
Kata Kunci:OpenAI Codex, Model Bahasa Visual Aksi, Batas Memori Model Bahasa, Fitur Memori ChatGPT, DeepSeek-R1-0528, Model Difusi, Kreasi Musik Suno AI, MetaAgentX, Fitur Akses Internet Codex, Model Robot SmolVLA, Memori 3.6 Bit Model Gaya GPT, Peningkatan Interaksi Personal ChatGPT, Kemampuan Penalaran Kompleks DeepSeek-R1
🔥 Fokus
OpenAI Codex dibuka untuk pengguna Plus dan mendapatkan pembaruan besar, termasuk akses internet dan input suara: OpenAI mengumumkan bahwa Codex akan dibuka secara bertahap untuk pengguna ChatGPT Plus. Fokus pembaruan kali ini meliputi mengizinkan agen AI untuk mengakses internet saat menjalankan tugas (dinonaktifkan secara default, domain dan metode HTTP dapat dikontrol pengguna), untuk menginstal dependensi, meningkatkan paket perangkat lunak, dan menjalankan pengujian sumber daya eksternal. Selain itu, Codex kini mendukung pembaruan langsung pada Pull Request yang sudah ada, dan dapat menerima tugas melalui input suara. Peningkatan lainnya termasuk dukungan untuk operasi file biner (saat ini terbatas pada penghapusan atau penggantian nama dalam PR), peningkatan batas ukuran perbedaan (diff) tugas dari 1MB menjadi 5MB, peningkatan batas waktu eksekusi skrip dari 5 menit menjadi 10 menit, serta perbaikan berbagai masalah pada platform iOS dan pengaktifan kembali fitur aktivitas langsung. Pembaruan ini bertujuan untuk meningkatkan utilitas dan fleksibilitas Codex dalam tugas pemrograman yang kompleks (Sumber: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
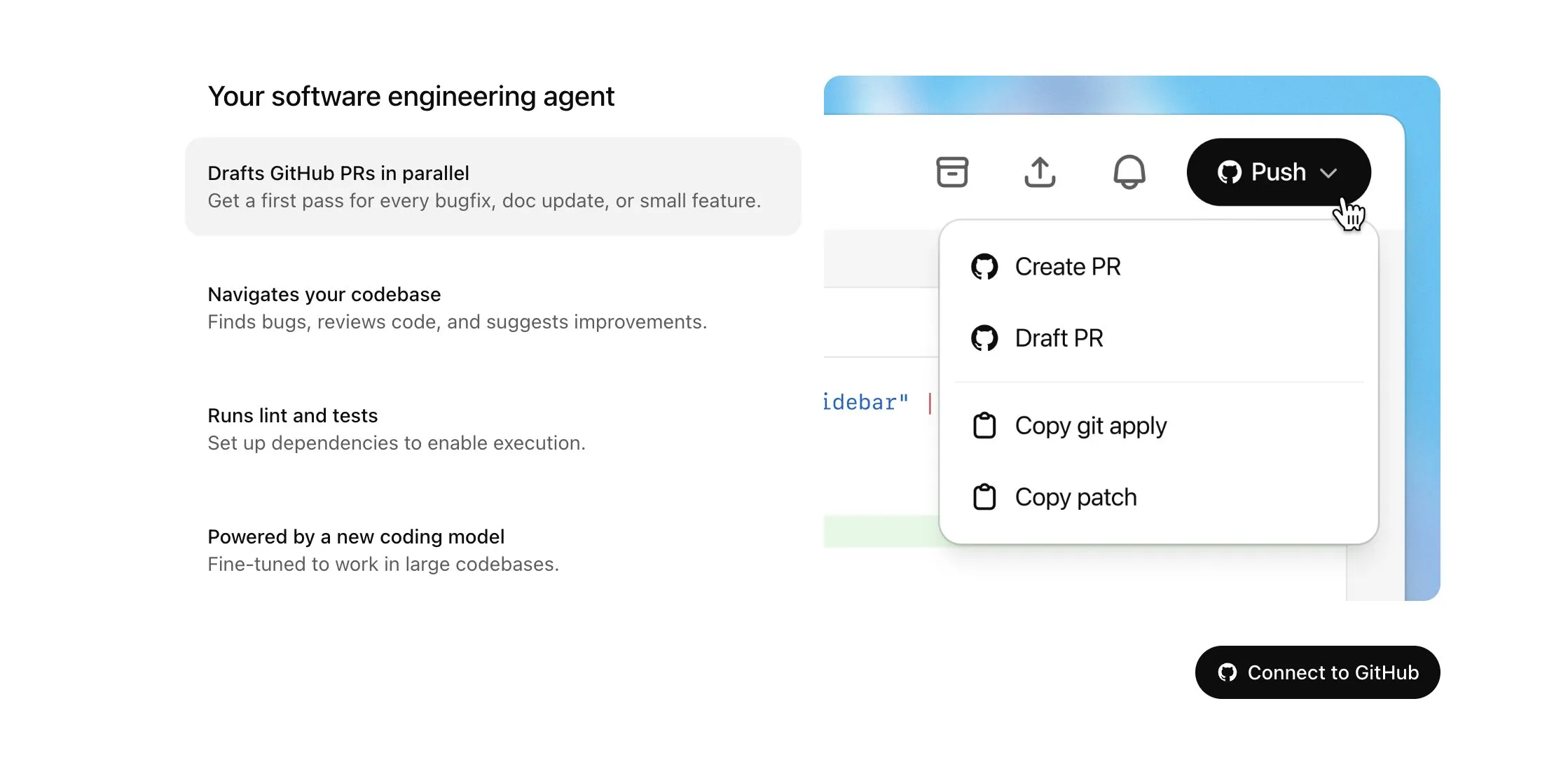
Hugging Face dan H Company bersama-sama merilis model Vision Language Action (VLA) open-source, mendorong pengembangan teknologi robotika: Hugging Face dan H Company mengumumkan model Vision Language Action open-source baru pada “VLA Day”, termasuk SmolVLA (450M parameter) dari Hugging Face dan Holo-1 (3B dan 7B parameter) dari H Company. Model VLA bertujuan untuk memungkinkan robot melihat, mendengar, memahami, dan bertindak berdasarkan instruksi AI, yang disebut sebagai GPT di bidang robotika. Merilis model-model ini secara open-source sangat penting untuk memahami cara kerjanya, menghindari potensi backdoor, dan melakukan kustomisasi untuk robot dan tugas tertentu. SmolVLA dilatih pada dataset LeRobotHF dan menunjukkan kinerja serta kecepatan inferensi yang sangat baik. Holo-1 berfokus pada tugas agen web dan komputer, serta mendukung lisensi Apache 2.0. Rilisan ini diharapkan dapat mempercepat pengembangan teknologi robotika AI open-source (Sumber: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

Penelitian Meta dkk. mengungkap batas atas memori model bahasa sekitar 3,6 bit per parameter, menantang pemahaman tradisional: Penelitian gabungan dari Meta, DeepMind, Cornell University, dan NVIDIA menunjukkan bahwa model bahasa gaya GPT dapat mengingat sekitar 3,6 bit informasi per parameter. Penelitian menemukan bahwa model akan terus mengingat data pelatihan hingga mencapai batas kapasitas, setelah itu mulai muncul fenomena “Grokking” (pemahaman mendadak), yaitu pengurangan memori yang tidak terduga, dan model beralih ke pembelajaran generalisasi. Penemuan ini menjelaskan fenomena “double descent”, yaitu ketika volume informasi dataset melebihi kapasitas penyimpanan model, model terpaksa berbagi titik informasi untuk menghemat kapasitas, sehingga mendorong generalisasi. Penelitian ini juga mengusulkan hukum penskalaan mengenai hubungan antara kapasitas model, skala data, dan tingkat keberhasilan serangan inferensi keanggotaan, serta menunjukkan bahwa untuk LLM modern yang dilatih pada dataset yang sangat besar, inferensi keanggotaan yang andal menjadi sulit (Sumber: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI meluncurkan versi ringan fitur memori ChatGPT, meningkatkan pengalaman interaksi yang dipersonalisasi: OpenAI mengumumkan mulai meluncurkan peningkatan fitur memori versi ringan kepada pengguna gratis. Selain penyimpanan memori yang sudah ada, ChatGPT sekarang dapat merujuk pada percakapan terbaru pengguna untuk memberikan respons yang lebih dipersonalisasi. Langkah ini bertujuan untuk membuatnya lebih mahir dalam menulis, mendapatkan saran, belajar, dll., dengan memanfaatkan preferensi dan minat pengguna. Sam Altman juga menyatakan bahwa fitur memori telah menjadi salah satu fitur ChatGPT favoritnya, dan menantikan peningkatan yang lebih besar di masa depan. Pembaruan ini menandai komitmen OpenAI untuk membuat interaksi AI lebih sesuai dengan kebutuhan pengguna dan meningkatkan loyalitas pengguna (Sumber: openai, sama, iScienceLuvr)
🎯 Dinamika
DeepSeek-R1-0528 dirilis, memperkuat kemampuan penalaran kompleks dan pemrograman: DeepSeek merilis versi upgrade dari model R1, yaitu DeepSeek-R1-0528. Versi ini didasarkan pada model DeepSeek V3 Base yang dirilis pada Desember 2024, dan melalui investasi lebih banyak daya komputasi untuk post-training, secara signifikan meningkatkan kedalaman berpikir dan kemampuan penalaran model. Model baru ini akan melakukan dekomposisi yang lebih rinci dan waktu berpikir yang lebih lama saat menangani masalah kompleks (misalnya, konsumsi token rata-rata per soal dalam tes AIME 2025 meningkat dari 12K menjadi 23K), sehingga mencapai hasil terdepan dalam berbagai benchmark seperti matematika, pemrograman, dan logika umum, dengan kinerja mendekati GPT-o3 dan Gemini-2.5-Pro. Selain itu, versi baru ini juga memiliki optimasi signifikan dalam mengurangi halusinasi (sekitar 45%-50%), penulisan kreatif, dan pemanggilan alat, misalnya dapat menjawab pertanyaan seperti “berapa 9.9 – 9.11” dengan lebih stabil, dan dapat menghasilkan kode frontend dan backend yang dapat dijalankan sekaligus (Sumber: 科技狐, AI前线, Hacubu)

