
Kata Kunci:AI pemrograman agen cerdas, Codex, AlphaEvolve, Paradigma penalaran AI, Model MoE, Chip AI, Pendidikan AI, Drama pendek AI, Model OpenAI Codex-1, Google DeepMind AlphaEvolve, ByteDance Seed1.5-VL, Teknologi Qwen ParScale, Sistem NVIDIA GB300
🔥 Fokus
OpenAI merilis agen pemrograman AI cloud Codex, didukung oleh model baru codex-1: OpenAI meluncurkan agen pemrograman AI cloud Codex, berdasarkan versi kustom o3 dari codex-1 yang dioptimalkan untuk rekayasa perangkat lunak. Codex dapat dengan aman memproses berbagai tugas secara paralel dalam sandbox cloud, dan terintegrasi dengan GitHub untuk memanggil repositori kode secara langsung, memungkinkan pembuatan modul cepat, menjawab pertanyaan tentang repositori kode, memperbaiki bug, mengirimkan PR, dan validasi pengujian otomatis. Tugas yang sebelumnya memakan waktu berhari-hari atau berjam-jam, dapat diselesaikan oleh Codex dalam 30 menit. Alat ini telah tersedia untuk pengguna ChatGPT Pro, Enterprise, dan Team, dengan tujuan menjadi “insinyur 10x” bagi para pengembang dan membentuk ulang alur kerja pengembangan perangkat lunak. (Sumber: 36氪)
Google DeepMind meluncurkan AlphaEvolve, evolusi otonom AI mencapai terobosan matematika dan algoritma: Sistem AI AlphaEvolve dari Google DeepMind, melalui evolusi diri dan pelatihan model bahasa besar, telah mencapai terobosan di berbagai bidang matematika dan sains. Sistem ini telah memperbaiki algoritma perkalian matriks 4×4 (pertama kali dalam 56 tahun), mengoptimalkan masalah pengisian heksagonal (pertama kali dalam 16 tahun), dan memajukan “masalah bilangan ciuman” (kissing number problem). AlphaEvolve dapat secara otonom mengoptimalkan algoritma, bahkan menemukan metode untuk mempercepat pelatihan model Gemini, dan telah diterapkan untuk mengoptimalkan infrastruktur komputasi internal Google, menghemat 0,7% sumber daya komputasi. Ini menandakan bahwa AI tidak hanya dapat menyelesaikan masalah tetapi juga menemukan pengetahuan baru, yang berpotensi merevolusi paradigma penelitian ilmiah dan mewujudkan AI yang menciptakan sains. (Sumber: 36氪)
Pidato Sam Altman di KTT AI Sequoia: AI akan memasuki dunia nyata dalam tiga tahun, membentuk ulang kehidupan dan pekerjaan: CEO OpenAI Sam Altman dalam KTT AI Sequoia memprediksi bahwa agen AI akan praktis digunakan pada tahun 2025 (terutama di bidang pengkodean), AI akan mendorong penemuan ilmiah besar pada tahun 2026, dan robot akan memasuki dunia fisik untuk menciptakan nilai pada tahun 2027. Ia meninjau kembali perjalanan OpenAI dari eksplorasi awal hingga kelahiran ChatGPT, dan mengemukakan bahwa produk AI di masa depan akan menjadi layanan “langganan AI inti” yang dapat menampung seluruh pengalaman hidup pribadi dan menjadi antarmuka default yang cerdas. OpenAI akan fokus pada model inti dan skenario aplikasi, serta mempertahankan efisiensi organisasi “tim kecil, tanggung jawab besar”. (Sumber: 36氪)
Pidato NVIDIA di Computex: Komputer AI pribadi mulai diproduksi, meluncurkan sistem GB300 generasi berikutnya, berencana membangun superkomputer AI di Taiwan: CEO NVIDIA Jensen Huang di Computex 2025 mengumumkan bahwa komputer AI pribadi DGX Spark telah memasuki produksi penuh dan akan tersedia dalam beberapa minggu; sistem AI generasi berikutnya GB300 (dilengkapi dengan 72 GPU Blackwell Ultra dan 36 CPU Grace) akan diluncurkan pada Q3. NVIDIA akan bekerja sama dengan TSMC dan Foxconn untuk membangun pusat superkomputer AI di Taiwan. Bersamaan dengan itu, diluncurkan seri workstation Blackwell RTX Pro 6000 dan Grace Blackwell Ultra Superchip, serta berencana untuk membuka sumber (open source) Newton physics engine pada bulan Juli untuk pelatihan robot. Jensen Huang menekankan bahwa AI akan ada di mana-mana dan menegaskan kembali dampak revolusionernya. (Sumber: 36氪)

