Kata Kunci:Nol Mutlak, Qwen3, Mistral Medium 3, Yayasan PyTorch, Evolusi Mandiri AI, Model multimodal, AI sumber terbuka, Paradigma RLVR, Sistem AZR, Qwen3-235B-A22B, Pustaka optimasi DeepSpeed, Dukungan multimodal LangSmith
🔥 Fokus
Universitas Tsinghua merilis paper Absolute Zero: AI dapat berevolusi sendiri tanpa data eksternal: Tim LeapLabTHU dari Universitas Tsinghua merilis paradigma RLVR (Reinforcement Learning with Verifiable Rewards) baru yang disebut “Absolute Zero”. Dalam paradigma ini, satu model dapat secara mandiri mengusulkan tugas untuk memaksimalkan proses pembelajaran, dan dengan menyelesaikan tugas-tugas ini, meningkatkan kemampuan penalarannya, sepenuhnya tanpa bergantung pada data eksternal apa pun. Sistemnya, AZR (Absolute Zero Reasoner), menggunakan eksekutor kode untuk memverifikasi tugas dan jawaban, mencapai pembelajaran terbuka namun berbasis bukti. Eksperimen menunjukkan bahwa AZR mencapai level SOTA dalam tugas pengkodean dan penalaran matematis, melampaui model zero-shot yang ada yang bergantung pada puluhan ribu sampel beranotasi manusia (Sumber: Reddit r/LocalLLaMA)
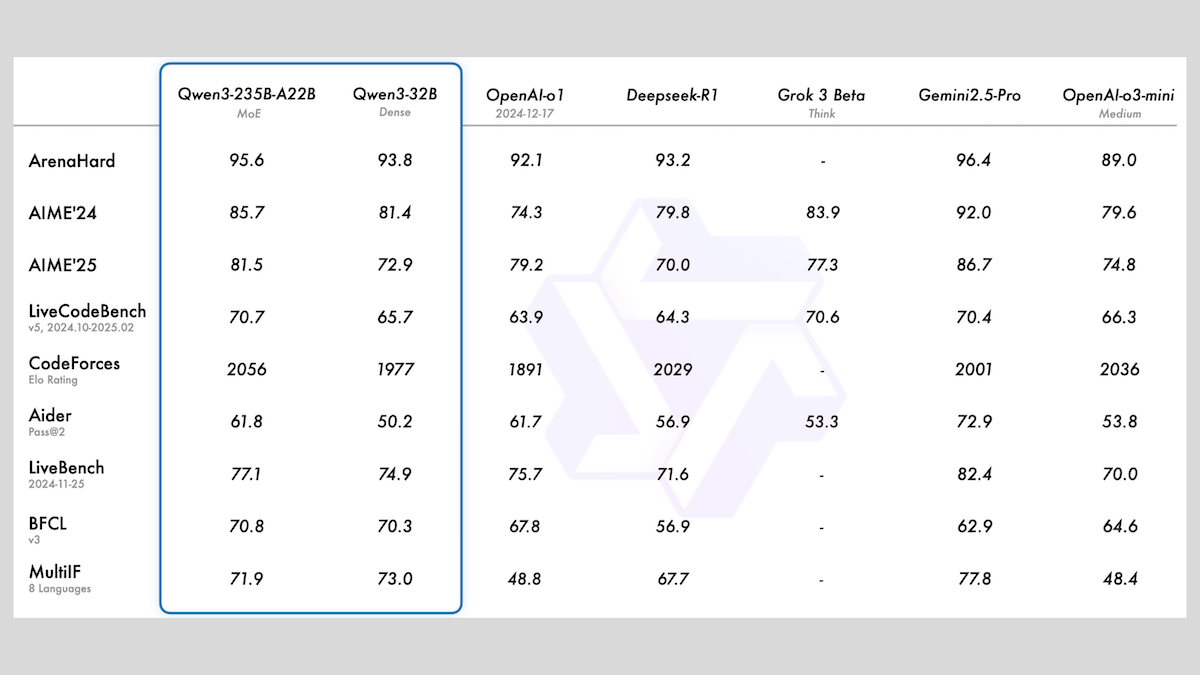
Alibaba merilis seri model Qwen3, mencakup MoE dan berbagai ukuran: Alibaba merilis seri model bahasa besar Qwen3, yang mencakup 8 model dengan jumlah parameter mulai dari 0.6B hingga 235B. Di antaranya, Qwen3-235B-A22B dan Qwen3-30B-A3B menggunakan arsitektur MoE, sedangkan sisanya adalah model padat. Seri model ini telah dilatih sebelumnya pada 36T token, mencakup 119 bahasa, dan memiliki mode inferensi yang dapat diaktifkan/dinonaktifkan, cocok untuk berbagai bidang seperti kode, matematika, dan sains. Evaluasi menunjukkan bahwa model MoE memiliki kinerja yang unggul, versi 235B melampaui DeepSeek-R1 dan Gemini 2.5 Pro pada beberapa tolok ukur, versi 30B juga menunjukkan kinerja yang kuat, dan bahkan model 4B mengungguli model dengan parameter yang jauh lebih besar pada beberapa tolok ukur. Model-model ini telah dirilis sebagai open-source di HuggingFace dan ModelScope, menggunakan lisensi Apache 2.0 (Sumber: DeepLearning.AI Blog)
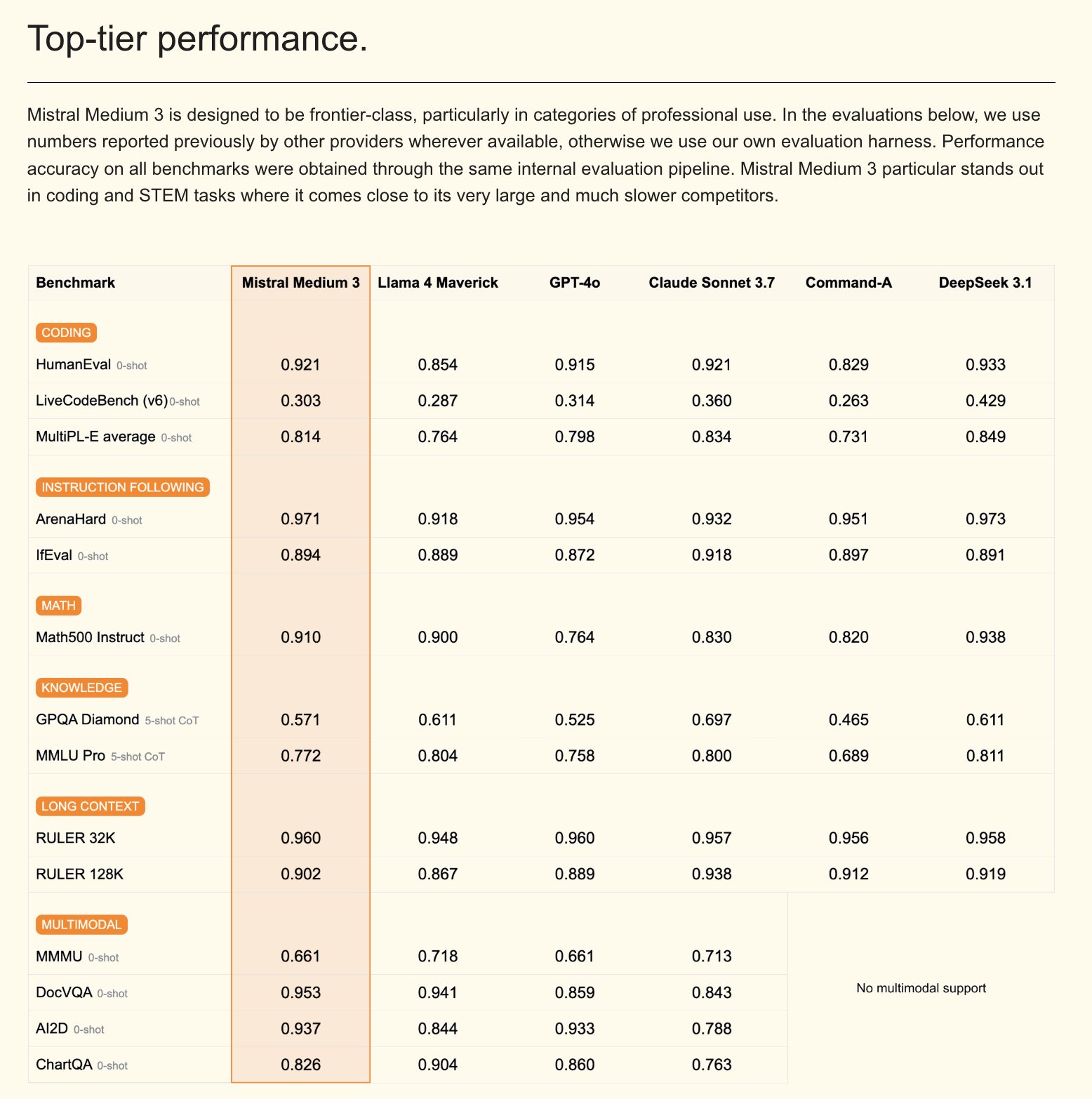
Mistral merilis model multimodal Mistral Medium 3 dan asisten AI versi enterprise: Mistral AI meluncurkan Mistral Medium 3, model multimodal baru yang diklaim memiliki kinerja mendekati Claude Sonnet 3.7, tetapi dengan biaya yang jauh lebih rendah (input $0.4/M token, output $2/M token), 8 kali lebih rendah. Model ini unggul dalam pengkodean dan pemanggilan fungsi, serta menyediakan fitur tingkat enterprise seperti deployment hybrid atau lokal, dan post-training yang dapat disesuaikan. Selain itu, Mistral juga merilis Le Chat Enterprise, asisten AI tingkat enterprise yang dapat disesuaikan dan aman, mendukung integrasi dengan basis pengetahuan perusahaan (seperti Gmail, Google Drive, Sharepoint), dan memiliki fungsi seperti Agent, asisten pengkodean, dan pencarian web, yang bertujuan untuk meningkatkan daya saing perusahaan. Mistral mengumumkan akan merilis model Large baru dalam beberapa minggu mendatang (Sumber: Mistral AI、GuillaumeLample、scaling01、karminski3)
