
Kata Kunci:AlphaEvolve, Claude Sonnet, GPT-4.1, Meta FAIR, Qwen3, Phi-4-reasoning, Regulasi AI, Agen pengkodean berbasis Gemini, Optimasi algoritma perkalian matriks, Optimasi efisiensi pusat data, Model multimodal multibahasa, Jaringan pelatihan AI terdesentralisasi, Seed1.5-VL
🔥 Fokus
Google DeepMind merilis AlphaEvolve: Agen pengkodean yang didukung Gemini, merevolusi penemuan algoritma: Google DeepMind meluncurkan AlphaEvolve, sebuah agen pengkodean AI yang didukung oleh Gemini, yang bertujuan untuk menemukan dan mengoptimalkan algoritma kompleks dengan menggabungkan kreativitas model bahasa besar dengan evaluator otomatis. AlphaEvolve telah berhasil merancang algoritma perkalian matriks yang lebih cepat, memecahkan masalah matematika terbuka seperti masalah tumpang tindih minimum Erdős dan masalah bilangan ciuman (kissing number problem), serta digunakan secara internal di Google untuk mengoptimalkan efisiensi pusat data (rata-rata memulihkan 0,7% sumber daya komputasi), desain chip, dan mempercepat pelatihan Gemini itu sendiri, menunjukkan potensi besar AI dalam penemuan ilmiah dan optimasi rekayasa. (Sumber: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic segera merilis model baru Claude Sonnet dan Opus, memperkuat kemampuan penalaran dan pemanggilan alat: Menurut laporan The Information, Anthropic berencana meluncurkan versi baru Claude Sonnet dan Claude Opus dalam beberapa minggu mendatang. Fitur inti model baru ini adalah kemampuan untuk beralih secara fleksibel antara “mode berpikir” dan “mode penggunaan alat”. Ketika menghadapi kendala saat menggunakan alat eksternal (seperti aplikasi, basis data) untuk memecahkan masalah, model dapat secara proaktif kembali ke “mode penalaran” untuk merefleksikan dan mengoreksi diri. Dalam hal pembuatan kode, model baru dapat secara otomatis menguji kode yang dihasilkan, dan jika ditemukan kesalahan, model akan berhenti sejenak, berpikir, dan memperbaikinya. Siklus tertutup “berpikir-bertindak-merefleksikan” ini diharapkan dapat secara signifikan meningkatkan kemampuan dan keandalan model dalam memecahkan masalah kompleks. (Sumber: steph_palazzolo, dotey)

Anggota parlemen Partai Republik AS usulkan larangan regulasi AI di tingkat federal dan negara bagian selama 10 tahun, memicu diskusi sengit: Anggota parlemen Partai Republik AS menambahkan klausul dalam RUU rekonsiliasi anggaran, mengusulkan larangan bagi pemerintah federal dan negara bagian untuk meregulasi model, sistem, atau sistem pengambilan keputusan otomatis AI selama sepuluh tahun ke depan, dan berencana mengalokasikan $500 juta untuk mendukung komersialisasi AI serta penerapannya dalam sistem IT pemerintah federal. Langkah ini dianggap oleh sebagian kalangan teknologi sebagai sinyal positif untuk melindungi inovasi AI dan mencegah regulasi yang menghambat, tetapi juga menimbulkan kekhawatiran tentang potensi risiko seperti maraknya DeepFake, hilangnya kendali atas privasi data, etika AI, dan dampak lingkungan. Jika disetujui, proposal ini akan berdampak signifikan pada legislasi AI yang ada dan yang akan datang. (Sumber: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI merilis model GPT-4.1 dan meluncurkan Pusat Evaluasi Keamanan, menekankan kemampuan pengkodean dan kepatuhan instruksi: OpenAI mengumumkan bahwa, atas permintaan pengguna, model GPT-4.1 tersedia di ChatGPT mulai hari ini (untuk pengguna Plus, Pro, Team; versi Enterprise dan Education akan menyusul). GPT-4.1 dioptimalkan khusus untuk tugas pengkodean dan kepatuhan instruksi, lebih cepat, dan dapat menjadi alternatif sehari-hari untuk o3 dan o4-mini dalam pengkodean. Sementara itu, GPT-4.1 mini akan menggantikan GPT-4o mini yang saat ini digunakan oleh semua pengguna. Selain itu, OpenAI meluncurkan Pusat Evaluasi Keamanan (Safety Evaluations Hub) untuk mempublikasikan hasil pengujian keamanan dan metrik modelnya, yang akan diperbarui secara berkala untuk meningkatkan transparansi komunikasi keamanan. (Sumber: openai, michpokrass)
Meta FAIR merilis beberapa hasil penelitian AI, berfokus pada penemuan molekul dan pemodelan atom: Meta AI (FAIR) mengumumkan rilis sumber terbuka terbaru di bidang prediksi sifat molekul, pemrosesan bahasa, dan ilmu saraf. Ini termasuk Open Molecules 2025 (OMol25), sebuah dataset penemuan molekul untuk simulasi sistem atom besar; Universal Model for Atoms (UMA), sebuah model potensial antar-atom berbasis pembelajaran mesin yang dapat diterapkan secara luas untuk pemodelan interaksi atom dalam material dan molekul; dan Adjoint Sampling, sebuah algoritma yang dapat diskalakan untuk melatih model generatif berdasarkan imbalan skalar. Selain itu, FAIR bekerja sama dengan Rothschild Foundation Hospital dalam penelitian yang mengungkapkan kesamaan signifikan dalam perkembangan bahasa antara manusia dan LLM. (Sumber: AIatMeta)
🎯 Perkembangan
ByteDance merilis model bahasa visual besar Seed1.5-VL, dengan 20 miliar parameter aktif menunjukkan performa luar biasa: ByteDance meluncurkan model multimodal visual-bahasa besarnya, Seed1.5-VL. Model ini, dengan hanya 20 miliar parameter aktif, menunjukkan performa yang sebanding dengan Gemini 2.5 Pro dan mencapai SOTA pada 38 dari 60 benchmark evaluasi publik. Seed1.5-VL meningkatkan kemampuan pemahaman dan penalaran multimodal umum, terutama menonjol dalam penentuan posisi visual, penalaran, pemahaman video, dan agen multimodal cerdas. Model ini telah tersedia melalui API di Volcano Engine, dengan harga inferensi input sebesar 0,003 yuan/ribu token dan output sebesar 0,009 yuan/ribu token. (Sumber: 机器之心)

Laporan teknis Qwen3 mengungkap: Menggabungkan mode berpikir dan non-berpikir, model besar mendistilasi model kecil: Alibaba merilis laporan teknis seri model Qwen3, yang mencakup 8 model dengan parameter mulai dari 0,6 miliar hingga 235 miliar. Inovasi inti terletak pada mode kerja ganda, di mana model dapat secara otomatis beralih antara “mode berpikir” (penalaran kompleks) dan “mode non-berpikir” (respons cepat) berdasarkan kompleksitas tugas, dengan mengalokasikan sumber daya komputasi secara dinamis melalui parameter “anggaran berpikir”. Pelatihan menggunakan pra-pelatihan tiga tahap (pengetahuan umum, peningkatan penalaran, teks panjang) dan pasca-pelatihan empat tahap (cold start rantai pemikiran panjang, pembelajaran penguatan penalaran, fusi mode berpikir, pembelajaran penguatan umum). Pada saat yang sama, strategi distilasi data “besar membawa kecil” diadopsi, menggunakan output model guru (seperti 235B) untuk melatih model siswa (seperti 30B), mencapai transfer pengetahuan. (Sumber: 36氪)

