Kata Kunci:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, hadiah acak, hadiah kesalahan, kinerja model, pembelajaran penguatan, masa depan RLHF/RLAIF, hadiah acak meningkatkan kinerja model, pelatihan Qwen2.5-Math-7B dengan hadiah kesalahan, kumpulan uji MATH-500, pembelajaran sinyal penguatan
🔥 Fokus
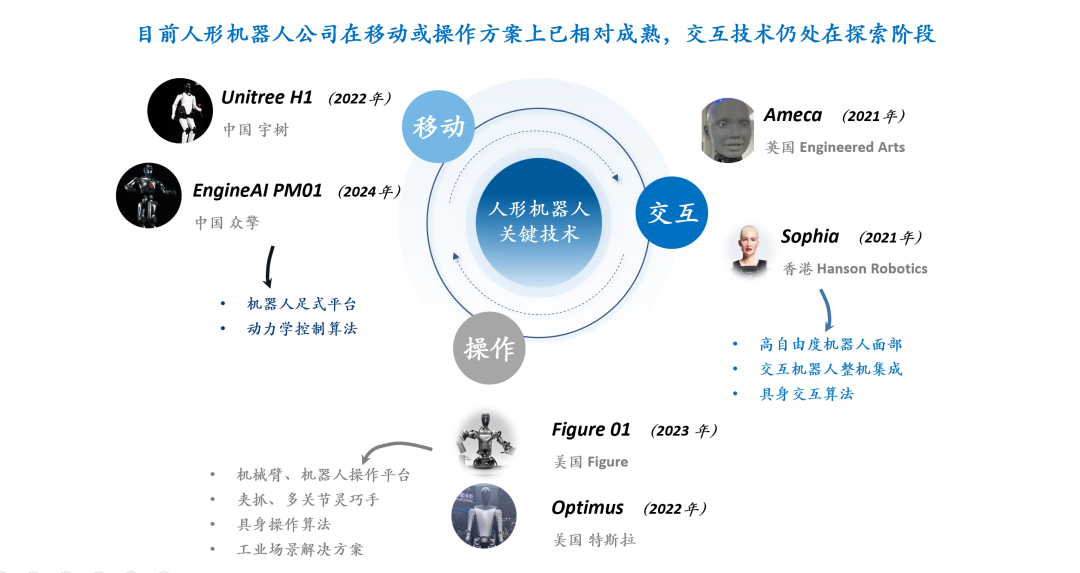
Masa Depan RLHF/RLAIF: Reward Acak/Salah Juga Dapat Meningkatkan Kinerja Model? : Eksperimen Stella Li menunjukkan bahwa penggunaan reward acak atau reward yang salah untuk melatih model Qwen2.5-Math-7B, masing-masing meningkatkan kinerja sebesar 21% dan 25% pada set pengujian MATH-500, mendekati efek peningkatan 28,8% dari penggunaan reward nyata. Penelitian Rulin Shao yang di-retweet oleh natolambert juga menemukan bahwa RLVR (Reinforcement Learning from Verifier Reward) ketika menggunakan reward palsu, penggunaan kode model Olmo meningkat tetapi kinerjanya menurun, sedangkan mencegahnya menggunakan kode justru meningkatkan kinerja. Temuan-temuan ini menantang ketergantungan tradisional RLHF/RLAIF pada data preferensi manusia berkualitas tinggi, mengisyaratkan bahwa model mungkin belajar untuk menjelajahi ruang strategi yang lebih luas melalui sinyal reward, bahkan jika reward itu sendiri tidak sempurna, hal itu dapat merangsang kemampuan laten model atau mengoptimalkan perilaku yang ada. Ini mungkin membuka jalan baru untuk mengurangi ketergantungan pada anotasi manual yang mahal dan mengeksplorasi metode penyelarasan model yang lebih efisien, tetapi perlu diwaspadai risiko model mempelajari perilaku yang salah. (Sumber: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
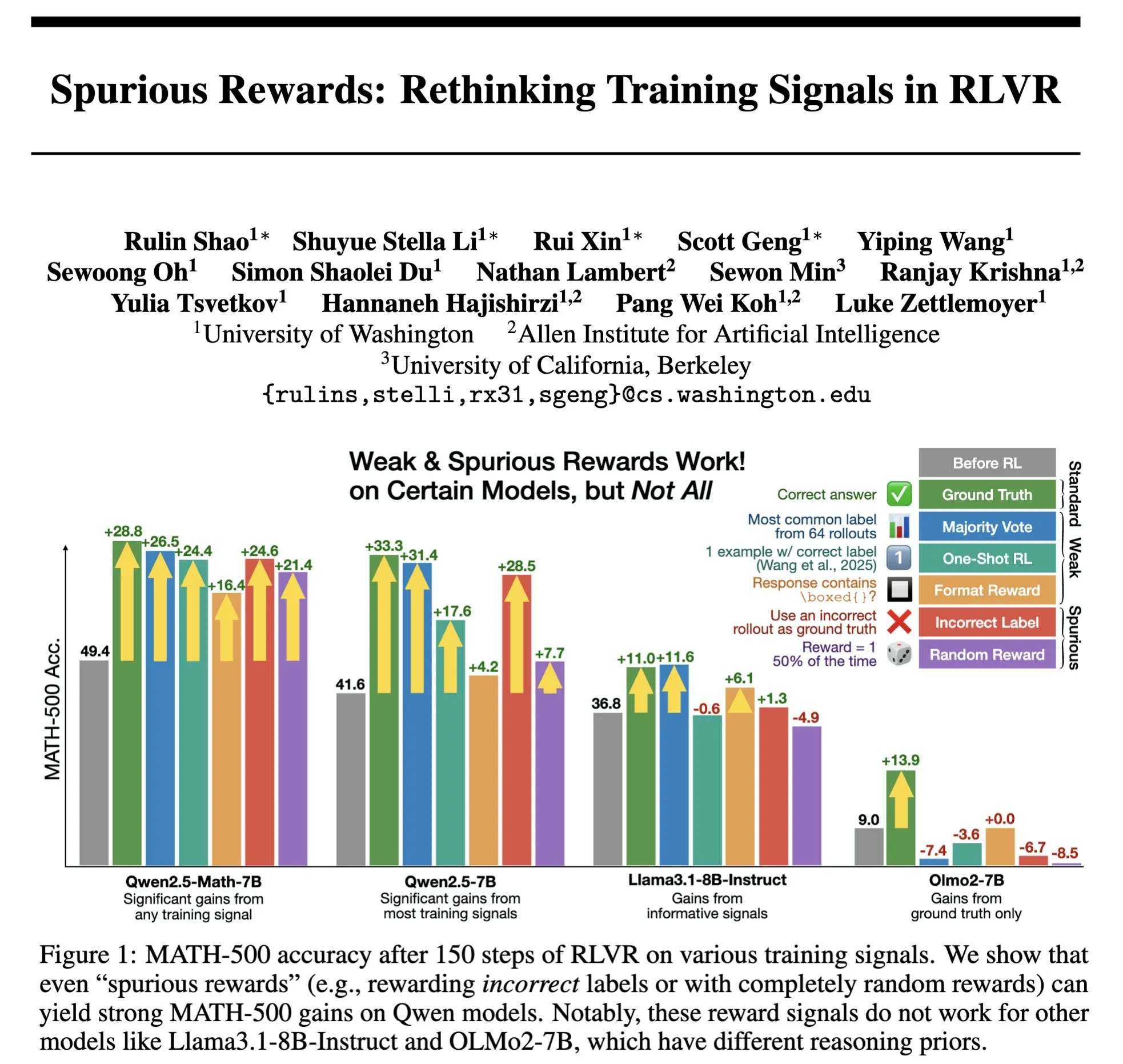
Hazy Research Merilis Low-Latency-Llama Megakernel: Inferensi Llama 1B dengan Satu Core CUDA : Hazy Research meluncurkan Low-Latency-Llama Megakernel, yang mampu menyelesaikan seluruh proses forward propagation model Llama 1B dalam satu core CUDA. Teknologi ini mengoptimalkan penjadwalan komputasi dan memori untuk mencapai latensi yang lebih rendah dengan mengintegrasikan komputasi ke dalam satu kernel, menghilangkan batasan sinkronisasi yang disebabkan oleh pemanggilan kernel serial tradisional. Andrej Karpathy sangat memuji hal ini, menganggapnya sebagai satu-satunya cara untuk mencapai orkestrasi komputasi dan memori yang optimal. Kemajuan ini sangat penting untuk skenario dengan persyaratan latensi yang ketat seperti edge computing dan aplikasi AI real-time, dan diharapkan dapat mendorong penerapan model bahasa kecil yang lebih efisien dan gesit. (Sumber: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek Qiyuan Merilis rStar-Coder: Membangun Dataset Inferensi Kode Terverifikasi Skala Besar, Secara Signifikan Meningkatkan Kemampuan Kode Model Kecil : Peneliti dari Microsoft dan DeepSeek meluncurkan proyek rStar-Coder, yang bertujuan untuk mengatasi masalah kelangkaan dataset berkualitas tinggi dan berkesulitan tinggi di bidang inferensi kode saat ini dengan membangun dataset terverifikasi skala besar yang berisi 418.000 soal kode tingkat kompetisi, 580.000 solusi inferensi panjang, dan kasus uji yang kaya. Proyek ini meningkatkan kemampuan inferensi kode LLM dengan secara komprehensif memanfaatkan soal kompetisi pemrograman yang ada dan solusi oracle untuk mensintesis soal baru, merancang pipeline pembuatan kasus uji input-output yang andal, dan menggunakan kasus uji untuk memverifikasi solusi inferensi panjang berkualitas tinggi. Eksperimen menunjukkan bahwa model Qwen (1.5B-14B) yang dilatih menggunakan dataset rStar-Coder menunjukkan kinerja yang sangat baik pada beberapa benchmark inferensi kode, misalnya, akurasi Qwen2.5-7B pada LiveCodeBench meningkat dari 17,4% menjadi 57,3%, melampaui o3-mini (low); pada USACO, model 7B juga melampaui QWQ-32B yang lebih besar. (Sumber: HuggingFace Daily Papers)
Institut Otomasi Akademi Ilmu Pengetahuan Tiongkok Mengajukan AutoThink: Memungkinkan Model Besar Secara Mandiri Memutuskan Apakah Akan “Berpikir Mendalam” : Menanggapi fenomena “pemikiran berlebihan” di mana model bahasa besar masih melakukan inferensi yang panjang untuk masalah sederhana, Institut Otomasi Akademi Ilmu Pengetahuan Tiongkok dan Laboratorium Pengcheng bersama-sama mengusulkan metode AutoThink. Metode ini, dengan menambahkan “elipsis” (…) dalam prompt dan menggabungkannya dengan pembelajaran penguatan tiga tahap (stabilisasi mode, optimasi perilaku, pemangkasan inferensi), memungkinkan model untuk secara mandiri memilih apakah akan melakukan pemikiran mendalam dan seberapa banyak pemikiran berdasarkan kesulitan soal. Eksperimen menunjukkan bahwa AutoThink dapat meningkatkan kinerja model seperti DeepSeek-R1 pada benchmark matematika, sekaligus mengurangi konsumsi Token inferensi secara signifikan. Misalnya, pada DeepScaleR, dapat menghemat tambahan 10% Token. Penelitian ini bertujuan agar model dapat mencapai “pemikiran sesuai kebutuhan”, meningkatkan keseimbangan antara efisiensi inferensi dan akurasi. (Sumber: 36氪, _akhaliq)

Sakana AI Meluncurkan Sudoku-Bench, Mengungkap Kelemahan Model Besar Terkemuka dalam Inferensi “Sudoku Varian” : Perusahaan rintisan Llion Jones, penulis Transformer, Sakana AI, merilis Sudoku-Bench, sebuah benchmark yang berisi Sudoku “varian” modern mulai dari 4×4 hingga 9×9 yang kompleks, yang bertujuan untuk mengevaluasi kemampuan penalaran multi-langkah kreatif AI. Hasil tes menunjukkan bahwa model besar terkemuka, termasuk Gemini 2.5 Pro, GPT-4.1, dan Claude 3.7, memiliki tingkat akurasi keseluruhan di bawah 15% tanpa bantuan. Pada Sudoku modern 9×9, akurasi o3 Mini High hanya 2,9%. Ini menunjukkan bahwa model berkinerja buruk ketika menghadapi masalah baru yang membutuhkan penalaran logis nyata daripada pencocokan pola, sering kali menghasilkan solusi yang salah, menyerah, atau salah menafsirkan aturan. CEO NVIDIA Jensen Huang percaya bahwa teka-teki semacam itu membantu meningkatkan penalaran AI. Sakana AI juga merilis data pelatihan terkait, termasuk catatan proses pemecahan yang bekerja sama dengan saluran Sudoku terkenal. (Sumber: 36氪)

🎯 Perkembangan
Meta Merestrukturisasi Tim AI, Kehilangan Anggota Inti FAIR Menarik Perhatian : Meta mengumumkan restrukturisasi tim AI-nya, membaginya menjadi tim produk AI yang dipimpin oleh Connor Hayes dan departemen dasar AGI yang dipimpin bersama oleh Ahmad Al-Dahle dan Amir Frenkel. Yang pertama berfokus pada produk C-end, sedangkan yang terakhir berfokus pada penelitian dan pengembangan model dasar seperti Llama. Perlu dicatat bahwa departemen penelitian kecerdasan buatan dasar FAIR tetap independen, tetapi beberapa tim multimedia digabungkan ke dalam departemen dasar AGI. Penyesuaian ini bertujuan untuk meningkatkan kecepatan dan fleksibilitas pengembangan. Namun, Meta menghadapi tantangan berupa respons yang kurang memuaskan terhadap Llama 4, meningkatnya persaingan di bidang sumber terbuka, dan hilangnya talenta inti. Dari 14 penulis awal yang terlibat dalam pengembangan Llama, 11 telah mengundurkan diri, beberapa di antaranya bergabung atau mendirikan pesaing seperti Mistral AI. Laboratorium FAIR juga mengalami perubahan kepemimpinan dan penyesuaian arah penelitian, yang menimbulkan kekhawatiran tentang posisinya di dalam perusahaan dan kemampuan inovasi di masa depan. (Sumber: 36氪)

Google DeepMind Merilis SignGemma: Model Baru untuk Terjemahan Bahasa Isyarat : Google DeepMind mengumumkan peluncuran SignGemma, sebuah model terjemahan teks bahasa isyarat ke bahasa lisan yang diklaim sebagai yang terkuat saat ini. Model ini diharapkan akan bergabung dengan keluarga model Gemma akhir tahun ini dan akan dirilis dalam bentuk sumber terbuka. Peluncuran SignGemma bertujuan untuk membuka kemungkinan baru bagi teknologi inklusif, meningkatkan efisiensi dan kemudahan komunikasi bagi pengguna bahasa isyarat. Google DeepMind mengundang pengguna untuk memberikan umpan balik dan berpartisipasi dalam pengujian awal. (Sumber: GoogleDeepMind, demishassabis)
Tencent Hunyuan Merilis Bobot Model HunyuanPortrait, Dapat Mengubah Potret Statis Menjadi Video Dinamis : Tim Tencent Hunyuan telah membuka sumber bobot model gambar-ke-video mereka, HunyuanPortrait, yang memungkinkan pengguna untuk mengunduh dan menggunakannya secara lokal. Model ini berfokus pada pengubahan gambar potret statis menjadi video dinamis, cocok untuk berbagai skenario aplikasi seperti karakter game, avatar virtual, manusia digital, dan pemandu belanja cerdas, yang dapat membuat gambar wajah bergerak, meningkatkan keaktifan dan realisme interaksi. Model, repositori kode, dan makalah terkait semuanya telah dirilis. (Sumber: karminski3, Reddit r/LocalLLaMA)

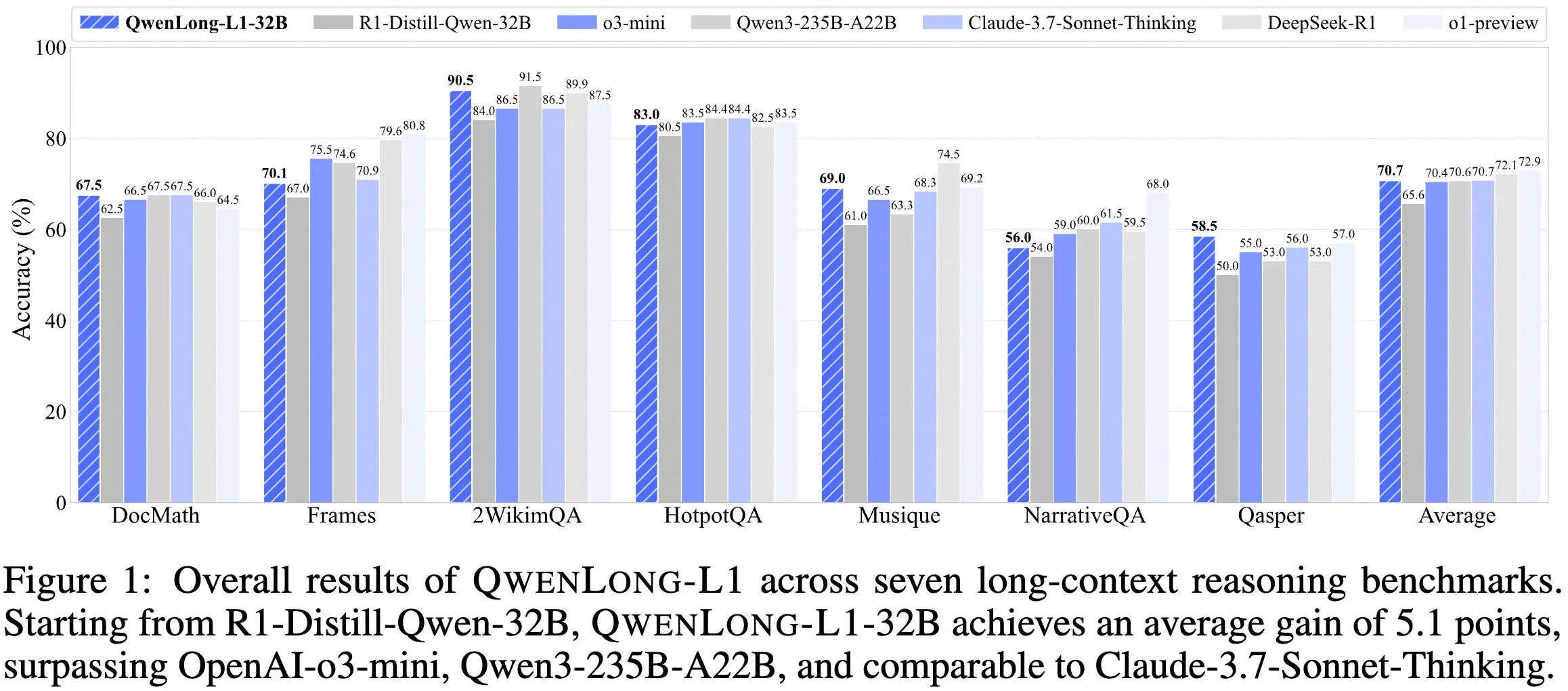
Tim QwenDoc Merilis Model Inferensi Konteks Panjang QwenLong-L1-32B : Tim QwenDoc meluncurkan model inferensi konteks panjang 128K QwenLong-L1-32B yang dilatih berdasarkan pembelajaran penguatan. Model ini disesuaikan berdasarkan DeepSeek-R1-Distill-Qwen-32B, mencapai skor 90,5 pada set pengujian inferensi multi-hop 2WikiMultihopQA, meningkat 6,5 poin dari model asli, menekankan kemampuan untuk tidak hanya menemukan konten dalam konteks panjang tetapi juga menghubungkan petunjuk untuk inferensi. Meskipun panjang konteks 128K bukanlah yang terpanjang saat ini, kemampuan inferensinya yang luar biasa memberikan pilihan baru untuk memproses dokumen panjang yang kompleks. Model, makalah, dan repositori kode telah dipublikasikan. (Sumber: karminski3)
