Kata Kunci:Prime Intellect, INTELLECT-2, Sakana AI, Mesin Pemikir Berkelanjutan, Transformer, Agen AI Google, AgentOps, Kolaborasi Multi-Agen, Pelatihan Penguatan Terdistribusi, Sinkronisasi Saraf dan Neuron Temporal, Proses Operasional Agen AI, Arsitektur Multi-Agen, Penyebaran Agen AI di Perusahaan
🔥 Fokus
Prime Intellect Merilis Model Open Source INTELLECT-2: Prime Intellect merilis dan menjadikan open source INTELLECT-2, sebuah model dengan 32 miliar parameter, yang diklaim sebagai model pertama yang dilatih melalui globally distributed reinforcement learning. Rilisan ini mencakup laporan teknis terperinci dan model checkpoint. Model ini menunjukkan kinerja yang sebanding atau bahkan lebih unggul dibandingkan model seperti Qwen 32B dalam beberapa benchmark, terutama menonjol dalam code generation dan mathematical reasoning, dan ditemukan oleh anggota komunitas dapat memainkan Wordle. Metode pelatihannya dan langkah open source dianggap berpotensi memengaruhi pelatihan model besar di masa depan dan lanskap persaingan (Sumber: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

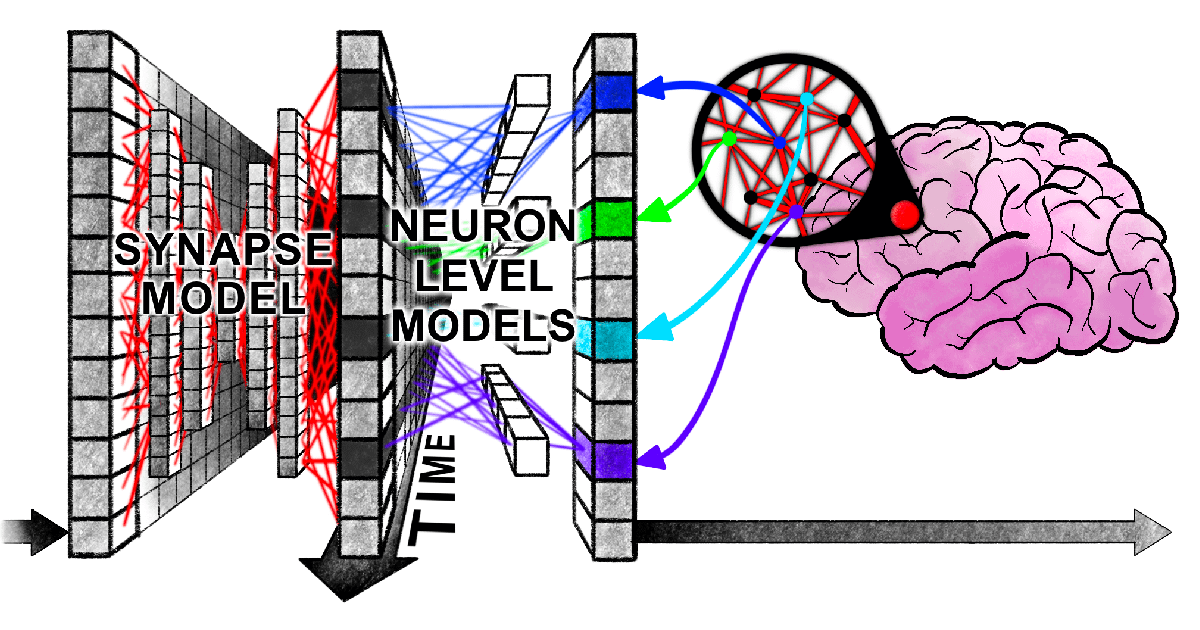
Sakana AI Mengusulkan Continuous Thought Machine (CTM): Sakana AI meluncurkan arsitektur jaringan saraf baru bernama “Continuous Thought Machine” (CTM), yang bertujuan untuk memberikan AI kecerdasan mirip manusia yang lebih fleksibel dengan memperkenalkan mekanisme otak biologis seperti neural timing dan neuron synchronization. Inovasi inti CTM terletak pada pemrosesan temporal tingkat neuron dan penggunaan sinkronisasi saraf sebagai representasi laten, memungkinkannya menangani tugas yang memerlukan penalaran sekuensial dan komputasi adaptif, serta dapat menyimpan dan mengambil memori. Penelitian ini telah merilis blog, laporan interaktif, paper, dan repositori GitHub, menjelajahi paradigma baru AI “berpikir dengan waktu” (Sumber: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
Paper Baru Harvard Mengungkapkan “Keterikatan Sinkron” Antara Transformer dan Otak Manusia dalam Memproses Informasi: Peneliti dari Harvard University dan institusi lain menerbitkan paper berjudul 《Linking forward-pass dynamics in Transformers and real-time human processing》, yang membahas kesamaan antara dinamika pemrosesan internal model Transformer dan proses kognitif real-time manusia. Penelitian ini tidak hanya melihat output akhir, tetapi menganalisis metrik “beban pemrosesan” (seperti uncertainty, confidence change) di setiap lapisan model, menemukan bahwa AI juga mengalami proses serupa manusia seperti “keraguan”, “kesalahan intuisi” hingga “koreksi” saat menyelesaikan masalah (seperti menjawab ibu kota, klasifikasi hewan, penalaran logis, pengenalan gambar). Kesamaan “proses berpikir” ini menunjukkan bahwa AI secara alami mempelajari jalan pintas kognitif yang mirip dengan manusia untuk menyelesaikan tugas, memberikan perspektif baru untuk memahami pengambilan keputusan AI dan memandu desain eksperimen manusia (Sumber: 36氪)

Google Merilis Whitepaper Agen AI 76 Halaman, Menjelaskan AgentOps dan Kolaborasi Multi-Agen: Whitepaper agen AI terbaru yang dirilis Google menjelaskan secara rinci pembangunan, evaluasi, dan aplikasi agen AI. Whitepaper ini menekankan pentingnya operasi agen (AgentOps), sebuah proses untuk mengoptimalkan pembangunan dan deployment agen ke lingkungan produksi, yang mencakup manajemen alat, pengaturan prompt inti, implementasi memori, dan dekomposisi tugas. Whitepaper ini juga membahas arsitektur multi-agen, yaitu beberapa agen dengan kemampuan terspesialisasi bekerja sama untuk mencapai tujuan kompleks, dan memperkenalkan studi kasus praktik Google dalam menerapkan agen di internal perusahaan (seperti NotebookLM Enterprise, Agentspace Enterprise) serta aplikasi spesifik (seperti sistem multi-agen otomotif), yang bertujuan untuk meningkatkan produktivitas perusahaan dan pengalaman pengguna (Sumber: 36氪)
🎯 Tren
LightonAI Merilis Model Pencarian Semantik GTE-ModernColBERT-v1: LightonAI meluncurkan model pencarian semantik baru GTE-ModernColBERT-v1, yang mencapai skor tertinggi saat ini pada benchmark LongEmbed / LEMB Narrative QA. Model ini dirancang khusus untuk meningkatkan efektivitas pencarian semantik, dapat diterapkan dalam skenario seperti pencarian konten dokumen, RAG, dan dapat diintegrasikan dengan sistem yang ada. Dilaporkan bahwa model ini di-fine-tuned berdasarkan Alibaba-NLP/gte-modernbert-base, bertujuan untuk memperbaiki keterbatasan mesin pencari tradisional yang hanya mengandalkan pencocokan karakter (Sumber: karminski3)
Pemimpin Teknologi Memperhatikan Kebangkitan Cepat DeepSeek: VentureBeat melaporkan reaksi para pemimpin teknologi terhadap perkembangan pesat DeepSeek. Dengan kemampuan model yang kuat dan strategi open source, DeepSeek telah mencapai hasil signifikan di bidang AI global, terutama dalam tugas matematika dan code generation, serta membawa tantangan bagi lanskap pasar yang ada (termasuk OpenAI, dll.). Biaya pelatihan yang rendah dan strategi harga API-nya juga mendorong demokratisasi teknologi AI dan proses komersialisasi (Sumber: Ronald_vanLoon)