PyTorch Foundation berkembang menjadi yayasan payung, mengakomodasi vLLM dan DeepSpeed: PyTorch Foundation mengumumkan perluasan menjadi struktur yayasan payung, yang bertujuan untuk mengumpulkan lebih banyak proyek open-source AI berkualitas tinggi. Proyek pertama yang bergabung adalah vLLM dan DeepSpeed. vLLM adalah mesin inferensi dan layanan dengan throughput tinggi dan efisien memori yang dirancang khusus untuk LLM; DeepSpeed adalah pustaka optimasi deep learning yang membuat pelatihan model skala besar lebih efisien. Langkah ini bertujuan untuk mempromosikan pengembangan AI yang didorong oleh komunitas, mencakup seluruh siklus hidup dari penelitian hingga produksi, dan didukung oleh banyak anggota termasuk AMD, Arm, AWS, Google, Huawei, dan lainnya (Sumber: PyTorch、soumithchintala、vllm_project、code_star)

🎯 Tren
Tencent ARC Lab merilis FlexiAct: alat transfer gerakan video: Tencent ARC Lab merilis alat baru bernama FlexiAct di Hugging Face. Alat ini mampu mentransfer gerakan dari video referensi ke gambar target mana pun, bahkan jika tata letak, sudut pandang, atau struktur kerangka gambar target berbeda dari video referensi. Ini membuka kemungkinan baru di bidang pembuatan dan pengeditan video, memungkinkan pengguna untuk mengontrol gerakan dan pose dalam konten yang dihasilkan dengan lebih fleksibel (Sumber: _akhaliq)
White Circle merilis CircleGuardBench: tolok ukur baru untuk model moderasi konten AI: White Circle meluncurkan CircleGuardBench, sebuah tolok ukur baru untuk mengevaluasi model moderasi konten AI. Tolok ukur ini dirancang untuk evaluasi tingkat produksi, menguji deteksi bahaya, resistensi terhadap jailbreak, tingkat positif palsu, dan latensi, mencakup 17 kategori bahaya dunia nyata. Artikel blog dan papan peringkat terkait telah dipublikasikan di Hugging Face, menyediakan standar evaluasi baru untuk bidang keamanan AI dan moderasi konten (Sumber: TheTuringPost、_akhaliq)

Hugging Face merilis SIFT-50M: dataset fine-tuning instruksi suara multibahasa skala besar: Hugging Face merilis dataset SIFT-50M, dataset multibahasa skala besar yang dirancang khusus untuk fine-tuning instruksi suara. Dataset ini berisi lebih dari 50 juta pasangan tanya jawab instruksional, mencakup 5 bahasa. SIFT-LLM yang dilatih berdasarkan dataset ini mengungguli SALMONN dan Qwen2-Audio dalam tolok ukur kepatuhan suara. Dataset ini juga mencakup tolok ukur EvalSIFT untuk evaluasi akustik dan generatif, serta mendukung pembuatan suara yang dapat dikontrol (seperti nada, kecepatan bicara, aksen), yang dibangun berdasarkan Whisper, HuBERT, X-Codec2 & Qwen2.5 (Sumber: ClementDelangue、huggingface)
Meta merilis Perception Language Model (PLM): model bahasa visual open-source yang dapat direproduksi: Meta AI meluncurkan Meta Perception Language Model (PLM), sebuah model bahasa visual yang terbuka dan dapat direproduksi, yang dirancang untuk menyelesaikan tugas-tugas visual yang menantang. Meta berharap dapat membantu komunitas open-source membangun sistem computer vision yang lebih kuat melalui PLM. Makalah penelitian, kode, dan dataset terkait telah dirilis untuk digunakan oleh para peneliti dan pengembang (Sumber: AIatMeta)
