuka. (Sumber: 量子位)

Character.ai meluncurkan fungsi pembuatan video AvatarFX, tokoh gambar dapat bergerak dan berinteraksi: Aplikasi pendamping AI terkemuka Character.ai (c.ai) meluncurkan fungsi AvatarFX, yang memungkinkan pengguna untuk menganimasikan tokoh dalam gambar statis (termasuk gambar non-manusia seperti hewan peliharaan), membuatnya dapat berbicara, bernyanyi, dan berinteraksi dengan pengguna. Fungsi ini didasarkan pada arsitektur DiT, menekankan fidelitas tinggi dan konsistensi temporal, dan dapat mempertahankan stabilitas bahkan dalam skenario kompleks seperti multi-karakter dan dialog urutan panjang. Saat ini AvatarFX telah dibuka untuk semua pengguna di versi web, dan akan segera diluncurkan di aplikasi. Sementara itu, c.ai juga mengumumkan fungsi baru seperti Scenes (adegan cerita interaktif), Imagine Animated Chat (catatan obrolan animasi), dan Stream (pembuatan cerita antar karakter), yang semakin memperkaya pengalaman kreasi AI. (Sumber: 量子位)

Nvidia meluncurkan model bahasa visual Llama-3.1 Nemotron-Nano-VL-8B-V1: Nvidia merilis model visual-ke-teks baru Llama-3.1-Nemotron-Nano-VL-8B-V1, yang mampu memproses input gambar, video, dan teks, serta menghasilkan output teks, dengan tingkat kemampuan penalaran dan pengenalan gambar tertentu. Peluncuran model ini merupakan wujud investasi berkelanjutan Nvidia di bidang AI multimodal. Sementara itu, diskusi komunitas menunjukkan bahwa pengabaian Llama-4 terhadap model di bawah 70B dapat membawa peluang bagi model seperti Gemma3 dan Qwen3 di pasar fine-tuning. (Sumber: karminski3)
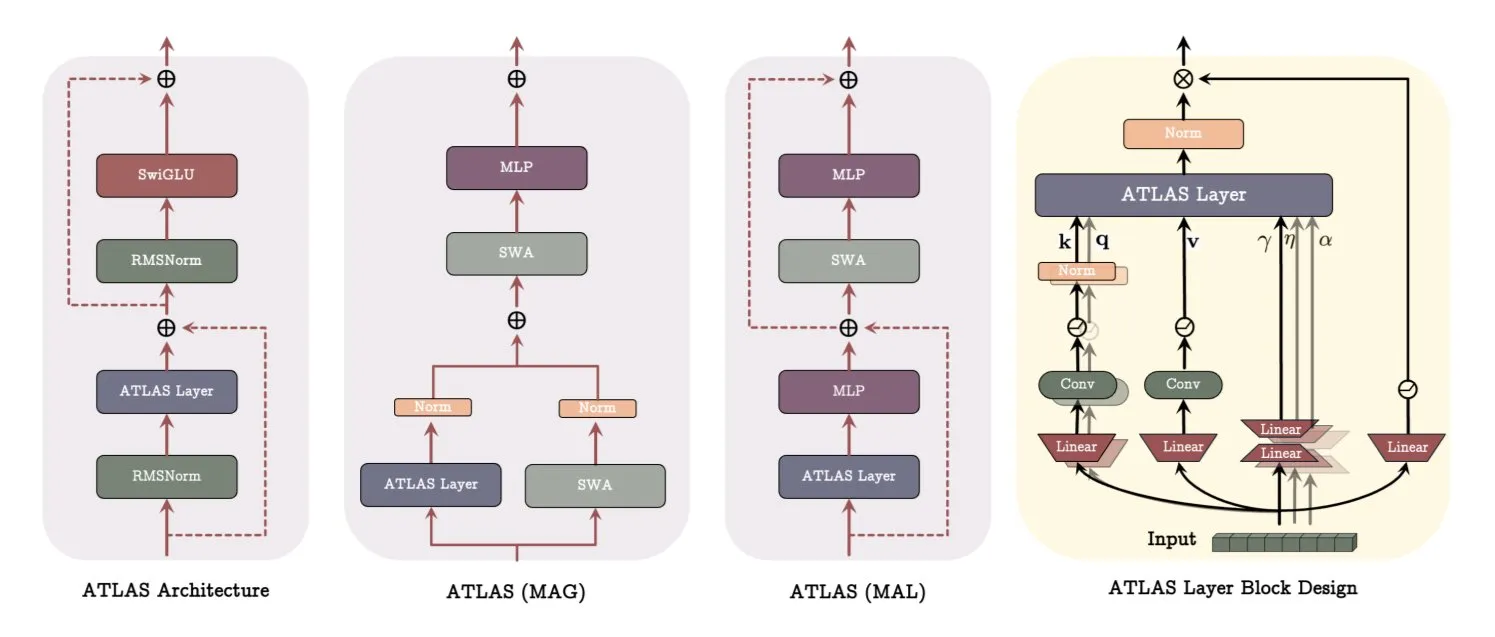
Google merilis makalah arsitektur ATLAS, merevolusi cara model belajar dan mengingat: Makalah terbaru Google memperkenalkan arsitektur model baru bernama ATLAS, yang bertujuan untuk mengoptimalkan kemampuan belajar dan mengingat model melalui memori aktif (aturan Omega memproses c token terbaru) dan manajemen kapasitas memori yang lebih cerdas (pemetaan fitur polinomial dan eksponensial). ATLAS menggunakan optimizer Muon untuk pembaruan memori yang lebih efektif, dan memperkenalkan desain seperti DeepTransformers dan Dot (Deep Omega Transformers), menggantikan perhatian tetap tradisional dengan mekanisme yang dapat dipelajari dan digerakkan oleh memori. Penelitian ini menandai langkah maju AI menuju sistem yang lebih cerdas dan sadar konteks, yang diharapkan dapat meningkatkan kemampuan AI dalam memproses dan memanfaatkan dataset skala besar. (Sumber: TheTuringPost)
Qwen merilis seri model Qwen3-Embedding, secara signifikan meningkatkan kinerja embedding: Tim Qwen merilis seri model Qwen3-Embedding baru, termasuk tiga versi: 0.6B, 4B, dan 8B. Model-model ini mendukung panjang konteks hingga 32k dan 100 bahasa, mencapai hasil SOTA pada MTEB (Massive Text Embedding Benchmark), dengan beberapa metrik mengungguli peringkat kedua sebesar 10 poin. Kemajuan ini menandai terobosan penting lainnya dalam teknologi embedding teks, menyediakan dasar yang lebih kuat untuk aplikasi seperti pencarian semantik dan RAG. (Sumber: AymericRoucher, ClementDelangue)

