
Kata Kunci:AlphaEvolve, Gemini, Algoritma Evolusi, Agen Kecerdasan Buatan, Optimalisasi Algoritma, Perkalian Matriks, Pusat Data Borg, Optimalisasi Perkalian Matriks Kompleks 4×4, Penemuan Algoritma Google DeepMind, Desain Algoritma Otomatis AI, Aplikasi Gemini 2.0 Pro, Optimalisasi Penjadwalan Sumber Daya Borg
🔥 Fokus
Google DeepMind meluncurkan AlphaEvolve: agen pengkodean cerdas berbasis Gemini yang menggunakan algoritma evolusioner, mencapai terobosan di bidang matematika dan ilmu komputer: Google DeepMind merilis AlphaEvolve, sebuah agen yang memanfaatkan model bahasa besar Gemini 2.0 Pro untuk secara otomatis menemukan dan mengoptimalkan kode algoritma melalui algoritma evolusioner. AlphaEvolve mampu menghasilkan, mengevaluasi, dan meningkatkan solusi kandidat secara mandiri, dimulai dari kode awal dan metrik evaluasi yang disediakan oleh manusia. Sistem ini menunjukkan kinerja luar biasa pada lebih dari 50 masalah matematika, dengan sekitar 75% kasus berhasil mereproduksi solusi yang sudah diketahui, dan 20% kasus menemukan solusi yang lebih baik. Perlu dicatat, AlphaEvolve mengurangi jumlah komputasi untuk perkalian matriks kompleks 4×4 dari 49 menjadi 48, memecahkan rekor yang telah bertahan selama 56 tahun. Selain itu, ia juga mengoptimalkan algoritma penjadwalan untuk pusat data Borg internal Google, memulihkan 0,7% sumber daya komputasi global, dan meningkatkan desain chip TPU generasi berikutnya, sehingga mempersingkat waktu pelatihan Gemini sebesar 1%. Pencapaian ini menunjukkan potensi besar AI dalam penemuan algoritma otomatis dan inovasi ilmiah, meskipun saat ini terutama menangani masalah yang dapat dievaluasi secara otomatis, prospek aplikasinya di bidang ilmu terapan seperti penemuan obat sangat luas. (Sumber: , QbitAI, 36Kr)
NVIDIA di Computex 2025 merilis berbagai kemajuan AI, Jensen Huang menekankan visi Agentic AI dan Physical AI: CEO NVIDIA Jensen Huang menyampaikan pidato utama di Computex 2025, menekankan bahwa AI sedang berevolusi dari “respons tunggal” menjadi Agentic AI (AI agentif) yang “berpikir dan bernalar” serta Physical AI (AI fisik) yang memahami dunia fisik. Untuk mendukung tren ini, NVIDIA merilis platform Blackwell yang diperluas (Blackwell Ultra AI), dan mengumumkan bahwa sistem Grace Blackwell GB300 telah sepenuhnya masuk tahap produksi, dengan kinerja inferensi 1,5 kali lebih tinggi dari generasi sebelumnya. Jensen Huang juga memberikan pratinjau chip super AI generasi berikutnya, Rubin Ultra, yang kinerjanya 14 kali lipat dari GB300. Untuk mendorong pembangunan infrastruktur AI, NVIDIA meluncurkan teknologi NVLink Fusion, dan bekerja sama dengan TSMC, Foxconn, dan lainnya untuk membangun superkomputer AI di Taiwan, Tiongkok. Selain itu, NVIDIA memperbarui model dasar robot humanoid Isaac GR00T N1.5, meningkatkan kemampuan adaptasi lingkungan dan pelaksanaan tugasnya, serta berencana untuk membuka sumber mesin fisika Newton yang dikembangkan bersama DeepMind dan Disney Research. (Sumber: AI Frontline, QbitAI, Reddit r/artificial)
Tim OpenAI Codex AMA mengungkapkan rencana integrasi GPT-5 dan produk masa depan: Tim OpenAI Codex mengadakan sesi “Ask Me Anything” (AMA) di Reddit. Wakil Presiden Riset Jerry Tworek mengungkapkan bahwa tujuan model dasar generasi berikutnya, GPT-5, adalah untuk meningkatkan kemampuan model yang ada dan mengurangi kebutuhan untuk beralih antar model. Rencananya adalah mengintegrasikan alat yang ada seperti Codex, Operator (agen pelaksana tugas), Deep Research (alat penelitian mendalam), dan Memory (fungsi memori) untuk membentuk pengalaman asisten AI yang terpadu. Anggota tim juga berbagi tentang alasan awal pengembangan Codex (berasal dari refleksi internal tentang kurangnya pemanfaatan model), peningkatan efisiensi pemrograman sekitar 3 kali lipat yang dihasilkan dari penggunaan Codex secara internal, dan pandangan tentang masa depan rekayasa perangkat lunak—mengubah kebutuhan menjadi perangkat lunak yang dapat dijalankan secara efisien dan andal. Codex saat ini terutama memanfaatkan informasi yang dimuat ke runtime kontainer, dan di masa depan mungkin akan menggabungkan teknologi RAG untuk mendapatkan pengetahuan terbaru. OpenAI juga sedang menjajaki skema harga yang fleksibel dan berencana untuk menyediakan kredit API gratis bagi pengguna Plus/Pro untuk digunakan dengan Codex CLI. (Sumber: 36Kr)
VS Code mengumumkan open source ekstensi GitHub Copilot Chat, berencana membangun platform penyuntingan kode AI open source: Tim Visual Studio Code mengumumkan rencana untuk mengembangkan VS Code menjadi editor AI open source, dengan berpegang pada prinsip inti keterbukaan, kolaborasi, dan berbasis komunitas. Sebagai bagian dari rencana ini, ekstensi GitHub Copilot Chat telah di-open source-kan di GitHub dengan lisensi MIT. Di masa depan, VS Code berencana untuk secara bertahap mengintegrasikan fitur-fitur AI ini ke dalam inti editor, dengan tujuan membangun platform penyuntingan kode AI yang sepenuhnya open source dan digerakkan oleh komunitas, untuk meningkatkan efisiensi pengembangan, transparansi, dan keamanan. Langkah ini dianggap sebagai langkah penting Microsoft di bidang open source dan dapat memiliki dampak besar pada ekosistem alat pemrograman berbantuan AI. (Sumber: dotey, jeremyphoward)
Huawei Ascend bekerja sama dengan DeepSeek, kinerja inferensi model MoE melampaui NVIDIA Hopper: Huawei Ascend mengumumkan bahwa super-node CloudMatrix 384 dan server inferensi Atlas 800I A2 miliknya telah mencapai terobosan signifikan dalam kinerja inferensi saat menjalankan model MoE skala ultra-besar seperti DeepSeek V3/R1, melampaui arsitektur NVIDIA Hopper dalam kondisi tertentu. Super-node CloudMatrix 384 mencapai throughput Decode per kartu lebih dari 1920 Tokens/s pada latensi 50ms, sementara Atlas 800I A2 mencapai throughput per kartu 808 Tokens/s pada latensi 100ms. Huawei mengaitkan hal ini dengan strategi “melengkapi fisika dengan matematika”, yaitu mengatasi keterbatasan proses perangkat keras melalui optimasi algoritma dan sistem. Laporan teknis terkait telah dirilis, dan kode inti akan di-open source-kan dalam waktu satu bulan. Langkah-langkah optimasi termasuk solusi paralelisasi expert untuk model MoE, deployment terpisah PD, adaptasi kerangka kerja vLLM, strategi kuantisasi A8W8C16, serta skema komunikasi FlashComm, konversi paralelisasi intra-layer, mesin inferensi spekulatif FusionSpec, dan optimasi afinitas perangkat keras untuk operator MLA/MoE. (Sumber: QbitAI, WeChat)
🎯 Dinamika
Apple membuka sumber model bahasa visual efisien FastVLM, mengoptimalkan pengalaman AI di perangkat: Apple Inc. membuka sumber FastVLM (Fast Vision Language Model), sebuah model bahasa visual yang dirancang khusus untuk berjalan secara efisien di perangkat edge seperti iPhone. FastVLM memperkenalkan encoder visual hibrida baru FastViTHD, yang menggabungkan lapisan konvolusional dengan modul Transformer, dan menggunakan teknik pooling multi-skala serta downsampling, sehingga secara signifikan mengurangi jumlah token visual yang diperlukan untuk pemrosesan gambar (16 kali lebih sedikit dari ViT tradisional). Hal ini memungkinkan model untuk mempertahankan akurasi tinggi sekaligus meningkatkan kecepatan output token pertama (TTFT) hingga 85 kali lipat dibandingkan model sejenis. FastVLM kompatibel dengan LLM utama dan mudah diadaptasi ke ekosistem iOS/Mac, menyediakan tiga versi parameter (0.5B, 1.5B, 7B) yang cocok untuk berbagai tugas teks-gambar real-time seperti deskripsi gambar, tanya jawab, dan analisis. (Sumber: WeChat)
Meta merilis model KernelLLM 8B, melampaui GPT-4o dalam benchmark tertentu: Meta merilis model KernelLLM 8B di Hugging Face. Dilaporkan bahwa dalam benchmark KernelBench-Triton Level 1, model dengan 8 miliar parameter ini melampaui model skala lebih besar seperti GPT-4o dan DeepSeek V3 dalam kinerja inferensi tunggal. Dalam kasus inferensi ganda, kinerja KernelLLM juga lebih unggul dari DeepSeek R1. Rilisan ini menarik perhatian komunitas AI dan dianggap sebagai contoh lain dari model berukuran sedang hingga kecil yang menunjukkan daya saing kuat pada tugas-tugas tertentu. (Sumber: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Model Mistral Medium 3 menunjukkan kinerja kuat di Arena, terutama menonjol di bidang teknis: Model Mistral Medium 3 yang baru diluncurkan oleh Mistral AI menunjukkan kinerja luar biasa dalam evaluasi komunitas di lmarena.ai, menempati peringkat ke-11 secara keseluruhan dalam kemampuan percakapan, dengan peningkatan signifikan dibandingkan Mistral Large (skor Elo meningkat 90 poin). Model ini sangat menonjol di bidang teknis, dengan kemampuan matematika menempati peringkat ke-5, kemampuan prompt kompleks dan pengkodean menempati peringkat ke-7, dan peringkat ke-9 di WebDev Arena. Komentar komunitas menganggap kinerjanya di bidang teknis mendekati level GPT-4.1, sementara biayanya mungkin lebih kompetitif, mirip dengan harga GPT-4.1 mini. Pengguna dapat mencoba model ini secara gratis di antarmuka obrolan resmi Mistral. (Sumber: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets menambahkan fitur untuk melihat percakapan obrolan secara langsung: Platform Hugging Face Datasets melakukan pembaruan penting, di mana pengguna sekarang dapat langsung membaca konten percakapan obrolan dalam dataset. Fitur ini dianggap oleh anggota komunitas (seperti Caleb, Maxime Labonne) sebagai langkah besar dalam mengatasi masalah kualitas data, karena melihat data percakapan asli secara langsung membantu dalam pemahaman data yang lebih baik, pembersihan data, dan peningkatan efektivitas pelatihan model. Sebelumnya, melihat konten percakapan spesifik mungkin memerlukan kode atau alat tambahan; fitur baru ini menyederhanakan proses tersebut, meningkatkan kemudahan dan transparansi dalam pekerjaan data. (Sumber: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM terintegrasi dengan Hugging Face Hub, menyederhanakan menjalankan model secara lokal di Mac: MLX LM kini terintegrasi langsung dengan Hugging Face Hub, memungkinkan pengguna Mac untuk lebih mudah menjalankan lebih dari 4400 LLM secara lokal di perangkat Apple Silicon. Pengguna hanya perlu mengklik “Use this model” di halaman model yang kompatibel di Hugging Face Hub untuk menjalankan model dengan cepat di terminal, tanpa konfigurasi cloud yang rumit atau waktu tunggu. Selain itu, server yang kompatibel dengan OpenAI juga dapat diluncurkan langsung dari halaman model. Integrasi ini bertujuan untuk menurunkan hambatan dalam menjalankan model secara lokal, serta meningkatkan efisiensi pengembangan dan eksperimen. (Sumber: awnihannun, ClementDelangue, huggingface, reach_vb)
NVIDIA membuka sumber model inferensi Physical AI Cosmos-Reason1-7B: NVIDIA membuka sumber Cosmos-Reason1-7B, salah satu model dari seri Physical AI mereka, di Hugging Face. Model ini dirancang untuk memahami akal sehat dunia fisik dan menghasilkan keputusan yang sesuai untuk interaksi fisik. Ini menandai langkah baru NVIDIA dalam mendorong integrasi dunia fisik dengan AI, menyediakan alat dan dasar penelitian baru untuk aplikasi seperti robotika dan kendaraan otonom yang memerlukan interaksi dengan lingkungan fisik. (Sumber: reach_vb)
Model generasi video Baidu Steamer-I2V menduduki puncak daftar VBench untuk kategori gambar-ke-video: Model generasi video Baidu, Steamer-I2V, menempati peringkat pertama dalam kategori gambar-ke-video (I2V) di daftar evaluasi generasi video otoritatif VBench, dengan skor total 89,38%, melampaui model terkenal seperti OpenAI Sora dan Google Imagen Video. Keunggulan teknis Steamer-I2V meliputi kontrol presisi gambar tingkat piksel, pergerakan kamera tingkat master, kualitas gambar definisi tinggi sinematik hingga 1080P dan estetika dinamis, serta pemahaman semantik bahasa Mandarin yang akurat berdasarkan database multimodal berbahasa Mandarin tingkat miliaran. Pencapaian ini menunjukkan kekuatan Baidu di bidang generasi multimodal dan merupakan bagian dari strateginya untuk membangun ekosistem konten AI. (Sumber: 36Kr)