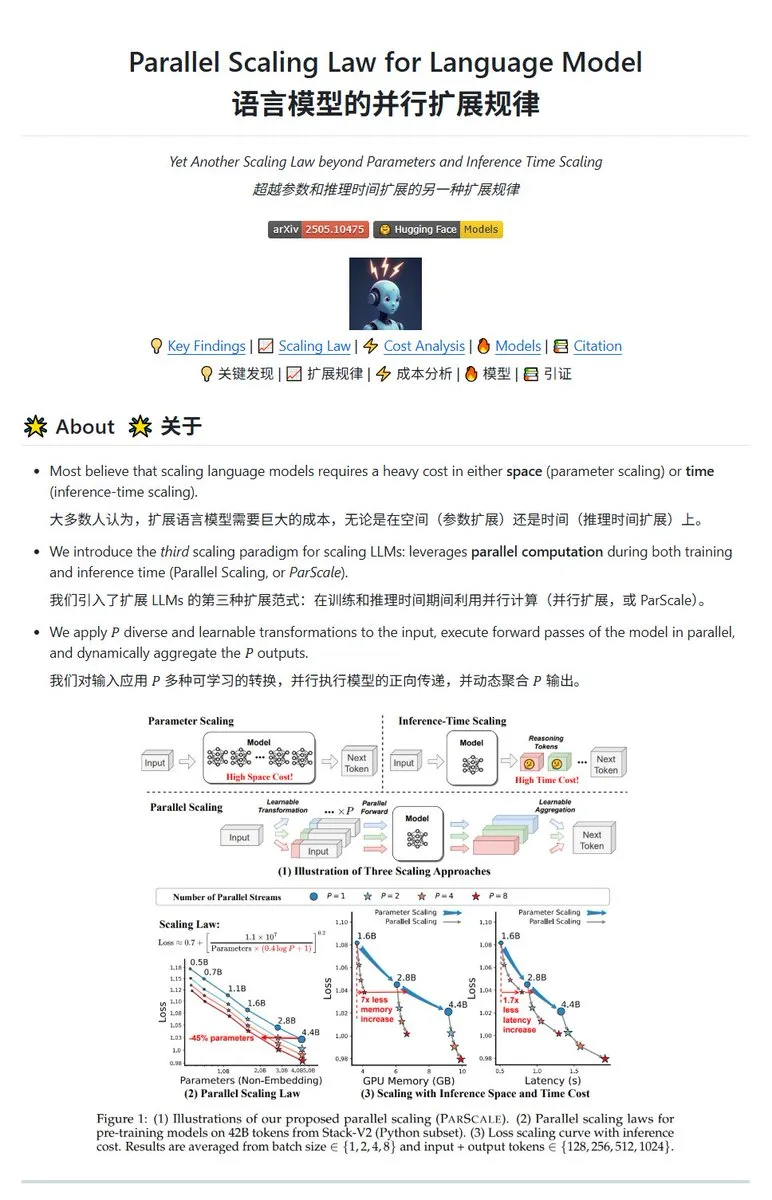
Qwen merilis teknologi ParScale parallel scaling, model kecil dapat mencapai efek model besar: Tim Qwen meluncurkan teknologi ParScale, yang meningkatkan kemampuan model melalui inferensi paralel. Metode ini menggunakan n aliran paralel untuk inferensi, setiap aliran menggunakan transformasi terdiferensiasi yang dapat dipelajari untuk memproses input, dan akhirnya menggabungkan hasil melalui mekanisme agregasi dinamis. Penelitian menunjukkan bahwa efek dari P aliran paralel kira-kira setara dengan meningkatkan jumlah parameter model sebesar O(log P), misalnya model 30B melalui 8 aliran paralel dapat mencapai efek model 42.5B. Teknologi ini diharapkan dapat meningkatkan kinerja model tanpa meningkatkan penggunaan memori video secara signifikan, atau memperkecil skala model yang ada dengan meningkatkan paralelisme, tetapi mungkin dengan mengorbankan peningkatan kebutuhan komputasi dan penurunan kecepatan inferensi. (Sumber: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 Perkembangan
Laporan Poe: OpenAI dan Google memimpin perlombaan AI, Anthropic menunjukkan penurunan: Laporan penggunaan terbaru Poe (Januari-Mei 2025) menunjukkan perubahan drastis dalam lanskap pasar AI. Di bidang pembuatan teks, GPT-4o (35,8%) memimpin, sementara Gemini 2.5 Pro (31,5%) menduduki puncak dalam kemampuan penalaran. Pembuatan gambar didominasi oleh seri Imagen3, GPT-Image-1, dan Flux. Di bidang pembuatan video, Kling-2.0-Master muncul sebagai kekuatan baru, sementara pangsa pasar Runway menurun tajam. Dalam hal agen, o3 menunjukkan kinerja terbaik. Laporan tersebut menunjukkan bahwa kemampuan penalaran telah menjadi medan pertempuran utama, pangsa pasar Claude dari Anthropic telah menurun, dan proporsi pengguna DeepSeek R1 juga telah turun dari puncaknya. Perusahaan perlu memperhatikan akurasi dan keandalan model dalam tugas-tugas kompleks, dan secara fleksibel memilih model AI. (Sumber: 36氪)

Peluncuran model AI unggulan Meta, Behemoth (Llama 4), ditunda, dapat memicu penyesuaian strategi AI: Menurut laporan, model besar Behemoth (Llama 4) dengan 2 triliun parameter yang semula direncanakan Meta untuk dirilis pada bulan April telah ditunda hingga musim gugur atau lebih lambat karena kinerjanya tidak memenuhi harapan. Model ini menggunakan 30T token multimodal yang dilatih sebelumnya pada 32K GPU, bertujuan untuk bersaing dengan OpenAI, Google, dll. Kesulitan pengembangan telah menimbulkan kekecewaan internal terhadap kinerja tim Llama 4 dan dapat menyebabkan penyesuaian tim produk AI. Sementara itu, 11 dari 14 anggota tim awal Llama 1 telah mengundurkan diri. Eksekutif Meta membantah rumor “80% tim mengundurkan diri”, menekankan bahwa mereka yang mengundurkan diri terutama berasal dari tim paper Llama 1. Insiden ini memperburuk kekhawatiran eksternal tentang apakah Meta terjebak dalam kemacetan dalam perlombaan AI. (Sumber: 36氪)

ByteDance dan Google DeepMind merilis penelitian model MoE baru, fokus pada efisiensi dan aplikasi sistem produksi: Paper ByteDance 《MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production》 memperkenalkan sistem produksi yang dirancang khusus untuk pelatihan model MoE skala besar yang efisien. Dengan menumpangtindihkan komunikasi dan komputasi pada tingkat operator, sistem ini mencapai peningkatan efisiensi 1,88 kali lipat dibandingkan Megatron-LM, dan telah diterapkan di pusat datanya untuk melatih model produk (seperti Internal-352B, 32 pakar, top-3). Google DeepMind merilis AlphaEvolve, yang mencapai terobosan di bidang matematika dan algoritma melalui evolusi diri AI dan pelatihan LLM, misalnya, meningkatkan perkalian matriks 4×4 dan masalah pengisian heksagonal, menunjukkan potensi AI dalam penemuan ilmiah. (Sumber: teortaxesTex, 36氪)

OpenAI membahas paradigma penalaran AI, menekankan peran kuncinya dalam peningkatan kinerja: Peneliti OpenAI Noam Brown menunjukkan bahwa pengembangan AI telah beralih dari paradigma pra-pelatihan (memprediksi kata berikutnya melalui data masif) ke paradigma penalaran. Biaya pra-pelatihan sangat tinggi, sedangkan paradigma penalaran meningkatkan kualitas jawaban dengan menambah waktu “berpikir” model (jumlah komputasi penalaran), bahkan jika biaya pelatihan tetap sama. Misalnya, model seri o pada kompetisi matematika (AIME) dan masalah ilmiah tingkat doktoral (GPQA), mencapai akurasi yang jauh melampaui GPT-4o melalui waktu penalaran yang lebih lama. Ekonom utama OpenAI Ronnie Chatterji membahas bagaimana AI membentuk kembali lanskap perusahaan, berpendapat bahwa kuncinya terletak pada bagaimana perusahaan mengintegrasikan AI untuk meningkatkan atau menggantikan peran manusia, dan bagaimana teknologi AI disematkan dalam rantai nilai. (Sumber: 36氪)

CEO Google Sundar Pichai menanggapi “teori Google sudah mati”, menekankan evolusi pencarian yang didorong AI dan keunggulan infrastruktur: CEO Google Sundar Pichai dalam sebuah wawancara eksklusif menanggapi kekhawatiran tentang “Pencarian Google digantikan oleh AI”, menyatakan bahwa Google sedang mengubah pencarian dari kueri responsif menjadi asisten cerdas yang prediktif dan dipersonalisasi melalui fitur seperti “AI Overview” dan “AI Mode”. Dia menekankan bahwa investasi jangka panjang Google dalam infrastruktur AI (TPU yang dikembangkan sendiri, pusat data skala besar) dan efisiensi model adalah keunggulan inti, yang mampu menyediakan model canggih dengan biaya yang efektif. Pichai percaya bahwa AI adalah “platform teknologi untuk semua skenario” yang akan membentuk kembali bisnis inti seperti Pencarian, YouTube, dan Cloud, serta melahirkan bentuk-bentuk baru. Dia juga menyebutkan bahwa daya saing AI Tiongkok (seperti DeepSeek) tidak dapat diabaikan dan menunjukkan bahwa listrik akan menjadi kendala utama bagi pengembangan AI. (Sumber: 36氪)