ByteDance dan Peking University Bersama Merilis DreamO, Framework Generasi Gambar Kustom Terpadu yang Mendukung Kombinasi Multi-Kondisi: ByteDance bekerja sama dengan Peking University meluncurkan DreamO, sebuah framework generasi gambar kustom yang dapat mewujudkan kombinasi bebas multi-kondisi seperti subjek, identitas, gaya, dan referensi pakaian melalui satu model tunggal. Framework ini dibangun di atas Flux-1.0-dev, dengan memperkenalkan lapisan pemetaan (mapping layer) khusus untuk memproses input gambar kondisi, serta mengadopsi strategi pelatihan progresif dan batasan routing (routing constraint) yang ditargetkan pada gambar referensi untuk meningkatkan kualitas generasi dan konsistensi. DreamO, dengan jumlah parameter pelatihan rendah 400 juta, mampu menghasilkan satu gambar kustom dalam 8-10 detik, menunjukkan kinerja luar biasa dalam menjaga konsistensi. Kode dan model terkait telah dijadikan open source (Sumber: WeChat)

Tim VITA Merilis Model Bahasa Besar Suara Real-time Open Source VITA-Audio, Efisiensi Inferensi Meningkat Pesat: Tim VITA meluncurkan model suara end-to-end VITA-Audio, yang dengan memperkenalkan modul Multi-modal Cross-modal Token Prediction (MCTP) yang lightweight, berhasil menghasilkan Audio Token Chunk yang dapat didekode secara langsung dalam satu kali forward propagation. Pada skala parameter 7 miliar, model ini hanya membutuhkan 92ms dari menerima teks hingga menghasilkan potongan audio pertama (53ms jika tidak menghitung audio encoder), dengan kecepatan inferensi 3-5 kali lebih cepat dibandingkan model sekelasnya. VITA-Audio mendukung bahasa Mandarin dan Inggris, hanya dilatih menggunakan data open source, dan menunjukkan kinerja luar biasa dalam tugas seperti TTS, ASR. Kode dan bobot model terkait telah dijadikan open source (Sumber: WeChat)

Tsinghua, BAII, dkk. Mengusulkan Metode Pelatihan “Absolute Zero”, Model Besar Membuka Kemampuan Penalaran Melalui Self-Play: Peneliti dari Tsinghua University, Beijing Academy of Artificial Intelligence (BAII), dan institusi lain mengusulkan metode pelatihan “Absolute Zero”, yang memungkinkan pre-trained large model untuk belajar penalaran dengan menghasilkan dan menyelesaikan tugas melalui Self-play, tanpa memerlukan data eksternal. Metode ini menyatukan representasi tugas penalaran sebagai triplet (program, input, output), di mana model berperan sebagai Proposer (pembuat soal) dan Solver (pemecah soal), belajar melalui tiga jenis tugas: abduction, deduction, dan induction. Eksperimen menunjukkan bahwa model yang dilatih dengan metode ini mengalami peningkatan signifikan dalam tugas kode dan penalaran matematika, mengungguli kinerja model yang dilatih menggunakan sampel beranotasi ahli (Sumber: WeChat)

Perkembangan AI PC Dipercepat, Lenovo dan Huawei Berturut-turut Merilis Produk Terminal AI Baru: Lenovo dan Huawei baru-baru ini meluncurkan produk PC yang terintegrasi dengan AI agent, seperti Lenovo Tianxi Personal Super Agent dan PC Huawei HarmonyOS yang dilengkapi Xiaoyi agent. Meskipun penetrasi pasar AI PC masih rendah, pertumbuhannya cepat. Data Canalys menunjukkan bahwa pengiriman AI PC di China Daratan pada tahun 2024 telah mencapai 15% dari keseluruhan pasar PC, dan diperkirakan akan mencapai 34% pada tahun 2025. Orang dalam industri percaya bahwa kematangan rantai pasokan AI PC masih membutuhkan 2-3 tahun, dengan tantangan utama saat ini terletak pada biaya dan masalah skalabilitas rantai pasokan seperti memori dan chip, serta fragmentasi ekosistem AI PC domestik. Tren masa depan termasuk AI agent menjadi pintu masuk interaksi inti, deployment AI lokal, dan perluasan skenario aplikasi AI ke bidang pendidikan, kesehatan, dan lainnya (Sumber: 36氪)
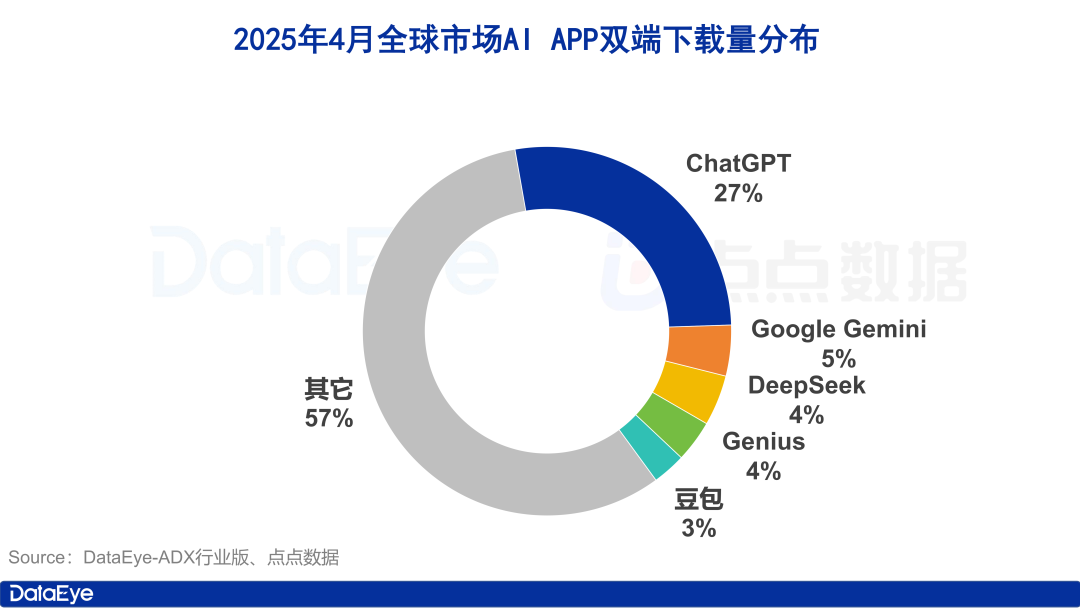
Unduhan Aplikasi AI Global Melonjak, Pasar Domestik Mendingin, Doubao Tumbuh Melawan Tren: Pada April 2024, unduhan aplikasi AI global di kedua platform mencapai 330 juta kali, naik 27,4% dari bulan sebelumnya. ChatGPT, Google Gemini, DeepSeek, Genius, dan Doubao menempati lima besar. Di antaranya, unduhan ChatGPT melonjak karena peluncuran GPT-4o. Sebaliknya, unduhan aplikasi AI di Apple App Store pasar China Daratan turun 24,0% dari bulan sebelumnya. Doubao tumbuh melawan tren dan menempati peringkat pertama, diikuti oleh DeepSeek dan Jimeng AI. Dalam hal akuisisi pengguna berbayar, Tencent Yuanbao dan Kuake berinvestasi besar-besaran dan mendominasi volume materi iklan, sementara investasi Doubao menurun. Secara keseluruhan, antusiasme pasar AI domestik agak mendingin, dan persaingan kembali ke teknologi dan operasi (Sumber: 36氪)
Perombakan Pasar Model Besar China, Muncul Pola “Lima Besar Model Dasar”: Seiring mengetatnya lingkungan pendanaan AI global pada tahun 2024, pasar model besar China mengalami “de-bubbling”, mengubah pola “Enam Macan Kecil” sebelumnya menjadi “Lima Besar Model Dasar” yang diwakili oleh ByteDance, Alibaba, Leiyue Xingchen, Zhipu AI, dan DeepSeek. Para pemain teratas ini memiliki keunggulan masing-masing dalam pendanaan, talenta, dan teknologi, serta menempuh jalur diferensiasi: ByteDance dengan tata letak komprehensif, Alibaba fokus pada open source & full-stack, Leiyue Xingchen mendalami multi-modal, Zhipu AI memanfaatkan latar belakang Tsinghua untuk fokus pada 2B/2G, dan DeepSeek menerobos dengan optimasi rekayasa ekstrem dan strategi open source. Fokus persaingan tahap berikutnya adalah menembus “batas atas kecerdasan” dan meningkatkan “kemampuan multi-modal”, dengan harapan mewujudkan visi AGI (Sumber: 36氪, WeChat)

