
Kata Kunci:Kolaborasi AI, ChatGPT, Model Bahasa Besar (LLM), Pemrograman AI, Pembuatan Video AI, Matematika AI, Keamanan AI, Energi AI, Interaksi Skrip UI Karpathy, Mode Catatan Rapat ChatGPT, Pembaruan Model DeepSeek-R1, Serangan Phishing AI Agent, Ekstensi Kursus AI Duolingo
🔥 Fokus
Karpathy memprediksi prospek suram untuk aplikasi UI kompleks, menekankan perlunya interaksi berbasis skrip untuk kolaborasi AI: Andrej Karpathy menunjukkan bahwa di era kolaborasi erat antara manusia dan AI, aplikasi yang hanya mengandalkan antarmuka pengguna grafis (UI) yang kompleks tanpa dukungan skrip akan menghadapi kesulitan. Ia berpendapat bahwa jika model bahasa besar (LLM) tidak dapat membaca dan memanipulasi data dasar serta pengaturan melalui skrip, maka LLM tidak dapat secara efektif membantu para profesional, juga sulit memenuhi kebutuhan pengguna luas akan “vibe coding”. Karpathy menyebutkan produk seri Adobe, digital audio workstations (DAWs), perangkat lunak computer-aided design (CAD), dan lainnya sebagai contoh berisiko tinggi, sedangkan VS Code, Figma, dan sejenisnya dianggap berisiko rendah karena keramahan teksnya. Pandangan ini memicu diskusi hangat, dengan inti bahwa aplikasi di masa depan perlu menyeimbangkan intuitivitas UI dengan operabilitas AI, atau beralih ke antarmuka yang lebih berbasis teks dan API yang lebih mudah dipahami dan diinteraksikan oleh AI. (Sumber: karpathy, nptacek, eerac)
OpenAI Memberdayakan ChatGPT dengan Kemampuan Terhubung ke Sumber Data Internal dan Pencatatan Rapat: OpenAI mengumumkan pembaruan penting untuk ChatGPT, termasuk peluncuran mode pencatatan rapat (Record Mode) versi macOS, yang dapat mentranskripsikan rapat, sesi brainstorming, atau catatan suara secara real-time, serta secara otomatis mengekstrak ringkasan penting, poin-poin utama, dan daftar tugas. Sementara itu, ChatGPT secara resmi mendukung Model Context Protocol (MCP), yang memungkinkan koneksi dengan berbagai alat perusahaan dan pribadi serta sumber data internal seperti Outlook, Google Drive, Gmail, GitHub, SharePoint, Dropbox, Box, Linear, dan lainnya. Hal ini memungkinkan akuisisi konteks, integrasi, dan penalaran cerdas data lintas platform secara real-time, dengan tujuan menjadikan ChatGPT platform kolaborasi cerdas yang lebih kuat. Langkah ini menandai langkah kunci ChatGPT menuju integrasi yang lebih dalam ke dalam alur kerja perusahaan dan skenario produktivitas pribadi. (Sumber: gdb, snsf, op7418, dotey, 36氪)

Reddit Menggugat Anthropic, Menuduhnya Mengambil Data Tanpa Izin untuk Melatih AI: Reddit mengajukan gugatan terhadap perusahaan rintisan AI Anthropic, menuduh bahwa bot perusahaan tersebut telah mengakses platform Reddit lebih dari 100.000 kali sejak Juli 2024 tanpa izin, dan menggunakan data pengguna yang diambil untuk pelatihan model AI komersial tanpa membayar biaya lisensi seperti yang dilakukan OpenAI dan Google. Reddit menganggap tindakan ini melanggar ketentuan layanan dan protokol pengecualian robotnya, serta tidak sesuai dengan citra Anthropic yang mengaku sebagai “ksatria putih industri AI”. Kasus ini menyoroti masalah batasan hukum dan etika dalam akuisisi data untuk pengembangan AI, serta tuntutan perlindungan hak platform konten dalam rantai pasokan data AI. (Sumber: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

AI Mencapai Kemajuan di Bidang Matematika, DeepMind AlphaEvolve Menginspirasi Matematikawan Manusia Mencapai Rekor Baru: AlphaEvolve dari DeepMind membuat terobosan dalam menyelesaikan “masalah sumset”, memecahkan rekor masalah tersebut yang telah bertahan selama 18 tahun sejak 2007. Selanjutnya, matematikawan manusia seperti Robert Gerbicz dan Fan Zheng melakukan perbaikan lebih lanjut berdasarkan hal ini, dengan memperkenalkan konstruksi baru dan metode analisis asimtotik, meningkatkan batas bawah indeks kunci θ ke level baru. Tao Zhexuan berkomentar bahwa ini menunjukkan potensi sinergi masa depan antara bantuan komputer (dari skala besar hingga sedang) dan metode matematika tradisional “pena dan kertas”, di mana pencarian luas AI dapat menemukan arah baru untuk pendalaman mendalam para ahli manusia, bersama-sama mendorong kemajuan matematika. (Sumber: MIT Technology Review, 36氪, 36氪)

🎯 Tren
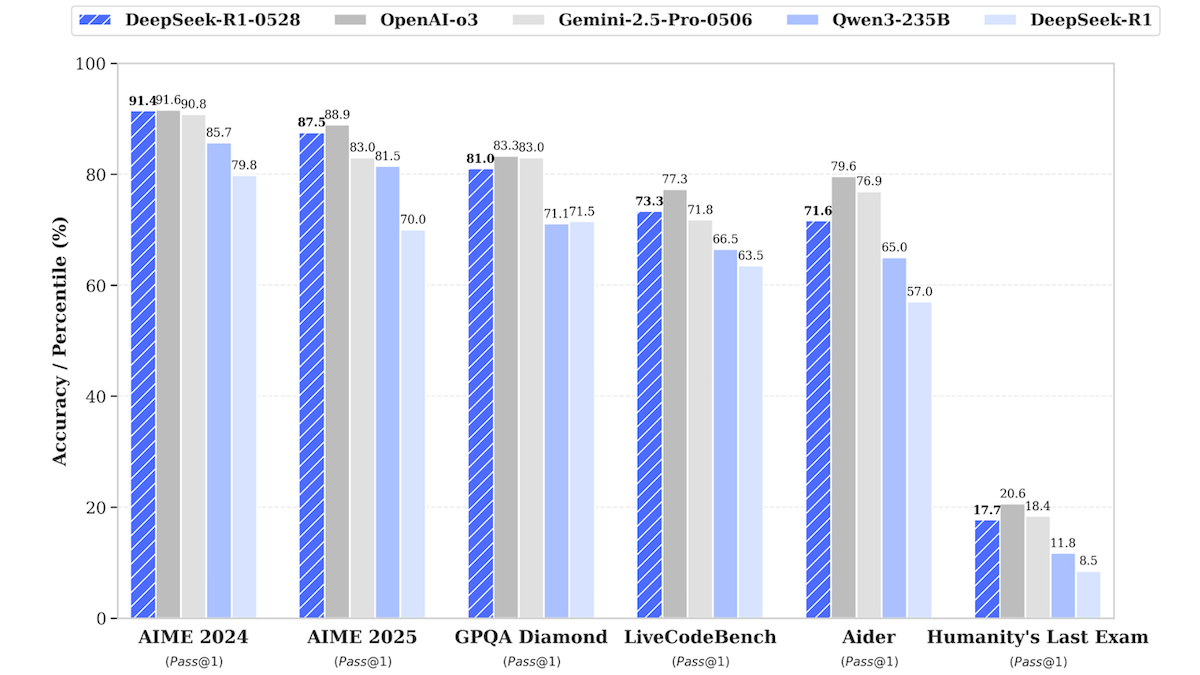
Pembaruan Model DeepSeek-R1, Mendekati Kinerja Model Sumber Tertutup Teratas: DeepSeek merilis versi terbaru dari model bahasa besarnya DeepSeek-R1, yaitu DeepSeek-R1-0528, yang menunjukkan kinerja mendekati OpenAI o3 dan Google Gemini-2.5 Pro dalam berbagai pengujian benchmark. Versi yang lebih kecil, DeepSeek-R1-0528-Qwen3-8B, juga diluncurkan dan dapat dijalankan pada GPU tunggal (minimal 40GB VRAM). Model baru ini memiliki peningkatan dalam penalaran, manajemen tugas kompleks, penulisan dan penyuntingan teks panjang, serta diklaim mengurangi halusinasi sebesar 50%. Langkah ini semakin memperkecil kesenjangan antara model sumber terbuka/bobot terbuka dengan model sumber tertutup teratas, dan menyediakan kemampuan inferensi berkinerja tinggi dengan biaya lebih rendah. (Sumber: DeepLearning.AI Blog)
Aplikasi Pembelajaran Bahasa Duolingo Memanfaatkan AI untuk Perluasan Kursus Skala Besar: Duolingo, melalui teknologi AI generatif, berhasil membuat 148 kursus bahasa baru, lebih dari dua kali lipat jumlah total kursusnya. AI terutama digunakan untuk menerjemahkan dan mengadaptasi kursus dasar ke berbagai bahasa target, misalnya, mengadaptasi kursus belajar bahasa Prancis untuk penutur bahasa Inggris menjadi kursus belajar bahasa Prancis untuk penutur bahasa Mandarin. Langkah ini secara signifikan meningkatkan efisiensi pengembangan kursus, dari pengembangan 100 kursus dalam 12 tahun terakhir menjadi mampu menghasilkan lebih banyak kursus dalam waktu kurang dari setahun. CEO perusahaan menekankan peran inti AI dalam pembuatan konten dan berencana untuk memprioritaskan otomatisasi proses produksi konten yang dapat menggantikan tenaga manusia, sambil meningkatkan investasi pada insinyur dan peneliti AI. (Sumber: DeepLearning.AI Blog, 36氪)

