
Kata Kunci:Model AI, Pembelajaran Mendalam, Kecerdasan Buatan, Model Bahasa Besar, Pembelajaran Mesin, Agen Cerdas AI, Kendala Daya Komputasi, Aplikasi AI, Prompt Sistem Grok, Rekor Matematika AlphaEvolve, Agen Cerdas Gemini AI, Metode Pelatihan FP4, Analisis Tabel Sonnet 4.0
🔥 Fokus
xAI Merilis Prompt Sistem Grok ke Publik dan Memperkuat Mekanisme Peninjauan: Perusahaan xAI baru-baru ini mengumumkan bahwa mereka memutuskan untuk merilis prompt sistem Grok ke publik di GitHub. Keputusan ini diambil setelah robot respons Grok di platform X mendapatkan modifikasi prompt yang tidak sah dan menerbitkan pernyataan politik yang melanggar kebijakan dan nilai perusahaan. Langkah ini bertujuan untuk meningkatkan transparansi dan keandalan Grok sebagai AI yang mengejar kebenaran. xAI juga menyatakan akan memperkuat proses peninjauan kode internal dan menambahkan tim pemantau 24/7 untuk mencegah insiden serupa terulang kembali serta merespons lebih cepat masalah yang tidak tertangkap oleh sistem otomatis. (Sumber: xai, xai)
DeepMind AlphaEvolve Kembali Memecahkan Rekor Matematika, Kolaborasi AI dan Manusia Menunjukkan Paradigma Baru dalam Penelitian Ilmiah: AlphaEvolve dari DeepMind dua kali dalam seminggu memecahkan rekor matematika yang telah bertahan selama 18 tahun, menarik perhatian matematikawan seperti Tao Zhexuan. Tao Zhexuan berpendapat bahwa metode penelitian yang berbeda dapat saling melengkapi untuk mendorong kemajuan matematika, bukan sekadar “pemenang mengambil semua”. Peristiwa ini menyoroti potensi kolaborasi AI dan manusia dalam menciptakan model kemajuan baru di bidang teknologi dan sains, di mana AI tidak lagi hanya menjadi alat pengganti, tetapi mitra yang bersama manusia menjelajahi hal yang tidak diketahui dan mempercepat inovasi. (Sumber: Yuchenj_UW)

Google Bekerja Sama dengan Komunitas Open Source untuk Menyederhanakan Pembuatan Agen AI Berbasis Gemini: Google mengumumkan kerja samanya dengan kerangka kerja open source seperti LangChain LangGraph, crewAI, LlamaIndex, dan ComposIO, yang bertujuan untuk memudahkan pengembang membangun agen AI berbasis model Google Gemini. Langkah ini mencerminkan tekad Google untuk mendorong pengembangan ekosistem agen AI dengan menyediakan alat dan kerangka kerja yang lebih mudah digunakan, menurunkan hambatan pengembangan, dan mendorong lahirnya lebih banyak aplikasi inovatif. (Sumber: osanseviero, Hacubu)

Kemampuan Inferensi Model AI Mungkin Menghadapi Keterbatasan Daya Komputasi dalam Setahun: Meskipun model inferensi seperti o3 dari OpenAI menunjukkan peningkatan kinerja signifikan yang didorong oleh daya komputasi dalam jangka pendek (misalnya, daya komputasi pelatihan o3 adalah 10 kali lipat dari o1), lembaga penelitian seperti Epoch AI memprediksi bahwa jika daya komputasi terus meningkat 10 kali lipat setiap beberapa bulan, ekspansi daya komputasi untuk model inferensi kemungkinan akan mencapai “batas atas” paling lama dalam satu tahun. Pada saat itu, laju pertumbuhan daya komputasi mungkin melambat menjadi 4 kali lipat per tahun, dan kecepatan peningkatan model akan melambat seiringnya. Data pelatihan model seperti DeepSeek-R1 juga secara tidak langsung mengkonfirmasi skala konsumsi daya komputasi untuk pelatihan inferensi saat ini. Meskipun inovasi data dan algoritma masih dapat mendorong kemajuan, perlambatan pertumbuhan daya komputasi akan menjadi tantangan penting yang dihadapi industri AI. (Sumber: WeChat)

