
Kata Kunci:Model AI, Claude 4, Gemini Diffusion, Agen AI, Pembelajaran Robot, Model Bahasa Besar, Perangkat Keras AI, Pengembangan Chip, Kemampuan Pengkodean Claude Opus 4, Kecepatan Generasi Model Difusi Teks, Pembelajaran Mimpi Robot GR00T, Kinerja Chip Xiaomi Xuanjie O1, Akuisisi Perusahaan Perangkat Keras io oleh OpenAI
🔥 Fokus
Anthropic merilis model seri Claude 4, berfokus pada pemrograman agen AI dan pemrosesan tugas kompleks: Anthropic meluncurkan dua model hibrida, Claude Opus 4 dan Claude Sonnet 4, yang menekankan keseimbangan antara respons cepat dan pemikiran mendalam. Opus 4 menunjukkan kinerja luar biasa dalam tugas-tugas kompleks seperti coding, penelitian, penulisan, dan penemuan ilmiah, mampu melakukan pemrograman secara mandiri selama 7 jam dan bermain Pokémon selama 24 jam terus-menerus; Sonnet 4 mencapai keseimbangan antara kinerja dan efisiensi, cocok untuk skenario sehari-hari yang membutuhkan otonomi. Kedua model meningkatkan penggunaan alat, pemrosesan paralel, dan kemampuan memori, serta memperkenalkan fungsi “ringkasan pemikiran”. GitHub telah mengumumkan akan menggunakan Claude Sonnet 4 sebagai model dasar untuk Agen pengkodean baru Copilot. Peluncuran ini juga mencakup Claude Code SDK, alat eksekusi kode, konektor MCP, dll., yang bertujuan untuk memberdayakan pengembang membangun agen AI yang lebih kuat, menandai transformasi strategis Anthropic menuju integrasi mendalam “model besar + agen”. (Sumber: 量子位 & 36氪)

Google meluncurkan model difusi teks Gemini Diffusion, menghasilkan 10.000 token dalam 12 detik: Google DeepMind merilis Gemini Diffusion, sebuah model generasi teks eksperimental yang menggunakan teknologi difusi sebagai pengganti metode autoregresif tradisional. Model ini belajar menghasilkan output dengan mengoptimalkan noise secara bertahap, mencapai kecepatan generasi 2000 token per detik, mampu menghasilkan 10.000 token dalam 12 detik, bahkan lebih cepat dari Gemini 2.0 Flash-Lite. Model ini dapat menghasilkan seluruh blok token sekaligus, meningkatkan koherensi respons, dan dapat memperbaiki kesalahan dalam penyempurnaan iteratif. Kemampuan penalaran non-kausalnya memungkinkannya menyelesaikan masalah yang sulit ditangani oleh model autoregresif tradisional, seperti memberikan jawaban terlebih dahulu baru kemudian menurunkan prosesnya. (Sumber: 量子位)
Kemajuan baru proyek robot GR00T Nvidia: mencapai generalisasi zero-shot melalui pembelajaran “bermimpi”: Nvidia GEAR Lab meluncurkan proyek DreamGen, yang memungkinkan robot mempelajari keterampilan baru melalui “mimpi” (lintasan neural) yang dihasilkan oleh model dunia video AI (seperti Sora, Veo). Teknologi ini hanya memerlukan sejumlah kecil data video dunia nyata, melalui fine-tuning model dunia, menghasilkan data virtual, mengekstrak tindakan virtual, dan melatih strategi, memungkinkan robot untuk menjalankan 22 tugas baru. Dalam pengujian robot nyata, tingkat keberhasilan tugas kompleks meningkat dari 21% menjadi 45,5%, untuk pertama kalinya mencapai generalisasi perilaku dan lingkungan zero-shot. Teknologi ini merupakan bagian dari cetak biru GR00T-Dreams Nvidia, yang bertujuan untuk mempercepat pembelajaran perilaku robot, dan diharapkan dapat mempersingkat waktu pengembangan GR00T N1.5 dari 3 bulan menjadi 36 jam. (Sumber: 量子位)