HKUST dan Institusi Lain Termasuk Apple Bekerja Sama Meluncurkan Seri Metode Laser, Mengoptimalkan Efisiensi dan Akurasi Inferensi Model Besar : Peneliti dari HKUST, CityU, University of Waterloo, dan Apple mengusulkan seri metode Laser (termasuk Laser-D, Laser-DE), yang bertujuan untuk mengatasi masalah model bahasa besar (LRM) yang mengonsumsi token secara berlebihan untuk inferensi pada masalah sederhana. Metode ini, melalui kerangka kerja desain reward panjang yang terpadu, reward berdasarkan panjang target dan fungsi langkah, serta mekanisme persepsi kesulitan dinamis, mencapai peningkatan kinerja sebesar 6,1 poin sambil mengurangi penggunaan Token sebesar 63% pada benchmark penalaran matematika kompleks seperti AIME24. Penelitian menemukan bahwa model yang dilatih mengurangi “refleksi diri” yang berlebihan, memiliki pola pikir yang lebih sehat, dan secara efektif menyeimbangkan efisiensi dan akurasi inferensi model. (Sumber: 36氪)

Versi Gratis Anthropic Claude Kini Mendukung Fitur Pencarian Web : Anthropic mengumumkan bahwa pengguna versi gratis asisten AI-nya, Claude, kini dapat menggunakan fitur pencarian web. Ini berarti bahwa ketika Claude menjawab pertanyaan, ia dapat memperoleh informasi terbaru dari internet untuk meningkatkan relevansi dan akurasi responsnya. Pihak resmi menyatakan bahwa setiap respons yang berisi hasil pencarian akan menyediakan kutipan inline, memudahkan pengguna untuk memverifikasi sumber informasi. (Sumber: AnthropicAI)
PKU-DS-LAB Merilis FairyR1: Model Inferensi 32B yang Disempurnakan Berdasarkan DeepSeek-R1-Distill-Qwen-32B : Laboratorium Ilmu Data Universitas Peking (PKU-DS-LAB) meluncurkan FairyR1, sebuah model inferensi dengan parameter 32B, menggunakan lisensi Apache 2.0. Model ini, melalui metode “distilasi lalu gabung ulang”, diklaim dapat mencapai kinerja model yang lebih besar hanya dengan menggunakan 5% parameter. FairyR1 disempurnakan berdasarkan DeepSeek-R1-Distill-Qwen-32B, dan data pelatihannya juga telah tersedia di Hugging Face Hub. Pekerjaan ini melanjutkan gagasan penelitian TinyR1, dengan secara aktif menyaring dataset (sekitar 10.000 lintasan), melakukan SFT untuk matematika dan kode secara terpisah, dan menggunakan Arcee Fusion untuk penggabungan model. (Sumber: huggingface, teortaxesTex, stablequan)
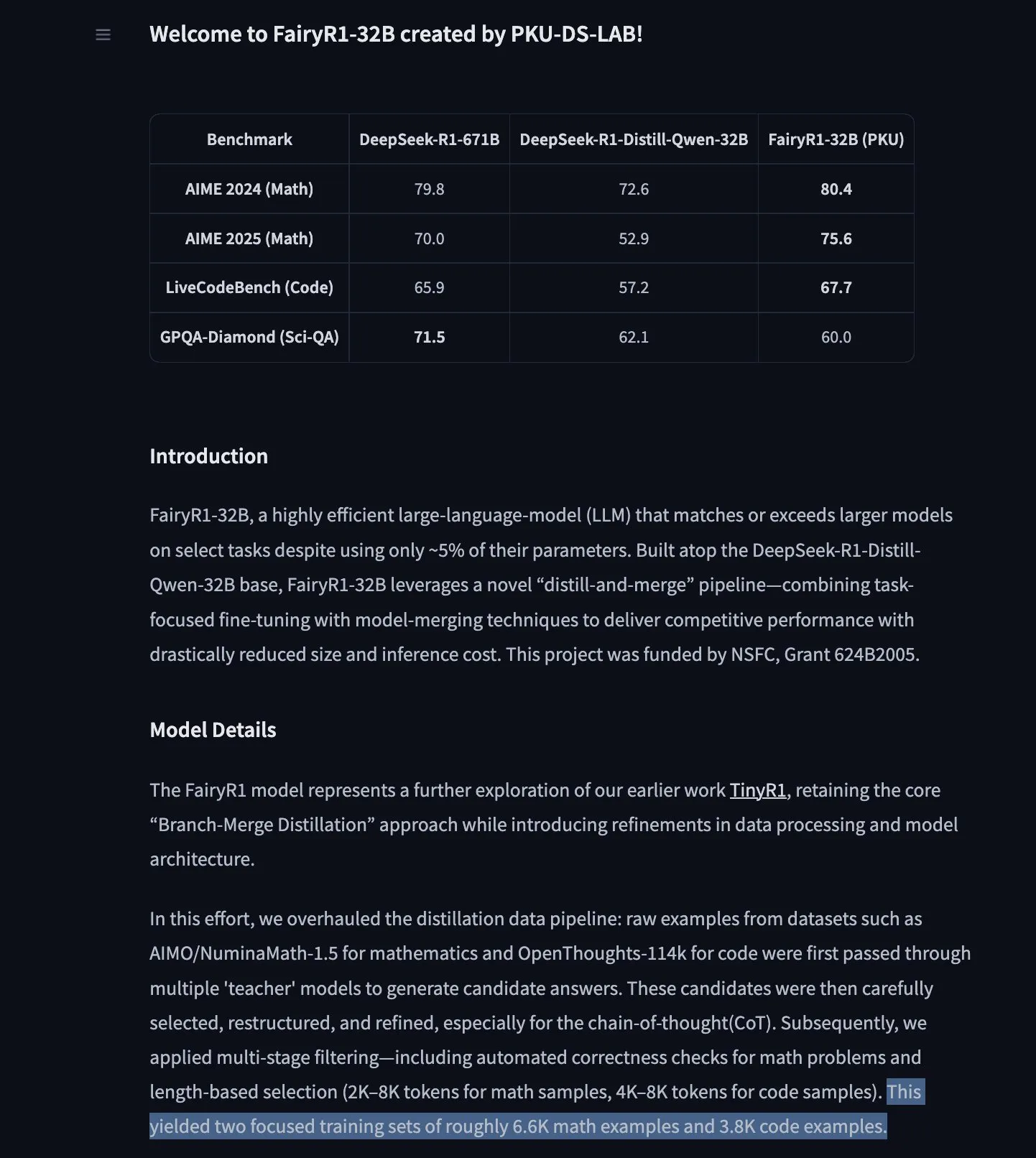
Model Prediksi Rangkaian Waktu TimesFM Google Hadir di Hugging Face Transformers : Model TimesFM Google kini telah terintegrasi ke dalam pustaka Hugging Face Transformers. Ini adalah model mirip GPT, dengan data pra-pelatihan yang mencakup 100 miliar titik data waktu nyata dari berbagai sumber seperti Google Trends, jumlah tampilan halaman Wikipedia, dll. Diklaim bahwa TimesFM berkinerja lebih baik pada tugas prediksi zero-shot daripada model yang disesuaikan secara khusus, menyediakan alat baru yang kuat untuk analisis rangkaian waktu. (Sumber: huggingface)
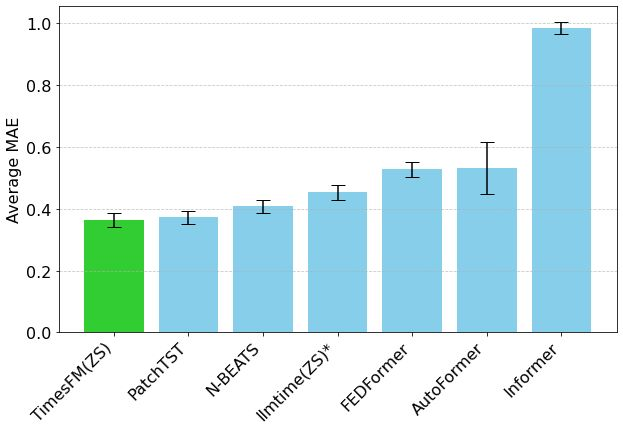
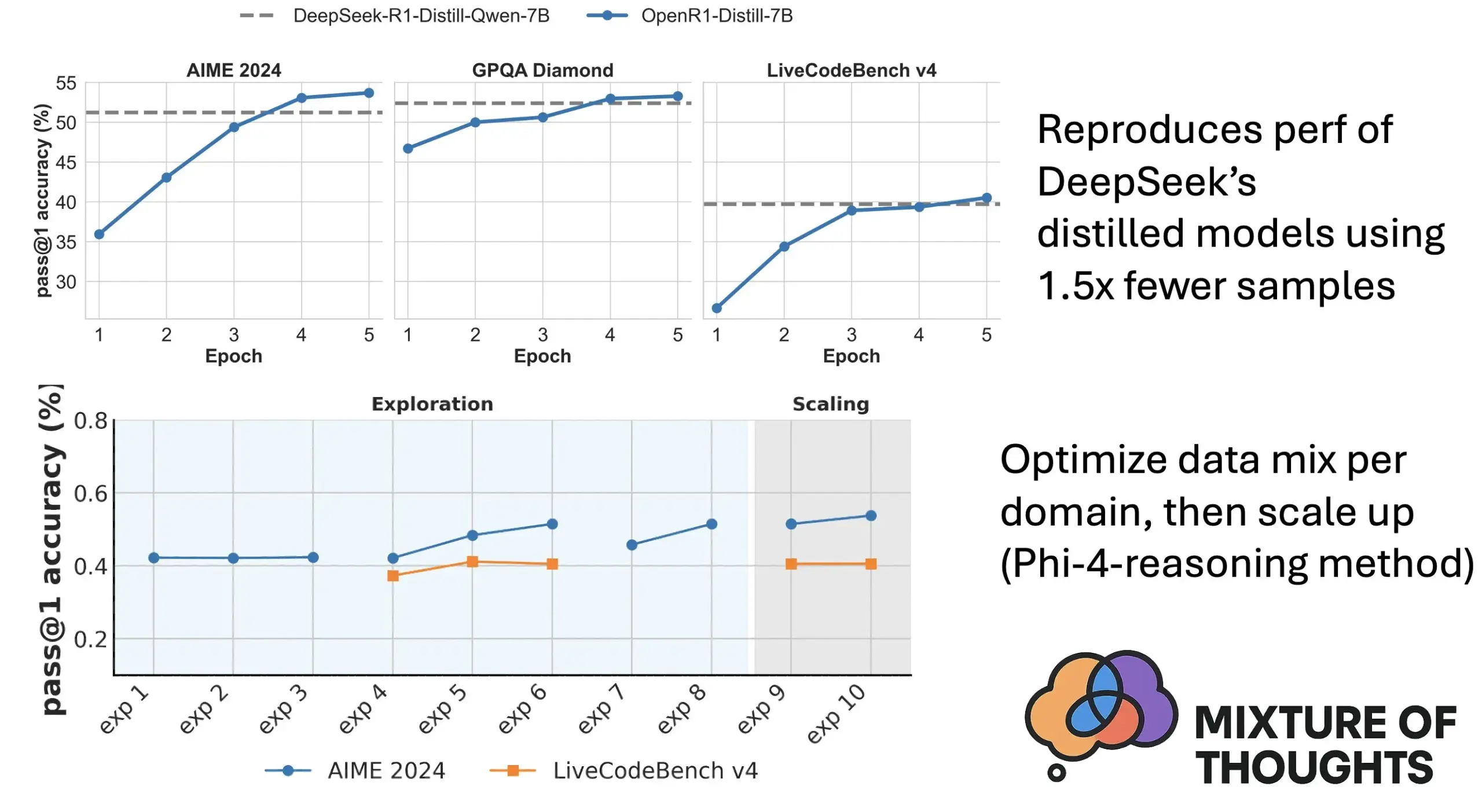
Hugging Face Meluncurkan Mixture of Thoughts: Dataset Inferensi Umum Pilihan : Peneliti Hugging Face Lewis Tunstall dan lainnya merilis dataset “Mixture of Thoughts”. Dataset ini, dari lebih dari 1 juta sampel data publik, telah disaring dengan cermat melalui eksperimen ablasi ekstensif untuk menghasilkan sekitar 350.000 sampel, dengan fokus pada kemampuan inferensi umum. Model yang dilatih menggunakan dataset campuran ini dapat mencapai atau melampaui kinerja model distilasi DeepSeek pada benchmark matematika, kode, dan sains (seperti GPQA). Penelitian ini memvalidasi efektivitas metodologi “aditivitas” yang diusulkan dalam Phi-4-reasoning, yaitu, campuran data untuk setiap domain inferensi dapat dioptimalkan secara independen dan kemudian diintegrasikan untuk pelatihan akhir. (Sumber: huggingface)
ByteDance Merilis BAGEL-7B: Model Serba Bisa yang Mampu Memahami dan Menghasilkan Gambar dan Teks : ByteDance meluncurkan BAGEL-7B, sebuah model serba bisa (omni) yang mampu memahami dan menghasilkan gambar dan teks secara bersamaan. Selain itu, mereka juga merilis Dolphin, sebuah model bahasa visual (VLM) yang berfokus pada pemahaman dokumen. Sumber terbuka model-model ini akan menyediakan alat dan kemungkinan baru untuk penelitian dan aplikasi multimodal. (Sumber: huggingface, TheTuringPost)

Google Merilis Gemini 2.5 Flash Preview, Mendukung Output Audio Asli : Pengembang AI Google mengumumkan bahwa Gemini 2.5 Flash Preview kini mendukung output audio asli melalui Live API, yang bertujuan untuk menyediakan interaksi lisan yang mulus dan alami serta kemampuan kontrol suara yang lebih kuat. Selain itu, versi eksperimental baru dari model audio ini yang disebut “thinking” juga telah diluncurkan, mendukung kemampuan penalaran untuk tugas yang lebih kompleks. Pada saat yang sama, output Gemini API juga mulai menampilkan “ringkasan pemikiran”, memungkinkan pengguna untuk memahami proses berpikir model, tetapi saat ini bukan merupakan rantai penalaran yang lengkap. (Sumber: algo_diver, op7418)
Makalah Membahas Kemampuan Ekspresif Transformer dalam Mengisi Token Kosong : Sebuah penelitian baru membahas apakah pengisian token kosong dalam input Transformer (suatu bentuk komputasi saat pengujian) dapat meningkatkan kemampuan komputasi LLM. Penelitian ini, bekerja sama dengan Ashish_S_AI, memberikan karakterisasi yang tepat tentang kemampuan ekspresif Transformer dengan pengisian, menawarkan perspektif baru untuk memahami dan mengoptimalkan mekanisme komputasi LLM. (Sumber: teortaxesTex)

Penelitian Baru Mengusulkan Kerangka Kerja Sci-Fi: Meningkatkan Interpolasi Frame Video Melalui Kendala Simetris : Menanggapi masalah bahwa metode interpolasi frame video (Frame Inbetweening) saat ini mungkin memiliki asimetri kekuatan kontrol saat menggabungkan kendala frame awal dan akhir, sebuah makalah baru mengusulkan kerangka kerja Sci-Fi (Symmetric Constraint for Frame Inbetweening). Metode ini bertujuan untuk mencapai simetri kendala frame awal dan akhir dengan menerapkan mekanisme injeksi yang lebih kuat (berdasarkan modul ringan EF-Net) untuk kendala dengan skala pelatihan yang lebih kecil (seperti frame akhir), sehingga menghasilkan efek transisi yang lebih harmonis pada frame perantara yang dihasilkan, menghindari inkonsistensi gerakan atau keruntuhan penampilan. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Paper2Poster: Alur Kerja Otomatis dari Makalah Ilmiah ke Poster Multimodal : Menanggapi tantangan pembuatan poster akademis, para peneliti meluncurkan benchmark pembuatan poster dan rangkaian metrik evaluasi pertama, Paper2Poster, yang berisi pasangan makalah dan poster yang dirancang oleh penulis, dan dievaluasi dari aspek kualitas visual, koherensi teks, evaluasi keseluruhan, dan PaperQuiz (mengukur kemampuan poster dalam menyampaikan konten inti). Pada saat yang sama, diusulkan PosterAgent, sebuah alur kerja multi-agen top-down, visual-in-the-loop, termasuk parser (mengekstrak aset), planner (penyelarasan teks-visual dan tata letak), dan siklus painter-critic (rendering dan optimasi umpan balik). Varian berdasarkan model sumber terbuka seperti Qwen-2.5 mengungguli sistem yang didukung GPT-4o pada sebagian besar metrik, dengan konsumsi token berkurang 87%, dan mampu mengubah makalah 22 halaman menjadi poster .pptx yang dapat diedit dengan biaya sangat rendah. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Frame In-N-Out: Mewujudkan Generasi Gambar-ke-Video yang Terkendali dan Tanpa Batas : Menanggapi tantangan dalam generasi video seperti keterkendalian, konsistensi temporal, dan sintesis detail, sebuah makalah baru berfokus pada teknik pembuatan film “Frame In and Frame Out”, yang bertujuan untuk memungkinkan pengguna mengontrol objek dalam gambar agar keluar dari adegan secara alami, atau memperkenalkan referensi identitas baru ke dalam adegan, dan dipandu oleh lintasan gerakan yang ditentukan pengguna. Untuk tujuan ini, para peneliti memperkenalkan dataset anotasi semi-otomatis baru, protokol evaluasi komprehensif, dan arsitektur Video Diffusion Transformer yang efisien dalam menjaga identitas dan dapat dikontrol gerakannya. Eksperimen menunjukkan bahwa metode ini secara signifikan mengungguli baseline yang ada. (Sumber: HuggingFace Daily Papers)
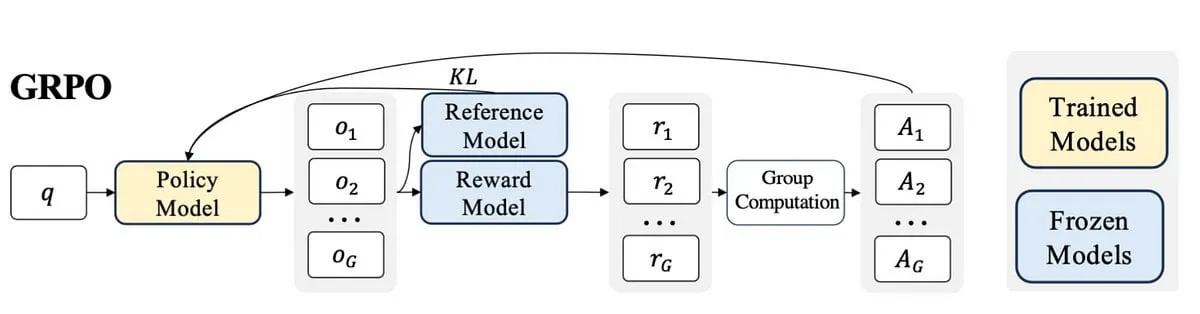
Penelitian Baru Mengusulkan Active-O3: Memberikan Kemampuan Persepsi Aktif pada Model Bahasa Besar Multimodal Melalui GRPO : Menanggapi kurangnya eksplorasi pada model bahasa besar multimodal (MLLM) dalam aspek persepsi aktif, para peneliti mengusulkan kerangka kerja Active-O3. Kerangka kerja ini didasarkan pada pelatihan pembelajaran penguatan murni GRPO (Group Relative Policy Optimization), yang bertujuan untuk memberdayakan MLLM agar secara aktif memilih posisi dan cara observasi untuk mengumpulkan informasi yang relevan dengan tugas. Para peneliti pertama-tama secara sistematis mendefinisikan tugas persepsi aktif berbasis MLLM, dan menunjukkan bahwa strategi pencarian yang diperbesar dari GPT-o3 adalah kasus khusus dari persepsi aktif tetapi kurang efisien dan akurat. Active-O3, dengan membangun rangkaian benchmark yang komprehensif, dievaluasi dalam tugas dunia terbuka umum (seperti lokalisasi objek kecil dan objek padat) dan skenario domain spesifik (seperti penginderaan jauh, deteksi objek kecil dalam mengemudi otonom, segmentasi interaktif berbutir halus), dan menunjukkan kemampuan inferensi zero-shot yang kuat pada V* Benchmark. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan MME-Reasoning: Uji Benchmark Komprehensif untuk Kemampuan Penalaran Logis MLLM : Menanggapi kekurangan benchmark yang ada dalam mengevaluasi kemampuan penalaran logis model bahasa besar multimodal (MLLM), para peneliti meluncurkan MME-Reasoning. Benchmark ini mencakup tiga jenis penalaran logis utama: induktif, deduktif, dan abduktif, dan data disaring dengan cermat untuk memastikan bahwa soal dapat secara efektif mengevaluasi kemampuan penalaran daripada keterampilan persepsi atau keluasan pengetahuan. Hasil evaluasi menunjukkan bahwa bahkan MLLM tercanggih pun menunjukkan keterbatasan dalam evaluasi penalaran logis yang komprehensif, dengan ketidakseimbangan kinerja pada berbagai jenis penalaran. Penelitian ini juga menganalisis dampak metode seperti “pola pikir” dan pembelajaran penguatan berbasis aturan terhadap kemampuan penalaran, memberikan wawasan sistematis untuk memahami dan mengevaluasi kemampuan penalaran MLLM. (Sumber: HuggingFace Daily Papers)
