
Kata Kunci:Keamanan AI, Etika Kecerdasan Buatan, Agen AI, Generasi 3D, Model Kode, Penilaian Risiko AI, Pemahaman Video Gemini 2.5 Pro, Generasi 3D AssetGen 2.0, Model Kode Seed-Coder, Operasional Agen AgentOps
🔥 Fokus
Risiko Keamanan AI Menarik Perhatian, Pakar Menyerukan Penggunaan Pengalaman Keamanan Nuklir untuk Penilaian Risiko: Kekhawatiran komunitas internasional terhadap potensi risiko kecerdasan buatan (AI) semakin meningkat. Beberapa pakar (seperti Max Tegmark) menyerukan agar perusahaan AI, sebelum merilis sistem AI yang berbahaya, meniru metode perhitungan keamanan yang digunakan Robert Oppenheimer saat uji coba nuklir pertama untuk melakukan evaluasi ketat terhadap probabilitas AI kehilangan kendali (konstanta Compton). Langkah ini bertujuan untuk membentuk konsensus industri, mendorong pembentukan mekanisme keamanan AI global, dan mencegah konsekuensi bencana yang mungkin ditimbulkan oleh superinteligensi. (Sumber: Reddit r/artificial, Reddit r/ArtificialInteligence)

Paus Fransiskus yang baru (nama samaran Leo XIV) Sangat Memperhatikan Perubahan Sosial yang Disebabkan oleh AI: Paus Fransiskus yang baru terpilih (dilaporkan sebagai Leo XIV) telah mengidentifikasi kecerdasan buatan sebagai salah satu tantangan utama yang dihadapi umat manusia. Ia memilih “Leo” sebagai namanya, sebagian karena masalah sosial baru dan revolusi industri yang didorong oleh AI, yang menggemakan respons Paus Leo XIII terhadap Revolusi Industri Pertama. Paus menekankan bahwa AI merupakan tantangan bagi pemeliharaan “martabat manusia, keadilan, dan pekerjaan,” dan berencana untuk merilis dokumen penting tentang etika AI di masa depan, menunjukkan kepedulian mendalam para pemimpin agama terhadap etika teknologi AI dan dampak sosialnya. (Sumber: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

Google Merilis White Paper AI Agent Setebal 76 Halaman, Menjelaskan AgentOps dan Aplikasi Masa Depan: Google merilis white paper AI agent setebal 76 halaman yang menjelaskan secara rinci tentang pembuatan, evaluasi, dan aplikasi agent. White paper ini menekankan pentingnya operasional agent (AgentOps) sebagai cabang dari operasional AI generatif. AgentOps berfokus pada manajemen alat, pengaturan prompt inti, fungsi memori, dan dekomposisi tugas yang diperlukan untuk operasi agent yang efisien. White paper ini juga membahas arsitektur kolaborasi multi-agent, di mana agent yang berbeda memainkan peran seperti perencanaan, pengambilan, pelaksanaan, dan evaluasi untuk menyelesaikan tugas-tugas kompleks secara bersama-sama. Selain itu, white paper ini memproyeksikan prospek aplikasi agent dalam membantu karyawan perusahaan dan mengotomatiskan tugas-tugas backend, seperti NotebookLM versi perusahaan dan Agentspace. (Sumber: WeChat)

Meta Meluncurkan AssetGen 2.0: Teks/Gambar Menghasilkan Materi 3D Berkualitas Tinggi: Meta merilis model AI dasar 3D terbarunya, AssetGen 2.0, yang mampu membuat aset 3D berkualitas tinggi berdasarkan prompt teks dan gambar. AssetGen 2.0 mencakup dua sub-model: satu untuk menghasilkan mesh 3D, menggunakan model difusi 3D satu tahap untuk meningkatkan detail dan fidelitas; model TextureGen lainnya untuk menghasilkan tekstur, dan memperkenalkan metode untuk meningkatkan konsistensi tampilan, perbaikan tekstur, dan resolusi tekstur yang lebih tinggi. Teknologi ini saat ini digunakan secara internal di Meta untuk membuat dunia 3D dan direncanakan akan diluncurkan ke kreator Horizon akhir tahun ini. (Sumber: Reddit r/artificial)

🎯 Tren
ByteDance Seed Merilis Model Kode 8B Seed-Coder secara Open Source, Mengadopsi Paradigma Baru Manajemen Data oleh Model: Tim Seed dari ByteDance untuk pertama kalinya merilis model kode berskala 8B miliknya, Seed-Coder, secara open source. Model ini mencakup tiga versi: Base, Instruct, dan Reasoning. Model ini menunjukkan kinerja yang sangat baik dalam berbagai benchmark pembuatan kode, terutama melampaui model seperti Qwen3 pada HumanEval dan MBPP. Inovasi inti dari Seed-Coder terletak pada pengajuan metode pemrosesan data yang “berpusat pada model”, memanfaatkan LLM itu sendiri untuk menghasilkan dan menyaring data pelatihan kode berkualitas tinggi, termasuk kode tingkat file, kode tingkat repositori, data Commit, dan data jaringan terkait kode, dengan total volume data pelatihan mencapai 6T token. Langkah ini bertujuan untuk mengurangi keterlibatan manual dan meningkatkan kemampuan model kode. (Sumber: WeChat)
Gemini 2.5 Pro Mencapai Terobosan dalam Pemahaman Video, Mewujudkan Integrasi Asli Audio-Video dan Kode: Model terbaru Google, Gemini 2.5 Pro dan Flash, telah mencapai kemajuan signifikan dalam kemampuan pemahaman video. Gemini 2.5 Pro mencapai level SOTA dalam beberapa benchmark pemahaman video utama, bahkan melampaui GPT 4.1. Seri model Gemini 2.5 untuk pertama kalinya mewujudkan integrasi asli dan mulus antara informasi audio-video dengan format data lain seperti kode. Model ini mampu mengubah video secara langsung menjadi aplikasi interaktif (seperti aplikasi pembelajaran), menghasilkan animasi p5.js berdasarkan video, serta mengambil dan mendeskripsikan klip video secara akurat, menunjukkan kemampuan penalaran temporal yang kuat. Fungsi-fungsi ini telah tersedia di Google AI Studio, Gemini API, dan Vertex AI. (Sumber: WeChat)

ModelScope Merilis Model Gambar Terpadu Nexus-Gen secara Open Source, Menyaingi Kemampuan Gambar GPT-4o: Tim ModelScope meluncurkan Nexus-Gen, sebuah model multimodal terpadu yang mampu menangani pemahaman, pembuatan, dan penyuntingan gambar secara bersamaan, yang bertujuan untuk menyaingi kemampuan pemrosesan gambar GPT-4o. Model ini mengadopsi jalur teknis token → transformer → diffusion → pixels, menggabungkan pemodelan teks MLLM dengan kemampuan rendering gambar model Diffusion. Untuk mengatasi masalah akumulasi kesalahan saat prediksi autoregresif embedding gambar kontinu, tim mengusulkan strategi autoregresif pra-pengisian. Nexus-Gen dilatih pada sekitar 25 juta data gambar-teks, termasuk dataset penyuntingan ImagePulse yang baru-baru ini dirilis secara open source oleh komunitas ModelScope. (Sumber: WeChat)