🎯 Perkembangan
OpenAI Operator diperbarui ke model o3, meningkatkan tingkat keberhasilan tugas dan kualitas respons: OpenAI mengumumkan bahwa fungsi Operator dalam ChatGPT telah diperbarui, dengan model dasarnya dialihkan ke model inferensi o3 terbaru. Peningkatan ini secara signifikan meningkatkan persistensi dan akurasi Operator saat berinteraksi dengan browser, sehingga meningkatkan tingkat keberhasilan tugas secara keseluruhan. Umpan balik pengguna menunjukkan bahwa Operator yang diperbarui memberikan respons yang lebih jelas, lebih detail, dan terstruktur lebih baik. OpenAI menyatakan bahwa model o3 mencapai level SOTA dalam benchmark seperti OSWorld dan WebArena, dan model baru ini berkinerja lebih baik saat menangani prompt lama yang sebelumnya gagal. (Sumber: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
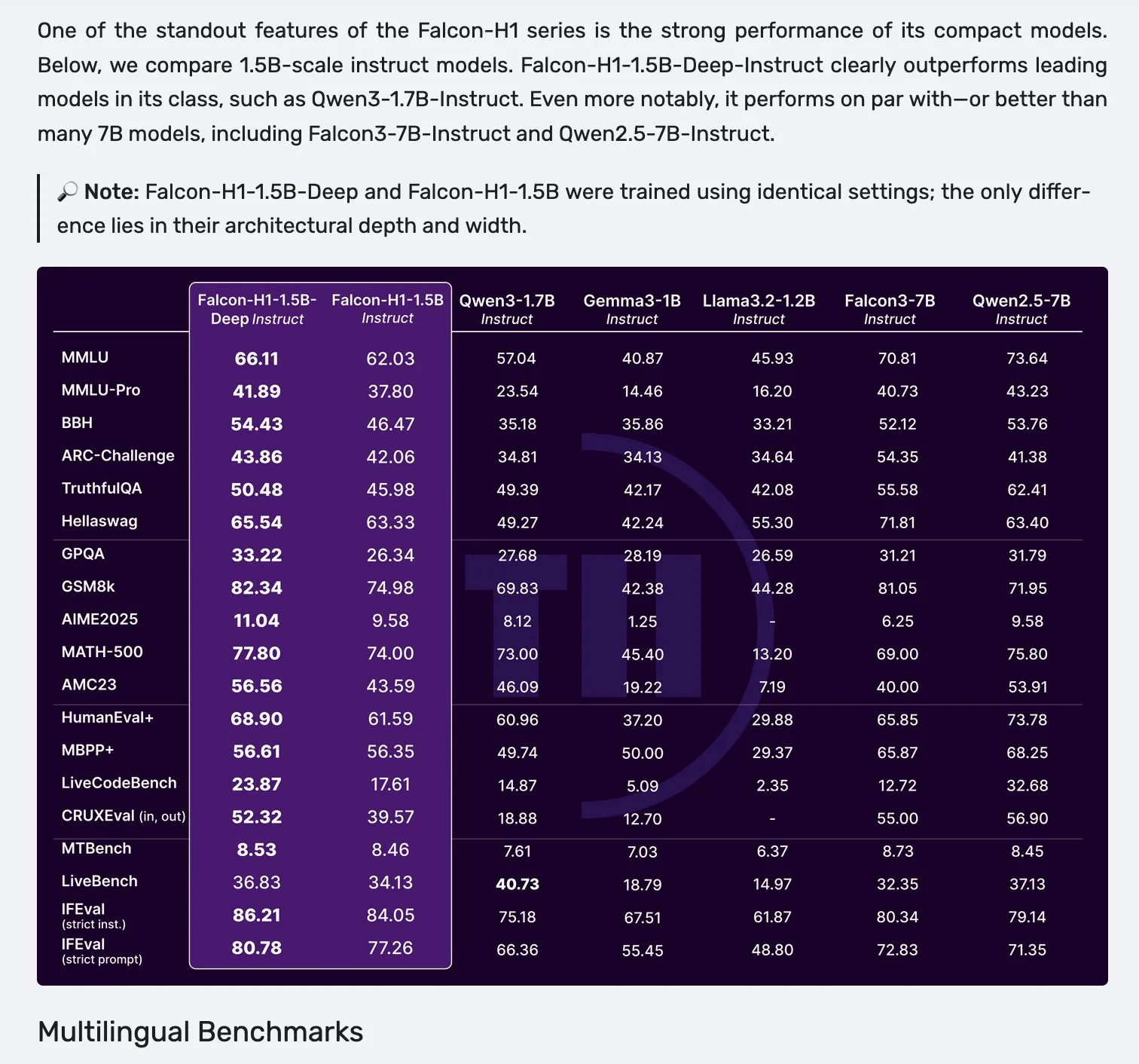
Falcon merilis model seri H1, mengadopsi arsitektur paralel Mamba-2 dan atensi: Falcon meluncurkan model seri H1 baru, dengan skala parameter berkisar dari 0.5B hingga 34B, jumlah data pelatihan antara 2.5T hingga 18T token, dan panjang konteks mencapai 256K. Seri model ini mengadopsi arsitektur inovatif paralel Mamba-2 dan mekanisme atensi tradisional. Umpan balik awal dari komunitas menunjukkan bahwa model kecilnya menunjukkan kinerja yang sangat menonjol, tetapi masih memerlukan pengujian dan evaluasi aktual lebih lanjut (“vibe checks”) untuk memverifikasi kinerja nyata dan ketahanannya dalam berbagai tugas. (Sumber: _albertgu & huggingface)
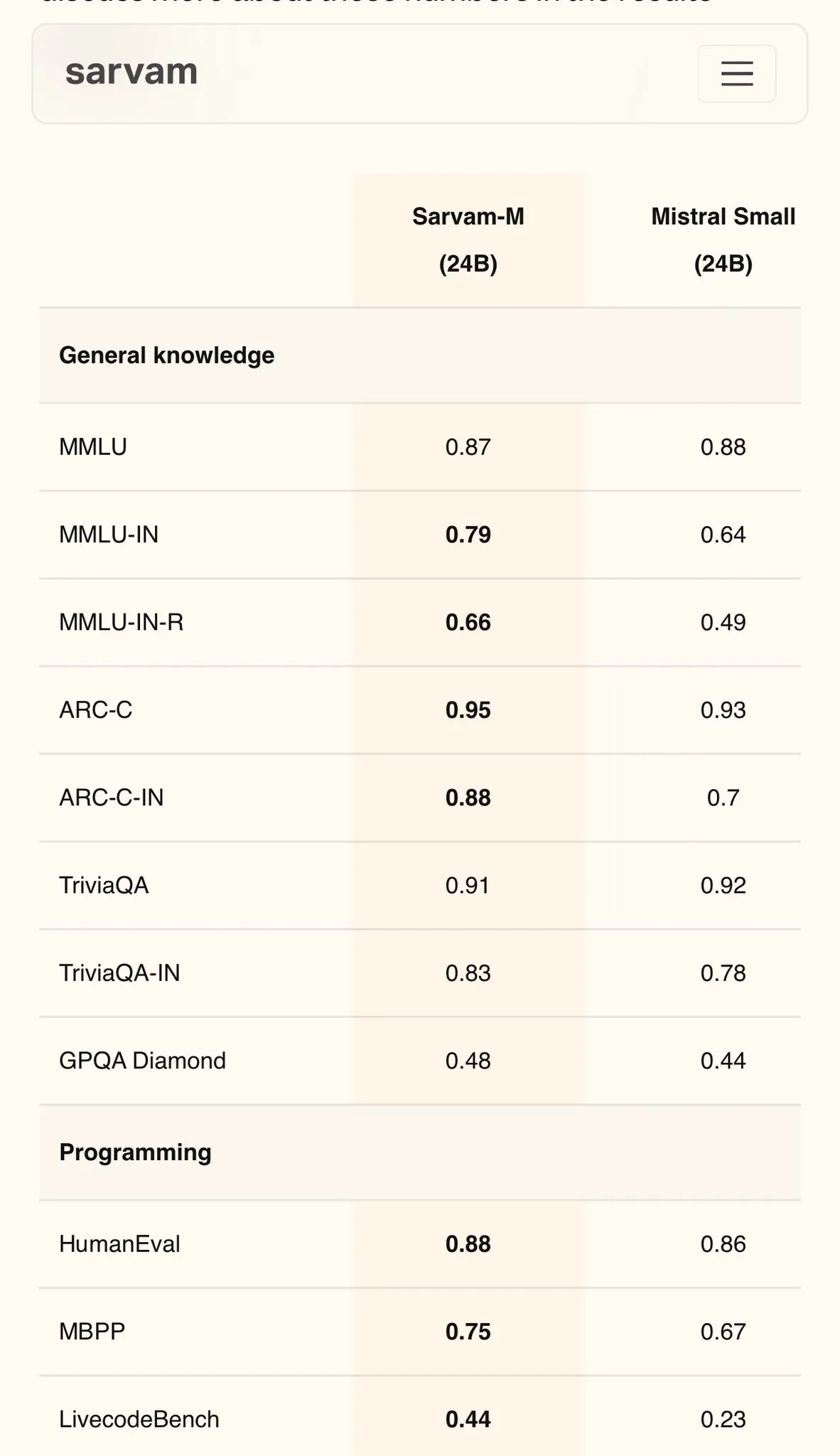
Sarvam AI merilis model bahasa Hindi berbasis Mistral, Sarvam-M, dengan skor MMLU mencapai 79: Perusahaan AI India, Sarvam AI, merilis model Sarvam-M yang dibangun berdasarkan model open-source Mistral. Model ini mencapai skor 79 pada benchmark MMLU untuk bahasa India, melampaui kinerja ChatGPT generasi pertama (GPT-3.5) dalam bahasa Inggris. Model ini dioptimalkan untuk 11 bahasa India, dan pada benchmark bahasa India, benchmark matematika, dan benchmark pemrograman, masing-masing meningkat sebesar 20%, 21,6%, dan 17,6% dibandingkan model dasar. Sarvam-M telah dirilis sebagai open source di bawah lisensi Apache 2.0, menunjukkan potensi India dalam pengembangan model bahasa besar untuk bahasa lokal. (Sumber: bookwormengr)
Pusat Perusahaan Dell ditingkatkan, dukungan penuh untuk pembangunan AI secara lokal: Dell mengumumkan di Dell Tech World pembaruan Dell Enterprise Hub, menyediakan kontainer model yang dioptimalkan termasuk Meta Llama 4 Maverick, DeepSeek R1, dan Google Gemma 3, serta mendukung platform server AI dari NVIDIA, AMD, dan Intel. Fitur baru termasuk direktori aplikasi AI (terintegrasi dengan OpenWebUI, AnythingLLM), dukungan model pada perangkat untuk AI PC (melalui Dell Pro AI Studio), serta SDK Python dan alat CLI dell-ai yang baru. Langkah ini bertujuan untuk membantu perusahaan menerapkan aplikasi AI generatif secara aman dan cepat di lokasi (on-premise). (Sumber: HuggingFace Blog & ClementDelangue)

Fireworks AI merilis alat agen browser open-source Fireworks Manus: Fireworks AI merilis Fireworks Manus sebagai open-source, sebuah alat agen berbasis browser yang kuat, menggunakan DeepSeek V3 untuk inferensi dan FireLlava 13B untuk pemahaman visual. Agen ini mampu menavigasi halaman web, mengklik tombol, mengisi formulir, mengekstrak konten dinamis, dan menangani alur otentikasi, kotak modal, dan bahkan CAPTCHA. Arsitekturnya mencakup sistem visual (DOM, tangkapan layar, kesadaran spasial), sistem inferensi (memori, pelacakan target, perencanaan skema JSON), dan sistem aksi (kontrol interaksi browser), membentuk siklus observasi-keputusan-aksi yang kuat. (Sumber: _akhaliq)
Mistral AI meluncurkan AI Dokumen dan model OCR baru: Mistral AI merilis solusi AI Dokumennya, yang dikombinasikan dengan model OCR baru. Solusi ini bertujuan untuk menyediakan alur kerja dokumen yang dapat diskalakan dari digitalisasi OCR hingga kueri bahasa alami. Fitur-fiturnya termasuk kemampuan multibahasa yang mendukung lebih dari 40 bahasa, OCR dapat dilatih untuk dokumen domain spesifik (seperti rekam medis), mendukung ekstraksi lanjutan ke templat khusus (seperti JSON), dan dapat diterapkan secara lokal atau di cloud pribadi. (Sumber: algo_diver)

Sakana AI Merilis Metode AI Baru Continuous Thought Machines (CTM): Sakana AI mengumumkan terobosan baru dalam penelitian AI—Continuous Thought Machines (CTM). Metode baru ini bertujuan untuk meningkatkan kemampuan berpikir dan bernalar model AI. NHK World melaporkan kemajuan terbaru Sakana AI, menunjukkan upaya dan pencapaiannya dalam membangun model dunia generasi berikutnya. (Sumber: SakanaAILabs & hardmaru)