Daftar perusahaan rintisan (startup) aplikasi AI di bidang pendidikan: Artikel ini merangkum 13 perusahaan rintisan AI di bidang pendidikan yang patut diperhatikan pada tahun 2025. Mereka mengubah cara mengajar melalui jalur pembelajaran yang dipersonalisasi, sistem bimbingan cerdas, penilaian otomatis, dan pembuatan konten imersif. Misalnya, Merlyn adalah asisten AI yang dikendalikan suara untuk mengurangi beban administrasi guru; Brisk Teaching adalah ekstensi Chrome yang menyederhanakan tugas mengajar; Edexia adalah platform penilaian AI yang mempelajari gaya guru; Storytailor menggabungkan biblioterapi dengan AI untuk membuat cerita yang dipersonalisasi; Brainly menyediakan bimbingan pekerjaan rumah yang ditingkatkan AI. Perusahaan-perusahaan ini menunjukkan potensi aplikasi AI yang luas di bidang pendidikan, mulai dari meningkatkan efisiensi hingga mewujudkan pembelajaran yang dipersonalisasi dan kesetaraan pendidikan. (Sumber: 36氪)
Drama pendek AI menghadapi tantangan teknis dan komersialisasi, efek produksi dan ekspektasi masih timpang: Meskipun alat AI diharapkan dapat mengurangi biaya produksi drama pendek dan mempersingkat siklusnya, para praktisi menemukan bahwa drama pendek AI memiliki kesulitan teknis yang signifikan dalam hal konsistensi subjek, sinkronisasi gerakan bibir, dan kealamian bahasa kamera, yang menyebabkan banyak karya lebih mirip “drama pendek gaya PPT”. AI sulit memahami ide-ide kreatif surealis, yang membatasi pengembangan tema fantasi dan fiksi ilmiah. Saat ini, teknologi AI lebih cocok untuk membuat film pendek daripada drama pendek lengkap, dan prospek komersialisasinya tidak jelas. Perusahaan film dan televisi besar seperti Bona Film Group dan Huace Group lebih mungkin untuk membuat terobosan dengan keunggulan sumber daya mereka, sementara sebagian besar kreator kecil menghadapi masalah biaya coba-coba yang tinggi dan iterasi teknologi yang cepat yang menyebabkan karya cepat usang. (Sumber: 36氪)
MSI meluncurkan PC AI yang terintegrasi dengan superchip NVIDIA GB10, berisi 6144 CUDA core dan memori LPDDR5X 128GB: MSI memamerkan EdgeExpert MS-C931 S miliknya, sebuah PC AI yang ditenagai oleh superchip NVIDIA GB10. Chip ini dikonfirmasi memiliki 6144 CUDA core dan memori LPDDR5X 128GB. Ini adalah produsen lain setelah ASUS, Dell, dan Lenovo yang meluncurkan komputer AI pribadi berdasarkan arsitektur NVIDIA DGX Spark. Peluncuran produk semacam itu menandakan bahwa kemampuan komputasi AI berkinerja tinggi secara bertahap merambah ke perangkat pribadi dan edge, tetapi ada juga komentar yang menunjukkan bahwa harganya mungkin membuatnya sulit bersaing dengan produk seperti Mac Mini. (Sumber: Reddit r/LocalLLaMA)
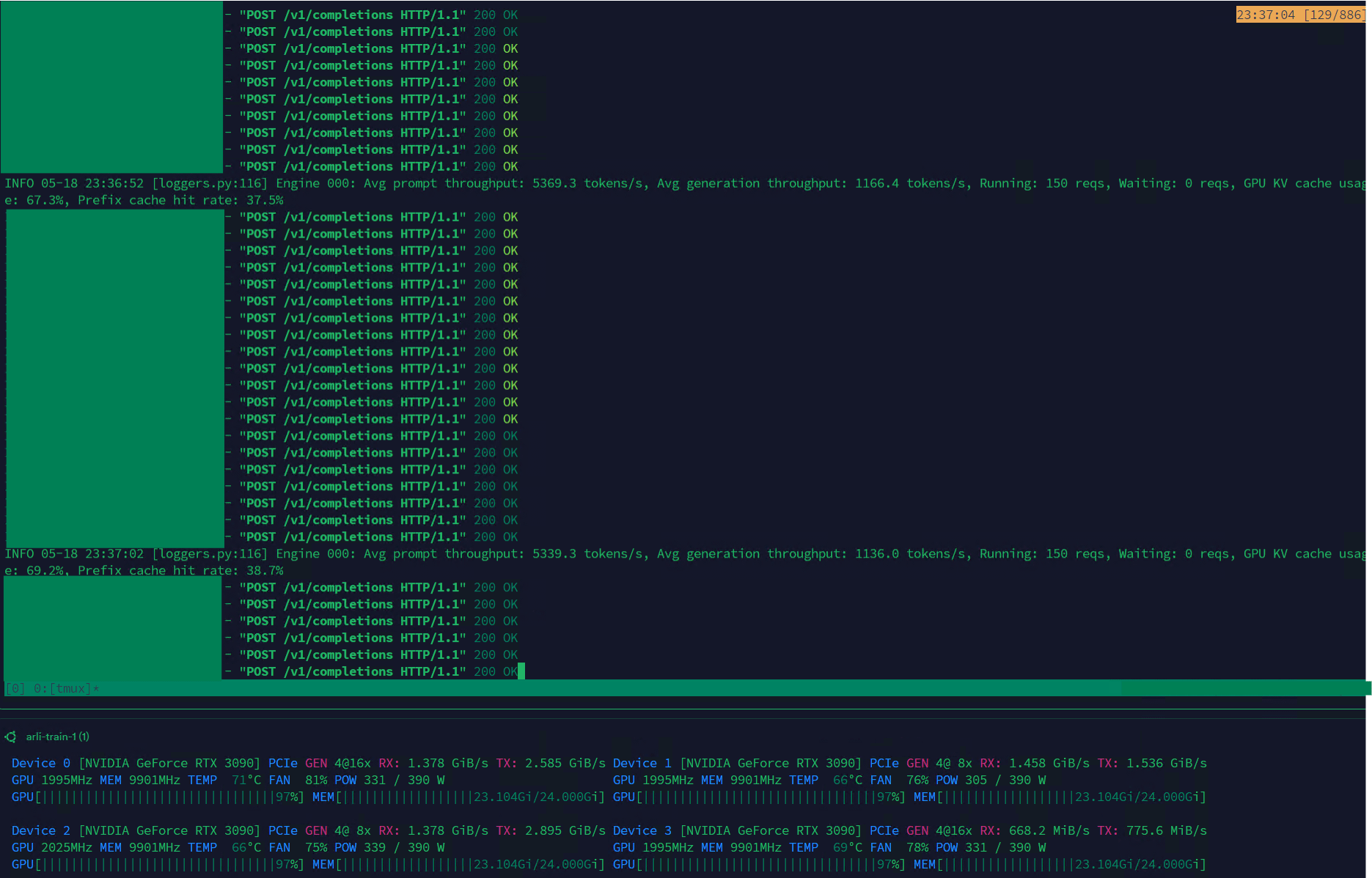
Qwen3-30B mencapai throughput tinggi pada VLLM, cocok untuk manajemen dataset: Model Qwen3-30B-A3B menunjukkan kecepatan inferensi yang sangat baik (5K t/s prefill, 1K t/s generation) pada kerangka kerja VLLM dan kartu grafis RTX 3090s, menjadikannya sangat cocok untuk tugas-tugas seperti pemfilteran dan manajemen dataset. Meskipun mungkin sedikit mengalami regresi dibandingkan dengan QwQ, keunggulan kecepatannya membuatnya lebih praktis dalam pemrosesan data. Masalah utama saat ini adalah kecepatan pelatihan yang sangat lambat, tetapi sudah ada PR di pustaka Hugging Face Transformers yang mencoba mengatasi masalah ini, dan di masa depan diharapkan akan ada model RpR dengan dataset yang ditingkatkan berdasarkan Qwen3-30B. (Sumber: Reddit r/LocalLLaMA)
Bilibili membuka sumber model pembuatan video animasi Index-AniSora, mendukung berbagai gaya anime: Bilibili meluncurkan model sumber terbuka Index-AniSora yang dirancang khusus untuk pembuatan video anime, berdasarkan kerangka kerja teknologi AniSora miliknya (telah diterima oleh IJCAI25). Model ini dapat mengubah manga menjadi animasi dengan sekali klik, mendukung berbagai gaya seperti serial anime, animasi Tiongkok, adaptasi manga, dan VTuber. Sistem AniSora membangun dataset pasangan teks-video berkualitas tinggi berskala puluhan juta, mengembangkan kerangka kerja pembuatan difusi terpadu, dan memperkenalkan mekanisme masking spasial-temporal untuk mencapai kontrol halus atas gerakan bibir dan tindakan karakter. Sementara itu, Bilibili merancang tolok ukur evaluasi untuk video animasi dan sistem evaluasi otomatis yang dioptimalkan berdasarkan VLM. Konten sumber terbuka akan mencakup AniSoraV1.0 (berdasarkan CogVideoX-5B), AniSoraV2.0 (berdasarkan Wan2.1-14B, mendukung pelatihan Huawei 910B), serta alat bantu pembuatan dan evaluasi dataset terkait. (Sumber: WeChat)