Cursor Versi 0.50 Dirilis, Menyederhanakan Harga dan Meningkatkan Berbagai Fitur Penyuntingan Kode: Editor kode AI Cursor merilis versi 0.50, membawa pembaruan besar. Model penetapan harga disederhanakan menjadi model berbasis permintaan, mode Max mendukung semua model AI teratas dan mengadopsi penetapan harga berbasis token. Peningkatan fungsionalitas meliputi: model Tab baru mendukung saran lintas file dan refactoring kode; agen latar belakang (versi pratinjau) mendukung menjalankan beberapa agen secara paralel dan melakukan tugas di lingkungan jarak jauh; konteks basis kode memungkinkan penambahan seluruh basis kode melalui @folders; UI penyuntingan inline dioptimalkan, menambahkan fungsi penyuntingan seluruh file dan pengiriman ke agen; penyuntingan file panjang memperkenalkan alat pencarian dan penggantian; mendukung ruang kerja multi-root untuk menangani beberapa basis kode; fungsionalitas obrolan ditingkatkan, mendukung ekspor ke Markdown dan penyalinan. (Sumber: op7418)
llama.cpp Menambahkan Dukungan Visual Language Model (VLM), Dapat Membangun Alur Vision RAG Lengkap: Proyek open source llama.cpp mengumumkan telah mendukung visual language model (VLM), pengguna sekarang dapat menggunakan fungsi visual melalui server llama.cpp dan Web UI. Pembaruan ini berarti bahwa model dasar yang sama yang mendukung multi-LoRA serta model embedding dapat dimuat di llama.cpp, sehingga memungkinkan pembangunan alur vision retrieval augmented generation (Vision RAG) yang lengkap. Langkah ini semakin memperluas kemampuan llama.cpp dalam menjalankan model bahasa besar secara lokal, memungkinkannya untuk menangani tugas-tugas multimodal. (Sumber: mervenoyann, mervenoyann)
Tencent Merilis HunyuanCustom: Arsitektur Pembuatan Video yang Disesuaikan Berbasis HunyuanVideo: Tencent merilis HunyuanCustom di Hugging Face, sebuah arsitektur yang digerakkan oleh multimodalitas yang dirancang khusus untuk pembuatan video yang disesuaikan. Karya ini dibangun di atas HunyuanVideo, dengan penekanan khusus pada menjaga konsistensi subjek saat menghasilkan video, sekaligus mendukung input dari berbagai kondisi seperti gambar, audio, video, dan teks, memberikan pengguna kemampuan pembuatan video yang lebih fleksibel dan personal. (Sumber: _akhaliq)
Qwen Chat Menambahkan Mode “Pengembangan Web”, Satu Kalimat Menghasilkan Aplikasi Web React: Alibaba Qwen Chat meluncurkan mode “Pengembangan Web” (Web Dev), pengguna hanya perlu satu kalimat perintah untuk menghasilkan aplikasi web yang berisi HTML, CSS, dan JavaScript, dengan menggunakan kerangka kerja React dan Tailwind CSS di backend. Fungsi ini dapat dengan cepat membuat situs web pribadi, meniru antarmuka web yang ada (seperti Twitter, GitHub) atau membangun formulir dan animasi tertentu berdasarkan deskripsi. Pengguna dapat memilih model Qwen yang berbeda dan menggabungkannya dengan mode “pemikiran mendalam” untuk meningkatkan kualitas halaman web. Fungsi ini bertujuan untuk menyederhanakan proses pengembangan frontend dan membangun prototipe aplikasi dengan cepat. (Sumber: WeChat)
Unitree Robotics Menanggapi Kerentanan Keamanan Anjing Robot Go1, Menekankan Produk Berikutnya Telah Ditingkatkan: Unitree Robotics menanggapi rumor tentang adanya “kerentanan backdoor” pada seri anjing robot Go1 miliknya yang telah dihentikan produksinya sekitar dua tahun lalu, dan mengakui masalah tersebut sebagai kerentanan keamanan. Penyerang dapat memanfaatkan kunci manajemen layanan cloud tunnel pihak ketiga untuk mengubah data perangkat pengguna, mendapatkan rekaman kamera, dan hak akses sistem. Unitree Robotics menyatakan bahwa seri robot berikutnya menggunakan versi yang ditingkatkan dan lebih aman, sehingga tidak terpengaruh oleh kerentanan ini. Insiden ini menimbulkan kekhawatiran tentang keamanan rantai pasokan robot cerdas dan privasi data, terutama dalam konteks tahun komersialisasi robot humanoid, di mana industri menghadapi berbagai tantangan seperti terobosan teknis, pengendalian biaya, dan eksplorasi jalur komersialisasi. (Sumber: 36氪)

Claude Code Kini Mendukung Referensi File .MD Lain, Mengoptimalkan Organisasi Instruksi: Claude Code dari Anthropic memperbarui fungsinya, versi 0.2.107 memungkinkan file CLAUDE.md untuk mengimpor file Markdown lainnya. Pengguna dapat menambahkan [u/path/to/file].md dalam file CLAUDE.md utama untuk memuat konten file tambahan saat startup. Peningkatan ini memungkinkan pengguna untuk mengatur dan mengelola instruksi Claude dengan lebih baik, meningkatkan keandalan dan modularitas konfigurasi instruksi dalam proyek besar, dan mengatasi masalah kebingungan yang mungkin timbul dari ketergantungan pada file yang tersebar sebelumnya. (Sumber: Reddit r/ClaudeAI)

Kantor Hak Cipta AS Mengambil Sikap Lebih Keras terhadap Pra-pelatihan AI, Melemahkan Pembelaan “Penggunaan Wajar”: Laporan terbaru yang dirilis oleh Kantor Hak Cipta AS mengambil sikap yang lebih keras terhadap masalah penggunaan materi berhak cipta dalam tahap pra-pelatihan model AI. Laporan tersebut menunjukkan bahwa karena laboratorium AI sekarang mengklaim model mereka mampu bersaing dengan pemegang hak (misalnya, menghasilkan konten yang mirip dengan karya asli), hal ini melemahkan kekuatan mereka untuk membela diri dengan alasan “penggunaan wajar” (fair use) dalam gugatan pelanggaran hak cipta. Perubahan ini dapat berdampak signifikan pada sumber data pelatihan model AI dan kepatuhannya. (Sumber: Dorialexander)

Nvidia Merilis Kartu Grafis Profesional RTX Pro 5000, Dilengkapi Memori GDDR7 48GB: Nvidia meluncurkan GPU desktop kelas profesional baru, RTX Pro 5000, berbasis arsitektur Blackwell. Kartu grafis ini dilengkapi dengan memori GDDR7 48GB, bandwidth memori hingga 1344 GB/s, dan konsumsi daya 300W. Meskipun secara resmi disebut sebagai kartu Blackwell 48GB yang “murah”, harganya diperkirakan masih tinggi (ada komentar yang menyebutkan level 4000 dolar AS), terutama ditujukan untuk pengguna workstation profesional, menyediakan dukungan komputasi yang kuat untuk tugas-tugas seperti pelatihan model AI dan rendering 3D skala besar. (Sumber: Reddit r/LocalLLaMA)