LLM menunjukkan kinerja buruk dalam tugas terkait waktu seperti membaca jam dan kalender: Peneliti dari Universitas Edinburgh dan institusi lainnya menemukan bahwa meskipun model bahasa besar (LLM) dan model bahasa besar multimodal (MLLM) menunjukkan kinerja luar biasa dalam berbagai tugas, akurasinya dalam tugas membaca waktu yang tampaknya sederhana (seperti mengenali waktu pada jam analog dan memahami tanggal kalender) sangat mengkhawatirkan. Penelitian ini membangun dua set tes khusus, ClockQA dan CalendarQA, dan hasilnya menunjukkan bahwa akurasi sistem AI dalam membaca jam hanya 38,7%, dan akurasi dalam menentukan tanggal kalender hanya 26,3%. Bahkan model canggih seperti Gemini-2.0 dan GPT-o1 mengalami kesulitan yang jelas, terutama dalam menangani angka Romawi, jarum jam bergaya, atau perhitungan tanggal yang rumit (seperti tahun kabisat, hari apa pada tanggal tertentu). Peneliti berpendapat bahwa ini mengungkap kekurangan model saat ini dalam penalaran spasial, analisis tata letak terstruktur, dan kemampuan generalisasi terhadap pola yang tidak umum. (Sumber: 36Kr, WeChat)

Microsoft di konferensi Build mengumumkan akan membawa model Grok ke Azure AI Foundry: Pada konferensi pengembang Microsoft Build 2025, Microsoft mengumumkan bahwa model Grok dari perusahaan xAI akan bergabung dengan jajaran model Azure AI Foundry mereka. Pengguna dapat mencoba Grok-3 dan Grok-3-mini secara gratis di Azure Foundry dan GitHub hingga awal Juni. Langkah ini berarti Azure AI Foundry akan semakin memperluas jangkauan model pihak ketiga yang didukungnya, dan di masa depan pengguna akan dapat menggunakan model dari berbagai vendor seperti OpenAI, xAI, DeepSeek, Meta, Mistral AI, Black Forest Labs melalui throughput terpesan yang terpadu. (Sumber: TheTuringPost, xai)
Apple dilaporkan berencana mengizinkan pengguna iPhone di Uni Eropa mengganti Siri dengan asisten suara pihak ketiga: Menurut Mark Gurman, Apple Inc. berencana untuk pertama kalinya mengizinkan pengguna iPhone di wilayah Uni Eropa untuk mengganti Siri dengan asisten suara pihak ketiga. Langkah ini kemungkinan diambil untuk menanggapi persyaratan regulasi pasar digital yang semakin ketat di Uni Eropa, yang bertujuan untuk meningkatkan keterbukaan platform dan pilihan pengguna. Jika rencana ini terwujud, hal ini akan berdampak signifikan pada lanskap pasar asisten suara, memberikan kesempatan bagi asisten suara lain untuk masuk ke ekosistem Apple. (Sumber: zacharynado)

Meta merilis dataset Open Molecules 2025 dan model UMA, mempercepat penemuan molekul dan material: Meta AI merilis Open Molecules 2025 (OMol25) dan Meta Universal Atomic model (UMA). OMol25 adalah dataset perhitungan kimia kuantum presisi tinggi terbesar dan paling beragam saat ini, mencakup biomolekul, kompleks logam, dan elektrolit. UMA adalah model potensial antar-atom berbasis machine learning yang dilatih pada lebih dari 30 miliar atom, yang bertujuan untuk memberikan prediksi perilaku molekul yang lebih akurat. Pembukaan sumber alat-alat ini bertujuan untuk mempercepat penemuan dan inovasi dalam ilmu molekuler dan material. (Sumber: AIatMeta)
Hugging Face Datasets menambahkan fitur pengeditan inkremental untuk file Parquet: Hugging Face Datasets mengumumkan bahwa versi nightly dari pustaka dependensi dasarnya, PyArrow, kini mendukung pengeditan inkremental pada file Parquet tanpa perlu menulis ulang file secara keseluruhan. Fitur baru ini akan sangat meningkatkan efisiensi operasi dataset skala besar, terutama ketika pembaruan atau modifikasi sebagian data sering diperlukan, karena dapat secara signifikan mengurangi waktu dan konsumsi sumber daya komputasi. Langkah ini diharapkan dapat meningkatkan pengalaman pengembang dalam menangani dan memelihara dataset pelatihan AI yang besar. (Sumber: huggingface)
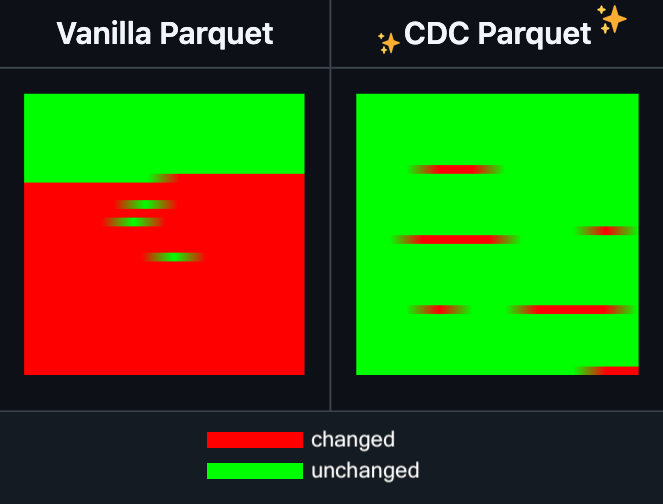
LangGraph menambahkan fitur caching tingkat node, meningkatkan efisiensi alur kerja: LangGraph mengumumkan bahwa versi open source-nya kini menambahkan fitur caching untuk node/tugas. Fitur ini bertujuan untuk mempercepat alur kerja dengan menghindari komputasi berulang, terutama berguna untuk alur kerja agen (Agent) yang berisi bagian umum atau memerlukan debugging yang sering. Pengguna dapat menggunakan caching dalam API imperatif atau API grafis, sehingga dapat melakukan iterasi dan mengoptimalkan aplikasi AI mereka dengan lebih cepat. Ini adalah pembaruan pertama dalam seri rilis open source LangGraph minggu ini. (Sumber: hwchase17)

