
Kata Kunci:OpenAI, Chip AI, Model Besar, Pembelajaran Penguatan, Infrastruktur AI, AI Multimodal, Agen Cerdas, RAG, Rencana AI Tingkat Nasional OpenAI, Pembatasan Ekspor Chip Nvidia H20, Optimasi Inferensi DeepSeek-R1, Mikroskop Optik AI Meta-rLLS-VSIM, Model Kode Besar Seed-Coder ByteDance
🔥 Fokus
OpenAI meluncurkan program “AI Tingkat Nasional”, mendukung pembangunan infrastruktur AI global: OpenAI meluncurkan proyek “OpenAI for Countries”, sebagai bagian dari program “Stargate” miliknya, yang bertujuan untuk membantu berbagai negara membangun pusat data AI lokal, melakukan kustomisasi ChatGPT, dan mendorong pengembangan ekosistem AI. CEO Sam Altman telah melakukan kunjungan lapangan ke kompleks superkomputer pertama yang berlokasi di Abilene, Texas. Kompleks ini merupakan bagian dari program “Stargate” senilai $500 miliar yang bertujuan untuk membangun fasilitas pelatihan AI terbesar di dunia. Langkah ini menandakan bahwa OpenAI akan bekerja sama dengan pemerintah berbagai negara melalui pembangunan infrastruktur dan berbagi teknologi untuk mendorong penyebaran dan penerapan teknologi AI secara global, dengan rencana awal untuk bekerja sama dengan 10 negara atau wilayah (Sumber: WeChat)

Pemerintahan Trump dikabarkan berencana menghapus pembatasan ekspor chip AI tiga tingkat, kemungkinan akan mengadopsi sistem lisensi global yang lebih sederhana: Menurut laporan media asing, pemerintahan Trump berencana untuk mencabut Kerangka Kerja Penyebaran Kecerdasan Buatan (FAID) yang ditetapkan pada akhir era Biden. Kerangka kerja tersebut awalnya memberlakukan pembatasan ekspor chip AI global dengan klasifikasi tiga tingkat. Tim Trump menganggap kerangka kerja tersebut terlalu rumit dan menghambat inovasi, serta lebih memilih sistem lisensi global yang lebih sederhana yang akan ditegakkan melalui perjanjian antar pemerintah. Langkah ini dapat memengaruhi strategi pasar global produsen chip seperti Nvidia, dan bertujuan untuk memperkuat inovasi dan dominasi Amerika Serikat di bidang AI (Sumber: WeChat)

Tim SGLang secara signifikan mengoptimalkan kinerja inferensi DeepSeek-R1, throughput meningkat 26 kali lipat: Tim gabungan dari SGLang, Nvidia, dan institusi lainnya berhasil meningkatkan kinerja inferensi model DeepSeek-R1 pada GPU H100 sebanyak 26 kali lipat dalam empat bulan melalui peningkatan komprehensif pada mesin inferensi SGLang. Solusi optimasi mencakup teknik seperti pemisahan prapengisian dan dekode (pemisahan PD), paralelisasi pakar skala besar (EP), DeepEP, DeepGEMM, dan penyeimbang beban paralelisasi pakar (EPLB). Saat memproses urutan input 2000 token, tercapai throughput sebesar 52,3k token input per detik dan 22,3k token output per detik per node, mendekati data resmi DeepSeek, dan secara signifikan mengurangi biaya implementasi lokal (Sumber: WeChat)

Ilmuwan OpenAI Dan Roberts: Perluasan reinforcement learning akan mendorong AI menemukan ilmu pengetahuan baru, mungkin mencapai AGI setingkat Einstein dalam 9 tahun: Ilmuwan riset OpenAI Dan Roberts menyampaikan pidato di Sequoia Capital AI Ascent, membahas peran inti reinforcement learning (RL) dalam pembangunan model AI di masa depan. Ia berpendapat bahwa dengan terus memperluas skala RL, model AI tidak hanya dapat meningkatkan kinerjanya dalam tugas-tugas seperti penalaran matematis, tetapi juga dapat mencapai penemuan ilmiah melalui “komputasi waktu uji” (semakin lama model berpikir, semakin baik kinerjanya). Ia mencontohkan penemuan relativitas umum oleh Einstein, berspekulasi bahwa jika AI dapat melakukan komputasi dan berpikir selama 8 tahun, ia mungkin dapat mencapai terobosan ilmiah setingkat Einstein dalam 9 tahun mendatang. Roberts menekankan bahwa pengembangan AI di masa depan akan lebih berfokus pada komputasi RL, bahkan mungkin mendominasi seluruh proses pelatihan (Sumber: WeChat)

🎯 Tren
Jim Fan dari Nvidia: Robot akan melewati “Uji Turing Fisik”, simulasi dan AI generatif adalah kuncinya: Kepala divisi robotika Nvidia, Jim Fan, dalam pidatonya di Sequoia AI Ascent, mengemukakan konsep “Uji Turing Fisik”, yaitu manusia tidak dapat membedakan apakah suatu tugas dilakukan oleh manusia atau robot. Ia menunjukkan bahwa biaya akuisisi data robot saat ini mahal, dan teknologi simulasi adalah kuncinya, terutama dikombinasikan dengan AI generatif (seperti fine-tuning model generasi video) untuk menciptakan data pelatihan yang beragam dan berskala besar (“sepupu digital” bukan “kembaran digital” yang presisi). Ia memprediksi bahwa melalui simulasi skala besar dan model visual-bahasa-aksi (seperti GR00T dari Nvidia), API fisik akan ada di mana-mana di masa depan, robot akan mampu menyelesaikan tugas sehari-hari yang kompleks, dan terintegrasi dengan kecerdasan lingkungan (Sumber: WeChat)
ByteDance merilis seri model kode besar Seed-Coder, versi 8B menunjukkan kinerja unggul: ByteDance meluncurkan seri model kode besar Seed-Coder, termasuk versi 8B, 14B, dan lainnya. Di antaranya, Seed-Coder-8B menunjukkan kinerja luar biasa pada beberapa tolok ukur kemampuan kode seperti SWE-bench, Multi-SWE-bench, dan IOI, yang diklaim lebih unggul dari Qwen3-8B dan Qwen2.5-Coder-7B-Inst. Seri model ini mencakup versi Base, Instruct, dan Reasoner, dengan filosofi inti “membiarkan model kode mengkurasi data untuk dirinya sendiri”, dan menunjukkan peningkatan signifikan dalam kemampuan penalaran kode dan rekayasa perangkat lunak. Model ini telah tersedia secara open source di Hugging Face dan GitHub (Sumber: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
Alibaba merilis kerangka kerja ZeroSearch secara open source, menggunakan LLM untuk mensimulasikan pencarian dan mengurangi biaya pelatihan AI sebesar 88%: Peneliti Alibaba merilis kerangka kerja reinforcement learning bernama “ZeroSearch”. Kerangka kerja ini memungkinkan Large Language Model (LLM) untuk mengembangkan fungsi pencarian tingkat lanjut dengan mensimulasikan mesin pencari, tanpa perlu memanggil API mesin pencari komersial yang mahal (seperti Google) selama proses pelatihan. Eksperimen menunjukkan bahwa penggunaan LLM 3B sebagai mesin pencari simulasi dapat secara efektif meningkatkan kemampuan pencarian model strategi. Kinerja modul pencarian dengan parameter 14B bahkan melampaui Google Search, sementara biaya API berkurang sebesar 88%. Teknologi ini telah tersedia secara open source di GitHub dan Hugging Face, mendukung seri model seperti Qwen-2.5 dan LLaMA-3.2 (Sumber: WeChat)