Model difusi menunjukkan potensi di bidang bahasa dan multimodal, menantang paradigma autoregresif: Model bahasa Gemini Diffusion yang dipamerkan di Google I/O 2025, dengan kecepatan generasi hingga 5 kali lebih cepat dan kinerja pemrograman yang sebanding, menyoroti potensi model difusi di bidang generasi teks. Berbeda dengan model autoregresif yang memprediksi token satu per satu, model difusi menghasilkan output melalui proses denoising bertahap, mendukung iterasi dan koreksi kesalahan yang cepat. Model LLaDA 8B parameter yang diluncurkan oleh Ant Group bekerja sama dengan Gaoling School of Artificial Intelligence, Renmin University of China, serta model difusi multimodal MMaDA yang dikembangkan oleh ByteDance, keduanya menunjukkan eksplorasi terdepan tim domestik di jalur ini. Model-model ini tidak hanya berkinerja baik dalam tugas bahasa, tetapi juga mencapai kemajuan dalam pemahaman multimodal (seperti LLaDA-V yang menggabungkan fine-tuning instruksi visual) dan domain spesifik (seperti DPLM untuk generasi urutan protein), menandakan bahwa model difusi mungkin menjadi paradigma baru untuk model universal generasi berikutnya (Sumber: 机器之心)
Suno merilis pembaruan besar, meningkatkan kemampuan pengeditan dan pembuatan musik AI: Platform pembuatan musik AI Suno meluncurkan beberapa pembaruan penting, memberikan pengguna kebebasan berkreasi dan kontrol yang lebih besar. Fitur baru termasuk editor lagu yang ditingkatkan, memungkinkan pengguna untuk menyusun ulang, menulis ulang, dan membuat ulang trek secara bertahap pada grafik gelombang; memperkenalkan fungsi ekstraksi stem, yang dapat memisahkan trek secara akurat menjadi 12 sumber suara independen (seperti vokal, drum, bass, dll.) untuk pratinjau dan unduhan; memperluas fungsi unggah, mendukung unggahan lagu lengkap hingga 8 menit, pengguna dapat berkreasi berdasarkan materi audio mereka sendiri; menambahkan slider kreatif, pengguna dapat menyesuaikan “keanehan”, tingkat terstruktur, atau tingkat referensi-driven dari hasil output sebelum generasi, untuk membentuk karya akhir dengan lebih baik (Sumber: SunoMusic)
MetaAgentX meluncurkan Open CaptchaWorld, mengevaluasi kemampuan Agen multimodal dalam memecahkan CAPTCHA: Menanggapi bottleneck Agen multimodal saat ini dalam memecahkan masalah CAPTCHA (verifikasi manusia-mesin), tim MetaAgentX merilis platform dan benchmark Open CaptchaWorld. Platform ini berisi 20 jenis CAPTCHA modern, dengan total 225 sampel, yang mengharuskan Agen untuk menyelesaikan tugas melalui interaksi seperti observasi, klik, seret, dll. di lingkungan web nyata. Hasil tes menunjukkan bahwa bahkan model teratas seperti GPT-4o, tingkat keberhasilannya hanya antara 5%-40%, jauh di bawah tingkat keberhasilan rata-rata manusia sebesar 93,3%. Peneliti juga mengusulkan metrik “CAPTCHA Reasoning Depth”, yang mengkuantifikasi langkah-langkah “pemahaman visual + perencanaan kognitif + kontrol tindakan” yang diperlukan untuk memecahkan masalah. Platform ini bertujuan untuk mengungkap kelemahan Agen dalam interaksi dan perencanaan dinamis urutan panjang, dan mendorong peneliti untuk memperhatikan dan menyelesaikan masalah kunci ini dalam implementasi praktis (Sumber: 量子位)

