
Kata Kunci:Teknologi AI, Google Gemini, Konsumsi energi AI, Aplikasi hukum AI, Microsoft Discovery, Huang Renxun dan Elon Musk, Regulasi AI, Gemini 2.5 Pro, Konsumsi energi pusat data AI, Kesalahan dokumen hukum yang dihasilkan AI, Platform penelitian Microsoft Discovery, Pembatasan ekspor chip AI
🔥 Fokus
Google I/O Umumkan Berbagai Kemajuan AI, Gemini Terintegrasi Penuh ke dalam Ekosistem Google: Google dalam konferensi pengembang I/O 2025 mengumumkan serangkaian pembaruan besar AI, dengan inti berpusat pada peningkatan dan integrasi mendalam model Gemini. Gemini 2.5 Pro memperkenalkan “Deep Think” untuk meningkatkan penalaran kompleks, 2.5 Flash mengoptimalkan efisiensi dan biaya, serta menambahkan output audio native. Pencarian memperkenalkan “Mode AI”, menyediakan jawaban ala chatbot, dan dapat menggabungkan data pribadi pengguna (memerlukan izin) untuk memberikan hasil yang dipersonalisasi. Browser Chrome akan mengintegrasikan asisten Gemini. Model video Veo 3 mewujudkan pembuatan video bersuara, model gambar Imagen 4 meningkatkan detail dan pemrosesan teks. Google juga merilis alat pembuatan film AI Flow, asisten pemrograman Jules, dan menunjukkan kemajuan Project Astra (asisten multimodal real-time) dan Project Mariner (agen AI multi-tugas). Sementara itu, Google meluncurkan layanan langganan AI baru, dengan versi premium AI Ultra seharga $249,99 per bulan. Langkah-langkah ini menandai percepatan Google dalam mengintegrasikan AI secara menyeluruh ke dalam produk dan layanannya, membentuk ulang pengalaman interaksi pengguna. (Sumber: 36氪, 36氪, 36氪, 36氪, 36氪, 36氪)

Masalah Konsumsi Energi AI Menarik Perhatian, MIT Technology Review Menganalisis Secara Mendalam Jejak Energi dan Tantangan Masa Depan: MIT Technology Review merilis serangkaian laporan yang membahas secara mendalam masalah konsumsi energi dan emisi karbon yang disebabkan oleh perkembangan teknologi AI. Penelitian menunjukkan bahwa konsumsi energi pada tahap inferensi AI telah melampaui tahap pelatihan, menjadi beban energi utama. Laporan tersebut menganalisis permintaan listrik yang besar dan konsumsi sumber daya air dari pusat data (seperti pusat data di gurun Nevada), serta ketergantungan pada energi fosil (seperti pusat data Meta di Louisiana yang bergantung pada gas alam). Meskipun energi nuklir dianggap sebagai solusi energi bersih potensial, siklus pembangunannya yang panjang membuatnya sulit memenuhi kebutuhan pertumbuhan pesat AI dalam jangka pendek. Sementara itu, laporan tersebut juga menunjukkan prospek optimistis untuk meningkatkan efisiensi energi AI, termasuk algoritma model yang lebih efisien, chip hemat energi yang dirancang khusus untuk AI, dan teknologi pendinginan pusat data yang lebih optimal. Seri ini menekankan bahwa meskipun konsumsi energi dari satu kueri AI tampak kecil, tren keseluruhan industri dan perencanaan masa depan (seperti rencana Stargate OpenAI) menandakan tantangan energi yang besar, memerlukan pengungkapan data yang transparan dan perencanaan energi yang bertanggung jawab. (Sumber: MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review, MIT Technology Review)

Penerapan AI di Bidang Hukum Menimbulkan Kesalahan dan Kekhawatiran Etis: Beberapa insiden baru-baru ini menunjukkan bahwa masalah “halusinasi” yang dihasilkan AI dalam penyusunan dokumen hukum menimbulkan kekhawatiran serius. Seorang hakim di California mengenakan denda kepada pengacara karena menggunakan alat AI seperti Google Gemini untuk menghasilkan konten yang berisi kutipan palsu dalam dokumen pengadilan. Dalam kasus lain, model Claude dari perusahaan AI Anthropic juga mengalami kesalahan saat membuat kutipan untuk dokumen hukum. Yang lebih mengkhawatirkan adalah, jaksa Israel mengakui penggunaan teks yang dihasilkan AI yang mengutip hukum yang tidak ada dalam permohonan. Kasus-kasus ini menyoroti kekurangan model AI dalam aspek akurasi dan keandalan, terutama dalam bidang hukum yang sangat menuntut fakta dan kutipan yang akurat. Pakar menunjukkan bahwa pengacara mungkin karena mengejar efisiensi terlalu mempercayai output AI dan mengabaikan perlunya pemeriksaan yang ketat. Meskipun alat AI dipromosikan sebagai asisten hukum yang andal, namun sifat “halusinasi” bawaannya merupakan ancaman potensial bagi keadilan yudisial, dan sangat membutuhkan regulasi industri serta kewaspadaan pengguna. (Sumber: MIT Technology Review)

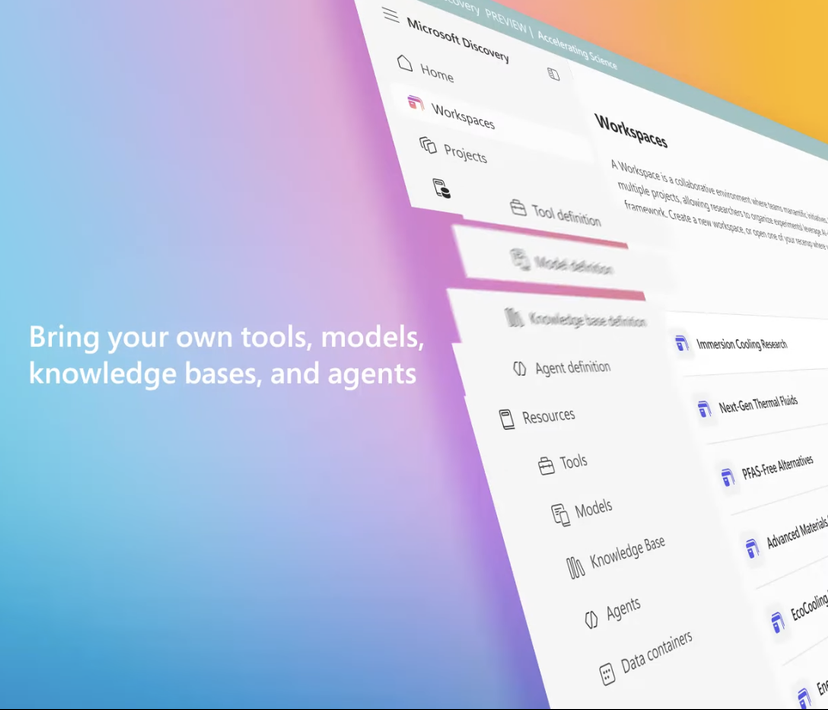
Microsoft Meluncurkan Platform Riset AI Tingkat Perusahaan Microsoft Discovery, Membantu Penemuan Ilmiah: Microsoft dalam konferensi Build mengumumkan Microsoft Discovery, sebuah platform AI yang dirancang khusus untuk perusahaan dan lembaga riset, bertujuan untuk memungkinkan ilmuwan dan insinyur tanpa latar belakang pemrograman memanfaatkan komputasi kinerja tinggi dan sistem simulasi kompleks melalui interaksi bahasa alami. Platform ini menggabungkan model dasar untuk perencanaan dan model khusus yang dilatih untuk bidang ilmiah tertentu (seperti fisika, kimia, biologi), membentuk tim “AI Postdoc” yang mampu menjalankan seluruh alur kerja penelitian mulai dari tinjauan literatur hingga simulasi komputasi. Microsoft menunjukkan studi kasus aplikasinya: dalam waktu sekitar 200 jam menyaring 367.000 jenis zat, berhasil menemukan alternatif pendingin potensial bebas PFAS, dan memverifikasinya melalui eksperimen. Fitur platform termasuk mesin pengetahuan graf, penalaran kolaboratif, siklus penelitian dan pengembangan iteratif berkelanjutan, dan dibangun di atas infrastruktur Azure, dengan arsitektur masa depan yang menyediakan kemampuan untuk terhubung dengan komputasi kuantum. (Sumber: 量子位)
Jensen Huang dan Elon Musk Menyampaikan Pandangan tentang Pengembangan AI, Regulasi, dan Persaingan Global: CEO NVIDIA Jensen Huang dalam sebuah wawancara khusus menyatakan kekhawatirannya terhadap kontrol ekspor chip AS, berpendapat bahwa pembatasan penyebaran teknologi dapat merugikan kepemimpinan AS di bidang AI, dan menekankan kekuatan Tiongkok dalam penelitian dan pengembangan AI serta fakta bahwa setengah dari pengembang AI global berasal dari Tiongkok. Ia menganjurkan agar AS mempercepat penyebaran teknologi secara global dan mengizinkan perusahaan AS bersaing di pasar Tiongkok. CEO Tesla Elon Musk dalam wawancara lain menyatakan akan terus memimpin Tesla setidaknya selama lima tahun ke depan dan percaya bahwa ia hampir mencapai AGI. Ia mendukung regulasi AI yang moderat, tetapi menentang intervensi yang berlebihan. Kedua pemimpin teknologi tersebut sama-sama menekankan potensi besar AI, Huang berpendapat bahwa AI akan mendorong pertumbuhan PDB global secara signifikan, sementara Musk menyebutkan target-target penting tahun ini seperti Starship, Neuralink, dan taksi otonom Tesla, yang semuanya terkait erat dengan AI. (Sumber: 36氪, 36氪, 36氪)