Microsoft merilis seri model Phi-4-reasoning, berbagi pengalaman pelatihan model penalaran: Microsoft meluncurkan tiga model: Phi-4-reasoning, Phi-4-reasoning-plus (keduanya 14 miliar parameter), dan Phi-4-mini-reasoning (3,8 miliar parameter), serta mempublikasikan metode dan pengalaman pelatihannya. Model-model ini, melalui fine-tuning model pra-pelatihan, berfokus pada peningkatan kemampuan seperti penalaran matematis. Misalnya, Phi-4-reasoning-plus menunjukkan kinerja luar biasa pada masalah matematika melalui pembelajaran penguatan, sementara Phi-4-mini-reasoning menjalani fine-tuning SFT dan RL secara bertahap. Laporan ini berbagi tentang ketidakstabilan yang mungkin muncul dalam pelatihan model kecil dan strategi penanganannya, serta pertimbangan mengenai pemilihan data dan desain fungsi imbalan dalam pelatihan RL model besar. Bobot model telah tersedia di Hugging Face di bawah lisensi MIT. (Sumber: DeepLearning.AI Blog)
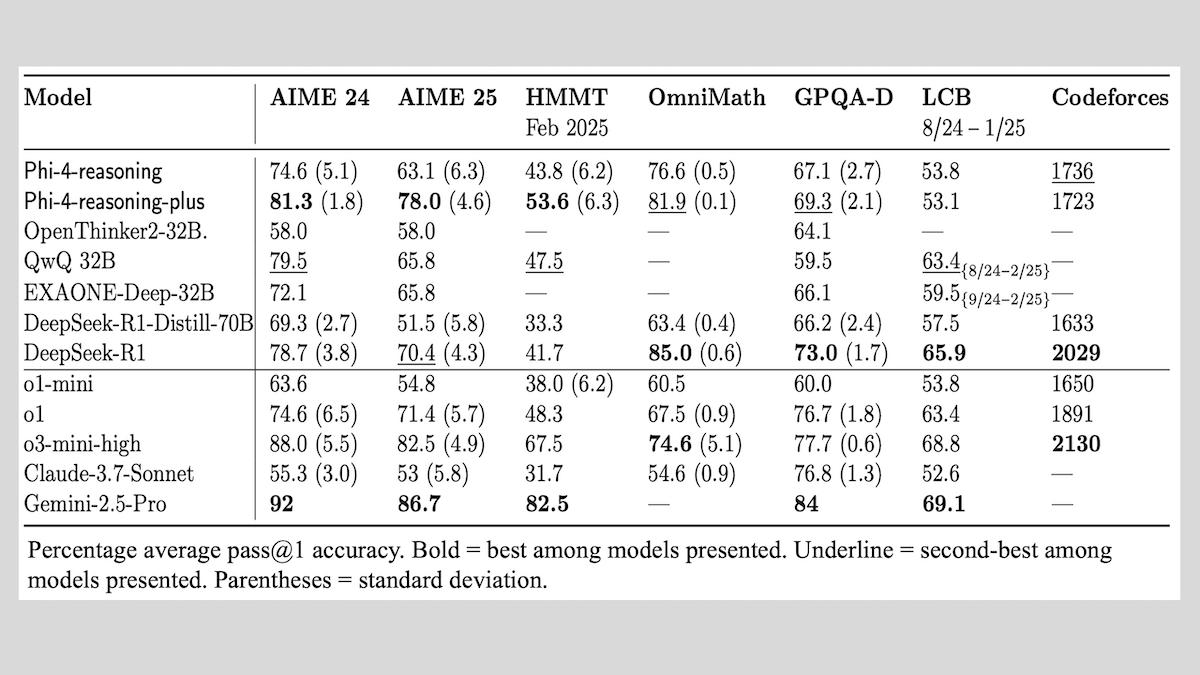
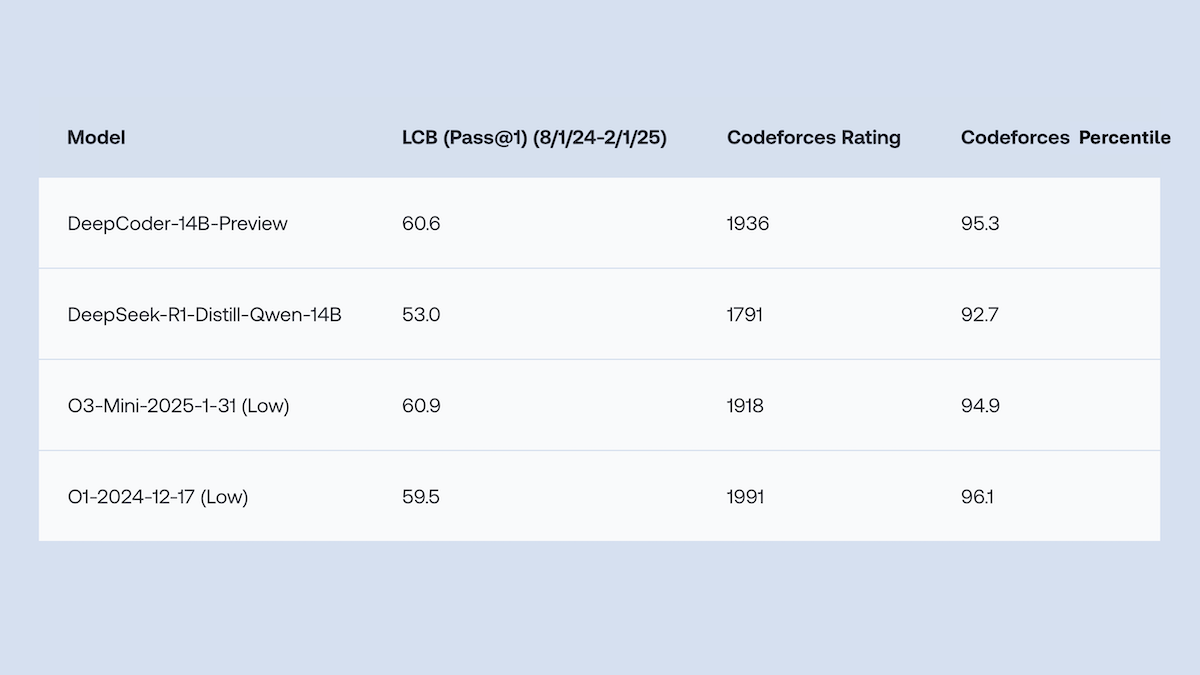
Together.AI dan Agentica merilis sumber terbuka DeepCoder-14B-Preview, performa pembuatan kode setara o1: Tim Together.AI dan Agentica merilis DeepCoder-14B-Preview, sebuah model pembuatan kode dengan 14 miliar parameter, yang performanya pada beberapa benchmark pengkodean setara dengan model yang lebih besar seperti DeepSeek-R1 dan OpenAI o1. Model ini, melalui fine-tuning pada DeepSeek-R1-Distilled-Qwen-14B, mengadopsi metode pembelajaran penguatan yang disederhanakan (menggabungkan optimasi GRPO dan DAPO), dan meningkatkan kemampuan pemrosesan paralel library RL Verl, secara signifikan mengurangi waktu pelatihan. Bobot model, kode, dataset, dan log pelatihan semuanya dirilis sebagai sumber terbuka di bawah lisensi MIT. (Sumber: DeepLearning.AI Blog)
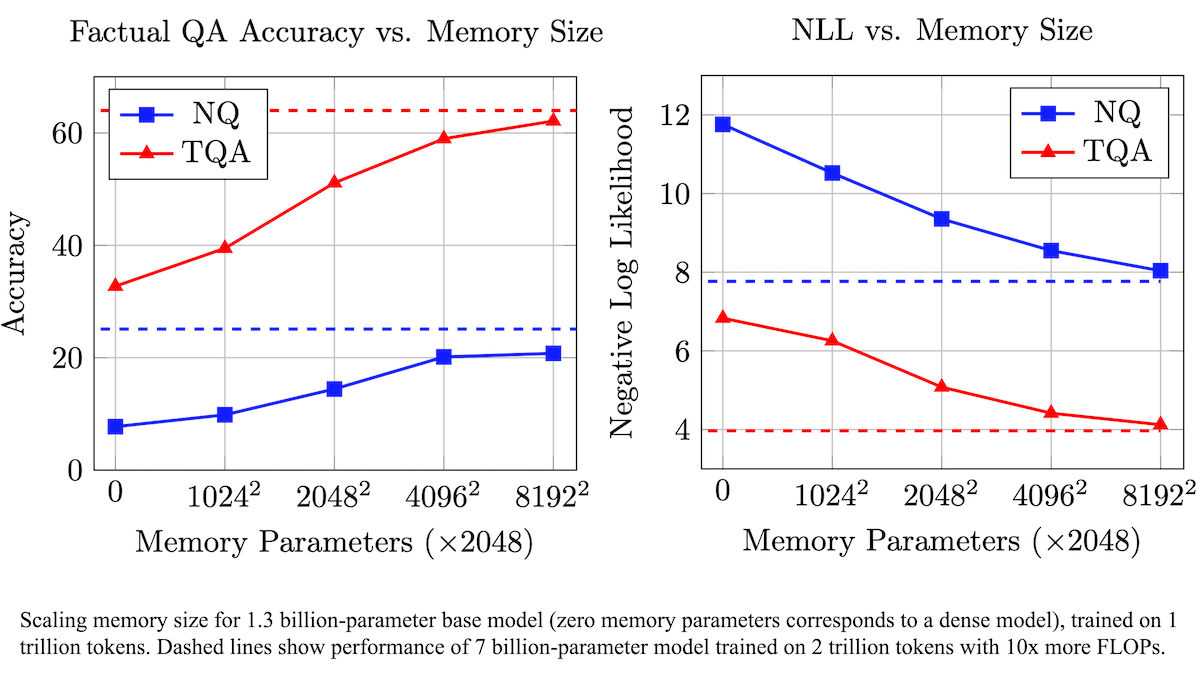
Meta usulkan lapisan memori yang dapat dilatih untuk meningkatkan akurasi faktual LLM, mengurangi kebutuhan komputasi: Peneliti Meta, dengan menambahkan lapisan memori yang dapat dilatih ke arsitektur Transformer, meningkatkan akurasi model bahasa besar dalam mengingat fakta, tanpa meningkatkan kebutuhan komputasi secara signifikan. Metode ini menyimpan informasi dengan mempelajari kunci dan nilai yang sesuai, dan mengadopsi strategi memecah kunci menjadi dua setengah kunci, secara efektif mengatasi hambatan komputasi saat mengambil kunci skala besar. Eksperimen menunjukkan bahwa model 8 miliar parameter yang dilengkapi dengan lapisan memori berkinerja lebih baik daripada model sejenis tanpa lapisan memori pada beberapa dataset tanya jawab, menunjukkan keunggulan dalam data pra-pelatihan dan kebutuhan jumlah komputasi. (Sumber: DeepLearning.AI Blog)
Alibaba merilis sumber terbuka seri model dasar video Wan2.1, mendukung pembuatan dan pengeditan video dari teks/gambar: Alibaba merilis Wan2.1, sebuah rangkaian model dasar video sumber terbuka yang komprehensif, termasuk versi 1,3 miliar dan 14 miliar parameter, di bawah lisensi Apache 2.0. Wan2.1 menunjukkan kinerja luar biasa dalam berbagai tugas seperti teks-ke-video, gambar-ke-video, pengeditan video, teks-ke-gambar, dan video-ke-audio, serta secara khusus mendukung pembuatan visual dari teks berbahasa Mandarin dan Inggris. Model T2V-1.3B-nya hanya membutuhkan VRAM 8,19GB, dapat berjalan pada GPU kelas konsumen, dan dapat menghasilkan video 480P berdurasi 5 detik dalam waktu 4 menit. Wan-VAE yang menyertainya dapat secara efisien melakukan encode dan decode video 1080P, dengan tetap mempertahankan informasi temporal. (Sumber: _akhaliq, Reddit r/LocalLLaMA)

