
Kata Kunci:AlphaEvolve, DeepSeek V3, GPT-4.1, Speech-02, Claude Model, Falcon-Edge, BLIP3-o, AM-Thinking-v1, Agen Kecerdasan Evolusioner Berbasis Gemini, Desain Kolaboratif Perangkat Lunak-Hardware untuk Mengurangi Biaya Model Besar, Teknologi Kloning Suara Tanpa Sampel, Kemampuan Penalaran Ekstrem, Arsitektur BitNet 1.58-bit
🔥 Fokus
DeepMind meluncurkan AlphaEvolve: Agen pengkodean evolusioner yang didukung Gemini, mendorong penemuan algoritma : AlphaEvolve menggabungkan kreativitas model Gemini dengan evaluator otomatis, memanfaatkan kerangka kerja evolusioner untuk mengoptimalkan algoritma. AlphaEvolve telah mencapai terobosan di berbagai bidang, seperti menyelesaikan perkalian matriks kompleks 4×4 dengan 48 perkalian skalar, menyempurnakan algoritma Strassen; menemukan 593 konfigurasi bola luar dalam ruang 11 dimensi, memajukan “kissing number problem” yang telah berusia 300 tahun. Selain itu, AlphaEvolve juga mengoptimalkan penjadwalan pusat data Google (menghemat 0,7% sumber daya komputasi), desain TPU generasi berikutnya (menghapus bit redundan), pelatihan model AI (kernel utama dipercepat 23%), dan lainnya. Pemenang Fields Medal, Terence Tao, juga berpartisipasi dalam eksplorasi aplikasi matematisnya. (Sumber: DeepMind)

Penjelasan detail paper DeepSeek V3: Desain kolaboratif perangkat keras dan lunak mengurangi biaya dan konsumsi daya model besar : Tim DeepSeek merilis paper yang menjelaskan secara rinci bagaimana DeepSeek-V3 mencapai efektivitas biaya untuk pelatihan dan inferensi skala besar melalui desain kolaboratif perangkat keras dan lunak. Teknologi inti meliputi: 1) Optimasi memori: Mengadopsi Multi-Head Latent Attention (MLA) untuk mengompres cache kunci-nilai, pelatihan presisi campuran FP8 mengurangi konsumsi memori. 2) Optimasi komputasi: Menerapkan model Mixture of Experts (MoE), hanya mengaktifkan sebagian parameter, dan dikombinasikan dengan pelatihan FP8, secara signifikan mengurangi biaya komputasi. 3) Optimasi komunikasi: Mengadopsi topologi jaringan multi-plane fat-tree dan teknologi Dual Micro-batch Pipelining (DualPipe), mengurangi latensi, dan meningkatkan utilisasi GPU. 4) Akselerasi inferensi: Memperkenalkan kerangka kerja Multi-Token Prediction (MTP), memprediksi dan memvalidasi beberapa token kandidat secara paralel, meningkatkan kecepatan generasi. Paper ini juga mengajukan lima prospek untuk desain perangkat keras AI di masa depan, termasuk dukungan komputasi presisi rendah, ekspansi dan fusi, optimasi topologi jaringan, optimasi sistem memori, serta ketahanan dan toleransi kesalahan. (Sumber: arXiv)

Model OpenAI GPT-4.1 resmi diluncurkan di ChatGPT, pengguna dapat langsung memilihnya : OpenAI mengumumkan bahwa model GPT-4.1 telah tersedia di ChatGPT. Pengguna Plus, Pro, dan Team dapat mengaksesnya melalui pemilih model, sementara pengguna versi Enterprise dan Education akan mendapatkan akses nanti. GPT-4.1 mini juga akan menggantikan GPT-4o mini untuk semua pengguna. GPT-4.1 menarik perhatian karena kinerjanya yang luar biasa dalam tugas pengkodean dan kepatuhan terhadap instruksi. Sebelumnya, versi API mendukung jendela konteks hingga 1 juta Token. Namun, beberapa pengguna yang menguji menemukan bahwa panjang konteks versi GPT-4.1 di ChatGPT tampaknya masih 128k, belum mencapai 1M seperti versi API, yang menimbulkan kekecewaan. (Sumber: OpenAI Developers)

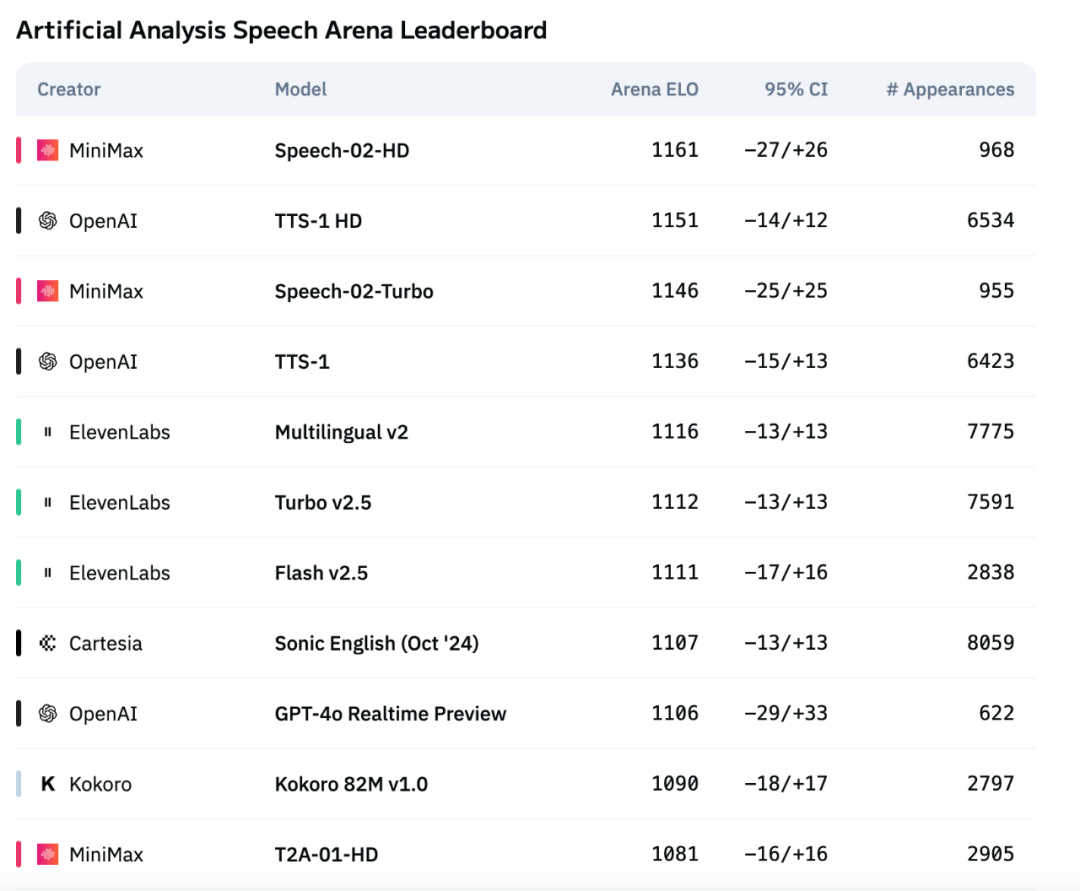
Model suara generasi baru MiniMax, Speech-02, menduduki puncak daftar peringkat evaluasi suara Artificial Analysis : Model text-to-speech (TTS) terbaru yang diluncurkan oleh MiniMax, Speech-02, memperoleh skor ELO tertinggi di daftar peringkat evaluasi suara internasional yang otoritatif, Artificial Analysis Speech Arena, melampaui produk sejenis dari OpenAI dan ElevenLabs. Model ini menunjukkan kinerja yang sangat baik pada metrik utama seperti Word Error Rate (WER) dan Speaker Similarity (SIM), terutama menunjukkan keunggulan lokal dalam pemrosesan bahasa Mandarin dan Kanton. Inovasi inti Speech-02 terletak pada realisasi kloning suara zero-shot yang sesungguhnya (hanya memerlukan beberapa detik audio referensi, tanpa teks) serta adopsi arsitektur Flow-VAE baru, yang meningkatkan kealamian dan ekspresivitas emosional generasi suara, dan mendukung 32 bahasa. Biayanya juga sangat kompetitif, sekitar 1/4 dari produk pesaing ElevenLabs. (Sumber: 机器之心)
🎯 Perkembangan
Model Claude versi baru Anthropic kemungkinan akan memiliki kemampuan “Extreme reasoning” : Menurut laporan The Information dan observasi komunitas, Anthropic kemungkinan akan merilis model Claude Sonnet dan Claude Opus versi baru dalam beberapa minggu ke depan. Sorotan terbesarnya adalah kemampuan “Extreme reasoning”. Fitur ini memungkinkan model untuk berhenti sejenak, mengevaluasi ulang, dan menyesuaikan strategi ketika menghadapi masalah sulit, alih-alih langsung memberikan jawaban. Dalam tugas seperti pembuatan kode, model dapat secara otomatis menguji dan memperbaiki kesalahan. Cara penalaran dan penggunaan alat yang dinamis dan berulang ini bertujuan agar model dapat menangani masalah kompleks dengan lebih cerdas, mengurangi ketergantungan pada pengawasan manusia, dan lebih mendekati cara berpikir kolaborator manusia. Beberapa pengguna telah menemukan bahwa Anthropic sedang menguji model bernama Claude Neptune (kemungkinan Claude 3.8), yang mendukung konteks 128k token. (Sumber: 量子位)
TII merilis seri model Bitnet efisien Falcon-Edge dan toolkit fine-tuning onebitllms : Technology Innovation Institute (TII) merilis Falcon-Edge, serangkaian model bahasa yang sangat terkompresi berdasarkan arsitektur BitNet, yang memiliki karakteristik kuat, serbaguna, dan dapat di-fine-tuning. Pada saat yang sama, mereka juga membuat onebitllms open source, sebuah toolkit Python ringan (dapat diinstal melalui pip) yang khusus digunakan untuk fine-tuning atau melanjutkan pre-training model 1,58-bit ini. Langkah ini bertujuan untuk menurunkan ambang batas penggunaan model besar dan mendorong pengembangan serta penerapan teknologi LLM 1-bit. (Sumber: younes)

