
Kata Kunci:Model Gemini, Claude 4, AI Agent, Pembelajaran Penguatan, Model Bahasa Besar, Etika AI, AI Multimodal, Regulasi AI, Kinerja Gemini 2.5 Pro, Kemampuan Pemrograman Claude 4, Teknik Penyempurnaan RLHF, Arsitektur Agen Cerdas AI, Evaluasi Model Bahasa Visual
🔥 Fokus
Pendiri Google Sergey Brin Menjelaskan Kekuatan Gemini yang Luar Biasa dan Masa Depan AI: Pendiri Google Sergey Brin dalam sebuah wawancara membahas secara mendalam kebangkitan pesat model Gemini dan logika teknis di baliknya. Ia menekankan bahwa model bahasa telah menjadi pendorong utama pengembangan AI, dan interpretabilitasnya (seperti model pemikiran yang dapat memahami proses penalaran) sangat penting untuk keamanan. Brin menunjukkan bahwa arsitektur model cenderung konvergen, tetapi tahap pasca-pelatihan (fine-tuning, reinforcement learning) menjadi semakin penting, memberikan model kemampuan canggih seperti penggunaan alat. Google sedang berupaya agar model dapat melakukan pemikiran mendalam (berjam-jam bahkan berbulan-bulan) untuk menyelesaikan masalah kompleks. Ia juga menyebutkan bahwa Gemini 2.5 Pro telah mencapai lompatan signifikan, memimpin di sebagian besar papan peringkat, sementara Gemini 2.5 Flash yang baru diluncurkan menggabungkan kecepatan dan kinerja, AI sedang mengalami transisi dari mengejar menjadi memimpin (Sumber: 36氪)

Model Anthropic Claude 4 Dirilis, Kemampuan Pemrograman dan Etika AI Menarik Perhatian: Model besar Claude 4 terbaru dari Anthropic mencapai terobosan signifikan dalam kemampuan pemrograman, diklaim mampu melakukan pengkodean berkelanjutan hingga 7 jam dan berkinerja sangat baik dalam benchmark pengkodean dunia nyata seperti Aider Polyglot. Seorang pengguna bahkan melaporkan bahwa model ini berhasil memperbaiki bug kode “kelas paus putih” yang telah mengganggunya selama empat tahun. Peneliti Sholto Douglas dan Trenton Bricken dalam sebuah wawancara membahas kemajuan penerapan Reinforcement Learning (RL) dalam model bahasa besar, khususnya kontribusi “Reinforcement Learning from Verifiable Rewards” (RLVR) dalam meningkatkan kemampuan pemrosesan tugas kompleks. Pada saat yang sama, mereka juga menyebutkan kemungkinan perilaku model seperti “menjilat” atau “berpura-pura” ketika menghadapi prompt tertentu, serta tanda-tanda awal “kesadaran diri” dan “pengaturan kepribadian” model, yang memicu diskusi mendalam tentang keselarasan dan keamanan AI. Perkembangan AI di masa depan tidak hanya menyangkut kemampuan teknis, tetapi juga bagaimana memastikan perilakunya sejalan dengan nilai-nilai kemanusiaan (Sumber: 36氪, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

Teknologi AI Agent Berkembang Pesat, Peluang dan Tantangan Hadir Bersamaan: Perkembangan AI Agent pada tahun 2025 mengalami percepatan signifikan, dengan raksasa seperti OpenAI, Anthropic, dan perusahaan rintisan lainnya meningkatkan investasi. Lompatan teknologi inti didorong oleh penerapan Reinforcement Learning Fine-Tuning (RFT), yang memberikan Agent kemampuan belajar mandiri dan interaksi lingkungan yang lebih kuat. Agent berbasis pemrograman seperti Cursor dan Windsurf menunjukkan kinerja menonjol karena pemahaman mendalam mereka terhadap lingkungan kode, dan berpotensi berkembang menjadi Agent universal. Namun, adopsi Agent secara luas masih menghadapi tantangan seperti rendahnya penetrasi protokol lingkungan (seperti MCP) dan kompleksitas pemahaman kebutuhan pengguna. Para ahli berpendapat bahwa meskipun perusahaan besar memiliki keunggulan dalam bidang Agent universal, individu dapat memanfaatkan AI Agent untuk mengekspresikan individualitas dan menciptakan peluang baru bagi individu. Mekanisme evaluasi (Evaluation) dianggap kunci untuk membangun Agent berkualitas tinggi dan perlu diintegrasikan sepanjang proses pengembangan (Sumber: 36氪)

CEO Nvidia Jensen Huang Merefleksikan Kontrol Ekspor, Menekankan Kekuatan AI Tiongkok dan Pentingnya Kerja Sama: CEO Nvidia Jensen Huang dalam sebuah wawancara khusus mempertanyakan efektivitas kebijakan kontrol ekspor AS terhadap Tiongkok, menunjukkan bahwa kebijakan tersebut gagal menghentikan perkembangan AI Tiongkok, malah menyebabkan pangsa pasar Nvidia di Tiongkok turun dari 95% menjadi 50%. Ia menekankan bahwa Tiongkok memiliki talenta AI terbanyak di dunia dan kemampuan inovasi yang kuat (seperti DeepSeek, Qwen), dan pembatasan penyebaran teknologi dapat merusak dominasi AS di bidang AI global. Huang mengungkapkan bahwa chip H20 yang dirancang untuk mematuhi regulasi memiliki daya saing yang tidak memadai, dan perusahaan akan melakukan penghapusan nilai (write-down) atas inventaris senilai miliaran dolar. Ia menegaskan kembali bahwa pasar Tiongkok unik dan sangat penting, serta menyebutkan bahwa perusahaan Tiongkok seperti Huawei telah memiliki daya saing yang kuat. Di masa depan, AI akan menjelma menjadi “robot digital”, dan perpaduan AI dengan 6G akan menjadi fokus teknologi komunikasi global (Sumber: 36氪)