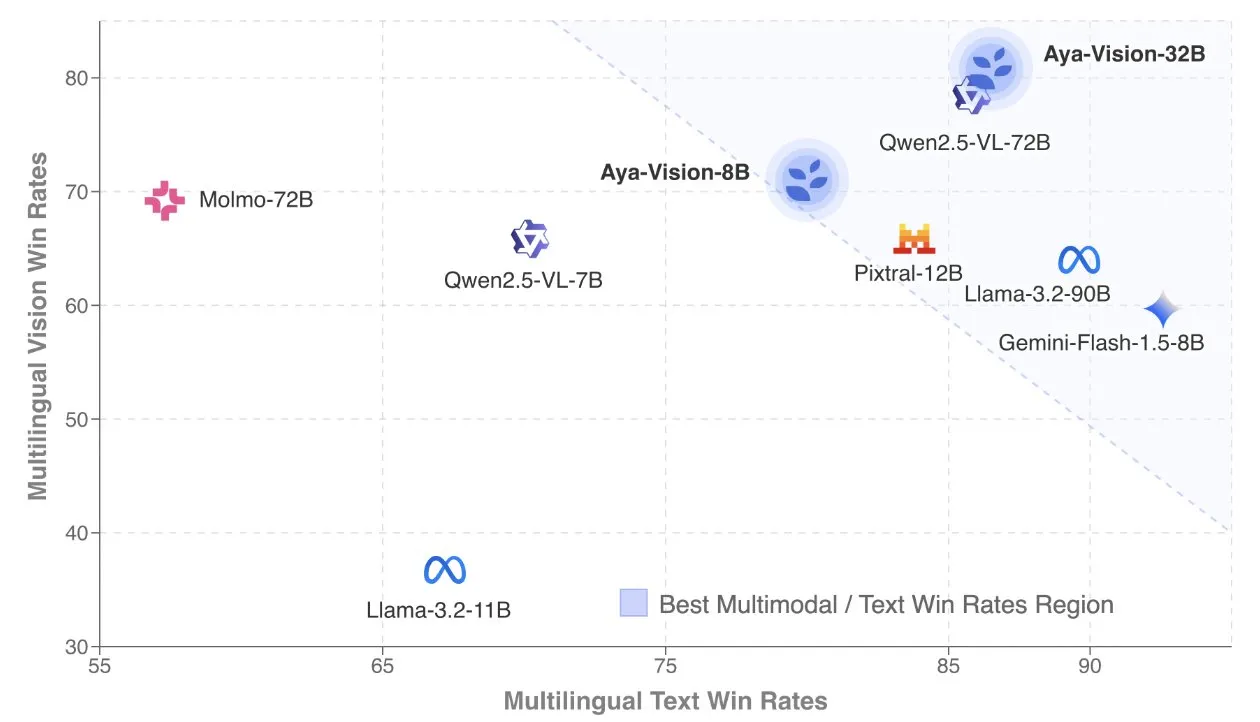
Cohere merilis laporan teknis Aya Vision, fokus pada model multimodal multibahasa: Cohere Labs mempublikasikan laporan teknis Aya Vision, yang merinci resep mereka untuk membangun model multimodal multibahasa SOTA. Model Aya Vision bertujuan untuk menyatukan kemampuan dalam 23 bahasa pada tugas multimodal dan teks. Laporan ini membahas kerangka kerja data multibahasa sintetis, desain arsitektur, metode pelatihan, penggabungan model lintas-modal, serta evaluasi komprehensif pada tugas generatif multibahasa terbuka. Model 8B-nya mengungguli model yang lebih besar seperti Pixtral-12B dalam hal performa, sementara model 32B lebih efisien, melampaui model yang ukurannya lebih dari dua kali lipat seperti Llama3.2-90B. (Sumber: sarahookr, Cohere Labs)
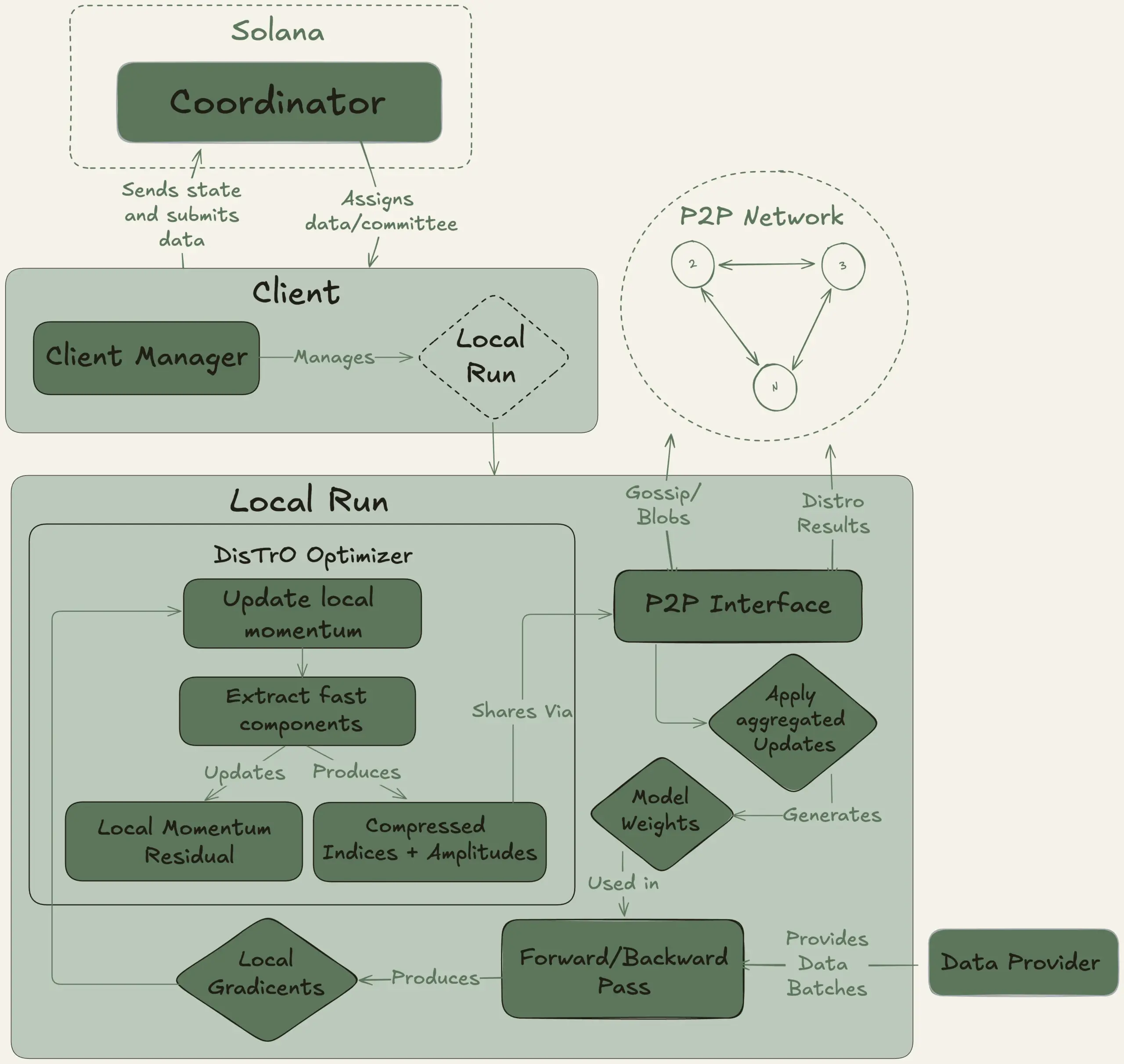
Nous Research meluncurkan proyek Psyche, bertujuan untuk pelatihan terdesentralisasi model besar 40 miliar parameter: Nous Research mengumumkan peluncuran jaringan Psyche, sebuah jaringan pelatihan AI terdesentralisasi yang bertujuan untuk mengumpulkan daya komputasi global guna melatih model AI yang kuat secara bersama-sama, memungkinkan individu dan komunitas kecil untuk berpartisipasi dalam pengembangan model skala besar. Testnet-nya telah memulai pra-pelatihan LLM 40 miliar parameter, menggunakan arsitektur MLA, dengan dataset yang mencakup FineWeb (14T), sebagian FineWeb-2 (4T), dan The Stack v2 (1T), dengan total sekitar 20T token. Setelah pelatihan model ini selesai, semua checkpoint (termasuk versi yang tidak di-anneal dan yang di-anneal) serta dataset akan dirilis sebagai sumber terbuka. (Sumber: eliebakouch, Teknium1)
Stability AI merilis model sumber terbuka Stable Audio Open Small, berfokus pada pembuatan teks-ke-audio yang cepat: Stability AI merilis model Stable Audio Open Small di Hugging Face, sebuah model yang dirancang khusus untuk pembuatan teks-ke-audio yang cepat dan menggunakan teknik pasca-pelatihan adversarial. Model ini bertujuan untuk menyediakan solusi pembuatan audio sumber terbuka yang efisien. (Sumber: _akhaliq)
Google Gemini Advanced terintegrasi dengan GitHub, memperkuat kemampuan bantuan pengkodean: Google mengumumkan bahwa Gemini Advanced kini terhubung dengan GitHub, lebih lanjut meningkatkan kemampuannya sebagai asisten pengkodean. Pengguna dapat langsung menghubungkan repositori GitHub publik atau pribadi, memanfaatkan Gemini untuk menghasilkan atau memodifikasi fungsi, menjelaskan kode kompleks, mengajukan pertanyaan terkait basis kode, melakukan debugging, dan operasi lainnya. Dengan mengklik tombol “+” di bilah prompt dan memilih “Impor kode”, lalu menempelkan URL GitHub, pengguna dapat mulai menggunakannya. (Sumber: algo_diver)
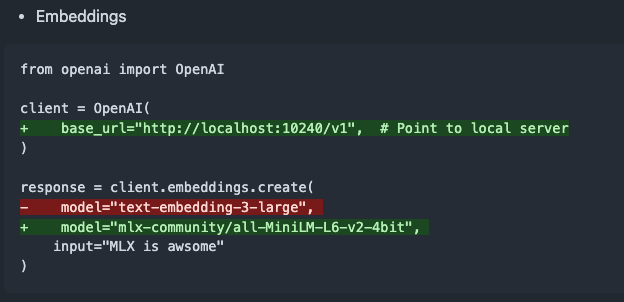
mlx-omni-server v0.4.0 dirilis, menambahkan layanan embeddings dan lebih banyak model TTS: mlx-omni-server diperbarui ke versi v0.4.0, memperkenalkan layanan /v1/embeddings baru, yang menyederhanakan pembuatan embedding melalui mlx-embeddings. Pada saat yang sama, lebih banyak model TTS (seperti kokoro, bark) diintegrasikan, dan mlx-lm ditingkatkan untuk mendukung model baru seperti qwen3. (Sumber: awnihannun)
Together Chat menambahkan fungsi pemrosesan file PDF: Together Chat mengumumkan dukungan untuk pengunggahan dan pemrosesan file PDF. Versi saat ini terutama mem-parsing konten teks dalam PDF dan meneruskannya ke model untuk diproses. Versi v2 direncanakan akan dirilis di masa mendatang, menambahkan fungsi OCR untuk membaca konten gambar dalam PDF. (Sumber: togethercompute)
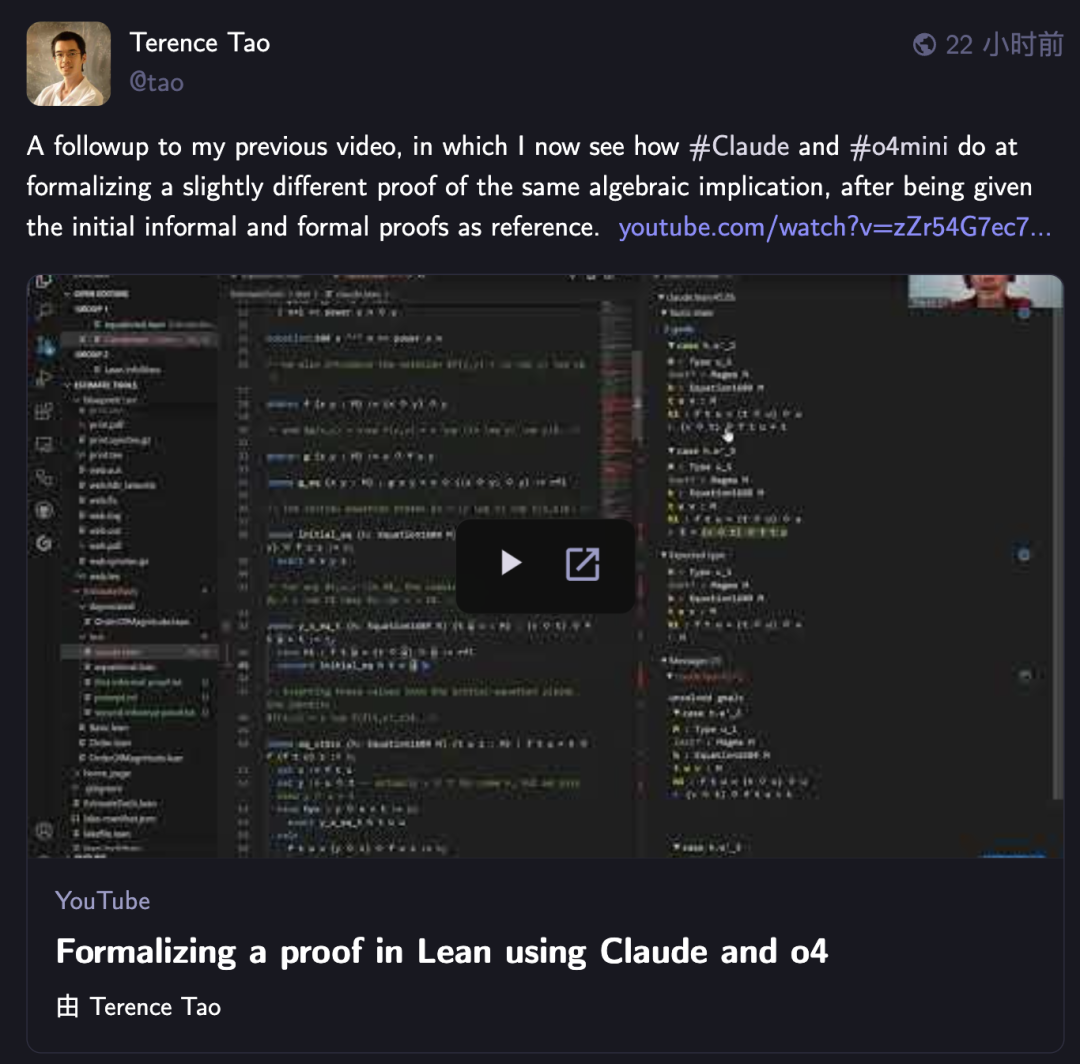
Terence Tao kembali tantang AI dengan pembuktian formal matematika, Claude ungguli o4-mini: Matematikawan Terence Tao, dalam seri video YouTube-nya, menguji kemampuan AI dalam pembuktian formal implikasi aljabar menggunakan asisten pembuktian Lean. Dalam eksperimen tersebut, Claude mampu menyelesaikan tugas dalam waktu sekitar 20 menit, meskipun selama proses kompilasi terungkap adanya kesalahpahaman terhadap aturan bilangan asli di Lean yang dimulai dari 0 dan masalah penanganan simetri, namun dapat diperbaiki dengan intervensi manual. Sebagai perbandingan, o4-mini menunjukkan kinerja yang lebih hati-hati, mampu mengidentifikasi masalah definisi fungsi pangkat, tetapi memilih untuk menyerah pada langkah pembuktian kunci dan gagal menyelesaikan tugas. Terence Tao menyimpulkan bahwa ketergantungan berlebihan pada otomatisasi dapat melemahkan pemahaman terhadap struktur keseluruhan pembuktian, dan tingkat otomatisasi optimal seharusnya berada di antara 0% hingga 100%, dengan tetap mempertahankan intervensi manusia untuk memperdalam pemahaman. (Sumber: 36氪)
Wawancara Altman: Tujuan akhir OpenAI adalah membangun layanan berlangganan AI inti: CEO OpenAI Sam Altman, dalam acara Sequoia Capital AI Ascent 2025, menyatakan bahwa “cita-cita Platonis” OpenAI adalah mengembangkan sistem operasi AI yang menjadi layanan berlangganan AI inti bagi pengguna. Ia membayangkan model AI di masa depan akan mampu memproses data seumur hidup pengguna (konteks triliunan token), mencapai penalaran yang sangat personal. Altman mengakui bahwa ini masih dalam “tahap PPT”, tetapi menekankan bahwa perusahaan bangga akan fleksibilitas dan kemampuan beradaptasinya. Ia juga berbicara tentang potensi interaksi suara AI, tahun 2025 akan menjadi tahun di mana agen AI bersinar, dan percaya bahwa pengkodean akan menjadi inti yang menggerakkan operasi model dan pemanggilan API. (Sumber: 36氪, 量子位)