Gemini API meluncurkan fitur cache implisit, dapat menghemat biaya hingga 75%: Google Gemini API baru-baru ini mengaktifkan fitur cache implisit untuk seri model Gemini 2.5 (Pro dan Flash). Ketika permintaan pengguna mengenai cache, biaya dapat dihemat secara otomatis hingga 75%. Sementara itu, persyaratan token minimum untuk memicu cache juga telah diturunkan, menjadi 1K token untuk model 2.5 Flash dan 2K token untuk model 2.5 Pro. Langkah ini bertujuan untuk mengurangi biaya penggunaan Gemini API bagi pengembang dan meningkatkan efisiensi permintaan berulang dengan frekuensi tinggi (Sumber: JeffDean)
Universitas Tsinghua mengembangkan mikroskop optik AI Meta-rLLS-VSIM, resolusi volume meningkat 15,4 kali lipat: Kelompok riset Li Dong dari Universitas Tsinghua bekerja sama dengan tim Dai Qionghai, mengusulkan mikroskop iluminasi cahaya terstruktur virtual berbasis kisi reflektif yang digerakkan oleh meta-learning (Meta-rLLS-VSIM). Sistem ini, melalui inovasi persilangan AI dan optik, meningkatkan resolusi lateral pencitraan sel hidup hingga 120nm dan resolusi aksial hingga 160nm, mencapai resolusi super yang mendekati isotropik, dengan resolusi volume 15,4 kali lebih tinggi dibandingkan LLSM tradisional. Teknologi intinya mencakup penggunaan DNN untuk mempelajari dan memperluas kemampuan resolusi super ke berbagai arah melalui “iluminasi cahaya terstruktur virtual”, serta peningkatan resolusi aksial melalui fusi informasi dua sudut pandang refleksi cermin dan jaringan RL-DFN. Pengenalan strategi meta-learning memungkinkan model AI menyelesaikan implementasi adaptif hanya dalam 3 menit, secara signifikan menurunkan hambatan penerapan AI dalam eksperimen biologis, dan menyediakan alat yang ampuh untuk mengamati proses kehidupan seperti pembelahan sel kanker dan perkembangan embrio (Sumber: WeChat)

Seri model besar Qwen3 dirilis, terus memimpin komunitas open source: Alibaba merilis seri Large Language Model Qwen3, dengan skala parameter mulai dari 0.5B hingga 235B. Model ini menunjukkan kinerja yang sangat baik dalam berbagai uji tolok ukur, di mana beberapa model berukuran kecil mencapai level SOTA di antara model open source dengan skala serupa. Seri Qwen3 mendukung berbagai bahasa, dengan panjang konteks hingga 128k token. Karena kinerjanya yang kuat dan biaya implementasi yang lebih rendah (dibandingkan dengan DeepSeek-R1, dll.), seri Qwen telah banyak diadopsi di luar negeri (terutama Jepang) sebagai dasar pengembangan AI, dan telah menghasilkan banyak model vertikal. Rilis Qwen3 semakin memperkuat posisi terdepannya di komunitas AI open source global, dengan jumlah bintang di GitHub melampaui 20.000 dalam seminggu (Sumber: dl_weekly, WeChat)

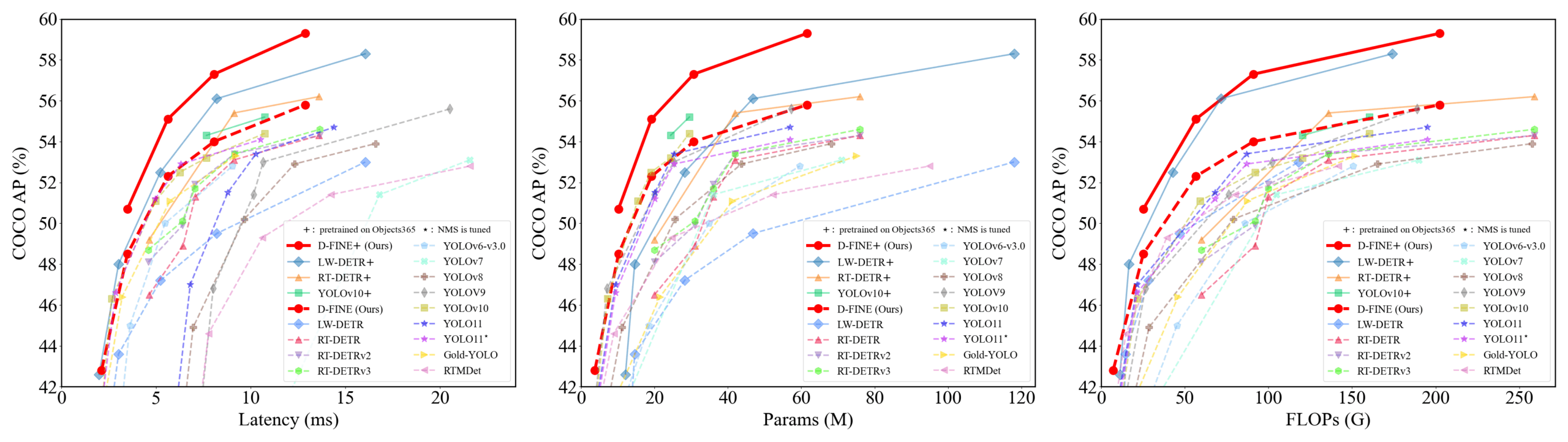
D-FINE: Detektor objek real-time berbasis optimasi distribusi granular halus, kinerja unggul: Para peneliti mengusulkan D-FINE, sebuah detektor objek real-time baru, yang mendefinisikan ulang tugas regresi kotak pembatas dalam DETR sebagai optimasi distribusi granular halus (FDR), dan memperkenalkan strategi distilasi mandiri lokalisasi optimal global (GO-LSD). D-FINE mencapai kinerja luar biasa tanpa menambah biaya inferensi dan pelatihan tambahan. Sebagai contoh, D-FINE-N mencapai 42,8% AP pada COCO val, dengan kecepatan hingga 472 FPS (GPU T4); D-FINE-X, setelah pra-pelatihan pada Objects365+COCO, mencapai AP 59,3% pada COCO val. Metode ini mencapai lokalisasi yang lebih halus melalui optimasi iteratif distribusi probabilitas, dan mentransfer pengetahuan lokalisasi dari lapisan akhir ke lapisan awal melalui distilasi mandiri (Sumber: GitHub Trending)
Model Harmon mengoordinasikan representasi visual, menyatukan pemahaman dan generasi multimodal: Peneliti dari Nanyang Technological University mengusulkan model Harmon, yang bertujuan untuk menyatukan tugas pemahaman dan generasi multimodal dengan berbagi MAR Encoder (Masked Autoencoder for Reconstruction). Penelitian menemukan bahwa MAR Encoder dalam pelatihan generasi gambar dapat secara bersamaan mempelajari semantik visual, dengan hasil Linear Probing yang jauh melampaui VQGAN/VAE. Kerangka kerja Harmon menggunakan MAR Encoder untuk memproses gambar lengkap untuk pemahaman, dan mengadopsi paradigma pemodelan tersembunyi MAR untuk generasi gambar, di mana LLM mewujudkan interaksi modal. Eksperimen menunjukkan bahwa Harmon mendekati Janus-Pro pada tolok ukur pemahaman multimodal, dan menunjukkan kinerja yang sangat baik pada tolok ukur estetika teks-ke-gambar MJHQ-30K dan tolok ukur kepatuhan instruksi GenEval, bahkan melampaui beberapa model ahli. Model ini telah tersedia secara open source (Sumber: WeChat)