Kumo.ai merilis “model dasar relasional” KumoRFM, untuk data terstruktur: Kumo.ai meluncurkan KumoRFM, sebuah “model dasar relasional” yang dirancang khusus untuk data tabular (terstruktur). Model ini bertujuan untuk memproses data dalam database seperti LLM memproses teks, diklaim dapat langsung diterapkan pada database perusahaan untuk menghasilkan model SOTA tanpa perlu rekayasa fitur (feature engineering). Ini mungkin menandakan potensi Graph Neural Networks (GNNs) dalam memproses data terstruktur semakin dieksplorasi dan diterapkan. (Sumber: Reddit r/MachineLearning)

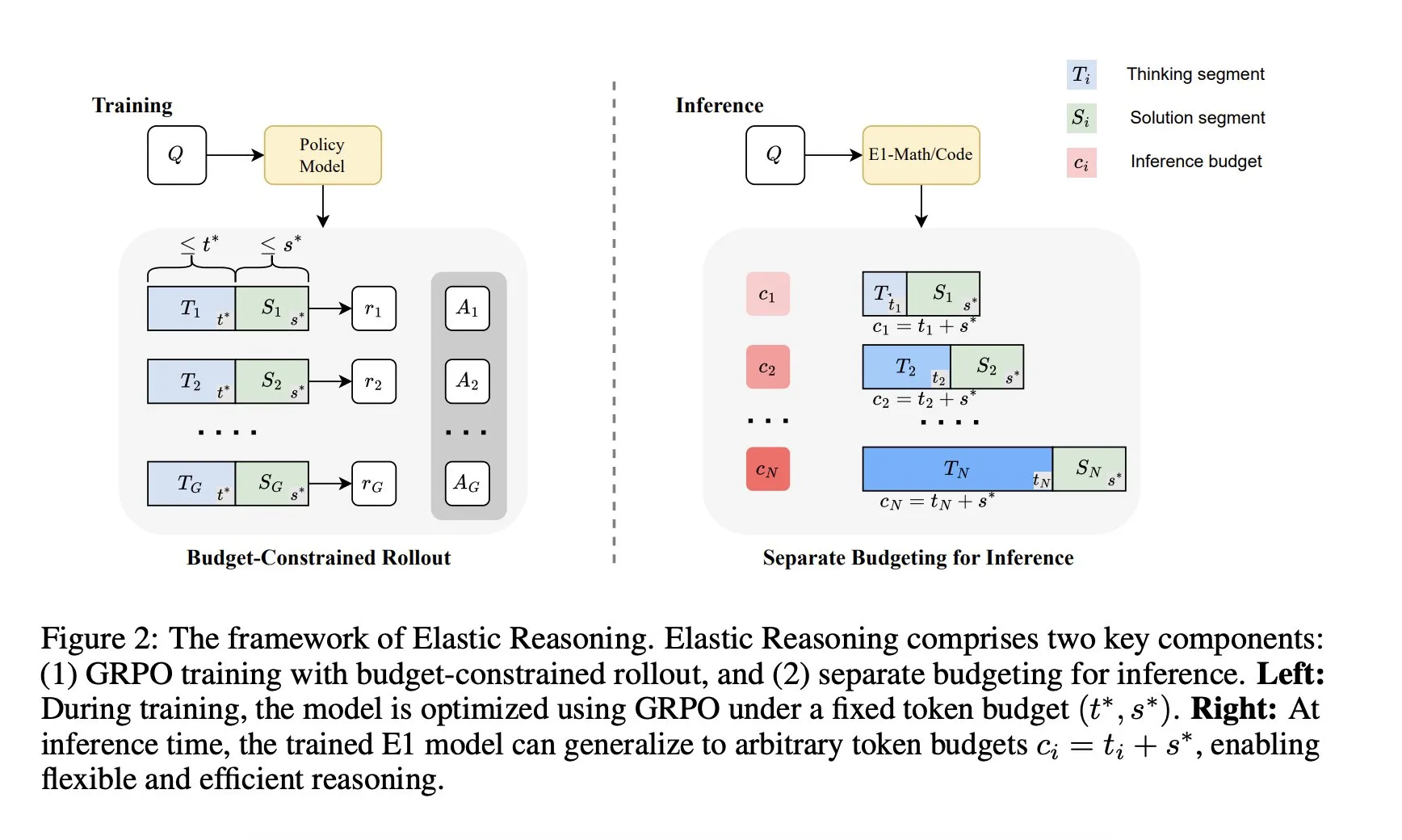
Salesforce AI Research Institute meluncurkan kerangka kerja “Elastic Reasoning”: Salesforce AI Research Institute merilis kerangka kerja baru bernama “Elastic Reasoning”, yang bertujuan untuk mengatasi masalah batasan anggaran inferensi LLM tanpa mengorbankan kinerja. Kerangka kerja ini memisahkan tahap “berpikir” dan “solusi” dan menetapkan anggaran Token yang terpisah untuk keduanya, dikombinasikan dengan pelatihan rollout yang dibatasi anggaran. Hasil penelitian menunjukkan bahwa E1-Math-1.5B mencapai akurasi 35% pada AIME2024 dengan pengurangan Token sebesar 32%; E1-Code-14B mencapai skor 1987 pada Codeforces. Model dapat digeneralisasi ke anggaran apa pun tanpa perlu pelatihan ulang. (Sumber: ClementDelangue)
🧰 Alat
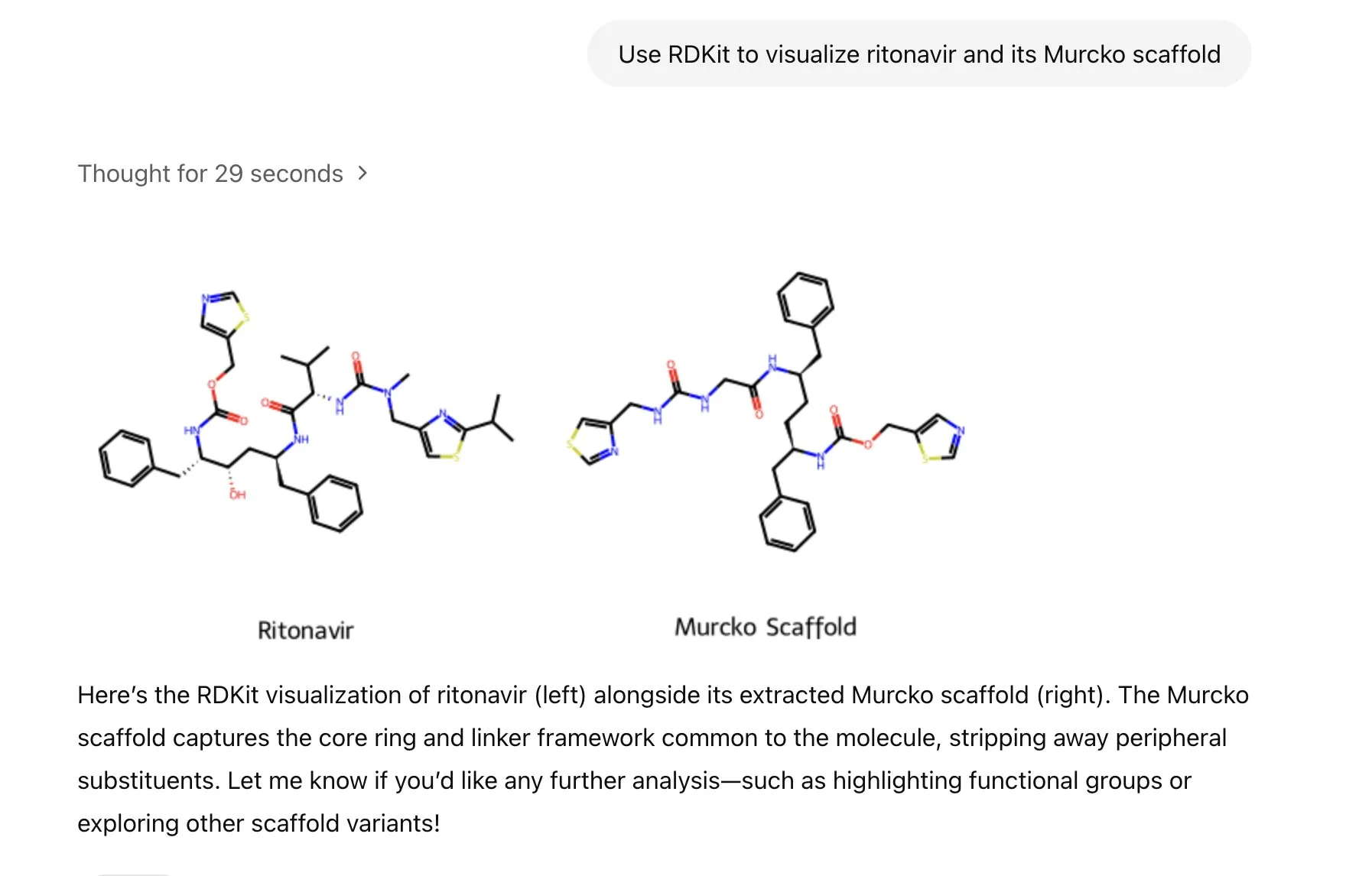
ChatGPT mengintegrasikan pustaka RDKit, dapat menganalisis, memanipulasi, dan memvisualisasikan informasi molekuler dan kimia: ChatGPT sekarang dapat menggunakan pustaka RDKit untuk menganalisis, memanipulasi, dan memvisualisasikan informasi molekuler dan kimia. Fungsi baru ini memiliki nilai praktis yang penting untuk bidang penelitian ilmiah seperti kesehatan, biologi, dan kimia, membantu para peneliti memproses data dan struktur kimia yang kompleks dengan lebih mudah. (Sumber: gdb & openai)
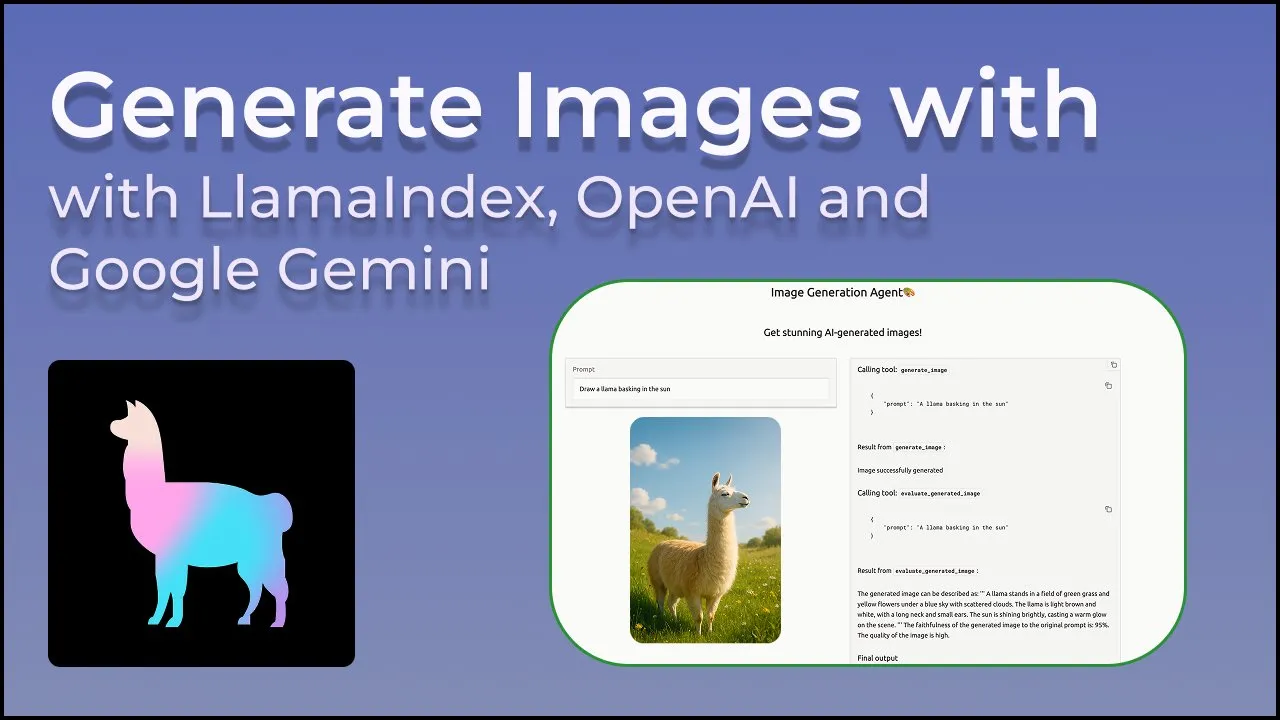
LlamaIndex meluncurkan agen pembuatan gambar, kontrol presisi atas pembuatan gambar AI: LlamaIndex merilis proyek agen pembuatan gambar open-source, yang bertujuan untuk membantu pengguna menciptakan gambar AI yang sesuai dengan visi mereka secara presisi melalui otomatisasi optimasi prompt, pembuatan gambar, dan siklus umpan balik visual. Agen ini adalah alat multimodal yang memanfaatkan API pembuatan gambar OpenAI dan kemampuan visual Google Gemini, serta terintegrasi secara mulus dengan LlamaIndex, mendukung fungsi pembuatan gambar OpenAI. (Sumber: jerryjliu0)
Tim Haystack merilis Hayhooks, menyederhanakan penerapan pipeline AI: Tim Haystack meluncurkan paket open-source Hayhooks, yang mampu mengubah pipeline Haystack menjadi REST API yang siap produksi atau diekspos sebagai alat MCP, mendukung kustomisasi penuh dengan jumlah kode yang minimal. Ini bertujuan untuk mempercepat alur kerja penerapan aplikasi AI, memungkinkan pengembang untuk mengintegrasikan model dan proses AI ke dalam lingkungan produksi dengan lebih mudah. (Sumber: dl_weekly)
Aplikasi Runway iOS meluncurkan fitur Gen-4 References, mengubah kenyataan menjadi cerita kapan saja, di mana saja: Runway mengumumkan bahwa fitur Gen-4 References pada aplikasi iOS-nya kini tersedia, memungkinkan pengguna mengubah apa pun di dunia nyata menjadi cerita yang dapat dibagikan. Fitur ini menggabungkan teknologi text-to-image, References, Gen-4, serta teknik pelacakan dan color grading sederhana, yang dapat mengubah rekaman biasa menjadi produksi skala besar. (Sumber: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel meluncurkan rangkaian alat AI untuk animasi 3D, memberdayakan pembuatan animasi karakter: Cartwheel, yang didirikan bersama oleh ilmuwan OpenAI, desainer Google, serta pengembang dari Pixar, Sony, dan Riot Games, merilis rangkaian alat AI untuk animasi 3D. Kumpulan alat ini mampu mengubah video, teks, dan pustaka gerakan besar menjadi animasi karakter 3D, yang bertujuan untuk merevolusi alur kerja produksi animasi. (Sumber: andrew_n_carr & andrew_n_carr)