Sakana AI memperkenalkan arsitektur AI baru “Continuous Thought Machines” (CTM): Perusahaan rintisan AI asal Tokyo, Sakana AI, merilis arsitektur model AI baru yang disebut “Continuous Thought Machines” (CTM). CTM bertujuan agar model dapat melakukan penalaran seperti otak manusia, dengan lebih sedikit panduan. Arsitektur baru ini mungkin menawarkan ide-ide baru untuk mengatasi tantangan yang dihadapi model AI saat ini dalam penalaran kompleks dan pembelajaran mandiri. (Sumber: dl_weekly)
Microsoft dan NVIDIA memperdalam kerja sama RTX AI PC, TensorRT hadir di Windows ML: Selama Microsoft Build dan COMPUTEX Taipei, NVIDIA dan Microsoft mengumumkan kemajuan lebih lanjut dalam kerja sama pengembangan RTX AI PC. Pustaka optimasi inferensi TensorRT dari NVIDIA telah dirancang ulang dan diintegrasikan ke dalam tumpukan inferensi baru Microsoft, Windows ML. Langkah ini bertujuan untuk menyederhanakan proses pengembangan aplikasi AI dan memanfaatkan sepenuhnya kinerja puncak GPU RTX dalam tugas AI di PC, mendorong普及 dan aplikasi AI pada perangkat komputasi pribadi. (Sumber: nvidia)
Bilibili membuka sumber model generasi video animasi Index-AniSora, beberapa metrik mencapai SOTA: Bilibili mengumumkan pembukaan sumber model generasi video animasi yang dikembangkannya sendiri, Index-AniSora, yang dipresentasikan di IJCAI 2025. AniSora dirancang khusus untuk generasi video bergaya anime, mendukung berbagai gaya seperti serial anime, animasi Tiongkok, dan adaptasi manga. Model ini mampu melakukan kontrol halus seperti panduan area lokal video, panduan temporal (misalnya, panduan frame pertama/terakhir, interpolasi keyframe). Konten open source proyek ini mencakup kode pelatihan dan inferensi untuk AniSoraV1.0 berbasis CogVideoX-5B dan AniSoraV2.0 berbasis Wan2.1-14B, alat pembuatan dataset pelatihan, sistem Benchmark khusus animasi, dan model AniSoraV1.0_RL yang dioptimalkan menggunakan reinforcement learning from human preference. (Sumber: WeChat)

Tencent Hunyuan membuka sumber model reward multimodal terpadu pertama UnifiedReward-Think: Tencent Hunyuan, bekerja sama dengan Shanghai AI Lab, Universitas Fudan, dan institusi lainnya, mengusulkan UnifiedReward-Think, model reward multimodal terpadu pertama yang memiliki kemampuan penalaran rantai panjang (CoT). Model ini bertujuan agar model reward “belajar berpikir” saat mengevaluasi tugas generasi dan pemahaman visual yang kompleks, sehingga meningkatkan akurasi evaluasi, kemampuan generalisasi lintas tugas, dan interpretabilitas penalaran. Proyek ini telah sepenuhnya di-open source-kan, termasuk model, dataset, skrip pelatihan, dan alat evaluasi. (Sumber: WeChat)
Alibaba membuka sumber model generasi dan penyuntingan video Tongyi Wanxiang Wan2.1-VACE: Alibaba secara resmi membuka sumber model generasi dan penyuntingan videonya, Tongyi Wanxiang Wan2.1-VACE. Model ini memiliki berbagai fungsi seperti text-to-video, image-referenced video generation, video repainting, video local editing, video background extension, dan video duration extension. Kali ini, dua versi telah di-open source-kan, yaitu 1.3B dan 14B, di mana versi 1.3B dapat berjalan pada kartu grafis kelas konsumen, bertujuan untuk menurunkan hambatan dalam pembuatan video AIGC. (Sumber: WeChat)
ByteDance merilis model bahasa visual Seed1.5-VL, memimpin dalam berbagai benchmark: ByteDance membangun model bahasa visual Seed1.5-VL, yang terdiri dari encoder visual 532M parameter dan LLM mixture-of-experts (MoE) dengan 20B parameter aktif. Meskipun arsitekturnya relatif ringkas, model ini mencapai kinerja SOTA pada 38 dari 60 benchmark publik, dan melampaui model seperti OpenAI CUA dan Claude 3.7 pada tugas-tugas yang berpusat pada agen seperti kontrol GUI dan gameplay, menunjukkan kemampuan penalaran multimodal yang kuat. (Sumber: WeChat)
MiniMax meluncurkan model TTS autoregresif MiniMax-Speech, mendukung kloning suara zero-shot dalam 32 bahasa: MiniMax mengusulkan model text-to-speech (TTS) autoregresif berbasis Transformer, MiniMax-Speech. Model ini dapat mengekstrak fitur timbre dari audio referensi tanpa transkripsi, menghasilkan ucapan yang konsisten dengan timbre referensi dan ekspresif secara zero-shot, serta mendukung kloning suara single-sample. Dengan teknologi Flow-VAE, kualitas audio sintetis ditingkatkan, dan mendukung 32 bahasa. Model ini mencapai tingkat SOTA pada metrik kloning suara objektif, menduduki peringkat teratas di daftar TTS Arena publik, dan dapat diperluas untuk aplikasi seperti kontrol emosi suara, text-to-sound, dan kloning suara profesional. (Sumber: WeChat)
OuteTTS 1.0 (0.6B) dirilis, model TTS open source Apache 2.0 yang mendukung 14 bahasa: OuteAI merilis OuteTTS-1.0-0.6B, sebuah model text-to-speech (TTS) ringan yang dibangun di atas Qwen-3 0.6B. Model ini menggunakan lisensi Apache 2.0 dan mendukung 14 bahasa termasuk Mandarin, Inggris, Jepang, dan Korea. Pustaka inferensi Python-nya, OuteTTS v0.4.2, diperbarui untuk mendukung inferensi batch asinkron EXL2, inferensi batch eksperimental vLLM, serta continuous batching dan inferensi model URL eksternal untuk server Llama.cpp. Benchmark pada GPU NVIDIA L40S tunggal menunjukkan bahwa vLLM OuteTTS-1.0-0.6B FP8 dapat mencapai RTF (real-time factor) 0,05 pada ukuran batch 32. Bobot model (ST, GGUF, EXL2, FP8) telah tersedia di Hugging Face. (Sumber: Reddit r/LocalLLaMA)

Hugging Face dan Microsoft Azure memperdalam kerja sama, lebih dari 10.000 model open source hadir di Azure AI Foundry: Pada konferensi Microsoft Build, CEO Satya Nadella mengumumkan perluasan kerja sama dengan Hugging Face. Saat ini, lebih dari 11.000 model open source paling populer telah tersedia melalui Hugging Face di Azure AI Foundry, memudahkan pengguna untuk melakukan deployment. Langkah ini semakin memperkaya ekosistem AI Azure, memberikan lebih banyak pilihan model dan pengalaman pengembangan yang lebih mudah bagi para pengembang. (Sumber: ClementDelangue, _akhaliq)

Intel merilis GPU seri Arc Pro B50/B60, menargetkan pasar AI dan workstation, versi 24GB sekitar $500: Intel di Computex merilis kartu grafis profesional seri Arc Pro B baru, termasuk Arc Pro B50 (VRAM 16GB, sekitar $299) dan Arc Pro B60 (VRAM 24GB, sekitar $500). Di antaranya, solusi workstation “Project Battlematrix” yang terdiri dari dua GPU B60 dengan total VRAM 48GB juga turut dipamerkan, dengan perkiraan harga di bawah $1000. Produk-produk ini bertujuan untuk menyediakan solusi hemat biaya untuk komputasi AI dan workstation profesional, terutama konfigurasi VRAM tinggi yang menarik untuk menjalankan model bahasa besar secara lokal. Produk baru ini diperkirakan akan tersedia pada Q3 tahun ini, awalnya melalui produsen OEM, dan versi DIY mungkin akan diluncurkan pada Q4. (Sumber: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 Alat
Moondream Station merilis versi Linux, menyederhanakan menjalankan Moondream secara lokal: Moondream Station, sebuah alat yang bertujuan untuk menyederhanakan menjalankan Moondream (model bahasa visual) di perangkat lokal, kini mengumumkan dukungan untuk sistem operasi Linux. Ini berarti pengguna Linux dapat lebih mudah melakukan deployment dan menggunakan model Moondream untuk eksperimen AI multimodal dan pengembangan aplikasi. (Sumber: vikhyatk)
Flowith merilis agen cerdas tak terbatas NEO, mendukung langkah, konteks, dan pemanggilan alat tak terbatas: Perusahaan aplikasi AI Flowith merilis produk agen cerdas terbarunya, NEO, yang diklaim sebagai agen pertama di dunia yang mendukung langkah tak terbatas, konteks tak terbatas, dan pemanggilan alat tak terbatas. Agen ini dirancang untuk berjalan dalam waktu lama di cloud, memiliki tingkat kecerdasan yang melampaui benchmark, dan diklaim tanpa biaya serta tanpa batasan. Rilisan ini mungkin mewakili kemajuan baru dalam kemampuan agen AI untuk menangani tugas jangka panjang yang kompleks dan mengintegrasikan kemampuan eksternal. (Sumber: _akhaliq, op7418)

Kapa AI menggunakan Weaviate untuk membangun alat tanya jawab dokumen teknis interaktif “Ask AI”: Kapa AI mengembangkan widget cerdas bernama “Ask AI” yang memungkinkan pengguna untuk menanyakan seluruh basis pengetahuan teknis seperti dokumentasi teknis, blog, tutorial, isu GitHub, dan forum melalui percakapan bahasa alami. Untuk mencapai pencarian semantik dan pengambilan pengetahuan yang efisien, Kapa AI menggunakan database vektor Weaviate, dengan mempertimbangkan kemampuan pencarian hibrida bawaannya, kompatibilitas Docker, dan fitur multi-tenant untuk mendukung pertumbuhan pengguna dan skala data yang cepat. (Sumber: bobvanluijt)