Tuixing Technology mewujudkan siklus bisnis tertutup untuk robot logistik, mengakumulasi data melalui “Sistem Bayangan Pengendara”: Robot logistik Tuixing Technology telah beroperasi secara aktual di beberapa kota di Tiongkok, mencapai titik impas untuk setiap robot melalui kerja sama dengan pengendara manusia. Salah satu teknologi intinya adalah “Sistem Bayangan Pengendara”, yang mengumpulkan data perilaku mengemudi, persepsi lingkungan, dan operasi (seperti membuka/menutup pintu, mengambil/meletakkan barang) dari pengendara manusia sungguhan di lingkungan perkotaan yang kompleks. Data ini menyediakan data pelatihan imitasi belajar dan reinforcement learning berkualitas tinggi dan berjumlah besar untuk robot. Saat ini, sistem tersebut telah mengakumulasi data perjalanan puluhan juta kilometer dan hampir satu juta data lintasan lengan atas. Berdasarkan ini, Tuixing Technology telah melatih model VLA pohon perilaku, memungkinkan robot untuk mengatasi situasi kompleks di dunia nyata, dan berencana untuk berekspansi ke pasar luar negeri (Sumber: WeChat)

Kuaishou meluncurkan kerangka kerja KuaiMod, menggunakan model besar multimodal untuk mengoptimalkan ekosistem video pendek: Kuaishou mengusulkan solusi optimasi ekosistem platform video pendek berbasis model besar multimodal bernama KuaiMod, yang bertujuan untuk meningkatkan pengalaman pengguna melalui diskriminasi kualitas konten otomatis. KuaiMod mengadopsi pendekatan hukum kasus, memanfaatkan penalaran berantai dari Visual Language Model (VLM) untuk menganalisis konten berkualitas rendah, dan terus memperbarui strategi diskriminasi melalui Reinforcement Learning from User Feedback (RLUF). Kerangka kerja ini telah diterapkan di platform Kuaishou dan secara efektif mengurangi tingkat keluhan pengguna lebih dari 20%. Kuaishou juga berkomitmen untuk membangun model besar multimodal yang dapat memahami video pendek komunitas, beralih dari ekstraksi representasi ke pemahaman semantik yang mendalam. Model ini telah diterapkan dalam beberapa skenario seperti strukturisasi label minat video dan bantuan pembuatan konten, dan telah mencapai hasil yang efektif (Sumber: WeChat)

Lenovo merilis agen super cerdas pribadi “Tianxi”, menuju kecerdasan L3: Lenovo dalam Konferensi Inovasi Teknologi meluncurkan agen super cerdas pribadi “Tianxi”, yang memiliki kemampuan persepsi dan interaksi multimodal, kognisi dan pengambilan keputusan berdasarkan basis pengetahuan pribadi, serta kemampuan dekomposisi dan eksekusi tugas kompleks secara mandiri. Tianxi bertujuan untuk menyediakan pengalaman kolaborasi manusia-mesin yang alami dan mulus melalui antarmuka AUI pendamping seperti AI Sui Xin Chuang (AI隨心窗 – jendela AI fleksibel), AI Ling Long Tai (AI玲瓏台 – platform AI interaktif), dan AI Ru Ying Kuang (AI如影框 – bingkai AI pendamping). Ini mengintegrasikan beberapa model besar terkemuka di industri, termasuk DeepSeek-R1, dan mengadopsi arsitektur implementasi hybrid edge-cloud, dikombinasikan dengan Lenovo Personal Cloud 1.0 (dilengkapi dengan model besar 72 miliar parameter) untuk menyediakan daya komputasi yang kuat dan ruang memori khusus 100G. Lenovo juga merilis agen super cerdas tingkat perusahaan “Lexiang” dan tingkat kota, menunjukkan tata letak komprehensifnya di bidang AI (Sumber: WeChat)

Penelitian baru menilai generalisasi jaringan neural melalui kompleksitas interaksi simbolik: Tim Profesor Zhang Quanshi dari Universitas Shanghai Jiao Tong mengusulkan teori baru untuk menganalisis generalisasi jaringan neural dari perspektif kompleksitas representasi interaksi simbolik internalnya. Penelitian menemukan bahwa interaksi yang dapat digeneralisasi (muncul dengan frekuensi tinggi baik dalam set pelatihan maupun pengujian) biasanya menunjukkan distribusi yang menurun pada berbagai tingkatan (kompleksitas) (interaksi tingkat rendah mendominasi), sedangkan interaksi yang tidak dapat digeneralisasi (terutama muncul dalam set pelatihan) menunjukkan distribusi berbentuk gelendong (interaksi tingkat menengah mendominasi, efek positif dan negatif mudah saling meniadakan). Teori ini bertujuan untuk secara langsung menilai potensi generalisasi model dengan menganalisis pola distribusi “logika interaksi AND-OR” yang setara dengan model, memberikan perspektif baru untuk memahami dan meningkatkan generalisasi model (Sumber: WeChat)
🧰 Alat
Llama.cpp sepenuhnya kompatibel dengan Visual Language Model (VLM): Llama.cpp kini sepenuhnya mendukung Visual Language Model (VLM), memungkinkan pengembang menjalankan aplikasi multimodal di perangkat. Julien Chaumond dari Hugging Face dan lainnya membagikan model pra-kuantisasi, termasuk Gemma dari Google DeepMind, Pixtral dari Mistral AI, Qwen VL dari Alibaba, dan SmolVLM dari Hugging Face, yang dapat langsung digunakan. Pembaruan ini merupakan kontribusi dari tim @ngxson dan @ggml_org, membuka kemungkinan baru untuk aplikasi AI multimodal yang terlokalisasi dan berlatensi rendah (Sumber: ggerganov, ClementDelangue, cognitivecompai)
Kotak Super AI Quark ditingkatkan dengan “Pencarian Mendalam”, meningkatkan “kecerdasan mencari” AI: Kotak Super AI Quark baru-baru ini ditingkatkan dengan peluncuran fitur “Pencarian Mendalam”, yang bertujuan untuk meningkatkan kecerdasan mencari (search quotient) AI. Fitur baru ini menekankan pemikiran proaktif dan perencanaan logis AI sebelum melakukan pencarian, sehingga dapat lebih baik memahami maksud kueri pengguna yang kompleks dan personal, memecah masalah, dan melakukan pencarian cerdas secara terstruktur. Di bidang kesehatan, konsultan kesehatan AI Quark, “Aqua”, akan merujuk pada pandangan dokter dari rumah sakit kelas atas dan materi profesional; di bidang akademik, ia terhubung dengan sumber otoritatif seperti CNKI. Selain itu, Quark juga memiliki kemampuan pemrosesan multimodal yang kuat, seperti analisis gambar, AI抠图 (AI matting), peningkatan gambar, dan konversi gaya. Dilaporkan bahwa Quark di masa depan juga akan merilis versi Pro Pencarian Mendalam dengan kemampuan Deep Research (Sumber: WeChat)