🎯 Tren
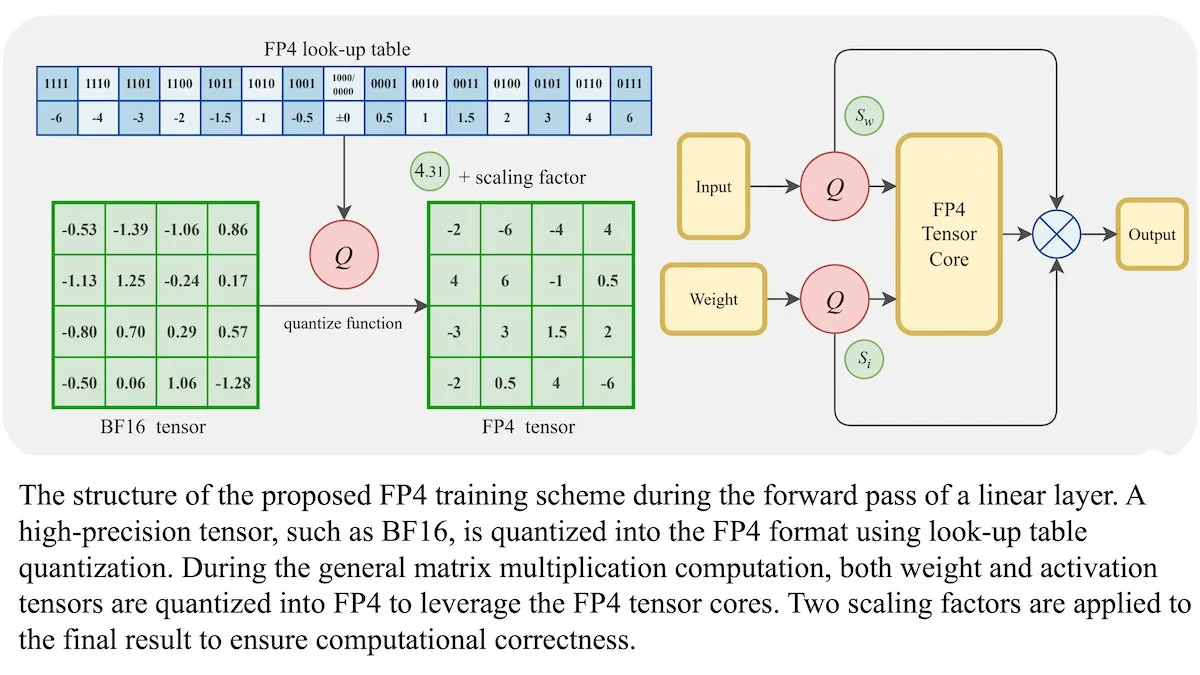
Metode Pelatihan LLM Baru: Presisi Floating-Point 4-bit (FP4) Dapat Mencapai Akurasi Setara BF16: Para peneliti menunjukkan bahwa Large Language Model (LLM) dapat dilatih menggunakan presisi floating-point 4-bit (FP4) tanpa mengorbankan akurasi. Dengan menggunakan FP4 untuk perkalian matriks, yang mencakup 95% dari beban komputasi pelatihan, kinerja yang sebanding dengan format BF16 yang umum digunakan berhasil dicapai. Tim memperkenalkan aproksimasi yang dapat didiferensiasi untuk mengatasi sifat non-diferensiabel dari kuantisasi, sehingga meningkatkan efisiensi pelatihan. Simulasi pada GPU Nvidia H100 menunjukkan bahwa FP4 berkinerja sebanding atau lebih baik dari BF16 dalam berbagai benchmark bahasa. (Sumber: DeepLearningAI)
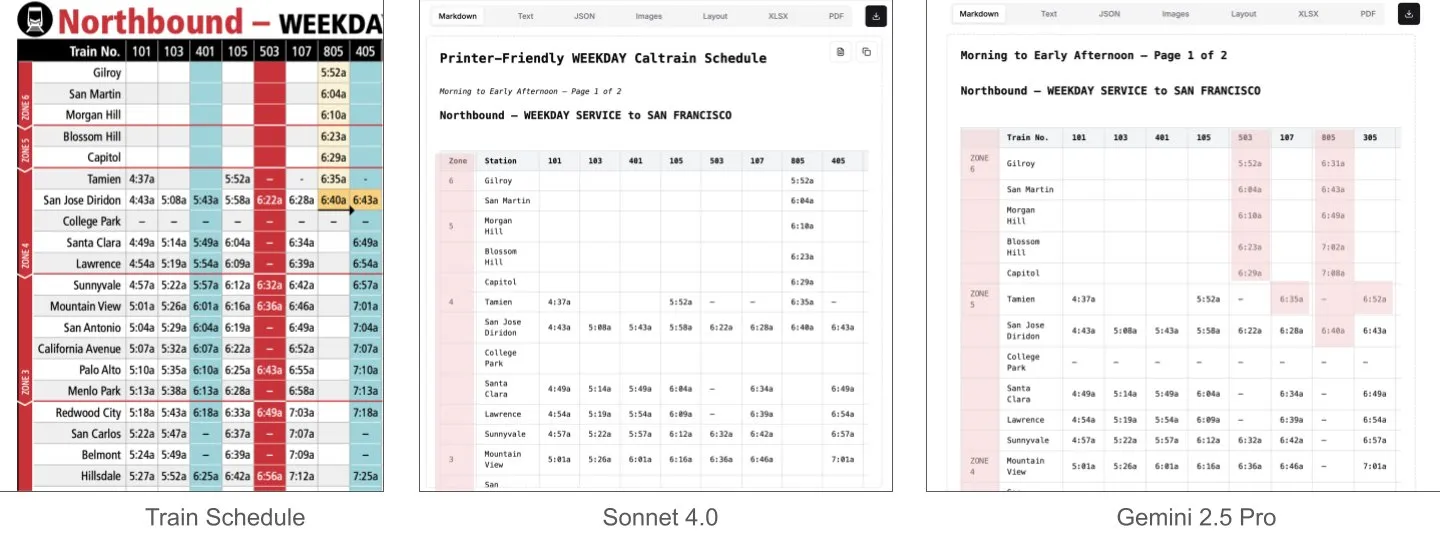
Sonnet 4.0 Lebih Unggul dari Gemini 2.5 Pro dalam Pemahaman Dokumen, Terutama Parsing Tabel: Jerry Liu dari LlamaIndex melalui pengujian komparatif menemukan bahwa Sonnet 4.0 dari Anthropic secara signifikan lebih unggul dalam kemampuan parsing tabel dibandingkan Gemini 2.5 Pro dari Google ketika memproses tangkapan layar jadwal Caltrain yang berisi data tabel padat. Gemini 2.5 Pro mengalami kesalahan penempatan kolom, sedangkan Sonnet 4.0 mampu merekonstruksi sebagian besar nilai dengan baik, hanya membuat kesalahan pada header tabel dan sejumlah kecil nilai lainnya. Meskipun Sonnet 4.0 saat ini lebih mahal dan lebih lambat, kinerjanya dalam inferensi visual dan parsing tabel sangat menonjol. (Sumber: jerryjliu0)
xAI, TWG Global, dan Palantir Berkolaborasi untuk Membentuk Ulang Aplikasi AI di Industri Jasa Keuangan: xAI mengumumkan kemitraan dengan TWG Global dan Palantir Technologies, yang bertujuan untuk bersama-sama merancang dan menerapkan solusi perusahaan berbasis AI guna membentuk ulang cara penyedia jasa keuangan mengadopsi AI dan memperluas teknologi. CEO Palantir Alex Karp dan Co-Chairman TWG Global Thomas Tull membahas dalam konferensi Milken Institute bagaimana kolaborasi ini akan mendorong inovasi AI di sektor keuangan. (Sumber: xai, xai)
Peningkatan Sensor pada DeepSeek-R1-0528 Setelah Pembaruan Memicu Diskusi Komunitas: Pengguna melaporkan bahwa DeepSeek-R1-0528 (model penuh 671B, FP8) secara signifikan lebih ketat dalam hal sensor konten dibandingkan dengan versi R1 sebelumnya. Misalnya, ketika ditanya tentang peristiwa sejarah yang sensitif, model baru akan memberikan jawaban yang lebih menghindar dan resmi, sedangkan R1 versi lama dapat memberikan informasi yang lebih langsung. Perubahan ini memicu diskusi di komunitas mengenai keterbukaan model, standar sensor, serta potensi dampaknya terhadap penelitian dan aplikasi, terutama dalam skenario yang bergantung pada model untuk mendapatkan informasi yang tidak disensor. (Sumber: Reddit r/LocalLLaMA)
Huawei Merilis Model Pangu Embedded, Menggabungkan Arsitektur Kognitif Sistem Ganda Berpikir Cepat dan Lambat: Tim Pangu Huawei, berdasarkan NPU Ascend, mengusulkan model Pangu Embedded, yang secara inovatif mengintegrasikan mode inferensi ganda “berpikir cepat” dan “berpikir lambat”. Model ini, melalui pelatihan dua tahap (distilasi iteratif dan penggabungan model, sistem hadiah dinamis multi-sumber RL) dan arsitektur kognitif yang dikendalikan pengguna atau beralih secara otomatis berdasarkan persepsi kesulitan masalah, bertujuan untuk mencapai keseimbangan dinamis antara efisiensi inferensi dan kedalaman, mengatasi kontradiksi model besar tradisional yang berpikir berlebihan pada masalah sederhana dan kurang berpikir pada tugas kompleks. (Sumber: WeChat)