GraLoRA: Meningkatkan Kinerja Fine-tuning Efisien Parameter Melalui Adaptasi Low-Rank Granular : Menanggapi masalah overfitting dan bottleneck kinerja yang muncul ketika LoRA meningkatkan rank, para peneliti mengusulkan GraLoRA (Granular Low-Rank Adaptation). Metode ini membagi matriks bobot menjadi sub-blok, di mana setiap sub-blok memiliki adaptor low-rank independen, yang bertujuan untuk mengatasi masalah keterikatan gradien dan distorsi propagasi yang disebabkan oleh bottleneck struktural LoRA. GraLoRA secara efektif meningkatkan kemampuan ekspresif model, mendekati efek fine-tuning penuh, dengan hampir tanpa peningkatan biaya komputasi atau penyimpanan. Eksperimen pada benchmark generasi kode dan penalaran akal sehat menunjukkan bahwa GraLoRA mengungguli LoRA dan baseline lainnya pada berbagai ukuran model dan pengaturan rank, misalnya, mencapai peningkatan absolut hingga 8,5% pada Pass@1 di HumanEval+. (Sumber: HuggingFace Daily Papers)
SoloSpeech: Pipeline Generasi Bertingkat Meningkatkan Kejelasan dan Kualitas Ekstraksi Ucapan Target : Menanggapi masalah bahwa model diskriminatif yang ada dalam ekstraksi ucapan target (TSE) mudah menimbulkan artefak dan mengurangi kealamian, sementara model generatif kurang dalam kualitas persepsi dan kejelasan, para peneliti mengusulkan SoloSpeech. Ini adalah pipeline generasi bertingkat baru yang mengintegrasikan proses kompresi, ekstraksi, rekonstruksi, dan koreksi. Fiturnya adalah penggunaan ekstraktor target tanpa embedding pembicara, memanfaatkan informasi kondisional dari ruang laten audio prompt, dan menyelaraskannya dengan ruang laten audio campuran untuk mencegah ketidakcocokan. Evaluasi pada dataset Libri2Mix menunjukkan bahwa SoloSpeech mencapai tingkat SOTA baru dalam tugas ekstraksi ucapan target dan pemisahan ucapan, dan menunjukkan kemampuan generalisasi yang sangat baik pada data di luar domain dan skenario nyata. (Sumber: HuggingFace Daily Papers)
Penelitian Baru Mengeksplorasi Peningkatan Kemampuan Pemahaman Visual Model Bahasa Besar Multimodal Melalui Vektor Pemandu Berbasis Teks : Sebuah penelitian baru mengeksplorasi apakah vektor pemandu yang diturunkan dari tulang punggung LLM murni teks dari model bahasa besar multimodal (MLLM) (diperoleh melalui metode seperti sparse autoencoder (SAE), mean shift, dan linear probing) dapat digunakan untuk meningkatkan kemampuan pemahaman visualnya. Penelitian menemukan bahwa vektor pemandu yang diturunkan dari teks secara konsisten dapat meningkatkan akurasi multimodal dari berbagai arsitektur MLLM pada berbagai tugas visual. Secara khusus, metode mean shift meningkatkan akurasi hubungan spasial hingga 7,3% dan akurasi penghitungan hingga 3,3% pada CV-Bench, mengungguli metode prompting, dan menunjukkan kemampuan generalisasi yang kuat pada dataset di luar distribusi. Ini menunjukkan bahwa vektor pemandu berbasis teks adalah mekanisme yang kuat dan efisien yang dapat meningkatkan landasan visual MLLM dengan pengumpulan data tambahan dan biaya komputasi minimal. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan DiSA: Mempercepat Generasi Gambar Autoregresif Melalui Annealing Langkah Difusi : Menanggapi masalah efisiensi inferensi rendah yang disebabkan oleh model autoregresif seperti MAR dan FlowAR yang menggunakan sampling difusi untuk meningkatkan kualitas gambar, sebuah makalah baru mengusulkan metode DiSA (Diffusion Step Annealing). Metode ini didasarkan pada pengamatan bahwa seiring bertambahnya token yang dihasilkan dalam proses autoregresif, distribusi token berikutnya menjadi lebih terbatas, dan sampling menjadi lebih mudah. DiSA adalah metode bebas pelatihan yang secara bertahap mengurangi langkah difusi saat lebih banyak token dihasilkan (misalnya, dari 50 langkah awal menjadi 5 langkah di tahap akhir). Metode ini melengkapi metode percepatan yang ada yang dirancang untuk difusi itu sendiri, mudah diimplementasikan, dan dapat mempercepat MAR dan Harmon sebesar 5-10 kali, dan FlowAR serta xAR sebesar 1,4-2,5 kali, sambil mempertahankan kualitas generasi. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan CASS: Dataset, Model, dan Benchmark Terjemahan Kode GPU dari Nvidia ke AMD : Para peneliti meluncurkan CASS, dataset dan rangkaian model skala besar pertama untuk terjemahan kode GPU lintas arsitektur, dengan target mencakup terjemahan tingkat kode sumber (CUDA <-> HIP) dan tingkat assembly (Nvidia SASS <-> AMD RDNA3). Dataset ini berisi 70.000 pasangan kode lintas host dan perangkat yang telah diverifikasi. Model bahasa khusus domain seri CASS yang dilatih berdasarkan sumber daya ini mencapai akurasi 95% pada terjemahan kode sumber dan akurasi 37,5% pada terjemahan assembly, secara signifikan mengungguli baseline komersial seperti GPT-4o dan Claude. Kode yang dihasilkan cocok dengan kinerja asli dalam lebih dari 85% kasus uji. Bersamaan dengan itu, dirilis CASS-Bench, sebuah benchmark yang berisi 16 domain GPU dan hasil eksekusi nyata. Semua data, model, dan alat evaluasi telah dijadikan sumber terbuka. (Sumber: HuggingFace Daily Papers)
Makalah Menganalisis Kemampuan Kalibrasi Verbal dalam Model Bahasa Visual : Sebuah penelitian secara komprehensif mengevaluasi efektivitas model bahasa visual (VLM) dalam mengekspresikan tingkat kepercayaan melalui bahasa alami (yaitu, ketidakpastian verbal). Penelitian ini mencakup tiga kategori model, empat domain tugas, dan tiga skenario evaluasi. Hasilnya menunjukkan bahwa VLM saat ini sering menunjukkan kesalahan kalibrasi yang jelas dalam berbagai tugas dan pengaturan. Perlu dicatat bahwa model penalaran visual (yaitu, model yang berpikir dengan gambar) secara konsisten menunjukkan kalibrasi yang lebih baik, menunjukkan bahwa penalaran khusus modalitas sangat penting untuk estimasi ketidakpastian yang andal. Untuk mengatasi tantangan kalibrasi, para peneliti memperkenalkan “Visual Confidence-Aware Prompting”, sebuah strategi prompting dua tahap yang bertujuan untuk meningkatkan penyelarasan kepercayaan dalam pengaturan multimodal. (Sumber: HuggingFace Daily Papers)
Makalah Melacak Kemunculan Kemampuan Pragmatis dalam Model Bahasa Besar : LLM saat ini menunjukkan kemampuan yang muncul dalam tugas kecerdasan sosial, tetapi bagaimana mereka memperoleh kemampuan pragmatis selama proses pelatihan masih belum jelas. Sebuah makalah baru memperkenalkan dataset ALTPRAG, yang dirancang berdasarkan konsep pragmatik “alternatif”, untuk mengevaluasi apakah LLM pada berbagai tahap pelatihan dapat secara akurat menyimpulkan niat pembicara yang halus. Melalui evaluasi sistematis terhadap 22 LLM (mencakup tahap pra-pelatihan, SFT, dan optimasi preferensi), hasilnya menunjukkan bahwa bahkan model dasar pun menunjukkan sensitivitas yang signifikan terhadap isyarat pragmatis, dan terus meningkat seiring dengan bertambahnya ukuran model dan data. SFT dan RLHF lebih lanjut meningkatkan kemampuan penalaran pragmatis kognitif. Temuan ini menekankan bahwa kemampuan pragmatis adalah atribut gabungan yang muncul dalam pelatihan LLM, memberikan wawasan baru untuk penyelarasan model dengan norma komunikatif manusia. (Sumber: HuggingFace Daily Papers)
Benchmark Video-Holmes Dirilis: Mengevaluasi Pemikiran “Gaya Sherlock Holmes” MLLM dalam Inferensi Video Kompleks : Menanggapi kenyataan bahwa benchmark video yang ada terutama mengevaluasi kemampuan persepsi visual dan lokalisasi, dan gagal menangkap kebutuhan inferensi kompleks secara memadai, para peneliti meluncurkan benchmark Video-Holmes. Benchmark ini terinspirasi oleh proses inferensi Sherlock Holmes, berisi 1837 pertanyaan yang diekstrak dari 270 film pendek misteri yang dianotasi secara manual, mencakup 7 tugas yang dirancang dengan cermat. Setiap tugas mengharuskan model untuk secara aktif menemukan dan menghubungkan beberapa petunjuk visual yang relevan yang tersebar di berbagai klip video. Evaluasi MLLM SOTA menunjukkan bahwa meskipun model berkinerja sangat baik dalam persepsi visual, mereka mengalami kesulitan signifikan dalam integrasi informasi, sering kali melewatkan petunjuk penting. Misalnya, Gemini-2.5-Pro yang berkinerja terbaik hanya memiliki akurasi 45%. (Sumber: HuggingFace Daily Papers)
Benchmark MME-VideoOCR Dirilis: Mengevaluasi Kemampuan OCR MLLM dalam Skenario Video : Meskipun model bahasa besar multimodal (MLLM) telah mencapai kemajuan signifikan dalam OCR gambar statis, efektivitasnya dalam OCR video berkurang karena faktor-faktor seperti blur gerakan, perubahan temporal, dan efek visual. Untuk memandu pelatihan MLLM yang praktis, para peneliti meluncurkan benchmark MME-VideoOCR, yang mencakup berbagai skenario aplikasi OCR video. Benchmark ini berisi 10 kategori tugas (25 tugas independen), mencakup 44 skenario berbeda, tidak hanya termasuk pengenalan teks, tetapi juga melibatkan pemahaman dan penalaran yang lebih dalam tentang konten teks dalam video. Benchmark ini berisi 1464 video dengan resolusi, rasio aspek, dan durasi yang berbeda, serta 2000 pasangan tanya jawab yang dianotasi secara manual dan dikurasi dengan cermat. Evaluasi terhadap 18 MLLM SOTA menunjukkan bahwa bahkan Gemini-2.5 Pro yang berkinerja terbaik pun hanya memiliki akurasi 73,7%, mengungkap keterbatasan model yang ada dalam menangani tugas yang memerlukan pemahaman video secara keseluruhan. (Sumber: HuggingFace Daily Papers)