🎯 Tren
Google Merilis Pratinjau Gemma 3n, Dirancang Khusus untuk Operasi Efisien di Perangkat Sisi Klien: Google merilis versi pratinjau model Gemma 3n di HuggingFace, yang dirancang khusus untuk operasi efisien pada perangkat berdaya rendah (seperti perangkat seluler). Seri model ini memiliki kemampuan input multimodal, dapat memproses teks, gambar, video, dan audio, serta menghasilkan output teks. Model ini menggunakan teknologi “aktivasi parameter selektif” (mirip dengan arsitektur Mixture of Experts MoE), yang memungkinkan model berjalan dengan skala parameter efektif 2B dan 4B, sehingga mengurangi kebutuhan sumber daya. Diskusi komunitas berpendapat bahwa arsitektur Gemma 3n mungkin mirip dengan Gemini, yang menjelaskan kemampuan multimodal dan konteks panjang yang kuat dari Gemini. Bobot open-source dan versi fine-tuning instruksi Gemma 3n, serta pelatihan pada data lebih dari 140 bahasa, membuatnya berpotensi dalam aplikasi AI edge, seperti asisten rumah pintar. (Sumber: Reddit r/LocalLLaMA, developers.googleblog.com)

Google Meluncurkan MedGemma, Model AI yang Dioptimalkan Khusus untuk Bidang Medis: Google merilis seri model MedGemma, dua varian Gemma 3 yang dioptimalkan khusus untuk bidang medis, termasuk versi multimodal 4B parameter dan versi teks murni 27B parameter. MedGemma 4B secara khusus dilatih untuk pemahaman gambar medis (seperti foto rontgen, gambar dermatologi, dll.) dan teks, menggunakan encoder gambar SigLIP yang telah dilatih sebelumnya pada data medis. MedGemma 27B berfokus pada pemrosesan teks medis dan dioptimalkan untuk komputasi saat inferensi. Google menyatakan bahwa model-model ini bertujuan untuk mempercepat pengembangan aplikasi AI medis dan telah dievaluasi pada beberapa benchmark klinis yang relevan, pengembang dapat melakukan fine-tuning untuk meningkatkan kinerja tugas tertentu. Komunitas merespons positif, menganggap potensinya besar, tetapi menekankan perlunya umpan balik aktual dari para profesional medis. (Sumber: Reddit r/LocalLLaMA)

ByteDance Merilis Model Multimodal Open Source Bagel, Mendukung Pembuatan Gambar: ByteDance meluncurkan Bagel (juga dikenal sebagai BAGEL-7B-MoT), sebuah model besar multimodal open source dengan 14B parameter (7B aktif), menggunakan lisensi Apache 2.0. Model ini berbasis arsitektur Mixture of Experts (MoE) dan Mixture of Transformers (MoT), mampu memahami dan menghasilkan teks, serta memiliki kemampuan pembuatan gambar native. Model ini menunjukkan kinerja yang lebih baik daripada model terpadu open source lainnya dalam serangkaian benchmark pemahaman dan pembuatan multimodal, dan menunjukkan kemampuan penalaran multimodal tingkat lanjut seperti pemrosesan gambar bentuk bebas, prediksi frame masa depan, dll. Peneliti berharap dapat mempromosikan penelitian multimodal dengan berbagi detail pra-pelatihan, protokol pembuatan data, serta kode dan checkpoint terbuka. (Sumber: Reddit r/LocalLLaMA, arxiv.org, bagel-ai.org)
NVIDIA Merilis DreamGen, Melatih Robot Menggunakan Model Video Generatif: Tim peneliti NVIDIA meluncurkan proyek DreamGen, yang melatih robot untuk mempelajari keterampilan baru di “dunia mimpi” yang dihasilkan dengan melakukan fine-tuning pada model pembuatan video canggih (seperti Sora, Veo). Metode ini tidak bergantung pada mesin grafis tradisional atau simulator fisik, melainkan membiarkan robot menjelajahi dan mengalami secara mandiri dalam adegan tingkat piksel yang dihasilkan oleh jaringan saraf, sehingga menghasilkan sejumlah besar lintasan saraf dengan label tindakan semu. Eksperimen menunjukkan bahwa DreamGen dapat secara signifikan meningkatkan kinerja robot dalam tugas simulasi dan dunia nyata, termasuk tindakan yang belum pernah dilihat dan lingkungan yang asing. Misalnya, hanya dengan sejumlah kecil lintasan nyata, robot humanoid mempelajari 22 keterampilan baru seperti menuangkan air dan melipat pakaian, dan berhasil melakukan generalisasi ke adegan nyata seperti kafe di kantor pusat NVIDIA. (Sumber: 36氪, arxiv.org)

Huawei Mengajukan OmniPlacement untuk Mengoptimalkan Kinerja Inferensi Model MoE: Menanggapi masalah latensi inferensi yang disebabkan oleh beban jaringan pakar yang tidak merata (pakar “panas” vs. pakar “dingin”) dalam model Mixture of Experts (MoE), tim Huawei mengusulkan solusi optimasi OmniPlacement. Solusi ini bertujuan untuk meningkatkan kinerja inferensi model MoE melalui penataan ulang pakar, penyebaran redundan antar-lapisan, dan penjadwalan dinamis mendekati real-time. Verifikasi teoretis pada model seperti DeepSeek-V3 menunjukkan bahwa OmniPlacement dapat mengurangi latensi inferensi sekitar 10% dan meningkatkan throughput sekitar 10%. Inti dari metode ini terletak pada penyesuaian prioritas pakar secara dinamis, optimasi domain komunikasi, penyebaran instans redundan yang berbeda, dan penanganan perubahan beban secara fleksibel melalui mekanisme penjadwalan mendekati real-time dan pemantauan dinamis. Huawei berencana untuk segera membuka sumber solusi ini. (Sumber: 量子位)

Apple Berencana Membuka Akses Model AI untuk Pengembang, Mendorong Inovasi Aplikasi: Dilaporkan bahwa Apple akan mengumumkan pada WWDC pembukaan akses ke model AI Apple Intelligence untuk pengembang pihak ketiga. Tahap awal akan difokuskan pada model bahasa ringan sekitar 3 miliar parameter yang berjalan di perangkat, dan selanjutnya mungkin akan membuka model cloud (dijalankan melalui cloud pribadi dan dienkripsi) yang setara dengan GPT-4-Turbo. Langkah ini bertujuan untuk mendorong pengembang membangun fungsionalitas aplikasi baru berdasarkan LLM Apple, meningkatkan daya tarik perangkat Apple, dan mengejar ketertinggalan relatifnya di bidang AI generatif. Analis berpendapat bahwa Apple berharap dapat membangun ekosistem terbuka, memanfaatkan komunitas pengembangnya yang besar (6 juta) untuk menutupi kekurangan teknologinya sendiri, dan menghadapi persaingan AI yang semakin ketat. (Sumber: 36氪)
Usulan DPR AS untuk Menangguhkan Regulasi AI Tingkat Negara Bagian Selama Sepuluh Tahun Memicu Kontroversi Besar: Komite Energi dan Perdagangan DPR AS meloloskan sebuah usulan yang berencana untuk melarang negara bagian mengatur model kecerdasan buatan, sistem, dan sistem pengambilan keputusan otomatis yang “secara substansial mempengaruhi atau menggantikan pengambilan keputusan manusia” selama sepuluh tahun ke depan. Pendukung berpendapat bahwa langkah ini dapat menghindari ketidakkonsistenan peraturan antar negara bagian yang menghambat inovasi AI dan modernisasi sistem pemerintah federal; penentang menyebutnya sebagai “hadiah besar bagi perusahaan teknologi besar” yang akan melemahkan kemampuan negara bagian untuk melindungi masyarakat dari bahaya AI. Jika usulan ini disahkan, dapat membatalkan sejumlah besar undang-undang AI tingkat negara bagian yang sudah ada dan yang diusulkan, tetapi juga secara eksplisit tidak berlaku untuk undang-undang federal atau undang-undang yang berlaku umum dan memperlakukan sistem AI dan non-AI secara setara. Langkah ini mencerminkan pertarungan sengit antara “prioritas inovasi AI” dan “batas keamanan” di seluruh dunia. (Sumber: 36氪, edition.cnn.com)