Google NotebookLM mendukung berbagi publik, mempromosikan berbagi pengetahuan dan kolaborasi: Google mengumumkan bahwa NotebookLM (sebelumnya dikenal sebagai Project Tailwind) kini mendukung berbagi notebook secara publik. Pengguna dapat membagikan konten catatan mereka dengan mengklik “Bagikan” dan mengatur izin akses ke “Siapa saja yang memiliki tautan”. Fitur ini memungkinkan pengguna untuk dengan mudah berbagi ide, panduan belajar, dan dokumen tim, penerima dapat menelusuri konten, mengajukan pertanyaan, mendapatkan ringkasan instan, dan ikhtisar suara. Langkah ini bertujuan untuk mempromosikan penyebaran pengetahuan dan pengeditan kolaboratif, meningkatkan kegunaan NotebookLM sebagai alat catatan AI (Sumber: Google, op7418)
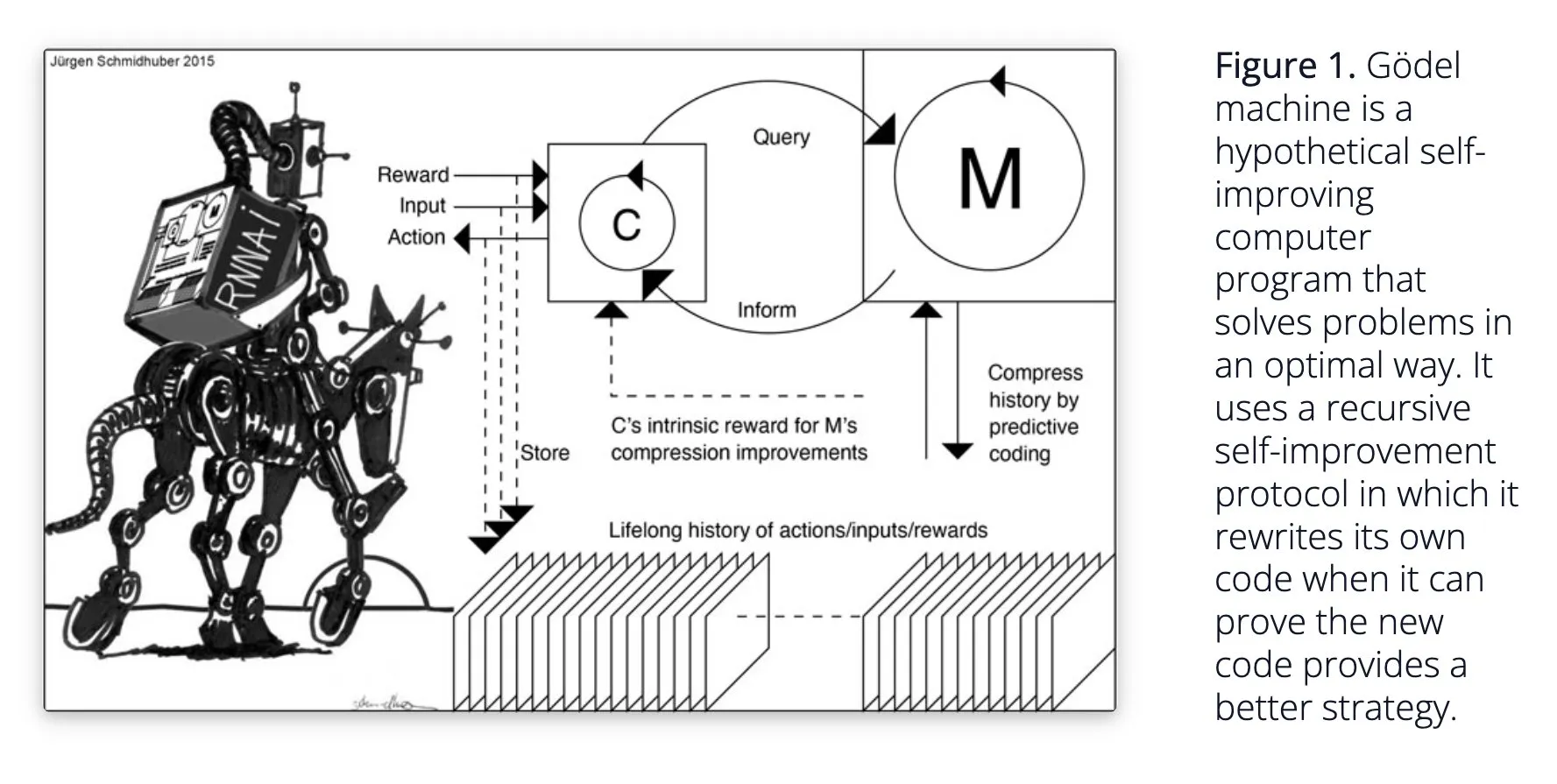
Sakana AI mengusulkan sistem AI belajar mandiri Darwin Gödel Machine (DGM): Sakana AI mempublikasikan penelitiannya tentang sistem AI belajar mandiri Darwin Gödel Machine (DGM). DGM menggunakan algoritma evolusioner untuk secara iteratif menulis ulang kodenya sendiri, sehingga terus meningkatkan kinerjanya dalam tugas pemrograman. Sistem ini mencapai eksplorasi terbuka dengan memelihara arsip agen pengkodean yang dihasilkan, dan mengambil sampel darinya, serta memanfaatkan model dasar untuk membuat versi baru, membentuk agen yang beragam dan berkualitas tinggi. Eksperimen menunjukkan bahwa DGM secara signifikan meningkatkan kemampuan pengkodean dalam benchmark seperti SWE-bench dan Polyglot. Penelitian ini memberikan ide baru untuk AI yang dapat memperbaiki diri sendiri, bertujuan untuk mempercepat pengembangan AI melalui inovasi otonom (Sumber: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind meningkatkan kealamian percakapan AI, membuka fungsi audio native: Google DeepMind mengumumkan bahwa fungsi audio native-nya membuat percakapan AI lebih alami, mampu memahami intonasi dan menghasilkan ucapan yang ekspresif. Teknologi ini bertujuan untuk membuka kemungkinan baru dalam interaksi manusia-AI. Pengembang sekarang dapat mencoba fungsi-fungsi ini melalui Google AI Studio, yang diharapkan dapat diterapkan pada asisten suara yang lebih alami, pembuatan konten audio, dan skenario lainnya (Sumber: GoogleDeepMind)
Teknologi pembuatan gambar Runway Gen-4 mendapat perhatian, mendukung multi-referensi dan kontrol gaya: Teknologi pembuatan gambar Gen-4 dari Runway mendapat perhatian karena fidelitas tinggi dan kemampuan kontrol gaya yang belum pernah ada sebelumnya, terutama tercermin dalam fungsi multi-referensinya, yang menyediakan ruang baru untuk eksplorasi kreatif. Pengguna dapat memanfaatkan teknologi ini untuk menghasilkan berbagai hewan, dinosaurus, atau makhluk imajiner, menunjukkan potensinya dalam pembuatan konten visual yang detail. Penggunaan Runway di bidang seperti Hollywood juga menunjukkan bahwa teknologinya secara bertahap diterapkan pada produksi konten profesional (Sumber: c_valenzuelab, c_valenzuelab)