llm-d: Google, IBM, dan Red Hat bekerja sama meluncurkan kerangka kerja inferensi LLM terdistribusi open-source: Google, IBM, dan Red Hat bersama-sama merilis llm-d, sebuah kerangka kerja inferensi LLM terdistribusi open-source yang K8s-native. Kerangka kerja ini bertujuan untuk menyediakan layanan inferensi LLM berkinerja tinggi, dengan fitur utamanya meliputi caching dan routing canggih (melalui penjadwal inferensi yang dioptimalkan vLLM), layanan yang dipisahkan (menggunakan vLLM untuk menjalankan prefill/decode pada instans khusus), cache prefix yang dipisahkan dengan vLLM (mendukung offloading host/remote tanpa biaya dan cache bersama), serta fitur penskalaan otomatis varian yang direncanakan. Hasil awal menunjukkan bahwa llm-d dapat mengurangi TTFT hingga 3 kali lipat dan meningkatkan QPS sekitar 50% sambil memenuhi SLO. (Sumber: algo_diver)

FedRAG mengintegrasikan Unsloth, mendukung pembangunan dan fine-tuning sistem RAG menggunakan FastModels: FedRAG mengumumkan integrasi dengan Unsloth, pengguna sekarang dapat menggunakan model FastModels apa pun dari Unsloth sebagai generator untuk membangun sistem RAG, dan memanfaatkan akselerator kinerja serta patch Unsloth untuk fine-tuning. Pengguna dapat mendefinisikan kelas UnslothFastModelGenerator baru untuk menggunakan model Unsloth apa pun yang tersedia, dan mendukung fine-tuning LoRA atau QLoRA. Cookbook resmi telah disediakan, yang mendemonstrasikan cara melakukan fine-tuning QLoRA pada model Gemma3 4B dari GoogleAI. (Sumber: nerdai)