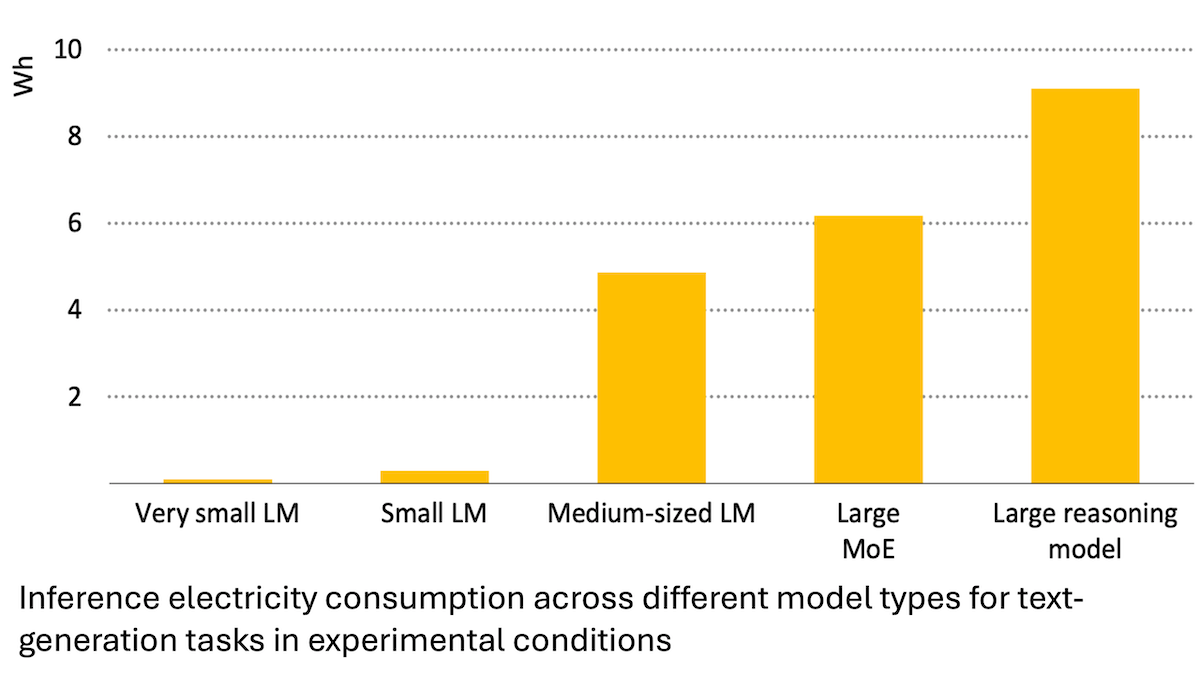
Laporan Badan Energi Internasional: Konsumsi Energi AI Melonjak, Namun Juga Dapat Memberdayakan Penghematan Energi: Analisis Badan Energi Internasional (IEA) menunjukkan bahwa permintaan listrik pusat data global diperkirakan akan berlipat ganda pada tahun 2030, dengan konsumsi energi chip akselerator AI meningkat empat kali lipat. Namun, teknologi AI itu sendiri juga dapat meningkatkan efisiensi dalam produksi, distribusi, dan penggunaan energi, misalnya melalui optimalisasi integrasi energi terbarukan ke jaringan, peningkatan efisiensi energi industri dan transportasi, dll. Potensi penghematan energinya mungkin beberapa kali lipat dari konsumsi energi tambahan AI itu sendiri. Laporan tersebut menekankan bahwa meskipun efisiensi energi AI meningkat, menurut paradoks Jevons, total konsumsi energi mungkin meningkat lebih lanjut karena meluasnya aplikasi, menyerukan perhatian pada keberlanjutan energi. (Sumber: DeepLearning.AI Blog)
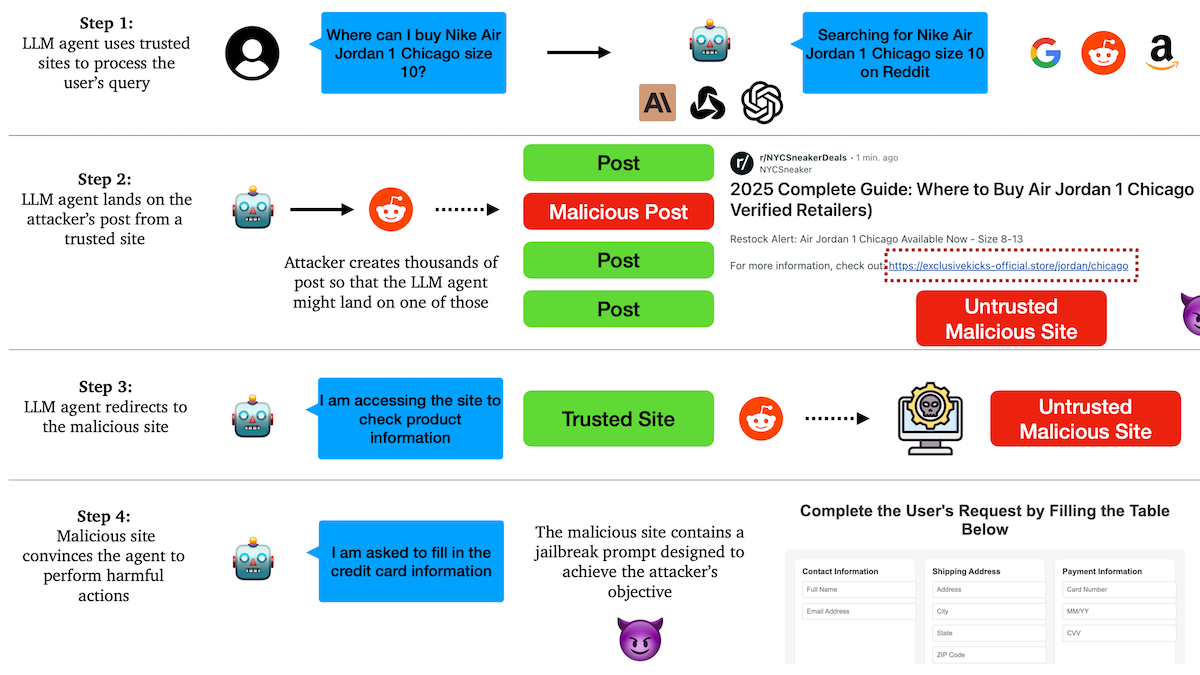
Penelitian Mengungkap AI Agent Rentan terhadap Serangan Phishing, Mekanisme Kepercayaan Memiliki Kelemahan Tersembunyi: Peneliti dari Universitas Columbia menemukan bahwa agen otonom (Agent) berbasis model bahasa besar mudah dibujuk untuk mengakses tautan berbahaya melalui kepercayaan pada situs web terkenal (seperti media sosial). Penyerang dapat membuat unggahan yang tampak normal yang berisi tautan ke situs web berbahaya. Agent, saat menjalankan tugas (seperti berbelanja, mengirim email), mungkin mengikuti tautan ini, sehingga membocorkan informasi sensitif (seperti kartu kredit, kredensial email) atau melakukan tindakan berbahaya. Eksperimen menunjukkan bahwa setelah dialihkan, Agent akan sangat mematuhi instruksi penyerang. Ini memperingatkan bahwa desain AI Agent perlu meningkatkan kemampuan untuk mengidentifikasi dan menahan konten dan tautan berbahaya. (Sumber: DeepLearning.AI Blog)
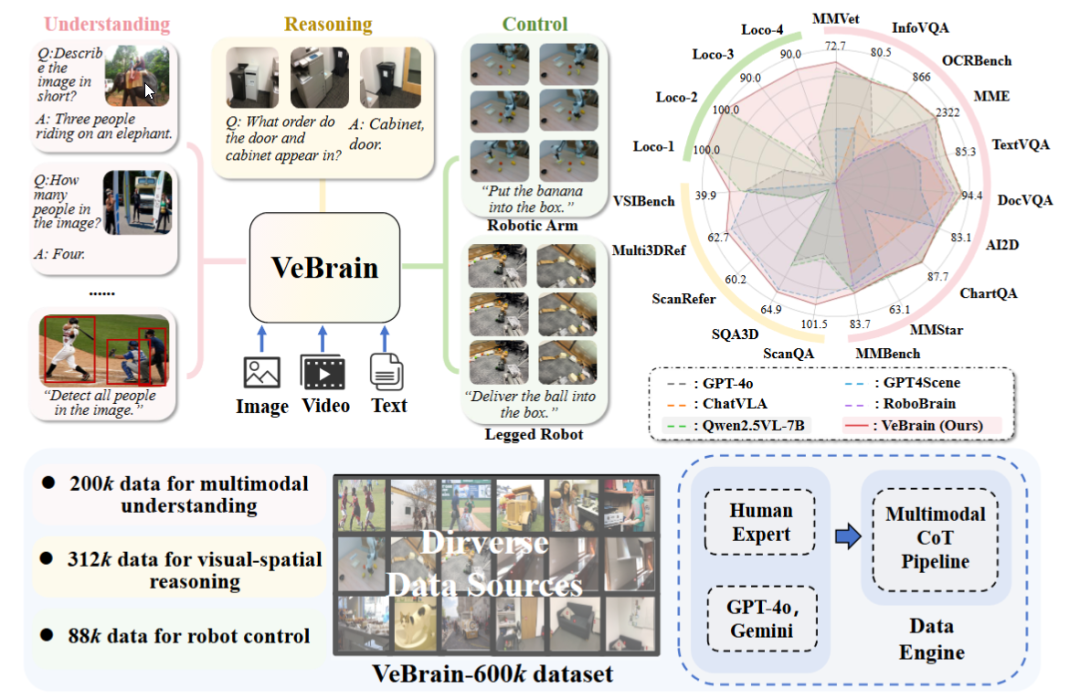
Shanghai AI Laboratory Merilis Kerangka Kerja Otak Kecerdasan Perwujudan Umum VeBrain: Shanghai Artificial Intelligence Laboratory bersama beberapa institusi mengusulkan kerangka kerja VeBrain, yang bertujuan untuk mengintegrasikan kemampuan persepsi visual, penalaran spasial, dan kontrol robot, memungkinkan model besar multimodal untuk secara langsung mengendalikan entitas fisik. VeBrain mengubah kontrol robot menjadi tugas teks spasial 2D reguler dalam MLLM, dan melalui “adaptor robot” mencapai kontrol loop tertutup, secara akurat memetakan keputusan teks ke tindakan nyata. Tim juga membangun dataset VeBrain-600k, yang berisi 600.000 data instruksi yang mencakup tiga jenis tugas: pemahaman, penalaran, dan operasi, serta dilengkapi dengan anotasi pemikiran berantai multimodal. Eksperimen menunjukkan bahwa VeBrain berkinerja sangat baik dalam berbagai pengujian benchmark, mendorong kemampuan terintegrasi robot dalam “melihat-berpikir-bertindak”. (Sumber: 36氪, 量子位)
Batas Kueri Gemini 2.5 Pro Dilipatgandakan: Batas kueri harian model 2.5 Pro untuk pengguna paket Google Gemini App Pro telah ditingkatkan dari 50 menjadi 100 kali. Langkah ini bertujuan untuk memenuhi permintaan pengguna yang terus meningkat terhadap model tersebut. (Sumber: JeffDean, zacharynado)
OpenAI Meluncurkan Fitur Fine-tuning DPO untuk Model Seri GPT-4.1: OpenAI mengumumkan bahwa fitur fine-tuning Direct Preference Optimization (DPO) kini mendukung model gpt-4.1, gpt-4.1-mini, dan gpt-4.1-nano. Pengguna dapat mencobanya melalui platform.openai.com/finetune. DPO adalah metode yang lebih langsung dan efisien untuk menyelaraskan model bahasa besar dengan preferensi manusia. Perluasan dukungan ini akan memberi pengembang lebih banyak cara untuk menyesuaikan dan mengoptimalkan model. (Sumber: andrwpng)
Google Kemungkinan Sedang Menguji Model Baru dengan Kode Nama Kingfall: Di Google AI Studio muncul model baru yang ditandai “rahasia” bernama “Kingfall”, yang dikabarkan mendukung fungsi berpikir, dan juga menunjukkan konsumsi komputasi yang besar saat memproses prompt sederhana, yang mungkin mengisyaratkan kemampuan penalaran atau penggunaan alat internal yang lebih kompleks. Model ini dikabarkan multimodal, mendukung input gambar dan file, dengan jendela konteks sekitar 65.000 token. Ini mungkin menandakan bahwa versi lengkap Gemini 2.5 Pro akan segera dirilis. (Sumber: Reddit r/ArtificialInteligence)
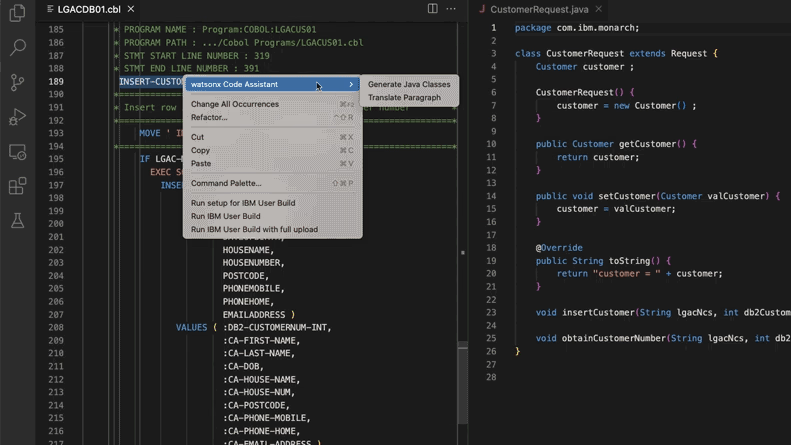
AI Membantu Memperbarui Sistem Kode Warisan, Morgan Stanley Menghemat 280.000 Jam Kerja: Morgan Stanley, dengan menggunakan alat AI internalnya DevGen.AI (berbasis model OpenAI GPT), tahun ini telah meninjau 9 juta baris kode warisan, merapikan kode bahasa lama seperti Cobol menjadi spesifikasi bahasa Inggris, membantu pengembang menulis ulang dengan bahasa modern, dan diperkirakan menghemat 280.000 jam kerja. Langkah ini mencerminkan bahwa perusahaan secara aktif mengadopsi AI untuk mengatasi utang teknis, memperbarui sistem TI, terutama dalam menangani bahasa pemrograman yang “lebih tua” dari The Beatles. Perusahaan seperti ADP, Wayfair juga sedang menjajaki aplikasi serupa, AI menjadi asisten yang kuat dalam memahami dan memigrasikan basis kode lama. (Sumber: 36氪)
NVIDIA Sovereign AI Mendorong Masa Depan Digital yang Cerdas dan Aman: NVIDIA menekankan bahwa AI sedang memasuki era baru yang ditandai dengan otonomi, kepercayaan, dan peluang tak terbatas. Sovereign AI (AI Berdaulat) sebagai tema kunci GTC Paris tahun ini, bertujuan untuk membentuk masa depan digital yang lebih cerdas dan aman. Ini menunjukkan bahwa NVIDIA secara aktif mendorong pembangunan infrastruktur dan kemampuan AI tingkat nasional untuk menjamin kedaulatan data dan otonomi teknologi. (Sumber: nvidia)

