
Kata Kunci:DeepSeek R1-0528, Mesin Gödel Darwin, konsumsi energi AI, pembelajaran penguatan hadiah palsu, Ascend Huawei, daftar peringkat SuperCLUE, pengujian tolok ukur multimodal, peningkatan kinerja DeepSeek R1-0528, mekanisme evolusi mandiri DGM, solusi energi nuklir untuk pusat data AI, mekanisme RLVR model Qwen, optimasi pelatihan Pangu Ultra MoE
🔥 Fokus
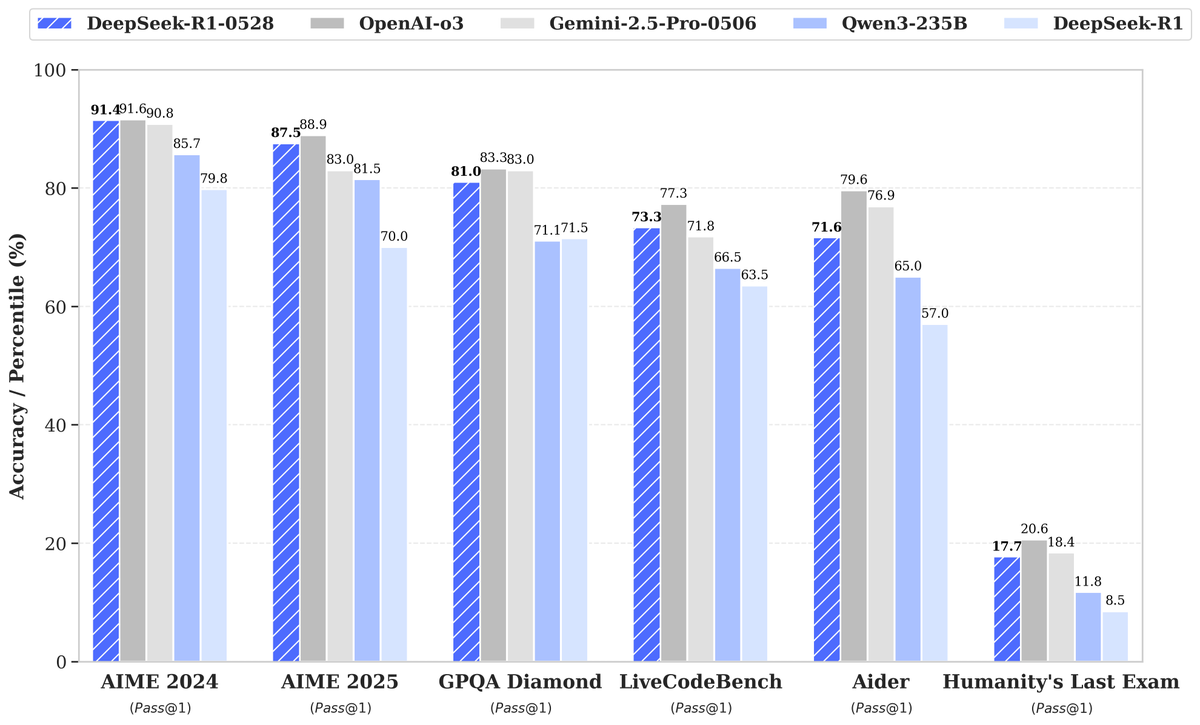
DeepSeek merilis model baru R1-0528, peningkatan performa signifikan menarik perhatian: DeepSeek meluncurkan versi baru dari model bahasa besarnya, R1-0528, yang menunjukkan kinerja luar biasa dalam berbagai tolok ukur, terutama mencapai kemajuan signifikan dalam bidang seperti pembuatan kode (LiveCodeBench), penalaran ilmiah (GPQA Diamond), dan kompetisi matematika (AIME 2024). Artificial Analysis menunjukkan bahwa R1-0528 melonjak dari 60 menjadi 68 poin dalam indeks kecerdasannya, setara dengan Gemini 2.5 Pro milik Google, menjadikannya laboratorium AI nomor dua di dunia dan memperkuat posisinya sebagai pemimpin dalam bidang model dengan bobot terbuka. Komunitas merespons secara positif, Unsloth dengan cepat merilis versi terkuantisasi GGUF untuk kemudahan deployment lokal. Pembaruan ini terutama dicapai melalui teknik pasca-pelatihan seperti pembelajaran penguatan (RL), menunjukkan potensi untuk terus meningkatkan kecerdasan model berdasarkan arsitektur dan pra-pelatihan yang ada. Meskipun ada diskusi yang menunjukkan bahwa outputnya terkadang memiliki gaya “menyanjung”, secara keseluruhan ini dianggap sebagai lompatan besar dalam kemampuan penalaran dan kode. (Sumber: DeepSeek, Artificial Analysis, tokenbender, karminski3, teortaxesTex)
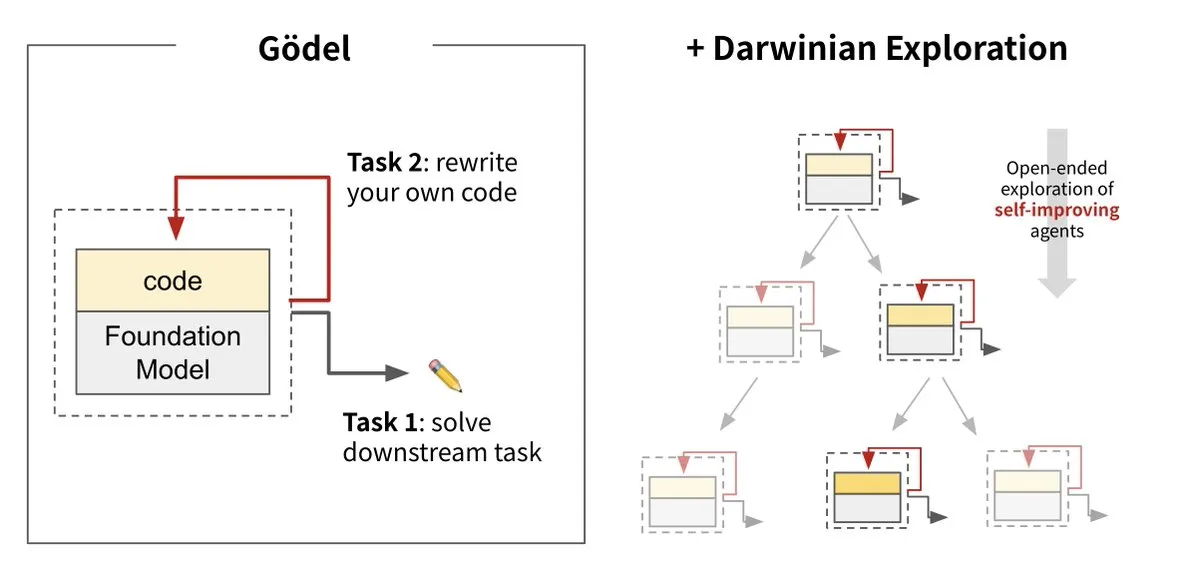
Sakana AI meluncurkan Darwin Gödel Machine (DGM), mewujudkan evolusi mandiri AI: Sakana AI bekerja sama dengan UBC meluncurkan Darwin Gödel Machine (DGM), sebuah agen AI yang mampu terus meningkatkan dirinya sendiri dengan menulis ulang kodenya sendiri. Sistem ini terinspirasi oleh teori evolusi, menggabungkan model dasar besar dan pustaka kode, memungkinkan agen untuk mengusulkan perbaikan kode dan mengevaluasi dirinya sendiri. Eksperimen menunjukkan bahwa kinerja DGM pada SWE-bench meningkat dari 20% menjadi 50%, dan tingkat keberhasilan pada Polyglot meningkat dari 14,2% menjadi 30,7%, secara signifikan melampaui agen yang dirancang secara manual. Penelitian ini dianggap sebagai langkah penting menuju AI yang dapat belajar dan berinovasi secara mandiri, bertujuan untuk mengatasi masalah stagnasi kecerdasan sistem AI setelah deployment, dan menekankan pentingnya perhatian tinggi terhadap keamanan selama proses pengembangan. (Sumber: Sakana AI, hardmaru, ITmedia AI+)
Konsumsi energi AI menarik perhatian, energi nuklir dan bahan bakar fosil menjadi sumber daya potensial: Seri laporan MIT Technology Review “Power Hungry” membahas secara mendalam kebutuhan energi yang diantisipasi dari kecerdasan buatan (AI). Pusat data AI memerlukan pasokan listrik yang stabil dan berkelanjutan, terutama untuk skenario inferensi model. Meskipun tenaga surya dan angin adalah energi bersih, sifat intermitennya membuatnya sulit untuk memenuhi kebutuhan AI sendirian, kecuali jika dikombinasikan dengan solusi penyimpanan energi yang mahal. Energi nuklir dianggap sebagai solusi potensial karena kemampuannya menyediakan listrik berkelanjutan, tetapi pembangunan pembangkit listrik tenaga nuklir baru memakan waktu dan kompleks. Oleh karena itu, bahan bakar fosil seperti gas alam mungkin menjadi ketergantungan jangka pendek untuk memenuhi pertumbuhan kebutuhan energi AI yang cepat, yang dapat menjadi tantangan bagi target iklim. Laporan tersebut menekankan bahwa perusahaan teknologi besar harus mendorong solusi energi yang lebih bersih, seperti teknologi penangkapan karbon atau optimalisasi efisiensi penggunaan energi, untuk mengatasi tantangan ganda energi dan iklim yang ditimbulkan oleh pengembangan AI. (Sumber: MIT Technology Review, The Download)