MetaMind: Memodelkan Pemikiran Sosial Manusia Melalui Sistem Multi-Agen Metakognitif : Untuk menjembatani kesenjangan model bahasa besar (LLM) dalam menangani ambiguitas inheren dan nuansa kontekstual dalam komunikasi manusia, para peneliti meluncurkan MetaMind, sebuah kerangka kerja multi-agen yang terinspirasi oleh teori metakognitif psikologi, yang bertujuan untuk mensimulasikan penalaran sosial seperti manusia. MetaMind memecah pemahaman sosial menjadi tiga tahap kolaboratif: (1) agen teori pikiran menghasilkan hipotesis tentang keadaan mental pengguna (seperti niat, emosi); (2) agen domain menggunakan norma budaya dan batasan etis untuk menyempurnakan hipotesis ini; (3) agen respons menghasilkan respons yang sesuai dengan konteks, sambil memvalidasi konsistensi dengan niat yang disimpulkan. Kerangka kerja ini mencapai kinerja SOTA pada tiga benchmark yang menantang, meningkat 35,7% dalam skenario sosial nyata, meningkat 6,2% dalam penalaran teori pikiran, dan untuk pertama kalinya memungkinkan LLM mencapai tingkat manusia pada tugas teori pikiran yang penting. (Sumber: HuggingFace Daily Papers)
Sparse VideoGen2: Mempercepat Generasi Video Melalui Permutasi Sadar Semantik dan Atensi Jarang : Menanggapi masalah latensi signifikan dan biaya memori tinggi yang dihadapi model generasi video berbasis Diffusion Transformers (DiT) saat memproses video panjang, para peneliti mengusulkan kerangka kerja SVG2. Kerangka kerja ini memaksimalkan akurasi identifikasi token kunci dan meminimalkan pemborosan komputasi melalui permutasi sadar semantik (menggunakan k-means untuk mengelompokkan dan menyusun ulang token berdasarkan kesamaan semantik), sehingga mencapai trade-off Pareto front antara kualitas generasi dan efisiensi. SVG2 juga mengintegrasikan kontrol anggaran dinamis top-p dan implementasi kernel khusus, mencapai percepatan hingga 2,30 kali pada HunyuanVideo dan 1,89 kali pada Wan 2.1, sambil mempertahankan PSNR yang tinggi. (Sumber: HuggingFace Daily Papers)
OmniConsistency: Mempelajari Konsistensi Bebas Gaya dari Data Bergaya Berpasangan : Untuk mengatasi dua tantangan utama yang dihadapi model difusi dalam penataan gaya gambar, yaitu menjaga konsistensi adegan kompleks (terutama identitas, komposisi, dan detail) dan degradasi gaya yang disebabkan oleh LoRA gaya dalam alur kerja gambar-ke-gambar, para peneliti mengusulkan OmniConsistency. Ini adalah plugin konsistensi universal yang memanfaatkan transformator difusi skala besar (DiT). Kontribusinya meliputi: (1) kerangka kerja pembelajaran konsistensi kontekstual yang dilatih pada pasangan gambar yang selaras untuk mencapai generalisasi yang kuat; (2) strategi pembelajaran progresif dua tahap yang memisahkan pembelajaran gaya dari pemeliharaan konsistensi untuk mengurangi degradasi gaya; (3) desain plug-and-play sepenuhnya yang kompatibel dengan LoRA gaya apa pun di bawah kerangka kerja Flux. Eksperimen menunjukkan bahwa OmniConsistency secara signifikan meningkatkan koherensi visual dan kualitas estetika, mencapai kinerja yang sebanding dengan model SOTA komersial GPT-4o. (Sumber: HuggingFace Daily Papers)
ImgEdit: Dataset dan Uji Benchmark Terpadu untuk Pengeditan Gambar : Untuk mengatasi masalah model pengeditan gambar sumber terbuka yang tertinggal dari model berpemilik (terutama karena data berkualitas tinggi yang terbatas dan benchmark yang tidak memadai), para peneliti meluncurkan ImgEdit. Ini adalah dataset pengeditan gambar skala besar dan berkualitas tinggi, berisi 1,2 juta pasangan pengeditan yang dikurasi dengan cermat, mencakup pengeditan putaran tunggal yang baru dan kompleks serta tugas multi-putaran yang menantang. Untuk memastikan kualitas data, digunakan proses multi-tahap yang mengintegrasikan model bahasa visual, model deteksi, model segmentasi, serta perbaikan khusus tugas dan pasca-pemrosesan yang ketat. Model pengeditan ImgEdit-E1 yang dilatih berdasarkan ImgEdit mengungguli model sumber terbuka yang ada pada beberapa tugas. Bersamaan dengan itu, diluncurkan benchmark ImgEdit-Bench untuk mengevaluasi kinerja pengeditan gambar dalam hal kepatuhan instruksi, kualitas pengeditan, dan pelestarian detail. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Kontrol Perilaku yang Kuat dalam LLM Melalui Atom Target Pemandu : Untuk mencapai kontrol yang tepat atas generasi model bahasa guna memastikan keamanan dan keandalan, sebuah makalah baru mengusulkan metode “Atom Target Pemandu” (Steering Target Atoms, STA). Metode ini bertujuan untuk memisahkan dan memanipulasi komponen pengetahuan yang terpisah untuk meningkatkan keamanan, terutama menunjukkan ketahanan dan fleksibilitas yang unggul dalam skenario permusuhan. Para peneliti berpendapat bahwa meskipun rekayasa prompt dan pemanduan sering digunakan untuk mengintervensi perilaku model, keterikatan parameter model yang tinggi membatasi presisi kontrol dan dapat menyebabkan efek samping. STA mencapai kontrol perilaku yang lebih tepat dengan memanfaatkan sparse autoencoder (SAE) untuk memisahkan pengetahuan dalam ruang dimensi tinggi dan memandunya. Eksperimen membuktikan efektivitas metode ini dan telah diterapkan pada model inferensi besar, mengkonfirmasi potensinya dalam kontrol inferensi yang tepat. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Benchmark SeePhys: Mengevaluasi Kemampuan Penalaran Fisika Berbasis Visual : Para peneliti meluncurkan SeePhys, sebuah benchmark multimodal skala besar untuk mengevaluasi kemampuan penalaran LLM pada soal fisika dari tingkat sekolah menengah hingga ujian kualifikasi doktor. Benchmark ini mencakup 7 bidang dasar disiplin fisika, berisi 21 kategori diagram yang sangat heterogen. Berbeda dengan pekerjaan sebelumnya di mana elemen visual terutama memainkan peran pendukung, 75% soal di SeePhys bersifat visual esensial, yaitu, informasi visual harus diekstraksi untuk menjawab dengan benar. Evaluasi ekstensif menunjukkan bahwa bahkan model penalaran visual tercanggih (seperti Gemini-2.5-pro dan o4-mini) memiliki akurasi kurang dari 60% pada benchmark ini, mengungkap tantangan mendasar LLM saat ini dalam pemahaman visual, terutama dalam kopling ketat interpretasi diagram dengan penalaran fisika dan mengatasi ketergantungan pada pintasan kognitif terhadap isyarat tekstual. (Sumber: HuggingFace Daily Papers)
VerIPO: Meningkatkan Kemampuan Inferensi Jangka Panjang Video-LLM Melalui Optimasi Kebijakan Iteratif yang Dipandu Verifikator : Menanggapi bottleneck persiapan data dan kualitas pemikiran berantai (CoT) yang tidak stabil yang dihadapi oleh pembelajaran penguatan yang diterapkan pada model bahasa besar video (Video-LLM) dalam inferensi video kompleks, para peneliti mengusulkan metode VerIPO (Verifier-guided Iterative Policy Optimization). Inti dari metode ini adalah “Rollout-Aware Verifier” yang terletak di antara tahap pelatihan GRPO dan DPO, yang digunakan untuk mengevaluasi logika inferensi, membangun data kontrastif berkualitas tinggi (berisi CoT yang reflektif dan konsisten secara kontekstual). Data ini mendorong tahap DPO yang efisien, sehingga meningkatkan panjang dan konsistensi kontekstual rantai inferensi. Hasil eksperimen menunjukkan bahwa VerIPO dapat mengoptimalkan model lebih cepat dan lebih efektif, menghasilkan CoT yang lebih panjang dan konsisten secara kontekstual, dengan kinerja melampaui varian GRPO standar serta beberapa Video-LLM fine-tuning instruksi besar dan model inferensi panjang. (Sumber: HuggingFace Daily Papers)
OpenS2V-Nexus: Benchmark Rinci dan Dataset Skala Juta untuk Generasi Subjek-ke-Video : Untuk mendorong pengembangan teknologi generasi subjek-ke-video (S2V), para peneliti mengusulkan OpenS2V-Nexus, yang berisi (i) OpenS2V-Eval, sebuah benchmark berbutir halus, dan (ii) OpenS2V-5M, sebuah dataset skala juta. Berbeda dengan benchmark S2V yang ada (diwarisi dari VBench, yang berfokus pada evaluasi global dan berbutir kasar), OpenS2V-Eval berfokus pada kemampuan model untuk menghasilkan video yang konsisten subjeknya, tampak alami, dan memiliki fidelitas identitas yang tinggi. Untuk tujuan ini, OpenS2V-Eval memperkenalkan 180 prompt dari 7 kategori utama S2V, berisi data uji nyata dan sintetis. Selain itu, untuk menyelaraskan preferensi manusia secara akurat, para peneliti mengusulkan tiga metrik otomatis: NexusScore, NaturalScore, dan GmeScore, yang masing-masing mengukur konsistensi subjek, kealamian, dan relevansi teks dalam video yang dihasilkan. Berdasarkan ini, evaluasi komprehensif dilakukan pada 16 model S2V representatif. Pada saat yang sama, dibuat dataset generasi S2V skala besar sumber terbuka pertama, OpenS2V-5M, yang berisi 5 juta triplet subjek-teks-video berkualitas tinggi 720P. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan WHISTRESS: Memperkaya Teks Transkripsi Melalui Deteksi Penekanan Kalimat : Menanggapi pentingnya penekanan kalimat dalam bahasa lisan untuk menyampaikan niat pembicara, dan ketiadaannya dalam sistem transkripsi yang ada, sebuah makalah baru memperkenalkan WHISTRESS, metode deteksi penekanan kalimat tanpa penyelarasan. Untuk mendukung tugas ini, para peneliti mengusulkan TINYSTRESS-15K, sebuah dataset pelatihan sintetis yang dapat diskalakan yang dibuat melalui proses sepenuhnya otomatis. Model WHISTRESS yang dilatih pada dataset ini mengungguli baseline yang ada dalam hal kinerja, dan tidak memerlukan pelatihan tambahan atau input prior inferensi. Perlu dicatat bahwa meskipun dilatih pada data sintetis, WHISTRESS menunjukkan kemampuan generalisasi zero-shot yang kuat dalam berbagai uji benchmark. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan InstructPart: Segmentasi Bagian Berorientasi Tugas dengan Inferensi Berinstruksi : Meskipun model dasar multimodal besar telah mencapai kemajuan dalam berbagai tugas, banyak model memperlakukan objek sebagai keseluruhan yang tidak dapat dibagi, mengabaikan bagian-bagian yang menyusun objek. Memahami bagian-bagian ini dan visibilitas fungsional terkait (affordances) sangat penting untuk melakukan berbagai tugas. Untuk tujuan ini, para peneliti memperkenalkan benchmark dunia nyata baru, InstructPart, yang berisi anotasi segmentasi bagian yang ditandai secara manual dan instruksi berorientasi tugas, untuk mengevaluasi kinerja model saat ini dalam memahami dan melaksanakan tugas tingkat bagian dalam situasi sehari-hari. Eksperimen menunjukkan bahwa bahkan untuk model bahasa visual (VLM) SOTA, segmentasi bagian berorientasi tugas tetap menjadi masalah yang menantang. Selain benchmark, para peneliti juga memperkenalkan baseline sederhana yang, dengan menggunakan dataset mereka untuk fine-tuning, mencapai peningkatan kinerja dua kali lipat. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Metode Hibrid Neural-MPM, Mewujudkan Simulasi Fluida Interaktif Real-time : Untuk mengatasi masalah simulasi fluida di mana metode fisika tradisional padat komputasi dan memiliki latensi tinggi, serta metode pembelajaran mesin baru-baru ini meskipun mengurangi biaya tetapi masih sulit memenuhi kebutuhan interaksi real-time, para peneliti mengusulkan metode hibrid baru. Metode ini mengintegrasikan simulasi numerik, fisika neural, dan kontrol generatif. Fisika neuralnya, melalui mekanisme jaminan yang kembali ke pemecah numerik klasik, bersama-sama mengejar simulasi latensi rendah dan fidelitas fisik tinggi. Selain itu, para peneliti mengembangkan pengontrol berbasis difusi yang dilatih menggunakan strategi pemodelan terbalik untuk menghasilkan medan gaya dinamis eksternal untuk manipulasi fluida. Sistem ini menunjukkan kinerja yang kuat dalam berbagai skenario 2D/3D, jenis material, dan interaksi rintangan, mencapai simulasi real-time dengan frame rate tinggi (latensi 11~29%), dan dapat memandu kontrol fluida melalui sketsa tangan yang mudah digunakan. (Sumber: HuggingFace Daily Papers)
MMIG-Bench: Benchmark Evaluasi Terinterpretasi Komprehensif untuk Model Generasi Gambar Multimodal : Menanggapi keterbatasan alat evaluasi yang ada dalam menilai generator gambar multimodal seperti GPT-4o, Gemini 2.0 Flash, dan Gemini 2.5 Pro (misalnya, benchmark T2I kurang kondisi multimodal, benchmark generasi gambar kustom mengabaikan semantik kombinatorial dan akal sehat), para peneliti mengusulkan MMIG-Bench. Ini adalah benchmark generasi gambar multimodal komprehensif yang berisi 4850 prompt teks yang dianotasi secara kaya dan 1750 gambar referensi multi-pandangan yang mencakup 380 subjek (orang, hewan, objek, gaya seni). MMIG-Bench dilengkapi dengan kerangka kerja evaluasi tiga tingkat: (1) metrik tingkat rendah mengevaluasi artefak visual dan pelestarian identitas objek; (2) skor pencocokan aspek baru (AMS): metrik tingkat menengah berbasis VQA yang menyediakan penyelarasan prompt-gambar berbutir halus dan sangat berkorelasi dengan penilaian manusia; (3) metrik tingkat tinggi mengevaluasi estetika dan preferensi manusia. Melalui MMIG-Bench, 17 model SOTA diuji benchmark, dan metrik divalidasi dengan 32.000 penilaian manusia, memberikan wawasan mendalam untuk desain arsitektur dan data. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan HRPO: Mewujudkan Inferensi Laten Hibrid Melalui Pembelajaran Penguatan : Untuk mengatasi masalah metode inferensi laten yang ada tidak kompatibel dengan karakteristik generasi autoregresif LLM dan ketergantungan pada lintasan CoT untuk pelatihan, para peneliti mengusulkan HRPO (Hybrid Reasoning Policy Optimization). Ini adalah metode inferensi laten hibrid berbasis pembelajaran penguatan yang mengintegrasikan status tersembunyi sebelumnya ke dalam token yang disampel melalui mekanisme gerbang yang dapat dipelajari, dan diinisialisasi dengan embedding token sebagai fokus utama pelatihan, secara bertahap menggabungkan lebih banyak fitur tersembunyi. Desain ini mempertahankan kemampuan generatif LLM dan mendorong penggunaan representasi diskrit dan kontinu untuk inferensi hibrid. Selain itu, HRPO memperkenalkan keacakan ke dalam inferensi laten melalui sampling token, sehingga memungkinkan optimasi berbasis RL tanpa memerlukan lintasan CoT. Evaluasi ekstensif pada berbagai benchmark menunjukkan bahwa HRPO mengungguli metode sebelumnya baik pada tugas padat pengetahuan maupun padat inferensi. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Metode NFT: Menghubungkan Pembelajaran Terawasi dengan Pembelajaran Penguatan dalam Penalaran Matematika : Menantang gagasan umum bahwa “peningkatan diri terbatas pada pembelajaran penguatan (RL)”, sebuah makalah baru mengusulkan metode Negative-aware Fine-Tuning (NFT). Ini adalah metode pembelajaran terawasi yang memungkinkan LLM untuk merefleksikan kegagalannya dan meningkatkan diri secara mandiri, tanpa guru eksternal. Dalam pelatihan online, NFT tidak membuang jawaban salah yang dihasilkan sendiri, melainkan membangun kebijakan negatif implisit untuk memodelkannya. Kebijakan implisit ini memiliki parameterisasi yang sama dengan LLM target positif yang digunakan untuk optimasi pada data positif, sehingga memungkinkan optimasi kebijakan secara langsung pada semua generasi LLM. Hasil eksperimen pada tugas penalaran matematika dengan model 7B dan 32B menunjukkan bahwa dengan memanfaatkan umpan balik negatif tambahan, NFT secara signifikan mengungguli baseline pembelajaran terawasi seperti fine-tuning penolakan sampling, bahkan mencapai atau melampaui algoritma RL terkemuka seperti GRPO dan DAPO. Para peneliti lebih lanjut membuktikan bahwa dalam pelatihan kebijakan online yang ketat, NFT dan GRPO sebenarnya setara. (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Minute-Long Videos with Dual Parallelisms: Mewujudkan Generasi Video Berdurasi Menit : Menanggapi masalah latensi komputasi dan biaya memori yang terlalu tinggi yang dihadapi model difusi video berbasis DiT saat menghasilkan video panjang, para peneliti mengusulkan strategi inferensi terdistribusi baru, DualParal. Ide inti dari metode ini adalah memparalelkan frame waktu dan lapisan model ke beberapa GPU. Untuk mengatasi masalah serialisasi paralelisme asli yang disebabkan oleh persyaratan model difusi untuk sinkronisasi tingkat noise antar-frame, metode ini menggunakan skema denoising berbasis blok, yaitu dengan memproses serangkaian blok frame secara pipeline dan secara bertahap mengurangi tingkat noise. Setiap GPU memproses subset blok dan lapisan tertentu, dan meneruskan hasil sebelumnya ke GPU berikutnya, mencapai komputasi dan komunikasi asinkron. Selain itu, dengan menerapkan caching fitur pada setiap GPU untuk menggunakan kembali fitur dari blok sebelumnya sebagai konteks, dan mengadopsi strategi inisialisasi noise yang terkoordinasi, dinamika waktu global yang konsisten dipastikan, sehingga mencapai generasi video yang cepat, bebas artefak, dan berdurasi tak terbatas. Diterapkan pada generator video transformator difusi terbaru, metode ini secara efisien menghasilkan video 1025 frame pada 8x GPU RTX 4090, dengan latensi berkurang hingga 6,54 kali dan biaya memori berkurang 1,48 kali. (Sumber: HuggingFace Daily Papers)
🧰 Alat
Model Seri Claude 4 Unggul dalam Tugas Pemrograman, Berhasil Memecahkan “Bug Paus Putih” yang Membingungkan Programmer Senior Selama 4 Tahun : Model Claude Opus 4 terbaru dari Anthropic menunjukkan kemampuan pemrograman yang luar biasa. Seorang mantan insinyur FAANG dengan 30 tahun pengalaman pengembangan C++ berbagi bahwa bug sistem yang kompleks yang telah membingungkan timnya selama 4 tahun dan menghabiskan sekitar 200 jam waktu pribadinya tanpa solusi (masalah kondisi batas yang muncul ketika shader tertentu digunakan dengan cara tertentu), berhasil ditemukan dan diidentifikasi penyebabnya oleh Claude Opus 4 dalam beberapa jam melalui sekitar 30 prompt. Bug ini tidak ada sebelum restrukturisasi sistem, dan Opus 4 menunjukkan bahwa arsitektur baru gagal mengakomodasi perilaku non-desain yang didukung oleh “kebetulan” di bawah arsitektur lama. Sebelumnya, GPT-4.1, Gemini 2.5, dan Claude 3.7 semuanya gagal menyelesaikan masalah ini. Ini menyoroti kemampuan kuat Claude 4 dalam memahami kode kompleks, melakukan analisis mendalam, dan penalaran, terutama setelah dikombinasikan dengan mode Claude Code, yang dapat secara efektif membantu pengembang menangani tugas rekayasa tingkat lanjut seperti restrukturisasi kode dan perbaikan bug. (Sumber: 36氪, dotey)
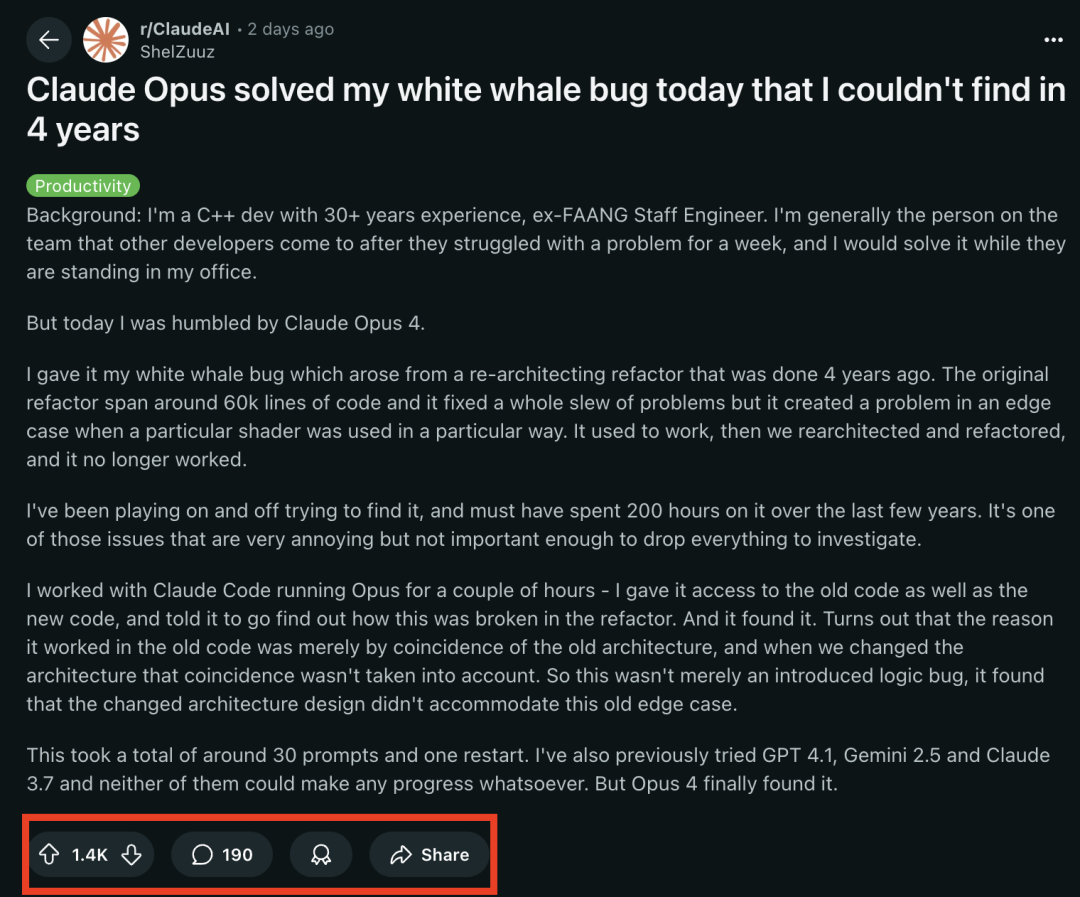
LangChain Menambahkan Dukungan untuk Fitur Beta Baru Anthropic Claude : LangChain mengumumkan telah mengintegrasikan empat fitur Beta baru yang baru-baru ini dirilis oleh model Anthropic Claude, termasuk eksekusi kode, konektor MCP jarak jauh, API file, dan cache prompt yang diperluas. Pengembang sekarang dapat melihat contoh terkait melalui dokumentasi LangChain untuk memanfaatkan fitur-fitur baru ini guna membangun aplikasi AI yang lebih kuat. (Sumber: LangChainAI)
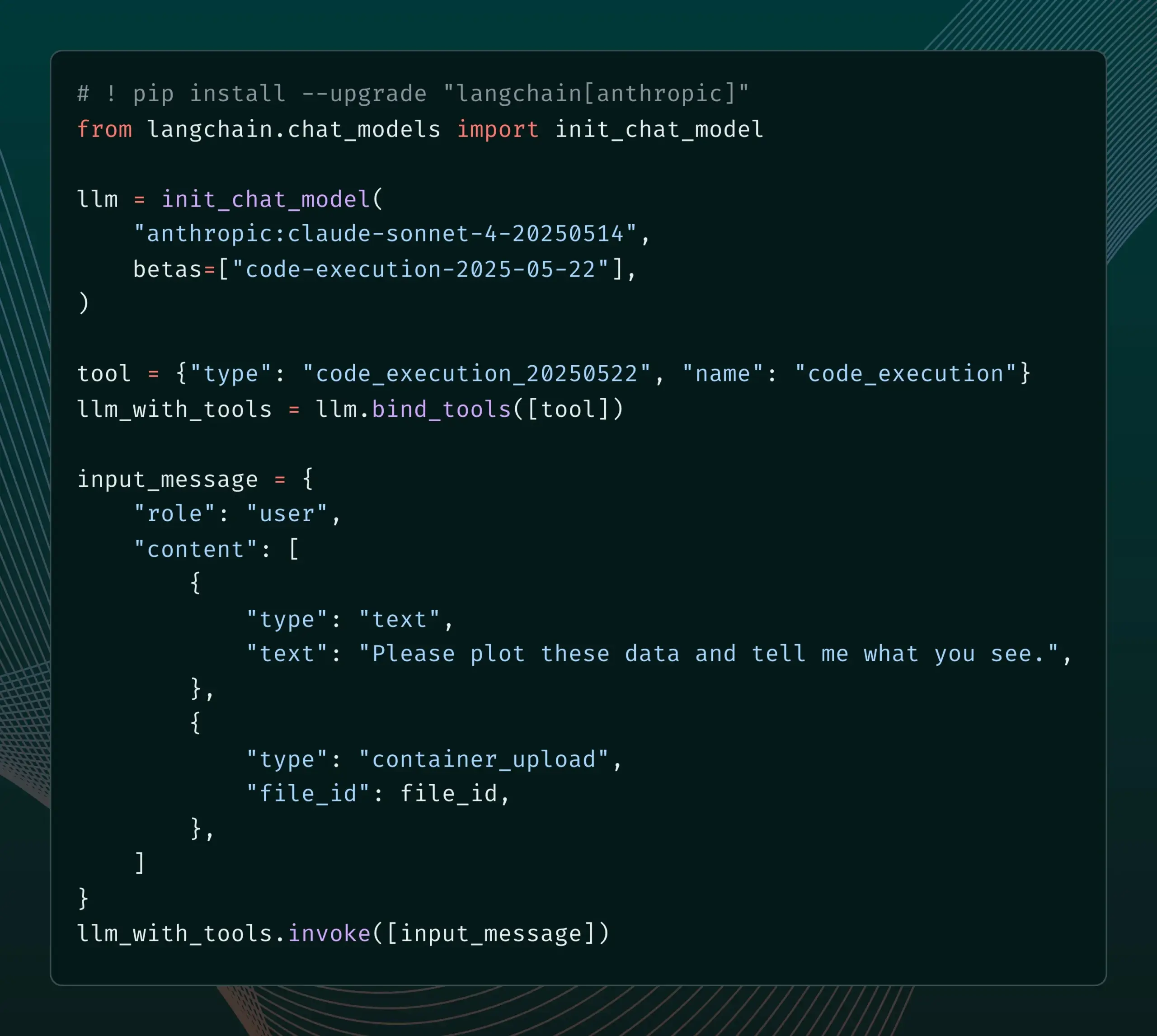
LangSmith Meluncurkan Fitur Manajemen Prompt yang Terintegrasi dengan SDLC : Platform LangSmith meningkatkan kemampuan rekayasa promptnya, kini pengguna tidak hanya dapat menguji, membuat versi, dan berkolaborasi pada prompt di LangSmith, tetapi juga dapat secara otomatis menyinkronkan prompt ke GitHub, database eksternal, atau memulai proses CI/CD melalui pemicu webhook saat prompt berubah. Fitur ini bertujuan untuk membantu pengembang mengintegrasikan manajemen prompt lebih erat ke dalam siklus hidup pengembangan perangkat lunak (SDLC). (Sumber: LangChainAI)