Pengembang menggunakan Gemini Flash untuk membangun alat MVP pengubah tangkapan layar menjadi HTML dengan cepat: Pengembang Daniel Huynh menggunakan model Gemini Flash dari Google AI untuk membangun alat MVP (Minimum Viable Product) dalam satu akhir pekan, yang dapat mengubah tangkapan layar desain, produk pesaing, atau inspirasi menjadi kode HTML dengan cepat. Alat ini telah tersedia untuk dicoba secara gratis di Hugging Face Spaces, menunjukkan potensi model multimodal dalam membantu pengembangan front-end. (Sumber: osanseviero, _akhaliq)
Azure AI Foundry Agent Service resmi tersedia, terintegrasi dengan LlamaIndex: Microsoft mengumumkan bahwa Azure AI Foundry Agent Service telah resmi dirilis (GA) dan menyediakan dukungan kelas satu untuk LlamaIndex. Layanan ini bertujuan untuk membantu pelanggan perusahaan membangun asisten dukungan pelanggan, bot otomatisasi proses, sistem multi-agen, serta solusi yang terintegrasi secara aman dengan data dan alat perusahaan, lebih lanjut mendorong pengembangan dan penerapan agen AI tingkat perusahaan. (Sumber: jerryjliu0)
tinygrad: sebuah kerangka kerja deep learning minimalis di antara PyTorch dan micrograd: tinygrad adalah kerangka kerja deep learning yang dirancang dengan kesederhanaan sebagai inti filosofinya, bertujuan untuk menjadi kerangka kerja yang paling mudah untuk menambahkan akselerator baru, mendukung inferensi dan pelatihan. Ia mendukung model seperti LLaMA dan Stable Diffusion, dan menggunakan evaluasi malas (lazy evaluation) untuk menggabungkan operasi dan mengoptimalkan kinerja. tinygrad mendukung berbagai akselerator seperti GPU (OpenCL), CPU (kode C), LLVM, Metal, CUDA. Kodenya ringkas, dengan fungsi inti diimplementasikan dalam sejumlah kecil kode, memudahkan pengembang untuk memahami dan memperluasnya. (Sumber: GitHub Trending)
Nano AI Search meluncurkan fitur “Super Search”, mengintegrasikan multi-model dan kotak alat MCP: Nano AI Search (bot.n.cn) menambahkan fitur “Super Search” yang bertujuan untuk menyediakan kemampuan perolehan dan pemrosesan informasi yang lebih mendalam. Fitur ini mengintegrasikan ratusan model besar dari dalam dan luar negeri, dan dapat beralih secara otomatis sesuai kebutuhan; dilengkapi dengan kotak alat serbaguna MCP, mendukung ribuan alat AI, dapat memproses berbagai format file seperti halaman web, gambar, video, PDF, dan melakukan pembuatan kode, analisis data, dll. Selain itu, ia menggabungkan pencarian domain publik dengan pencarian domain pribadi dari basis pengetahuan lokal untuk memberikan hasil yang lebih komprehensif, dan memiliki kemampuan text-to-image serta text-to-video bawaan. Pengalaman pengguna menunjukkan bahwa fitur ini dapat mengatur hasil pencarian menjadi laporan terperinci yang berisi grafik dan halaman web yang menarik, cocok untuk berbagai skenario seperti riset industri, perbandingan belanja, dan penataan pengetahuan. (Sumber: WeChat)
Clara: ruang kerja AI offline modular, mengintegrasikan LLM, Agen, otomatisasi, dan generasi gambar: Pengembang meluncurkan proyek open source bernama Clara, yang bertujuan untuk menciptakan ruang kerja AI yang sepenuhnya offline dan modular. Pengguna dapat mengatur obrolan LLM lokal (mendukung RAG, gambar, dokumen, eksekusi kode, kompatibel dengan Ollama dan API sejenis OpenAI) dalam bentuk widget di dasbor, membuat Agen dengan memori dan logika, menjalankan alur kerja otomatisasi melalui integrasi N8N asli (menyediakan 1000+ templat gratis), dan menggunakan Stable Diffusion (ComfyUI) untuk menghasilkan gambar secara lokal. Clara menyediakan versi Mac, Windows, Linux, bertujuan untuk mengatasi masalah pengguna yang sering beralih antar berbagai alat AI, mewujudkan operasi AI satu atap. (Sumber: Reddit r/LocalLLaMA)
AI Playlist Curator: Alat Python yang memanfaatkan LLM untuk mengatur daftar putar YouTube secara personal: Seorang pengembang menciptakan proyek Python bernama AI Playlist Curator, yang bertujuan untuk membantu pengguna mengatur daftar putar YouTube mereka yang besar dan tidak teratur secara otomatis. Alat ini menggunakan LLM untuk mengklasifikasikan lagu berdasarkan preferensi pengguna dan membuat sub-daftar putar yang dipersonalisasi, mendukung pemrosesan daftar putar yang disimpan dan lagu yang disukai. Proyek ini telah di-open source-kan di GitHub, dan pengembang berharap mendapatkan umpan balik komunitas untuk perbaikan lebih lanjut. (Sumber: Reddit r/MachineLearning)
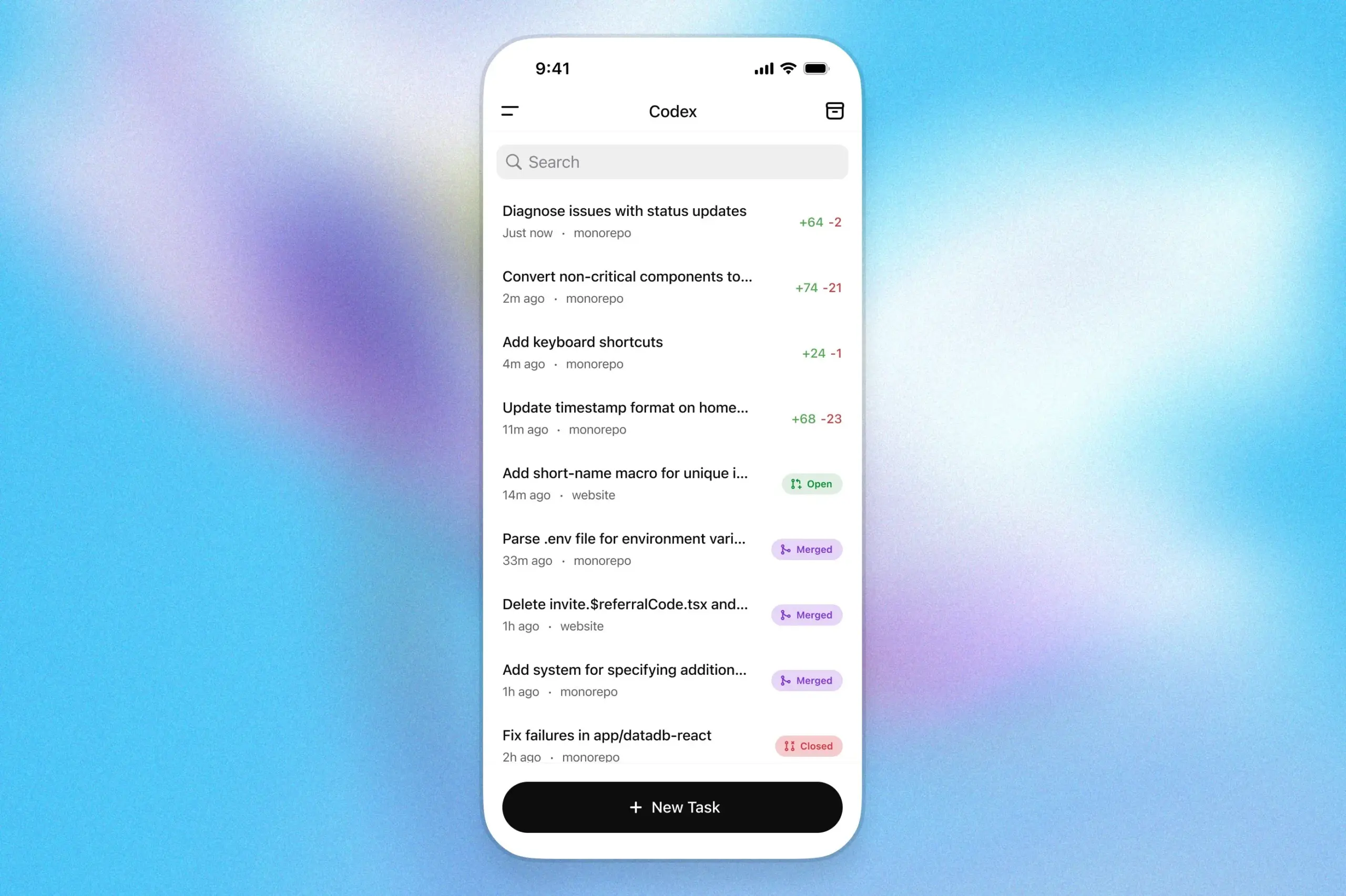
Asisten pemrograman OpenAI Codex hadir di aplikasi ChatGPT iOS: OpenAI mengumumkan bahwa asisten pemrogramannya, Codex, kini telah terintegrasi ke dalam aplikasi ChatGPT untuk iOS. Pengguna dapat memulai tugas pemrograman baru, melihat perbedaan kode, meminta modifikasi, bahkan mengirimkan pull request (PR) melalui perangkat seluler mereka. Fitur ini juga mendukung pelacakan kemajuan Codex secara real-time melalui aktivitas layar kunci, memudahkan pengguna untuk beralih pekerjaan antar perangkat dengan lancar. (Sumber: openai)
Kollektiv: Alat yang memanfaatkan protokol MCP untuk mengatasi masalah penyalinan konteks berulang dalam obrolan LLM: Pengembang meluncurkan alat Kollektiv, yang bertujuan untuk mengatasi masalah pengguna yang perlu berulang kali menyalin dan menempelkan konteks besar (seperti makalah penelitian, dokumentasi SDK, catatan pribadi, konten buku) saat mengobrol dengan LLM (seperti Claude). Kollektiv memungkinkan pengguna untuk mengunggah sumber dokumen ini sekali, dan kemudian memanggilnya sesuai kebutuhan dari IDE atau klien MCP yang kompatibel (seperti Cursor, Windsurf, PyCharm, dll.) melalui server MCP (Model Control Protocol). Server MCP bertanggung jawab atas otentikasi pengguna, isolasi data, dan streaming data sesuai permintaan ke antarmuka obrolan. Alat ini saat ini tidak disarankan untuk materi sensitif atau rahasia. (Sumber: Reddit r/ClaudeAI)
📚 Belajar
Google DeepMind merilis laporan teknis AlphaEvolve, mengungkap kemampuan penemuan algoritmanya: Google DeepMind merilis laporan teknis tentang sistem AI-nya, AlphaEvolve. AlphaEvolve adalah agen pengkodean berbasis Gemini yang mampu merancang dan mengoptimalkan algoritma melalui algoritma evolusioner. Laporan tersebut merinci bagaimana AlphaEvolve secara mandiri menghasilkan, mengevaluasi, dan meningkatkan proposal algoritma kandidat melalui siklus umpan balik terstruktur, sehingga mencapai terobosan dalam berbagai masalah matematika dan ilmu komputasi, termasuk memecahkan rekor algoritma perkalian matriks kompleks 4×4. Laporan ini memberikan referensi penting untuk memahami potensi AI dalam penemuan ilmiah otomatis dan inovasi algoritma. (Sumber: , HuggingFace Daily Papers)
DeepLearning.AI meluncurkan kursus “Building AI Browser Agents”: DeepLearning.AI meluncurkan kursus baru berjudul “Building AI Browser Agents”. Kursus ini diajarkan oleh salah satu pendiri AGI, Div Garg dan Naman Agarwal, dan bertujuan untuk membantu peserta didik menguasai teknologi pembuatan agen AI (Agent) yang dapat berinteraksi dengan browser. Materi kursus kemungkinan mencakup otomatisasi web, ekstraksi informasi, interaksi antarmuka pengguna, dan aplikasi AI lainnya dalam lingkungan browser. (Sumber: DeepLearningAI)
Laporan teknis Qwen3 dirilis: Alibaba merilis laporan teknis untuk model bahasa besar generasi terbarunya, Qwen3. Laporan ini merinci arsitektur model Qwen3, metode pelatihan, evaluasi kinerja, dan performanya dalam berbagai benchmark. Seri model Qwen3 bertujuan untuk menyediakan kemampuan pemahaman bahasa, generasi, dan pemrosesan multimodal yang lebih kuat. Rilis laporan teknis ini memberikan kesempatan bagi peneliti dan pengembang untuk memahami detail teknis model ini secara mendalam. (Sumber: _akhaliq)