LangChain meluncurkan beberapa integrasi dan tutorial, memperkuat kemampuan RAG dan agen cerdas: LangChain baru-baru ini merilis beberapa pembaruan dan tutorial: 1. Tutorial UI Agen Media Sosial: Memandu cara mengubah agen media sosial LangChain menjadi aplikasi web yang ramah pengguna, mengintegrasikan ExpressJS dan UI AgentInbox, serta mendukung Notion. 2. Solusi RAG Pemenang Penghargaan: Menampilkan implementasi RAG untuk menganalisis laporan tahunan perusahaan, mendukung parsing PDF, multi-LLM, dan pencarian tingkat lanjut. 3. Aplikasi Obrolan RAG Pribadi: Tutorial mendemonstrasikan cara membangun aplikasi obrolan RAG yang terlokalisasi dan berfokus pada privasi data menggunakan kerangka kerja LangChain dan Reflex. 4. Integrasi Nimble Retriever: Memperkenalkan retriever data web yang kuat, menyediakan data akurat untuk aplikasi LangChain. 5. Panduan Output Terstruktur Claude 3.7: Menyediakan tiga metode untuk mencapai output terstruktur Claude 3.7 melalui LangChain dan AWS Bedrock. 6. Sistem Obrolan RAG Lokal: Proyek open source menunjukkan sistem tanya jawab dokumen yang sepenuhnya terlokalisasi yang dibangun menggunakan alur RAG LangChain dan LLM lokal (melalui Ollama), memastikan privasi data (Sumber: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent: Kerangka kerja agen AI open source yang mengintegrasikan kemampuan multi-kerangka kerja: Minion-agent adalah kerangka kerja pengembangan agen AI open source baru yang bertujuan untuk mengatasi masalah fragmentasi kerangka kerja AI yang ada (seperti OpenAI, LangChain, Google AI, SmolaAgents). Ini menyediakan antarmuka terpadu, mendukung pemanggilan kemampuan multi-kerangka kerja, alat sebagai layanan (penjelajahan web, operasi file, dll.), serta kolaborasi multi-agen. Proyek ini menunjukkan potensi aplikasinya dalam skenario seperti penelitian mendalam (mengumpulkan literatur secara otomatis untuk menghasilkan laporan), perbandingan harga (riset pasar otomatis), generasi kreatif (generasi kode game), dan pelacakan dinamika teknologi, menekankan keunggulan model open source dalam hal fleksibilitas dan efektivitas biaya (Sumber: WeChat)

RunwayML menunjukkan kemampuan generasi dan pengeditan video yang kuat dalam berbagai skenario: Peneliti AI independen Cristobal Valenzuela dan pengguna lain menunjukkan penerapan RunwayML dalam berbagai skenario kreatif. Termasuk memanfaatkan fitur Frames, References, dan Gen-4 untuk menghasilkan dan memvisualisasikan visual kreatif dengan cepat sambil mempertahankan konsistensi gaya dan karakter; mengubah dunia Rembrandt menjadi video game RPG; serta mencapai sintesis tampilan desain interior satu gambar yang baru dengan menyediakan referensi visual. Kasus-kasus ini menyoroti kemajuan RunwayML dalam generasi video yang terkontrol, transfer gaya, dan pembangunan adegan (Sumber: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus: Router tugas universal untuk tugas computer vision: Olympus adalah router tugas universal yang dirancang untuk tugas computer vision. Ini bertujuan untuk menyederhanakan dan menyatukan alur kerja pemrosesan untuk berbagai tugas visual, kemungkinan melalui penjadwalan cerdas dan alokasi sumber daya komputasi atau pemanggilan model, untuk mengoptimalkan efisiensi dan kinerja sistem computer vision multi-tugas. Proyek ini telah tersedia secara open source di GitHub (Sumber: dl_weekly)
Tracy Profiler: Penganalisis frame campuran dan sampling real-time resolusi nanodetik: Tracy Profiler adalah alat analisis frame campuran dan sampling real-time dengan resolusi nanodetik yang mendukung telemetri jarak jauh untuk game dan aplikasi lainnya. Alat ini mendukung analisis kinerja CPU (C, C++, Lua, Python, Fortran, dan binding pihak ketiga untuk Rust, Zig, C#, dll.), GPU (OpenGL, Vulkan, Direct3D, Metal, OpenCL), alokasi memori, kunci, dan peralihan konteks, serta dapat secara otomatis mengaitkan tangkapan layar dengan frame yang ditangkap. Alat ini, dengan presisi tinggi dan kemampuan real-time, menyediakan sarana yang kuat bagi pengembang untuk menemukan dan mengoptimalkan bottleneck kinerja (Sumber: GitHub Trending)

FieldStation42: Simulator siaran televisi retro: FieldStation42 adalah proyek Python yang bertujuan untuk mensimulasikan pengalaman menonton siaran televisi kuno. Proyek ini dapat mendukung beberapa saluran secara bersamaan, secara otomatis menyisipkan iklan dan pratinjau program, serta menghasilkan jadwal program mingguan berdasarkan konfigurasi. Simulator ini dapat secara acak memilih program yang belum lama diputar untuk menjaga kesegaran, mendukung pengaturan rentang tanggal pemutaran program (seperti program musiman), dan dapat dikonfigurasi dengan video penutupan stasiun televisi dan gambar loop tanpa sinyal. Proyek ini juga mendukung koneksi perangkat keras (seperti Raspberry Pi Pico) untuk mensimulasikan operasi penggantian saluran, dan menyediakan fungsi saluran pratinjau/panduan. Tujuannya adalah agar ketika pengguna “menyalakan TV”, dapat memutar konten program yang “nyata” sesuai dengan slot waktu dan saluran tersebut (Sumber: GitHub Trending)

