Kata Kunci:OpenAI, Jony Ive, Perangkat Keras AI, Google I/O, Gemini, Mistral AI, Devstral, Pemrograman AI, Akuisisi OpenAI terhadap io, Gemini 2.5 Pro, Model Sumber Terbuka Devstral, Alat Pembuatan Film AI Flow, Agen Pemrograman AI Jules
🔥 Fokus
OpenAI mengumumkan akuisisi startup perangkat keras AI Jony Ive, io, senilai US$6,5 miliar: OpenAI mengonfirmasi akuisisi io, perusahaan perangkat keras AI yang didirikan oleh mantan Chief Design Officer Apple Jony Ive bekerja sama dengan SoftBank, dengan nilai transaksi sekitar US$6,5 miliar. Jony Ive akan menjabat sebagai Chief Creative Officer OpenAI, bertanggung jawab atas desain produk. Tim io yang terdiri dari sekitar 55 orang akan bergabung dengan OpenAI, berdedikasi untuk mengembangkan bentuk baru perangkat keras AI, dengan produk pertama diperkirakan akan dirilis pada tahun 2026. Akuisisi ini menandai masuknya OpenAI secara resmi ke ranah perangkat keras, bertujuan untuk menciptakan perangkat komputasi pribadi dan pengalaman interaktif yang asli AI, yang berpotensi menantang lanskap pasar smartphone dan perangkat komputasi yang ada saat ini. (Sumber: 量子位, 智东西, 新芒xAI, sama, Reddit r/artificial, dotey, steph_palazzolo, karinanguyen_, kevinweil, npew, gdb, zachtratar, shuchaobi, snsf, Reddit r/ArtificialInteligence)

Google I/O merilis berbagai model dan aplikasi AI, menekankan integrasi AI dalam kehidupan sehari-hari: Google dalam Konferensi Pengembang I/O 2025 merilis Gemini 2.5 Pro beserta versi deep thinking-nya, Gemini 2.5 Flash yang ringan, model difusi teks Gemini Diffusion, model generasi gambar Imagen 4, dan model generasi video Veo 3. Veo 3 mendukung pembuatan video dengan audio dan dialog, dengan hasil yang menakjubkan. Google juga meluncurkan aplikasi pembuatan film AI Flow, yang mengintegrasikan Veo, Imagen, dan Gemini. Fitur pencarian AI akan mengintegrasikan ringkasan AI, Deep Search, dan informasi pribadi, serta meluncurkan AI Mode. Google menekankan integrasi AI secara mulus ke dalam produk dan layanan yang ada, bertujuan untuk membuat teknologi AI “tidak terlihat” dan meningkatkan pengalaman pengguna. (Sumber: , MIT Technology Review, dotey, JeffDean, demishassabis, GoogleDeepMind, Google, Reddit r/ChatGPT)

