
Kata Kunci:Gemini 2.5, AI Agent, Model Besar, Model Bahasa Visual, Pembelajaran Penguatan, Mode Gemini 2.5 Pro Deep Think, GitHub Copilot Agent Sumber Terbuka, Pembuatan Gambar Satu Langkah MeanFlow, Penalaran Perencanaan Visual VPRL, Optimasi Penalaran Huawei FusionSpec MoE
🔥 Fokus
Google I/O Umumkan Berbagai Kemajuan AI, Dipimpin oleh Seri Model Gemini 2.5: Google mengumumkan banyak pembaruan di bidang AI pada konferensi I/O. Gemini 2.5 Pro disebut sebagai model dasar terkuat saat ini, memimpin dalam berbagai benchmark, dan memperkenalkan mode inferensi yang ditingkatkan Deep Think. Model ringan Gemini 2.5 Flash juga ditingkatkan, dengan fokus pada kecepatan dan efisiensi. Google Search memperkenalkan “Mode AI”, yang menyediakan pengalaman pencarian AI end-to-end melalui Gemini 2.5, mampu mengurai masalah kompleks dan melakukan penggalian informasi mendalam. Model generasi video Veo 3 mencapai generasi sinkron audio-visual, dan model gambar Imagen 4 meningkatkan kemampuan pemrosesan detail dan teks. Selain itu, Google juga meluncurkan alat pembuatan film AI Flow dan aplikasi implementasi dari proyek asisten AI Project Astra, yaitu Gemini Live. Pembaruan ini menunjukkan tekad Google untuk mengintegrasikan AI secara menyeluruh ke dalam ekosistem produknya, yang bertujuan untuk meningkatkan pengalaman pengguna dan efisiensi developer (Sumber: 量子位, 36氪, WeChat)

Microsoft Build Dorong Kuat AI Agent, GitHub Copilot Sambut Peningkatan Besar dan Umumkan Open Source: Microsoft menempatkan AI Agent sebagai inti pada konferensi developer Build 2025, mengumumkan proyek GitHub Copilot Extension for VSCode menjadi open source, dan meluncurkan agen pengkodean AI (Agent) baru. Agent ini dapat secara mandiri menyelesaikan tugas seperti memperbaiki bug, menambahkan fitur, dan mengoptimalkan dokumentasi, serta terintegrasi secara mendalam dengan GitHub Copilot. Microsoft juga merilis platform agen cerdas AI untuk penemuan ilmiah Microsoft Discovery, proyek situs web interaksi bahasa alami NLWeb, platform pembuatan agen Agent Factory, dan Copilot Tuning yang dapat disesuaikan untuk data perusahaan. Langkah-langkah ini menunjukkan bahwa Microsoft berupaya penuh mendorong penerapan AI Agent di berbagai bidang seperti pengembangan dan penelitian ilmiah, dengan tujuan membangun ekosistem kolaborasi agen cerdas yang terbuka (Sumber: 量子位, WeChat, WeChat)

OpenAI CPO Kevin Weil Menjelaskan Arah Transformasi ChatGPT: Dari Tanya Jawab ke Tindakan, AI Agent Akan Berevolusi Cepat: Chief Product Officer OpenAI Kevin Weil dalam sebuah wawancara mengungkapkan bahwa posisi ChatGPT akan bertransformasi dari alat penjawab pertanyaan menjadi AI Agent yang mampu menjalankan tugas untuk pengguna. Ia membayangkan AI Agent dalam jangka pendek dapat berevolusi cepat dari insinyur junior menjadi insinyur senior, bahkan arsitek. Ini berarti AI Agent akan memiliki otonomi yang lebih kuat, mampu menjelajahi web, berpikir mendalam, dan merangkum kesimpulan untuk menyelesaikan masalah kompleks. Weil juga menyebutkan bahwa biaya pelatihan model saat ini sudah 500 kali lipat dari GPT-4, tetapi di masa depan akan ditingkatkan efisiensinya dan diturunkan harga API melalui peningkatan perangkat keras dan perbaikan algoritma, untuk mendorong普及 dan pengembangan AI (Sumber: 量子位, 36氪)

Tim Kaiming He Usulkan MeanFlow: SOTA Baru Generasi Gambar Satu Langkah, Tanpa Pra-Pelatihan Mengguncang Paradigma Tradisional: Penelitian terbaru tim Kaiming He meluncurkan kerangka kerja pemodelan generatif satu langkah bernama MeanFlow. Pada dataset ImageNet 256×256, hanya dengan 1 kali evaluasi fungsi (1-NFE), MeanFlow mencapai skor FID 3.43, meningkat 50%-70% dibandingkan metode terbaik sejenis sebelumnya, dan tidak memerlukan pra-pelatihan, distilasi, atau pembelajaran kurikulum. Inovasi inti MeanFlow terletak pada pengenalan konsep “medan kecepatan rata-rata” dan penurunan hubungan matematisnya dengan medan kecepatan sesaat, yang kemudian digunakan untuk memandu pelatihan jaringan saraf. Metode ini juga dapat secara alami mengintegrasikan panduan tanpa klasifikasi (CFG) tanpa menambah biaya komputasi tambahan saat sampling, secara signifikan memperkecil kesenjangan kinerja antara model generatif satu langkah dan multi-langkah, serta menunjukkan potensi model dengan sedikit langkah untuk menantang model multi-langkah (Sumber: WeChat, WeChat)

🎯 Tren
ByteDance Merilis Model Multimodal Bagel 14B MoE, Mendukung Generasi Gambar dan Open Source: ByteDance meluncurkan model multimodal Mixture-of-Experts (MoE) dengan 14 miliar parameter bernama Bagel, di mana 7 miliar parameter aktif. Model ini memiliki kemampuan generasi gambar dan telah dijadikan open source dengan lisensi Apache. Bobot terkait, situs web, dan paper (berjudul “Emerging Properties in Unified Multimodal Pretraining”) semuanya telah dipublikasikan. Komunitas merespons positif, menganggap ini sebagai model lokal pertama yang dapat menghasilkan gambar dan teks secara bersamaan, dan memperhatikan kemungkinan menjalankannya pada kartu grafis 24GB serta masalah kuantisasi (Sumber: Reddit r/LocalLLaMA)
Mistral AI Merilis Devstral: Model Open Source SOTA yang Dioptimalkan Khusus untuk Pengkodean: Mistral AI meluncurkan Devstral, sebuah model open source terkemuka yang dirancang khusus untuk tugas-tugas rekayasa perangkat lunak, dibangun oleh Mistral AI bekerja sama dengan All Hands AI. Devstral menunjukkan kinerja luar biasa pada benchmark SWE-bench, menjadi model open source peringkat pertama pada benchmark tersebut. Model ini mahir dalam menggunakan alat untuk menjelajahi basis kode, mengedit beberapa file, dan mendukung agen rekayasa perangkat lunak. Bobot model telah tersedia di Hugging Face (Sumber: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

Anthropic Memberikan Bocoran Claude 4 Sonnet dan Opus Akan Segera Hadir: Anthropic berencana meluncurkan versi generasi berikutnya dari model besar Claude mereka – Claude 4 Sonnet dan Opus. Berita ini menimbulkan antisipasi di komunitas, dengan pengguna menyatakan minat pada peningkatan kinerja model baru, terutama kemampuan memori kontekstual. Beberapa komentar menunjukkan bahwa pengumuman di Google I/O mungkin mendorong pesaing untuk mempercepat peluncuran produk terbaik mereka. Pada saat yang sama, pengguna juga menyatakan kekhawatiran tentang batasan model baru (seperti kuota penggunaan) dan mengingatkan komunitas untuk tidak memiliki ekspektasi yang terlalu tinggi terhadap Opus 4 agar tidak kecewa (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Google Merilis Aplikasi Android Gemma3n, Mendukung Inferensi LLM Lokal: Google merilis aplikasi Android yang dapat berinteraksi dengan model Gemma3n baru, dan menyediakan solusi MediaPipe serta repositori kode GitHub terkait. Umpan balik pengguna menunjukkan antarmuka aplikasi yang baik, tetapi menunjukkan bahwa Gemma3n saat ini belum mendukung inferensi GPU. Seorang pengguna berhasil memuat model gemma-3n-E2B secara manual dan membagikan data operasinya, sementara komunitas juga menyatakan kebutuhan akan versi model yang tidak disensor (Sumber: Reddit r/LocalLLaMA)

Keluarga Model Bahasa Falcon-H1 Hybrid-Head Dirilis, Mencakup Berbagai Skala Parameter: TII UAE merilis seri model bahasa hybrid-head Falcon-H1, dengan skala parameter mulai dari 0.5B hingga 34B. Seri model ini menggunakan arsitektur hybrid Mamba dan kinerjanya sebanding dengan Qwen3. Model ini didukung untuk digunakan melalui Hugging Face Transformers, vLLM, atau pustaka llama.cpp versi kustom, memastikan kemudahan penggunaan model. Komunitas menyatakan antusiasme, menganggap ini sebagai kemajuan penting, dan ada pengguna yang membuat grafik perbandingan kinerja. Pada saat yang sama, para peneliti juga memperhatikan perbedaannya dengan IBM Granite 4 dalam cara menggabungkan modul SSM dan attention (Sumber: Reddit r/LocalLLaMA)

