
Kata Kunci:Anthropic, Claude 3.5 Haiku, Qwen3, Phi-4-reasoning, LLM Fisika, LangGraph, AI Agent, Metode Pelacakan Sirkuit (Attribution Graphs), Kemampuan Pengkodean Qwen3-235B-A22B, Komputasi Penalaran Phi-4-reasoning, Agen Pemeriksaan Faktur LangGraph, Moondream Station VLM Lokal, Model Bahasa Besar (LLM), Kemampuan penalaran AI, Grafik atribusi untuk pelacakan sirkuit, Pengkodean model Qwen3, Komputasi waktu nyata untuk penalaran, Agen AI untuk pemeriksaan faktur, Model Visi Bahasa Lokal (VLM)
🔥 Fokus
Anthropic merilis penelitian biologi LLM, mendalami mekanisme internal model: Anthropic merilis posting blog penelitian mendalam berjudul “On the Biology of a Large Language Model”, menggunakan metode pelacakan sirkuitnya (Attribution Graphs) untuk menyelidiki mekanisme internal model Claude 3.5 Haiku dalam berbagai konteks. Penelitian ini, melalui pelatihan “model pengganti” (Transcoder) yang lebih mudah dianalisis, mengungkap bagaimana model melakukan penjumlahan (melalui berbagai jalur perkiraan daripada algoritma yang tepat), melakukan diagnosis medis (membentuk konsep diagnostik internal), dan menangani halusinasi serta penolakan (adanya sirkuit penolakan default yang dapat ditekan oleh fitur “jawaban yang diketahui”). Studi ini memberikan perspektif baru untuk memahami cara kerja internal LLM, tetapi juga memicu diskusi tentang keterbatasan metodologi dan posisi Anthropic sendiri (Sumber: YouTube – Yannic Kilcher
)

Model seri Qwen3 menunjukkan performa kuat, menarik perhatian komunitas open source: Model bahasa besar seri Qwen3 yang dirilis Alibaba berkinerja sangat baik di berbagai benchmark, terutama dalam kemampuan coding. Hasil Aider Polyglot Coding Benchmark menunjukkan bahwa performa Qwen3-235B-A22B (tanpa chain-of-thought diaktifkan) tampaknya mengungguli Claude 3.7 dengan token chain-of-thought 32k yang diaktifkan, dan dengan biaya yang jauh lebih rendah. Sementara itu, Qwen3-32B juga melampaui GPT-4.5 dan GPT-4o dalam benchmark ini. Komunitas juga secara aktif mengeksplorasi pruning model Qwen3 (seperti memangkas 30B menjadi 16B) dan fine-tuning (seperti menggunakan Unsloth untuk fine-tuning dengan VRAM rendah), lebih lanjut menurunkan hambatan aplikasi untuk model berperforma tinggi, menandakan bahwa model besar open source dari Tiongkok mungkin akan menempati posisi penting di pasar (Sumber: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
Microsoft merilis model Phi-4-reasoning, fokus pada penalaran kompleks: Microsoft merilis model Phi-4-reasoning di Hugging Face, sebuah model penalaran dengan 14 miliar parameter. Model ini mencapai performa state-of-the-art (SOTA) pada tugas penalaran kompleks dengan memanfaatkan komputasi saat inferensi (inference-time compute). Ini menunjukkan bahwa desain model sedang mengeksplorasi peningkatan kemampuan spesifik dengan menambah jumlah komputasi pada tahap inferensi, bukan hanya bergantung pada perluasan skala model, memberikan ide baru untuk mencapai performa tinggi pada model kecil (Sumber: _akhaliq)
Kemajuan baru dalam penelitian fisika LLM: “Momen Galileo” untuk desain arsitektur: Zeyuan Allen-Zhu merilis bagian keempat dari seri penelitian tentang fisika model bahasa besar, dengan fokus pada desain arsitektur. Penelitian ini, melalui lingkungan pra-pelatihan sintetis yang terkontrol, mengungkap batasan dan potensi nyata dari berbagai arsitektur LLM (seperti Transformer, Mamba). Penelitian ini memperkenalkan lapisan residual horizontal ringan bernama “Canon”, yang secara signifikan meningkatkan kemampuan penalaran model. Pada saat yang sama, penelitian menemukan bahwa keunggulan model Mamba sebagian besar berasal dari lapisan conv1d tersembunyinya, bukan SSM itu sendiri. Serangkaian eksperimen ini memberikan perspektif baru dan teori dasar untuk memahami dan mengoptimalkan arsitektur LLM (Sumber: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 Tren
Amazon merilis model kecerdasan buatan umum “Amazon Artificial General Intelligence”: Model ini memiliki panjang konteks 1 juta token dan kemampuan input multimodal, dioptimalkan untuk code generation, RAG, pemahaman video/dokumen, function calling, dan interaksi Agent. Harga ditetapkan $2.5/juta token untuk input dan $12.5/juta token untuk output. Evaluasi awal menunjukkan performanya di AI Index sebanding dengan Llama-4 Scout, tetapi kalah dalam kecepatan dan biaya, mungkin cocok untuk skenario aplikasi multimodal konteks panjang atau Agent tertentu (Sumber: scaling01)