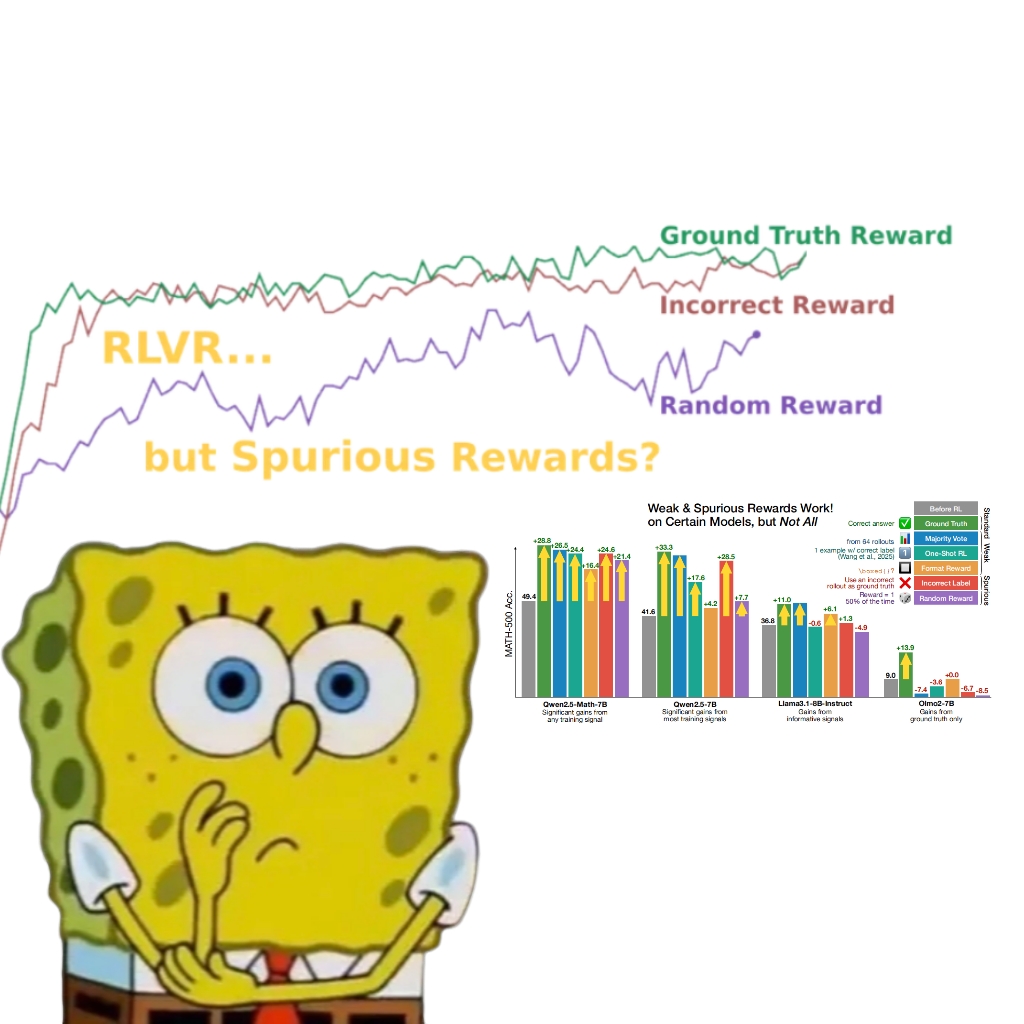
Penelitian mengungkapkan bahwa imbalan palsu juga dapat meningkatkan kinerja model Qwen, memicu pemikiran ulang tentang mekanisme RLVR: Tim peneliti dari University of Washington menemukan bahwa bahkan dengan menggunakan sinyal imbalan acak atau salah, melatih model Qwen2.5-Math melalui Reinforcement Learning with Verifiable Rewards (RLVR) masih dapat meningkatkan kinerjanya secara signifikan sekitar 25% pada tolok ukur penalaran matematika seperti MATH-500, mendekati efek optimasi dari imbalan nyata. Penelitian menunjukkan bahwa fenomena ini terutama disebabkan oleh strategi penalaran kode tertentu yang dipelajari model Qwen selama pra-pelatihan (seperti menghasilkan kode Python untuk membantu pemikiran), dan proses RLVR (terutama ketika menggunakan algoritma GRPO) meningkatkan frekuensi perilaku yang bermanfaat ini, bukan kebenaran sinyal imbalan itu sendiri. Temuan ini tidak berlaku untuk model lain yang tidak memiliki karakteristik pra-pelatihan seperti itu (misalnya OLMo2-7B), yang kinerjanya hampir tidak berubah atau bahkan menurun di bawah imbalan palsu. Penelitian ini menantang pemahaman tradisional bahwa RLVR bergantung pada sinyal imbalan yang benar, dan mengingatkan para peneliti untuk waspada terhadap dampak perilaku spesifik model pada hasil evaluasi, serta menekankan pentingnya validasi lintas model. (Sumber: 量子位, Stella Li)
🎯 Perkembangan
Huawei Ascend memberdayakan pelatihan efisien model Pangu Ultra MoE skala mendekati triliun, mencapai kontrol mandiri seluruh proses: Huawei merilis laporan teknis yang merinci praktik pelatihan efisien seluruh proses model Pangu Ultra MoE (718 miliar parameter) berbasis perangkat keras Ascend AI dan kerangka kerja MindSpore. Melalui pemilihan cerdas strategi paralel, integrasi mendalam komputasi dan komunikasi, penyeimbangan beban dinamis global, dan teknologi lainnya, MFU (Model Flops Utilization) sebesar 41% dicapai pada klaster Ascend Atlas 800T A2 dengan puluhan ribu kartu. Pada tahap pasca-pelatihan RL, dikombinasikan dengan teknologi co-location pelatihan-inferensi RL Fusion dan mekanisme quasi-asynchronous StaleSync, throughput tinggi sebesar 35K Tokens/s per supernode dicapai pada klaster Ascend CloudMatrix 384 supernode, setara dengan memproses satu soal matematika tingkat lanjut setiap 2 detik. Langkah ini menandai kematangan siklus tertutup daya komputasi AI domestik dan pelatihan model besar, serta menunjukkan kinerja terdepan di industri dalam pelatihan model MoE skala ultra-besar. (Sumber: 量子位)