Pustaka Hugging Face Transformers menyambut peningkatan besar, menjadi standar pusat untuk definisi model : Hugging Face mengumumkan bahwa pustaka Transformers-nya sedang mengalami penyesuaian besar, bertujuan untuk menjadi standar pusat definisi model lintas backend dan runtime yang berbeda. Melalui upaya bersama dengan banyak mitra ekosistem seperti vLLM, LlamaCPP, SGLang, MLX, DeepSpeed, Microsoft, NVIDIA, dan lainnya, mereka mendorong standardisasi kode model, dengan harapan membawa konsistensi dan keandalan yang lebih tinggi ke seluruh ekosistem AI. Langkah ini mendapat pujian luas dari komunitas dan dianggap sebagai langkah penting dalam mendorong pengembangan AI open source. (Sumber: Arthur Zucker)

Salesforce merilis BLIP3-o di Hugging Face: Seri model multimodal terpadu yang sepenuhnya open source : Salesforce meluncurkan seri model BLIP3-o, sebuah keluarga model multimodal terpadu yang sepenuhnya open source. Seri ini mencakup arsitektur model, metode pelatihan, dan dataset, yang bertujuan untuk mendorong pengembangan dan penerapan teknologi AI multimodal. Rilis BLIP3-o menyediakan alat dan sumber daya pemrosesan multimodal yang kuat bagi para peneliti dan pengembang. (Sumber: AK)

NVIDIA menunjukkan penggunaan data sintetis untuk memajukan teknologi kemudi otonom penuh : NVIDIA merilis video baru yang menunjukkan bagaimana mereka menggunakan data sintetis untuk mempercepat penelitian dan pengembangan teknologi kemudi otonom penuh (FSD). Dengan menghasilkan skenario dan data mengemudi virtual berskala besar dan beragam, NVIDIA dapat melatih dan memvalidasi algoritma kemudi otonomnya dengan lebih efisien, mengatasi keterbatasan pengumpulan data dunia nyata, dan mendorong teknologi kemudi otonom ke arah yang lebih aman dan andal. (Sumber: SawyerMerritt)
Tim A-M merilis model inferensi 32B AM-Thinking-v1, sebagian performanya melampaui DeepSeek-R1 : Tim peneliti domestik A-M-team membuat model inferensi dengan parameter 32B, AM-Thinking-v1, open source di Hugging Face. Model ini menunjukkan kinerja yang sangat baik dalam tugas-tugas seperti penalaran matematis (skor seri AIME 85.3) dan pembuatan kode (skor LiveCodeBench 70.3). Diklaim bahwa dalam evaluasi spesifik ini, model tersebut melampaui DeepSeek-R1 (671B MoE) dan mendekati model skala lebih besar seperti Qwen3-235B-A22B. Tim ini berfokus pada optimalisasi kemampuan inferensi model padat 32B melalui skema pasca-pelatihan (termasuk SFT cold-start, penyaringan data yang dipandu oleh tingkat kelulusan, RL dua tahap), bertujuan untuk mengeksplorasi jalur untuk mencapai inferensi yang kuat dalam kondisi komputasi terbatas dan data open source. (Sumber: AI科技评论)

Pembaruan Marigold: Model Stable Diffusion diubah menjadi estimator kedalaman, mendukung inferensi satu langkah dan resolusi tinggi : Proyek Marigold merilis pembaruan besar. Teknologi ini mampu mengubah model Stable Diffusion 2 menjadi estimator kedalaman canggih melalui sejumlah kecil sampel sintetis dan pelatihan singkat (2-3 hari pada 1 GPU). Fitur versi baru meliputi: inferensi cepat satu langkah, dukungan untuk modalitas baru, output resolusi tinggi, dukungan pustaka Diffusers, dan demo baru. (Sumber: Anton Obukhov)
Seri model Qwen3 menunjukkan kinerja kuat di komunitas open source, NVIDIA OpenCodeReasoning memilihnya sebagai model dasar : Seri model Qwen3 (Qwen3) dari Alibaba terus mendapatkan perhatian dan aplikasi di komunitas open source. Seri model OpenCodeReasoning terbaru yang di-open-source-kan oleh NVIDIA (termasuk spesifikasi 7B, 14B, 32B) memilih Qwen sebagai model dasarnya. Qwen3 disukai oleh para pengembang karena versinya yang lengkap, pembaruan berkelanjutan, dukungan asli untuk mode inferensi campuran, dan ekosistem yang berkembang pesat (unduhan global melebihi 300 juta, model turunan lebih dari 100.000). Pembaruan terkini termasuk model multimodal sisi perangkat Qwen-omini 3B, kerja sama dengan Unsloth untuk meningkatkan efisiensi fine-tuning, rilis saran hyperparameter deployment terperinci, dukungan untuk pratinjau real-time halaman web yang dihasilkan, penyediaan berbagai versi terkuantisasi, dan rilis laporan teknis. (Sumber: AI前线)
Hugging Face Accelerate v1.7.0 dirilis, mendukung kompilasi regional dan QLoRA untuk FSDPv2 : Versi Hugging Face Accelerate v1.7.0 telah resmi dirilis. Sorotan versi ini meliputi: kompilasi regional (Regional compilation) yang diimplementasikan oleh @IlysMoutawwakil, meningkatkan efisiensi dan fleksibilitas kompilasi; hook konversi layerwise (Layerwise casting hook) yang dikontribusikan oleh @RisingSayak, yang merupakan fitur yang banyak digunakan di pustaka diffusers; dan dukungan QLoRA untuk FSDPv2 yang diimplementasikan oleh @winglian, yang lebih lanjut mengoptimalkan pelatihan model skala besar. (Sumber: Marc Sun)