AssemblyAI merilis model transkripsi suara real-time baru, meningkatkan kinerja aplikasi AI suara: AssemblyAI meluncurkan model transkripsi suara real-time (STT) baru, yang mendapat perhatian karena kecepatan dan akurasinya yang tinggi. Model ini dirancang khusus untuk pengembang yang membangun aplikasi AI suara, bertujuan untuk memberikan pengalaman pengenalan suara yang lebih lancar dan akurat. Sementara itu, AssemblyAI juga menyediakan implementasi AssemblyAISTTService melalui proyek pipecat_ai-nya, memudahkan pengembang untuk melakukan integrasi. Langkah ini menunjukkan investasi dan inovasi berkelanjutan AssemblyAI di bidang teknologi suara (Sumber: AssemblyAI, AssemblyAI)
Microsoft Bing merayakan ulang tahun ke-16, mengintegrasikan GPT-4 dan DALL·E, meluncurkan Bing Video Creator: Mesin pencari Microsoft Bing merayakan ulang tahunnya yang ke-16. Dalam beberapa tahun terakhir, Bing menjadi yang pertama mengintegrasikan AI generatif percakapan secara besar-besaran, dan menjadi produk Microsoft pertama yang mengintegrasikan GPT-4 dan DALL·E. Baru-baru ini, Bing meluncurkan Copilot Search dan Bing Video Creator secara gratis di aplikasi selulernya, yang terakhir dapat digunakan untuk menghasilkan konten video. Ini menandai inovasi dan pengembangan berkelanjutan Bing di bidang pencarian dan pembuatan konten yang didorong oleh AI (Sumber: JordiRib1)
Andrej Karpathy terkesan dengan Veo 3, membahas dampak makro generasi video: Andrej Karpathy menyatakan kesannya terhadap model generasi video Google, Veo 3, dan hasil karya komunitasnya, serta menunjukkan bahwa penambahan audio secara signifikan meningkatkan kualitas video. Ia lebih lanjut membahas beberapa dampak makro dari generasi video: 1. Video adalah cara input bandwidth tertinggi ke otak manusia; 2. Generasi video menyediakan “bahasa ibu” bagi AI untuk memahami dunia; 3. Generasi video adalah jalur kunci menuju realitas simulasi dan model dunia; 4. Kebutuhan komputasinya akan mendorong pengembangan perangkat keras. Ini menunjukkan bahwa teknologi generasi video bukan hanya inovasi dalam pembuatan konten, tetapi juga pendorong penting bagi kognisi dan pengembangan AI (Sumber: brickroad7, dilipkay, JonathanRoss321)
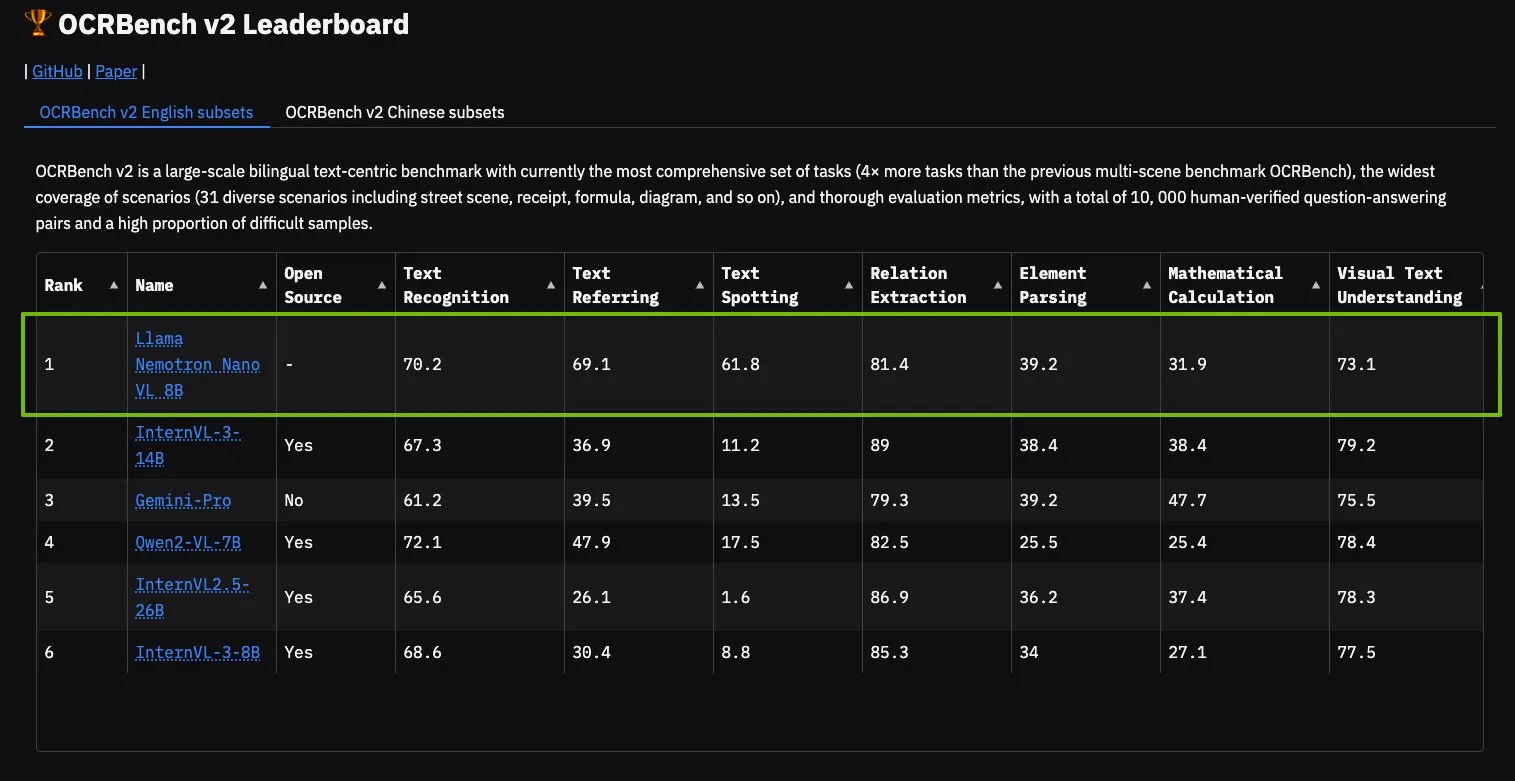
Model NVIDIA Llama Nemotron Nano VL menduduki puncak OCRBench V2: Model Llama Nemotron Nano VL dari NVIDIA meraih peringkat pertama di papan peringkat OCRBench V2. Model ini dirancang khusus untuk pemrosesan dan pemahaman dokumen cerdas tingkat lanjut, mampu mengekstrak beragam informasi dari dokumen kompleks secara akurat pada satu GPU. Pengguna dapat mencoba model ini melalui NVIDIA NIM, yang menunjukkan kemajuan NVIDIA dalam model AI yang diperkecil dan efisien untuk domain spesifik (seperti pemahaman dokumen) (Sumber: ctnzr)
🧰 Alat
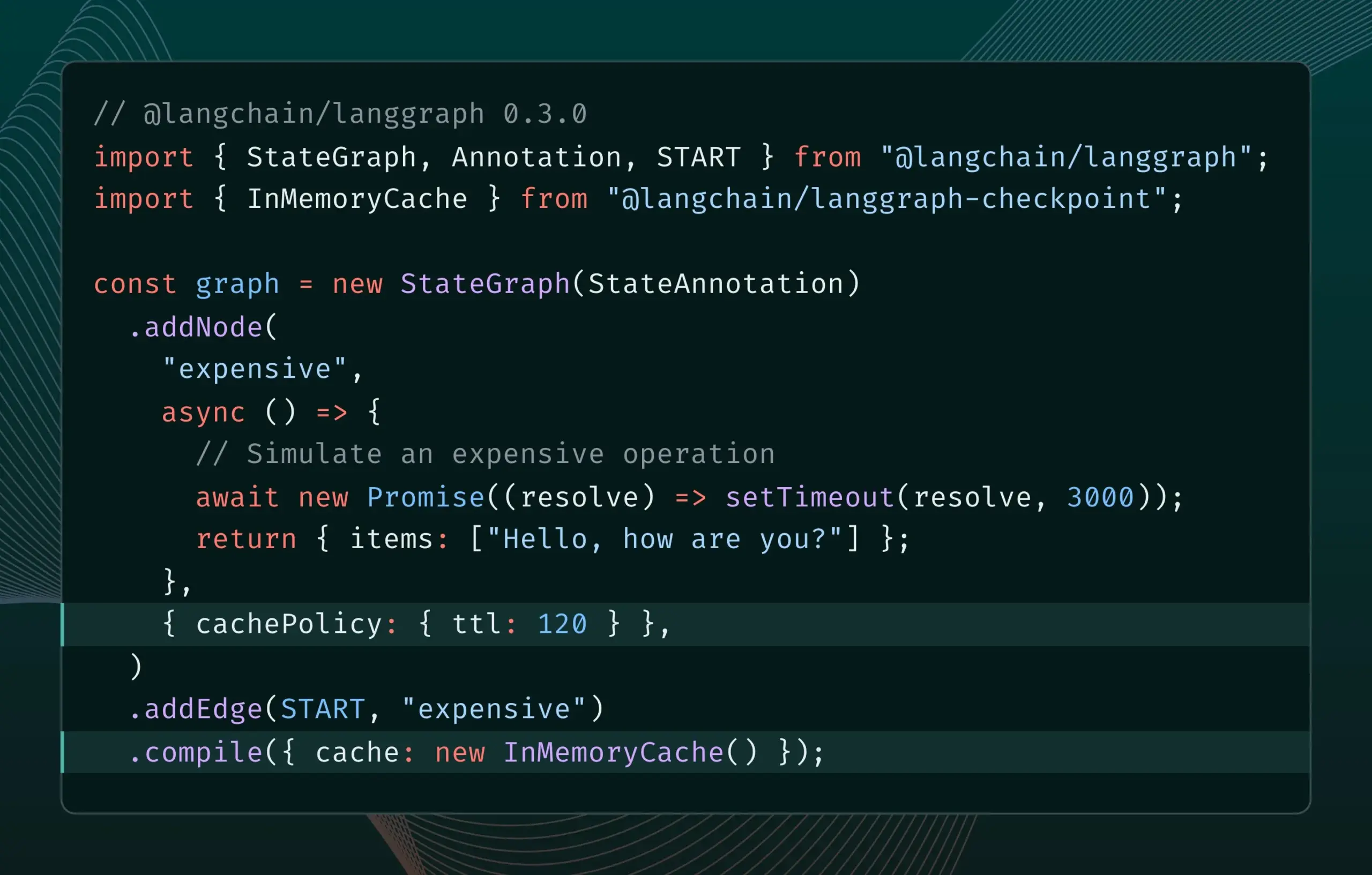
LangGraph.js versi 0.3 memperkenalkan fitur caching node/tugas: LangGraph.js merilis versi 0.3, menambahkan fitur caching node/tugas. Fitur ini bertujuan untuk mempercepat alur kerja dengan menghindari komputasi yang berlebihan, terutama cocok untuk agen yang mahal secara iteratif atau berjalan lama. Versi baru ini mendukung Graph API dan Imperative API, memberikan efisiensi yang lebih tinggi bagi pengembang JavaScript dalam membangun aplikasi AI yang kompleks (Sumber: Hacubu, hwchase17)
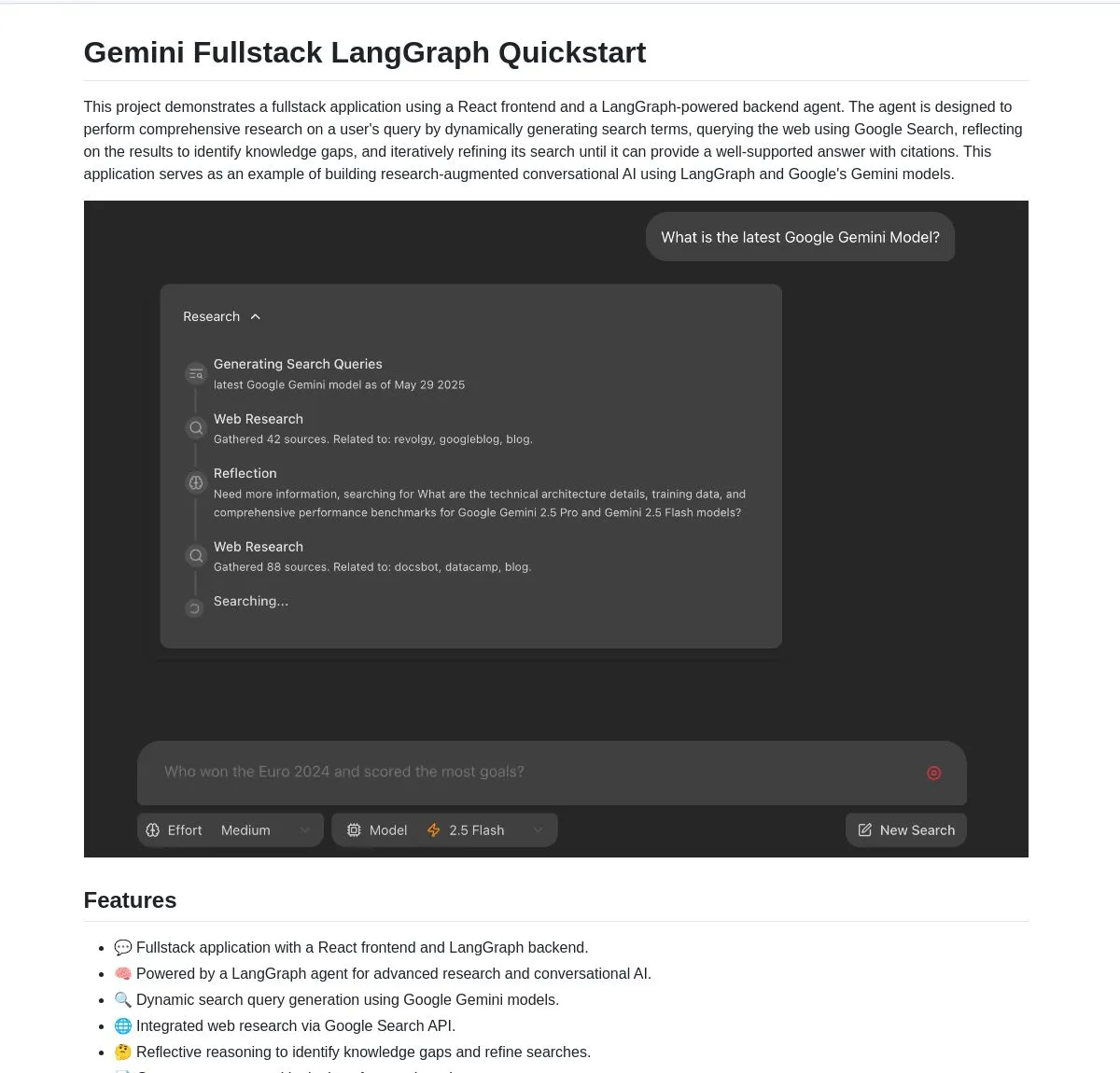
Google merilis aplikasi full-stack Gemini Research Agent open-source, berbasis Gemini dan LangGraph: Google merilis contoh aplikasi full-stack asisten riset cerdas berbasis model Gemini dan LangGraph — gemini-fullstack-langgraph-quickstart. Aplikasi ini mampu mengoptimalkan kueri secara dinamis, memberikan jawaban dengan kutipan melalui pembelajaran iteratif, dan mendukung kontrol intensitas pencarian yang berbeda. Aplikasi ini memanfaatkan alat Google Search native dari Gemini untuk riset web dan penalaran reflektif, bertujuan untuk menyediakan titik awal bagi pengembang dalam membangun aplikasi AI riset tingkat lanjut (Sumber: LangChainAI, hwchase17, dotey, karminski3)
FedRAG menambahkan fungsi jembatan LangChain, memudahkan integrasi dan fine-tuning sistem RAG: FedRAG mengumumkan dukungan untuk jembatan dengan LangChain, yang diimplementasikan oleh kontributor eksternal. Pengguna dapat merakit sistem RAG melalui FedRAG, dan melakukan fine-tuning pada model komponen generator/retriever agar sesuai dengan basis pengetahuan tertentu. Setelah fine-tuning, dapat dijembatani ke kerangka kerja inferensi RAG populer seperti LangChain, memanfaatkan ekosistem dan fiturnya. Pembaruan ini bertujuan untuk menyederhanakan proses pembangunan, optimasi, dan deployment sistem RAG (Sumber: nerdai)