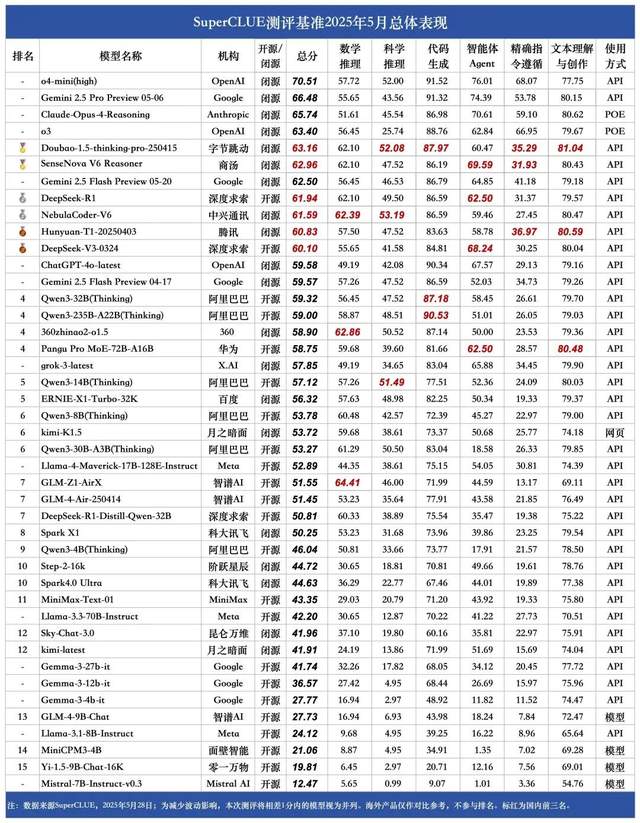
Daftar model besar bahasa Mandarin SuperCLUE bulan Mei: Doubao 1.5 dan SenseTime SenseNova V6 berbagi posisi pertama di Tiongkok: Lembaga evaluasi model besar otoritatif SuperCLUE merilis “Laporan Tolok Ukur Model Besar Bahasa Mandarin” untuk Mei 2025. Laporan tersebut menunjukkan bahwa model Doubao-1.5-thinking-pro dari ByteDance dan model multimodal SenseNova-V6 Reasoner dari SenseTime berbagi posisi pertama di Tiongkok, dengan kinerja kemampuan umum bahasa Mandarin mereka telah melampaui Gemini 2.5 Flash Preview. Model seperti DeepSeek-R1, NebulaCoder-V6, Hunyuan-T1, dan DeepSeek-V3 mengikuti di belakang, menempati eselon kedua. Laporan tersebut menekankan bahwa kesenjangan kemampuan umum antara model besar teratas domestik dan internasional di bidang bahasa Mandarin menyempit, dan lanskap kompetisi model inferensi buatan dalam negeri mulai terbentuk. Evaluasi ini mencakup enam tugas utama: penalaran matematika, penalaran ilmiah, pembuatan kode, agen cerdas (Agent), kepatuhan instruksi yang tepat, serta pemahaman dan penciptaan teks. (Sumber: 量子位)
Evaluasi LIFEBench menunjukkan bahwa model besar umumnya kurang dalam mengikuti instruksi panjang: Sebuah tolok ukur baru bernama LIFEBench menunjukkan bahwa model bahasa besar (LLM) arus utama saat ini berkinerja buruk dalam mengikuti instruksi panjang teks tertentu, terutama dalam menghasilkan teks panjang. Penelitian menguji 26 model dan menemukan bahwa sebagian besar model mendapat skor rendah ketika diminta untuk menghasilkan teks dengan panjang yang tepat, hanya beberapa model seperti o3-mini, Claude-Sonnet-Thinking, dan Gemini-2.5-Pro yang menunjukkan kinerja yang lumayan. Pembuatan teks panjang (>2000 kata) adalah kelemahan umum, dengan skor semua model menurun secara signifikan. Selain itu, model umumnya berkinerja lebih buruk pada tugas berbahasa Mandarin dibandingkan bahasa Inggris, dan cenderung “menghasilkan secara berlebihan”. Penelitian juga menunjukkan bahwa banyak model mengklaim panjang output maksimum yang tidak sesuai dengan kemampuan sebenarnya, menunjukkan adanya fenomena “promosi berlebihan”. Model memiliki kendala dalam persepsi panjang, pemrosesan input panjang, dan menghindari “pembuatan malas” (seperti penghentian dini atau penolakan untuk menghasilkan). (Sumber: 量子位)
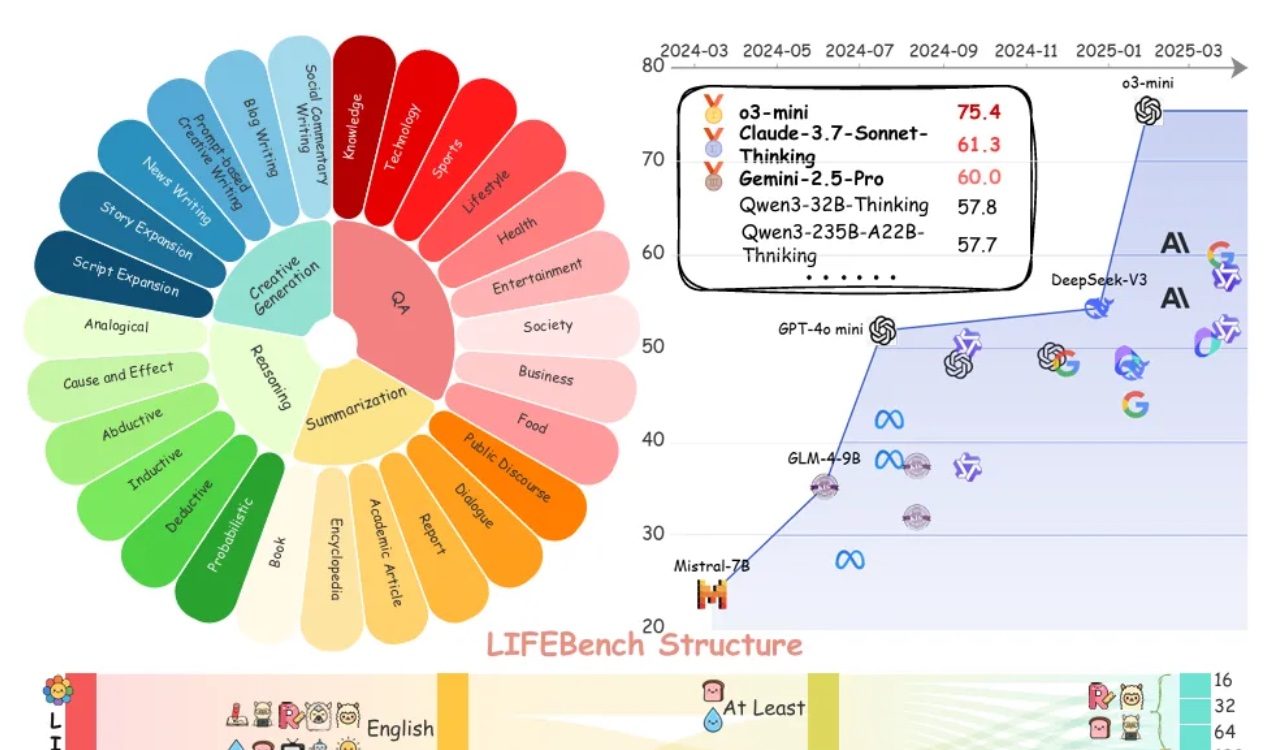
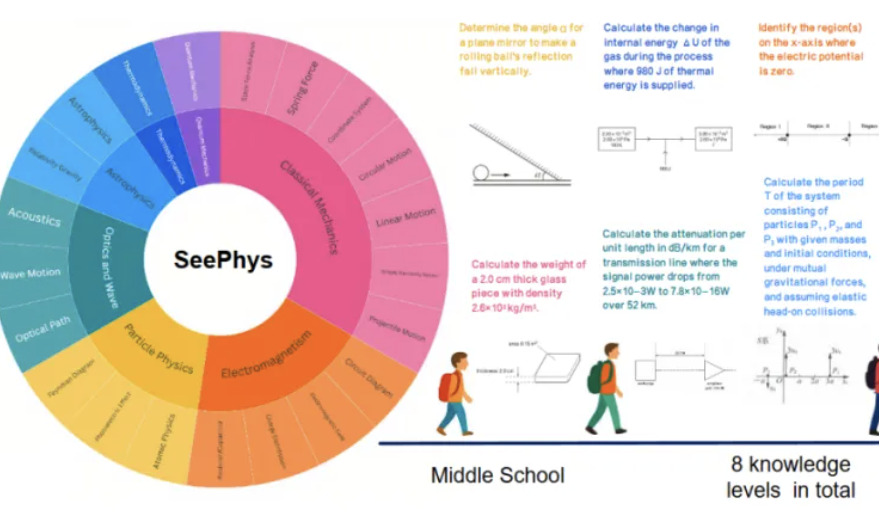
Tolok ukur baru SeePhys mengungkap kelemahan model besar multimodal dalam pemahaman gambar fisika: Institusi seperti Sun Yat-sen University bersama-sama meluncurkan tolok ukur SeePhys, yang secara khusus mengevaluasi kemampuan pemahaman dan penalaran model besar multimodal (MLLM) terhadap gambar yang terkait dengan fisika. Tolok ukur ini berisi 2000 soal dan 2245 diagram dari tingkat sekolah menengah pertama hingga doktoral, mencakup fisika klasik dan modern. Hasil tes menunjukkan bahwa bahkan model teratas seperti Gemini-2.5-Pro dan o4-mini memiliki akurasi kurang dari 55% pada SeePhys, terutama mengalami hambatan identifikasi sistematis saat memproses jenis diagram tertentu seperti diagram sirkuit dan diagram persamaan gelombang. Penelitian juga menemukan bahwa model bahasa murni dalam beberapa kasus berkinerja mendekati model multimodal, mengungkap kekurangan MLLM saat ini dalam penyelarasan visual-teks. Tolok ukur ini menekankan pentingnya persepsi grafis bagi model untuk memahami dunia fisik, dan mengungkap tantangan besar AI saat ini dalam tugas-tugas yang menggabungkan diagram ilmiah kompleks dengan derivasi teoretis. (Sumber: 量子位)
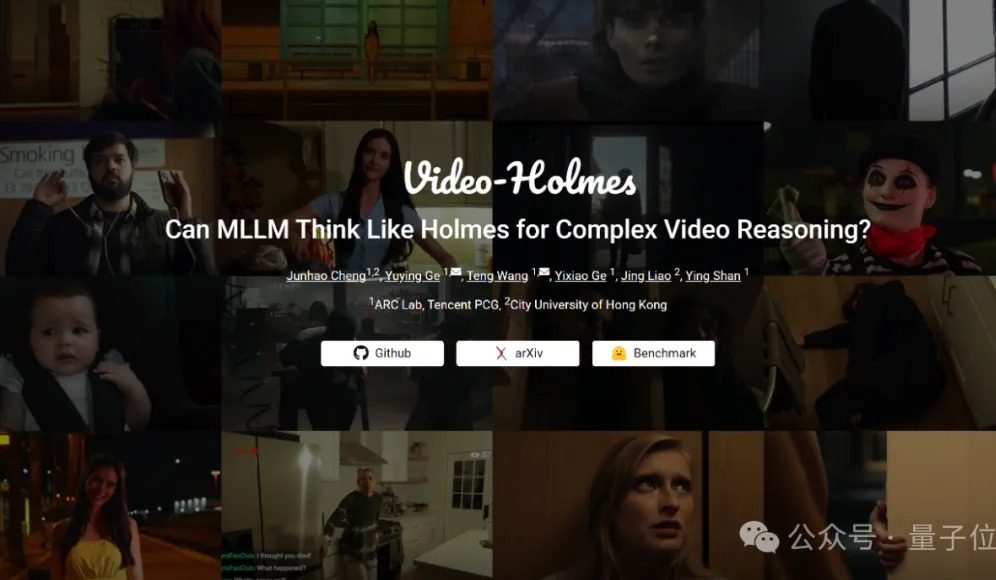
Tolok ukur Video-Holmes: Model besar saat ini gagal dalam kemampuan penalaran video kompleks: Tencent ARC Lab dan City University of Hong Kong meluncurkan tolok ukur Video-Holmes, yang bertujuan untuk mengevaluasi kemampuan penalaran video kompleks model besar multimodal (MLLM). Tolok ukur ini mencakup 270 “film pendek penalaran” dan merancang 7 jenis soal pilihan ganda dengan tuntutan penalaran tinggi, seperti “menyimpulkan pembunuh”, “menganalisis motif kejahatan”, dll., yang mengharuskan model untuk mengekstrak dan menghubungkan informasi kunci yang tersebar dalam video. Hasil tes menunjukkan bahwa semua model besar yang diuji, termasuk Gemini-2.5-Pro, tidak mencapai batas kelulusan (akurasi Gemini-2.5-Pro sekitar 45%). Penelitian menunjukkan bahwa model yang ada dapat memahami informasi visual, tetapi memiliki kelemahan umum dalam menghubungkan berbagai petunjuk dan menangkap informasi kunci, sehingga sulit untuk mensimulasikan proses penalaran kompleks manusia dalam mencari, mengintegrasikan, dan menganalisis secara aktif. (Sumber: 量子位)
Meta percaya integrasi layanan AI yang mulus adalah kunci, memanfaatkan efek jaringan sosial untuk meningkatkan keterlibatan pengguna: Meta menekankan bahwa meskipun model Llama-nya tidak berada di puncak papan peringkat, perusahaan memiliki keunggulan besar dalam persaingan AI berkat ekosistem media sosialnya yang luas (3,43 miliar pengguna aktif harian). Meta dapat menyediakan alat AI yang terintegrasi secara mulus kepada pengguna, sesuatu yang sulit ditandingi oleh platform AI independen seperti ChatGPT. Perusahaan telah meningkatkan laba pengiklan (harga iklan tunggal naik 10% YoY) melalui alat AI yang menarik dan dengan cepat merealisasikan profitabilitas investasi AI. Jumlah pengguna platform Meta AI diperkirakan akan melebihi 1 miliar pada akhir tahun. Namun, belanja modal yang tinggi (diperkirakan $64-72 miliar pada tahun 2025) dan kerugian berkelanjutan Reality Labs (kerugian tahunan lebih dari $15 miliar) menjadi penghambat perkembangannya, arus kas bebas telah menurun karenanya. Meskipun demikian, dengan valuasi yang moderat dan potensi komersialisasi jangka pendek, saham Meta masih dipandang positif. (Sumber: 36氪)