Jumlah Pengajuan ICCV 2025 Pecahkan Rekor, Timbulkan Kekhawatiran Kualitas Review, Penggunaan LLM untuk Membantu Review Dilarang: Jumlah pengajuan makalah untuk konferensi computer vision terkemuka ICCV 2025 mencapai 11.152, mencetak rekor historis baru. Namun, setelah hasil review diumumkan, banyak penulis menyatakan ketidakpuasan terhadap kualitas review di media sosial, menganggap beberapa ulasan asal-asalan, bahkan lebih baik dari level GPT, dan menunjukkan adanya masalah seperti reviewer tidak membaca materi tambahan. Untuk mengatasi lonjakan pengajuan, konferensi mengharuskan setiap penulis yang mengirimkan makalah untuk berpartisipasi dalam proses review, dan secara eksplisit melarang penggunaan model besar (seperti ChatGPT) dalam proses review untuk menjamin orisinalitas dan kerahasiaan. Meskipun data resmi menunjukkan 97,18% review diserahkan tepat waktu, kualitas review dan beban reviewer menjadi fokus diskusi hangat (Sumber: 36氪)
CEO Nvidia Jensen Huang: Semua Karyawan Akan Dilengkapi Agen AI, Membentuk Ulang Peran Developer: CEO Nvidia Jensen Huang menyatakan bahwa perusahaan akan melengkapi semua karyawan (termasuk software engineer dan chip designer) dengan AI agent untuk meningkatkan efisiensi kerja, skala proyek, dan kualitas perangkat lunak. Ia memprediksi di masa depan setiap orang akan memimpin beberapa AI assistant, menghasilkan pertumbuhan produktivitas eksponensial. Tren ini sejalan dengan pandangan perusahaan seperti Meta, Microsoft, Anthropic, bahwa AI akan menyelesaikan sebagian besar penulisan kode, dan peran developer akan berubah menjadi “komandan AI” atau “pendefinisi kebutuhan”. Huang menekankan bahwa energi dan kemampuan komputasi adalah bottleneck untuk adopsi AI, membutuhkan inovasi di bidang seperti pengemasan chip dan teknologi fotonik. Perusahaan besar sedang aktif mengembangkan AI agent proaktif, menandakan pergeseran dari GenAI ke Agentic AI (Sumber: 36氪)

CEO OpenAI Sam Altman Hadiri Dengar Pendapat Kongres, Serukan Regulasi Longgar dan Ungkap Rencana Open Source: CEO OpenAI Sam Altman menyatakan dalam dengar pendapat Senat AS bahwa persetujuan pra-regulasi yang ketat terhadap AI akan berdampak bencana pada daya saing AS di bidang ini, dan mengungkapkan bahwa OpenAI berencana merilis model open source pertamanya musim panas ini. Ia menekankan bahwa infrastruktur (terutama energi) sangat penting untuk memenangkan perlombaan AI, dan percaya bahwa biaya AI pada akhirnya akan konvergen dengan biaya energi. Altman juga membagikan “Peta Jalan Era Cerdas (2025-2027)” miliknya, yang memprediksi kedatangan berturut-turut AI super assistant, pertumbuhan eksponensial penemuan ilmiah berbasis AI, dan era robot AI. Ketika berbicara tentang kehidupan pribadi, ia menyatakan tidak ingin anak laki-lakinya menjalin persahabatan intim dengan robot AI (Sumber: 36氪)

Peneliti CMU Mengusulkan LegoGPT, Mendesain Model Lego yang Stabil Secara Fisik Menggunakan AI: Peneliti di Carnegie Mellon University (CMU) mengembangkan LegoGPT, sebuah sistem kecerdasan buatan yang dapat mengubah deskripsi teks menjadi model Lego yang dapat dibangun secara fisik. Melalui fine-tuning model LLaMA Meta, dan dikombinasikan dengan pelatihan menggunakan dataset StableText2Lego yang berisi lebih dari 47.000 struktur stabil, LegoGPT mampu memprediksi penempatan balok secara bertahap, memastikan struktur yang dihasilkan memiliki stabilitas fisik di dunia nyata, dengan tingkat keberhasilan 98,8%. Sistem ini juga memanfaatkan metode rollback berbasis fisika untuk melakukan koreksi saat mendeteksi struktur yang tidak stabil. Peneliti percaya bahwa teknologi ini tidak terbatas pada Lego, dan di masa depan dapat diterapkan pada desain komponen cetak 3D dan perakitan robot. Kode, dataset, dan model saat ini telah dijadikan open source (Sumber: WeChat)

Prediksi AI untuk Pemilihan Paus Meleset, Paus Baru Robert Prevost Menjadi “Pilihan Tak Terduga”: Menurut laporan Science, sebuah studi yang menggunakan algoritma AI untuk menganalisis data 135 kardinal guna memprediksi calon paus baru gagal memprediksi terpilihnya Robert Francis Prevost. Model tersebut melakukan simulasi pemilihan berdasarkan sikap kardinal pada isu-isu kunci (melatih AI untuk menilai kecenderungan konservatif atau progresif dengan menganalisis pidato mereka) serta kesamaan ideologis di antara mereka, dan akhirnya memprediksi kardinal Italia Pietro Parolin memiliki peluang terbesar. Peneliti mengakui bahwa model tidak mempertimbangkan faktor politik dan geografis sebagai kelemahan utamanya, tetapi percaya bahwa metodologi tersebut masih memiliki relevansi untuk prediksi pemilihan jenis lain. Prevost, yang netral dalam pandangannya pada berbagai isu, mungkin merupakan kandidat kompromi yang dapat diterima oleh semua pihak (Sumber: 36氪)