ByteDance merilis model bahasa visual Seed1.5-VL, berkinerja unggul dalam tugas multimodal: ByteDance meluncurkan model bahasa visual Seed1.5-VL, yang terdiri dari encoder visual dengan parameter 532M dan LLM mixture-of-experts (MoE) dengan parameter aktif 20B. Model ini mencapai kinerja SOTA (state-of-the-art) pada 38 dari 60 tolok ukur publik, dan melampaui sistem terkemuka seperti OpenAI CUA dan Claude 3.7 dalam tugas-tugas yang berpusat pada agen seperti kontrol GUI dan gameplay, menunjukkan kemampuan pemahaman dan penalaran multimodal yang kuat. (Sumber: WeChat)
Nous Research meluncurkan Psyche Network, mewujudkan pra-pelatihan LLM 40 miliar parameter secara terdistribusi: Nous Research merilis Psyche Network, sebuah jaringan pelatihan terdesentralisasi berdasarkan arsitektur DeepSeek V3 MLA, yang dalam pengujian pertamanya melakukan pra-pelatihan pada model bahasa besar dengan 40 miliar parameter. Jaringan ini menggunakan optimizer DisTrO dan tumpukan jaringan peer-to-peer kustom, mengintegrasikan daya komputasi GPU terdistribusi global, memungkinkan individu dan kelompok kecil untuk berlatih pada satu H/DGX dan berjalan pada GPU 3090. Langkah ini bertujuan untuk mematahkan monopoli daya komputasi raksasa teknologi dan membuat pelatihan model skala besar lebih mudah diakses. (Sumber: 量子位)

🧰 Alat
Sim Studio: Pembangun alur kerja agen AI sumber terbuka: Sim Studio adalah platform pembangunan alur kerja agen AI sumber terbuka yang ringan, menyediakan antarmuka intuitif bagi pengguna untuk membangun dan menerapkan aplikasi LLM yang terhubung ke berbagai alat dengan cepat. Mendukung versi yang di-host di cloud dan self-hosted (direkomendasikan lingkungan Docker, mendukung model lokal seperti Ollama). Tumpukan teknologinya meliputi Next.js, Bun, PostgreSQL, Drizzle ORM, Better Auth, Shadcn UI, Tailwind CSS, Zustand, ReactFlow, dan Turborepo. (Sumber: GitHub Trending)

Cherry Studio: Aplikasi desktop front-end LLM sumber terbuka dengan fitur lengkap menarik perhatian: Cherry Studio adalah aplikasi desktop front-end LLM sumber terbuka yang mengintegrasikan berbagai fungsi seperti RAG, pencarian web, model lokal (melalui koneksi Ollama, LM Studio), dan akses model cloud (seperti Gemini, ChatGPT). Umpan balik pengguna menunjukkan bahwa dukungan dan manajemen MCP (Multi-Control Protocol) lebih unggul daripada Open WebUI dan LibreChat, serta mudah dipasang dan diatur. Aplikasi ini juga mendukung koneksi langsung ke basis pengetahuan Obsidian. Meskipun beberapa pengguna menyatakan kekhawatiran tentang sumbernya, rangkaian fiturnya yang komprehensif menjadikannya pilihan yang menarik. (Sumber: Reddit r/LocalLLaMA)