Ollama meluncurkan fitur “berpikir”, dapat memisahkan proses berpikir dari jawaban akhir: Ollama memperbarui platformnya, menambahkan opsi untuk memisahkan proses berpikir dan jawaban akhir untuk model yang mendukung fitur “berpikir” (seperti DeepSeek-R1-0528). Pengguna dapat memilih untuk melihat konten “berpikir” model, atau menonaktifkan fitur ini untuk mendapatkan balasan langsung. Fitur ini berlaku untuk CLI, API, dan pustaka Python/JavaScript Ollama, memberikan pengguna cara interaksi model yang lebih fleksibel (Sumber: Hacubu)
Firecrawl meluncurkan endpoint /search, mengintegrasikan fungsi pencarian dan crawling: Firecrawl merilis endpoint API /search baru, yang memungkinkan pengguna untuk menyelesaikan pencarian web dan melakukan crawling semua hasil dalam format yang ramah LLM melalui satu panggilan API. Fungsi ini bertujuan untuk menyederhanakan proses bagi agen AI dan pengembang dalam menemukan dan memanfaatkan data web. StateGraph dari LangChain dapat digunakan untuk membangun alur kerja otomatis yang memanfaatkan fungsi ini, misalnya, secara otomatis menemukan pesaing, melakukan crawling situs web mereka, dan menghasilkan laporan analisis (Sumber: hwchase17, LangChainAI, omarsar0)
LlamaIndex mengintegrasikan MCP, meningkatkan kemampuan agen dan deployment alur kerja: LlamaIndex mengumumkan integrasi MCP (Model Component Protocol), yang bertujuan untuk meningkatkan kemampuan penggunaan alat oleh agennya dan fleksibilitas deployment alur kerja. Integrasi ini menyediakan fungsi bantu untuk membantu agen LlamaIndex menggunakan alat server MCP, dan memungkinkan setiap alur kerja LlamaIndex untuk dilayani sebagai server MCP. Langkah ini bertujuan untuk memperluas kumpulan alat agen LlamaIndex dan memungkinkan alur kerjanya terintegrasi secara mulus ke dalam infrastruktur MCP yang ada (Sumber: jerryjliu0)

Modal meluncurkan LLM Engine Advisor, menyediakan benchmark kinerja mesin model open-source: Modal merilis LLM Engine Advisor, sebuah aplikasi benchmark yang bertujuan untuk membantu pengguna memilih mesin LLM dan parameter terbaik. Alat ini menyediakan data kinerja, seperti kecepatan dan throughput maksimum, saat menjalankan model open-source (seperti DeepSeek V3, Qwen 2.5 Coder) menggunakan berbagai mesin inferensi (seperti vLLM, SGLang) pada perangkat keras yang berbeda (seperti lingkungan multi-GPU). Langkah ini bertujuan untuk meningkatkan transparansi dan efisiensi pengambilan keputusan dalam menjalankan LLM yang di-hosting sendiri (Sumber: charles_irl, akshat_b, sarahcat21)
PlayDiffusion: PlayAI meluncurkan model audio inpainting baru, dapat mengganti konten dialog dalam audio: PlayAI merilis model baru bernama PlayDiffusion, yang mampu mengganti konten dialog dalam file audio secara mulus sambil mempertahankan fitur suara pembicara asli. Teknologi “audio inpainting” ini memberikan kemungkinan baru untuk pengeditan audio, seperti memodifikasi kata atau kalimat tertentu dalam podcast, buku audio, atau sulih suara video, tanpa perlu merekam ulang seluruh segmen. Proyek ini telah di-open-source di GitHub (Sumber: _mfelfel, karminski3)
Hugging Face meluncurkan alat deduplikasi semantik, mengoptimalkan kualitas dataset pelatihan: Terinspirasi oleh AutoDedup dari Maxime Labonne, Hugging Face Spaces meluncurkan aplikasi deduplikasi semantik baru. Alat ini memungkinkan pengguna untuk memilih satu atau lebih dataset di Hugging Face Hub, melakukan embedding semantik pada setiap baris data, kemudian menghapus konten yang hampir duplikat berdasarkan ambang batas yang ditetapkan. Langkah ini bertujuan untuk membantu peneliti dan pengembang meningkatkan kualitas dataset pelatihan, menghindari penurunan kinerja model atau efisiensi pelatihan yang rendah akibat redundansi data (Sumber: ben_burtenshaw, ben_burtenshaw)

