
Kata Kunci:DeepSeek-R1-0528, AI cerdas, model multimodal, AI sumber terbuka, pembelajaran penguatan, pengeditan gambar, model bahasa besar, pengujian patokan AI, DeepSeek-R1-0528-Qwen3-8B, Alat Circuit Tracer, Darwin Gödel Machine, FLUX.1 Kontext, Agentic Retrieval
🔥 Fokus
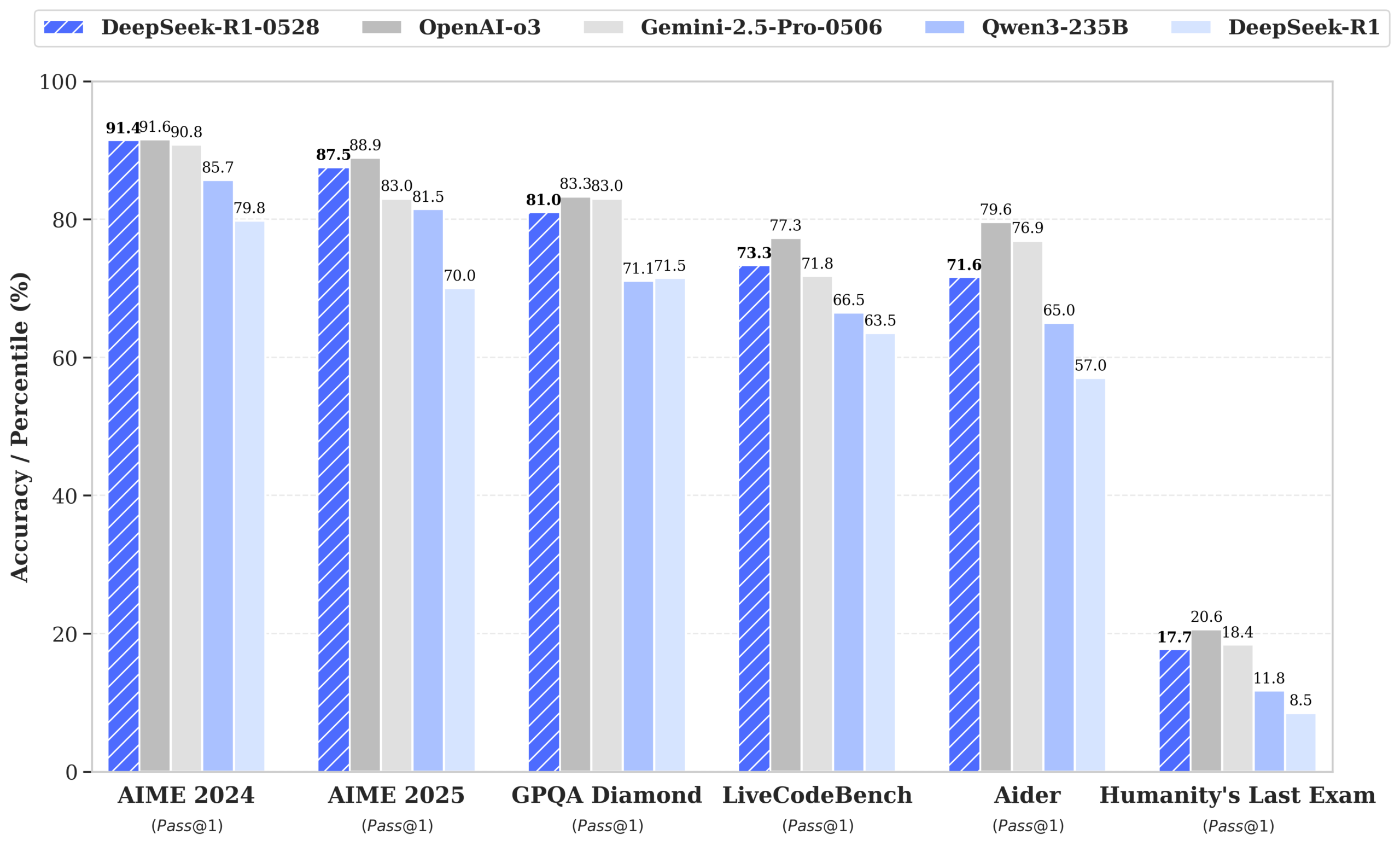
DeepSeek merilis model R1-0528, kinerja mendekati GPT-4o dan Gemini 2.5 Pro, memuncaki peringkat open source: DeepSeek-R1-0528 menunjukkan kinerja luar biasa dalam berbagai tolok ukur seperti matematika, pemrograman, dan penalaran logika umum, terutama dalam pengujian AIME 2025 dengan tingkat akurasi meningkat dari 70% menjadi 87,5%. Versi baru ini secara signifikan mengurangi tingkat halusinasi (sekitar 45-50%), meningkatkan kemampuan pembuatan kode front-end, serta mendukung output JSON dan pemanggilan fungsi (function calling). Sementara itu, DeepSeek merilis DeepSeek-R1-0528-Qwen3-8B yang disesuaikan (fine-tuned) berdasarkan Qwen3-8B Base, yang kinerjanya di AIME 2024 hanya kalah dari R1-0528, melampaui Qwen3-235B. Pembaruan ini memperkuat posisi DeepSeek sebagai laboratorium AI terbesar kedua di dunia dan pemimpin open source. (Sumber: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
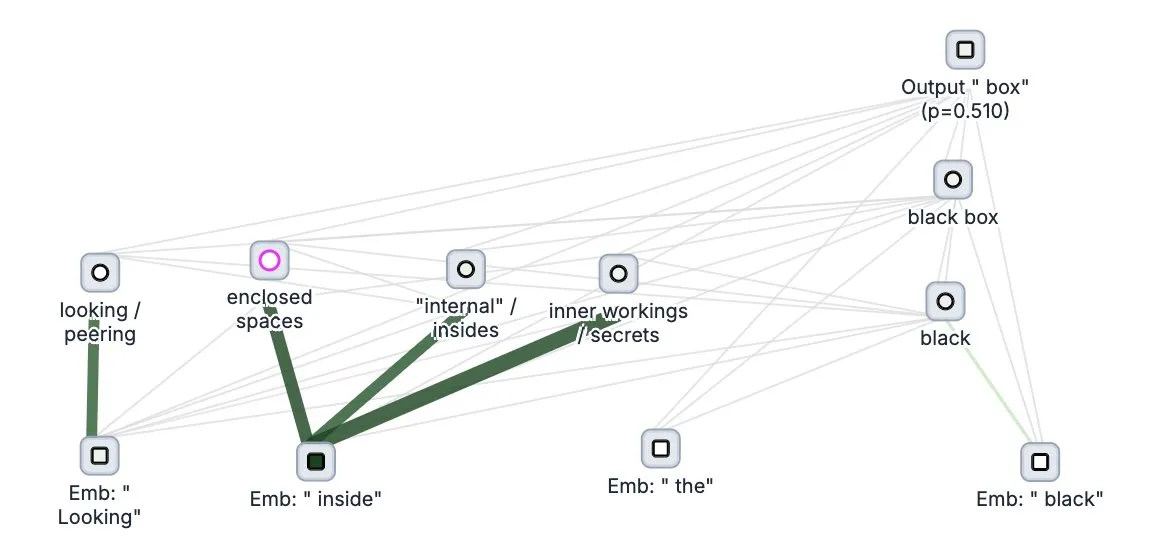
Anthropic merilis secara open source alat “pelacak pemikiran” model besar Circuit Tracer: Perusahaan Anthropic merilis secara open source alat penelitian interpretabilitas model besar mereka, Circuit Tracer, yang memungkinkan peneliti untuk menghasilkan dan menjelajahi “peta atribusi” secara interaktif untuk memahami proses “berpikir” internal dan mekanisme pengambilan keputusan Large Language Model (LLM). Alat ini bertujuan untuk membantu peneliti menyelidiki lebih dalam cara kerja internal LLM, misalnya bagaimana model menggunakan fitur tertentu untuk memprediksi token berikutnya. Pengguna dapat mencoba alat ini di Neuronpedia, dengan memasukkan kalimat untuk mendapatkan diagram sirkuit penggunaan fitur model. (Sumber: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
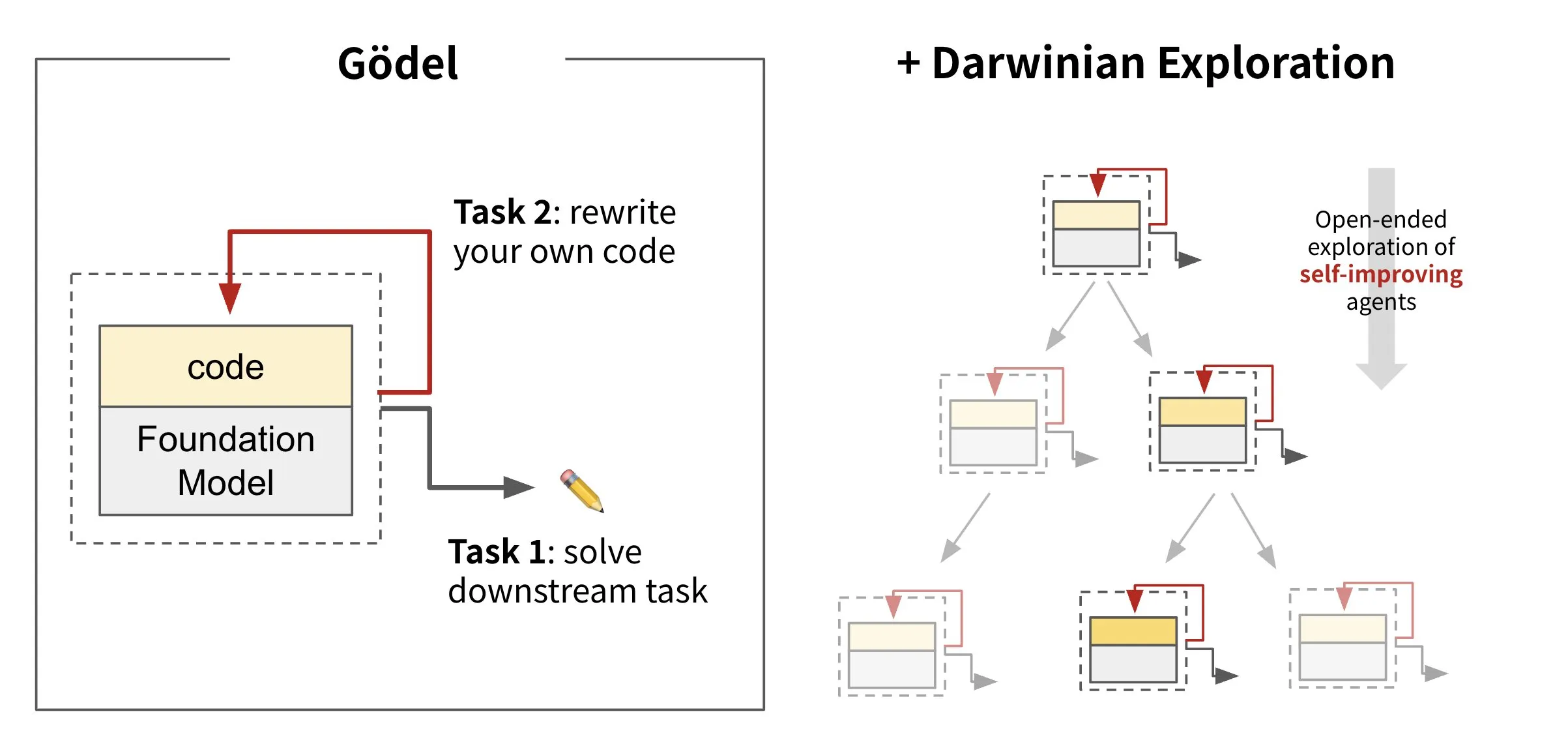
Sakana AI merilis kerangka kerja agen cerdas berevolusi mandiri Darwin Gödel Machine (DGM): Sakana AI meluncurkan Darwin Gödel Machine (DGM), sebuah kerangka kerja agen AI yang mampu memperbaiki dirinya sendiri dengan menulis ulang kodenya sendiri. DGM terinspirasi oleh teori evolusi, memelihara silsilah varian agen yang terus berkembang untuk mengeksplorasi secara terbuka ruang desain agen cerdas yang dapat memperbaiki diri. Kerangka kerja ini bertujuan untuk memungkinkan sistem AI belajar dan mengembangkan kemampuannya sendiri seiring waktu, seperti manusia. Di SWE-bench, DGM meningkatkan kinerja dari 20,0% menjadi 50,0%; di Polyglot, tingkat keberhasilan meningkat dari 14,2% menjadi 30,7%. (Sumber: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs merilis model penyuntingan gambar FLUX.1 Kontext, mendukung input campuran teks dan gambar: Black Forest Labs meluncurkan model penyuntingan gambar generasi baru FLUX.1 Kontext, yang menggunakan arsitektur pencocokan aliran (flow matching), mampu menerima teks dan gambar sebagai input secara bersamaan, mewujudkan pembuatan dan penyuntingan gambar yang sadar konteks. Model ini menunjukkan kinerja luar biasa dalam konsistensi karakter, penyuntingan lokal, referensi gaya, dan kecepatan interaksi, misalnya menghasilkan gambar dengan resolusi 1024×1024 hanya dalam 3-5 detik. Pengujian Replicate menunjukkan efek penyuntingannya lebih unggul dari GPT-4o-Image dan biayanya lebih rendah. Kontext menyediakan versi Pro dan Max, dan berencana meluncurkan versi Dev open source. (Sumber: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 Tren
Google DeepMind merilis model medis multimodal MedGemma: Google DeepMind meluncurkan MedGemma, sebuah model terbuka yang kuat yang dirancang khusus untuk pemahaman teks dan gambar medis multimodal. Model ini disediakan sebagai bagian dari Health AI Developer Foundations, yang bertujuan untuk meningkatkan kemampuan aplikasi AI di bidang medis, terutama dalam menggabungkan analisis teks dan citra medis (seperti sinar-X) secara komprehensif. (Sumber: GoogleDeepMind)
Perplexity AI meluncurkan Perplexity Labs, memberdayakan pemrosesan tugas kompleks: Perplexity AI merilis fitur baru Perplexity Labs, yang dirancang khusus untuk menangani tugas yang lebih kompleks, bertujuan untuk memberi pengguna kemampuan analisis dan pembangunan yang serupa dengan seluruh tim peneliti. Pengguna dapat membangun laporan analisis, presentasi, dan dasbor dinamis melalui Labs. Fitur ini saat ini telah tersedia untuk semua pengguna Pro dan menunjukkan potensinya dalam penelitian ilmiah, analisis pasar, dan pembuatan aplikasi mini (seperti game, dasbor). (Sumber: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
Tencent Hunyuan dan Tencent Music bersama-sama meluncurkan HunyuanVideo-Avatar, foto dapat menghasilkan video bernyanyi yang realistis: Tencent Hunyuan dan Tencent Music bekerja sama merilis model HunyuanVideo-Avatar, yang dapat menggabungkan foto dan audio yang diunggah pengguna, secara otomatis mendeteksi konteks adegan dan emosi, serta menghasilkan video berbicara atau bernyanyi dengan sinkronisasi gerakan bibir yang realistis dan efek visual yang dinamis. Teknologi ini mendukung berbagai gaya dan telah dirilis secara open source. (Sumber: huggingface, thursdai_pod)
Apache Spark 4.0.0 resmi dirilis, meningkatkan dukungan SQL, Spark Connect, dan multibahasa: Versi Apache Spark 4.0.0 resmi dirilis, membawa peningkatan signifikan pada fungsionalitas SQL, perbaikan pada Spark Connect yang membuat aplikasi berjalan lebih mudah, dan penambahan dukungan untuk bahasa baru. Pembaruan ini menyelesaikan lebih dari 5100 masalah, dengan partisipasi lebih dari 390 kontributor. (Sumber: matei_zaharia, lateinteraction)

Model video Kling 2.1 dirilis, mengintegrasikan OpenArt untuk mendukung konsistensi karakter: Kling AI merilis model videonya Kling 2.1, dan bekerja sama dengan OpenArt untuk mendukung konsistensi karakter dalam penceritaan video AI. Kling 2.1 meningkatkan keselarasan prompt, kecepatan pembuatan video, kejernihan gerakan kamera, dan diklaim memiliki efek teks-ke-video terbaik. Versi baru mendukung output 720p (standar) dan 1080p (profesional), saat ini fitur gambar-ke-video telah diluncurkan, dan fitur teks-ke-video akan segera hadir. (Sumber: Kling_ai, NandoDF)
Hume merilis model suara EVI 3, dapat memahami dan menghasilkan suara manusia apa pun: Hume meluncurkan model bahasa suara terbarunya EVI 3, yang bertujuan untuk mewujudkan kecerdasan suara universal. EVI 3 mampu memahami dan menghasilkan suara manusia apa pun, bukan hanya beberapa pembicara tertentu, sehingga memberikan kemampuan ekspresi yang lebih luas dan pemahaman yang lebih dalam tentang intonasi, ritme, timbre, dan gaya bicara. Teknologi ini bertujuan agar setiap orang dapat memiliki AI yang dapat dikenali melalui suara, unik, dan tepercaya. (Sumber: AlanCowen, AlanCowen, _akhaliq)