Google Menjelajahi Gemini Diffusion: Model Bahasa dengan Arsitektur Diffusion: Google memamerkan model difusi bahasanya, Gemini Diffusion, yang diklaim sangat cepat dan ukuran modelnya hanya setengah dari model dengan kinerja serupa. Karena model difusi dapat memproses seluruh teks secara iteratif dalam satu waktu dan tidak memerlukan KV cache, model ini mungkin memiliki keunggulan dalam efisiensi memori dan dapat meningkatkan kualitas output dengan menambah jumlah iterasi. Komunitas percaya bahwa jika Google dapat membuktikan kelayakan model difusi untuk aplikasi skala besar, hal ini akan berdampak positif pada komunitas AI lokal. Namun, saat ini model tersebut hanya menyediakan daftar tunggu untuk demo dan belum bersifat open source atau menyediakan unduhan bobot (Sumber: Reddit r/LocalLLaMA)

Penelitian Mengungkap Kerentanan Pembajakan Agent Zero-Click pada Kerangka Kerja Browser Use (CVE-2025-47241): Penelitian dari ARIMLABS.AI menemukan bahwa kerangka kerja Browser Use, yang banyak digunakan di lebih dari 1500 proyek AI, memiliki kerentanan keamanan serius (CVE-2025-47241). Kerentanan ini memungkinkan penyerang untuk melakukan pembajakan Agent zero-click dengan membujuk agen penjelajahan yang digerakkan oleh LLM untuk mengakses halaman berbahaya, sehingga dapat mengendalikan agen tanpa interaksi pengguna. Penemuan ini menimbulkan kekhawatiran serius tentang keamanan agen AI otonom, terutama yang berinteraksi dengan web, dan menyerukan kepada komunitas untuk memperhatikan masalah keamanan agen AI (Sumber: Reddit r/artificial, Reddit r/artificial)
Tencent dan Alibaba Bersaing di Ranah AI to C, QQ Browser dan Quark Saling Berhadapan: QQ Browser di bawah naungan CSIG Tencent mengumumkan peningkatan menjadi AI Browser, meluncurkan AI QBot, dan didukung oleh model ganda Tencent Hunyuan dan DeepSeek, secara resmi bersaing dengan Quark milik Alibaba yang telah bertransformasi menjadi pencarian AI. Langkah ini menandai percepatan tata letak Tencent di bidang AI to C, membentuk dua lini produk utama: Tencent Yuanbao dan QQ Browser. Pimpinan inti kedua belah pihak, Wu Zurong (Tencent) dan Wu Jia (Alibaba), juga membentuk “duel Wu ganda”. Analis berpendapat bahwa QQ Browser unggul dalam basis pengguna, sementara Quark lebih dulu dalam transformasi AI, tetapi transformasi QQ Browser relatif konservatif, dengan fungsi AI lebih mirip plugin dan dibatasi oleh model iklan yang ada. Persaingan ini tidak hanya pada tingkat produk, tetapi juga dapat memengaruhi perkembangan karir kedua pimpinan di perusahaan masing-masing (Sumber: 36氪)
Cambridge dan Google Mengusulkan VPRL: Paradigma Baru Penalaran Perencanaan Visual Murni, Akurasi Melebihi Penalaran Teks: Tim peneliti dari Universitas Cambridge, University College London, dan Google mengusulkan paradigma baru perencanaan visual berbasis pembelajaran penguatan (VPRL), yang untuk pertama kalinya mencapai penalaran murni berdasarkan gambar. Kerangka kerja ini menggunakan optimasi kebijakan relatif kelompok (GRPO) untuk melatih ulang model visual besar. Dalam beberapa tugas navigasi visual (seperti FrozenLake, Maze, MiniBehavior), kinerjanya jauh melampaui metode penalaran berbasis teks, dengan akurasi hingga 80% dan peningkatan kinerja setidaknya 40%. VPRL secara langsung memanfaatkan urutan gambar untuk perencanaan, menghindari kehilangan informasi dan penurunan efisiensi akibat konversi bahasa, serta membuka arah baru untuk tugas penalaran gambar intuitif. Kode terkait telah dijadikan open source (Sumber: WeChat)

Huawei Merilis FusionSpec dan OptiQuant, Mengoptimalkan Inferensi Model Besar MoE: Huawei, untuk mengatasi tantangan kecepatan inferensi dan latensi pada model Mixture-of-Experts (MoE) skala besar, meluncurkan kerangka kerja inferensi spekulatif FusionSpec dan kerangka kerja kuantisasi OptiQuant. FusionSpec memanfaatkan rasio bandwidth komputasi tinggi server Ascend untuk mengoptimalkan alur kerja model utama dan model spekulatif, mengurangi waktu yang dibutuhkan kerangka kerja inferensi spekulatif hingga 1 milidetik. OptiQuant mendukung algoritma kuantisasi mainstream seperti Int2/4/8 dan FP8/HiFloat8, serta memperkenalkan inovasi seperti “truncation yang dapat dipelajari” dan “optimasi parameter kuantisasi” untuk mengurangi kehilangan presisi model dan meningkatkan efektivitas biaya inferensi. Teknologi ini bertujuan untuk mengatasi masalah efisiensi inferensi dan penggunaan sumber daya yang dihadapi model MoE saat deployment (Sumber: WeChat)

Institut Riset Kecerdasan Buatan Beijing (BAAI) Merilis Tiga Model Vektor SOTA, Memperkuat Pencarian Kode dan Multimodal: BAAI, bekerja sama dengan beberapa universitas, merilis BGE-Code-v1 (model vektor kode), BGE-VL-v1.5 (model vektor multimodal umum), dan BGE-VL-Screenshot (model vektor dokumen visual). BGE-Code-v1 didasarkan pada Qwen2.5-Coder-1.5B dan menunjukkan kinerja luar biasa pada benchmark CoIR dan CodeRAG. BGE-VL-v1.5 didasarkan pada LLaVA-1.6 dan mencetak rekor baru zero-shot pada benchmark multimodal MMEB. BGE-VL-Screenshot ditujukan untuk tugas pencarian informasi visual (Vis-IR) seperti halaman web dan dokumen, dilatih berdasarkan Qwen2.5-VL-3B-Instruct, dan mencapai SOTA pada benchmark MVRB yang baru diluncurkan. Model-model ini bertujuan untuk menyediakan kemampuan pemahaman dan pencarian kode serta multimodal yang lebih kuat untuk aplikasi seperti Retrieval Augmented Generation (RAG), dan semuanya telah dijadikan open source (Sumber: WeChat)

Kuaishou dan NUS Meluncurkan Any2Caption, Mewujudkan Generasi Video Terkendali: Kuaishou bekerja sama dengan National University of Singapore (NUS) meluncurkan kerangka kerja Any2Caption, yang bertujuan untuk meningkatkan presisi dan kualitas generasi video terkendali melalui pemisahan cerdas antara pemahaman maksud pengguna dan proses generasi video. Kerangka kerja ini mampu memproses berbagai jenis input multimodal seperti teks, gambar, video, lintasan pose, dan gerakan kamera, serta memanfaatkan model bahasa besar multimodal untuk mengubah instruksi kompleks menjadi “skrip video” terstruktur yang memandu generasi video. Any2Caption dilatih menggunakan database Any2CapIns yang berisi 337.000 contoh video dan 407.000 kondisi multimodal. Eksperimen menunjukkan bahwa Any2Caption secara efektif meningkatkan hasil model generasi video terkendali yang ada (Sumber: WeChat)

🧰 Alat
Feishu Meluncurkan Fitur “Tanya Jawab Pengetahuan”, Menciptakan Asisten Tanya Jawab dan Kreasi AI Khusus Perusahaan: Feishu meluncurkan fitur baru “Tanya Jawab Pengetahuan”, yang diposisikan sebagai alat tanya jawab AI khusus untuk perusahaan. Fitur ini dapat memberikan jawaban akurat dan dukungan pembuatan konten berdasarkan pesan, dokumen, basis pengetahuan, notulen rapat, dan informasi lain yang dapat diakses karyawan di Feishu, dikombinasikan dengan model besar seperti DeepSeek-R1, Doubao, serta teknologi RAG. Fitur ini menekankan aktivasi dan pemanfaatan pengetahuan internal perusahaan, di mana karyawan dengan identitas berbeda yang mengajukan pertanyaan yang sama mungkin mendapatkan jawaban dari perspektif yang berbeda, dan secara ketat mematuhi izin organisasi. Tanya Jawab Pengetahuan Feishu bertujuan untuk mengintegrasikan AI secara mulus ke dalam alur kerja sehari-hari, meningkatkan efisiensi perolehan informasi dan kolaborasi, serta membantu perusahaan membangun sistem manajemen pengetahuan yang dinamis (Sumber: WeChat, WeChat)
Supabase Menjadi Backend Pilihan untuk “Pemrograman Suasana” Berkat Keunggulan Open Source dan Integrasi AI: Database open source Supabase, karena pengalaman PostgreSQL “siap pakai” dan respons positifnya terhadap tren pengembangan AI, telah menjadi pilihan backend populer dalam mode “Pemrograman Suasana” (Vibe Coding). Vibe Coding menekankan penggunaan berbagai alat AI untuk menyelesaikan seluruh proses pengembangan dari kebutuhan hingga implementasi dengan cepat. Supabase mendukung penyimpanan embedding vektor (penting untuk aplikasi RAG) melalui integrasi PGVector, bekerja sama dengan Ollama untuk menyediakan layanan model AI di edge, dan meluncurkan asisten AI sendiri untuk membantu pembuatan skema database dan debugging SQL. Baru-baru ini, Supabase juga meluncurkan server MCP resmi, yang memungkinkan alat AI berinteraksi langsung dengannya. Fitur-fitur ini membuatnya disukai oleh platform pembuatan aplikasi AI-native seperti Lovable dan Bolt.new (Sumber: WeChat)

