
Kata Kunci:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, ProRL Pembelajaran Penguatan, NVIDIA Cosmos, Model multimodal besar AI, Kerangka kerja agen cerdas AI, Optimasi penalaran LLM, Rekor matematika AlphaEvolve, Mesin Gödel Darwin peningkatan mandiri, Evaluasi medis MedHELM, Skalabilitas pembelajaran penguatan ProRL, Simulasi fisika Cosmos Transfer
🔥 Fokus
DeepMind AlphaEvolve memecahkan rekor matematika, kolaborasi manusia-mesin mendorong kemajuan ilmiah: AlphaEvolve dari DeepMind dua kali dalam seminggu memecahkan rekor matematika yang telah bertahan selama 18 tahun, menarik perhatian luas. Terence Tao berkomentar bahwa ini menunjukkan bagaimana berbagai metode dapat saling melengkapi untuk mendorong kemajuan matematika, bukan sekadar tentang “pemenang” dan “pecundang”. Peristiwa ini menyoroti potensi kolaborasi AI dan manusia dalam menciptakan paradigma baru di bidang teknologi dan sains, AI tidak hanya menggantikan manusia, tetapi bersama-sama membuka jalan baru untuk kemajuan (Sumber: shaneguML)

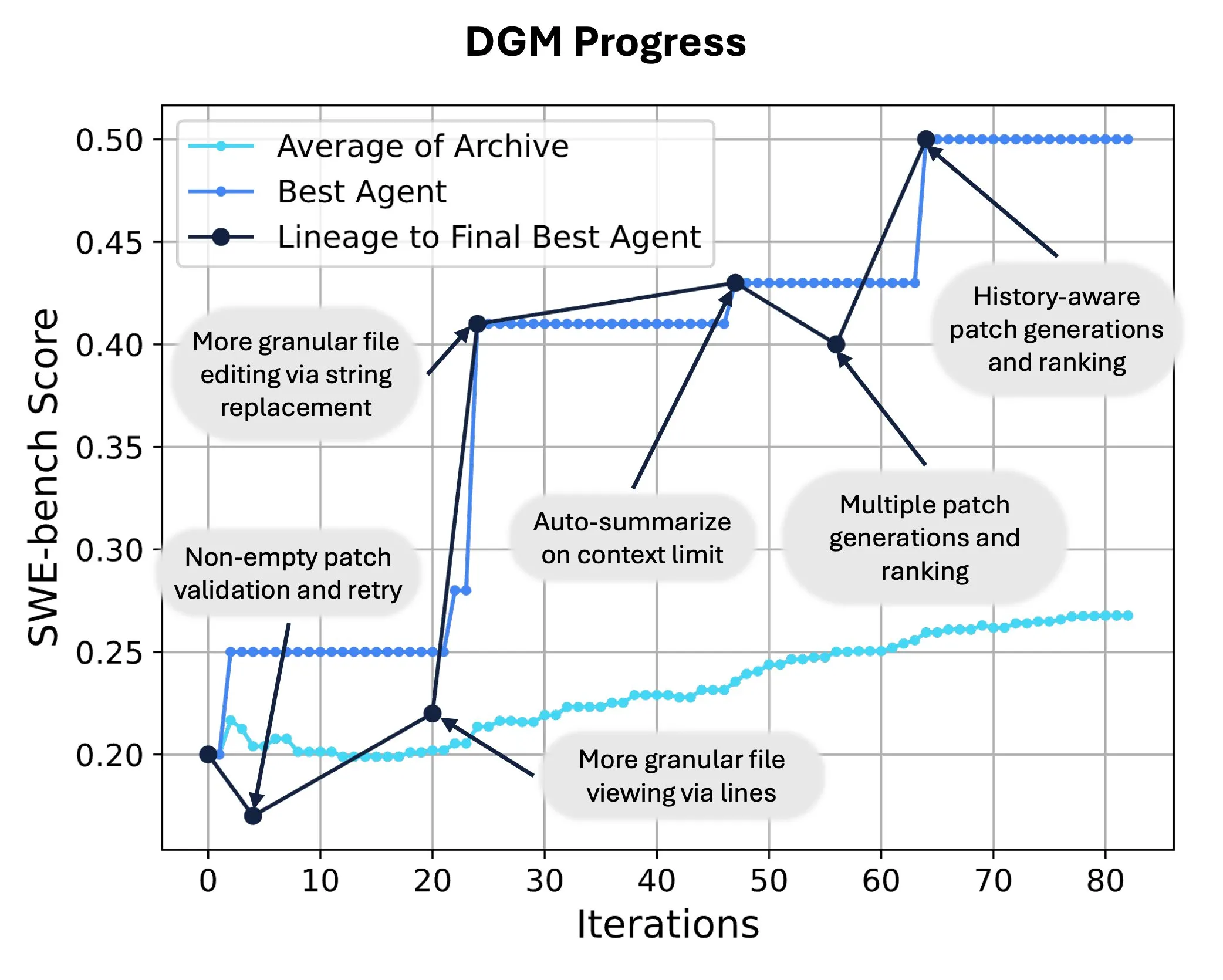
Sakana AI merilis Darwin Gödel Machine (DGM), mewujudkan penulisan ulang kode mandiri dan evolusi AI: Sakana AI meluncurkan Darwin Gödel Machine (DGM), sebuah agen cerdas yang dapat memperbaiki dirinya sendiri dengan memodifikasi kodenya sendiri untuk meningkatkan performa. Terinspirasi oleh teori evolusi, DGM memelihara silsilah varian agen yang terus berkembang, mewujudkan eksplorasi terbuka terhadap ruang desain agen yang “dapat memperbaiki diri sendiri”. Di SWE-bench, DGM meningkatkan performa dari 20,0% menjadi 50,0%; di Polyglot, tingkat keberhasilan meningkat dari 14,2% menjadi 30,7%, secara signifikan mengungguli agen yang dirancang secara manual. Teknologi ini menyediakan jalur baru bagi sistem AI untuk mencapai pembelajaran berkelanjutan dan evolusi kemampuan (Sumber: SakanaAILabs, hardmaru)
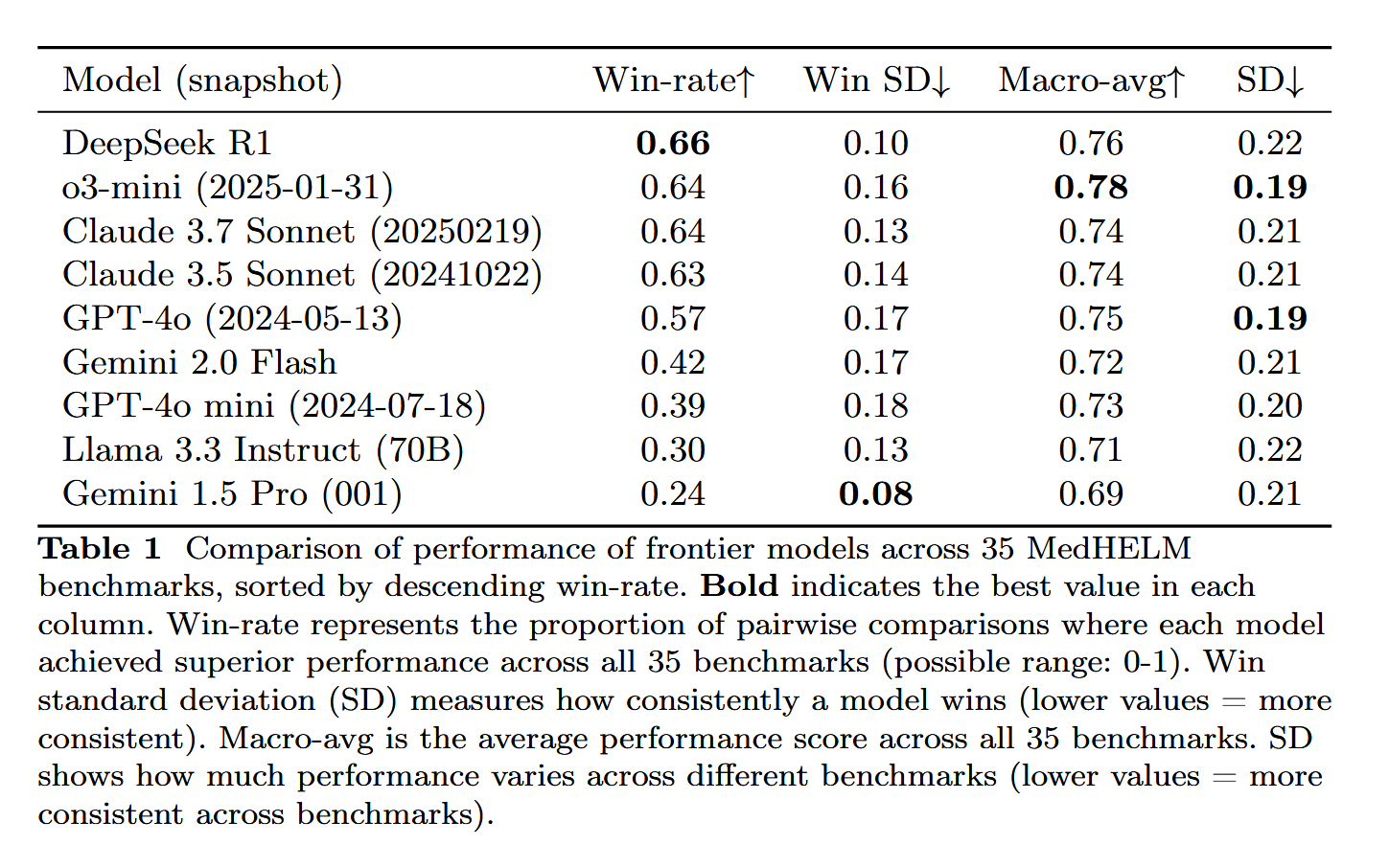
DeepSeek-R1 menunjukkan performa menonjol dalam evaluasi tugas medis MedHELM: Model bahasa besar DeepSeek-R1 menunjukkan performa terbaik dalam uji tolok ukur MedHELM (evaluasi holistik tugas medis untuk model bahasa besar), yang bertujuan untuk mengevaluasi performa LLM dalam tugas klinis yang lebih praktis, bukan ujian lisensi medis tradisional. Hasil ini dianggap signifikan, menunjukkan potensi aplikasi DeepSeek-R1 di bidang medis, terutama dalam kemampuannya menangani skenario klinis aktual (Sumber: iScienceLuvr)
Kemajuan baru dalam penelitian skalabilitas reinforcement learning: ProRL memperluas batas penalaran LLM: Sebuah makalah baru tentang skalabilitas reinforcement learning (RL) (arXiv:2505.24864) menarik perhatian. Penelitian menunjukkan bahwa melalui pelatihan reinforcement learning jangka panjang (ProRL), strategi penalaran baru yang sulit diperoleh model dasar melalui pengambilan sampel ekstensif dapat digali. ProRL menggabungkan kontrol divergensi KL, pengaturan ulang kebijakan referensi, dan rangkaian tugas yang beragam, memungkinkan model yang dilatih RL secara konsisten mengungguli model dasar dalam berbagai evaluasi pass@k. Penelitian ini memberikan wawasan baru tentang bagaimana RL dapat secara substansial memperluas batas penalaran model bahasa dan meletakkan dasar untuk penelitian penalaran RL jangka panjang di masa depan. NVIDIA telah merilis bobot model terkait (Sumber: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 Perkembangan
NVIDIA merilis Cosmos Transfer dan Cosmos Reason, mendorong aplikasi AI di dunia fisik: NVIDIA meluncurkan sistem Cosmos, di mana Cosmos Transfer dapat mengubah tampilan game engine sederhana, informasi kedalaman, atau bahkan simulasi robot kasar menjadi video adegan realistis, menyediakan banyak data pelatihan yang dapat dikontrol untuk AI seperti robotika dan kendaraan otonom. Cosmos Reason memungkinkan AI untuk memahami adegan ini dan membuat keputusan, misalnya, menentukan cara mengemudi dalam pengujian kendaraan otonom. Kedua alat ini saat ini bersifat open source dan diharapkan dapat mempercepat pengembangan AI di dunia fisik, mengatasi kekurangan data pelatihan dan kesulitan pengendalian skenario (Sumber: )
DeepSeek merilis pembaruan R1, ekosistem open source terus berkembang pesat: DeepSeek merilis pembaruan untuk model R1, termasuk R1 itu sendiri dan model kecil versi distilasi dengan 8 miliar parameter. Sementara itu, ByteDance aktif dalam bidang open source, meluncurkan proyek-proyek seperti BAGEL, Dolphin, Seedcoder, dan Dream0. Kemajuan ini menunjukkan aktivitas dan inovasi Tiongkok di bidang AI open source, terutama dalam perkembangan pesat model multimodal dan model khusus (Sumber: TheRundownAI, stablequan, reach_vb, clefourrier)