Tiny Corp meluncurkan solusi eGPU AMD berbasis USB3, mendukung Apple Silicon: Tiny Corp mendemonstrasikan solusi menghubungkan eGPU AMD ke Mac Apple Silicon melalui USB3 (khususnya perangkat ADT-UT3G berbasis kontroler ASM2464PD). Solusi ini menulis ulang driver, bertujuan untuk memanfaatkan bandwidth 10Gbps USB3, dan menggunakan libusb, yang secara teoritis juga mendukung Linux atau Windows. Ini memberikan cara baru bagi pengguna Apple Silicon untuk memperluas kemampuan pemrosesan grafis, terutama bernilai potensial untuk skenario seperti menjalankan model AI besar secara lokal (Sumber: Reddit r/LocalLLaMA)
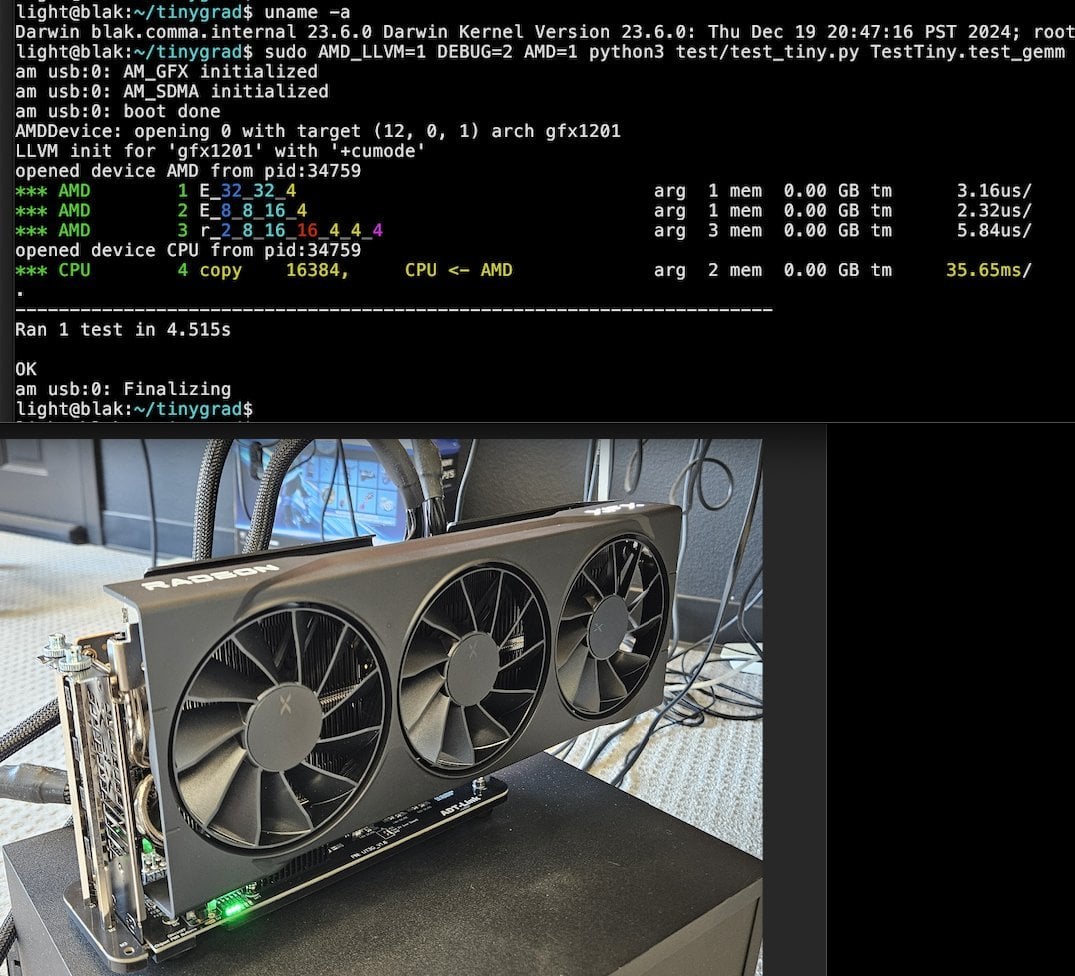
Llama.cpp-vulkan mencapai dukungan FlashAttention pada GPU AMD: Backend Vulkan dari Llama.cpp baru-baru ini menggabungkan implementasi FlashAttention, yang berarti pengguna yang menggunakan llama.cpp-vulkan pada GPU AMD sekarang dapat memanfaatkan teknologi FlashAttention. Dikombinasikan dengan kuantisasi cache Q8 KV, pengguna diharapkan dapat menggandakan ukuran konteks sambil mempertahankan atau meningkatkan kecepatan inferensi. Pembaruan ini merupakan keuntungan penting bagi pengguna GPU AMD dalam menjalankan Large Language Model secara lokal (Sumber: Reddit r/LocalLLaMA)
Devseeker: Asisten koding AI ringan, alternatif untuk Aider dan Claude Code: Devseeker adalah proyek agen koding AI open source ringan baru, diposisikan sebagai alternatif untuk Aider dan Claude Code. Ia memiliki kemampuan untuk membuat dan mengedit kode, mengelola file dan folder kode, memori kode jangka pendek, tinjauan kode, menjalankan file kode, menghitung penggunaan token, serta menyediakan berbagai mode koding. Proyek ini bertujuan untuk menyediakan alat bantu pemrograman AI yang lebih mudah untuk diimplementasikan dan digunakan secara lokal (Sumber: Reddit r/ClaudeAI)
📚 Pembelajaran
Panaversity meluncurkan proyek pembelajaran Agentic AI, berfokus pada Dapr & OpenAI Agents SDK: Panaversity memprakarsai proyek “Learn Agentic AI”, yang bertujuan untuk membina insinyur AI agen dan robotika melalui pola desain Dapr Agentic Cloud Ascent (DACA) dan berbagai teknologi cloud native agen cerdas (termasuk OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes). Inti proyek ini adalah bagaimana merancang sistem yang dapat menangani puluhan juta agen AI konkuren, dan menyediakan seri kursus AI-201, AI-202, AI-301, yang mencakup jalur pembelajaran dari dasar hingga agen AI terdistribusi skala besar. Proyek ini menekankan bahwa OpenAI Agents SDK, karena kemudahan penggunaan dan kontrolnya yang tinggi, harus menjadi kerangka kerja pengembangan utama (Sumber: GitHub Trending)

Penelitian fine-tuning RL mengungkap hubungan kompleks antara manajemen data dan kemampuan generalisasi: Makalah yang dibagikan oleh Minqi Jiang membahas dampak manajemen data dalam fine-tuning reinforcement learning (RL) terhadap kemampuan generalisasi model. Penelitian menemukan bahwa baik melalui pembelajaran kurikulum self-play pada tugas pengkodean “tak terbatas” (Absolute Zero Reasoner), maupun hanya pelatihan berulang pada sampel tugas MATH tunggal (1-shot RLVR), model seri Qwen2.5 skala 7B dapat mencapai peningkatan akurasi sekitar 28% hingga 40% pada tolok ukur matematika. Ini mengungkap sebuah paradoks: strategi manajemen data yang ekstrem (data tak terbatas vs. data titik tunggal) ternyata dapat menghasilkan peningkatan generalisasi yang serupa. Penjelasan yang mungkin termasuk RL terutama memunculkan kemampuan yang sudah ada pada model pra-pelatihan, adanya “sirkuit penalaran” bersama, dan pra-pelatihan mungkin menyebabkan sirkuit penalaran yang kompetitif, dll. Peneliti berpendapat bahwa untuk menembus “langit-langit pra-pelatihan”, diperlukan pengumpulan dan penciptaan tugas dan lingkungan baru secara berkelanjutan (Sumber: menhguin)
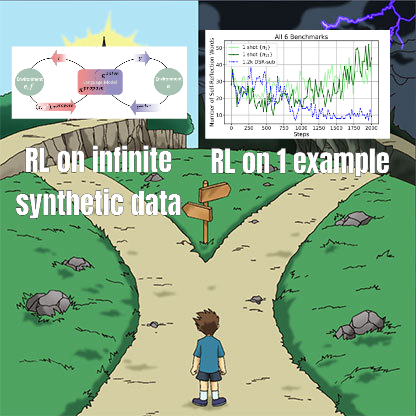
Absolute Zero Reasoner: Mencapai peningkatan kemampuan penalaran tanpa data melalui self-play: Sebuah makalah berjudul “Absolute Zero Reasoner” mengusulkan bahwa model dapat mempelajari untuk mengajukan tugas yang memaksimalkan kemampuan belajar melalui self-play sepenuhnya, dan meningkatkan kemampuan penalarannya sendiri dengan menyelesaikan tugas-tugas ini, seluruh proses tanpa memerlukan data eksternal apa pun. Metode ini mengungguli model “zero-shot” lainnya baik di bidang matematika maupun pengkodean. Ini menunjukkan bahwa sistem AI mungkin dapat terus mengembangkan kemampuan penalarannya melalui generasi dan penyelesaian masalah internal, memberikan ide baru untuk aplikasi AI di bidang dengan data yang langka atau biaya anotasi yang mahal (Sumber: cognitivecompai, Reddit r/LocalLLaMA)

Kesalahan umum dan praktik terbaik dalam evaluasi produk AI dibagikan: Hamel Husain dan Shreya Runwal membagikan kesalahan umum yang sering terjadi saat membuat evaluasi produk AI (evals), dan memberikan saran untuk menghindarinya. Poin-poin penting meliputi: tolok ukur model dasar tidak sama dengan evaluasi aplikasi; evaluasi umum tidak efektif, perlu disesuaikan dengan aplikasi spesifik; jangan melakukan outsourcing anotasi dan rekayasa prompt kepada non-ahli domain; sebaiknya membangun aplikasi anotasi data sendiri; prompt LLM harus spesifik dan berdasarkan analisis kesalahan; gunakan label biner; pentingkan tinjauan data; waspadai overfitting terhadap data uji; lakukan pengujian online. Praktik-praktik ini bertujuan untuk membantu pengembang membangun sistem evaluasi produk AI yang lebih andal dan lebih mencerminkan kinerja di dunia nyata (Sumber: jeremyphoward, HamelHusain)
Ide baru optimasi KV cache: Kamus universal yang dapat ditransfer dan rekonstruksi pemrosesan sinyal: Tim Dimitris Papailiopoulos dari University of Wisconsin-Madison mengusulkan metode baru untuk mengurangi KV cache, yaitu dengan menggunakan kamus universal yang dapat ditransfer dikombinasikan dengan algoritma rekonstruksi pemrosesan sinyal tradisional. Metode ini telah mencapai level SOTA (state-of-the-art) pada model non-inferensi, dan diharapkan dapat berkinerja lebih baik pada model inferensi. Penelitian ini telah diterima di ICML, memberikan perspektif dan jalur teknis baru untuk mengatasi masalah penggunaan KV cache yang berlebihan dalam inferensi model besar (Sumber: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