Microsoft Bing Video Creator diluncurkan, berbasis model OpenAI Sora dan tersedia gratis: Microsoft meluncurkan Bing Video Creator dalam aplikasi Bing-nya. Fitur ini berbasis model Sora dari OpenAI dan memungkinkan pengguna membuat video melalui prompt teks secara gratis. Ini adalah pertama kalinya model Sora dibuka secara gratis untuk publik dalam skala besar. Meskipun gratis, saat ini fiturnya terbatas, seperti durasi video hanya 5 detik, rasio 9:16, dan kecepatan pembuatan yang relatif lambat. Umpan balik pengguna menunjukkan bahwa efeknya masih kalah dibandingkan model video SOTA saat ini (seperti Keling, Veo3), yang memicu diskusi tentang kecepatan iterasi teknologi Sora dan strategi produk Microsoft. (Sumber: 36氪)
OpenAI meluncurkan beberapa fitur tingkat perusahaan, meningkatkan integrasi di tempat kerja: OpenAI merilis serangkaian fitur baru yang ditujukan untuk pengguna perusahaan, termasuk menyediakan konektor khusus untuk aplikasi seperti Google Drive, serta mengimplementasikan fungsi perekaman rapat, transkripsi, dan ringkasan di ChatGPT, dan mendukung SSO (single sign-on) serta penetapan harga edisi perusahaan berbasis kredit. Pembaruan ini bertujuan untuk mengintegrasikan ChatGPT lebih dalam ke alur kerja perusahaan, meningkatkan efisiensi kantor. (Sumber: TheRundownAI, EdwardSun0909)
Hugging Face merilis model robot efisien SmolVLA, dapat berjalan di MacBook: Hugging Face meluncurkan model robot bernama SmolVLA, yang memiliki ciri khas efisiensi sangat tinggi, bahkan dapat berjalan di MacBook. Setelah di-fine-tune pada sejumlah kecil data demonstrasi (misalnya 31), model ini dapat mencapai atau melampaui kinerja baseline tugas tunggal pada tugas tertentu (seperti operasi Koch Arm), menunjukkan potensinya dalam penerapan AI robot di lingkungan dengan sumber daya terbatas. (Sumber: mervenoyann, sytelus)
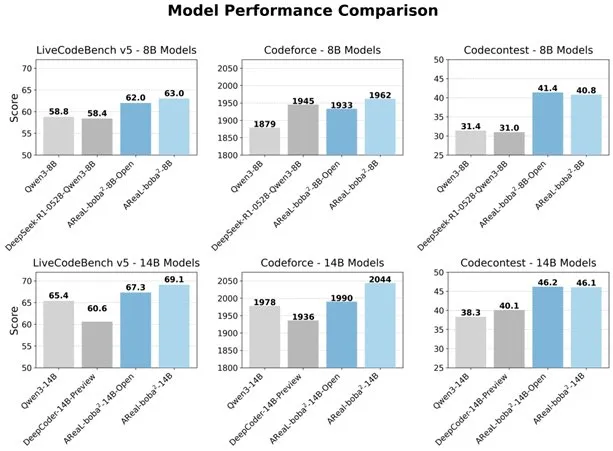
Alibaba merilis sistem RL sepenuhnya asinkron AReaL-boba² sumber terbuka, meningkatkan kemampuan kode LLM: Tim Qwen Alibaba merilis sistem reinforcement learning sepenuhnya asinkron AReaL-boba² sumber terbuka, yang dirancang khusus untuk model bahasa besar (LLM), dan mencapai efek reinforcement learning kode SOTA pada Qwen3-14B. Sistem ini, melalui desain kolaboratif sistem dan algoritma, mencapai percepatan pelatihan 2,77 kali lipat, mencapai skor 69,1 pada LiveCodeBench, dan mendukung reinforcement learning multi-putaran. (Sumber: _akhaliq)
DuckDB meluncurkan ekstensi DuckLake, mengintegrasikan data lake dengan format katalog: DuckDB merilis ekstensi DuckLake, sebuah format lakehouse terbuka berbasis SQL dan Parquet. DuckLake menyimpan metadata dalam database katalog dan data dalam file Parquet. Melalui ekstensi ini, DuckDB dapat langsung membaca dan menulis data di DuckLake, mendukung pembuatan tabel, modifikasi, kueri, time travel, dan evolusi skema, yang bertujuan untuk menyederhanakan pembangunan dan pengelolaan data lake. (Sumber: GitHub Trending)
Model Context Protocol (MCP) Ruby SDK dirilis: Model Context Protocol (MCP) merilis Ruby SDK resmi, yang dikelola bersama dengan Shopify, untuk mengimplementasikan server MCP. MCP bertujuan untuk menyediakan cara standar bagi model AI (terutama Agent) untuk menemukan dan memanggil alat, mengakses sumber daya, dan menjalankan prompt yang telah ditentukan sebelumnya. SDK ini mendukung JSON-RPC 2.0 dan menyediakan fungsi inti seperti registrasi alat, manajemen prompt, dan akses sumber daya, memudahkan pengembang untuk membangun aplikasi AI yang sesuai dengan spesifikasi MCP. (Sumber: GitHub Trending)
Teknologi AI membantu baterai seng mencapai efisiensi 99,8% dan operasi 4300 jam: Melalui optimasi kecerdasan buatan, baterai seng generasi baru mencapai efisiensi Coulomb 99,8% dan waktu operasi hingga 4300 jam. Aplikasi AI di bidang ilmu material, khususnya dalam desain baterai dan prediksi kinerja, mendorong terobosan dalam teknologi penyimpanan energi, yang diharapkan dapat membawa solusi energi yang lebih efisien dan tahan lama untuk bidang-bidang seperti kendaraan listrik dan perangkat elektronik portabel. (Sumber: Ronald_vanLoon)