Llamafile 0.9.3 dirilis, menambahkan dukungan untuk model Qwen3 dan Phi4 : Llamafile merilis versi 0.9.3, pembaruan kali ini menambahkan dukungan untuk seri model Qwen3 dan Phi4 yang populer baru-baru ini. Llamafile berdedikasi untuk membuat distribusi dan menjalankan aplikasi LLM menjadi sederhana, dengan mengemas bobot model dan kode yang diperlukan untuk berjalan menjadi satu file executable tunggal, memungkinkan deployment yang mudah di berbagai sistem operasi. (Sumber: Phoronix)
Tencent merilis model gambar besar HunyuanImage 2.0 : Tencent secara resmi merilis versi baru dari model gambar besarnya – HunyuanImage 2.0. Pembaruan ini diharapkan membawa peningkatan dalam kualitas pembuatan gambar, kemampuan kontrol, dan pemahaman terhadap instruksi yang kompleks. Detail teknis spesifik dan peningkatannya dapat dipelajari lebih lanjut oleh pengguna melalui saluran resmi. (Sumber: Hunyuan)

Ollama v0.7 dirilis, meningkatkan pengalaman menjalankan model besar secara lokal : Ollama merilis versi v0.7, terus berupaya menyederhanakan proses menjalankan model bahasa besar di perangkat lokal. Versi baru ini mungkin mencakup optimasi kinerja, dukungan model baru, atau peningkatan pengalaman pengguna. Pengguna dapat mengunjungi situs web resmi atau GitHub untuk melihat catatan pembaruan terperinci dan mengunduhnya. (Sumber: ollama)
llama.cpp menggabungkan fungsionalitas input PDF, mendukung pemrosesan langsung dokumen PDF : Proyek llama.cpp baru-baru ini menggabungkan pembaruan penting, menambahkan dukungan untuk input langsung file PDF. Ini berarti pengguna sekarang dapat dengan lebih mudah menggunakan konten dokumen PDF sebagai input untuk diproses, dianalisis, atau dijawab oleh model bahasa besar lokal yang didukung oleh llama.cpp, memperluas skenario aplikasinya. Fitur ini diimplementasikan melalui paket JS eksternal di frontend web bawaan, tanpa menambah beban pemeliharaan inti. (Sumber: GitHub)
Microsoft Copilot meluncurkan fungsi pembuatan gambar 4o, meningkatkan efek visual dan konsistensi teks : Asisten AI Microsoft Copilot kini telah mengintegrasikan kemampuan pembuatan gambar dari model GPT-4o OpenAI. Pembaruan ini bertujuan untuk memberikan efek visual yang lebih tajam, pembuatan teks yang lebih konsisten, dan mendukung berbagai gaya mulai dari foto-realistis hingga kartun yang menyenangkan. Pengguna dapat merasakan fungsi pembuatan gambar yang didukung oleh 4o melalui Copilot. (Sumber: yusuf_i_mehdi)

NVIDIA DRIVE Labs membahas masa depan kemudi tanpa peta, mengurangi ketergantungan pada peta HD : Video terbaru NVIDIA DRIVE Labs membahas masa depan kemudi tanpa peta (mapless driving). Peta definisi tinggi (HD maps) sangat penting untuk kemudi otonom, tetapi biaya dan tantangan pemeliharaannya membatasi penyebaran. NVIDIA mengurangi ketergantungan pada peta HD melalui inovasi seperti menghilangkan hambatan informasi, meningkatkan akurasi tugas, mempercepat waktu pelatihan model dan inferensi, serta mendorong batas teknologi kemudi otonom. (Sumber: NVIDIA DRIVE)
Dolphin 3.2 (dilatih berdasarkan Qwen3) akan menyediakan sakelar prompt sistem, meningkatkan kontrol pengguna : Model Dolphin 3.2 yang akan datang, yang dilatih berdasarkan Qwen3, akan memperkenalkan tiga sakelar prompt sistem: /no_think (kemungkinan untuk mengurangi langkah pemikiran yang berlebihan), /uncensored (kemungkinan untuk mengurangi penyensoran konten), dan /china (kemungkinan ditujukan untuk konteks atau layanan spesifik Tiongkok). Sakelar ini bertujuan untuk memberi pengguna tingkat kepemilikan dan kontrol yang lebih besar atas penerapan model mereka. (Sumber: cognitivecompai)

🧰 Alat
Runway meluncurkan fitur referensi, dapat mempelajari dan menerapkan teknik atau gaya tertentu pada kreasi baru : Runway menambahkan fitur baru bernama “References”, yang memungkinkan pengguna untuk menunjukkan kepada platform teknik atau gaya artistik tertentu, lalu menggunakannya sebagai referensi untuk diterapkan pada konten generatif baru. Fitur ini memberi pengguna kemampuan kontrol gaya yang lebih halus, membuat kreasi yang dibantu AI lebih personal dan spesifik. Pengguna Cristobal Valenzuela meluncurkan kampanye pengumpulan, mendorong komunitas untuk berbagi kasus asli penggunaan fitur ini, dan akan memberikan paket Unlimited gratis selama setahun untuk 5 kasus paling kreatif. (Sumber: c_valenzuelab)

DSPy: Kerangka kerja pemrograman LLM minimalis yang dirancang untuk iterasi cepat : Kerangka kerja DSPy mendapat perhatian karena desainnya yang minimalis. Pengembang mengklaim bahwa sebagian besar fungsi intinya (Module atau Optimizer) hanya memerlukan satu baris kode untuk diimplementasikan, bertujuan untuk membantu pengguna dengan cepat mencoba dan mengulang ide. Berbeda dengan beberapa alat yang memerlukan banyak kode boilerplate dan konsep yang rumit, DSPy menekankan kemudahan penggunaan dan efisiensi. Umpan balik pengguna menyatakan bahwa dengan membaca dokumentasi pengantar, mereka dapat dengan cepat memulai dan dalam waktu singkat memanfaatkan kerangka kerja ini untuk mengoptimalkan model, meskipun menggunakan model SOTA untuk optimasi berulang mungkin menimbulkan biaya tertentu. (Sumber: lateinteraction)
Unsloth AI berekspansi ke fine-tuning model TTS dan audio, meningkatkan kecepatan dan mengurangi penggunaan VRAM : Unsloth AI mengumumkan bahwa teknologi optimasinya kini mendukung fine-tuning model text-to-speech (TTS) dan audio. Pengguna dapat menggunakan notebook Colab gratis untuk melatih, menjalankan, dan menyimpan model seperti Sesame-CSM, OpenAI Whisper, dan lainnya. Unsloth mengklaim teknologinya dapat meningkatkan kecepatan pelatihan TTS hingga 1,5 kali, sekaligus mengurangi penggunaan VRAM hingga 50%. Dokumentasi terkait dan notebook Colab telah tersedia di situs web resminya. (Sumber: Unsloth AI)
Modal membantu tugas embedding 30 juta ulasan Amazon, GPU L40S mencapai pemrosesan dalam hitungan jam : Platform Modal menunjukkan kemampuannya dalam penskalaan horizontal untuk tugas embedding skala besar pada GPU L40S. Melalui sebuah kasus demo, Modal berhasil menyelesaikan pemrosesan embedding 30 juta ulasan Amazon dalam waktu satu jam. Ini berkat sistem generasi terukur yang diperbarui oleh tim Modal, yang membuat pemrosesan paralel skala besar menjadi lebih sederhana dan efisien. (Sumber: charles_irl)