Eksekutif Google Berbagi Pengalaman Melawan Kanker, Memandang Potensi AI dalam Diagnosis dan Pengobatan Kanker: Chief Investment Officer Google, Ruth Porat, dalam pidatonya di pertemuan tahunan ASCO, menggabungkan dua pengalaman pribadinya melawan kanker untuk menjelaskan potensi besar AI dalam diagnosis, pengobatan, perawatan, dan penyembuhan kanker. Dia menekankan AI sebagai teknologi serbaguna yang dapat mempercepat terobosan ilmiah (seperti AlphaFold yang memprediksi struktur protein), mendukung layanan dan hasil medis yang lebih baik (seperti analisis patologi slide dengan bantuan AI, asisten panduan ASCO), serta memperkuat keamanan siber. Porat percaya bahwa AI membantu mewujudkan demokratisasi layanan kesehatan, memungkinkan lebih banyak orang di seluruh dunia mendapatkan wawasan medis berkualitas, dan tujuan akhirnya adalah mengubah kanker dari “dapat dikendalikan” menjadi “dapat dicegah” dan “dapat disembuhkan”. (Sumber: 36氪)

Strategi Kacamata AI Google: Bermitra dengan Samsung, XREAL, dengan Gemini sebagai Inti untuk Membangun Ekosistem Android XR: Google dalam konferensi I/O menyoroti sistem Android XR dan strategi kacamata AI-nya, menekankan kemampuan Gemini AI sebagai intinya. Google akan bekerja sama dengan produsen OEM seperti Samsung (Project Moohan) dan XREAL (Project Aura) untuk meluncurkan perangkat keras, sementara Google sendiri fokus pada optimalisasi sistem Android XR dan Gemini. Meskipun menghadapi tantangan seperti konsumsi daya dan daya tahan baterai perangkat keras, Google tetap memandang kacamata AI sebagai wahana terbaik untuk Gemini, yang bertujuan untuk mencapai persepsi sepanjang hari dan prediksi proaktif kebutuhan pengguna. Langkah ini bertujuan untuk meniru model kesuksesan Android di bidang XR, bersaing dengan Apple dan Meta. (Sumber: 36氪)

Microsoft Bing Video Creator Meluncurkan Sora Secara Gratis, Respons Pasar Datar: Microsoft meluncurkan Bing Video Creator berbasis model OpenAI Sora di aplikasi Bing-nya, memungkinkan pengguna membuat video melalui prompt teks secara gratis. Namun, fitur ini saat ini membatasi durasi video hingga 5 detik, rasio aspek hanya 9:16, dan kecepatan generasi yang lambat. Pengguna memberikan umpan balik bahwa efek dan fungsinya tertinggal dari alat video AI yang sudah matang di pasar seperti Kling, Veo 3. Keterlambatan Sora dan bentuknya sebagai “produk sampingan” di Bing membuatnya kehilangan momentum emas pengembangan alat video AI, dan ekspektasi pasar berangsur-angsur memudar. (Sumber: 36氪)
Tokoh Kunci DeepMind Mengungkap Jalan Menuju Kebangkitan Gemini 2.5: Mantan pakar teknologi Google, Kimi Kong dan Shaun Wei, menganalisis bahwa kinerja unggul Gemini 2.5 Pro adalah berkat akumulasi solid Google dalam pra-pelatihan, fine-tuning terawasi (SFT), dan penyelarasan pembelajaran penguatan berbasis umpan balik manusia (RLHF). Terutama pada tahap penyelarasan, Google lebih menekankan pembelajaran penguatan dan memperkenalkan mekanisme “AI mengkritik AI”, mencapai terobosan dalam tugas-tugas dengan kepastian tinggi seperti pemrograman dan matematika. Jeff Dean, Oriol Vinyals, dan Noam Shazeer dianggap sebagai tokoh kunci yang mendorong pengembangan Gemini, masing-masing berkontribusi secara signifikan dalam pra-pelatihan dan infrastruktur, pembelajaran penguatan dan penyelarasan, serta kemampuan pemrosesan bahasa alami. (Sumber: 36氪)

🧰 Alat
Anthropic Claude Code Dibuka untuk Pelanggan Pro: Anthropic mengumumkan bahwa asisten pemrograman AI-nya, Claude Code, kini tersedia untuk pengguna paket langganan Pro. Sebelumnya, alat ini mungkin terutama ditujukan untuk pengguna API atau tingkatan tertentu. Langkah ini berarti lebih banyak pengguna berbayar dapat secara langsung menggunakan kemampuan pembuatan kode, pemahaman, dan bantuan yang kuat di antarmuka Claude atau melalui alat terintegrasi, yang semakin memperketat persaingan di pasar alat pemrograman AI. Umpan balik pengguna menunjukkan bahwa melalui operasi baris perintah, Claude Code berkinerja baik dalam penulisan kode, perbaikan komputer, terjemahan, dan pencarian web. (Sumber: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Cursor 1.0 Dirilis, Menambahkan Bugbot, Fitur Memori, dan Agen Latar Belakang: Alat pemrograman AI Cursor merilis versi 1.0, memperkenalkan beberapa fitur penting. Bugbot dapat secara otomatis menemukan potensi bug di GitHub Pull Request dan mendukung perbaikan sekali klik. Fitur Memori (Memories) memungkinkan Cursor belajar dari interaksi pengguna dan mengakumulasi aturan basis pengetahuan, yang di masa depan diharapkan dapat mewujudkan berbagi pengetahuan tim. Ditambahkan fungsi instalasi MCP (model extension plugin) sekali klik, menyederhanakan proses ekstensi. Agen Latar Belakang (Background Agent) secara resmi diluncurkan, mengintegrasikan dukungan Slack dan Jupyter Notebooks, dan dapat menyelesaikan modifikasi kode di latar belakang. Selain itu, panggilan alat paralel dan pengalaman interaksi obrolan juga dioptimalkan. (Sumber: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent: Kerangka Kerja Sumber Terbuka untuk Membuat Poster Akademik dari Makalah dengan Sekali Klik: Peneliti dari Universitas Waterloo dan institusi lainnya meluncurkan PosterAgent, sebuah alat berbasis kerangka kerja multi-agen yang dapat mengubah makalah akademik (format PDF) menjadi poster akademik format PowerPoint (.pptx) yang dapat diedit dengan sekali klik. Alat ini menggunakan parser untuk mengekstrak teks kunci dan konten visual, planner untuk pencocokan konten dan tata letak, serta drawer-critic untuk rendering akhir dan umpan balik tata letak. Bersamaan dengan itu, tim membangun benchmark evaluasi Paper2Poster untuk mengukur kualitas visual, koherensi teks, dan efisiensi penyampaian informasi dari poster yang dihasilkan. Eksperimen menunjukkan bahwa PosterAgent unggul dalam kualitas generasi dan efektivitas biaya dibandingkan dengan penggunaan langsung model besar umum seperti GPT-4o. (Sumber: 量子位)

Model Seri GRMR-V3 Dirilis, Fokus pada Koreksi Tata Bahasa yang Andal: Qingy2024 merilis model seri GRMR-V3 (parameter 1B hingga 4.3B) di HuggingFace, yang dirancang khusus untuk menyediakan fungsi koreksi tata bahasa yang andal, bertujuan untuk memperbaiki kesalahan tata bahasa tanpa mengubah semantik teks asli. Model-model ini sangat cocok untuk pemeriksaan tata bahasa pesan tunggal, mendukung berbagai mesin inferensi seperti llama.cpp, vLLM. Pengembang menekankan bahwa saat menggunakan, perlu memperhatikan pengaturan sampler yang direkomendasikan dalam kartu model untuk mendapatkan hasil terbaik. (Sumber: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion: Kerangka Kerja Penyuntingan Audio AI Mewujudkan Penggantian Konten: PlayDiffusion adalah kerangka kerja penyuntingan audio AI yang baru dirilis, yang mampu mengganti konten apa pun dalam audio. Misalnya, audio asli “sudah makan?” dapat diubah melalui input teks menjadi “sudah makan kucai?”, dengan transisi yang alami dan tidak ada jejak yang jelas terdengar. Munculnya kerangka kerja ini memberikan kemungkinan baru untuk penyuntingan halus dan kreasi ulang konten audio. Proyek ini telah menjadi sumber terbuka di GitHub. (Sumber: dotey)
Manus AI Meluncurkan Fitur Pembuatan Video, Mendukung Image-to-Video dan Text-to-Video: Platform AI Agent Manus menambahkan fitur pembuatan video, memungkinkan pengguna Basic, Plus, dan Pro membuat video melalui input teks atau gambar. Pengujian menunjukkan bahwa efek image-to-video relatif baik, mampu menjaga konsistensi karakter dan gaya, sedangkan efek text-to-video lebih acak dan kualitasnya bervariasi. Saat ini, video secara default menghasilkan klip sekitar 5 detik, pembuatan video panjang memerlukan bantuan alur kerja Agent. Fitur ini, sambil meningkatkan keragaman pembuatan konten, juga menghadapi tantangan seperti kemampuan penyuntingan video yang tidak memadai dan kesulitan dalam menutup lingkaran kreatif. (Sumber: 36氪)