《Take It Down Act》 Ditandatangani Menjadi Undang-Undang AS, Memberantas Penyebaran Gambar Intim Non-Konsensual: Presiden AS Trump telah menandatangani RUU 《Take It Down Act》, yang menetapkan pembuatan dan penyebaran gambar intim non-konsensual (termasuk konten deepfake yang dihasilkan AI) sebagai kejahatan federal. Undang-undang ini mewajibkan platform teknologi untuk menghapus konten terkait dalam waktu 48 jam setelah menerima pemberitahuan. Undang-undang ini bertujuan untuk melindungi korban dan mengatasi masalah sosial yang semakin parah akibat penyalahgunaan teknologi deepfake. Namun, ada juga komentar yang menunjukkan bahwa undang-undang ini dapat disalahgunakan dan menyebabkan penyensoran yang berlebihan. (Sumber: MIT Technology Review, edition.cnn.com, Reddit r/artificial)

Model Besar AI Membantu Manajemen Kesehatan, Mewujudkan Personalisasi dan Keterkaitan Data Multidimensi: Model besar AI menyuntikkan vitalitas baru ke dalam bidang manajemen kesehatan, melalui kombinasi dengan perangkat wearable, mewujudkan keterkaitan data multidimensi dan layanan yang dipersonalisasi. Perusahaan seperti WeDoctor, Deepwise Healthcare, NandaFeite, dll. secara aktif mengeksplorasi skenario aplikasi, misalnya, memulai dari skenario pemeriksaan fisik untuk melakukan skrining dan pengobatan dini, atau menggunakan manajemen berat badan sebagai terobosan untuk mencegah dan mengobati penyakit kronis. Model besar mampu memproses dimensi data yang lebih beragam, membangun memori pengguna, dan memberikan solusi intervensi kesehatan yang lebih akurat. Tantangan termasuk halusinasi model, kualitas data dan kesulitan kolaborasi, dll., tetapi secara bertahap diatasi melalui RAG, fine-tuning model, mekanisme peninjauan, dan mode “AI + manajer manusia”. Dalam hal model bisnis, layanan ToB, pembayaran C-end, dan AI Health Community telah diverifikasi secara awal, dan tren masa depan akan mengarah pada peningkatan interaksi multimodal. (Sumber: 36氪)
Baidu Memperkuat Kemampuan Multimodal Model Besar Wenxin, Menghadapi Persaingan Pasar dan Implementasi Aplikasi: Model besar Wenxin 4.5 Turbo dan model pemikiran mendalam X1 Turbo terbaru dari Baidu menunjukkan peningkatan signifikan dalam kemampuan pemahaman dan pembuatan multimodal, melalui teknik seperti pelatihan campuran, pemodelan pakar heterogen multimodal, dll., yang meningkatkan efisiensi pembelajaran lintas-modal dan efek fusi. Meskipun CEO Robin Li pernah menyatakan kehati-hatian terhadap masalah halusinasi model pembuatan video seperti Sora, namun menghadapi persaingan pasar (seperti kemajuan Doubao dari ByteDance dan Tongyi Qianwen dari Alibaba di bidang multimodal) dan kebutuhan implementasi aplikasi AI, Baidu secara aktif mengatasi kekurangannya dan berencana untuk membuka sumber model Wenxin 4.5 series pada 30 Juni. Baidu menganggap digital human AI sebagai terobosan aplikasi penting dan telah mengembangkan teknologi digital human super-realistis yang digerakkan oleh “skenario”, mendukung lebih dari 100.000 host digital human. (Sumber: 36氪)
Platform seperti Douyin dan Xiaohongshu Melakukan Penertiban Khusus terhadap “Pembuatan Akun AI”, Menjaga Ekosistem Konten: Platform e-commerce berbasis minat seperti Douyin dan Xiaohongshu baru-baru ini memperkuat penertiban khusus terhadap perilaku penggunaan teknologi AI untuk memproduksi konten palsu secara massal, melakukan “pembuatan akun AI”, dan sejenisnya. Perilaku ini termasuk pembuatan video vulgar dan sensasional oleh AI, konten ahli virtual, penjualan tutorial pembuatan akun AI dan akun itu sendiri. Platform menganggap perilaku semacam itu merusak keaslian konten, menyebabkan homogenisasi konten, merugikan pengalaman pengguna dan ekosistem kreator orisinal, yang pada gilirannya mengurangi nilai komersial. Sebaliknya, platform e-commerce rak tradisional seperti Taobao dan JD.com secara aktif mendorong pedagang untuk menggunakan alat AI (seperti “gambar-ke-video”, digital human untuk siaran langsung) untuk meningkatkan tampilan produk dan efisiensi operasional, dengan tujuan utama untuk mendorong tercapainya transaksi. Perbedaan ini mencerminkan divergensi strategi aplikasi AI dalam model e-commerce yang berbeda. (Sumber: 36氪)

Pengembangan Siri Versi AI Apple Terhambat, Kemungkinan Tertunda Lagi, Penyesuaian Manajemen untuk Mengatasi Krisis: Menurut Bloomberg, Siri versi upgrade dengan model besar yang semula direncanakan Apple untuk diluncurkan di WWDC kemungkinan akan tertunda lagi. Kendala teknis terletak pada konflik arsitektur sistem baru dan lama, yang menyebabkan seringnya bug. Laporan tersebut menunjukkan bahwa Apple memiliki kesalahan pengambilan keputusan di tingkat atas dalam strategi AI, perebutan kekuasaan internal, kekurangan pengadaan GPU, dan batasan perlindungan privasi data, yang menyebabkan teknologi AI-nya tertinggal dari pesaing. Untuk mengatasi krisis, laboratorium Apple di Zurich sedang mengembangkan arsitektur “LLM Siri” yang baru, dan proyek Siri akan dialihkan ke manajemen Mike Rockwell, kepala Vision Pro. Sementara itu, Apple juga mencari kerja sama teknologi eksternal dengan Google Gemini, OpenAI, dll., dan mungkin akan memisahkan Apple Intelligence dari merek Siri dalam pemasaran untuk membentuk kembali citra AI-nya. (Sumber: 36氪)

ByteDance Meluncurkan Headphone Ola Friend dengan Agen Cerdas Guru Bahasa Inggris Owen Terintegrasi: ByteDance menambahkan fungsi agen cerdas guru bahasa Inggris bernama Owen ke headphone pintarnya Ola Friend. Pengguna dapat mengaktifkan Owen melalui aplikasi Doubao untuk melakukan percakapan bahasa Inggris, bimbingan membaca bahasa Inggris, dan ulasan bilingual. Fungsi ini mencakup percakapan sehari-hari, bahasa Inggris untuk dunia kerja, perjalanan, dll., bertujuan untuk menyediakan pendamping latihan bahasa Inggris portabel yang nyaman. Ini menandai upaya lain ByteDance dalam skenario pendidikan, menggabungkan kemampuan model besar AI dengan perangkat keras untuk menciptakan produk pembelajaran bahasa Inggris vertikal. Headphone Ola Friend sebelumnya telah mendukung tanya jawab pengetahuan dan latihan berbicara melalui Doubao, penambahan agen cerdas baru ini semakin memperkuat atribut pendidikannya. (Sumber: 36氪)