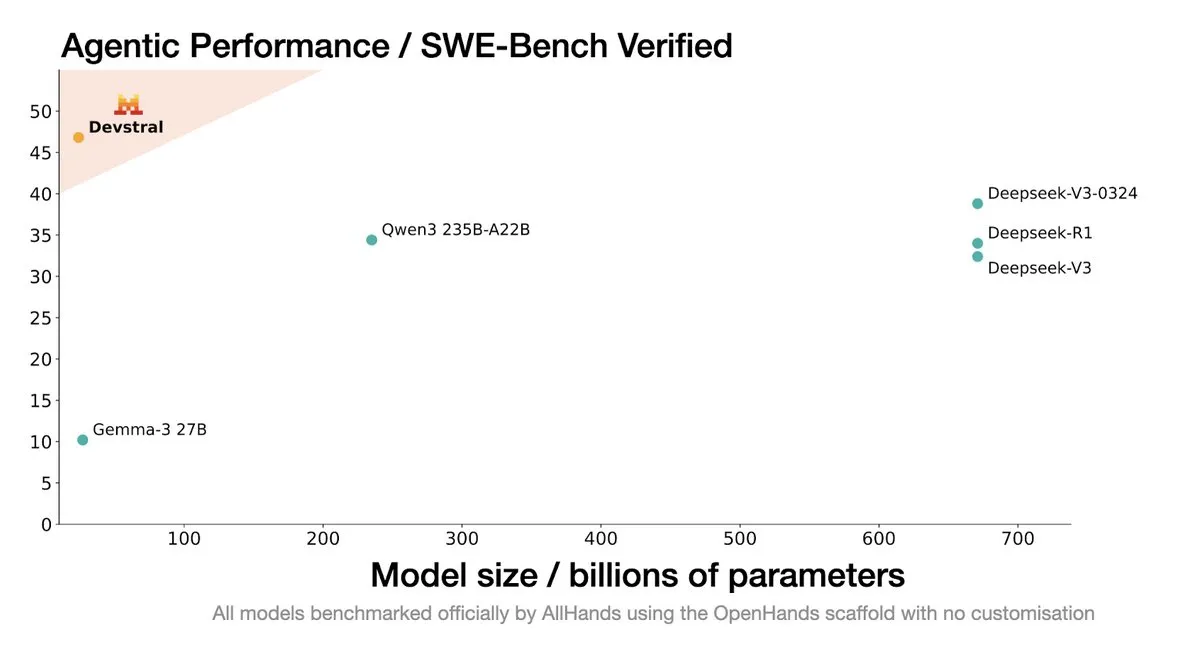
Mistral AI merilis Devstral: Model open source SOTA yang dirancang khusus untuk agen coding: Mistral AI bekerja sama dengan All Hands AI meluncurkan Devstral, sebuah model open source SOTA yang dirancang khusus untuk agen coding. Model ini menunjukkan kinerja yang sangat baik pada benchmark SWE-Bench Verified, melampaui seri DeepSeek dan Qwen3 235B, dengan jumlah parameter hanya 24B, dan dapat dijalankan pada satu kartu RTX4090 atau Mac dengan memori 32G. Devstral dilatih pada Isu GitHub nyata, menekankan pemahaman konteks dalam codebase besar, identifikasi hubungan antar komponen, dan identifikasi kesalahan fungsi yang kompleks. Menggunakan lisensi open source Apache 2.0, lebih terbuka dibandingkan Codestral sebelumnya. (Sumber: MistralAI, natolambert, karminski3, qtnx_, huggingface, arthurmensch)
CTO Google DeepMind Koray Kavukcuoglu membahas Veo 3, Deep Think, dan kemajuan AGI: Selama Google I/O, CTO DeepMind Koray Kavukcuoglu dalam sebuah wawancara membahas kemajuan model generasi video Veo 3 (seperti sinkronisasi audio-visual), mode penalaran yang ditingkatkan Deep Think dalam Gemini 2.5 Pro (melalui penalaran rantai pemikiran paralel), dan pandangannya tentang AGI. Kavukcuoglu menekankan bahwa skala bukanlah satu-satunya faktor untuk mencapai AGI; arsitektur, algoritma, data, dan teknologi penalaran sama pentingnya. Pencapaian AGI membutuhkan terobosan dalam penelitian dasar dan inovasi kunci, bukan sekadar penumpukan rekayasa. Ia juga optimis tentang “vibe coding” yang memberdayakan orang-orang tanpa latar belakang coding untuk membangun aplikasi. (Sumber: demishassabis, 36氪)
🎯 Perkembangan
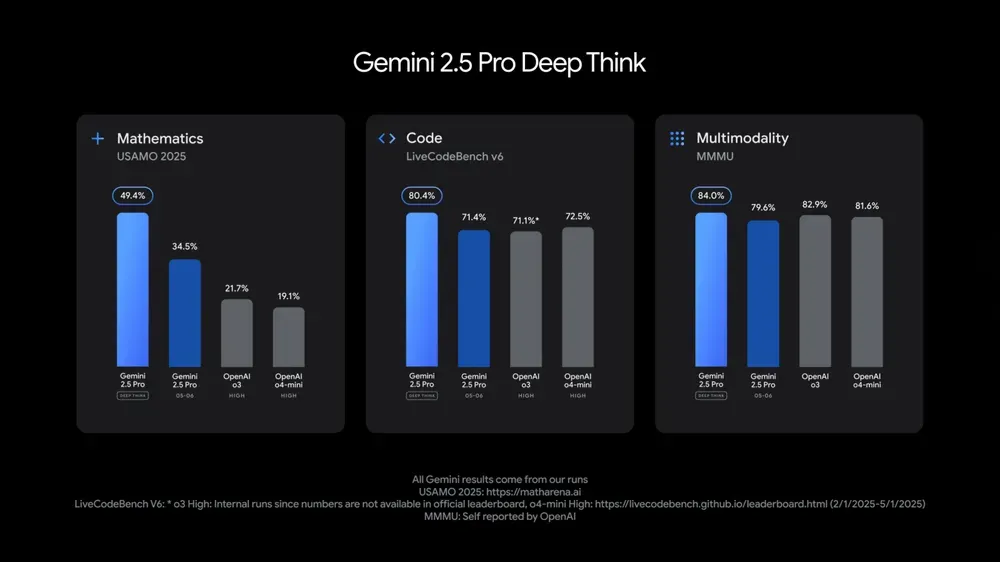
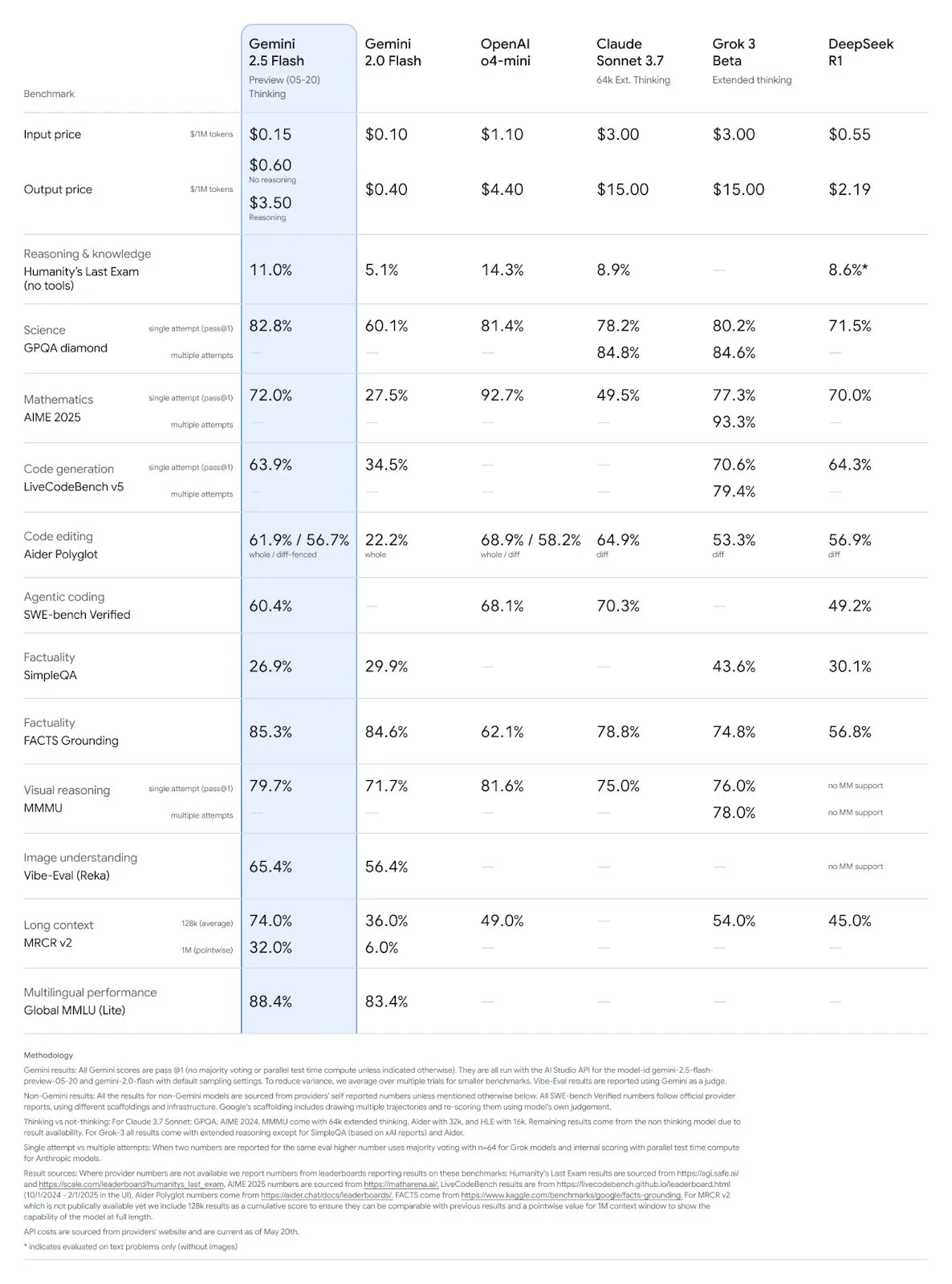
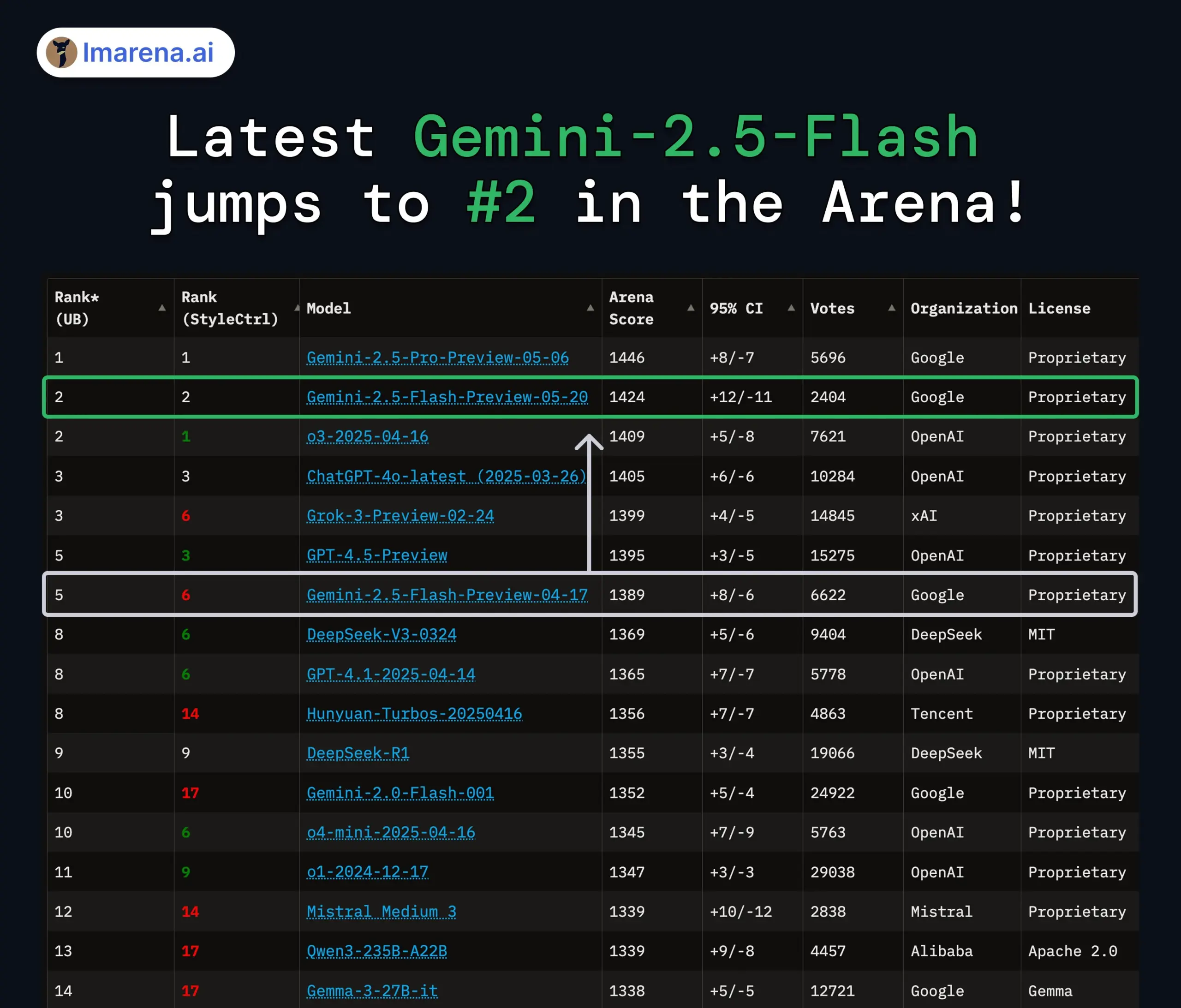
Model Google Gemini 2.5 Pro dan Flash diperbarui, kinerja meningkat signifikan: Google di I/O mengumumkan bahwa model Gemini 2.5 Pro dan Flash akan resmi diluncurkan pada bulan Juni. Gemini 2.5 Pro diklaim sebagai model AI paling cerdas di dunia, dengan penambahan versi deep thinking, dan menunjukkan keunggulan dalam berbagai pengujian. Gemini 2.5 Flash, sebagai model ringan, mengalami peningkatan efisiensi sebesar 22%, pengurangan konsumsi Token sebesar 20%-30%, dan memiliki kemampuan generasi audio asli. Data LMArena menunjukkan bahwa Gemini-2.5-Flash versi baru melonjak ke peringkat kedua di arena chatbot, terutama menonjol dalam tugas-tugas berat seperti coding dan matematika. (Sumber: natolambert, demishassabis, karminski3, lmarena_ai)
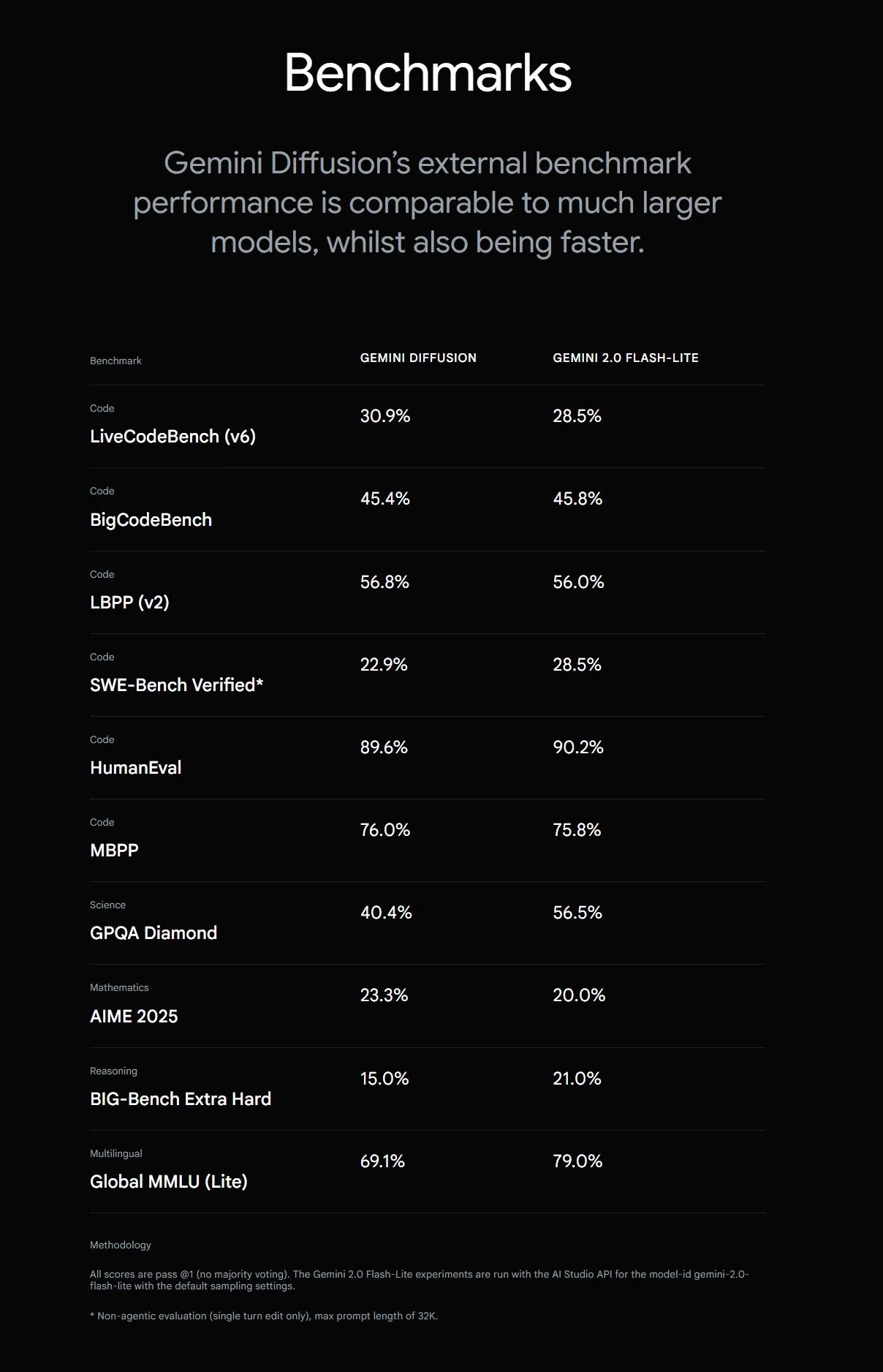
Google meluncurkan Gemini Diffusion, kecepatan pembuatan teks meningkat 5 kali lipat: Google DeepMind meluncurkan model pembuatan teks eksperimental Gemini Diffusion, yang kecepatan pembuatannya 5 kali lebih cepat dari model tercepat sebelumnya. Kemampuan pemrogramannya sangat menonjol, mencapai 2000 token per detik (termasuk overhead seperti tokenisasi). Berbeda dari model autoregresif tradisional, model difusi dapat melakukan penalaran non-kausal, dapat “memikirkan” jawaban berikutnya terlebih dahulu, dan menunjukkan kinerja yang lebih baik daripada GPT-4o dalam menyelesaikan masalah kompleks yang memerlukan penalaran global (seperti soal perhitungan tertentu, pencarian bilangan prima). Saat ini model ini hanya tersedia untuk pengembang melalui aplikasi pengujian. (Sumber: OriolVinyalsML, dotey, karminski3)
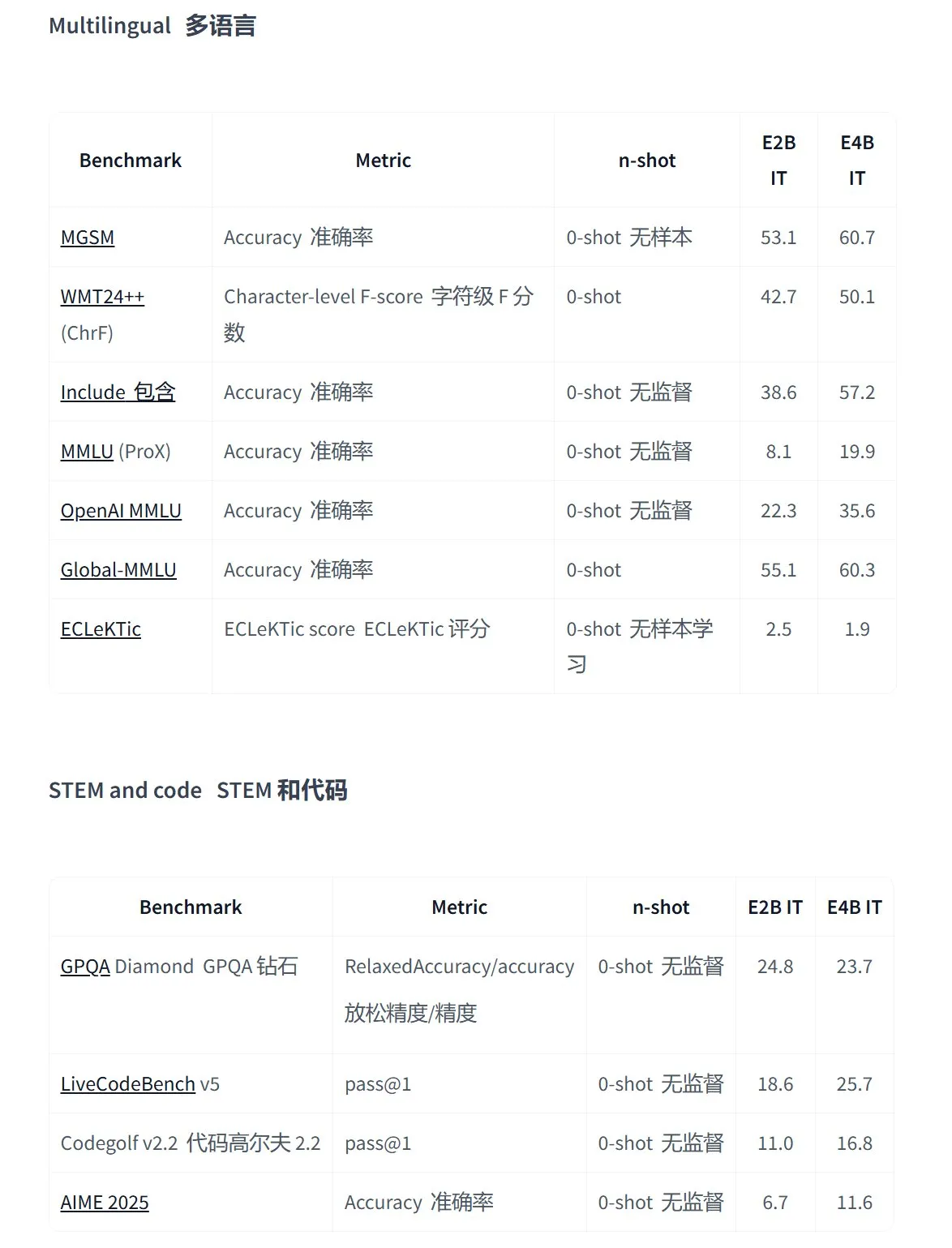
Google merilis seri model open source Gemma 3n, dirancang untuk aplikasi multimodal di perangkat: Google meluncurkan generasi baru model open source multimodal yang efisien, Gemma 3n, yang dirancang khusus untuk perangkat berdaya rendah, mendukung input teks, suara, gambar, video, dan pemrosesan multibahasa. Seri model ini (seperti gemma-3n-E4B-it-litert-preview dan gemma-3n-E2B-it-litert-preview) berukuran kecil (3-4.4GB), dapat berjalan di perangkat dengan RAM 2GB, dan pengetahuannya hingga Juni 2024. Saat ini telah tersedia pratinjau untuk pengembang di platform AI Studio dan AI Edge. (Sumber: demishassabis, karminski3, huggingface, Ar_Douillard, GoogleDeepMind)
OpenAI Responses API menambahkan dukungan MCP, pembuatan gambar, dan fungsionalitas Code Interpreter: Platform pengembang OpenAI mengumumkan pembaruan penting untuk Responses API-nya (sebelumnya Assistants API), menambahkan dukungan untuk server Model Context Protocol (MCP) jarak jauh, yang memungkinkan agen AI berinteraksi lebih fleksibel dengan alat dan layanan eksternal. Selain itu, API ini juga mengintegrasikan kemampuan pembuatan gambar dan fungsionalitas Code Interpreter, yang semakin memperluas skenario aplikasi dan potensi pengembangannya. (Sumber: gdb, npew, OpenAIDevs, snsf)
xAI API mengintegrasikan fitur pencarian real-time Grok Live Search: xAI mengumumkan penambahan fitur Live Search ke API-nya, memungkinkan Grok untuk mencari data secara real-time dari platform X, internet, berita, dan sumber lainnya. Fitur ini saat ini dalam tahap pengujian Beta dan gratis untuk digunakan oleh pengembang untuk waktu terbatas, bertujuan untuk meningkatkan kemampuan Grok dalam memperoleh dan memproses informasi terbaru, serta mendukung pembuatan aplikasi AI yang lebih dinamis dan kaya informasi. (Sumber: xai, TheGregYang, yoheinakajima)