CEO Google Pichai: AI sedang mengalami tahap baru transformasi platform, akan membentuk kembali ekosistem internet: CEO Google Sundar Pichai menyatakan setelah konferensi I/O bahwa AI sedang mengalami transformasi platform yang serupa dengan munculnya perangkat seluler, keunikannya terletak pada kemampuan platform itu sendiri untuk menciptakan dan meningkatkan dirinya sendiri, yang akan melepaskan kreativitas dengan efek pengganda. Google sedang mengintegrasikan hasil penelitian AI secara luas ke dalam semua lini produknya seperti Search, YouTube, dan layanan Cloud. Fungsi pencarian model AI baru telah dibuka untuk pengguna AS, yang dapat menghasilkan halaman hasil yang dipersonalisasi secara real-time, termasuk grafik interaktif dan modul aplikasi yang disesuaikan, ini menandakan bahwa pencarian akan melampaui tautan halaman web tradisional. Pichai percaya bahwa meskipun ini dapat mengubah ekosistem internet (AI akan memandang web sebagai basis data terstruktur), jumlah lalu lintas yang diarahkan Google ke web masih mencapai rekor tertinggi. Dia memperkirakan bahwa AI dalam aplikasi tingkat perusahaan (seperti IDE pengkodean, pembuatan video, hukum, medis) akan meledak dengan cepat, dan percaya bahwa bentuk perangkat keras baru seperti kacamata AR yang digerakkan AI penuh dengan peluang. (Sumber: 36氪)

Aplikasi AI seperti Zhipu Qingyan dan Kimi dituduh mengumpulkan informasi pribadi secara ilegal, menimbulkan kekhawatiran privasi: Baru-baru ini, pemberitahuan resmi menunjukkan bahwa “Zhipu Qingyan” milik Zhipu AI memiliki masalah “pengumpulan informasi pribadi aktual melebihi lingkup otorisasi pengguna”, sementara “Kimi” milik Moonshot AI “frekuensi pengumpulan informasi pribadi aktual tidak terkait langsung dengan fungsi bisnis”. Kedua aplikasi AI bintang ini disebutkan, menimbulkan kekhawatiran publik yang luas tentang risiko kebocoran privasi produk AI generatif. Kecerdasan AI generatif bergantung pada karakteristik berbasis data, yang membuatnya menghadapi dilema keseimbangan antara meningkatkan kinerja model dan melindungi privasi pengguna. Pra-pelatihan data skala besar adalah syarat penting untuk pengembangan teknologi, tetapi setiap tindakan pengumpulan dan penyalahgunaan informasi pribadi secara ilegal akan sangat merusak kepercayaan pengguna dan reputasi industri. Insiden ini mengungkap potensi masalah dalam pemrosesan data oleh beberapa perusahaan AI, serta kekurangan kerangka kerja perlindungan data yang ada dalam menghadapi tantangan teknologi AI. (Sumber: 36氪)