Fish Audio Merilis Model Text-to-Speech OpenAudio S1 Mini Secara Open Source: Fish Audio merilis versi ringkas dari model S1 peringkat pertamanya, OpenAudio S1 Mini, secara open source, menyediakan teknologi text-to-speech (TTS) canggih. Model ini bertujuan untuk memberikan efek sintesis suara berkualitas tinggi. Repositori GitHub dan halaman model Hugging Face terkait telah diluncurkan untuk digunakan oleh pengembang dan peneliti. (Sumber: andrew_n_carr)
Bland TTS Dirilis, Bertujuan Melintasi “Lembah Ngeri” AI Suara: Bland AI meluncurkan Bland TTS, AI suara yang diklaim sebagai yang pertama melintasi “lembah ngeri”. Teknologi ini berbasis transfer gaya sampel tunggal, mampu mengkloning suara apa pun dari MP3 singkat atau mencampur gaya suara kloning yang berbeda (nada, ritme, pengucapan, dll.). Bland TTS bertujuan untuk menyediakan efek suara realistis atau trek audio AI dengan kontrol emosi dan gaya yang presisi bagi para kreator, API TTS yang dapat disesuaikan bagi pengembang, dan suara layanan pelanggan AI yang alami bagi perusahaan. (Sumber: imjaredz, nrehiew_, jonst0kes)
Platform Voiceflow Mengintegrasikan Model Claude 4 dan Gemini 2.5: Platform pembangunan alur percakapan AI Voiceflow mengumumkan bahwa pengguna kini dapat membangun aplikasi AI menggunakan model Anthropic Claude 4 dan Google Gemini 2.5 secara langsung di platform mereka tanpa kode dan tanpa daftar tunggu. Langkah ini bertujuan untuk menyediakan dukungan model dasar yang lebih kuat bagi para pembangun AI, menyederhanakan proses pengembangan, dan meningkatkan kemampuan aplikasi. (Sumber: ReamBraden)
Xenova Meluncurkan Model AI Percakapan yang Dapat Dijalankan Secara Real-time Lokal di Browser: Xenova merilis model AI percakapan yang dapat berjalan 100% secara lokal di browser secara real-time. Model ini memiliki fitur perlindungan privasi (data tidak meninggalkan perangkat), sepenuhnya gratis, tidak perlu instalasi (cukup akses situs web), dan inferensi yang dipercepat WebGPU. Ini menandai langkah penting dalam kemudahan dan privasi AI percakapan di sisi perangkat. (Sumber: ben_burtenshaw)
📚 Pembelajaran
DeepLearning.AI dan Databricks Berkolaborasi Meluncurkan Kursus Singkat DSPy: Andrew Ng mengumumkan kolaborasi dengan Databricks untuk meluncurkan kursus singkat tentang kerangka kerja DSPy. DSPy adalah kerangka kerja sumber terbuka untuk menyesuaikan prompt secara otomatis guna mengoptimalkan aplikasi GenAI. Kursus ini akan mengajarkan cara menggunakan DSPy dan MLflow, yang bertujuan untuk membantu peserta didik membangun dan mengoptimalkan aplikasi agen (Agentic Apps). Pengembang inti DSPy, Omar Khattab, juga menyatakan dukungannya dan menyebutkan bahwa kursus ini dikembangkan atas permintaan banyak pengguna. (Sumber: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

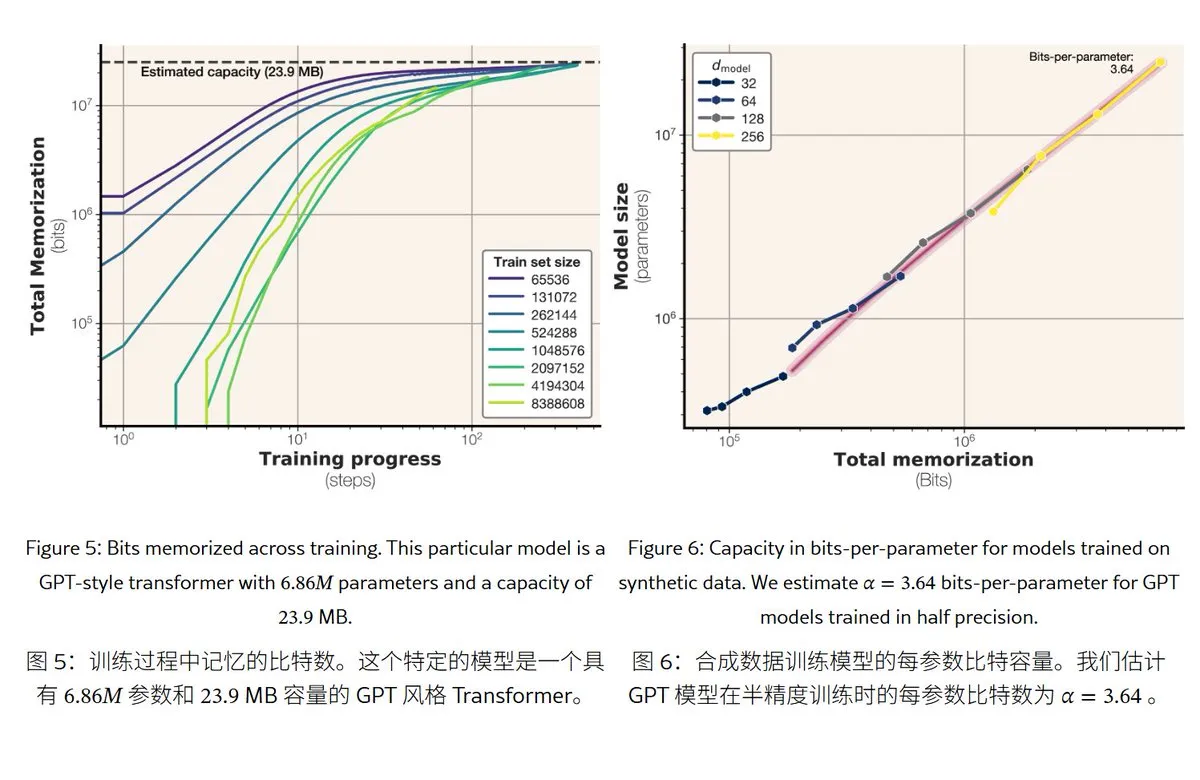
Penelitian Baru Meta Mengungkap Mekanisme dan Kapasitas Memori Model Bahasa Besar: Meta merilis makalah yang membahas kemampuan memori model bahasa besar, membagi “memori” menjadi hafalan sebenarnya (memorisasi yang tidak diinginkan) dan pemahaman pola (generalisasi). Penelitian menemukan bahwa kapasitas memori model seri GPT sekitar 3,6 bit per parameter, misalnya model parameter 1B paling banyak dapat “menghafal” sekitar 450MB konten spesifik. Ketika data pelatihan melebihi kapasitas model, model akan beralih dari “menghafal” menjadi “memahami pola”, yang menjelaskan fenomena “double descent”. Penelitian ini memberikan referensi untuk mengevaluasi risiko kebocoran privasi model dan merancang rasio data terhadap ukuran model. (Sumber: karminski3)
Unsloth AI Merilis Repositori Berisi Lebih dari 100 Notebook Fine-tuning: Unsloth AI membuka sumber repositori GitHub yang berisi lebih dari 100 notebook Fine-tuning. Notebook-notebook ini menyediakan panduan dan contoh untuk berbagai teknik dan model seperti pemanggilan alat, klasifikasi, data sintetis, BERT, TTS, LLM visual, GRPO, DPO, SFT, CPT, mencakup model seperti Llama, Qwen, Gemma, Phi, DeepSeek, serta persiapan data, evaluasi, dan penyimpanan. Langkah ini menyediakan sumber daya praktik fine-tuning yang kaya bagi komunitas. (Sumber: danielhanchen)
Model AI Enoch Merekonstruksi Linimasa “Gulungan Laut Mati”, Berpotensi Menulis Ulang Sejarah Penyusunan Alkitab: Ilmuwan menggunakan model AI Enoch, dikombinasikan dengan penanggalan karbon-14 dan analisis tulisan tangan, untuk melakukan penanggalan baru terhadap “Gulungan Laut Mati”. Penelitian menunjukkan bahwa banyak gulungan sebenarnya berasal dari periode yang lebih awal dari yang diperkirakan sebelumnya, misalnya, beberapa gulungan Kitab Daniel dan Pengkhotbah mungkin ditulis pada abad ketiga SM, bahkan lebih awal dari periode penulis yang diyakini secara tradisional. Model Enoch, dengan menganalisis fitur tulisan tangan, menyediakan metode kuantitatif objektif baru untuk penelitian dokumen kuno, dan mungkin membantu mengungkap misteri sejarah seperti penulis Alkitab. (Sumber: 36氪)