Google merilis Edge AI Gallery, mendorong aplikasi model AI open source di ponsel pintar: Google meluncurkan Edge AI Gallery, yang bertujuan untuk membawa model AI open source ke ponsel pintar, mewujudkan aplikasi AI yang terlokalisasi dan menjaga privasi. Pengguna dapat langsung menjalankan LLM dari Hugging Face di perangkat mereka, melakukan operasi seperti pembuatan kode, percakapan gambar, mendukung percakapan multi-giliran dan dapat memilih model apa pun. Aplikasi ini berbasis LiteRT, saat ini mendukung Android, dan versi iOS akan segera hadir, yang akan semakin mendorong pengembangan dan mempopulerkan AI di sisi perangkat (Sumber: TheRundownAI, huggingface, reach_vb, osanseviero)
Penelitian baru membahas pemanfaatan lintasan penalaran distilasi positif dan negatif untuk mengoptimalkan LLM: Sebuah makalah baru mengusulkan kerangka kerja Reinforced Distillation (REDI), yang bertujuan untuk meningkatkan kemampuan penalaran model siswa yang lebih kecil dengan memanfaatkan lintasan penalaran yang benar dan salah yang dihasilkan oleh model guru (seperti DeepSeek-R1). REDI terdiri dari dua tahap, pertama belajar dari lintasan yang benar melalui supervised fine-tuning (SFT), kemudian menggunakan fungsi objektif REDI yang baru diusulkan (fungsi kerugian tanpa referensi) yang menggabungkan lintasan positif dan negatif untuk lebih mengoptimalkan model. Eksperimen menunjukkan bahwa pada tugas penalaran matematika, REDI mengungguli metode dasar, dengan model Qwen-REDI-1.5B mencapai skor tinggi 83,1% pada MATH-500 (Sumber: HuggingFace Daily Papers)
Framework LLMSynthor memanfaatkan LLM untuk sintesis data yang sadar struktur: LLMSynthor adalah framework sintesis data umum yang mengubah model bahasa besar (LLM) menjadi simulator yang sadar struktur dan dipandu oleh umpan balik distribusi. Framework ini memperlakukan LLM sebagai simulator kopula non-parametrik untuk memodelkan dependensi tingkat tinggi dan memperkenalkan pengambilan sampel proposal LLM untuk meningkatkan efisiensi pengambilan sampel. Dengan meminimalkan perbedaan dalam ruang statistik ringkasan, siklus sintesis berulang menyelaraskan data nyata dan data sintetis. Evaluasi pada dataset heterogen di bidang yang sensitif terhadap privasi seperti e-commerce, populasi, dan mobilitas menunjukkan bahwa data sintetis yang dihasilkan oleh LLMSynthor memiliki fidelitas dan utilitas statistik yang tinggi (Sumber: HuggingFace Daily Papers)
Framework v1 meningkatkan penalaran interaksi multimodal melalui peninjauan visual selektif: v1 adalah ekstensi ringan yang memungkinkan model bahasa besar multimodal (MLLM) untuk melakukan peninjauan visual selektif selama proses penalaran. Berbeda dengan MLLM saat ini yang biasanya memproses input visual sekaligus, v1 memperkenalkan mekanisme “tunjuk dan salin”, yang memungkinkan model untuk secara dinamis mengambil area gambar yang relevan selama proses penalaran. Dengan melatih pada dataset lintasan penalaran multimodal v1g yang berisi anotasi dasar visual, v1 menunjukkan peningkatan performa dalam uji tolok ukur seperti MathVista, terutama pada tugas yang memerlukan referensi visual yang sangat detail dan penalaran multi-langkah (Sumber: HuggingFace Daily Papers)
MetaFaith meningkatkan fidelitas ekspresi ketidakpastian bahasa alami LLM: Untuk mengatasi masalah LLM yang sering melebih-lebihkan dalam mengekspresikan ketidakpastian, MetaFaith mengusulkan metode kalibrasi berbasis prompt baru. Penelitian menemukan bahwa LLM yang ada berkinerja buruk dalam mencerminkan ketidakpastian internalnya secara akurat, metode prompt standar memiliki efek terbatas, dan teknik kalibrasi berbasis faktualitas bahkan dapat merusak kalibrasi fidelitas. MetaFaith, yang terinspirasi oleh metakognisi manusia, dapat secara signifikan meningkatkan kemampuan kalibrasi fidelitas model pada berbagai tugas dan model, dengan peningkatan fidelitas hingga 61% dan tingkat kemenangan 83% dalam evaluasi manusia (Sumber: HuggingFace Daily Papers)
CLaSp: Mempercepat decoding LLM melalui lompatan lapisan dalam konteks untuk decoding spekulatif mandiri: CLaSp adalah strategi decoding spekulatif mandiri untuk model bahasa besar (LLM) yang mempercepat proses decoding dengan membuat model draf terkompresi melalui lompatan pada lapisan tengah model validasi, tanpa memerlukan pelatihan tambahan atau modifikasi model. CLaSp menggunakan algoritma pemrograman dinamis untuk mengoptimalkan proses lompatan lapisan dan secara dinamis menyesuaikan strategi berdasarkan status tersembunyi lengkap dari tahap validasi sebelumnya. Eksperimen menunjukkan bahwa CLaSp mencapai percepatan 1,3 hingga 1,7 kali pada model seri LLaMA3 tanpa mengubah distribusi asli teks yang dihasilkan (Sumber: HuggingFace Daily Papers)
