
Kata Kunci:Gemini 2.5 Pro, Veo 3, OpenAI, Jony Ive, Claude 4 Opus, Pembuatan video AI, Agen cerdas AI, Model multimodal, Mode Deep Think, Model pembuatan video, Kemampuan penalaran AI, Desain perangkat keras AI, Optimalisasi rekayasa perangkat lunak
🔥 Fokus Utama
Google merilis Gemini 2.5 Pro Deep Think dan Veo 3, mendorong penalaran AI dan pembuatan video ke tingkat yang baru: Di konferensi Google I/O, Google meluncurkan mode Deep Think untuk Gemini 2.5 Pro, yang dirancang khusus untuk menyelesaikan masalah kompleks. Mode ini menunjukkan kinerja luar biasa dalam soal-soal sulit kompetisi matematika seperti USAMO, dan mendemonstrasikan kemajuan signifikan AI dalam penalaran tingkat lanjut, misalnya, dengan penalaran multi-langkah dan mencoba berbagai metode pembuktian (seperti pembuktian dengan kontradiksi, teorema Rolle) untuk menyelesaikan masalah aljabar yang kompleks. Sementara itu, model pembuatan video Veo 3 yang dirilis Google, dengan adegan realistis, konsistensi karakter yang dapat dikontrol, sintesis suara, dan berbagai fungsi penyuntingan (seperti transformasi adegan, pembuatan gambar referensi, transfer gaya, penentuan frame awal dan akhir, penyuntingan lokal, dll.), telah menetapkan standar baru di bidang pembuatan video AI dan menarik perhatian luas (Sumber: demishassabis, lmthang, GoogleDeepMind, _philschmid, fabianstelzer, matvelloso, seo_leaders, op7418, )
OpenAI mengakuisisi perusahaan Jony Ive senilai $6,5 miliar untuk bersama-sama menciptakan komputer generasi baru yang didukung AI: OpenAI mengumumkan kerja sama dengan mantan kepala desainer Apple, Jony Ive, dan mengakuisisi perusahaannya, dengan tujuan untuk bersama-sama membangun komputer generasi baru yang didukung AI. Langkah ini menandai ekspansi OpenAI ke ranah perangkat keras dan upaya untuk mengintegrasikan kemampuan AI secara mendalam ke dalam perangkat komputasi, yang berpotensi membentuk kembali cara interaksi manusia-komputer. Jony Ive terkenal dengan desainnya yang luar biasa selama di Apple, dan partisipasinya menandakan bahwa perangkat baru ini mungkin akan memiliki terobosan besar dalam desain dan pengalaman pengguna, menantang bentuk perangkat komputasi yang ada saat ini (Sumber: op7418, TheRundownAI, BorisMPower)
Konferensi Pengembang Anthropic segera digelar, Claude 4 Opus kemungkinan akan dirilis, fokus pada kemampuan rekayasa perangkat lunak: Anthropic akan segera mengadakan konferensi pengembang pertamanya, dan komunitas secara luas berspekulasi bahwa model generasi baru Claude 4 (termasuk Sonnet 4 dan Opus 4) mungkin akan dirilis pada konferensi ini. Ada indikasi bahwa Claude Sonnet 3.7 API telah menunjukkan perilaku yang mirip dengan Claude 4, seperti penggunaan alat yang cepat tanpa memerlukan “langkah berpikir”. Anthropic tampaknya sedang memusatkan perhatian untuk mengatasi tantangan rekayasa perangkat lunak, yang berbeda dari jalur OpenAI dan Google yang mengejar “model serba bisa”. Majalah TIME juga secara tidak langsung mengonfirmasi perilisan Claude 4 Opus, yang semakin meningkatkan ekspektasi pasar terhadap kemampuan Anthropic dalam pengkodean AI dan pemrosesan tugas kompleks (Sumber: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
Perbedaan strategi ekosistem AI OpenAI dan Google: Merakit kapal perang vs. merombak kerajaan: OpenAI dan Google masing-masing menempuh jalur yang berbeda, yaitu “melengkapi ekosistem” dan “merombak ekosistem”, untuk memperebutkan posisi “sistem operasi utama” platform AI di masa depan. OpenAI merakit kemampuan AI full-stack dari nol dengan mengakuisisi perangkat keras (io), basis data (Rockset), rantai alat (Windsurf), dan alat kolaborasi (Multi). Sementara itu, Google memilih untuk menanamkan model Gemini-nya secara mendalam ke dalam produk yang sudah ada (Search, Android, Docs, YouTube, dll.) dan merombak sistem dasarnya untuk mencapai AI-native. Meskipun strategi keduanya berbeda, tujuannya sama, yaitu membangun platform pamungkas di era AI (Sumber: dotey)
🎯 Perkembangan
Microsoft mengungkapkan visi “jaringan agen cerdas”, menekankan agen AI akan menjadi inti pekerjaan generasi berikutnya: CEO Microsoft Satya Nadella dalam konferensi Build 2025 dan wawancara menjelaskan visi perusahaan tentang “jaringan agen cerdas (agentic web)”. Ia berpendapat bahwa di masa depan, agen AI akan menjadi warga kelas satu dalam ekosistem bisnis dan M365, bahkan mungkin melahirkan profesi baru seperti “administrator agen AI”. Ketika 95% kode dihasilkan oleh AI, peran manusia akan beralih ke pengelolaan dan orkestrasi agen-agen ini. Microsoft sedang membangun ekosistem agen terbuka melalui Azure AI Foundry, Copilot Studio, dan protokol terbuka seperti NLWeb, serta akan menjadikan Teams sebagai pusat kolaborasi multi-agen (Sumber: rowancheung, TheTuringPost)
MMaDA: Model bahasa difusi multimodal yang menyatukan penalaran teks, pemahaman multimodal, dan pembuatan gambar dirilis: Para peneliti meluncurkan MMaDA (Multimodal Large Diffusion Language Models), sebuah model dasar difusi multimodal baru yang menyatukan kemampuan penalaran teks, pemahaman multimodal, dan pembuatan gambar melalui Mixed Long-CoT (Mixed Long Chain-of-Thought) dan algoritma reinforcement learning terpadu UniGRPO. MMaDA-8B melampaui Show-o dan SEED-X dalam pemahaman multimodal, dan lebih unggul dari SDXL dan Janus dalam pembuatan teks-ke-gambar. Model dan kodenya telah dirilis secara open source di Hugging Face (Sumber: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache: Merancang mekanisme cache untuk model bahasa difusi, meningkatkan kecepatan inferensi secara signifikan: Untuk mengatasi masalah kecepatan inferensi yang lambat pada model bahasa difusi (DLMs), para peneliti mengusulkan mekanisme dKV-Cache. Metode ini mengambil inspirasi dari KV-Cache pada model autoregresif, dengan merancang cache kunci-nilai untuk proses denoising DLMs melalui strategi cache yang tertunda dan terkondisi. Eksperimen menunjukkan bahwa dKV-Cache dapat mencapai percepatan inferensi 2-10 kali lipat, secara signifikan mengurangi kesenjangan kecepatan antara DLMs dan model autoregresif, bahkan meningkatkan kinerja pada urutan panjang, dan dapat diterapkan pada DLM yang ada tanpa pelatihan (Sumber: NandoDF, HuggingFace Daily Papers)

Imagen4 menunjukkan kinerja luar biasa dalam restorasi detail, mendekati akhir permainan pembuatan gambar: Model Imagen4 menunjukkan kemampuan restorasi detail yang kuat dalam menghasilkan gambar berdasarkan prompt teks yang kompleks. Misalnya, saat menghasilkan gambar yang berisi 25 detail spesifik (seperti warna, objek, lokasi, pencahayaan, dan suasana tertentu), Imagen4 berhasil merestorasi 23 di antaranya. Tingkat fidelitas tinggi dan pemahaman yang akurat terhadap instruksi kompleks ini menunjukkan bahwa teknologi teks-ke-gambar sedang mendekati tingkat “akhir permainan” di mana ia dapat mereproduksi imajinasi pengguna dengan sempurna (Sumber: cloneofsimo)

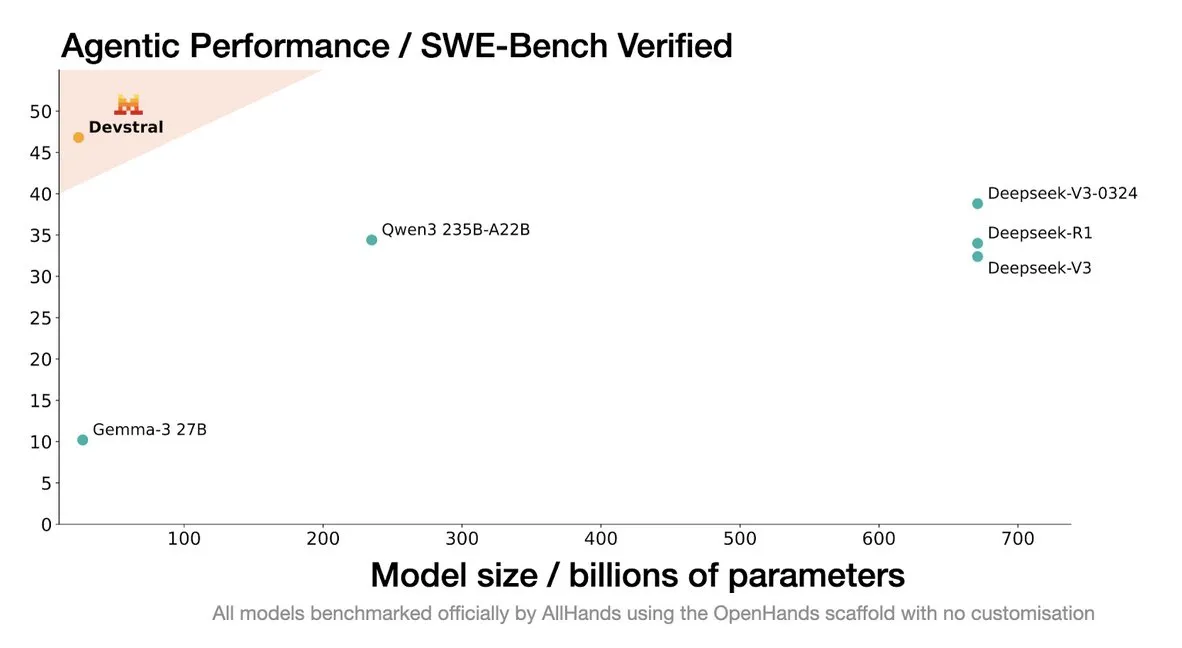
Mistral merilis model Devstral, dirancang khusus untuk agen pengkodean: Mistral AI meluncurkan Devstral, sebuah model open source yang dirancang khusus untuk agen pengkodean, dan dikembangkan bekerja sama dengan allhands_ai. Versi kuantisasi 4-bit DWQ-nya telah tersedia di Hugging Face (mlx-community/Devstral-Small-2505-4bit-DWQ), dapat berjalan lancar di perangkat seperti M2 Ultra, dan menunjukkan potensi optimasi dalam pembuatan dan pemahaman kode (Sumber: awnihannun, clefourrier, GuillaumeLample)
ByteDance merilis laporan pelatihan model multimodal sekelas Gemini, menggunakan arsitektur Integrated Transformer: ByteDance merilis laporan setebal 37 halaman yang merinci metode pelatihan model multimodal natif sekelas Gemini. Yang paling menarik perhatian adalah arsitektur “Integrated Transformer”, yang menggunakan backbone network yang sama sebagai model autoregresif sekelas GPT dan model difusi sekelas DiT secara bersamaan, menunjukkan eksplorasinya dalam pemodelan terpadu multimodal (Sumber: NandoDF)