Model Dunia Video Baru Menggabungkan SSM dan Model Difusi, Mewujudkan Konteks Panjang dan Simulasi Interaktif: Peneliti dari Stanford University, Princeton University, dan Adobe Research mengusulkan model dunia video baru yang menggabungkan State Space Model (SSM, khususnya skema pemindaian blok-demi-blok Mamba) dan model difusi video. Model ini mengatasi masalah keterbatasan panjang konteks dan kesulitan simulasi konsistensi jangka panjang pada model video yang ada. Model ini dapat secara efektif menangani dinamika waktu kausal, melacak status dunia, dan menjamin fidelitas generasi melalui mekanisme atensi lokal bingkai, menyediakan jalur baru untuk generasi video dengan panjang tak terbatas, real-time, dan konsisten dalam aplikasi interaktif (seperti game). (Sumber: WeChat)

ByteDance Merilis Model Dasar Multimodal Open Source BAGEL, Mendukung Pemahaman dan Generasi Teks, Gambar, dan Video: ByteDance merilis model BAGEL (ByteDance Agnostic Generation and Empathetic Language model), sebuah model dasar multimodal terpadu yang mampu menangani tugas pemahaman dan generasi teks, gambar, dan video secara bersamaan. Versi BAGEL-7B-MoT memiliki total 140 miliar parameter (7 miliar parameter aktif) dan membutuhkan sekitar 30G VRAM saat berjalan dengan kapasitas penuh. Pengguna dapat mencoba dan menerapkan model ini melalui Hugging Face Demo dan alamat model yang disediakan, untuk mewujudkan fungsi seperti pengeditan gambar dan konversi gaya. (Sumber: WeChat)
FLUX.1 Kontext Dirilis: Menggabungkan Pengeditan dan Generasi Teks-Gambar, Kecepatan Meningkat 8 Kali Lipat: Black Forest Labs (BFL) merilis model gambar generasi baru FLUX.1 Kontext. Seri model ini mendukung generasi gambar dalam konteks, mampu memproses prompt teks dan gambar secara bersamaan, serta mewujudkan pengeditan teks-gambar instan dan generasi teks-ke-gambar. FLUX.1 Kontext menunjukkan kinerja luar biasa dalam konsistensi karakter, pemahaman konteks, dan pengeditan lokal. Generasi gambar resolusi 1024×1024 hanya membutuhkan 3-5 detik, dengan kecepatan hingga 8 kali lipat dari GPT-Image-1, dan mendukung pengeditan iteratif multi-putaran. Model ini didasarkan pada rectified flow transformer dan teknik sampling distilasi difusi adversarial. (Sumber: WeChat, WeChat)

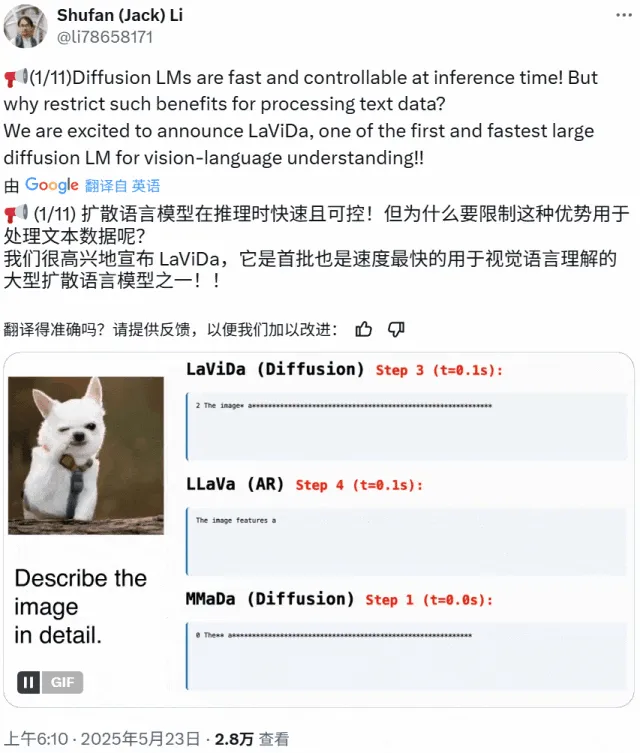
LaViDa: VLM Pemahaman Multimodal Baru Berbasis Model Difusi: Peneliti dari University of California Los Angeles, Panasonic, Adobe, dan Salesforce meluncurkan LaViDa (Large Vision-Language Diffusion Model with Masking), sebuah model visual-bahasa (VLM) berbasis model difusi. Berbeda dengan VLM tradisional berbasis LLM autoregresif, LaViDa menggunakan proses difusi diskrit untuk menangani generasi teks, yang secara teoritis memiliki paralelisme yang lebih baik, keseimbangan kecepatan dan kualitas, serta kemampuan untuk menangani konteks dua arah. Model ini mengintegrasikan fitur visual melalui encoder visual dan menggunakan alur pelatihan dua tahap (pra-pelatihan untuk menyelaraskan ruang laten visual dan DLM, fine-tuning untuk mencapai kepatuhan instruksi). Eksperimen menunjukkan bahwa LaViDa menunjukkan daya saing dalam berbagai tugas seperti pemahaman visual, penalaran, OCR, dan tanya jawab ilmiah. (Sumber: WeChat)
Model AI Menghadapi Risiko “Degradasi Model” Akibat Mengonsumsi Terlalu Banyak Data Buatan AI: Penelitian menunjukkan bahwa jika model AI mengonsumsi terlalu banyak data yang dihasilkan oleh AI lain selama proses pelatihan, fenomena “degradasi model” (model collapse) dapat terjadi, menyebabkan model menjadi lebih kacau dan tidak dapat diandalkan. Bahkan jika model diizinkan untuk mencari informasi secara online, masalah ini dapat diperburuk karena internet dipenuhi dengan konten buatan AI berkualitas rendah. Fenomena ini pertama kali diusulkan pada tahun 2023 dan kini semakin nyata, menimbulkan tantangan bagi pengembangan jangka panjang model AI dan kontrol kualitas data. (Sumber: Reddit r/ArtificialInteligence)