Karminski3 bagikan versi modifikasi komunitas Qwen3-30B, jumlah pakar aktif dua kali lipat: Komunitas pengembang memodifikasi model Qwen3, meluncurkan versi Qwen3-30B-A6B-16-Extreme. Dengan memodifikasi parameter model, jumlah pakar aktif ditingkatkan dari A3B menjadi A6B, yang diklaim dapat membawa sedikit peningkatan kualitas, tetapi kecepatan generasi akan melambat. Pengguna juga dapat mencapai efek serupa dengan memodifikasi parameter runtime llama.cpp --override-kv http://qwen3moe.expert_used_count=int:24, atau melakukan operasi sebaliknya untuk mengurangi jumlah aktivasi Qwen3-235B-A22B guna mempercepat. (Sumber: karminski3)

🧰 Alat
OpenMemory MCP dirilis: Sistem memori bersama yang berjalan lokal, menghubungkan berbagai alat AI: Tim mem0ai meluncurkan OpenMemory MCP, sebuah server memori pribadi yang dibangun berdasarkan Model Context Protocol (MCP). Ini mendukung operasi 100% lokal, bertujuan untuk mengatasi masalah informasi konteks yang tidak dibagikan antar alat AI saat ini (seperti Cursor, Claude Desktop, Windsurf, Cline) dan hilangnya memori setelah sesi berakhir. Data pengguna disimpan secara lokal, memastikan keamanan privasi. OpenMemory MCP menyediakan API operasi memori standar (tambah, hapus, cari, ubah), dan memiliki dasbor terpusat bagi pengguna untuk mengelola memori dan hak akses klien, dengan penyebaran yang disederhanakan melalui Docker. (Sumber: 36氪, AI进修生)