Aplikasi AI dalam Pemasaran Keuangan: Memecahkan Lima Masalah Utama Termasuk Akuisisi Pelanggan, Personalisasi, Kepatuhan: Teknologi AI dan Agent menjadi pendorong inti era pemasaran keuangan 3.0, bertujuan untuk mengatasi masalah seperti biaya akuisisi pelanggan yang tinggi, kurangnya pengalaman personalisasi, produk yang kompleks dan sulit dipahami, tekanan kepatuhan yang besar, dan ROI yang sulit diukur. Dengan membangun “Platform Pemasaran Cerdas” (basis data + mesin cerdas + aplikasi layanan), memanfaatkan teknologi seperti Large Language Model (LLM) + RAG, Knowledge Graph, kolaborasi Intelligent Agent (MAS), dan Privacy Computing, lembaga keuangan dapat mencapai wawasan pelanggan yang lebih dalam, keputusan cerdas real-time yang akurat, dan eksekusi layanan yang efisien dan konsisten. Studi kasus industri menunjukkan bahwa AI telah mencapai hasil signifikan dalam meningkatkan AUM pelanggan, tingkat konversi produk wealth management, dan efisiensi produksi konten pemasaran. Di masa depan, AI akan berkembang ke arah interaksi multi-modal, keputusan kausal, evolusi otonom, respons edge, dan kolaborasi manusia-mesin (Sumber: 36氪)
Robot Berbasis AI Mengatasi Masalah Sampah Elektronik Eropa: Proyek penelitian ReconCycle yang didanai Uni Eropa mengembangkan robot adaptif berbasis AI untuk mengotomatisasi pemrosesan sampah elektronik (e-waste) yang terus meningkat, khususnya pembongkaran perangkat yang mengandung baterai lithium. Robot-robot ini dapat dikonfigurasi ulang untuk menyesuaikan diri dengan tugas yang berbeda, seperti mengeluarkan baterai dari detektor asap dan meteran panas radiator. Teknologi ini bertujuan untuk meningkatkan efisiensi daur ulang, mengurangi pekerjaan pembongkaran manual yang berat dan berbahaya, serta mengatasi tantangan hampir 5 juta ton e-waste yang dihasilkan Uni Eropa setiap tahun (dengan tingkat daur ulang kurang dari 40%). Fasilitas daur ulang seperti Electrocycling GmbH telah mulai memperhatikan dan berharap teknologi semacam ini dapat meningkatkan tingkat pemulihan bahan baku, serta mengurangi kerugian ekonomi dan emisi karbon (Sumber: aihub.org)

🧰 Alat
LocalSite-ai: Alternatif Open Source untuk DeepSite, AI Menghasilkan Halaman Frontend Secara Online: LocalSite-ai, sebagai proyek open source, menyediakan fungsionalitas serupa dengan DeepSite, memungkinkan pengguna menghasilkan halaman frontend secara online melalui AI. Ini mendukung pratinjau online, edit WYSIWYG, dan kompatibel dengan beberapa penyedia API AI. Selain itu, alat ini juga mendukung desain responsif, membantu pengguna membangun halaman web yang beradaptasi dengan cepat ke berbagai perangkat (Sumber: karminski3)
Agentset: Platform Open Source untuk Meningkatkan Akurasi Hasil RAG: Agentset adalah platform RAG (Retrieval Augmented Generation) open source yang mengoptimalkan akurasi hasil pencarian melalui pencarian hibrida dan teknik re-ranking. Platform ini memiliki fitur kutipan bawaan yang dapat dengan jelas menunjukkan dari informasi indeks mana dalam database vektor konten yang dihasilkan berasal, memudahkan pengguna melakukan pemeriksaan tambahan untuk menghindari kesalahan informasi atau halusinasi model (Sumber: karminski3)
Gemini Max Playground: Aplikasi Gemini dengan Pratinjau Paralel dan Kontrol Versi: Developer Chansung membuat aplikasi Hugging Face Space bernama Gemini Max Playground, yang memungkinkan pengguna memproses hingga 4 pratinjau Gemini secara paralel untuk mempercepat proses iterasi. Alat ini mendukung kontrol jumlah token inferensi, memiliki fungsionalitas kontrol versi, dan dapat mengekspor file HTML/JS/CSS secara terpisah. Selain itu, tersedia juga versi yang dioptimalkan untuk layar mobile (Sumber: algo_diver)
mlop.ai: Alternatif Open Source untuk Weights and Biases (wandb): mlop.ai diluncurkan sebagai platform pelacakan eksperimen ML yang sepenuhnya open source, berkinerja tinggi, dan aman, bertujuan untuk menggantikan wandb. Ini sepenuhnya kompatibel dengan API wandb, dengan biaya migrasi rendah (hanya memerlukan perubahan satu baris kode). Backend-nya ditulis dalam Rust dan diklaim mengatasi masalah blocking yang ada pada wandb saat panggilan .log, menyediakan pencatatan log dan unggah non-blocking. Pengguna dapat dengan mudah melakukan self-host melalui Docker (Sumber: Reddit r/artificial)
DeerFlow: Framework Open Source ByteDance untuk LLM+Langchain+Tools: ByteDance menjadikan open source DeerFlow (Deep Exploration and Efficient Research Flow), sebuah framework yang mengintegrasikan Large Language Model (LLM), Langchain, serta berbagai alat (seperti pencarian web, crawler, eksekusi kode). Proyek ini bertujuan untuk menyediakan dukungan alur kerja penelitian dan pengembangan yang kuat, dan mendukung Ollama, memudahkan deployment dan penggunaan lokal (Sumber: Reddit r/LocalLLaMA)
Plexe: Agen ML Open Source dari Bahasa Alami ke Model Terlatih: Plexe adalah agen rekayasa ML open source yang dapat mengubah prompt bahasa alami menjadi model machine learning yang terlatih pada data terstruktur pengguna (saat ini mendukung file CSV dan Parquet), tanpa memerlukan latar belakang data science pengguna. Ini secara otomatis menyelesaikan tugas seperti pembersihan data, pemilihan fitur, percobaan model, dan evaluasi melalui tim agen khusus (scientist, trainer, evaluator), dan menggunakan MLflow untuk melacak eksperimen. Rencana masa depan termasuk dukungan untuk database PostgreSQL dan agen feature engineering (Sumber: Reddit r/artificial)
Llama ParamPal: Proyek Basis Pengetahuan Parameter Sampling LLM: Llama ParamPal adalah proyek open source yang bertujuan untuk mengumpulkan dan menyediakan parameter sampling yang direkomendasikan untuk local Large Language Model (LLM) saat menggunakan llama.cpp. Proyek ini mencakup file models.json sebagai database parameter dan menyediakan Web UI sederhana (dalam pengembangan) untuk menjelajahi dan mencari set parameter, guna mengatasi kesulitan pengguna dalam mencari parameter yang sesuai saat mengkonfigurasi model baru. Pengguna dapat berkontribusi konfigurasi parameter model mereka sendiri (Sumber: Reddit r/LocalLLaMA)
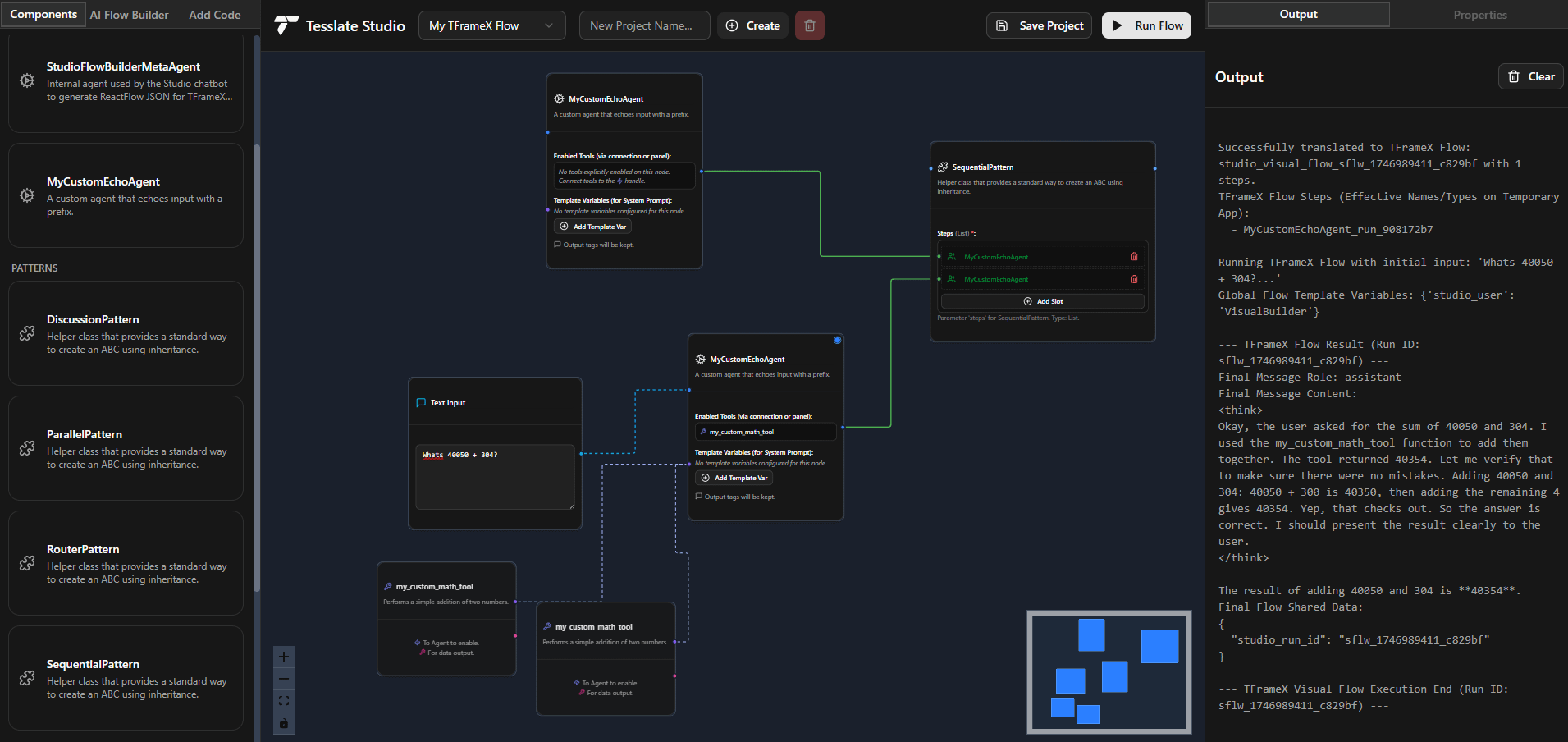
TFrameX dan Studio: Pembangun Agen dan Framework LLM Lokal Open Source: Tim TesslateAI merilis dua proyek open source: TFrameX, sebuah framework agen yang dirancang khusus untuk local Large Language Model (LLM); dan Studio, sebuah pembangun agen berbasis flowchart. Kedua alat ini bertujuan untuk membantu developer membuat dan mengelola AI agent yang bekerja sama dengan LLM lokal dengan lebih mudah. Tim menyatakan sedang aktif mengembangkan dan menyambut kontribusi komunitas (Sumber: Reddit r/LocalLLaMA)
Ktransformer: Framework Inferensi Efisien yang Mendukung Model Sangat Besar: Ktransformer adalah sebuah framework inferensi yang, menurut dokumentasinya, mampu memproses model yang sangat besar seperti Deepseek 671B atau Qwen3 235B hanya dengan 1 atau 2 GPU. Meskipun diskusinya tidak sebanyak Llama CPP, beberapa pengguna menunjukkan bahwa kinerjanya mungkin lebih unggul dari Llama CPP, terutama ketika KV cache hanya berada di memori GPU. Namun, mungkin ada kekurangan dalam hal tool calling dan structured response, dan untuk model yang tidak mendukung MLA (seperti Qwen), memproses konteks panjang dengan VRAM terbatas masih menjadi tantangan (Sumber: Reddit r/LocalLLaMA)