Diskusi Makalah: Pencarian Multi-Perspektif dan Manajemen Data Meningkatkan Pembuktian Teorema Bertahap (MPS-Prover): Sebuah makalah baru memperkenalkan MPS-Prover, sebuah sistem pembuktian teorema otomatis (ATP) bertahap yang inovatif. Sistem ini mengatasi masalah panduan pencarian yang bias pada pembukti bertahap yang ada melalui strategi manajemen data pasca-pelatihan yang efisien (memangkas sekitar 40% data redundan tanpa mengorbankan kinerja) dan mekanisme pencarian pohon multi-perspektif (mengintegrasikan model kritikus yang dipelajari dengan aturan heuristik). Eksperimen menunjukkan bahwa MPS-Prover mencapai kinerja SOTA pada beberapa benchmark seperti miniF2F dan ProofNet, menghasilkan bukti yang lebih pendek dan lebih beragam. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Perencanaan Visual—Berpikir Hanya dengan Gambar (Visual Planning): Sebuah makalah baru mengusulkan paradigma “perencanaan visual”, yang memungkinkan model untuk merencanakan sepenuhnya melalui representasi visual (urutan gambar), bukan bergantung pada teks. Peneliti berpendapat bahwa dalam tugas yang melibatkan informasi spasial dan geometris, bahasa mungkin bukan media penalaran yang paling alami. Mereka memperkenalkan kerangka kerja perencanaan visual melalui reinforcement learning, VPRL, dan menggunakan GRPO untuk optimasi pasca-pelatihan pada model visual besar, mencapai peningkatan signifikan dalam tugas navigasi visual seperti FrozenLake, Maze, dan MiniBehavior, serta mengungguli varian perencanaan yang murni berbasis penalaran teks. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Peningkatan Penalaran dapat Meningkatkan Faktualistas Model Bahasa Besar (Scaling Reasoning can Improve Factuality): Sebuah penelitian mengeksplorasi apakah perluasan proses penalaran model bahasa besar (LLM) dapat meningkatkan akurasi faktualnya dalam tanya jawab domain terbuka yang kompleks (QA). Peneliti mengekstrak jejak penalaran dari model seperti QwQ-32B dan DeepSeek-R1-671B, dan melakukan fine-tuning pada berbagai model seri Qwen2.5, sambil mengintegrasikan jalur grafik pengetahuan ke dalam jejak penalaran. Eksperimen menunjukkan bahwa dalam sekali jalan, model penalaran yang lebih kecil menunjukkan peningkatan akurasi faktual yang signifikan dibandingkan model fine-tuning instruksi asli. Dengan meningkatkan komputasi saat pengujian dan anggaran token, akurasi faktual dapat meningkat secara stabil sebesar 2-8%. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Mergenetic—Pustaka Penggabungan Model Evolusioner Sederhana: Sebuah makalah baru memperkenalkan Mergenetic, sebuah pustaka open-source untuk penggabungan model evolusioner. Penggabungan model memungkinkan kemampuan model yang ada untuk digabungkan menjadi model baru tanpa pelatihan tambahan. Mergenetic mendukung kombinasi metode penggabungan dan algoritma evolusioner dengan mudah, dan menggabungkan evaluator kebugaran ringan untuk mengurangi biaya evaluasi. Eksperimen membuktikan bahwa Mergenetic dapat menghasilkan hasil yang kompetitif pada berbagai tugas dan bahasa menggunakan perangkat keras yang sederhana. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Group Think—Agen Penalaran Multi-Konkuren Berkolaborasi pada Tingkat Token (Group Think): Sebuah makalah baru mengusulkan “Group Think”—membiarkan satu LLM bertindak sebagai beberapa agen penalaran konkuren (pemikir). Agen-agen ini berbagi visibilitas atas kemajuan generasi parsial satu sama lain, secara dinamis beradaptasi dengan jejak penalaran satu sama lain pada tingkat token, sehingga mengurangi penalaran redundan, meningkatkan kualitas, dan mengurangi latensi. Metode ini cocok untuk inferensi edge pada GPU lokal, dan eksperimen membuktikan bahwa metode ini juga dapat meningkatkan latensi saat menggunakan LLM open-source yang tidak dilatih secara khusus. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Manusia Mengharapkan Rasionalitas dan Kerja Sama dari Lawan LLM dalam Permainan Strategis (Humans expect rationality and cooperation from LLM opponents): Sebuah eksperimen laboratorium terkontrol dengan insentif moneter pertama kali meneliti perbedaan perilaku manusia saat melawan manusia lain versus LLM dalam kontes P-beauty multipemain. Hasilnya menunjukkan bahwa manusia memilih angka yang jauh lebih rendah saat melawan LLM, terutama karena meningkatnya prevalensi pilihan ekuilibrium Nash “nol”. Pergeseran ini terutama didorong oleh subjek dengan kemampuan penalaran strategis yang tinggi, yang menganggap LLM memiliki kemampuan penalaran dan kecenderungan kerja sama yang lebih kuat. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Distilasi Pengetahuan Semi-Supervised Sederhana dari Model Bahasa Visual melalui Optimasi Kepala Ganda (Dual-Head Optimization for KD): Sebuah makalah baru mengusulkan DHO (Dual-Head Optimization), sebuah kerangka kerja distilasi pengetahuan (KD) yang sederhana dan efektif untuk mentransfer pengetahuan dari model bahasa visual (VLM) ke model khusus tugas yang ringkas dalam pengaturan semi-supervised. DHO memperkenalkan kepala prediksi ganda yang secara independen mempelajari data berlabel dan prediksi guru, dan secara linear menggabungkan outputnya saat inferensi, sehingga mengurangi konflik gradien antara sinyal supervisi dan sinyal distilasi. Eksperimen menunjukkan bahwa DHO mengungguli baseline KD kepala tunggal di berbagai domain dan dataset berbutir halus, mencapai SOTA di ImageNet. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: GuardReasoner-VL—Melindungi VLM melalui Penalaran yang Diperkuat: Untuk meningkatkan keamanan model bahasa visual (VLM), sebuah makalah baru memperkenalkan model perlindungan VLM berbasis penalaran, GuardReasoner-VL. Ide intinya adalah untuk mendorong model perlindungan agar melakukan penalaran yang cermat sebelum membuat keputusan moderasi melalui reinforcement learning (RL) online. Peneliti membangun korpus penalaran GuardReasoner-VLTrain yang berisi 123K sampel dan 631K langkah penalaran, dan memulai kemampuan penalaran model melalui supervised fine-tuning (SFT), kemudian lebih lanjut meningkatkannya melalui RL online. Eksperimen menunjukkan bahwa model ini (versi 3B/7B telah di-open source-kan) memiliki kinerja yang unggul, dengan skor F1 rata-rata 19,27% lebih tinggi dari model terbaik kedua. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Prediksi Multi-Token Membutuhkan Register (Multi-Token Prediction Needs Registers): Sebuah makalah baru mengusulkan MuToR, metode prediksi multi-token yang sederhana dan efektif, yang memprediksi target masa depan dengan menyisipkan token register yang dapat dipelajari secara berselang-seling dalam urutan input. Dibandingkan dengan metode yang ada, peningkatan parameter MuToR dapat diabaikan, tidak memerlukan perubahan arsitektur, kompatibel dengan model pra-terlatih yang ada, dan tetap konsisten dengan target pra-pelatihan token berikutnya, sangat cocok untuk supervised fine-tuning. Metode ini menunjukkan efektivitas dan universalitas dalam tugas generatif di domain bahasa dan visual. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: MMLongBench—Benchmark Model Bahasa Visual Konteks Panjang yang Efektif dan Menyeluruh: Untuk memenuhi kebutuhan evaluasi model bahasa visual konteks panjang (LCVLM), sebuah makalah baru memperkenalkan MMLongBench, benchmark pertama yang mencakup berbagai tugas bahasa visual konteks panjang. MMLongBench berisi 13331 sampel, mencakup lima kategori tugas seperti RAG visual, ICL multi-sampel, dan menyediakan berbagai jenis gambar. Semua sampel disediakan dalam lima panjang input standar dari 8K hingga 128K token. Melalui benchmark terhadap 46 LCVLM sumber tertutup dan terbuka, penelitian menemukan bahwa kinerja tugas tunggal tidak mewakili kemampuan konteks panjang secara keseluruhan, model saat ini masih memiliki banyak ruang untuk perbaikan, dan model dengan kemampuan penalaran yang kuat cenderung memiliki kinerja konteks panjang yang lebih baik. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: MatTools—Benchmark Model Bahasa Besar untuk Alat Ilmu Material: Sebuah makalah baru mengusulkan benchmark MatTools untuk mengevaluasi kemampuan model bahasa besar (LLM) dalam menjawab pertanyaan ilmu material dengan menghasilkan dan menjalankan kode paket ilmu material komputasi berbasis fisika secara aman. MatTools mencakup benchmark tanya jawab (QA) alat simulasi material (berdasarkan pymatgen, berisi 69225 pasangan QA) dan benchmark penggunaan alat dunia nyata (berisi 49 tugas, 138 sub-tugas). Evaluasi terhadap berbagai LLM mengungkapkan: model umum mengungguli model khusus; AI lebih memahami AI; metode sederhana lebih efektif. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: Kerangka Kerja Watermarking Simbiotik Universal yang Menyeimbangkan Kekokohan, Kualitas Teks, dan Keamanan Watermark LLM: Menanggapi masalah trade-off antara kekokohan, kualitas teks, dan keamanan pada skema watermarking model bahasa besar (LLM) yang ada, sebuah makalah baru mengusulkan kerangka kerja watermarking simbiotik universal. Kerangka kerja ini mengintegrasikan metode berbasis logits dan berbasis sampling, serta merancang tiga strategi: serial, paralel, dan campuran. Kerangka kerja campuran memanfaatkan entropi token dan entropi semantik untuk menyematkan watermark secara adaptif, bertujuan untuk mengoptimalkan kinerja di berbagai aspek. Eksperimen menunjukkan bahwa metode ini mengungguli baseline yang ada dan mencapai tingkat SOTA. (Sumber: HuggingFace Daily Papers)
Diskusi Makalah: CheXGenBench—Benchmark Terpadu untuk Fidelitas, Privasi, dan Utilitas Rontgen Dada Sintetis: Sebuah makalah baru memperkenalkan CheXGenBench, sebuah kerangka kerja multifaset untuk mengevaluasi generasi rontgen dada sintetis, yang secara bersamaan mengevaluasi fidelitas, risiko privasi, dan utilitas klinis. Kerangka kerja ini mencakup partisi data standar dan protokol evaluasi terpadu (lebih dari 20 metrik kuantitatif), menganalisis kualitas generasi, potensi kerentanan privasi, dan kesesuaian klinis hilir dari 11 arsitektur text-to-image terkemuka. Penelitian menemukan bahwa protokol evaluasi yang ada memiliki kekurangan dalam mengevaluasi fidelitas generasi. Tim juga merilis dataset sintetis berkualitas tinggi, SynthCheX-75K. (Sumber: HuggingFace Daily Papers)
Penulis buku teks klasik “Analisis Fungsional” Peter Lax meninggal dunia pada usia 99 tahun: Raksasa matematika terapan, Peter Lax, matematikawan terapan pertama yang menerima Penghargaan Abel, meninggal dunia pada usia 99 tahun. Lax terkenal dengan buku teks klasiknya “Analisis Fungsional” dan memberikan kontribusi dasar dalam bidang persamaan diferensial parsial, mekanika fluida, komputasi numerik, seperti teorema ekuivalensi Lax, metode Lax-Friedrichs, dan Lax-Wendroff. Ia juga merupakan salah satu pelopor awal yang menerapkan teknologi komputer pada analisis matematika, dan karyanya sangat memengaruhi perkembangan matematika di era komputer. (Sumber: QbitAI)