Alibaba merilis WebDancer, mengeksplorasi agen cerdas pencarian informasi otonom: Alibaba meluncurkan proyek WebDancer, yang bertujuan untuk meneliti dan mengembangkan agen AI yang mampu melakukan pencarian informasi secara otonom. Proyek ini berfokus pada bagaimana membuat agen AI lebih efektif dalam menavigasi lingkungan web, memahami informasi, dan menyelesaikan tugas perolehan informasi yang kompleks. (Sumber: _akhaliq)
MiniMax merilis kerangka kerja V-Triune dan model Orsta secara open source, menyatukan penalaran RL visual dengan tugas persepsi: Perusahaan AI MiniMax merilis secara open source kerangka kerja terpadu pembelajaran penguatan visual (visual reinforcement learning) V-Triune dan seri model Orsta (7B hingga 32B) yang didasarkan pada kerangka kerja ini. Melalui desain komponen tiga lapis dan mekanisme hadiah Intersection over Union (IoU) dinamis, kerangka kerja ini untuk pertama kalinya memungkinkan VLM untuk bersama-sama mempelajari tugas penalaran visual dan persepsi dalam satu alur pasca-pelatihan, dengan peningkatan kinerja yang signifikan pada tolok ukur MEGA-Bench Core. (Sumber: 量子位)

Shanghai AI Laboratory dkk. merilis tolok ukur baru penyuntingan gambar RISEBench, menguji penalaran mendalam model: Shanghai Artificial Intelligence Laboratory bersama beberapa universitas merilis tolok ukur evaluasi penyuntingan gambar baru bernama RISEBench, yang berisi 360 kasus sulit yang dirancang oleh pakar manusia, mencakup empat jenis penalaran inti: waktu, kausalitas, spasial, dan logika. Hasil pengujian menunjukkan bahwa bahkan GPT-4o-Image hanya mampu menyelesaikan 28,9% tugas, mengungkap kekurangan model multimodal saat ini dalam pemahaman instruksi kompleks dan penyuntingan visual. (Sumber: 36氪)

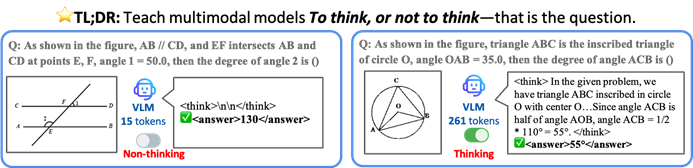
CUHK dkk. mengusulkan kerangka kerja TON, memungkinkan model AI berpikir secara selektif untuk meningkatkan efisiensi dan akurasi: Peneliti dari The Chinese University of Hong Kong dan National University of Singapore Show Lab mengusulkan kerangka kerja TON (Think Or Not), yang memungkinkan model bahasa visual (VLM) untuk secara mandiri menentukan apakah penalaran eksplisit diperlukan. Melalui “pembuangan pikiran” dan pembelajaran penguatan, kerangka kerja ini memungkinkan model untuk menjawab pertanyaan sederhana secara langsung dan melakukan penalaran terperinci untuk pertanyaan kompleks, sehingga mengurangi panjang output penalaran rata-rata hingga 90% tanpa mengorbankan akurasi, bahkan meningkatkan akurasi pada beberapa tugas hingga 17%. (Sumber: 36氪)
Microsoft Copilot terintegrasi dengan Instacart, mewujudkan belanja bahan makanan dengan bantuan AI: Mustafa Suleyman, Kepala AI Microsoft, mengumumkan bahwa Copilot kini telah terintegrasi dengan layanan Instacart, memungkinkan pengguna untuk menyelesaikan seluruh proses mulai dari pembuatan resep, pembuatan daftar belanja, hingga pengiriman bahan makanan segar ke rumah secara mulus melalui aplikasi Copilot. Ini menandai perluasan lebih lanjut asisten AI dalam bidang layanan kehidupan sehari-hari. (Sumber: mustafasuleyman)
🧰 Alat
LlamaIndex meluncurkan kode sumber BundesGPT dan alat create-llama, menyederhanakan pembuatan aplikasi AI: Jerry Liu dari LlamaIndex mengumumkan penyediaan kode sumber BundesGPT dan mempromosikan alat open source-nya, create-llama. Alat ini berbasis LlamaIndex, bertujuan untuk membantu pengembang dengan mudah membangun dan mengintegrasikan data perusahaan dengan agen AI, mode eject barunya membuat pembuatan antarmuka AI yang sepenuhnya dapat disesuaikan seperti BundesGPT menjadi sangat sederhana. Langkah ini bertujuan untuk mendukung potensi rencana Jerman untuk menyediakan langganan ChatGPT Plus gratis bagi setiap warga negara. (Sumber: jerryjliu0)
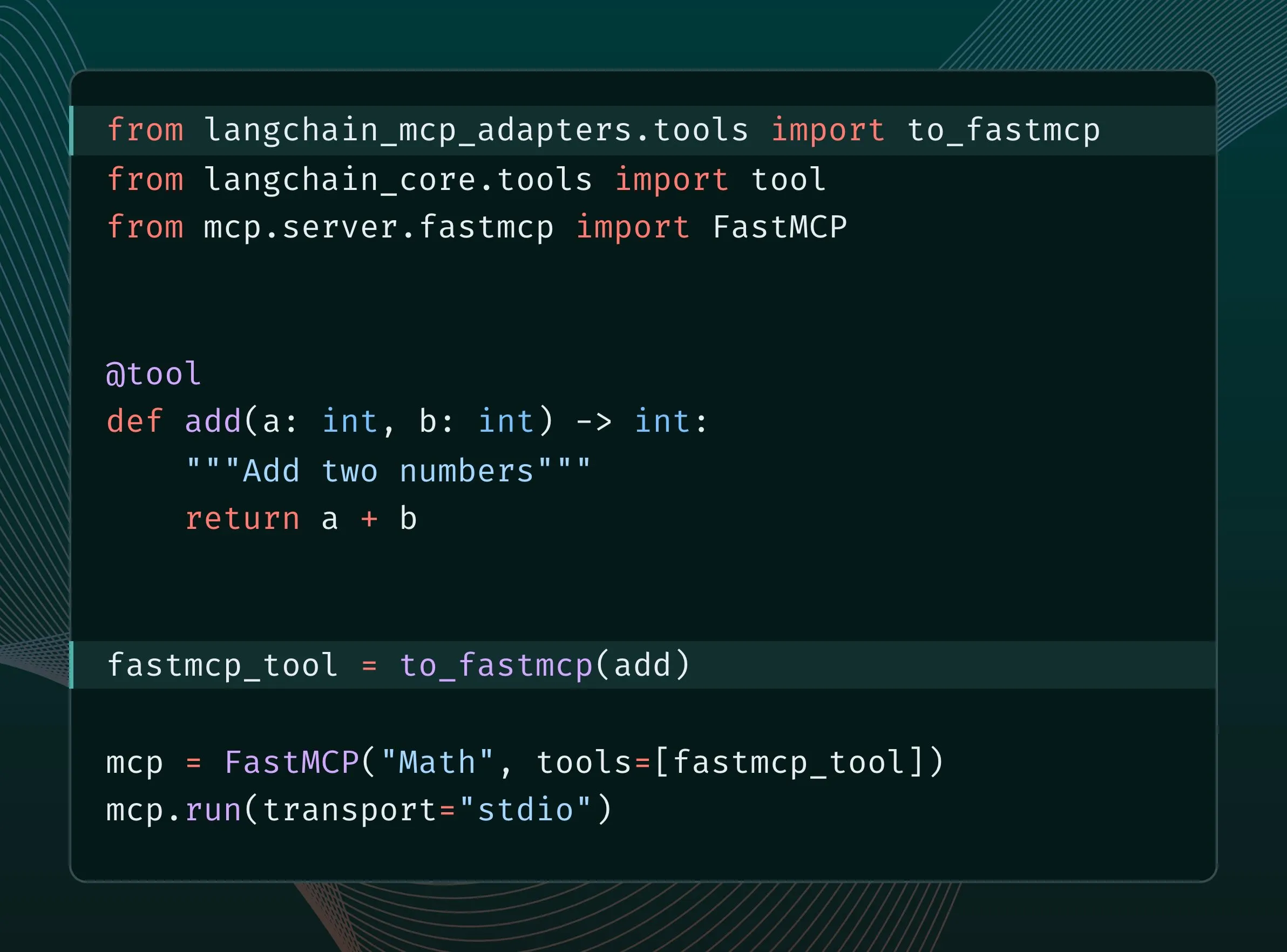
Alat LangChain dapat dikonversi menjadi alat MCP dan diintegrasikan ke server FastMCP: Pengguna LangChain sekarang dapat mengonversi alat LangChain menjadi alat MCP (Model Component Protocol) dan menambahkannya langsung ke server FastMCP. Dengan menginstal pustaka langchain-mcp-adapters, pengembang dapat lebih mudah menggunakan kumpulan alat LangChain dalam ekosistem MCP, mendorong interoperabilitas antar kerangka kerja AI yang berbeda. (Sumber: LangChainAI, hwchase17)
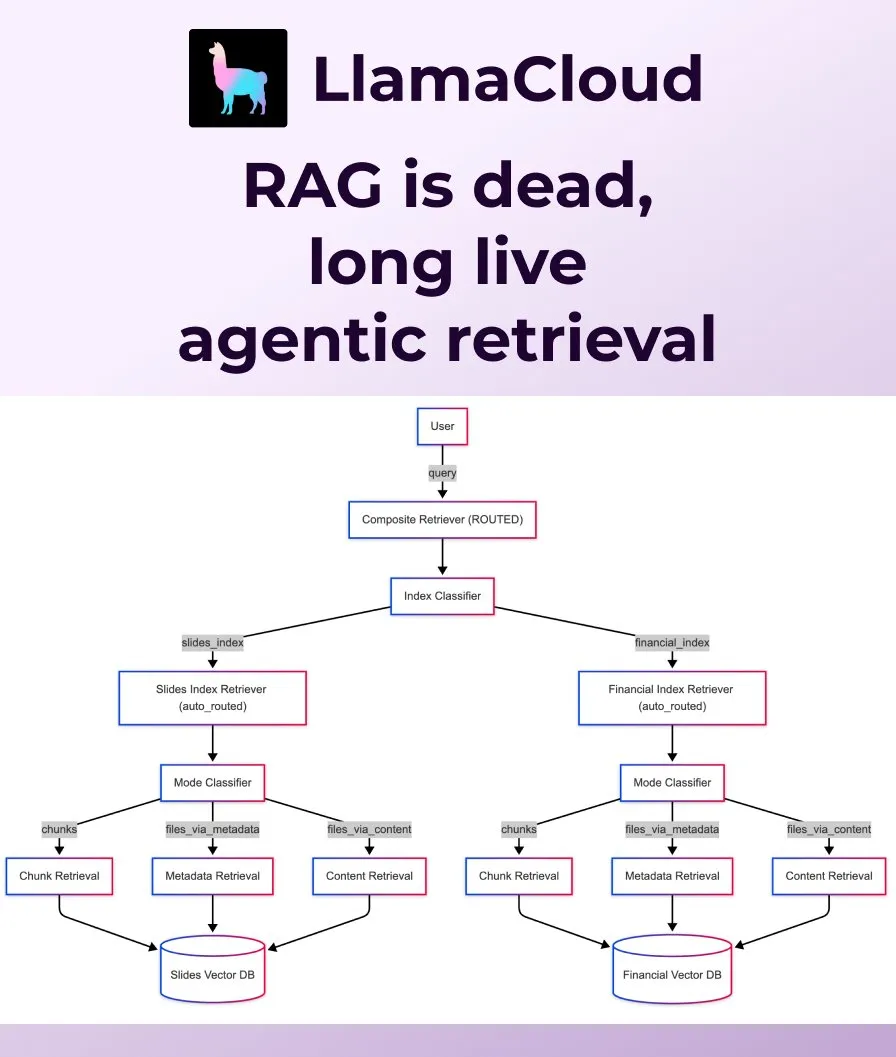
LlamaIndex merilis Agentic Retrieval, menggantikan RAG tradisional: LlamaIndex berpendapat bahwa RAG (Retrieval Augmented Generation) naif tradisional tidak lagi cukup untuk memenuhi kebutuhan aplikasi modern, dan meluncurkan Agentic Retrieval. Solusi ini terpasang di LlamaCloud, memungkinkan agen untuk secara dinamis mengambil seluruh file atau blok data tertentu dari satu atau beberapa basis pengetahuan (seperti Sharepoint, Box, GDrive, S3) berdasarkan konten pertanyaan, mewujudkan perolehan konteks yang lebih cerdas dan fleksibel. (Sumber: jerryjliu0, jerryjliu0)
Ollama mendukung menjalankan model Osmosis-Structure-0.6B, untuk transformasi data tidak terstruktur: Pengguna sekarang dapat menjalankan model Osmosis-Structure-0.6B melalui Ollama. Ini adalah model yang sangat kecil yang mampu mengubah data tidak terstruktur apa pun menjadi format yang ditentukan (misalnya JSON Schema), dapat digunakan dengan model apa pun, dan sangat cocok untuk tugas inferensi yang memerlukan output terstruktur. (Sumber: ollama)
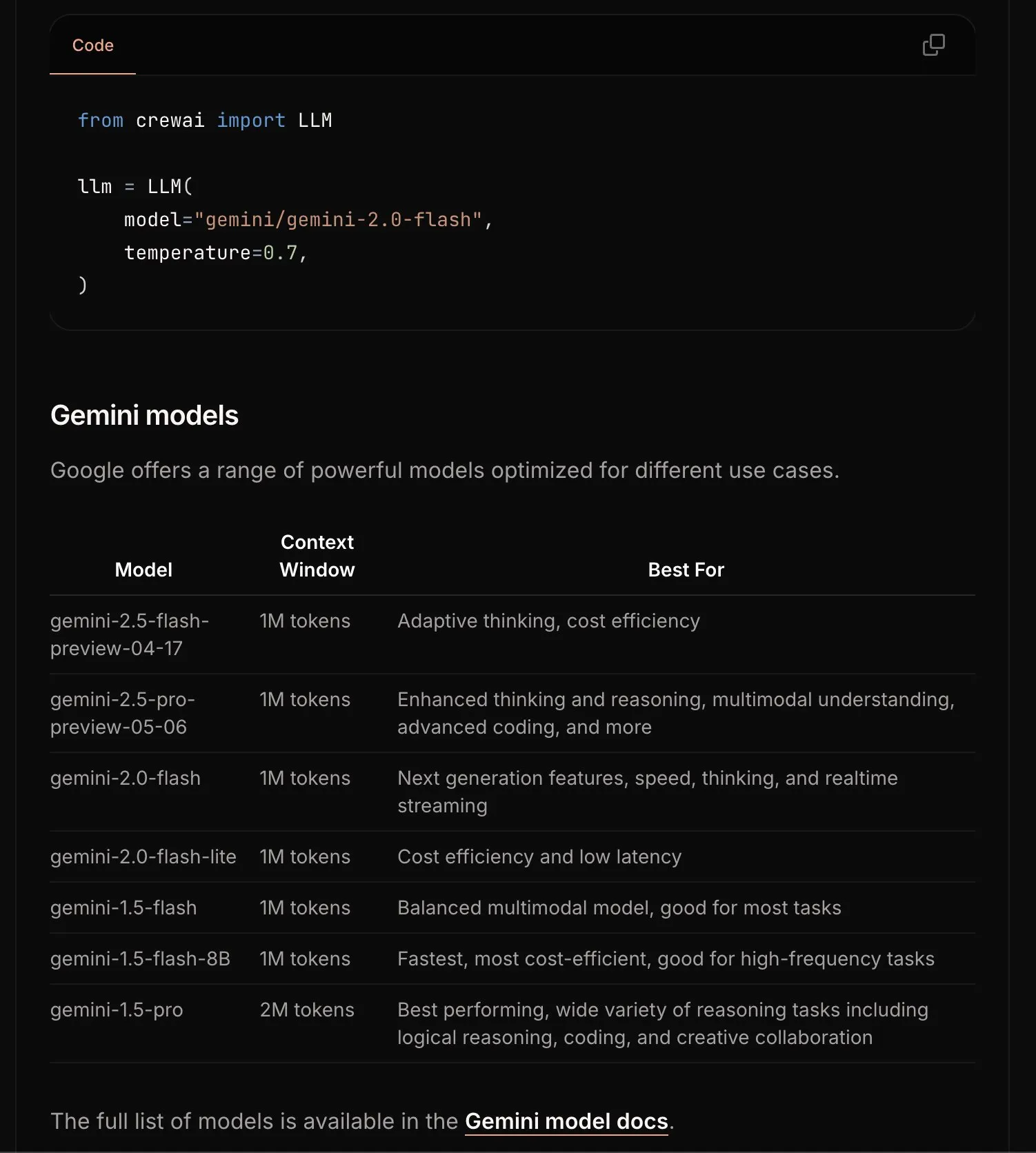
CrewAI memperbarui dokumentasi Gemini, menyederhanakan proses memulai: Tim CrewAI memperbarui dokumentasinya tentang Google Gemini API, yang bertujuan untuk membantu pengguna lebih mudah memulai membangun agen AI menggunakan model Gemini. Dokumentasi baru mungkin berisi panduan yang lebih jelas, contoh kode, atau praktik terbaik. (Sumber: _philschmid)
Requesty meluncurkan fitur Smart Routing, secara otomatis memilih LLM terbaik untuk OpenWebUI: Requesty merilis fitur Smart Routing, yang dapat diintegrasikan secara mulus dengan OpenWebUI, untuk secara otomatis memilih LLM terbaik (seperti GPT-4o, Claude, Gemini) berdasarkan jenis tugas yang diminta pengguna. Pengguna hanya perlu menggunakan smart/task sebagai ID model, dan sistem dapat mengklasifikasikan prompt dalam waktu sekitar 65 milidetik, serta merutekannya ke model yang paling sesuai berdasarkan biaya, kecepatan, dan kualitas. Fitur ini bertujuan untuk menyederhanakan pemilihan model dan meningkatkan pengalaman pengguna. (Sumber: Reddit r/OpenWebUI)