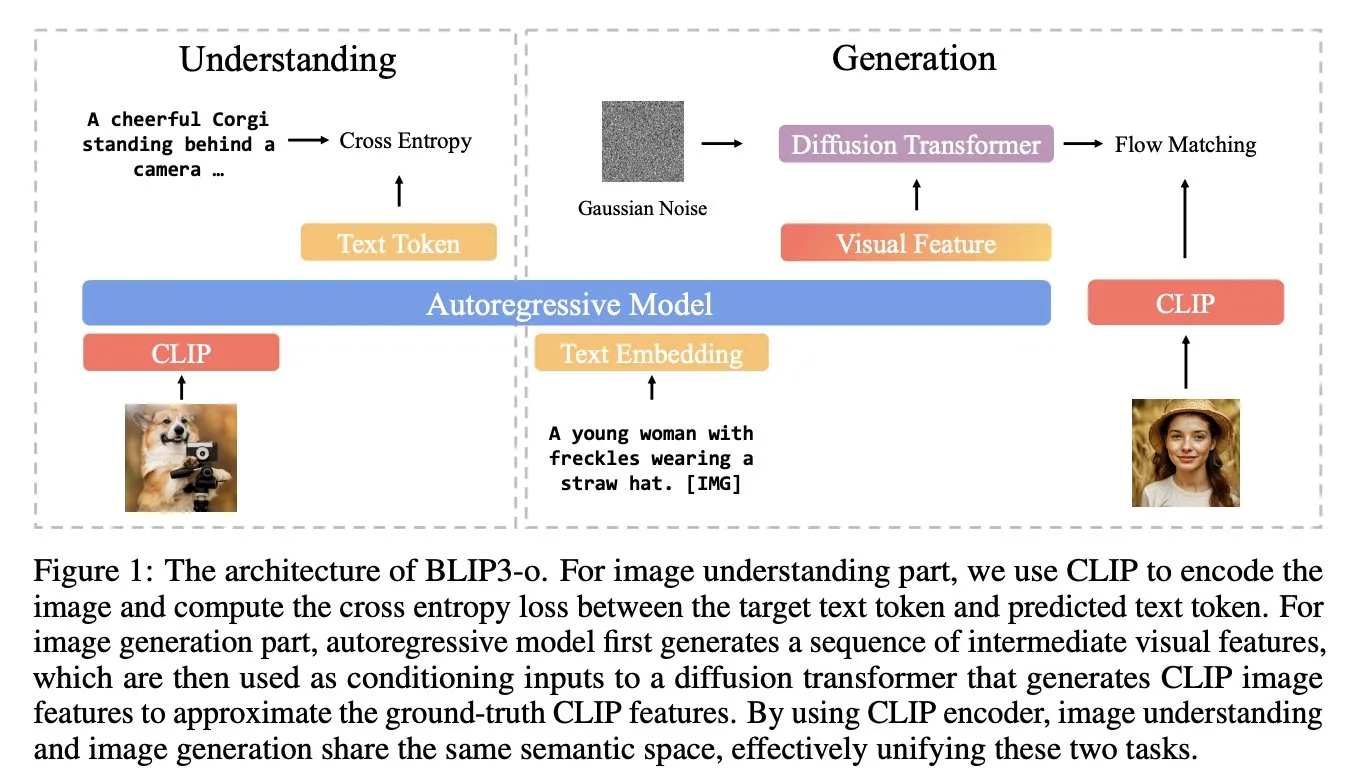
BLIP3-o: Salesforce meluncurkan seri model multimodal terpadu sepenuhnya open source, membuka kemampuan pembuatan gambar sekelas GPT-4o: Tim peneliti Salesforce merilis seri model BLIP3-o, sekelompok model multimodal terpadu yang sepenuhnya open source, yang bertujuan untuk mencoba membuka kemampuan pembuatan gambar serupa GPT-4o. Proyek ini tidak hanya merilis model secara open source, tetapi juga mempublikasikan dataset pra-pelatihan yang berisi 25 juta data, mendorong keterbukaan penelitian multimodal (Sumber: arankomatsuzaki)
Google meluncurkan pratinjau Gemma 3n E4B, model multimodal yang dirancang khusus untuk perangkat berdaya rendah: Google merilis model Gemma 3n E4B-it-litert-preview di Hugging Face. Model ini dirancang untuk memproses input teks, gambar, video, dan audio, serta menghasilkan output teks. Versi saat ini mendukung input teks dan visual. Gemma 3n menggunakan arsitektur Matformer yang baru, yang memungkinkan penyarangan beberapa model dan aktivasi parameter 2B atau 4B secara efektif, dioptimalkan khusus untuk berjalan secara efisien pada perangkat berdaya rendah. Model ini dilatih berdasarkan sekitar 11 triliun token data multimodal, dengan pengetahuan hingga Juni 2024 (Sumber: Tim_Dettmers, Reddit r/LocalLLaMA)
Penelitian mengungkapkan fenomena Language Specific Knowledge (LSK) dalam model bahasa besar: Sebuah studi baru mengeksplorasi fenomena “Language Specific Knowledge” (LSK) yang ada dalam model bahasa, yaitu model mungkin berkinerja lebih baik dalam bahasa non-Inggris tertentu ketika menangani topik atau domain tertentu dibandingkan dalam bahasa Inggris. Studi tersebut menemukan bahwa kinerja model dapat ditingkatkan dengan melakukan penalaran chain-of-thought dalam bahasa tertentu (bahkan bahasa dengan sumber daya rendah). Ini menunjukkan bahwa teks spesifik budaya lebih kaya dalam bahasa yang sesuai, sehingga pengetahuan spesifik mungkin hanya ada dalam bahasa “ahli”. Para peneliti merancang metode LSKExtractor untuk mengukur dan memanfaatkan LSK ini, dengan peningkatan akurasi rata-rata relatif sebesar 10% pada beberapa model dan dataset (Sumber: HuggingFace Daily Papers)
Efek pembuatan video DeepMind Veo 3 menakjubkan, detail realistis menarik perhatian: Model pembuatan video Veo 3 dari Google DeepMind menunjukkan kemampuan pembuatan video yang kuat, termasuk transformasi adegan, penggerak gambar referensi, transfer gaya, konsistensi karakter, penentuan frame awal dan akhir, penskalaan video, penambahan objek, dan kontrol aksi. Realisme video yang dihasilkan dan kemampuannya memahami instruksi kompleks membuat pengguna kagum dengan pesatnya perkembangan teknologi pembuatan video AI, bahkan ada pengguna yang menggunakannya untuk membuat iklan dengan efek yang sebanding dengan produksi profesional (Sumber: demishassabis, , Reddit r/ChatGPT)
Model bahasa visual Moondream meluncurkan versi kuantisasi 4-bit, secara signifikan mengurangi memori GPU dan meningkatkan kecepatan: Model bahasa visual (VLM) Moondream merilis versi kuantisasi 4-bit, yang menghasilkan pengurangan penggunaan memori GPU sebesar 42% dan peningkatan kecepatan inferensi sebesar 34%, sambil mempertahankan akurasi 99,4%. Optimasi ini membuat VLM kecil yang kuat ini lebih mudah untuk diterapkan dan digunakan dalam tugas-tugas seperti deteksi objek, dan disambut baik oleh para pengembang (Sumber: Sentdex, vikhyatk)
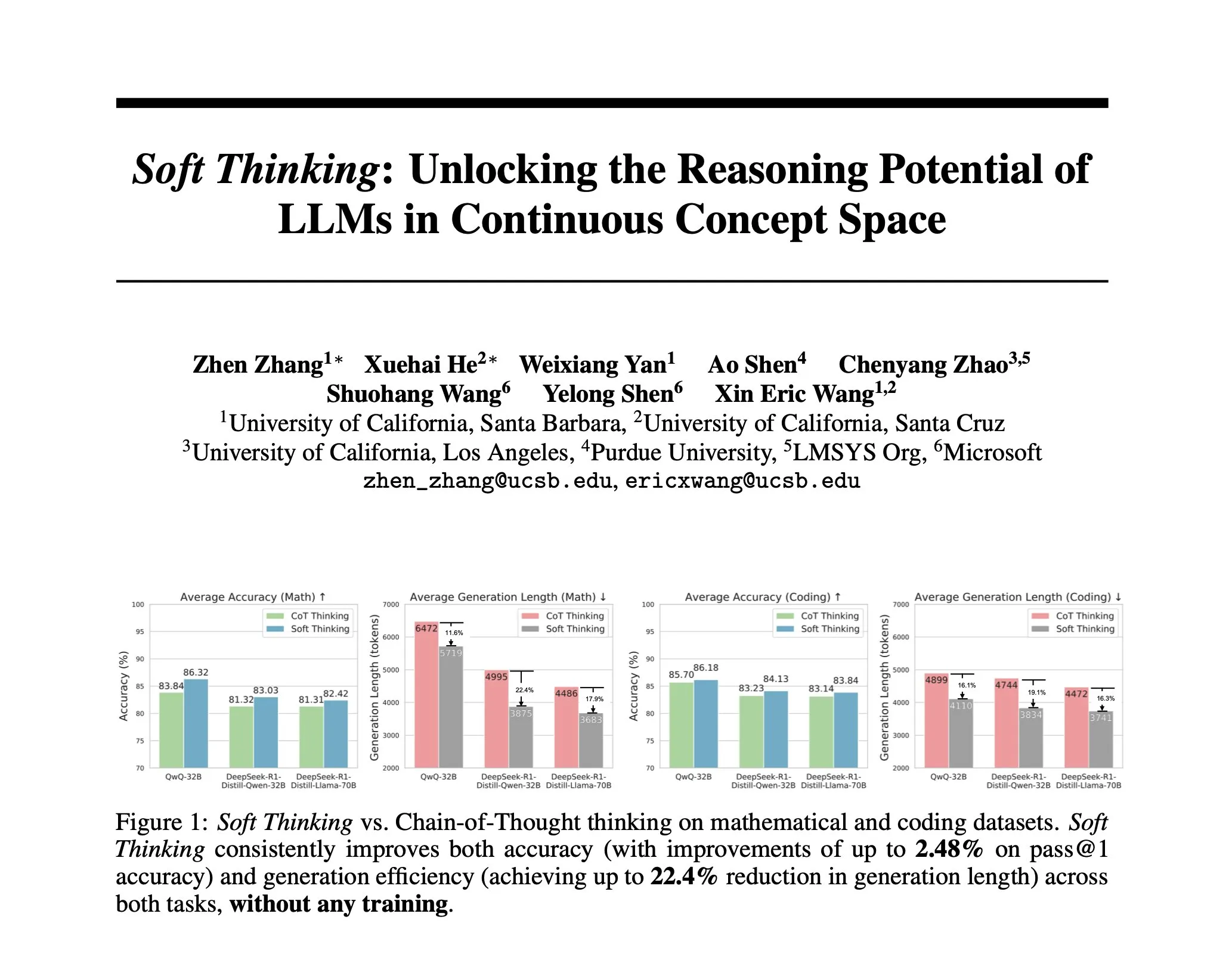
Penelitian mengusulkan Soft Thinking: Metode tanpa pelatihan untuk meniru penalaran “lunak” manusia: Untuk membuat penalaran AI lebih mendekati pemikiran manusia yang lancar dan tidak dibatasi oleh token diskrit, para peneliti mengusulkan metode Soft Thinking. Metode ini tidak memerlukan pelatihan tambahan, dengan menghasilkan token konsep abstrak yang berkelanjutan. Token-token ini menggabungkan berbagai makna secara halus melalui campuran embedding yang diberi bobot probabilitas, sehingga mencapai representasi yang lebih kaya dan eksplorasi jalur penalaran yang berbeda secara mulus. Eksperimen menunjukkan bahwa metode ini meningkatkan akurasi hingga 2,48% (pass@1) dalam benchmark matematika dan kode, sekaligus mengurangi penggunaan token hingga 22,4% (Sumber: arankomatsuzaki)
Kerangka kerja IA-T2I: Memanfaatkan internet untuk meningkatkan kemampuan model teks-ke-gambar dalam memproses pengetahuan yang tidak pasti: Untuk mengatasi kekurangan model teks-ke-gambar yang ada dalam memproses prompt teks yang mengandung pengetahuan yang tidak pasti (seperti peristiwa terkini, konsep langka), kerangka kerja IA-T2I (Internet-Augmented Text-to-Image Generation) diusulkan. Kerangka kerja ini melalui modul pengambilan aktif menentukan apakah gambar referensi diperlukan, memanfaatkan modul pemilihan gambar hierarkis untuk memilih gambar yang paling sesuai dari hasil mesin pencari untuk meningkatkan model T2I, dan melalui mekanisme refleksi diri terus mengevaluasi dan mengoptimalkan gambar yang dihasilkan. Pada dataset Img-Ref-T2I yang dibangun khusus, IA-T2I berkinerja lebih baik sekitar 30% (evaluasi manusia) dibandingkan GPT-4o (Sumber: HuggingFace Daily Papers)
MoI (Mixture of Inputs) meningkatkan kualitas generasi autoregresif dan kemampuan penalaran: Untuk mengatasi masalah hilangnya informasi distribusi token selama proses generasi autoregresif standar, para peneliti mengusulkan metode Mixture of Inputs (MoI). Metode ini tidak memerlukan pelatihan tambahan. Setelah menghasilkan satu token, ia mencampurkan token diskrit yang dihasilkan dengan distribusi token yang sebelumnya dibuang untuk membangun input baru. Melalui estimasi Bayesian, distribusi token dianggap sebagai prior, token sampel dianggap sebagai observasi, dan ekspektasi posterior kontinu menggantikan vektor one-hot tradisional sebagai input model baru. MoI secara konsisten meningkatkan kinerja beberapa model seperti Qwen-32B dan Nemotron-Super-49B pada tugas penalaran matematika, pembuatan kode, dan tanya jawab tingkat doktoral (Sumber: HuggingFace Daily Papers)
ConvSearch-R1: Mengoptimalkan penulisan ulang kueri dalam pencarian percakapan melalui reinforcement learning: Untuk mengatasi masalah ambiguitas, penghilangan, dan referensi dalam kueri yang bergantung pada konteks dalam pencarian percakapan, kerangka kerja ConvSearch-R1 diusulkan. Kerangka kerja ini untuk pertama kalinya mengadopsi metode self-driven, secara langsung memanfaatkan sinyal pengambilan untuk mengoptimalkan penulisan ulang kueri melalui reinforcement learning, sepenuhnya menghilangkan ketergantungan pada pengawasan penulisan ulang eksternal (seperti anotasi manual atau model besar). Metode dua tahapnya mencakup pemanasan strategi self-driven dan reinforcement learning berbasis panduan pengambilan (menggunakan mekanisme hadiah insentif berjenjang). Eksperimen menunjukkan bahwa ConvSearch-R1 secara signifikan mengungguli metode SOTA sebelumnya pada dataset TopiOCQA dan QReCC (Sumber: HuggingFace Daily Papers)
Kerangka kerja ASRR mewujudkan penalaran adaptif yang efisien untuk model bahasa besar: Untuk mengatasi masalah biaya komputasi yang berlebihan pada model penalaran besar (LRMs) karena penalaran yang berlebihan pada tugas-tugas sederhana, para peneliti mengusulkan kerangka kerja Adaptive Self-Recovery Reasoning (ASRR). Kerangka kerja ini dengan mengungkapkan “mekanisme pemulihan diri internal” model (secara implisit melengkapi penalaran dalam pembuatan jawaban), menekan penalaran yang tidak perlu, dan memperkenalkan penyesuaian hadiah panjang yang peka terhadap akurasi, secara adaptif mengalokasikan upaya penalaran berdasarkan kesulitan masalah. Eksperimen menunjukkan bahwa ASRR dapat secara signifikan mengurangi anggaran penalaran dan meningkatkan tingkat tidak berbahaya pada benchmark keamanan dengan kerugian kinerja yang minimal (Sumber: HuggingFace Daily Papers)