🧰 Alat
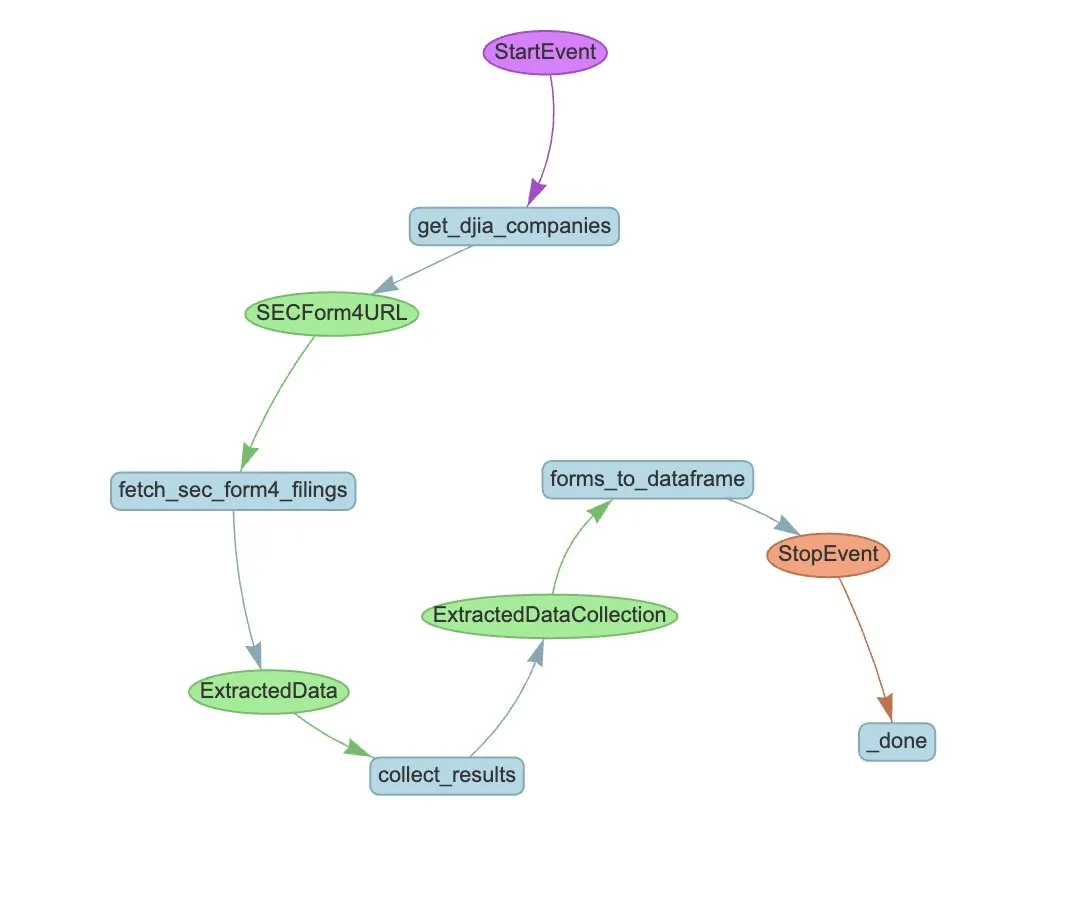
LlamaIndex meluncurkan LlamaExtract dan alur kerja Agent untuk otomatisasi ekstraksi SEC Form 4: LlamaIndex menunjukkan cara menggunakan LlamaExtract dan alur kerja Agent untuk secara otomatis mengekstrak informasi terstruktur dari file SEC Form 4. SEC Form 4 adalah dokumen penting bagi eksekutif perusahaan publik, direktur, dan pemegang saham utama untuk mengungkapkan transaksi saham. Dengan membangun agen ekstraksi dan alur kerja yang dapat diskalakan, pengajuan Form 4 dari semua perusahaan dalam Dow Jones Industrial Average dapat diproses secara efisien, meningkatkan transparansi pasar dan efisiensi analisis data. (Sumber: jerryjliu0)
Cognee: Alat sumber terbuka untuk menyediakan memori dinamis bagi AI Agent: Cognee adalah proyek sumber terbuka yang bertujuan untuk menyediakan kemampuan memori dinamis bagi AI Agent, diklaim dapat diintegrasikan hanya dengan 5 baris kode. Ini membangun pipeline ECL (Extract, Cognify, Load) yang dapat diskalakan dan modular, membantu Agent terhubung dan mengambil percakapan, dokumen, gambar, dan transkripsi audio masa lalu untuk menggantikan sistem RAG tradisional, mengurangi kesulitan dan biaya pengembangan, serta mendukung pemrosesan dan pemuatan data dari lebih dari 30 sumber data. (Sumber: GitHub Trending)