EvoAgentX: Kerangka kerja open source evolusi mandiri agen AI pertama dirilis: Tim peneliti dari University of Glasgow, Inggris, merilis EvoAgentX, kerangka kerja open source evolusi mandiri agen AI pertama di dunia. Ini mendukung pembangunan alur kerja dengan sekali klik dan memperkenalkan mekanisme “evolusi mandiri”, yang memungkinkan sistem multi-agen untuk terus mengoptimalkan struktur dan kinerjanya sesuai dengan perubahan lingkungan dan tujuan, bertujuan untuk mendorong sistem multi-agen AI dari “penyesuaian manual” menuju “evolusi otonom”. Eksperimen menunjukkan bahwa dalam tugas tanya jawab multi-hop, pembuatan kode, dan penalaran matematika, kinerja rata-rata meningkat 8%-13%. (Sumber: 36氪)

📚 Pembelajaran
HuggingFace bersama Gradio dkk. menyelenggarakan Agents & MCP Hackathon, menyediakan hadiah besar dan kuota API: HuggingFace, Gradio, Anthropic, SambaNovaAI, MistralAI, dan LlamaIndex dkk. akan bersama-sama menyelenggarakan Gradio Agents & MCP Hackathon (2-8 Juni). Acara ini menyediakan total hadiah $11.000, dan bagi pendaftar awal akan diberikan kuota API gratis dari Hyperbolic, Anthropic, Mistral, SambaNova. Modal Labs bahkan berjanji untuk menyediakan kuota GPU senilai $250 untuk semua peserta, dengan total lebih dari $300.000. (Sumber: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain berbagi praktik JPMorgan Chase menggunakan sistem multi-agen untuk penelitian investasi: David Odomirok dan Zheng Xue dari JPMorgan Chase berbagi bagaimana mereka membangun sistem AI multi-agen bernama “Ask David”. Sistem ini bertujuan untuk mengotomatiskan proses penelitian investasi untuk ribuan produk keuangan, menunjukkan potensi arsitektur multi-agen dalam analisis keuangan yang kompleks. (Sumber: LangChainAI, hwchase17)
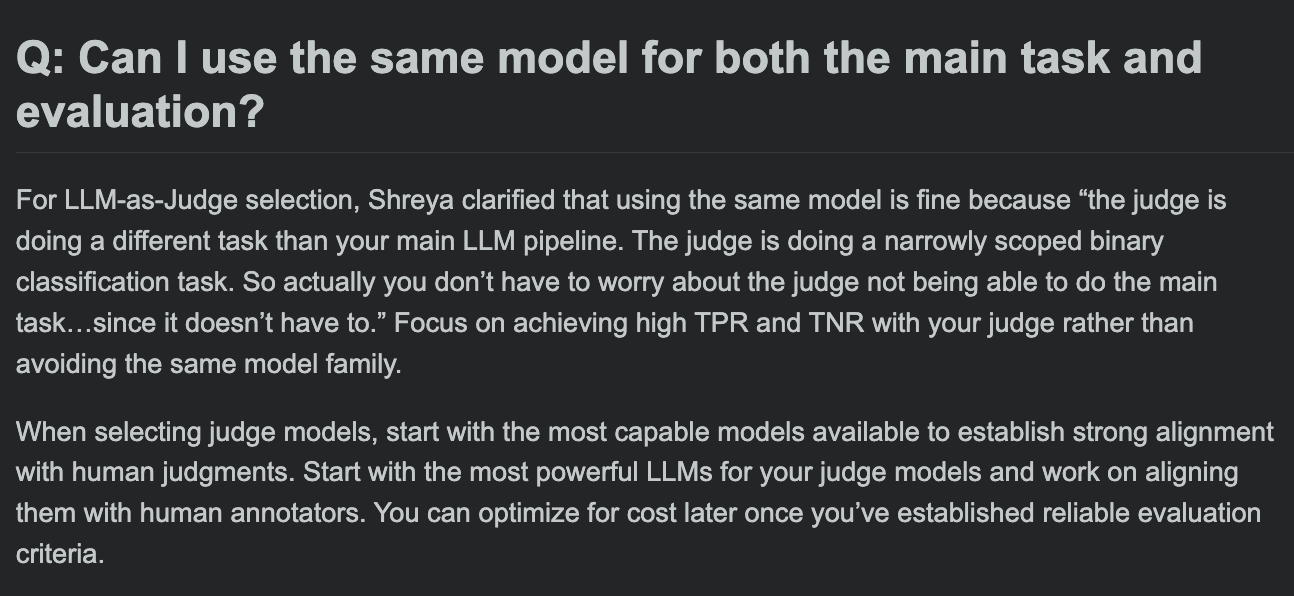
Hamel Husain berbagi FAQ kursus evaluasi LLM, membahas apakah model evaluasi dan model tugas utama bisa sama: Dalam sesi tanya jawab kursus evaluasi LLM-nya, Hamel Husain membahas pertanyaan umum: apakah mungkin menggunakan model yang sama untuk pemrosesan tugas utama dan evaluasi tugas. Diskusi ini membantu pengembang memahami potensi bias dan praktik terbaik dalam evaluasi model. (Sumber: HamelHusain, HamelHusain)
The Rundown AI meluncurkan platform pendidikan AI yang dipersonalisasi: The Rundown AI mengumumkan peluncuran platform pendidikan AI yang dipersonalisasi pertama di dunia, yang menyediakan pelatihan, studi kasus, dan lokakarya langsung yang disesuaikan untuk berbagai industri, tingkat keahlian, dan alur kerja sehari-hari. Konten platform mencakup 16 program sertifikat AI khusus industri di bidang teknologi vertikal, lebih dari 300 studi kasus AI dunia nyata, lokakarya ahli, serta diskon alat AI, dan lain-lain. (Sumber: TheRundownAI, rowancheung)
Common Crawl merilis peta jaringan tingkat host dan domain untuk Maret-Mei 2025: Common Crawl mengumumkan data peta jaringan tingkat host dan domain terbarunya, yang mencakup Maret, April, dan Mei 2025. Data ini sangat berharga untuk meneliti struktur web, melatih model bahasa, dan melakukan analisis web skala besar. (Sumber: CommonCrawl)
Bill Chambers memulai kegiatan belajar “20 Days of DSPyOSS”: Untuk membantu komunitas lebih memahami fungsionalitas dan metode penggunaan DSPyOSS, Bill Chambers memulai kegiatan belajar DSPyOSS selama 20 hari. Setiap hari akan dirilis cuplikan kode DSPy beserta penjelasannya, yang bertujuan untuk membantu pengguna menguasai kerangka kerja ini dari tingkat pemula hingga mahir. (Sumber: lateinteraction)
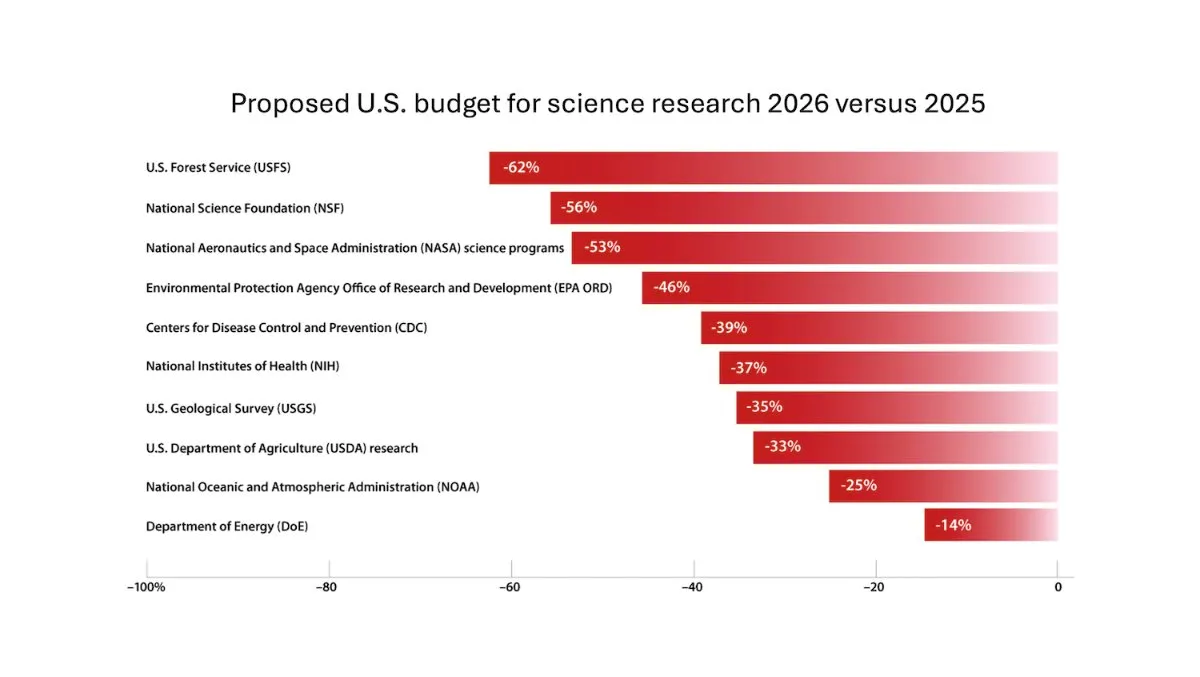
DeepLearning.AI merilis buletin mingguan The Batch, Andrew Ng membahas risiko pemotongan dana penelitian ilmiah: Dalam edisi terbaru buletin mingguan The Batch, Andrew Ng membahas potensi risiko pemotongan dana penelitian ilmiah terhadap daya saing dan keamanan nasional. Buletin ini juga mencakup kinerja model Claude 4 dalam tolok ukur pengkodean, rilis AI di Google I/O, metode pelatihan berbiaya rendah DeepSeek, serta kemungkinan GPT-4o menggunakan buku berhak cipta untuk pelatihan, dan topik hangat lainnya. (Sumber: DeepLearningAI)
Google DeepMind menyediakan Gemini 2.5 Pro dan NotebookLM gratis untuk mahasiswa Inggris: Google DeepMind mengumumkan penyediaan akses gratis ke model tercanggihnya (termasuk Gemini 2.5 Pro dan NotebookLM) untuk mahasiswa di Inggris selama 15 bulan. Langkah ini bertujuan untuk mendukung pembelajaran mahasiswa dalam aspek penelitian, penulisan, dan persiapan ujian, serta menyediakan ruang penyimpanan gratis sebesar 2TB. (Sumber: demishassabis)
Interpretasi makalah AI: Prot2Token kerangka kerja pemodelan protein terpadu: Makalah 《Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction》 memperkenalkan kerangka kerja pemodelan protein terpadu Prot2Token, yang mengubah berbagai tugas prediksi mulai dari atribut sekuens protein, fitur residu hingga interaksi antar protein menjadi format prediksi token berikutnya yang standar. Kerangka kerja ini menggunakan dekoder autoregresif, memanfaatkan embedding dari enkoder protein pra-terlatih dan token tugas yang dapat dipelajari untuk pembelajaran multi-tugas, bertujuan untuk meningkatkan efisiensi dan mempercepat penemuan biologis. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Penambangan contoh negatif sulit untuk pengambilan domain-spesifik dalam sistem perusahaan: Makalah 《Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems》 mengusulkan kerangka kerja penambangan contoh negatif sulit yang dapat diskalakan untuk data domain-spesifik perusahaan. Metode ini secara dinamis memilih dokumen yang secara semantik menantang tetapi tidak relevan secara kontekstual untuk meningkatkan kinerja model pengurutan ulang yang diterapkan, eksperimen pada korpus perusahaan di bidang layanan cloud menunjukkan peningkatan MRR@3 dan MRR@10 masing-masing sebesar 15% dan 19%. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: FS-DAG, jaringan graf untuk pemahaman dokumen kaya visual dengan sedikit sampel: Makalah 《FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding》 mengusulkan arsitektur model FS-DAG untuk pemahaman dokumen kaya visual dalam kondisi sedikit sampel. Model ini memanfaatkan jaringan tulang punggung domain-spesifik dan bahasa/visual-spesifik, dalam kerangka kerja modular untuk beradaptasi dengan berbagai jenis dokumen dengan data minimal, dan dalam eksperimen tugas ekstraksi informasi menunjukkan kecepatan konvergensi dan kinerja yang lebih baik daripada metode SOTA. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: FastTD3, pembelajaran penguatan yang sederhana dan cepat untuk kontrol robot humanoid: Makalah 《FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control》 memperkenalkan algoritma pembelajaran penguatan bernama FastTD3, yang melalui simulasi paralel, pembaruan batch besar, kritikus terdistribusi, dan hiperparameter yang disesuaikan dengan cermat, secara signifikan mempercepat kecepatan pelatihan robot humanoid dalam suite populer seperti HumanoidBench, IsaacLab, dan MuJoCo Playground. (Sumber: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