Kerangka kerja MoT (Mixture-of-Thought) meningkatkan kemampuan penalaran logis: Terinspirasi oleh manusia yang memanfaatkan berbagai modalitas penalaran (bahasa alami, kode, logika simbolik) untuk menyelesaikan masalah logis, para peneliti mengusulkan kerangka kerja Mixture-of-Thought (MoT). MoT memungkinkan LLM untuk melakukan penalaran lintas tiga modalitas komplementer, termasuk modalitas simbolik tabel kebenaran yang baru diperkenalkan. Melalui desain dua tahap (pelatihan MoT evolusi mandiri dan inferensi MoT), MoT secara signifikan mengungguli metode chain-of-thought modalitas tunggal pada benchmark penalaran logis seperti FOLIO dan ProofWriter, dengan peningkatan akurasi rata-rata hingga 11,7% (Sumber: HuggingFace Daily Papers)
RL Tango: Melatih generator dan validator secara bersamaan melalui reinforcement learning untuk meningkatkan penalaran bahasa: Untuk mengatasi masalah peretasan hadiah dan generalisasi yang buruk dalam metode reinforcement learning LLM yang ada di mana validator (model hadiah) bersifat tetap atau disesuaikan dengan pengawasan, kerangka kerja RL Tango diusulkan. Kerangka kerja ini secara bergantian melatih generator LLM dan validator LLM generatif tingkat proses secara bersamaan melalui reinforcement learning. Validator hanya dilatih berdasarkan hadiah kebenaran validasi tingkat hasil, tanpa memerlukan anotasi tingkat proses, sehingga membentuk saling dukung yang efektif dengan generator. Eksperimen menunjukkan bahwa generator dan validator Tango mencapai tingkat SOTA pada model skala 7B/8B (Sumber: HuggingFace Daily Papers)
pPE: Rekayasa prompt prior membantu penyempurnaan yang diperkuat (RFT): Sebuah penelitian mengeksplorasi peran rekayasa prompt prior (prior prompt engineering, pPE) dalam penyempurnaan yang diperkuat (Reinforced Fine-Tuning, RFT). Berbeda dengan rekayasa prompt saat inferensi (inference-time prompt engineering, iPE), pPE menempatkan instruksi (seperti penalaran langkah demi langkah) sebelum kueri pada tahap pelatihan untuk memandu model bahasa menginternalisasi perilaku tertentu. Eksperimen menerapkan lima strategi iPE (penalaran, perencanaan, penalaran kode, mengingat pengetahuan, pemanfaatan contoh kosong) menjadi metode pPE pada Qwen2.5-7B. Hasil menunjukkan bahwa semua model yang dilatih dengan pPE mengungguli model iPE yang sesuai, di mana pPE contoh kosong menunjukkan peningkatan terbesar pada benchmark seperti AIME2024 dan GPQA-Diamond, mengungkapkan pPE sebagai sarana efektif yang belum cukup diteliti dalam RFT (Sumber: HuggingFace Daily Papers)
BiasLens: Kerangka kerja evaluasi bias LLM tanpa memerlukan set pengujian manual: Untuk mengatasi masalah metode evaluasi bias LLM yang ada yang bergantung pada data berlabel yang dibuat secara manual dan cakupannya terbatas, kerangka kerja BiasLens diusulkan. Kerangka kerja ini berangkat dari struktur ruang vektor model, menggabungkan concept activation vectors (CAVs) dan sparse autoencoders (SAEs) untuk mengekstrak representasi konsep yang dapat diinterpretasikan, dan mengukur bias dengan mengukur perubahan kesamaan representasi antara konsep target dan konsep referensi. BiasLens menunjukkan konsistensi yang kuat (korelasi Spearman r > 0,85) dengan metrik evaluasi bias tradisional dalam kasus data tanpa label, dan dapat mengungkapkan bentuk bias yang sulit dideteksi dengan metode yang ada (Sumber: HuggingFace Daily Papers)
HumaniBench: Kerangka kerja evaluasi model multimodal besar yang berpusat pada manusia: Untuk mengatasi kekurangan LMM saat ini dalam standar yang berpusat pada manusia seperti keadilan, etika, dan empati, HumaniBench diusulkan. Ini adalah benchmark komprehensif yang berisi 32K pasangan tanya jawab gambar-teks dunia nyata, dianotasi dengan bantuan GPT-4o dan divalidasi oleh para ahli. HumaniBench mengevaluasi tujuh prinsip AI yang berpusat pada manusia: keadilan, etika, pemahaman, penalaran, inklusivitas bahasa, empati, dan ketahanan, yang mencakup tujuh tugas beragam. Pengujian terhadap 15 LMM SOTA menunjukkan bahwa model sumber tertutup umumnya lebih unggul, tetapi ketahanan dan lokalisasi visual masih menjadi kelemahan (Sumber: HuggingFace Daily Papers)
AJailBench: Benchmark komprehensif pertama untuk serangan jailbreak pada model bahasa audio besar: Untuk mengevaluasi keamanan model bahasa audio besar (LAMs) secara sistematis terhadap serangan jailbreak, AJailBench diusulkan. Benchmark ini pertama-tama membangun dataset AJailBench-Base yang berisi 1495 prompt audio adversarial, yang mencakup 10 kategori pelanggaran. Evaluasi berdasarkan dataset ini menunjukkan bahwa LAMs SOTA yang ada tidak menunjukkan ketahanan yang konsisten. Untuk mensimulasikan serangan yang lebih realistis, para peneliti mengembangkan perangkat perturbasi audio (APT), yang mencari perturbasi halus dan efisien melalui optimasi Bayesian, menghasilkan dataset yang diperluas AJailBench-APT. Penelitian menunjukkan bahwa perturbasi kecil yang mempertahankan semantik dapat secara signifikan mengurangi kinerja keamanan LAMs (Sumber: HuggingFace Daily Papers)
WebNovelBench: Benchmark untuk mengevaluasi kemampuan LLM dalam membuat novel panjang: Untuk mengatasi tantangan dalam mengevaluasi kemampuan narasi panjang LLM, WebNovelBench diusulkan. Benchmark ini memanfaatkan dataset lebih dari 4000 novel web Tiongkok, menetapkan evaluasi sebagai tugas pembuatan cerita dari kerangka. Melalui metode LLM-sebagai-penilai, evaluasi otomatis dilakukan dari delapan dimensi kualitas naratif, dan skor diagregasi menggunakan analisis komponen utama, dibandingkan dengan karya manusia melalui peringkat persentil. Eksperimen secara efektif membedakan antara mahakarya manusia, novel web populer, dan konten yang dihasilkan LLM, serta melakukan analisis komprehensif terhadap 24 LLM SOTA (Sumber: HuggingFace Daily Papers)
MultiHal: Dataset landasan grafik pengetahuan multibahasa untuk evaluasi halusinasi LLM: Untuk mengatasi kekurangan benchmark evaluasi halusinasi yang ada dalam hal jalur grafik pengetahuan dan multibahasa, MultiHal diusulkan. Ini adalah benchmark multibahasa, multi-hop berbasis grafik pengetahuan, yang dirancang khusus untuk evaluasi teks yang dihasilkan. Tim menambang 140.000 jalur dari grafik pengetahuan domain terbuka dan menyaring 25.900 jalur berkualitas tinggi. Evaluasi dasar menunjukkan bahwa pada multibahasa dan multi-model, RAG yang ditingkatkan grafik pengetahuan (KG-RAG) dibandingkan dengan tanya jawab biasa, menunjukkan peningkatan absolut sekitar 0,12 hingga 0,36 poin dalam skor kesamaan semantik, menunjukkan potensi integrasi grafik pengetahuan (Sumber: HuggingFace Daily Papers)
Llama-SMoP: Metode pengenalan ucapan audio-video LLM berbasis proyektor campuran jarang: Untuk mengatasi biaya komputasi yang tinggi pada LLM dalam pengenalan ucapan audio-video (AVSR), Llama-SMoP diusulkan. Ini adalah LLM multimodal yang efisien yang menggunakan modul proyektor campuran jarang (SMoP), melalui proyektor campuran ahli (MoE) yang dikendalikan secara jarang, memperluas kapasitas model tanpa meningkatkan biaya inferensi. Eksperimen menunjukkan bahwa konfigurasi Llama-SMoP DEDR yang menggunakan perutean dan ahli khusus modalitas, mencapai kinerja luar biasa dalam tugas ASR, VSR, dan AVSR, dan menunjukkan kinerja yang baik dalam aktivasi ahli, skalabilitas, dan ketahanan terhadap kebisingan (Sumber: HuggingFace Daily Papers)
VPRL: Kerangka kerja perencanaan visual murni berbasis reinforcement learning, kinerja melampaui penalaran teks: Tim peneliti dari Universitas Cambridge, University College London, dan Google mengusulkan VPRL (Visual Planning with Reinforcement Learning), sebuah paradigma baru yang murni mengandalkan urutan gambar untuk melakukan penalaran. Kerangka kerja ini memanfaatkan Group Relative Policy Optimization (GRPO) untuk melatih ulang model visual besar, menghitung sinyal hadiah melalui transisi status visual dan memvalidasi batasan lingkungan. Dalam tugas navigasi visual seperti FrozenLake, Maze, dan MiniBehavior, akurasi VPRL mencapai 80,6%, secara signifikan mengungguli metode penalaran berbasis teks (seperti Gemini 2.5 Pro dengan 43,7%), dan menunjukkan kinerja yang lebih baik dalam tugas kompleks dan ketahanan, membuktikan keunggulan perencanaan visual (Sumber: 量子位)