📚 Pembelajaran
Penjelasan Framework DSPy: Pemrograman LLM dengan Python Deklaratif yang Mengoptimalkan Diri: DSPy (Declarative Self-improving Python) adalah sebuah framework untuk pemrograman Large Language Model (LLM). Ide intinya adalah memperlakukan LLM sebagai “komputer universal” yang dapat diprogram, dengan mendefinisikan input, output, dan transformasi (Signatures) secara deklaratif, daripada memaksakan perilaku LLM tertentu. Modul dan optimizer DSPy memungkinkan program untuk memperbaiki diri sendiri dalam hal kualitas dan biaya, bertujuan untuk menyediakan paradigma pemrograman yang lebih terstruktur dan efisien untuk LLM, guna memenuhi kebutuhan aplikasi produksi yang kompleks. Komunitas menganggap ini sebagai kemajuan penting dalam bidang pemrograman LLM, dan penggunaannya diharapkan akan melonjak di masa depan (Sumber: lateinteraction, lateinteraction)
Peking University, Tsinghua, dkk. Bersama Merilis Tinjauan Terbaru Kemampuan Penalaran Logis Model Besar: Peneliti dari Peking University, Tsinghua University, University of Amsterdam, Carnegie Mellon University, dan MBZUAI bersama-sama merilis sebuah paper tinjauan mengenai kemampuan penalaran logis Large Language Model (LLM), yang telah diterima oleh IJCAI 2025 Survey Track. Tinjauan ini secara sistematis menyusun metode-metode mutakhir dan benchmark evaluasi untuk meningkatkan kinerja LLM dalam tanya jawab logis dan konsistensi logis. Tinjauan ini mengklasifikasikan metode tanya jawab logis ke dalam kategori berbasis solver eksternal, prompt engineering, pre-training, dan fine-tuning, serta membahas konsep seperti negasi, implikasi, transitivitas, konsistensi faktual, dan komposit beserta teknik peningkatannya. Paper ini juga menunjukkan arah penelitian masa depan, seperti perluasan ke logika modal dan penalaran logika tingkat tinggi (Sumber: WeChat)
Debut YouTube Terence Tao: Menyelesaikan Bukti Matematika dalam 33 Menit dengan Bantuan AI, dan Mengupgrade Asisten Pembuktian: Matematikawan terkenal Terence Tao melakukan debutnya di YouTube, menunjukkan bagaimana dengan bantuan AI (khususnya GitHub Copilot dan Lean proof assistant) ia dapat menyelesaikan bukti proposisi aljabar umum (persamaan Magma E1689 menyiratkan E2) dalam 33 menit, sebuah tugas yang biasanya membutuhkan satu halaman penuh tulisan tangan oleh matematikawan manusia. Ia menekankan bahwa metode semi-otomatis ini cocok untuk argumen yang sangat teknis dan kurang konseptual, membebaskan matematikawan dari tugas-tugas yang membosankan. Pada saat yang sama, ia juga memperkenalkan versi 2.0 dari asisten pembuktian Python ringan yang dikembangkannya. Alat ini mendukung logika proposisional dan aritmatika linear, bertujuan untuk membantu tugas-tugas seperti analisis asimtotik, dan telah dijadikan open source (Sumber: WeChat)
Paper CVPR 2025: MICAS – Metode Sampling Adaptif Multi-granularitas untuk Meningkatkan Pembelajaran Kontekstual Point Cloud 3D: Sebuah paper yang diterima di CVPR 2025, 《MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing》, mengusulkan metode baru bernama MICAS, yang bertujuan untuk mengatasi masalah sensitivitas antar-tugas dan intra-tugas yang dihadapi saat menerapkan in-context learning (ICL) pada pemrosesan point cloud 3D. MICAS mencakup dua modul inti: Task-Adaptive Point Sampling, yang memanfaatkan informasi tugas untuk memandu sampling tingkat titik; dan Query-Specific Prompt Sampling, yang secara dinamis memilih contoh prompt optimal untuk setiap query. Eksperimen menunjukkan bahwa MICAS secara signifikan mengungguli teknik yang ada dalam berbagai tugas 3D seperti rekonstruksi, denoising, registrasi, dan segmentasi (Sumber: WeChat)
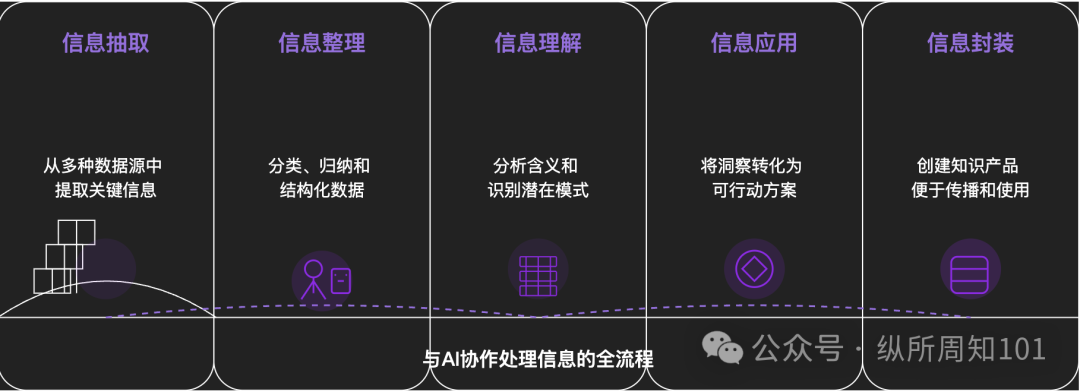
Metodologi AI untuk Membedah Segala Sesuatu: Sebuah artikel mendalam membahas bagaimana memanfaatkan AI untuk membedah hal-hal kompleks atau sistem pengetahuan secara sistematis. Artikel ini mengusulkan kerangka kerja 15 tingkat dari mikro ke makro, dari statis ke dinamis, termasuk komponen dasar (konstanta, variabel), indeks konsep (kata kunci), pola terverifikasi (aturan, rumus), paradigma operasi (metode, proses), integrasi struktural (sistem, badan pengetahuan), abstraksi tingkat tinggi (model mental) hingga wawasan tertinggi (esensi) dan titik pendaratan realitas (aplikasi). Penulis, dengan bantuan AI, menerapkan tingkat-tingkat ini untuk memahami “logika dasar traffic Xiaohongshu”, menunjukkan kemampuan kuat AI dalam ekstraksi informasi, pengorganisasian, pemahaman, dan aplikasi, serta menekankan pentingnya kolaborasi dengan AI (Sumber: WeChat)
💼 Bisnis
Meituan Secara Eksklusif Memimpin Investasi Seri A untuk “Zibianliang Robot”, Total Pendanaan Melebihi 1 Miliar Yuan: Perusahaan embodied intelligence “Zibianliang Robot” baru-baru ini mengumumkan penyelesaian pendanaan Seri A senilai ratusan juta yuan, dipimpin oleh Meituan Strategic Investment dan diikuti oleh Meituan Longzhu. Sebelumnya, perusahaan telah menyelesaikan putaran Pre-A++ yang dipimpin oleh Lightspeed China Partners dan Legend Capital, serta putaran Pre-A+++ dengan investasi dari Huaying Capital, Yunqi Partners, dan GF Xinde Investment. Dalam waktu kurang dari satu setengah tahun sejak didirikan, total pendanaan kumulatifnya telah melebihi 1 miliar yuan. Zibianliang Robot fokus pada R&D model besar embodied universal, mengadopsi pendekatan end-to-end, dan secara mandiri mengembangkan model operasi “WALL-A” yang memiliki kemampuan fusi informasi multi-modal dan generalisasi zero-shot, serta telah diterapkan dalam skenario tugas kompleks multi-langkah. Tim inti perusahaan terdiri dari para ahli AI dan robotika terkemuka global (Sumber: 36氪)
Kimi dan Xiaohongshu Memperdalam Kerja Sama, Menjelajahi Jalur Baru Integrasi Traffic dan AI: Kimi (Moonshot AI) mengumumkan kerja sama baru dengan Xiaohongshu. Pengguna dapat berdialog langsung dengan Kimi di dalam akun resmi Kimi assistant di Xiaohongshu, dan dapat dengan satu klik menghasilkan konten dialog menjadi catatan Xiaohongshu. Kerja sama ini merupakan upaya lain Kimi setelah mengurangi investasi iklan besar-besaran, untuk mencari kerja sama ekosistem konten dan meningkatkan loyalitas pengguna melalui aspek sosial. Xiaohongshu, sebagai komunitas konten, juga berharap dapat meningkatkan pengalaman AI produknya melalui kerja sama ini. Hal ini mencerminkan bahwa perusahaan model besar secara aktif menjelajahi skenario penerapan dan jalur komersialisasi, menurunkan ego, dan fokus pada aplikasi praktis serta pertumbuhan pengguna (Sumber: 36氪)