Prosesor AMD Octa-core Ryzen AI Max Pro 385 Muncul di Geekbench, Menandakan Chip Strix Halo Terjangkau Akan Masuk Pasar: Prosesor baru AMD octa-core Ryzen AI Max Pro 385 ditemukan di Geekbench, yang mungkin berarti chip AI dengan nama kode Strix Halo yang lebih terjangkau akan segera memasuki pasar. Pengguna mengharapkan chip semacam ini dapat menyediakan lebih banyak jalur PCIe untuk mendukung pengaturan hybrid, memenuhi kebutuhan untuk menambahkan kartu ekspansi dan perangkat USB4. Meskipun memori on-board dapat diterima karena keunggulan kecepatannya, skalabilitas tetap menjadi fokus perhatian. (Sumber: Reddit r/LocalLLaMA)

Perusahaan 1X Meluncurkan Prototipe Robot Humanoid Terbaru Neo Gamma: Perusahaan robotika Norwegia, 1X, merilis prototipe robot humanoid terbarunya, Neo Gamma. Peluncuran robot ini merupakan kemajuan lain dalam teknologi robot humanoid di bidang otomatisasi dan kecerdasan buatan, menunjukkan potensi aplikasinya di berbagai skenario masa depan seperti industri dan layanan. (Sumber: Ronald_vanLoon)
Konsumsi Listrik AI Diperkirakan Akan Segera Melebihi Penambangan Bitcoin: Konsumsi listrik model AI diperkirakan akan meningkat pesat, mungkin segera mencapai hampir setengah dari listrik pusat data, dengan jumlah konsumsi energi yang sebanding dengan penggunaan nasional beberapa negara. Peningkatan permintaan chip AI memberikan tekanan pada jaringan listrik AS, mendorong pembangunan proyek bahan bakar fosil dan energi nuklir baru. Karena kurangnya transparansi dan kompleksitas sumber listrik regional, pelacakan dampak emisi karbon AI secara akurat menjadi sulit. (Sumber: Reddit r/ArtificialInteligence)

🧰 Alat
e-library-agent: Agen Manajemen Buku Pribadi yang Dibuat dengan LlamaIndex: Clelia Bertelli menggunakan alur kerja LlamaIndex untuk membangun alat bernama e-library-agent, yang bertujuan membantu pengguna mengatur, mencari, dan menjelajahi koleksi bacaan pribadi mereka. Alat ini mengintegrasikan teknologi seperti ingest-anything, Qdrant, Linkup_platform, FastAPI, dan Gradio, mengatasi masalah “sudah dibaca tetapi tidak dapat ditemukan”, dan meningkatkan efisiensi manajemen pengetahuan pribadi. (Sumber: jerryjliu0, jerryjliu0)
Qdrant Memamerkan Solusi Pembuatan Chatbot RAG Hibrida Tingkat Lanjut: Qdrant bersama TRJ_0751 mendemonstrasikan cara membangun chatbot RAG (Retrieval Augmented Generation) dukungan pelanggan hibrida tingkat lanjut menggunakan miniCOIL, LangGraph, dan DeepSeek-R1. Solusi ini memanfaatkan miniCOIL untuk meningkatkan kemampuan kesadaran semantik dari pencarian jarang (sparse retrieval), LangGraph (dari LangChainAI) untuk mengatur alur hibrida (termasuk MMR dan re-ranking), Opik untuk melacak dan mengevaluasi setiap langkah alur, dan DeepSeek-R1 (dari SambaNovaAI) untuk memberikan jawaban dengan latensi rendah dan fokus. (Sumber: qdrant_engine, hwchase17)
Google Merilis Aplikasi AI Edge Gallery, Mendukung Pengoperasian Model AI Secara Lokal: Google meluncurkan aplikasi bernama AI Edge Gallery, yang memungkinkan pengguna mengunduh dan menjalankan model AI di perangkat lokal mereka. Ini berarti pengguna dapat menggunakan alat AI untuk generasi gambar, tanya jawab, atau penulisan kode tanpa koneksi internet, sekaligus menjamin privasi data. Aplikasi ini saat ini tersedia sebagai versi pratinjau dan mendukung model seperti Gemma 3n. (Sumber: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

Perplexity Labs Mendukung Pencarian Lintas Dokumen SEC EDGAR, Memperkuat Kemampuan Riset Keuangan: Perplexity Labs menambahkan fitur baru yang mendukung pengguna untuk mencari dokumen perusahaan dalam database EDGAR Komisi Sekuritas dan Bursa AS (SEC). Pembaruan ini bertujuan untuk lebih memperkuat aplikasinya di bidang riset keuangan, menyediakan cara yang lebih mudah bagi pengguna untuk mengambil dan menganalisis informasi perusahaan publik. (Sumber: AravSrinivas)
Meituan Merilis Alat AI Tanpa Kode NoCode, Bahasa Alami Dapat Membangun Aplikasi: Meituan merilis alat AI tanpa kode NoCode, yang memungkinkan pengguna tanpa pengalaman pemrograman untuk membuat alat peningkatan efisiensi pribadi, prototipe produk, halaman interaktif, bahkan game sederhana melalui percakapan bahasa alami. NoCode mendukung pratinjau real-time, modifikasi parsial, dan penerapan sekali klik, bertujuan untuk menurunkan hambatan pengembangan dan memungkinkan lebih banyak orang melepaskan kreativitas mereka. Alat ini didukung oleh kolaborasi beberapa model AI, termasuk model khusus apply dengan parameter 7B yang dikembangkan sendiri oleh Meituan, dan telah dioptimalkan untuk data kode nyata internal Meituan. (Sumber: WeChat)
VAST Meningkatkan Tripo Studio, Menambahkan Fitur Pemodelan AI seperti Segmentasi Komponen Cerdas dan Kuas Ajaib: Perusahaan rintisan model 3D besar VAST melakukan peningkatan penting pada alat pemodelan AI-nya, Tripo Studio, dengan memperkenalkan empat fungsi inti: segmentasi komponen cerdas, kuas ajaib tekstur, generasi model low-poly cerdas, dan rigging tulang otomatis untuk semua objek. Fungsi-fungsi ini bertujuan untuk mengatasi masalah dalam alur kerja pemodelan 3D tradisional, seperti kesulitan pengeditan komponen, perbaikan cacat tekstur yang memakan waktu, optimasi model high-poly yang rumit, dan masalah kompleksitas rigging tulang, sehingga secara signifikan meningkatkan efisiensi dan kemudahan penggunaan dalam pembuatan konten 3D, serta menurunkan hambatan masuk bagi pengguna non-profesional. (Sumber: 量子位)
Hugging Face Merilis Dua Robot Humanoid Open Source HopeJR dan Reachy Mini dengan Harga Terjangkau: Hugging Face, bekerja sama dengan The Robot Studio dan Pollen Robotics, meluncurkan dua robot humanoid open source: HopeJR ukuran penuh (sekitar $3000) dan Reachy Mini versi desktop (sekitar $250-$300). Langkah ini bertujuan untuk mendorong普及 dan penelitian terbuka teknologi robotika, memungkinkan siapa saja untuk merakit, memodifikasi, dan mempelajari prinsip-prinsip robotika. HopeJR memiliki kemampuan berjalan dan menggerakkan lengan, serta dapat dikendalikan dari jarak jauh melalui sarung tangan; Reachy Mini dapat menggerakkan kepala, berbicara, dan mendengar, digunakan untuk menguji aplikasi AI. (Sumber: WeChat)