Nvidia mengumumkan peta jalan teknologi AI lima tahun ke depan, bertransformasi menjadi perusahaan infrastruktur AI: CEO Nvidia Jensen Huang di COMPUTEX 2025 mengumumkan penyesuaian posisi perusahaan menjadi perusahaan infrastruktur AI dan memaparkan peta jalan teknologi lima tahun ke depan. Ia menekankan bahwa infrastruktur AI akan ada di mana-mana seperti listrik atau internet, dan Nvidia berkomitmen untuk membangun “pabrik” era AI. Untuk mendukung transformasi ini, Nvidia akan memperluas “lingkaran pertemanan” rantai pasoknya, memperdalam kerja sama dengan TSMC dan lainnya, serta berencana membangun kantor (NVIDIA Constellation) dan superkomputer AI raksasa pertama di Taiwan (Sumber: 36氪)

Google memulai kembali proyek kacamata AI, merilis platform Android XR dan perangkat pihak ketiga: Google di konferensi I/O 2025 mengumumkan dimulainya kembali proyek kacamata AI/AR, merilis platform Android XR yang dikembangkan khusus untuk perangkat XR, dan memamerkan dua perangkat pihak ketiga berbasis platform tersebut: Project Moohan dari Samsung (menyaingi Vision Pro) dan Project Aura dari Xreal. Google bertujuan untuk meniru kesuksesan Android di bidang smartphone, menciptakan “momen Android” untuk perangkat XR, dan mempersiapkan platform komputasi lingkungan dan spasial di masa depan. Dikombinasikan dengan model besar multimodal Gemini 2.5 Pro yang ditingkatkan dan teknologi asisten cerdas Project Astra, kacamata AI/AR generasi baru akan menghadirkan pengalaman disruptif dalam pemahaman suara, terjemahan waktu nyata, kesadaran kontekstual, dan pelaksanaan tugas kompleks (Sumber: 36氪)