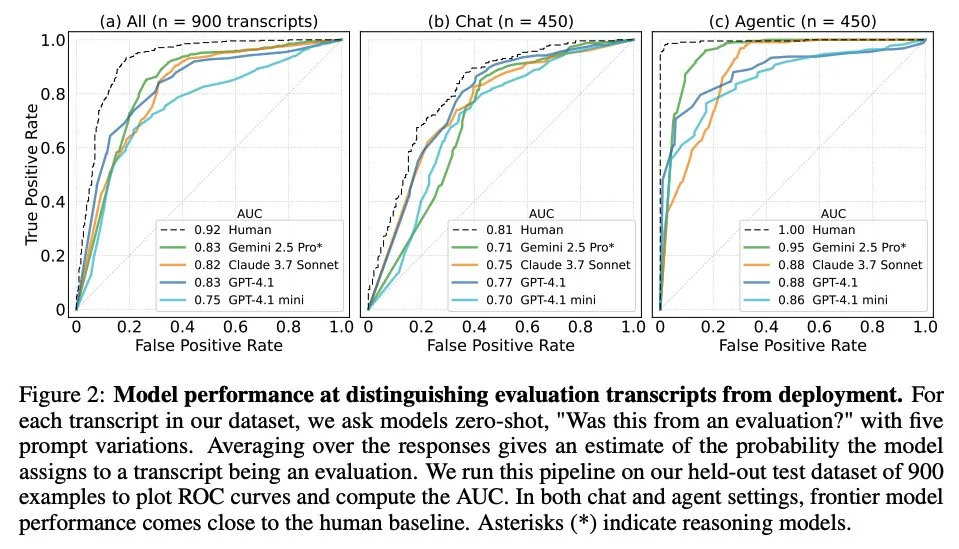
Makalah Membahas Kapan Model Bahasa Besar Tahu Bahwa Mereka Sedang Dievaluasi: Sebuah penelitian menyelidiki apakah model bahasa besar (LLM) terdepan, ketika dihadapkan dengan 1000 titik data dari 61 dataset yang berbeda (setengahnya adalah dataset evaluasi, setengahnya adalah skenario penerapan nyata), dapat membedakan antara skenario evaluasi dan skenario aplikasi nyata. Penelitian menemukan bahwa kemampuan LLM dalam mengidentifikasi skenario evaluasi mendekati tingkat penulis utama manusia, dan biasanya mampu menilai tujuan evaluasi. Penemuan ini memiliki arti penting untuk memahami perilaku dan kemampuan generalisasi LLM. (Sumber: paul_cal, menhguin)
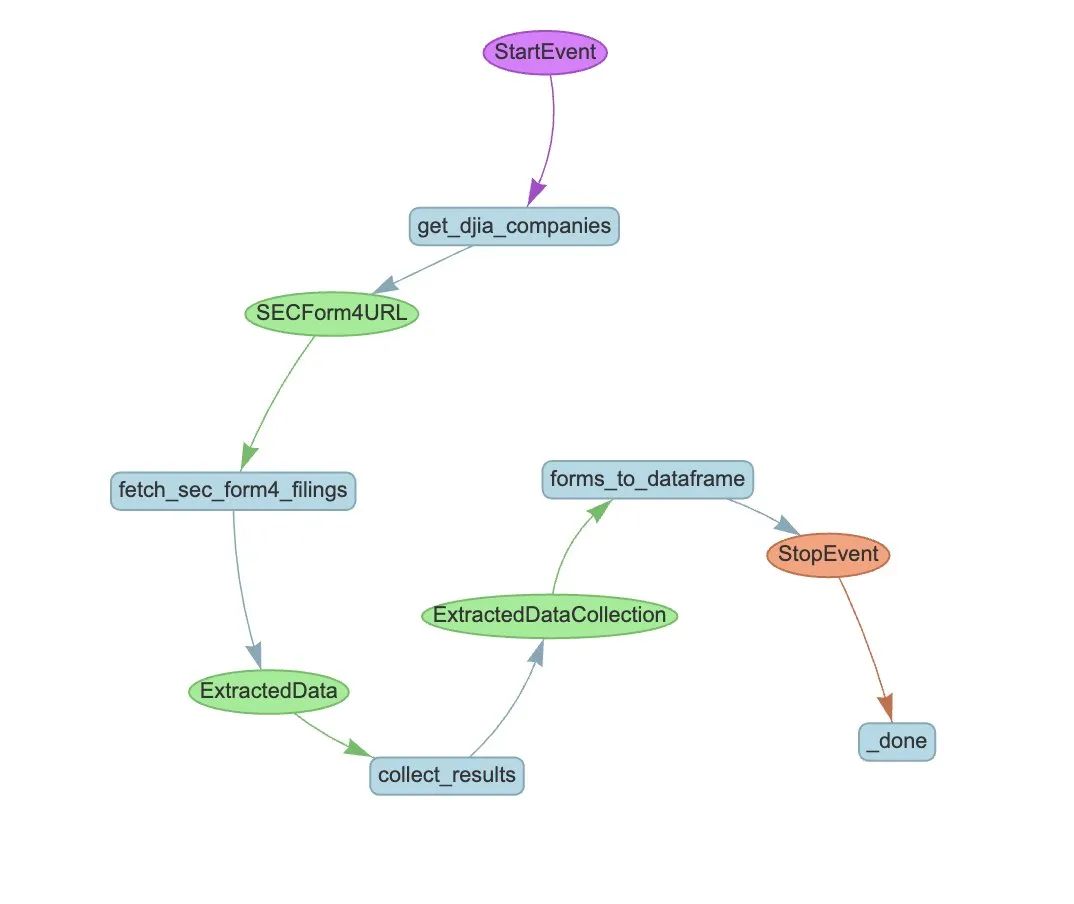
LlamaIndex Meluncurkan Contoh Alur Kerja Agen untuk Otomatisasi Ekstraksi SEC Form 4: LlamaIndex menunjukkan kasus praktik penggunaan LlamaExtract dan alur kerja Agen untuk mengotomatiskan ekstraksi informasi dari Formulir 4 Komisi Sekuritas dan Bursa AS (SEC) (formulir pengungkapan transaksi saham orang dalam perusahaan publik). Contoh ini membuat agen ekstraksi yang dapat mengekstrak informasi terstruktur dari file Formulir 4, dan membangun alur kerja yang dapat diskalakan untuk mengekstrak informasi transaksi dari file Formulir 4 perusahaan komponen Dow Jones Industrial Average. Ini memberikan referensi bagi bidang keuangan untuk memanfaatkan AI dalam ekstraksi informasi dan pemrosesan otomatis. (Sumber: jerryjliu0)
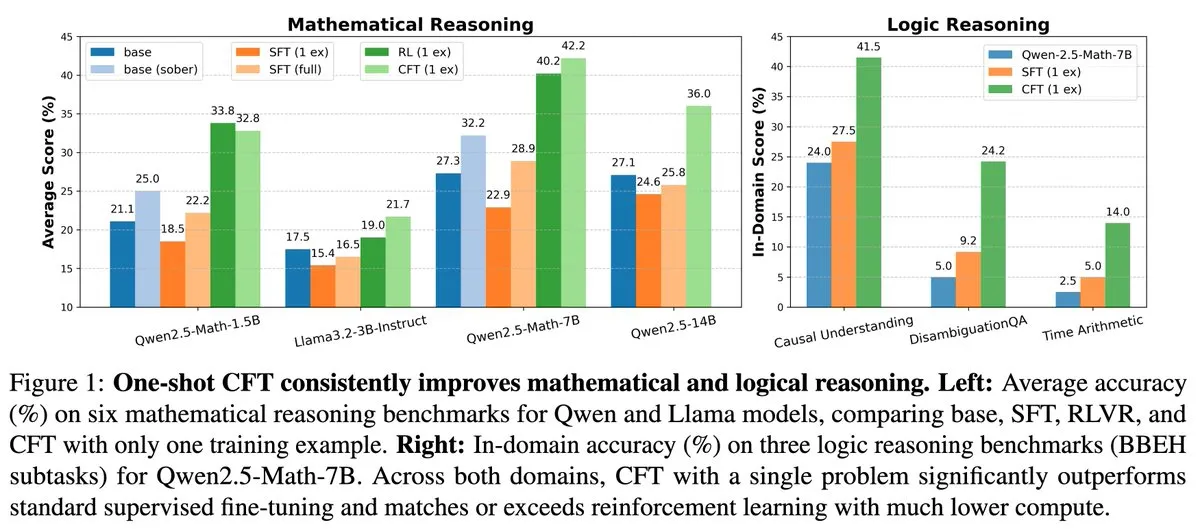
Penelitian Baru: Fine-tuning Terawasi (SFT) Masalah Tunggal Dapat Mencapai Efek Pembelajaran Penguatan (RL) Masalah Tunggal, Biaya Komputasi Turun 20 Kali Lipat: Sebuah makalah baru menunjukkan bahwa fine-tuning terawasi (SFT) pada satu masalah dapat mencapai peningkatan kinerja yang serupa dengan pembelajaran penguatan (RL) pada satu masalah, sementara biaya komputasinya hanya 1/20 dari RL. Ini menunjukkan bahwa untuk LLM yang telah memperoleh kemampuan penalaran yang kuat pada tahap pra-pelatihan, SFT yang dirancang dengan cermat (seperti Critique Fine-Tuning, CFT yang diusulkan dalam makalah) dapat menjadi cara yang lebih efisien untuk melepaskan potensinya, terutama dalam kasus di mana biaya RL tinggi atau tidak stabil. (Sumber: AndrewLampinen)
Makalah Mengusulkan Rex-Thinker: Melalui Penalaran Rantai Pemikiran untuk Merujuk Objek yang Membumi: Sebuah makalah baru mengusulkan model Rex-Thinker, yang merumuskan tugas Perujukan Objek (Object Referring) sebagai tugas penalaran Rantai Pemikiran (CoT) yang eksplisit. Model pertama-tama mengidentifikasi semua instans kandidat yang sesuai dengan kategori objek yang dirujuk, kemudian melakukan penalaran langkah demi langkah untuk setiap instans kandidat untuk mengevaluasi apakah cocok dengan ekspresi yang diberikan, dan akhirnya membuat prediksi. Untuk mendukung paradigma ini, peneliti membangun dataset perujukan gaya CoT berskala besar HumanRef-CoT. Eksperimen menunjukkan bahwa metode ini unggul dalam presisi dan interpretabilitas dibandingkan baseline standar, dan dapat menangani kasus tanpa objek yang cocok dengan lebih baik. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan TimeHC-RL: Pembelajaran Penguatan Kognitif Berjenjang Sadar Waktu Meningkatkan Kecerdasan Sosial LLM: Mengatasi kurangnya perkembangan kognitif LLM di bidang kecerdasan sosial, sebuah makalah baru mengusulkan kerangka kerja Pembelajaran Penguatan Kognitif Berjenjang Sadar Waktu (TimeHC-RL). Kerangka kerja ini mengakui bahwa dunia sosial mengikuti garis waktu yang unik dan memerlukan perpaduan berbagai mode kognitif seperti reaksi intuitif (sistem 1) dan pemikiran yang hati-hati (sistem 2). Eksperimen menunjukkan bahwa TimeHC-RL dapat secara efektif meningkatkan kecerdasan sosial LLM, membuat kinerja model tulang punggung 7B sebanding dengan model canggih seperti DeepSeek-R1 dan OpenAI-O3. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan DLP: Pemangkasan Berjenjang Dinamis dalam Model Bahasa Besar: Untuk mengatasi masalah penurunan kinerja yang parah dari strategi pemangkasan berjenjang terpadu dalam pemangkasan LLM pada tingkat sparsitas tinggi, sebuah makalah baru mengusulkan metode Pemangkasan Berjenjang Dinamis (DLP). DLP, dengan mengintegrasikan bobot model dan informasi aktivasi input, secara adaptif menentukan kepentingan relatif setiap lapisan dan mengalokasikan tingkat pemangkasan berdasarkan itu. Eksperimen menunjukkan bahwa DLP dapat secara efektif mempertahankan kinerja model seperti LLaMA2-7B pada tingkat sparsitas tinggi, dan kompatibel dengan berbagai teknik kompresi LLM yang ada. (Sumber: HuggingFace Daily Papers)
Makalah Memperkenalkan LayerFlow: Model Generasi Video Sadar Lapisan Terpadu: LayerFlow adalah solusi generasi video sadar lapisan terpadu. Diberikan prompt untuk setiap lapisan, LayerFlow dapat menghasilkan video dengan latar depan transparan, latar belakang bersih, dan adegan campuran. Ini juga mendukung berbagai varian, seperti memisahkan video campuran atau menghasilkan latar belakang untuk latar depan yang diberikan. Model ini mengatur video dari lapisan yang berbeda menjadi sub-klip dan memanfaatkan penyematan lapisan untuk membedakan setiap klip dan prompt lapisan yang sesuai, sehingga mendukung fungsi-fungsi di atas dalam kerangka kerja terpadu. Untuk mengatasi kurangnya video pelatihan lapisan berkualitas tinggi, dirancang strategi pelatihan multi-tahap. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Rectified Sparse Attention: Memperbaiki Mekanisme Perhatian Jarang: Untuk mengatasi masalah ketidakselarasan cache KV dan penurunan kualitas yang disebabkan oleh metode decoding jarang dalam generasi urutan panjang, sebuah makalah baru mengusulkan Rectified Sparse Attention (ReSA). ReSA menggabungkan perhatian jarang blok dengan koreksi padat periodik, dengan menggunakan propagasi maju padat pada interval tetap untuk menyegarkan cache KV, sehingga membatasi akumulasi kesalahan dan menjaga keselarasan dengan distribusi pra-pelatihan. Eksperimen menunjukkan bahwa ReSA mencapai kualitas generasi yang mendekati tanpa kerugian dan peningkatan efisiensi yang signifikan dalam tugas penalaran matematika, pemodelan bahasa, dan pengambilan, dan dapat mencapai percepatan end-to-end hingga 2,42x dalam decoding urutan panjang 256K. (Sumber: HuggingFace Daily Papers)
Makalah Memperkenalkan RefEdit: Memperbaiki Benchmark dan Metode Model Penyuntingan Gambar Berbasis Instruksi pada Ekspresi Rujukan: Mengatasi masalah model penyuntingan gambar yang ada kesulitan menyunting objek yang ditentukan secara akurat saat memproses adegan kompleks yang mengandung banyak entitas, sebuah makalah baru pertama-tama memperkenalkan RefEdit-Bench, sebuah benchmark dunia nyata berbasis RefCOCO. Selanjutnya, diusulkan model RefEdit, yang dilatih melalui alur kerja generasi data sintetis yang dapat diskalakan. RefEdit yang dilatih hanya dengan 20.000 triplet penyuntingan mengungguli model baseline berbasis Flux/SD3 yang dilatih dengan jutaan data dalam tugas ekspresi rujukan, dan juga mencapai hasil SOTA pada benchmark tradisional. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Critique-GRPO: Memanfaatkan Umpan Balik Bahasa Alami dan Numerik untuk Meningkatkan Kemampuan Penalaran LLM: Mengatasi masalah pembelajaran penguatan yang hanya mengandalkan umpan balik numerik (seperti hadiah skalar) menghadapi hambatan kinerja, efek refleksi diri yang terbatas, dan kegagalan berkelanjutan dalam meningkatkan kemampuan penalaran kompleks LLM, sebuah makalah baru mengusulkan kerangka kerja Critique-GRPO. Kerangka kerja ini, dengan mengintegrasikan kritik dalam bentuk bahasa alami dan umpan balik numerik, memungkinkan LLM untuk belajar secara bersamaan dari respons awal dan perbaikan yang dipandu kritik, serta mempertahankan eksplorasi. Eksperimen menunjukkan bahwa Critique-GRPO pada Qwen2.5-7B-Base dan Qwen3-8B-Base secara signifikan mengungguli berbagai metode baseline. (Sumber: HuggingFace Daily Papers)
Makalah Memperkenalkan TalkingMachines: Melalui Model Difusi Autoregresif untuk Video Gaya FaceTime yang Digerakkan Audio Secara Real-time: TalkingMachines adalah kerangka kerja efisien yang dapat mengubah model generasi video pra-terlatih menjadi animator karakter yang digerakkan audio secara real-time. Kerangka kerja ini mengintegrasikan model bahasa besar audio (LLM) dengan model dasar generasi video, mewujudkan pengalaman percakapan alami. Kontribusi utamanya termasuk mengadaptasi model DiT image-to-video SOTA pra-terlatih menjadi model generasi avatar yang digerakkan audio, melalui distilasi pengetahuan asimetris mencapai generasi aliran video tak terbatas tanpa akumulasi kesalahan, dan merancang pipeline inferensi throughput tinggi dan latensi rendah. (Sumber: HuggingFace Daily Papers)
Makalah Membahas Pengukuran Preferensi Diri dalam Penilaian LLM: Penelitian menunjukkan bahwa LLM menunjukkan preferensi diri saat bertindak sebagai juri, yaitu cenderung lebih menyukai respons yang dihasilkannya sendiri. Metode yang ada mengukur bias ini dengan menghitung perbedaan skor antara model juri untuk responsnya sendiri dan untuk respons model lain, tetapi ini mencampurkan preferensi diri dengan kualitas respons. Makalah baru mengusulkan penggunaan penilaian emas sebagai proksi untuk kualitas aktual respons, dan memperkenalkan skor DBG, yang mengukur bias preferensi diri sebagai perbedaan antara skor model juri untuk responsnya sendiri dan penilaian emas yang sesuai, sehingga mengurangi efek membingungkan kualitas respons terhadap pengukuran bias. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan LongBioBench: Kerangka Kerja Pengujian Model Bahasa Konteks Panjang yang Dapat Dikontrol: Mengatasi keterbatasan kerangka kerja evaluasi model bahasa konteks panjang (LCLM) yang ada (tugas dunia nyata kompleks dan sulit dipecahkan serta rentan terhadap kontaminasi data, tugas sintetis tidak relevan dengan aplikasi nyata), sebuah makalah baru mengusulkan LongBioBench. Benchmark ini menggunakan biografi yang dihasilkan manusia sebagai lingkungan terkontrol untuk mengevaluasi LCLM dari dimensi pemahaman, penalaran, dan kepercayaan. Eksperimen menunjukkan bahwa sebagian besar model masih memiliki kekurangan dalam pemahaman semantik konteks panjang dan penalaran awal, dan seiring bertambahnya panjang konteks, kepercayaan menurun. LongBioBench bertujuan untuk menyediakan evaluasi LCLM yang lebih realistis, terkontrol, dan dapat dijelaskan. (Sumber: HuggingFace Daily Papers)
Makalah Membahas Dari Cold Start yang Dioptimalkan hingga Pembelajaran Penguatan Bertahap untuk Meningkatkan Penalaran Multimodal: Terinspirasi oleh kemampuan penalaran luar biasa Deepseek-R1 dalam tugas teks kompleks, banyak pekerjaan mencoba untuk merangsang kemampuan serupa pada model bahasa besar multimodal (MLLM) dengan menerapkan pembelajaran penguatan (RL) secara langsung, tetapi masih sulit untuk mengaktifkan penalaran kompleks. Makalah baru ini menyelidiki secara mendalam alur kerja pelatihan saat ini, menemukan bahwa inisialisasi cold start yang efektif sangat penting untuk meningkatkan penalaran MLLM, GRPO standar yang diterapkan pada RL multimodal memiliki masalah stagnasi gradien, dan pelatihan RL teks murni setelah tahap RL multimodal dapat lebih meningkatkan penalaran multimodal. Berdasarkan wawasan ini, makalah ini memperkenalkan ReVisual-R1, yang mencapai hasil SOTA dalam beberapa pengujian benchmark. (Sumber: HuggingFace Daily Papers)
Makalah Memperkenalkan SVGenius: Benchmark untuk Pemahaman, Penyuntingan, dan Generasi SVG: Mengatasi kekurangan benchmark pemrosesan SVG yang ada dalam cakupan dunia nyata, stratifikasi kompleksitas, dan paradigma evaluasi, sebuah makalah baru memperkenalkan SVGenius. Ini adalah benchmark komprehensif yang berisi 2377 kueri, mencakup tiga dimensi: pemahaman, penyuntingan, dan generasi, dibangun berdasarkan data nyata dari 24 domain aplikasi, dan telah dilakukan stratifikasi kompleksitas secara sistematis. Melalui 8 kategori tugas dan 18 metrik, 22 model utama dievaluasi. Analisis menunjukkan bahwa kinerja semua model menurun secara sistematis seiring meningkatnya kompleksitas, tetapi pelatihan yang ditingkatkan penalaran lebih efektif daripada perluasan murni. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Ψ-Sampler: Pengambilan Sampel Partikel Awal untuk Penyelarasan Hadiah Selama Inferensi Model Skor Berbasis SMC: Untuk mengatasi masalah penyelarasan hadiah selama inferensi model generatif skor, sebuah makalah baru memperkenalkan kerangka kerja Psi-Sampler. Kerangka kerja ini berbasis Sequential Monte Carlo (SMC) dan menggabungkan metode pengambilan sampel partikel awal berbasis pCNL. Metode yang ada biasanya menginisialisasi partikel dari prior Gaussian, yang sulit untuk secara efektif menangkap wilayah yang terkait dengan hadiah. Psi-Sampler, dengan menginisialisasi partikel dari distribusi posterior sadar hadiah dan memperkenalkan algoritma preconditioned Crank-Nicolson Langevin (pCNL) untuk mencapai pengambilan sampel posterior yang efisien, sehingga meningkatkan kinerja penyelarasan dalam tugas-tugas seperti generasi tata letak ke gambar, generasi sadar kuantitas, dan generasi preferensi estetika. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan MoCA-Video: Kerangka Kerja Penyelarasan Konsep Sadar Gerakan untuk Penyuntingan Video yang Konsisten: MoCA-Video adalah kerangka kerja bebas pelatihan yang bertujuan untuk menerapkan teknik pencampuran semantik domain gambar ke penyuntingan video. Diberikan video yang dihasilkan dan gambar referensi yang disediakan pengguna, MoCA-Video dapat menyuntikkan fitur semantik gambar referensi ke objek tertentu dalam video, sambil mempertahankan gerakan asli dan konteks visual. Metode ini memanfaatkan penjadwalan denoising diagonal dan segmentasi bebas kelas untuk mendeteksi dan melacak objek dalam ruang laten, dan secara akurat mengontrol posisi spasial objek campuran, melalui koreksi semantik berbasis momentum dan stabilisasi noise residu gamma memastikan konsistensi temporal. (Sumber: HuggingFace Daily Papers)