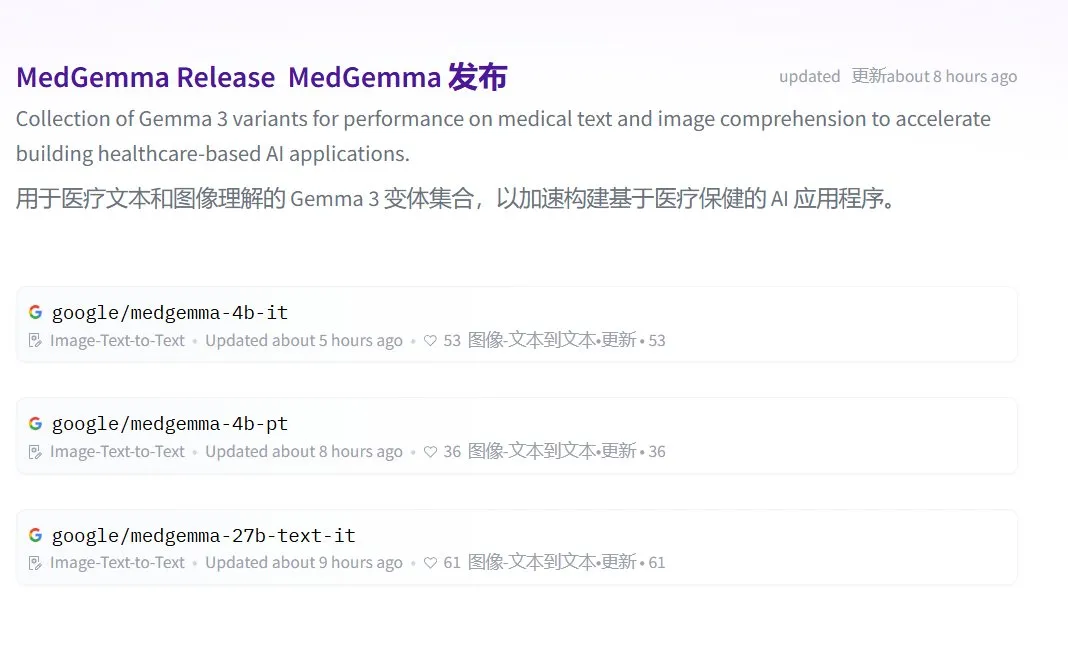
Google merilis seri model besar medis open source MedGemma: Google meluncurkan model medis open source MedGemma berdasarkan arsitektur Gemma 3, termasuk medgemma-4b-pt (model dasar), medgemma-4b-it (multimodal, diagnosis citra medis), dan medgemma-27b-text-it (teks murni, konsultasi rekam medis). Model-model ini dilatih secara khusus untuk pemahaman teks dan gambar medis, bertujuan untuk meningkatkan kemampuan aplikasi AI di bidang medis, seperti diagnosis berbantu, analisis rekam medis, dll. Model-model ini telah tersedia di Hugging Face. (Sumber: JeffDean, karminski3)
Berbagai produk model besar Tencent Hunyuan ditingkatkan, meluncurkan platform terbuka untuk agen cerdas: Tencent Hunyuan mengumumkan peningkatan iteratif untuk model flagship pemikiran cepat TurboS dan model pemikiran mendalam T1. TurboS masuk dalam sepuluh besar global dalam kemampuan kode dan matematika. Model baru yang diluncurkan adalah model penalaran visual mendalam T1-Vision dan model panggilan suara end-to-end Hunyuan Voice. Knowledge engine asli ditingkatkan menjadi “Platform Pengembangan Agen Cerdas Tencent Cloud”, mengintegrasikan kemampuan RAG dan Agen. Hunyuan Image 2.0, 3D v2.5, dan model generasi visual game juga diperbarui secara bersamaan, dan berencana untuk terus membuka sumber model dasar multimodal dan plugin. (Sumber: 36氪)