LangChain meluncurkan versi resmi platform LangGraph dan beberapa pembaruan, memperkuat pengembangan agen AI dan observabilitas: LangChain, dalam konferensi Interrupt, mengumumkan ketersediaan umum (GA) platform LangGraph-nya. Platform ini dirancang khusus untuk membangun dan mengelola alur kerja agen AI yang berjalan lama dan stateful, mendukung penyebaran sekali klik, penskalaan horizontal, serta API untuk memori, interaksi manusia-dalam-siklus (HIL), riwayat percakapan, dll. Pada saat yang sama, LangGraph Studio V2 dirilis sebagai IDE agen, mendukung operasi lokal, pengeditan konfigurasi langsung, integrasi dengan Playground, dan kemampuan untuk menarik data pelacakan dari lingkungan produksi untuk debugging lokal. Selain itu, LangChain juga meluncurkan platform pembangunan agen tanpa kode sumber terbuka Open Agent Platform (OAP), dan meningkatkan observabilitas agen LangSmith dalam hal pemanggilan alat dan jejak. (Sumber: LangChainAI, hwchase17)
PatronusAI merilis Percival: Agen AI yang dapat mengevaluasi dan memperbaiki agen AI lainnya: PatronusAI meluncurkan Percival, yang diklaim sebagai agen AI pertama yang mampu mengevaluasi dan secara otomatis memperbaiki kesalahan agen AI lainnya. Percival tidak hanya dapat mendeteksi kegagalan dalam catatan pelacakan agen, tetapi juga mengusulkan saran perbaikan. Diklaim bahwa pada dataset TRAIL yang berisi kesalahan yang dianotasi secara manual dari GAIA dan SWE-Bench, performa Percival 2,9 kali lebih tinggi daripada LLM SOTA. Fungsinya termasuk secara otomatis menyarankan solusi perbaikan prompt agen, menangkap lebih dari 20 jenis kegagalan agen (mencakup penggunaan alat, koordinasi perencanaan, kesalahan spesifik domain, dll.), dan mengurangi waktu debugging manual dari beberapa jam menjadi kurang dari 1 menit. (Sumber: rebeccatqian, basetenco)
PyWxDump: Alat pengambilan dan ekspor informasi WeChat, mendukung pelatihan AI: PyWxDump adalah alat Python yang digunakan untuk mendapatkan informasi akun WeChat (nama panggilan, akun, nomor ponsel, email, kunci basis data), mendekripsi basis data, melihat riwayat obrolan secara lokal, dan dapat mengekspor riwayat obrolan ke format CSV, HTML, dll., yang dapat digunakan untuk skenario seperti pelatihan AI, balasan otomatis, dll. Alat ini mendukung pengambilan informasi multi-akun dan semua versi WeChat, serta menyediakan UI berbasis web untuk melihat riwayat obrolan. (Sumber: GitHub Trending)

Airweave: Alat yang memungkinkan agen AI mencari di aplikasi apa pun, kompatibel dengan protokol MCP: Airweave adalah alat yang bertujuan untuk memungkinkan agen AI melakukan pencarian semantik terhadap konten aplikasi apa pun. Alat ini kompatibel dengan Model Context Protocol (MCP), dapat terhubung secara mulus ke berbagai aplikasi, basis data, atau API, mengubah kontennya menjadi pengetahuan yang dapat digunakan oleh agen. Fungsi utamanya meliputi sinkronisasi data, ekstraksi dan transformasi entitas, arsitektur multi-tenant, pembaruan inkremental, pencarian semantik, dan kontrol versi, dll. (Sumber: GitHub Trending)

iFLYTEK merilis earphone AI generasi baru iFLYBUDS Pro3 dan Air2 yang ditenagai otak AI viaim: Future Intelligence merilis earphone konferensi AI iFLYBUDS Pro3 dan iFLYBUDS Air2 dari iFLYTEK, kedua earphone ini ditenagai oleh otak AI viaim yang baru. viaim adalah agen AI yang ditujukan untuk perkantoran bisnis pribadi, mengintegrasikan empat modul inti: pemrosesan persepsi cerdas end-to-end, penalaran kolaboratif agen cerdas, kemampuan multimodal real-time, dan perlindungan privasi keamanan data. Earphone ini mendukung perekaman yang mudah (panggilan, rekaman di tempat, rekaman audio dan video), asisten AI (secara otomatis menghasilkan ringkasan judul, pertanyaan yang ditargetkan), terjemahan multibahasa (32 bahasa, terjemahan simultan, terjemahan tatap muka, terjemahan panggilan), dll., serta meningkatkan kualitas suara dan kenyamanan pemakaian. (Sumber: WeChat)

KoboldCpp Smart Launcher dirilis: Alat penyetelan otomatis Tensor Offload untuk mengoptimalkan performa LLM: Sebuah alat GUI dan CLI bernama KoboldCpp Smart Launcher dirilis, bertujuan untuk membantu pengguna secara otomatis menemukan strategi Tensor Offload terbaik untuk KoboldCpp saat menjalankan LLM secara lokal. Dengan mengalokasikan tensor secara lebih granular antara CPU dan GPU (bukan seluruh lapisan), alat ini diklaim dapat meningkatkan kecepatan generasi lebih dari dua kali lipat tanpa menambah kebutuhan VRAM. Misalnya, kecepatan QwQ Merge pada GPU 12GB VRAM meningkat dari 3,95 t/s menjadi 10,61 t/s. (Sumber: Reddit r/LocalLLaMA)
OpenBMB merilis sumber terbuka AgentCPM-GUI: Agen GUI on-device pertama yang dioptimalkan untuk bahasa Mandarin: Tim OpenBMB merilis sumber terbuka AgentCPM-GUI, agen GUI (antarmuka pengguna grafis) on-device pertama yang dioptimalkan khusus untuk aplikasi berbahasa Mandarin. Agen ini meningkatkan kemampuan penalaran melalui Reinforcement Fine-Tuning (RFT), mengadopsi desain ruang aksi yang ringkas, dan memiliki kemampuan grounding GUI berkualitas tinggi, yang bertujuan untuk meningkatkan pengalaman pengguna dalam mengoperasikan berbagai aplikasi dalam lingkungan berbahasa Mandarin. (Sumber: Reddit r/LocalLLaMA)
MAESTRO: Aplikasi penelitian AI yang mengutamakan lokal, mendukung kolaborasi multi-agen dan LLM kustom: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator) adalah aplikasi penelitian berbasis AI yang baru dirilis, menekankan kontrol dan kemampuan lokal. Aplikasi ini menyediakan kerangka kerja modular, termasuk ekstraksi dokumen, alur RAG yang kuat, dan sistem multi-agen (perencanaan, penelitian, refleksi, penulisan), yang dapat menangani masalah penelitian kompleks. Pengguna dapat berinteraksi melalui Streamlit Web UI atau CLI, menggunakan kumpulan dokumen mereka sendiri dan LLM lokal atau API pilihan mereka. (Sumber: Reddit r/LocalLLaMA)
Contextual AI meluncurkan parser dokumen yang dioptimalkan untuk RAG: Contextual AI merilis parser dokumen baru yang dirancang khusus untuk sistem Retrieval Augmented Generation (RAG). Alat ini bertujuan untuk menyediakan parsing dokumen tidak terstruktur yang kompleks dengan akurasi tinggi dengan menggabungkan model visual, OCR, dan bahasa visual, mampu mempertahankan struktur hierarki dokumen, menangani modalitas kompleks seperti tabel, bagan, dan grafik, serta menyediakan kotak pembatas dan tingkat kepercayaan untuk audit pengguna, sehingga mengurangi kehilangan konteks dan halusinasi dalam sistem RAG yang disebabkan oleh kegagalan parsing. (Sumber: douwekiela)
Gradio menambahkan fungsi undo/redo pada ImageEditor: Komponen ImageEditor Gradio kini telah menambahkan tombol undo (batalkan) dan redo (ulangi), memberikan pengguna fungsi pengeditan gambar Python yang mirip dengan aplikasi berbayar profesional, meningkatkan interaktivitas dan kemudahan penggunaan. (Sumber: _akhaliq)
RunwayML meluncurkan fitur baru References, mendukung pengujian material, pakaian, lokasi, dan pose secara zero-shot: Fitur References RunwayML telah diperbarui, pengguna dapat menggunakan gambar pratinjau material 3D tradisional sebagai input untuk menerapkan materialnya ke objek apa pun, mencapai transfer material dan visualisasi secara zero-shot. Selain itu, fitur baru ini juga mendukung pengujian zero-shot untuk pakaian, lokasi, dan pose karakter, memperluas kemungkinan generasi kreatif dan pembuatan prototipe cepat. (Sumber: c_valenzuelab, c_valenzuelab)

Mita AI meluncurkan fitur “Belajar Apa Hari Ini”, AI membantu pembelajaran terstruktur: Mita AI meluncurkan fitur baru “Belajar Apa Hari Ini”, yang bertujuan untuk mengubah peran AI dari asisten pencarian informasi dan pemrosesan dokumen menjadi “guru AI” yang dapat secara aktif membimbing dan mengajar. Setelah pengguna mengunggah atau mencari materi, fitur ini dapat secara otomatis menghasilkan kursus video dan penjelasan PPT yang sistematis dan terstruktur, membantu pengguna menyusun poin-poin pengetahuan, dan mendukung pemilihan kedalaman penjelasan yang berbeda (pemula/ahli) dan gaya (bercerita/kakak galak, dll.) sesuai dengan tingkat pengguna. Selain itu, fitur ini juga mendukung pertanyaan di tengah pelajaran dan tes setelah pelajaran. (Sumber: WeChat)