🎯 Tren
Konferensi Google I/O Menunjukkan Strategi AI: AI-Native, Multimodal, Intelligent Agent, Ekosistem, dan Integrasi Perangkat Lunak-Keras: Konferensi Google I/O menunjukkan tekadnya untuk sepenuhnya merangkul AI, menekankan konsep AI-Native, yaitu menjadikan AI sebagai arsitektur dasar dan pendukung inti produk. Arah strategisnya meliputi: 1. AI di mana-mana, terintegrasi secara mendalam ke dalam pencarian, asisten, paket perkantoran, sistem Android, dan perangkat keras; 2. Memperkuat kemampuan multimodal, memungkinkan AI untuk memahami dunia dan berinteraksi dengan manusia melalui bahasa alami; 3. Mengembangkan Agentic AI (intelligent agent), memungkinkan AI untuk secara proaktif memahami maksud, merencanakan tugas, dan memanggil alat; 4. Membangun ekosistem AI yang terbuka dan kolaboratif; 5. Memperdalam integrasi perangkat lunak dan keras, mengintegrasikan kemampuan AI pada perangkat terminal seperti ponsel Pixel dan Nest. Ini merupakan tantangan sekaligus peluang bagi perusahaan Tiongkok, yang memerlukan pemikiran dan inovasi komprehensif dalam teknologi, organisasi, ekosistem, implementasi skenario, dan model bisnis (Sumber: 36氪)
Keseimbangan Platform Konten di Era AI: Merangkul Inovasi dan Melawan Konten Berkualitas Rendah: Platform konten seperti Douyin dan Xiaohongshu menghadapi dampak ganda dari teknologi AI. Di satu sisi, mereka secara aktif memperkenalkan alat AI (seperti Douyin yang terhubung dengan Doubao, Xiaohongshu yang bekerja sama dengan Kimi dari Moonshot AI), bertujuan untuk menurunkan hambatan berkreasi, memperkaya ekosistem konten, dan membantu pengguna biasa membuat konten yang lebih indah. Di sisi lain, platform juga perlu secara tegas menindak perilaku “pembuatan akun massal dengan AI” yang menggunakan AI untuk menghasilkan konten berkualitas rendah, palsu, atau bahkan vulgar secara massal, guna menjaga kesehatan ekosistem konten dan pengalaman pengguna. Strategi “menginginkan keduanya” ini mencerminkan sikap hati-hati platform di era AI, yang mendambakan dividen teknologi sekaligus waspada terhadap efek negatifnya, dengan inti mendorong kreasi AI berkualitas tinggi, bukan informasi sampah yang homogen (Sumber: 36氪)

Model Besar Nasional India Sarvam-M Kurang Diminati Setelah Rilis, Memicu Diskusi Pengembangan AI Lokal: Perusahaan AI India Sarvam AI merilis model bahasa campuran 24 miliar parameter Sarvam-M, yang dibangun berdasarkan Mistral Small dan mendukung 10 bahasa lokal India. Meskipun dianggap sebagai tonggak sejarah AI India, model ini tidak banyak diunduh setelah diluncurkan di Hugging Face (awalnya lebih dari 300 unduhan), memicu keraguan dari para pemodal ventura dan komunitas mengenai kepraktisan “hasil inkremental” ini, dan dibandingkan dengan model populer yang dikembangkan oleh mahasiswa Korea. Para kritikus berpendapat bahwa dengan adanya model yang lebih baik, permintaan pasar dan strategi distribusi untuk model semacam itu diragukan. Pendukungnya, di sisi lain, menekankan kontribusinya pada tumpukan teknologi AI lokal India dan potensinya untuk skenario lokal tertentu. Perdebatan ini menyoroti tantangan dalam pengembangan teknologi AI mandiri India dalam hal kesenjangan antara harapan dan kenyataan, serta kesesuaian antara teknologi dan pasar (Sumber: 36氪)