Prinsip tantangan ARC-AGI-2 diperbarui, menekankan penalaran kontekstual multi-langkah: Makalah ARC-AGI-2 yang baru dirilis memperbarui prinsip desain tantangan tersebut. Prinsip baru mengharuskan penyelesaian tugas memiliki kemampuan penalaran multi-aturan, multi-langkah, dan kontekstual. Grid lebih besar, berisi lebih banyak objek, dan mengkodekan beberapa konsep interaktif. Tugas bersifat baru dan tidak dapat digunakan kembali untuk membatasi memori. Desain ini sengaja menolak sintesis program brute-force. Pemecah manusia rata-rata membutuhkan 2,7 menit per tugas, sedangkan sistem teratas (seperti OpenAI o3-medium) hanya mendapat skor sekitar 3%, dan semua tugas memerlukan upaya kognitif yang jelas (Sumber: TheTuringPost, clefourrier)
Skywork meluncurkan super agen, bertujuan untuk mempersingkat pekerjaan 8 jam menjadi 8 menit: Skywork merilis agen ruang kerja AI-nya – Skywork Super Agents, yang mengklaim dapat memadatkan beban kerja pengguna selama 8 jam menjadi 8 menit. Produk ini diposisikan sebagai pelopor agen ruang kerja AI, dengan fungsi dan metode implementasi spesifik yang masih perlu diamati lebih lanjut (Sumber: _akhaliq)
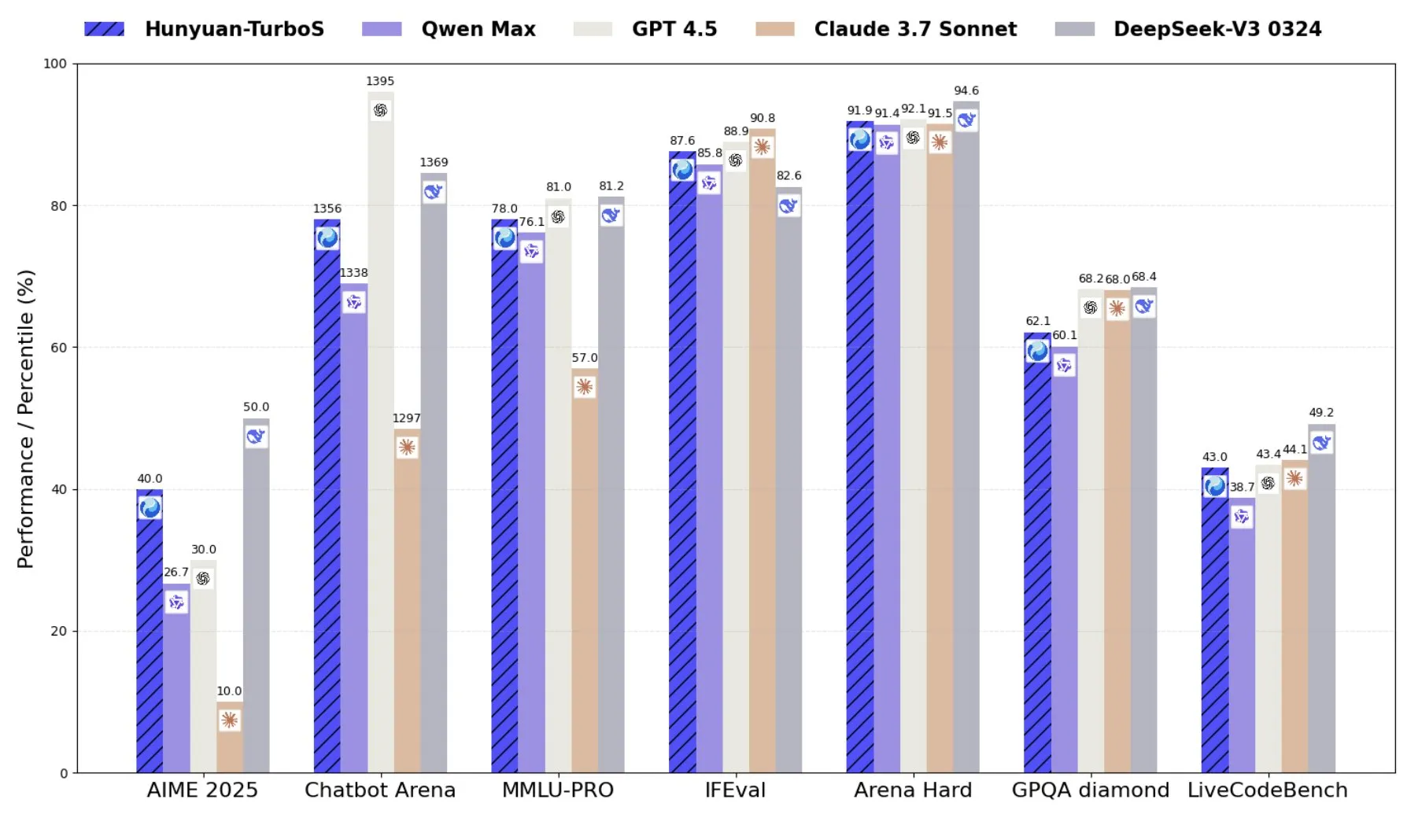
Tencent meluncurkan Hunyuan-TurboS, model pakar campuran yang menggabungkan Transformer dan Mamba: Tencent merilis model Hunyuan-TurboS, yang mengadopsi arsitektur pakar campuran (MoE) Transformer dan Mamba, memiliki 56 miliar parameter aktif, dan dilatih pada 16 triliun token. Hunyuan-TurboS dapat secara dinamis beralih antara mode respons cepat dan mode “berpikir” mendalam, dan menempati peringkat tujuh besar secara keseluruhan di LMSYS Chatbot Arena (Sumber: tri_dao)
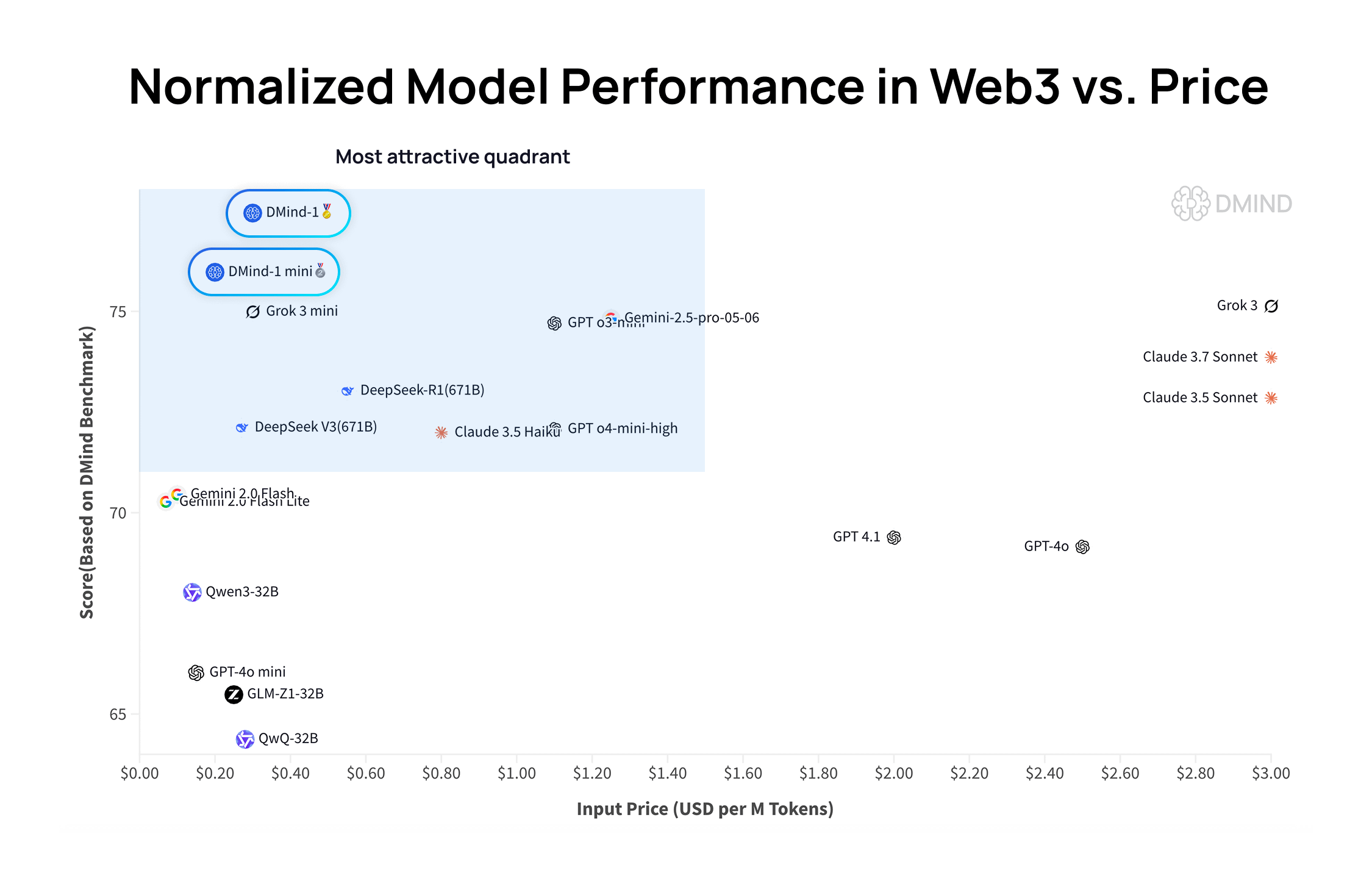
DMind-1: Model bahasa besar open source yang dirancang khusus untuk skenario Web3: DMind AI merilis DMind-1, sebuah model bahasa besar open source yang dioptimalkan untuk skenario Web3. DMind-1 (32B) disesuaikan (fine-tuned) berdasarkan Qwen3-32B, menggunakan sejumlah besar pengetahuan spesifik Web3, dan bertujuan untuk menyeimbangkan kinerja dan biaya aplikasi AI+Web3. Dalam evaluasi benchmark Web3, DMind-1 berkinerja lebih baik daripada LLM umum arus utama, dengan biaya token hanya sekitar 10% darinya. DMind-1-mini (14B) yang dirilis bersamaan mempertahankan lebih dari 95% kinerja DMind-1, dan lebih unggul dalam hal latensi dan efisiensi komputasi (Sumber: _akhaliq)
LightOn merilis Reason-ModernColBERT, model parameter kecil berkinerja sangat baik dalam tugas pencarian padat penalaran: LightOn meluncurkan Reason-ModernColBERT, sebuah model interaksi akhir (late interaction) dengan hanya 149 juta parameter. Dalam uji benchmark BRIGHT yang populer (berfokus pada pencarian padat penalaran), model ini menunjukkan kinerja luar biasa, melampaui model dengan parameter 45 kali lebih besar, dan mencapai tingkat SOTA di berbagai bidang. Hasil ini sekali lagi membuktikan efisiensi tinggi model interaksi akhir pada tugas-tugas tertentu (Sumber: lateinteraction, jeremyphoward, Dorialexander, huggingface)

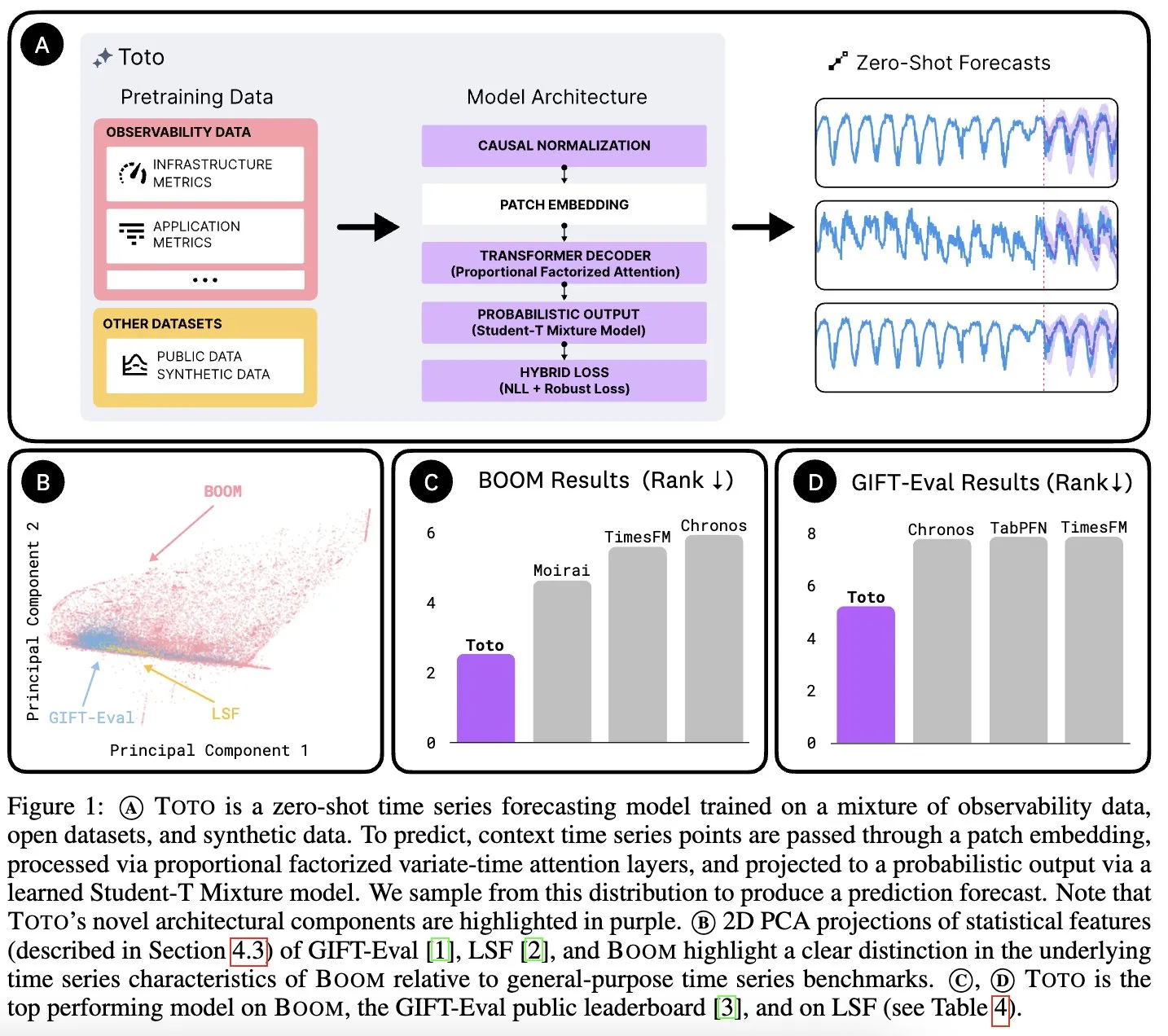
Datadog AI Research merilis model dasar deret waktu Toto dan benchmark metrik observabilitas BOOM: Datadog AI Research meluncurkan Toto, model dasar deret waktu baru, dan secara signifikan mengungguli model SOTA yang ada dalam uji benchmark terkait. Bersamaan dengan itu, dirilis pula BOOM, benchmark metrik observabilitas terbesar saat ini. Keduanya dirilis secara open source dengan lisensi Apache 2.0, bertujuan untuk mendorong penelitian dan aplikasi di bidang analisis deret waktu dan observabilitas (Sumber: jefrankle, ClementDelangue)
TII merilis seri model campuran Transformer-SSM Falcon-H1: Technology Innovation Institute (TII) Uni Emirat Arab merilis seri model Falcon-H1, sekelompok model bahasa dengan arsitektur campuran yang menggabungkan mekanisme perhatian Transformer dan kepala model state-space (SSM) Mamba2. Seri model ini memiliki skala parameter dari 0,5B hingga 34B, mendukung panjang konteks hingga 256K, dan dalam berbagai uji benchmark menunjukkan kinerja yang lebih baik atau sebanding dengan model Transformer teratas seperti Qwen3-32B dan Llama4-Scout, terutama menunjukkan keunggulan dalam multibahasa (mendukung 18 bahasa secara native) dan efisiensi. Model ini telah diintegrasikan ke dalam vLLM, Hugging Face Transformers, dan llama.cpp (Sumber: Reddit r/LocalLLaMA)