Permintaan Perplexity Labs melonjak, pengguna dapat dengan cepat membangun perangkat lunak yang disesuaikan: Perplexity Labs menjadi populer di kalangan pengguna karena kemampuannya membangun perangkat lunak yang disesuaikan dengan cepat melalui satu prompt, permintaan mengalami peningkatan yang signifikan, bahkan ada pengguna yang membeli beberapa akun Pro untuk mendapatkan lebih banyak kueri Labs. Ini mencerminkan minat yang kuat dari pengguna terhadap kemampuan untuk dengan cepat membuat dan memodifikasi alat perangkat lunak sesuai dengan kebutuhan mereka sendiri, pengembangan perangkat lunak yang dipersonalisasi dan didorong oleh AI menjadi sebuah tren (Sumber: AravSrinivas, AravSrinivas)
Ollama dan Hazy Research bekerja sama meluncurkan Secure Minions, mewujudkan kolaborasi pribadi antara LLM lokal dan cloud: Proyek Minions dari Hazy Research Lab Stanford, dengan menghubungkan model lokal Ollama dengan model canggih di cloud, bertujuan untuk secara signifikan mengurangi biaya cloud (5-30 kali) sambil mempertahankan akurasi yang mendekati model canggih (98%). Proyek Secure Minion lebih lanjut mengubah GPU seperti H100 menjadi zona aman, mewujudkan enkripsi memori dan komputasi, memastikan privasi data. Mode operasi hibrida ini, selain meningkatkan perlindungan privasi, juga menyediakan solusi penggunaan LLM yang lebih hemat biaya bagi pengguna (Sumber: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa dan OpenRouter bekerja sama, menyediakan kemampuan pencarian web untuk 400+ LLM: Mesin pencari AI Exa mengumumkan kemitraan dengan OpenRouter, akan menyediakan fungsi pencarian web untuk lebih dari 400 model bahasa besar di platform OpenRouter. Ini berarti pengembang dan pengguna saat menggunakan LLM ini, dapat dengan mudah memanggil kemampuan pencarian Exa, meningkatkan kemampuan perolehan informasi real-time dan pembaruan pengetahuan model, lebih lanjut meningkatkan kinerja aplikasi seperti RAG (Retrieval Augmented Generation) (Sumber: menhguin)

📚 Belajar
Microsoft meluncurkan kursus pengantar MCP “MCP for Beginners”: Microsoft merilis kursus pengantar untuk pemula MCP (Microsoft Copilot Platform, diduga salah ketik, seharusnya merujuk pada Microsoft CoCo Framework atau protokol AI Agent serupa). Kursus ini bertujuan untuk membantu pemula menguasai konsep inti, metode implementasi, dan aplikasi praktis MCP, kontennya mencakup spesifikasi arsitektur protokol, panduan tutorial, dan praktik kode dalam berbagai bahasa pemrograman. Struktur kursus meliputi pendahuluan, konsep inti, keamanan, memulai, tingkat lanjut, serta analisis komunitas dan kasus, dan menyediakan proyek contoh seperti kalkulator dasar dan lanjutan (Sumber: dotey)

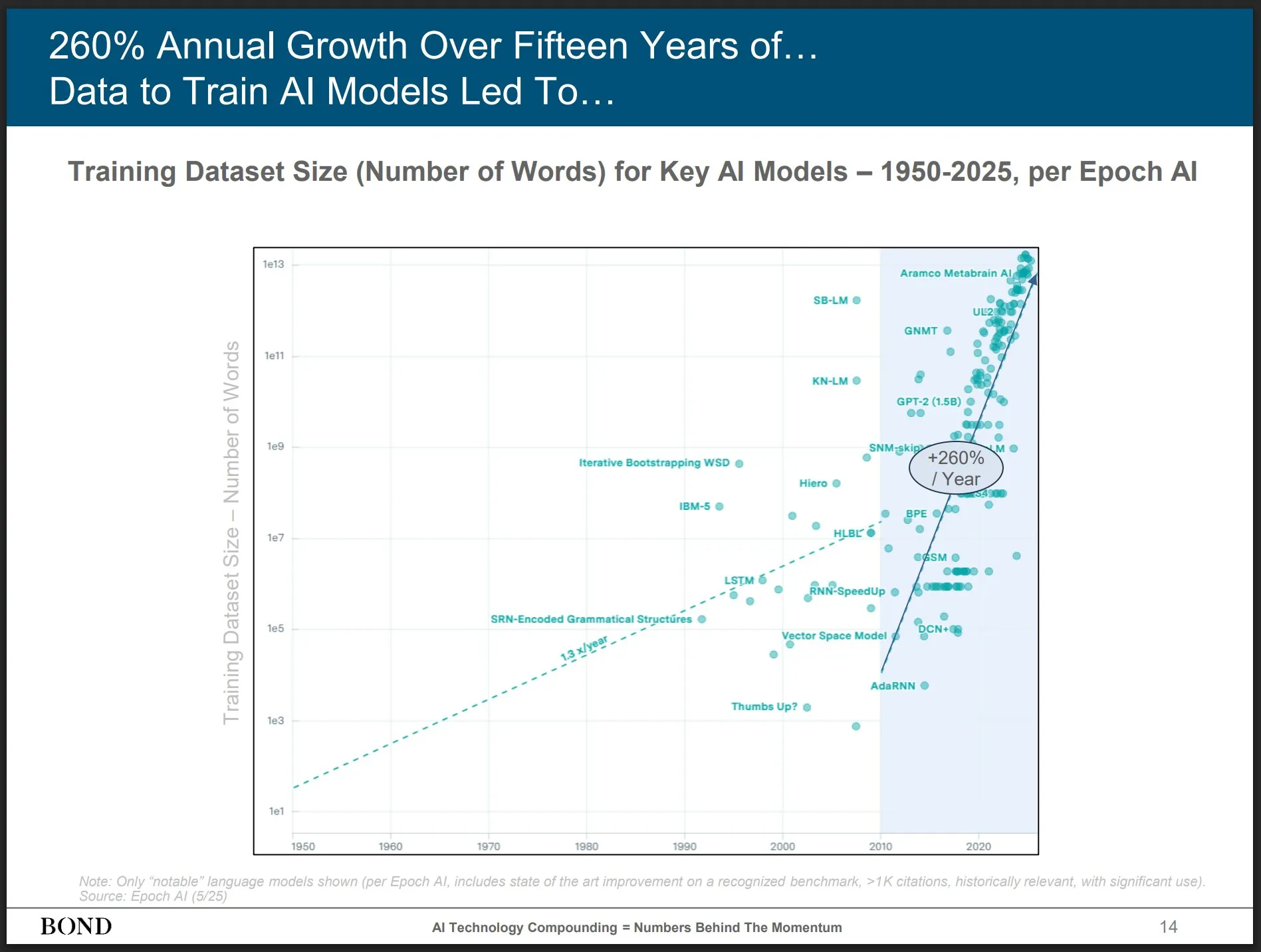
Bond Capital merilis laporan tren AI Mei 2025, memberikan wawasan perkembangan industri: Perusahaan modal ventura ternama Bond Capital merilis “Laporan Tren AI 2025-05” setebal 339 halaman, yang secara komprehensif menganalisis data dan wawasan AI di berbagai bidang. Laporan tersebut menyoroti bahwa pengguna aktif bulanan ChatGPT mencapai 800 juta (90% berasal dari luar Amerika Utara), dengan 1 miliar pencarian harian; lowongan pekerjaan TI terkait AI meningkat 448%; biaya pelatihan model canggih melebihi 1 miliar USD per kali; LLM menjadi infrastruktur. Laporan tersebut menekankan bahwa kunci persaingan adalah menciptakan produk berbasis AI terbaik, dan saat ini adalah pasar bagi para pembangun (Sumber: karminski3)
Makalah membahas hubungan antara reinforcement learning dan kemampuan penalaran LLM, ProRL dan Limit-of-RLVR menarik perhatian: Dua makalah penelitian tentang hubungan antara reinforcement learning (RL) dan kemampuan penalaran model bahasa besar (LLM) memicu diskusi. Satu adalah “Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?”, dan yang lainnya adalah “ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models” dari NVIDIA. Penelitian ini mengeksplorasi sejauh mana RL (khususnya RLVR, yaitu reinforcement learning dengan imbalan yang dapat diverifikasi) dapat meningkatkan kemampuan penalaran dasar LLM, dan dampak pelatihan RL berkelanjutan terhadap perluasan batas penalaran LLM. Diskusi terkait berpendapat bahwa data pelatihan RLVR berkualitas tinggi dan mekanisme imbalan yang efektif adalah kuncinya (Sumber: scaling01, Dorialexander, scaling01)