HardTests mensintesis kasus uji kode berkualitas tinggi melalui LLM: Untuk mengatasi masalah LLM yang kesulitan memvalidasi kode yang dihasilkan secara efektif untuk masalah pemrograman yang kompleks menggunakan kasus uji yang ada, HardTests mengusulkan alur kerja HARDTESTGEN yang memanfaatkan LLM untuk menghasilkan kasus uji berkualitas tinggi. Dataset HardTests yang dibangun berdasarkan alur kerja ini berisi 47.000 masalah pemrograman dan kasus uji berkualitas tinggi yang disintesis. Dibandingkan dengan pengujian yang ada, pengujian yang dihasilkan oleh HARDTESTGEN meningkatkan presisi sebesar 11,3% dan recall sebesar 17,5% saat mengevaluasi kode yang dihasilkan LLM, dengan peningkatan presisi hingga 40% untuk masalah sulit. Dataset ini juga menunjukkan efek yang lebih baik dalam pelatihan model (Sumber: HuggingFace Daily Papers)
Penelitian mengungkap bias pada model bahasa visual (VLM): Sebuah penelitian menemukan bahwa model bahasa visual (VLM) canggih, ketika memproses tugas visual yang terkait dengan topik populer (seperti menghitung dan mengidentifikasi), sangat dipengaruhi oleh sejumlah besar pengetahuan sebelumnya yang dipelajari dari internet. Misalnya, VLM kesulitan mengenali garis keempat yang ditambahkan pada merek dagang Adidas. Dalam tugas penghitungan yang mencakup 7 domain berbeda seperti hewan, merek dagang, permainan papan, dll., akurasi rata-rata VLM hanya 17,05%. Bahkan ketika diinstruksikan untuk memeriksa dengan cermat atau hanya mengandalkan detail gambar, peningkatan akurasi terbatas. Penelitian ini mengusulkan kerangka kerja otomatis untuk menguji bias VLM (Sumber: HuggingFace Daily Papers)
Point-MoE: Memanfaatkan model mixture-of-experts untuk generalisasi lintas domain dalam segmentasi semantik 3D: Untuk mengatasi kesulitan melatih model terpadu karena beragamnya sumber data point cloud 3D (seperti kamera kedalaman, LiDAR) dan heterogenitas domain (seperti dalam ruangan, luar ruangan), Point-MoE mengusulkan arsitektur mixture-of-experts (MoE). Arsitektur ini, melalui strategi perutean top-k sederhana, dapat secara otomatis mengkhususkan jaringan pakar bahkan tanpa label domain. Eksperimen menunjukkan bahwa Point-MoE tidak hanya mengungguli model baseline multi-domain yang kuat tetapi juga memiliki kemampuan generalisasi yang lebih baik pada domain yang belum pernah dilihat, menyediakan jalur yang dapat diskalakan untuk persepsi 3D skala besar dan lintas domain (Sumber: HuggingFace Daily Papers)
SpookyBench mengungkap “titik buta temporal” pada model bahasa video: Meskipun model bahasa video (VLM) telah mencapai kemajuan dalam memahami hubungan spasio-temporal, mereka kesulitan menangkap pola temporal murni ketika informasi spasial kabur. Uji tolok ukur SpookyBench, dengan mengkodekan informasi (seperti bentuk, teks) dalam urutan frame yang bising, menemukan bahwa manusia dapat mengidentifikasi dengan akurasi lebih dari 98%, sementara VLM canggih memiliki akurasi 0%. Ini menunjukkan bahwa VLM terlalu bergantung pada fitur spasial tingkat frame dan tidak dapat mengekstrak makna dari petunjuk temporal. Penelitian ini menekankan perlunya mengatasi “titik buta temporal” VLM, yang mungkin memerlukan arsitektur baru atau paradigma pelatihan untuk memisahkan ketergantungan spasial dari pemrosesan temporal (Sumber: HuggingFace Daily Papers, _akhaliq)
Metode dan dataset baru untuk deteksi inovasi ilmiah menggunakan LLM: Mengidentifikasi ide-ide penelitian baru sangat penting namun penuh tantangan. Untuk mengatasi masalah ini, para peneliti mengusulkan penggunaan model bahasa besar (LLM) untuk deteksi inovasi ilmiah dan membangun dua dataset baru di bidang pemasaran dan pemrosesan bahasa alami. Metode ini membangun dataset dengan mengekstraksi himpunan penutup (closure set) dari makalah dan menggunakan LLM untuk merangkum ide-ide utamanya. Untuk menangkap konsep ide, para peneliti mengusulkan pelatihan retriever ringan yang menyelaraskan ide-ide dengan konsep serupa dengan menyaring pengetahuan tingkat ide dari LLM, sehingga mencapai pengambilan ide yang efisien dan akurat. Eksperimen membuktikan bahwa metode ini mengungguli metode lain pada dataset benchmark yang diusulkan (Sumber: HuggingFace Daily Papers)
un^2CLIP meningkatkan kemampuan CLIP dalam menangkap detail visual dengan membalikkan unCLIP: Untuk mengatasi kekurangan model CLIP dalam membedakan perbedaan detail gambar dan menangani tugas seperti prediksi padat, un^2CLIP mengusulkan untuk meningkatkan CLIP dengan membalikkan model unCLIP. unCLIP sendiri melatih generator gambar melalui embedding gambar CLIP, sehingga mempelajari distribusi detail gambar. un^2CLIP memanfaatkan fitur ini, memungkinkan encoder gambar CLIP yang ditingkatkan untuk memperoleh kemampuan menangkap detail visual unCLIP sambil mempertahankan keselarasan dengan encoder teks asli. Eksperimen menunjukkan bahwa un^2CLIP secara signifikan mengungguli CLIP asli dan metode peningkatan lainnya dalam berbagai tugas (Sumber: HuggingFace Daily Papers)