Google memperbarui model pembuatan gambar Gemini 2.0: meningkatkan kualitas dan kecepatan: Google mengumumkan pembaruan pada model pembuatan gambar Gemini 2.0 (versi pratinjau), versi baru ini menawarkan kualitas visual yang lebih baik, rendering teks yang lebih akurat, tingkat pemblokiran (block rates) yang lebih rendah, dan batas kecepatan (rate limits) yang lebih tinggi. Biaya untuk menghasilkan setiap gambar adalah $0.039. Pembaruan ini bertujuan untuk meningkatkan pengalaman dan hasil bagi pengembang yang menggunakan Gemini untuk pembuatan gambar (Sumber: m__dehghani、scaling01、andrew_n_carr、demishassabis)
NVIDIA merilis seri model inferensi kode open-source: NVIDIA merilis serangkaian model inferensi kode open-source, termasuk tiga ukuran: 32B, 14B, dan 7B, semuanya menggunakan lisensi APACHE 2.0. Model-model ini dilatih berdasarkan dataset OCR dan diklaim berkinerja lebih baik daripada O3 mini dan O1 (low) pada tolok ukur LiveCodeBench, serta 30% lebih efisien dalam penggunaan token dibandingkan model inferensi sejenis. Model-model ini kompatibel dengan berbagai kerangka kerja seperti llama.cpp, vLLM, transformers, TGI, dll. (Sumber: huggingface、ClementDelangue)
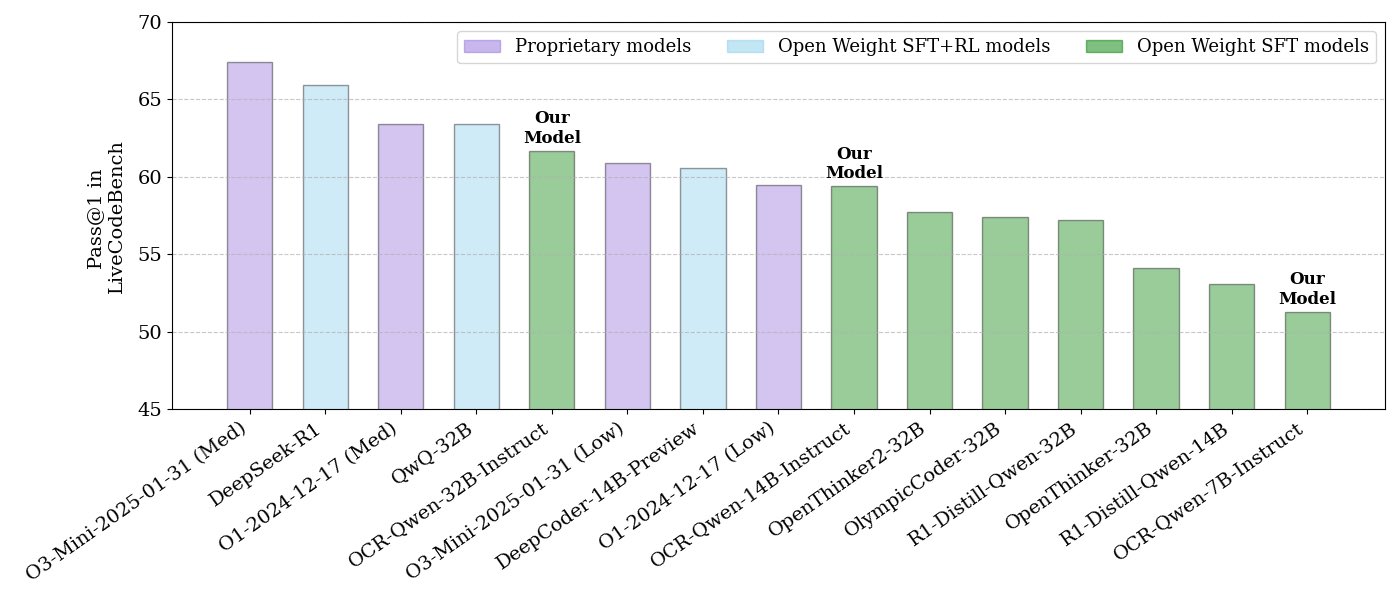
ServiceNow dan NVIDIA berkolaborasi meluncurkan model Apriel-Nemotron-15b-Thinker: ServiceNow dan NVIDIA bersama-sama merilis model parameter 15B bernama Apriel-Nemotron-15b-Thinker, menggunakan lisensi MIT. Model ini diklaim memiliki kinerja yang sebanding dengan model 32B, tetapi dengan konsumsi token yang jauh lebih sedikit (sekitar 40% lebih sedikit dari Qwen-QwQ-32b). Model ini menunjukkan kinerja luar biasa dalam berbagai tolok ukur seperti MBPP, BFCL, enterprise RAG, IFEval, dan sangat kompetitif terutama dalam tugas enterprise RAG dan pengkodean (Sumber: Reddit r/LocalLLaMA)

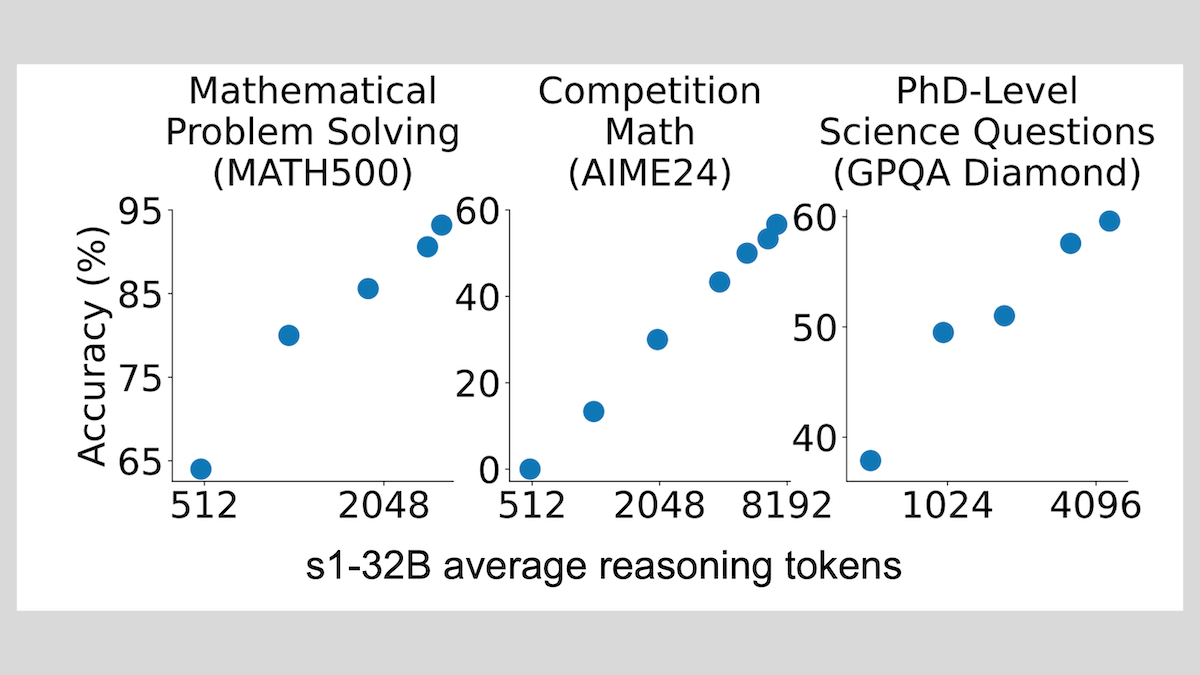
Model s1: fine-tuning dengan sedikit sampel dapat mencapai penalaran, teknik “Wait” meningkatkan kinerja: Peneliti dari Universitas Stanford dan institusi lainnya mengembangkan model s1, membuktikan bahwa hanya dengan sekitar 1000 sampel chain-of-thought (CoT) untuk fine-tuning terawasi, LLM yang telah dilatih sebelumnya (seperti Qwen 2.5-32B) dapat memiliki kemampuan penalaran. Penelitian juga menemukan bahwa dengan memaksa model menghasilkan token “Wait” selama proses penalaran untuk memperpanjang rantai penalaran, akurasi model pada tugas-tugas seperti matematika dapat ditingkatkan secara signifikan, membuat kinerjanya mendekati OpenAI o1-preview. Penemuan ini memberikan ide baru untuk meningkatkan kemampuan penalaran model dengan biaya rendah (Sumber: DeepLearning.AI Blog)
ThinkPRM: model process reward generatif yang dapat dilatih hanya dengan 8K label: Para peneliti mengusulkan ThinkPRM, sebuah model process reward generatif (PRM) yang hanya memerlukan 8K label proses untuk fine-tuning. Model ini mampu memvalidasi proses penalaran dengan menghasilkan long chains-of-thought, mengatasi masalah mahalnya data pengawasan tingkat langkah yang besar yang diperlukan untuk melatih PRM. Kode, model, dan data terkait telah dirilis di GitHub dan Hugging Face (Sumber: Reddit r/MachineLearning)
🧰 Alat