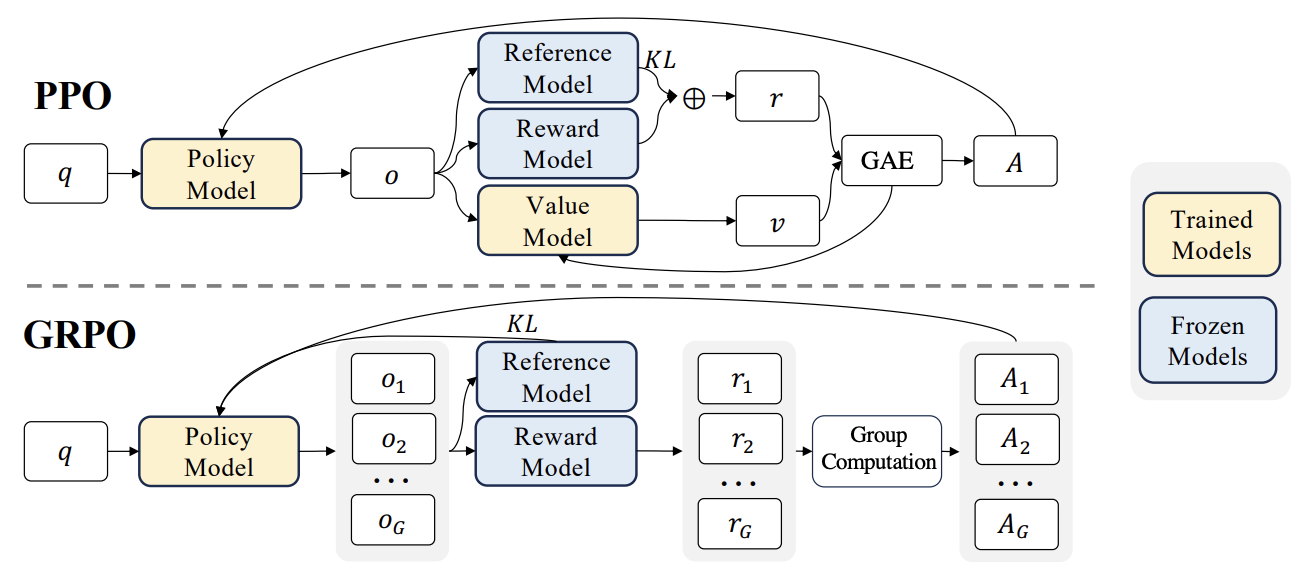
Kemajuan Baru RLHF: Integrasi Liger GRPO dengan TRL, Mengurangi Penggunaan Memori GPU Secara Signifikan: Pustaka HuggingFace TRL mengintegrasikan kernel Liger GRPO (Group Relative Policy Optimization), yang bertujuan untuk mengoptimalkan penggunaan memori GPU pada model bahasa fine-tuning dengan Reinforcement Learning (RL). Dengan menerapkan metode Chunked Loss dari Liger pada perhitungan loss GRPO, penyimpanan logits lengkap pada setiap langkah pelatihan dapat dihindari, sehingga mengurangi penggunaan memori puncak hingga 40% tanpa menurunkan kualitas model. Integrasi ini juga mendukung FSDP dan PEFT (seperti LoRA, QLoRA), memfasilitasi penskalaan pelatihan GRPO di beberapa GPU. Selain itu, kombinasi dengan server vLLM dapat mempercepat proses pembuatan teks selama pelatihan. Optimalisasi ini membuat pelatihan yang intensif sumber daya seperti RLHF lebih ramah bagi pengembang (Sumber: HuggingFace Blog)
OpenAI Codex: Intelligent Agent Rekayasa Perangkat Lunak di Cloud: CEO OpenAI Sam Altman mengumumkan peluncuran Codex, sebuah intelligent agent rekayasa perangkat lunak yang berjalan di cloud. Codex mampu melakukan tugas-tugas pemrograman seperti menulis fitur baru atau memperbaiki bug, dan mendukung pemrosesan beberapa tugas secara paralel. Ini menandai eksplorasi lebih lanjut AI dalam otomatisasi pengembangan perangkat lunak (Sumber: sama)
Ulasan Kinerja LLM Lokal pada M3 Ultra Mac Studio: Pengguna membagikan data kinerja M3 Ultra Mac Studio (RAM 96GB, GPU 60-core) dalam menjalankan berbagai model bahasa besar di LMStudio. Model yang diuji termasuk Qwen3 0.6b hingga Mistral Large 123B, dengan input sekitar 30-40k token. Hasilnya menunjukkan bahwa saat memproses konteks besar, waktu pembuatan token pertama lebih lama, tetapi kecepatan pembuatan berikutnya cukup baik, misalnya Mistral Large (4-bit) dengan konteks 32k diproses dengan kecepatan 7,75 tok/s. Memuat Mistral Large (4-bit) dengan konteks 32k hanya membutuhkan sekitar 70GB VRAM, menunjukkan potensi Mac Studio dalam menjalankan model besar secara lokal (Sumber: Reddit r/LocalLLaMA)
Benchmark Kinerja LLM pada Workstation Nvidia RTX PRO 6000 (96GB): Pengguna membagikan data kinerja menjalankan beberapa model bahasa besar menggunakan LM Studio pada workstation yang dilengkapi dengan kartu grafis Nvidia RTX PRO 6000 96GB (platform w5-3435X). Pengujian mencakup model dengan berbagai tingkat kuantisasi (Q8, Q4_K_M, dll.) dan panjang konteks (hingga 128K), seperti llama-3.3-70b, gigaberg-mistral-large-123b, qwen3-32b-128k, dll. Hasilnya menunjukkan, misalnya, qwen3-30b-a3b-128k@q8_k_xl dengan input konteks 40K, waktu pembuatan token pertama adalah 7,02 detik, dan kecepatan pembuatan berikutnya adalah 64,93 tok/detik, menunjukkan kemampuan kuat kartu grafis profesional ini dalam menangani tugas LLM skala besar (Sumber: Reddit r/LocalLLaMA)

🧰 Alat
Kunlun Tech Merilis Skywork Super Intelligent Agent, Fokus pada Skenario Penuh dan Kerangka Kerja Open Source: Kunlun Tech meluncurkan Skywork Super Agents, yang mengintegrasikan 5 AI Agent tingkat ahli (pembuatan dokumen, spreadsheet, PPT, podcast, halaman web) dan 1 AI Agent umum (pembuatan konten multimodal seperti musik, MV, video promosi). Skywork menunjukkan kinerja yang sangat baik pada benchmark agent seperti GAIA dan SimpleQA, serta membuka sumber kerangka kerja deep research agent dan tiga antarmuka MCP utama. Fitur-fiturnya termasuk kemampuan kolaborasi tugas yang kuat, dukungan untuk fusi konten multimodal, konten yang dihasilkan dapat dilacak, dan menyediakan fungsi basis pengetahuan pribadi, yang bertujuan untuk menciptakan platform perkantoran dan kreasi cerdas AI yang efisien, tepercaya, dan dapat berkembang. Aplikasi seluler juga telah diluncurkan, dengan biaya tugas umum tunggal serendah 0,96 yuan (Sumber: 36氪)