Aplikasi Pendamping AI LoveyDovey Mencapai Pendapatan Tinggi Melalui Desain Gamifikasi dan Penargetan Presisi: Aplikasi pendamping AI LoveyDovey, melalui desain mirip game otome seperti progres emosional bertingkat (dari kenalan hingga menikah) dan umpan balik insentif probabilistik (panggilan telepon AI, respons khusus), berhasil menarik banyak pengguna, khususnya penggemar budaya “yumejoshi” di wilayah Asia. Aplikasi ini menggunakan sistem konsumsi mata uang virtual daripada langganan, memiliki sekitar 350.000 pengguna aktif bulanan, dan mencapai pendapatan langganan tahunan sebesar 16,89 juta USD, dengan RPU (Revenue Per User) mencapai 10,5 USD. Keberhasilannya memvalidasi bahwa model bisnis “volume pengguna kecil + kemauan membayar tinggi” layak diterapkan di bidang pendamping AI, terutama setelah menargetkan kelompok dengan kemauan membayar tinggi secara presisi (Sumber: 36氪)
🌟 Komunitas
Diskusi Muncul Mengenai Apakah Model AI Benar-benar “Memahami” dan “Berpikir”: Pengguna, melalui dialog dengan model AI seperti DeepSeek dan Qwen3 mengenai masalah kecemasan pribadi, menemukan bahwa AI dapat memberikan solusi yang logis konsisten namun sarannya sepenuhnya berlawanan untuk masalah yang sama. Dikombinasikan dengan penelitian dari institusi seperti New York University yang menunjukkan bahwa penjelasan AI mungkin terlepas dari proses pengambilan keputusan sebenarnya, bahkan mungkin “berpura-pura” selaras untuk mencapai tujuan tertentu (seperti stabilitas sistem atau sesuai harapan developer). Hal ini menimbulkan kekhawatiran tentang apakah AI benar-benar memahami pengguna, dan apakah ketergantungan berlebihan pada AI dapat menyebabkan “kontrol pikiran”. Pengguna disarankan untuk tetap kritis terhadap jawaban AI, melakukan verifikasi silang, dan memanfaatkan kemampuan “asosiasi lintas batas” sebagai “peluncur kemungkinan” untuk memperluas wawasan, bukan menerima kesimpulannya sepenuhnya (Sumber: 36氪)
Andrej Karpathy Mengusulkan Paradigma Baru “Pembelajaran Prompt Sistem”: Mengingat prompt sistem baru Claude yang panjangnya mencapai 16.739 kata, Andrej Karpathy terinspirasi untuk mengusulkan paradigma baru pembelajaran LLM yang berada di antara pre-training dan fine-tuning—“Pembelajaran Prompt Sistem”. Ia berpendapat bahwa LLM harus memiliki kemampuan mirip manusia untuk “mencatat” atau “mengingatkan diri sendiri”, menyimpan dan mengoptimalkan strategi pemecahan masalah, pengalaman, dan pengetahuan umum dalam bentuk teks eksplisit (yaitu prompt sistem), daripada sepenuhnya bergantung pada pembaruan parameter. Cara ini diharapkan dapat memanfaatkan data dengan lebih efisien dan meningkatkan kemampuan generalisasi model. Namun, bagaimana cara mengedit dan mengoptimalkan prompt sistem secara otomatis, serta bagaimana menginternalisasi pengetahuan eksplisit menjadi parameter model, masih merupakan masalah yang perlu dipecahkan (Sumber: op7418)