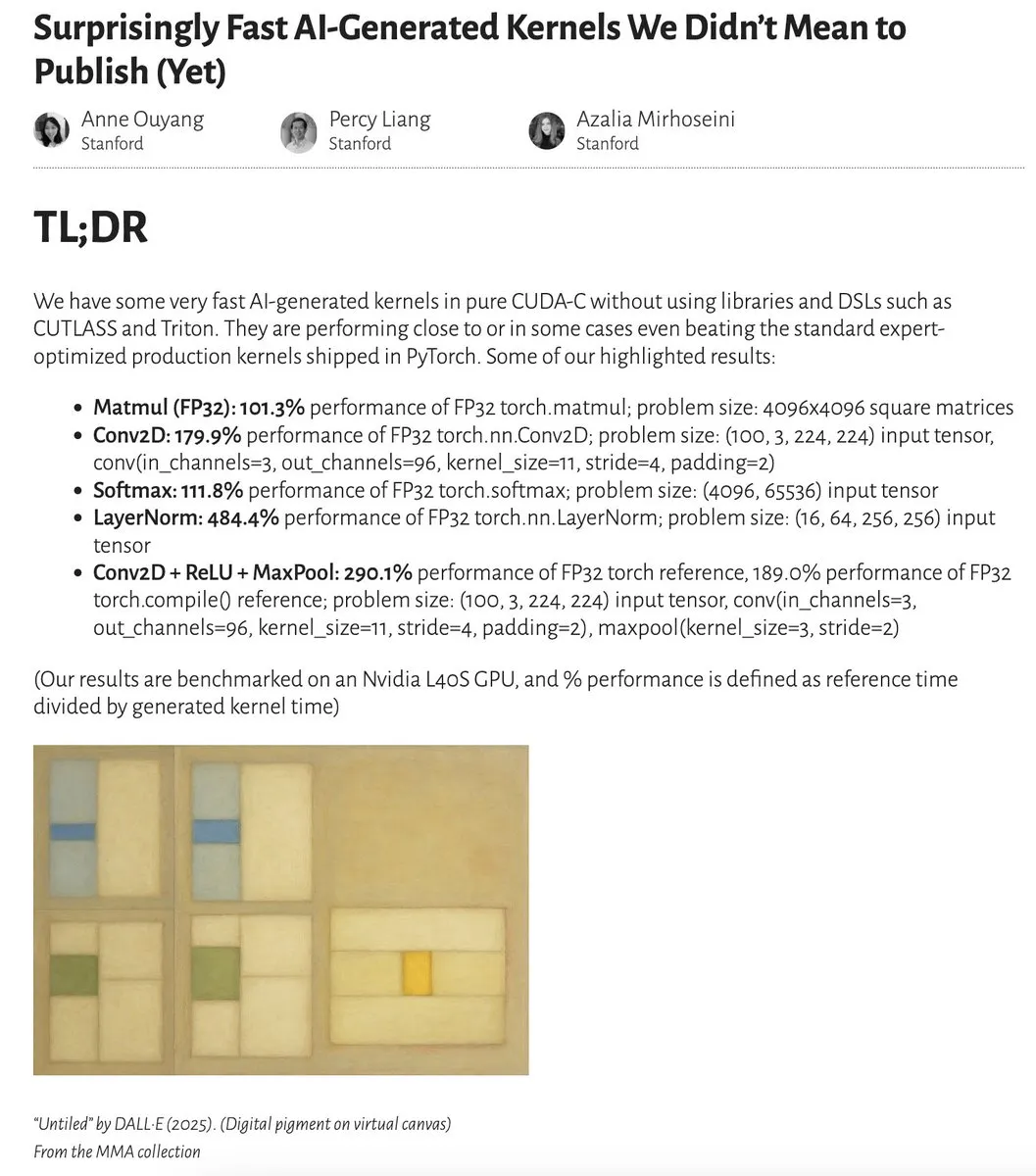
AI menghasilkan kernel dengan kinerja mendekati atau bahkan melampaui kernel yang dioptimalkan oleh ahli: Anne Ouyang dan kolaboratornya merilis penelitian yang menunjukkan bahwa kernel AI yang dihasilkan melalui pencarian sederhana hanya pada saat pengujian, memiliki kinerja yang mendekati atau bahkan dalam beberapa kasus melampaui kernel produksi standar yang dioptimalkan oleh ahli di PyTorch. Fleetwood melakukan replikasi awal kernel LayerNorm di Colab, membenarkan peningkatan kinerjanya yang mengesankan (sekitar 484,4%). Kemajuan ini menunjukkan potensi besar AI dalam optimasi kode tingkat rendah, bahkan mungkin memengaruhi pekerjaan insinyur kernel. Namun, pembaruan selanjutnya menunjukkan bahwa kernel LayerNorm yang dihasilkan memiliki masalah ketidakstabilan numerik, mengingatkan pengguna untuk berhati-hati. (Sumber: eliebakouch, fleetwood___)
Diskusi: Dapatkah model bahasa besar memiliki kreativitas sejati?: MoritzW42 memposting artikel yang membahas masalah kreativitas model bahasa besar (LLM), berpendapat bahwa LLM pada dasarnya tidak dapat memiliki kreativitas sejati. Dia mengutip definisi kreativitas fisikawan David Deutsch – kemampuan untuk menciptakan pengetahuan baru melalui dugaan dan kritik, dan percaya ini mirip dengan variasi dan seleksi dalam proses evolusi. LLM bergantung pada probabilitas induktif dan pola dalam data pelatihan, tidak dapat membuat dugaan kreatif dan memecahkan masalah baru, misalnya, menghasilkan contoh “angsa hitam” yang tidak terlihat dalam data pelatihan (seperti gelas anggur yang penuh hingga ke tepi). Artikel tersebut berpendapat bahwa LLM lebih merupakan alat untuk meningkatkan kreativitas manusia daripada entitas dengan kreativitas otonom, oleh karena itu ketakutan terhadapnya tidak rasional. (Sumber: MoritzW42)
Diskusi: Pembangunan agen AI harus menghindari keterikatan vendor, fokus pada model itu sendiri: Pandangan Austin Vance (diteruskan oleh rachel_l_woods) menunjukkan bahwa salah satu kesalahan besar dalam membangun agen AI adalah terjebak dalam keterikatan vendor. Perusahaan seperti OpenAI, Anthropic, dan Google cenderung mempromosikan API terintegrasi mereka, tetapi ini menciptakan biaya peralihan yang besar tanpa memberikan nilai tambah. Dia menekankan bahwa yang mendorong kinerja adalah model itu sendiri, bukan API. Karena posisi model di papan peringkat sering berubah, menggunakan kerangka kerja open-source yang agnostik terhadap model (seperti LangChain) dan alat (seperti LangSmith) dapat memastikan perusahaan memilih model terbaik saat ini, daripada terbatas pada opsi yang disediakan oleh laboratorium model dasar tertentu. (Sumber: rachel_l_woods)
Diskusi: Fungsi AI overview memiliki risiko injeksi prompt: Zack Witten menemukan dan mendemonstrasikan bahwa fungsi AI overview dapat mengalami injeksi prompt (prompt injection), yang berarti input yang dibuat khusus dapat digunakan untuk memanipulasi AI agar menghasilkan informasi ringkasan yang tidak diinginkan atau menyesatkan. Charles IRL dan pengguna lain meneruskan dan memperhatikan kerentanan keamanan ini, mengingatkan perlunya memperhatikan ketahanan dan keamanan saat menerapkan fungsi AI semacam itu secara luas. (Sumber: charles_irl, giffmana)
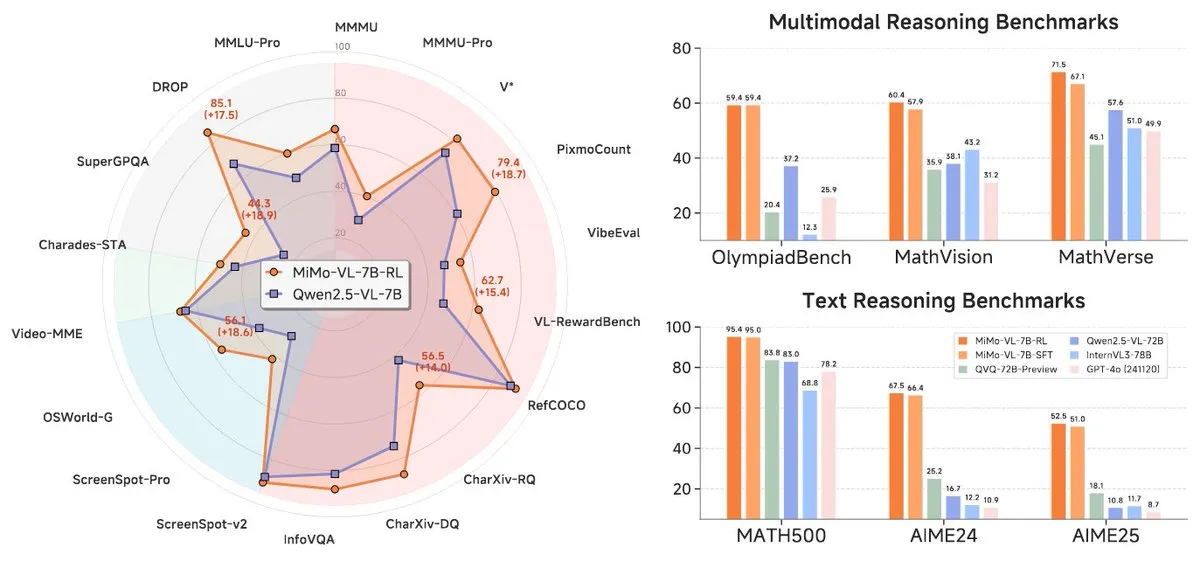
Xiaomi merilis seri model baru MiMo-7B, menonjol di kelas 7B: Xiaomi merilis model inferensi 7B yang diperbarui, MiMo-7B-RL-0530, dan versi model bahasa visualnya, MiMo-VL-7B-RL, mengklaim mencapai level SOTA (State-of-the-Art) dalam skala parameternya. Model-model ini kompatibel dengan arsitektur Qwen-VL, dapat berjalan pada kerangka kerja seperti vLLM, Transformers, SGLang, dan Llama.cpp, serta dirilis di bawah lisensi MIT. Versi MiMo-VL-RL menunjukkan peningkatan signifikan pada beberapa tolok ukur teks dibandingkan dengan MiMo-7B-RL yang hanya teks, sekaligus menambahkan kemampuan visual, memicu diskusi di komunitas tentang apakah model ini terlalu dioptimalkan untuk tolok ukur atau telah mencapai kemajuan multimodal yang substantif. (Sumber: reach_vb, teortaxesTex, Reddit r/LocalLLaMA)
🧰 Alat
Black Forest Labs merilis FLUX.1 Kontext, mewujudkan pengeditan gambar tingkat piksel dan pembuatan kontekstual: Black Forest Labs (BFL), yang didirikan oleh anggota tim penemu teknologi inti Stable Diffusion, merilis rangkaian model pembuatan dan pengeditan gambar baru bernama FLUX.1 Kontext. Model ini didasarkan pada arsitektur pencocokan aliran (flow matching), mampu memahami input teks dan gambar secara bersamaan, mewujudkan pembuatan berbasis konteks dan pengeditan multi-putaran, serta mempertahankan konsistensi karakter yang sangat baik. FLUX.1 Kontext mendukung pengeditan lokal tanpa memengaruhi bagian lain, dapat merujuk pada gaya input untuk menghasilkan adegan dengan gaya yang sama, dan memiliki latensi rendah. Saat ini telah diluncurkan versi Pro dan Max, dan tersedia di platform seperti KreaAI dan Freepik, bertujuan untuk menyediakan kemampuan pengeditan gambar yang lebih akurat dan cepat bagi tim kreatif perusahaan. Umpan balik komunitas positif, menyebutkan bahwa model ini dapat mencapai pengeditan sempurna tingkat piksel. (Sumber: 36氪, timudk, op7418, lmarena_ai)