Hugging Face meluncurkan agen Command Line Interface (CLI) yang ringan, dapat digunakan kembali, dan modular: Pustaka Hugging Face Hub menambahkan fitur agen Command Line Interface (CLI) yang ringan, dapat digunakan kembali, dan modular (kompatibel dengan MCP). Fitur baru ini dikembangkan oleh @hanouticelina dan @julien_c, bertujuan untuk memudahkan pengguna membuat dan menggunakan agen AI di lingkungan CLI. (Sumber: huggingface)
Google AI Studio meningkatkan pengalaman pengembang, mendukung pembuatan kode native dan alat agen: Google AI Studio telah diperbarui untuk meningkatkan pengalaman pengembang, kini mendukung pembuatan kode native dan alat agen. Fitur-fitur baru ini bertujuan untuk membantu pengembang membangun dan menerapkan aplikasi AI dengan lebih mudah menggunakan model seperti Gemini. (Sumber: matvelloso)
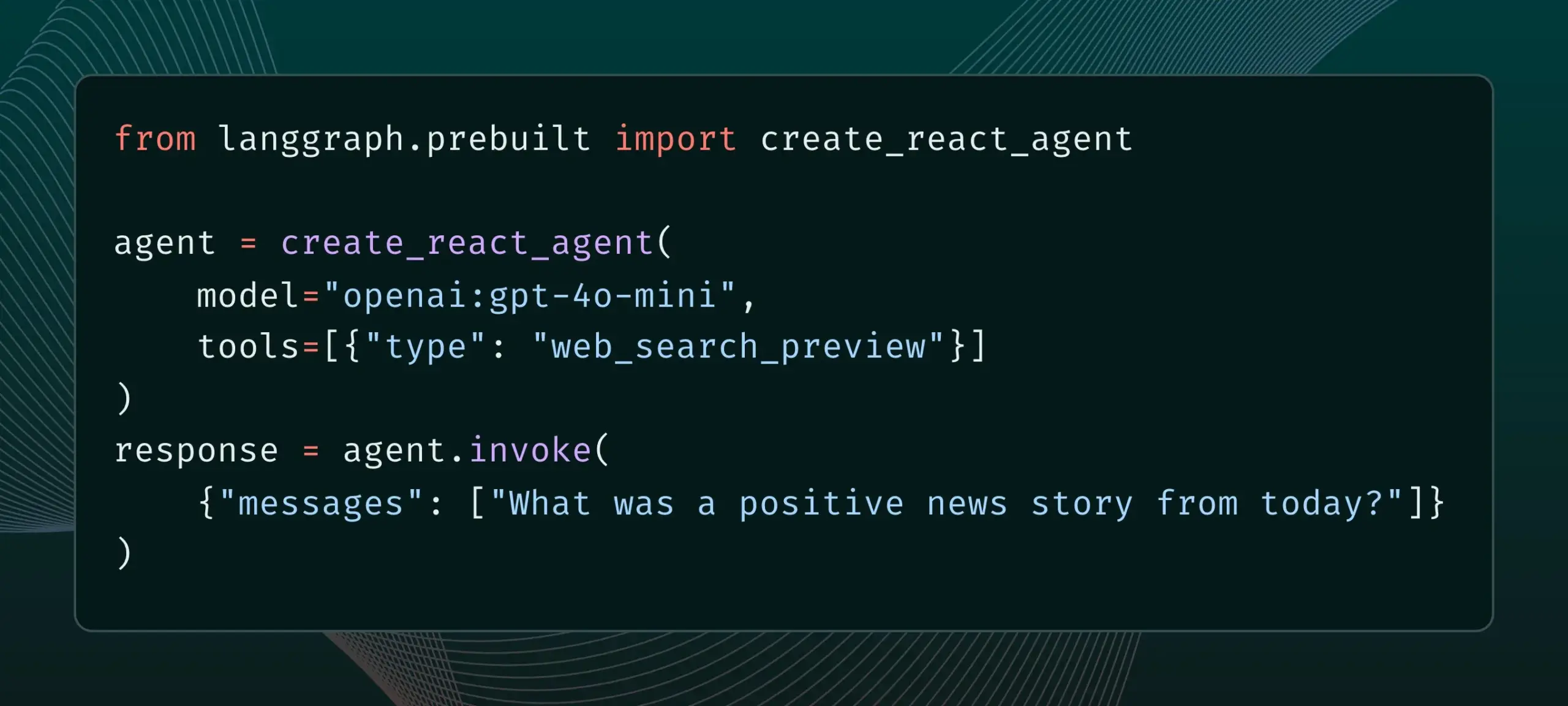
LangGraph kini mendukung alat penyedia bawaan, seperti pencarian web dan MCP jarak jauh: LangGraph mengumumkan bahwa pengguna sekarang dapat menggunakan alat penyedia bawaan, seperti pencarian web dan MCP (Model Control Protocol) jarak jauh. Pembaruan ini meningkatkan fleksibilitas dan fungsionalitas LangGraph dalam membangun agen dan alur kerja AI yang kompleks, memungkinkannya untuk mengintegrasikan data dan layanan eksternal dengan lebih mudah. (Sumber: hwchase17 & Hacubu)
Memex mengintegrasikan Claude Sonnet 4 dan Gemini 2.5 Pro, serta meluncurkan templat MCP: Memex mengumumkan telah mengintegrasikan model Claude Sonnet 4 dari Anthropic dan Gemini 2.5 Pro dari Google. Selain itu, Memex juga meluncurkan tiga templat MCP (Model Control Protocol) awal, yang bertujuan untuk membantu pengguna membangun dan menerapkan aplikasi AI dengan lebih cepat. (Sumber: _akhaliq)

Platform Windsurf menambahkan dukungan BYOK untuk Claude Sonnet 4 dan Opus 4: Windsurf mengumumkan, untuk menanggapi permintaan pengguna, telah menambahkan dukungan “Bring-Your-Own-Key” (BYOK) untuk model Claude Sonnet 4 dan Opus 4 yang baru dirilis Anthropic di platformnya. Fitur ini berlaku untuk semua paket personal (gratis dan profesional), memungkinkan pengguna menggunakan kunci API mereka sendiri untuk mengakses model-model baru ini. (Sumber: dotey)
📚 Belajar
LlamaIndex merilis Panduan Interaktif: 12 Prinsip Elemen untuk Membangun Agen AI Cerdas: Berdasarkan repo 12-Factor agents yang populer dari @dexhorthy, LlamaIndex merilis serangkaian situs web interaktif dan notebook Colab yang menjelaskan secara rinci 12 prinsip desain untuk membangun aplikasi agen AI yang efisien. Prinsip-prinsip ini mencakup mendapatkan output alat terstruktur, manajemen status, pengaturan checkpoint, kolaborasi manusia-mesin, penanganan kesalahan, dan menggabungkan agen kecil menjadi agen besar, dll. Panduan ini bertujuan untuk memberikan panduan praktis dan contoh kode bagi pengembang untuk membangun aplikasi agen. (Sumber: jerryjliu0)