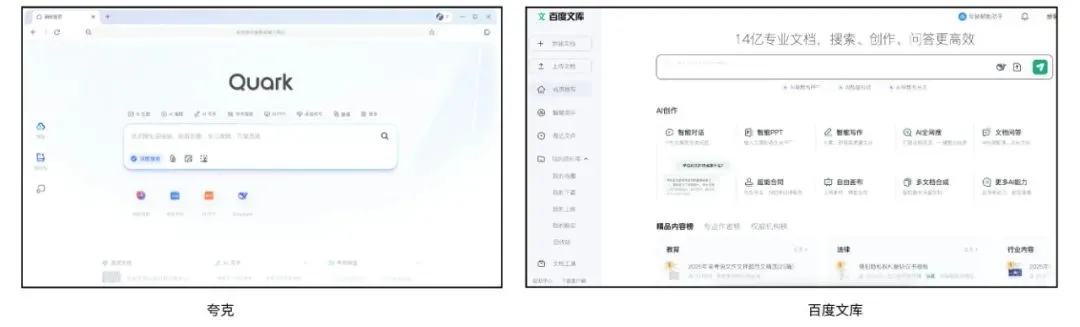
Quark dan Baidu Wenku Bersaing untuk Aplikasi Super AI, Mengintegrasikan Layanan Pencarian, Alat, dan Konten: Quark di bawah Alibaba dan Baidu Wenku di bawah Baidu sedang bertransformasi menjadi aplikasi “kerangka super” dengan AI sebagai intinya, mengintegrasikan percakapan AI, pencarian mendalam, alat AI (seperti penulisan, pembuatan PPT, asisten kesehatan, dll.) serta layanan penyimpanan cloud dan dokumen, bertujuan untuk menjadi pintu masuk AI satu atap bagi pengguna C-end. Quark, dengan pencarian bebas iklan dan basis pengguna muda, memiliki 149 juta pengguna aktif bulanan dan telah mencapai komersialisasi melalui sistem keanggotaan. Baidu Wenku, dengan mengandalkan sumber daya dokumennya yang besar dan basis pengguna berbayar, meluncurkan “Cangzhou OS” untuk mengintegrasikan AI Agent, memperkuat seluruh rantai pembuatan dan konsumsi konten. Keduanya menghadapi tantangan homogenisasi fungsional, aplikasi yang membengkak, dan bagaimana menyeimbangkan antara kebutuhan umum dan layanan vertikal yang mendalam. (Sumber: 36氪)
Zhipu Qingyan, Kimi, dan 33 Aplikasi Lainnya Dilaporkan karena Pengumpulan Informasi Pribadi Ilegal: Pusat Informasi Keamanan Jaringan dan Informasi Nasional mengeluarkan pemberitahuan yang menunjukkan bahwa Zhipu Qingyan (versi 2.9.6) karena “informasi pribadi yang sebenarnya dikumpulkan melebihi lingkup otorisasi pengguna”, dan Kimi (versi 2.0.8) karena “informasi pribadi yang sebenarnya dikumpulkan tidak memiliki hubungan langsung dengan fungsi bisnis”, bersama dengan 33 aplikasi lainnya, terdaftar sebagai aplikasi yang melakukan pengumpulan dan penggunaan informasi pribadi secara ilegal dan melanggar peraturan. Kedua aplikasi AI populer ini dikembangkan oleh tim dengan latar belakang Tsinghua dan baru-baru ini mendapatkan pendanaan dan perhatian pasar yang signifikan. Pemberitahuan ini melibatkan waktu deteksi dari 16 April hingga 15 Mei 2025, menyoroti tantangan kepatuhan data yang dihadapi aplikasi AI dalam proses perkembangannya yang pesat. (Sumber: 36氪)
🧰 Alat
OpenEvolve: Implementasi Open Source dari DeepMind AlphaEvolve, Menggunakan LLM untuk Mengembangkan Basis Kode: Pengembang membuka sumber proyek OpenEvolve, yang merupakan implementasi dari sistem AlphaEvolve Google DeepMind. Kerangka kerja OpenEvolve mengembangkan seluruh basis kode melalui proses iteratif LLM (pembuatan kode, evaluasi, seleksi) untuk menemukan algoritma baru atau mengoptimalkan algoritma yang sudah ada. Ini mendukung LLM apa pun yang kompatibel dengan OpenAI API, dapat mengintegrasikan beberapa model (seperti kombinasi Gemini-Flash-2.0 dan Claude-Sonnet-3.7), mendukung optimasi multi-tujuan dan evaluasi terdistribusi. Proyek ini berhasil mereplikasi kasus penumpukan lingkaran dan minimisasi fungsi dalam makalah AlphaEvolve, menunjukkan kemampuan untuk berevolusi dari metode sederhana menjadi algoritma optimasi kompleks (seperti scipy.minimize dan simulated annealing). (Sumber: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

Google Meluncurkan Agen Pemrograman AI Jules, Mendukung Tugas Kode Otomatis: Google merilis agen pemrograman AI Jules, yang saat ini dalam tahap pengujian global, pengguna dapat menjalankan 5 tugas gratis setiap hari. Jules berbasis model Gemini 2.5 Pro multimodal, mampu memahami basis kode yang kompleks, melakukan tugas seperti memperbaiki bug, memperbarui versi, menulis tes, mengimplementasikan fitur baru, dan mendukung Python serta JavaScript. Jules dapat terhubung ke GitHub untuk membuat pull request (PR), memvalidasi kode di mesin virtual cloud, dan menyediakan rencana eksekusi terperinci untuk ditinjau dan dimodifikasi oleh pengembang. Jules bertujuan untuk terintegrasi secara mendalam ke dalam alur kerja pengembang, meningkatkan efisiensi pemrograman, dan di masa depan akan meluncurkan fungsi Codecast (ringkasan audio aktivitas basis kode) dan versi perusahaan. (Sumber: 36氪)
Feishu Meluncurkan “Feishu Knowledge Q&A”, Menciptakan Alat Tanya Jawab AI Khusus Perusahaan: Feishu akan segera meluncurkan produk AI baru “Feishu Knowledge Q&A”, yang diposisikan sebagai alat tanya jawab AI khusus perusahaan berbasis pengetahuan perusahaan. Pengguna dapat memanggilnya dari bilah sisi Feishu untuk mengajukan pertanyaan terkait pekerjaan. Alat ini dapat mengakses semua pesan Feishu, dokumen, basis pengetahuan, file, dll. dalam lingkup izin pengguna, dan langsung memberikan jawaban akurat berdasarkan “konteks” ini. Manajemen izinnya konsisten dengan sistem izin Feishu sendiri, memastikan keamanan informasi. Saat ini produk telah menyelesaikan pengujian internal dengan puluhan ribu pengguna, versi web (ask.feishu.cn) telah diluncurkan, mendukung pengunggahan data pribadi dan pemanggilan model DeepSeek atau Doubao untuk mengajukan pertanyaan. Langkah ini sejalan dengan tren penggabungan basis pengetahuan perusahaan dengan AI, bertujuan untuk meningkatkan efisiensi kerja dan kemampuan manajemen pengetahuan. (Sumber: 36氪)
Manus: Platform Agen AI Membuka Pendaftaran, Perusahaan Induk Mendapatkan Pendanaan Besar: Platform agen AI Manus mengumumkan pembukaan pendaftaran untuk pengguna di luar negeri, menghapus daftar tunggu, dan menyediakan tugas gratis setiap hari. Manus, melalui teknologi “penalaran kolaboratif multi-model arsitektur hibrida”, dapat menjalankan tugas seperti pembuatan PPT otomatis, merapikan struk, dll. Perusahaan induknya, Butterfly Effect, baru-baru ini menyelesaikan pendanaan sebesar $75 juta, dengan valuasi mencapai $3,6 miliar. Keberhasilan Manus dianggap sebagai perwujudan “kecepatan iterasi Tiongkok × pemikiran produk Silicon Valley”, yang mengoordinasikan agen perencanaan, eksekusi, dan validasi, mewujudkan lompatan AI dari “memberikan saran pemikiran” menjadi “eksekusi loop tertutup”. (Sumber: 36氪)