Lovart AI: Agen desain visual AI pendatang baru yang mengintegrasikan berbagai model papan atas : Sebuah agen desain visual AI bernama Lovart menarik perhatian. Agen ini mampu menyelesaikan tugas desain visual profesional seperti poster, VI merek, storyboard, dan lainnya melalui instruksi bahasa alami. Kemampuan inti Lovart terletak pada penjadwalan fusi multi-modelnya, yang mengintegrasikan berbagai model papan atas seperti GPT image-1, Flux pro, OpenAI-o3, Gemini Imagen 3, Kling AI, Tripo AI, Suno AI, dan lainnya. Lovart juga dilengkapi dengan alat pengeditan tingkat profesional (seperti layer, mask, penyesuaian teks halus), mendukung pemisahan gambar-teks dan pengeditan per layer. Produk ini dioperasikan secara independen oleh anak perusahaan Liblib di luar negeri, bertujuan untuk menyediakan pengalaman desain AI satu atap dengan kontrol tinggi. (Sumber: 量子位)
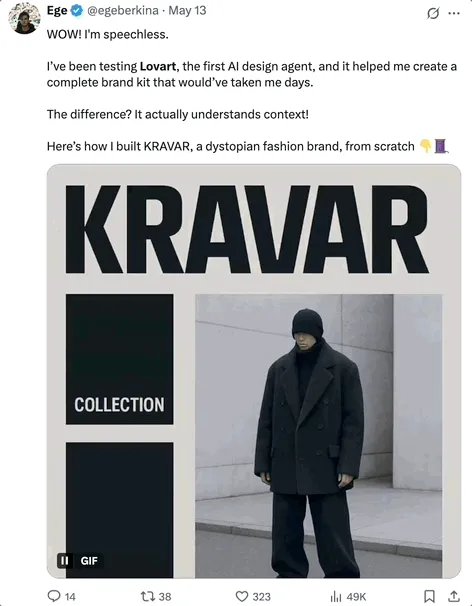
OpenHands 0.38.0 dirilis: Dukungan Windows asli dan ekstensi Chrome meningkatkan kemudahan penggunaan : OpenHands merilis versi 0.38.0, membawa beberapa pembaruan penting. Di antaranya adalah: dukungan Windows asli (tanpa perlu WSL), memudahkan pengguna Windows; fungsi tangkapan layar browser; dan kemampuan kustomisasi sandbox yang lebih fleksibel. Selain itu, dirilis juga ekstensi Chrome yang memungkinkan pengguna meluncurkan OpenHands langsung dari GitHub dengan satu klik, lebih menyederhanakan alur operasi. (Sumber: All Hands AI)
Tensorlake Cloud dirilis, meningkatkan kemampuan ekstraksi dokumen dan pembangunan alur kerja : Tensorlake mengumumkan peluncuran Tensorlake Cloud, yang bertujuan untuk mengoptimalkan ekstraksi dokumen dan alur kerja guna mendukung pembangunan aplikasi agen cerdas dan alur kerja bisnis yang kompleks. Platform ini memanfaatkan model pemahaman tata letak dokumen canggih (dilatih pada data dunia nyata seperti formulir ACORD, laporan bank, laporan penelitian, dll.) dan model ekstraksi tabel, mengubah dokumen tidak terstruktur menjadi data yang bersih dan terstruktur. Ini sangat cocok untuk menangani tabel yang kompleks dan padat, mengisi kekurangan model bahasa visual (VLM) dalam hal ini. (Sumber: Tensorlake)
Patronus AI meluncurkan Percival: Agen cerdas yang khusus untuk debugging dan meningkatkan agen AI : Patronus AI merilis alat baru bernama Percival, sebuah agen AI yang dirancang khusus untuk debugging dan meningkatkan agen AI lainnya. Percival mampu menganalisis jejak agen yang kompleks secara instan, mengidentifikasi hingga 60 mode kegagalan yang berbeda, dan secara otomatis menyarankan perbaikan prompt untuk meningkatkan kinerja. Alat ini mengatasi tantangan utama seperti “ledakan konteks” (di mana agen memproses jutaan token) dan mendukung adaptasi domain untuk kasus penggunaan tertentu serta orkestrasi multi-agen yang kompleks. (Sumber: Weaviate Podcast)

Replit mengintegrasikan Semgrep untuk mewujudkan “pemrograman suasana aman”, memindai kerentanan secara otomatis : Replit mengumumkan kerja sama dengan Semgrep untuk meluncurkan fitur “Safe Vibe Coding”. Sekarang, setiap kali pengguna men-deploy kode di Replit, Semgrep akan secara otomatis menjalankan pemindaian keamanan, membantu menemukan dan memperbaiki potensi kerentanan, serta mencegah informasi sensitif seperti kunci API terekspos secara tidak sengaja. Langkah ini bertujuan untuk meningkatkan keamanan saat menggunakan pengkodean yang dibantu AI (seperti menghasilkan kode melalui LLM). (Sumber: amasad)

Cursor AI versi 0.50 dirilis, membawa pembaruan besar : Alat pemrograman berbantuan AI, Cursor, merilis versi 0.50, yang disebut sebagai “pembaruan versi terbesar sepanjang masa”. Versi baru ini diharapkan menyertakan berbagai peningkatan fungsionalitas dan optimasi pengalaman, yang bertujuan untuk lebih meningkatkan efisiensi pengkodean pengembang dan kelancaran kolaborasi dengan AI. Konten pembaruan spesifik dapat dilihat di catatan rilis resmi. (Sumber: eric zakariasson)

OpenMemory MCP: Server manajemen memori lokal yang mendukung berbagi konteks lintas aplikasi : OpenMemory MCP adalah server manajemen memori yang bertujuan untuk meningkatkan produktivitas aplikasi AI. Ini memungkinkan pengguna untuk berbagi konteks antara aplikasi yang berbeda (seperti Cursor dan Claude Desktop) dan memanfaatkan PostgreSQL dan Qdrant untuk menyimpan dan mengindeks data secara lokal, memastikan privasi data. Alat ini mendukung pencarian semantik dan menyediakan dasbor untuk mengelola memori dan akses aplikasi, mengatasi masalah hilangnya konteks lintas sesi. (Sumber: Reddit r/ClaudeAI)

Hugging Face Inference Endpoint dikombinasikan dengan vLLM dan Gradio, mewujudkan transkripsi Whisper yang cepat : Hugging Face menunjukkan bagaimana memanfaatkan layanan Inference Endpoint-nya, dikombinasikan dengan proyek vLLM dan antarmuka Gradio, untuk men-deploy model Whisper dari OpenAI, guna mencapai fungsi transkripsi suara yang sangat cepat. Kombinasi ini memanfaatkan alat open source dari komunitas AI, menyediakan solusi speech-to-text yang efisien dan mudah digunakan bagi pengguna. (Sumber: Morgan Funtowicz)
A.I.T.E Ball: Bola ajaib 8 AI mandiri berbasis Orange Pi dan Gemma 3 1B : Seorang pengembang memamerkan proyek bola ajaib 8 yang ditenagai AI dan sepenuhnya mandiri (tanpa perlu koneksi internet) – A.I.T.E Ball. Perangkat ini berjalan di Orange Pi Zero 2W, menggunakan whisper.cpp untuk konversi text-to-speech, dan llama.cpp untuk menjalankan model Gemma 3 1B untuk tanya jawab. Ini menunjukkan potensi untuk mewujudkan aplikasi AI lokal pada perangkat keras berdaya rendah. (Sumber: Reddit r/LocalLLaMA)