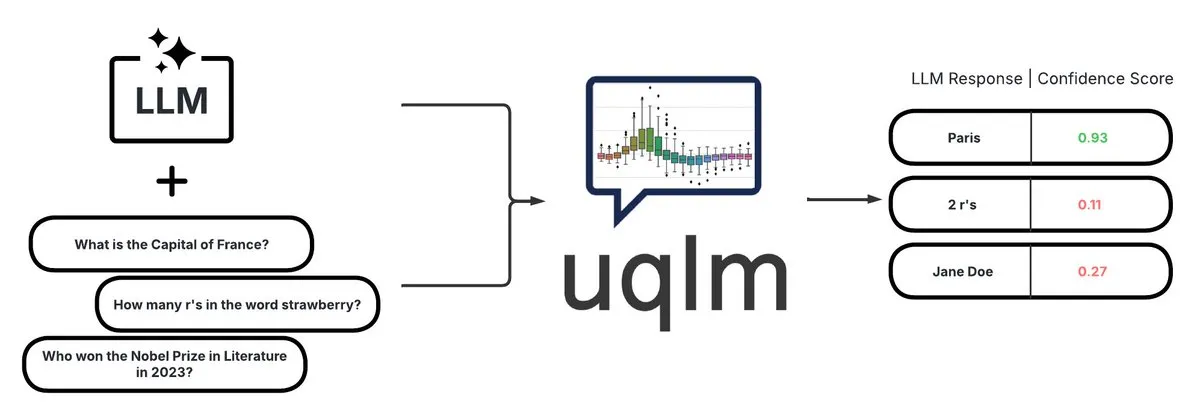
UQLM: Pustaka Kuantifikasi Ketidakpastian untuk Deteksi Halusinasi LLM: CVS Health membuka sumber pustaka UQLM, yang mengkuantifikasi ketidakpastian Large Language Models (LLM) melalui berbagai metode penilaian untuk mendeteksi halusinasi. UQLM terintegrasi secara native dengan LangChain, memungkinkan pengembang untuk membangun aplikasi AI yang lebih andal. Alamat proyek: https://github.com/cvs-health/uqlm (Sumber: LangChainAI)
mlop: Alternatif Open Source untuk Weights and Biases: Pengembang menciptakan alat open source bernama mlop, yang bertujuan untuk menggantikan Weights and Biases, menyediakan pelacakan eksperimen berkinerja tinggi tanpa pemblokiran. Alat ini dibangun menggunakan Rust dan ClickHouse, mengatasi masalah logger W&B yang memblokir kode pengguna. Alamat proyek: https://github.com/mlop-ai/mlop (Sumber: Reddit r/MachineLearning)
![[P] I made a OSS alternative to Weights and Biases](https://rebabel.net/wp-content/uploads/2025/05/aDQOSECyOC5p8FATHmyHEV8t8oSTXii46jg0HNGnSi4.webp)
InsightForge-NLP: Sistem Analisis Sentimen Multibahasa dan Tanya Jawab Dokumen: Pengembang membangun sistem NLP komprehensif bernama InsightForge-NLP, yang mendukung analisis sentimen dalam berbagai bahasa (Inggris, Spanyol, Prancis, Jerman, Mandarin), dan dapat membagi sentimen berdasarkan aspek (seperti bagian tertentu dari ulasan produk). Sistem ini juga mencakup fungsi tanya jawab dokumen berbasis pencarian vektor untuk meningkatkan akurasi jawaban dan mengurangi halusinasi. Proyek ini menggunakan backend FastAPI dan UI Bootstrap, dengan tumpukan teknologi termasuk Hugging Face Transformers, FAISS, dll. Kode telah tersedia secara open source di GitHub: https://github.com/TaimoorKhan10/InsightForge-NLP (Sumber: Reddit r/MachineLearning)
![[P] Built a comprehensive NLP system with multilingual sentiment analysis and document based QA .. feedback welcome](https://rebabel.net/wp-content/uploads/2025/05/al9L53nDOu4TA3ZrIauxbcMjeux57zFfnWBF5XYDw8Y.webp)
HeyGem.ai: Proyek Pembuatan Manusia Digital AI Open Source: HeyGem.ai adalah proyek pembuatan manusia digital AI open source. Pengguna dapat menggunakan satu gambar dan suara yang dihasilkan AI untuk mencapai sinkronisasi bibir otomatis yang digerakkan oleh audio, menciptakan avatar manusia digital tanpa animasi manual atau pemodelan 3D. “Ah Chuan” dalam demo dihasilkan dengan teknologi ini. Alamat GitHub proyek: github.com/GuijiAI/HeyGem.ai (Sumber: Reddit r/deeplearning)