Claude Code kini tersedia untuk pengguna Pro, dan meluncurkan GitHub Action versi komunitas: Asisten pemrograman AI Anthropic, Claude Code, telah dibuka untuk pelanggan Pro, yang dapat menggunakannya melalui plugin IDE JetBrains dan cara lainnya. Pengembang komunitas juga telah meluncurkan versi fork dari Claude Code GitHub Action, yang memungkinkan pengguna berbayar untuk langsung memanggil Claude Code dalam GitHub Issues atau PR, memanfaatkan kuota langganan mereka untuk menyelesaikan tugas seperti peninjauan kode dan menjawab pertanyaan, tanpa perlu membayar biaya API tambahan. (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
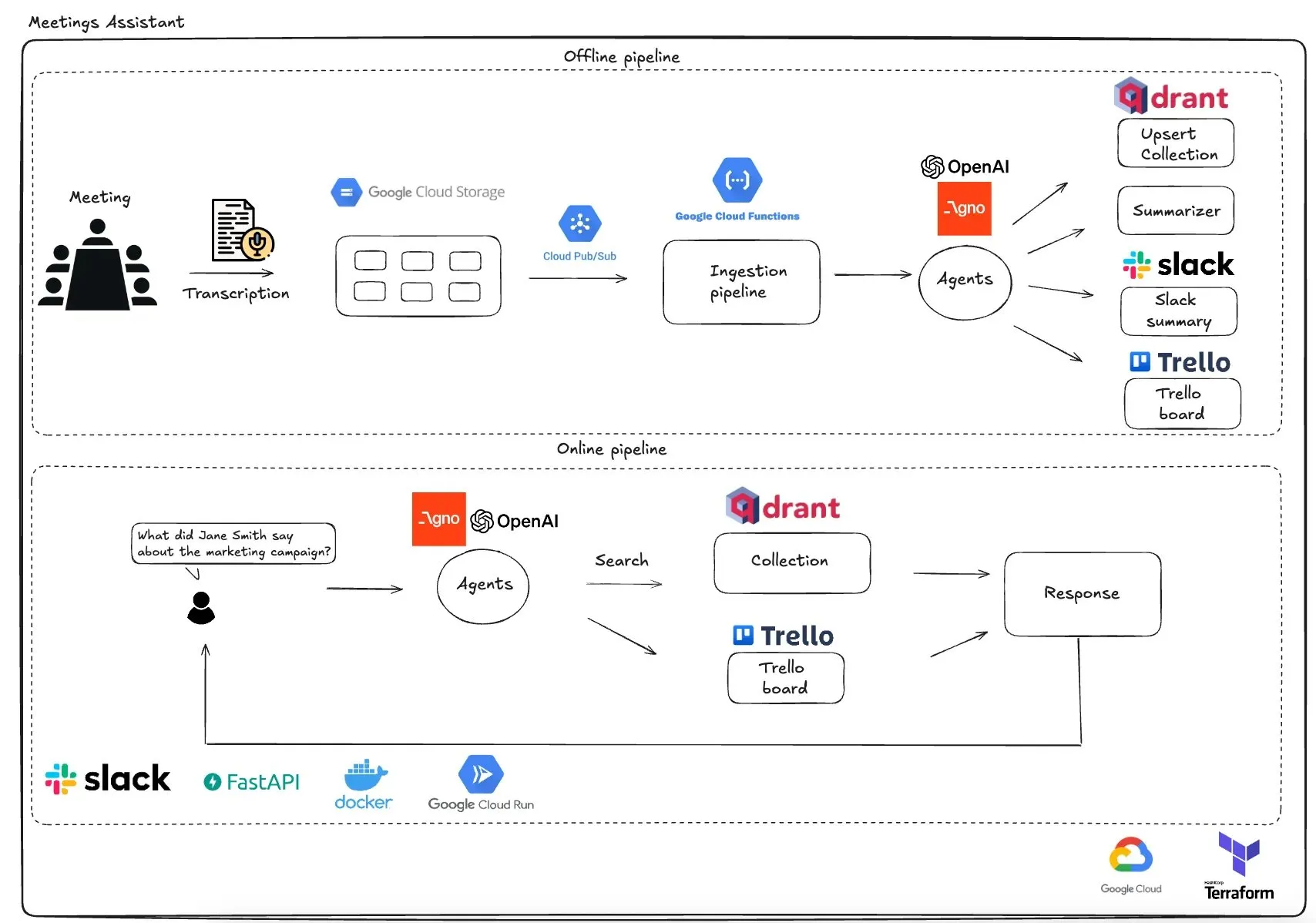
Qdrant meluncurkan asisten rapat multi-agen berbasis GCP: Qdrant mendemonstrasikan sistem asisten rapat multi-agen yang sepenuhnya tanpa server. Sistem ini mampu mentranskripsikan konten rapat, menggunakan agen LLM untuk meringkas, menyimpan informasi kontekstual dalam database vektor Qdrant, dan menyinkronkan tugas ke Trello, dengan hasil akhir dikirim langsung di Slack. Sistem ini menggunakan AgnoAgi untuk orkestrasi agen, FastAPI yang berjalan di Cloud Run, dan menggunakan OpenAI untuk embedding dan inferensi. (Sumber: qdrant_engine)
Microsoft merilis GUI-Actor, mewujudkan penentuan lokasi elemen GUI tanpa koordinat: Microsoft merilis GUI-Actor di Hugging Face, sebuah metode penentuan lokasi elemen GUI (Graphical User Interface) tanpa koordinat. Metode ini memungkinkan agen AI untuk secara langsung menunjuk ke blok visual asli (visual patches) melalui token <actor> khusus, daripada bergantung pada prediksi koordinat berbasis teks, yang bertujuan untuk meningkatkan akurasi dan ketahanan operasi agen GUI. (Sumber: _akhaliq)