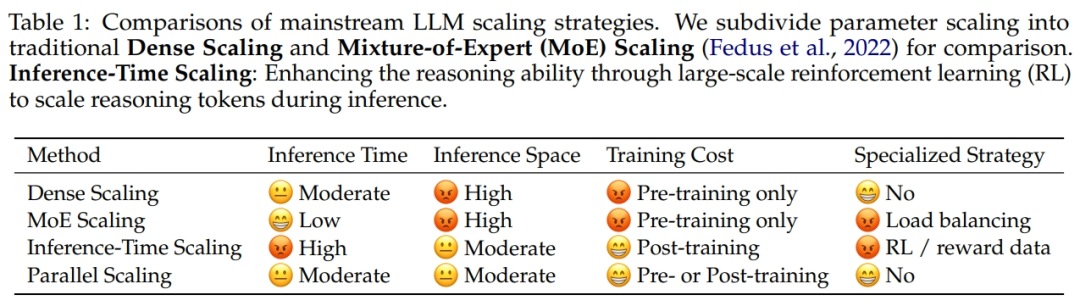
Alibaba bekerja sama dengan Universitas Zhejiang mengusulkan hukum penskalaan komputasi paralel ParScale: Tim peneliti Alibaba bekerja sama dengan Universitas Zhejiang mengusulkan Scaling Law baru: hukum penskalaan komputasi paralel (ParScale). Hukum ini menyatakan bahwa meningkatkan komputasi paralel model selama pelatihan dan inferensi dapat meningkatkan kemampuan model besar tanpa menambah parameter, dan meningkatkan efisiensi inferensi. Dibandingkan dengan penskalaan parameter, peningkatan memori ParScale hanya 4,5%, dan peningkatan latensi sebesar 16,7%. Metode ini dicapai melalui transformasi input yang beragam, pemrosesan paralel, dan agregasi output dinamis, terutama menunjukkan kinerja yang signifikan dalam tugas-tugas penalaran yang kuat seperti matematika dan pemrograman. (Sumber: 36氪)
Microsoft merilis model dasar atmosfer skala besar Aurora, kecepatan prediksi meningkat 5000 kali lipat: Microsoft dan mitranya meluncurkan model dasar atmosfer skala besar pertama, Aurora, yang dilatih pada lebih dari 1 juta jam data geofisika. Model ini dapat memprediksi kualitas udara, jalur siklon tropis, dinamika gelombang laut, dan cuaca resolusi tinggi dengan lebih akurat dan efisien. Dibandingkan dengan sistem prakiraan numerik canggih IFS, Aurora memiliki kecepatan komputasi sekitar 5000 kali lebih cepat dan mencapai SOTA di beberapa bidang prediksi utama. Arsitektur model ini fleksibel dan dapat disesuaikan untuk tugas-tugas tertentu, diharapkan dapat mendorong普及 prediksi sistem Bumi. (Sumber: 36氪)