📚 Belajar
Andrew Ng dan Anthropic bekerja sama meluncurkan kursus baru: Membangun Aplikasi AI Kaya Konteks dengan MCP: DeepLearning.AI milik Andrew Ng bekerja sama dengan Anthropic meluncurkan kursus baru “MCP: Build Rich-Context AI Apps with Anthropic”, yang diajarkan oleh Direktur Pendidikan Teknis Anthropic, Elie Schoppik. Kursus ini berfokus pada Model Context Protocol (MCP), sebuah protokol terbuka yang bertujuan untuk menstandarisasi akses LLM ke alat, data, dan prompt eksternal. Peserta akan mempelajari arsitektur inti MCP, membuat chatbot yang kompatibel dengan MCP, membangun dan menerapkan server MCP, serta menghubungkannya ke aplikasi yang didukung Claude dan server pihak ketiga lainnya untuk menyederhanakan pengembangan aplikasi AI kaya konteks. (Sumber: AndrewYNg, DeepLearningAI)
FlashInfer: Makalah Terbaik MLSys 2025, mesin atensi inferensi LLM yang efisien dan dapat disesuaikan: Proyek FlashInfer, hasil kolaborasi Zihao Ye dari Universitas Washington, NVIDIA, Chen Tianqi dari OctoAI, dan lainnya, meraih penghargaan Makalah Terbaik MLSys 2025. FlashInfer adalah mesin atensi yang efisien dan dapat disesuaikan yang dirancang untuk optimasi layanan inferensi LLM. Dengan mengoptimalkan akses memori (menggunakan format blok renggang dan format yang dapat disusun untuk memproses KV cache), menyediakan templat komputasi atensi fleksibel berbasis kompilasi JIT, serta memperkenalkan mekanisme penjadwalan tugas dengan penyeimbangan beban, FlashInfer secara signifikan meningkatkan performa inferensi LLM dan telah diintegrasikan ke dalam proyek seperti vLLM dan SGLang. (Sumber: 机器之心)
Makalah ICML 2025: Memberikan analisis teoretis untuk Graph Prompting dari perspektif manipulasi data: Qunzhong Wang, Dr. Xiangguo Sun, dan Profesor Hong Cheng dari The Chinese University of Hong Kong mempresentasikan makalah di ICML 2025, yang untuk pertama kalinya menyediakan kerangka kerja teoretis sistematis untuk efektivitas graph prompting dari perspektif “manipulasi data”. Penelitian ini memperkenalkan konsep “graf jembatan” (bridging graph), membuktikan bahwa mekanisme graph prompting secara teoretis setara dengan melakukan operasi tertentu pada data graf input, memungkinkannya diproses dengan benar oleh model pra-pelatihan untuk beradaptasi dengan tugas baru. Makalah ini menurunkan batas atas kesalahan, menganalisis sumber dan kontrolabilitas kesalahan, serta memodelkan distribusi kesalahan, memberikan dasar teoretis untuk desain dan aplikasi graph prompting. (Sumber: WeChat)
Makalah ICML 2025: Menghindari keruntuhan model dengan menyintesis data teks melalui pengeditan tingkat token: Tim peneliti dari Shanghai Jiao Tong University dan institusi lainnya mempresentasikan makalah di ICML 2025, membahas masalah “keruntuhan model” (model collapse) yang disebabkan oleh data sintetis, dan mengusulkan strategi pembuatan data yang disebut “Token-Level Editing”. Metode ini, dengan melakukan pengeditan mikro pada token yang “terlalu percaya diri” oleh model pada data nyata, alih-alih menghasilkan teks baru sepenuhnya, bertujuan untuk membangun data semi-sintetis dengan struktur yang lebih stabil dan kemampuan generalisasi yang lebih kuat. Analisis teoretis menunjukkan bahwa metode ini dapat secara efektif membatasi kesalahan pengujian dan menghindari keruntuhan kinerja model seiring bertambahnya putaran iterasi. Eksperimen pada tahap pra-pelatihan, pra-pelatihan berkelanjutan, dan fine-tuning terawasi semuanya memvalidasi efektivitas metode ini. (Sumber: WeChat)

Makalah ICML 2025: OmniAudio, menghasilkan audio spasial 3D dari video panorama 360°: Tim OmniAudio di ICML 2025 memamerkan teknologi yang menghasilkan audio spasial first-order ambisonics (FOA) langsung dari video panorama 360°. Untuk mengatasi masalah kelangkaan data, tim membangun dataset 360V2SA skala besar bernama Sphere360 (lebih dari 100.000 klip, 288 jam). OmniAudio menggunakan pelatihan dua tahap: pra-pelatihan pencocokan aliran coarse-to-fine secara self-supervised, pertama melatih dengan audio stereo biasa yang diubah menjadi pseudo-FOA, kemudian fine-tuning dengan FOA asli; kemudian menggabungkan dengan encoder video dua cabang untuk fine-tuning terawasi, mengekstraksi fitur perspektif global dan lokal, menghasilkan audio spasial dengan fidelitas tinggi dan arah yang akurat. (Sumber: 量子位)

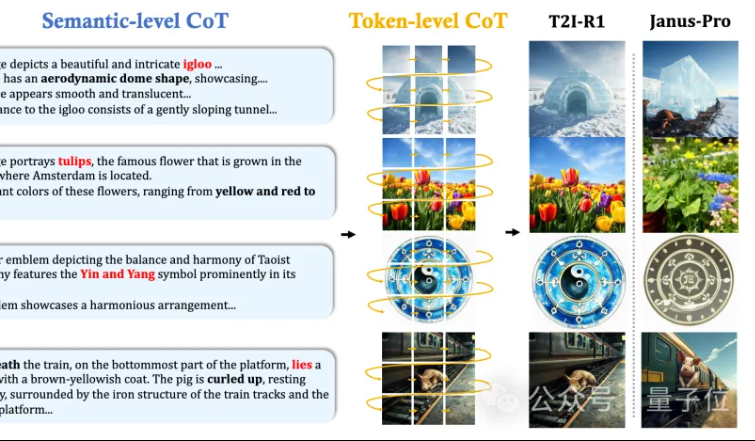
MMLab CUHK usulkan T2I-R1: Memperkenalkan penalaran CoT dua tingkat dan pembelajaran penguatan untuk teks-ke-gambar: Tim MMLab dari The Chinese University of Hong Kong merilis T2I-R1, model teks-ke-gambar pertama yang ditingkatkan dengan penalaran berbasis pembelajaran penguatan. Model ini secara inovatif mengusulkan kerangka kerja penalaran Chain-of-Thought (CoT) dua tingkat: Semantic-CoT (penalaran teks, merencanakan struktur global gambar) dan Token-CoT (pembuatan token gambar blok demi blok, fokus pada detail tingkat rendah). Melalui metode pembelajaran penguatan BiCoT-GRPO, kedua tingkat CoT ini dioptimalkan secara kolaboratif dalam satu LMM terpadu (Janus-Pro), tanpa memerlukan model tambahan. Model imbalan menggunakan integrasi beberapa model pakar visual, memastikan keandalan evaluasi dan mencegah overfitting. Eksperimen menunjukkan bahwa T2I-R1 dapat lebih baik memahami maksud pengguna, menghasilkan gambar yang lebih sesuai dengan harapan, dan secara signifikan mengungguli model dasar pada benchmark T2I-CompBench dan WISE. (Sumber: 量子位, WeChat)
OpenAI merilis library evaluasi model bahasa ringan simple-evals: OpenAI merilis simple-evals sebagai sumber terbuka, sebuah library ringan untuk mengevaluasi model bahasa, yang bertujuan untuk mentransparansikan data akurasi rilis model terbarunya. Library ini menekankan pengaturan evaluasi zero-shot dan chain-of-thought, serta menyediakan perbandingan kinerja model yang terperinci pada beberapa benchmark seperti MMLU, MATH, GPQA, termasuk model OpenAI sendiri (seperti o3, o4-mini, GPT-4.1, GPT-4o) serta model utama lainnya (seperti Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5). (Sumber: GitHub Trending)
LLM Engineer’s Handbook versi Korea dirilis: Buku “LLM Engineer’s Handbook” karya Maxime Labonne kini tersedia dalam versi Korea, diterjemahkan oleh Woocheol Cho. Versi bahasa lain dari buku panduan ini, seperti Rusia, Mandarin, Polandia, juga akan segera dirilis, menyediakan sumber belajar bagi pengembang LLM di seluruh dunia. (Sumber: maximelabonne)