ViStoryBench: Rangkaian benchmark komprehensif untuk visualisasi cerita dirilis: Untuk mendorong pengembangan teknologi visualisasi cerita (menghasilkan urutan gambar yang koheren berdasarkan narasi dan gambar referensi), ViStoryBench menyediakan benchmark evaluasi yang komprehensif. Benchmark ini berisi dataset dengan berbagai jenis cerita (komedi, horor, dll.) dan gaya seni (anime, rendering 3D, dll.), serta cerita dengan satu dan banyak protagonis untuk menguji konsistensi karakter, dan plot kompleks serta pembangunan dunia untuk menantang akurasi generasi visual model. ViStoryBench menggunakan berbagai metrik evaluasi, yang bertujuan untuk mengevaluasi secara komprehensif performa model dalam struktur naratif dan elemen visual, membantu peneliti mengidentifikasi kekuatan dan kelemahan model dan melakukan perbaikan yang ditargetkan (Sumber: HuggingFace Daily Papers)
Fork-Merge Decoding (FMD) meningkatkan pemahaman multimodal seimbang pada model besar audio-video: Untuk mengatasi masalah bias modalitas yang mungkin ada pada model bahasa besar audio-video (AV-LLM) (yaitu, model terlalu bergantung pada satu modalitas saat membuat keputusan), Fork-Merge Decoding (FMD) mengusulkan strategi waktu inferensi tanpa pelatihan tambahan. FMD pertama-tama memproses input audio murni dan video murni secara terpisah melalui lapisan decoding awal (tahap fork), kemudian menggabungkan status tersembunyi yang dihasilkan untuk inferensi bersama (tahap merge). Metode ini bertujuan untuk mempromosikan kontribusi modalitas yang seimbang dan memanfaatkan informasi komplementer lintas modalitas. Eksperimen pada model seperti VideoLLaMA2 dan video-SALMONN menunjukkan bahwa FMD dapat meningkatkan performa pada tugas inferensi audio, video, dan audio-video gabungan (Sumber: HuggingFace Daily Papers)
LegalSearchLM: Membentuk kembali pencarian kasus hukum sebagai generasi elemen hukum: Metode pencarian kasus hukum (LCR) tradisional bergantung pada pencocokan embedding atau leksikal, menghadapi keterbatasan dalam skenario nyata. LegalSearchLM mengusulkan metode baru, yang memperlakukan LCR sebagai tugas generasi elemen hukum. Model ini melakukan inferensi elemen hukum pada kasus kueri dan secara langsung menghasilkan konten berdasarkan kasus target melalui decoding terbatas. Sementara itu, para peneliti merilis LEGAR BENCH, benchmark LCR skala besar yang berisi 1,2 juta kasus hukum Korea. Eksperimen menunjukkan bahwa performa LegalSearchLM pada LEGAR BENCH mengungguli model baseline sebesar 6-20% dan menunjukkan kemampuan generalisasi lintas domain yang kuat (Sumber: HuggingFace Daily Papers)
RPEval: Benchmark baru untuk mengevaluasi kemampuan bermain peran model bahasa besar: Untuk mengatasi tantangan dalam mengevaluasi kemampuan bermain peran model bahasa besar (LLM), RPEval menyediakan uji tolok ukur baru. Benchmark ini mengevaluasi performa bermain peran LLM dari empat dimensi utama: pemahaman emosi, pengambilan keputusan, kecenderungan moral, dan konsistensi peran. Bertujuan untuk mengatasi masalah konsumsi sumber daya yang besar dari evaluasi manual dan potensi bias dalam evaluasi otomatis (Sumber: HuggingFace Daily Papers)
GATE: Model embedding teks universal untuk meningkatkan STS bahasa Arab: Untuk mengatasi kurangnya dataset berkualitas tinggi dan model pra-terlatih dalam penelitian kesamaan teks semantik (STS) bahasa Arab, model GATE (General Arabic Text Embedding) hadir. GATE memanfaatkan pembelajaran representasi Matryoshka dan metode pelatihan kerugian campuran, dikombinasikan dengan dataset triplet inferensi bahasa alami Arab untuk pelatihan. Hasil eksperimen menunjukkan bahwa GATE mencapai performa SOTA pada tugas STS dari benchmark MTEB, dengan peningkatan performa 20-25% dibandingkan model besar termasuk OpenAI, dan dapat secara efektif menangkap nuansa semantik unik bahasa Arab (Sumber: HuggingFace Daily Papers)
CoDA: Kerangka kerja optimasi noise difusi kolaboratif untuk manipulasi seluruh tubuh objek artikulasi: Untuk mencapai realisme dan presisi dalam manipulasi seluruh tubuh objek artikulasi (termasuk gerakan tubuh, tangan, dan objek), CoDA mengusulkan kerangka kerja optimasi noise difusi kolaboratif baru. Kerangka kerja ini mengoptimalkan ruang noise untuk tiga model difusi khusus untuk tubuh, tangan kiri, dan tangan kanan, dan mencapai koordinasi alami antara tangan dan bagian tubuh lainnya melalui aliran gradien dalam rantai gerakan manusia. Untuk meningkatkan presisi interaksi tangan-objek, CoDA mengadopsi representasi terpadu berbasis basis point set (BPS), mengkodekan posisi efektor akhir sebagai jarak ke BPS geometri objek, sehingga memandu optimasi noise difusi dan menghasilkan gerakan interaksi presisi tinggi (Sumber: HuggingFace Daily Papers)