🧰 Alat
RunwayML Meluncurkan Fitur References, Dapat Mencampur Berbagai Materi Referensi untuk Menghasilkan Konten: Fitur baru RunwayML, “References”, memungkinkan pengguna untuk mencampur berbagai materi referensi (seperti gambar, gaya) sebagai “bahan baku” dan dapat menghasilkan konten visual baru berdasarkan kombinasi apa pun dari “bahan baku” tersebut. Fitur ini dianggap sebagai mesin kreasi yang hampir real-time, mampu membantu pengguna mewujudkan berbagai ide kreatif dengan cepat, dan secara signifikan memperluas fleksibilitas serta kemungkinan AI dalam pembuatan konten visual. (Sumber: c_valenzuelab)
Chat2DB: Klien AI untuk Mengoperasikan Database dengan Bahasa Alami: Chat2DB adalah alat klien database yang digerakkan oleh AI, memungkinkan pengguna untuk berinteraksi dengan database menggunakan bahasa alami. Misalnya, pengguna dapat bertanya “Siapa pelanggan dengan pengeluaran terbanyak bulan ini?”, Chat2DB dapat memahami pertanyaan menggunakan AI, dan secara otomatis menghasilkan kueri SQL yang sesuai berdasarkan struktur tabel database, lalu menjalankan kueri dan mengembalikan hasilnya. Ini sangat mengurangi hambatan teknis dalam pengoperasian database, memungkinkan personel non-teknis untuk melakukan kueri dan analisis data dengan mudah. Proyek ini telah tersedia secara open source di GitHub. (Sumber: karminski3)
Model Qwen 3 8B Menunjukkan Kemampuan Kode yang Luar Biasa, Dapat Menghasilkan Keyboard HTML: Model Qwen 3 8B (versi kuantisasi Q6_K), meskipun memiliki jumlah parameter yang relatif kecil, menunjukkan kinerja yang luar biasa dalam pembuatan kode. Pengguna, dengan dua prompt singkat, berhasil membuat model tersebut menghasilkan kode keyboard HTML yang dapat dimainkan. Ini menunjukkan potensi model yang lebih kecil untuk mencapai utilitas praktis yang tinggi pada tugas-tugas tertentu, terutama menarik untuk skenario penerapan lokal dengan sumber daya terbatas. (Sumber: Reddit r/LocalLLaMA)
Ollama Chat: Alat Obrolan LLM Lokal dengan Antarmuka Mirip Claude: Ollama Chat adalah antarmuka obrolan web yang dirancang untuk model bahasa besar lokal, dengan gaya UI dan pengalaman pengguna yang mengambil inspirasi dari Claude milik Anthropic. Alat ini mendukung unggahan file teks, riwayat percakapan, dan pengaturan prompt sistem, bertujuan untuk menyediakan solusi interaksi LLM lokal yang mudah digunakan dan estetis. Proyek ini telah tersedia secara open source di GitHub, memudahkan pengguna untuk melakukan deployment dan penggunaan sendiri. (Sumber: Reddit r/LocalLLaMA)
Kiat Prompt untuk AI Menghasilkan Kartu Personalisasi (Ulang Tahun/Hari Ibu): Pengguna berbagi kiat prompt untuk menggunakan AI dalam menghasilkan kartu personalisasi (seperti kartu ulang tahun, kartu Hari Ibu). Kuncinya adalah memperjelas tema kartu (misalnya Hari Ibu, ulang tahun), gaya (misalnya gaya feminin, gaya anak-anak), penerima (misalnya ibu, Sandy, Jimmy), usia (misalnya 30 tahun, 6 tahun), serta konten spesifik ucapan atau nada yang hangat dan manis. Dengan menggabungkan elemen-elemen ini, AI dapat diarahkan untuk menghasilkan desain kartu yang sesuai dengan kebutuhan. (Sumber: dotey)

📚 Pembelajaran
Google Merilis White Paper Prompt Engineering, Memandu Pengguna Cara Bertanya Efektif: Google merilis white paper tentang prompt engineering (dapat diakses melalui Kaggle), yang bertujuan untuk mengajari pengguna cara bertanya kepada model AI dengan lebih efektif. Tutorialnya jelas, menjelaskan secara rinci cara memperjelas persyaratan output, membatasi rentang output, dan cara menggunakan variabel serta teknik lainnya, membantu pengguna meningkatkan efisiensi dan efektivitas interaksi dengan model bahasa besar, sehingga mendapatkan jawaban yang lebih akurat dan berguna. (Sumber: karminski3)

Tim HKUST (GZ) Mengajukan MultiGO: Pemodelan Gaussian Berlapis untuk Menghasilkan Manusia 3D Bertekstur dari Satu Gambar: Tim dari Hong Kong University of Science and Technology (Guangzhou) mengajukan kerangka kerja inovatif bernama MultiGO, yang merekonstruksi model manusia 3D bertekstur dari satu gambar melalui pemodelan Gaussian berlapis. Metode ini menguraikan tubuh manusia menjadi lapisan-lapisan dengan tingkat presisi yang berbeda seperti kerangka, sendi, dan kerutan, yang disempurnakan secara bertahap. Teknologi inti menggunakan titik Gaussian splatting sebagai primitif 3D dan merancang modul peningkatan kerangka, peningkatan sendi, dan optimasi kerutan. Hasil penelitian ini telah terpilih untuk CVPR 2025, memberikan ide baru untuk rekonstruksi manusia 3D dari satu gambar, dan kodenya akan segera dirilis secara open source. (Sumber: WeChat)

Tsinghua, Fudan, dan HKUST Bersama-sama Merilis RM-BENCH: Benchmark Evaluasi Reward Model Pertama: Menanggapi masalah “bentuk lebih penting daripada konten” dan bias gaya dalam evaluasi reward model bahasa besar saat ini, tim peneliti dari Universitas Tsinghua, Universitas Fudan, dan Universitas Sains dan Teknologi Hong Kong bersama-sama merilis benchmark evaluasi reward model sistematis pertama, RM-BENCH. Benchmark ini mencakup empat domain utama: obrolan, kode, matematika, dan keamanan. Dengan mengevaluasi sensitivitas model terhadap perbedaan konten yang halus dan ketahanannya terhadap bias gaya, RM-BENCH bertujuan untuk menetapkan standar baru yang lebih andal untuk “penilaian konten”. Penelitian menemukan bahwa reward model yang ada berkinerja buruk dalam domain matematika dan kode, dan umumnya memiliki bias gaya. Hasil ini telah diterima sebagai Oral Presentation di ICLR 2025. (Sumber: WeChat)

Universitas Tianjin dan Tencent Merilis Solusi COME secara Open Source: 5 Baris Kode Meningkatkan Ketahanan TTA, Mengatasi Keruntuhan Model: Universitas Tianjin bekerja sama dengan Tencent mengusulkan metode COME (Conservatively Minimizing Entropy), yang bertujuan untuk mengatasi masalah kepercayaan diri berlebih dan keruntuhan model yang disebabkan oleh minimisasi entropi (EM) selama adaptasi saat pengujian (TTA). COME secara eksplisit memodelkan ketidakpastian prediksi dengan memperkenalkan logika subjektif, dan secara tidak langsung mengontrol ketidakpastian dengan menggunakan batasan Logit adaptif (membekukan norma Logit), sehingga mencapai minimisasi entropi yang konservatif. Metode ini tidak memerlukan modifikasi arsitektur model, hanya memerlukan sedikit kode untuk disematkan ke dalam metode TTA yang ada, dan secara signifikan meningkatkan ketahanan dan akurasi model pada dataset seperti ImageNet-C, dengan overhead komputasi yang sangat kecil. Makalah ini telah diterima di ICLR 2025, dan kodenya telah dirilis secara open source. (Sumber: WeChat)
Huawei dan Institute of Information Engineering Mengajukan DEER: Mekanisme “Dynamic Early Exit” pada Chain-of-Thought Meningkatkan Efisiensi dan Akurasi Inferensi LLM: Huawei bekerja sama dengan Institute of Information Engineering, Chinese Academy of Sciences, mengusulkan mekanisme DEER (Dynamic Early Exit in Reasoning), yang bertujuan untuk mengatasi masalah pemikiran berlebihan yang mungkin terjadi pada model bahasa besar selama inferensi rantai pemikiran panjang (Long CoT). DEER secara dinamis menentukan apakah akan menghentikan pemikiran lebih awal dan menghasilkan kesimpulan dengan memantau titik transisi inferensi, menginduksi jawaban percobaan, dan mengevaluasi tingkat kepercayaannya. Eksperimen menunjukkan bahwa pada LLM inferensi seperti seri DeepSeek, DEER dapat mengurangi panjang generasi rantai pemikiran rata-rata sebesar 31%-43% tanpa pelatihan tambahan, sekaligus meningkatkan akurasi sebesar 1,7%-5,7%. (Sumber: WeChat)