Model Anthropic Claude sekarang menyediakan fitur pencarian web dalam paket berbayar global: Fitur ini memungkinkan Claude melakukan pencarian cepat saat menangani tugas sehari-hari, dan untuk pertanyaan yang lebih kompleks, akan menjelajahi beberapa sumber termasuk Google Workspace. Ini meningkatkan kemampuan Claude untuk mendapatkan informasi real-time dan menangani tugas yang memerlukan pengetahuan eksternal (Sumber: menhguin)

IBM merilis model arsitektur hibrida granite-4.0-tiny-7B-A1B-preview: Pratinjau model 7B ini mengadopsi arsitektur hibrida Mamba-2 dan Transformer, di mana setiap blok Transformer berisi 9 blok Mamba. Ide desainnya adalah memanfaatkan blok Mamba untuk menangkap konteks global dan meneruskannya ke lapisan atensi untuk analisis konteks lokal. Skor MMLU awal cukup baik, tetapi hasil tes kemampuan lain seperti matematika dan pemrograman belum diumumkan (Sumber: karminski3)
OpenAI ChatGPT menambahkan fitur belanja: OpenAI sedang menguji coba fitur belanja di ChatGPT, yang bertujuan untuk menyederhanakan proses pencarian, perbandingan, dan pembelian produk. Fitur baru termasuk tampilan hasil produk yang ditingkatkan, detail produk visual yang mencakup harga dan ulasan, serta tautan pembelian langsung. OpenAI menekankan bahwa hasil produk dipilih secara independen dan bukan iklan (Sumber: sama)
Detail pelatihan model Qwen3 0.6B menarik perhatian: Pengguna Dorialexander menunjukkan bahwa, berdasarkan informasi, model Qwen 0.6B tampaknya juga dilatih menggunakan hingga 36T token. Jika benar, ini akan mencetak rekor baru yang melampaui hukum Chinchilla (sekitar 60.000 token per parameter), menunjukkan tren peningkatan kemampuan model kecil dengan sangat meningkatkan jumlah data pelatihan (Sumber: Dorialexander)