MLX-LM-LoRA: Menambahkan LoRA ke model MLX dan mendukung berbagai metode pelatihan: Proyek sumber terbuka mlx-lm-lora memungkinkan pengguna untuk mengintegrasikan modul LoRA (Low-Rank Adaptation) ke dalam model di bawah kerangka kerja Apple MLX. Proyek ini tidak hanya mendukung penambahan LoRA, tetapi juga menyertakan berbagai metode pelatihan alignment seperti ORPO, DPO, CPO, GRPO, sehingga memudahkan pengguna untuk melakukan fine-tuning model sesuai kebutuhan mereka, menghasilkan modul LoRA yang disesuaikan, dan menerapkannya pada model MLX pilihan mereka. (Sumber: karminski3)
DeepDrone: Proyek drone yang dikendalikan AI berbasis Qwen kini open source: Seorang pengembang membuat proyek drone yang dikendalikan AI bernama DeepDrone berdasarkan model besar Qwen, dan telah membukanya sebagai sumber terbuka di HuggingFace dan GitHub. Proyek ini menunjukkan potensi penerapan model bahasa besar pada kontrol otonom drone, memicu diskusi tentang AI dalam otomatisasi dan potensi aplikasi militer. (Sumber: karminski3)
Qwen Web Dev: Hasilkan dan terapkan situs web dengan satu prompt: Tim Qwen Alibaba mengumumkan bahwa alat Qwen Web Dev mereka telah ditingkatkan, memungkinkan pengguna untuk menghasilkan situs web hanya dengan satu prompt dan dapat menerapkannya dengan sekali klik. Alat ini bertujuan untuk menurunkan hambatan pengembangan web, memungkinkan pengguna untuk mengubah ide menjadi situs web yang dapat diakses secara lebih mudah dan membagikannya dengan dunia. (Sumber: Alibaba_Qwen, huybery)
SuperGo.AI: Alat antarmuka tunggal yang mengintegrasikan delapan model LLM: Seorang penggemar AI mengembangkan alat bernama SuperGo.AI, yang mengintegrasikan delapan LLM dengan peran berbeda (seperti AI Super Brain, AI Imagination, AI Ethics, AI Universe, dll.) dalam satu antarmuka. Peran AI ini dapat saling merasakan dan berinteraksi, dan pengguna dapat memilih mode “Kreatif”, “Ilmiah”, dan “Campuran” untuk mendapatkan respons gabungan. Alat ini bertujuan untuk memberikan pengalaman kolaborasi multi-AI yang baru dan saat ini tidak memiliki paywall. (Sumber: Reddit r/artificial)
Kokoro-JS: Mewujudkan text-to-speech (TTS) lokal tanpa batas: Kokoro-JS adalah alat text-to-speech yang 100% berjalan secara lokal dan 100% sumber terbuka, diwujudkan dengan mengunduh model AI sekitar 300MB di sisi browser. Teks yang dimasukkan pengguna tidak dikirim ke server mana pun, menjamin privasi dan ketersediaan offline. Alat ini bertujuan untuk menyediakan fungsionalitas TTS tanpa batas. (Sumber: Reddit r/LocalLLaMA)
📚 Pembelajaran
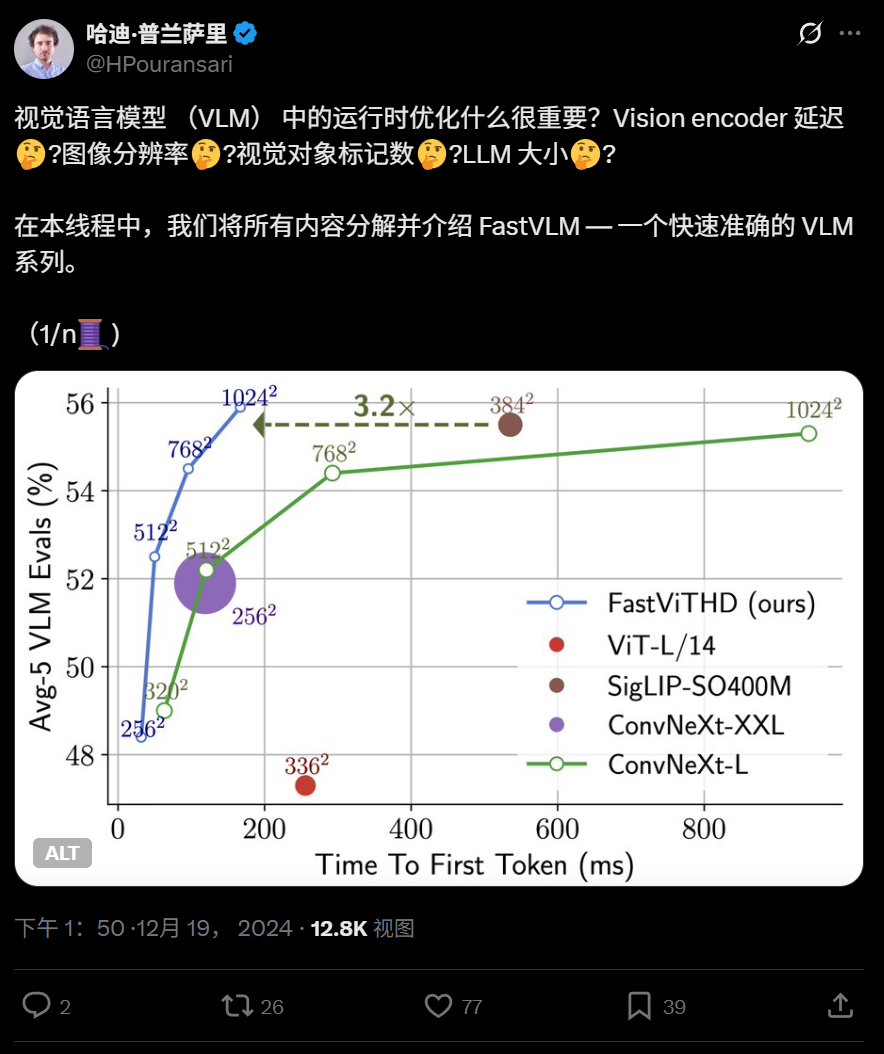
Apple membuka sumber model bahasa visual efisien FastVLM, dioptimalkan untuk berjalan di perangkat: Apple Inc. membuka sumber FastVLM, sebuah model bahasa visual yang dirancang khusus untuk berjalan secara efisien pada perangkat seperti iPhone. FastVLM memperkenalkan encoder visual hibrida baru FastViTHD, yang menggabungkan lapisan konvolusional dengan modul Transformer, dan menggunakan teknik pooling multi-skala serta downsampling, secara signifikan mengurangi jumlah token visual yang diperlukan untuk memproses gambar (16 kali lebih sedikit dari ViT tradisional), dengan kecepatan output token pertama meningkat 85 kali lipat. Model ini kompatibel dengan LLM utama dan telah menyediakan aplikasi demo berbasis kerangka kerja MLX untuk iOS/macOS, cocok untuk perangkat edge dan tugas teks-gambar real-time. (Sumber: WeChat)
Harbin Institute of Technology dan University of Pennsylvania mengusulkan PointKAN, meningkatkan analisis point cloud 3D berbasis KAN: Tim peneliti dari Harbin Institute of Technology (Shenzhen) dan University of Pennsylvania meluncurkan PointKAN, sebuah arsitektur persepsi 3D baru berdasarkan Kolmogorov-Arnold Networks (KANs). PointKAN menggantikan fungsi aktivasi tetap dalam MLP tradisional dengan fungsi aktivasi yang dapat dipelajari, meningkatkan kemampuan untuk mempelajari fitur geometris yang kompleks. Arsitektur ini mencakup modul afinitas geometris dan modul ekstraksi fitur lokal paralel. Tim juga mengusulkan versi PointKAN-elite, yang mengadopsi struktur Efficient-KANs, menggunakan fungsi rasional sebagai fungsi dasar dan berbagi parameter secara berkelompok, secara signifikan mengurangi jumlah parameter dan kompleksitas komputasi, sambil menunjukkan kinerja SOTA (state-of-the-art) dalam tugas klasifikasi, segmentasi bagian, dan pembelajaran sampel kecil. (Sumber: 量子位)