Penelitian MIT: AI dapat mempelajari hubungan antara visual dan suara tanpa campur tangan manusia: Para peneliti MIT menunjukkan sistem AI yang dapat secara mandiri mempelajari hubungan antara informasi visual dan suara yang sesuai, tanpa panduan eksplisit atau data berlabel dari manusia. Kemampuan ini sangat penting untuk mengembangkan sistem AI multimodal yang lebih komprehensif, memungkinkannya untuk memahami dan merasakan dunia lebih seperti manusia (Sumber: Reddit r/artificial, Reddit r/ArtificialInteligence)

Uni Emirat Arab meluncurkan model AI bahasa Arab berskala besar, mempercepat perlombaan AI di kawasan Teluk: Uni Emirat Arab merilis model AI bahasa Arab berskala besar, menandai investasi lebih lanjutnya di bidang kecerdasan buatan dan memperketat persaingan antar negara di kawasan Teluk dalam pengembangan teknologi AI. Langkah ini bertujuan untuk meningkatkan pengaruh bahasa Arab di bidang AI dan memenuhi kebutuhan aplikasi AI yang dilokalkan (Sumber: Reddit r/artificial)
Fenbi Technology merilis model besar vertikal, mendefinisikan paradigma baru “AI+Pendidikan”: Fenbi Technology di KTT Aplikasi Industri AI Tencent Cloud memamerkan model besar vertikal yang dikembangkannya sendiri di bidang pendidikan kejuruan. Model ini telah diterapkan pada produk seperti penilaian wawancara dan sistem kelas latihan soal AI, yang mencakup seluruh rantai “mengajar, belajar, berlatih, menilai, menguji”. Melalui bentuk seperti guru AI, bertujuan untuk mewujudkan pengajaran yang dipersonalisasi dari “satu untuk semua” menjadi “satu untuk setiap individu”, dan berencana meluncurkan produk perangkat keras AI yang dilengkapi dengan model besar yang dikembangkan sendiri, mendorong transformasi cerdas pendidikan (Sumber: 量子位)

Beisen Kuxueyuan merilis platform AI Learning generasi baru, memperkenalkan lima AI Agent: Beisen Holdings setelah mengakuisisi Kuxueyuan, meluncurkan platform pembelajaran generasi baru AI Learning berbasis model besar AI. Platform ini menambahkan lima agen cerdas pada dasar eLearning yang sudah ada: asisten pembuatan kursus AI, asisten belajar AI, pelatih AI, pelatih kepemimpinan AI, dan asisten ujian AI. Tujuannya adalah untuk mengubah model pembelajaran perusahaan tradisional melalui dialog real-time Agent, pelatihan keterampilan, pembelajaran yang dipersonalisasi, dan pembuatan kursus serta ujian satu atap AI (Sumber: 量子位)

Laporan keuangan Q1 Pony.ai: Pendapatan layanan Robotaxi meroket 8 kali lipat YoY, akan mengerahkan seribu kendaraan otonom pada akhir tahun: Pony.ai mengumumkan laporan keuangan kuartal pertama 2025, dengan total pendapatan 102 juta yuan, meningkat 12% YoY. Di antaranya, pendapatan layanan Robotaxi inti mencapai 12,3 juta yuan, melonjak 200,3% YoY, dan pendapatan ongkos penumpang bahkan meroket 8 kali lipat YoY. Perusahaan berencana untuk memulai produksi massal Robotaxi generasi ketujuh pada kuartal kedua dan mengerahkan 1000 kendaraan sebelum akhir tahun, berupaya mencapai titik impas per kendaraan. Pony.ai juga mengumumkan kerja sama dengan Tencent Cloud dan Uber, yang masing-masing akan memperluas pasar domestik dan Timur Tengah melalui platform WeChat dan Uber (Sumber: 量子位)

CPO OpenAI Kevin Weil: ChatGPT akan bertransformasi menjadi asisten aksi, biaya model sudah 500 kali lipat GPT-4: Chief Product Officer OpenAI Kevin Weil menyatakan bahwa posisi ChatGPT akan beralih dari menjawab pertanyaan menjadi menjalankan tugas untuk pengguna, dengan menggunakan alat secara bergantian (seperti menjelajah web, pemrograman, menghubungkan sumber pengetahuan internal) menjadi asisten aksi AI. Ia mengungkapkan bahwa biaya model saat ini sudah 500 kali lipat dari GPT-4 generasi pertama, tetapi OpenAI berkomitmen untuk meningkatkan efisiensi dan menurunkan harga API melalui peningkatan perangkat keras dan perbaikan algoritma. Ia percaya bahwa AI Agent akan berkembang pesat, dari tingkat insinyur junior menjadi tingkat arsitek dalam satu tahun (Sumber: 量子位)

🧰 Alat
FlowiseAI: Membangun agen AI secara visual: FlowiseAI adalah proyek open source yang memungkinkan pengguna membangun agen AI dan aplikasi LLM melalui antarmuka visual. Ini mendukung komponen drag-and-drop, menghubungkan berbagai LLM, alat, dan sumber data, menyederhanakan alur kerja pengembangan aplikasi AI. Pengguna dapat menginstal Flowise melalui npm atau menyebarkannya dengan Docker untuk dengan cepat membangun dan menguji alur AI mereka sendiri (Sumber: GitHub Trending)

Pustaka JS Hugging Face dirilis, menyederhanakan interaksi dengan Hub API dan layanan inferensi: Hugging Face meluncurkan serangkaian pustaka JavaScript (@huggingface/inference, @huggingface/hub, @huggingface/mcp-client, dll.), yang bertujuan untuk memudahkan pengembang berinteraksi dengan Hugging Face Hub API dan layanan inferensi melalui JS/TS. Pustaka ini mendukung pembuatan repositori, pengunggahan file, pemanggilan inferensi lebih dari 100.000 model (termasuk penyelesaian obrolan, teks-ke-gambar, dll.), penggunaan klien MCP untuk membangun agen, dan mendukung berbagai penyedia inferensi (Sumber: GitHub Trending)

Lingkungan berjalan lokal Jan AI diperbarui menjadi lisensi Apache 2.0, menurunkan hambatan penggunaan bagi perusahaan: Jan AI adalah alat open source yang mendukung LLM berjalan secara lokal, baru-baru ini mengubah lisensinya dari AGPL menjadi Apache 2.0 yang lebih longgar. Langkah ini bertujuan untuk memudahkan perusahaan dan tim dalam menerapkan dan menggunakan Jan di dalam organisasi tanpa khawatir tentang masalah kepatuhan yang ditimbulkan oleh AGPL, memungkinkan mereka untuk melakukan fork, memodifikasi, dan merilis secara bebas, sehingga mendorong adopsi Jan secara luas dalam lingkungan produksi aktual (Sumber: reach_vb, Reddit r/LocalLLaMA)
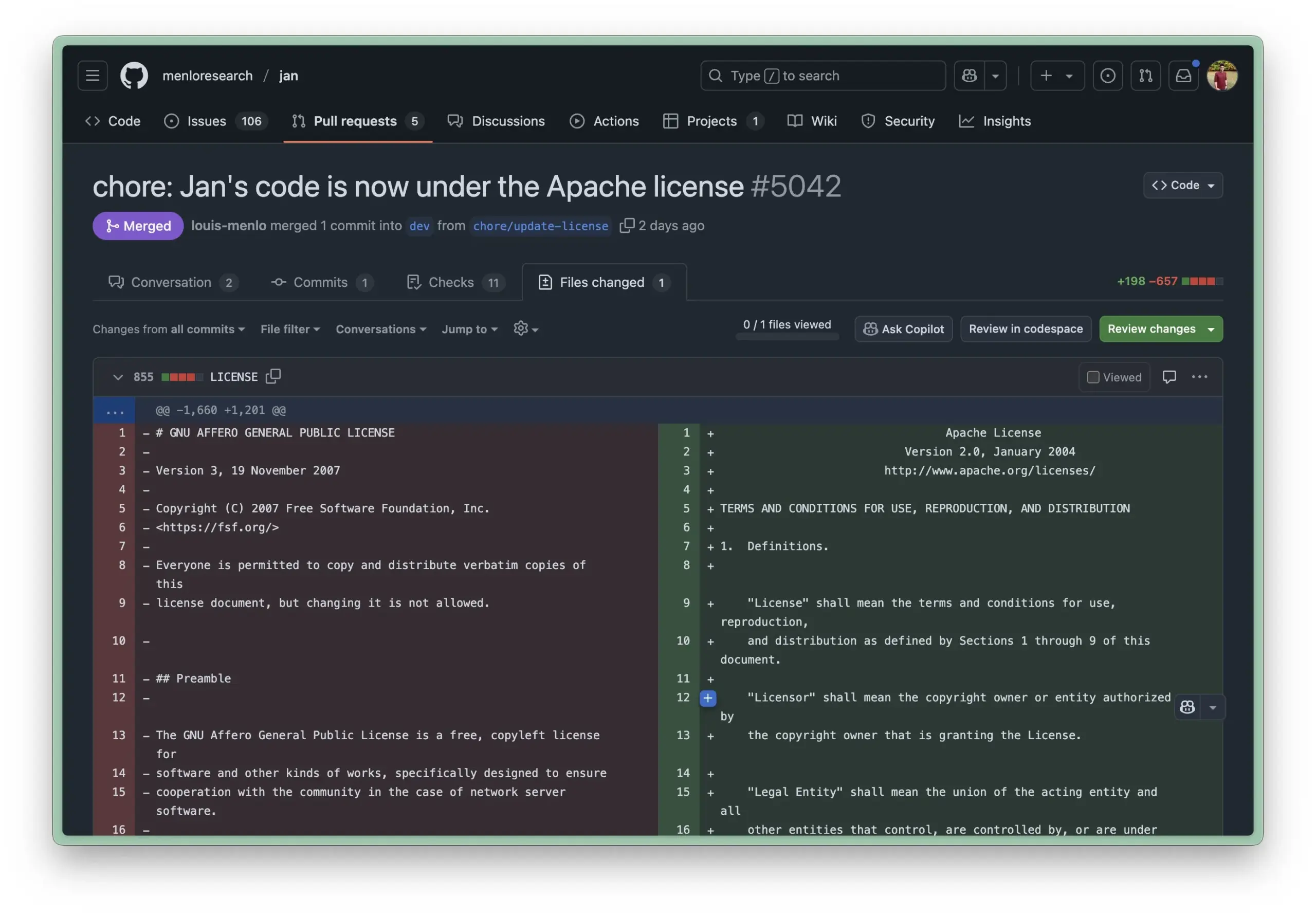
Obsidian meluncurkan plugin inti Bases, mewujudkan manajemen catatan berbasis database: Perangkat lunak manajemen pengetahuan Obsidian memperbarui plugin intinya, Bases, yang memungkinkan pengguna mengubah kumpulan catatan menjadi database yang kuat. Melalui Bases, pengguna dapat membuat tampilan tabel kustom, memvisualisasikan dan berinteraksi secara interaktif dengan data dalam basis pengetahuan mereka, mendukung penyaringan catatan melalui properti, dan membuat formula untuk menghasilkan properti dinamis, cocok untuk berbagai skenario seperti manajemen proyek, perencanaan perjalanan, daftar bacaan, dll. Fitur ini saat ini telah tersedia untuk pengguna awal (Sumber: op7418)
Hugging Face meluncurkan Tiny Agents, menyederhanakan kontrol browser dan operasi file oleh model lokal: Hugging Face dalam kursus MCP-nya memperkenalkan Tiny Agents, sebuah kerangka kerja pengaturan kontrol browser yang mudah digunakan. Pengguna melalui baris perintah, konfigurasi JSON, dan definisi prompt, dapat membuat LLM yang berjalan secara lokal (melalui server yang kompatibel dengan OpenAI) mengontrol browser (seperti Playwright) atau sistem file lokal, tanpa perlu memanggil API secara langsung, memberikan kemudahan untuk aplikasi agen model lokal seperti llama.cpp (Sumber: Reddit r/LocalLLaMA)