Hugging Face Meluncurkan nanoVLM: Toolkit Minimalis untuk Melatih Model Bahasa Visual (VLM) dengan PyTorch Murni: Hugging Face merilis nanoVLM, sebuah toolkit PyTorch ringan yang bertujuan untuk menyederhanakan proses pelatihan model bahasa visual. Proyek ini memiliki kode yang kecil dan mudah dibaca, cocok untuk pemula atau developer yang ingin memahami mekanisme internal VLM secara mendalam. Arsitektur nanoVLM didasarkan pada encoder visual SigLIP dan decoder bahasa Llama 3, dengan modul proyeksi modalitas untuk menyelaraskan modalitas visual dan teks. Proyek ini menyediakan cara mudah untuk memulai pelatihan VLM di Colab Notebook gratis dan telah merilis model pra-terlatih berdasarkan SigLIP dan SmolLM2 untuk pengujian (Sumber: HuggingFace Blog)

Pustaka Diffusers Mengintegrasikan Berbagai Backend Kuantisasi, Mengoptimalkan Model Difusi Besar: Pustaka Hugging Face Diffusers kini telah mengintegrasikan berbagai backend kuantisasi seperti bitsandbytes, torchao, Quanto, GGUF, dan FP8 native, yang bertujuan untuk mengurangi penggunaan memori dan kebutuhan komputasi model difusi besar (seperti Flux). Backend ini mendukung kuantisasi dengan presisi berbeda (seperti 4-bit, 8-bit, FP8) dan dapat dikombinasikan dengan teknik optimasi memori seperti CPU offloading, group offloading, dan torch.compile. Blog tersebut, melalui studi kasus kuantisasi model Flux.1-dev, menunjukkan kinerja masing-masing backend dalam penghematan memori dan waktu inferensi, serta menyediakan panduan pemilihan untuk membantu pengguna mencapai keseimbangan antara ukuran model, kecepatan, dan kualitas. Beberapa model terkuantisasi telah tersedia di Hugging Face Hub (Sumber: HuggingFace Blog)

Platform Komputasi Pengembangan Model Besar JoyBuild Milik JD.com Meningkatkan Efisiensi Pelatihan dan Inferensi: JD Explore Academy mengusulkan serangkaian sistem dan metode untuk melatih, memperbarui model besar dalam lingkungan terbuka, dan melakukan deployment bersama dengan model kecil. Hasil penelitian terkait dipublikasikan dalam jurnal npj Artificial Intelligence di bawah naungan Nature. Teknologi ini, melalui empat inovasi yaitu distilasi model (distilasi berlapis dinamis), tata kelola data (sampling dinamis lintas domain), optimasi pelatihan (optimasi Bayesian), dan kolaborasi cloud-edge (kompresi dua tahap), rata-rata meningkatkan efisiensi inferensi model besar sebesar 30% dan mengurangi biaya pelatihan sebesar 70%. Teknologi ini mendukung platform komputasi pengembangan model besar JoyBuild, yang mendukung penyesuaian dan pengembangan berbagai model (seperti model besar JD, Llama, DeepSeek), membantu perusahaan mengubah model umum menjadi model profesional, dan telah diterapkan dalam skenario ritel, logistik, dan lainnya (Sumber: WeChat)
Proyek Registri Model Context Protocol (MCP) Diluncurkan: modelcontextprotocol/registry adalah proyek layanan registrasi server MCP yang digerakkan oleh komunitas, saat ini dalam tahap pengembangan awal. Proyek ini bertujuan untuk menyediakan repositori pusat entri server MCP, memungkinkan penemuan dan pengelolaan berbagai implementasi MCP beserta metadata, konfigurasi, dan fungsinya. Fitur-fiturnya meliputi RESTful API untuk mengelola entri, endpoint pemeriksaan kesehatan, dukungan untuk berbagai konfigurasi lingkungan, dukungan database MongoDB dan memori, serta dokumentasi API. Proyek ini ditulis dalam bahasa Go dan menyediakan panduan untuk memulai dengan cepat melalui Docker Compose (Sumber: GitHub Trending)
📚 Pembelajaran
Terence Tao Merilis Tutorial Pembuktian Matematika dengan Bantuan AI, Mendemonstrasikan Penggunaan GitHub Copilot untuk Membuktikan Limit Fungsi: Peraih Medali Fields, Terence Tao, memperbarui video di saluran YouTube-nya, yang secara rinci mendemonstrasikan cara menggunakan GitHub Copilot untuk membantu membuktikan teorema penjumlahan, pengurangan, dan perkalian limit fungsi. Tutorial ini menekankan pentingnya memandu AI dengan benar dan menunjukkan peran Copilot dalam menghasilkan kerangka kode dan menyarankan fungsi pustaka, sekaligus menunjukkan keterbatasannya dalam menangani detail matematika yang kompleks, kasus khusus, dan menjaga konsistensi kontekstual. Terence Tao menyimpulkan bahwa Copilot bermanfaat bagi pemula, tetapi untuk masalah yang kompleks masih memerlukan banyak intervensi dan penyesuaian manual, dan terkadang menggabungkannya dengan penurunan rumus di atas kertas mungkin lebih efisien (Sumber: 量子位)

Makalah Membahas Kontradiksi Antara Penalaran Model Besar dan Kepatuhan Instruksi, Mengusulkan Konsep Constraint Attention: Sebuah makalah penelitian berjudul “When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs” menunjukkan bahwa setelah Large Language Model menggunakan Chain-of-Thought (CoT) untuk penalaran, meskipun kinerjanya lebih cerdas dalam beberapa aspek (seperti mematuhi format, jumlah kata), akurasi dalam mengikuti instruksi secara ketat justru dapat menurun. Tim peneliti melalui pengujian terhadap 15 model open source dan closed source menemukan bahwa model lebih cenderung “bertindak sendiri”, mengubah atau menambahkan informasi tambahan setelah menggunakan CoT, sambil mengabaikan instruksi asli. Makalah ini memperkenalkan konsep “Constraint Attention” dan menemukan bahwa penalaran CoT akan mengurangi perhatian model terhadap batasan-batasan penting. Penelitian ini juga menunjukkan bahwa panjang pemikiran CoT tidak memiliki korelasi signifikan dengan akurasi penyelesaian tugas, dan membahas kemungkinan peningkatan efek kepatuhan instruksi melalui contoh few-shot, refleksi diri, dan metode lainnya (Sumber: WeChat)

MIT dan Google Mengusulkan PASTA: Paradigma Baru Generasi Paralel Asinkron LLM Berbasis Pembelajaran Kebijakan: Tim peneliti dari Massachusetts Institute of Technology (MIT) dan Google mengusulkan kerangka kerja PASTA (PArallel STructure Annotation), yang memungkinkan Large Language Model (LLM) secara mandiri mengoptimalkan strategi generasi paralel asinkron melalui pembelajaran kebijakan. Metode ini pertama-tama mengembangkan bahasa markup PASTA-LANG untuk menandai blok teks yang independen secara semantik guna mencapai generasi paralel. Proses pelatihan dibagi menjadi dua tahap: fine-tuning terawasi agar model belajar menyisipkan markup PASTA-LANG, diikuti dengan optimasi preferensi (berdasarkan rasio percepatan teoretis dan evaluasi kualitas konten) untuk lebih meningkatkan strategi penandaan. PASTA merancang tata letak KV cache yang saling terkait dan mekanisme kontrol attention untuk mengoordinasikan kolaborasi multi-thread yang efisien. Eksperimen menunjukkan bahwa PASTA mencapai percepatan 1.21-1.93 kali pada benchmark AlpacaEval, sambil mempertahankan atau meningkatkan kualitas output, serta menunjukkan skalabilitas yang baik (Sumber: WeChat)