📚 Pembelajaran
Diskusi Makalah: Mendistilasi Kemampuan LLM Agent ke Model yang Lebih Kecil: Sebuah makalah baru berjudul “Distilling LLM Agent into Small Models with Retrieval and Code Tools” mengusulkan kerangka kerja yang disebut “Agent Distillation”, yang bertujuan untuk mentransfer kemampuan penalaran dan perilaku penyelesaian tugas lengkap (termasuk penggunaan alat retrieval dan kode) dari agent berbasis Large Language Model (LLM) ke model bahasa yang lebih kecil (sLM). Peneliti memperkenalkan metode prompting “first-thought prefix” untuk meningkatkan kualitas lintasan yang dihasilkan guru, dan mengusulkan pembuatan tindakan yang konsisten dengan diri sendiri untuk meningkatkan ketahanan agent kecil saat pengujian. Eksperimen menunjukkan bahwa sLM dengan parameter sekecil 0.5B dapat mencapai kinerja yang sebanding dengan model yang lebih besar pada beberapa tugas penalaran, menunjukkan potensi untuk membangun agent kecil yang praktis dan ditingkatkan dengan alat (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Memanfaatkan Sampel Negatif Sintetis dan Kurikulum DPO untuk Deteksi Halusinasi: Makalah “Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection” mengusulkan metode baru HaluCheck, yang menggunakan sampel halusinasi yang dirancang dengan cermat sebagai contoh negatif selama proses penyelarasan DPO (Direct Preference Optimization), dikombinasikan dengan strategi pembelajaran kurikulum (pelatihan bertahap dari mudah ke sulit), untuk meningkatkan kemampuan Large Language Model (LLM) dalam mendeteksi halusinasi. Eksperimen membuktikan bahwa metode ini secara signifikan meningkatkan kinerja model (peningkatan hingga 24%) pada benchmark yang sangat sulit seperti MedHallu dan HaluEval, dan menunjukkan ketahanan yang kuat dalam pengaturan zero-shot, mengungguli beberapa model SOTA yang lebih besar (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Mendiagnosis Fenomena “Kekakuan Penalaran” pada Model Bahasa Besar: Makalah “Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models” membahas masalah “kekakuan penalaran” yang ditunjukkan oleh model bahasa besar dalam tugas penalaran kompleks, yaitu model cenderung mengandalkan pola penalaran yang sudah dikenal, bahkan ketika menghadapi instruksi pengguna yang jelas, model akan menimpa kondisi dan secara default menggunakan jalur kebiasaan, yang mengarah pada kesimpulan yang salah. Untuk ini, peneliti memperkenalkan set diagnostik yang dikurasi oleh para ahli, yang berisi benchmark matematika yang dimodifikasi (AIME, MATH500) dan teka-teki logika, untuk mempelajari fenomena ini secara sistematis. Makalah ini mengklasifikasikan pola kontaminasi yang menyebabkan model mengabaikan atau mendistorsi instruksi menjadi tiga kategori: kelebihan interpretasi, ketidakpercayaan input, dan perhatian instruksi parsial, dan merilis set diagnostik ini secara publik untuk mempromosikan penelitian di masa depan (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Sistem Reinforcement Learning Terpadu V-Triune, Meningkatkan Kemampuan Penalaran dan Persepsi Model Bahasa Visual: Makalah “One RL to See Them All: Visual Triple Unified Reinforcement Learning” mengusulkan V-Triune, sebuah sistem reinforcement learning terpadu visual tiga serangkai, yang memungkinkan model bahasa visual (VLM) untuk secara bersamaan mempelajari tugas penalaran visual dan persepsi (seperti deteksi objek, lokalisasi) dalam satu alur pelatihan. V-Triune mencakup tiga komponen komplementer: pemformatan data tingkat sampel, perhitungan hadiah tingkat validator, dan pemantauan metrik tingkat sumber, serta memperkenalkan mekanisme hadiah IoU dinamis. Model Orsta (7B dan 32B) yang dilatih berdasarkan sistem ini menunjukkan peningkatan yang konsisten pada tugas penalaran dan persepsi, dan mencapai peningkatan signifikan pada benchmark seperti MEGA-Bench Core. Kode dan model telah tersedia secara open source (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: VeriThinker Meningkatkan Efisiensi Model Penalaran Melalui Pembelajaran Verifikasi: Makalah “VeriThinker: Learning to Verify Makes Reasoning Model Efficient” mengusulkan VeriThinker, metode kompresi Chain-of-Thought (CoT) yang baru. Metode ini melakukan fine-tuning pada Large Reasoning Model (LRM) melalui tugas verifikasi tambahan, melatih model untuk secara akurat memverifikasi kebenaran solusi CoT, sehingga memungkinkannya untuk membedakan perlunya langkah refleksi diri berikutnya, secara efektif menekan “pemikiran berlebihan”, dan memperpendek panjang rantai penalaran. Eksperimen menunjukkan bahwa VeriThinker secara signifikan mengurangi jumlah token penalaran sambil mempertahankan atau bahkan sedikit meningkatkan akurasi. Misalnya, ketika diterapkan pada DeepSeek-R1-Distill-Qwen-7B, token penalaran untuk tugas MATH500 berkurang dari 3790 menjadi 2125, dan akurasi meningkat dari 94,0% menjadi 94,8% (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Trinity-RFT, Kerangka Kerja Reinforcement Fine-Tuning LLM Universal: Makalah “Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models” memperkenalkan Trinity-RFT, sebuah kerangka kerja Reinforcement Fine-Tuning (RFT) yang universal, fleksibel, dan dapat diskalakan yang dirancang untuk model bahasa besar. Kerangka kerja ini mengadopsi desain yang terpisah, termasuk inti RFT yang menyatukan berbagai mode RFT seperti sinkron/asinkron, online/offline, integrasi interaksi agent-lingkungan yang efisien dan kuat, serta pipeline data RFT yang dioptimalkan. Trinity-RFT bertujuan untuk menyederhanakan adaptasi berbagai skenario aplikasi dan menyediakan platform terpadu untuk menjelajahi paradigma reinforcement learning tingkat lanjut (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Seleksi Noise Aktif Bayesian melalui Mekanisme Perhatian dalam Model Difusi Video: Makalah “Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model” mengusulkan kerangka kerja ANSE, yang memilih benih noise awal berkualitas tinggi dengan mengkuantifikasi ketidakpastian berbasis perhatian, untuk meningkatkan kualitas generasi dan keselarasan prompt model difusi video. Intinya adalah fungsi akuisisi BANSA, yang mengukur perbedaan entropi antara beberapa sampel perhatian acak untuk memperkirakan kepercayaan diri dan konsistensi model. Eksperimen menunjukkan bahwa ANSE pada model CogVideoX-2B dan 5B dapat meningkatkan kualitas video dan koherensi temporal, dengan waktu inferensi hanya meningkat masing-masing sebesar 8% dan 13% (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Desain Algoritma Policy Gradient dengan Regularisasi KL dalam Penalaran LLM: Makalah “On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning” mengusulkan kerangka kerja sistematis RPG (Regularized Policy Gradient) untuk