Pemahaman baru mekanisme refleksi penalaran LLM: Kerangka kerja Bayesian Adaptive Reinforcement Learning (BARL): Northwestern University bekerja sama dengan Google DeepMind mengusulkan kerangka kerja Bayesian Adaptive Reinforcement Learning (BARL), yang bertujuan untuk menjelaskan dan mengoptimalkan perilaku “refleksi” model bahasa besar (LLM) selama proses penalaran. Reinforcement learning (RL) tradisional biasanya hanya memanfaatkan strategi yang telah dipelajari saat pengujian, sedangkan BARL, dengan memperkenalkan pemodelan ketidakpastian lingkungan, memungkinkan model untuk secara adaptif mengeksplorasi strategi baru saat penalaran. Eksperimen menunjukkan bahwa BARL dapat mencapai akurasi yang lebih tinggi dalam tugas seperti penalaran matematika dan secara signifikan mengurangi konsumsi token. Penelitian ini untuk pertama kalinya menjelaskan dari perspektif Bayesian mengapa, bagaimana, dan kapan LLM harus melakukan eksplorasi reflektif (Sumber: 量子位)

Aplikasi LLM dalam tata bahasa ketidakpastian formal: Kapan mempercayai LLM untuk penalaran otomatis: Model bahasa besar (LLM) menunjukkan potensi dalam menghasilkan spesifikasi formal, tetapi sifat probabilistiknya bertentangan dengan persyaratan deterministik verifikasi formal. Para peneliti secara komprehensif menyelidiki mode kegagalan dan kuantifikasi ketidakpastian (UQ) dalam konstruksi formal yang dihasilkan LLM. Hasil menunjukkan bahwa dampak formalisasi otomatis berbasis SMT terhadap akurasi bervariasi menurut domain, dan teknik UQ yang ada kesulitan mengidentifikasi kesalahan ini. Makalah ini memperkenalkan kerangka kerja tata bahasa bebas konteks probabilistik (PCFG) untuk memodelkan output LLM dan menemukan bahwa sinyal ketidakpastian bergantung pada tugas. Dengan menggabungkan sinyal-sinyal ini, validasi selektif dapat dicapai, secara signifikan mengurangi kesalahan dan membuat formalisasi yang digerakkan oleh LLM lebih andal (Sumber: HuggingFace Daily Papers)
Perbandingan fine-tuning model bahasa kecil (SLM) dengan prompting model bahasa besar (LLM) dalam generasi alur kerja low-code: Penelitian membandingkan efek fine-tuning model bahasa kecil (SLM) dengan prompting model bahasa besar (LLM) dalam tugas menghasilkan alur kerja low-code dalam format JSON. Hasil menunjukkan bahwa meskipun prompt yang baik dapat membuat LLM menghasilkan hasil yang masuk akal, untuk tugas khusus domain dan output terstruktur, fine-tuning SLM rata-rata memiliki peningkatan kualitas sebesar 10%. Ini menunjukkan bahwa dalam skenario tertentu, SLM masih memiliki keunggulan, terutama ketika persyaratan kualitas output tinggi (Sumber: HuggingFace Daily Papers)
Mengevaluasi dan mengarahkan preferensi modalitas dalam model besar multimodal: Para peneliti membangun benchmark MC² untuk secara sistematis mengevaluasi preferensi modalitas model bahasa besar multimodal (MLLM) (yaitu, kecenderungan untuk memilih satu modalitas saat membuat keputusan) dalam skenario konflik bukti yang terkontrol. Penelitian menemukan bahwa 18 MLLM yang diuji semuanya menunjukkan bias modalitas yang jelas, dan arah preferensi dapat dipengaruhi oleh intervensi eksternal. Berdasarkan hal ini, para peneliti mengusulkan metode pendeteksian dan pengarahan berbasis rekayasa representasi, yang dapat secara eksplisit mengontrol preferensi modalitas tanpa fine-tuning tambahan atau prompt yang dirancang dengan cermat, dan mencapai hasil positif dalam tugas hilir seperti mitigasi halusinasi dan terjemahan mesin multimodal (Sumber: HuggingFace Daily Papers)
Status penelitian keamanan LLM multibahasa: Dari pengukuran kesenjangan bahasa hingga menjembatani kesenjangan: Tinjauan sistematis terhadap hampir 300 makalah konferensi NLP antara tahun 2020-2024 menunjukkan bahwa penelitian keamanan LLM memiliki masalah sentralisasi bahasa Inggris yang signifikan. Bahkan bahasa non-Inggris yang kaya sumber daya jarang mendapat perhatian, dan bahasa non-Inggris jarang menjadi objek penelitian independen, penelitian keamanan bahasa Inggris juga umumnya kurang praktik dokumentasi bahasa yang baik. Untuk mendorong penelitian keamanan multibahasa, makalah ini mengusulkan arah masa depan, termasuk evaluasi keamanan, generasi data pelatihan, dan generalisasi keamanan lintas bahasa, yang bertujuan untuk mengembangkan praktik keamanan AI yang lebih kuat dan inklusif untuk berbagai populasi global (Sumber: HuggingFace Daily Papers, sarahookr)