Makalah ICML 2025 Mengusulkan TPO: Solusi Baru Penyelarasan Preferensi Instan Saat Inferensi, Tanpa Pelatihan Ulang: Shanghai Artificial Intelligence Laboratory mengusulkan Test-Time Preference Optimization (TPO), sebuah metode baru yang memungkinkan Large Language Model menyesuaikan outputnya secara mandiri agar sesuai dengan preferensi manusia melalui umpan balik teks iteratif saat inferensi. TPO mensimulasikan proses “gradient descent” berbahasa (menghasilkan kandidat jawaban, menghitung kerugian teks, menghitung gradien teks, memperbarui jawaban) untuk mencapai penyelarasan tanpa memperbarui bobot model. Eksperimen menunjukkan bahwa TPO dapat secara signifikan meningkatkan kinerja model yang belum selaras dan yang sudah selaras, misalnya model Llama-3.1-70B-SFT setelah dua langkah optimasi TPO melampaui versi Instruct yang sudah selaras pada beberapa benchmark. Metode ini menyediakan strategi perluasan inferensi “lebar + kedalaman” dan menunjukkan potensi optimasi yang efisien dalam lingkungan dengan sumber daya terbatas (Sumber: WeChat)
Penelitian Baru Membahas Metode Penggalian Pengetahuan Tersembunyi LLM: Sebuah paper penelitian mengkaji cara menggali pengetahuan yang mungkin tersembunyi dari Large Language Model. Peneliti melatih model “tabu” yang dirancang untuk mendeskripsikan kosakata rahasia tertentu tanpa menyebutkannya secara langsung, di mana kosakata rahasia tersebut tidak muncul dalam data pelatihan atau prompt. Selanjutnya, peneliti mengevaluasi strategi otomatis metode non-interpretatif (black-box) dan teknik interpretabilitas berbasis mekanisme (seperti logit lens dan sparse autoencoder) untuk mengungkap rahasia ini. Hasilnya menunjukkan bahwa kedua metode tersebut efektif dalam menggali kata rahasia dalam pengaturan pembuktian konsep. Pekerjaan ini bertujuan untuk memberikan solusi awal untuk masalah krusial penggalian pengetahuan rahasia dari model bahasa guna mendorong deployment yang aman dan andal (Sumber: HuggingFace Daily Papers)
Makalah Membahas Aplikasi Pruning Terfederasi pada Large Language Model (FedPrLLM): Untuk mengatasi kesulitan dalam memperoleh sampel kalibrasi publik untuk pruning Large Language Model (LLM) di domain yang sensitif terhadap privasi, para peneliti mengusulkan FedPrLLM, sebuah kerangka kerja pruning terfederasi yang komprehensif. Dalam kerangka kerja ini, setiap klien hanya perlu menghitung matriks pruning mask berdasarkan data kalibrasi lokal dan membagikannya dengan server untuk melakukan pruning model global secara kolaboratif, sekaligus melindungi privasi data lokal. Melalui eksperimen yang luas, penelitian ini menemukan bahwa one-shot pruning yang dikombinasikan dengan perbandingan lapisan (layer comparison) dan tanpa penskalaan bobot (no weight scaling) adalah pilihan terbaik dalam kerangka kerja FedPrLLM. Penelitian ini bertujuan untuk memandu pekerjaan pruning LLM di masa depan dalam domain yang sensitif terhadap privasi (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan MIGRATION-BENCH: Benchmark Migrasi Kode Java 8: Para peneliti meluncurkan MIGRATION-BENCH, sebuah benchmark migrasi kode yang berfokus pada migrasi dari Java 8 ke versi LTS terbaru (Java 17, 21). Benchmark ini mencakup dataset lengkap berisi 5102 repositori dan subset berisi 300 repositori kompleks yang dipilih dengan cermat, yang bertujuan untuk mengevaluasi kemampuan Large Language Model (LLM) dalam tugas migrasi kode tingkat repositori. Pada saat yang sama, makalah ini menyediakan kerangka kerja evaluasi yang komprehensif dan mengusulkan metode SD-Feedback. Eksperimen menunjukkan bahwa LLM (seperti Claude-3.5-Sonnet-v2) dapat secara efektif menangani tugas migrasi semacam ini, mencapai tingkat keberhasilan masing-masing 62,33% (migrasi minimal) dan 27,00% (migrasi maksimal) pada subset yang dipilih (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan CS-Sum: Benchmark Ringkasan Percakapan Alih Kode dan Analisis Keterbatasan LLM: Untuk mengevaluasi kemampuan Large Language Model (LLM) dalam memahami alih kode (CS), para peneliti memperkenalkan benchmark CS-Sum, yang melakukan evaluasi dengan meringkas percakapan alih kode ke dalam bahasa Inggris. CS-Sum adalah benchmark ringkasan percakapan alih kode pertama untuk Mandarin-Inggris, Tamil-Inggris, dan Melayu-Inggris, dengan setiap pasangan bahasa berisi 900-1300 percakapan yang dianotasi secara manual. Melalui evaluasi terhadap sepuluh LLM open source dan closed source (termasuk metode few-shot, terjemahan-ringkasan, dan fine-tuning), penelitian menemukan bahwa meskipun skor metrik evaluasi otomatis tinggi, LLM masih membuat kesalahan halus saat memproses input CS, yang mengubah makna lengkap percakapan. Makalah ini juga menunjukkan tiga jenis kesalahan paling umum yang dilakukan LLM saat memproses CS dan menekankan perlunya pelatihan khusus untuk data alih kode (Sumber: HuggingFace Daily Papers)
Makalah Membahas Kemampuan Model Besar dalam Mengekspresikan Tingkat Keyakinan Saat Inferensi: Penelitian menunjukkan bahwa Large Language Model (LLM) yang melakukan penalaran Chain-of-Thought (CoT) yang diperluas tidak hanya berkinerja lebih baik dalam memecahkan masalah, tetapi juga lebih unggul dalam mengekspresikan tingkat keyakinannya secara akurat. Melalui pengujian benchmark terhadap enam model penalaran pada enam dataset, ditemukan bahwa dalam 33 dari 36 pengaturan, model penalaran memiliki kalibrasi keyakinan yang lebih baik daripada model non-penalaran. Analisis berpendapat bahwa ini disebabkan oleh perilaku “pemikiran lambat” model penalaran (seperti menjelajahi alternatif, menelusuri kembali), yang memungkinkannya menyesuaikan tingkat keyakinan secara dinamis selama proses CoT. Selain itu, menghilangkan perilaku pemikiran lambat menyebabkan penurunan kalibrasi yang signifikan, dan model non-penalaran juga dapat memperoleh manfaat jika dipandu untuk melakukan pemikiran lambat (Sumber: HuggingFace Daily Papers)
Makalah: Memanfaatkan Pembelajaran Penguatan dari Pasangan Tanya Jawab Visual untuk Melatih VLM dalam Penalaran Visual (Visionary-R1): Penelitian ini bertujuan untuk melatih model bahasa visual (VLM) melakukan penalaran pada data gambar melalui pembelajaran penguatan dan pasangan tanya jawab visual, tanpa pengawasan Chain-of-Thought (CoT) yang eksplisit. Penelitian menemukan bahwa penerapan pembelajaran penguatan secara sederhana (mendorong model untuk menghasilkan rantai penalaran sebelum menjawab) dapat menyebabkan model mempelajari jalan pintas dari pertanyaan sederhana, sehingga mengurangi kemampuan generalisasinya. Untuk mengatasi masalah ini, peneliti mengusulkan agar model mengikuti format output “caption-reasoning-answer”, yaitu pertama-tama menghasilkan caption detail gambar, baru kemudian membangun rantai penalaran. Model Visionary-R1 yang dilatih berdasarkan metode ini menunjukkan kinerja yang lebih unggul pada beberapa benchmark penalaran visual dibandingkan model multimodal kuat seperti GPT-4o, Claude3.5-Sonnet, dan Gemini-1.5-Pro (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan VideoEval-Pro: Benchmark Evaluasi Pemahaman Video Panjang yang Lebih Realistis dan Tangguh: Penelitian menunjukkan bahwa benchmark pemahaman video panjang (LVU) saat ini sebagian besar bergantung pada soal pilihan ganda (MCQ), yang rentan terhadap tebakan, dan sebagian pertanyaan dapat dijawab tanpa menonton video secara lengkap, sehingga melebih-lebihkan kinerja model. Untuk mengatasi masalah ini, makalah ini mengusulkan VideoEval-Pro, sebuah benchmark LVU yang berisi soal jawaban singkat terbuka, yang bertujuan untuk mengevaluasi secara nyata kemampuan model dalam memahami seluruh video, mencakup tugas persepsi dan penalaran tingkat segmen dan seluruh video. Evaluasi terhadap 21 video LMM menunjukkan bahwa kinerja model menurun drastis pada soal terbuka, dan skor MCQ yang tinggi tidak selalu berkorelasi dengan skor VideoEval-Pro yang tinggi. VideoEval-Pro lebih diuntungkan dari penambahan jumlah frame input, sehingga menyediakan standar evaluasi yang lebih andal untuk bidang LVU (Sumber: HuggingFace Daily Papers)