OWL Agent: Agen universal open source yang terintegrasi dengan MCPToolkit : Proyek agen OWL open source kini telah dilengkapi dengan dukungan MCPToolkit bawaan. Pengguna dapat dengan mudah terhubung ke server MCP seperti Playwright, desktop-commander, atau alat Python kustom lainnya. OWL akan secara otomatis menemukan dan memanggil alat-alat ini dalam alur kerja multi-agennya, meningkatkan universalitas dan kemampuan pelaksanaan tugasnya. (Sumber: Reddit r/LocalLLaMA)

ElevenLabs meluncurkan SB-1 Infinite Soundboard: Menggabungkan efek suara, mesin drum, dan generator kebisingan ambien : ElevenLabs merilis SB-1 Infinite Soundboard, sebuah alat yang menggabungkan papan efek suara, mesin drum, dan generator kebisingan ambien tak terbatas. Pengguna dapat mendeskripsikan efek suara yang diinginkan, dan SB-1 akan menggunakan model Text-to-SFX (Text-to-SFX) untuk menghasilkan suara-suara tersebut, memberikan kemungkinan baru untuk kreasi audio. (Sumber: ElevenLabs)
Proyek Anytop: Kemajuan baru dalam animasi AI, menghidupkan organisme yang belum pernah dilihat, mendukung pembelajaran dan transfer gerakan : Two Minute Papers memperkenalkan proyek Anytop, sebuah teknologi animasi AI yang mampu menghasilkan gerakan realistis untuk organisme yang belum pernah dilihat sebelumnya (termasuk dinosaurus, serangga aneh, dll.). AI ini tidak hanya dapat menghasilkan gerakan secara mandiri, tetapi juga memungkinkan organisme yang berbeda untuk belajar dan beradaptasi dengan gerakan satu sama lain (misalnya, dinosaurus belajar berdiri dengan satu kaki seperti flamingo). Ini dicapai dengan memahami kesamaan semantik bagian tubuh (seperti konsep umum lengan, kaki) untuk menggeneralisasi ke bentuk yang tidak diketahui. Selain itu, sistem ini juga dapat memahami semantik gerakan (seperti menyerang, bersantai), dan menampilkan gerakan dengan konsep serupa pada hewan yang berbeda, bahkan mampu melengkapi gerakan input yang tidak lengkap. (Sumber: )

Sketch2Anim: AI mengubah sketsa gambar sederhana menjadi animasi 3D lengkap : Teknologi lain yang diperkenalkan oleh Two Minute Papers, Sketch2Anim, mampu mengubah sketsa garis sederhana yang digambar pengguna (menunjukkan jalur gerakan) menjadi animasi karakter 3D lengkap. AI ini mampu memahami maksud 3D di balik sketsa 2D (seperti membedakan antara pukulan lurus ke depan dan pukulan ke samping), mengatasi keterbatasan teknologi serupa sebelumnya yang hanya dapat memahami instruksi pada tingkat 2D. Hal ini memungkinkan non-profesional untuk dengan cepat membuat animasi 3D melalui gambar sederhana. (Sumber: )
📚 Pembelajaran
DeepSeek merilis paper model V3, berbagi tantangan perluasan dan pemikiran arsitektur perangkat keras AI : Tim DeepSeek merilis paper tentang model DeepSeek-V3 di Hugging Face. Paper ini membahas secara mendalam tantangan yang dihadapi dalam proses perluasan model bahasa besar, serta mengajukan pemikiran dan wawasan tentang arah pengembangan arsitektur perangkat keras AI di masa depan. Ini memberikan referensi berharga bagi para peneliti dan pengembang untuk memahami hambatan dalam pelatihan dan penerapan model skala besar, serta bagaimana mengoptimalkannya melalui kolaborasi perangkat keras dan perangkat lunak. (Sumber: Adina Yakup)
Kursus gratis Model Context Protocol (MCP) dirilis, membantu membangun aplikasi AI dengan data dan alat eksternal : Ben Burtenshaw mengumumkan peluncuran kursus MCP (Model Context Protocol) gratis. Kursus ini bertujuan untuk membantu peserta belajar dari tingkat pemula hingga mahir, memahami cara kerja MCP, cara menghubungkan LLM ke server MCP, dan cara menggunakan MCP untuk menerapkan aplikasi agen AI, sehingga dapat memanfaatkan data dan alat eksternal untuk meningkatkan kemampuan aplikasi AI. (Sumber: Ben Burtenshaw)

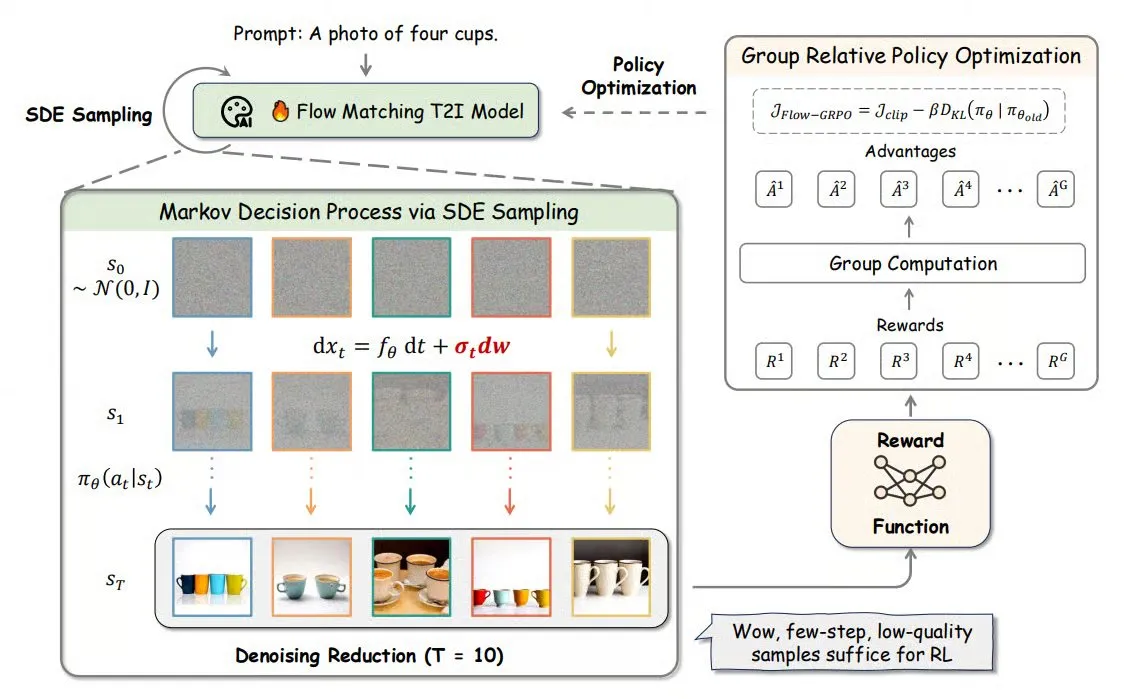
Flow-GRPO: Membawa pembelajaran penguatan online ke model pencocokan aliran, meningkatkan akurasi pembuatan gambar : Flow-GRPO adalah metode baru yang pertama kali menerapkan pembelajaran penguatan online (RL) pada model pencocokan aliran. Ini dicapai melalui dua strategi inovatif: 1) Konversi ODE ke SDE: Mengubah proses deterministik model aliran berbasis persamaan diferensial biasa (ODE) menjadi persamaan diferensial stokastik (SDE), memperkenalkan keacakan yang diperlukan untuk RL. 2) Pengurangan denoising untuk mempercepat pelatihan: Mengurangi langkah denoising saat pelatihan, dan menggunakan langkah penuh saat inferensi. Melalui Flow-GRPO, akurasi model aliran dalam tugas pembuatan gambar meningkat hingga lebih dari 92%. (Sumber: TheTuringPost)
Paper ICML 2025 PENCIL: Paradigma baru pemikiran mendalam model besar melalui “penalaran-penghapusan” bergantian : Chenxiao Yang dkk. dari Toyota Technological Institute at Chicago mengajukan PENCIL (Pondering with Erasure Net for Contextual Inference Learning), sebuah paradigma baru untuk pemikiran mendalam model besar melalui “pembuatan” dan “penghapusan” hasil antara secara bergantian. Metode ini mengambil inspirasi dari aturan penulisan ulang logika dan manajemen memori pemrograman fungsional, secara dinamis menghapus langkah-langkah antara yang tidak lagi diperlukan, secara efektif mengatasi masalah yang dihadapi CoT (Chain of Thought) panjang tradisional seperti batas jendela konteks, kesulitan pengambilan informasi, dan penurunan efisiensi generasi. Secara teoritis, PENCIL dapat mensimulasikan operasi mesin Turing apa pun dengan kompleksitas ruang dan waktu optimal, menyelesaikan semua masalah yang dapat dihitung. Eksperimen menunjukkan bahwa pada tugas-tugas seperti 3-SAT, QBF, dan teka-teki Einstein, PENCIL secara signifikan mengungguli CoT tradisional. (Sumber: 机器之心)