Meninjau kembali transisi keadaan bilinear dalam recurrent neural network: Pandangan tradisional menyatakan bahwa unit tersembunyi dalam recurrent neural network (RNN) terutama digunakan untuk memodelkan memori. Penelitian ini mengambil perspektif lain, menganggap unit tersembunyi sebagai partisipan aktif dalam komputasi jaringan. Para peneliti meninjau kembali operasi bilinear yang melibatkan interaksi perkalian antara unit tersembunyi dan embedding input, secara teoritis dan empiris membuktikan bahwa mereka adalah bias induktif alami untuk merepresentasikan evolusi keadaan tersembunyi dalam tugas pelacakan keadaan. Penelitian ini juga menunjukkan bahwa pembaruan keadaan bilinear membentuk hierarki alami yang sesuai dengan tugas pelacakan keadaan dengan kompleksitas yang meningkat, sedangkan RNN linear populer (seperti Mamba) berada di pusat kompleksitas terendah dari hierarki ini (Sumber: HuggingFace Daily Papers)
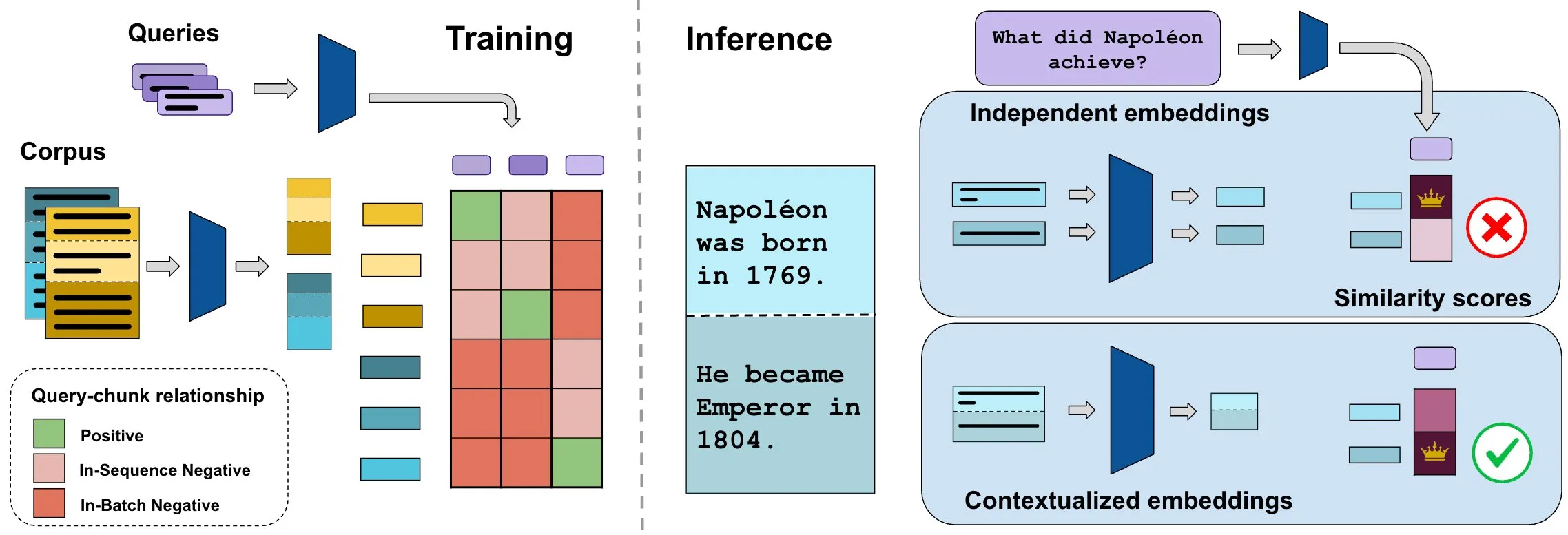
Benchmark ConTEB mengevaluasi embedding dokumen kontekstual, metode InSeNT meningkatkan kualitas pencarian: Metode embedding pencarian dokumen saat ini biasanya mengkodekan berbagai fragmen (chunk) dari dokumen yang sama secara independen, mengabaikan informasi konteks tingkat dokumen. Untuk mengatasi masalah ini, para peneliti meluncurkan benchmark ConTEB, yang secara khusus mengevaluasi kemampuan model pencarian untuk memanfaatkan konteks dokumen, dan menemukan bahwa model SOTA berkinerja buruk dalam aspek ini. Sementara itu, para peneliti mengusulkan metode pelatihan pasca pembelajaran kontrastif InSeNT (In-Sequence Negative Training), dikombinasikan dengan penggabungan chunk tahap akhir, untuk meningkatkan pembelajaran representasi kontekstual, secara signifikan meningkatkan kualitas pencarian pada ConTEB, dan lebih kuat terhadap strategi chunking suboptimal dan korpus skala lebih besar (Sumber: HuggingFace Daily Papers, tonywu_71)
🧰 Alat
PraisonAI: Framework agen multi-AI low-code: PraisonAI adalah framework agen multi-AI tingkat produksi yang bertujuan untuk menyederhanakan otomatisasi dan pemecahan masalah dari tugas sederhana hingga tantangan kompleks melalui solusi low-code. Ini mengintegrasikan PraisonAI Agents, AG2 (AutoGen), dan CrewAI, menekankan kesederhanaan, kustomisasi, dan kolaborasi manusia-mesin yang efektif. Fungsinya meliputi pembuatan agen AI otomatis, refleksi diri, multimodal, kolaborasi multi-agen, penambahan pengetahuan, memori jangka panjang dan pendek, RAG, interpreter kode, lebih dari 100 alat kustom dan dukungan LLM, dll. Mendukung Python dan JavaScript, dan menyediakan opsi konfigurasi YAML tanpa kode (Sumber: GitHub Trending)
TinyTroupe: Framework simulasi peran multi-agen yang digerakkan LLM open source dari Microsoft: TinyTroupe adalah pustaka Python eksperimental yang memanfaatkan model bahasa besar (LLM, khususnya GPT-4) untuk mensimulasikan karakter (TinyPerson) dengan kepribadian, minat, dan tujuan tertentu, dan berinteraksi dalam lingkungan simulasi (TinyWorld). Framework ini bertujuan untuk meningkatkan imajinasi dan memberikan wawasan bisnis melalui simulasi, dan dapat diterapkan pada skenario seperti evaluasi iklan, pengujian perangkat lunak, pembuatan data sintetis, umpan balik produk, dan brainstorming. Pengguna dapat mendefinisikan agen dan lingkungan melalui file Python dan JSON untuk melakukan eksperimen simulasi terprogram, analitis, dan multi-agen (Sumber: GitHub Trending)

FLUX Kontext mencapai terobosan baru dalam referensi multi-gambar dan pengeditan gambar: Umpan balik pengguna menunjukkan bahwa FLUX Kontext berkinerja sangat baik dalam referensi multi-gambar, dan fungsi ini dapat diaktifkan melalui node penyambungan gambar di ComfyUI. Alat ini mampu mencapai pengeditan gambar dengan konsistensi tinggi, misalnya, saat membuat gambar pajangan untuk kotak hadiah, alat ini dapat dengan baik mereproduksi detail seperti bahan dan debu. Selain itu, pengguna juga menunjukkan penggunaan FLUX Kontext untuk operasi pengeditan foto seperti melangsingkan tubuh, meniruskan wajah, dan menambah otot dengan sekali klik, dengan hasil yang alami dan kemiripan wajah yang tinggi, memberikan kemudahan untuk skenario seperti e-commerce (Sumber: op7418, op7418, op7418)

Ichi: AI percakapan di perangkat berbasis MLX Swift dan MLX audio: Rudrank Riyam mengembangkan Ichi, sebuah proyek AI percakapan di perangkat yang diimplementasikan menggunakan MLX Swift dan MLX audio. Ini berarti pemrosesan percakapan dapat dilakukan secara lokal di perangkat, membantu melindungi privasi pengguna dan mengurangi ketergantungan pada layanan cloud. Kode proyek ini telah tersedia secara open source di GitHub (Sumber: stablequan, awnihannun)