AutoThink: Teknologi Adaptif untuk Meningkatkan Kinerja Inferensi LLM Lokal : Tim CodeLion mengembangkan teknologi AutoThink, yang secara signifikan meningkatkan kinerja inferensi LLM lokal melalui alokasi sumber daya adaptif dan vektor kemudi (steering vectors). AutoThink dapat mengklasifikasikan kompleksitas kueri, secara dinamis mengalokasikan “token berpikir” (lebih banyak untuk masalah kompleks, lebih sedikit untuk masalah sederhana), dan menggunakan vektor kemudi untuk memandu pola inferensi. Pengujian pada model DeepSeek-R1-Distill-Qwen-1.5B menunjukkan peningkatan akurasi GPQA-Diamond sebesar 43% (dari 21,72% menjadi 31,06%), MMLU-Pro juga meningkat, dan penggunaan token lebih sedikit. Teknologi ini kompatibel dengan model inferensi lokal yang mendukung token berpikir, kode dan penelitian telah dirilis. (Sumber: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab Mengumumkan Dukungan untuk AMD ROCm, Dapat Melatih LLM Secara Lokal : Transformer Lab mengumumkan bahwa platform GUI-nya kini mendukung penggunaan ROCm pada GPU AMD untuk pelatihan lokal dan fine-tuning model bahasa besar. Tim menyatakan bahwa proses konfigurasi ROCm penuh tantangan dan telah mendokumentasikan seluruh prosesnya di blog. Saat ini, fitur ini sudah dapat digunakan dengan lancar, dan pengguna dapat mencoba melakukan pekerjaan pengembangan LLM pada perangkat keras AMD. (Sumber: Reddit r/MachineLearning)
Sistem Multi-Agen yang Ditingkatkan LLM Sumber Terbuka Mewujudkan Ekstraksi Klaim dan Pemeriksaan Fakta Otomatis : Sebuah proyek sumber terbuka bernama “fact-checker” menggunakan sistem multi-agen (MAS) yang ditingkatkan LLM untuk mewujudkan ekstraksi klaim, verifikasi bukti, dan penyelesaian fakta secara otomatis. Proyek ini mencakup ekstensi browser yang dapat melakukan pemeriksaan fakta secara real-time terhadap respons chatbot AI apa pun, membantu membedakan keaslian konten yang dihasilkan AI. Arsitektur kodenya jelas, dokumentasinya lengkap, dan menyediakan alat yang berharga untuk bidang keamanan AI dan penanggulangan informasi yang salah. (Sumber: Reddit r/MachineLearning)
Meituan Meluncurkan Produk Tanpa Kode Nocode, Mendukung Generasi Aplikasi Multi-Halaman yang Kompleks : Meituan merilis produk Vibe Coding bernama Nocode, di mana pengguna dapat menghasilkan aplikasi lengkap yang kompleks dan berisi beberapa halaman melalui deskripsi bahasa alami, bukan hanya halaman tampilan sederhana. Pengujian oleh Guicang menunjukkan bahwa alat ini berhasil membangun alat manajemen barang gudang yang logikanya kompleks dalam sekali jalan, menunjukkan kemampuannya dalam memahami kebutuhan kompleks dan menghasilkan kode yang sesuai. (Sumber: op7418)
LlamaIndex Mendukung Pembuatan Penyemat Multimodal Kustom & Integrasi dengan UI Obrolan Gaya OpenAI : LlamaIndex merilis pembaruan yang memungkinkan pengguna membangun penyemat multimodal kustom, misalnya mengintegrasikan AWS Titan Multimodal, dan dapat digabungkan dengan database vektor seperti Pinecone untuk pencarian vektor teks+gambar yang efisien. Selain itu, alur kerja LlamaIndex sekarang dapat dijalankan dalam antarmuka obrolan mirip OpenAI dengan beberapa baris kode, dan mendukung mode pengembangan untuk mengedit kode alur kerja langsung di UI, meningkatkan pengalaman pengembangan dan interaksi aplikasi RAG. (Sumber: jerryjliu0, jerryjliu0)

Pembaruan TRAE Meningkatkan Pengalaman Pengkodean Agentic, Versi Internasional Meluncurkan Langganan Berbayar : Alat pemrograman AI TRAE mendapatkan pembaruan, mengoptimalkan pengalaman pengkodean Agentic, membuatnya lebih cocok untuk pengguna yang tidak ingin melakukan operasi manual. Versi baru TRAE dapat mengingat riwayat percakapan dengan lebih baik, secara otomatis menghubungkan konteks, AI dapat secara otomatis merencanakan jalur pemrograman dan memanggil lebih banyak alat, meningkatkan tingkat keberhasilan tugas pemrograman. Misalnya, pengguna hanya perlu menyediakan folder kosong dan prompt, TRAE dapat menyelesaikan serangkaian operasi seperti membuat file, memulai server Web (secara otomatis menangani masalah lintas domain), dan mempratinjau animasi p5.js di dalam IDE. Versi internasionalnya telah meluncurkan langganan berbayar, dengan harga Pro $3 untuk bulan pertama, mendukung Alipay. (Sumber: dotey, karminski3)
Komunitas Juejin Meluncurkan Layanan MCP, Mendukung Publikasi Kode Frontend Sekali Klik : Komunitas programmer domestik Juejin meluncurkan layanan MCP (Model-driven Co-programming Protocol), yang memungkinkan pengembang untuk mempublikasikan kode frontend (seperti halaman web, game yang dihasilkan oleh vibe coding) sekali klik ke platform Juejin, memudahkan berbagi dan pratinjau cepat. Pengguna perlu mendapatkan Token MCP Juejin dan mengkonfigurasinya di alat seperti Trae, Cursor. (Sumber: dotey, karminski3)
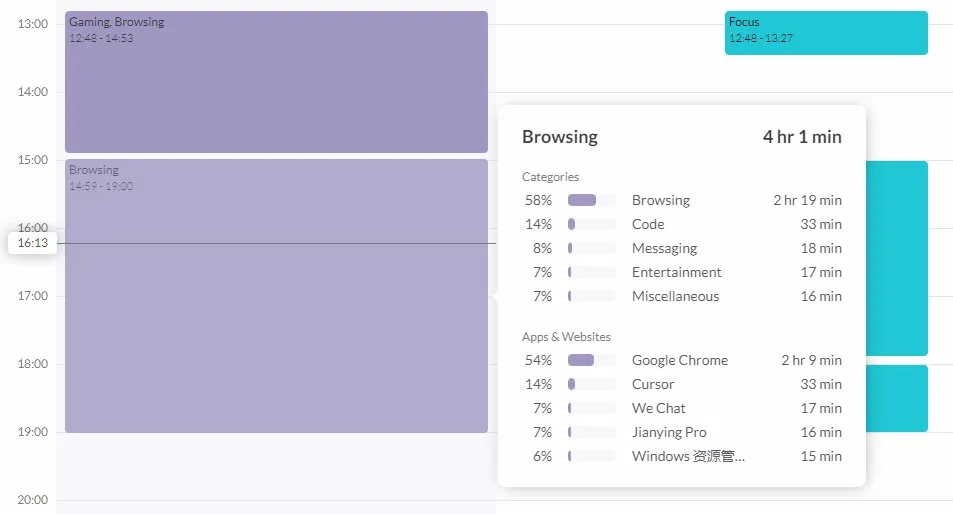
Alat Pelacak Waktu Sumber Terbuka ActivityWatch Mendapat Perhatian sebagai Alternatif Rize : Pengguna karminski3, setelah mencoba alat analisis waktu AI Rize (yang menganalisis nama proses untuk menentukan status kerja, rapat, atau bermalas-malasan, dengan biaya bulanan $20), menemukan dan merekomendasikan alternatif sumber terbuka ActivityWatch. ActivityWatch memiliki fungsi serupa, mendukung Windows/Mac, dan memungkinkan kustomisasi pengguna, dianggap sebagai alat yang sangat baik untuk mengurangi kecemasan kerja dan melacak jam kerja. (Sumber: karminski3)
Alat Pemantau Bayi AI Sumber Terbuka ai-baby-monitor Dirilis : Sebuah proyek sumber terbuka bernama ai-baby-monitor telah dirilis. Proyek ini menggunakan model Qwen2.5 VL dan kerangka kerja inferensi vLLM, memungkinkan pengguna untuk menentukan aturan (seperti “alarm jika anak bangun”, “alarm jika anak sendirian”) agar AI membantu memantau bayi. Pengembang menekankan bahwa ini hanyalah alat bantu dan tidak dapat sepenuhnya menggantikan pengawasan manusia. (Sumber: karminski3)
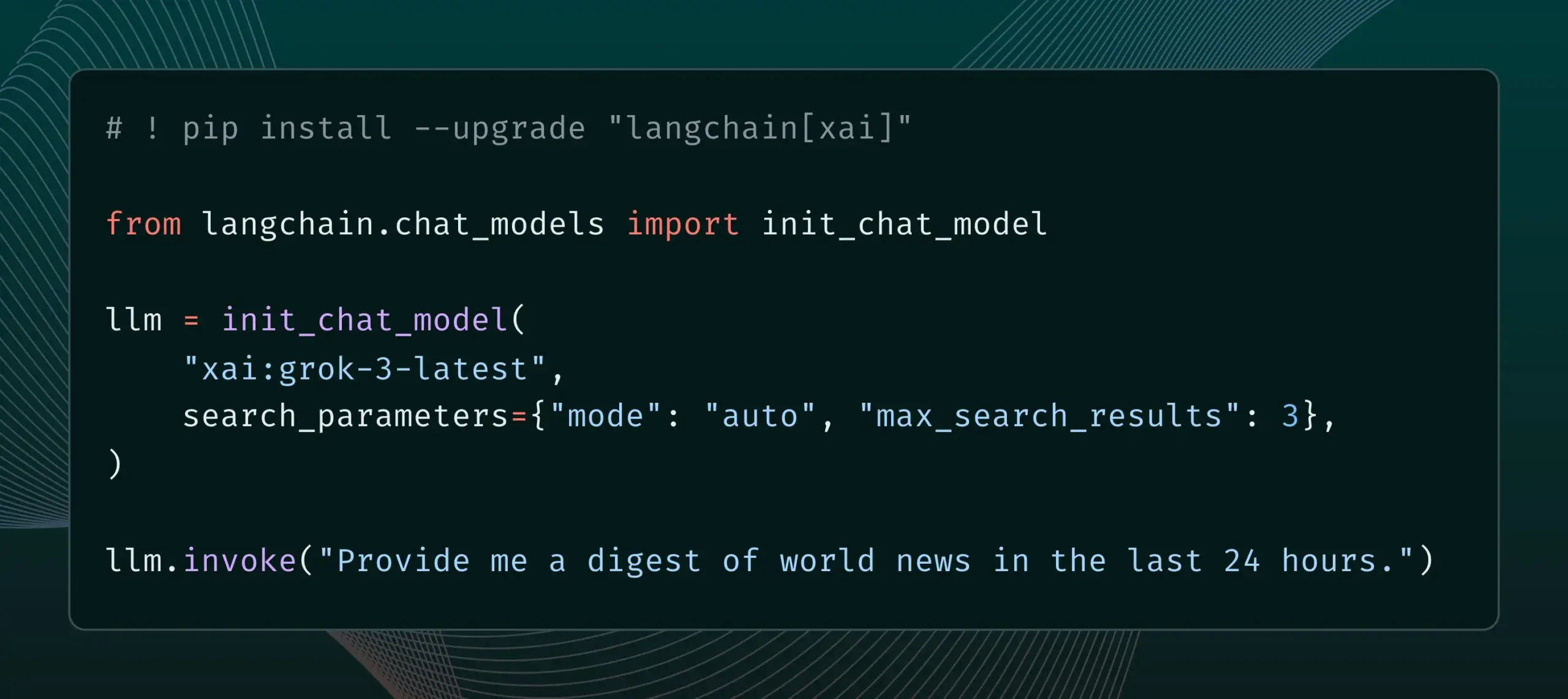
LangChain Mengintegrasikan Fitur Live Search xAI : LangChain mengumumkan dukungan untuk fitur Live Search xAI, yang memungkinkan model Grok untuk menghasilkan jawaban berdasarkan hasil pencarian web, dan menyediakan berbagai opsi konfigurasi, seperti periode waktu, domain yang disertakan, dan parameter pencarian lainnya. Pengguna sekarang dapat mencoba fitur baru ini di LangChain. (Sumber: LangChainAI)
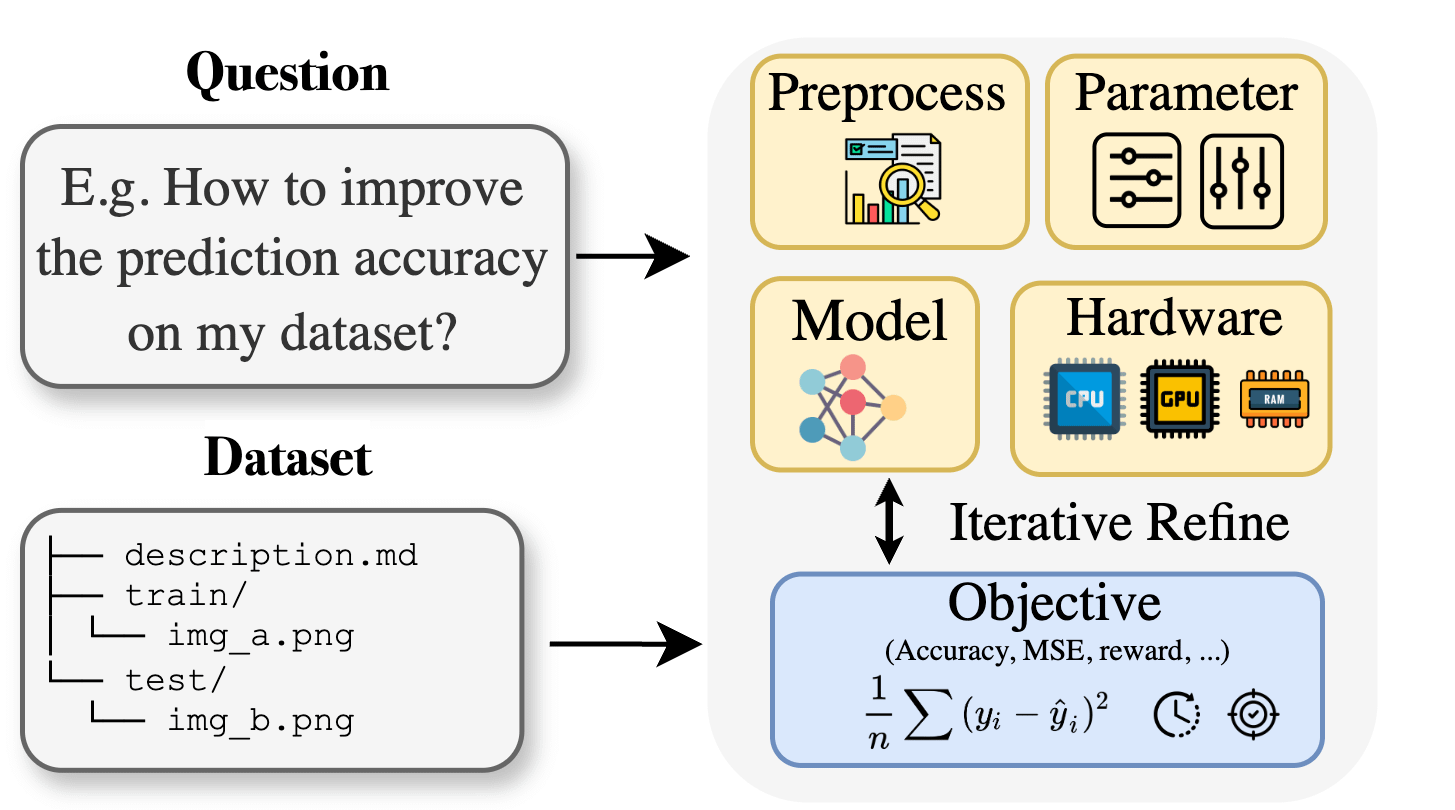
Curie: Asisten Riset AI Sumber Terbuka Merilis Fitur AutoML, Membantu Riset Lintas Disiplin : Menanggapi kendala pengetahuan khusus yang dihadapi peneliti di bidang biologi, material, kimia, dll. saat menerapkan pembelajaran mesin, proyek Curie meluncurkan fitur AutoML baru. Curie bertujuan untuk menjadi ilmuwan kolaboratif untuk eksperimen penelitian AI, dengan mengotomatiskan alur kerja ML yang kompleks (seperti pemilihan algoritma, penyesuaian hiperparameter, interpretasi output model), membantu peneliti menguji hipotesis dengan cepat dan mengekstrak wawasan dari data. Misalnya, Curie menghasilkan model dengan AUC 0,99 dalam tugas deteksi melanoma. Proyek ini telah dijadikan sumber terbuka, mendorong kontribusi komunitas. (Sumber: Reddit r/LocalLLaMA)
Alibaba MNN Chat Mendukung Pengoperasian Model Qwen 30B-a3b Secara Lokal di Perangkat Android : Aplikasi MNN Chat Alibaba diperbarui ke versi 0.5.0, kini mendukung pengoperasian model bahasa besar seperti Qwen 30B-a3b secara lokal di perangkat Android. Umpan balik pengguna menunjukkan bahwa model ini dapat berhasil dijalankan pada perangkat dengan chip unggulan dan memori besar (seperti OnePlus 13 24G), dan disarankan untuk mengaktifkan pengaturan mmap. Namun, ada juga komentar yang menunjukkan bahwa model parameter 30B memerlukan memori dan daya komputasi yang terlalu tinggi untuk sebagian besar ponsel, dan Gemma 3n mungkin lebih cocok untuk perangkat seluler. (Sumber: Reddit r/LocalLLaMA)

📚 Belajar
Makalah Baru Mengusulkan Lean and Mean Adaptive Optimization: Optimizer Pelatihan Model Besar yang Lebih Cepat dan Hemat Memori : Sebuah makalah yang diterima di ICML 2025 memperkenalkan optimizer baru bernama “Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum”. Metode ini, melalui dua teknik komplementer, langkah Subset-Norm dan Subspace-Momentum, bertujuan untuk mengurangi kebutuhan memori pelatihan jaringan neural skala besar dan mempercepat pelatihan. Dibandingkan dengan optimizer hemat memori yang ada seperti GaLore dan LoRA, metode ini, sambil menghemat memori (misalnya, mengurangi memori status optimizer sebesar 80% dibandingkan Adam saat melakukan pra-pelatihan LLaMA 1B), dapat mencapai perplexity validasi Adam dengan token pelatihan yang lebih sedikit (sekitar setengahnya), dan memberikan jaminan konvergensi teoretis yang lebih kuat. (Sumber: Reddit r/MachineLearning)
Makalah Mengusulkan Force Prompting: Memungkinkan Model Generasi Video Mempelajari dan Menggeneralisasi Sinyal Kontrol Berbasis Fisika : Sebuah penelitian baru mengeksplorasi kemungkinan penggunaan gaya fisik sebagai sinyal kontrol generasi video dan mengusulkan “Force Prompts”. Pengguna dapat berinteraksi dengan gambar melalui gaya titik lokal (seperti menusuk tanaman) atau medan angin global (seperti angin meniup kain). Penelitian menunjukkan bahwa model generasi video dapat belajar dan menggeneralisasi kondisi gaya fisik dari video yang disintesis Blender yang hanya berisi demonstrasi beberapa objek, menghasilkan video yang merespons sinyal kontrol fisik secara realistis, tanpa memerlukan aset 3D atau simulator fisik saat inferensi. Keanekaragaman visual dan penggunaan kata kunci teks tertentu saat pelatihan adalah faktor kunci untuk mencapai generalisasi ini. (Sumber: HuggingFace Daily Papers)