Algoritma rekomendasi X (Twitter) akan diganti dengan versi ringan Grok: Elon Musk mengumumkan bahwa algoritma rekomendasi platform X sedang diganti dengan versi ringan dari Grok, yang diharapkan akan secara signifikan meningkatkan efek rekomendasi. Umpan balik pengguna menunjukkan peningkatan efek algoritma, berspekulasi mungkin terkait dengan perubahan personel Exa AI baru-baru ini dan X mulai menggunakan Embeddings untuk rekomendasi (Sumber: menhguin, colin_fraser, paul_cal)
Allen AI merilis model MoE sepenuhnya terbuka OLMoE: Model ini adalah model Mixture of Experts (MoE) canggih, dengan 1,3 miliar parameter aktif dan 6,9 miliar total parameter. Sepenuhnya open source berarti komunitas dapat dengan bebas menggunakan, memodifikasi, dan meneliti model ini, mendorong pengembangan dan penerapan arsitektur MoE (Sumber: dl_weekly)
Model Mistral-Small-3.1-24B-Instruct-2503 mendapat perhatian: Pengguna Reddit membahas model Mistral-Small-3.1-24B-Instruct-2503, yang memiliki skor UGI (Uncensored General Intelligence) tinggi dan berkinerja lebih baik dalam pemahaman bahasa alami dan coding dibandingkan model sejenis dengan skor tinggi. Pengguna menganggapnya sebagai pilihan ideal untuk inferensi tanpa sensor pada GPU tunggal dan mendukung penggunaan alat. Namun, juga disebutkan bahwa gaya penulisannya mungkin agak membosankan dan berulang, kurang kreatif dibandingkan model seperti Gemma 3 (Sumber: Reddit r/LocalLLaMA)
🧰 Alat
CreateMVP 2.0 dirilis, mengoptimalkan alur kerja pengembangan berbasis AI: CreateMVP diperbarui ke versi 2.0, bertujuan untuk mengatasi masalah hasil yang kurang memuaskan saat langsung meminta AI untuk membangun aplikasi. Versi baru ini membantu pengguna membuat “cetak biru” yang lebih akurat untuk AI dengan menyediakan UI yang lebih lancar, metode otentikasi yang mudah (mendukung Replit, Google, GitHub, segera mendukung XAI), menghasilkan rencana pengembangan yang lebih detail (meningkat dari 11KB menjadi 40KB+), pratinjau file instan, dan integrasi obrolan dengan model AI teratas, memastikan AI membangun aplikasi sesuai dengan visi pengguna (Sumber: amasad)
LlamaIndex meluncurkan Agent pencocokan faktur: Alat ini menunjukkan penerapan AI Agent dalam tugas otomatisasi massal, bukan interaksi obrolan tradisional. Alat ini dapat memproses sejumlah besar dokumen faktur tidak terstruktur, mengekstrak detail relevan, secara otomatis mencocokkan dengan pesanan pembelian, dan menandai perbedaan. Intinya adalah lapisan kecerdasan dokumen Agentic berbasis LlamaCloud parsing/extraction dan LlamaIndex.TS workflow inference, menunjukkan potensi Agent dalam otomatisasi proses bisnis nyata dan dianggap akan menggantikan RPA tradisional (Sumber: jerryjliu0)
LangGraph Expense Tracker: Sistem manajemen pengeluaran otomatis: Ini adalah contoh sistem manajemen pengeluaran otomatis yang dibangun menggunakan LangGraph. Sistem ini mampu memproses faktur, memanfaatkan fitur ekstraksi data cerdas, menyimpan informasi di PostgreSQL, dan menyertakan langkah verifikasi manual. Proyek ini menunjukkan kemampuan LangGraph dalam membangun alur kerja otomatisasi bisnis praktis (Sumber: LangChainAI, Hacubu, hwchase17)
Moondream Station dirilis: Jalankan VLM secara lokal: Moondream merilis Moondream Station, memungkinkan pengguna menjalankan model bahasa visual (VLM) Moondream secara lokal di Mac, tanpa perlu terhubung ke cloud. Menyediakan akses melalui CLI atau port lokal, pengaturannya sederhana dan sepenuhnya gratis, menurunkan hambatan untuk menerapkan dan menggunakan VLM secara lokal (Sumber: vikhyatk)
ChaiGenie: Ekstensi pencarian dokumen Chrome berbasis LangChain: ChaiGenie adalah ekstensi Chrome yang mengintegrasikan Gemini dan Qdrant dari LangChain untuk menyediakan fungsionalitas pencarian dokumen. Mendukung multi-bahasa dan pencarian berbasis vektor, bertujuan untuk meningkatkan efisiensi pengguna dalam mencari dan memahami konten dokumen saat menjelajahi web (Sumber: LangChainAI)

Research Agent: Aplikasi web asisten penelitian sekali klik: Ini adalah aplikasi web yang dibangun di atas kerangka kerja asisten penelitian berbasis LangGraph, yang bertujuan untuk menyederhanakan proses penelitian. Pengguna hanya perlu satu klik untuk mendapatkan hasil penelitian, menunjukkan potensi aplikasi LangGraph dalam membangun alur kerja berbasis AI untuk menyederhanakan tugas-tugas kompleks (Sumber: LangChainAI)