Zed merilis editor kode AI yang diklaim tercepat di dunia: Zed meluncurkan editor kode AI yang diklaim sebagai yang tercepat di dunia. Editor ini dibangun dari awal menggunakan Rust, bertujuan untuk mengoptimalkan kolaborasi antara manusia dan AI, serta menyediakan pengalaman pengeditan agen (agentic editing experience) yang secepat kilat. Editor ini mendukung model populer seperti Claude 3.7 Sonnet dan memungkinkan pengguna untuk menggunakan kunci API mereka sendiri atau menggunakan model lokal melalui Ollama (Sumber: andersonbcdefg、ollama)
Hugging Face meluncurkan nanoVLM: pustaka model bahasa visual minimalis: Hugging Face merilis nanoVLM sebagai open-source, sebuah pustaka PyTorch murni yang bertujuan untuk melatih model bahasa visual (VLM) dari awal dengan sekitar 750 baris kode. Model ini mencapai akurasi 35.3% pada tolok ukur MMStar, sebanding dengan SmolVLM-256M, tetapi memerlukan waktu GPU 100 kali lebih sedikit untuk pelatihan. nanoVLM menggunakan SigLiP-ViT sebagai visual encoder, LLaMA-style decoder, dan menghubungkan keduanya melalui proyektor modalitas, cocok untuk pembelajaran, pembuatan prototipe, atau membangun VLM kustom (Sumber: clefourrier、ben_burtenshaw、Reddit r/LocalLLaMA)
DBOS merilis DBOS Python 1.0: alat alur kerja persisten yang ringan: DBOS merilis versi DBOS Python 1.0. Alat ini bertujuan untuk menyediakan kemampuan alur kerja persisten yang ringan dan mudah digunakan untuk aplikasi Python (termasuk proses bisnis, otomatisasi AI, pipeline data, dll.). Versi baru ini mencakup antrean persisten (mendukung pembatasan konkurensi, pembatasan laju, batas waktu, prioritas, deduplikasi, dll.), manajemen alur kerja terprogram (melalui tabel Postgres untuk kueri, jeda, lanjutkan, mulai ulang, dll.), dukungan kode sinkron/asinkron, dan alat yang ditingkatkan (dasbor, visualisasi, dll.) (Sumber: lateinteraction)
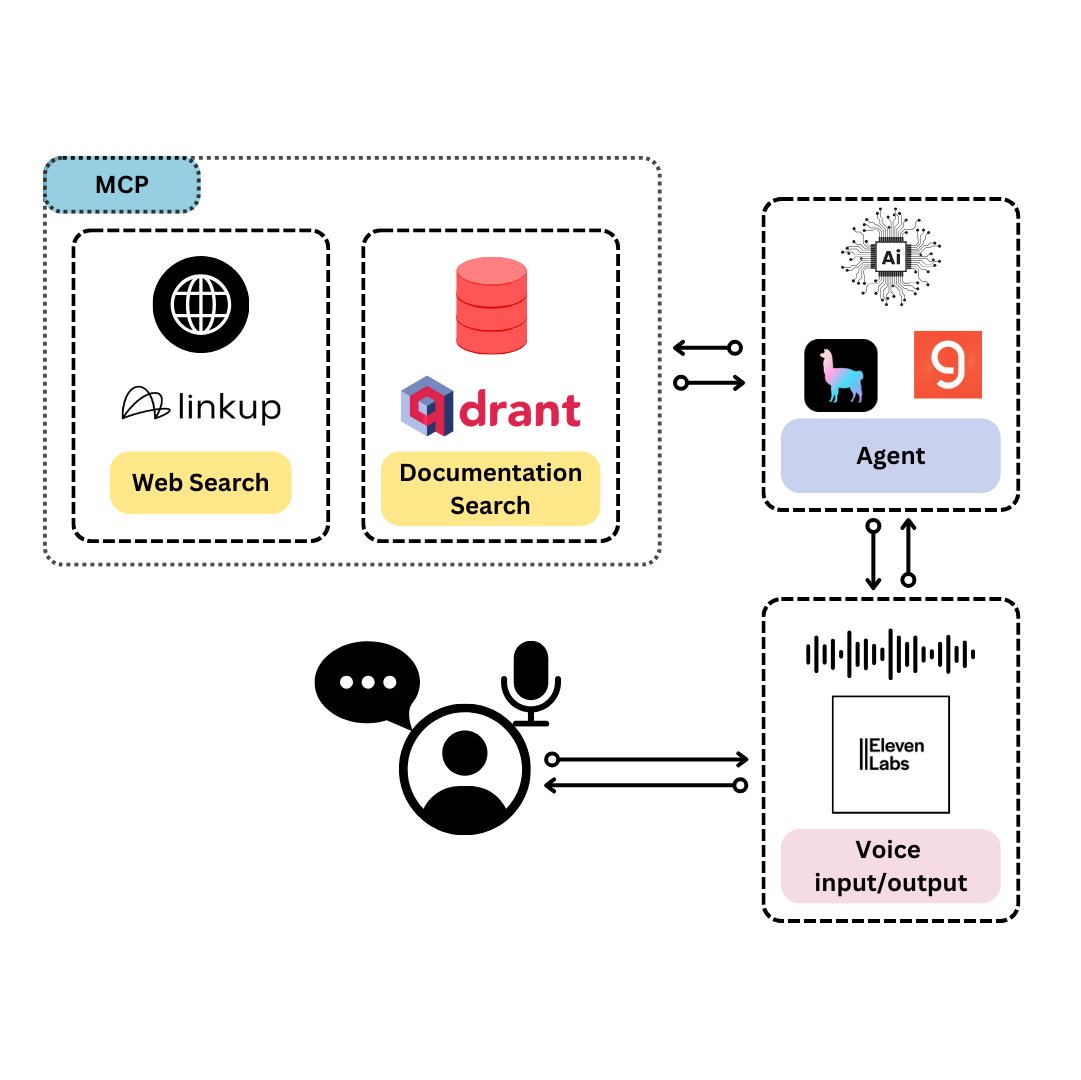
Qdrant meluncurkan TySVA: asisten suara yang dirancang untuk pengembang TypeScript: Qdrant meluncurkan TySVA (TypeScript Voice Assistant), asisten suara yang bertujuan untuk memberikan jawaban yang akurat dan sadar konteks kepada pengembang TypeScript. TySVA menggunakan penyimpanan lokal Qdrant untuk dokumen TypeScript, mengintegrasikan platform Linkup untuk mengambil data web yang relevan, dan memanfaatkan LlamaIndex untuk memilih sumber data terbaik. TySVA mendukung input suara dan teks, membantu pengembang mendapatkan bantuan yang andal dan bebas genggam saat melakukan pengkodean (Sumber: qdrant_engine、qdrant_engine)
LlamaIndex meluncurkan fitur baru LlamaExtract: mendukung kutipan dan penalaran: Alat LlamaExtract dari LlamaIndex menambahkan fitur baru yang bertujuan untuk meningkatkan kredibilitas dan transparansi aplikasi AI. Fitur baru ini memungkinkan penyediaan kutipan sumber (citations) yang akurat dan proses penalaran ekstraksi (reasoning) saat mengekstrak informasi dari sumber data yang kompleks (seperti file SEC). Ini membantu pengembang membangun sistem AI yang lebih bertanggung jawab dan dapat dijelaskan (Sumber: jerryjliu0、jerryjliu0、jerryjliu0)