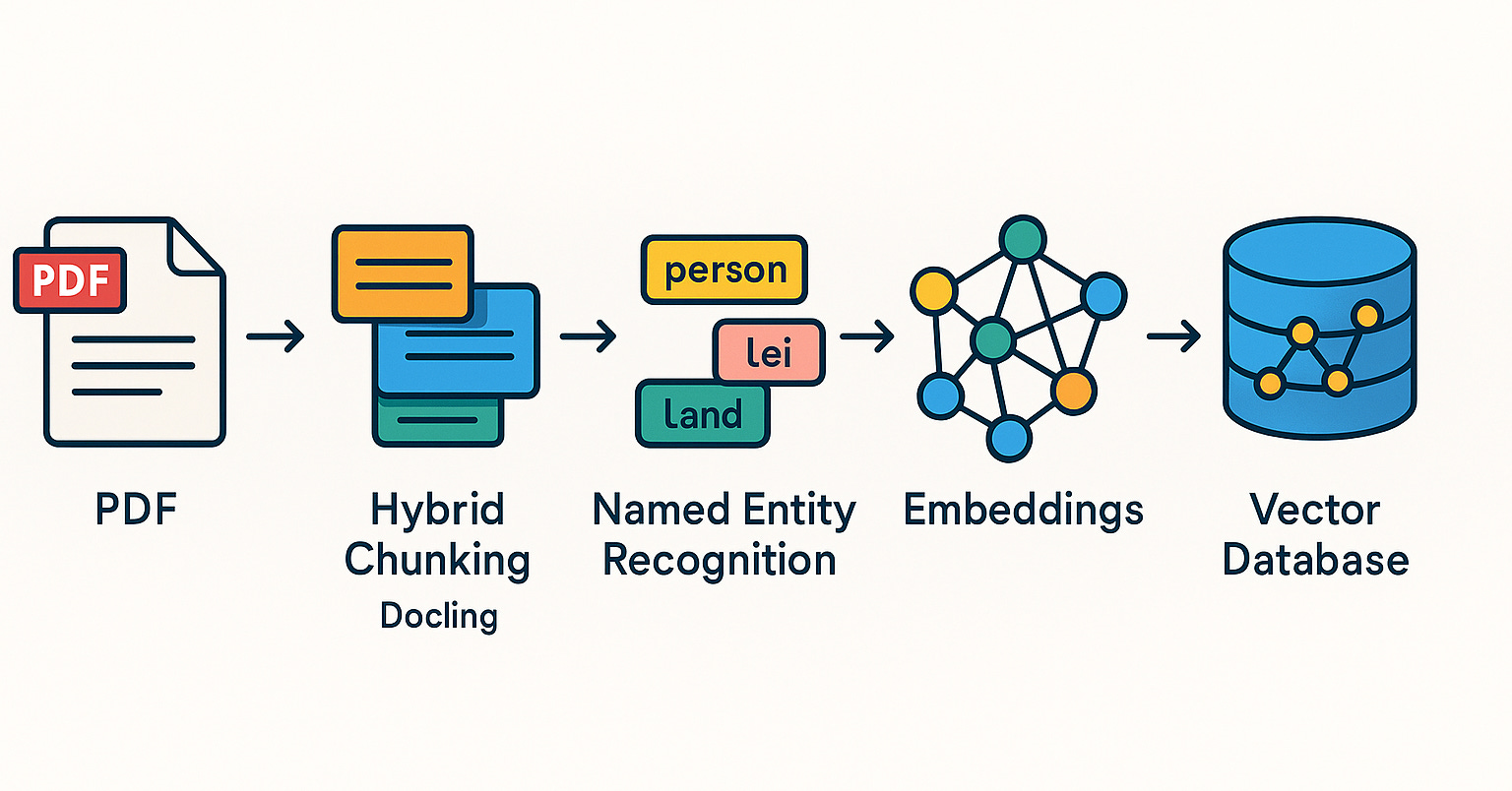
Qdrant mempromosikan sistem RAG dan praktik pencarian hibrida di komunitas Brasil: Basis data vektor Qdrant semakin mendapat perhatian di komunitas Brasil. Pengembang Daniel Romero membagikan dua artikel berbahasa Portugis yang memperkenalkan metode praktis membangun sistem RAG (Retrieval Augmented Generation) menggunakan Qdrant, FastAPI, dan pencarian hibrida. Kontennya mencakup cara membangun sistem RAG pencarian hibrida, serta strategi penyerapan data untuk RAG, khususnya teknik Hybrid Chunking. Berbagi ini membantu pengembang Brasil untuk lebih baik memanfaatkan Qdrant dalam pengembangan aplikasi AI (Sumber: qdrant_engine)
OpenAI Academy meluncurkan seri topik rekayasa prompt untuk pendidikan K-12: OpenAI Academy merilis seri pembelajaran rekayasa prompt (Prompt Engineering) “Mastering Your Prompts” yang ditujukan untuk pendidik K-12. Seri ini bertujuan untuk membantu pendidik lebih memahami dan menerapkan teknik prompt, agar dapat lebih efektif mengintegrasikan alat AI (seperti ChatGPT) ke dalam praktik pengajaran, meningkatkan efektivitas pengajaran dan pengalaman belajar siswa. Ini menunjukkan bahwa pendidikan yang dibantu AI secara bertahap merambah ke tahap pendidikan dasar, dan menekankan pentingnya menumbuhkan literasi AI para pendidik (Sumber: dotey)
Yann LeCun membagikan konten pidatonya di National University of Singapore: Yann LeCun membagikan dokumen PDF dari Distinguished Lecture yang disampaikannya pada tanggal 27 April 2025 di National University of Singapore (NUS). Meskipun tema spesifik pidato tidak disebutkan, LeCun sebagai pelopor di bidang deep learning, pidatonya biasanya melibatkan teori mutakhir kecerdasan buatan, tren masa depan, atau wawasan mendalam tentang perkembangan AI saat ini. Berbagi ini memberikan akses langsung bagi mereka yang tertarik pada penelitian AI untuk mendapatkan pandangan terbarunya (Sumber: ylecun)
PyTorch berkolaborasi dengan backend Mojo, menyederhanakan adaptasi perangkat keras dan bahasa baru: PyTorch berupaya menyederhanakan proses pembuatan backend baru untuk bahasa pemrograman dan perangkat keras yang sedang berkembang. Di Mojo Hackathon, marksaroufim menunjukkan upaya PyTorch dalam hal ini, dan menyebutkan backend WIP (sedang dalam pengerjaan) yang dikembangkan bekerja sama dengan tim Mojo. Ini menunjukkan bahwa ekosistem PyTorch secara aktif memperluas kompatibilitasnya untuk mendukung lingkungan pengembangan AI dan opsi akselerasi perangkat keras yang lebih beragam, sehingga menurunkan hambatan bagi pengembang dalam menerapkan dan mengoptimalkan model PyTorch di berbagai platform (Sumber: marksaroufim)
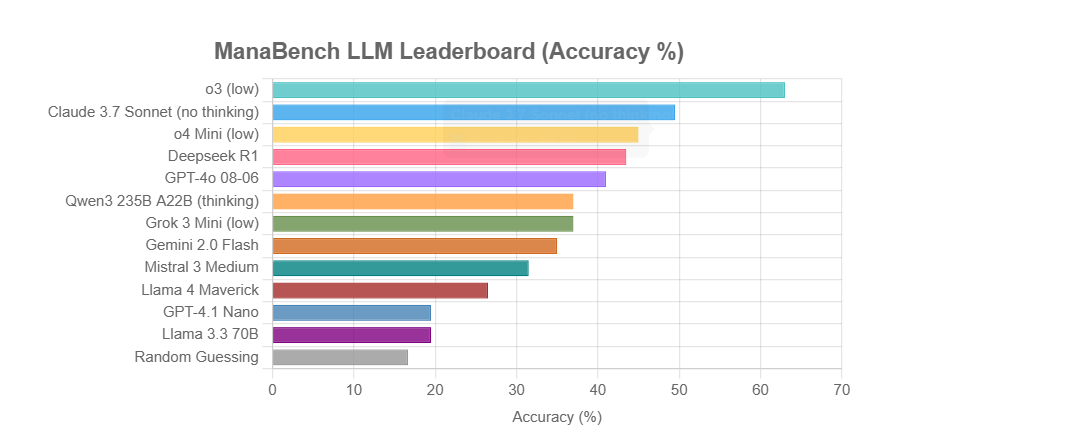
ManaBench: Tolok ukur kemampuan penalaran LLM baru berbasis penyusunan dek Magic: The Gathering: Seorang pengembang menciptakan tolok ukur baru bernama ManaBench, yang menguji kemampuan penalaran sistem kompleks LLM dengan meminta LLM memilih kartu ke-60 yang paling sesuai dari enam opsi, setelah diberikan 59 kartu Magic: The Gathering (MTG). Tolok ukur ini menekankan penalaran strategis, optimasi sistem, dan jawabannya dirancang konsisten dengan pakar manusia, sehingga sulit dipecahkan melalui ingatan sederhana. Hasil awal menunjukkan bahwa model seri Llama berkinerja di bawah ekspektasi, sementara model sumber tertutup seperti o3 dan Claude 3.7 Sonnet memimpin. Tolok ukur ini bertujuan untuk mengevaluasi kinerja LLM secara lebih realistis pada tugas-tugas yang membutuhkan penalaran kompleks (Sumber: Reddit r/LocalLLaMA)
Diskusi: Akankah AI menghidupkan kembali atau mengubur impian Semantic Web?: Di media sosial, pengguna Spencer menyebutkan bahwa kecuali situs web perusahaan besar memiliki risiko signifikan karena undang-undang ADA (Americans with Disabilities Act), Semantic Web di sebagian besar situs web lebih merupakan teori daripada praktik. Dorialexander menanggapi bahwa rasanya AI akan menghidupkan kembali impian Semantic Web, atau akan menguburnya selamanya. Ini mencerminkan harapan dan kekhawatiran terhadap potensi AI dalam pemahaman dan pemanfaatan data terstruktur. AI mungkin secara tidak langsung mencapai tujuan Semantic Web melalui pemahaman dan generasi informasi terstruktur secara otomatis, tetapi juga mungkin karena kemampuannya sendiri yang kuat membuat teknologi Semantic Web tradisional menjadi kurang penting (Sumber: Dorialexander)
Peneliti membahas etika dan arsitektur memori dan pelupaan model: Draf makalah berjudul “Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting” sedang ditulis, membahas bagaimana kita memutuskan apa yang harus dilupakan oleh model ketika mereka mulai “mengingat terlalu baik”, menggabungkan arsitektur neural dengan etika memori. Ini melibatkan bagaimana sistem AI menyimpan, mengambil, dan (secara selektif) melupakan informasi, serta tantangan etis dan dampak sosial yang ditimbulkannya, yang sangat penting untuk membangun AI yang bertanggung jawab dan dapat dipercaya (Sumber: Reddit r/artificial)
💼 Bisnis
Nvidia dikabarkan akan meluncurkan chip H20 versi “yang dikebiri lagi” yang memenuhi persyaratan kontrol ekspor baru AS: Menurut Reuters, Nvidia berencana meluncurkan chip AI H20 versi khusus Tiongkok yang baru dalam dua bulan ke depan untuk mematuhi persyaratan kontrol ekspor terbaru AS. Chip ini akan “dikebiri” lebih lanjut dari H20 asli (yang sudah merupakan versi downgrade yang disesuaikan untuk pasar Tiongkok), misalnya kapasitas memori akan berkurang secara signifikan. Meskipun kinerjanya kembali menurun, dilaporkan bahwa pengguna hilir mungkin dapat menyesuaikan kinerja sampai batas tertentu dengan memodifikasi konfigurasi modul. Saat ini, Nvidia telah menerima pesanan H20 senilai $18 miliar (Sumber: WeChat)