Muyan-TTS: Model TTS open source, latensi rendah, dan dapat disesuaikan: Tim ChatPods merilis Muyan-TTS, model text-to-speech yang sepenuhnya open source, bertujuan untuk mengatasi masalah kualitas model TTS open source yang ada yang kurang tinggi atau kurang terbuka. Didasarkan pada LLaMA-3.2-3B dan SoVITS yang dioptimalkan, mendukung zero-shot TTS dan kloning suara, serta menyediakan alur kerja pelatihan dan pemrosesan data yang lengkap, memudahkan pengembang untuk melakukan fine-tuning dan pengembangan sekunder, terutama cocok untuk skenario aplikasi yang membutuhkan suara yang disesuaikan (Sumber: Reddit r/MachineLearning)
Integrasi Mem0 dengan pipeline Open Web UI: Pengguna cloudsbird membuat integrasi pipeline filter Open Web UI untuk Mem0 (MCP tidak resmi), memberikan opsi lain untuk menggunakan fungsi memori Mem0 di Open Web UI (Sumber: Reddit r/OpenWebUI)
Alat YNAB API Request mewujudkan manajemen keuangan pribadi lokal: Pengguna Megaphonix membuat alat OpenWebUI yang memanfaatkan API YNAB (You Need A Budget), memungkinkan pengguna menanyakan informasi keuangan pribadi (seperti transaksi, pengeluaran kategori, kekayaan bersih, dll.) melalui LLM secara lokal, tanpa mengirim data sensitif ke luar. Ini mengatasi kebutuhan untuk menangani informasi pribadi sensitif dengan aman saat menjalankan LLM secara lokal (Sumber: Reddit r/OpenWebUI)
Ekstensi browser AI text-to-speech gratis GPT-Reader: Pengembang mempromosikan ekstensi browser AI text-to-speech gratis yang dibuatnya, GPT-Reader, yang saat ini memiliki lebih dari 4000 pengguna. Alat ini bertujuan untuk memudahkan pengguna mengubah konten teks halaman web menjadi audio untuk didengarkan (Sumber: Reddit r/artificial)
sunnypilot: Sistem bantuan mengemudi open source: sunnypilot adalah fork dari openpilot comma.ai, menyediakan sistem bantuan mengemudi open source. Mendukung lebih dari 300 model mobil, memodifikasi perilaku interaksi bantuan mengemudi, dan sejauh mungkin mematuhi kebijakan keselamatan comma.ai. Proyek ini memanfaatkan teknologi AI (meskipun model spesifik tidak disebutkan secara eksplisit, sistem semacam ini biasanya melibatkan computer vision dan algoritma kontrol) untuk meningkatkan pengalaman berkendara (Sumber: GitHub Trending)