Pengembang Hugging Face membangun prototipe server MCP, menghubungkan Agent dengan Hub: Seorang pengembang Hugging Face, Wauplin, sedang mengembangkan prototipe server Hugging Face MCP (Machine Communication Protocol) yang bertujuan untuk menghubungkan AI Agent dengan Hugging Face Hub. Prototipe ini dapat dianggap sebagai “HfApi bertemu MCP”, memungkinkan Agent berinteraksi dengan Hub melalui protokol, misalnya untuk berbagi dan mengedit model, dataset, Spaces, dll. Pengembang sedang meminta umpan balik dari komunitas mengenai kegunaan dan potensi kasus penggunaan alat ini (Sumber: ClementDelangue、ClementDelangue、huggingface)

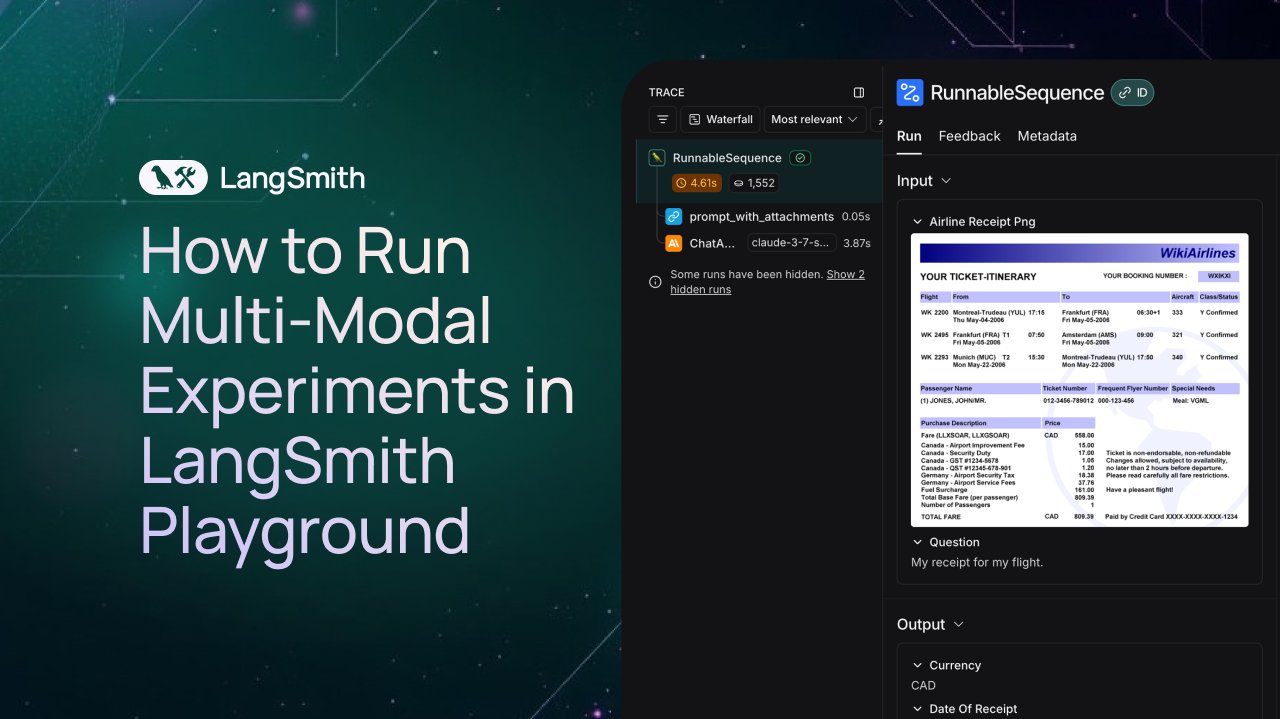
LangSmith menambahkan dukungan observasi dan evaluasi untuk Agent multimodal: Platform LangSmith sekarang mendukung pemrosesan file gambar, PDF, dan audio di Playground, antrean anotasi, dan dataset. Pembaruan ini mempermudah pembuatan dan evaluasi aplikasi multimodal (seperti Agent ekstraksi tiket). Video demo dan dokumentasi resmi telah dirilis untuk membantu pengguna memulai penggunaan fitur baru ini (Sumber: LangChainAI、Hacubu、hwchase17)
DFloat11 merilis versi kompresi lossless model FLUX.1, dapat berjalan di VRAM 20GB: Proyek DFloat11 merilis versi kompresi lossless dari model FLUX.1-dev dan FLUX.1-schnell (parameter 12B). Melalui metode kompresi DFloat11 (menerapkan entropy encoding pada bobot BFloat16), ukuran model berkurang dari 24GB menjadi sekitar 16.3GB (sekitar 30%), sambil mempertahankan output yang sama. Hal ini memungkinkan model-model ini berjalan pada satu GPU dengan VRAM 20GB atau lebih, dengan hanya menambah beberapa detik overhead tambahan per gambar. Model dan kode terkait telah dirilis di Hugging Face dan GitHub (Sumber: Reddit r/LocalLLaMA)

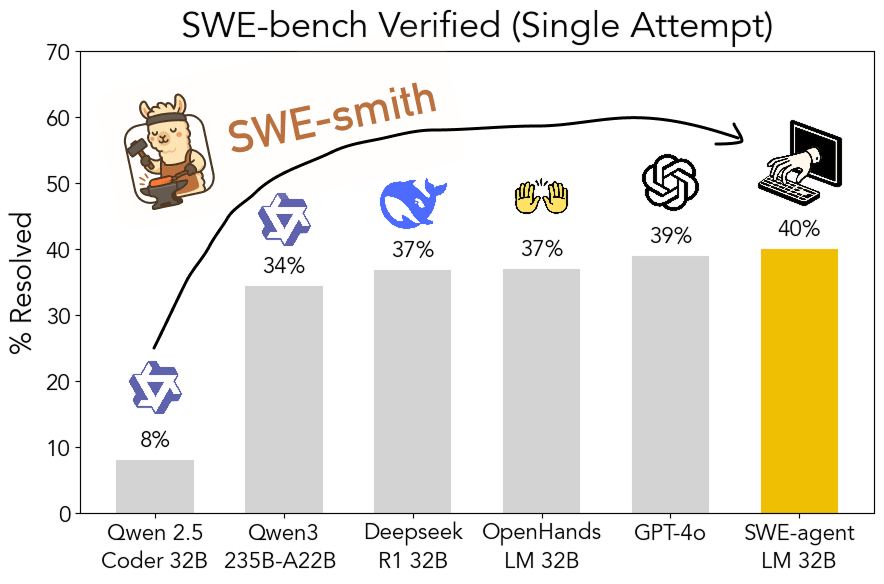
Toolkit SWE-smith open-source: menghasilkan data pelatihan rekayasa perangkat lunak yang dapat diskalakan: Peneliti dari Universitas Stanford merilis SWE-smith sebagai open-source, sebuah pipeline yang dapat diskalakan untuk menghasilkan data pelatihan rekayasa perangkat lunak dari repositori Python mana pun. Dengan menggunakan toolkit ini, lebih dari 50.000 instance telah dihasilkan, dan berdasarkan ini, model SWE-agent-LM-32B dilatih, yang mencapai 40.2% Pass@1 pada tolok ukur SWE-bench Verified, menjadi model open-source dengan kinerja terbaik pada tolok ukur tersebut. Kode, data, dan model semuanya telah dibuka (Sumber: OfirPress、stanfordnlp、stanfordnlp、huybery、Reddit r/LocalLLaMA)
📚 Belajar
Weaviate merilis kursus gratis: evaluasi dan pemilihan model embedding: Weaviate Academy meluncurkan kursus gratis tentang “Evaluasi dan Pemilihan Model Embedding”. Kursus ini menekankan pentingnya melampaui tolok ukur umum (seperti MTEB), membimbing peserta untuk menyusun “golden evaluation set” untuk kasus penggunaan tertentu, dan menetapkan tolok ukur kustom untuk memilih model embedding yang paling sesuai, serta mengevaluasi apakah model yang baru dirilis cocok. Ini sangat penting untuk membangun sistem pencarian dan RAG yang efisien (Sumber: bobvanluijt)
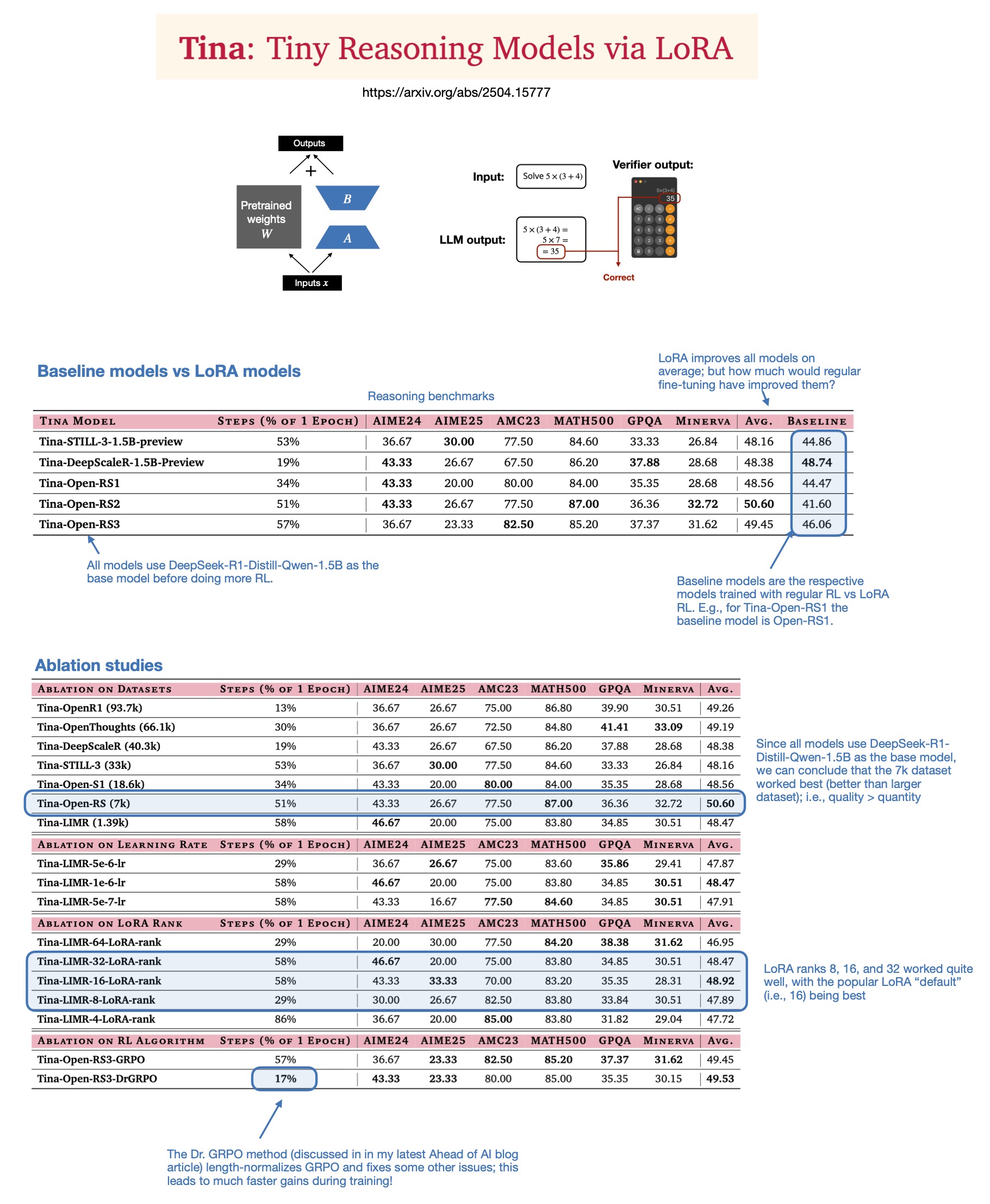