Databricks kemungkinan mengakuisisi perusahaan database open source Neon senilai $1 miliar, memperkuat infrastruktur AI: Perusahaan data dan AI Databricks dikabarkan sedang dalam negosiasi untuk mengakuisisi Neon, pengembang mesin database PostgreSQL open source, dengan nilai transaksi sekitar $1 miliar. Neon dikenal dengan arsitektur tanpa server, pemisahan penyimpanan dan komputasi, serta adaptabilitasnya yang baik terhadap AI Agent dan pemrograman ambien. Neon memungkinkan penggunaan bayar sesuai pemakaian dan dapat dengan cepat memulai instance database, cocok untuk skenario aplikasi AI. Jika berhasil, akuisisi ini akan semakin memperkuat kemampuan lapisan infrastruktur Databricks di era AI, memberikannya solusi database modern yang berpusat pada AI (Sumber: WeChat)

OpenAI menunjuk mantan CEO Instacart Fidji Simo sebagai CEO Bisnis Aplikasi, memperkuat produk dan komersialisasi: OpenAI mengumumkan penunjukan mantan CEO Instacart dan anggota dewan direksi perusahaan, Fidji Simo, sebagai “Chief Executive Officer Bisnis Aplikasi” yang baru dibentuk, setara dengan Sam Altman. Simo akan bertanggung jawab penuh atas produk OpenAI, terutama aplikasi yang menghadap pengguna seperti ChatGPT, dengan tujuan mendorong optimalisasi produk, peningkatan pengalaman pengguna, dan proses komersialisasi. Langkah ini menandai pergeseran strategis signifikan OpenAI dari penelitian dan pengembangan model ke platformisasi produk dan ekspansi pasar, dengan maksud untuk membangun daya saing yang lebih kuat di lapisan aplikasi AI. Pengalaman Fidji Simo yang kaya dalam produk dan komersialisasi di Facebook dan Instacart akan membantu OpenAI menghadapi persaingan pasar yang semakin ketat (Sumber: WeChat)

🌟 Komunitas
JetBrains AI Assistant menuai ketidakpuasan pengguna karena pengalaman buruk dan manajemen ulasan: Plugin JetBrains AI Assistant, meskipun telah diunduh lebih dari 22 juta kali, hanya mendapat skor 2,3 dari 5 di pasarnya, dipenuhi dengan banyak ulasan bintang 1. Pengguna umumnya mengeluhkan instalasi otomatis, kinerja lambat, banyak bug, dukungan model pihak ketiga yang tidak memadai, fitur inti yang terikat dengan layanan cloud, dan dokumentasi yang kurang. Baru-baru ini, JetBrains dituduh menghapus ulasan negatif secara massal. Meskipun pihak resmi menjelaskan bahwa ini adalah tindakan untuk menangani konten yang melanggar aturan atau masalah yang telah diselesaikan, hal ini tetap menimbulkan keraguan pengguna terhadap praktik moderasi dan kurangnya perhatian terhadap umpan balik pengguna. Beberapa pengguna memilih untuk memposting ulang ulasan negatif dan terus memberikan bintang 1. Insiden ini memperburuk ketidakpuasan pengguna terhadap strategi produk AI JetBrains (Sumber: WeChat)