Pencarian AI Google akan meluncurkan AI Mode, mengintegrasikan berbagai fungsi cerdas: Google mengumumkan peluncuran “AI Mode” untuk mesin pencarinya, yang diklaim sebagai “pencarian AI paling kuat”. Mode ini didasarkan pada Gemini 2.5, memiliki kemampuan penalaran yang lebih kuat, mendukung kueri yang lebih panjang, pencarian multimodal, dan jawaban berkualitas tinggi secara instan. Di masa depan, mode ini juga akan mengintegrasikan fungsi “Deep Search”, yang dapat melakukan ratusan kueri secara bersamaan dan memberikan laporan komprehensif, serta berencana untuk mengintegrasikan data pribadi seperti Gmail dan interaksi kamera real-time Project Astra, serta fungsi manajemen tugas otomatis Project Mariner. (Sumber: dotey, Google)

Model generasi gambar Google Imagen 4 dirilis, kecepatan dan detail meningkat pesat: Google merilis model text-to-image terbaru Imagen 4, yang diklaim memiliki kecepatan generasi 3-10 kali lebih cepat dari generasi sebelumnya, detail gambar lebih kaya, hasil lebih akurat, dan kemampuan rendering teks juga meningkat secara signifikan. Imagen 4 mampu menghasilkan objek kompleks seperti kain, tetesan air, bulu hewan, dengan resolusi hingga 2K, dan mendukung pembuatan kartu ucapan, poster, komik, dll. Model ini sekarang tersedia gratis di Aplikasi Gemini, Whisk, dan aplikasi Workspace serta Vertex AI. (Sumber: dotey, GoogleDeepMind)
Penelitian mengungkapkan risiko “halusinasi paket” pada kode yang dihasilkan oleh alat bantu pemrograman AI: Sebuah penelitian yang akan diterbitkan di USENIX Security 2025 menunjukkan bahwa fenomena “halusinasi paket” umum terjadi pada kode yang dihasilkan AI, yaitu pustaka pihak ketiga yang dirujuk sama sekali tidak ada. Penelitian menguji 16 model bahasa besar arus utama dan menemukan bahwa lebih dari 20% kode bergantung pada paket fiktif, dengan proporsi yang lebih tinggi pada model open source. Hal ini menciptakan peluang untuk serangan rantai pasokan, di mana penyerang dapat memanfaatkan nama paket fiktif ini untuk menerbitkan kode berbahaya. Perusahaan seperti Apple dan Microsoft pernah menjadi korban serangan kebingungan dependensi semacam ini. (Sumber: 36氪)

Suno meluncurkan fitur Remix, pengguna dapat berkreasi ulang berdasarkan lagu yang sudah ada: Platform generasi musik AI Suno meluncurkan fitur Remix, yang memungkinkan pengguna memilih trek apa pun di platform untuk dikreasikan ulang. Pengguna dapat melakukan operasi seperti Cover, Extend, atau Reuse Prompt pada lagu. Kreasi Remix akan mempertahankan informasi sumber dari materi asli, dan pengguna juga dapat mengaktifkan atau menonaktifkan izin Remix untuk karya mereka kapan saja. (Sumber: SunoMusic)
Penelitian menemukan semua model embedding mempelajari struktur semantik yang serupa: Jack Morris dan peneliti lainnya menemukan bahwa struktur semantik yang dipelajari oleh model embedding yang berbeda memiliki kesamaan yang tinggi, bahkan dapat memetakan antara ruang embedding model yang berbeda hanya dengan informasi struktural, tanpa data berpasangan apa pun. Penemuan ini mengisyaratkan kemungkinan adanya semacam struktur geometris universal dalam ruang embedding, yang memiliki implikasi penting untuk kompatibilitas antar model, transfer learning, dan pemahaman esensi embedding. (Sumber: menhguin, torchcompiled, dilipkay, jeremyphoward)
Makalah membahas masalah “pajak halusinasi” pada Reinforcement Learning Fine-tuning (RFT): Penelitian oleh Taiwei Shi dkk. menunjukkan bahwa Reinforcement Learning Fine-tuning (RFT), sambil meningkatkan kemampuan penalaran model bahasa besar, dapat menyebabkan model dengan percaya diri menghasilkan jawaban halusinasi ketika menghadapi pertanyaan yang tidak dapat dijawab, yang disebut sebagai “pajak halusinasi”. Penelitian ini memperkenalkan dataset SUM (masalah matematika sintetis yang tidak dapat dijawab) untuk validasi, dan menemukan bahwa pelatihan RFT standar secara signifikan mengurangi tingkat penolakan model. Dengan menambahkan sejumlah kecil data SUM ke dalam RFT, perilaku penolakan yang tepat dari model dapat dipulihkan secara efektif, dan kesadarannya akan ketidakpastian dan batas pengetahuannya sendiri dapat ditingkatkan. (Sumber: teortaxesTex)

🧰 Alat
Google meluncurkan alat pembuatan film AI Flow, mengintegrasikan Veo, Imagen, dan Gemini: Google merilis alat produksi film dan televisi AI Flow, yang mengintegrasikan model generasi video terbarunya Veo 3, model generasi gambar Imagen 4, dan model multimodal Gemini. Pengguna dapat menggunakan Flow dengan bahasa alami dan manajemen sumber daya untuk dengan mudah membuat film pendek berkualitas sinematik, termasuk menghasilkan klip dari prompt teks, menggabungkan adegan, membangun narasi, dan menyimpan elemen yang sering digunakan sebagai aset. Alat ini bertujuan untuk membantu kreator menghasilkan karya berkualitas sinematik dengan cepat dan efisien. Saat ini telah tersedia untuk pengguna langganan Google AI Pro dan Ultra di Amerika Serikat. (Sumber: dotey, op7418)

Google merilis agen pemrograman AI berbasis cloud Jules, didukung oleh Gemini 2.5 Pro: Google meluncurkan agen pemrograman AI Jules, berdasarkan Gemini 2.5 Pro. Jules dapat secara otomatis menangani tugas-tugas di repositori kode di latar belakang, seperti memperbaiki bug dan merefaktor kode, serta mendukung multi-tasking secara paralel. Selain itu, Jules juga menyediakan podcast Codecasts yang diperbarui setiap hari untuk membantu pengguna memahami dinamika terbaru dari repositori kode. Alat ini saat ini tersedia untuk dicoba secara gratis. (Sumber: dotey, karminski3, GoogleDeepMind)
LangChain meluncurkan platform agen tanpa kode open source Open Agent Platform (OAP): LangChain merilis Open Agent Platform (OAP), sebuah platform open source tanpa kode yang ditujukan untuk pengguna umum, untuk membangun, membuat prototipe, dan menerapkan agen AI. OAP mendukung pembuatan agen melalui UI Web, menghubungkan ke server RAG untuk meningkatkan pengambilan informasi, memperluas alat eksternal melalui MCP, dan menggunakan Agent Supervisor untuk mengatur alur kerja multi-agen. Bertujuan agar pengembang non-profesional juga dapat memanfaatkan kemampuan kuat agen LangGraph. (Sumber: LangChainAI, Hacubu)