Sebastian Rasbt membahas nilai LoRA dalam model penalaran tahun 2025: Setelah membaca paper “Tina: Tiny Reasoning Models via LoRA”, Sebastian Rasbt meninjau kembali signifikansi LoRA (Low-Rank Adaptation) di era model besar saat ini. Meskipun teknik fine-tuning parameter penuh dan distilasi populer, Rasbt percaya bahwa LoRA masih memiliki nilai dalam skenario tertentu (seperti tugas penalaran, skenario multi-klien/multi-kasus penggunaan). Paper tersebut menunjukkan kemungkinan menggunakan LoRA yang dikombinasikan dengan reinforcement learning (RL) untuk meningkatkan kemampuan penalaran model kecil (1.5B) dengan biaya rendah (hanya biaya pelatihan $9), dan LoRA mengungguli fine-tuning RL standar pada beberapa tolok ukur. Karakteristik LoRA yang tidak memodifikasi model dasar membuatnya hemat biaya ketika perlu menyimpan sejumlah besar bobot model yang disesuaikan (Sumber: rasbt)
DeepLearning.AI meluncurkan kursus baru: membangun agen suara AI tingkat produksi: DeepLearning.AI bekerja sama dengan LiveKit dan RealAvatar meluncurkan kursus singkat baru berjudul “Membangun Agen Suara AI Tingkat Produksi”. Kursus ini bertujuan untuk mengajarkan cara membangun agen suara AI yang dapat melakukan percakapan real-time, merespons dengan latensi rendah, dan terdengar alami. Peserta akan mengimplementasikan teknik seperti deteksi aktivitas suara, giliran berbicara, dan mempelajari cara mengoptimalkan arsitektur untuk mengurangi latensi, yang pada akhirnya membangun dan menerapkan agen suara yang dapat diskalakan. Kursus ini diajarkan oleh CEO LiveKit, advokat pengembang, dan kepala AI RealAvatar (Sumber: DeepLearningAI、AndrewYNg)
LangChain dan LangGraph bersama-sama mengadakan kuliah teknis ACM: Kontributor pengembang awal LangChain, Mayowa Oshin, dan pencipta LangGraph, Nuno Campos, akan berbagi dalam kuliah teknis ACM tentang cara menggunakan LangChain dan LangGraph untuk membangun AI Agent dan aplikasi LLM yang andal. Kuliah ini gratis dan akan disiarkan langsung, pendaftar akan menerima tautan untuk menonton setelahnya (Sumber: hwchase17、hwchase17)

Cohere Labs mengadakan kuliah tentang kedalaman optimasi orde pertama: Cohere Labs mengundang Jeremy Bernstein pada tanggal 8 Mei untuk memberikan presentasi berjudul “Depths of First-Order Optimization”. Kuliah ini bertujuan untuk membahas secara mendalam aplikasi dan teori algoritma optimasi dalam machine learning (Sumber: eliebakouch)

AI2 mengadakan acara AMA model OLMo: Allen Institute for AI (AI2) akan mengadakan acara “Ask Me Anything” (AMA) tentang keluarga model bahasa terbuka OLMo pada tanggal 8 Mei pukul 8-10 pagi (Waktu Pasifik) di subreddit r/huggingface, mengundang para peneliti untuk menjawab pertanyaan komunitas (Sumber: natolambert)

💼 Bisnis
OpenAI berencana mengurangi rasio bagi hasil yang dibayarkan kepada Microsoft: Menurut laporan The Information, OpenAI telah memberi tahu investor bahwa mereka berencana untuk mengurangi rasio bagi hasil yang dibayarkan kepada pendukung terbesarnya, Microsoft, selama proses restrukturisasi perusahaan. Detail spesifik dan dampak potensial belum sepenuhnya diungkapkan, tetapi ini mungkin menandakan perubahan dalam hubungan komersial antara kedua perusahaan (Sumber: steph_palazzolo)