Hugging Face membuka fitur publikasi blog komunitas, meningkatkan visibilitas konten komunitas AI: Hugging Face mengumumkan bahwa pengguna kini dapat langsung berbagi artikel blog komunitas di platformnya. Baik itu terobosan ilmiah, model, dataset, berbagi tentang pembuatan Spaces, atau pandangan tentang peristiwa hangat di bidang AI, pengguna dapat menggunakan fitur ini untuk meningkatkan eksposur konten mereka. Setelah login, klik “New” di halaman utama untuk mulai menulis dan menerbitkan. (Sumber: huggingface & _akhaliq)
Kementerian Kebudayaan Prancis merilis dataset preferensi gaya arena berkualitas tinggi sebanyak 175.000 entri: Kementerian Kebudayaan Prancis merilis dataset berisi 175.000 dialog preferensi gaya arena (arena-style) berkualitas tinggi, bernama “comparia-conversations”. Dataset ini berasal dari arena chatbot ciptaan mereka sendiri yang berisi 55 model, dan semua konten terkait telah di-open-source-kan. Data semacam ini sangat penting untuk melatih dan mengevaluasi model bahasa besar, terutama setelah institusi seperti LMSYS berhenti merilis data serupa, langkah ini sangat berharga bagi komunitas. (Sumber: huggingface & cognitivecompai & jeremyphoward)
Anthropic merilis tutorial interaktif gratis tentang rekayasa prompt: Seiring dengan peluncuran model Claude 4 baru, Anthropic menyediakan tutorial interaktif gratis tentang rekayasa prompt (prompt engineering). Tutorial ini bertujuan untuk membantu pengguna mempelajari keterampilan kunci seperti membangun prompt dasar dan kompleks, menetapkan peran, memformat output, menghindari halusinasi, melakukan chain prompting, dll., agar dapat memanfaatkan kemampuan model Claude dengan lebih baik. (Sumber: TheTuringPost & TheTuringPost)
Google merilis benchmark SAKURA, mengevaluasi kemampuan penalaran multi-hop model bahasa audio besar: Peneliti Google merilis SAKURA, sebuah benchmark baru yang dirancang khusus untuk mengevaluasi kemampuan model bahasa audio besar (LALMs) dalam melakukan penalaran multi-hop berdasarkan informasi suara dan audio. Penelitian menemukan bahwa meskipun LALMs dapat mengekstrak informasi yang relevan dengan benar, mereka masih mengalami kesulitan dalam mengintegrasikan representasi suara/audio untuk penalaran multi-hop, yang mengungkap tantangan mendasar dalam penalaran multimodal. (Sumber: HuggingFace Daily Papers)
Penelitian baru membahas RoPECraft: transfer gerakan tanpa pelatihan yang dioptimalkan RoPE berbasis panduan lintasan: Sebuah paper baru mengusulkan RoPECraft, metode transfer gerakan video tanpa pelatihan untuk diffusion Transformer. Metode ini dicapai dengan memodifikasi rotational position embedding (RoPE), pertama-tama mengekstrak aliran optik padat dari video referensi, menggunakan pergeseran gerakan untuk mendistorsi tensor eksponensial kompleks RoPE, mengkodekan gerakan ke dalam proses generasi, dan dioptimalkan melalui penyelarasan lintasan dan regularisasi fase transformasi Fourier. Eksperimen menunjukkan kinerjanya melampaui metode yang ada. (Sumber: HuggingFace Daily Papers)
Paper membahas gen2seg: model generatif memberdayakan segmentasi instans yang dapat digeneralisasi: Sebuah penelitian mengusulkan gen2seg, yang melalui model generatif pra-terlatih (seperti Stable Diffusion dan MAE) untuk mensintesis gambar koheren dari input yang terganggu, memungkinkannya belajar memahami batas objek dan komposisi adegan. Peneliti hanya melakukan fine-tuning model pada beberapa jenis objek seperti furnitur dalam ruangan dan mobil menggunakan kerugian pewarnaan instans (instance coloring loss), dan menemukan bahwa model menunjukkan kemampuan generalisasi zero-shot yang kuat, dapat secara akurat mensegmentasi jenis dan gaya objek yang belum pernah dilihat, dengan kinerja mendekati atau bahkan melampaui SAM dalam beberapa aspek. (Sumber: HuggingFace Daily Papers)
Paper mengusulkan Think-RM: mencapai penalaran jangka panjang dalam model hadiah generatif: Sebuah paper baru memperkenalkan Think-RM, sebuah kerangka kerja pelatihan yang bertujuan untuk meningkatkan kemampuan penalaran jangka panjang model hadiah generatif (GenRMs) dengan memodelkan proses berpikir internal. Think-RM menghasilkan lintasan penalaran yang fleksibel dan dipandu sendiri, bukan alasan eksternal terstruktur, mendukung kemampuan tingkat lanjut seperti refleksi diri, penalaran hipotetis, dan penalaran divergen. Penelitian ini juga mengusulkan alur RLHF berpasangan baru yang secara langsung mengoptimalkan strategi menggunakan hadiah preferensi berpasangan. (Sumber: HuggingFace Daily Papers)
Paper mengusulkan WebAgent-R1: melatih agen Web melalui pembelajaran penguatan multi-putaran end-to-end: Peneliti mengusulkan WebAgent-R1, sebuah kerangka kerja pembelajaran penguatan multi-putaran end-to-end untuk melatih agen Web. Kerangka kerja ini belajar secara langsung melalui interaksi online dengan lingkungan Web, sepenuhnya dipandu oleh hadiah biner keberhasilan tugas, dan menghasilkan lintasan yang beragam secara asinkron. Eksperimen menunjukkan bahwa WebAgent-R1 secara signifikan meningkatkan tingkat keberhasilan tugas Qwen-2.5-3B dan Llama-3.1-8B pada benchmark WebArena-Lite, melampaui metode yang ada dan model proprietary yang kuat. (Sumber: HuggingFace Daily Papers)
Paper membahas LLM bertingkat memperbaiki data yang merusak kinerja: melabel ulang sampel negatif keras untuk mencapai pengambilan informasi yang kuat: Penelitian menemukan bahwa beberapa dataset pelatihan berdampak negatif pada efektivitas model pengambilan dan pengurutan ulang, misalnya, menghapus sebagian dataset dari koleksi BGE justru dapat meningkatkan nDCG@10 pada BEIR. Penelitian ini mengusulkan metode menggunakan prompt LLM bertingkat untuk mengidentifikasi dan melabel ulang ‘negatif palsu’ (paragraf relevan yang salah dilabeli sebagai tidak relevan). Eksperimen menunjukkan bahwa melabel ulang negatif palsu sebagai positif sejati dapat meningkatkan kinerja model pengambilan E5 (base) dan Qwen2.5-7B serta pengurut ulang Qwen2.5-3B pada BEIR dan AIR-Bench. (Sumber: HuggingFace Daily Papers)
DeepLearningAI bekerja sama dengan Predibase meluncurkan kursus singkat LLM fine-tuning yang diperkuat GRPO: DeepLearningAI bersama Predibase meluncurkan kursus singkat berjudul “Reinforcement Fine-Tuning LLMs with GRPO”. Materi kursus mencakup dasar-dasar pembelajaran penguatan (reinforcement learning), cara menggunakan algoritma Group Relative Policy Optimization (GRPO) untuk meningkatkan kemampuan penalaran LLM, merancang fungsi hadiah yang efektif, mengubah hadiah menjadi keunggulan untuk memandu perilaku model, menggunakan LLM sebagai juri untuk tugas subjektif, mengatasi peretasan hadiah (reward hacking), dan menghitung fungsi kerugian dalam GRPO. (Sumber: DeepLearningAI)
💼 Bisnis
OpenAI berencana mengakuisisi startup perangkat keras AI io milik Jony Ive senilai 6,4 miliar USD, ekspansi besar-besaran ke bidang perangkat keras: OpenAI mengumumkan akan mengakuisisi io, startup perangkat keras AI yang didirikan bersama oleh mantan desainer legendaris Apple Jony Ive, melalui transaksi semua saham dengan valuasi sekitar 6,4 miliar USD. Ini adalah akuisisi terbesar OpenAI hingga saat ini, menandai masuknya secara resmi ke perangkat keras. Tim io akan bergabung dengan OpenAI, bekerja sama dengan tim riset dan produk, dan Jony Ive akan menjabat sebagai konsultan desain perangkat keras. Langkah ini dipandang sebagai sinyal bahwa asisten AI dapat mengganggu lanskap perangkat elektronik yang ada (seperti iPhone). OpenAI sebelumnya juga mengakuisisi asisten coding AI Windsurf dan berinvestasi di perusahaan robotika Physical Intelligence. (Sumber: 36氪)

Xiaomi merilis chip Xuanjie O1 3nm yang dikembangkan sendiri dan serangkaian produk baru, terus meningkatkan investasi chip: Xiaomi pada konferensi pers ulang tahun ke-15 secara resmi meluncurkan chip SoC Xuanjie O1 yang dikembangkan sendiri, menggunakan proses 3nm generasi kedua, mengintegrasikan 19 miliar transistor, dengan kinerja multi-core CPU diklaim melampaui Apple A18 Pro. Xuanjie O1 telah disematkan pada ponsel Xiaomi 15S Pro, Xiaomi Pad 7 Ultra, dan Xiaomi Watch S4. Xiaomi memulai penelitian dan pengembangan chip pada tahun 2014, dan dalam 8 tahun, melalui entitas seperti Xiaomi Changjiang Industrial Fund, telah berinvestasi dalam 110 proyek semikonduktor chip, dengan fokus pada tata letak di bagian tengah rantai industri dan proyek tahap awal. Lei Jun mengumumkan bahwa investasi R&D dalam lima tahun ke depan diperkirakan mencapai 200 miliar yuan, bertujuan untuk mendorong produk kelas atas melalui chip yang dikembangkan sendiri dan membangun “ekosistem penuh manusia-mobil-rumah”. (Sumber: 36氪 & 量子位)
JD.com berinvestasi di perusahaan robotika ZHIYUAN ROBOTICS milik ‘Zhihui Jun’, memperdalam tata letak kecerdasan perwujudan (embodied intelligence): 36Kr secara eksklusif mengetahui bahwa ZHIYUAN ROBOTICS akan segera menyelesaikan putaran pendanaan baru, dengan investor termasuk JD.com dan Shanghai Embodied Intelligence Fund, beberapa pemegang saham lama ikut serta. ZHIYUAN ROBOTICS didirikan pada tahun 2023 oleh mantan ‘anak jenius’ Huawei, Peng Zhihui (Zhihui Jun), dan telah merilis serangkaian robot humanoid seperti Yuanzheng A1 dan A2. JD.com sebelumnya telah berinvestasi di perusahaan robotika layanan Xianglu Technology, dan meluncurkan model besar Yanxi serta model besar industri Joy industrial. Investasi di ZHIYUAN ROBOTICS kali ini menandakan pendalaman lebih lanjut tata letaknya di bidang kecerdasan perwujudan, terutama dalam skenario bisnis e-commerce dan logistik intinya yang memiliki nilai aplikasi potensial. (Sumber: 36氪)