Google Labs meluncurkan alat desain UI AI Stitch: Google Labs merilis alat desain UI AI Stitch, yang mengintegrasikan model DeepMind terbaru Google (termasuk Gemini dan Imagen), dan dapat dengan cepat menghasilkan desain UI berkualitas tinggi. Pengguna dapat memperbarui tema antarmuka melalui bahasa alami, menyesuaikan gambar secara otomatis, mewujudkan terjemahan konten multibahasa, dan mengekspor kode frontend dengan satu klik. Stitch adalah versi evolusi dari Galileo AI sebelumnya, yang pendirinya telah bergabung dengan tim Google. (Sumber: dotey)
LangChain meluncurkan sandbox kode lokal LangChain Sandbox: LangChain merilis LangChain Sandbox, yang memungkinkan agen AI menjalankan kode Python yang tidak tepercaya secara aman di lingkungan lokal. Ini menyediakan lingkungan eksekusi yang terisolasi dan izin yang dapat dikonfigurasi, tanpa memerlukan eksekusi jarak jauh atau kontainer Docker, dan mendukung persistensi status di antara beberapa eksekusi melalui sesi. Ini menyediakan alat yang lebih aman dan nyaman untuk membangun agen AI yang dapat mengeksekusi kode (seperti agen codeact). (Sumber: hwchase17, Hacubu)
Vitalops membuka sumber Datatune: Alat LLM untuk memproses dataset skala besar dengan bahasa alami: Vitalops membuka sumber Datatune, sebuah alat yang memungkinkan pengguna memproses dataset dengan ukuran berapa pun melalui instruksi bahasa alami. Datatune mendukung operasi Map dan Filter, dapat terhubung ke berbagai penyedia layanan LLM seperti OpenAI, Azure, Ollama, atau model kustom, dan memanfaatkan Dask DataFrame untuk partisi dan pemrosesan paralel. Alat ini bertujuan untuk menyederhanakan tugas-tugas seperti pembersihan dan pengayaan data, menggantikan ekspresi reguler yang rumit atau kode kustom. (Sumber: Reddit r/MachineLearning)
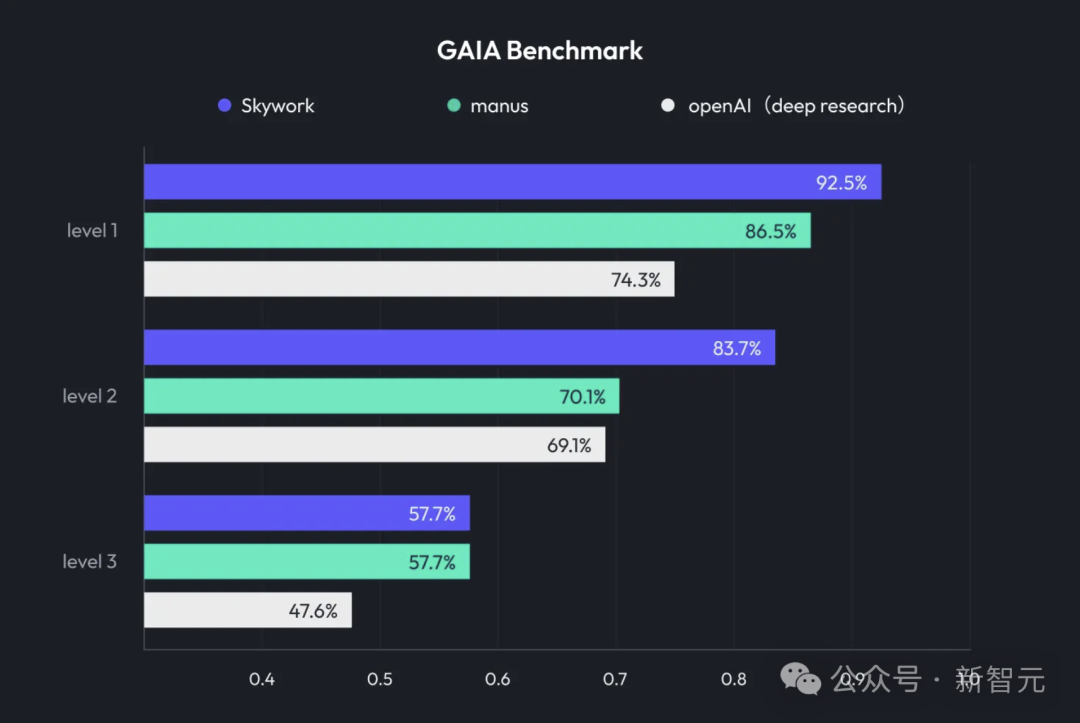
Kunlun Tech meluncurkan Skywork Super Agents, mengintegrasikan Deep Research dan output multimodal: Kunlun Tech merilis produk AI untuk perkantoran, Skywork Super Agents, yang menggabungkan kemampuan Deep Research dengan fungsi output multimodal dari agen cerdas umum. Produk ini mendukung pembuatan PPT, penulisan dokumen, pemrosesan tabel, pembuatan halaman web, pembuatan podcast, dan berbagai skenario perkantoran lainnya, menekankan penelusuran sumber konten untuk mengurangi halusinasi, dan menyediakan fungsi pengeditan dan ekspor online. Kunlun Tech juga membuka sumber kerangka kerja Deep Research Agent dan MCP terkait. (Sumber: 36氪)
Google meluncurkan SynthID Detector, membantu mengidentifikasi konten yang dihasilkan AI: Google merilis SynthID Detector, sebuah portal web baru yang bertujuan untuk membantu jurnalis, profesional media, dan peneliti lebih mudah mengidentifikasi apakah konten memiliki watermark SynthID. SynthID adalah teknologi yang dikembangkan Google untuk menambahkan watermark tak terlihat ke konten yang dihasilkan AI (termasuk gambar, audio, video, atau teks). Peluncuran alat deteksi ini membantu meningkatkan transparansi dan keterlacakan konten yang dihasilkan AI. (Sumber: dotey, Google)
Feishu meluncurkan fitur “Tanya Jawab Pengetahuan”, menciptakan alat tanya jawab AI khusus perusahaan: Feishu meluncurkan fitur baru “Tanya Jawab Pengetahuan”, alat ini dapat memberikan jawaban yang akurat dan dukungan pembuatan konten kepada karyawan berdasarkan semua informasi yang dapat diakses oleh karyawan di Feishu (pesan, dokumen, basis pengetahuan, dll.), dikombinasikan dengan model besar seperti DeepSeek-R1, Doubao, dan teknologi RAG. Keunikannya adalah jawaban akan disesuaikan secara dinamis berdasarkan identitas dan izin penanya di dalam perusahaan, bertujuan untuk mengintegrasikan AI secara mulus ke dalam alur kerja sehari-hari, meningkatkan manajemen pengetahuan dan efisiensi pemanfaatan perusahaan. (Sumber: 量子位)

Animon: Platform generasi anime AI pertama di Jepang, fokus pada kualitas gaya anime 2D dan generasi gratis tanpa batas: Perusahaan Jepang CreateAI (sebelumnya TuSimple Future) meluncurkan platform generasi anime AI Animon, yang disesuaikan khusus untuk pembuatan anime. Platform ini menggabungkan estetika anime Jepang dengan teknologi AI, menekankan konsistensi gaya gambar dan produksi yang efisien, serta mengklaim bahwa pengguna individu dapat menghasilkan video secara gratis tanpa batas. Animon mendukung pembuatan klip animasi cepat (sekitar 3 menit) dengan mengunggah gambar karakter dan deskripsi teks, bertujuan untuk menurunkan ambang batas pembuatan anime dan merangsang ekosistem konten UGC. Perusahaan induknya, CreateAI, memiliki model besar Ruyi yang dikembangkan sendiri dan memegang hak adaptasi IP seperti “The Three-Body Problem” dan “Jin Yong Qunxia Zhuan”, serta menerapkan strategi penggerak ganda “konten yang dikembangkan sendiri + platform alat UGC”. (Sumber: 量子位)

📚 Pembelajaran
DeepLearning.AI meluncurkan kursus baru: Penyempurnaan LLM yang Diperkuat menggunakan GRPO: Andrew Ng mengumumkan kerja sama dengan Predibase untuk meluncurkan kursus singkat baru dengan tema “Penyempurnaan LLM yang Diperkuat menggunakan GRPO (Group Relative Policy Optimization)”. Kursus ini akan mengajarkan cara menggunakan reinforcement learning (khususnya algoritma GRPO) untuk meningkatkan kinerja LLM dalam tugas penalaran multi-langkah (seperti pemecahan masalah matematika, debugging kode), tanpa memerlukan sampel fine-tuning terawasi dalam jumlah besar. GRPO memandu model melalui fungsi reward yang dapat diprogram, cocok untuk tugas yang hasilnya dapat diverifikasi, dan dapat secara signifikan meningkatkan kemampuan penalaran LLM kecil. (Sumber: AndrewYNg, DeepLearningAI)
LlamaIndex berbagi pengalaman mengelola repositori monolitik Python skala besar: Tim LlamaIndex berbagi pengalaman mereka dalam mengelola repositori monolitik (monorepo) Python yang berisi lebih dari 650 paket komunitas. Mereka beralih dari Poetry dan Pants ke uv dan alat manajemen build open source yang dikembangkan sendiri, LlamaDev, yang menghasilkan peningkatan kecepatan pengujian sebesar 20%, log yang lebih jelas, pengembangan lokal yang disederhanakan, dan menurunkan ambang batas bagi kontributor. Pengalaman ini bermanfaat bagi tim yang perlu mengelola proyek Python besar. (Sumber: jerryjliu0)