Lokakarya Pembelajaran Mesin untuk Audio ML4Audio di ICML 2025 diumumkan: Lokakarya Pembelajaran Mesin untuk Audio (ML for Audio) yang populer akan kembali diadakan selama ICML 2025 di Vancouver, pada hari Sabtu, 19 Juli. Lokakarya ini akan mengundang pembicara ternama seperti Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti, dan Pratyusha Rakshit. Batas waktu pengiriman makalah adalah 23 Mei. (Sumber: sedielem)
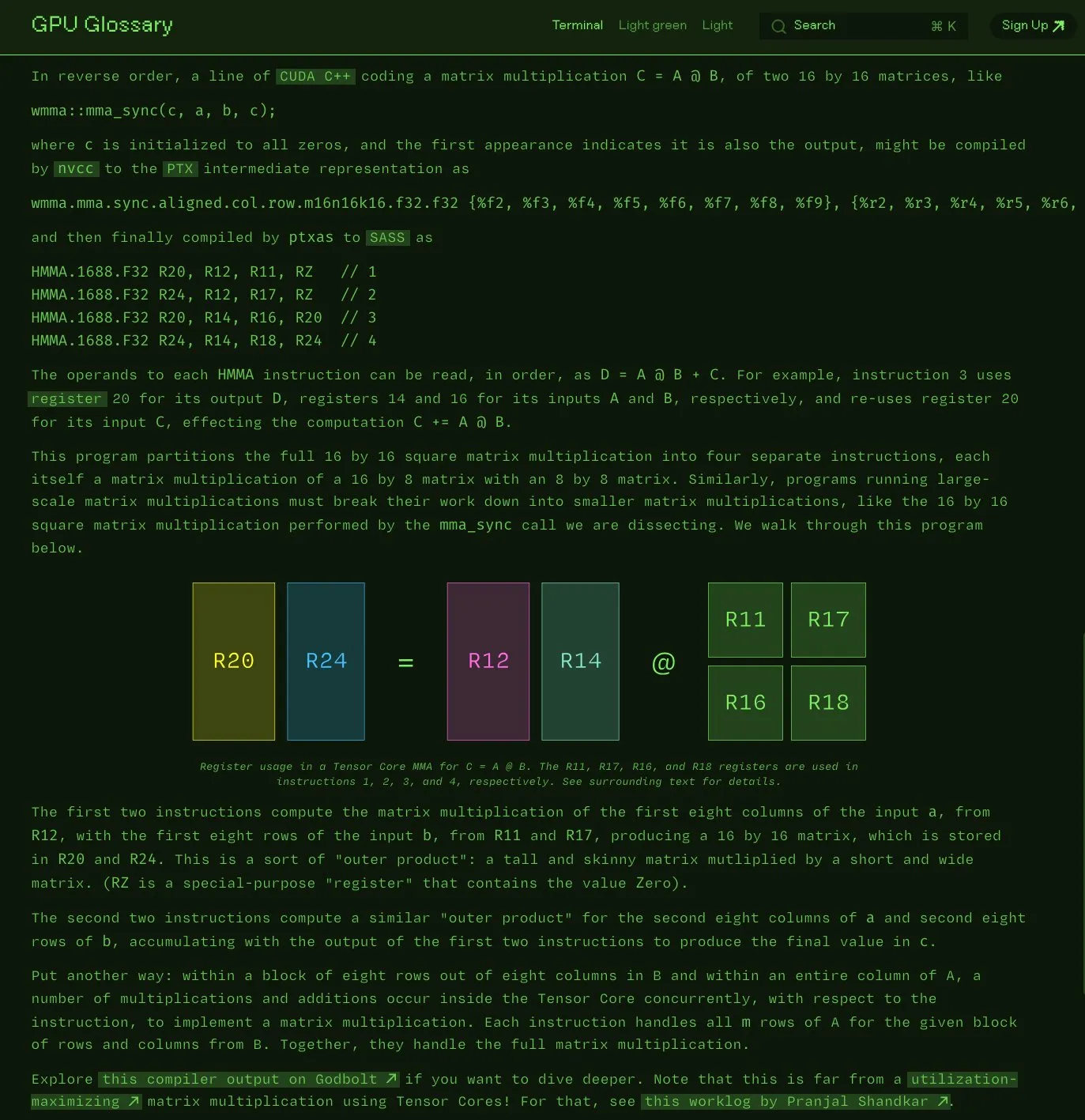
Charles Frye merilis sumber terbuka Glosarium GPU: Charles Frye mengumumkan bahwa Glosarium GPU (GPU Glossary) yang ditulisnya kini tersedia sebagai sumber terbuka. Glosarium ini bertujuan untuk membantu memahami konsep terkait perangkat keras dan pemrograman GPU, baru-baru ini diperbarui dengan dekomposisi instruksi SASS untuk operasi perkalian-akumulasi matriks sederhana (mma) yang dilakukan oleh Tensor Core. Proyek ini dihosting di GitHub dan mencantumkan beberapa tugas yang masih harus diselesaikan. (Sumber: charles_irl)
OpenAI merilis panduan rekayasa prompt GPT-4.1, menekankan instruksi terstruktur dan jelas: OpenAI meluncurkan panduan rekayasa prompt untuk GPT-4.1, yang bertujuan untuk membantu pengguna membangun prompt secara lebih efektif, terutama untuk aplikasi yang memerlukan output terstruktur, penalaran, penggunaan alat, dan berbasis agen. Panduan ini menekankan pentingnya peran dan tujuan yang jelas, memberikan instruksi yang jelas (termasuk nada, format, batasan), sub-instruksi opsional, penalaran/perencanaan langkah demi langkah, definisi format output yang tepat, dan penggunaan contoh, serta memberikan beberapa tips praktis seperti menyorot instruksi kunci, menggunakan struktur input Markdown atau XML, dll. (Sumber: Reddit r/MachineLearning)

Kaggle dan Hugging Face memperdalam kerja sama, menyederhanakan pemanggilan dan penemuan model: Kaggle mengumumkan penguatan kerja sama dengan Hugging Face. Pengguna kini dapat langsung meluncurkan model Hugging Face di Kaggle Notebooks, menemukan contoh kode publik yang relevan, dan menjelajah secara mulus antara kedua platform. Integrasi ini bertujuan untuk memperluas aksesibilitas model, memungkinkan pengguna Kaggle memanfaatkan sumber daya model dalam ekosistem Hugging Face dengan lebih mudah. (Sumber: huggingface)
FedRAG: Kerangka kerja sumber terbuka untuk fine-tuning sistem RAG, mendukung federated learning: Peneliti Vector Institute meluncurkan FedRAG, sebuah kerangka kerja sumber terbuka yang bertujuan untuk menyederhanakan fine-tuning sistem Retrieval Augmented Generation (RAG). Kerangka kerja ini tidak hanya mendukung pelatihan terpusat yang tipikal, tetapi juga secara khusus memperkenalkan arsitektur federated learning untuk mengakomodasi kebutuhan pelatihan pada dataset terdistribusi. FedRAG kompatibel dengan ekosistem PyTorch dan Hugging Face, mendukung penggunaan Qdrant sebagai penyimpanan basis pengetahuan, dan dapat dihubungkan ke LlamaIndex. (Sumber: nerdai)

💼 Bisnis
Induk perusahaan Cursor, Anysphere, capai ARR $200 juta dalam dua tahun, valuasi melonjak hingga $9 miliar: Perusahaan Anysphere, yang dipimpin oleh Michael Truell, seorang dropout MIT berusia 25 tahun, dengan editor kode AI-nya, Cursor, berhasil mencapai pendapatan berulang tahunan (ARR) sebesar $200 juta dalam dua tahun tanpa melakukan promosi pasar, dan valuasi perusahaan dengan cepat mencapai $9 miliar. Cursor, dengan mengintegrasikan AI secara mendalam ke dalam alur kerja pengembangan, telah membentuk kembali paradigma pengembangan perangkat lunak, berfokus pada layanan bagi pengembang individu, dan mendapatkan pengakuan luas serta promosi dari mulut ke mulut dari pengembang di seluruh dunia. Thrive Capital memimpin putaran pendanaan terbarunya. (Sumber: 36氪)