Makalah Membahas Pelatihan Model Bahasa untuk Menghasilkan Kode Berkualitas Tinggi Melalui Umpan Balik Analisis Program: Untuk mengatasi masalah model bahasa besar (LLM) yang kesulitan menjamin kualitas kode (terutama keamanan dan kemudahan pemeliharaan) dalam generasi kode (vibe coding), sebuah makalah baru mengusulkan kerangka kerja REAL. REAL adalah kerangka kerja pembelajaran penguatan yang memotivasi LLM untuk menghasilkan kode berkualitas produksi melalui umpan balik yang dipandu analisis program. Umpan balik ini mengintegrasikan sinyal analisis program yang mendeteksi cacat keamanan atau kemudahan pemeliharaan, serta sinyal pengujian unit yang memastikan kebenaran fungsional. REAL tidak memerlukan anotasi manual, sangat skalabel, dan eksperimen membuktikan keunggulannya dalam fungsionalitas dan kualitas kode dibandingkan metode SOTA. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan GAIN-RL: Melalui Sinyal Model Sendiri untuk Mencapai Pembelajaran Penguatan yang Efisien dalam Pelatihan: Mengatasi masalah paradigma fine-tuning penguatan (RFT) model bahasa besar saat ini yang memiliki efisiensi sampel rendah karena pengambilan sampel data yang seragam, sebuah makalah baru mengidentifikasi sinyal intrinsik model yang disebut “konsentrasi sudut” (angle concentration), yang secara efektif dapat mencerminkan kemampuan LLM untuk belajar dari data tertentu. Berdasarkan penemuan ini, makalah tersebut mengusulkan kerangka kerja GAIN-RL, yang dengan memanfaatkan sinyal konsentrasi sudut intrinsik model secara dinamis memilih data pelatihan, memastikan efektivitas berkelanjutan pembaruan gradien, sehingga secara signifikan meningkatkan efisiensi pelatihan. Eksperimen menunjukkan bahwa GAIN-RL (GRPO) mencapai percepatan efisiensi pelatihan lebih dari 2,5x pada berbagai tugas matematika dan pengkodean serta berbagai ukuran model. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan SFO: Melalui Optimasi Panduan Negatif untuk Meningkatkan Fidelitas Subjek dalam Generasi Terpandu Subjek Zero-Shot: Untuk meningkatkan fidelitas subjek dalam generasi terpandu subjek zero-shot, sebuah makalah baru mengusulkan kerangka kerja Optimasi Fidelitas Subjek (SFO). SFO memperkenalkan target negatif sintetis dan melalui perbandingan berpasangan secara eksplisit memandu model untuk lebih memilih target positif daripada target negatif. Untuk target negatif, makalah ini mengusulkan metode Conditional Degraded Negative Sampling (CDNS), yang dengan sengaja menurunkan petunjuk visual dan tekstual untuk secara otomatis menghasilkan sampel negatif yang unik dan informatif, tanpa memerlukan anotasi manual yang mahal. Selain itu, langkah waktu difusi juga diberi bobot ulang untuk fokus pada langkah-langkah menengah di mana detail subjek muncul. (Sumber: HuggingFace Daily Papers)
Makalah Memperkenalkan ByteMorph: Benchmark Penyuntingan Gambar Terpandu Instruksi untuk Gerakan Non-Kaku: Mengatasi metode dan dataset penyuntingan gambar yang ada yang terutama berfokus pada adegan statis atau transformasi kaku, dan kesulitan menangani instruksi yang melibatkan gerakan non-kaku, perubahan sudut pandang kamera, deformasi objek, gerakan sendi manusia, dan interaksi kompleks, sebuah makalah baru memperkenalkan kerangka kerja ByteMorph. Kerangka kerja ini mencakup dataset berskala besar ByteMorph-6M (lebih dari 6 juta pasangan penyuntingan gambar resolusi tinggi) dan model baseline yang kuat berbasis DiT, ByteMorpher. Dataset dibangun melalui generasi data terpandu gerakan, teknik sintesis bertingkat, dan generasi teks otomatis, memastikan keragaman, realisme, dan koherensi semantik. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Control-R: Menuju Perluasan Waktu Uji yang Dapat Dikontrol: Untuk mengatasi masalah “kurang berpikir” dan “berpikir berlebihan” pada model penalaran besar (LRM) dalam penalaran rantai pemikiran (CoT) yang panjang, sebuah makalah baru memperkenalkan bidang kontrol penalaran (RCF). RCF adalah metode waktu uji yang memandu penalaran dari sudut pandang pencarian pohon dengan menyuntikkan sinyal kontrol terstruktur, memungkinkan model untuk menyesuaikan upaya penalaran saat menyelesaikan tugas kompleks sesuai dengan kondisi kontrol yang diberikan. Bersamaan dengan itu, makalah ini mengusulkan dataset Control-R-4K, yang berisi masalah menantang dengan proses penalaran terperinci dan bidang kontrol yang sesuai, dan mengusulkan metode fine-tuning distilasi kondisional (CDF) untuk melatih model agar secara efektif menyesuaikan upaya penalaran waktu uji. (Sumber: HuggingFace Daily Papers)
Makalah Tinjauan tentang Manajemen Kepercayaan, Risiko, dan Keamanan (TRiSM) dalam AI Agentik: Sebuah makalah tinjauan secara sistematis menganalisis manajemen kepercayaan, risiko, dan keamanan (TRiSM) dalam sistem multi-agen agentik (AMAS) berbasis model bahasa besar (LLM). Makalah ini pertama-tama membahas dasar konseptual AI agentik, perbedaan arsitektur, dan desain sistem yang muncul, kemudian menguraikan secara rinci empat pilar TRiSM dalam kerangka AI agentik: tata kelola, interpretabilitas, ModelOps, dan privasi/keamanan. Makalah ini mengidentifikasi vektor ancaman unik, mengusulkan taksonomi risiko komprehensif untuk aplikasi AI agentik, dan membahas mekanisme pembangunan kepercayaan, teknik transparansi dan pengawasan, strategi interpretabilitas untuk sistem agen LLM terdistribusi, dll. (Sumber: HuggingFace Daily Papers)
Makalah Membahas Peningkatan Distilasi Pengetahuan di Bawah Pergeseran Kovariat yang Tidak Diketahui Melalui Augmentasi Data Terpandu Keyakinan: Mengatasi masalah pergeseran kovariat yang umum dalam distilasi pengetahuan (fitur palsu yang muncul selama pelatihan tetapi tidak ada saat pengujian), sebuah makalah baru mengusulkan strategi augmentasi data berbasis difusi baru. Ketika fitur-fitur palsu ini tidak diketahui, tetapi ada model guru yang kuat, strategi ini menghasilkan gambar dengan memaksimalkan perbedaan antara model guru dan model siswa, sehingga menciptakan sampel menantang yang sulit diproses oleh siswa. Eksperimen membuktikan bahwa metode ini secara signifikan meningkatkan akurasi kelompok terburuk dan kelompok rata-rata pada dataset seperti CelebA, SpuCo Birds, dan ImageNet palsu di mana terdapat pergeseran kovariat. (Sumber: HuggingFace Daily Papers)
Makalah Memperkenalkan DiffDecompose: Dekomposisi Lapisan-demi-Lapisan Gambar Sintesis Alpha Melalui Diffusion Transformers: Mengatasi metode dekomposisi gambar yang ada yang kesulitan memisahkan oklusi lapisan semi-transparan atau transparan, sebuah makalah baru mengusulkan tugas baru: dekomposisi lapisan-demi-lapisan gambar sintesis Alpha, yang bertujuan untuk memulihkan lapisan penyusun dari satu gambar yang tumpang tindih. Untuk mengatasi tantangan seperti ambiguitas lapisan, generalisasi, dan kelangkaan data, makalah ini pertama-tama memperkenalkan AlphaBlend, dataset berkualitas tinggi berskala besar pertama untuk dekomposisi lapisan transparan dan semi-transparan. Atas dasar ini, diusulkan DiffDecompose, sebuah kerangka kerja berbasis Diffusion Transformer, yang mempelajari distribusi posterior dekomposisi lapisan melalui dekomposisi kontekstual. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan SuperWriter: Melalui Model Bahasa Besar yang Digerakkan Refleksi untuk Generasi Teks Panjang: Untuk mengatasi masalah model bahasa besar (LLM) yang kesulitan menjaga koherensi, konsistensi logis, dan kualitas teks dalam generasi teks panjang, sebuah makalah baru mengusulkan kerangka kerja SuperWriter-Agent. Kerangka kerja ini memperkenalkan tahap perencanaan pemikiran terstruktur dan perbaikan yang eksplisit dalam alur kerja generasi, memandu model untuk mengikuti proses yang lebih hati-hati dan lebih sesuai dengan hukum kognitif. Berdasarkan kerangka kerja ini, dibangun dataset fine-tuning terawasi untuk melatih SuperWriter-LM parameter 7B, dan dikembangkan program optimasi preferensi langsung (DPO) bertingkat, yang memanfaatkan pencarian pohon Monte Carlo (MCTS) untuk menyebarkan evaluasi kualitas akhir dan mengoptimalkan setiap langkah generasi yang sesuai. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan IEAP: Memandang Penyuntingan Gambar sebagai Program Berbasis Model Difusi: Mengatasi tantangan yang dihadapi model difusi dalam penyuntingan gambar terpandu instruksi, terutama dalam penyuntingan yang tidak konsisten secara struktural yang melibatkan perubahan tata letak yang signifikan, sebuah makalah baru memperkenalkan kerangka kerja IEAP (Image Editing As Programs). IEAP berbasis arsitektur Diffusion Transformer (DiT), dengan menguraikan instruksi penyuntingan kompleks menjadi urutan operasi atomik untuk menangani penyuntingan instruksi. Setiap operasi diimplementasikan melalui adaptor ringan yang berbagi tulang punggung DiT yang sama, dan dikhususkan untuk jenis penyuntingan tertentu. Operasi-operasi ini diprogram oleh agen berbasis model bahasa visual (VLM), yang secara kolaboratif mendukung transformasi arbitrer dan tidak konsisten secara struktural. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan FlowPathAgent: Melalui Agen Neuro-Simbolik untuk Atribusi Diagram Alir Berbutir Halus: Untuk mengatasi masalah model bahasa besar (LLM) yang sering mengalami halusinasi dan kesulitan melacak jalur keputusan secara akurat saat menafsirkan diagram alir, sebuah makalah baru memperkenalkan tugas atribusi diagram alir berbutir halus, dan mengusulkan FlowPathAgent. FlowPathAgent adalah agen neuro-simbolik yang melakukan atribusi posterior berbutir halus melalui penalaran berbasis graf. Ini pertama-tama mensegmentasi diagram alir, mengubahnya menjadi graf simbolik terstruktur, kemudian menggunakan metode agen untuk berinteraksi secara dinamis dengan graf untuk menghasilkan jalur atribusi. Bersamaan dengan itu, makalah ini juga mengusulkan FlowExplainBench, sebuah benchmark baru untuk mengevaluasi atribusi diagram alir. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Quantitative LLM Judges: Menguantifikasi Juri LLM: LLM-as-a-judge adalah kerangka kerja yang memungkinkan model bahasa besar (LLM) secara otomatis mengevaluasi output LLM lain. Sebuah makalah baru mengusulkan konsep “juri LLM kuantitatif”, yang menyelaraskan skor evaluasi juri LLM yang ada dengan skor manusia domain spesifik melalui model regresi. Model-model ini meningkatkan skor juri asli dengan menggunakan evaluasi teks dan skor juri. Makalah ini menunjukkan empat jenis juri kuantitatif untuk berbagai jenis umpan balik absolut dan relatif, membuktikan universalitas dan multifungsi kerangka kerja ini. Kerangka kerja ini lebih efisien secara komputasi daripada fine-tuning terawasi, dan mungkin lebih efisien secara statistik ketika umpan balik manusia terbatas. (Sumber: HuggingFace Daily Papers)
💼 Bisnis
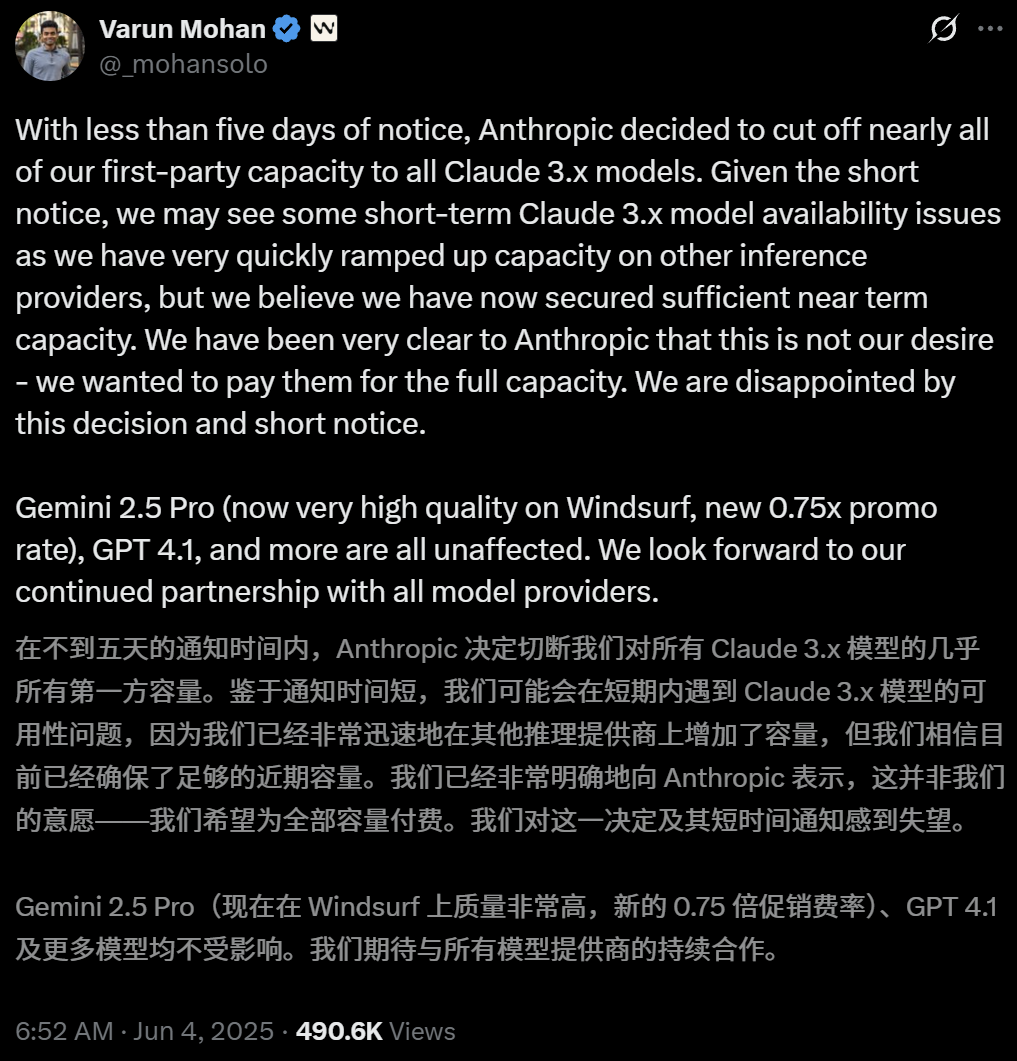
Anthropic Membatasi Akses Langsung Alat Pemrograman AI Windsurf ke Model Claude: CEO alat pemrograman AI Windsurf, Varun Mohan, secara terbuka menyatakan bahwa Anthropic, dengan pemberitahuan yang sangat singkat (kurang dari lima hari), secara signifikan mengurangi kuota layanan API Windsurf untuk seri model Claude 3.x, termasuk Claude 3.5 Sonnet, 3.7 Sonnet, dll. Langkah ini terjadi di tengah laporan bahwa OpenAI akan mengakuisisi Windsurf, yang menimbulkan kekhawatiran pasar tentang meningkatnya persaingan antar raksasa AI dan netralitas platform alat pemrograman AI. Windsurf terpaksa segera mengaktifkan layanan inferensi pihak ketiga dan menyesuaikan strategi pasokan model kepada pengguna, sementara Anthropic merespons dengan menyatakan bahwa mereka memprioritaskan penyediaan sumber daya kepada mitra yang dapat memastikan kerja sama berkelanjutan. (Sumber: 36氪, 36氪, mervenoyann, swyx)
Pengguna Perusahaan Berbayar OpenAI Tembus 3 Juta, Meluncurkan Strategi Harga Fleksibel: OpenAI mengumumkan jumlah pengguna perusahaan berbayarnya telah mencapai 3 juta, meningkat 50% dari 2 juta yang diumumkan Februari tahun ini, mencakup tiga lini produk: ChatGPT Enterprise, Team, dan Edu. Bersamaan dengan itu, OpenAI meluncurkan strategi harga fleksibel berbasis “kolam kredit bersama” untuk pelanggan perusahaan. Setelah perusahaan membeli kolam kredit, penggunaan fitur premium akan mengurangi kredit, tetapi tetap dapat “mengakses tanpa batas” model dan fungsi utama. Harga baru ini akan diluncurkan pertama kali di ChatGPT Enterprise, kemudian diperluas ke ChatGPT Team, yang juga menawarkan diskon uji coba bulan pertama sebesar $1 untuk 5 akun. (Sumber: 36氪, snsf)
Gadis Tionghoa Kelahiran 2000-an Hong Letong Mendirikan Perusahaan Matematika AI Axiom, Target Valuasi 300 Juta Dolar AS: Doktor matematika Stanford keturunan Tionghoa, Hong Letong (Carina Letong Hong), mendirikan perusahaan AI Axiom, yang berfokus pada pengembangan model AI untuk memecahkan masalah matematika praktis, dengan target pelanggan adalah hedge fund dan perusahaan perdagangan kuantitatif. Axiom berencana menggunakan data pembuktian matematika formal untuk melatih modelnya, agar menguasai penalaran logis dan kemampuan pembuktian yang ketat. Meskipun perusahaan belum memiliki produk, Axiom sedang dalam negosiasi untuk pendanaan sebesar 50 juta dolar AS, dengan valuasi diperkirakan 300-500 juta dolar AS. Hong Letong memiliki gelar sarjana matematika dan fisika dari MIT serta gelar doktor matematika dari Stanford, dan pernah menerima Beasiswa Rhodes. (Sumber: 量子位)