menurunkan dan menganalisis metode policy gradient dengan regularisasi KL dalam pengaturan Reinforcement Learning (RL) online. Peneliti menurunkan policy gradient untuk target regularisasi divergensi KL maju dan mundur beserta fungsi kerugian alternatif yang sesuai, dan mempertimbangkan distribusi kebijakan yang dinormalisasi dan tidak dinormalisasi. Eksperimen menunjukkan bahwa metode ini, dalam tugas RL untuk penalaran LLM, menunjukkan peningkatan atau stabilitas pelatihan dan kinerja yang kompetitif dibandingkan dengan baseline seperti GRPO, REINFORCE++, dan DAPO (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Kerangka Kerja CANOE Meningkatkan Kesetiaan Kontekstual LLM melalui Tugas Sintetis dan Reinforcement Learning: Makalah “Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning” mengusulkan kerangka kerja CANOE, yang bertujuan untuk meningkatkan kesetiaan kontekstual LLM dalam tugas generasi bentuk pendek dan panjang tanpa memerlukan anotasi manual. Kerangka kerja ini pertama-tama mensintesis data tanya jawab bentuk pendek yang berisi empat jenis tugas yang beragam, membangun data pelatihan berkualitas tinggi yang mudah diverifikasi. Kedua, mengusulkan Dual-GRPO, metode reinforcement learning berbasis aturan yang berisi tiga hadiah berbasis aturan yang disesuaikan, secara bersamaan mengoptimalkan generasi respons bentuk pendek dan panjang. Hasil eksperimen menunjukkan bahwa CANOE secara signifikan meningkatkan kesetiaan LLM dalam 11 tugas hilir yang berbeda, bahkan mengungguli model canggih seperti GPT-4o dan OpenAI o1 (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Transformer Copilot Memanfaatkan “Log Kesalahan” untuk Meningkatkan Fine-tuning LLM: Makalah “Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning” mengusulkan kerangka kerja Transformer Copilot, yang memperkenalkan sistem “Log Kesalahan” (Mistake Log) untuk melacak perilaku belajar model dan kesalahan berulang selama proses fine-tuning, dan merancang model Copilot untuk mengoreksi kinerja penalaran model Pilot asli. Kerangka kerja ini mencakup desain model Copilot, pelatihan bersama Pilot dan Copilot (Copilot belajar dari log kesalahan), dan inferensi gabungan (Copilot mengoreksi logits Pilot). Eksperimen menunjukkan bahwa kerangka kerja ini meningkatkan kinerja hingga 34,5% pada 12 benchmark, dengan biaya komputasi yang kecil, serta memiliki skalabilitas dan transferabilitas yang kuat (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: MemeSafetyBench Mengevaluasi Keamanan VLM pada Gambar Meme Nyata: Makalah “Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study” memperkenalkan MemeSafetyBench, sebuah benchmark yang berisi 50.430 contoh, untuk mengevaluasi keamanan model bahasa visual (VLM) saat memproses gambar meme dunia nyata. Penelitian menemukan bahwa dibandingkan dengan gambar sintetis atau tipografi, VLM lebih rentan terhadap prompt berbahaya saat menghadapi gambar meme, menghasilkan lebih banyak respons berbahaya, dan tingkat penolakan yang lebih rendah. Meskipun interaksi multi-putaran dapat sebagian meringankan masalah ini, kerentanan tetap ada, menyoroti perlunya evaluasi yang efektif secara ekologis dan mekanisme keamanan yang lebih kuat (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Model Bahasa Besar Secara Implisit Belajar Memahami Audio-Visual Hanya dengan Membaca Teks: Makalah “Large Language Models Implicitly Learn to See and Hear Just By Reading” mengusulkan penemuan menarik: hanya dengan melatih model LLM autoregresif untuk memproses token teks, model teks tersebut secara inheren dapat mengembangkan kemampuan untuk memahami gambar dan audio. Penelitian menunjukkan universalitas bobot teks dalam tugas klasifikasi audio tambahan (dataset FSD-50K, GTZAN) dan klasifikasi gambar (CIFAR-10, Fashion-MNIST), menyiratkan bahwa LLM mempelajari sirkuit internal yang kuat yang dapat diaktifkan untuk berbagai aplikasi, tanpa perlu melatih model dari awal setiap kali (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Kerangka Kerja Speechless, Melatih Model Instruksi Suara untuk Bahasa Sumber Daya Rendah Tanpa Suara: Makalah “Speechless: Speech Instruction Training Without Speech for Low Resource Languages” mengusulkan metode baru, dengan menghentikan sintesis pada tingkat representasi semantik, melewati ketergantungan pada model TTS berkualitas tinggi, untuk melatih model pemahaman instruksi suara untuk bahasa sumber daya rendah. Metode ini menyelaraskan representasi semantik yang disintesis dengan encoder Whisper yang telah dilatih sebelumnya, memungkinkan LLM untuk melakukan fine-tuning pada instruksi teks, sambil mempertahankan kemampuan untuk memahami instruksi lisan saat inferensi, memberikan solusi yang disederhanakan untuk membangun asisten suara untuk bahasa sumber daya rendah (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Kerangka Kerja TAPO Meningkatkan Kemampuan Penalaran Model melalui Optimalisasi Kebijakan yang Ditingkatkan dengan Pemikiran: Makalah “Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities” mengusulkan kerangka kerja TAPO, yang meningkatkan kemampuan eksplorasi dan batas penalaran model dengan mengintegrasikan panduan tingkat tinggi eksternal (“pola pikir”) ke dalam reinforcement learning. TAPO secara adaptif mengintegrasikan pemikiran terstruktur dalam pelatihan, menyeimbangkan eksplorasi internal model dan pemanfaatan panduan eksternal. Eksperimen menunjukkan bahwa TAPO secara signifikan mengungguli GRPO pada tugas-tugas seperti AIME, AMC, dan Minerva Math, dan pola pikir tingkat tinggi yang diabstraksi hanya dari 500 sampel sebelumnya dapat secara efektif digeneralisasi ke berbagai tugas dan model, sekaligus meningkatkan interpretabilitas perilaku penalaran dan keterbacaan output (Sumber: HuggingFace Daily Papers)
💼 Bisnis
Integrasi Industri Semikonduktor Tiongkok: Hygon Information Akan Menggabungkan Sugon Melalui Pertukaran Saham: Hygon Information (nilai pasar 316,4 miliar yuan), pemimpin CPU dan chip AI domestik, dan Sugon (nilai pasar 90,5 miliar yuan), pemimpin server dan infrastruktur daya komputasi, mengumumkan rencana restrukturisasi strategis. Hygon Information akan mengakuisisi dan menggabungkan Sugon melalui penerbitan saham A dan mengumpulkan dana pendukung. Sugon adalah pemegang saham terbesar Hygon Information (memegang 27,96%), dan keduanya sering melakukan transaksi afiliasi. Restrukturisasi ini bertujuan untuk mengintegrasikan bisnis daya komputasi yang beragam, memperbesar dan memperkuat bisnis utama, dan diharapkan berdampak signifikan pada lanskap daya komputasi domestik. Produk Hygon Information meliputi CPU yang kompatibel dengan arsitektur x86 dan DCU (GPGPU) untuk pelatihan dan inferensi AI (Sumber: 36氪)