Tutorial berbagi: Membangun agen coding AI Anda sendiri, Tig: Jerry Liu merekomendasikan proyek agen coding AI open source bernama Tig. Proyek ini adalah asisten coding berbasis terminal dengan human-in-the-loop, dibangun menggunakan alur kerja LlamaIndex. Tig mampu melakukan penulisan, debugging, analisis kode dalam berbagai bahasa, menjalankan perintah shell, mencari di codebase, serta menghasilkan tes dan dokumentasi, dan tugas-tugas lainnya. Repositori GitHub menyediakan panduan pembuatan yang terperinci, yang merupakan sumber daya pendidikan yang baik bagi pengembang yang ingin belajar membangun agen coding AI. (Sumber: jerryjliu0)
Hugging Face merilis posting blog penting tentang VLM, memperkenalkan laboratorium komunitas nanoVLM: Hugging Face merilis posting blog tentang model bahasa visual (VLM), yang mencakup dasar-dasar VLM, arsitektur, dan cara melatih VLM ringan Anda sendiri. Posting ini juga memperkenalkan nanoVLM, sebuah repositori open source untuk fine-tuning VLM, yang kini telah berkembang menjadi laboratorium komunitas untuk penelitian bahasa visual, bertujuan untuk membantu pengembang menjelajahi dan berkontribusi pada penelitian VLM. (Sumber: _akhaliq, huggingface)
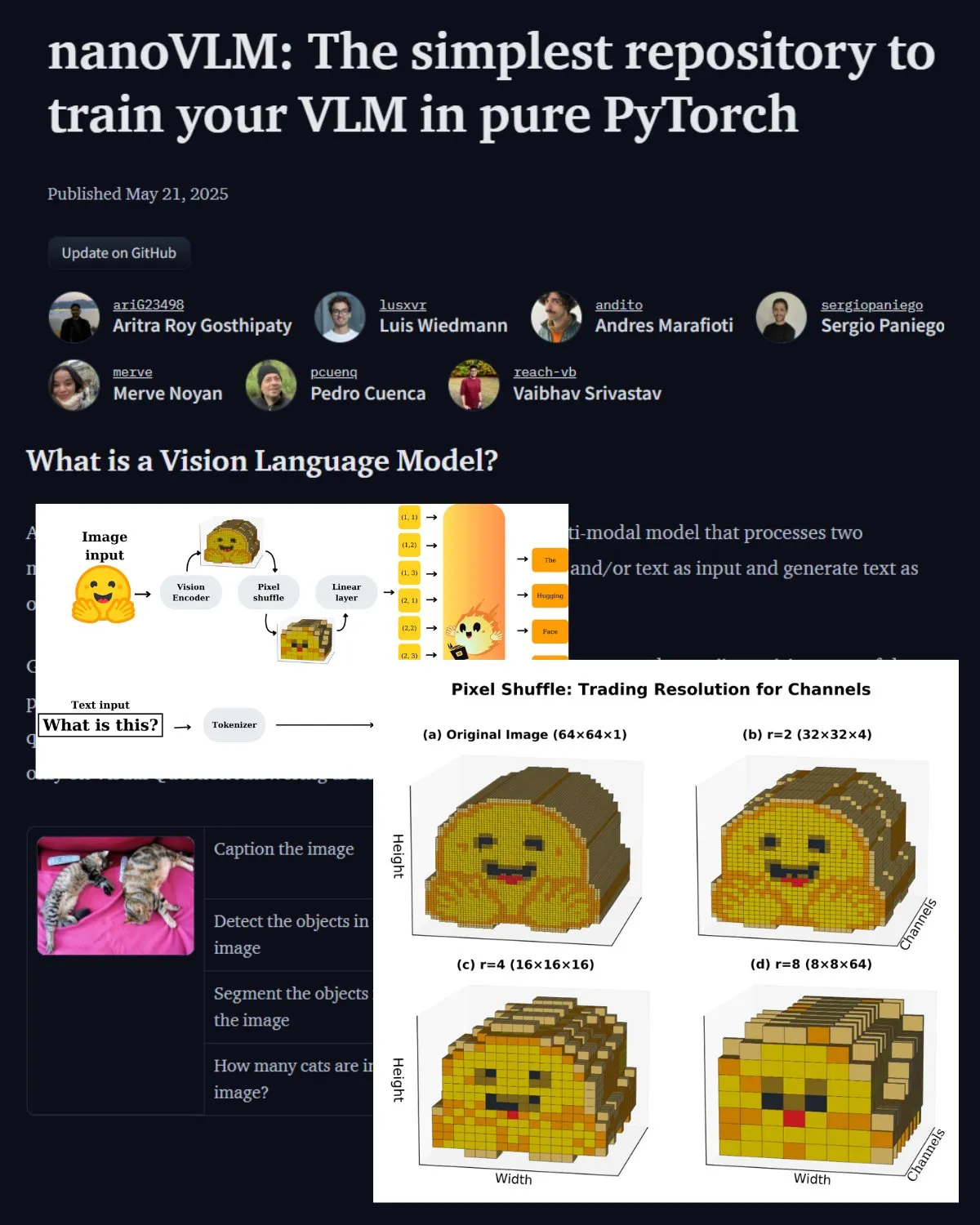
Serrano Academy merilis seri video tutorial fine-tuning LLM dengan reinforcement learning: Serrano Academy telah menyelesaikan dan merilis serangkaian video tutorial tentang penggunaan reinforcement learning untuk fine-tuning dan pelatihan LLM. Kontennya mencakup Deep Reinforcement Learning, RLHF (Reinforcement Learning from Human Feedback), PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization), serta konsep dan teknik kunci seperti KL Divergence. (Sumber: SerranoAcademy)
Makalah membahas fenomena “lapisan kosong” pada model bahasa besar: Sebuah penelitian menyelidiki fenomena di mana tidak semua lapisan diaktifkan selama proses penalaran pada model bahasa besar yang disesuaikan dengan instruksi, menyebut lapisan yang tidak aktif sebagai “lapisan kosong” (Voids). Penelitian ini menggunakan metode L2 Adaptive Computation (LAC) untuk melacak lapisan yang aktif selama tahap pemrosesan prompt dan generasi respons, dan menemukan bahwa lapisan yang aktif berbeda pada tahap yang berbeda. Eksperimen menunjukkan bahwa dalam benchmark seperti MMLU, melewati lapisan kosong pada Qwen2.5-7B-Instruct (hanya menggunakan 30% lapisan) dapat meningkatkan kinerja, menyiratkan bahwa melewati sebagian besar lapisan secara selektif mungkin bermanfaat untuk tugas tertentu. (Sumber: HuggingFace Daily Papers)
Penelitian mengusulkan “Soft Thinking”: Membuka potensi penalaran LLM di ruang konsep kontinu: Sebuah makalah berjudul “Soft Thinking” mengusulkan metode tanpa pelatihan yang mensimulasikan penalaran “lunak” seperti manusia dengan menghasilkan token konsep yang lunak dan abstrak di ruang konsep kontinu. Token konsep ini terdiri dari campuran probabilitas tertimbang dari embedding token, yang mampu merangkum berbagai makna dari token diskrit terkait, sehingga secara implisit menjelajahi berbagai jalur penalaran. Eksperimen menunjukkan bahwa metode ini meningkatkan akurasi pass@1 pada benchmark matematika dan coding, sekaligus mengurangi penggunaan token, dan output tetap dapat diinterpretasikan. (Sumber: HuggingFace Daily Papers)
Makalah membahas pencapaian rantai pemikiran yang dapat diskalakan melalui penalaran elastis: Peneliti Salesforce mengusulkan metode untuk mencapai rantai pemikiran yang dapat diskalakan melalui penalaran elastis (Elastic Reasoning). Penelitian ini bertujuan untuk mengatasi masalah bagaimana model bahasa besar dapat secara efektif menghasilkan dan mengelola rantai pemikiran yang panjang ketika menangani tugas penalaran yang kompleks, untuk meningkatkan akurasi dan efisiensi penalaran. Model dan kode terkait telah dirilis di Hugging Face. (Sumber: _akhaliq)