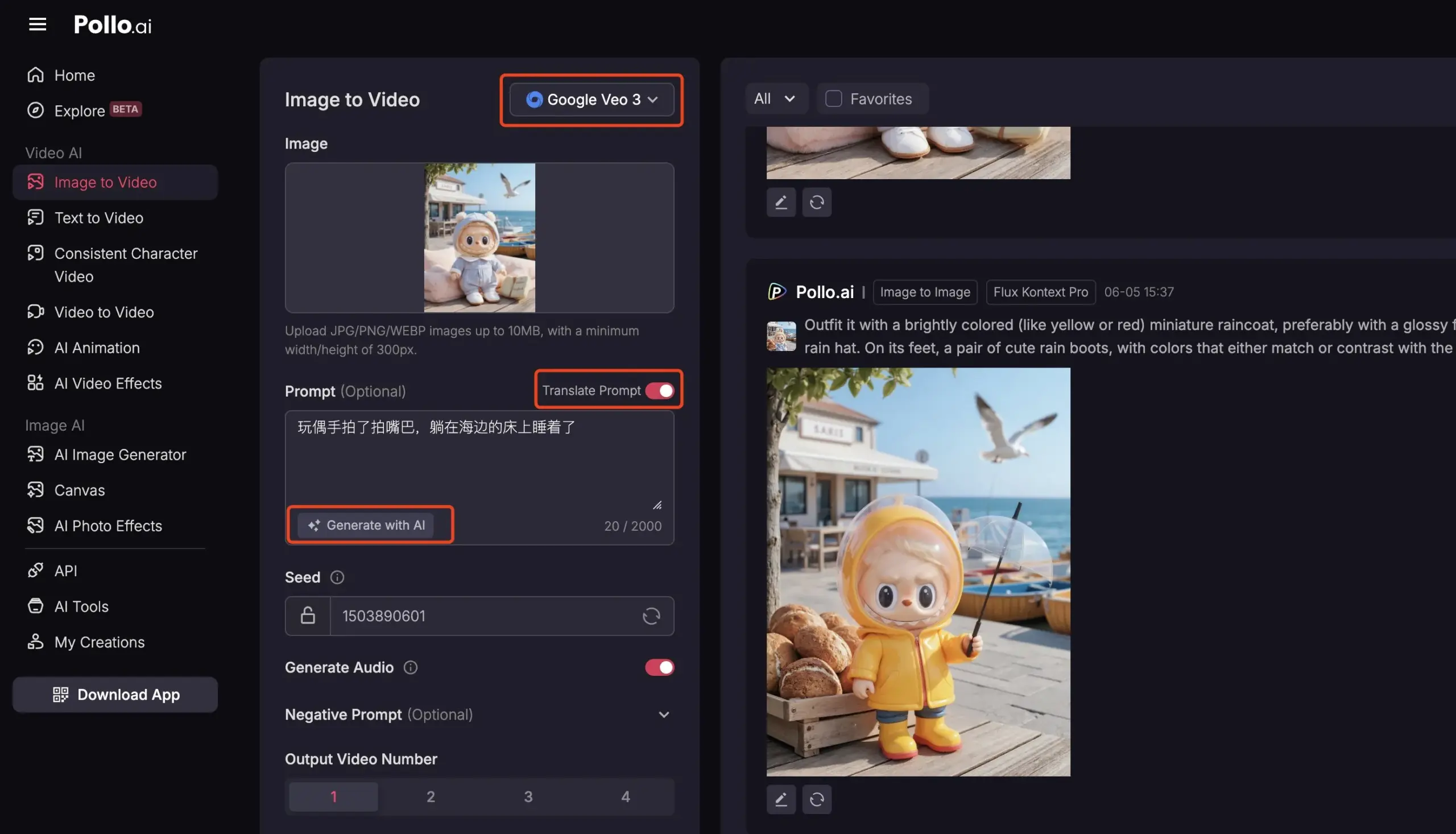
Pollo AI mengintegrasikan Veo3 dan FLUX Kontext, menyediakan layanan video AI komprehensif: Platform alat AI Pollo AI baru-baru ini sering diperbarui, mengintegrasikan model pembuatan video Google Veo3 dan fungsi pengeditan gambar FLUX Kontext. Pengguna dapat menggunakan FLUX Kontext di platform ini untuk memodifikasi gambar dan kemudian langsung mengirimkannya ke Veo3 untuk menghasilkan video. Platform ini juga menyediakan antarmuka API, mendukung akses sekali jalan ke berbagai model video besar utama di pasar, dan memiliki fungsi bantu bawaan seperti pembuatan prompt AI dan terjemahan multi-bahasa, yang bertujuan untuk meningkatkan kemudahan dan efisiensi pembuatan video AI. (Sumber: op7418)
📚 Pembelajaran
Analisis Mendalam Meta-Learning: Membuat AI Belajar Cara Belajar: Meta-Learning, juga dikenal sebagai “belajar untuk belajar”, memiliki ide inti untuk melatih model agar dapat beradaptasi dengan cepat terhadap tugas-tugas baru, bahkan hanya dengan sedikit sampel. Proses ini biasanya melibatkan dua model: base-learner yang belajar dengan cepat untuk beradaptasi dengan tugas spesifik (seperti klasifikasi gambar dengan sedikit sampel) dalam siklus pembelajaran internal, dan meta-learner yang mengelola dan memperbarui parameter atau strategi base-learner dalam siklus pembelajaran eksternal, untuk meningkatkan kemampuannya dalam menyelesaikan tugas-tugas baru. Setelah pelatihan selesai, base-learner akan menggunakan pengetahuan yang dipelajari oleh meta-learner untuk inisialisasi. (Sumber: TheTuringPost, TheTuringPost)