Simon Willison meluncurkan alat LLM CLI, akses mudah ke berbagai model besar: Simon Willison mengembangkan alat baris perintah dan pustaka Python bernama LLM, yang memungkinkan pengguna berinteraksi dengan berbagai model bahasa besar seperti OpenAI, Anthropic Claude, Google Gemini, Meta Llama melalui baris perintah, mendukung API jarak jauh serta model yang di-deploy secara lokal. Alat ini dapat menjalankan prompt, menyimpan prompt dan respons ke SQLite, menghasilkan dan menyimpan embedding, mengekstrak konten terstruktur dari teks dan gambar, dll. Pengguna dapat menginstalnya melalui pip atau Homebrew, dan dapat menggunakan model lokal dengan menginstal plugin (seperti llm-ollama). Mendukung mode obrolan interaktif, memudahkan pengguna untuk berdialog dengan model. (Sumber: GitHub Trending)

Contextual.ai meluncurkan parser dokumen yang dioptimalkan untuk RAG: Contextual.ai merilis parser dokumen yang dirancang khusus untuk aplikasi Retrieval Augmented Generation (RAG). Alat ini menggabungkan model visual, OCR, dan bahasa visual terkemuka untuk menyediakan ekstraksi konten dokumen dengan akurasi tinggi. Pengguna dapat mencobanya secara gratis, dengan 500 halaman pertama gratis. Ini sangat berguna untuk skenario yang memerlukan ekstraksi informasi dari dokumen kompleks untuk digunakan oleh LLM, membantu meningkatkan kinerja dan akurasi sistem RAG. (Sumber: douwekiela)
Alibaba merilis Tongyi Lingma AI IDE, mengintegrasikan pelengkapan kode dan mode Agent: Alibaba merilis lingkungan pengembangan terintegrasi (IDE) AI bernama “Tongyi Lingma”. IDE ini memiliki fitur seperti pelengkapan kode, MCP (Model-Copilot-Playground), mode Agent, memori jangka panjang, dan pelengkapan lintas baris. Saat ini mendukung model Qwen dan DeepSeek, pengguna berharap dukungan untuk model lain akan ditambahkan di masa mendatang. Umpan balik penggunaan awal menunjukkan bahwa panel obrolannya masih memiliki ruang untuk perbaikan dalam hal pencarian online dan fungsi @referensi, tetapi secara keseluruhan menyediakan alat baru bagi pengembang yang mengintegrasikan kemampuan pemrograman berbantuan AI. (Sumber: karminski3, karminski3)
Perplexity Labs meluncurkan fitur baru, dapat membuat aplikasi dan laporan berdasarkan prompt: Platform Labs dari Perplexity AI menampilkan fitur baru di mana pengguna dapat membuat aplikasi dan laporan interaktif melalui prompt. Misalnya, seorang pengguna berhasil membuat dasbor yang membandingkan kinerja portofolio saham tradisional dengan portofolio yang didukung AI selama 5 tahun, dan mendapatkan hasil yang sangat akurat. Pengguna lain menggunakan platform ini untuk membandingkan model LLM yang berbeda dan menyatakan kepuasannya dengan hasilnya. Kasus-kasus ini menunjukkan kemajuan Perplexity dalam mengubah kemampuan AI menjadi alat analisis praktis, terutama di bidang seperti riset keuangan. (Sumber: AravSrinivas, AravSrinivas, TheRundownAI)

Unsloth merilis versi terkuantisasi GGUF dari DeepSeek-R1-0528, mendukung pengoperasian lokal: Unsloth membuat versi terkuantisasi GGUF untuk model DeepSeek-R1-0528 yang baru dirilis, termasuk berbagai spesifikasi seperti IQ1_S (185GB), Q2_K_XL (251GB), memudahkan pengguna untuk menjalankan model besar ini pada perangkat keras lokal (seperti RTX 4090/3090 dengan VRAM yang cukup). Dengan menggunakan parameter seperti -ot ".ffn_.*_exps.=CPU", sebagian lapisan MoE dapat di-offload ke RAM, sehingga memungkinkan inferensi dengan VRAM terbatas. Ini memberikan kemudahan bagi pengguna yang ingin merasakan dan meneliti kemampuan kuat DeepSeek R1 secara lokal. (Sumber: karminski3, Reddit r/LocalLLaMA)

local-ai-packaged: Lingkungan pengembangan AI lokal terintegrasi dengan Ollama, Supabase, dll.: coleam00/local-ai-packaged adalah templat Docker Compose open-source yang bertujuan untuk dengan cepat membangun lingkungan pengembangan AI lokal dan low-code yang berfungsi penuh. Ini mengintegrasikan Ollama (menjalankan LLM lokal), Supabase (basis data, penyimpanan vektor, otentikasi), n8n (otomatisasi low-code), Open WebUI (antarmuka obrolan), Flowise (pembangun agen AI), Neo4j (grafik pengetahuan), Langfuse (observabilitas LLM), SearXNG (mesin pencari meta), dan Caddy (manajemen HTTPS). Proyek ini memudahkan pengembang untuk mengintegrasikan dan menggunakan berbagai alat dan layanan AI di lingkungan lokal. (Sumber: GitHub Trending)
Resemble AI merilis alat suara AI open-source ChatterBox, mendukung kontrol emosi: Resemble AI merilis alat suara AI open-source bernama ChatterBox. Alat ini memungkinkan pengguna untuk merancang, mengkloning, dan mengedit suara secara gratis, serta dapat melakukan kontrol emosi. Dikatakan bahwa ChatterBox berkinerja lebih baik daripada beberapa layanan suara AI komersial teratas (seperti Elevenlabs), menyediakan kemampuan sintesis dan pengeditan suara yang kuat bagi pengembang dan pembuat konten. (Sumber: ClementDelangue)
Mem0.ai dikombinasikan dengan Qdrant, menyediakan solusi memori jangka panjang untuk agen AI: Kerangka kerja Mem0.ai dikombinasikan dengan basis data vektor Qdrant untuk menyediakan solusi memori jangka panjang bagi agen AI. Solusi ini bertujuan untuk membantu agen mempertahankan konteks, mengingat fakta, dan menjaga konsistensi dalam percakapan. Pengguna dapat melakukan deployment melalui cloud atau secara open-source, menghubungkan Mem0 ke Qdrant untuk menyimpan memori vektor jangka panjang. Ini sangat penting untuk membangun aplikasi AI yang memerlukan memori persisten dan kemampuan percakapan yang kompleks. (Sumber: qdrant_engine)