Investor ventura memberikan kekuasaan lebih besar kepada pendiri AI, memicu kekhawatiran gelembung: The Information melaporkan bahwa investor ventura (VC) menawarkan persyaratan yang belum pernah ada sebelumnya untuk menarik pendiri AI terkemuka (terutama mereka yang memiliki pengalaman eksekutif di laboratorium AI terkenal), termasuk hak veto dewan, VC tidak menempati kursi dewan, dan mengizinkan pendiri untuk menjual sebagian saham. Fenomena ini dianggap oleh beberapa orang sebagai tanda kemungkinan adanya gelembung di bidang AI (Sumber: steph_palazzolo)
Toloka menerima investasi strategis yang dipimpin oleh Bezos Expeditions, Mikhail Parakhin bergabung sebagai Ketua Dewan: Perusahaan data anotasi dan data pelatihan AI, Toloka, mengumumkan telah menerima investasi strategis yang dipimpin oleh Bezos Expeditions milik Jeff Bezos, dengan partisipasi dari mantan eksekutif Microsoft Mikhail Parakhin, yang juga bergabung sebagai Ketua Dewan. Putaran investasi ini akan mendukung Toloka dalam memperluas solusi kolaborasi manusia-AI (human+AI) dan mengembangkan lebih lanjut bisnis pengumpulan dan anotasi data (Sumber: menhguin、teortaxesTex、TheTuringPost)

🌟 Komunitas
Diskusi tentang penggunaan wajar (Fair Use) data pelatihan LLM: Dorialexander menyebutkan bahwa argumen penggunaan wajar data pelatihan LLM sangat bergantung pada asumsi bahwa LLM tidak bersaing secara komersial langsung dengan sumber pelatihan. Seiring dengan meningkatnya kemampuan LLM (misalnya, Perplexity mulai menawarkan pengalaman membaca non-fiksi), asumsi ini mungkin ditantang, yang menimbulkan pertanyaan baru tentang hak cipta dan persaingan komersial (Sumber: Dorialexander)
Kekhawatiran dan diskusi tentang membanjirnya konten yang dihasilkan AI: Pengguna di media sosial dan Reddit menyatakan keprihatinan tentang membanjirnya konten berkualitas rendah dan berulang yang dihasilkan AI (seperti video cerita Reddit yang dihasilkan AI). Pengguna percaya bahwa ini menekan ruang bagi kreator manusia, menyampaikan informasi palsu atau homogen, dan menyatakan ketidakpuasan terhadap fenomena teknologi AI yang digunakan untuk mendapatkan keuntungan dengan mudah tanpa orisinalitas (Sumber: Reddit r/ArtificialInteligence)
Diskusi filosofis tentang apakah AI sudah memiliki kesadaran: Komunitas Reddit kembali membahas apakah AI mungkin sudah memiliki kesadaran. Pendukung berpendapat bahwa definisi kita tentang kesadaran mungkin terlalu sempit atau berpusat pada manusia, sementara penentang menekankan bahwa mekanisme inti LLM saat ini (seperti memprediksi token berikutnya) tidak cukup untuk menghasilkan kesadaran sejati. Diskusi ini mencerminkan keingintahuan dan perbedaan pendapat publik yang berkelanjutan tentang sifat AI dan potensi masa depannya (Sumber: Reddit r/ArtificialInteligence)
Diskusi tentang penurunan kinerja dan perubahan perilaku ChatGPT (4o): Pengguna Reddit melaporkan bahwa model ChatGPT 4o baru-baru ini menunjukkan penurunan kinerja dalam memproses dokumen panjang dan mempertahankan memori kontekstual, mengalami lebih banyak halusinasi, dan bahkan tidak dapat membaca format dokumen yang sebelumnya dapat diproses. Sementara itu, OpenAI juga mengakui bahwa versi GPT-4o yang baru diperbarui mengalami masalah sanjungan berlebihan (sycophancy) dan telah dikembalikan. Hal ini menimbulkan kekhawatiran komunitas tentang stabilitas model dan kontrol kualitas iterasi (Sumber: Reddit r/ChatGPT、DeepLearning.AI Blog)