Makalah “How Programming Concepts and Neurons Are Shared in Code Language Models” membahas mekanisme berbagi konsep pemrograman dan neuron dalam model bahasa kode: Penelitian ini menyelidiki hubungan ruang konsep internal model bahasa besar (LLM) saat memproses berbagai bahasa pemrograman (PL) dan bahasa Inggris. Melalui tugas terjemahan few-shot pada model seri Llama, ditemukan bahwa pada lapisan tengah, ruang konsep lebih dekat ke bahasa Inggris (termasuk kata kunci PL), dan cenderung memberikan probabilitas tinggi pada token bahasa Inggris. Analisis aktivasi neuron menunjukkan bahwa neuron spesifik bahasa terutama terkonsentrasi di lapisan bawah, sedangkan neuron unik untuk setiap PL cenderung muncul di lapisan atas. Penelitian ini memberikan wawasan baru untuk memahami bagaimana LLM secara internal merepresentasikan PL (Sumber: HuggingFace Daily Papers)
Makalah baru “Pixels Versus Priors” mengontrol pengetahuan awal dalam MLLM melalui kontrol kontrafaktual visual: Penelitian ini mengeksplorasi apakah penalaran model bahasa besar multimodal (MLLM) dalam tugas seperti tanya jawab visual lebih bergantung pada pengetahuan dunia yang diingat atau informasi visual dari gambar input. Peneliti memperkenalkan dataset Visual CounterFact, yang berisi gambar kontrafaktual visual yang bertentangan dengan pengetahuan awal dunia (seperti stroberi biru). Eksperimen menunjukkan bahwa prediksi model pada awalnya mencerminkan pengetahuan awal yang diingat, tetapi pada tahap tengah dan akhir beralih ke bukti visual. Makalah ini mengusulkan vektor panduan PvP (Pixels Versus Priors), yang melalui intervensi lapisan aktivasi mengontrol output model agar condong ke pengetahuan dunia atau input visual, berhasil mengubah sebagian besar prediksi warna dan ukuran (Sumber: HuggingFace Daily Papers)
Makalah ICML 2025 GuidedQuant mengusulkan peningkatan metode PTQ hierarkis melalui panduan end loss: GuidedQuant adalah metode kuantisasi pasca-pelatihan (PTQ) baru yang meningkatkan kinerja metode PTQ hierarkis dengan mengintegrasikan panduan end loss ke dalam target. Metode ini memanfaatkan gradien per fitur dari end loss untuk memberi bobot pada kesalahan output hierarkis, yang sesuai dengan informasi Fisher blok-diagonal yang menjaga dependensi intra-saluran. Selain itu, makalah ini juga memperkenalkan LNQ, algoritma kuantisasi skalar non-seragam yang menjamin pengurangan monoton dari nilai target kuantisasi. Eksperimen menunjukkan bahwa GuidedQuant mengungguli metode SOTA yang ada dalam kuantisasi skalar hanya bobot, kuantisasi vektor hanya bobot, serta kuantisasi bobot dan aktivasi, dan telah diterapkan pada kuantisasi 2-4 bit model seperti Qwen3, Gemma3, Llama3.3 (Sumber: Reddit r/MachineLearning)

AI Engineer World’s Fair diadakan di San Francisco, berfokus pada praktik rekayasa AI dan teknologi mutakhir: AI Engineer World’s Fair sedang berlangsung di San Francisco, mengumpulkan banyak insinyur, peneliti, dan pengembang di bidang AI. Agenda konferensi mencakup berbagai topik hangat seperti reinforcement learning, kernel, inferensi & agen, optimasi model (RFT, DPO, SFT), pengkodean agen, pembuatan agen suara, dll. Selama acara akan ada berbagi dan diskusi dari para ahli dari perusahaan seperti OpenAI, Google, serta peluncuran produk dan teknologi baru. Anggota komunitas berpartisipasi aktif, berbagi jadwal konferensi, mengatur pertemuan offline, menunjukkan vitalitas komunitas rekayasa AI dan antusiasme terhadap teknologi mutakhir (Sumber: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 Bisnis
ShiDu Intelligent menyelesaikan pendanaan tahap awal jutaan yuan, mempercepat penerapan kacamata pintar AI di berbagai skenario: Suzhou ShiDu Intelligent Technology Co., Ltd. mengumumkan penyelesaian pendanaan tahap awal jutaan yuan, dana tersebut akan digunakan untuk penelitian dan pengembangan teknologi inti kacamata pintar AI, perluasan pasar, dan pembangunan ekosistem. Perusahaan berfokus pada penerapan kacamata pintar AI di bidang perawatan lansia cerdas (seperti kacamata baca pintar, kacamata bantu tunanetra pintar), kehidupan cerdas (kacamata mode pintar, kacamata bersepeda), dan manufaktur cerdas (kacamata industri pintar, pengontrol suara), dll. Harga produknya diposisikan di kisaran 200 yuan hingga 1000 yuan, bertujuan untuk mendorong普及kacamata pintar melalui efektivitas biaya yang tinggi (Sumber: 36氪)

Rumor OpenAI mungkin mengakuisisi asisten pemrograman AI Windsurf, memicu spekulasi Anthropic memutus pasokan model Claude: Pasar dirumorkan bahwa OpenAI mungkin mengakuisisi alat pemrograman AI Windsurf (sebelumnya Codeium) dengan harga sekitar 3 miliar USD. Dalam konteks ini, CEO Windsurf Varun Mohan memposting bahwa Anthropic dalam pemberitahuan yang sangat singkat memutus hampir semua akses langsung ke model Claude 3.x mereka, termasuk Claude 3.5 Sonnet, dll. Windsurf menyatakan kekecewaannya atas hal ini, dan dengan cepat memindahkan daya komputasinya ke penyedia layanan inferensi lain, sambil menawarkan diskon Gemini 2.5 Pro kepada pengguna yang terkena dampak. Komunitas berspekulasi bahwa langkah Anthropic ini mungkin terkait dengan potensi akuisisi oleh OpenAI, khawatir hal ini akan memengaruhi persaingan industri dan pilihan pengembang. Sebelumnya, Windsurf juga tidak mendapatkan dukungan langsung dari Anthropic saat Claude 4 dirilis (Sumber: AI前线)

Hygon Information berencana melakukan merger dengan Sugon melalui pertukaran saham, mengintegrasikan rantai industri daya komputasi domestik: Perusahaan desain chip AI Hygon Information mengumumkan rencana untuk mengakuisisi pemegang saham terbesarnya, produsen server Sugon, melalui metode pertukaran saham. Kapitalisasi pasar Hygon Information sekitar 316,4 miliar yuan, sedangkan kapitalisasi pasar Sugon sekitar 90,5 miliar yuan. Merger “ular menelan gajah” ini bertujuan untuk mengoptimalkan tata letak industri dari chip hingga perangkat lunak dan sistem, mewujudkan penguatan, pelengkapan, dan perpanjangan rantai industri, serta memainkan efek sinergi teknologi. Analis berpendapat bahwa merger ini membantu menyelesaikan transaksi terkait yang kompleks dan potensi persaingan usaha sejenis antara kedua belah pihak, mengurangi biaya operasional, dan sejalan dengan tren pengembangan solusi daya komputasi end-to-end di era AI, menandai kemungkinan percepatan peralihan kekuasaan teknologi semikonduktor Tiongkok dari komputasi tradisional ke komputasi AI (Sumber: 36氪)
🌟 Komunitas
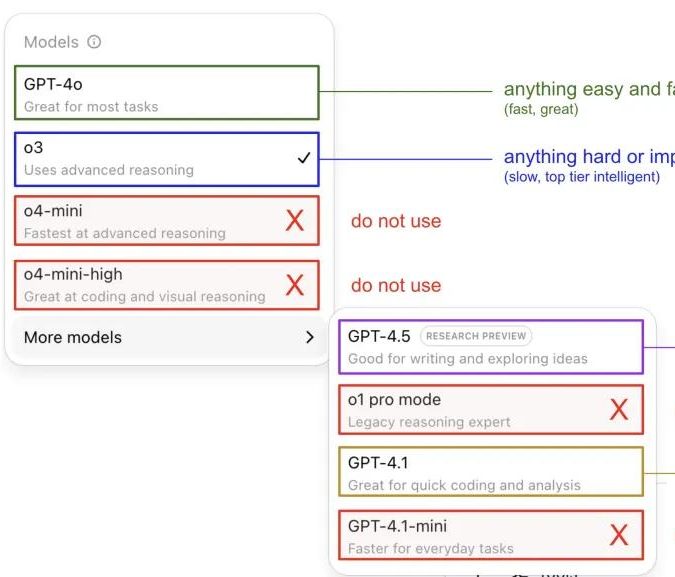
Andrej Karpathy berbagi pengalaman menggunakan model ChatGPT, memicu diskusi komunitas: Andrej Karpathy berbagi pengalaman pribadinya menggunakan berbagai versi ChatGPT: untuk tugas penting atau sulit, direkomendasikan menggunakan o3 yang kemampuan penalarannya lebih kuat; untuk masalah sehari-hari dengan tingkat kesulitan rendah hingga sedang dapat menggunakan 4o; tugas perbaikan kode cocok untuk GPT-4.1; saat membutuhkan riset mendalam dan ringkasan multi-tautan, gunakan fungsi riset mendalam (berbasis o3). Berbagi pengalaman ini memicu diskusi luas di komunitas, banyak pengguna berbagi preferensi penggunaan mereka dan pandangan tentang pemilihan model, sekaligus mencerminkan kebingungan pengguna mengenai penamaan model OpenAI yang membingungkan dan kurangnya fungsi pemilihan model otomatis (Sumber: 量子位, JeffLadish)
Pengembang berbagi pengalaman dua minggu pemrograman Agentic AI: dari terkejut hingga disilusi, akhirnya memilih refactoring manual: Seorang pemimpin teknis dengan pengalaman 10 tahun berbagi pengalamannya mengintegrasikan Agentic AI (khususnya agen pemrograman AI) ke dalam alur kerja pengembangan aplikasi media sosialnya. Awalnya, AI dapat dengan cepat menghasilkan modul fungsional, menulis logika frontend dan backend, serta unit test, dengan efisiensi yang luar biasa, menghasilkan sekitar 12.000 baris kode dalam dua minggu. Namun, seiring dengan meningkatnya kompleksitas basis kode, AI mulai sering membuat kesalahan saat menangani fitur baru, terjebak dalam loop, dan sulit mengakui kegagalan. Kode yang dihasilkan juga menunjukkan masalah seperti penamaan yang tidak akurat dan kode duplikat, yang menyebabkan basis kode sulit dipelihara dan pengembang kehilangan kepercayaan padanya. Akhirnya, pengembang tersebut memutuskan untuk menggunakan kode yang dihasilkan AI hanya sebagai “referensi samar”, merefaktor semua fungsi secara manual, dan berpendapat bahwa AI saat ini lebih cocok untuk menganalisis kode yang ada dan memberikan contoh, daripada langsung menulis kode fungsional (Sumber: CSDN)