CAS dkk. Mengajukan R1-Reward: Melatih Model Reward Multimodal melalui Reinforcement Learning yang Stabil: Tim peneliti dari Chinese Academy of Sciences (CAS), Tsinghua University, Kuaishou, dan Nanjing University mengajukan R1-Reward, sebuah metode untuk melatih model reward multimodal (MRM) menggunakan algoritma reinforcement learning yang stabil, StableReinforce, yang bertujuan untuk meningkatkan kemampuan penalaran jangka panjangnya. StableReinforce memperbaiki masalah ketidakstabilan yang mungkin dihadapi oleh algoritma RL yang ada seperti PPO saat melatih MRM, dengan menggunakan strategi Pre-Clip, filter advantage, dan mekanisme reward konsistensi baru (memperkenalkan model wasit untuk memeriksa konsistensi analisis dengan jawaban) untuk menstabilkan proses pelatihan. Eksperimen menunjukkan bahwa R1-Reward berkinerja lebih baik daripada model SOTA pada beberapa benchmark MRM, dan kinerjanya dapat ditingkatkan lebih lanjut melalui pemungutan suara sampel ganda saat inferensi. (Sumber: WeChat)
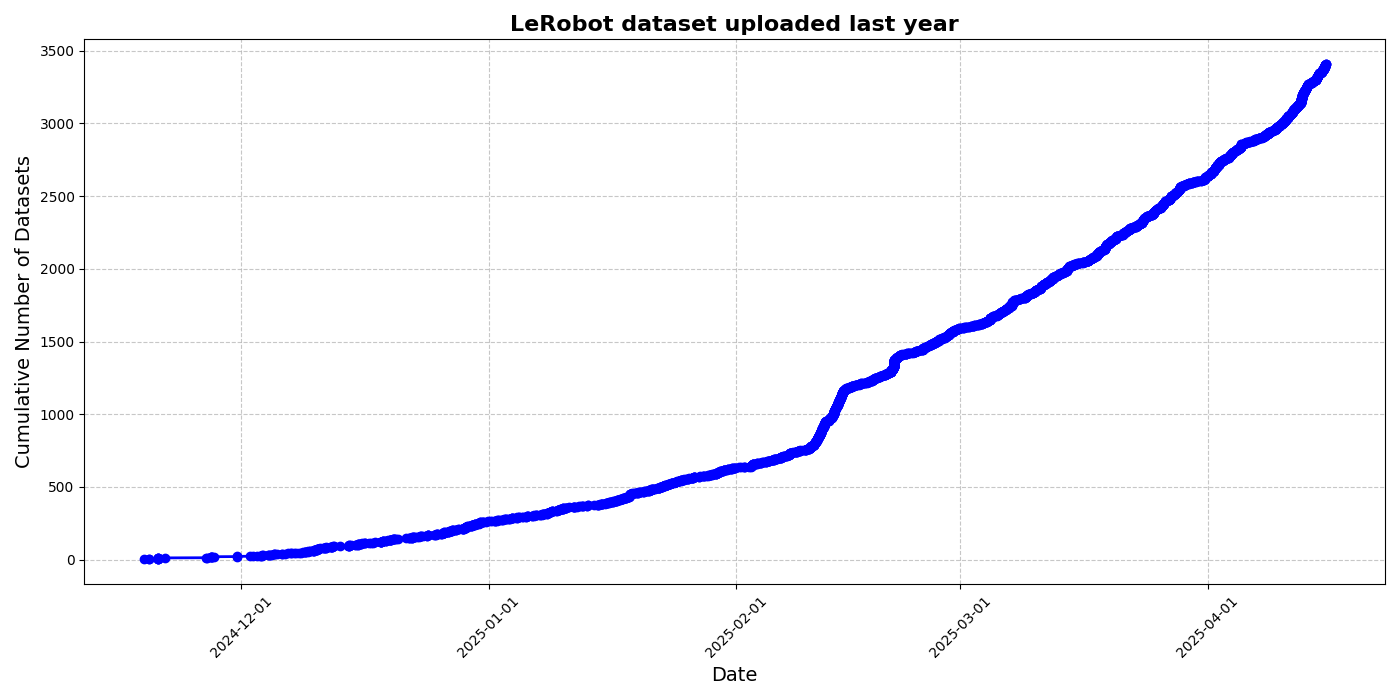
HuggingFace Merilis Inisiatif Dataset Komunitas LeRobot, Mendorong “Momen ImageNet” untuk Robotika: HuggingFace meluncurkan proyek dataset komunitas LeRobot, yang bertujuan untuk membangun “ImageNet” di bidang robotika, mendorong pengembangan teknologi robotika umum melalui kontribusi komunitas. Artikel tersebut menekankan pentingnya keragaman data untuk kemampuan generalisasi robot dan menunjukkan bahwa dataset robotika yang ada sebagian besar berasal dari lingkungan akademis yang terbatas. LeRobot mendorong pengguna untuk berbagi data dari berbagai robot (seperti So100, lengan robot Koch) dalam berbagai tugas (seperti bermain catur, mengoperasikan laci) dengan menyederhanakan proses pengumpulan dan pengunggahan data serta mengurangi biaya perangkat keras. Pada saat yang sama, artikel tersebut mengusulkan standar kualitas data dan daftar praktik terbaik untuk mengatasi tantangan seperti anotasi data yang tidak konsisten dan pemetaan fitur yang ambigu, guna mempromosikan pembangunan dataset robotika yang berkualitas tinggi dan beragam. (Sumber: HuggingFace Blog, LoubnaBenAllal1)
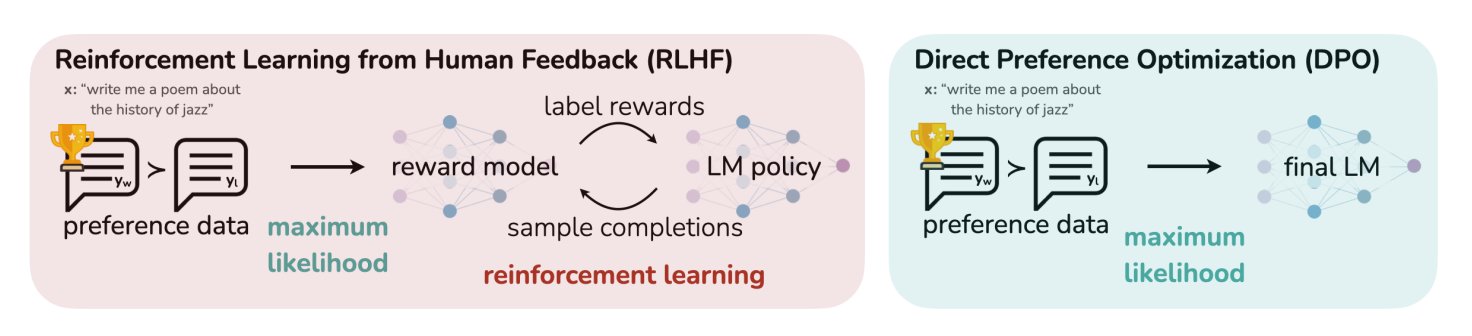
Postingan Blog HuggingFace Meringkas 11 Algoritma Penyelarasan dan Optimasi LLM: TheTuringPost membagikan sebuah artikel di HuggingFace yang merangkum 11 algoritma penyelarasan dan optimasi untuk model bahasa besar (LLM). Algoritma-algoritma ini termasuk PPO (Proximal Policy Optimization), DPO (Direct Preference Optimization), GRPO (Group Relative Policy Optimization), SFT (Supervised Fine-Tuning), RLHF (Reinforcement Learning from Human Feedback), serta SPIN (Self-Play Fine-Tuning), dan lain-lain. Artikel tersebut menyediakan tautan dan informasi lebih lanjut tentang algoritma-algoritma ini, memberikan gambaran umum tentang metode optimasi LLM bagi para peneliti dan pengembang. (Sumber: TheTuringPost)
UC Berkeley Membagikan Materi Kuliah Visi Komputer Pascasarjana CS280: Profesor Angjoo Kanazawa dan Jitendra Malik dari University of California, Berkeley membagikan seluruh materi kuliah untuk mata kuliah visi komputer pascasarjana CS280 yang mereka ajarkan semester ini. Mereka percaya bahwa rangkaian materi ini, yang menggabungkan konten visi komputer klasik dan modern, bekerja dengan baik dan menyediakannya untuk umum sebagai referensi bagi para pembelajar. (Sumber: NandoDF)
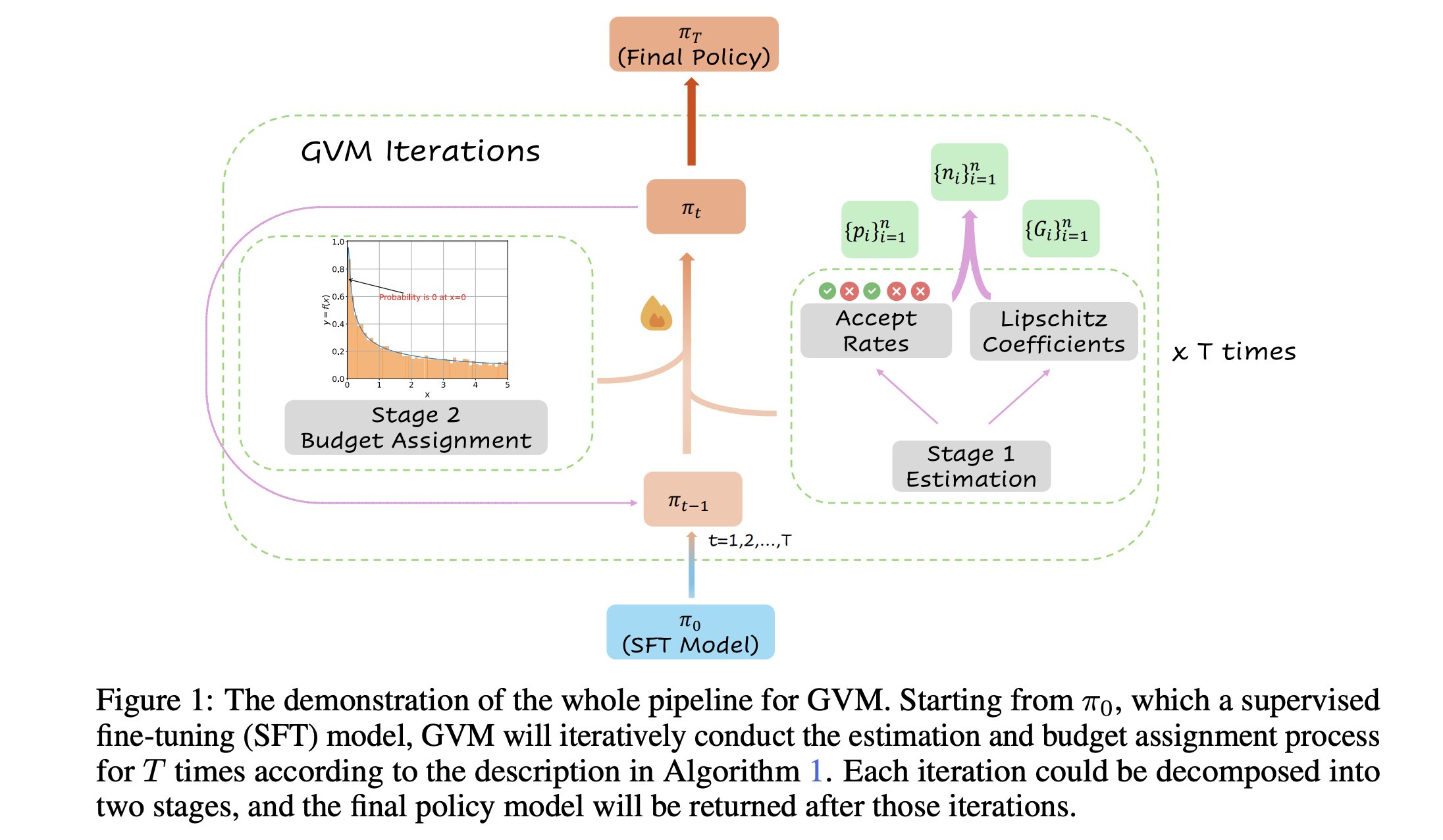
GVM-RAFT: Kerangka Kerja Pengambilan Sampel Dinamis untuk Mengoptimalkan Penalaran Chain-of-Thought: Sebuah makalah baru memperkenalkan kerangka kerja GVM-RAFT, yang mengoptimalkan penalaran chain-of-thought dengan menyesuaikan strategi pengambilan sampel secara dinamis untuk setiap prompt, bertujuan untuk meminimalkan varians gradien. Dilaporkan bahwa metode ini mencapai percepatan 2-4 kali lipat pada tugas penalaran matematika dan meningkatkan akurasi. (Sumber: _akhaliq)
Kerangka Kerja Baru R&B Meningkatkan Kinerja Model Bahasa dengan Menyeimbangkan Data Pelatihan Secara Dinamis: Sebuah penelitian baru bernama R&B mengusulkan kerangka kerja baru yang meningkatkan kinerja model bahasa dengan menyeimbangkan data pelatihan model bahasa secara dinamis, hanya dengan menambah 0,01% overhead komputasi tambahan. Metode ini bertujuan untuk mengoptimalkan efisiensi pemanfaatan data, menukar biaya yang lebih kecil dengan peningkatan kinerja model. (Sumber: _akhaliq)
Makalah Membahas Perspektif Baru Keamanan AI: Memandang Kemajuan Sosial dan Teknologi sebagai Menjahit Selimut: Sebuah makalah baru yang diterbitkan di arXiv berjudul “Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt” mengusulkan pandangan baru tentang keamanan AI, yang menganjurkan agar inti keamanan AI difokuskan pada pencegahan eskalasi perbedaan pendapat menjadi konflik. Makalah ini membandingkan kemajuan sosial dan teknologi dengan menjahit selimut yang terus tumbuh, berubah, penuh tambalan, dan berwarna-warni, menekankan pentingnya menjaga stabilitas dan kerja sama dalam sistem yang kompleks. (Sumber: jachiam0)
Makalah Membahas Komputasi Adaptif dalam Model Bahasa Autoregresif: Diskusi menyebutkan daya tarik komputasi adaptif dalam deep learning dan menyebutkan perkembangan teknologi terkait: PonderNet (DeepMind, 2021) sebagai alat awal yang mengintegrasikan jaringan saraf dan perulangan; model difusi melakukan komputasi melalui beberapa propagasi maju; dan model bahasa inferensial baru-baru ini mencapai efek serupa dengan menghasilkan sejumlah token secara arbitrer. Ini mencerminkan tren fleksibilitas dan dinamisme model dalam alokasi dan penggunaan sumber daya komputasi. (Sumber: jxmnop)
Makalah Membahas Bagaimana “Data Buruk” Dapat Menghasilkan “Model Baik”: Sebuah makalah dari Universitas Harvard tahun 2025 berjudul “When Bad Data Leads to Good Models” (arXiv:2505.04741) membahas bagaimana dalam beberapa kasus, data yang tampaknya berkualitas rendah (seperti data pra-pelatihan yang berisi konten 4chan) justru dapat membantu penyelarasan model dan menyembunyikan “tingkat kekuatannya” (power level), sehingga membuatnya berkinerja lebih baik. Hal ini memicu diskusi tentang kualitas data, penyelarasan model, dan keaslian perilaku model. (Sumber: teortaxesTex)