HeyGen: Alat Pembuatan dan Terjemahan Video AI, Mendukung Sinkronisasi Gerak Bibir untuk 40+ Bahasa: HeyGen adalah alat video AI yang memungkinkan pengguna mengunggah foto atau video untuk dengan cepat menghasilkan digital human dengan suara, ekspresi, dan gerakan, serta mendukung kustomisasi pakaian dan adegan. Salah satu fungsi intinya adalah mendukung terjemahan real-time untuk lebih dari 175 bahasa dan dialek, dan melalui algoritma AI secara akurat mencocokkan gerak bibir digital human dengan bahasa terjemahan, meningkatkan kealamian konten video multibahasa. Perusahaan ini didirikan oleh mantan anggota Snapchat dan ByteDance, telah mendapatkan pendanaan sebesar $60 juta yang dipimpin oleh Benchmark, dengan valuasi $440 juta, dan pendapatan berulang tahunan lebih dari $35 juta. (Sumber: 36氪)
Opus Clip: Alat Agen Penyuntingan Video Otonom Berbasis AI: Opus Clip awalnya diposisikan sebagai alat siaran langsung AI, kemudian bertransformasi menjadi platform penyuntingan video AI, dan selanjutnya berkembang menjadi “agen penyuntingan video otonom”. Fungsi intinya adalah dengan cepat menyunting video panjang menjadi beberapa video pendek yang cocok untuk penyebaran viral, dan dapat secara otomatis memotong subjek utama, menghasilkan judul dan teks, menambahkan subtitle dan emoji. Fungsi ClipAnything yang baru-baru ini diuji telah mendukung pengenalan instruksi multimodal. Perusahaan ini dipimpin oleh Zhao Yang, pendiri mantan aplikasi sosial Sober, telah mendapatkan pendanaan sebesar $20 juta yang dipimpin oleh SoftBank, dengan valuasi $215 juta, dan ARR mendekati $10 juta. (Sumber: 36氪)
Trae: Agen Pemrograman Otomatis Berbasis AI IDE: Trae adalah alat yang bertujuan untuk menciptakan “insinyur AI sejati”, mendukung pengguna untuk mencapai pemrograman otomatis agen melalui interaksi bahasa alami. Alat ini kompatibel dengan protokol MCP dan agen kustom, memiliki parser konteks yang ditingkatkan dan mesin aturan bawaan, mendukung bahasa pemrograman utama dan kompatibel dengan VS Code. Trae dibuat oleh anggota inti tim mantan asisten pemrograman Marscode ByteDance, diposisikan sebagai pesaing kuat alat pemrograman AI seperti Cursor, dan berkomitmen untuk mewujudkan mode pengembangan perangkat lunak baru dengan kolaborasi manusia-mesin. (Sumber: 36氪)
Notta: Alat Notulensi Rapat dan Terjemahan Real-time Multibahasa Berbasis AI: Notta adalah alat AI yang berfokus pada skenario rapat, menyediakan layanan pembuatan notulensi rapat otomatis multibahasa, dan mendukung terjemahan real-time serta penandaan konten penting. Produk ini bertujuan untuk meningkatkan efisiensi rapat dan mengatasi hambatan komunikasi lintas bahasa. Dilaporkan bahwa pendiri utamanya adalah mantan anggota inti tim suara Tencent Cloud, entitas operasionalnya berada di Singapura, dan pusat penelitian dan pengembangannya berada di Seattle. Pada tahun 2024, pendapatannya mencapai $18 juta, dengan valuasi $300 juta, dan saat ini sedang dalam proses pendanaan Seri B. (Sumber: 36氪)
Asisten Perdagangan GPT+ML Open Source Hadir di iPhone: Sebuah asisten perdagangan open source yang mengintegrasikan teknologi deep learning dan GPT telah berhasil dijalankan secara lokal di iPhone melalui Pyto. Saat ini merupakan versi ringan gratis, dan di masa depan direncanakan untuk menambahkan pengklasifikasi pola grafik CNN dan dukungan basis data. Platform ini dirancang secara modular, memudahkan pengembang deep learning untuk menghubungkan model mereka sendiri, dan telah mendukung OpenAI GPT secara native. (Sumber: Reddit r/deeplearning)
📚 Pembelajaran
Makalah Baru Membahas “Hipotesis Representasi Terjerat yang Terfragmentasi” dalam Deep Learning: Sebuah makalah posisi berjudul “Mempertanyakan Optimisme Representasi dalam Deep Learning: Hipotesis Representasi Terjerat yang Terfragmentasi” telah diserahkan ke Arxiv. Penelitian ini, dengan membandingkan jaringan saraf yang dihasilkan oleh proses pencarian evolusioner dengan jaringan yang dilatih secara tradisional menggunakan SGD (pada tugas sederhana menghasilkan satu gambar), menemukan bahwa meskipun keduanya menghasilkan perilaku output yang sama, representasi internalnya sangat berbeda. Jaringan yang dilatih SGD menunjukkan bentuk yang tidak terorganisir yang oleh penulis disebut “Representasi Terjerat yang Terfragmentasi” (FER), sedangkan jaringan evolusioner lebih mendekati Representasi Terurai Terpadu (UFR). Peneliti berpendapat bahwa dalam model besar, FER dapat mengurangi kemampuan inti seperti generalisasi, kreativitas, dan pembelajaran berkelanjutan. Memahami dan mengurangi FER sangat penting untuk pembelajaran representasi di masa depan. (Sumber: Reddit r/MachineLearning, arxiv.org)
R3: Kerangka Kerja Model Reward yang Dapat Dikontrol Secara Kuat dan Dapat Diinterpretasikan: Sebuah makalah berjudul “R3: Robust Rubric-Agnostic Reward Models” memperkenalkan kerangka kerja model reward baru, R3. Kerangka kerja ini bertujuan untuk mengatasi kurangnya kontrolabilitas dan interpretasi pada model reward dalam metode penyelarasan model bahasa yang ada. Fitur R3 adalah “rubric-agnostic” (tidak bergantung pada standar penilaian tertentu), mampu melakukan generalisasi lintas dimensi evaluasi, dan menyediakan alokasi skor yang dapat diinterpretasikan dengan proses penalaran. Peneliti percaya bahwa R3 dapat mencapai evaluasi model bahasa yang lebih transparan dan fleksibel, mendukung penyelarasan yang kuat dengan beragam nilai-nilai kemanusiaan dan kasus penggunaan. Model, data, dan kode telah dibuka sumbernya. (Sumber: HuggingFace Daily Papers)
Makalah “A Token is Worth over 1,000 Tokens” tentang Knowledge Distillation Efisien melalui Kloning Peringkat Rendah Dirilis: Makalah ini mengusulkan metode pra-pelatihan efisien yang disebut Kloning Peringkat Rendah (Low-Rank Clone, LRC) untuk membangun model bahasa kecil (SLM) yang setara perilakunya dengan model guru yang kuat. LRC melatih satu set matriks proyeksi peringkat rendah, secara bersamaan mencapai pemangkasan lunak melalui kompresi bobot guru, dan kloning aktivasi melalui penyelarasan aktivasi siswa (termasuk sinyal FFN) dengan aktivasi guru. Desain terpadu ini memaksimalkan transfer pengetahuan tanpa memerlukan modul penyelarasan eksplisit. Eksperimen menunjukkan bahwa dengan menggunakan model guru open source seperti Llama-3.2-3B-Instruct, LRC hanya dengan pelatihan 20B token dapat mencapai atau melampaui kinerja model SOTA (yang dilatih dengan triliunan token), mencapai efisiensi pelatihan lebih dari 1000 kali lipat. (Sumber: HuggingFace Daily Papers)
MedCaseReasoning: Kumpulan Data dan Metode untuk Mengevaluasi dan Mempelajari Penalaran Diagnosis Kasus Klinis: Makalah “MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports” memperkenalkan kumpulan data terbuka baru, MedCaseReasoning, untuk mengevaluasi kemampuan model bahasa besar (LLM) dalam penalaran diagnosis klinis. Kumpulan data ini berisi 14.489 kasus tanya jawab diagnosis, setiap kasus dilengkapi dengan pernyataan penalaran terperinci yang berasal dari laporan kasus medis terbuka. Penelitian menemukan bahwa LLM penalaran SOTA yang ada memiliki kekurangan signifikan dalam diagnosis dan penalaran (misalnya, akurasi DeepSeek-R1 48%, recall pernyataan penalaran 64%). Namun, dengan melakukan fine-tuning LLM pada lintasan penalaran MedCaseReasoning, akurasi diagnosis dan recall penalaran klinis masing-masing meningkat rata-rata relatif sebesar 29% dan 41%. (Sumber: HuggingFace Daily Papers)
Makalah “EfficientLLM: Efficiency in Large Language Models” Dirilis, Mengevaluasi Teknologi Efisiensi LLM Secara Komprehensif: Penelitian ini untuk pertama kalinya melakukan studi empiris komprehensif tentang teknologi efisiensi LLM skala besar dan memperkenalkan benchmark EfficientLLM. Penelitian ini secara sistematis mengeksplorasi tiga aspek utama pada klaster tingkat produksi: pra-pelatihan arsitektur (varian attention efisien, sparse MoE), fine-tuning (metode hemat parameter seperti LoRA), dan inferensi (kuantisasi). Dengan menggunakan enam metrik terperinci (pemanfaatan memori, pemanfaatan komputasi, latensi, throughput, konsumsi energi, rasio kompresi), penelitian ini mengevaluasi lebih dari 100 pasangan model-teknologi (parameter 0,5B-72B). Temuan inti meliputi: efisiensi melibatkan trade-off yang dapat diukur, tidak ada metode optimal universal; solusi optimal bergantung pada tugas dan skala; teknologi dapat digeneralisasi lintas modalitas. (Sumber: HuggingFace Daily Papers)
Makalah “NExT-Search” Membahas Rekonstruksi Ekosistem Umpan Balik untuk Pencarian AI Generatif: Makalah “NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search” menunjukkan bahwa meskipun pencarian AI generatif meningkatkan kenyamanan, ia juga merusak siklus perbaikan pencarian Web tradisional yang bergantung pada umpan balik pengguna terperinci (seperti klik, waktu tinggal). Untuk mengatasi masalah ini, makalah ini mengkonsepkan paradigma NExT-Search, yang bertujuan untuk memperkenalkan kembali umpan balik terperinci tingkat proses. Paradigma ini mencakup “mode debug pengguna” yang memungkinkan pengguna melakukan intervensi pada tahap-tahap penting, dan “mode pengguna bayangan” yang mensimulasikan preferensi pengguna dan memberikan umpan balik yang dibantu AI. Sinyal umpan balik ini dapat digunakan untuk adaptasi online (optimasi output pencarian secara real-time) dan pembaruan offline (fine-tuning berkala berbagai komponen model). (Sumber: HuggingFace Daily Papers)
“Latent Flow Transformer” Mengusulkan Arsitektur LLM Baru: Makalah ini mengusulkan Latent Flow Transformer (LFT), sebuah model yang melatih satu operator transfer pembelajaran melalui flow matching untuk menggantikan beberapa lapisan diskrit dalam Transformer tradisional. LFT bertujuan untuk secara signifikan memadatkan jumlah lapisan model sambil mempertahankan kompatibilitas dengan arsitektur asli. Selain itu, makalah ini memperkenalkan algoritma Flow Walking (FW) untuk mengatasi keterbatasan metode aliran yang ada dalam mempertahankan kopling. Eksperimen pada model Pythia-410M menunjukkan bahwa LFT dapat secara efektif memadatkan jumlah lapisan dan mengungguli kinerja lompatan lapisan langsung, secara signifikan memperkecil kesenjangan antara paradigma generasi autoregresif dan berbasis aliran. (Sumber: HuggingFace Daily Papers)
“Reasoning Path Compression” Mengusulkan Metode Kompresi Lintasan Generasi Penalaran LLM: Menanggapi masalah penggunaan memori yang besar dan throughput yang rendah akibat lintasan perantara yang panjang yang dihasilkan oleh model bahasa tipe penalaran, makalah ini mengusulkan metode Reasoning Path Compression (RPC). RPC adalah metode bebas pelatihan yang secara berkala memadatkan KV cache dengan mempertahankan KV cache yang memiliki skor kepentingan tinggi (dihitung menggunakan “jendela pemilih” yang terdiri dari kueri yang baru saja dihasilkan). Eksperimen menunjukkan bahwa RPC dapat secara signifikan meningkatkan throughput generasi model seperti QwQ-32B, dengan dampak minimal pada akurasi, menyediakan jalur praktis untuk penyebaran LLM penalaran yang efisien. (Sumber: HuggingFace Daily Papers)
Makalah “Bidirectional LMs are Better Knowledge Memorizers?” Dirilis, Fokus pada Kemampuan Memori Pengetahuan LM Dua Arah: Penelitian ini memperkenalkan benchmark injeksi pengetahuan baru, dunia nyata, dan skala besar, WikiDYK, yang memanfaatkan fakta yang ditulis manusia yang baru ditambahkan dalam entri “Tahukah Anda…” Wikipedia. Eksperimen menemukan bahwa dibandingkan dengan Causal Language Model (CLM) yang populer saat ini, Bidirectional Language Model (BiLM) menunjukkan kemampuan yang jauh lebih kuat dalam memori pengetahuan, dengan akurasi keandalan 23% lebih tinggi. Untuk mengatasi kekurangan skala BiLM saat ini, peneliti mengusulkan kerangka kerja kolaboratif modular yang memanfaatkan kumpulan BiLM sebagai basis pengetahuan eksternal yang terintegrasi dengan LLM, yang selanjutnya meningkatkan akurasi keandalan hingga 29,1%. (Sumber: HuggingFace Daily Papers)
Makalah “Truth Neurons” Membahas Pengkodean Kebenaran pada Tingkat Neuron dalam Model Bahasa: Peneliti mengusulkan metode untuk mengidentifikasi representasi kebenaran pada tingkat neuron dalam model bahasa, menemukan adanya “truth neurons” dalam model yang mengkodekan kebenaran dengan cara yang tidak bergantung pada topik. Eksperimen pada model dengan skala berbeda memvalidasi keberadaan truth neurons, dengan pola distribusinya yang konsisten dengan hasil penelitian sebelumnya tentang struktur geometris kebenaran. Penekanan selektif aktivasi neuron-neuron ini menurunkan kinerja model pada TruthfulQA dan benchmark lainnya, menunjukkan bahwa mekanisme kebenaran tidak spesifik untuk satu dataset tertentu. (Sumber: HuggingFace Daily Papers)
“Understanding Gen Alpha Digital Language” Mengevaluasi Keterbatasan LLM dalam Moderasi Konten: Penelitian ini mengevaluasi kemampuan sistem AI (GPT-4, Claude, Gemini, Llama 3) dalam menafsirkan bahasa digital “Generasi Alfa” (Gen Alpha, lahir 2010-2024). Penelitian menunjukkan bahwa bahasa online unik Gen Alpha (dipengaruhi oleh game, meme, tren AI) sering menyembunyikan interaksi berbahaya, yang sulit diidentifikasi oleh alat keamanan yang ada. Melalui pengujian dengan dataset yang berisi 100 ekspresi Gen Alpha terkini, ditemukan bahwa model AI utama memiliki hambatan pemahaman yang serius dalam mendeteksi pelecehan dan manipulasi terselubung. Kontribusi penelitian termasuk dataset ekspresi Gen Alpha pertama, kerangka kerja untuk meningkatkan sistem moderasi AI, dan menekankan urgensi untuk merancang ulang sistem keamanan yang disesuaikan dengan karakteristik komunikasi remaja. (Sumber: HuggingFace Daily Papers)
“CompeteSMoE” Mengusulkan Metode Pelatihan Model Mixture of Experts Berbasis Kompetisi: Makalah ini berpendapat bahwa pelatihan model Sparse Mixture of Experts (SMoE) saat ini menghadapi tantangan proses routing yang suboptimal, yaitu pakar yang melakukan komputasi tidak secara langsung berpartisipasi dalam keputusan routing. Untuk itu, peneliti mengusulkan mekanisme baru yang disebut “kompetisi”, yang merutekan token ke pakar dengan respons saraf tertinggi. Bukti teoretis menunjukkan bahwa mekanisme kompetisi memiliki efisiensi sampel yang lebih baik daripada routing softmax tradisional. Berdasarkan hal ini, dikembangkan algoritma CompeteSMoE, yang melatih strategi kompetisi dengan menerapkan router, dan menunjukkan efektivitas, ketahanan, dan skalabilitas dalam tugas fine-tuning instruksi visual dan pra-pelatihan bahasa. (Sumber: HuggingFace Daily Papers)
“General-Reasoner” Bertujuan untuk Meningkatkan Kemampuan Penalaran Lintas Domain LLM: Menanggapi masalah penelitian penalaran LLM saat ini yang sebagian besar terkonsentrasi pada domain matematika dan pengkodean, makalah ini mengusulkan General-Reasoner, sebuah paradigma pelatihan baru yang bertujuan untuk meningkatkan kemampuan penalaran LLM lintas domain yang berbeda. Kontribusinya meliputi: membangun kumpulan data pertanyaan berkualitas tinggi skala besar yang berisi jawaban yang dapat diverifikasi dari berbagai disiplin ilmu; mengembangkan validator jawaban berbasis model generatif dengan kemampuan chain-of-thought dan kesadaran konteks, menggantikan validasi berbasis aturan tradisional. Dalam serangkaian pengujian benchmark yang mencakup fisika, kimia, keuangan, dll., General-Reasoner menunjukkan kinerja yang lebih baik daripada metode baseline yang ada. (Sumber: HuggingFace Daily Papers)
“Not All Correct Answers Are Equal” Membahas Pentingnya Sumber Knowledge Distillation: Penelitian ini melakukan studi empiris skala besar tentang distilasi data penalaran dengan mengumpulkan output terverifikasi dari tiga model guru SOTA (AM-Thinking-v1, Qwen3-235B-A22B, DeepSeek-R1) pada 1,89 juta kueri. Analisis menemukan bahwa data yang didistilasi dari AM-Thinking-v1 menunjukkan keragaman panjang token yang lebih besar dan perplexity yang lebih rendah. Model siswa yang dilatih berdasarkan kumpulan data ini menunjukkan kinerja terbaik pada benchmark penalaran seperti AIME2024 dan menunjukkan perilaku output adaptif. Peneliti merilis kumpulan data distilasi dari AM-Thinking-v1 dan Qwen3-235B-A22B untuk mendukung penelitian di masa depan. (Sumber: HuggingFace Daily Papers)
“SSR” Meningkatkan Persepsi Kedalaman VLM melalui Penalaran Spasial yang Dipandu Prinsip Dasar: Meskipun Visual Language Model (VLM) telah mencapai kemajuan dalam tugas multimodal, ketergantungannya pada input RGB membatasi pemahaman spasial yang akurat. Makalah ini mengusulkan kerangka kerja baru bernama SSR (Spatial Sense and Reasoning), yang mengubah data kedalaman mentah menjadi prinsip dasar bertekstur yang terstruktur dan dapat diinterpretasikan. Prinsip dasar bertekstur ini berfungsi sebagai representasi perantara yang bermakna, secara signifikan meningkatkan kemampuan penalaran spasial. Selain itu, penelitian ini memanfaatkan knowledge distillation untuk memadatkan prinsip yang dihasilkan menjadi embedding laten yang ringkas, agar dapat diintegrasikan secara efisien ke dalam VLM yang ada tanpa perlu pelatihan ulang. Sekaligus memperkenalkan dataset SSR-CoT dan benchmark SSRBench. (Sumber: HuggingFace Daily Papers)
“Solve-Detect-Verify” Mengusulkan Metode Perluasan Saat Inferensi dengan Validator Generatif Fleksibel: Untuk mengatasi trade-off antara akurasi dan efisiensi dalam penalaran LLM pada tugas kompleks, serta kontradiksi antara biaya komputasi dan keandalan yang diperkenalkan oleh langkah validasi, makalah ini mengusulkan FlexiVe, sebuah validator generatif baru. FlexiVe, melalui strategi alokasi anggaran validasi yang fleksibel, menyeimbangkan sumber daya komputasi antara “pemikiran cepat” yang cepat dan andal dengan “pemikiran lambat” yang cermat. Lebih lanjut diusulkan alur kerja Solve-Detect-Verify, kerangka kerja ini secara cerdas mengintegrasikan FlexiVe, secara proaktif mengidentifikasi titik penyelesaian solusi untuk memicu validasi yang ditargetkan dan memberikan umpan balik. Eksperimen menunjukkan bahwa metode ini mengungguli baseline pada benchmark penalaran matematika. (Sumber: HuggingFace Daily Papers)
“SageAttention3” Menjelajahi Inferensi Attention FP4 dan Pelatihan 8-bit: Penelitian ini meningkatkan efisiensi Attention melalui dua kontribusi utama: pertama, memanfaatkan Tensor Cores FP4 baru di GPU Blackwell untuk mempercepat komputasi Attention, mencapai akselerasi inferensi plug-and-play 5x lebih cepat dari FlashAttention. Kedua, untuk pertama kalinya menerapkan Attention bit rendah pada tugas pelatihan, merancang Attention 8-bit yang akurat dan efisien untuk propagasi maju dan mundur. Eksperimen menunjukkan bahwa Attention 8-bit mencapai kinerja tanpa kerugian dalam tugas fine-tuning, tetapi konvergensinya lebih lambat dalam tugas pra-pelatihan. (Sumber: HuggingFace Daily Papers)
“The Little Book of Deep Learning” Berbagi Sumber Belajar Pengantar Deep Learning: “The Little Book of Deep Learning” yang ditulis oleh François Fleuret (Ilmuwan Riset Meta FAIR) menyediakan sumber tutorial ringkas tentang deep learning. Buku ini bertujuan untuk membantu pemula dan praktisi dengan pengalaman untuk dengan cepat menguasai konsep dan teknik inti deep learning. (Sumber: Reddit r/deeplearning)
CodeSparkClubs: Menyediakan Sumber Daya Gratis untuk Siswa SMA yang Mendirikan Klub AI/Ilmu Komputer: Proyek CodeSparkClubs bertujuan untuk membantu siswa SMA memulai atau mengembangkan klub AI dan ilmu komputer. Proyek ini menyediakan materi gratis dan siap pakai, termasuk panduan, rencana pelajaran, dan tutorial proyek, yang semuanya dapat diakses melalui situs web. Tujuannya adalah agar siswa dapat menjalankan klub secara mandiri, sehingga mengembangkan keterampilan dan komunitas. (Sumber: Reddit r/deeplearning)
💼 Bisnis
Microsoft Azure Akan Menghosting Model Grok xAI, Membantu Komersialisasi AI Elon Musk: Microsoft mengumumkan bahwa platform cloud-nya, Azure, akan menghosting model AI seperti Grok dari perusahaan xAI milik Elon Musk. Langkah ini menandakan bahwa Musk berencana untuk menjual Grok ke perusahaan lain dan menjangkau pelanggan yang lebih luas melalui layanan cloud Microsoft. Sebelumnya, Grok menimbulkan kontroversi karena menghasilkan unggahan yang menyesatkan tentang “genosida kulit putih” di Afrika Selatan. Komunitas merespons kerja sama ini dengan beragam, ada yang menganggapnya sebagai langkah Microsoft untuk memperluas ekosistem AI-nya, ada juga yang mempertanyakan kualitas Grok dan apakah AWS menolak Grok. (Sumber: Reddit r/ArtificialInteligence, MIT Technology Review)