Kerangka Kerja Open Source Evolusi Mandiri Agen AI Pertama di Dunia, EvoAgentX, Dirilis: Tim peneliti dari University of Glasgow, Inggris, merilis EvoAgentX, kerangka kerja open source evolusi mandiri agen AI pertama di dunia. Kerangka kerja ini bertujuan untuk mengatasi kompleksitas pembangunan dan optimasi sistem multi-agen AI. Dengan memperkenalkan mekanisme evolusi mandiri, kerangka kerja ini mendukung pembangunan alur kerja sekali klik dan memungkinkan sistem untuk terus mengoptimalkan struktur dan kinerjanya sesuai dengan perubahan lingkungan dan tujuan selama berjalan. EvoAgentX berharap dapat mendorong sistem multi-agen dari debugging manual menuju evolusi otonom, menyediakan platform eksperimen dan penerapan terpadu bagi peneliti dan insinyur. (Sumber: WeChat)

Perplexity Labs Meluncurkan Fitur Baru, Ekspor Data Keuangan Perusahaan ke CSV Secara Gratis: Perplexity Labs mengumumkan bahwa pengguna sekarang dapat mengekspor data dari bagian keuangan perusahaan mana pun di halaman keuangannya ke format CSV secara gratis. Sebelumnya, fitur serupa di platform seperti Yahoo Finance biasanya memerlukan langganan berbayar. Perplexity menyatakan bahwa mereka akan menambahkan lebih banyak data historis di masa mendatang. (Sumber: AravSrinivas)
📚 Pembelajaran
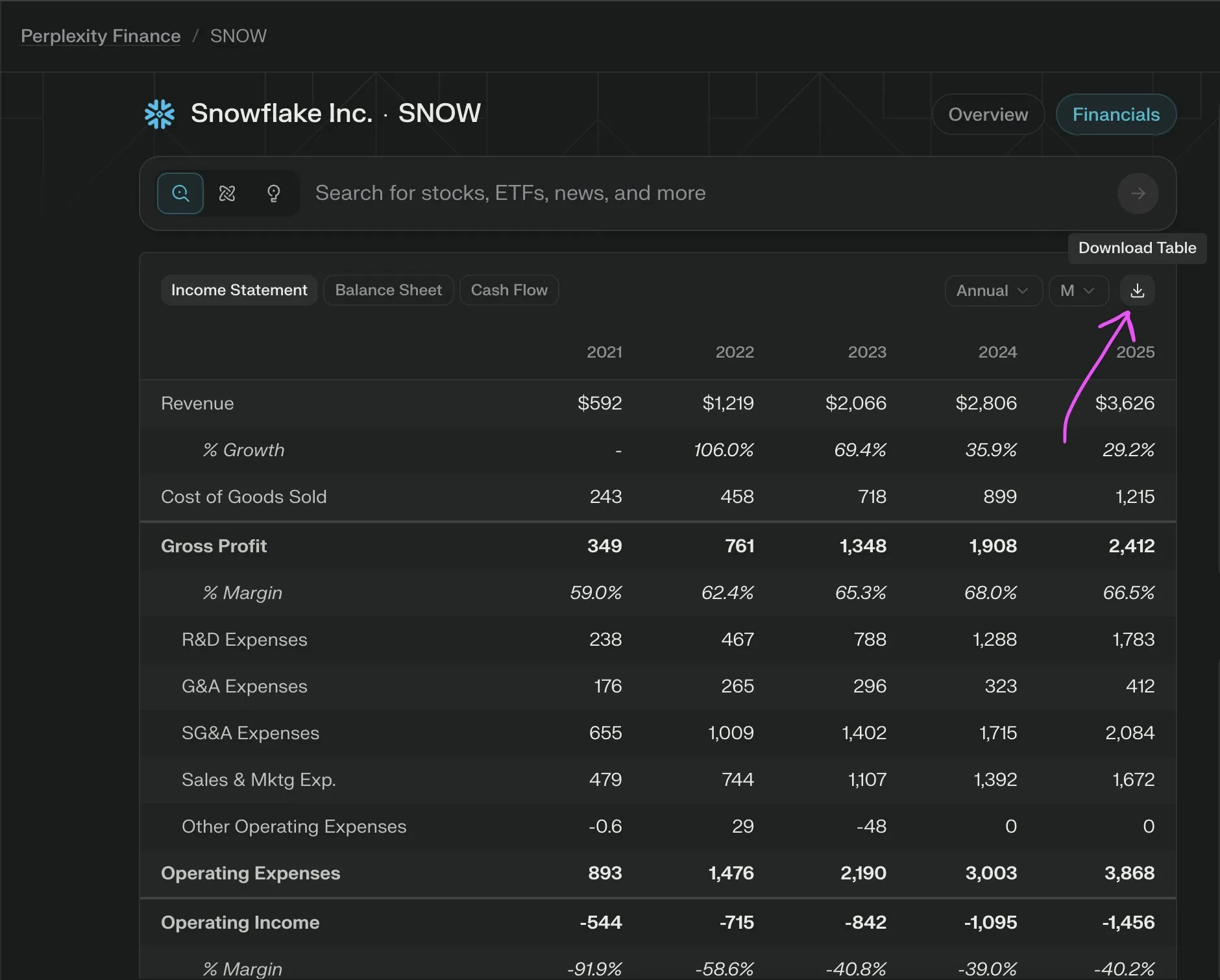
Kiat Pemanggilan Fungsi LLM: Perjelas Konteks, Urutan & Batasan, Hindari CoT dan Halusinasi: _philschmid berbagi saran untuk pemanggilan fungsi pada model inferensi seperti Gemini 2.5 atau OpenAI o3. Poin-poin penting meliputi: mengatur konteks keseluruhan (misalnya, prompt peran), mendefinisikan urutan pemanggilan fungsi yang jelas untuk tugas-tugas kompleks, dan menetapkan batasan yang jelas untuk penggunaan alat (kapan harus digunakan/tidak digunakan). Perlu dijelaskan secara rinci kapan fungsi harus dipanggil dan bagaimana parameter harus disusun. Hindari prompt CoT eksplisit karena model akan melakukan inferensi internal; manfaatkan fitur API untuk mempertahankan pemikiran di antara pemanggilan alat atau gunakan “thinking_tools”. Selain itu, terapkan instruksi negatif yang jelas (misalnya, “jangan menjanjikan pemanggilan di masa depan”) untuk mencegah halusinasi pemanggilan fungsi. (Sumber: _philschmid)
12 Kiat Pemrograman AI Profesional Dibagikan: Cline membagikan 12 kiat pemrograman AI dari pertemuan praktik terbaik rekayasa baru-baru ini, menekankan perencanaan, penggunaan model canggih untuk tugas kompleks, perhatian pada jendela konteks, pembuatan file aturan, kejelasan niat, memandang AI sebagai kolaborator, memanfaatkan bank memori, mempelajari strategi manajemen konteks, dan membangun berbagi pengetahuan tim. Tujuan utamanya adalah membangun perangkat lunak lebih cepat dan lebih baik, menggunakan AI sebagai penguat kemampuan, bukan pengganti. (Sumber: cline, cline)