Ulasan Makalah 《A Controllable Examination for Long-Context Language Models》: Makalah ini membahas keterbatasan kerangka evaluasi model bahasa konteks panjang (LCLM) yang ada (tugas dunia nyata kompleks dan sulit dipecahkan, rentan terhadap kontaminasi data; tugas sintetis seperti NIAH kurang koherensi kontekstual), dan mengusulkan tiga karakteristik yang harus dimiliki kerangka evaluasi ideal: konteks yang mulus, pengaturan yang dapat dikontrol, dan evaluasi yang kuat. Makalah ini juga memperkenalkan LongBioBench, sebuah tolok ukur baru yang menggunakan biografi yang dibuat secara artifisial sebagai lingkungan terkontrol untuk mengevaluasi LCLM dari dimensi pemahaman, penalaran, dan kepercayaan. Eksperimen menunjukkan bahwa sebagian besar model masih memiliki kekurangan dalam pemahaman semantik, penalaran awal, dan kepercayaan konteks panjang. (Sumber: HuggingFace Daily Papers)
Ulasan Makalah 《Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning》: Terinspirasi oleh kemampuan penalaran luar biasa Deepseek-R1 dalam tugas teks kompleks, penelitian ini mengeksplorasi cara meningkatkan kemampuan penalaran kompleks model bahasa besar multimodal (MLLM) melalui optimasi cold start dan reinforcement learning (RL) bertahap. Penelitian menemukan bahwa inisialisasi cold start yang efektif sangat penting untuk meningkatkan penalaran MLLM; inisialisasi hanya dengan data teks yang dipilih dengan cermat dapat melampaui banyak model yang ada. GRPO standar mengalami masalah stagnasi gradien ketika diterapkan pada RL multimodal, sedangkan pelatihan RL teks murni berikutnya dapat lebih meningkatkan penalaran multimodal. Berdasarkan temuan ini, para peneliti meluncurkan ReVisual-R1, yang mencapai hasil SOTA pada beberapa tolok ukur yang menantang. (Sumber: HuggingFace Daily Papers)
Ulasan Makalah 《Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem》: Penelitian ini mengusulkan metode yang efisien untuk melepaskan potensi penalaran LLM yang telah dilatih sebelumnya: Critique Fine-Tuning (CFT) pada satu masalah. Dengan mengumpulkan berbagai solusi yang dihasilkan model untuk satu masalah, dan menggunakan LLM guru untuk memberikan kritik terperinci, data kritik dibangun untuk fine-tuning. Eksperimen menunjukkan bahwa setelah melakukan CFT pada satu masalah pada model seri Qwen dan Llama, terjadi peningkatan kinerja yang signifikan pada berbagai tugas penalaran, misalnya Qwen-Math-7B-CFT mengalami peningkatan rata-rata 15-16% pada tolok ukur penalaran matematika dan logika, dengan biaya komputasi yang jauh lebih rendah daripada reinforcement learning. (Sumber: HuggingFace Daily Papers)
Ulasan Makalah 《SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation》: Untuk mengatasi masalah cakupan terbatas, kurangnya stratifikasi kompleksitas, dan paradigma evaluasi yang terfragmentasi pada tolok ukur pemrosesan SVG (Scalable Vector Graphics) yang ada, SVGenius hadir. Ini adalah tolok ukur komprehensif yang berisi 2377 kueri, mencakup tiga dimensi: pemahaman, pengeditan, dan pembuatan, dibangun berdasarkan data nyata dari 24 bidang aplikasi, dan telah dilakukan stratifikasi kompleksitas secara sistematis. Melalui 8 kategori tugas dan 18 metrik, 22 model utama dievaluasi, mengungkapkan keterbatasan model saat ini dalam menangani SVG yang kompleks, dan menunjukkan bahwa pelatihan yang ditingkatkan dengan penalaran lebih efektif daripada sekadar memperluas skala. (Sumber: HuggingFace Daily Papers)
Log Pembaruan Hugging Face Hub Dirilis: Hugging Face Hub telah merilis log pembaruan terbarunya. Pengguna dapat memeriksanya untuk mengetahui fitur baru platform, pembaruan pustaka model, perluasan dataset, serta peningkatan rantai alat dan dinamika terbaru lainnya. Ini membantu pengguna komunitas untuk mengetahui dan memanfaatkan sumber daya dan kemampuan terbaru dari ekosistem Hugging Face secara tepat waktu. (Sumber: huggingface, _akhaliq)
Maxime Labonne dan penulis lainnya merilis banyak LLM Notebooks sumber terbuka: Penulis LLM Engineers’ Handbook, Maxime Labonne dan Iustin Paul, merilis serangkaian Jupyter Notebooks terkait LLM. Notebooks ini kaya akan konten, tidak hanya mencakup teknik fine-tuning dasar, tetapi juga mencakup evaluasi otomatis, lazy merges, pembuatan model campuran ahli (frankenMoEs), serta teknik penghapusan sensor dan topik lanjutan lainnya, menyediakan sumber daya praktis yang berharga bagi pengembang dan peneliti LLM. (Sumber: maximelabonne)
DeepLearningAI merilis buletin mingguan The Batch, membahas bagaimana AI Fund membina para pembangun AI: Andrew Ng dalam edisi terbaru buletin mingguan The Batch, berbagi pengalaman dan strategi AI Fund dalam membina talenta dan pembangun AI. Edisi buletin ini juga mencakup kinerja model sumber terbuka baru DeepSeek yang setara dengan LLM teratas, Duolingo yang menggunakan AI untuk memperluas kursus bahasa, pertimbangan konsumsi energi AI, serta potensi penyesatan tautan berbahaya terhadap AI Agent dan topik hangat lainnya. (Sumber: DeepLearningAI)