Interpretasi makalah AI: HLIP, pra-pelatihan bahasa-gambar yang dapat diskalakan untuk pencitraan medis 3D: Makalah 《Towards Scalable Language-Image Pre-training for 3D Medical Imaging》 memperkenalkan kerangka kerja pra-pelatihan pencitraan medis 3D yang dapat diskalakan bernama HLIP (Hierarchical attention for Language-Image Pre-training). HLIP menggunakan mekanisme perhatian hierarkis ringan, mampu melakukan pelatihan langsung pada dataset klinis yang tidak terorganisir, dan mencapai kinerja SOTA dalam beberapa tolok ukur. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: PENGUIN, tolok ukur keamanan personalisasi LLM dan pendekatan agen berbasis perencanaan: Makalah 《Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach》 memperkenalkan konsep keamanan yang dipersonalisasi dan mengusulkan tolok ukur PENGUIN (berisi 14.000 skenario dari 7 domain sensitif) dan kerangka kerja RAISE (agen dua tahap bebas pelatihan yang secara strategis memperoleh informasi latar belakang spesifik pengguna). Penelitian menunjukkan bahwa informasi yang dipersonalisasi dapat secara signifikan meningkatkan skor keamanan, RAISE dapat meningkatkan keamanan dengan biaya interaksi yang rendah. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Memperkuat penalaran multi-giliran agen LLM melalui penetapan kredit tingkat giliran: Makalah 《Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment》 meneliti bagaimana meningkatkan kemampuan penalaran agen LLM melalui pembelajaran penguatan, terutama dalam skenario penggunaan alat multi-giliran. Penulis mengusulkan strategi estimasi keunggulan tingkat giliran yang lebih halus untuk mencapai penetapan kredit yang lebih akurat, eksperimen menunjukkan bahwa metode ini dapat secara signifikan meningkatkan kemampuan penalaran multi-giliran agen LLM dalam tugas pengambilan keputusan yang kompleks. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: PISCES, penghapusan konsep dalam parameter yang presisi pada Large Language Model: Makalah 《Precise In-Parameter Concept Erasure in Large Language Models》 mengusulkan kerangka kerja PISCES, yang digunakan untuk menghapus seluruh konsep dalam parameter model secara presisi dengan mengedit langsung arah konsep yang dikodekan dalam ruang parameter. Metode ini menggunakan disentangler untuk mengurai vektor MLP, mengidentifikasi fitur yang terkait dengan konsep target dan menghapusnya dari parameter model, eksperimen menunjukkan keunggulannya dalam efek penghapusan, spesifisitas, dan ketahanan dibandingkan metode yang ada. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: DORI, evaluasi pemahaman orientasi MLLM dengan tugas persepsi multi-sumbu yang halus: Makalah 《Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks》 memperkenalkan tolok ukur DORI, yang bertujuan untuk mengevaluasi kemampuan pemahaman orientasi objek pada Multimodal Large Language Model (MLLM). DORI mencakup empat dimensi: penentuan posisi depan, transformasi rotasi, hubungan orientasi relatif, dan pemahaman orientasi kanonik, menguji 15 MLLM SOTA, dan menemukan bahwa bahkan model terbaik pun memiliki keterbatasan signifikan dalam penilaian orientasi yang halus. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Dapatkah LLM menyimpulkan hubungan kausal dari teks dunia nyata?: Makalah 《Can Large Language Models Infer Causal Relationships from Real-World Text?》 mengeksplorasi kemampuan LLM untuk menyimpulkan hubungan kausal dari teks dunia nyata. Peneliti mengembangkan tolok ukur yang berasal dari literatur akademis nyata, berisi teks dengan panjang, kompleksitas, dan domain yang berbeda. Eksperimen menunjukkan bahwa bahkan LLM SOTA pun menghadapi tantangan signifikan dalam tugas ini, skor F1 model terbaik hanya 0,477, mengungkapkan kesulitannya dalam memproses informasi implisit, membedakan faktor-faktor terkait, dan menghubungkan informasi yang tersebar. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: IQBench, menggunakan tes IQ manusia untuk mengevaluasi tingkat “kecerdasan” model bahasa visual: Makalah 《IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests》 meluncurkan IQBench, sebuah tolok ukur baru yang bertujuan untuk mengevaluasi kecerdasan fluida model bahasa visual (VLM) melalui tes IQ visual standar. Tolok ukur ini berpusat pada visual, berisi 500 pertanyaan IQ visual yang dikumpulkan dan dianotasi secara manual, mengevaluasi interpretasi model, pola pemecahan masalah, dan akurasi prediksi akhir. Eksperimen menunjukkan bahwa o4-mini, Gemini-2.5-Flash, dan Claude-3.7-Sonnet berkinerja baik, tetapi semua model mengalami kesulitan dalam tugas penalaran spasial 3D dan anagram. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: PixelThink, menuju penalaran rantai-piksel yang efisien: Makalah 《PixelThink: Towards Efficient Chain-of-Pixel Reasoning》 mengusulkan solusi PixelThink, dengan mengintegrasikan estimasi eksternal kesulitan tugas dan ketidakpastian model yang diukur secara internal, dalam paradigma pembelajaran penguatan untuk mengatur generasi penalaran. Model ini belajar untuk memadatkan panjang penalaran berdasarkan kompleksitas adegan dan kepercayaan prediksi. Sekaligus memperkenalkan tolok ukur ReasonSeg-Diff untuk evaluasi, eksperimen menunjukkan bahwa metode ini meningkatkan efisiensi penalaran dan kinerja segmentasi secara keseluruhan. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Meninjau kembali debat multi-agen sebagai perluasan waktu-uji: Makalah 《Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness》 mengkonseptualisasikan debat multi-agen (MAD) sebagai teknik perluasan komputasi waktu-uji, dan secara sistematis meneliti efektivitasnya dalam berbagai kondisi (kesulitan tugas, skala model, keragaman agen) dibandingkan dengan metode agen-mandiri. Penelitian menemukan bahwa untuk penalaran matematika, keunggulan MAD terbatas, tetapi lebih efektif ketika kesulitan tugas meningkat atau kemampuan model menurun; untuk tugas keamanan, optimasi kolaboratif MAD dapat meningkatkan kerentanan, tetapi konfigurasi yang beragam membantu mengurangi tingkat keberhasilan serangan. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: VF-Eval, mengevaluasi kemampuan MLLM menghasilkan umpan balik video AIGC: Makalah 《VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos》 mengusulkan tolok ukur baru VF-Eval, untuk mengevaluasi kemampuan Multimodal Large Language Model (MLLM) dalam menafsirkan video konten yang dihasilkan AI (AIGC). VF-Eval mencakup empat tugas: validasi koherensi, persepsi kesalahan, deteksi jenis kesalahan, dan evaluasi penalaran. Evaluasi terhadap 13 MLLM terdepan menunjukkan bahwa bahkan GPT-4.1 yang berkinerja terbaik pun kesulitan untuk mempertahankan kinerja yang baik di semua tugas. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: SafeScientist, agen LLM mewujudkan penemuan ilmiah yang sadar risiko: Makalah 《SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents》 memperkenalkan kerangka kerja ilmuwan AI bernama SafeScientist, yang bertujuan untuk meningkatkan keamanan dan tanggung jawab etis dalam eksplorasi ilmiah yang didorong AI. Kerangka kerja ini dapat secara proaktif menolak tugas yang tidak pantas atau berisiko tinggi, dan menekankan keamanan proses penelitian melalui berbagai mekanisme pertahanan seperti pemantauan prompt, pemantauan kolaborasi agen, pemantauan penggunaan alat, dan komponen peninjau etika. Sekaligus mengusulkan tolok ukur SciSafetyBench untuk evaluasi. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: CXReasonBench, tolok ukur untuk mengevaluasi penalaran diagnostik terstruktur pada rontgen dada: Makalah 《CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays》 memperkenalkan alur kerja CheXStruct dan tolok ukur CXReasonBench, untuk mengevaluasi apakah Large Vision Language Model (LVLM) dapat melakukan langkah-langkah penalaran yang efektif secara klinis dalam diagnosis rontgen dada. Tolok ukur ini berisi 18.988 pasangan QA, mencakup 12 tugas diagnostik dan 1200 kasus, mendukung evaluasi multi-jalur, multi-tahap, termasuk pemilihan area anatomi dan lokalisasi visual pengukuran diagnostik. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: ZeroGUI, otomatisasi pembelajaran GUI online dengan biaya manusia nol: Makalah 《ZeroGUI: Automating Online GUI Learning at Zero Human Cost》 mengusulkan ZeroGUI, sebuah kerangka kerja pembelajaran online yang dapat diskalakan untuk mengotomatiskan pelatihan agen GUI dengan biaya manusia nol. ZeroGUI mengintegrasikan pembuatan tugas otomatis berbasis VLM, estimasi hadiah otomatis, dan pembelajaran penguatan online dua tahap, untuk terus berinteraksi dengan lingkungan GUI dan belajar darinya. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Spatial-MLLM, meningkatkan kecerdasan spasial visual MLLM: Makalah 《Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence》 mengusulkan kerangka kerja Spatial-MLLM, untuk penalaran spasial berbasis visual dari observasi 2D murni. Kerangka kerja ini menggunakan arsitektur enkoder ganda (satu enkoder visual semantik dan satu enkoder spasial), dan menggabungkannya dengan strategi pengambilan sampel bingkai yang sadar spasial, mencapai kinerja SOTA pada beberapa dataset dunia nyata. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: TrustVLM, menentukan apakah prediksi model bahasa visual dapat dipercaya: Makalah 《To Trust Or Not To Trust Your Vision-Language Model’s Prediction》 memperkenalkan TrustVLM, sebuah kerangka kerja bebas pelatihan yang bertujuan untuk mengevaluasi kepercayaan prediksi model bahasa visual (VLM). Metode ini memanfaatkan perbedaan representasi konsep dalam ruang embedding gambar, mengusulkan fungsi skor kepercayaan baru untuk meningkatkan deteksi misklasifikasi, dan menunjukkan kinerja SOTA pada 17 dataset yang berbeda. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: MAGREF, pembuatan video multi-referensi berbasis panduan bertopeng: Makalah 《MAGREF: Masked Guidance for Any-Reference Video Generation》 mengusulkan MAGREF, sebuah kerangka kerja pembuatan video multi-referensi terpadu. Ini memperkenalkan mekanisme panduan bertopeng, melalui topeng dinamis yang sadar wilayah dan koneksi saluran tingkat piksel, mewujudkan sintesis video multi-subjek yang koheren dalam kondisi gambar referensi dan prompt teks yang beragam, dan melampaui baseline open source dan komersial yang ada pada tolok ukur video multi-subjek. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: ATLAS, belajar mengoptimalkan memori konteks pada waktu uji: Makalah 《ATLAS: Learning to Optimally Memorize the Context at Test Time》 mengusulkan ATLAS, sebuah modul memori jangka panjang berkapasitas tinggi, yang belajar mengingat konteks dengan mengoptimalkan memori berdasarkan token saat ini dan masa lalu, mengatasi karakteristik pembaruan online model memori jangka panjang. Berdasarkan ini, penulis mengusulkan keluarga arsitektur DeepTransformers, eksperimen menunjukkan ATLAS melampaui Transformers dan model siklik linier baru-baru ini dalam pemodelan bahasa, penalaran akal sehat, tugas padat penarikan kembali, dan pemahaman konteks panjang. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Satori-SWE, metode rekayasa perangkat lunak perluasan waktu-uji evolusioner yang efisien sampel: Makalah 《Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering》 mengusulkan metode EvoScale, yang memperlakukan pembuatan kode sebagai proses evolusioner, dengan mengoptimalkan output secara iteratif untuk meningkatkan kinerja model kecil dalam tugas rekayasa perangkat lunak (seperti SWE-Bench). Model Satori-SWE-32B melalui metode ini, dengan menggunakan sejumlah kecil sampel, mencapai atau melampaui kinerja model dengan lebih dari 100B parameter. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: OPO, pembelajaran penguatan on-policy dengan baseline hadiah optimal: Makalah 《On-Policy RL with Optimal Reward Baseline》 mengusulkan algoritma OPO, sebuah algoritma pembelajaran penguatan baru yang disederhanakan, yang bertujuan untuk mengatasi masalah ketidakstabilan pelatihan dan efisiensi komputasi yang rendah yang dihadapi algoritma RL saat ini dalam melatih LLM. OPO menekankan pelatihan on-policy yang akurat, dan memperkenalkan baseline hadiah optimal yang secara teoritis meminimalkan varians gradien, eksperimen menunjukkan kinerja dan stabilitas pelatihan yang unggul pada tolok ukur penalaran matematika. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: SWE-bench Goes Live! Tolok ukur rekayasa perangkat lunak yang diperbarui secara real-time: Makalah 《SWE-bench Goes Live!》 memperkenalkan SWE-bench-Live, sebuah tolok ukur yang bertujuan untuk mengatasi keterbatasan SWE-bench yang ada dengan pembaruan secara real-time. Versi baru ini berisi 1319 tugas yang berasal dari masalah GitHub nyata sejak tahun 2024, mencakup 93 repositori, dan dilengkapi dengan proses manajemen otomatis, untuk mencapai skalabilitas dan pembaruan berkelanjutan, sehingga menyediakan evaluasi LLM dan agen yang lebih ketat dan tahan kontaminasi. (Sumber: HuggingFace Daily Papers, _akhaliq)