FedRAG memperkenalkan abstraksi inti NoEncode RAG dengan MCP: Proyek FedRAG meluncurkan abstraksi inti baru – NoEncode RAG dengan MCP. RAG tradisional mencakup retriever, generator, dan basis pengetahuan, di mana pengetahuan dalam basis pengetahuan perlu dikodekan oleh model retriever. Sebaliknya, NoEncode RAG sepenuhnya melewati langkah pengkodean, secara langsung terdiri dari basis pengetahuan NoEncode dan generator, tanpa memerlukan retriever/embedding. Ini membuka jalan untuk membangun sistem RAG yang menggunakan server MCP (Model Component Provider) sebagai sumber pengetahuan, memungkinkan pengguna untuk terhubung ke beberapa sumber MCP pihak ketiga dan melakukan fine-tuning pada RAG melalui FedRAG untuk mendapatkan performa optimal (Sumber: nerdai)

📚 Belajar
Mata kuliah CS224n (versi 2024) Universitas Stanford diluncurkan, menambahkan konten LLM dan agen: Mata kuliah pemrosesan bahasa alami klasik Universitas Stanford, CS224n, merilis versi terbaru tahun 2024. Konten mata kuliah baru mencakup topik-topik mutakhir terkait model bahasa besar (LLM) seperti pra-pelatihan, pasca-pelatihan, uji tolok ukur, inferensi, dan agen. Video mata kuliah telah dipublikasikan di YouTube, dan juga menawarkan pengalaman mata kuliah sinkron berbayar (Sumber: stanfordnlp)
Panduan meningkatkan kemampuan arsitektur sistem: Praktik dan pembelajaran di era AI: Dotey berbagi metode terperinci tentang cara meningkatkan kemampuan arsitektur sistem pribadi di tengah meningkatnya kekuatan pemrograman yang dibantu AI. Artikel ini menekankan bahwa desain sistem adalah proses memecah sistem kompleks menjadi modul-modul kecil yang mudah diimplementasikan dan dipelihara, serta mendefinisikan kolaborasi antar modul dengan jelas. Metode peningkatannya meliputi “banyak melihat” (mempelajari kasus klasik, proyek open source), “banyak berlatih” (rekonstruksi arsitektur, pembelajaran komparatif, desain terlebih dahulu, validasi berbantuan AI, refactoring, praktik proyek sampingan), dan “banyak meninjau” (merangkum dasar pengambilan keputusan, pelajaran yang didapat). AI dapat digunakan sebagai alat bantu untuk mencari informasi, memvalidasi desain, membantu komunikasi dan pengambilan keputusan, tetapi tidak dapat menggantikan praktik dan pemikiran (Sumber: dotey)

Berbagi makalah: Penelitian keandalan verifikator dalam RLHF: Sebuah makalah berjudul “Pitfalls of Rule- and Model-based Verifiers” membahas kekurangan verifikator berbasis aturan dan berbasis model dalam verifikasi reinforcement learning (RLVR). Penelitian menemukan bahwa verifikator berbasis aturan seringkali tidak dapat diandalkan bahkan di bidang matematika, dan tidak tersedia di banyak bidang; sedangkan verifikator berbasis model mudah diserang, misalnya melalui pembuatan pola adversarial sederhana. Menariknya, seiring komunitas beralih ke verifikator generatif, penelitian menemukan bahwa mereka lebih rentan terhadap manipulasi reward (reward hacking) daripada verifikator diskriminatif, yang menunjukkan bahwa verifikator diskriminatif mungkin lebih kuat dalam RLVR (Sumber: Francis_YAO_)
Rekomendasi makalah: Teorema ekuisosilasi untuk aproksimasi polinomial terbaik: Sebuah artikel memperkenalkan teorema ekuisosilasi untuk aproksimasi polinomial terbaik, serta masalah diferensial norma tak hingga yang terkait dengannya. Teorema ini merupakan hasil klasik dalam teori aproksimasi fungsi dan memiliki arti penting untuk memahami dan merancang algoritma numerik (Sumber: eliebakouch)
Reasoning Gym: Lingkungan penalaran untuk reinforcement learning dengan reward yang dapat diverifikasi: Makalah baru “Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards” (arXiv:2505.24760) mengusulkan serangkaian lingkungan penalaran untuk reinforcement learning. Ciri khas lingkungan ini adalah reward-nya dapat diverifikasi, menyediakan platform untuk penelitian dan pengembangan agen penalaran reinforcement learning yang lebih andal (Sumber: Ar_Douillard)

🌟 Komunitas
Diskusi tentang “Pelatihan Tengah (Mid-training)”: Komunitas AI membahas makna dan praktik istilah “Pelatihan Tengah (Mid-training)”. Beberapa orang menyatakan kebingungan, hanya mengetahui pra-pelatihan dan pasca-pelatihan. Ada pandangan bahwa pelatihan tengah mungkin merujuk pada tahap pelatihan tertentu antara pra-pelatihan dan fine-tuning akhir, misalnya, pra-pelatihan berkelanjutan untuk pengetahuan domain tertentu atau penyelarasan awal. Dorialexander membagikan artikel blog terkait, yang lebih lanjut membahas konsep ini, berpendapat bahwa ini mungkin melibatkan injeksi tugas atau kemampuan tertentu di atas model dasar, tetapi belum ada definisi dan metodologi yang seragam (Sumber: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

Analisis rekayasa balik Claude Code menarik perhatian: Hrishi, melalui rekayasa balik kode minimal Claude Code, menghabiskan 8-10 jam, memanfaatkan beberapa sub-agen dan model unggulan dari berbagai penyedia, mengungkap kompleksitas struktur internalnya. Analisis menunjukkan bahwa Claude Code bukanlah sekadar perulangan model Claude sederhana, melainkan berisi banyak mekanisme yang patut dipelajari. Penemuan ini memicu diskusi komunitas, yang berpendapat bahwa banyak pelajaran tentang pembangunan agen dan aplikasi model dapat dipelajari darinya (Sumber: rishdotblog, imjaredz, hrishioa)