💼 Bisnis
Reddit menggugat Anthropic, menuduh penggunaan data pengguna tanpa izin untuk melatih AI: Reddit telah mengajukan gugatan terhadap perusahaan AI Anthropic, menuduh penggunaan robot otomatis untuk mengambil konten Reddit tanpa izin guna melatih model AI-nya (seperti Claude), yang merupakan pelanggaran kontrak dan persaingan tidak sehat. Kasus ini menyoroti kontroversi saat ini dalam pengembangan AI terkait legalitas pengambilan data dan pelatihan model, serta mencerminkan meningkatnya perhatian platform konten terhadap perlindungan nilai data mereka. (Sumber: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

Amazon berencana menginvestasikan $10 miliar untuk membangun pusat data AI di North Carolina: Amazon mengumumkan akan menginvestasikan $10 miliar di North Carolina untuk membangun pusat data baru guna mendukung kebutuhan bisnis AI yang terus meningkat. Langkah ini mencerminkan investasi berkelanjutan perusahaan teknologi besar dalam infrastruktur AI, yang bertujuan untuk memenuhi kebutuhan komputasi dan penyimpanan skala besar yang diperlukan untuk pelatihan dan inferensi model AI. (Sumber: Reddit r/artificial)

Anthropic memangkas akses API model Claude untuk Windsurf.ai, memicu kekhawatiran risiko platform: Platform pengembangan aplikasi AI Windsurf.ai mengungkapkan bahwa Anthropic, dengan pemberitahuan kurang dari 5 hari, secara drastis mengurangi kapasitas akses API-nya ke model Claude 3.x dan Claude 4. Langkah ini memaksa Windsurf.ai untuk segera mencari penyedia pihak ketiga guna menjamin layanan bagi pengguna berbayar, dan menyediakan opsi BYOK (Bring Your Own Key) untuk pengguna gratis dan Pro. Insiden ini memperburuk kekhawatiran pengembang tentang risiko platform penyedia model AI, yaitu penyedia model dapat kapan saja menyesuaikan strategi layanan mereka, bahkan bersaing dengan aplikasi hilir. (Sumber: swyx, scaling01, mervenoyann)
🌟 Komunitas
Konferensi Insinyur AI (@aiDotEngineer) menjadi perbincangan hangat, fokus pada desain Agent dan kewirausahaan AI: Konferensi Insinyur AI (@aiDotEngineer) yang diadakan di San Francisco menjadi fokus perbincangan hangat di komunitas. LlamaIndex berbagi pola desain Agent yang efektif dalam lingkungan produksi; Anthropic di konferensi tersebut mengeluarkan “daftar permintaan” untuk perusahaan rintisan, dengan fokus pada penerapan server MCP di bidang baru, penyederhanaan pembangunan server, dan keamanan aplikasi AI (seperti tool poisoning); Graphite memamerkan alat peninjauan kode yang didukung AI. Konferensi tersebut juga membahas tantangan penelitian dasar dalam memperluas model GPT generasi berikutnya dan isu-isu lainnya. (Sumber: swyx, swyx, swyx, iScienceLuvr)

Peneliti Rohan Anil bergabung dengan Anthropic menarik perhatian: Peneliti Rohan Anil mengumumkan akan bergabung dengan tim Anthropic, berita ini menarik perhatian dan diskusi luas di komunitas AI. Banyak orang dalam industri dan pengamat mengucapkan selamat dan menantikan kontribusi barunya bagi pekerjaan penelitian Anthropic. Hal ini juga mencerminkan potensi dampak perpindahan talenta AI papan atas terhadap lanskap industri. (Sumber: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
Pengadilan meminta OpenAI untuk menyimpan semua log ChatGPT, memicu diskusi kebijakan penyimpanan data: Dilaporkan bahwa OpenAI diminta oleh pengadilan untuk menyimpan semua log ChatGPT, termasuk “obrolan sementara” dan permintaan API yang seharusnya dihapus. Berita ini memicu diskusi di komunitas tentang kebijakan penyimpanan data, terutama untuk aplikasi yang menggunakan API OpenAI, ini mungkin berarti kebijakan penyimpanan data mereka sendiri tidak akan dapat dipatuhi sepenuhnya, sehingga menimbulkan tantangan baru bagi privasi pengguna dan manajemen data. Disarankan agar pengguna memprioritaskan penggunaan model lokal jika memungkinkan untuk melindungi data. (Sumber: code_star, TomLikesRobots)

Meluasnya konten buatan AI dan fenomena “AI Slop” menimbulkan kekhawatiran: Konten buatan AI berkualitas rendah dan menarik perhatian (disebut “AI Slop”) di media sosial semakin meningkat, mulai dari postingan buatan AI di Reddit hingga gambar AI seperti “udang Yesus” di Facebook, menimbulkan kekhawatiran pengguna tentang kualitas informasi dan memburuknya lingkungan online. Konten ini biasanya dihasilkan secara murah oleh bot atau pencari lalu lintas, yang bertujuan untuk mendapatkan suka dan berbagi melalui “umpan partisipasi”. Penelitian menunjukkan bahwa sebagian besar lalu lintas internet telah terdiri dari “bot jahat”, yang menyebarkan informasi palsu dan mencuri data. Fenomena ini tidak hanya memengaruhi pengalaman pengguna, tetapi juga mengancam demokrasi dan komunikasi politik, sekaligus berpotensi mencemari data pelatihan model AI di masa depan. (Sumber: aihub.org)