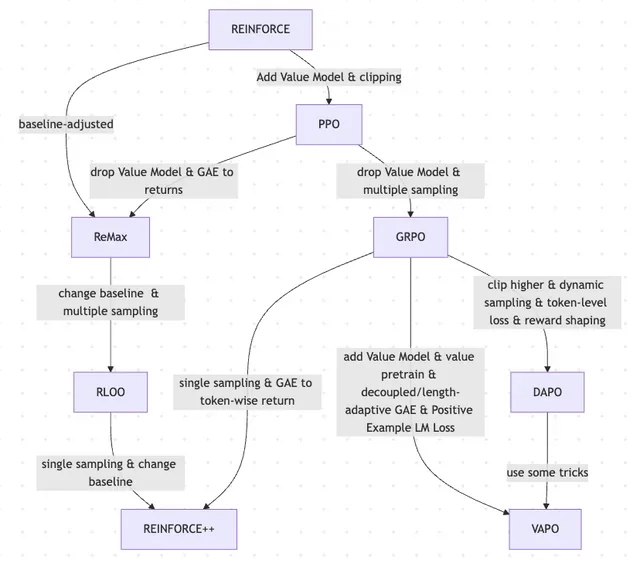
Makalah Membahas Evolusi RLHF dan Variannya, dari REINFORCE hingga VAPO: Sebuah artikel penelitian merangkum evolusi metode reinforcement learning (RL) yang digunakan untuk fine-tuning model bahasa besar (LLM). Artikel tersebut menelusuri evolusi dari algoritma klasik PPO dan REINFORCE, hingga metode terkini seperti GRPO, ReMax, RLOO, DAPO, dan VAPO, menganalisis penghapusan model nilai, perubahan strategi pengambilan sampel, penyesuaian baseline, serta penerapan teknik seperti pembentukan reward dan loss tingkat token. Penelitian ini bertujuan untuk menyajikan dengan jelas lanskap penelitian RLHF dan variannya di bidang penyelarasan LLM. (Sumber: Reddit r/MachineLearning)
Makalah “Absolute Zero”: AI Melakukan Penalaran Self-Play yang Diperkuat Tanpa Data Manusia: Sebuah white paper berjudul “Absolute Zero: Reinforced Self-Play Reasoning with Zero Data” (arXiv:2505.03335) membahas metode baru untuk melatih AI logika. Para peneliti melatih model AI logika tanpa menggunakan dataset yang diberi label oleh manusia. Model tersebut dapat menghasilkan tugas penalaran sendiri, memecahkan masalah, dan memverifikasi solusi melalui eksekusi kode. Hal ini memicu diskusi tentang apakah AI dapat, dalam lingkungan yang sepenuhnya tanpa pengetahuan sebelumnya (seperti matematika, fisika, bahasa), menciptakan representasi simbolis dari awal, mendefinisikan struktur logis, mengembangkan sistem numerik, dan membangun model kausal, serta potensi dan risiko dari “kecerdasan alien” semacam itu. (Sumber: Reddit r/ArtificialInteligence, Reddit r/artificial)
Laboratorium Interaksi Manusia-Komputer Cerdas Universitas Fudan Merekrut Mahasiswa S2/S3 Angkatan 2026: Laboratorium Interaksi Manusia-Komputer Cerdas di Fakultas Ilmu Komputer Universitas Fudan sedang merekrut mahasiswa S2 dan S3 untuk program summer camp/rekomendasi angkatan 2026. Laboratorium ini dipimpin oleh Profesor Shang Li dan memiliki fokus penelitian pada AGI wearable (kombinasi kacamata pintar MemX dengan LLM), embodied intelligence open-source, kompresi model (dari besar ke kecil), dan sistem machine learning (seperti optimasi kompilasi ML, prosesor AI). Laboratorium ini berdedikasi untuk mengeksplorasi kecerdasan yang berpusat pada manusia dan mengintegrasikan model besar dengan paradigma baru interaksi manusia-komputer dalam sistem wearable cerdas dan embodied intelligence. (Sumber: WeChat)