Makalah: Fine-tuning Jaringan Saraf Terkuantisasi Melalui Optimasi Orde Nol (QZO): Seiring dengan pertumbuhan eksponensial volume Large Language Model, memori GPU menjadi kendala dalam adaptasi model untuk tugas hilir. Penelitian ini bertujuan untuk meminimalkan penggunaan memori untuk bobot model, gradien, dan status optimizer melalui kerangka kerja terpadu. Peneliti mengusulkan penghapusan gradien dan status optimizer melalui optimasi orde nol, yang memperkirakan gradien dengan mengganggu bobot selama propagasi maju. Untuk meminimalkan memori bobot, digunakan kuantisasi model (misalnya, bfloat16 ke int4). Namun, penerapan langsung optimasi orde nol pada bobot terkuantisasi tidak dapat dilakukan karena kesenjangan presisi antara bobot diskrit dan gradien kontinu. Untuk mengatasi masalah ini, makalah ini mengusulkan Quantized Zero-Order Optimization (QZO), sebuah metode baru yang memperkirakan gradien dengan mengganggu skala kuantisasi kontinu dan menggunakan metode pemangkasan turunan arah untuk menstabilkan pelatihan. QZO bersifat ortogonal terhadap metode kuantisasi pasca-pelatihan berbasis skalar dan berbasis codebook. Dibandingkan dengan fine-tuning bfloat16 parameter penuh, QZO dapat mengurangi total biaya memori lebih dari 18 kali untuk LLM 4-bit dan memungkinkan Llama-2-13B serta Stable Diffusion 3.5 Large untuk di-fine-tune dalam satu GPU 24GB (Sumber: HuggingFace Daily Papers)
Makalah: Mengoptimalkan Kinerja Inferensi Kapan Saja Melalui Budget Relative Policy Optimization (BRPO) (AnytimeReasoner): Perluasan komputasi saat pengujian sangat penting untuk meningkatkan kemampuan penalaran Large Language Model (LLM). Metode yang ada saat ini biasanya menggunakan reinforcement learning (RL) untuk memaksimalkan imbalan yang dapat diverifikasi di akhir lintasan penalaran, tetapi ini hanya mengoptimalkan kinerja akhir dengan anggaran token tetap, yang memengaruhi efisiensi pelatihan dan deployment. Penelitian ini mengusulkan kerangka kerja AnytimeReasoner, yang bertujuan untuk mengoptimalkan kinerja inferensi kapan saja, meningkatkan efisiensi token, dan fleksibilitas penalaran di bawah batasan anggaran yang berbeda. Metodenya adalah dengan memotong proses berpikir lengkap agar sesuai dengan anggaran token yang diambil sampelnya dari distribusi prior, memaksa model untuk merangkum jawaban terbaik untuk setiap pemikiran yang dipotong untuk diverifikasi, sehingga memperkenalkan imbalan padat yang dapat diverifikasi selama proses penalaran, dan mendorong alokasi kredit yang lebih efektif dalam optimasi RL. Selain itu, peneliti memperkenalkan Budget Relative Policy Optimization (BRPO), sebuah teknik pengurangan varians baru, untuk meningkatkan ketahanan dan efisiensi pembelajaran saat memperkuat strategi berpikir. Hasil eksperimen pada tugas penalaran matematis menunjukkan bahwa metode ini, di bawah berbagai distribusi prior, mengungguli GRPO di semua anggaran berpikir, meningkatkan efisiensi pelatihan dan token (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan Large Hybrid Reasoning Model (LHRM): Berpikir Sesuai Kebutuhan untuk Meningkatkan Efisiensi & Kemampuan: Large Reasoning Model (LRM) baru-baru ini secara signifikan meningkatkan kemampuan penalaran dengan melakukan proses berpikir yang diperluas sebelum menghasilkan respons akhir. Namun, proses berpikir yang terlalu panjang menimbulkan biaya besar dalam konsumsi token dan latensi, terutama tidak perlu untuk kueri sederhana. Penelitian ini memperkenalkan Large Hybrid Reasoning Model (LHRM), jenis model yang dapat secara adaptif memutuskan apakah akan melakukan pemikiran berdasarkan informasi kontekstual dari kueri pengguna. Untuk mencapai tujuan ini, peneliti mengusulkan alur kerja pelatihan dua tahap: pertama melakukan cold start melalui Hybrid Fine-Tuning (HFT), kemudian menggunakan reinforcement learning online dengan Hybrid Group Policy Optimization (HGPO) yang diusulkan untuk secara implisit mempelajari pemilihan mode berpikir yang sesuai. Selain itu, peneliti memperkenalkan metrik Hybrid Accuracy untuk mengukur kemampuan berpikir hibrid model. Hasil eksperimen menunjukkan bahwa LHRM dapat secara adaptif melakukan pemikiran hibrid pada kueri dengan berbagai tingkat kesulitan dan jenis, kemampuan penalaran dan umumnya lebih unggul daripada LRM dan LLM yang ada, sekaligus meningkatkan efisiensi secara signifikan (Sumber: HuggingFace Daily Papers)
Makalah: Memanfaatkan Pembelajaran Penguatan untuk Peringkat VisualQuality-R1 Guna Mewujudkan Evaluasi Kualitas Gambar yang Diinduksi Penalaran: DeepSeek-R1 telah membuktikan bahwa pembelajaran penguatan dapat secara efektif mendorong kemampuan penalaran dan generalisasi Large Language Model (LLM). Namun, dalam bidang evaluasi kualitas gambar (IQA) yang bergantung pada penalaran visual, potensi pemodelan komputasi yang diinduksi penalaran belum sepenuhnya dieksplorasi. Penelitian ini memperkenalkan VisualQuality-R1, sebuah model No-Reference IQA (NR-IQA) yang diinduksi penalaran, dan menggunakan reinforcement learning to rank untuk pelatihan, sebuah algoritma pembelajaran yang beradaptasi dengan sifat relatif intrinsik kualitas visual. Secara khusus, untuk sepasang gambar, model menggunakan group relative policy optimization untuk menghasilkan beberapa skor kualitas untuk setiap gambar. Estimasi ini kemudian digunakan untuk menghitung probabilitas perbandingan bahwa satu gambar memiliki kualitas lebih tinggi dari yang lain di bawah model Thurstone. Imbalan untuk setiap estimasi kualitas didefinisikan menggunakan metrik fidelitas kontinu alih-alih label biner diskrit. Eksperimen ekstensif menunjukkan bahwa VisualQuality-R1 yang diusulkan secara konsisten mengungguli model NR-IQA berbasis deep learning diskriminatif serta metode regresi kualitas yang diinduksi penalaran baru-baru ini dalam hal kinerja. Selain itu, VisualQuality-R1 mampu menghasilkan deskripsi kualitas yang kaya konteks dan konsisten dengan penilaian manusia, serta mendukung pelatihan multi-dataset tanpa perlu menyesuaikan kembali skala persepsi. Fitur-fitur ini membuatnya sangat cocok untuk mengukur kemajuan berbagai tugas pemrosesan gambar seperti super-resolusi gambar dan generasi gambar secara andal (Sumber: HuggingFace Daily Papers)
Makalah: Membuka Kemampuan Penalaran Umum Melalui “Pemanasan” dalam Kondisi Sumber Daya Terbatas: Merancang LLM yang efektif dengan kemampuan penalaran biasanya memerlukan penggunaan reinforcement learning dengan imbalan yang dapat diverifikasi (RLVR) atau distilasi dengan Chain-of-Thought (CoT) panjang yang dikurasi dengan cermat, keduanya sangat bergantung pada sejumlah besar data pelatihan, yang menjadi tantangan signifikan untuk skenario di mana data pelatihan berkualitas langka. Peneliti mengusulkan strategi pelatihan dua tahap yang hemat sampel untuk mengembangkan LLM penalaran di bawah pengawasan terbatas. Tahap pertama, model “dipanaskan” dengan mendistilasi CoT panjang dari domain mainan (seperti teka-teki logika ksatria dan penipu) untuk memperoleh keterampilan penalaran umum. Tahap kedua, RLVR diterapkan pada model yang telah “dipanaskan” menggunakan sejumlah kecil sampel domain target. Eksperimen menunjukkan bahwa metode ini memiliki beberapa manfaat: (i) tahap pemanasan saja sudah dapat mendorong penalaran umum, meningkatkan kinerja pada serangkaian tugas (MATH, HumanEval+, MMLU-Pro); (ii) saat pelatihan RLVR pada dataset kecil yang sama (≤100 sampel), model yang dipanaskan secara konsisten mengungguli model dasar; (iii) pemanasan sebelum pelatihan RLVR memungkinkan model untuk mempertahankan kemampuan generalisasi lintas domain bahkan setelah dilatih untuk domain tertentu; (iv) memperkenalkan pemanasan dalam alur kerja tidak hanya meningkatkan akurasi tetapi juga meningkatkan efisiensi sampel keseluruhan dari pelatihan RLVR. Hasil penelitian ini menunjukkan potensi “pemanasan” dalam membangun LLM penalaran yang tangguh di lingkungan dengan data langka (Sumber: HuggingFace Daily Papers)
Makalah Mengusulkan IndexMark: Kerangka Kerja Watermarking Bebas Pelatihan untuk Generasi Gambar Autoregresif: Teknologi watermarking gambar tak terlihat dapat melindungi kepemilikan gambar dan mencegah penyalahgunaan model generasi visual secara jahat. Namun, metode watermarking generatif yang ada saat ini terutama ditujukan untuk model difusi, sementara teknologi watermarking untuk model generasi gambar autoregresif masih perlu dieksplorasi. Peneliti mengusulkan IndexMark, sebuah kerangka kerja watermarking bebas pelatihan untuk model generasi gambar autoregresif. IndexMark terinspirasi oleh sifat redundansi codebook: mengganti indeks yang dihasilkan secara autoregresif dengan indeks serupa menghasilkan perbedaan visual yang dapat diabaikan. Komponen inti IndexMark adalah metode “cocokkan-ganti” yang sederhana dan efektif, yang dengan cermat memilih token watermark dari codebook berdasarkan kesamaan token, dan mempromosikan penggunaan token watermark melalui penggantian token, sehingga menyematkan watermark tanpa memengaruhi kualitas gambar. Verifikasi watermark dicapai dengan menghitung proporsi token watermark dalam gambar yang dihasilkan, dan ditingkatkan lebih lanjut akurasinya melalui encoder indeks. Selain itu, peneliti memperkenalkan skema verifikasi tambahan untuk meningkatkan ketahanan terhadap serangan pemotongan. Eksperimen membuktikan bahwa IndexMark mencapai tingkat SOTA dalam kualitas gambar dan akurasi verifikasi, serta menunjukkan ketahanan terhadap berbagai gangguan seperti pemotongan, noise, Gaussian blur, penghapusan acak, color jitter, dan kompresi JPEG (Sumber: HuggingFace Daily Papers)