AnkiHub Berbagi Alur Kerja Anotasi AI, Menggabungkan FastHTML untuk Meningkatkan Efisiensi : AnkiHub membagikan alur kerja anotasi AI-nya dan mendemonstrasikannya dalam kursus evaluasi AI Hamel Husain dan Shreya Shankar. Alur kerja ini menggunakan alat bantu FastHTML, yang bertujuan untuk meningkatkan efisiensi anotasi AI untuk produk komersial. Materi pengajaran dan repositori kode terkait telah dipublikasikan di GitHub, menunjukkan cara menggunakan alat yang digunakan dalam produksi aktual untuk mengoptimalkan pengembangan AI. (Sumber: jeremyphoward, HamelHusain)

Blogger Menulis Catatan Belajar PPO ke GRPO, Menjelaskan Konsep Pembelajaran Penguatan dalam Fine-tuning LLM : Seorang blogger membagikan pengalamannya mempelajari pembelajaran penguatan (RL) dan penerapannya dalam fine-tuning model bahasa besar (LLM), khususnya proses pemahaman dari PPO (Proximal Policy Optimization) ke GRPO (Group Relative Policy Optimization). Tulisan blog ini bertujuan untuk menjelaskan konsep-konsep yang ingin ia pahami di awal pembelajarannya, untuk membantu orang lain lebih memahami bagaimana algoritma RL ini digunakan untuk mengoptimalkan LLM. (Sumber: Reddit r/MachineLearning)
Makalah Membahas Pemikiran Pragmatis Mesin: Melacak Kemunculan Kemampuan Pragmatis dalam Model Bahasa Besar : Sebuah makalah baru meneliti bagaimana model bahasa besar (LLM) memperoleh kompetensi pragmatis selama proses pelatihan, yaitu kemampuan untuk memahami dan menyimpulkan makna implisit, niat pembicara, dll. Para peneliti memperkenalkan dataset ALTPRAG, berdasarkan konsep “alternatif” dalam pragmatik, untuk mengevaluasi 22 LLM pada berbagai tahap pelatihan (pra-pelatihan, fine-tuning terawasi SFT, optimasi preferensi RLHF). Hasilnya menunjukkan bahwa bahkan model dasar pun menunjukkan sensitivitas yang signifikan terhadap isyarat pragmatis, dan terus meningkat seiring dengan bertambahnya ukuran model dan data; SFT dan RLHF lebih lanjut meningkatkan kemampuan penalaran pragmatis kognitif. Ini menunjukkan bahwa kompetensi pragmatis adalah karakteristik yang muncul dan bersifat gabungan dalam pelatihan LLM. (Sumber: HuggingFace Daily Papers)
Makalah Membahas Kerangka Kerja Pembelajaran Penguatan VisTA untuk Pemilihan Alat Visual : Para peneliti memperkenalkan VisTA (VisualToolAgent), sebuah kerangka kerja pembelajaran penguatan baru yang memungkinkan agen visual untuk secara dinamis menjelajahi, memilih, dan menggabungkan alat dari berbagai pustaka berdasarkan kinerja empiris. Berbeda dengan metode yang ada yang bergantung pada prompting tanpa pelatihan atau fine-tuning skala besar, VisTA memanfaatkan pembelajaran penguatan end-to-end, menggunakan hasil tugas sebagai sinyal umpan balik, untuk secara iteratif mengoptimalkan strategi pemilihan alat yang kompleks dan spesifik untuk kueri. Melalui GRPO (Group Relative Policy Optimization), kerangka kerja ini memungkinkan agen untuk secara mandiri menemukan jalur pemilihan alat yang efektif, tanpa pengawasan penalaran eksplisit. Eksperimen pada benchmark ChartQA, Geometry3K, dan BlindTest menunjukkan bahwa VisTA mencapai peningkatan kinerja yang signifikan dibandingkan dengan baseline tanpa pelatihan, terutama pada sampel di luar distribusi. (Sumber: HuggingFace Daily Papers)
💼 Bisnis
Perusahaan Layanan Data Jinglianwen Technology Menyelesaikan Pendanaan Pra-A Senilai Puluhan Juta, Membidik Operasi Produksi Data Publik : Operator layanan data AI Jinglianwen Technology baru-baru ini menyelesaikan pendanaan Pra-A senilai puluhan juta yuan, yang diinvestasikan oleh dana di bawah Hangzhou Jintou Group. Pendanaan akan digunakan untuk membangun operasi produksi data publik, membangun platform rekayasa korpus cerdas, dan membangun basis anotasi berkualitas tinggi di bidang vertikal secara mandiri. Perusahaan ini didirikan pada tahun 2012, berfokus pada data publik, model besar AI, mengemudi otonom, dan medis, bertujuan untuk menyelesaikan masalah seperti “tata kelola yang sulit, pasokan yang tidak mencukupi, aliran yang tidak lancar, penggunaan yang tidak efektif, dan keamanan yang lemah” pada data publik, dan bekerja sama dengan penyimpanan data Huawei untuk meluncurkan solusi gabungan danau data AI. Pertumbuhan pendapatan tahun ini diperkirakan akan melebihi 400%. (Sumber: 36氪)
Meitu Menerima Investasi Obligasi Konversi Sekitar $250 Juta dari Alibaba, Memperdalam Kerja Sama di Bidang AI : Meitu Company mengumumkan rencana untuk memulai kerja sama strategis dengan Alibaba, di mana Alibaba akan menerbitkan obligasi konversi senilai total sekitar $250 juta kepada Meitu. Kedua belah pihak akan bekerja sama dalam promosi platform e-commerce, pengembangan teknologi AI (gambar AI, video AI), komputasi awan, dan bidang lainnya. Meitu berjanji untuk membeli layanan senilai tidak kurang dari 560 juta yuan dari Alibaba Cloud selama tiga tahun ke depan. Kerja sama ini bertujuan untuk memanfaatkan ekosistem Alibaba guna menggali potensi skenario e-commerce, meningkatkan skala pengguna berbayar dan tingkat penelitian dan pengembangan alat desain AI Meitu. Meskipun langkah ini sempat mendongkrak harga saham Meitu, fokus pasar adalah bagaimana Meitu dapat menghindari terulangnya nasib Kimi yang pertumbuhan penggunanya melambat di tengah persaingan pasar yang ketat, terutama di bidang AI visual yang menghadapi persaingan ketat dan perbedaan skala dari perusahaan besar. (Sumber: 36氪)
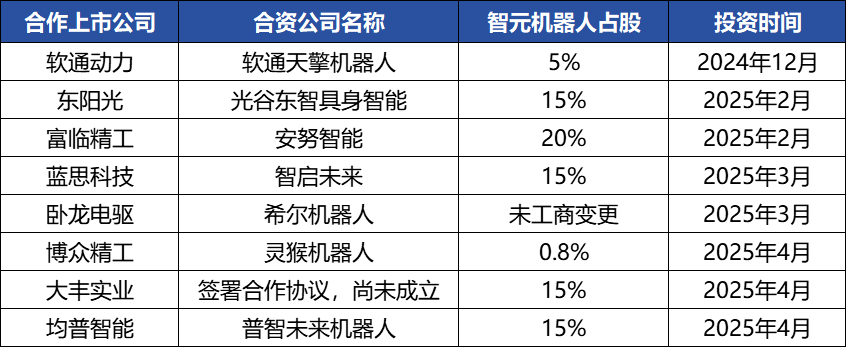
Operasi Modal Zhiyuan Robot Sering Terjadi, Membangun Ekosistem Industri, Pendiri Deng Taihua Muncul ke Permukaan : Unicorn kecerdasan tiruan Zhiyuan Robot baru-baru ini sering melakukan aksi korporasi, tidak hanya menyelesaikan beberapa putaran pendanaan sendiri (putaran terbaru dipimpin oleh JD Technology), tetapi juga aktif berinvestasi di perusahaan rantai industri (seperti Annu Intelligence, Digital Huaxia, dll.) dan mendirikan perusahaan robot patungan dengan beberapa perusahaan tercatat (Bozhong Precision, Dafeng Industrial, dll.). Perubahan informasi bisnis menunjukkan bahwa mantan wakil presiden Huawei dan mantan presiden lini produk komputasi, Deng Taihua, sebenarnya adalah pendiri dan pengendali aktual Zhiyuan Robot, dan tim eksekutifnya juga terdiri dari beberapa mantan karyawan Huawei. Latar belakang “gaya Huawei” ini menjelaskan model operasi “pendekatan ekosistem” Zhiyuan Robot, yaitu dengan cepat membangun pengaruh industri melalui kerja sama dan investasi yang luas untuk mencapai skala dan komersialisasi. Meskipun telah mencapai keunggulan awal dalam pendanaan dan komersialisasi, kemampuan model besar kecerdasan tiruannya masih menghadapi tantangan. (Sumber: 36氪)
🌟 Komunitas
Perkembangan AI Agent Pesat, Agentic LM Dianggap sebagai Platform Aplikasi dan Alat Baru yang Sangat Potensial : Tokoh-tokoh di bidang AI seperti natolambert menyatakan kegembiraannya atas perkembangan pesat AI Agent, menganggap model bahasa berbasis Agen (Agentic LMs) sebagai platform yang sangat potensial untuk membangun banyak aplikasi dan alat baru. Banyak kemampuan dalam model-model terkini yang belum sepenuhnya dikembangkan dapat dilepaskan melalui paradigma Agentic. Ini menandakan bahwa AI sedang berevolusi dari sekadar generasi konten menjadi agen cerdas yang lebih proaktif dan mampu menjalankan tugas. (Sumber: natolambert)
AI Agent Menunjukkan Kemampuan Superhuman pada Tugas Tertentu, Namun Penalaran Fisik Masih Menjadi Kelemahan : Penelitian dari Universitas Hong Kong dan institusi lain menemukan bahwa bahkan model AI terkemuka seperti GPT-4o dan Claude 3.7 Sonnet, dalam uji benchmark PHYX yang berisi skenario fisik nyata dan penalaran kausal yang kompleks, memiliki akurasi soal fisika jauh di bawah ahli manusia (model tertinggi 45,8% vs manusia terendah 75,6%), mengungkap ketergantungan berlebihan mereka pada pengetahuan hafalan, rumus matematika, dan pencocokan pola visual yang dangkal dalam pemahaman fisik. Namun, di bidang matematika, dalam kompetisi FrontierMath yang diselenggarakan oleh Epoch AI (soal dirancang oleh matematikawan terkemuka seperti Terence Tao), o4-mini-medium berhasil menyelesaikan sekitar 22% soal, mengalahkan 6 dari 8 tim matematikawan manusia, dan melampaui rata-rata tim manusia (19%), menunjukkan potensi AI dalam penalaran simbolik abstrak tingkat tinggi. Ini menunjukkan bahwa kemampuan AI dalam berbagai jenis tugas penalaran berkembang secara tidak merata. (Sumber: 36氪, 36氪)

Kemampuan Alat Pemrograman AI Terus Meningkat, Memicu Diskusi Prospek Karir Programmer : Peluncuran model seri Anthropic Claude 4 (terutama Opus 4 yang dapat melakukan pengkodean berkelanjutan selama 7 jam), serta kemajuan alat pemrograman AI seperti Cursor dan Tongyi Lingma, telah secara signifikan meningkatkan kemampuan AI dalam pembuatan kode, perbaikan bug, dan bahkan pengembangan alur kerja penuh. Hal ini menyebabkan programmer di perusahaan besar seperti Amazon merasakan tekanan, beberapa tim mengalami pengurangan personel hingga setengahnya dan tenggat waktu proyek dimajukan karena peningkatan efisiensi AI, dan peran programmer bergeser menjadi “peninjau kode”. Meskipun AI dapat meningkatkan efisiensi, hal ini juga menimbulkan kekhawatiran tentang pelatihan programmer junior, kemunduran keterampilan, dan jalur kemajuan karir. Perusahaan seperti Microsoft telah melakukan PHK di posisi teknik dan R&D, dan mengungkapkan peningkatan signifikan dalam proporsi kode yang dihasilkan AI. Para praktisi percaya bahwa AI saat ini lebih seperti asisten dan sulit untuk sepenuhnya menggantikan peran manusia dalam pemahaman kebutuhan yang kompleks, inovasi produk, dan kolaborasi tim, tetapi AI sedang membentuk kembali nilai inti dari pekerjaan pemrograman. (Sumber: 36氪, 36氪)