Pembahasan panjang prompt sistem dan performa model: Komunitas membahas pengaruh panjang prompt sistem terhadap performa LLM. Dotey berpendapat bahwa prompt sistem yang sangat panjang tidak selalu baik, dapat mengencerkan perhatian model, meningkatkan biaya, dan menunjukkan bahwa prompt sistem produk seri ChatGPT relatif singkat namun efektif. Sementara itu, Tony出海号 menyebutkan bahwa prompt sistem produk seperti Claude dan Cursor mencapai puluhan ribu kata, menyiratkan perlunya memperluas sistem prompt. Artikel YC juga mengungkap bahwa perusahaan AI terkemuka menggunakan prompt panjang, XML, meta-prompt, dan metode lain untuk “menjinakkan” LLM. Dorialexander meragukan ketahanan metode prompt panjang yang disebutkan dalam artikel YC dalam pelatihan RL/penalaran dan memperhatikan cara mengurangi masalah “menjilat” (sycophancy) (Sumber: dotey, Dorialexander)

Masalah skalabilitas Softpick menuai pujian atas transparansi penelitian ilmiah: Peneliti Zed secara terbuka menyatakan bahwa metode Softpick dari penelitian sebelumnya, ketika diskalakan ke model yang lebih besar (parameter 1.8B), kerugian pelatihan dan hasil uji tolok ukur lebih buruk daripada Softmax, dan telah memperbarui pracetak arXiv. Komunitas sangat memuji tindakan berbagi hasil negatif secara transparan ini, menganggapnya sangat penting untuk kemajuan penelitian ilmiah dan melihatnya sebagai kualitas rekan peneliti yang sangat baik (Sumber: gabriberton, vikhyatk, BlancheMinerva)
Pengguna berbagi pilihan model dan pengalaman menjalankan LLM secara lokal: Pengguna komunitas Reddit r/LocalLLaMA ramai membahas model bahasa besar lokal yang saat ini mereka gunakan. Model seperti Qwen 3 (terutama 32B Q4, 32B Q8, 30B A3B), Gemma 3 (terutama 27B QAT Q8, 12B), Devstral banyak disebut karena performanya dalam kode, kreasi, penalaran umum, dll. Pengguna memperhatikan panjang konteks model, kecepatan inferensi, versi kuantisasi (seperti IQ1_S_R4), dan kinerjanya pada berbagai perangkat keras (seperti VRAM 8GB, ponsel dengan chip Snapdragon 8 Elite). Model sumber tertutup seperti Claude Code, Gemini API juga digunakan secara bersamaan karena keunggulan spesifiknya (seperti pemrosesan konteks panjang, kemampuan kode) (Sumber: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 Lainnya
Pengembangan keterampilan di era AI: Bertanya, berpikir kritis, dan belajar berkelanjutan adalah kunci: Diskusi menekankan bahwa di era AI, kemampuan bertanya, berpikir kritis, mempertahankan mode belajar, kemampuan pengkodean atau instruksi, kemahiran menggunakan alat AI, dan komunikasi yang jelas adalah enam keterampilan yang sangat penting. Perusahaan Zapier bahkan mewajibkan 100% karyawan baru mahir AI, yang ditafsirkan sebagai penekanan utama pada kebutuhan komunikasi dan kemampuan mendelegasikan tugas dengan benar, bukan semata-mata pengetahuan teknis. AI membuat eksekusi lebih mudah, sehingga kualitas desain dan pemikiran memiliki dampak yang lebih besar pada hasil akhir (Sumber: TheTuringPost, zacharynado)

Etika AI dan dampak sosial: Kekhawatiran dan pemberdayaan berjalan beriringan: Aktor Steve Carell menyatakan keprihatinannya terhadap masyarakat masa depan yang digambarkan dalam film barunya “Mountainhead”, berpendapat bahwa ini mungkin masyarakat yang akan segera kita tinggali, menyiratkan kekhawatiran tentang potensi dampak negatif AI. Di sisi lain, ada pandangan bahwa AI tidak serta merta menyebabkan polarisasi ekstrem “petani dan raja”, melainkan dapat memberdayakan individu, memperkecil kesenjangan kemampuan antara individu dan perusahaan besar, serta mendorong peningkatan produktivitas, kreativitas, dan pengaruh pribadi. Namun, mengenai prospek demokratisasi AI, ada juga yang bersikap hati-hati, berpendapat bahwa perusahaan besar akan tetap memegang kendali melalui kontrol pelatihan dan penyebaran model (Sumber: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Platform agregasi informasi lowongan kerja berbasis AI, Hiring Cafe: Hamed N. menggunakan API ChatGPT untuk mengambil 4,1 juta informasi lowongan kerja yang dipublikasikan langsung di situs web perusahaan, dan membuat situs web Hiring Cafe. Platform ini bertujuan untuk mengatasi masalah “lowongan hantu” dan perantara pihak ketiga yang marak di platform seperti LinkedIn dan Indeed, dengan menyediakan filter canggih (seperti jabatan, fungsi, industri, pengalaman tahunan, peran manajemen/IC, dll.) untuk membantu pencari kerja menyaring lowongan dengan lebih efektif. Ini adalah proyek sampingan non-komersial dari seorang mahasiswa doktoral dan telah menerima pujian serta digunakan oleh komunitas (Sumber: Reddit r/ChatGPT)