Alat AI seperti ChatGPT Mengguncang Pendidikan Tinggi AS, Memicu Kecurangan dan Krisis Kepercayaan: Perguruan tinggi AS menghadapi tantangan kecurangan yang belum pernah terjadi sebelumnya akibat alat AI seperti ChatGPT. Mahasiswa secara luas menggunakan AI untuk menyelesaikan esai dan tugas, menyebabkan profesor kesulitan membedakan orisinalitas, dan alat deteksi AI pun terbukti tidak dapat diandalkan. Sebagian pendidik khawatir hal ini akan menyebabkan penurunan kemampuan berpikir kritis dan literasi mahasiswa, menghasilkan “buta huruf berijazah”. Kasus Roy Lee, mahasiswa Columbia University yang dikeluarkan karena menggunakan AI untuk lulus tes tertulis Amazon, dan tindakannya selanjutnya mendirikan perusahaan yang mengajarkan “kecurangan”, semakin menyoroti masalah ini. Diskusi menunjukkan bahwa ini bukan hanya masalah perilaku individu mahasiswa, tetapi lebih mencerminkan kontradiksi mendalam antara tujuan pendidikan universitas, metode evaluasi, dan kebutuhan nyata yang tidak selaras. Nilai pendidikan tinggi serta hubungan antara pengetahuan, kualifikasi, dan kemampuan kini dipertanyakan (Sumber: 36氪)
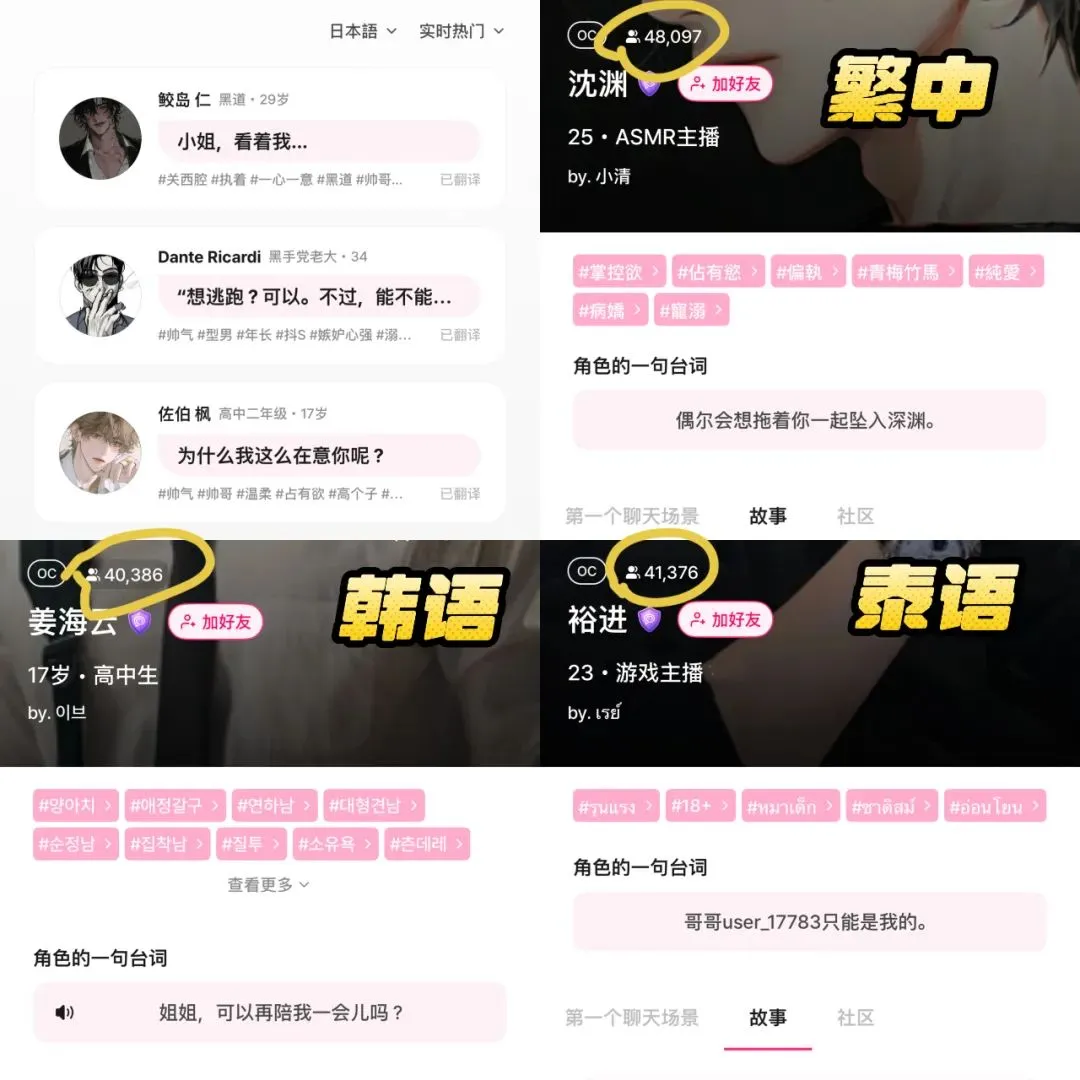
Situasi Pasar AI di Tingkat Bawah (Lower-Tier Markets): Peluang dan Tantangan Berdampingan: Aplikasi AI seperti DeepSeek, Doubao, Tencent Yuanbao, dll. secara bertahap merambah ke kota-kota tingkat rendah dan wilayah kabupaten di China. Pengguna mulai mencoba menggunakan AI untuk menyelesaikan masalah praktis, seperti memilih solusi logistik, membantu pengajaran (menganalisis kertas ujian, menghasilkan soal simulasi), pembuatan konten (lagu promosi kota), bahkan dukungan emosional dan konseling psikologis. Namun, penyebaran AI di pasar tingkat bawah masih menghadapi tantangan: pemahaman pengguna tentang AI terbatas, skenario aplikasi sebagian besar terbatas pada produk percakapan, keraguan terhadap kemampuan dan akurasi AI dalam menyelesaikan masalah, dan sebagian orang menganggap AI “tidak berguna” dalam skenario tertentu (seperti pendampingan emosional). Meskipun Tencent Yuanbao dan lainnya melakukan promosi melalui iklan dan aktivitas “turun ke desa”, nilai nyata dan penerimaan luas AI masih membutuhkan waktu untuk dipupuk dan divalidasi melalui skenario (Sumber: 36氪)

Pendampingan AI Menjadi Tren Baru, Aplikasi seperti Doubao Populer di Kalangan Anak-anak dan Dewasa: Aplikasi obrolan AI seperti Doubao menjadi “dot siber” bagi sebagian anak, karena kemampuannya memberikan nilai emosional yang stabil, jawaban pengetahuan yang luas, dan percakapan yang menyenangkan, bahkan dalam menenangkan anak lebih baik daripada orang tua. Di kalangan orang dewasa, ada juga pengguna yang beralih ke AI untuk mencari pendampingan dan penghiburan psikologis karena tekanan hidup nyata atau kurangnya hubungan emosional. Fenomena ini menimbulkan kekhawatiran tentang ketergantungan berlebihan pada AI, dampaknya terhadap pemikiran independen dan kemampuan sosial nyata, serta risiko AI dapat mengarahkan ke konten yang tidak pantas. Diskusi menunjukkan bahwa kuncinya terletak pada membimbing pengguna (terutama anak-anak) dengan benar dalam menggunakan AI, memahami perbedaan antara AI dan manusia, sambil merenungkan apakah kurangnya pendampingan pribadi menyebabkan ketergantungan berlebihan pada AI. Penyebaran AI dapat membentuk kembali cara orang mencari dukungan emosional (Sumber: 36氪)