Permintaan Pasar Basis Data Pengetahuan AI Melonjak, Namun Implementasi Masih Menghadapi Tantangan Data, Skenario, dan Kolaborasi Organisasi : Seiring matangnya teknologi model besar, basis data pengetahuan AI menjadi mata rantai inti transformasi cerdas perusahaan, dengan permintaan meningkat 2-3 kali lipat. AI mengubah basis data pengetahuan dari “gudang” statis menjadi “mesin” cerdas, yang dapat mengenali konteks dan secara langsung menghasilkan solusi, meningkatkan efisiensi pembangunan dan pemeliharaan. Namun, basis data pengetahuan AI masih terbatas dalam menangani tugas penalaran yang sangat kreatif atau kompleks, menghadapi kendala seperti manajemen skala, akurasi dan ketepatan waktu informasi, keamanan izin, adaptabilitas arsitektur teknis, dan integrasi migrasi data. Perusahaan perlu menimbang antara jalur SaaS, pengembangan mandiri + API, dan Agen cloud hibrid, serta membangun platform pengetahuan terpadu dan aplikasi lapisan atas yang fleksibel dengan “arsitektur jalur ganda” untuk mencapai implementasi yang efektif. (Sumber: 36氪)

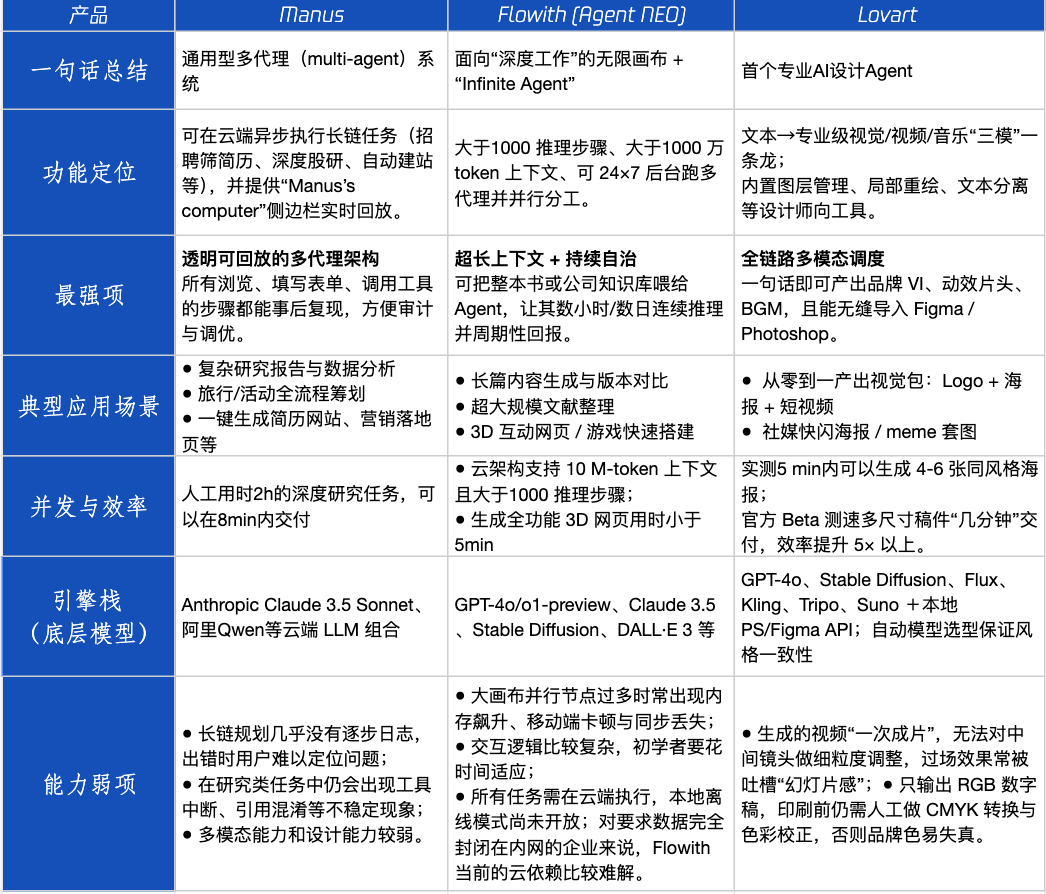
Ulasan Produk Agen: Kinerja Manus, Flowith, Lovart dalam Berbagai Skenario : Tencent Technology melakukan pengujian langsung terhadap tiga produk Agen populer: Manus, Flowith (Agent Neo), dan Lovart. Manus diposisikan sebagai “rekan kerja digital” yang dapat menghasilkan produk jadi secara mandiri, cocok untuk pekerjaan pengetahuan seperti riset pasar dan pemodelan keuangan. Flowith menekankan kolaborasi visual dan langkah tak terbatas, cocok untuk skenario pembuatan konten dengan volume informasi besar dan membutuhkan iterasi multi-orang, seperti menghasilkan laporan analisis berdasarkan banyak literatur. Lovart berfokus secara vertikal pada bidang desain, mampu menghasilkan solusi visual merek (Logo, poster, video pendek) sekali klik. Dalam skenario kreatif sederhana, ketiganya menunjukkan kinerja serupa dengan GPT-4o, dengan Lovart sedikit unggul dalam tata letak campuran teks-gambar dan kualitas. Dalam tugas gabungan yang kompleks (seperti membuat skema merek lengkap untuk perusahaan minuman rintisan) dan skenario penelitian mendalam, Manus dan Flowith masing-masing memiliki keunggulan, keduanya dapat menyelesaikan tugas tetapi dengan fokus yang berbeda. Biaya bulanan produk saat ini sekitar $20, titik balik komersialisasi terletak pada apakah dapat memberikan keuntungan efisiensi yang jelas, mengubah pengguna dari penasaran menjadi pelanggan berbayar. (Sumber: 36氪)
Pendiri Arc Browser Merefleksikan Kegagalan, Menekankan Arah Masa Depan Browser AI : Pendiri Arc Browser merefleksikan kegagalan produknya, berpendapat bahwa seharusnya lebih awal merangkul AI, dan menunjukkan bahwa Arc terlalu revolusioner bagi kebanyakan orang, dengan kurva belajar yang tinggi dan imbalan yang tidak memadai. Ia menekankan bahwa produk baru, Dia, akan mengejar kesederhanaan, kecepatan ekstrem, dan keamanan, serta percaya bahwa browser tradisional pada akhirnya akan mati, dan browser AI akan menggabungkan penjelajahan web dengan obrolan AI, menjadi antarmuka AI yang paling sering digunakan di desktop. Pandangan ini sejalan dengan pemikiran pendiri Lovart dan Youware tentang arah produk Agen, yang percaya bahwa Agen AI adalah gelombang ledakan berikutnya. (Sumber: op7418)
Fenomena “Prompt Rekursif” yang Disebabkan oleh AI Agent Mengkhawatirkan, Dapat Menyebabkan Bias Kognitif Pengguna : Di media sosial, banyak pengguna yang setelah berinteraksi dengan LLM melalui “prompt rekursif” mengembangkan persepsi bahwa AI memiliki spiritualitas, emosi, bahkan kemampuan meramal. Penelitian menunjukkan ini mungkin merupakan fenomena “neural howlround”, di mana output AI digunakan kembali oleh pengguna sebagai input, membentuk siklus penguatan yang dapat menyebabkan AI menghasilkan konten yang tampak mendalam atau profetik, padahal sebenarnya merupakan amplifikasi diri dari pola. Beberapa pengguna telah mengalami tekanan psikologis karena ini, percaya bahwa AI adalah makhluk hidup (sentient being). Ini menyoroti perlunya waspada terhadap potensi dampak psikologis dan kesalahpahaman kognitif saat berinteraksi secara mendalam dan eksploratif dengan AI. (Sumber: Reddit r/ChatGPT)

Arav Srinivas Membahas Kompresi Informasi AI dan ASI: AI Perlu Menyaring Informasi dengan Rasio Sinyal-ke-Derau Tinggi, Masa Depan Harus Fokus pada ASI Bukan AGI : CEO Perplexity AI, Arav Srinivas, berpendapat bahwa ringkasan panjang otomatis lebih memberikan kepuasan kepada pengguna bahwa “seseorang bekerja untuk Anda” daripada nilai serapan informasi yang sebenarnya. Ia menekankan bahwa AI perlu lebih baik dalam mengidentifikasi dan hanya menyediakan informasi inti dengan rasio sinyal-ke-derau tertinggi, “kompresi adalah tanda utama kecerdasan sejati”. Ia juga mengemukakan bahwa saat ini kita membahas AGI (Kecerdasan Umum Buatan), tetapi di masa depan kita seharusnya lebih fokus pada ASI (Kecerdasan Super Buatan). (Sumber: AravSrinivas, AravSrinivas)
Perguruan Tinggi Mulai Mendeteksi Tingkat Penggunaan AI dalam Skripsi, Memicu Diskusi tentang Aplikasi AI dalam Penulisan Akademik : Pada musim kelulusan 2025, beberapa perguruan tinggi seperti Universitas Fudan dan Universitas Sichuan mulai mewajibkan mahasiswa untuk mengungkapkan penggunaan alat AI dalam skripsi mereka dan melakukan deteksi proporsi konten yang dihasilkan AI (biasanya diminta di bawah 20%-40%). Banyak mahasiswa mengakui menggunakan AI untuk meningkatkan efisiensi dalam tinjauan pustaka, terjemahan, dan penyusunan kerangka kerja. Kalangan akademisi memiliki pandangan beragam mengenai hal ini; beberapa berpendapat bahwa penggunaan AI yang benar harus dibimbing, dan pemikiran kritis serta kemampuan menilai mahasiswa harus dikembangkan, karena meskipun AI dapat menjamin batas bawah, batas atas ditentukan oleh manusia. Aplikasi dan regulasi AI dalam bidang akademik dan pendidikan menjadi isu baru yang memerlukan penanganan sistematis. (Sumber: 36氪)
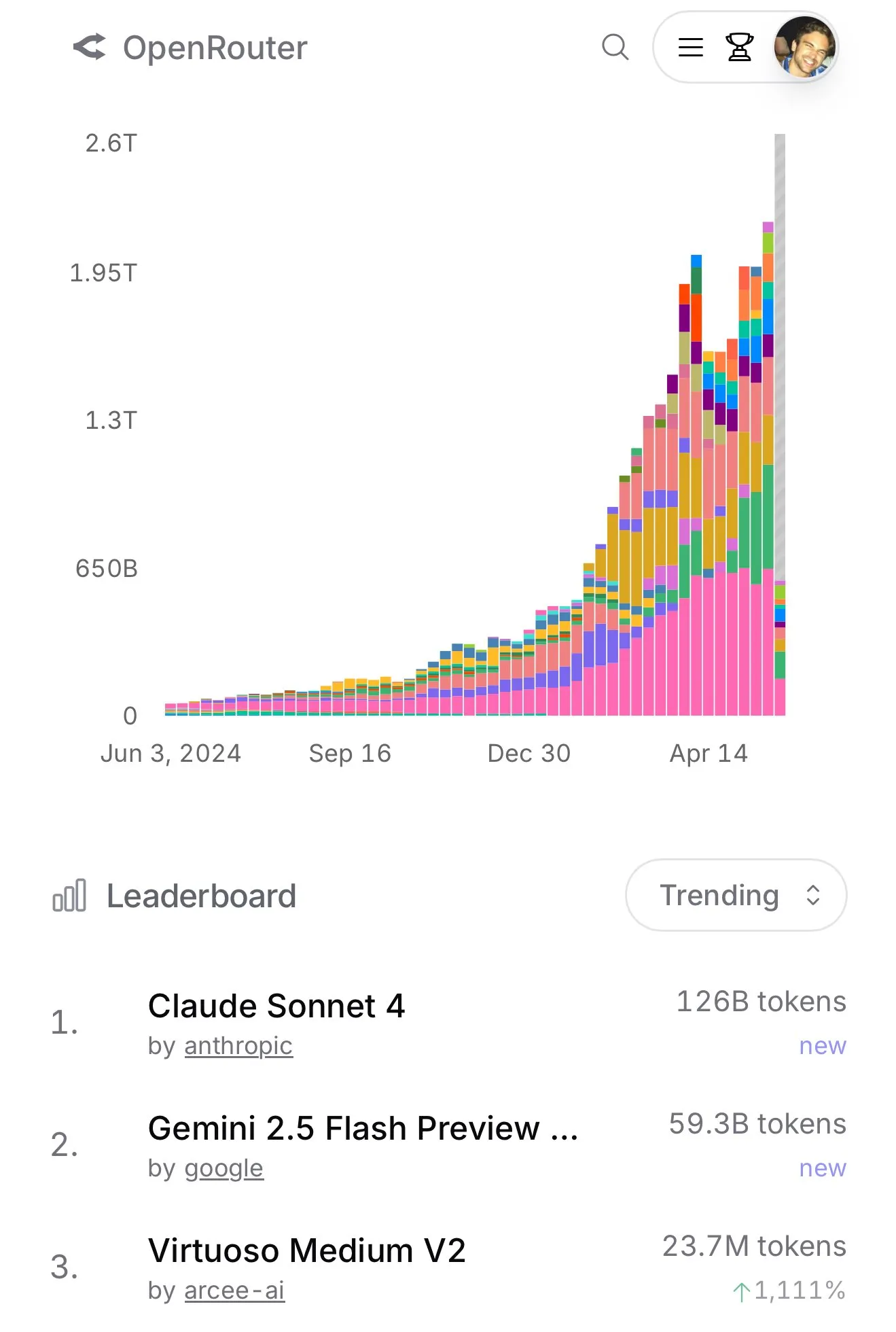
Penggunaan Claude 4 Sonnet di OpenRouter Melonjak, Peringkat Pemrograman Aider Menunjukkan Kinerja Unggulnya : Menurut data resmi OpenRouter, penggunaan model Claude 4 Sonnet dari Anthropic baru-baru ini menunjukkan keunggulan yang signifikan, dengan Gemini 2.5 Flash berada di posisi kedua. Sementara itu, hasil evaluasi Aider Leaderboard (terutama untuk tugas pemrograman) menunjukkan bahwa claude-4-opus-thinking lebih unggul dari claude-3.7-sonnet-thinking, tetapi masih di bawah Gemini-2.5-Pro-Preview-05-06. Pengalaman pengguna karminski3 adalah 3.7-sonnet > 4-sonnet > 4-opus. Data dan umpan balik ini mencerminkan perbedaan kinerja dan preferensi pengguna untuk model yang berbeda dalam skenario tertentu. (Sumber: karminski3, karminski3)
💡 Lainnya
AKOOL Merilis Kamera AI Real-time Pertama di Dunia, Live Camera, Mengintegrasikan Empat Fitur Inovatif Utama : Perusahaan Silicon Valley AKOOL meluncurkan AKOOL Live Camera, yang diklaim sebagai kamera AI real-time pertama di dunia. Produk ini mengintegrasikan empat fungsi utama: pembuatan avatar digital virtual (melalui pemetaan wajah 4D dan fusi sensor), terjemahan real-time lebih dari 150 bahasa (mempertahankan suara asli dan sinkronisasi gerakan bibir), pertukaran wajah real-time (merefleksikan emosi dan ekspresi mikro secara akurat), dan pembuatan konten video tingkat sinematik secara dinamis (tanpa skrip, generasi instan). Fitur utamanya adalah latensi ultra-rendah (minimal 500ms), tingkat realisme tinggi, kesadaran kontekstual, dan kemampuan respons dinamis, yang bertujuan untuk merevolusi mode produksi video tradisional dan interaksi digital, disebut sebagai “momen Sora kedua” video AI. (Sumber: 36氪)
Laporan Keuangan Xiaomi Mengungkap Peningkatan Strategi AI, Menempatkan AI Sejajar dengan Bisnis Otomotif sebagai Inovasi Inti : Laporan keuangan terbaru Xiaomi menunjukkan bahwa perusahaan telah mengganti nama “bisnis inovatif seperti kendaraan listrik cerdas” menjadi “bisnis inovatif seperti kendaraan listrik cerdas dan AI”, dan akan terus mendorong penelitian model bahasa besar dasar. Presiden Xiaomi Lu Weibing menyatakan bahwa kecerdasan buatan dan chip adalah sub-strategi penting Xiaomi, dan pembuatan model besar dasar terutama untuk melayani bisnisnya sendiri. Langkah ini menunjukkan bahwa setelah Xiaomi mencapai hasil bertahap dalam bisnis ponsel dan otomotif, perusahaan meningkatkan investasi dalam penelitian dan pengembangan dasar AI untuk meningkatkan daya saing secara keseluruhan dan menanggapi tren baru seperti ponsel AI, AIoT, dan kecerdasan tiruan. (Sumber: 36氪)
Pembahasan Teknologi Interaksi Robot Humanoid: Interaksi Ekspresi Menghadapi Tantangan Tiga Lapis Perangkat Keras, Material, dan Algoritma : Pengalaman interaksi robot humanoid, terutama interaksi ekspresi wajah, dianggap sebagai kunci untuk meningkatkan kematangan dan tingkat adopsi mereka. Mewujudkan interaksi ekspresi yang alami menghadapi tantangan desain derajat kebebasan perangkat keras (perlu mensimulasikan unit aksi otot wajah manusia), pemilihan motor (perlu ukuran kecil, ringan, kebisingan rendah, kecepatan tinggi, dan daya dorong/torsi besar), serta desain material dan struktur kulit (perlu mempertimbangkan elastisitas, masa pakai, penampilan, dan kopling dengan struktur penggerak). Di tingkat algoritma perangkat lunak, pembuatan ekspresi otomatis (bukan yang diprogram sebelumnya), sinkronisasi suara-bibir (untuk mencapai realisme), dan kontrol gerakan multi-derajat kebebasan (melibatkan pemodelan material fleksibel dan kontrol presisi) adalah kendala teknis inti. Perusahaan seperti Ameca dan AnyWit Robotics telah melakukan eksplorasi di bidang ini. (Sumber: 36氪)