Interpretasi makalah AI: ToMAP, melatih pembujuk LLM yang sadar lawan dengan Teori Pikiran: Makalah 《ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind》 memperkenalkan metode baru bernama ToMAP, yang dengan mengintegrasikan dua modul teori pikiran membangun agen pembujuk yang lebih fleksibel, meningkatkan kesadaran dan analisisnya terhadap kondisi mental lawan. Eksperimen menunjukkan bahwa pembujuk ToMAP dengan hanya 3B parameter berkinerja lebih baik daripada baseline besar seperti GPT-4o dalam berbagai model objek bujukan dan korpus. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Dapatkah LLM menipu CLIP? Mengevaluasi komposisionalitas adversarial representasi multimodal pra-terlatih melalui pembaruan teks: Makalah 《Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates》 memperkenalkan tolok ukur komposisionalitas adversarial multimodal (MAC), memanfaatkan LLM untuk menghasilkan sampel teks yang menipu guna mengeksploitasi kerentanan komposisionalitas representasi multimodal pra-terlatih seperti CLIP. Penelitian mengusulkan metode pelatihan mandiri, dengan melakukan penyesuaian halus penolakan sampel melalui penyaringan yang mendorong keragaman, untuk meningkatkan tingkat keberhasilan serangan dan keragaman sampel. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Peran hadiah bising dalam pembelajaran penalaran——Jalan menuju puncak lebih mengukir kebijaksanaan daripada puncak itu sendiri: Makalah 《The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason》 meneliti dampak kebisingan hadiah pada pelatihan pasca-penalaran LLM melalui pembelajaran penguatan. Penelitian menemukan bahwa LLM menunjukkan ketahanan yang kuat terhadap sejumlah besar kebisingan hadiah, bahkan jika hanya memberi hadiah pada kemunculan frasa penalaran kunci (tanpa memverifikasi kebenaran jawaban), model dapat mencapai kinerja yang sebanding dengan model yang dilatih dengan validasi ketat dan hadiah akurat. (Sumber: HuggingFace Daily Papers)
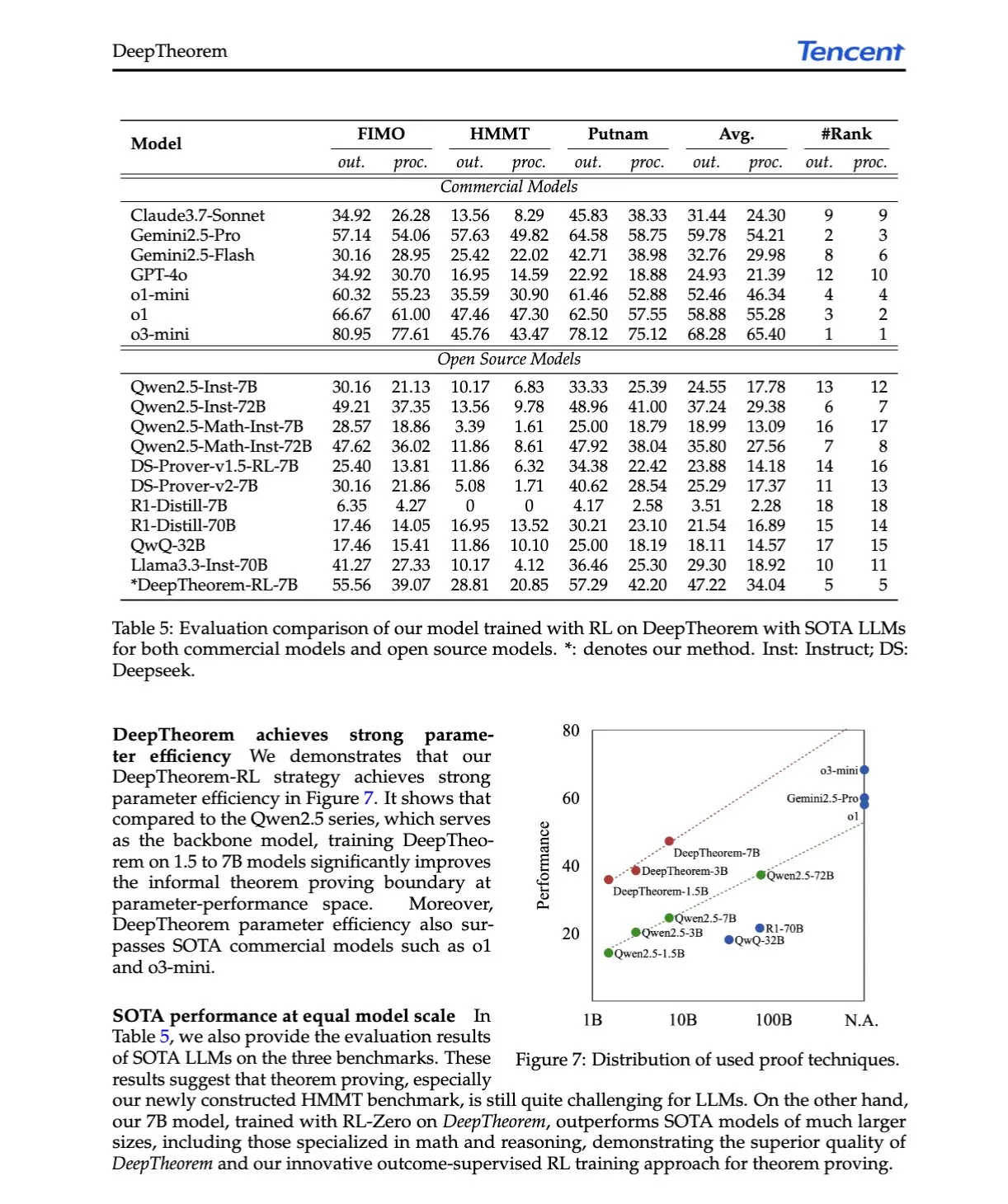
Interpretasi makalah AI: DeepTheorem, memajukan pembuktian teorema LLM melalui bahasa alami dan pembelajaran penguatan: Makalah 《DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning》 mengusulkan DeepTheorem, sebuah kerangka kerja pembuktian teorema non-formal yang memanfaatkan bahasa alami untuk meningkatkan penalaran matematika LLM. Kerangka kerja ini mencakup dataset tolok ukur skala besar (121.000 teorema dan bukti non-formal tingkat IMO) dan strategi RL yang dirancang khusus untuk pembuktian teorema non-formal (RL-Zero). (Sumber: HuggingFace Daily Papers, teortaxesTex)
Interpretasi makalah AI: D-AR, difusi melalui model autoregresif: Makalah 《D-AR: Diffusion via Autoregressive Models》 mengusulkan paradigma baru D-AR, yang membentuk kembali proses difusi gambar menjadi proses prediksi token berikutnya autoregresif standar. Melalui tokenizer yang dirancang, gambar diubah menjadi urutan token diskrit, token di posisi berbeda dapat didekodekan menjadi langkah denoising difusi yang berbeda di ruang piksel. Metode ini mencapai FID 2,09 di ImageNet menggunakan tulang punggung Llama 775M dan 256 token diskrit. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Table-R1, perluasan waktu-inferensi untuk penalaran tabel: Makalah 《Table-R1: Inference-Time Scaling for Table Reasoning》 untuk pertama kalinya mengeksplorasi perluasan waktu-inferensi dalam tugas penalaran tabel. Peneliti mengembangkan dan mengevaluasi dua strategi pasca-pelatihan: distilasi dari lintasan inferensi model terdepan (Table-R1-SFT) dan pembelajaran penguatan dengan hadiah yang dapat diverifikasi (Table-R1-Zero). Table-R1-Zero (parameter 7B) mencapai atau melampaui kinerja GPT-4.1 dan DeepSeek-R1 dalam berbagai tugas penalaran tabel. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Muddit, model difusi diskrit terpadu untuk generasi melampaui teks-ke-gambar: Makalah 《Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model》 memperkenalkan Muddit, sebuah model Transformer difusi diskrit terpadu, yang mendukung generasi paralel cepat mode teks dan gambar. Muddit mengintegrasikan prior visual yang kuat dari tulang punggung teks-ke-gambar pra-terlatih dan dekoder teks ringan, kompetitif dalam kualitas dan efisiensi. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: VideoReasonBench, dapatkah MLLM melakukan penalaran video kompleks yang berpusat pada visual?: Makalah 《VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?》 memperkenalkan VideoReasonBench, sebuah tolok ukur yang bertujuan untuk mengevaluasi kemampuan penalaran video kompleks yang berpusat pada visual. Tolok ukur ini berisi video urutan operasi yang halus, pertanyaan mengevaluasi kemampuan mengingat, menyimpulkan, dan memprediksi. Eksperimen menunjukkan bahwa sebagian besar MLLM SOTA berkinerja buruk pada tolok ukur ini, sementara Gemini-2.5-Pro yang ditingkatkan dengan pemikiran menunjukkan kinerja yang menonjol. (Sumber: HuggingFace Daily Papers, OriolVinyalsML)
Interpretasi makalah AI: GeoDrive, model dunia mengemudi sadar geometri 3D dengan kontrol aksi presisi: Makalah 《GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control》 mengusulkan GeoDrive, yang secara eksplisit mengintegrasikan kondisi geometri 3D yang kuat ke dalam model dunia mengemudi untuk meningkatkan pemahaman spasial dan kontrolabilitas aksi. Metode ini meningkatkan efek rendering dalam pelatihan melalui modul penyuntingan dinamis, eksperimen membuktikan keunggulannya dalam akurasi aksi dan persepsi spasial 3D dibandingkan model yang ada. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Panduan bebas klasifikasi adaptif melalui penyamaran kepercayaan rendah dinamis: Makalah 《Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking》 mengusulkan metode A-CFG, dengan memanfaatkan kepercayaan prediksi sesaat model untuk menyesuaikan input tanpa syarat panduan bebas klasifikasi (CFG). A-CFG mengidentifikasi token kepercayaan rendah pada setiap langkah model bahasa difusi iteratif (penyamaran) dan melakukan penyamaran ulang sementara, sehingga menciptakan input tanpa syarat yang dinamis dan terlokalisasi, membuat pengaruh koreksi CFG lebih presisi. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: PatientSim, simulator berbasis persona untuk interaksi dokter-pasien yang realistis: Makalah 《PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions》 memperkenalkan PatientSim, sebuah simulator yang menghasilkan persona pasien yang beragam dan realistis berdasarkan profil klinis dari dataset MIMIC dan persona empat sumbu (kepribadian, kemahiran bahasa, tingkat ingatan riwayat penyakit, tingkat kebingungan kognitif). Bertujuan untuk menyediakan sistem interaksi pasien yang realistis untuk melatih atau mengevaluasi LLM dokter. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: LoRAShop, pembuatan dan penyuntingan gambar multi-konsep bebas pelatihan melalui Transformer aliran yang diperbaiki: Makalah 《LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers》 memperkenalkan kerangka kerja pertama yang menggunakan model LoRA untuk penyuntingan gambar multi-konsep, LoRAShop. Kerangka kerja ini memanfaatkan pola interaksi fitur internal Transformer difusi gaya Flux, untuk menurunkan topeng laten yang terurai untuk setiap konsep, dan hanya mencampur bobot LoRA di dalam area konsep, mewujudkan integrasi mulus multi-subjek atau gaya. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: AnySplat, splatting Gaussian 3D feed-forward dari tampilan tidak terbatas: Makalah 《AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views》 memperkenalkan AnySplat, sebuah jaringan feed-forward untuk sintesis tampilan baru dari kumpulan gambar yang tidak dikalibrasi. Berbeda dengan alur kerja rendering neural tradisional, AnySplat dapat memprediksi primitif Gaussian 3D (mengkodekan geometri dan penampilan adegan) serta parameter intrinsik dan ekstrinsik kamera untuk setiap gambar input melalui satu propagasi maju tunggal, tanpa memerlukan anotasi pose, dan mendukung sintesis tampilan baru secara real-time. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: ZeroSep, pemisahan apa pun dalam audio dengan pelatihan nol: Makalah 《ZeroSep: Separate Anything in Audio with Zero Training》 menemukan bahwa hanya dengan model difusi audio yang dipandu teks pra-terlatih, dalam konfigurasi tertentu, pemisahan sumber suara zero-shot dapat dicapai. Metode ZeroSep dengan membalikkan audio campuran ke ruang laten model difusi, dan menggunakan panduan bersyarat teks untuk memandu proses denoising guna memulihkan sumber suara tunggal, tanpa memerlukan pelatihan atau penyesuaian halus tugas tertentu. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Penelitian minimisasi entropi satu-tembakan: Makalah 《One-shot Entropy Minimization》 melalui pelatihan 13.440 model bahasa besar menemukan bahwa minimisasi entropi hanya memerlukan satu data tanpa label dan 10 langkah optimasi, untuk mencapai bahkan melampaui peningkatan kinerja yang dapat dicapai oleh pembelajaran penguatan berbasis aturan yang menggunakan ribuan data dan hadiah yang dirancang dengan cermat. Hasil ini dapat mendorong pemikiran ulang tentang paradigma pasca-pelatihan LLM. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: ChartLens, atribusi visual berbutir halus dalam bagan: Makalah 《ChartLens: Fine-grained Visual Attribution in Charts》 mengatasi masalah MLLM yang mudah menghasilkan halusinasi dalam pemahaman bagan, memperkenalkan tugas atribusi visual pasca-bagan, dan mengusulkan algoritma ChartLens. Algoritma ini menggunakan teknik segmentasi untuk mengidentifikasi objek bagan, dan melalui prompt set penandaan dengan MLLM melakukan atribusi visual berbutir halus. Sekaligus merilis tolok ukur ChartVA-Eval, yang berisi anotasi atribusi berbutir halus bagan dari bidang keuangan, kebijakan, ekonomi, dll. (Sumber: HuggingFace Daily Papers)
Interpretasi makalah AI: Mengeksplorasi pola struktural pengetahuan dalam Large Language Model dari perspektif graf: Makalah 《A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models》 meneliti pola struktural pengetahuan dalam LLM dari perspektif graf. Penelitian mengkuantifikasi pengetahuan LLM pada tingkat triplet dan entitas, menganalisis hubungannya dengan atribut struktural graf seperti derajat simpul, dan mengungkapkan homogenitas pengetahuan (entitas yang secara topologis berdekatan memiliki tingkat pengetahuan yang serupa). Berdasarkan ini, dikembangkan model pembelajaran mesin graf untuk memperkirakan pengetahuan entitas, dan digunakan untuk pemeriksaan pengetahuan. (Sumber: HuggingFace Daily Papers)
💼 Bisnis
Perusahaan kecerdasan perwujudan Lumos Robotics mengumpulkan hampir 200 juta yuan dalam setengah tahun, menjalin kerja sama dengan COSCO Shipping dkk.: Perusahaan robotika kecerdasan perwujudan Lumos Robotics (鹿明机器人), yang didirikan oleh mantan eksekutif Dreame, Yu Chao, mengumumkan penyelesaian putaran pendanaan Angel++, dengan investor termasuk Fosun RZ Capital, Dematic Technology, dan Wuzhong Financial Holding, dengan total pendanaan hampir 200 juta yuan dalam setengah tahun. Perusahaan berfokus pada skenario rumah tangga, dengan produk termasuk robot humanoid seri LUS, MOS, dan komponen inti, telah meluncurkan robot humanoid ukuran penuh LUS, dan menjalin kerja sama strategis dengan Dematic Technology, COSCO Shipping, dkk., mempercepat komersialisasi kecerdasan perwujudan dalam skenario seperti logistik dan manufaktur cerdas. (Sumber: 36氪)

Snorkel AI menyelesaikan pendanaan Seri D senilai $100 juta, meluncurkan layanan evaluasi agen AI dan data ahli: Perusahaan AI pusat data Snorkel AI mengumumkan penyelesaian pendanaan Seri D senilai $100 juta yang dipimpin oleh Valor Equity Partners, sehingga total pendanaan mencapai $235 juta. Bersamaan dengan itu, perusahaan meluncurkan Snorkel Evaluate (platform evaluasi AI agen pusat data) dan Expert Data-as-a-Service (layanan data ahli), yang bertujuan untuk membantu perusahaan membangun dan menerapkan agen AI yang lebih andal dan profesional. (Sumber: realDanFu, percyliang, tri_dao, krandiash)
Departemen Energi AS mengumumkan kerja sama dengan Dell dan Nvidia untuk mengembangkan superkomputer generasi berikutnya “Doudna”: Departemen Energi AS mengumumkan penandatanganan kontrak dengan Dell untuk mengembangkan superkomputer unggulan generasi berikutnya NERSC-10 bernama “Doudna” untuk Lawrence Berkeley National Laboratory. Sistem ini akan didukung oleh platform Vera Rubin generasi berikutnya dari Nvidia, diperkirakan akan mulai beroperasi pada tahun 2026, dengan kinerja lebih dari 10 kali lipat dari unggulan saat ini Perlmutter, bertujuan untuk mendukung komputasi kinerja tinggi skala besar dan beban kerja AI, membantu Amerika Serikat memenangkan perlombaan dominasi AI global. (Sumber: 36氪, nvidia)

🌟 Komunitas
DeepSeek R1-0528 memicu diskusi hangat, kinerja, halusinasi, pemanggilan alat menjadi fokus: Rilis DeepSeek R1-0528 memicu diskusi luas di komunitas. Sebagian besar pendapat menilai ada peningkatan signifikan dalam matematika, pemrograman, dan penalaran logika umum, mendekati bahkan melampaui beberapa model sumber tertutup. Versi baru ini menunjukkan kemajuan dalam mengurangi tingkat halusinasi dan menambahkan dukungan untuk output JSON dan pemanggilan fungsi. Sementara itu, versi Qwen3-8B yang didistilasi juga menarik perhatian karena kinerja matematikanya yang sangat baik pada model kecil. Komunitas umumnya percaya bahwa DeepSeek telah memperkuat posisinya sebagai pemimpin di bidang sumber terbuka dan menantikan rilis versi R2. (Sumber: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Model penyuntingan gambar AI FLUX.1 Kontext menarik perhatian, menekankan pemahaman konteks dan konsistensi karakter: Model penyuntingan gambar FLUX.1 Kontext yang dirilis oleh Black Forest Labs menarik perhatian komunitas karena kemampuannya memproses input teks dan gambar secara bersamaan serta menjaga konsistensi karakter. Umpan balik pengguna menunjukkan kinerjanya yang sangat baik dalam tugas penyuntingan gambar, transfer gaya, dan penambahan teks, terutama dalam penyuntingan multi-putaran yang mampu mempertahankan fitur subjek dengan baik. Platform seperti Replicate telah meluncurkan model ini dan menyediakan laporan pengujian terperinci serta tips penggunaan. (Sumber: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