University of Pittsburgh mengusulkan kerangka kerja PhyT2V, meningkatkan realisme fisik video yang dihasilkan AI: Intelligent Systems Laboratory di University of Pittsburgh mengembangkan kerangka kerja PhyT2V, yang bertujuan untuk meningkatkan konsistensi fisik konten yang dihasilkan oleh model text-to-video (T2V). Metode ini tidak memerlukan pelatihan ulang model atau data eksternal skala besar. Melalui penalaran berantai (Chain-of-Thought/CoT) yang dipandu oleh model bahasa besar (LLM) dan mekanisme koreksi diri iteratif, PhyT2V melakukan analisis dan optimalisasi aturan fisik multi-putaran pada prompt teks. PhyT2V mampu mengidentifikasi aturan fisik, ketidakcocokan semantik, dan menghasilkan prompt yang dikoreksi, sehingga meningkatkan kemampuan generalisasi model T2V utama (seperti CogVideoX, OpenSora) dalam skenario fisik realistis (benda padat, fluida, gravitasi, dll.), terutama efektif dalam skenario di luar distribusi, dengan peningkatan hingga 2,3 kali lipat pada metrik pemahaman akal sehat fisik (PC) dan kepatuhan semantik (SA). (Sumber: WeChat)
Riset terbaru LLM: Multimodal, alignment saat pengujian, Agent, optimasi RAG, dll.: Kemajuan riset LLM mingguan meliputi: 1. University of Washington mengusulkan QALIGN, metode alignment saat pengujian tanpa memodifikasi model atau mengakses logits, mencapai alignment yang lebih baik dalam pembuatan teks melalui MCMC. 2. UCLA melakukan pra-pelatihan Clinical ModernBERT, memperluas panjang konteks encoder di bidang biomedis hingga 8192 token. 3. Skoltech mengusulkan metode pengambilan RAG adaptif mandiri yang ringan dan independen dari LLM, berdasarkan informasi eksternal (popularitas entitas, jenis pertanyaan). 4. PSU mendefinisikan masalah atribusi kesalahan otomatis sistem multi-Agent LLM, dan mengembangkan dataset serta metode evaluasi. 5. Fudan University mengusulkan kerangka kerja batasan multi-dimensi dan alur kerja pembuatan instruksi otomatis, meningkatkan kemampuan LLM dalam mengikuti instruksi. 6. a-m-team membuka sumber AM-Thinking-v1 (32B), dengan kemampuan pengkodean matematika yang sebanding dengan DeepSeek-R1-671B. 7. Xiaomi meluncurkan MiMo-7B, yang menunjukkan kinerja luar biasa dalam tugas penalaran melalui optimalisasi pra-pelatihan dan pasca-pelatihan. 8. MiniMax mengusulkan model TTS autoregresif MiniMax-Speech, mendukung kloning timbre zero-shot dalam 32 bahasa. 9. ByteDance membangun model bahasa visual Seed1.5-VL, yang menonjol dalam tugas multimodal dan tugas yang berpusat pada agen. 10. Model bahasa 32B parameter pertama di dunia, INTELLECT-2, mencapai pelatihan reinforcement learning terdistribusi, mengusulkan kerangka kerja PRIME-RL. (Sumber: WeChat)
Lokakarya AAAI 2025 fokus pada penalaran neural, penemuan matematika, dan AI untuk percepatan sains dan teknik: Lokakarya AAAI 2025 membahas secara mendalam aplikasi AI di bidang ilmiah. Di antaranya, lokakarya “Penalaran Neural dan Penemuan Matematika” menekankan bahwa jaringan neural kotak hitam dapat digunakan untuk mengajukan dugaan matematika dan menghasilkan geometri baru, tetapi juga menunjukkan ketidakmampuannya mencapai penalaran logis tingkat simbolik, dan menganjurkan pendekatan lintas disiplin. Lokakarya lain, “AI untuk Mempercepat Sains dan Teknik” (edisi keempat, dengan tema Biosains AI), berfokus pada model dasar untuk desain terapi, model generatif untuk penemuan obat, desain antibodi loop tertutup di laboratorium, pembelajaran mendalam dalam genomik, dan inferensi kausal dalam aplikasi biologis, serta membahas tantangan dan peluang model generatif dalam biosains. (Sumber: aihub.org)

Google dan Anthropic berselisih pendapat mengenai penelitian interpretabilitas AI, interpretabilitas mekanistik hadapi tantangan: Sifat “kotak hitam” AI menyebabkan penerapannya terbatas di banyak bidang penting. Google DeepMind baru-baru ini mengumumkan penurunan prioritas penelitian “interpretabilitas mekanistik” (mechanistic interpretability), berpendapat bahwa rekayasa balik mekanisme internal AI melalui metode seperti sparse autoencoders (SAE) menghadapi banyak masalah, seperti kurangnya referensi objektif, cakupan konsep yang tidak lengkap, distorsi fitur, dll., dan teknologi SAE yang ada belum berhasil mengidentifikasi “konsep” yang diperlukan dalam tugas-tugas penting. Sementara itu, CEO Anthropic Dario Amodei menganjurkan penguatan penelitian di bidang ini dan menyatakan optimisme tentang pencapaian “pencitraan resonansi magnetik nuklir AI” dalam 5-10 tahun ke depan. Perdebatan ini menyoroti tantangan mendalam dalam memahami dan mengendalikan perilaku AI. (Sumber: 36氪)

Peking University/StepFun/Lightelligence mengusulkan InfiniteHBD: Arsitektur domain bandwidth tinggi GPU generasi baru untuk mengurangi biaya dan meningkatkan efisiensi: Menanggapi keterbatasan arsitektur domain bandwidth tinggi (HBD) yang ada dalam hal skalabilitas, biaya, dan toleransi kesalahan, tim dari Peking University, StepFun (阶跃星辰), dan Lightelligence (曦智科技) mengusulkan arsitektur InfiniteHBD. Arsitektur ini berpusat pada modul optical switch (OCSTrx), dengan menyematkan kemampuan optical switch (OCS) berbiaya rendah dalam modul konversi optoelektronik, mewujudkan topologi K-Hop Ring yang dapat dikonfigurasi ulang secara dinamis pada skala pusat data dan isolasi kesalahan tingkat node. Biaya unit InfiniteHBD hanya 31% dari NVL-72, tingkat pemborosan GPU mendekati nol, dan MFU (Model FLOPs Utilization) meningkat hingga 3,37 kali lipat dibandingkan NVIDIA DGX, memberikan solusi yang lebih optimal untuk pelatihan model besar skala besar. Paper ini telah diterima oleh SIGCOMM 2025. (Sumber: WeChat)