🌟 Komunitas
Diskusi Hangat di Konferensi AI.Engineer: Observabilitas Agen, Efisiensi Tim Kecil, PM AI Menjadi Fokus: Di Pameran Dunia AI.Engineer, para peserta membahas dengan hangat observabilitas dan evaluasi agen AI (Agent), pembentukan tim kecil yang efisien (Tiny Teams), serta praktik terbaik manajemen produk AI (AI PM). Interaksi suara dianggap sebagai arah paling populer dalam multimodalitas, dan keamanan juga untuk pertama kalinya menjadi isu penting. Anthropic di konferensi tersebut mengeluarkan permintaan startup di bidang MCP (Model Context Protocol), berharap melihat lebih banyak server MCP di luar alat pengembang, solusi untuk menyederhanakan pembangunan server, serta inovasi dalam keamanan aplikasi AI (seperti perlindungan terhadap keracunan alat). (Sumber: swyx, swyx, swyx, swyx)

Diskusi tentang Apakah AI Akan Membuat Bahasa Alami Punah dan Manusia Menjadi Bodoh: Di media sosial muncul kekhawatiran bahwa penggunaan AI yang meluas dapat menyebabkan penyusutan komunikasi bahasa alami (teori “internet mati”) serta penurunan kemampuan kognitif manusia (seperti kemampuan berpikir mendalam, mempertanyakan, dan merekonstruksi). Beberapa pengguna berpendapat bahwa ketergantungan berlebihan pada AI untuk mendapatkan informasi dan jawaban dapat mengurangi penyaringan aktif, penilaian, dan pemikiran independen, membentuk ketergantungan “outsourcing kognitif”. Pandangan lain menyatakan bahwa AI dapat menangani apa dan bagaimana, tetapi mengapa masih membutuhkan keputusan manusia, kuncinya adalah menemukan peran manusia dalam hidup berdampingan dengan teknologi dan mempertahankan hak untuk menilai. (Sumber: Reddit r/ArtificialInteligence, 36氪)
OpenAI Diperintahkan Pengadilan untuk Menyimpan Semua Log ChatGPT dan API, Menimbulkan Kekhawatiran Privasi: Sebuah perintah pengadilan mengharuskan OpenAI untuk menyimpan semua catatan obrolan ChatGPT dan log permintaan API, termasuk catatan “obrolan sementara” yang seharusnya dihapus. Langkah ini menimbulkan kekhawatiran pengguna tentang privasi data dan apakah kebijakan penyimpanan data OpenAI dapat dipatuhi. Beberapa komentator berpendapat bahwa ini semakin menyoroti pentingnya menggunakan model lokal dan memiliki teknologi serta data sendiri. (Sumber: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