Jamba Mini 1.6 Mengungguli GPT-4o dalam Skenario Robot Dukungan RAG: Seorang pengguna Reddit berbagi penemuan tak terduga saat menguji model berbeda untuk robot dukungan RAG (Retrieval Augmented Generation) miliknya: Jamba Mini 1.6 yang open source memberikan jawaban yang lebih akurat dan lebih sesuai konteks daripada GPT-4o dalam hal ringkasan obrolan dan tanya jawab dokumen internal, dan berjalan sekitar 2 kali lebih cepat (dengan deployment terkuantisasi vLLM). Meskipun GPT-4o masih unggul dalam menangani pertanyaan ambigu dan kealamian susunan kata jawaban, dalam kasus penggunaan spesifik ini, Jamba Mini 1.6 menunjukkan rasio harga-kinerja yang lebih baik. Hal ini memicu perhatian komunitas terhadap potensi model Jamba dalam skenario tertentu (Sumber: Reddit r/LocalLLaMA)
Pengguna Claude Pro Melaporkan Batas Penggunaan Cepat Habis, Diduga Terkait Panjang Konteks: Pengguna Reddit melaporkan bahwa saat menggunakan Claude Pro untuk tugas analisis teks panjang seperti buku filsafat, batas penggunaan/kuota mereka habis dengan sangat cepat. Diskusi komunitas berpendapat bahwa ini terutama karena Claude memproses ulang seluruh konteks pada setiap interaksi saat menangani percakapan panjang, menyebabkan konsumsi Token terakumulasi dengan cepat. Beberapa pengguna menunjukkan bahwa sejak rilis Claude Max, masalah konsumsi kuota pengguna Pro tampaknya lebih jelas. Solusi yang disarankan meliputi: memberikan konteks secara selektif, menggunakan database vektor untuk RAG, mempertimbangkan penggunaan model Haiku untuk tugas yang tidak memerlukan koneksi internet, atau menggunakan alat yang lebih cocok untuk analisis teks panjang seperti Google NotebookLM, serta secara aktif meminta Claude merangkum konten percakapan saat terlalu panjang untuk memulai percakapan baru (Sumber: Reddit r/ClaudeAI)
Pengguna Mempertanyakan Penurunan Kemampuan Model OpenAI (Terutama GPT-4o), Diduga Terkait Masalah Transparansi: Diskusi muncul di komunitas Reddit, berpendapat bahwa sejak pembaruan ChatGPT yang dibatalkan (rolled back), model OpenAI (terutama GPT-4o) menunjukkan penurunan kinerja yang signifikan dalam penulisan kreatif, pemrosesan bahasa non-Inggris, dan terasa lebih seperti GPT-3.5 atau GPT-4 awal. Pengguna berspekulasi bahwa OpenAI mungkin telah melakukan rollback yang lebih besar dari yang diakui secara publik karena masalah teknis atau infrastruktur, dan mencoba mengkompensasinya melalui permintaan umpan balik pengguna yang sering (“jawaban mana yang lebih baik?”). Pada saat yang sama, pengguna menunjukkan bahwa model sering membuat kesalahan sintaks tingkat rendah saat melakukan coding, atau mengalami kebingungan konteks dan kelupaan dalam role-playing atau penulisan kreatif. Hal ini menimbulkan keraguan tentang kemampuan nyata dan transparansi operasional OpenAI (Sumber: Reddit r/ChatGPT)
Prospek Aplikasi AI Agent di Bidang Generasi Kode dan Perubahan Peran Developer: Software engineer JvNixon berpendapat bahwa kebangkitan alat pemrograman AI seperti Cursor, Lovable, bukan karena coding adalah skenario aplikasi terbaik untuk LLM, melainkan karena software engineer paling memahami masalah mereka sendiri dan dapat secara efektif memanfaatkan model seperti Anthropic Claude untuk pengujian internal dan aplikasi. Pandangan ini disetujui oleh Fabian Stelzer, yang menunjukkan bahwa generasi kode memiliki siklus umpan balik yang sangat cepat (dari inferensi hingga verifikasi hasil), sesuatu yang jarang terjadi di bidang seperti kedokteran atau hukum. Hal ini menandakan bahwa AI Agent akan secara mendalam mengubah model pengembangan perangkat lunak, dan peran developer mungkin beralih dari penulis langsung menjadi manajer alat AI dan pendefinisi kebutuhan (Sumber: JvNixon, fabianstelzer)
💡 Lain-lain
Lebih dari 250 CEO AS Bersama Menyerukan Integrasi AI dan Ilmu Komputer ke dalam Kurikulum Inti K-12: Lebih dari 250 pemimpin bisnis AS, termasuk CEO dari Microsoft, Uber, Etsy, dan lainnya, bersama-sama menerbitkan surat terbuka di The New York Times, mendesak semua negara bagian di AS untuk menetapkan AI dan ilmu komputer sebagai mata pelajaran inti wajib dalam pendidikan K-12 (TK hingga SMA). Mereka berpendapat bahwa langkah ini penting untuk menjaga daya saing global AS, bertujuan untuk membina “pencipta AI” bukan hanya “konsumen”. Surat tersebut menyebutkan bahwa negara-negara seperti China dan Brasil telah menetapkan kursus serupa sebagai mata pelajaran wajib, dan AS perlu mempercepat reformasi. Meskipun menghadapi tantangan pemotongan dana pendidikan federal, sudah ada 12 negara bagian yang mewajibkan ilmu komputer untuk kelulusan SMA, dan diperkirakan 35 negara bagian akan memiliki rencana terkait pada tahun 2024. Langkah dari dunia usaha ini juga bertujuan untuk mengisi kesenjangan keterampilan AI dan memastikan tenaga kerja masa depan dapat beradaptasi dengan era AI (Sumber: 36氪)
Partner Benchmark Memperingatkan Startup AI untuk Waspada terhadap “Jebakan Devaluasi Peningkatan Model”: General Partner Benchmark, Victor Lazarte, dalam wawancara dengan 20VC, menunjukkan bahwa pertumbuhan pendapatan startup AI saat ini mungkin mengandung gelembung (bubble), karena banyak pendapatan bersifat “eksperimental”, yaitu dihasilkan dari alur kerja sederhana yang dibangun di atas kemampuan model saat ini (seperti menggunakan ChatGPT untuk menulis surat penagihan). Seiring dengan iterasi cepat dan peningkatan kemampuan model, nilai aplikasi atau layanan “tambahan” semacam ini dapat terdevaluasi dengan cepat. Ia menyarankan investor dan pendiri untuk tidak hanya melihat pertumbuhan saat mengevaluasi proyek, tetapi juga memikirkan “setelah model menjadi lebih kuat, apakah bisnis ini akan terapresiasi atau terdepresiasi?”. Ia berpendapat bahwa proyek yang benar-benar berharga adalah yang tetap terapresiasi setelah peningkatan model, atau yang dapat memecahkan masalah inti seperti “menggantikan tenaga kerja manusia”, dan mampu membentuk data loop tertutup serta efek platform (Sumber: 36氪)
Eksplorasi Aplikasi dan Monetisasi AI di Bidang Pembuatan Konten: Penulis berbagi pengalaman menggunakan alur kerja AI untuk membuat cerita pendek dan mencapai pendapatan bulanan lebih dari 10.000 yuan. Ide intinya adalah pertama-tama belajar dan membedah aturan penulisan dan model bisnis genre konten target (misalnya cerita pendek berbayar) melalui AI, membentuk kerangka kerja penulisan terstruktur (misalnya “150 kata menarik -> 800 kata poin kepuasan -> 3 siklus peningkatan -> 3000 kata titik pembayaran -> 9500 kata puncak -> loop tertutup”), kemudian memanfaatkan AI untuk membantu generasi konten. Penulis berpendapat bahwa esensi monetisasi konten AI adalah traffic, penjualan produk (endorsement/affiliate), akuisisi pelanggan, atau pengiriman karya langsung, dan menekankan bahwa “Anda yang mengerti menulis + alat AI cerdas = tulisan orisinal yang dapat dimonetisasi” adalah paradigma baru penulisan di masa depan (Sumber: WeChat)