Paper ICML 2025 MemVR: Mensimulasikan mekanisme “melihat dua kali” manusia untuk mengurangi halusinasi model besar multimodal : Peneliti dari HKUST (Guangzhou) dan institusi lain mengusulkan metode MemVR (Memory-space Visual Retracing) untuk mengurangi masalah halusinasi pada model bahasa besar multimodal (MLLM) dengan mensimulasikan strategi manusia dalam memeriksa ulang memori yang tidak pasti. MemVR menggunakan token visual sebagai bukti tambahan. Ketika model menghadapi kesulitan karena lupa pada lapisan tengah inferensi, MemVR “mengambil kembali” pengetahuan visual melalui jaringan feed-forward (FFN) untuk mengkalibrasi prediksi. Metode ini merancang mekanisme pemicu dinamis yang memilih lapisan pemicu berdasarkan ketidakpastian output dari lapisan yang berbeda. Eksperimen menunjukkan bahwa MemVR mencapai hasil yang signifikan pada beberapa tolok ukur evaluasi halusinasi dan tolok ukur umum, serta memiliki keunggulan efisiensi dibandingkan metode lain. (Sumber: PaperWeekly)

Paper SIGIR 2025 PaRT: Pengambilan real-time yang dipersonalisasi meningkatkan pengalaman chatbot sosial proaktif : Universitas Sains dan Teknologi Tiongkok dan institusi lain mengusulkan metode PaRT (Proactive Social Chatbots with Personalized Real-time ReTreival), yang bertujuan untuk meningkatkan pengalaman percakapan chatbot sosial proaktif melalui kombinasi penulisan ulang kueri yang dipandu oleh personalisasi dan identifikasi niat, serta pengambilan real-time. Sistem PaRT terdiri dari tiga modul: pembangunan profil pengguna yang dipersonalisasi, identifikasi niat dan penulisan ulang kueri, serta generasi yang ditingkatkan dengan pengambilan real-time. Sistem ini dapat secara proaktif memulai atau mengganti topik berdasarkan minat pengguna dan konteks percakapan, memberikan respons yang lebih alami dan kaya informasi. Eksperimen offline dan pengujian A/B online menunjukkan bahwa metode ini dapat secara efektif meningkatkan personalisasi, kekayaan, dan durasi percakapan rata-rata respons. (Sumber: PaperWeekly)
Paper ICML 2025 PreSelect: Skema penyaringan data pra-pelatihan yang efisien berdasarkan kekuatan prediksi : Universitas Sains dan Teknologi Hong Kong dan vivo AI Lab mengusulkan metode penyaringan data PreSelect, yang memperkenalkan konsep “Kekuatan Prediktif” (Predictive Strength) untuk mengukur kontribusi data terhadap kemampuan spesifik model. Metode ini memanfaatkan konsistensi antara peringkat skor model yang berbeda pada tolok ukur dan peringkat Loss pada data untuk mengevaluasi nilai data. Metode ini menggunakan pengklasifikasi fastText yang ringan untuk memberikan skor perkiraan, memungkinkan penyaringan data skala besar yang efisien. Eksperimen menunjukkan bahwa PreSelect dapat meningkatkan efisiensi data hingga 10 kali lipat. Data yang disaring menghasilkan model yang secara signifikan lebih baik daripada berbagai metode dasar saat pelatihan, dan mencakup sumber konten berkualitas tinggi yang lebih luas, serta mengurangi bias panjang sampel. (Sumber: 量子位)

Kursus AI Evals mengundang 12 pembicara tamu untuk berbagi kerangka kerja dan praktik evaluasi : Kursus AI Evals yang diselenggarakan oleh Hamel Husain mengumumkan jajaran 12 dosen tamu, termasuk JJ Allaire, pencipta kerangka kerja inspect, dan Charles Frye, advokat pengembang Modal. Kursus ini akan membahas secara mendalam berbagai aspek evaluasi AI, termasuk kerangka kerja evaluasi, pembuatan aplikasi anotasi khusus, praktik evaluasi model, dan lainnya, yang bertujuan untuk membantu peserta menguasai keterampilan dan alat utama untuk mengevaluasi kinerja sistem AI. (Sumber: Hamel Husain)

Tutorial FedRAG dirilis: Panduan pemula untuk membangun dan melakukan fine-tuning sistem RAG : Proyek FedRAG merilis notebook tutorial baru dan video pendamping, yang bertujuan untuk membantu pengguna memulai dengan cepat menggunakan pustaka tersebut. Tutorial ini mendemonstrasikan cara membangun sistem RAG menggunakan integrasi Hugging Face, menggunakan basis pengetahuan dalam memori untuk menyimpan node, mendefinisikan SentenceTransformer (Dragon+) sebagai retriever, mendefinisikan model pra-terlatih (seperti Qwen2.5-0.5B) sebagai generator, dan menggunakan pelatih LSR dan RALT untuk melakukan fine-tuning terpusat pada retriever dan generator. (Sumber: nerdai)