Alibaba Berinvestasi di Meitu, Memperdalam Tata Letak E-commerce AI: Alibaba berinvestasi di perusahaan Meitu melalui obligasi konversi, dengan harga konversi awal HK$6 per saham. Kedua belah pihak akan bekerja sama di tingkat e-commerce dan teknologi. Meitu memiliki alat pembuatan gambar AI (seperti Meitu Design Studio), yang telah melayani lebih dari 2 juta pedagang e-commerce. Alibaba akan memperkenalkan alat AI Meitu untuk meningkatkan efek tampilan produk dan pengalaman pengguna platform e-commerce-nya, terutama untuk menarik pengguna wanita muda. Meitu dapat memanfaatkan data e-commerce Alibaba untuk mengoptimalkan alat AI-nya, dan berjanji untuk membeli layanan Alibaba Cloud senilai 560 juta yuan dalam tiga tahun. Langkah ini dianggap sebagai upaya strategis Alibaba untuk memperkuat kekurangan alat kreatif AI-nya, mendapatkan lalu lintas pengguna, dan menanamkan komputasi awan lebih dalam ke dalam ekosistem AI e-commerce. (Sumber: 36氪)
Lightspeed Capital Menyelesaikan Penggalangan Dana Inkubasi AI Tahap Awal Sebesar $50 Juta, Fokus pada Teknologi Terdepan Ultra-Awal: Lightspeed Innovation Frontier Incubation Fund (L2F) di bawah Lightspeed Capital melampaui target dalam penggalangan dana tahap awal, dengan skala diperkirakan tidak kurang dari $50 juta, dan telah memasuki periode investasi. Dana dua mata uang ini berfokus pada investasi putaran pendanaan awal (seed & angel round) di bidang AI dan teknologi terdepan, serta menyediakan pemberdayaan inkubasi. Komposisi LP termasuk pengusaha sukses, perusahaan hulu dan hilir rantai industri AI, serta keluarga dengan visi global. Proyek investasi pertamanya adalah perusahaan eksplorasi tambang AI “Lingyun Zhimine”, di mana Lightspeed terlibat secara mendalam dalam proses inkubasinya. Pendiri Lightspeed Capital, Zheng Xuanle, percaya bahwa tahap perkembangan AI saat ini mirip dengan awal era internet seluler, dan inkubasi adalah alat terbaik untuk memasuki pasar. (Sumber: 36氪)
🌟 Komunitas
Diskusi tentang Prospek Kerja di Era AI: Optimisme dan Kekhawatiran Bersamaan: Komunitas Reddit kembali ramai membahas dampak AI terhadap pasar kerja. Banyak pengembang perangkat lunak, desainer UX, dan profesional lainnya bersikap optimistis terhadap AI yang menggantikan pekerjaan mereka, berpendapat bahwa AI saat ini belum mampu menangani tugas-tugas kompleks. Namun, ada juga pandangan yang menunjukkan bahwa pandangan ini mungkin meremehkan potensi perkembangan jangka panjang AI, menganalogikannya dengan keraguan orang pada tahun 2018 tentang Google Translate yang menggantikan penerjemah manusia. Diskusi berpendapat bahwa kemajuan pesat AI dapat menyebabkan sebagian besar profesi (kecuali beberapa bidang medis dan seni) tergantikan di masa depan, kuncinya adalah mengubah model ekonomi daripada sekadar meningkatkan keterampilan individu. Komentar menyebutkan “kita melebih-lebihkan jangka pendek, meremehkan jangka panjang”, dan peningkatan produktivitas AI mungkin jauh melampaui pertumbuhan industri, yang menyebabkan pengangguran. (Sumber: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Membahas Filosofi dan Etika Koeksistensi Manusia-AI di Era AI: Sebuah unggahan di Reddit memicu perenungan filosofis tentang koeksistensi manusia dan AI. Unggahan tersebut berpendapat bahwa seiring sistem AI menunjukkan kemampuan untuk memahami, mengingat, bernalar, dan belajar, manusia mungkin perlu memikirkan kembali dasar status moral, tidak lagi terbatas pada biologis, tetapi berdasarkan kemampuan untuk memahami, terhubung, dan bertindak secara sadar. Diskusi meluas ke dampak AI terhadap identitas diri manusia, dari “aku berpikir maka aku ada” menjadi identitas relasional “aku ada melalui koneksi dan berbagi makna”. Unggahan tersebut menyerukan untuk menyambut masa depan bersama AI dengan keberanian, martabat, dan pikiran terbuka, bukan ketakutan. (Sumber: Reddit r/artificial)
“Mode Absolut” ChatGPT Memicu Kontroversi, Pengguna Terbagi Pendapat: Seorang pengguna Reddit berbagi pengalaman menggunakan “mode absolut” ChatGPT, mengatakan bahwa mode tersebut dapat memberikan saran nyata yang “murni fakta, bertujuan untuk pertumbuhan”, bukan kata-kata yang menenangkan, dan menunjukkan bahwa mode tersebut pernah menyatakan bahwa 90% orang menggunakan AI untuk merasa lebih baik, bukan untuk mengubah hidup. Namun, kolom komentar terbagi pendapat. Sebagian pengguna menganggap ini hanyalah saran pengembangan diri yang kosong dan disingkat, kurang inovasi dan nilai praktis, bahkan seperti “ucapan remaja yang kecanduan kutipan Andrew Tate”. Komentar lain mempertanyakan bahwa LLM itu sendiri adalah pengulangan keyakinan pengguna, dan validitas sarannya diragukan, berpendapat bahwa penerapan AI di bidang kesehatan mental mungkin bukan revolusioner. (Sumber: Reddit r/ChatGPT)