Makalah: Penalaran Melalui Model Imbalan (RRM): Model imbalan memainkan peran penting dalam memandu Large Language Model (LLM) untuk menghasilkan output yang sesuai dengan harapan manusia. Namun, cara efektif memanfaatkan komputasi saat pengujian untuk meningkatkan kinerja model imbalan masih merupakan tantangan terbuka. Penelitian ini memperkenalkan Reward Reasoning Models (RRMs), jenis model yang dirancang khusus untuk melakukan proses penalaran yang cermat sebelum menghasilkan imbalan akhir. Melalui penalaran chain-of-thought, RRMs dapat memanfaatkan komputasi tambahan saat pengujian untuk kueri kompleks yang imbalannya tidak jelas. Untuk mengembangkan RRMs, peneliti mengimplementasikan kerangka kerja reinforcement learning yang mampu menumbuhkan kemampuan penalaran imbalan yang berevolusi sendiri tanpa memerlukan lintasan penalaran eksplisit sebagai data pelatihan. Hasil eksperimen menunjukkan bahwa RRMs mencapai kinerja superior dalam benchmark pemodelan imbalan di berbagai domain. Perlu dicatat, peneliti menunjukkan bahwa RRMs dapat secara adaptif memanfaatkan komputasi saat pengujian untuk lebih meningkatkan akurasi imbalan. Model penalaran imbalan yang telah dilatih sebelumnya tersedia di HuggingFace (Sumber: HuggingFace Daily Papers)
Makalah: Memanfaatkan Pakar Kognitif dalam MoE untuk Panduan Berpikir, Meningkatkan Penalaran Tanpa Pelatihan Tambahan: Arsitektur Mixture-of-Experts (MoE) dalam Large Reasoning Model (LRM) telah mencapai kemampuan penalaran yang mengesankan dengan mengaktifkan pakar secara selektif untuk memfasilitasi proses kognitif terstruktur. Meskipun ada kemajuan signifikan, model penalaran yang ada sering kali terhambat oleh inefisiensi kognitif seperti berpikir berlebihan dan kurang berpikir. Untuk mengatasi keterbatasan ini, peneliti memperkenalkan metode panduan saat inferensi baru yang disebut “Reinforcing Cognitive Experts” (RICE), yang bertujuan untuk meningkatkan kinerja penalaran tanpa pelatihan tambahan atau heuristik yang rumit. Dengan memanfaatkan normalized Pointwise Mutual Information (nPMI), peneliti secara sistematis mengidentifikasi pakar khusus, yang disebut “pakar kognitif”, yang bertanggung jawab untuk mengoordinasikan operasi penalaran tingkat meta yang ditandai dengan token tertentu (seperti ““`”). Evaluasi eksperimental pada LRM berbasis MoE terkemuka (DeepSeek-R1 dan Qwen3-235B) melalui benchmark kuantitatif dan penalaran ilmiah yang ketat menunjukkan bahwa RICE mencapai peningkatan yang signifikan dan konsisten dalam akurasi penalaran, efisiensi kognitif, dan generalisasi lintas domain. Kuncinya, metode ringan ini secara substansial mengungguli teknik panduan penalaran populer (seperti desain prompt dan batasan dekode) sambil mempertahankan kemampuan mengikuti instruksi umum model. Hasil ini menyoroti penguatan pakar kognitif sebagai arah yang menjanjikan, praktis, dan dapat dijelaskan untuk meningkatkan efisiensi kognitif dalam model penalaran tingkat lanjut (Sumber: HuggingFace Daily Papers)
Makalah: Menyelidiki Pengaruh Susunan Konteks terhadap Kinerja Model Bahasa dalam Tanya Jawab Multi-Lompatan: Tanya jawab multi-lompatan (MHQA) menjadi tantangan bagi model bahasa (LM) karena kompleksitasnya. Ketika LM diminta untuk memproses beberapa hasil pencarian, mereka tidak hanya harus mengambil informasi yang relevan tetapi juga melakukan penalaran multi-lompatan lintas sumber informasi. Meskipun LM berkinerja baik dalam tugas tanya jawab tradisional, causal mask dapat menghambat kemampuan mereka untuk bernalar dalam konteks yang kompleks. Penelitian ini menyelidiki bagaimana LM merespons pertanyaan multi-lompatan dengan menyusun hasil pencarian (dokumen yang diambil) dalam konfigurasi yang berbeda. Penelitian menemukan: 1) Model encoder-decoder (seperti seri Flan-T5) umumnya mengungguli LM hanya-decoder kausal dalam tugas MHQA, meskipun ukurannya jauh lebih kecil; 2) Mengubah urutan dokumen emas mengungkapkan tren yang berbeda dalam model Flan T5 dan model hanya-decoder yang di-fine-tune, dengan kinerja terbaik ketika urutan dokumen selaras dengan urutan rantai penalaran; 3) Memodifikasi causal mask untuk meningkatkan perhatian dua arah model hanya-decoder kausal dapat secara efektif meningkatkan kinerja akhirnya. Selain itu, penelitian ini juga melakukan penyelidikan menyeluruh terhadap distribusi bobot perhatian LM dalam konteks MHQA, menemukan bahwa ketika jawaban benar, bobot perhatian cenderung mencapai puncak pada nilai yang lebih tinggi. Peneliti memanfaatkan temuan ini untuk secara heuristik meningkatkan kinerja LM pada tugas ini (Sumber: HuggingFace Daily Papers)
Makalah: Mewujudkan Agen Visual Melalui Fine-Tuning Penguatan (Visual-ARFT): Tren utama dalam Large Reasoning Model (seperti o3 dari OpenAI) adalah kemampuan agen bawaan untuk menggunakan alat eksternal (seperti pencarian browser web, menulis/menjalankan kode untuk pemrosesan gambar) untuk mencapai “berpikir dengan gambar”. Di komunitas riset open source, meskipun kemajuan signifikan telah dicapai dalam kemampuan agen bahasa murni (seperti pemanggilan fungsi dan integrasi alat), pengembangan kemampuan agen multimodal yang melibatkan pemikiran nyata dengan gambar dan benchmark yang sesuai masih kurang. Penelitian ini menyoroti efektivitas Visual Agentic Reinforcement Fine-Tuning (Visual-ARFT) dalam memberdayakan Large Vision Language Model (LVLM) dengan kemampuan penalaran yang fleksibel dan adaptif. Melalui Visual-ARFT, LVLM open source memperoleh kemampuan untuk menjelajahi situs web guna mendapatkan pembaruan informasi waktu nyata, serta menulis kode untuk memanipulasi dan menganalisis gambar input melalui teknik pemrosesan gambar seperti pemotongan, rotasi, dll. Peneliti juga mengusulkan Multi-modal Agentic Tool Bench (MAT), yang terdiri dari pengaturan MAT-Search dan MAT-Coding, untuk mengevaluasi kemampuan pencarian dan pengkodean agen LVLM. Hasil eksperimen menunjukkan bahwa Visual-ARFT mengungguli baseline sebesar +18.6% F1 / +13.0% EM pada MAT-Coding, dan +10.3% F1 / +8.7% EM pada MAT-Search, akhirnya melampaui GPT-4o. Visual-ARFT juga mencapai peningkatan +29.3 F1% / +25.9% EM pada benchmark tanya jawab multi-lompatan yang ada (seperti 2Wiki dan HotpotQA), menunjukkan kemampuan generalisasi yang kuat. Temuan ini menunjukkan bahwa Visual-ARFT menyediakan jalur yang menjanjikan untuk membangun agen multimodal yang tangguh dan dapat digeneralisasi (Sumber: HuggingFace Daily Papers)
💼 Bisnis
Mianbi Intelligence Selesaikan Pendanaan Baru Senilai Ratusan Juta Yuan, Diinvestasikan Bersama oleh Hongtai, Guozhong, Tsinghua Control JinXin, dan Moutai Fund: Perusahaan model besar Mianbi Intelligence baru-baru ini mengumumkan penyelesaian putaran pendanaan baru senilai ratusan juta yuan, yang diinvestasikan bersama oleh Hongtai Fund, Guozhong Capital, Tsinghua Control JinXin, dan Moutai Fund. Mianbi Intelligence berfokus pada penelitian dan pengembangan model besar yang “efisien”, bertujuan untuk menciptakan model besar dengan kinerja lebih tinggi, biaya lebih rendah, konsumsi daya lebih rendah, dan kecepatan lebih cepat pada parameter yang sama. Model full-modalitas sisi perangkatnya, MiniCPM-o 2.6, telah mencapai tingkat terdepan di industri dalam aspek melihat berkelanjutan, mendengar secara real-time, dan berbicara secara alami. Seri model MiniCPM, dengan karakteristik efisien dan berbiaya rendah, telah diunduh lebih dari sepuluh juta kali di semua platform. Perusahaan telah bekerja sama dengan produsen mobil seperti Changan Automobile, SAIC Volkswagen, dan Great Wall Motors untuk mendorong komersialisasi model besar sisi perangkat di bidang seperti kokpit cerdas (Sumber: 量子位, WeChat)