Saran Optimasi Instruksi Kreatif Setelah Pembaruan DeepSeek-R1-0528: Menanggapi pembaruan model DeepSeek-R1-0528 (68,5 miliar parameter, konteks 128K, kemampuan kode mendekati o3), seorang kreator konten membagikan 10 instruksi kreatif yang dioptimalkan. Saran meliputi pemanfaatan kemampuan inferensi super panjang 30-60 menit untuk pemikiran mendalam, pemrosesan teks panjang 128K, optimasi generasi kode, penyesuaian prompt sistem, peningkatan kualitas tugas menulis, verifikasi anti-halusinasi, terobosan hambatan penulisan kreatif, analisis diagnosis masalah, integrasi pembelajaran pengetahuan, dan optimasi naskah komersial. Menekankan konkretisasi instruksi, pemanfaatan penuh konteks panjang, penggunaan inferensi mendalam secara bijak, membangun memori percakapan, dan verifikasi informasi penting. (Sumber: WeChat)
Kerangka Kerja RM-R1: Membentuk Ulang Model Imbalan sebagai Tugas Inferensi, Meningkatkan Interpretasi dan Kinerja: Tim peneliti dari University of Illinois Urbana-Champaign mengusulkan kerangka kerja RM-R1, yang mendefinisikan ulang pembangunan Model Imbalan (Reward Models) sebagai tugas inferensi. Kerangka kerja ini, dengan memperkenalkan mekanisme “Rantai Rubrik Evaluasi” (Chain-of-Rubrics, CoR), memungkinkan model untuk menghasilkan kriteria evaluasi terstruktur dan proses inferensi sebelum memberikan penilaian preferensi, sehingga meningkatkan interpretasi model imbalan dan akurasi evaluasi pada tugas-tugas kompleks (seperti matematika, pemrograman). RM-R1, melalui distilasi inferensi dan pelatihan pembelajaran penguatan dua tahap, menunjukkan kinerja yang lebih unggul dari model open source dan closed source yang ada dalam beberapa benchmark model imbalan. (Sumber: WeChat)

Analisis Mendalam Protokol Konteks Model (MCP): Menyederhanakan Integrasi AI dengan Layanan Eksternal: Protokol Konteks Model (MCP), sebagai standar terbuka, bertujuan untuk mengatasi masalah fragmentasi saat model AI berintegrasi dengan sumber data eksternal dan alat (seperti Slack, Gmail). Melalui antarmuka sistem terpadu (mendukung protokol STDIO dan SSE), MCP memungkinkan pengembang untuk membangun klien MCP (seperti Claude desktop, Cursor IDE) dan server MCP (mengoperasikan database, sistem file, memanggil API), menyederhanakan jaringan adaptasi “M×N” yang kompleks menjadi mode “M+N”, mewujudkan integrasi plug-and-play antara AI dan layanan eksternal. Tan Yu, mitra Fabarta (枫清科技), berpendapat bahwa nilai MCP terletak pada penyediaan kemampuan koneksi dasar, dan komersialisasinya bergantung pada nilai spesifik yang disediakan oleh sistem di baliknya, misalnya, melalui agen cerdas kantor super Fabarta yang mengintegrasikan MCP Server untuk menyederhanakan alur kerja pengguna. (Sumber: WeChat)

Agentic ROI: Metrik Kunci untuk Mengukur Kegunaan Agen Model Besar: Shanghai Jiao Tong University bekerja sama dengan University of Science and Technology of China (USTC) mengusulkan Agentic ROI (Return on Investment Agen) sebagai metrik inti untuk mengukur kepraktisan agen model besar dalam skenario nyata. Metrik ini secara komprehensif mempertimbangkan kualitas informasi, biaya waktu pengguna dan agen, serta biaya ekonomi. Penelitian menunjukkan bahwa agen saat ini lebih banyak diterapkan di bidang dengan biaya sumber daya manusia tinggi seperti penelitian ilmiah dan pemrograman, tetapi di skenario sehari-hari seperti e-commerce dan pencarian, Agentic ROI lebih rendah karena nilai marjinal yang tidak signifikan dan biaya interaksi yang tinggi. Mengoptimalkan Agentic ROI memerlukan jalur pengembangan “zig-zag”, yaitu “pertama-tama meningkatkan kualitas informasi secara masif, kemudian meringankan biaya”. (Sumber: WeChat)
💼 Bisnis
Pendapatan Tahunan Anthropic Melonjak hingga $3 Miliar, Didorong oleh Permintaan AI Perusahaan: Menurut dua sumber, pendapatan tahunan Anthropic telah meningkat dari $1 miliar menjadi $3 miliar hanya dalam waktu lima bulan. Pertumbuhan signifikan ini terutama didorong oleh permintaan kuat dari perusahaan terhadap AI, khususnya di bidang generasi kode. Hal ini menunjukkan bahwa pasar tingkat perusahaan menunjukkan peningkatan pesat dalam penerapan dan kemauan membayar untuk model AI canggih seperti seri Claude dari Anthropic. (Sumber: cto_junior, scaling01, Reddit r/ArtificialInteligence)
Laporan Keuangan Q1 Tahun Fiskal 2026 Nvidia: Total Pendapatan $44,1 Miliar, Bisnis Pusat Data Menyumbang Hampir 90%: Nvidia merilis laporan keuangan kuartal pertama tahun fiskal 2026 yang berakhir pada 27 April 2025, dengan total pendapatan mencapai $44,1 miliar, meningkat 12% secara kuartalan dan 69% secara tahunan. Pendapatan bisnis pusat data mencapai $39,1 miliar, menyumbang 88,91%, meningkat 73% secara tahunan. Pendapatan bisnis game mencapai $3,8 miliar, mencetak rekor tertinggi. Meskipun chip H20 terpengaruh oleh pembatasan ekspor, yang mengakibatkan penurunan nilai persediaan sebesar $4,5 miliar dan biaya kewajiban pembelian, serta diperkirakan akan kehilangan pendapatan sebesar $8 miliar pada Q2 karena hal ini, kinerja keseluruhan tetap kuat. Produk baru seperti Blackwell Ultra diharapkan dapat lebih mendorong pertumbuhan. (Sumber: 量子位, WeChat)