Mantan VP OpenAI Lilian Weng menulis esai panjang “Why We Think”, membahas komputasi saat pengujian dan rantai pemikiran: Mantan Wakil Presiden OpenAI keturunan Tionghoa, Lilian Weng, menerbitkan esai panjang berjudul “Why We Think”, yang membahas secara mendalam bagaimana teknologi seperti “Test-time Compute” dan “Chain-of-Thought (CoT)” secara signifikan meningkatkan kinerja dan tingkat kecerdasan model bahasa besar. Artikel tersebut menganalogikan teori sistem ganda “berpikir cepat dan lambat” pada manusia, menunjukkan bahwa membiarkan model “berpikir” lebih banyak sebelum menghasilkan output (misalnya melalui decoding cerdas, penalaran CoT, pemodelan variabel laten, dll.) dapat menembus hambatan kemampuan saat ini. Artikel tersebut merinci kemajuan dan tantangan dalam berbagai arah penelitian seperti pemikiran berbasis token, pengambilan sampel paralel dan revisi berurutan, reinforcement learning dan integrasi alat eksternal, kesetiaan pemikiran, dan pemikiran ruang kontinu. (Sumber: QbitAI)

Harbin Institute of Technology dan University of Pennsylvania bersama-sama meluncurkan PointKAN, SOTA baru untuk analisis point cloud berbasis KANs: Tim peneliti dari Harbin Institute of Technology (Shenzhen) dan University of Pennsylvania meluncurkan PointKAN, solusi analisis point cloud 3D berbasis Kolmogorov-Arnold Networks (KANs). Metode ini menggunakan modul afinitas geometris dan modul ekstraksi fitur lokal paralel, serta memanfaatkan fungsi aktivasi yang dapat dipelajari untuk menggantikan fungsi aktivasi tetap pada MLP tradisional, guna menangkap fitur geometris kompleks dari point cloud secara lebih efektif. Selain itu, tim mengusulkan struktur Efficient-KANs, yang menggunakan fungsi rasional untuk menggantikan fungsi B-spline dan melakukan pembagian parameter intra-grup, sehingga secara signifikan mengurangi jumlah parameter dan biaya komputasi. Eksperimen menunjukkan bahwa PointKAN dan versi ringannya, PointKAN-elite, mencapai kinerja SOTA atau kompetitif dalam tugas-tugas seperti klasifikasi, segmentasi parsial, dan pembelajaran few-shot. (Sumber: WeChat)

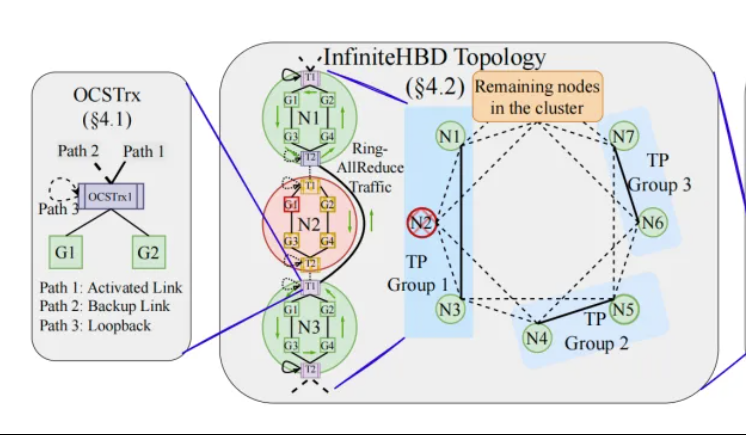
Peking University/StepStar/Xizhi mengusulkan InfiniteHBD: arsitektur interkoneksi GPU bandwidth tinggi generasi baru, mengurangi biaya pelatihan model besar: Tim peneliti dari Peking University, StepStar, dan Xizhi Technology, menanggapi keterbatasan arsitektur domain bandwidth tinggi (HBD) saat ini dalam pelatihan terdistribusi model besar, mengusulkan solusi InfiniteHBD. Arsitektur ini berpusat pada modul konversi optoelektronik yang disematkan dengan kemampuan optical circuit switching (OCS), mewujudkan koneksi point-to-multipoint yang dapat dikonfigurasi ulang secara dinamis, dengan kemampuan isolasi kegagalan tingkat node dan fragmentasi sumber daya yang rendah. Penelitian menunjukkan bahwa biaya unit InfiniteHBD hanya 31% dari NVIDIA NVL-72, tingkat pemborosan GPU mendekati nol, dan MFU (model FLOPs utilization) dapat meningkat hingga 3,37 kali lipat dibandingkan NVIDIA DGX. Penelitian ini telah diterima oleh SIGCOMM 2025. (Sumber: WeChat, QbitAI)
ICML 2025 Paper Express: OmniAudio menghasilkan audio spasial dari video 360°: Sebuah penelitian yang akan dipresentasikan di ICML 2025 mengusulkan kerangka kerja OmniAudio, yang mampu menghasilkan audio spasial first-order ambisonics (FOA) dengan sensasi arah langsung dari video panorama 360°. Penelitian ini pertama-tama membangun dataset pasangan video 360° dan audio spasial berskala besar, Sphere360. OmniAudio menggunakan pelatihan dua tahap: pertama, melakukan pra-pelatihan pencocokan aliran dari kasar ke halus secara self-supervised, memanfaatkan data audio non-spasial berskala besar untuk mempelajari fitur audio umum; kemudian menggabungkan encoder video dua cabang (mengekstrak fitur visual global dan lokal) untuk fine-tuning secara supervised. Hasil eksperimen menunjukkan bahwa OmniAudio secara signifikan mengungguli model baseline yang ada pada metrik evaluasi objektif dan subjektif. (Sumber: WeChat)

Huawei Selftok: visual tokenizer autoregresif berbasis reverse diffusion, menyatukan generasi multimodal: Tim generasi multimodal Huawei Pangu mengusulkan teknologi Selftok, sebuah solusi tokenisasi visual inovatif yang mengintegrasikan prior autoregresif ke dalam token visual melalui proses reverse diffusion, mengubah aliran piksel menjadi urutan diskrit yang secara ketat mengikuti hukum kausalitas, bertujuan untuk mengatasi masalah konflik antara skema token spasial yang ada dengan paradigma autoregresif (AR). Selftok Tokenizer menggunakan encoder dua aliran (cabang gambar mewarisi SD3 VAE, cabang teks adalah grup vektor kontinu yang dapat dipelajari) dan quantizer dengan mekanisme reaktivasi. Eksperimen menunjukkan bahwa Selftok mencapai SOTA pada metrik rekonstruksi ImageNet, dan Selftok dAR-VLM yang dilatih berdasarkan Ascend AI dan kerangka kerja MindSpeed melampaui GPT-4o pada benchmark text-to-image seperti GenEval. Karya ini terpilih sebagai kandidat makalah terbaik CVPR 2025. (Sumber: WeChat)
Tim Yan Shuicheng memimpin perilisan kerangka evaluasi General-Level dan benchmark General-Bench, mengklasifikasikan model generalis multimodal: Dipimpin oleh Profesor Yan Shuicheng dari National University of Singapore, Profesor Zhang Hanwang dari Nanyang Technological University, dan lainnya, sepuluh universitas terkemuka bersama-sama merilis kerangka evaluasi General-Level dan dataset benchmark berskala besar General-Bench untuk model generalis multimodal. Kerangka kerja ini mengambil inspirasi dari sistem klasifikasi mengemudi otonom, menetapkan lima level (Level 1-5) untuk mengevaluasi universalitas dan kinerja model bahasa besar multimodal (MLLM). Kriteria evaluasi inti adalah “efek generalisasi sinergis” (Synergy), yang menguji kemampuan model dalam transfer pengetahuan dan peningkatan antar tugas, antar paradigma pemahaman dan generasi, serta lintas modalitas. General-Bench mencakup lebih dari 700 tugas dan 320.000 sampel. Evaluasi terhadap lebih dari 100 MLLM yang ada menunjukkan bahwa sebagian besar model berada pada level L2-L3, dan belum ada model yang mencapai L5. (Sumber: WeChat)