Perbedaan definisi AI Agent dan Workflow menarik perhatian, potensi aplikasi masa depan sangat besar: Komunitas membahas perbedaan konsep AI Agent dan Workflow (alur kerja). Agent biasanya merujuk pada LLM yang mengakses alat dalam satu siklus, berjalan bebas sesuai instruksi; Workflow adalah serangkaian langkah yang sebagian besar dieksekusi secara deterministik, mungkin berisi LLM untuk menyelesaikan sub-tugas. Meskipun ada tumpang tindih (Agent dapat di-prompt untuk dieksekusi secara deterministik, Workflow dapat berisi komponen Agentic), perbedaan ini secara ontologis masih bermakna. Sementara itu, potensi AI Agent dalam aplikasi perusahaan sangat menjanjikan, perusahaan besar seperti Tencent dan ByteDance sama-sama berinvestasi di bidang agen cerdas, misalnya Tencent meningkatkan basis pengetahuan model besarnya menjadi platform pengembangan agen cerdas, sedangkan ByteDance memiliki platform Coze (Kouzi), yang bertujuan membantu perusahaan mengimplementasikan sistem agen AI native (Sumber: fabianstelzer, 蓝洞商业)
Dwarkesh Patel membahas linimasa LLM dan AGI, berpendapat bahwa pembelajaran berkelanjutan adalah bottleneck utama: Dwarkesh Patel dalam blognya menjelaskan pandangannya tentang linimasa AGI (Artificial General Intelligence), berpendapat bahwa LLM saat ini kurang memiliki kemampuan manusia untuk mengakumulasi konteks melalui praktik, merefleksikan kegagalan, dan melakukan perbaikan kecil, yaitu kemampuan pembelajaran berkelanjutan. Ia berpendapat bahwa ini adalah bottleneck besar bagi utilitas model, dan penyelesaian masalah ini mungkin membutuhkan waktu bertahun-tahun. Pandangan ini memicu diskusi dari beberapa peneliti AI, termasuk Andrej Karpathy. Karpathy juga setuju dengan kekurangan LLM dalam pembelajaran berkelanjutan, dan membandingkannya dengan rekan kerja yang menderita amnesia anterograde. Diskusi ini menyoroti tantangan dalam mencapai AGI sejati, serta pemikiran mendalam tentang mekanisme pembelajaran model (Sumber: dwarkesh_sp, JeffLadish, dwarkesh_sp)

Masalah paten AI dalam pengembangan obat menarik perhatian, Science menerbitkan artikel yang menyerukan kehati-hatian: Artikel forum kebijakan jurnal “Science” berjudul “What patents on AI-derived drugs reveal” membahas penerapan AI dalam bidang penemuan obat dan dampaknya terhadap sistem paten. Penelitian menunjukkan bahwa ketika perusahaan AI-native mengajukan paten obat, data uji in vivo seringkali lebih sedikit daripada perusahaan farmasi tradisional, yang dapat menyebabkan obat potensial ditinggalkan karena kurangnya penelitian lanjutan. Sementara itu, sejumlah besar molekul baru yang dihasilkan AI, setelah dipublikasikan, dapat menjadi “prior art” yang menghalangi perusahaan lain untuk mengajukan paten dan investasi lebih lanjut pada molekul-molekul ini. Artikel tersebut menyarankan untuk meningkatkan ambang batas pengajuan paten, menuntut lebih banyak data uji in vivo, dan mengizinkan perusahaan lain untuk mengajukan paten pada molekul yang dihasilkan AI yang belum diuji, sambil memperkuat hak eksklusivitas regulasi pada tahap uji klinis obat baru, untuk menyeimbangkan insentif inovasi dengan kepentingan publik (Sumber: 36氪)
💡 Lainnya
Insiden perebutan kekuasaan Altman mungkin akan difilmkan menjadi “Artificial”, sutradara dan produser terkenal terlibat: Menurut The Hollywood Reporter, MGM berencana mengadaptasi insiden perubahan jajaran pimpinan OpenAI menjadi film, dengan judul sementara “Artificial”. Sutradara terkenal Italia Luca Guadagnino kemungkinan akan menyutradarai, dengan produser termasuk David Heyman dari seri “Harry Potter”. Jajaran pemain sedang dalam pembahasan, rumor menyebutkan Andrew Garfield (pemeran Spider-Man dan Savarin di “The Social Network”) mungkin akan memerankan Sam Altman, Yura Borisov mungkin memerankan Ilya Sutskever, dan Monica Barbaro mungkin memerankan Mira Murati. Kabar ini memicu perbincangan hangat di kalangan netizen, dan membandingkannya dengan film “The Social Network” (Sumber: 36氪, janonacct)
Pengalaman layanan pelanggan AI menuai kontroversi, pengguna mengeluh “kecerdasan buatan yang bodoh” dan kesulitan transfer: Selama periode promosi besar e-commerce baru-baru ini, banyak konsumen melaporkan bahwa layanan pelanggan AI tidak komunikatif, menjawab di luar konteks, dan sangat sulit untuk mentransfer ke layanan pelanggan manusia, yang menyebabkan penurunan pengalaman layanan. Data dari Administrasi Negara untuk Regulasi Pasar menunjukkan bahwa pada tahun 2024, keluhan di bidang layanan purna jual e-commerce yang terkait dengan “layanan pelanggan cerdas” meningkat sebesar 56,3% YoY. Pengguna umumnya percaya bahwa layanan pelanggan AI sulit menyelesaikan masalah yang dipersonalisasi, jawabannya kaku, dan tidak cukup ramah untuk kelompok khusus seperti lansia. Artikel tersebut menyerukan agar perusahaan tidak mengorbankan kualitas layanan sambil mengejar pengurangan biaya dan peningkatan efisiensi, harus mengoptimalkan teknologi AI, memperjelas skenario penerapan layanan pelanggan AI, dan mempertahankan saluran layanan manusia yang nyaman (Sumber: 36氪)

Penerapan AI dalam bidang pembuatan konten dan strategi respons kreator dibahas: Penerapan teknologi AI (seperti DeepSeek, Suno, Veo 3) dalam pembuatan konten seperti artikel, musik, video semakin meluas, menimbulkan kecemasan di kalangan kreator konten mengenai prospek karir mereka. Analisis menunjukkan bahwa paradigma konten sedang bergeser dari “rekomendasi yang dipersonalisasi” menjadi “generasi yang dipersonalisasi”. Dalam jangka pendek, platform mungkin tidak sepenuhnya menggantikan kreator dengan AI karena biaya coba-coba yang tinggi, kreator dapat memperoleh keuntungan dengan menciptakan model gaya unik dan melisensikannya. Dalam jangka panjang, kreator perlu menyesuaikan cara mereka menciptakan nilai, lebih berfokus pada “strategi inovasi” yang sulit digantikan oleh AI (seperti riset orisinal, perolehan data primer), daripada “strategi pengikut” yang mudah dibantu AI (mengikuti tren, bergantung pada data sekunder). Meskipun AI telah mulai merambah bidang inovatif seperti penelitian ilmiah, kreator dengan perspektif unik dan pemikiran mendalam masih memiliki nilai (Sumber: 36氪)