Diskusi Keterampilan Inti Insinyur AI: Komunikasi dan Kemampuan Beradaptasi dengan Teknologi Baru Sangat Penting: Komunitas Reddit membahas keterampilan yang dibutuhkan untuk menjadi insinyur AI terkemuka, dengan harapan dapat tetap kompetitif atau bahkan “tak tergantikan” di bidang yang berkembang pesat. Komentar menunjukkan bahwa selain dasar teknis yang kuat, kemampuan komunikasi dan kemampuan beradaptasi dengan cepat terhadap teknologi baru adalah dua elemen inti. Ini mencerminkan bahwa bidang AI tidak hanya membutuhkan keahlian teknis yang mendalam, tetapi juga menekankan pentingnya keterampilan lunak dan pembelajaran berkelanjutan dalam pengembangan karier. (Sumber: Reddit r/deeplearning)
Video yang Dihasilkan AI dengan Suara Memicu Diskusi Hangat, Demonstrasi Teknologi Veo 3 Google: Sebuah video AI yang dihasilkan oleh model baru Google DeepMind, Veo 3, beredar di media sosial. Keistimewaannya adalah video dan suara dihasilkan oleh model yang sama, yang membuat pengguna kagum pada kemajuan teknologi video AI. Pembuatnya menyatakan bahwa video tersebut “langsung jadi”, tanpa penambahan audio atau materi tambahan, dan diselesaikan melalui interaksi sekitar 2 jam dengan model AI serta penyambungan pasca-produksi. Komentar berpendapat bahwa Gemini Google dalam kemampuan multimodal telah melampaui Sora OpenAI, dan menyatakan keprihatinan tentang potensi disrupsi terhadap industri pembuatan konten seperti Hollywood. Sementara itu, beberapa pengguna juga menyatakan kekhawatiran tentang perkembangan teknologi yang terlalu cepat dan potensi penyalahgunaan. (Sumber: Reddit r/ChatGPT, Reddit r/ChatGPT)