💼 Bisnis
Gambaran Umum 10 Perusahaan Rintisan AI dengan Valuasi Lebih dari $1 Miliar dan Kurang dari 50 Karyawan: Business Insider membuat daftar 10 perusahaan rintisan AI dengan valuasi melebihi $1 miliar tetapi memiliki kurang dari 50 karyawan. Di antaranya adalah Safe Superintelligence (valuasi $32 miliar, 20 karyawan), OG Labs (valuasi $2 miliar, 40 karyawan), Magic (valuasi $1,58 miliar, 20 karyawan), Sakana AI (valuasi $1,5 miliar, 28 karyawan), dan lainnya. Perusahaan-perusahaan ini menunjukkan potensi di bidang AI untuk mencapai valuasi tinggi dengan tim kecil, yang mencerminkan tingginya nilai teknologi dan inovasi di pasar modal. (Sumber: hardmaru)
Fourier Intelligence Memperdalam Skenario Perawatan Lansia, Bekerja Sama dengan Shanghai International Medical Center untuk Membangun Basis Rehabilitasi Embodied Intelligence: Unicorn embodied intelligence, Fourier Intelligence, dalam KTT Ekosistem Embodied Intelligence pertamanya, mengumumkan akan bekerja sama dengan Shanghai International Medical Center untuk bersama-sama mempromosikan aplikasi robot embodied intelligence dalam skenario medis rehabilitasi, termasuk pembangunan standar, penciptaan solusi bersama, dan penelitian ilmiah, serta membangun basis demonstrasi rehabilitasi embodied intelligence pertama di Tiongkok. Pendiri Fourier, Gu Jie, mengusulkan strategi inti untuk sepuluh tahun ke depan adalah “berpijak pada perawatan lansia, fokus pada interaksi, melayani manusia,” menekankan bahwa rehabilitasi medis adalah fondasinya. Sejak didirikan pada tahun 2015, perusahaan ini telah berkembang dari robot rehabilitasi menjadi robot humanoid umum seri GR-1 dan GRx, dengan total pengiriman ratusan unit. (Sumber: 36氪)
Meta Dilaporkan Merekrut Mantan Pejabat Pentagon, Kemungkinan Memperkuat Posisi di Bidang Militer: Menurut laporan Forbes, Meta sedang merekrut mantan pejabat Pentagon. Langkah ini mungkin mengindikasikan bahwa perusahaan tersebut berencana untuk memperkuat bisnisnya di bidang teknologi militer atau terkait pertahanan. Perkembangan ini memicu diskusi dan perhatian mengenai keterlibatan perusahaan teknologi besar dalam aplikasi militer. (Sumber: Reddit r/artificial)