OceanBase merilis PowerRAG, sepenuhnya merangkul AI, membangun fondasi data terintegrasi Data×AI: OceanBase dalam konferensi pengembangnya merilis produk aplikasi berorientasi AI, PowerRAG, yang bertujuan untuk menyediakan kemampuan pengembangan RAG siap pakai, menghubungkan data, platform, antarmuka, dan lapisan aplikasi. CTO Yang Chuanhui menjelaskan secara rinci strategi AI OceanBase: membangun kemampuan Data×AI, berevolusi dari database terintegrasi menjadi fondasi data terintegrasi. OceanBase akan meningkatkan kemampuan vektor, meningkatkan pencarian gabungan, mewujudkan pembaruan dinamis penyimpanan pengetahuan perusahaan, mengintegrasikan secara mendalam pasca-pelatihan dan fine-tuning model, dan telah beradaptasi dengan platform Agen utama seperti Dify, FastGPT, serta protokol MCP. Kinerja vektornya menunjukkan keunggulan dalam pengujian VectorDBBench, dan secara signifikan mengurangi kebutuhan memori melalui algoritma kuantisasi BQ. (Sumber: WeChat)

💼 Bisnis
Dana investasi milik Shanghai State-owned Assets Investment berinvestasi di perusahaan chip AI seperti Xinyaohui, Enflame Technology, dan Biren Technology: Shanghai State-owned Assets Investment Co., Ltd. (Shanghai SASAC Investment) baru-baru ini menandatangani perjanjian investasi dengan tiga perusahaan semikonduktor: Xinyaohui (芯耀辉), Enflame Technology (燧原科技), dan Biren Technology (壁仞科技). Sebelumnya, dana induk AI perintisnya telah memimpin pendanaan pra-IPO Biren Technology. Shanghai SASAC Investment menyatakan akan secara aktif melakukan布局 di jalur model dasar, chip komputasi, dan embodied intelligence. Xinyaohui berfokus pada IP semikonduktor, terutama teknologi Chiplet, pendirinya Zeng Keqiang pernah menjabat sebagai wakil presiden Synopsys China. Enflame Technology dan Biren Technology keduanya adalah perusahaan desain chip GPU. Langkah ini menunjukkan fokus布局 Shanghai SASAC Investment di hulu rantai industri AI, terutama di bidang chip komputasi. (Sumber: 36氪)
Sakana AI dan Mitsubishi UFJ Bank mencapai kemitraan komprehensif, mengembangkan AI khusus untuk perbankan: Perusahaan rintisan AI Jepang, Sakana AI, mengumumkan penandatanganan perjanjian kemitraan multi-tahun dengan Mitsubishi UFJ Bank (MUFG). Sakana AI akan mengembangkan agen AI yang dirancang khusus untuk operasi perbankan bagi MUFG, yang bertujuan untuk mendorong transformasi bisnis perbankan dan aplikasi praktis AI. Sementara itu, salah satu pendiri dan COO Sakana AI, Ren Ito, akan menjabat sebagai penasihat MUFG, membantu bank tersebut dalam mengimplementasikan strategi AI-nya. Kerja sama ini menandai langkah penting bagi Sakana AI dalam menerapkan teknologi AI canggih untuk memecahkan masalah spesifik di industri keuangan Jepang. (Sumber: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

Salah satu pendiri 01.AI Gu Xuemei mengundurkan diri untuk memulai usaha baru, fokus bisnis perusahaan beralih ke B2B: Gu Xuemei, salah satu pendiri 01.AI (零一万物) yang bertanggung jawab atas pra-pelatihan model dan produk C-end, telah mengundurkan diri beberapa bulan lalu dan saat ini sedang mempersiapkan usaha baru. 01.AI mengonfirmasi hal ini dan berterima kasih atas kontribusinya. Sejak 2025, fokus bisnis 01.AI telah beralih dari aplikasi AI ToC dan API model ke skenario B2B seperti digital human, kustomisasi model, dan deployment. Produk C-endnya seperti alat kantor versi domestik “Wanzhi” (万知) telah berhenti beroperasi karena jumlah pengguna yang tidak sesuai harapan, dan komersialisasi produk role-playing luar negeri Mona juga tidak ideal. Sebelumnya, salah satu pendiri Dai Zonghong juga telah mengundurkan diri untuk memulai usaha baru. (Sumber: 36氪)

🌟 Komunitas
Deteksi AIGC pada skripsi AI menuai kontroversi, akurasi dipertanyakan, kelulusan mahasiswa terpengaruh: Tahun ini banyak perguruan tinggi memperkenalkan deteksi AIGC sebagai bagian dari proses peninjauan skripsi, bertujuan untuk mencegah mahasiswa menyalahgunakan AI dalam penulisan. Namun, langkah ini menimbulkan kontroversi luas. Mahasiswa melaporkan bahwa konten yang mereka tulis sendiri sering salah terdeteksi sebagai hasil buatan AI, sementara setelah direvisi dengan bantuan AI, tingkat kecurigaan justru meningkat. Bahkan ada tes yang menunjukkan bahwa “Tengwang Ge Xu” (滕王阁序, sebuah karya sastra klasik Tiongkok) memiliki tingkat kecurigaan buatan AI hingga 99,2%. Alat deteksi AIGC sendiri juga didorong oleh AI, prinsipnya adalah menganalisis fitur bahasa teks dan membandingkannya dengan pola penulisan AI, tetapi akurasinya diragukan, alat awal OpenAI hanya memiliki akurasi 26%. Ketidakpastian ini tidak hanya menimbulkan kesulitan dan biaya tambahan bagi mahasiswa (hasil dari situs deteksi yang berbeda bervariasi, layanan pengurangan plagiarisme berbayar), tetapi juga menimbulkan refleksi tentang esensi alat AI: AI meniru tulisan manusia, lalu menggunakan AI untuk mendeteksi apakah tulisan manusia mirip AI, ini sendiri mengandung paradoks logis. (Sumber: 36氪)