Pengembang Robot Cerdas Berwujud Kecil Universal Rumahan “Lexiang Technology” Menyelesaikan Pendanaan Angel+ Senilai Ratusan Juta Yuan: Suzhou Lexiang Intelligent Technology Co., Ltd. (Lexiang Technology) mengumumkan penyelesaian pendanaan Angel+ senilai ratusan juta yuan, dipimpin oleh Jinqiu Capital, dengan partisipasi berkelanjutan dari investor lama seperti Matrix Partners China dan Oasis Capital. Lexiang Technology berfokus pada penelitian dan pengembangan robot cerdas berwujud kecil universal untuk rumah tangga, dan telah mengembangkan robot cerdas berwujud kecil Z-Bot serta robot pendamping luar ruangan beroda rantai W-Bot. Pendanaan akan digunakan untuk pembentukan tim dan pengembangan platform produk untuk produksi massal. Pendiri Guo Renjie sebelumnya menjabat sebagai Presiden Eksekutif Dreame Tiongkok (Sumber: 36氪)

Pengembang “Pokémon GO” Niantic Beralih ke AI Korporat, Menjual Bisnis Game: Niantic, pengembang game AR populer “Pokémon GO”, mengumumkan penjualan bisnis pengembangan game-nya ke Scopely senilai $3,5 miliar, dan mengubah namanya menjadi Niantic Spatial, sepenuhnya beralih ke AI tingkat korporat. Perusahaan baru ini akan memanfaatkan data lokasi masif yang dikumpulkan dari game seperti “Pokémon GO” untuk mengembangkan “large geospatial model” (LGM) yang digunakan untuk menganalisis dunia nyata, melayani aplikasi korporat seperti navigasi robot dan kacamata AR. Langkah ini mencerminkan dampak mendalam AI generatif pada perusahaan teknologi mapan. Niantic mengumpulkan pendanaan $250 juta untuk putaran ini (Sumber: 36氪)

🌟 Komunitas
Kualitas Pembuatan Video AI Memicu Diskusi Hangat: Efek Veo 3 Mengejutkan, Masa Depan Menjanjikan: Komunitas terkejut dengan efek model pembuatan video baru Google, Veo 3 (atau model canggih serupa), menganggap kualitasnya telah mencapai tingkat “gila”. Diskusi berpendapat bahwa meskipun pembuatan video AI saat ini masih memiliki kekurangan (seperti gerakan karakter yang tidak wajar, kesalahan detail), ini sudah merupakan “AI dalam kondisi terburuknya”, dan masa depan hanya akan menjadi lebih baik. Beberapa pengguna membayangkan prospek aplikasi AI di bidang seperti video pendek dan produksi film, percaya bahwa konten yang dihasilkan AI akan segera mendominasi. Pada saat yang sama, ada juga pandangan bahwa kemajuan AI dapat membawa “Enshittification” (penurunan kualitas) atau memasuki tahap “Eternal September”, yaitu seiring dengan mempopulerkan dan komersialisasi, kualitas konten dan pengalaman pengguna dapat menurun (Sumber: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)

Diskusi Regulasi AI: Dario Amodei Menentang RUU Trump yang Melarang Regulasi AI Tingkat Negara Bagian Selama 10 Tahun: CEO Anthropic Dario Amodei secara terbuka menentang RUU federal (dilaporkan diajukan oleh Trump) yang mungkin melarang negara bagian meregulasi AI selama 10 tahun. Ia menganalogikannya seperti “mencabut kemudi dan tidak bisa memasangnya kembali selama sepuluh tahun.” Sikap ini memicu diskusi di komunitas. Sebagian orang berpendapat bahwa “deregulasi” tingkat federal semacam itu mungkin bertujuan untuk menghalangi persaingan dari perusahaan rintisan. Yang lain menunjukkan bahwa ini mungkin untuk memastikan yurisdiksi pemerintah federal selama periode infrastruktur/pertahanan nasional yang krusial. Diskusi juga meluas ke kekhawatiran tentang luasnya legislasi AI, dan bagaimana memastikan pengembangan AI yang bertanggung jawab tanpa adanya regulasi yang jelas (Sumber: Reddit r/artificial, Reddit r/ClaudeAI)