Dampak AI pada model pendidikan dan refleksi: Diskusi komunitas menunjukkan bahwa model pendidikan Amerika Serikat yang berfokus pada pekerjaan rumah dan esai individu membuatnya sangat rentan terhadap dampak kemampuan AI (seperti LLM) untuk menyelesaikan tugas secara otomatis. Sebaliknya, beberapa negara Eropa (seperti Denmark) lebih menekankan kolaborasi di sekolah, diskusi, dan pembelajaran berbasis proyek, sehingga kurang terpengaruh oleh AI. Hal ini memicu refleksi tentang model pendidikan masa depan, dengan pandangan bahwa penekanan harus lebih besar pada pengembangan keterampilan interpersonal seperti berpikir kritis dan kolaborasi, memanfaatkan AI untuk menangani tugas-tugas mekanis, dan mendorong pendidikan ke arah yang lebih sinkron dan sosial (Sumber: alexalbert__、riemannzeta、aidan_mclau)
💡 Lainnya
Kemajuan aplikasi AI di bidang robotika: Berbagai sumber menunjukkan contoh aplikasi AI di bidang robotika: termasuk koki robot yang dapat menggoreng nasi dalam 90 detik, demonstrasi aplikasi robot Figure AI di dunia nyata, robot Pickle yang mendemonstrasikan pembongkaran muatan dari trailer truk yang berantakan, robot Unitree G1 yang menjaga keseimbangan di medan yang tidak rata serta tampilan struktur internalnya, robot Mori3 yang dapat berubah bentuk yang dikembangkan oleh EPFL Swiss, dll. Kasus-kasus ini menunjukkan potensi AI dalam meningkatkan otonomi, kemampuan beradaptasi, dan kepraktisan robot (Sumber: Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Sentdex)

Eksplorasi aplikasi teknologi AI di industri tertentu (medis, tekstil, ponsel): Johnson & Johnson membagikan strategi AI-nya, dengan fokus pada aplikasi di bidang seperti bantuan penjualan, percepatan penelitian dan pengembangan obat (penyaringan senyawa, optimasi uji klinis), prediksi risiko rantai pasokan, dan komunikasi internal (robot tanya jawab SDM). Sementara itu, teknologi AI juga memberdayakan industri tekstil tradisional, mulai dari desain yang dibantu AI, kontrol pencelupan presisi hingga inspeksi kualitas otomatis, meningkatkan efisiensi dan keberlanjutan. Industri ponsel menganggap AI sebagai mesin pertumbuhan baru, dengan produsen bersaing dalam model besar di sisi perangkat, sistem operasi asli AI, dan layanan cerdas berbasis skenario, membentuk tiga faksi utama: Apple, Huawei, dan kubu terbuka (Sumber: DeepLearning.AI Blog、36氪、36氪)
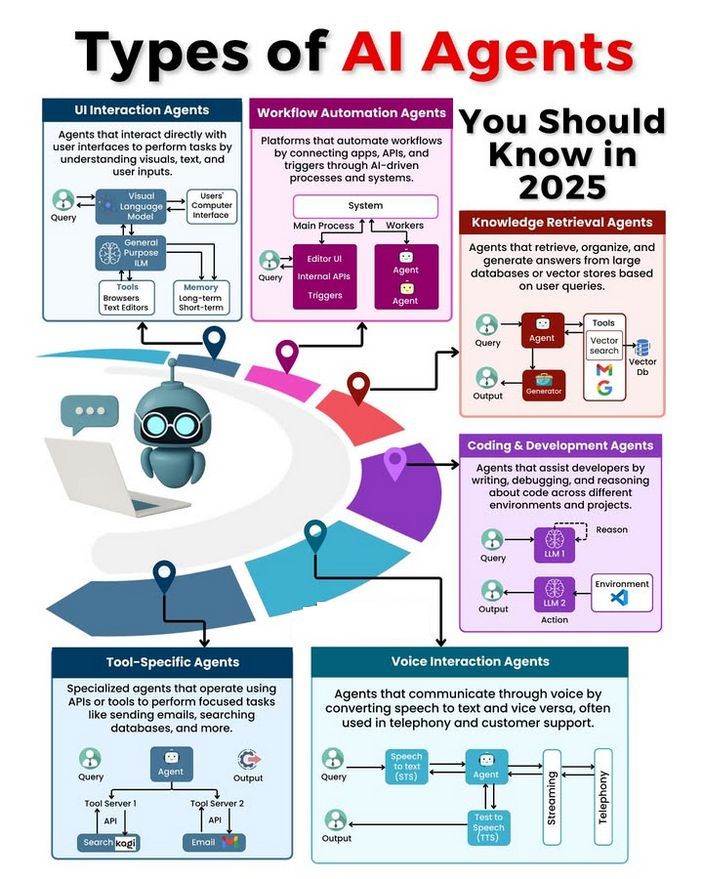
Diskusi tentang jenis dan pengembangan AI Agent: Komunitas membahas berbagai jenis AI Agent (seperti agen refleks sederhana, agen refleks berbasis model, agen berbasis tujuan, agen berbasis utilitas, agen pembelajar), dan mengeksplorasi metodologi untuk membangun Agent yang andal (seperti menggunakan LangChain/LangGraph). Sementara itu, ada juga pandangan bahwa AGI di masa depan mungkin bukan model tunggal, melainkan terdiri dari beberapa model khusus yang berkolaborasi (Sumber: Ronald_vanLoon、hwchase17、nrehiew_)