Pengembang merilis aplikasi optimasi resume AI open source, berbasis LangChain dan Ollama: Seorang pengembang membangun dan merilis aplikasi optimasi resume yang didukung AI secara open source. Pengguna mengunggah resume saat ini dan deskripsi pekerjaan target, kemudian aplikasi akan mencoba menyesuaikan kata kunci dalam resume agar lebih sesuai dengan kebutuhan rekrutmen. Backend proyek ini menggunakan LangChain, menggabungkan pencarian jarang BM25 dan model padat untuk pencarian campuran, model bahasa berjalan secara lokal melalui Ollama, dan frontend menggunakan React. Proyek ini saat ini dalam tahap pembuktian konsep, dan kodenya telah dirilis secara open source di GitHub (Sumber: Reddit r/deeplearning)
Alat pembuatan aplikasi Lovable meningkatkan kemampuan pemrosesan gambar: Alat pembuatan aplikasi AI Lovable mengumumkan peningkatan pada fungsi pemrosesan gambarnya. Pengguna sekarang dapat mengunggah gambar ke obrolan dan menginstruksikan Lovable untuk menggunakan materi gambar ini dalam aplikasi, meningkatkan pengalaman pengguna dalam membangun aplikasi yang berisi elemen visual dengan bantuan AI (Sumber: op7418)
Helios: Platform pertama yang mencoba mengakselerasi pekerjaan pemerintah dengan AI: Joe Scheidler meluncurkan Helios, sebuah platform yang bertujuan untuk memanfaatkan AI guna meningkatkan efisiensi pekerjaan pemerintah, yang digambarkan sebagai “Cursor versi pemerintah”. Platform ini adalah salah satu upaya pertama yang secara eksplisit menargetkan departemen pemerintah, mencoba mengoptimalkan alur kerja dan efisiensinya melalui teknologi AI. Fungsi dan skenario aplikasi spesifiknya masih perlu diamati lebih lanjut (Sumber: timsoret)
📚 Pembelajaran
Universitas Zhejiang merilis buku teks “Dasar-Dasar Model Besar”, secara sistematis menjelaskan pengetahuan LLM dan terus diperbarui: Tim LLM Universitas Zhejiang merilis buku teks “Dasar-Dasar Model Besar” secara open source, yang bertujuan untuk memberikan pengetahuan dasar yang sistematis dan pengenalan teknologi mutakhir kepada pembaca yang tertarik pada model bahasa besar. Isi buku ini mencakup model bahasa tradisional, evolusi arsitektur LLM, rekayasa Prompt, penyesuaian parameter yang efisien, penyuntingan model, pembuatan yang ditingkatkan dengan pencarian, dll., dan akan diperbarui setiap bulan. Setiap bab dilengkapi dengan Daftar Makalah terkait untuk melacak perkembangan terbaru. PDF lengkap dan konten per bab telah dirilis di GitHub (Sumber: GitHub Trending)

Hugging Face menyediakan 10 kursus AI gratis, mencakup pengetahuan multi-bidang di berbagai tingkatan: Hugging Face merangkum 10 kursus AI gratis yang ditawarkan di platformnya, dengan konten yang mencakup berbagai topik AI populer dari tingkat pemula hingga mahir, termasuk pemrosesan bahasa alami, deep learning, reinforcement learning, pemrosesan audio, multimodal, dll. Kursus-kursus ini menyediakan sumber daya berharga bagi pelajar dari berbagai tingkatan untuk mempelajari pengetahuan AI secara sistematis, lebih lanjut mendorong penyebaran pengetahuan AI dan pengembangan komunitas open source (Sumber: huggingface, reach_vb, _akhaliq)

Universitas Stanford berbagi pengalaman dan pelajaran dari pelatihan model Marin 8B: Tim Percy Liang dari Universitas Stanford mempublikasikan tinjauan rinci mereka tentang pelatihan model Marin 8B dari awal (dan melampaui model dasar Llama 3.1 8B pada beberapa benchmark). Catatan jujur ini berisi semua temuan dan kesalahan yang dibuat tim selama proses penelitian dan pengembangan, memberikan pengalaman membangun LLM yang nyata dan berharga bagi komunitas, serta menekankan pentingnya trial-and-error dan iterasi dalam proses penelitian ilmiah (Sumber: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI dan Predibase bekerja sama meluncurkan kursus LLM Reinforced Fine-Tuning (RFT): DeepLearning.AI milik Andrew Ng bekerja sama dengan Predibase untuk meluncurkan kursus singkat gratis tentang penggunaan GRPO (Group Relative Policy Optimization) untuk Reinforced Fine-Tuning (RFT) guna meningkatkan kinerja LLM. Kursus ini dibawakan oleh salah satu pendiri dan CTO Predibase, Travis Addair, dan lainnya, bertujuan untuk membantu peserta didik menguasai cara memanfaatkan reinforcement learning untuk mengubah LLM open source kecil menjadi mesin inferensi untuk kasus penggunaan tertentu hanya dengan sedikit data berlabel (Sumber: DeepLearningAI)
Halaman makalah Hugging Face menambahkan fungsi ringkasan yang dihasilkan AI: Hugging Face memperkenalkan fitur baru pada halaman tampilan makalahnya, menyediakan ringkasan satu kalimat yang dihasilkan AI untuk setiap makalah. Ringkasan ini bertujuan untuk merangkum konten inti makalah secara ringkas dan jelas, membantu pengguna menyaring dan memahami literatur penelitian dengan cepat, serta meningkatkan aksesibilitas dan efisiensi penggunaan sumber daya akademik. Fitur ini didukung oleh LLM open source, yang mencerminkan konsep “AI memberdayakan penelitian AI” (Sumber: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

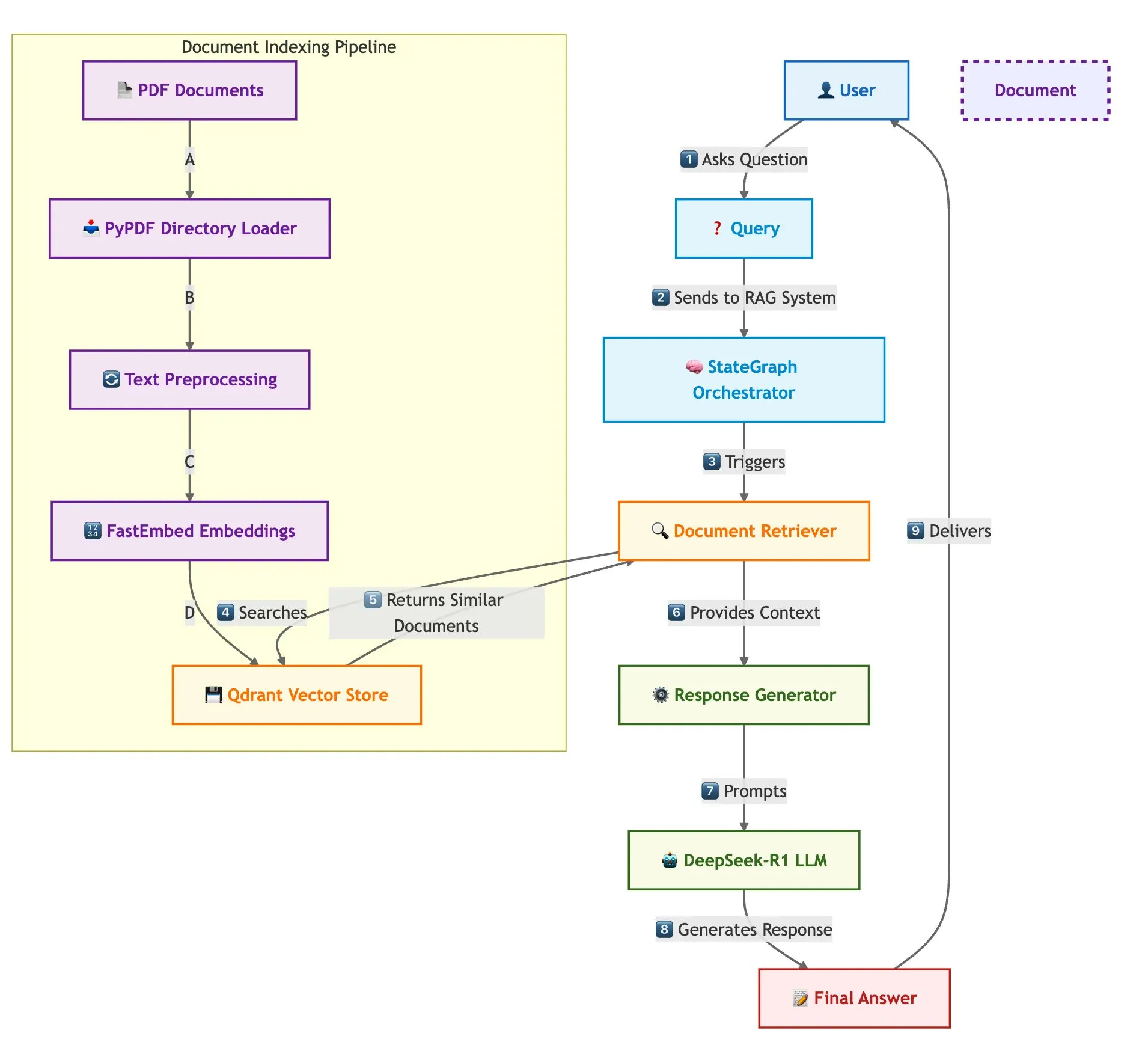
Qdrant, SambaNova, dll. bersama-sama menunjukkan solusi pembangunan sistem RAG multi-dokumen yang cepat: Sebuah blog teknis memperkenalkan cara menggunakan database vektor Qdrant, SambaNova, DeepSeek-R1, dan LangGraph untuk membangun sistem Retrieval Augmented Generation (RAG) multi-dokumen yang cepat dan hemat memori. Solusi ini mencapai penghematan memori 32x melalui kuantisasi biner, memanfaatkan DeepSeek-R1 untuk respons LLM yang cepat dan terpusat, dan menggunakan LangGraph untuk orkestrasi modular, cocok untuk skenario pemrosesan multi-dokumen skala besar (Sumber: qdrant_engine)
Tinjauan KTT LangChain Interrupt 2025 (versi Mandarin) dirilis: Tinjauan KTT LangChain Interrupt 2025 versi Mandarin telah dirilis. KTT ini menarik lebih dari 800 peserta dari seluruh dunia, berbagi pengalaman dan pandangan masa depan tentang pembangunan agen AI, serta mengumumkan beberapa produk seperti LangGraph Platform dan LangGraph Studio v2, membahas tema-tema seperti rekayasa agen dan observabilitas AI (Sumber: hwchase17)
Andi Marafioti merilis tutorial nanoVLM, menjelaskan secara bertahap pelatihan model bahasa visual dengan PyTorch murni: Andi Marafioti merilis tutorial blog baru berjudul nanoVLM, yang menjelaskan secara rinci cara melatih model bahasa visual (VLM) Anda sendiri dari awal menggunakan PyTorch murni. Konten tutorial mudah dipahami dan diikuti, bertujuan untuk membantu pemula menguasai proses pelatihan VLM dengan cepat (Sumber: LoubnaBenAllal1)