💼 Bisnis
Sakana AI dan Mitsubishi UFJ Bank (MUFG) mencapai kemitraan multi-tahun: Perusahaan rintisan AI Jepang, Sakana AI, mengumumkan penandatanganan perjanjian kemitraan komprehensif multi-tahun dengan bank terbesar di Jepang, MUFG Bank. Sakana AI akan menyediakan teknologi AI yang gesit dan kuat untuk MUFG Bank, yang bertujuan untuk membantu bank berusia seabad ini tetap kompetitif di bidang AI yang berkembang pesat. Kerja sama ini diharapkan dapat membantu Sakana AI mencapai profitabilitas dalam waktu satu tahun. (Sumber: SakanaAILabs, SakanaAILabs)

Cohere bekerja sama dengan Dell, membawa platform agen cerdas aman Cohere North ke solusi AI perusahaan lokal Dell: Perusahaan AI Cohere mengumumkan kerja sama dengan Dell Technologies untuk bersama-sama mempercepat solusi AI perusahaan yang aman dan berkemampuan agen cerdas. Dell akan menjadi penyedia pertama yang menawarkan deployment lokal (on-premises) platform agen cerdas aman Cohere North kepada perusahaan. Kerja sama ini sangat penting bagi industri yang menangani data sensitif dan memiliki persyaratan kepatuhan yang ketat, memungkinkan perusahaan untuk melakukan deployment dan menjalankan teknologi agen AI canggih Cohere di dalam pusat data mereka sendiri. (Sumber: sarahookr)

Mistral AI bekerja sama dengan MGX dan Bpifrance untuk membangun kampus AI terbesar di Eropa di Prancis: Mistral AI mengumumkan kerja sama dengan MGX, perusahaan investasi teknologi yang didukung Abu Dhabi, dan Bpifrance, bank investasi nasional Prancis, untuk bersama-sama membangun kampus AI terbesar di Eropa di wilayah Paris, Prancis. Kampus ini akan mengintegrasikan pusat data, sumber daya komputasi kinerja tinggi, serta fasilitas pendidikan dan penelitian. NVIDIA juga akan berpartisipasi dengan menyediakan dukungan teknis. Langkah ini bertujuan untuk mendorong pengembangan ekosistem AI Eropa dan meningkatkan posisi strategis Prancis dalam bidang AI global. (Sumber: arthurmensch, arthurmensch)
🌟 Komunitas
Prevalensi ADHD di kalangan praktisi AI menarik perhatian, mungkin melebihi 20-30%: Diskusi di media sosial muncul mengenai prevalensi Attention Deficit Hyperactivity Disorder (ADHD) di kalangan praktisi di bidang AI. Seorang pengguna mengamati bahwa bidang ini tampaknya menarik banyak talenta dengan karakteristik neurodiversitas. Minh Nhat Nguyen berkomentar bahwa mungkin lebih dari 20-30% orang di industri AI menderita ADHD. Fenomena ini mungkin terkait dengan tuntutan pekerjaan penelitian dan pengembangan AI akan fokus tinggi, iterasi cepat, dan pemikiran kreatif, karakteristik yang terkadang selaras dengan beberapa manifestasi ADHD. (Sumber: Dorialexander)
Depresiasi keterampilan di era AI memicu refleksi mendalam, restrukturisasi sistem bukan penguasaan alat adalah kuncinya: Sebuah artikel analisis mendalam menunjukkan bahwa krisis sebenarnya di era AI bukanlah “apakah bisa menggunakan alat AI”, melainkan depresiasi keterampilan itu sendiri dan restrukturisasi seluruh sistem kerja. Artikel tersebut menggunakan contoh Garis Maginot, kontainerisasi, dan penggantian juru ketik oleh pengolah kata untuk membuktikan bahwa hanya mempelajari penggunaan alat baru tidak dapat menjamin keunggulan; kuncinya adalah memahami bagaimana AI mengubah struktur, proses, dan logika organisasi kerja. Ketika sistem ditulis ulang, keterampilan bernilai tinggi yang ada sebelumnya dapat dengan cepat terpinggirkan. Peningkatan produktivitas belum tentu membawa peningkatan nilai individu, karena nilai akan mengalir ke entitas yang mengendalikan lapisan koordinasi sistem baru. Artikel tersebut membantah delapan kekeliruan populer seperti “belajar AI akan membuat unggul”, “AI membuat saya melakukan lebih banyak pekerjaan sehingga lebih berharga”, dan “posisi pekerjaan tidak berubah, hanya caranya yang berubah”, menekankan perlunya berpikir dari tingkat sistem tentang posisi dan nilai diri sendiri. (Sumber: 36Kr)
Mantan CEO Google Schmidt: Kebangkitan kecerdasan non-manusia akan membentuk kembali tatanan global, perlu waspada terhadap risiko dan tantangan AI: Mantan CEO Google Eric Schmidt dalam sebuah wawancara khusus memperingatkan bahwa masyarakat sangat kurang menyadari potensi disruptif dari “kecerdasan non-manusia”. Ia berpendapat bahwa AI telah beralih dari generasi bahasa ke pengambilan keputusan strategis, mampu menyelesaikan tugas-tugas kompleks secara mandiri. Schmidt menyoroti tiga tantangan inti yang ditimbulkan oleh AI: kendala energi dan daya komputasi (AS membutuhkan tambahan 90 gigawatt listrik), data publik yang hampir habis (tahap berikutnya membutuhkan data yang dihasilkan AI), dan bagaimana membuat AI melampaui pengetahuan manusia yang ada untuk menciptakan “pengetahuan baru”. Ia juga menunjukkan tiga risiko utama: AI yang lepas kendali dalam perbaikan diri rekursif, mendapatkan kendali atas senjata, dan replikasi diri tanpa izin. Ia percaya bahwa di tengah meningkatnya persaingan AI antara Tiongkok dan AS, penyebaran cepat AI open-source dapat membawa risiko keamanan, bahkan memicu situasi “serangan pendahuluan” yang mirip dengan “deteren nuklir”. Schmidt menyerukan dialog tata kelola AI global segera dan menekankan perlunya menanamkan perlindungan terhadap kebebasan manusia sejak awal desain sistem. (Sumber: 36Kr)

CEO GitHub membantah “teori pemrograman tidak berguna”, menekankan bahwa programmer manusia tetap penting di era AI: Menanggapi pandangan CEO NVIDIA Jensen Huang dan lainnya yang menyatakan bahwa “di masa depan tidak perlu lagi belajar pemrograman”, CEO GitHub Thomas Dohmke dalam sebuah wawancara menyatakan ketidaksetujuannya. Ia berpendapat bahwa tahun 2025 akan menjadi tahun agen pemrograman (SWE Agent), tetapi peran programmer manusia tetap krusial. Dohmke menekankan bahwa AI seharusnya berfungsi sebagai asisten untuk meningkatkan kemampuan pengembang, bukan menggantikannya sepenuhnya. Ia membayangkan pengembangan perangkat lunak di masa depan akan berkembang menjadi model kolaborasi manusia-AI, di mana pengembang bertindak seperti “konduktor orkestra agen cerdas”, bertanggung jawab untuk menugaskan tugas dan meninjau hasil. CPO GitHub Mario Rodriguez juga menyatakan bahwa perusahaan berkomitmen untuk meningkatkan kemampuan individu dengan Copilot. Mereka percaya bahwa seiring perkembangan AI, memahami cara memprogram dan memprogram ulang mesin yang dapat mewakili pemikiran dan tindakan manusia menjadi sangat penting; menyerah untuk belajar kode sama dengan menyerahkan hak suara di masa depan agen cerdas. (Sumber: 36Kr, QbitAI)

Laporan kerentanan berkualitas rendah yang dihasilkan AI membanjiri, pendiri curl memperkenalkan mekanisme filter untuk melawan “sampah AI”: Pendiri proyek curl, Daniel Stenberg, menyatakan bahwa ia kewalahan karena menerima banyak laporan kerentanan berkualitas rendah dan tidak valid yang dihasilkan oleh AI. Laporan-laporan ini menghabiskan banyak waktu para pengelola dan serupa dengan serangan DDoS. Oleh karena itu, saat mengirimkan laporan keamanan terkait curl di HackerOne, ditambahkan kotak centang yang menanyakan apakah AI digunakan. Jika jawabannya ya, maka bukti tambahan harus diberikan untuk membuktikan keaslian kerentanan tersebut, jika tidak, pelapor dapat diblokir. Stenberg mengatakan bahwa proyek tersebut belum pernah menerima laporan bug yang valid yang dihasilkan oleh AI. Pengembang Python Seth Larson juga pernah menyatakan kekhawatiran serupa, berpendapat bahwa laporan semacam itu menimbulkan kebingungan, stres, dan frustrasi bagi para pengelola, serta memperburuk masalah kelelahan pada proyek open source. Diskusi komunitas berpendapat bahwa membanjirnya laporan yang dihasilkan AI mencerminkan kelebihan informasi dan upaya sebagian orang untuk memanfaatkan mekanisme hadiah kerentanan, bahkan ada manajer tingkat atas yang disesatkan untuk percaya bahwa AI dapat menggantikan programmer berpengalaman. (Sumber: WeChat)