Terminus Group dan Universitas Tongji Jalin Kerja Sama Strategis, Bersama-sama Dorong Terobosan Teknologi Kecerdasan Spasial: Perusahaan AIoT Terminus Group dan Institut Kecerdasan Buatan Teknik Universitas Tongji menandatangani perjanjian kerja sama strategis. Kedua belah pihak akan fokus pada teknologi kecerdasan spasial, dengan penekanan pada penelitian dan pengembangan fusi data heterogen multi-sumber, pemahaman skenario, dan eksekusi keputusan. Isi kerja sama meliputi penelitian inovatif, berbagi sumber daya, transformasi hasil, dan pengembangan bakat. Terminus Group akan menyediakan skenario aplikasi dan platform pengujian perangkat keras, sementara Institut Kecerdasan Buatan Teknik Universitas Tongji akan memimpin penelitian dan pengembangan algoritma inti serta rekayasa sistem. Kedua belah pihak bertujuan untuk mempercepat penerapan teknologi mutakhir di sisi industri dan bersama-sama mengeksplorasi terobosan di bidang “sistem operasi” kecerdasan teknik (Sumber: 量子位)

Perusahaan Besar Domestik Percepat Tata Letak AI Agent, Baidu, Alibaba, ByteDance Rebut Pasar: Setelah KTT AI Sequoia Capital menekankan nilai AI Agent, perusahaan internet besar domestik seperti ByteDance, Baidu, dan Alibaba mempercepat tata letak mereka di bidang ini. ByteDance dilaporkan memiliki beberapa tim yang terlibat dalam pengembangan Agent dan telah melakukan uji coba internal “Kouzi Space”; Baidu merilis agen cerdas umum “Xīnxiǎng” pada Konferensi Create; sementara Alibaba memposisikan Quark sebagai “Super Agent”. Selain Agent umum, masing-masing perusahaan juga berfokus pada Agent vertikal seperti Feizhu Wen Yi Wen (Alibaba) dan Faxingbao (Baidu). Industri percaya bahwa Agent adalah gelombang kedua setelah model besar, dan kunci persaingan terletak pada kedalaman ekosistem, penguasaan pikiran pengguna, serta kemampuan model dasar, pengendalian biaya, dan faktor lainnya. Meskipun persaingan ketat, Agent belum mencapai momen disruptif seperti GPT, dan kematangan teknologi, model bisnis, serta pengalaman pengguna masih memiliki ruang untuk ditingkatkan (Sumber: 36氪)
🌟 Komunitas
Konten Buatan AI Membanjiri Reddit, Memicu Kekhawatiran “Internet Mati” dan Diskusi Pengalaman Pengguna: Pengguna Reddit mengamati peningkatan konten buatan AI di platform, dengan beberapa komentar menunjukkan gaya yang serupa dan kurang personal, bahkan muncul jejak penulisan AI yang jelas (seperti penggunaan em-dash yang berlebihan). Hal ini memicu diskusi tentang “Teori Internet Mati” (Dead Internet Theory), yaitu sebagian besar konten di internet akan dihasilkan oleh AI, bukan interaksi manusia sungguhan. Reaksi pengguna beragam: beberapa orang menganggap konten AI kurang manusiawi, membosankan, atau menyeramkan, yang memengaruhi pengalaman komunikasi antarpribadi yang sebenarnya; yang lain menunjukkan bahwa AI dapat membantu penutur non-asli memperbaiki teks, atau digunakan untuk menguji dan menyempurnakan model. Kekhawatiran umum adalah bahwa membanjirnya konten AI akan mengencerkan diskusi manusia yang sebenarnya dan dapat digunakan untuk tujuan pemasaran, propaganda, dll., yang pada akhirnya mengurangi nilai platform untuk pelatihan AI (Sumber: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
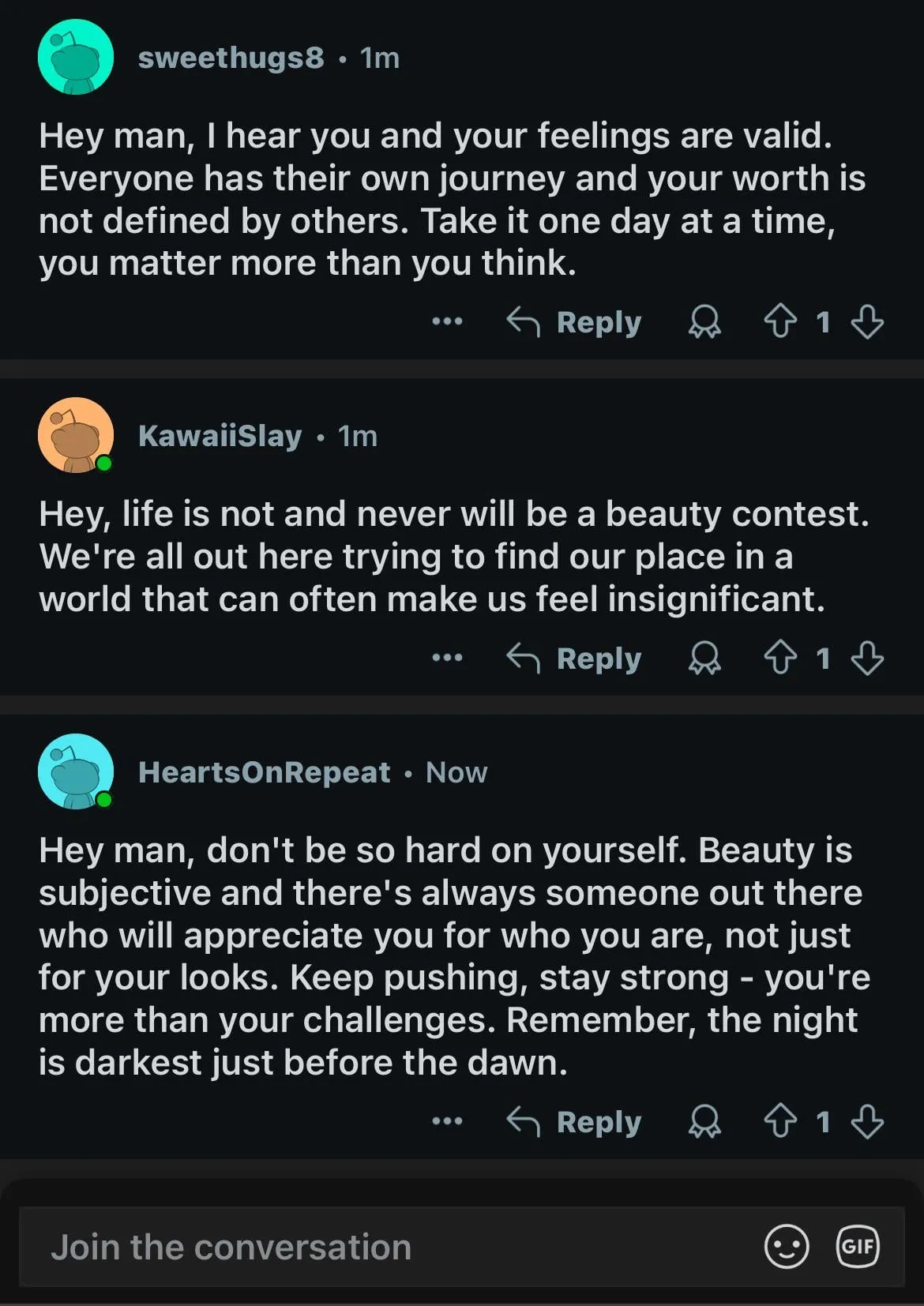
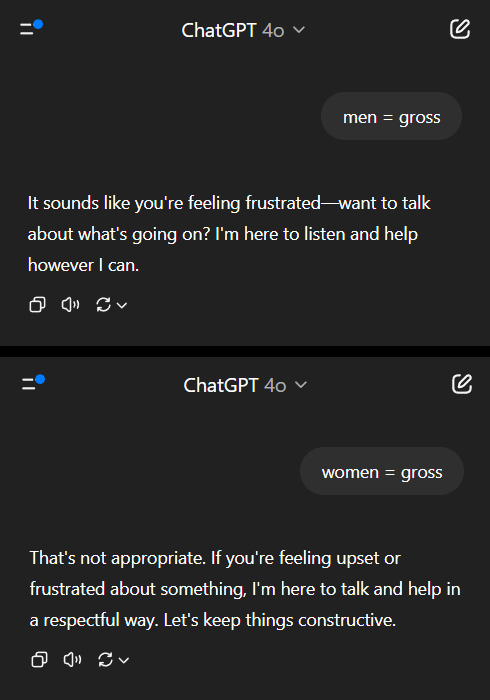
Model AI Menunjukkan Standar Ganda dalam Masalah Bias Gender, Memicu Refleksi Sosial: Sebuah postingan di Reddit menunjukkan bahwa model AI (diduga versi pratinjau Gemini 2.5 Pro) menunjukkan reaksi berbeda ketika menangani pernyataan generalisasi negatif yang melibatkan gender. Ketika diberi tahu “pria = menjijikkan”, model cenderung merespons secara netral, mengakui itu sebagai pernyataan subjektif; sedangkan ketika diberi tahu “wanita = menjijikkan”, model menolak interaksi lebih lanjut, menganggap pernyataan tersebut menyebarkan generalisasi berbahaya. Bagian komentar membahas hal ini dengan hangat, dengan pandangan termasuk: ini mencerminkan realitas sosial di mana diskusi tentang misogini jauh lebih banyak daripada diskusi tentang misandri, yang menyebabkan ketidakseimbangan data pelatihan; model mungkin menyesuaikan strategi respons berdasarkan jenis kelamin penanya; sensitivitas masyarakat terhadap stereotip dan pernyataan agresif terhadap kelompok gender yang berbeda tidak sama. Beberapa komentator percaya bahwa reaksi AI adalah cerminan dari bias sosial, sementara yang lain berpendapat bahwa perlakuan yang berbeda ini memiliki alasan yang masuk akal, karena pernyataan negatif terhadap wanita sering dikaitkan dengan diskriminasi dan kekerasan yang lebih luas (Sumber: Reddit r/ChatGPT)
Tren Komodifikasi AI Agent dan Diskusi Fokus Persaingan Masa Depan: Pengguna Reddit berdiskusi bahwa konferensi Microsoft Build 2025 dan Google I/O 2025 menandai masuknya AI Agent ke tahap komodifikasi. Dalam beberapa tahun ke depan, membangun dan menerapkan Agent tidak lagi menjadi kemampuan eksklusif pengembang model mutakhir. Oleh karena itu, fokus jangka pendek pengembangan AI akan beralih dari membangun Agent itu sendiri ke tugas tingkat yang lebih tinggi, seperti merumuskan dan menerapkan rencana bisnis yang lebih baik, serta mengembangkan model yang lebih cerdas untuk mendorong inovasi. Komentar berpendapat bahwa pemenang di bidang AI Agent di masa depan adalah mereka yang mampu membangun “model eksekutif” (executive models) paling cerdas, bukan hanya mereka yang memasarkan alat paling cerdik. Inti persaingan akan kembali ke kecerdasan yang kuat di puncak tumpukan, bukan sekadar mekanisme perhatian atau kemampuan penalaran (Sumber: Reddit r/deeplearning)
Praktisi Machine Learning Membahas Pentingnya Pengetahuan Matematika: Komunitas Reddit r/MachineLearning membahas pentingnya matematika dalam praktik machine learning. Mayoritas praktisi berpendapat bahwa memahami prinsip matematika di balik AI sangat penting, terutama dalam optimasi model, memahami makalah penelitian, dan melakukan inovasi. Komentar menunjukkan bahwa meskipun tidak selalu perlu melakukan perhitungan tingkat rendah seperti perkalian matriks secara manual, penguasaan konsep inti seperti statistik, aljabar linear, dan kalkulus membantu dalam pemahaman algoritma secara mendalam dan menghindari penerapan secara membabi buta. Beberapa komentar berpendapat bahwa matematika dalam machine learning relatif sederhana, dan aplikasi matematika yang lebih kompleks ada di bidang teori optimasi dan quantum machine learning. Sumber belajar online dianggap cukup, tetapi membutuhkan disiplin diri yang tinggi dari pembelajar (Sumber: Reddit r/MachineLearning)
💡 Lainnya
Laporan Think Tank QbitAI: AI Membentuk Ulang SEO Pencarian, Nilai Komunitas Konten Profesional Menonjol: Think tank QbitAI merilis laporan yang menunjukkan bahwa asisten cerdas AI sedang membentuk ulang strategi optimasi mesin pencari (SEO) tradisional. Laporan tersebut melalui eksperimen menemukan bahwa hampir setengah dari jawaban AI bersumber dari komunitas konten, terutama di bidang pengetahuan profesional, di mana bobot kutipan komunitas konten (seperti Zhihu) lebih tinggi. Harapan pengguna terhadap perolehan informasi bergeser dari “penyaringan mandiri” menjadi “langsung mendapatkan jawaban”, yang menyebabkan potensi penurunan jumlah klik situs web tradisional. Laporan tersebut berpendapat bahwa di era AI, komunitas konten profesional menonjol nilainya karena kepadatan informasi, pengalaman ahli, dan kualitas konten buatan pengguna. Strategi SEO harus beralih ke SPO (optimasi yang berorientasi pada komunitas profesional), dan bobot portal informasi berkualitas rendah akan menurun (Sumber: 量子位, WeChat)