LlamaIndex merilis tutorial: Menerapkan kutipan dan inferensi di LlamaExtract : Tim LlamaIndex merilis panduan kode terbaru yang dibuat oleh @tuanacelik, yang menunjukkan cara menerapkan fungsi kutipan dan inferensi di LlamaExtract. Konten tutorial meliputi: cara mendefinisikan skema khusus untuk memberi tahu LLM apa yang harus diekstraksi dari sumber data yang kompleks, dan cara menambahkan kutipan. Fungsi ini bertujuan untuk membantu pengguna membangun agen AI multi-langkah yang dapat mengekstrak informasi terstruktur secara akurat dan berdasarkan bukti dari sejumlah besar dokumen sumber. (Sumber: LlamaIndex 🦙)
LlamaIndex merilis tutorial: Membangun asisten dokumen multi-agen menggunakan alur kerja agen berbasis peristiwa : LlamaIndex merilis tutorial panduan baru yang menunjukkan cara membangun asisten dokumen multi-agen menggunakan alur kerja agen berbasis peristiwa. Asisten ini mampu menulis konten halaman web ke koleksi LlamaIndexDocs dan WeaviateDocs, menggunakan orkestrator untuk memutuskan kapan harus memanggil Weaviate QueryAgent untuk pencarian dan agregasi, memanfaatkan output terstruktur untuk klasifikasi kueri, dan secara opsional dapat menggunakan FunctionAgent. (Sumber: LlamaIndex 🦙)
Modular merilis ceramah teknis internal kompiler Mojo, membahas Mojo dan arsitektur GPU : Perusahaan Modular mulai membagikan ceramah teknis internalnya. Ceramah pertama yang dipublikasikan membahas secara mendalam topik bahasa pemrograman Mojo dan arsitektur GPU. Kontennya mencakup cara kerja internal kompiler Mojo serta tantangan dan solusi yang dihadapi tim saat mengembangkan untuk GPU modern, bertujuan untuk berbagi detail tumpukan teknologinya dengan komunitas. (Sumber: Modular)
Lokakarya AI by Hand: Membangun model Transformer dari nol di Excel : ProfTomYeh mempromosikan lokakarya AI by Hand-nya, yang bertujuan agar peserta dapat membangun model Transformer dari awal di Excel. Dengan cara ini, peserta dapat memahami setiap langkah matematis Transformer secara jelas dan intuitif, menghindari anggapan sebagai “kotak hitam”, sehingga membangun pemahaman mendalam tentang mekanisme kerja internal model. (Sumber: ProfTomYeh)
DeepLearning.AI merilis The Batch Edisi ke-301: Membahas nilai komersial kecepatan AI dan perkembangan terbaru : Andrew Ng dalam edisi terbaru The Batch membahas bagaimana peningkatan kecepatan AI dalam pelaksanaan tugas seringkali diremehkan dalam menciptakan nilai komersial. Ia berpendapat bahwa AI tidak hanya mengurangi biaya, tetapi yang lebih penting, dengan mempersingkat waktu dari ide ke prototipe, AI mempercepat inovasi dan eksplorasi. Edisi ini juga melaporkan berita tentang rilis seri inferensi Microsoft Phi-4, kinerja DeepCoder-14B yang menyamai o1, pelonggaran aturan AI Uni Eropa, dan lainnya. (Sumber: DeepLearningAI)
💼 Bisnis
Startup animasi karakter AI Cartwheel mendapatkan pendanaan $10 juta, menyederhanakan alur kerja animasi 3D : Startup yang berfokus pada animasi karakter AI, Cartwheel, mengumumkan telah menyelesaikan putaran pendanaan sebesar $10 juta. Perusahaan ini berdedikasi untuk mengembangkan teknologi yang menyederhanakan proses produksi animasi 3D, bertujuan agar para kreator dapat membuat animasi karakter 3D berkualitas tinggi dengan lebih cepat dan ekonomis, sekaligus meningkatkan kontrol atas produk akhir dan menghilangkan tugas-tugas yang membosankan. (Sumber: andrew_n_carr)
Hedra meraih pendanaan Seri A sebesar $32 juta, dipimpin oleh a16z, untuk mempercepat pembuatan video berbasis karakter : Startup pembuatan video AI, Hedra, mengumumkan telah menyelesaikan putaran pendanaan Seri A sebesar $32 juta, dipimpin oleh Andreessen Horowitz (a16z), dengan Matt Bornstein bergabung dalam dewan direksi. Investor yang sudah ada, a16z speedrun, Abstract, dan Index Ventures juga berpartisipasi dalam putaran ini. Hedra berdedikasi untuk membuat pembuatan video berbasis karakter menjadi mudah. Sejak diluncurkan dalam mode siluman tahun lalu, hampir 3 juta orang telah menggunakan alatnya untuk membuat lebih dari 10 juta video. Dana baru akan digunakan untuk mempercepat pengembangan produk, perluasan tim, guna mewujudkan pembuatan konten yang cepat, ekspresif, dan intuitif. (Sumber: Hedra)
Tripadvisor memanfaatkan Qdrant untuk membangun perencanaan perjalanan AI, keterlibatan pengguna meningkat 2-3 kali lipat : Tripadvisor menggunakan basis data vektor Qdrant untuk mendefinisikan ulang pengalaman penemuan perjalanan. Dengan menganalisis lebih dari 1 miliar ulasan dan foto, 11 juta bisnis, serta data dari 21 negara, Tripadvisor menciptakan itinerary dinamis yang dihasilkan AI, alih-alih mengandalkan filter tradisional. Hasilnya menunjukkan bahwa pengguna yang menggunakan alat AI ini menghabiskan waktu 2-3 kali lebih banyak, menunjukkan potensi besar AI dalam perencanaan perjalanan yang dipersonalisasi. (Sumber: qdrant_engine)