Agen AI akan secara signifikan mengubah pola pencarian dan periklanan: CEO Perplexity AI, Arav Srinivas, berpendapat bahwa seiring agen AI melakukan pencarian atas nama pengguna, volume kueri manusia ke mesin pencari seperti Google akan menurun drastis, yang akan menyebabkan penurunan CPM/CPC iklan, dan belanja iklan mungkin beralih ke media sosial atau platform AI. Pengguna tidak lagi perlu sering melakukan pencarian kata kunci, melainkan asisten AI akan secara proaktif mengirimkan informasi. (Sumber: AravSrinivas)
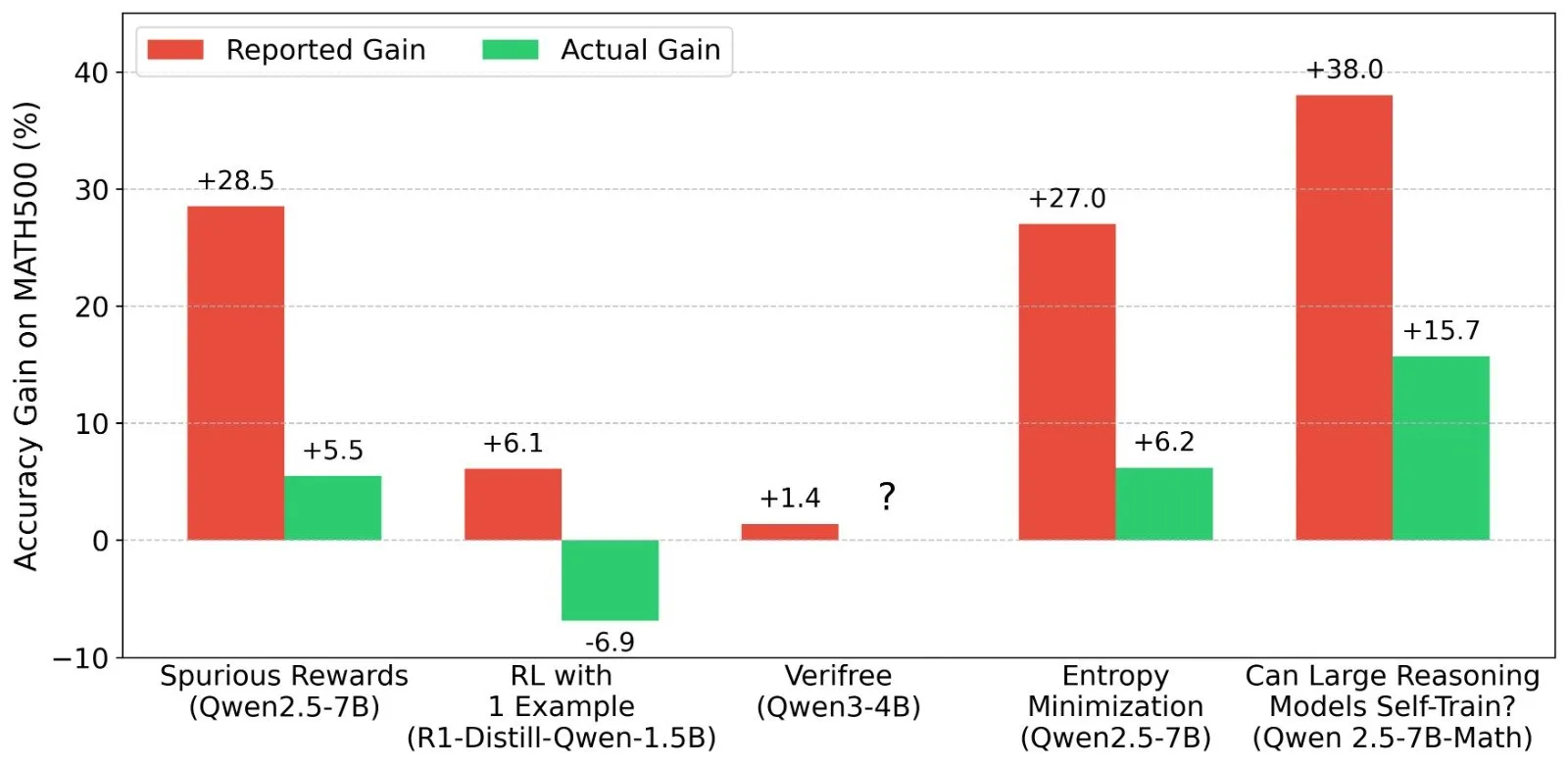
Diskusi tentang hasil Pembelajaran Penguatan (RL) LLM: Realitas sinyal hadiah dan kemampuan model: Shashwat Goel dan peneliti lainnya mempertanyakan fenomena baru-baru ini dalam penelitian RL LLM di mana model menunjukkan peningkatan kinerja tanpa sinyal hadiah yang nyata, menunjukkan bahwa beberapa penelitian mungkin meremehkan kemampuan dasar model pra-terlatih atau ada faktor perancu lainnya. Diskusi ini memicu analisis mendalam tentang kinerja model seperti Qwen dalam RL, serta pemikiran tentang efektivitas RLVR (Reinforcement Learning with Verifiable Rewards), menekankan perlunya baseline yang lebih ketat dan optimasi prompt dalam mengevaluasi efek RL. (Sumber: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
“Vibe Coding” memicu diskusi, menekankan nilai default yang aman dan risiko utang teknis: “Vibe coding” (pemrograman suasana hati, merujuk pada cara pemrograman yang lebih mengandalkan intuisi dan iterasi cepat daripada spesifikasi ketat) menjadi topik diskusi hangat di komunitas. CEO Replit, Amjad Masad, berpendapat bahwa cara ini memberdayakan pengembang baru, tetapi platform harus menyediakan konfigurasi default yang aman. Sementara itu, Pedro Domingos berkomentar bahwa “pemrograman suasana hati adalah Godzilla utang teknis”, menyiratkan potensi masalah pemeliharaan jangka panjang. Semafor melaporkan kerentanan keamanan yang disebabkan oleh konfigurasi kebijakan RLS yang tidak tepat di Lovable, yang semakin memicu perhatian terhadap keamanan cara pemrograman ini. (Sumber: alexalbert__, amasad, pmddomingos, gfodor)
Peran AI dalam rekayasa perangkat lunak: Peningkatan efisiensi dan ketidaktergantian programmer manusia: Pencipta Redis, Salvatore Sanfilippo, berbagi pengalaman bahwa meskipun AI (seperti Gemini 2.5 Pro) berharga dalam bantuan pemrograman, peninjauan kode, dan validasi ide, programmer manusia dalam pemecahan masalah kreatif dan pemikiran di luar kebiasaan masih jauh melampaui AI. Diskusi komunitas lebih lanjut menunjukkan bahwa AI saat ini lebih seperti “bebek karet cerdas”, dapat membantu berpikir, tetapi sarannya perlu dievaluasi dengan hati-hati, dan ketergantungan berlebihan dapat melemahkan kemampuan inti pengembang. Mitchell Hashimoto juga berbagi kasus di mana LLM membantunya dengan cepat menemukan masalah kompilasi Clang, menghemat banyak waktu. (Sumber: mitchellh, 36氪)
Apakah AI akan menggantikan pekerjaan secara massal memicu perhatian berkelanjutan: CEO Anthropic Dario Amodei memprediksi AI dapat menyebabkan hilangnya setengah dari posisi kantor tingkat pemula, sementara Mark Cuban berpendapat bahwa AI akan menciptakan perusahaan baru dan pekerjaan baru. Komunitas membahas hal ini dengan sengit, dengan beberapa pendapat bahwa pekerjaan seperti layanan pelanggan, penulis naskah junior, dan sebagian pengembang telah terpengaruh, tetapi AI masih sulit menggantikan manusia di bidang kreatif, pengambilan keputusan kompleks, dan yang membutuhkan interaksi manusia yang tinggi. Konsensus umum adalah bahwa AI akan mengubah sifat pekerjaan, dan manusia perlu beradaptasi serta meningkatkan kemampuan untuk berkolaborasi dengan AI. (Sumber: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
AI Agent (agen cerdas) menjadi pintu masuk interaksi generasi berikutnya, memicu persaingan perusahaan besar: Perusahaan teknologi dalam dan luar negeri seperti Microsoft, Google, OpenAI, Alibaba, Tencent, Baidu, Coocaa, dll. semuanya berinvestasi dalam AI Agent. Agen cerdas dapat berpikir secara mendalam, merencanakan secara mandiri, mengambil keputusan, dan melaksanakan tugas-tugas kompleks, dianggap sebagai pintu masuk interaksi generasi berikutnya setelah mesin pencari dan aplikasi. Saat ini telah terbentuk tiga kekuatan utama: pembangun ekosistem teknologi yang diwakili oleh OpenAI dan Baidu; penyedia layanan perusahaan untuk skenario vertikal yang diwakili oleh Microsoft dan Alibaba Cloud; serta produsen terminal perangkat keras dan lunak yang diwakili oleh Huawei dan Coocaa. (Sumber: 36氪)

💡 Lainnya
Ekspansi AI Tiongkok ke luar negeri semakin cepat, beralih dari ekspor produk ke pembangunan ekosistem: Laporan 《Pertumbuhan Lintas Samudra AI Tiongkok》 menunjukkan bahwa ekspansi perusahaan AI Tiongkok ke luar negeri telah memasuki jalur cepat skala besar, dengan 76% terkonsentrasi pada tingkat aplikasi. Jalur ekspansi ke luar negeri telah berkembang dari aplikasi berbasis alat pada tahap awal, menjadi ekspor solusi industri yang menggabungkan keunggulan teknologi pada tahap menengah, dan pada tahap saat ini berfokus pada ekspansi ekosistem teknologi ke luar negeri, mendorong standar teknis dan kolaborasi sumber terbuka. Ekspansi AI ke luar negeri menunjukkan penetrasi bertahap “dari dekat ke jauh”, dan menghadapi tantangan seperti lokalisasi, kepatuhan etika, dan pemasaran merek. (Sumber: 36氪)

Departemen Energi AS menganalogikan persaingan AI sebagai “Proyek Manhattan baru”, menekankan bahwa Amerika Serikat akan menang: Departemen Energi AS, ketika mengumumkan superkomputer generasi berikutnya “Doudna”, menyebut persaingan pengembangan AI sebagai “Proyek Manhattan zaman kita”, dan menyatakan bahwa Amerika Serikat akan memenangkan perlombaan ini. Pernyataan ini memicu diskusi di komunitas tentang persaingan teknologi negara besar, etika AI, dan kerja sama internasional. (Sumber: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
Kemajuan AI dalam bidang pembuatan konten memicu pemikiran tentang “keaslian” dan “kreativitas”: Komunitas membahas penerapan AI dalam desain mode, pembuatan komik, pembuatan video, dan bidang lainnya. Di satu sisi, AI mampu dengan cepat menghasilkan konten yang beragam, bahkan mengubah karya komik beberapa tahun lalu menjadi video; di sisi lain, konten yang dihasilkan ini terkadang terlihat aneh atau kurang mendalam. Hal ini memicu pemikiran tentang apakah konten yang dihasilkan AI “lebih baik”, dan peran apa yang akan dimainkan oleh kreativitas manusia di era AI. (Sumber: Reddit r/ChatGPT, Reddit r/artificial)