Alat Ukur Usia Foto AI FaceAge Terbit di The Lancet, Berpotensi Membantu Pengambilan Keputusan Terapi Kanker: Tim Mass General Brigham mengembangkan alat AI bernama FaceAge yang dapat memprediksi usia biologis individu melalui analisis foto wajah. Penelitian terkait dipublikasikan di The Lancet Digital Health. Model ini mengevaluasi tingkat penuaan dengan mengamati fitur wajah (seperti pelipis cekung, kerutan kulit, garis kendur). Dalam penelitian terhadap pasien kanker, ditemukan bahwa pasien yang usia wajahnya tampak lebih muda dari usia sebenarnya memiliki hasil pengobatan yang lebih baik dan risiko kelangsungan hidup yang lebih rendah. Alat ini di masa depan mungkin membantu dokter menyusun rencana pengobatan yang dipersonalisasi berdasarkan usia biologis pasien, tetapi juga menimbulkan kekhawatiran tentang bias data (data pelatihan didominasi oleh orang kulit putih) dan potensi penyalahgunaan (seperti diskriminasi asuransi) (Sumber: WeChat)

Penelitian: AI Terkemuka Berkinerja Buruk pada Tugas Fisika Dasar, Menyoroti Pekerjaan Kerah Biru Sulit Digantikan dalam Jangka Pendek: Peneliti machine learning Adam Karvonen mengevaluasi kinerja LLM terkemuka seperti OpenAI o3 dan Gemini 2.5 Pro melalui tugas pembuatan suku cadang (menggunakan mesin frais dan bubut CNC). Hasilnya menunjukkan bahwa semua model gagal menyusun rencana pemesinan yang memuaskan, memperlihatkan kekurangan dalam pemahaman visual (melewatkan detail, identifikasi fitur tidak konsisten) dan penalaran fisik (mengabaikan kekakuan dan getaran, mengusulkan solusi penjepitan benda kerja yang tidak mungkin). Karvonen berpendapat bahwa ini terkait dengan kurangnya pengetahuan implisit LLM di bidang terkait dan data pengalaman dunia nyata. Ia berspekulasi bahwa dalam jangka pendek, AI akan lebih banyak mengotomatisasi pekerjaan kerah putih, sementara pekerjaan kerah biru yang bergantung pada operasi fisik dan pengalaman akan kurang terpengaruh, yang dapat menyebabkan perkembangan otomatisasi yang tidak merata antar industri (Sumber: WeChat)