Databricks umumkan akuisisi perusahaan Serverless Postgres, Neon: Databricks telah setuju untuk mengakuisisi Neon, sebuah perusahaan Serverless Postgres yang berfokus pada pengembang. Neon dikenal dengan arsitektur basis datanya yang inovatif, menawarkan kecepatan, penskalaan elastis, serta fungsionalitas branching dan forking, fitur-fitur ini menarik bagi pengembang dan agen AI. Akuisisi ini bertujuan untuk bersama-sama membangun fondasi basis data yang terbuka dan Serverless untuk pengembang dan agen AI. (Sumber: jefrankle, matei_zaharia)
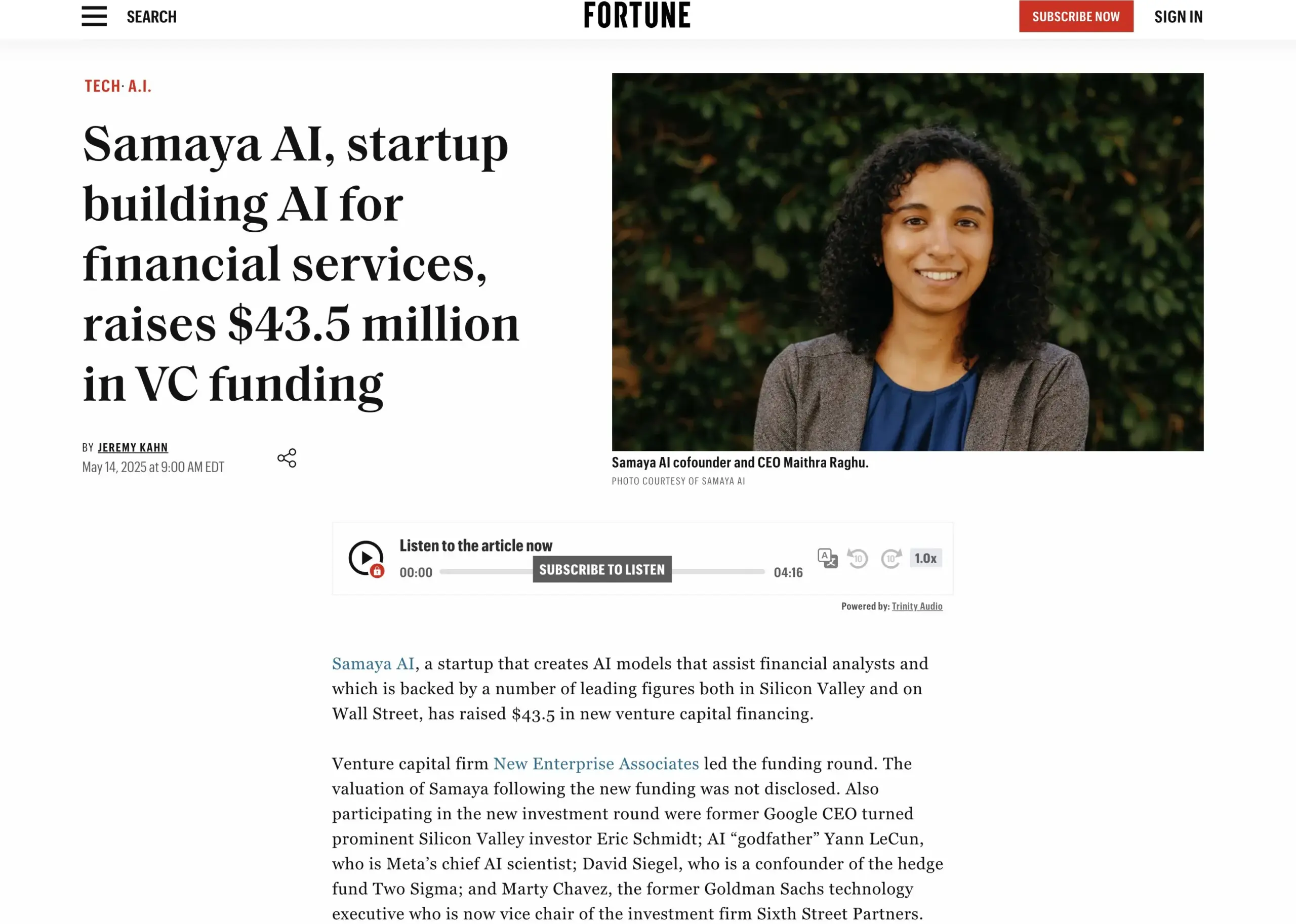
Startup layanan keuangan AI Samaya AI raih pendanaan $43,5 juta: Samaya AI mengumumkan perolehan pendanaan sebesar $43,5 juta yang dipimpin oleh NEA, untuk membangun agen AI ahli yang ditujukan bagi layanan keuangan, dengan tujuan mentransformasi pekerjaan berbasis pengetahuan secara masif. Perusahaan yang didirikan pada tahun 2022 ini berfokus pada pembuatan solusi AI khusus untuk alur kerja keuangan yang kompleks. Agen AI ahlinya yang berbasis LLM hasil pengembangan sendiri telah digunakan oleh ribuan pengguna di institusi ternama seperti Morgan Stanley, diterapkan dalam skenario seperti uji tuntas, pemodelan ekonomi, dan dukungan keputusan, dengan menekankan presisi, transparansi, dan bebas halusinasi. (Sumber: maithra_raghu)
🌟 Komunitas
Apakah AI akan menggantikan insinyur perangkat lunak? Komunitas ramai membahas perlunya peningkatan keterampilan: Media sosial kembali diramaikan dengan diskusi tentang apakah AI akan menggantikan insinyur perangkat lunak. Pandangan umum menyatakan bahwa AI tidak akan sepenuhnya menggantikan insinyur perangkat lunak, karena pengembangan perangkat lunak jauh lebih dari sekadar pengkodean itu sendiri. Namun, bagi mereka yang terutama melakukan pekerjaan pengkodean berulang, kurang memiliki pemahaman menyeluruh tentang sistem, atau “code monkeys”, jika tidak dapat meningkatkan keterampilan, memperdalam pemahaman arsitektur sistem dan pemecahan masalah kompleks, maka mereka menghadapi risiko tinggi untuk digantikan oleh alat bantu AI. (Sumber: cto_junior, cto_junior)
Masa Depan Agen AI: Peluang dan Tantangan Bersamaan, Pemimpin Industri Optimis akan Potensinya: CEO OpenAI, Sam Altman, memprediksi tahun 2025 akan menjadi tahun di mana Agen AI unjuk gigi, mereka akan lebih banyak terlibat dalam pekerjaan nyata. Liu Zhiyi dalam wawancaranya juga menekankan bahwa Agen sedang bertransformasi dari alat pasif menjadi sistem eksekusi aktif, perkembangannya bergantung pada kemajuan model dasar serta kemampuan interaksi dengan dunia fisik. Meskipun saat ini Agen masih memiliki kekurangan dalam hal kecepatan respons, kontrol halusinasi, dll., kemampuannya untuk menjalankan tugas secara otonom dan membantu pembelajaran model besar sangat diantisipasi, dan telah mulai diterapkan di bidang seperti layanan pelanggan cerdas dan penasihat investasi keuangan. (Sumber: 36氪, 量子位)

Perplexity AI dan PayPal, Venmo jalin kerja sama, integrasikan pembayaran e-commerce dan perjalanan: Perplexity AI mengumumkan akan bekerja sama dengan PayPal dan Venmo untuk mengintegrasikan fungsi pembayaran dalam platformnya untuk belanja e-commerce, pemesanan perjalanan, serta asisten suara dan browser Comet yang akan datang. Langkah ini bertujuan untuk menyederhanakan seluruh proses komersial mulai dari penjelajahan, pencarian, pemilihan hingga pembayaran yang aman, guna meningkatkan pengalaman pengguna. (Sumber: AravSrinivas, perplexity_ai)
Diskusi tentang evaluasi model AI: IFEval dan ChartQA menjadi sorotan, perlu waspada terhadap kontaminasi data pelatihan: Dalam diskusi komunitas, IFEval dianggap sebagai salah satu benchmark evaluasi kepatuhan instruksi yang sangat baik karena desainnya yang sederhana namun cerdas. Sementara itu, ada pengguna yang menunjukkan bahwa data pengujian ChartQA mengandung noise, jawaban yang ambigu, dan inkonsistensi, sehingga mungkin perlu dihilangkan. Vikhyatk mengingatkan bahwa banyak model yang mengklaim mencapai akurasi tinggi pada benchmark mungkin memiliki masalah kontaminasi data pelatihan yang tidak terdeteksi. (Sumber: clefourrier, vikhyatk)

Hak cipta dan etika konten buatan AI menjadi perhatian: Audible berencana menggunakan narasi AI, tokoh buatan AI untuk kencan online menimbulkan kekhawatiran: Audible mengumumkan rencana untuk menggunakan narasi buatan AI untuk memproduksi buku audio, bertujuan untuk “menghidupkan lebih banyak cerita”, memicu diskusi tentang penerapan AI dalam industri kreatif. Di sisi lain, seorang pengguna di Reddit memposting bahwa ibunya berinteraksi dengan sosok “pria sejati” yang diduga dihasilkan oleh AI di situs kencan, khawatir ibunya tertipu. Hal ini menyoroti potensi risiko konten buatan AI dalam hal keaslian, manipulasi emosional, dan penipuan. (Sumber: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 Lainnya
Perusahaan Tiongkok “Star Computing” berhasil meluncurkan 12 satelit komputasi luar angkasa pertama, memulai era baru komputasi berbasis luar angkasa: Proyek “Star Computing” yang dipimpin oleh Guoxing Aerospace berhasil mengirimkan 12 satelit komputasi pertama ke luar angkasa, membentuk konstelasi komputasi luar angkasa pertama di dunia. Setiap satelit memiliki kemampuan komputasi dan interkoneksi luar angkasa, dengan kemampuan komputasi tunggal meningkat dari tingkat T menjadi tingkat P. Konstelasi awal ini memiliki daya komputasi di orbit sebesar 5 POPS, dan kecepatan komunikasi laser antar satelit mencapai 100 Gbps. Langkah ini bertujuan untuk membangun infrastruktur komputasi cerdas berbasis luar angkasa, mengatasi masalah konsumsi energi besar dan kesulitan pendinginan komputasi di darat, serta mendukung pemrosesan data eksplorasi luar angkasa secara real-time di orbit, mewujudkan “data langit, komputasi langit”. Rencana ke depan adalah meluncurkan 2800 satelit untuk membentuk jaringan komputasi luar angkasa yang besar. (Sumber: 量子位)

NVIDIA merilis tinjauan tahunan, menekankan AI sebagai inti revolusi industri baru, kecerdasan adalah produk: NVIDIA dalam tinjauan tahunannya menyatakan bahwa dunia sedang memasuki revolusi industri baru, dengan produk intinya adalah “kecerdasan”. NVIDIA berkomitmen untuk membangun infrastruktur cerdas, mengubah komputasi menjadi kekuatan generatif yang mendorong perkembangan di berbagai industri. (Sumber: nvidia)

NBA dan Kuaishou Kling AI bekerja sama meluncurkan film pendek AI “Dunk Curry Masa Kecil”: NBA bekerja sama dengan model video teks-ke-video besar mirip Sora milik Kuaishou, Kling AI, untuk memproduksi film pendek AI berjudul “Childhood Curry’s Dunk” yang dibuat oleh AI TALK. Film ini mencoba menggunakan Kling AI untuk merekonstruksi adegan dunk Curry yang “melintasi ruang dan waktu”, untuk menyemangati babak playoff NBA, dengan penampilan khusus dari Barkley, O’Neal, dan Jokic. (Sumber: TomLikesRobots)