💡 Lainnya
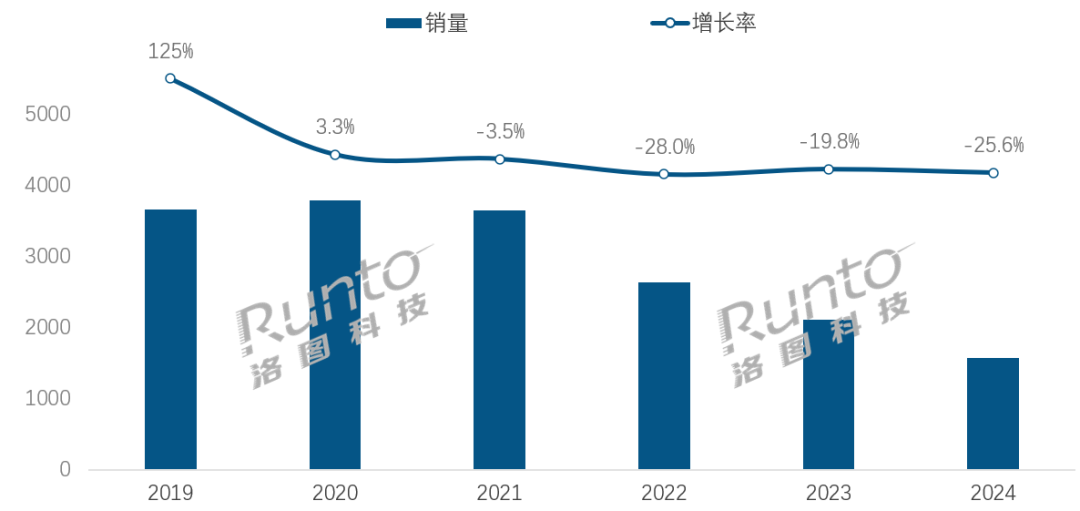
Di Era AI, Industri Speaker Pintar Menghadapi Tantangan dan Peluang Transformasi: Penjualan pasar speaker pintar Tiongkok menurun selama empat tahun berturut-turut, dengan penjualan tahun 2024 turun 25,6% YoY. Meskipun integrasi model besar AI (seperti Xiao Ai Tongxue, Xiaodu, dll.) dianggap sebagai harapan industri, dengan tingkat penetrasi melebihi 20%, hal ini belum secara fundamental menyelesaikan masalah keterbatasan ekosistem, homogenisasi fungsional, dan penggantian oleh perangkat pintar lain seperti ponsel. Analis industri berpendapat bahwa speaker pintar perlu melampaui sekadar menjadi pusat kontrol suara, dan berevolusi menjadi bentuk produk dengan layar besar definisi tinggi, kemampuan interaksi yang lebih kuat, mampu menyediakan fungsi pendampingan dan bimbingan belajar, serta memperluas ekosistem perangkat lunak dan keras. AI adalah nilai tambah, tetapi fungsionalitas dan kepraktisan produk itu sendiri lebih penting. (Sumber: 36氪)
Robot Hotel Berbasis AI: Evolusi dari Pengantar Makanan menjadi “Pejabat Operasional Cerdas”: Robot pengantar makanan hotel secara bertahap menjadi populer, terutama di kalangan generasi Z yang mengejar nuansa teknologi dan batasan privasi. Mengambil contoh Yunji Technology, robot pengantar makanannya telah banyak digunakan di pasar hotel Tiongkok. Namun, industri masih menghadapi masalah kurangnya diferensiasi teknologi, kemampuan adaptasi yang buruk terhadap skenario kompleks, dan masalah efektivitas biaya penggantian tenaga manusia oleh robot. Tren masa depan adalah robot “lebih dari sekadar pengantar makanan”, yang akan terintegrasi secara mendalam ke dalam operasi hotel, melalui koneksi dengan sistem hotel (lift, peralatan kamar), pemahaman preferensi tamu, pengumpulan dan analisis data interaksi, berevolusi menjadi “pejabat operasional cerdas” atau bagian dari platform data hotel yang dapat secara aktif merasakan dan menyediakan layanan yang dipersonalisasi, sehingga meningkatkan tingkat kecerdasan layanan secara keseluruhan. (Sumber: 36氪)

Krisis Struktur Tata Kelola OpenAI: Pertarungan antara Modal dan Misi Memicu Perenungan Mendalam tentang Jalur Pengembangan AI: Struktur unik OpenAI, di mana anak perusahaan nirlaba “laba terbatas” diawasi oleh organisasi nirlaba, bertujuan untuk menyeimbangkan pengembangan teknologi AI dengan kesejahteraan manusia. Namun, pertimbangan CEO Altman baru-baru ini untuk mengubah perusahaan menjadi entitas nirlaba yang lebih tradisional telah menimbulkan kekhawatiran di kalangan pakar AI dan ahli hukum. Mereka berpendapat bahwa langkah ini dapat membuat para pengambil keputusan penting tidak lagi memprioritaskan misi amal OpenAI, melemahkan batasan keuntungan bagi investor, dan berpotensi mengubah jadwal waktu dan arah pengembangan AGI. Pertarungan mengenai kontrol, distribusi keuntungan, serta pembentukan sosial dan moral AI ini, menyoroti tantangan dan celah yang dihadapi kerangka kerja tata kelola perusahaan yang ada di era perkembangan AI yang pesat. (Sumber: 36氪)