📚 Pembelajaran
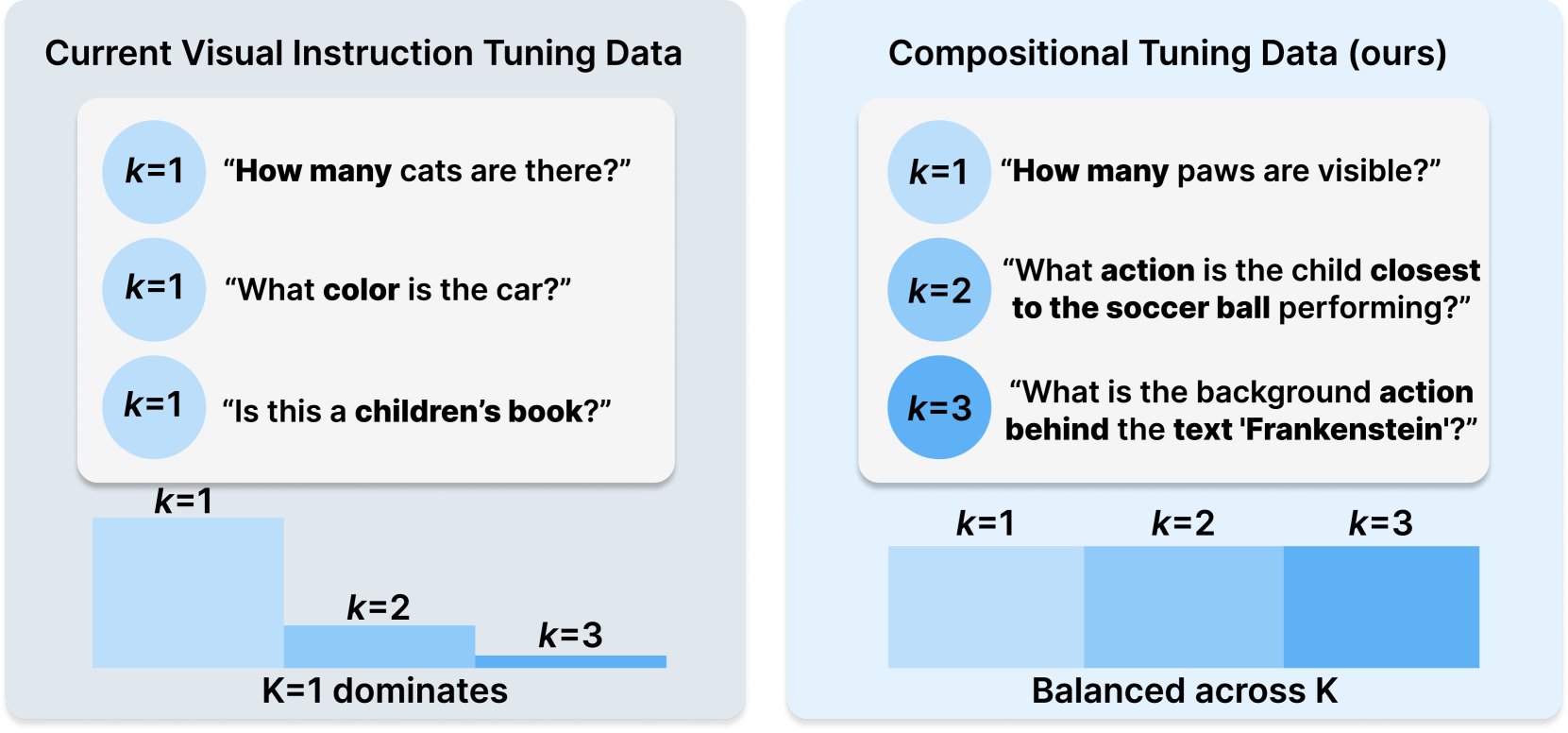
Princeton & Meta AI merilis resep dataset COMPACT: Penelitian ini dirilis di Hugging Face, mengusulkan resep data baru COMPACT, yang bertujuan untuk memperluas kemampuan Multimodal LLM dengan secara eksplisit mengontrol kompleksitas komposisi sampel pelatihan. Ini memberikan ide baru untuk meningkatkan metode pelatihan model multimodal dan meningkatkan kemampuannya untuk memahami konsep komposisi yang kompleks (Sumber: _akhaliq)
Unsloth merilis tutorial fine-tuning Qwen3: Unsloth menyediakan tutorial fine-tuning untuk model Qwen3, secara signifikan menurunkan hambatan fine-tuning. Pengguna hanya memerlukan VRAM 16GB untuk melakukan fine-tuning model Qwen3-14B, dan VRAM 17.5GB untuk fine-tuning model Qwen3-30B-A3B. Ini memungkinkan lebih banyak peneliti dan pengembang untuk melakukan pelatihan yang disesuaikan pada model open source canggih dengan sumber daya perangkat keras yang terbatas (Sumber: karminski3)
LangGraph dikombinasikan dengan Azure OpenAI membangun chatbot pencarian web cerdas: Sebuah tutorial Medium menunjukkan cara menggabungkan penggunaan LangGraph dan Azure OpenAI, serta mengintegrasikan kemampuan pencarian web Tavily, untuk membangun chatbot cerdas. Tutorial ini mencakup manajemen state dan routing kondisional untuk mencapai integrasi pencarian yang mulus, memberikan panduan praktis untuk membangun aplikasi AI yang lebih kuat yang dapat memanfaatkan informasi web real-time (Sumber: LangChainAI, hwchase17)

Blog AI Stanford membahas hubungan antara penghafalan verbatim LLM dan kemampuan umum: Sebuah artikel blog AI Stanford mendalami hubungan intrinsik antara penghafalan verbatim (verbatim memorization) model bahasa besar (LLM) dan kemampuan umumnya. Memahami hubungan ini sangat penting untuk mengevaluasi risiko model, mengoptimalkan metode pelatihan, dan menjelaskan perilaku model (Sumber: dl_weekly)
Panduan integrasi Gemini dengan LangChain: Philipp Schmid merilis panduan pengembang yang merinci cara mengintegrasikan model Gemini Google dengan kerangka kerja LangChain. Panduan ini mencakup kemampuan multimodal, pemanggilan alat (tool calling), dan implementasi output terstruktur, serta menyertakan dukungan untuk model terbaru dan contoh kode praktis, memudahkan pengembang memanfaatkan kemampuan kuat Gemini untuk membangun aplikasi LangChain (Sumber: LangChainAI, _philschmid)