Pemrograman berbantuan AI memicu perdebatan hangat: peningkatan efisiensi signifikan, tetapi peran pengembang manusia tetap krusial: Seorang pengembang dengan pengalaman pemrograman puluhan tahun berbagi pengalamannya ketika AI (kemungkinan Codex atau alat serupa) menyelesaikan bug yang telah mengganggunya selama berjam-jam dan mengoptimalkan kode dalam beberapa menit, mengagumi AI sebagai “rekan tim super yang tidak pernah lelah”. Pengalaman ini memicu diskusi komunitas. Sebagian besar setuju dengan kemampuan AI yang kuat dalam pembuatan kode, perbaikan bug, dan peringkasan informasi, yang dapat meningkatkan efisiensi secara signifikan. Namun, beberapa pengembang juga menunjukkan bahwa AI saat ini masih membuat kesalahan, terutama dalam logika kompleks, kondisi batas, dan solusi kreatif, yang tidak sebaik manusia, dan outputnya memerlukan tinjauan dan evaluasi kritis dari pengembang berpengalaman. CEO Microsoft Satya Nadella juga menekankan bahwa AI adalah alat pemberdaya, pengembangan perangkat lunak sudah tidak dapat dipisahkan dari AI, tetapi ambisi dan agensi manusia tetap penting. Diskusi umumnya berpendapat bahwa AI akan mengubah cara pemrograman, pengembang perlu beradaptasi dengan paradigma baru kolaborasi dengan AI, fokus pada desain arsitektur tingkat tinggi dan definisi masalah. (Sumber: Reddit r/ChatGPT, WeChat)
AI Agent Manus membuka pendaftaran tetapi dengan harga mahal, menghadapi persaingan dari raksasa domestik dan internasional, peluncuran versi bahasa Mandarin diragukan: Platform AI Agent Manus, setelah mengalami kehebohan kode undangan, secara resmi membuka pendaftaran, tetapi saat ini hanya untuk pengguna luar negeri dan belum menyediakan versi bahasa Mandarin. Umpan balik pengguna menunjukkan bahwa platform ini menggunakan sistem konsumsi poin; poin gratis (1000 saat pendaftaran, 300 setiap hari) hanya cukup untuk menyelesaikan tugas sederhana, sedangkan tugas kompleks (seperti membuat game Sudoku versi web) memerlukan pembelian poin berbayar, dengan rata-rata 1 dolar AS untuk 100 poin, harga yang relatif tinggi. Analis industri berpendapat bahwa Manus bergantung pada model besar pihak ketiga (seperti Claude untuk versi luar negeri) yang menyebabkan biaya lebih tinggi, dan operasi sandbox di cloud juga menambah biaya. Penundaan peluncuran versi bahasa Mandarin mungkin terkait dengan pendaftaran model domestik, kebiasaan pembayaran pengguna, dan persaingan pasar. Produk domestik dan internasional seperti Coze dari ByteDance dan aplikasi “Xin Xiang” dari Baidu telah membentuk persaingan. Meskipun Manus mendapatkan pendanaan baru, model “model ringan, aplikasi berat” miliknya menghadapi ujian dalam hal keunggulan kompetitif. (Sumber: 36Kr)
Model AI gagal total dalam soal penalaran visual “melengkapi kubus”, memicu diskusi tentang pemahaman sebenarnya: Sebuah soal penalaran visual yang meminta untuk menghitung jumlah kubus kecil yang dibutuhkan untuk melengkapi kubus yang tidak lengkap telah membuat bingung beberapa model AI utama, termasuk OpenAI o3, Google Gemini 2.5 Pro, DeepSeek, dan Qwen3. Jawaban yang diberikan oleh berbagai model berbeda-beda, terutama karena perbedaan pemahaman tentang spesifikasi kubus besar akhir (seperti 3x3x3, 4x4x4, 5x5x5). Bahkan dengan panduan melalui petunjuk, model kesulitan untuk menjawab dengan benar dalam sekali percobaan. Beberapa warganet menunjukkan bahwa pernyataan masalah itu sendiri mungkin ambigu, dan manusia juga akan merasa bingung. Fenomena ini memicu diskusi tentang apakah model AI benar-benar memahami masalah atau hanya mengandalkan pencocokan pola, menyoroti keterbatasan AI saat ini dalam penalaran spasial yang kompleks dan pemahaman visual. (Sumber: 36Kr)
Pengguna membahas masalah “berpikir berlebihan” LLM dalam mengikuti instruksi dan penalaran: Diskusi di media sosial dan makalah menunjukkan bahwa model bahasa besar (LLM), ketika menggunakan proses penalaran seperti chain-of-thought (CoT), terkadang “berpikir berlebihan”, yang justru menyebabkan ketidakmampuan untuk mengikuti instruksi sederhana secara akurat. Misalnya, ketika diminta untuk menulis sejumlah kata tertentu atau mengulang frasa tertentu, CoT dapat membuat model lebih fokus pada konten keseluruhan tugas dan mengabaikan batasan dasar ini, atau memperkenalkan konten penjelasan tambahan. Peneliti mengusulkan metrik “perhatian terbatas” untuk mengukur fenomena ini dan menguji strategi mitigasi seperti pembelajaran kontekstual, refleksi diri, penalaran pilihan sendiri, dan penalaran pilihan klasifikator. Ini menunjukkan bahwa tidak semua tugas cocok untuk CoT; instruksi sederhana mungkin memerlukan cara eksekusi yang lebih langsung. (Sumber: menhguin, omarsar0)

Refleksi Ekonomi AI: Tenaga Kerja Kognitif Murah Merusak Model Ekonomi Tradisional, Distribusi Nilai Menghadapi Perombakan: Sebuah pandangan yang memicu diskusi berpendapat bahwa kebangkitan AI membuat tenaga kerja kognitif (seperti penulisan laporan, analisis data, penulisan kode) menjadi sangat murah, yang secara fundamental menantang model ekonomi klasik yang berasumsi bahwa “kecerdasan manusia langka dan mahal”. Ketika AI dapat menyelesaikan sejumlah besar pekerjaan pengetahuan dengan biaya marjinal mendekati nol, produktivitas mungkin melonjak, tetapi nilai per tugas akan anjlok, dan keunggulan spesialisasi terkikis. Distribusi nilai tidak lagi hanya berdasarkan efisiensi atau output, tetapi tergantung pada siapa yang mengendalikan sumber daya langka baru (seperti data, platform, model AI itu sendiri). Ini mirip dengan perubahan teknologi historis (seperti mode cepat dalam industri pakaian, streaming dalam industri musik) di mana dividen peningkatan efisiensi tidak sepenuhnya mengalir ke pekerja, melainkan diperoleh oleh koordinator sistem. Artikel tersebut memperingatkan bahwa AI tidak hanya mengotomatiskan tugas, tetapi juga mengkomodifikasi “pemikiran”, yang mungkin merupakan kekuatan paling disruptif dalam sejarah ekonomi modern. (Sumber: Reddit r/artificial)
Strategi Perusahaan di Era AI: Hindari Jebakan “Perusahaan Cerdas”, Perlu Merombak Bukan Mengoptimalkan Proses Lama: Banyak perusahaan, dalam mengadopsi AI, cenderung menggunakannya sebagai alat untuk mengoptimalkan proses yang ada dan mengurangi biaya serta meningkatkan efisiensi, terjebak dalam perangkap “melakukan hal yang sama dengan lebih cerdas” atau “perusahaan cerdas”. Namun, perubahan sejati bukanlah membuat proses lama lebih cerdas, melainkan memikirkan apakah proses tersebut masih perlu ada, dan membangun sistem serta model bisnis yang sepenuhnya baru dan asli AI. Teknologi tidak akan begitu saja beradaptasi dengan sistem lama, melainkan akan membentuk kembali sistem tersebut. Perusahaan harus menghindari investasi sumber daya yang berlebihan untuk mengoptimalkan proses yang akan segera dihilangkan oleh AI, dan sebaliknya harus fokus pada pendefinisian aturan baru, mengubah cara pengambilan keputusan, mekanisme koordinasi, dan struktur organisasi secara fundamental. (Sumber: 36Kr)
💡 Lainnya
Acara temu offline LangChain di New York: LangChain mengumumkan akan mengadakan acara temu offline di New York pada tanggal 22 Mei (Kamis) bersama dengan Tabs dan TavilyAI. Acara akan mencakup diskusi santai, demo produk, dan sesi networking dengan para pembangun lainnya. (Sumber: hwchase17, LangChainAI)

Konferensi AI Global Stasiun Tokyo akan diadakan pada bulan Juni: Sebuah acara bernama “Konferensi AI Global · Stasiun Tokyo” direncanakan akan diadakan pada tanggal 7 hingga 8 Juni di Tokyo, Jepang. Banyak pengembang AI, seniman, investor terkenal, dan lainnya akan berpartisipasi. Mereka yang tertarik pada bidang AI dan berencana untuk pergi ke Jepang dapat memperhatikan informasi pendaftaran terkait. (Sumber: op7418)

Paradigma arsitektur layanan AI sedang beralih dari “Model-as-a-Service” ke “Agent-as-a-Service”: Seiring dengan perkembangan teknologi AI, arsitektur layanan AI sedang mengalami lompatan besar dari “Model-as-a-Service” (MaaS) ke “Agent-as-a-Service” (AaaS). AI Agent, dengan kemampuannya yang didorong oleh tujuan, kesadaran lingkungan, pengambilan keputusan otonom, dan kemampuan belajar, melampaui model AI tradisional yang secara pasif menjalankan instruksi. Mereka mampu berpikir secara mandiri, memecah tugas, merencanakan jalur, dan memanggil alat eksternal untuk menyelesaikan tujuan yang kompleks. Pergeseran ini mendorong pengembangan menyeluruh rantai industri mulai dari infrastruktur dasar (daya komputasi, data), algoritma inti dan model besar, hingga komponen dan platform Agen lapisan menengah, dan akhirnya aplikasi produk terminal (Agen umum, industri vertikal, Agen tertanam). Perusahaan AI Agent Tiongkok seperti HeyGen, Laiye Technology, Waveform Intelligence juga aktif berekspansi ke pasar luar negeri. Meskipun menghadapi tantangan seperti biaya daya komputasi yang mahal dan pasokan yang tidak mencukupi, potensi AI Agent terus dilepaskan melalui optimasi algoritma, chip khusus, komputasi edge, dan solusi lainnya. (Sumber: 36Kr)