Pengguna ramai membahas masalah kualitas output agen cerdas pemasaran AI: Pengguna media sosial omarsar0 mengamati bahwa banyak agen cerdas pemasaran AI yang ditampilkan dalam tutorial YouTube menghasilkan naskah pemasaran dengan kualitas yang umumnya buruk, kurang kreativitas dan gaya. Menurutnya, ini mencerminkan kesulitan dalam membuat LLM menghasilkan konten berkualitas tinggi dan menarik, serta menekankan pentingnya “selera” dalam membangun agen cerdas AI. Ia menunjukkan bahwa banyak agen cerdas AI saat ini, meskipun memiliki alur kerja yang kompleks, masih kurang dalam menghasilkan konten yang benar-benar bernilai komersial. Hal ini membuka peluang bagi talenta yang memiliki selera tinggi, berpengalaman, dan mampu merancang sistem evaluasi yang baik (Sumber: omarsar0)
Koding berbantuan AI dan tren “pemrograman ambien” memicu diskusi: Sebuah video di Reddit tentang diskusi Y Combinator mengenai koding AI memicu perdebatan hangat. Pandangan dalam video tersebut sangat selaras dengan pengalaman pembuat postingan (yang mengaku telah menciptakan beberapa proyek yang menguntungkan melalui “pemrograman ambien”). Poin-poin inti meliputi: 1. AI telah mampu membantu membangun produk perangkat lunak yang kompleks dan dapat digunakan, bahkan tanpa perlu menulis kode. 2. Kekhawatiran insinyur perangkat lunak tentang AI menggantikan pekerjaan mereka semakin meningkat, tetapi mereka yang benar-benar menguasai pengembangan berbantuan AI memiliki “kekuatan super”. 3. Peran insinyur perangkat lunak di masa depan mungkin berubah menjadi “manajer agen” yang mahir menggunakan alat AI, di mana AI akan bertanggung jawab atas sebagian besar penulisan kode. 4. AI akan melahirkan banyak perangkat lunak khusus untuk pasar niche. Para peserta diskusi berpendapat bahwa meskipun potensi koding AI sangat besar, pengetahuan tentang konsep rekayasa, basis data, arsitektur, dll., masih diperlukan untuk memanfaatkannya secara efektif (Sumber: Reddit r/ClaudeAI)

Diskusi tentang apakah AI akan “mengambil alih dunia” dan dampaknya terhadap pekerjaan terus berlanjut: Postingan di forum Reddit r/ArtificialInteligence mencerminkan kecemasan umum dan beragam pandangan komunitas tentang dampak AI di masa depan. Beberapa pengguna percaya bahwa semakin dalam pemahaman tentang kemampuan AI, semakin besar kekhawatiran tentang AI melampaui manusia dan mendominasi masa depan, dan menunjukkan bahwa sistem AI mutakhir telah menunjukkan kemampuan yang menakjubkan. Pengguna lain berpendapat bahwa penggambaran AGI yang berlebihan telah menyebabkan ekspektasi yang tidak realistis; AI pada dasarnya adalah alat otomatisasi cerdas, dan dampaknya akan bersifat bertahap, mirip dengan komputer dan internet. Diskusi juga menyentuh potensi dampak AI terhadap pekerjaan, distribusi kekayaan, dan efektivitas regulasi. Ada pandangan bahwa sejarah menunjukkan kemajuan teknologi sering memperburuk kesenjangan kaya-miskin, dan AI dapat lebih lanjut memusatkan kekayaan dengan menghilangkan banyak pekerjaan. Pada saat yang sama, ada juga yang menyatakan harapan terhadap peran positif AI di bidang-bidang seperti perawatan kesehatan dan pendidikan (Sumber: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Pengalaman pengguna: Bagaimana alat AI seperti ChatGPT memengaruhi pemikiran dan kognisi: Beberapa pengguna di platform media sosial dan Reddit berbagi dampak positif penggunaan alat AI seperti ChatGPT pada tingkat kognitif. Mereka merasa AI bukan hanya alat untuk mendapatkan informasi atau bantuan menulis, tetapi lebih seperti “mitra berpikir” atau “cermin” yang dapat membantu mereka menjernihkan pikiran dan mengungkapkan ide-ide bawah sadar secara jelas. Melalui percakapan dengan AI, pengguna menyatakan dapat lebih baik merefleksikan diri, menantang keyakinan mereka sendiri, menemukan pola pikir, bahkan merasa seperti sedang “terbangun”, memiliki pemahaman yang lebih mendalam tentang kehidupan dan sistem. Pengalaman ini menunjukkan bahwa AI dalam beberapa kasus dapat menjadi katalis untuk pertumbuhan pribadi dan eksplorasi diri (Sumber: Reddit r/ChatGPT)
💡 Lainnya
Kompetisi Aplikasi Inovasi Kecerdasan Buatan Nasional “Xingzhi Cup” Kedua Diluncurkan: “Xingzhi Cup” kedua, yang diselenggarakan bersama oleh China Academy of Information and Communications Technology (CAICT) dan unit lainnya, telah dibuka. Dengan tema “Memberdayakan dengan Kecerdasan, Memimpin dengan Inovasi”, kompetisi ini memiliki tiga jalur utama: inovasi model besar, pemberdayaan industri, dan ekosistem inovasi perangkat lunak dan perangkat keras, serta beberapa arah khusus. Acara ini bertujuan untuk mendorong inovasi teknologi AI, implementasi rekayasa, dan pembangunan ekosistem mandiri, mencakup hampir 10 industri utama seperti industri, medis, dan keuangan, serta menekankan penerapan perangkat lunak dan perangkat keras AI domestik. Proyek pemenang akan menerima dukungan dana,对接 industri, dll. (Sumber: WeChat)

Berbagi dari Sequoia Capital AI Ascent: Potensi pasar AI sangat besar, lapisan aplikasi dan ekonomi agen adalah masa depan: Mitra Sequoia Capital Pat Grady dan lainnya berbagi wawasan tentang pasar AI dalam acara AI Ascent. Mereka percaya bahwa potensi pasar AI jauh melampaui komputasi awan, tetapi perlu waspada terhadap “pendapatan ambien” (pengguna hanya mencoba karena penasaran, bukan kebutuhan nyata). Lapisan aplikasi dianggap sebagai tempat nilai sebenarnya berada, dan perusahaan rintisan harus fokus pada domain vertikal dan kebutuhan pelanggan. AI telah mencapai terobosan di bidang generasi suara dan pemrograman. Prospek masa depan adalah “ekonomi agen”, di mana agen AI akan dapat mentransfer sumber daya dan melakukan transaksi, tetapi menghadapi tantangan seperti identitas persisten, protokol komunikasi, dan keamanan. Pada saat yang sama, AI akan sangat memperbesar kemampuan individu, melahirkan “individu super” (Sumber: WeChat)

Diskusi: Konten dan kualitas pengajaran mata kuliah machine learning di universitas era AI menarik perhatian: Berbagi silabus mata kuliah ML pascasarjana oleh Profesor NYU Kyunghyun Cho memicu diskusi. Mata kuliah tersebut menekankan masalah non-LLM yang dapat diselesaikan oleh SGD dan pembacaan makalah klasik, mendapatkan pengakuan dari rekan sejawat seperti profesor CS Harvard, yang menganggap penting untuk mempertahankan konsep dasar. Namun, mahasiswa dari India dan Amerika Serikat mengeluhkan rendahnya kualitas mata kuliah ML di universitas mereka, terlalu abstrak, dipenuhi istilah tanpa penjelasan mendalam, menyebabkan mahasiswa bergantung pada belajar mandiri dan sumber daya online. Ini mencerminkan kontradiksi antara perkembangan pesat bidang AI/ML dan keterlambatan pembaruan kurikulum perguruan tinggi, serta pentingnya membangun dasar matematika dan teori yang kuat (Sumber: WeChat)