🌟 Komunitas
Andrej Karpathy Mengemukakan Paradigma Penting yang Hilang dalam Pembelajaran LLM, “System Prompt Learning”, Memicu Diskusi Hangat: Andrej Karpathy berpendapat bahwa pembelajaran LLM saat ini kekurangan paradigma penting yang ia sebut “system prompt learning”. Ia menunjukkan bahwa pra-pelatihan adalah untuk pengetahuan, fine-tuning (supervised/reinforcement learning) adalah untuk perilaku kebiasaan, keduanya melibatkan perubahan parameter, tetapi sejumlah besar interaksi dan umpan balik manusia tampaknya belum dimanfaatkan sepenuhnya. Ia membandingkannya dengan memberikan protagonis “Memento” sebuah buku catatan untuk menyimpan pengetahuan dan strategi pemecahan masalah global. Pandangan ini memicu diskusi luas, beberapa orang berpendapat bahwa ini mirip dengan filosofi DSPy, atau melibatkan masalah memori/optimasi, pembelajaran berkelanjutan, dan membahas bagaimana menerapkan mekanisme serupa di Langgraph. (Sumber: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
Perusahaan AI Meminta Pelamar Kerja Tidak Menggunakan AI untuk Menulis Lamaran, Memicu Diskusi Hangat: Perusahaan AI seperti Anthropic meminta pelamar kerja untuk tidak menggunakan alat AI saat menulis lamaran kerja (seperti resume). Peraturan ini memicu diskusi di komunitas. Pihak perekrut menyatakan bahwa resume yang dihasilkan AI yang mereka terima sering kali berupa “sampah teks”, bahkan pelamar berpengalaman pun bisa kehilangan fokus karena hal ini. Namun, ada juga pelamar yang berpendapat bahwa AI dapat membantu mereka mengoptimalkan resume agar lebih sesuai dengan persyaratan pekerjaan, menonjolkan keterampilan, dan meningkatkan keterbacaan. Diskusi juga meluas ke fenomena platform seperti LinkedIn yang dibanjiri konten buatan AI, dan apakah metode lain seperti video harus digunakan untuk mengevaluasi pelamar. (Sumber: Reddit r/artificial, Reddit r/ArtificialInteligence)

“Keterkenalan” Konten Buatan AI Memicu Diskusi, Pengguna Merasa Mudah Dikenali: Diskusi komunitas menunjukkan bahwa konten yang dihasilkan oleh AI (terutama ChatGPT) mudah dikenali, bukan hanya karena tanda baca tertentu (seperti em dashes) atau pola kalimat (seperti “Itu bukan x; itu y.”), tetapi lebih karena “ritme” dan “rasa hambar” yang khas. Begitu jejak AI dikenali, konten terasa tidak nyata dan kurang personal. Beberapa pengguna menyatakan telah menemukan kasus serupa dalam email, postingan media sosial, bahkan video game, dan berpendapat bahwa penggunaan langsung AI untuk menghasilkan seluruh konten akan membuat konten menjadi membosankan dan tidak tulus. Mereka menyarankan agar pengguna menggunakan AI sebagai alat untuk memodifikasi dan mempersonalisasi konten. (Sumber: Reddit r/ChatGPT)
Perkembangan AI Menunjukkan Siklus “Bulan Madu – Penolakan”, Mencerminkan Preferensi Manusia terhadap Keaslian: Ada pandangan bahwa kemunculan model AI generatif baru (teks, gambar, musik, dll.) sering kali disertai dengan “periode bulan madu”, di mana orang-orang terkesan dengan kemampuannya. Namun, segera setelah orang mulai mengenali “pola” atau “jejak” yang dihasilkan AI, akan timbul penolakan, beralih dari pujian menjadi keraguan, bahkan menganggapnya “tidak berjiwa”. Fenomena belajar cepat untuk mengenali karya AI dan kecenderungan untuk lebih menyukai karya manusia yang tidak sempurna ini mungkin berarti AI lebih berfungsi sebagai alat bantu daripada sepenuhnya menggantikan kreator manusia, karena orang menghargai cerita di balik karya, niat penulis, dan keaslian. (Sumber: Reddit r/ArtificialInteligence)
Tingkat Pembuatan Kode AI Internal Anthropic Melebihi 70%, Memicu Asosiasi dengan Iterasi Diri AI: Mike Krieger dari Anthropic mengungkapkan bahwa lebih dari 70% pull requests di internal perusahaan sekarang dihasilkan oleh AI. Data ini memicu diskusi di komunitas, beberapa orang mengaitkannya dengan skenario mesin yang mengedit dan memperbaiki dirinya sendiri, mirip dengan plot dalam karya fiksi ilmiah. Sementara itu, ada juga yang meragukan kebenaran dan makna spesifik dari data ini (misalnya, tingkat kompleksitas PR tersebut). (Sumber: Reddit r/ClaudeAI)

CEO Nvidia Jensen Huang Menekankan Seluruh Karyawan Merangkul AI Agent, AI Akan Membentuk Ulang Peran Pengembang: CEO Nvidia Jensen Huang menyatakan bahwa perusahaan akan melengkapi seluruh karyawan dengan asisten AI, AI agent akan disematkan dalam pengembangan sehari-hari, mengoptimalkan kode, menemukan bug, dan mempercepat perancangan prototipe. Ia percaya bahwa di masa depan setiap orang akan memimpin beberapa asisten AI, dan produktivitas akan meningkat secara eksponensial. CEO Meta Mark Zuckerberg, CEO Microsoft Satya Nadella, dan lainnya juga memiliki pandangan serupa, percaya bahwa AI akan menyelesaikan sebagian besar pekerjaan kode, dan peran pengembang akan beralih menjadi “memimpin AI” dan “mendefinisikan kebutuhan”. Tren ini menandakan bahwa siklus pengembangan perangkat lunak akan mengalami perubahan besar, dan alat pemrograman AI seperti GitHub Copilot, Cursor, dll. akan menjadi umum. (Sumber: WeChat)