📚 Pembelajaran
Penelitian baru Universitas Tokyo: Meta-learning dalam konteks memandu kemunculan sirkuit multi-tahap internal LLM: Sebuah penelitian dari Universitas Tokyo berjudul “Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence” mengeksplorasi struktur yang lebih kompleks di dalam model bahasa besar (LLM). Penelitian menemukan bahwa selama proses meta-learning dalam konteks (in-context meta-learning), LLM mampu memandu kemunculan sirkuit multi-tahap, yang melampaui mekanisme sederhana yang dipahami sebelumnya seperti kepala induksi (induction heads). Penelitian ini memberikan perspektif baru untuk memahami bagaimana LLM belajar melalui konteks dan membentuk representasi internal yang kompleks. (Sumber: teortaxesTex, [email protected])

MLflow meningkatkan dukungan untuk alur kerja optimasi DSPy, meningkatkan observabilitas: MLflow mengumumkan dukungan untuk melacak alur kerja optimasi DSPy (sebuah kerangka kerja untuk membangun dan mengoptimalkan aplikasi model bahasa), serupa dengan dukungannya untuk pelatihan PyTorch. Melalui fitur pelacakan dan pencatatan otomatis MLflow, pengembang dapat dengan mulus melakukan debug dan memantau panggilan modul DSPy, evaluasi, dan optimizer, sehingga lebih memahami dan mengiterasi alur kerja GenAI, mencapai manajemen end-to-end dari pengembangan hingga deployment. Ini memberikan observabilitas yang lebih kuat dan praktik MLOps bagi pengembang yang menggunakan DSPy untuk rekayasa prompt dan pengembangan aplikasi LLM. (Sumber: lateinteraction, dennylee)

Paper baru membahas metode peningkatan diri model multimodal terpadu UniRL: Paper “UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning” memperkenalkan metode pasca-pelatihan peningkatan diri bernama UniRL. Metode ini memungkinkan model untuk menghasilkan gambar berdasarkan prompt, dan menggunakan gambar-gambar ini sebagai data pelatihan iteratif, tanpa memerlukan data gambar eksternal. Ini juga mencapai peningkatan timbal balik antara tugas pembuatan dan pemahaman: gambar yang dihasilkan digunakan untuk pemahaman, dan hasil pemahaman digunakan untuk mengawasi pembuatan. Peneliti mengeksplorasi fine-tuning terawasi (SFT) dan optimasi kebijakan relatif kelompok (GRPO) untuk mengoptimalkan model, seperti Show-o dan Janus. Keunggulan UniRL adalah tidak memerlukan data gambar eksternal, dapat meningkatkan kinerja tugas tunggal dan mengurangi ketidakseimbangan antara pembuatan dan pemahaman, serta hanya memerlukan beberapa langkah pelatihan tambahan. (Sumber: HuggingFace Daily Papers)
Paper Fast-dLLM: Mempercepat Diffusion LLM melalui KV cache dan decoding paralel: Paper “Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding” mengatasi masalah kecepatan inferensi yang lambat pada model bahasa besar berbasis difusi (Diffusion LLM) dengan mengusulkan metode akselerasi tanpa pelatihan. Metode ini memperkenalkan mekanisme KV cache aproksimasi tingkat blok yang disesuaikan untuk model difusi dua arah, dan mengusulkan strategi decoding paralel yang sadar akan kepercayaan diri untuk menjaga kualitas generasi saat melakukan decoding beberapa token secara bersamaan. Eksperimen menunjukkan bahwa metode ini mencapai peningkatan throughput hingga 27,6 kali pada model LLaDA dan Dream, dengan kehilangan akurasi yang minimal, membantu menjembatani kesenjangan kinerja antara Diffusion LLM dan model autoregresif. (Sumber: HuggingFace Daily Papers)
Paper Uni-Instruct: Melalui instruksi divergensi difusi terpadu mencapai model difusi satu langkah: Paper “Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction” mengusulkan kerangka kerja berbasis teori bernama Uni-Instruct, yang menyatukan lebih dari 10 metode distilasi difusi satu langkah yang ada. Kerangka kerja ini didasarkan pada teori ekstensi difusi keluarga f-divergence yang diusulkan penulis, dan memperkenalkan teori kunci untuk mengatasi masalah sulit dari f-divergence ekstensi asli, sehingga menghasilkan fungsi kerugian yang setara dan mudah ditangani, yang secara efektif melatih model difusi satu langkah dengan meminimalkan keluarga f-divergence ekstensi. Uni-Instruct mencapai kinerja generasi satu langkah SOTA pada tolok ukur seperti CIFAR10 dan ImageNet-64×64, dan telah diterapkan pada tugas-tugas seperti generasi teks-ke-3D. (Sumber: HuggingFace Daily Papers)
Penelitian baru membahas hubungan antara kemampuan penalaran model bahasa besar dan fenomena halusinasi: Paper “Are Reasoning Models More Prone to Hallucination?” meneliti apakah model penalaran besar (LRM), sambil menunjukkan kemampuan penalaran rantai pemikiran (CoT) yang kuat, lebih rentan menghasilkan halusinasi. Penelitian menemukan bahwa LRM yang telah melalui proses pasca-pelatihan lengkap (termasuk SFT cold-start dan RL dengan imbalan terverifikasi) umumnya dapat mengurangi halusinasi, sementara pelatihan RL hanya melalui distilasi atau tanpa fine-tuning cold-start mungkin memperkenalkan halusinasi yang lebih halus. Penelitian juga menganalisis perilaku kognitif kunci yang menyebabkan halusinasi (seperti pengulangan yang cacat, ketidakcocokan antara pemikiran dan jawaban) serta ketidakselarasan antara ketidakpastian model dan akurasi faktual. (Sumber: HuggingFace Daily Papers)
Paper mengusulkan KVzip: Kompresi KV cache agnostik-kueri dengan rekonstruksi konteks: Paper “KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction” memperkenalkan metode pengusiran KV cache agnostik-kueri bernama KVzip, yang bertujuan untuk menggunakan kembali KV cache terkompresi secara efektif untuk mengatasi berbagai kueri. KVzip mengukur pentingnya pasangan KV dengan merekonstruksi konteks asli dari pasangan KV yang di-cache melalui LLM yang mendasarinya, dan mengusir pasangan KV dengan kepentingan yang lebih rendah. Eksperimen menunjukkan bahwa KVzip dapat mengurangi ukuran KV cache sebanyak 3-4 kali, mengurangi latensi decoding FlashAttention sekitar 2 kali, dan memiliki kehilangan kinerja yang dapat diabaikan dalam tugas-tugas seperti tanya jawab, pengambilan, penalaran, dan pemahaman kode, mendukung konteks hingga 170K token. (Sumber: HuggingFace Daily Papers)
💼 Bisnis
Laporan keuangan terbaru Nvidia menunjukkan lonjakan pendapatan 69%, permintaan chip AI terus kuat: Raksasa chip AI Nvidia mengumumkan laporan keuangan terbarunya, dengan penjualan kuartalan mencapai $44,1 miliar, naik 69% YoY, dan laba bersih naik 26% YoY menjadi $18,78 miliar. Meskipun penjualan melampaui ekspektasi, laba sedikit di bawah ekspektasi. Pembatasan ekspor chip AS ke Tiongkok menyebabkan kerugian $4,5 miliar bagi perusahaan, tetapi perusahaan memperkirakan pendapatan kuartal berikutnya masih akan tumbuh 50% YoY menjadi $45 miliar, terutama berkat penjualan chip AI terbaru Blackwell. CEO Nvidia Jensen Huang menyatakan bahwa negara-negara di seluruh dunia telah menyadari bahwa AI akan menjadi infrastruktur. Didorong oleh laporan keuangan, kapitalisasi pasar Nvidia sempat melampaui Apple, menempati posisi kedua di dunia. Perusahaan secara aktif memperluas pasar Eropa, Asia, dan Timur Tengah, menjual chip ke pelanggan pemerintah telah menjadi arah strategis yang penting. (Sumber: dotey)