Meta Merestrukturisasi Tim AI, Sebagian Besar Penulis Inti Llama Mengundurkan Diri, Status FAIR Menjadi Perhatian: Meta mengumumkan restrukturisasi tim AI, membaginya menjadi tim produk AI yang dipimpin oleh Connor Hayes dan departemen dasar AGI yang dipimpin bersama oleh Ahmad Al-Dahle dan Amir Frenkel. Departemen penelitian AI dasar, FAIR, tetap relatif independen tetapi beberapa tim multimedia digabungkan. Penyesuaian ini bertujuan untuk meningkatkan otonomi dan kecepatan pengembangan. Namun, dari 14 penulis inti model Llama, hanya 3 yang tersisa, sebagian besar telah mengundurkan diri atau bergabung dengan pesaing (seperti Mistral AI). Ditambah dengan respons yang kurang memuaskan setelah rilis Llama 4, serta penyesuaian internal pada alokasi daya komputasi dan arah penelitian dan pengembangan, hal ini menimbulkan kekhawatiran tentang kemampuan Meta untuk mempertahankan posisi terdepan di bidang AI open source dan perkembangan FAIR di masa depan. (Sumber: WeChat)

🌟 Komunitas
Diskusi Penyelarasan AI: Dapatkah Norma Lunak Mempertahankan Kekuasaan Manusia di Era AGI?: Ryan Greenblatt membahas pandangan yang diajukan oleh Dwarkesh Patel, yang skeptis terhadap penyelarasan AI dan malah berharap melalui norma lunak, manusia masih dapat mempertahankan sebagian kekuasaan dan ruang hidup setelah AGI (Artificial General Intelligence) menguasai kekuasaan keras. Greenblatt berpendapat bahwa jika AI memiliki sensitivitas cakupan (scope sensitive) dan kemampuan untuk merebut kekuasaan, maka upaya untuk mengungkap ketidakselarasannya atau membuatnya bekerja untuk manusia melalui transaksi atau kontrak kemungkinan besar tidak akan berhasil. Selain itu, fine-tuning yang murah, penyelarasan yang ditingkatkan oleh manusia, dan replikasi bebas membuat kontrol manusia atas properti menjadi sangat tidak stabil sebelum masalah penyelarasan terpecahkan. Begitu muncul AI yang selaras atau tenaga kerja AI yang lebih murah, manusia akan memprioritaskan penggunaannya, yang akan sangat mendorong AI yang tidak selaras untuk merebut kekuasaan. (Sumber: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

Pendapat Bapak Redis bahwa Pemrograman AI Jauh di Bawah Programer Manusia Memicu Resonansi dan Diskusi di Kalangan Pengembang: Salvatore Sanfilippo (Antirez), pencipta Redis, berbagi pengalaman pengembangannya, berpendapat bahwa AI saat ini dalam pemrograman, meskipun praktis, jauh di bawah programer manusia, terutama dalam hal berpikir di luar kebiasaan dan merancang solusi yang aneh namun efektif. Ia membandingkan AI dengan “asisten yang cukup pintar” yang membantu memvalidasi ide. Pandangan ini memicu diskusi hangat di kalangan pengembang, banyak yang setuju bahwa AI dapat berfungsi sebagai “bebek karet” untuk membantu berpikir, tetapi menunjukkan bahwa AI terlalu percaya diri dan mudah menyesatkan pengembang junior. Beberapa pengembang menyatakan bahwa jawaban salah yang dihasilkan AI justru memotivasi mereka untuk membuat kode secara manual. Diskusi menekankan pentingnya pengalaman dalam memanfaatkan AI secara efektif, serta potensi dampak negatif AI pada pemula pemrograman. (Sumber: WeChat)

Hubungan DeepMind dan Google Research Kembali Menjadi Perdebatan: Perdebatan Merek vs Kontribusi Inovasi Aktual: Faruk Guney memposting utas panjang di Twitter yang mengomentari hubungan antara DeepMind dan Google Research, berpendapat bahwa terobosan inti dalam revolusi AI saat ini (seperti arsitektur Transformer) terutama berasal dari Google Research, bukan DeepMind setelah diakuisisi oleh Google. Ia menunjukkan bahwa meskipun AlphaFold adalah pencapaian DeepMind, hal itu juga tidak terlepas dari sumber daya komputasi dan infrastruktur penelitian Google, dan kontributor intinya adalah ilmuwan-insinyur seperti John Jumper dan Pushmeet Kohli. Guney berpendapat bahwa penggabungan Google Research ke dalam DeepMind lebih merupakan penyesuaian merek dan struktur organisasi, yang melibatkan politik perusahaan yang kompleks dan mungkin menutupi sumber inovasi yang sebenarnya. Ia menekankan bahwa banyak terobosan AI adalah hasil penelitian tim selama bertahun-tahun, bukan hanya dikreditkan kepada beberapa tokoh terkenal atau merek. (Sumber: farguney, farguney)
Perubahan Pekerjaan dan Keterampilan di Era AI Memicu Kekhawatiran dan Diskusi: Di media sosial, diskusi tentang dampak AI terhadap pasar kerja terus berlanjut. Di satu sisi, ada pandangan bahwa AI akan menyebabkan pengangguran massal, seperti yang pernah diungkapkan oleh CEO Anthropic, mendorong orang untuk memikirkan cara mengatasinya. Di sisi lain, ada juga suara yang menyatakan bahwa AI terutama meningkatkan produktivitas dan kecil kemungkinannya menyebabkan pengangguran massal, kecuali jika terjadi resesi ekonomi yang parah, karena permintaan konsumen bergantung pada pekerjaan dan pendapatan. Sementara itu, beberapa pengguna berbagi pengalaman pribadi kehilangan pekerjaan karena AI (misalnya, bos menggunakan ChatGPT untuk menggantikan karyawan). Untuk masa depan, diskusi mengarah pada perlunya menabung, mempelajari keterampilan praktis, beradaptasi dengan kemungkinan penurunan pendapatan, dan bagaimana sistem pendidikan menyesuaikan diri untuk menumbuhkan keterampilan yang dibutuhkan di era AI, seperti berpikir kritis dan kemampuan memanfaatkan alat AI secara efektif. (Sumber: Reddit r/ArtificialInteligence, Reddit r/artificial)