Diskusi biaya LLM: Gemini hemat biaya, biaya pengkodean Claude 4 menjadi perhatian: Diskusi komunitas menunjukkan bahwa biaya penggunaan LLM saat ini sangat bervariasi. Misalnya, biaya penggunaan Gemini untuk memproses seluruh dokumen asuransi dan mengajukan banyak pertanyaan hanya sekitar $0,01, menunjukkan efektivitas biaya yang tinggi. Sebaliknya, meskipun model Claude 4 berkinerja baik dalam tugas seperti pengkodean, biaya penggunaan mode maksimal (max mode) pada platform seperti Cursor.ai relatif tinggi, mendorong pengguna untuk beralih ke pilihan yang lebih hemat biaya seperti Google Gemini 2.5 Pro. (Sumber: finbarrtimbers, Teknium1)
AI Agent menghadapi tantangan dalam menyelesaikan CAPTCHA (verifikasi manusia-mesin) dalam skenario halaman web nyata: Tim MetaAgentX merilis platform Open CaptchaWorld, yang berfokus pada evaluasi kemampuan agen interaktif multimodal dalam menyelesaikan CAPTCHA. Pengujian menunjukkan bahwa bahkan model SOTA seperti GPT-4o, ketika menangani 20 jenis CAPTCHA interaktif dalam lingkungan halaman web nyata, tingkat keberhasilannya hanya 5%-40%, jauh di bawah tingkat keberhasilan rata-rata manusia sebesar 93,3%. Ini menunjukkan bahwa AI Agent saat ini masih memiliki kendala dalam pemahaman visual, perencanaan multi-langkah, pelacakan status, dan interaksi yang presisi, menjadikan CAPTCHA sebagai salah satu hambatan utama dalam penerapannya secara praktis. (Sumber: 量子位)

Pasar pelatihan AI Agent sedang panas, kualitas kursus dan prospek kerja menjadi perhatian: Seiring dengan munculnya konsep AI Agent, kursus pelatihan terkait juga bermunculan dalam jumlah besar. Beberapa lembaga pelatihan mengklaim menyediakan bimbingan komprehensif dari tingkat pemula hingga penempatan kerja, bahkan menjanjikan “jaminan kerja”, dengan biaya kursus berkisar dari beberapa ratus yuan hingga puluhan ribu yuan. Namun, kualitas kursus di pasar bervariasi, beberapa kursus dituduh memiliki konten yang dangkal, pemasaran yang berlebihan, bahkan mirip dengan kelas kilat AI yang “memanfaatkan orang”. Peserta dan pengamat bersikap hati-hati terhadap efektivitas aktual pelatihan semacam itu, kualifikasi instruktur, dan kebenaran janji “jaminan kerja”, khawatir hal itu dapat menjadi “permintaan palsu” lainnya dalam periode transisi pengembangan AI. (Sumber: 36氪)

💡 Lainnya
Kemajuan aplikasi AI di bidang robotika: tangan dengan persepsi taktil, robot amfibi, dan anjing robot pemadam kebakaran: Teknologi AI mendorong batas kemampuan robot. Para peneliti telah mengembangkan tangan mekanik dengan kemampuan persepsi taktil, memungkinkannya berinteraksi lebih baik dengan lingkungan. Copperstone HELIX Neptune mendemonstrasikan robot amfibi yang digerakkan AI, yang mampu beroperasi di berbagai medan. Tiongkok telah meluncurkan anjing robot pemadam kebakaran yang mampu menyemprotkan air setinggi 60 meter, menaiki tangga, dan melakukan siaran langsung penyelamatan. Kemajuan ini menunjukkan potensi AI dalam meningkatkan persepsi, pengambilan keputusan, dan pelaksanaan tugas kompleks oleh robot. (Sumber: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

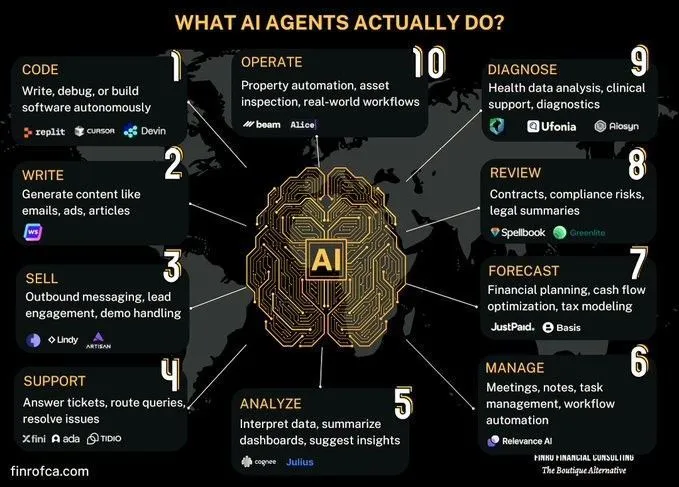
Diskusi perbandingan AI Agent dan Generative AI: Muncul diskusi di komunitas mengenai perbedaan dan hubungan antara AI Agent (AI cerdas) dan Generative AI (AI generatif). Generative AI terutama berfokus pada penciptaan konten, sedangkan AI Agent lebih menekankan pada pengambilan keputusan otonom dan pelaksanaan tugas berdasarkan persepsi, perencanaan, dan tindakan. Memahami perbedaan keduanya membantu dalam memahami arah pengembangan teknologi AI dan skenario aplikasi dengan lebih baik. (Sumber: Ronald_vanLoon, Ronald_vanLoon)
Membahas tantangan AI dalam otomatisasi proses organisasi yang kompleks: AI telah mencapai kemajuan dalam mengotomatisasi atau membantu tugas-tugas tertentu, tetapi untuk menggantikan tenaga kerja manusia atau tim guna mencapai transformasi ekonomi yang lebih luas, AI menghadapi kompleksitas yang sangat besar. Banyak organisasi memiliki proses penting yang tidak terdokumentasi secara eksplisit, berisiko tinggi tetapi jarang terjadi, dan mungkin telah menjadi kebiasaan sehingga alasannya terlupakan. AI Agent sulit mempelajari pengetahuan implisit semacam ini melalui coba-coba, karena biayanya mahal dan kesempatan belajarnya terbatas. Ini membutuhkan paradigma teknologi baru, bukan sekadar machine learning sederhana. (Sumber: random_walker)