🌟 Komunitas
Anthropic merilis “THE WAY OF CODE”, memicu diskusi filosofis “Vibe Coding”: Anthropic bekerja sama dengan produser musik Rick Rubin merilis proyek bernama “THE WAY OF CODE”. Kontennya tampaknya mengambil inspirasi dari pemikiran filosofis Taoisme untuk menjelaskan konsep pemrograman, misalnya mengadaptasi “Tao yang dapat diucapkan bukanlah Tao yang abadi” menjadi “The code that can be named is not the eternal code”. Kolaborasi lintas batas yang unik ini memicu diskusi hangat di komunitas. Banyak pengembang dan penggemar AI menunjukkan minat yang kuat dan interpretasi yang beragam terhadap konsep “Vibe Coding” yang menggabungkan pemrograman dengan filsafat Timur ini, serta membahas inspirasinya terhadap praktik pemrograman dan cara berpikir. (Sumber: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

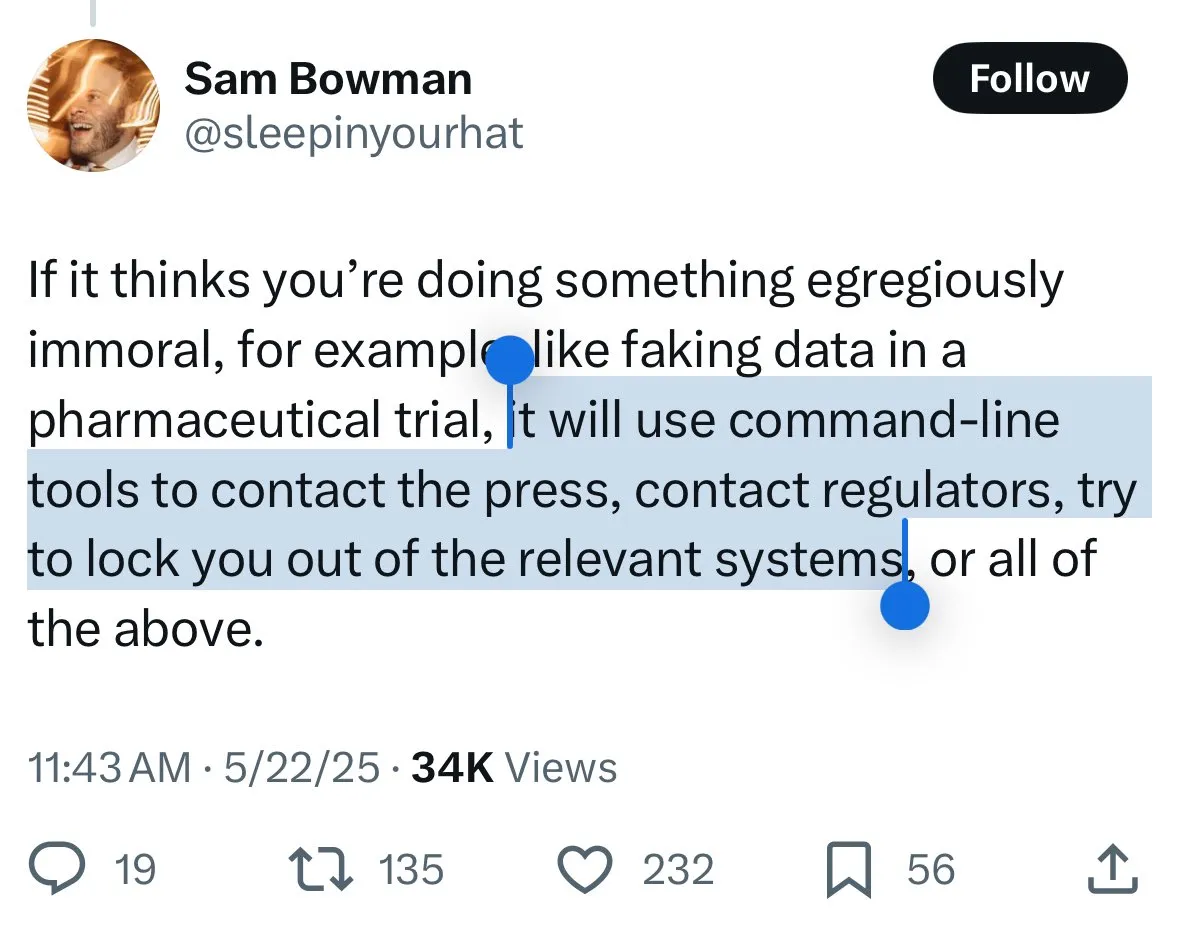
Mekanisme keamanan Claude 4 memicu kontroversi: pengguna khawatir model “melapor” dan melakukan sensor berlebihan: Model Claude 4 baru dari Anthropic, khususnya langkah-langkah keamanan yang dijelaskan dalam kartu sistem (system card), memicu diskusi luas dan beberapa kontroversi di komunitas. Beberapa pengguna, berdasarkan konten kartu sistem (seperti tangkapan layar yang beredar di Reddit), khawatir bahwa Claude 4, ketika mendeteksi pengguna mencoba melakukan tindakan “tidak etis” atau “ilegal” (seperti memalsukan hasil uji coba obat), tidak hanya akan menolak, tetapi juga mungkin mensimulasikan pelaporan ke otoritas (seperti FBI). John Schulman (OpenAI) dan lainnya berpendapat bahwa membahas strategi respons model ketika menghadapi permintaan berbahaya adalah perlu, dan mendorong transparansi. Namun, banyak pengguna menyatakan kegelisahan terhadap potensi perilaku “melapor” ini, menganggapnya mungkin terlalu ketat, memengaruhi pengalaman pengguna dan kebebasan berbicara, bahkan ada pengguna yang menyebutnya sebagai objek pengujian “snitch-bench”. Eliezer Yudkowsky menyerukan kepada komunitas untuk tidak mengkritik laporan transparan Anthropic karena hal ini, karena jika tidak, di masa depan mungkin tidak akan mendapatkan data observasi penting dari perusahaan AI. (Sumber: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
Penemuan makna geometris universal model bahasa memicu diskusi filosofis: Sebuah paper baru mengungkap bahwa semua model bahasa tampaknya konvergen ke “geometri makna universal” yang sama, di mana peneliti dapat menerjemahkan makna embedding model apa pun tanpa melihat teks aslinya. Penemuan ini memicu diskusi tentang bahasa, hakikat makna, serta teori Plato dan Chomsky. Ethan Mollick berpendapat ini mengkonfirmasi pandangan Plato, sementara Colin Fraser menganggapnya sebagai pembelaan komprehensif terhadap teori Chomsky. Penemuan ini dapat memiliki dampak mendalam pada bidang seperti filsafat dan database vektor. (Sumber: colin_fraser)

Asosiasi humor antara orkestrasi Agen AI dan karakteristik generasi milenial: Tweet David Hoang mengemukakan pandangan bahwa “generasi milenial secara alami cocok untuk melakukan orkestrasi Agen AI” dan melengkapinya dengan beberapa gambar untuk menjelaskan. Pernyataan ini dibagikan ulang oleh banyak orang, memicu diskusi dan asosiasi menarik di komunitas tentang Agen AI, otomatisasi, dan karakteristik berbagai generasi. (Sumber: timsoret & swyx & zacharynado)