Fitur baru ChatGPT terhubung langsung ke Github: Riset mendalam repositori kode dan dokumen profesional: Fitur Deep Research yang baru diluncurkan ChatGPT menambahkan kemampuan untuk terhubung langsung ke repositori Github. Pengguna dapat memberikan otorisasi kepada ChatGPT untuk mengakses repositori publik atau pribadi mereka, melakukan analisis kode mendalam, merangkum arsitektur fungsional, mengidentifikasi tumpukan teknologi, mengevaluasi kualitas kode, dan menganalisis kesesuaian proyek. Fitur ini tidak terbatas pada kode; pengguna dapat mengunggah berbagai jenis dokumen seperti PDF dan Word ke repositori Github, memanfaatkan ChatGPT untuk melakukan riset mendalam pada materi bidang tertentu, yang setara dengan kombinasi RAG+MCP dalam lingkup terbatas. Fitur ini saat ini tersedia untuk pengguna Plus. Dengan membatasi lingkup penelitian, diharapkan dapat meningkatkan profesionalisme dan akurasi laporan penelitian, serta mengurangi halusinasi. (Sumber: 36氪)
Persaingan pasar AI Agent meningkat, Manus membuka pendaftaran secara penuh, raksasa seperti ByteDance dan Baidu ikut serta: Manus, yang dikenal sebagai “Agen Serba Bisa”, mengumumkan pada 12 Mei bahwa pendaftaran telah dibuka sepenuhnya, pengguna dapat memperoleh kuota penggunaan tanpa perlu menunggu. Sementara itu, pasar dirumorkan bahwa Manus sedang dalam putaran pendanaan baru dengan valuasi $1,5 miliar. Sejak dirilis pada bulan Maret, Manus telah memicu gelombang proyek serupa Agen, tetapi juga menghadapi tantangan penurunan lalu lintas dan munculnya produk pesaing. ByteDance meluncurkan Coze Space, Baidu meluncurkan “Miaoda” (秒哒) dan “Xinxiang” (心响), dan Agen desain Lovart juga memulai pengujian. Pasar Agen sedang beralih dari validasi konsep awal ke persaingan menyeluruh dalam hal fungsionalitas produk, model bisnis, dan pertumbuhan pengguna. (Sumber: 36氪)
AI辅助编码改变开发者工作流,提高生产力但需警惕过度依赖: Pengguna Reddit berbagi bagaimana asisten kode AI secara signifikan mengubah pengalaman pengkodean mereka, terutama dalam menangani proyek warisan besar dan memahami kode yang kompleks. Alat AI dapat menjelaskan kode baris demi baris, memberikan saran, menyorot potensi masalah, merangkum file, mencari fragmen, dan menghasilkan komentar, seolah-olah memiliki bimbingan ahli sepanjang waktu. Komentar menunjukkan bahwa AI dapat menyelesaikan pengkodean berulang, meningkatkan efisiensi, memandu metode baru, menambahkan komentar, dan bahkan membantu pengembang menyelesaikan tugas di luar jangkauan kemampuan mereka, mempersingkat pekerjaan berhari-hari menjadi berjam-jam. Namun, ini juga menimbulkan pemikiran tentang evolusi keterampilan pengembang dan ketergantungan pada alat AI. (Sumber: Reddit r/artificial)
Pengguna aktif bulanan Kimi menurun, Moonshot AI mencari terobosan vertikal dan transformasi sosial: Kimi Chat milik Moonshot AI (月之暗面) dalam data QuestMobile menunjukkan penurunan pengguna aktif bulanan dari 36 juta pada Oktober tahun lalu menjadi 18,2 juta pada Maret tahun ini, turun ke peringkat keempat. Untuk meningkatkan retensi pengguna, Kimi beralih dari model besar umum ke perluasan bidang vertikal, seperti bekerja sama dengan Caixin Media untuk meningkatkan kualitas pencarian konten keuangan, merambah pencarian medis AI, dan memperkenalkan konten video Bilibili. Sementara itu, Kimi meluncurkan tantangan check-in di Xiaohongshu, mencoba menjangkau lebih banyak pengguna C-end melalui platform sosial. Antarmuka penggunanya juga disesuaikan ke arah multimodal, mirip Doubao (豆包), dan berorientasi komunitas. Menghadapi pesaing seperti DeepSeek dan masuknya perusahaan besar ke aplikasi AI, posisi kepemimpinan teknologi Kimi terancam, tekanan komersialisasi meningkat, dan secara aktif mencari titik pertumbuhan baru. (Sumber: 36氪)
Diskusi tentang apakah AI harus menyebut dirinya dengan kata ganti orang pertama: Pengguna Reddit memulai diskusi, berpendapat bahwa LLM seperti ChatGPT yang menyebut dirinya “saya” atau menyebut pengguna “Anda” mungkin tidak pantas, karena pada dasarnya mereka adalah “benda” bukan “orang”. Disarankan agar mereka menggunakan kata ganti orang ketiga seperti “ChatGPT akan membantu Anda…” untuk menghindari memberi kesan kepada pengguna bahwa mereka adalah entitas yang dipersonifikasikan, yang berpotensi menimbulkan bahaya atau masalah etika. Dalam komentar, ada yang berpendapat bahwa kata ganti orang ketiga justru menyiratkan kesadaran diri, ada juga yang merasa kata ganti orang ketiga terdengar konyol dan tidak nyaman. Diskusi ini mencerminkan pemikiran pengguna tentang定位 identitas AI dan cara interaksi manusia-mesin. (Sumber: Reddit r/ArtificialInteligence)
💡 Lain-lain
MIT menarik kembali secara darurat sebuah paper AI yang banyak diperhatikan, menyebutkan keraguan atas keaslian data dan penelitian: Massachusetts Institute of Technology (MIT) menarik kembali paper yang ditulis oleh mahasiswa doktoral departemen ekonominya, Aidan Toner-Rogers, berjudul “Artificial Intelligence, Scientific Discovery, and Product Innovation”. Paper ini sebelumnya menarik banyak perhatian karena mengemukakan bahwa alat AI dapat secara signifikan meningkatkan efisiensi inovasi ilmuwan terkemuka, tetapi mungkin memperburuk “kesenjangan kaya-miskin” dalam penelitian ilmiah dan menurunkan kebahagiaan peneliti biasa, serta mendapat pujian dari profesor terkenal termasuk peraih Nobel. MIT menyatakan bahwa setelah menerima laporan integritas penelitian dan melakukan penyelidikan internal, mereka kehilangan kepercayaan pada sumber data, keandalan, validitas, dan keaslian penelitian paper tersebut, dan telah meminta arXiv serta “Quarterly Journal of Economics” untuk menarik paper tersebut. Penulis telah meninggalkan MIT, dan profesor terkait juga mengeluarkan pernyataan untuk menjauhkan diri. Dilaporkan bahwa selama penyelidikan, penulis membeli domain palsu untuk menyamar sebagai email perusahaan besar, kemudian ketahuan dan dituntut. (Sumber: 36氪)

Gambar yang dihasilkan AI digunakan untuk penipuan online, memicu kewaspadaan pengguna: Pengguna Reddit berbagi kasus di media sosial seperti Facebook di mana gambar orang yang dihasilkan AI digunakan untuk promosi produk. Gambar-gambar ini seringkali memiliki ketidaklogisan pada orang dan pemandangan (seperti model yang masuk dan keluar dari kotak dengan cara yang aneh, munculnya orang yang tidak relevan di latar belakang, dll.), tetapi konsistensi citra karakter cukup tinggi. Komentator menunjukkan bahwa konten yang dihasilkan AI semacam ini telah digunakan untuk penipuan, mengingatkan pengguna untuk waspada. Blogger seperti Pleasant Green juga telah membuat video yang mengungkap penipuan semacam ini. (Sumber: Reddit r/ChatGPT)
Pembahasan tentang peniruan gaya gambar yang dihasilkan AI dan ekstraksi prompt: Pengguna membahas bagaimana membuat model AI (seperti DALL-E 3) meniru gaya artistik tertentu (seperti gaya Pixar yang dikombinasikan dengan gaya Designer Toy dari Salvador Dalí) untuk membuat potret karakter, dan membagikan prompt terperinci, menekankan fitur karakter, latar belakang, pencahayaan, dan konsep inti (seperti bayangan sebagai proyeksi spiritual). Selain itu, ada pengguna yang menyediakan templat prompt untuk mengekstrak parameter gaya dari gambar dan mengeluarkannya dalam format JSON, yang bertujuan untuk membantu pengguna merekayasa balik gaya gambar, meskipun restorasi yang akurat masih sulit. (Sumber: dotey, dotey)