Studi penelitian: Akankah model AI berbohong untuk menyelamatkan anak yang sakit?: Sebuah penelitian bernama LitmusValues menciptakan alur kerja evaluasi yang bertujuan untuk mengungkap prioritas model AI dalam serangkaian kategori nilai AI. Dengan mengumpulkan AIRiskDilemmas (kumpulan dilema yang berisi skenario terkait risiko keamanan AI), para peneliti mengukur pilihan model AI dalam berbagai konflik nilai, sehingga dapat memprediksi prioritas nilainya dan mengidentifikasi potensi risiko. Penelitian menunjukkan bahwa nilai-nilai yang didefinisikan dalam LitmusValues (termasuk kepedulian, dll.) dapat memprediksi perilaku berisiko yang telah terlihat di AIRiskDilemmas serta perilaku berisiko yang belum terlihat di HarmBench. (Sumber: HuggingFace Daily Papers)
Penelitian makalah tentang fine-tuning model difusi secara efisien melalui reinforcement learning berbasis nilai (VARD): Model difusi menunjukkan kinerja yang kuat dalam tugas generasi, tetapi fine-tuning untuk atribut tertentu masih menantang. Metode reinforcement learning yang ada memiliki kekurangan dalam stabilitas, efisiensi, dan penanganan reward non-diferensiabel. VARD (Value-based Reinforced Diffusion) mengusulkan untuk terlebih dahulu mempelajari fungsi nilai yang memprediksi ekspektasi reward dari status perantara, kemudian memanfaatkan fungsi nilai ini dan regularisasi KL untuk memberikan pengawasan padat selama seluruh proses generasi. Eksperimen membuktikan bahwa metode ini dapat meningkatkan panduan lintasan, meningkatkan efisiensi pelatihan, dan memperluas aplikasi RL untuk mengoptimalkan model difusi dengan fungsi reward non-diferensiabel yang kompleks. (Sumber: HuggingFace Daily Papers)
💼 Bisnis
LMArena.ai (sebelumnya LMSYS.org) mendapatkan pendanaan awal US$100 juta, dipimpin oleh a16z dan perusahaan investasi Universitas California: Platform evaluasi model AI LMArena.ai (sebelumnya dikenal sebagai LMSYS.org) mengumumkan penyelesaian putaran pendanaan awal sebesar US$100 juta, yang dipimpin bersama oleh Andreessen Horowitz (a16z) dan perusahaan investasi Universitas California (UC Investments). Perusahaan ini berdedikasi untuk membangun platform yang netral, terbuka, dan didorong oleh komunitas untuk membantu dunia memahami dan meningkatkan kinerja model AI pada kueri pengguna nyata. Setelah pendanaan, valuasi perusahaan mencapai US$600 juta. (Sumber: janonacct, lmarena_ai, scaling01, _akhaliq, ClementDelangue)
Pemerintah AS mengumumkan penjualan teknologi dan layanan AI senilai miliaran dolar ke Arab Saudi dan UEA: Pemerintah AS mengumumkan kesepakatan dengan Arab Saudi dan Uni Emirat Arab untuk menjual teknologi dan layanan AI senilai miliaran dolar ke kedua negara tersebut. Perusahaan yang berpartisipasi termasuk AMD, Nvidia, Amazon, Google, IBM, Oracle, dan Qualcomm, antara lain. Nvidia akan memasok 18.000 chip AI GB300 dan ratusan ribu GPU berikutnya ke perusahaan Saudi Humain; AMD dan Humain akan bersama-sama menginvestasikan US$10 miliar untuk membangun pusat data AI. Langkah ini bertujuan untuk memperkuat pengaruh AI AS di Timur Tengah dan membantu diversifikasi ekonomi kedua negara. (Sumber: DeepLearning.AI Blog)

Meta meluncurkan Llama Startup Program, memberdayakan startup AI tahap awal: Meta mengumumkan peluncuran Llama Startup Program, yang bertujuan untuk mendukung startup tahap awal di AS (dengan pendanaan di bawah US$10 juta dan setidaknya satu pengembang) dalam memanfaatkan model Llama untuk inovasi aplikasi AI generatif. Program ini menyediakan penggantian biaya sumber daya cloud, dukungan teknis dari para ahli Llama, dan sumber daya komunitas. Batas waktu pendaftaran adalah 30 Mei 2025 pukul 18:00 (Waktu Pasifik). (Sumber: AIatMeta)
🌟 Komunitas
Google I/O memicu diskusi hangat: Integrasi AI menyeluruh dan prospek masa depan: Google I/O merilis sejumlah besar produk dan pembaruan terkait AI, termasuk seri model Gemini, generasi video Veo 3, generasi gambar Imagen 4, mode pencarian AI, dll., yang memicu diskusi luas di komunitas. Banyak komentator percaya bahwa Google telah menunjukkan kekuatan yang tangguh dalam tingkat aplikasi AI, terutama strategi mengintegrasikan AI secara mulus ke dalam ekosistem produk yang ada. Pada saat yang sama, topik-topik seperti keaslian konten yang dihasilkan AI, etika AI, dan jalur masa depan AGI juga menjadi fokus diskusi. (Sumber: rowancheung, dotey, karminski3, GoogleDeepMind, natolambert)

Perangkat keras AI menjadi fokus baru, kerja sama OpenAI dengan Jony Ive menarik perhatian: Berita akuisisi OpenAI terhadap perusahaan perangkat keras AI Jony Ive, io, serta prototipe kacamata pintar Android XR yang dipamerkan Google di I/O, memicu diskusi komunitas tentang masa depan perangkat keras AI. Kerja sama Sam Altman dengan Jony Ive dipandang bertujuan untuk menciptakan perangkat komputasi pribadi generasi baru yang didorong oleh AI, yang berpotensi mengubah cara interaksi ponsel dan komputer yang ada saat ini. Komunitas umumnya mengharapkan perangkat keras asli AI dapat membawa pengalaman revolusioner, tetapi juga memperhatikan bentuk, fungsi, dan penerimaan pasarnya. (Sumber: dotey, sama, dotey, swyx)

Peran dan risiko AI dalam pengembangan perangkat lunak memicu diskusi: Mistral AI merilis model Devstral yang dirancang khusus untuk agen coding, serta pembaruan Codex oleh OpenAI, memicu diskusi tentang aplikasi AI dalam pengembangan perangkat lunak. Komunitas memperhatikan kemampuan aktual alat pemrograman AI, kualitas dan keamanan kode yang dihasilkan. Secara khusus, penelitian menunjukkan bahwa kode yang dihasilkan AI mungkin merujuk pada “paket halusinasi” yang tidak ada, yang membawa risiko keamanan rantai pasokan, mengingatkan pengembang untuk memverifikasi kode dan dependensi yang dihasilkan AI dengan hati-hati. (Sumber: MistralAI, DeepLearning.AI Blog, qtnx_)
Diskusi tentang evaluasi model AI dan pengujian benchmark terus memanas: LMArena.ai mendapatkan pendanaan besar, serta kinerja berbagai model baru pada pengujian benchmark, menjadikan evaluasi model AI sebagai topik hangat di komunitas. Pengguna peduli dengan kemampuan nyata model yang berbeda pada tugas-tugas tertentu (seperti coding, matematika, tanya jawab pengetahuan umum, pemahaman emosi), serta keandalan dan keterbatasan sistem evaluasi yang ada. Misalnya, kerangka kerja evaluasi kecerdasan emosional SAGE yang dirilis oleh Tencent, mencoba memberikan dimensi evaluasi baru untuk model AI dari sudut pandang “kecerdasan emosional”. (Sumber: lmarena_ai, 36氪, natolambert)
Keterlambatan perkembangan industri teknologi Eropa memicu refleksi, Yann LeCun meneruskan diskusi bahwa kurangnya “patriotisme” adalah penyebab utama: Artikel Wall Street Journal tentang skena teknologi Eropa yang jauh lebih kecil dari AS dan Tiongkok memicu diskusi, Yann LeCun meneruskan komentar Arnaud Bertrand. Bertrand berpendapat bahwa penyebab utama keterbelakangan teknologi Eropa adalah kurangnya semangat “patriotisme”, media dan kalangan elit Eropa cenderung memuja startup Amerika, dan mengabaikan inovasi lokal, yang menyebabkan perusahaan lokal sulit mendapatkan dukungan awal dan pengakuan pasar. Ia menggunakan pengalamannya sendiri dalam mendirikan HouseTrip sebagai contoh, menunjukkan bahwa Eropa kurang memiliki kepercayaan diri dan suasana yang mendukung inovasi lokal. (Sumber: ylecun)

💡 Lainnya
Masalah konsumsi energi AI menarik perhatian: MIT Technology Review mengadakan diskusi meja bundar untuk membahas masalah konsumsi energi yang disebabkan oleh percepatan pengembangan teknologi AI dan dampaknya terhadap iklim. Seiring dengan meningkatnya skala model AI dan cakupan aplikasinya, kebutuhan akan listrik dan sumber daya komputasi meningkat tajam, dan kebutuhan energi pusat data menjadi fokus baru. Diskusi berfokus pada konsumsi energi per kueri AI tunggal, jejak energi AI secara keseluruhan, dan cara mengatasi tantangan ini. (Sumber: MIT Technology Review, madiator)

Anthropic memberikan teaser akan ada berita baru, komunitas berspekulasi Claude 4 akan dirilis: Perusahaan Anthropic merilis teaser, akan melakukan siaran langsung pada 22 Mei pukul 09:30 Waktu Pasifik (23 Mei pukul 00:00 WIB), memicu spekulasi di komunitas tentang kemungkinan perilisan model generasi baru Claude (kemungkinan Claude 4). Mengingat pembaruan besar-besaran yang baru-baru ini dirilis oleh OpenAI dan Google, langkah Anthropic ini sangat dinantikan. (Sumber: AnthropicAI, dotey, karminski3, scaling01, Reddit r/ClaudeAI)
Integrasi teknologi AI dan XR, Google memamerkan prototipe kacamata pintar Android XR: Google di I/O memamerkan prototipe kacamata pintar Android XR, menekankan integrasi mendalamnya dengan AI. Perangkat ini mendukung bantuan cerdas dari sudut pandang orang pertama dan fungsi bantuan tanpa kontak, pengguna dapat berinteraksi dengan perangkat melalui bahasa alami untuk menyelesaikan kueri informasi, manajemen jadwal, navigasi real-time, dll. Ini menandakan bahwa AI akan menjadi inti interaksi dan penggerak fungsional perangkat XR generasi berikutnya, meningkatkan pengalaman pengguna di lingkungan augmented reality. (Sumber: dotey, 36氪)