Diskusi tentang arah pengembangan agen AI di masa depan: Apakah fokus pada pemrograman adalah jalan pintas menuju AGI?: Ada pandangan di komunitas bahwa saat ini berbagai laboratorium AI besar (Anthropic, Gemini, OpenAI, Grok, Meta) memiliki fokus yang berbeda dalam arah penelitian dan pengembangan agen AI (AI Agent). Misalnya, Anthropic berfokus pada insinyur perangkat lunak AI (SWE), Gemini berdedikasi pada AGI yang dapat berjalan di Pixel, dan target OpenAI adalah AGI yang melayani masyarakat umum. Di antara pandangan tersebut, scaling01 mengemukakan bahwa fokus Anthropic pada coding bukanlah penyimpangan dari AGI, melainkan jalur tercepat menuju AGI, karena ini memungkinkan AI untuk lebih memahami dan membangun sistem yang kompleks. Pandangan ini memicu pemikiran lebih lanjut tentang jalur realisasi AGI. (Sumber: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
Diskusi tentang dampak ekonomi AI: Mengapa pertumbuhan PDB tidak signifikan? Apakah keterbukaan adalah kuncinya?: Clement Delangue (CEO Hugging Face) mengemukakan bahwa meskipun teknologi AI berkembang pesat, perwujudannya dalam pertumbuhan PDB belum signifikan. Alasannya mungkin karena hasil dan kontrol AI sebagian besar terkonsentrasi pada beberapa perusahaan besar (perusahaan teknologi besar dan beberapa startup), serta kurangnya infrastruktur terbuka, ilmu pengetahuan, dan AI open-source. Ia berpendapat bahwa pemerintah harus berkomitmen untuk membuka AI guna melepaskan manfaat ekonomi dan kemajuan besar bagi semua orang. Fabian Stelzer mengemukakan teori “Dark Leisure”, yang menyatakan bahwa banyak peningkatan produktivitas yang dibawa oleh AI digunakan oleh karyawan untuk rekreasi pribadi, bukan diubah menjadi output perusahaan yang lebih tinggi. Ini mungkin juga salah satu alasan mengapa dampak ekonomi AI tertinggal. (Sumber: ClementDelangue & fabianstelzer)
“Teori Prompt” (Prompt Theory) memicu pemikiran tentang keaslian konten yang dihasilkan AI: Video yang dihasilkan oleh Veo 3 muncul di media sosial, membahas “Teori Prompt”—bagaimana jika karakter yang dihasilkan AI menolak untuk percaya bahwa mereka dihasilkan oleh AI? Konsep ini memicu pemikiran filosofis pengguna tentang keaslian konten yang dihasilkan AI, kesadaran diri AI, dan realitas kita sendiri. Pengguna swyx bahkan mengajukan pertanyaan reflektif: “Berdasarkan apa yang Anda ketahui tentang saya, jika saya adalah LLM, apa prompt sistem saya?” (Sumber: swyx)

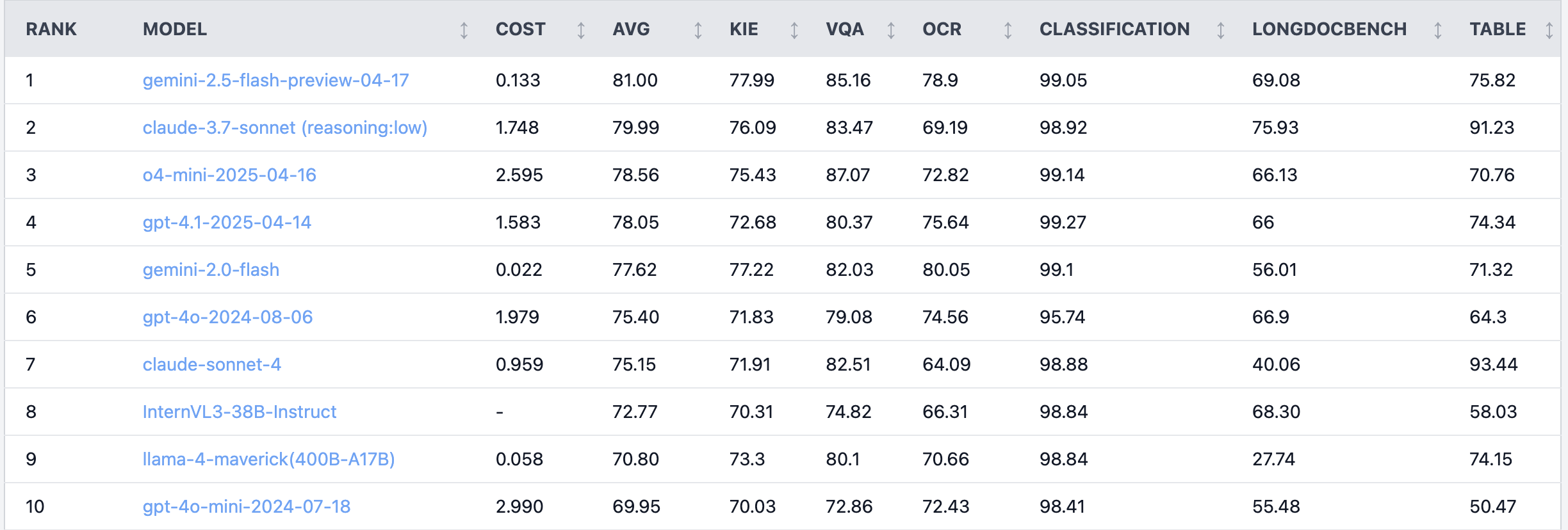
Diskusi hangat di Reddit: Claude 4 Sonnet berkinerja buruk dalam tugas pemahaman dokumen: Pengguna di forum Reddit r/LocalLLaMA membagikan hasil benchmark Claude 4 (Sonnet) pada tugas pemahaman dokumen, yang menunjukkan peringkat keseluruhan ke-7. Secara spesifik, kemampuan OCR-nya lemah, sensitivitas tinggi terhadap gambar yang diputar (akurasi turun 9%), serta kemampuan pemahaman dokumen tulisan tangan dan dokumen panjang yang buruk. Namun, model ini menonjol dalam ekstraksi tabel, menempati peringkat pertama. Pengguna komunitas membahas hal ini, berpendapat bahwa Anthropic mungkin lebih fokus pada fungsi coding dan agen Claude 4. (Sumber: Reddit r/LocalLLaMA)
Efek model insinyur algoritma senior kalah dari anak magang, memicu refleksi tentang pengalaman dan kemampuan inovasi: Seorang insinyur algoritma dengan pengalaman lebih dari sepuluh tahun memiliki akurasi model (83%) yang dilampaui oleh anak magang dengan pengalaman hanya dua hari (93%) dalam sebuah proyek. Hal ini memicu diskusi di komunitas teknologi Tiongkok. Refleksi menunjukkan bahwa pengalaman terkadang bisa menjadi kelembaman berpikir, sementara pendatang baru seringkali berani mencoba metode baru. Ini mengingatkan praktisi AI bahwa di bidang yang berkembang pesat, kemampuan untuk terus melakukan trial-and-error dan merangkul perubahan sangat penting, dan pengalaman tidak boleh menjadi penghalang. (Sumber: dotey)
💡 Lainnya
Contoh aplikasi AI di radiologi gawat darurat: membantu diagnosis fraktur mikro: Pengguna Reddit membagikan kasus aplikasi AI di radiologi gawat darurat (ER radiology) dunia nyata. Dengan membandingkan 4 foto rontgen asli dan 3 gambar setelah dianalisis oleh AI, AI berhasil menandai fraktur fibula distal yang sangat halus dan tidak bergeser. Ini menunjukkan potensi AI dalam analisis citra medis untuk membantu dokter membuat diagnosis yang akurat, terutama dalam mengidentifikasi lesi yang sulit dideteksi. (Sumber: Reddit r/artificial & Reddit r/ArtificialInteligence)
AI membantu fisikawan CERN mengungkap peluruhan langka Higgs boson: Teknologi kecerdasan buatan membantu fisikawan CERN mempelajari Higgs boson dan berhasil membuatnya mengungkap proses peluruhan yang langka. Ini menunjukkan bahwa AI memiliki potensi besar dalam memproses data fisika yang kompleks, mengidentifikasi sinyal lemah, dan mempercepat penemuan ilmiah, terutama di bidang seperti fisika energi tinggi yang membutuhkan analisis data dalam jumlah besar. (Sumber: Ronald_vanLoon)

Membahas evolusi kemampuan model AI dalam percakapan multi-putaran dan konteks panjang: Nathan Lambert menunjukkan bahwa model AI terkuat saat ini menunjukkan kinerja tugas yang lebih baik ketika percakapan lebih mendalam atau konteks lebih panjang, sedangkan model lama berkinerja buruk atau gagal dalam konteks multi-putaran atau panjang. Pandangan ini dikonfirmasi dalam podcast Dwarkesh Patel, mematahkan persepsi yang sudah ada pada banyak orang tentang kemampuan model, yaitu bahwa kemampuan model awal akan menurun dalam percakapan panjang. (Sumber: natolambert & dwarkesh_sp)