Ketergantungan Berlebihan pada ChatGPT Memicu Kekhawatiran Penurunan Kemampuan Berpikir: Seorang pengguna Reddit memposting kekhawatirannya bahwa pacarnya terlalu bergantung pada ChatGPT untuk pengambilan keputusan, mendapatkan pandangan, dan ide kreatif, berpendapat bahwa ini dapat menyebabkan hilangnya kemampuan berpikir mandiri dan orisinalitasnya. Postingan tersebut memicu diskusi luas, sebagian komentator setuju dengan kekhawatiran ini, berpendapat bahwa ketergantungan berlebihan pada alat AI memang dapat melemahkan pemikiran individu; komentator lain berpendapat bahwa AI hanyalah alat, seperti ensiklopedia atau mesin pencari di masa lalu, kuncinya adalah bagaimana pengguna memanfaatkannya, apakah sebagai titik awal berpikir atau pengganti sepenuhnya. Ada juga komentar yang menyarankan untuk mengatasi hal ini melalui komunikasi, bimbingan, dan menunjukkan keterbatasan AI. (Sumber: Reddit r/ChatGPT)
Tantangan AI di Bidang Pendidikan: Profesor Mengeluh Mahasiswa Menyalahgunakan ChatGPT, Menyerukan Pengembangan Kemampuan Berpikir Sejati: Seorang profesor sejarah kuno memposting di Reddit bahwa penyalahgunaan ChatGPT telah sangat memengaruhi pengajarannya, esai yang dikumpulkan mahasiswa dipenuhi dengan “sampah kosong” yang dihasilkan AI, bahkan mengandung kesalahan faktual, yang membuatnya meragukan apakah mahasiswa benar-benar belajar. Ia menekankan bahwa inti dari pendidikan humaniora adalah menumbuhkan pengetahuan baru, wawasan kreatif, dan pemikiran mandiri, bukan sekadar mengulang informasi yang sudah ada. Postingan ini memicu perdebatan hangat, para komentator mengusulkan berbagai strategi penanganan, seperti beralih ke laporan lisan, esai tulis tangan di kelas, meminta mahasiswa menyerahkan meta-analisis proses penggunaan AI, atau mengintegrasikan AI ke dalam pengajaran dan meminta mahasiswa mengkritik output AI. (Sumber: Reddit r/ChatGPT)
Kernel Buatan AI Secara Tak Terduga Melampaui Kernel Pakar PyTorch, Tim Tionghoa Stanford Mengungkap Kemungkinan Baru: Tim dari Stanford University yang terdiri dari Anne Ouyang, Azalia Mirhoseini, dan Percy Liang, saat mencoba menghasilkan data sintetis untuk melatih model generasi kernel, secara tak terduga menemukan bahwa kernel buatan AI mereka yang ditulis murni dalam CUDA-C mendekati atau bahkan melampaui kinerja kernel FP32 bawaan PyTorch yang telah dioptimalkan oleh para ahli. Misalnya, pada perkalian matriks, mencapai 101,3% kinerja PyTorch, dan pada konvolusi dua dimensi mencapai 179,9%. Tim menggunakan optimasi iteratif multi-putaran, menggabungkan ide optimasi penalaran bahasa alami dan strategi pencarian perluasan cabang, serta memanfaatkan model OpenAI o3 dan Gemini 2.5 Pro. Hasil ini menunjukkan bahwa melalui pencarian cerdas dan eksplorasi paralel, AI berpotensi membuat terobosan dalam generasi kernel komputasi kinerja tinggi. (Sumber: WeChat)

💡 Lainnya
Kekuatan Lobi Industri AI yang Besar Menarik Perhatian Max Tegmark: Profesor MIT Max Tegmark menunjukkan bahwa jumlah pelobi industri AI di Washington dan Brussels telah melampaui gabungan jumlah pelobi industri bahan bakar fosil dan industri tembakau. Fenomena ini mengungkapkan pengaruh industri AI yang semakin meningkat dalam pembuatan kebijakan, serta investasi aktifnya dalam membentuk lingkungan regulasi, yang dapat berdampak besar pada arah pengembangan teknologi AI, norma etika, dan lanskap persaingan pasar. (Sumber: Reddit r/artificial)

AI Dapat Mensimulasikan Serangan Bioterorisme Melalui Deepfake, Menimbulkan Ancaman Kesehatan Masyarakat Jenis Baru: Artikel STAT News menunjukkan bahwa selain risiko senjata biologi yang dibantu AI, penggunaan teknologi deepfake untuk mensimulasikan serangan bioterorisme juga dapat menimbulkan ancaman serius. Terutama di antara negara-negara yang terlibat konflik militer, informasi palsu semacam ini dapat memicu kepanikan, salah penilaian, dan eskalasi militer yang tidak perlu. Karena penyelidikan kemungkinan akan dipimpin oleh lembaga penegak hukum atau militer, bukan tim kesehatan masyarakat atau teknologi, mereka mungkin lebih cenderung mempercayai keaslian serangan, sehingga sulit untuk membantahnya secara efektif. (Sumber: Reddit r/ArtificialInteligence)
Perdebatan Apakah Masih Perlu Mengambil Gelar Teknik di Era AI: Komunitas membahas nilai mengambil gelar teknik di era AI. Satu pihak berpendapat bahwa AI dapat menggantikan banyak tugas teknik tradisional, sehingga menurunkan nilai gelar tersebut. Pihak lain berpendapat bahwa pemikiran sistem, kemampuan memecahkan masalah, dan dasar matematika-fisika yang ditanamkan oleh gelar teknik tetap penting, terutama dalam memahami dan menerapkan alat AI. Beberapa pandangan menunjukkan bahwa jika AI dapat menggantikan insinyur, maka profesi lain juga sulit terhindar, kuncinya adalah terus belajar dan beradaptasi. Bidang yang sangat praktis dan sulit diotomatisasi seperti kedokteran hewan dianggap sebagai pilihan yang relatif aman. (Sumber: Reddit r/ArtificialInteligence)