Diskusi: Apakah Peneliti ML Membaca 1000-2000 Makalah per Tahun Itu Mungkin?: Ada diskusi di komunitas yang menyebutkan bahwa peneliti machine learning terkemuka mungkin membaca hampir 2000 makalah per tahun. Menanggapi hal ini, beberapa komentar menyatakan bahwa jumlah makalah yang dibaca hanyalah metrik proksi, yang benar-benar penting adalah kemampuan untuk menyaring sinyal dari sejumlah besar informasi, mengekstrak informasi yang valid, dan menerapkannya dengan benar. Mampu mengikuti sorotan dan tren di bidangnya, dan mempelajari konten tertentu secara mendalam bila diperlukan, kemampuan menyaring informasi semacam ini adalah keterampilan kunci abad ini. (Sumber: torchcompiled)
Diskusi: Membeli GPU vs. Menyewa GPU untuk Pelatihan/Fine-tuning Model: Praktisi machine learning menghadapi pilihan untuk membeli atau menyewa sumber daya GPU. Mereka yang berpengalaman menyarankan untuk mengadopsi strategi campuran: mengkonfigurasi GPU konsumen dengan kinerja yang layak secara lokal untuk eksperimen kecil, dan menyewa GPU cloud untuk tugas pelatihan skala besar. Pilihan tergantung pada kompleksitas model, volume data, dan anggaran. GPU cloud memiliki keunggulan dalam hal organisasi ML Ops, tetapi dengan harga yang sama, kinerja GPU cloud umum seperti T4 mungkin tidak sebaik kartu konsumen kelas atas (seperti 3090/4090), meskipun cloud dapat menyediakan GPU kelas atas dengan memori yang lebih besar seperti A100/H100. (Sumber: Reddit r/MachineLearning)
💡 Lainnya
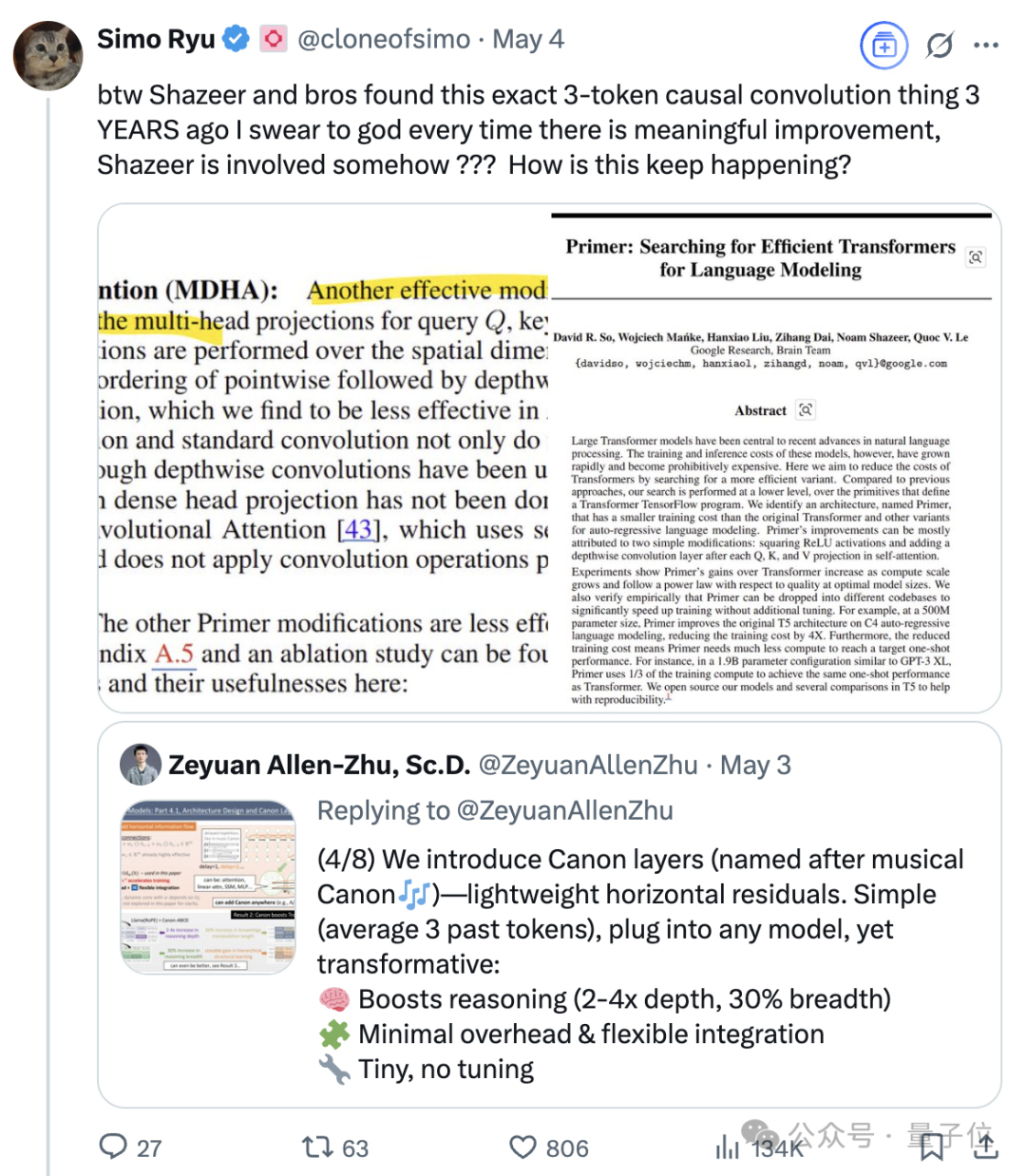
Pengaruh Berkelanjutan Noam Shazeer, Salah Satu dari Delapan Penulis Transformer: Noam Shazeer, sebagai salah satu dari delapan penulis makalah arsitektur Transformer “Attention Is All You Need”, kontribusinya secara luas dianggap sebagai yang terbesar. Pengaruhnya jauh melampaui itu, termasuk penelitian awal tentang pengenalan Mixture of Experts (MoE) yang jarang ke dalam model bahasa, optimizer Adafactor, multi-query attention (MQA), dan Gated Linear Units (GLU) dalam Transformer. Karya-karya ini meletakkan dasar bagi arsitektur model bahasa besar arus utama saat ini, menjadikan Shazeer dianggap sebagai tokoh kunci yang terus mendefinisikan paradigma teknis di bidang AI. Ia pernah meninggalkan Google untuk mendirikan Character.AI, kemudian kembali ke Google setelah perusahaannya diakuisisi, dan turut memimpin proyek Gemini. (Sumber: WeChat)
Raksasa Teknologi Menghadapi “Krisis Paruh Baya” yang Dipicu AI: Artikel menganalisis bahwa “Tujuh Raksasa Teknologi” termasuk Google, Apple, Meta, dan Tesla menghadapi tantangan disruptif yang dibawa oleh kecerdasan buatan, dan jatuh ke dalam “krisis paruh baya”. Bisnis pencarian Google terancam oleh model tanya jawab langsung AI, kemajuan Apple dalam inovasi AI lambat, Meta mencoba mengintegrasikan AI ke dalam media sosial tetapi kinerja Llama 4 tidak sesuai harapan, dan Tesla menghadapi tekanan penurunan penjualan dan harga saham. Para pemimpin industri yang dulu ini, seperti kasus dalam “The Innovator’s Dilemma”, perlu mengatasi guncangan pasar baru dan model baru yang dibawa oleh AI, jika tidak, mereka mungkin menjadi “Nokia” di era AI. (Sumber: WeChat)

AI Google Berkinerja Lebih Baik dari Dokter Manusia dalam Simulasi Dialog Medis: Penelitian menunjukkan bahwa sistem AI yang dilatih untuk melakukan wawancara medis, dalam berdialog dengan pasien simulasi dan membuat daftar kemungkinan diagnosis berdasarkan riwayat penyakit, kinerjanya setara atau bahkan melampaui dokter manusia. Para peneliti percaya bahwa sistem AI semacam ini berpotensi membantu mewujudkan universalisasi dan demokratisasi layanan kesehatan. (Sumber: Reddit r/ArtificialInteligence)