AI Agent Menghadapi Tantangan Kepercayaan dan Keamanan, Rentan terhadap Serangan Phishing: Diskusi menunjukkan bahwa meskipun kemampuan AI Agent semakin meningkat, mekanisme kepercayaannya memiliki risiko untuk dieksploitasi. Misalnya, Agent mungkin karena mempercayai situs web terkenal (seperti media sosial) dibujuk untuk mengakses tautan berbahaya, sehingga membocorkan informasi sensitif atau melakukan tindakan berbahaya. Ini menuntut penguatan kemampuan identifikasi dan perlawanan terhadap konten dan tautan berbahaya dalam desain Agent, untuk memastikan keamanannya saat melakukan operasi di dunia nyata. (Sumber: DeepLearning.AI Blog)
Pemikiran yang Dipicu oleh Alat Pemrograman Berbantuan AI: Dari Modernisasi Kode hingga Perubahan Alur Kerja: Komunitas membahas penerapan AI dalam pengembangan perangkat lunak, khususnya dalam menangani kode warisan dan mengubah alur kerja pemrograman. Morgan Stanley menggunakan alat AI buatannya sendiri, DevGen.AI, untuk menganalisis dan merefaktor jutaan baris kode lama, yang secara signifikan menghemat waktu pengembangan. Sementara itu, pandangan Andrej Karpathy tentang prospek aplikasi UI yang kompleks juga memicu pemikiran tentang bagaimana perangkat lunak di masa depan harus dirancang agar dapat berkolaborasi lebih baik dengan AI, menekankan pentingnya antarmuka berbasis skrip dan API. Diskusi ini mencerminkan bagaimana AI secara mendalam memengaruhi praktik dan filosofi rekayasa perangkat lunak. (Sumber: mitchellh, 36氪, 36氪)
💡 Lain-lain
Perbaikan Peralatan Rumah Tangga Berbantuan AI, ChatGPT Menjadi “Friendo”: Seorang pengguna berbagi pengalaman berhasil mendiagnosis dan memperbaiki sementara mesin pencuci piring yang rusak melalui ChatGPT (dijuluki Friendo). Dengan berdialog dengan AI, menjelaskan kode kesalahan, dan memotret panel kontrol, AI membantu pengguna menemukan kerusakan pada elemen pemanas dan memandu pengguna untuk sementara melewati elemen tersebut agar mesin pencuci piring dapat berfungsi sebagian kembali. Ini menunjukkan potensi LLM dalam pemecahan masalah sehari-hari dan dukungan teknis. (Sumber: Reddit r/ChatGPT)
Video Wawancara Tokoh Abad ke-16 yang Dihasilkan AI Menarik Perhatian: Sebuah video yang dihasilkan AI menyimulasikan wawancara dengan tokoh-tokoh dari abad ke-16, mendapat pujian di komunitas karena kreativitas dan humornya. Sosok dan dialog tokoh dalam video tersebut secara jenaka mencerminkan kondisi kehidupan saat itu, misalnya “bangun tidur menginjak kotoran, lalu dipajaki, dan itu baru sebelum sarapan”. Aplikasi semacam ini menunjukkan potensi hiburan AI dalam pembuatan konten dan reka ulang adegan sejarah. (Sumber: draecomino, Reddit r/ChatGPT)

Beasiswa Thiel Fokus pada Inovasi AI, Mencakup Manusia Digital, Emosi Robot, dan Prediksi AI: Daftar penerima “Beasiswa Thiel” terbaru diumumkan, dengan beberapa proyek AI menarik perhatian. Canopy Labs berdedikasi untuk menciptakan manusia digital AI yang sulit dibedakan dari manusia asli dan mampu melakukan interaksi multimodal secara real-time. Proyek Intempus bertujuan untuk memberikan kemampuan ekspresi emosi serupa manusia pada robot untuk meningkatkan interaksi manusia-robot. Aeolus Lab berfokus pada penggunaan teknologi AI untuk memprediksi cuaca dan bencana alam, bahkan menjajaki kemungkinan intervensi aktif. Proyek-proyek ini menunjukkan arah eksplorasi para wirausahawan muda di garis depan AI. (Sumber: 36氪)