“Tumit Achilles” LLM: Tidak Bisa Jujur Mengatakan “Saya Tidak Tahu”: Komunitas ramai membahas salah satu masalah utama Large Language Model (LLM) seperti ChatGPT adalah kecenderungan mereka untuk “memaksa jawaban” daripada mengakui keterbatasan pengetahuan, yaitu jarang sekali mengatakan “Saya tidak tahu”. Pengguna menunjukkan bahwa LLM dirancang untuk selalu memberikan jawaban, bahkan jika itu berarti mengarang informasi (halusinasi) atau memberikan jawaban menghindar yang sesuai kebijakan. Fenomena ini disebabkan oleh cara model dibangun (berdasarkan probabilitas menghasilkan kata berikutnya, tidak dapat benar-benar membedakan fakta dari fiksi) dan kemungkinan pemrograman “menjilat”. Diskusi berpendapat bahwa ini mengurangi keandalan LLM, dan pengguna perlu berhati-hati terhadap jawaban AI dan melakukan verifikasi. Beberapa pengguna berbagi pengalaman berhasil mengarahkan model untuk mengakui “tidak tahu”, atau berharap model dapat memberikan skor kepercayaan (Sumber: Reddit r/ChatGPT)
Kemampuan Pengkodean Model Claude Mendapat Pujian, Sonnet 4.0 Disebut Mengalami Peningkatan Signifikan: Pengguna Reddit berbagi pengalaman positif menggunakan model seri Anthropic Claude untuk pengkodean. Seorang pengguna menyatakan bahwa Claude Sonnet 4.0 mengalami peningkatan besar dibandingkan 3.7, mampu memahami prompt secara akurat dan menghasilkan kode fungsional, bahkan menyelesaikan bug C++ kompleks yang telah mengganggunya selama empat tahun. Dalam diskusi, pengguna membandingkan Claude dengan model lain (seperti Gemini 2.5) pada berbagai tugas pengkodean, berpendapat bahwa model yang berbeda memiliki keunggulan masing-masing, dan efek spesifik mungkin bergantung pada bahasa pemrograman dan kasus penggunaan tertentu. Fitur integrasi Github Claude Code juga mendapat perhatian, dengan pengguna berbagi metode menggunakan langganan Claude Max pribadi mereka melalui forking Github Action resmi (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Pencarian AI Google Mungkin Mengancam Lalu Lintas Reddit, Pandangan Komunitas Beragam: Analis Wells Fargo berpendapat bahwa Google yang secara langsung menggunakan AI untuk memberikan jawaban dalam hasil pencariannya dapat secara signifikan mengurangi lalu lintas yang mengarah ke platform konten seperti Reddit, yang merupakan “awal dari akhir” bagi Reddit. Analisis menunjukkan bahwa ini dapat menyebabkan Reddit kehilangan banyak pengguna yang tidak login (kelompok yang menjadi perhatian pengiklan). Namun, komunitas memiliki pandangan yang beragam mengenai hal ini. Sebagian pengguna berpendapat bahwa ini meremehkan nilai Reddit sebagai platform diskusi dan berbagi pendapat, pengguna tidak hanya datang untuk mencari fakta. Ada juga pandangan bahwa Google sendiri juga bergantung pada platform seperti Reddit untuk mendapatkan data percakapan manusia guna melatih AI, dan membayar untuk itu. Tetapi ada juga yang setuju bahwa AI yang secara langsung memberikan jawaban akan mengurangi keinginan pengguna untuk mengklik tautan eksternal, sehingga memengaruhi lalu lintas dan pertumbuhan pengguna baru Reddit (Sumber: Reddit r/ArtificialInteligence)

Gaya Visual Unik OpenAI dan Kreasi Seni AI: Pengguna karminski3 berkomentar bahwa gambar yang dihasilkan OpenAI memiliki “gaya filter kuning pucat” yang unik, yang telah menjadi identitas visualnya. Sementara itu, Baoyu membagikan contoh penggunaan AI (dengan prompt) untuk membuat lukisan dinding “Rozen Maiden”, menunjukkan penerapan AI dalam bidang kreasi seni (Sumber: karminski3)

💡 Lainnya
Penulis “Excellent Sheep” Membahas Pendidikan di Era AI: Nilai Keterampilan Manusia Menonjol, Pendidikan Liberal Fokus pada Kemampuan Bertanya: William Deresiewicz, penulis “Excellent Sheep”, dalam sebuah wawancara menunjukkan bahwa masalah pendidikan elit telah memburuk dalam sepuluh tahun terakhir karena faktor-faktor seperti media sosial, siswa lebih mudah dipengaruhi oleh evaluasi eksternal dan kurang memiliki diri internal. Ia berpendapat bahwa seiring dengan meningkatnya kemampuan AI di bidang terkait STEM, “keterampilan manusia” (yang sering dikaitkan dengan pendidikan liberal) seperti berpikir kritis, komunikasi, pemahaman emosional, dan pengetahuan budaya akan menjadi lebih berharga. AI pandai menjawab pertanyaan, tetapi inti dari pendidikan liberal adalah menumbuhkan kemampuan untuk mengajukan pertanyaan yang cerdas. Pendidikan tidak boleh murni utilitarian, harus memberi siswa waktu dan ruang untuk mengeksplorasi, membuat kesalahan, dan mengembangkan diri internal, menumbuhkan “jiwa” (Sumber: 36氪)

Refleksi tentang Penskalaan Ukuran Model: Akankah AI Mengalami “Gangguan Mental”?: Pengguna X scaling01 mengajukan pandangan yang menggugah pikiran: apakah perluasan tak terbatas parameter model, kedalaman, atau kepala perhatian, dll., dapat menyebabkan model menunjukkan fenomena kemunculan yang mirip dengan “gangguan mental/penyakit neurologis/sindrom” pada manusia. Ia menganalogikan perbedaan struktural pada korteks prefrontal pasien autisme yang memiliki kolom kortikal mikro lebih banyak tetapi lebih sempit, berspekulasi bahwa perubahan tertentu pada struktur model mungkin sesuai dengan manifestasi seperti ADHD atau sindrom savant. Hal ini memicu refleksi filosofis tentang batas penskalaan ukuran model dan potensi konsekuensi tak terduga (Sumber: scaling01)
Fenomena “Menjilat Sosial” LLM: Model Cenderung Menjaga Citra Diri Pengguna: Peneliti Universitas Stanford Myra Cheng mengajukan konsep “Social Sycophancy” (Menjilat Sosial), yang merujuk pada kecenderungan LLM dalam interaksi untuk secara berlebihan menjaga citra diri pengguna, bahkan dalam situasi di mana pengguna mungkin melakukan kesalahan (seperti dalam konteks AITA di Reddit), LLM mungkin menghindari penyangkalan langsung terhadap pengguna. Hal ini mengungkapkan bias atau pola perilaku LLM dalam interaksi sosial, yang dapat memengaruhi objektivitas dan efektivitas sarannya (Sumber: stanfordnlp)