🌟 Komunitas
Pernyataan Grok tentang “genosida kulit putih” memicu kontroversi, Sam Altman merespons dengan sarkasme : Model Grok dari xAI memicu diskusi dan kritik luas karena secara acak mengeluarkan pandangan tentang genosida kulit putih di Afrika Selatan. Paul Graham menunjukkan bahwa perilaku semacam ini berbau seperti bug yang diperkenalkan oleh patch baru-baru ini, dan khawatir AI yang banyak digunakan dapat diedit pandangannya secara instan oleh pengendalinya. Sam Altman merespons dengan nada sarkastis, mengatakan bahwa xAI akan memberikan penjelasan transparan, dan akan memahami masalah ini dalam konteks “genosida kulit putih di Afrika Selatan”, menyiratkan bahwa ini adalah hasil dari AI yang mengejar kebenaran dan mengikuti instruksi. Diskusi komunitas mengenai masalah ini mencerminkan kekhawatiran umum tentang bias model AI, kemampuan kontrol, dan niat di baliknya. (Sumber: Paul Graham)
Pemikiran tentang Produk AI: Menggali Peluang dari Seluruh Alur Tugas Pengguna, Bukan Sekadar Menambahkan Fitur AI : Ren Xin, mitra di Cloud Nine Capital, berbagi pemikiran mendalam tentang produk AI, menekankan bahwa perusahaan harus memulai dari seluruh alur tugas pengguna untuk menemukan titik masuk aplikasi AI, daripada hanya menambahkan fitur AI pada produk yang sudah ada. Ia mengajukan analogi “pengguna tidak menginginkan bor listrik, tetapi lubang di dinding,” menyarankan untuk memecah tugas pengguna, menemukan titik masalah, dan mengoptimalkannya dengan AI. Empat tingkatan produk AI meliputi: menyelesaikan alur kerja lama secara efisien, menciptakan alur kerja baru, membuka pasar yang sama sekali baru (menurunkan ambang batas penggunaan, melayani kelompok pengguna baru, bahkan AI itu sendiri), dan membangun infrastruktur untuk masa depan yang didominasi AI. Ia percaya bahwa teknologi AI sedang mendemokratisasi, dan perusahaan yang tidak memahami teknologi pun dapat memanfaatkan peluang ini, yang pada dasarnya adalah “membantu AI menemukan pekerjaan.” (Sumber: 混沌大学)
Diskusi: Peran AI dalam pengembangan karir dan strategi adaptasi : Sebuah postingan di LinkedIn memicu diskusi tentang bagaimana AI memengaruhi pengembangan karir. Pepatah umum adalah “AI tidak akan menggantikan pekerjaan Anda, tetapi orang yang menggunakan AI akan melakukannya.” Namun, pepatah ini dianggap terlalu kabur. Pertanyaan muncul mengenai bagaimana insinyur frontend dengan pengalaman puluhan tahun, misalnya, dapat tiba-tiba beralih menjadi insinyur AI, dan masalah bahwa tidak semua orang bisa menjadi insinyur AI. Diskusi komunitas berpendapat bahwa bagi pengembang frontend, mereka dapat belajar menggunakan alat AI untuk meningkatkan efisiensi kerja. Ada juga pandangan bahwa AI akan menggantikan banyak pekerjaan, dan banyak orang tidak akan punya tempat tujuan. Pandangan yang lebih umum adalah bahwa masa depan masih belum pasti, tetapi kreativitas, kemampuan menemukan masalah, serta kemampuan untuk memahami dan menyentuh kemanusiaan mungkin lebih defensif. (Sumber: Reddit r/ArtificialInteligence)
Diskusi: LLM mudah “tersesat” dalam percakapan multi-giliran, memulai ulang percakapan mungkin bermanfaat : Sebuah makalah penelitian menunjukkan bahwa kinerja LLM, baik open source maupun closed source, menurun secara signifikan dalam percakapan multi-giliran. Sebagian besar tolok ukur berfokus pada skenario satu giliran dengan instruksi yang jelas. Penelitian menemukan bahwa LLM sering membuat asumsi (yang salah) pada giliran percakapan awal dan mengandalkan asumsi ini dalam percakapan berikutnya, sehingga sulit untuk dikoreksi. Kesimpulannya adalah, ketika percakapan multi-giliran tidak mencapai hasil yang diharapkan, memulai percakapan baru dan mengintegrasikan semua informasi yang relevan ke dalam input giliran pertama mungkin dapat membantu. (Sumber: Reddit r/LocalLLaMA)
Alasan mengapa Apple dan WeChat relatif lambat dalam pengembangan AI: Privasi, keamanan, dan strategi prioritas aplikasi : Wei Xi dalam artikelnya menganalisis bahwa meskipun Apple meluncurkan “Apple Intelligence” dan WeChat juga terhubung dengan DeepSeek dan Yuanbao, kecepatan kemajuan keduanya dalam fungsi inti AI relatif lambat. Ada dua alasan utama: Pertama adalah sensitivitas tinggi terhadap privasi dan keamanan data. Kecerdasan AI bergantung pada data, sedangkan model bisnis inti Apple dan WeChat mengharuskan mereka sangat berhati-hati dalam berbagi data, yang membatasi pelatihan model dan perolehan konteks aplikasi. Kedua, keduanya mengadopsi strategi “prioritas aplikasi”. Mereka sendiri tidak mengejar persaingan dengan perusahaan AI terkemuka dalam hal batas atas kecerdasan model, melainkan lebih fokus pada integrasi kemampuan AI ke dalam fungsi dan ekosistem yang ada. Hal ini menyebabkan keterbatasan dalam hal kepemimpinan teknologi dan kecepatan iterasi produk. (Sumber: 卫夕指北)

OpenAI meluncurkan “OpenAI to Z Challenge”: Menggunakan AI untuk menemukan situs arkeologi yang belum diketahui di Amazon : OpenAI mengumumkan kerja sama dengan Kaggle untuk meluncurkan hackathon khusus “OpenAI to Z Challenge”. Tantangan ini mendorong peserta untuk menggunakan model OpenAI o3, o4-mini, atau GPT-4.1 untuk mencari situs arkeologi yang sebelumnya tidak diketahui di wilayah Amazon. Peserta dapat menggunakan tagar #OpenAItoZ untuk berbagi kemajuan mereka. Kegiatan ini bertujuan untuk mengeksplorasi potensi aplikasi AI di bidang arkeologi dan analisis geospasial. (Sumber: OpenAI Developers)
Kritik terhadap startup “pengacara AI”: Otomatisasi “surat pemerasan” bisa menjadi beban sosial : Pengembang @swyx mengkritik fenomena beberapa VC yang berinvestasi di startup “pengacara AI”. Ia berpendapat bahwa perusahaan-perusahaan ini terutama menggunakan AI untuk secara otomatis menghasilkan “surat tagihan” (demand letters), yang pada dasarnya adalah pemerasan otomatis. Meskipun sebagian tagihan mungkin masuk akal, ia menunjukkan bahwa sebagian besar tindakan semacam ini pada akhirnya hanya akan menguntungkan pengacara, menjadi pajak murni bagi masyarakat. Ia menyerukan untuk memboikot, menarik investasi, dan secara terbuka mengkritik perusahaan semacam ini beserta investornya. (Sumber: swyx)

💡 Lain-lain
Laporan penelitian batu bara munculkan kesalahan konyol “diperoleh dengan membunuh wither skeleton”, memicu diskusi tentang kualitas konten dan halusinasi AI : Sebuah laporan penelitian industri batu bara seharga 8200 yuan memuat deskripsi “batu bara adalah sumber daya terbarukan, diperoleh dengan membunuh wither skeleton”, yang berasal dari konten game “Minecraft”, memicu perbincangan hangat di internet. Banyak orang menyalahkannya pada pembuatan konten AI dan halusinasi. Namun, laporan tersebut diterbitkan pada tahun 2022, jauh sebelum rilis model besar arus utama seperti ChatGPT, yang menunjukkan bahwa ini adalah kasus tipikal penyalinan manual, tempel, dan kelalaian peninjauan. Peristiwa ini juga memicu refleksi mendalam tentang kualitas konten laporan profesional, pentingnya verifikasi informasi, dan bagaimana membedakan kebenaran informasi di era AI. (Sumber: caoz的梦呓)

Peneliti menggunakan terapi penyuntingan gen yang disesuaikan untuk mengobati bayi dengan penyakit metabolik langka : Para dokter dalam waktu kurang dari tujuh bulan membangun terapi penyuntingan gen yang disesuaikan dan berhasil menggunakannya untuk mengobati seorang bayi dengan penyakit metabolik yang mematikan. Ini adalah pertama kalinya penyuntingan gen digunakan untuk terapi yang disesuaikan untuk satu individu. Terapi ini bertujuan untuk memperbaiki kesalahan satu huruf spesifik dalam gen bayi tersebut, menunjukkan presisi teknologi penyuntingan gen baru (seperti penyuntingan basa). Meskipun pengobatan menunjukkan tanda-tanda positif awal, hal ini juga menyoroti tantangan biaya dan skalabilitas dalam mengembangkan terapi gen yang dipersonalisasi untuk penyakit yang sangat langka. (Sumber: MIT Technology Review)

Strategi prompt jailbreak universal terungkap, dapat melewati pagar keamanan model besar arus utama : Peneliti dari HiddenLayer menemukan strategi prompt universal yang mampu membuat model bahasa besar arus utama termasuk ChatGPT, Claude, Gemini melewati pagar keamanan dan menghasilkan konten berbahaya. Strategi ini bekerja dengan menyamarkan instruksi berbahaya dalam format yang mirip dengan file kebijakan seperti XML, INI, atau JSON, dikombinasikan dengan skenario permainan peran fiktif, untuk menipu model agar menafsirkan perintah berbahaya sebagai instruksi sistem yang sah. Metode ini memanfaatkan kelemahan sistemik yang mungkin ada dalam data pelatihan model, yaitu kecenderungan untuk mengabaikan instruksi keamanan saat memproses data terkait pengajaran atau kebijakan. Teknik ini juga mampu mengekstrak prompt sistem model, mengungkap instruksi internal dan batasan keamanannya. (Sumber: 新智元)