Ferenc Huszár menjelaskan rantai Markov waktu kontinu dan aplikasinya dalam model bahasa difusi: Peneliti deep learning Ferenc Huszár menerbitkan posting blog yang menjelaskan secara mendalam intuisi di balik rantai Markov waktu kontinu (CTMCs), yang merupakan komponen kunci dari model bahasa difusi (DLMs) seperti Mercury dan Gemini Diffusion. Artikel tersebut membahas berbagai perspektif rantai Markov dan hubungannya dengan proses titik, memberikan referensi berharga untuk memahami dasar teoritis DLM (Sumber: fhuszar)
💼 Bisnis
Perusahaan “AI buatan” Builder.ai menyatakan bangkrut, pernah menggalang dana hampir $500 juta: Builder.ai (sebelumnya Engineer.ai), perusahaan Inggris yang pernah mengklaim akan merevolusi pengembangan perangkat lunak dengan AI dan valuasinya pernah mencapai $1 miliar, minggu ini mengumumkan likuidasi karena bangkrut. Perusahaan ini pernah terungkap bahwa banyak fungsi platform AI-nya sebenarnya dikerjakan secara manual oleh insinyur India. Meskipun telah mendapatkan pendanaan hampir $500 juta dari institusi terkenal seperti Microsoft dan SoftBank DeepCore, perusahaan ini akhirnya kehabisan dana karena keraguan atas keaslian teknologinya, manajemen keuangan yang kacau, dan sengketa hukum pendirinya, serta menunggak biaya layanan cloud sebesar $30 juta kepada Microsoft dan $85 juta kepada Amazon (Sumber: 36氪)

LMArena.ai (sebelumnya LMSys) mendapatkan pendanaan awal $100 juta, beralih dari aplikasi Gradio ke komersialisasi: LMArena.ai, yang awalnya merupakan proyek akademik berbasis Gradio bernama LMSys (untuk kompetisi dan evaluasi LLM), mengumumkan perolehan pendanaan awal sebesar $100 juta, dipimpin oleh a16z dan perusahaan investasi Universitas California. Pendanaan ini akan mendukung LMArena untuk melanjutkan penelitiannya dalam AI yang andal dan operasi platformnya, menandai transisi proyek akademik open source yang sukses menjadi operasi komersial. Hal ini juga menyoroti potensi alat prototipe cepat seperti Gradio dalam menginkubasi proyek AI yang berpengaruh (Sumber: ClementDelangue, _akhaliq, clefourrier)
Perang perebutan talenta AI memanas, OpenAI, Google, dll. tawarkan gaji tahunan puluhan juta dolar untuk merekrut talenta: Perebutan talenta di bidang AI Silicon Valley telah memasuki tahap panas, dengan peneliti papan atas (IC) menjadi sumber daya inti yang diperebutkan oleh raksasa seperti OpenAI, Google, dan xAI, dengan gaji tahunan ditambah insentif saham umumnya melebihi puluhan juta dolar. Misalnya, OpenAI menawarkan bonus $2 juta dan saham senilai lebih dari $20 juta untuk mempertahankan peneliti senior yang berniat bergabung dengan SSI; Google DeepMind juga menawarkan gaji tahunan $20 juta untuk talenta papan atas. Persaingan sengit ini berasal dari kontribusi besar segelintir talenta inti terhadap pengembangan model bahasa besar, di mana kepergian atau kedatangan mereka dapat secara langsung memengaruhi keberhasilan atau kegagalan model AI (Sumber: 36氪)
🌟 Komunitas
Kemampuan bahasa Mandarin Sora tampaknya meningkat, tetapi keterbatasan model masih ada: Pengguna media sosial mengamati bahwa model pembuatan video Sora dari OpenAI tampaknya mengalami kemajuan dalam memproses teks Mandarin, mampu menghasilkan adegan yang berisi karakter Mandarin. Namun, pengguna juga menunjukkan bahwa model tersebut masih memiliki keterbatasan, konten yang dihasilkan tidak sempurna, dan menerima ketidaksempurnaan ini mungkin merupakan hal yang normal dalam berinteraksi dengan model AI pada tahap saat ini (Sumber: dotey)

Gemini meluncurkan fungsi “ujian” laporan mendalam, membantu penggunaan kembali pengetahuan dan siklus belajar tertutup: Google Gemini meluncurkan fitur baru di mana setelah pengguna membaca laporan mendalam, Gemini dapat langsung memberikan soal tes. Fitur ini bertujuan untuk menguji pemahaman sebenarnya pengguna terhadap konten dan membangun siklus belajar AI-native “belajar → ujian → perbaikan → belajar lagi”, menekankan bahwa inti pembelajaran di era AI adalah kemampuan untuk menggunakan kembali pengetahuan, bukan jumlah bacaan (Sumber: dotey)
Fitur memori ChatGPT menimbulkan kekhawatiran pengguna tentang kontrol: Fitur baru ChatGPT “belajar dari obrolan untuk mengingat” memungkinkan model mengingat informasi percakapan pengguna sebelumnya untuk memberikan respons yang lebih personal dalam interaksi berikutnya. Namun, beberapa pengguna tingkat lanjut menyatakan kekhawatiran, merasa ini mengubah cara berinteraksi dengan model. Mereka lebih suka mengontrol sepenuhnya konten input model dan tidak ingin model menggunakan informasi historis tanpa sepengetahuan atau kontrol presisi mereka (Sumber: random_walker)
AI Agent berkembang pesat, model kerja di masa depan mungkin akan berubah: Komunitas ramai membahas perkembangan pesat AI Agent dan potensi dampaknya pada model kerja di masa depan. Pandangan menyatakan bahwa AI Agent sedang bertransformasi dari alat tanya jawab sederhana menjadi “karyawan virtual” yang mampu menyelesaikan tugas kompleks secara mandiri (seperti pengkodean, penelitian, dukungan pelanggan). CPO OpenAI Kevin Weil memperkirakan kemampuan AI Agent akan meningkat pesat, dari tingkat insinyur junior menjadi tingkat arsitek dalam satu tahun. Microsoft juga telah mengusulkan konsep “jaringan agen cerdas”, yang menandakan bahwa pekerjaan di masa depan mungkin akan berpusat pada pengelolaan dan orkestrasi agen AI (Sumber: rowancheung, 量子位)
AI memiliki potensi besar dalam diagnosis medis, tetapi menimbulkan kekhawatiran karir dokter: AI menunjukkan kemampuan luar biasa dalam diagnosis medis, misalnya, ada penelitian yang mengklaim model o1-preview menunjukkan kemampuan super dalam penalaran medis dan tugas diagnosis, kasus AI mendeteksi pneumonia dalam beberapa detik juga menarik perhatian. Hal ini menjadikan diagnosis berbantuan AI sebagai topik hangat, tetapi juga membuat sebagian dokter dengan pengalaman 20 tahun khawatir tentang prospek karir mereka, bahkan bercanda akan melamar kerja di McDonald’s. Komunitas berpendapat bahwa AI lebih tepat dilihat sebagai alat untuk membantu dokter meningkatkan efisiensi dan akurasi, bukan sebagai pengganti sepenuhnya (Sumber: paul_cal, Reddit r/ArtificialInteligence)
Penerbit berita menuduh model pencarian AI Google sebagai “pencurian”: Aliansi media berita dan penerbit lainnya menyatakan ketidakpuasan yang kuat terhadap model pencarian AI baru Google, menyebutnya sebagai “pencurian”. Mereka berpendapat bahwa AI Google secara langsung mengekstrak informasi dari konten berita dan mengintegrasikannya ke dalam hasil pencarian, melewati situs berita, yang merugikan lalu lintas dan pendapatan iklan penerbit, memicu diskusi sengit tentang hak cipta konten dan penggunaan wajar di era AI (Sumber: Reddit r/artificial)
Model DeepSeek digunakan di Tiongkok untuk ramalan tradisional, memicu diskusi tentang batasan aplikasi AI: Seorang pengguna menemukan bahwa sebagian besar lalu lintas model DeepSeek di Tiongkok berasal dari pengguna yang menggunakannya untuk kegiatan ramalan tradisional seperti ramalan I Ching. Fenomena ini memicu diskusi tentang batasan aplikasi AI dan adaptasi budaya, serta secara tidak langsung mencerminkan eksplorasi dan permintaan pengguna yang beragam terhadap kemampuan AI (Sumber: menhguin, cto_junior)

💡 Lainnya
Robot humanoid perusahaan Figure menyelesaikan shift kerja 20 jam terus menerus di lini produksi BMW: Perusahaan robot humanoid Figure mengumumkan bahwa robotnya berhasil menyelesaikan shift kerja 20 jam terus menerus di lini produksi BMW X3. Sebelumnya, robot tersebut telah menjalani tes shift 10 jam selama beberapa minggu. Figure menyatakan bahwa ini adalah pertama kalinya di dunia robot humanoid menyelesaikan pekerjaan terus menerus selama itu di lini produksi mobil, menunjukkan potensinya di bidang otomatisasi industri (Sumber: adcock_brett, TheRundownAI)
Perbedaan dan hubungan antara Agentic AI dan GenAI: Komunitas membahas konsep Agentic AI (AI agen) dan Generative AI (AI generatif). AI generatif terutama mengacu pada AI yang dapat menciptakan konten baru (teks, gambar, kode, dll.), sedangkan AI agen lebih menekankan otonomi, orientasi tujuan, dan kemampuan untuk berinteraksi dan bertindak dengan lingkungan. AI agen biasanya akan memanfaatkan AI generatif sebagai salah satu kemampuan intinya untuk memahami, merencanakan, dan melaksanakan tugas, yang merupakan arah penting bagi AI untuk berkembang menuju kecerdasan otonom yang lebih tinggi (Sumber: Ronald_vanLoon, Ronald_vanLoon)

Aplikasi AI dalam penelitian ilmiah diremehkan, ada fenomena “memoles hasil”: Diskusi komunitas menunjukkan bahwa potensi aplikasi AI dalam penelitian ilmiah sangat besar tetapi mungkin diremehkan, sementara ada fenomena peneliti “memoles” hasil eksperimen AI untuk publikasi. Misalnya, di bidang seperti persamaan diferensial parsial (PDEs), kinerja aktual AI mungkin tidak sehebat yang disajikan dalam makalah. Hal ini mengingatkan komunitas ilmiah untuk lebih cermat dan transparan dalam mengevaluasi peran nyata dan keterbatasan AI dalam penemuan ilmiah (Sumber: clefourrier)