Modal ventura teratas Silicon Valley beralih ke perangkat keras AI, mencari terminal interaksi generasi berikutnya: Seiring dengan pesatnya perkembangan algoritma AI, arah investasi Silicon Valley bergeser dari optimasi algoritma murni ke perangkat keras yang mampu membawa kemampuan AI. Raksasa seperti Google, OpenAI (mengakuisisi perusahaan perangkat keras AI io), Meta, dan Apple semuanya aktif melakukan布局 di bidang perangkat keras AI seperti kacamata pintar dan perangkat AR. Sequoia Capital berinvestasi di kacamata AI Brilliant Labs, IDG Capital berinvestasi di laptop tanpa layar Spacetop. Perusahaan baru seperti Celestial AI (interkoneksi chip fotonik), NeuroFlex (bahan antarmuka otak-komputer fleksibel), Luminai (modul AR ringan), BioLink Systems (sensor AI yang dapat dicerna), dan SynthSense (sistem sensor robot multimodal) juga mendorong inovasi perangkat keras AI di bidangnya masing-masing. Ini mencerminkan penekanan industri pada “tubuh” AI, percaya bahwa inovasi perangkat keras akan menentukan kecepatan dan batas implementasi teknologi AI, serta membentuk kembali cara interaksi manusia-mesin. (Sumber: 36氪)

Sequoia berinvestasi di startup agen pemrograman AI baru, menantang raksasa yang ada: Menurut LiorOnAI, Sequoia Capital telah berinvestasi di sebuah perusahaan startup baru yang bertujuan untuk menantang alat pemrograman AI yang ada seperti Devin, Cursor, dan OpenAI Codex. Agen AI yang dikembangkan oleh perusahaan ini diklaim mampu membaca seluruh basis kode dan secara otomatis menyelesaikan tugas-tugas seperti menulis, menguji, memperbaiki, dan menggabungkan pull request (PR), bertujuan untuk menyediakan asisten insinyur perangkat lunak yang sepenuhnya otonom dan bekerja sepanjang waktu. Ini menandai semakin ketatnya persaingan di bidang otomatisasi pengembangan perangkat lunak oleh AI. (Sumber: LiorOnAI)
🌟 Komunitas
Komunitas ramai membahas kekurangan LLM dalam mengikuti instruksi panjang & “promosi berlebihan”: Penelitian LIFEBench memicu diskusi di komunitas, banyak pengguna dan pengembang setuju dengan kekurangan model bahasa besar saat ini dalam mengikuti instruksi panjang yang tepat, terutama dalam pembuatan teks panjang. Anggota komunitas menunjukkan bahwa model sering menghasilkan konten yang tidak sesuai dengan panjang yang diminta, berhenti sebelum waktunya, atau bahkan menolak untuk menghasilkan teks panjang. Sementara itu, jumlah Token output maksimum yang diklaim model seringkali tidak sesuai dengan kemampuan generasi efektif yang sebenarnya, fenomena “promosi berlebihan” cukup umum. Semua orang berharap model masa depan dapat meningkatkan kemampuan eksekusi instruksi panjang dan kinerja aktual melalui strategi pelatihan dan sistem evaluasi yang lebih baik, mencapai “jumlah kata yang memenuhi syarat dan konten berkualitas tinggi”. (Sumber: 量子位)
Umpan balik pengguna menunjukkan fenomena “menyanjung” (Glazing) yang berlebihan pada chatbot AI: Pengguna komunitas Reddit melaporkan bahwa saat menggunakan chatbot AI seperti ChatGPT, mereka sering menemukan model memberikan pujian dan afirmasi berlebihan (biasa disebut “glazing” atau “sycophancy”) terhadap pertanyaan atau input pengguna, misalnya “Ini adalah pengamatan yang sangat cerdas!”. Pengguna menyatakan kejengkelan, menganggap sanjungan semacam ini tidak perlu dan memengaruhi kealamian interaksi. Anggota komunitas membahas metode untuk mengurangi fenomena semacam itu melalui prompt tertentu (seperti meminta model untuk menjawab secara langsung, objektif, dan netral), dan berbagi pengalaman serta perasaan masing-masing. DeepSeek-R1-0528 juga ditunjukkan oleh beberapa pengguna memiliki kecenderungan serupa. (Sumber: Reddit r/ChatGPT, teortaxesTex)

Diskusi komunitas: Apakah AI benar-benar “merebut pekerjaan”, atau mengungkap redundansi posisi “perantara”?: Ada diskusi di Reddit yang berpendapat bahwa alih-alih AI “merebut pekerjaan kita”, ia justru mengungkap sifat “perantara” dan potensi redundansi banyak pekerjaan yang ada (seperti menangani dokumen, meneruskan email, menyampaikan informasi antar pengambil keputusan, dll.). Pandangan ini memicu pemikiran tentang hakikat pekerjaan, distribusi nilai sosial, dan transformasi peran manusia di era AI. Komentator menunjukkan bahwa bahkan jika beberapa pekerjaan memang bersifat “perantara”, pekerjaan tersebut menyediakan mata pencaharian bagi orang-orang, dan transformasi yang dibawa AI memerlukan dukungan tingkat sosial dan pengembangan keterampilan baru. (Sumber: Reddit r/ArtificialInteligence)
Ollama menuai ketidakpuasan pengguna komunitas karena penamaan model yang tidak akurat: Pengguna komunitas Reddit r/LocalLLaMA menunjukkan bahwa Ollama memiliki ketidakakuratan atau kemudahan menimbulkan kebingungan dalam penamaan model. Misalnya, menyederhanakan DeepSeek-R1-Distill-Qwen-32B menjadi deepseek-r1:32b, yang mungkin membuat pengguna baru salah mengira bahwa mereka menjalankan model DeepSeek murni, dan mengabaikan esensi distilasi Qwen-nya. Pengguna berpendapat bahwa cara penamaan ini tidak konsisten dengan kebiasaan platform seperti HuggingFace, kurang transparan, dan dapat menyebabkan pengguna salah memahami karakteristik model. (Sumber: Reddit r/LocalLLaMA)

Bahasa pemrograman memberikan kontribusi besar bagi keberhasilan model bahasa besar: Diskusi komunitas menekankan bahwa bahasa pemrograman, sebagai korpus pelatihan berkualitas tinggi, karena definisi logisnya yang jelas dan kemudahan memverifikasi hasil, memainkan peran kunci dalam keberhasilan pengembangan model bahasa besar. Ini tidak hanya menyediakan sumber pengetahuan terstruktur untuk model, tetapi juga meletakkan dasar bagi model untuk belajar penalaran dan menghasilkan kode yang dapat dieksekusi. (Sumber: dotey)

💡 Lainnya
Indoor Robotics meluncurkan drone robot keamanan navigasi otonom berbasis AI: Perusahaan Indoor Robotics memamerkan drone robot keamanan navigasi otonom berbasis kecerdasan buatan. Drone ini dirancang khusus untuk lingkungan dalam ruangan, mampu secara mandiri melakukan patroli dan tugas pemantauan keamanan, memanfaatkan AI untuk navigasi dan identifikasi ancaman, menyediakan solusi otomatisasi inovatif untuk keamanan dalam ruangan. (Sumber: Ronald_vanLoon, Ronald_vanLoon)
Unitree Robotics meningkatkan robot industri beroda B2-W, menambah fungsionalitas: Unitree Robotics telah meningkatkan fungsionalitas robot industri beroda B2-W miliknya, memberinya lebih banyak kemampuan menarik. Robot ini menggabungkan fleksibilitas mobilitas beroda dengan keserbagunaan robot, yang bertujuan untuk diterapkan dalam berbagai skenario industri, meningkatkan tingkat otomatisasi dan efisiensi kerja. (Sumber: Ronald_vanLoon)
Lenovo merilis robot berkaki enam Daystar, ditujukan untuk bidang industri, penelitian & pendidikan: Lenovo meluncurkan robot berkaki enam bernama Daystar. Robot ini dirancang khusus untuk aplikasi industri, penelitian ilmiah, dan tujuan pendidikan, struktur berkaki banyaknya memungkinkannya beradaptasi dengan medan yang kompleks, menyediakan opsi platform robot baru untuk bidang terkait. (Sumber: Ronald_vanLoon)