Tutorial Pengantar LangGraph: Praktik alur kerja stateful: Sebuah tutorial yang diterbitkan di AI@GoPubby, melalui contoh analisis ulasan situs web, menunjukkan kemampuan alur kerja stateful LangGraph. Pelajar dapat memahami cara membangun aplikasi AI terstruktur menggunakan node yang saling terhubung dan logika sekuensial (Sumber: LangChainAI, hwchase17)
Pemikiran mendalam CEO LangChain tentang kerangka kerja Agentic (Terjemahan Bahasa Mandarin): Duta LangChain Harry Zhang menerjemahkan dan membagikan posting blog pemikiran CEO LangChain Harrison tentang kerangka kerja Agentic. Artikel tersebut menganalisis dan merangkum fungsi lebih dari 15 kerangka kerja Agent di industri dan menafsirkan cerita di baliknya, memberikan referensi berharga untuk memahami lanskap pengembangan teknologi Agent saat ini dan arah masa depan (Sumber: LangChainAI)
Kemajuan penelitian Latent Meta Attention: Pengguna Reddit membahas mekanisme atensi baru bernama Latent Meta Attention. Pengembang mengklaim mekanisme ini menantang asumsi dasar Transformer, mampu mencapai atau bahkan melampaui performa model yang ada dengan ukuran model yang lebih kecil (misalnya, mereplikasi performa BERT dengan model setengah ukuran), tetapi karena kurangnya dana dan dukungan lembaga penelitian formal, metode spesifik belum dipublikasikan (Sumber: Reddit r/deeplearning)

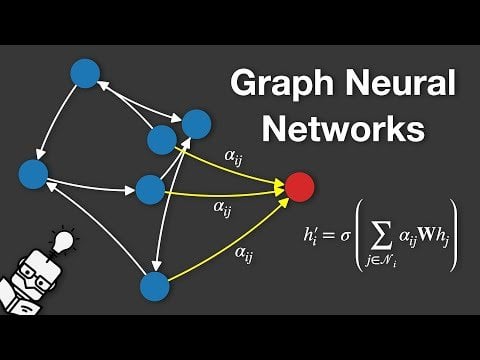
Video penjelasan Graph Neural Networks (GNN): Sebuah video yang menjelaskan Graph Neural Networks (GNNs) telah dipublikasikan di YouTube. GNN adalah model deep learning untuk memproses data terstruktur graf, dengan aplikasi luas dalam analisis jejaring sosial, sistem rekomendasi, prediksi struktur molekul, dll. Video ini bertujuan membantu penonton memahami prinsip dasar dan cara kerja GNN (Sumber: Reddit r/deeplearning)
Menggunakan GRPO untuk melatih LLM melakukan penjadwalan acara: Pengguna anakin87 berbagi pengalaman proyek menggunakan GRPO (Generalized Reward Policy Optimization) untuk melatih model bahasa melakukan penjadwalan acara. Proyek ini tidak bergantung pada sampel fine-tuning terawasi tradisional, melainkan melalui fungsi reward agar model belajar membuat jadwal berdasarkan daftar acara dan prioritas. Penulis berbagi pelajaran yang didapat dari pengaturan masalah, pembuatan data, pemilihan model, desain reward, dan proses pelatihan, serta membuat kode dan modelnya open source, memberikan studi kasus praktis untuk mengeksplorasi pelatihan LLM berbasis reward (Sumber: Reddit r/LocalLLaMA)

Berbagi sumber daya kursus AI gratis: LinkedIn AI Hub membagikan peta jalan pembelajaran AI lengkap, terinspirasi oleh kursus sertifikat AI Universitas Stanford dan disederhanakan untuk pelajar dari berbagai tingkatan. Konten mencakup dari keterampilan dasar hingga proyek praktis, dan menyediakan sumber daya berharga serta detail kursus (Sumber: Reddit r/deeplearning)
Diskusi mendalam pra-pelatihan konteks panjang Gemini: Logan Kilpatrick melakukan diskusi mendalam dengan co-lead pra-pelatihan konteks panjang Gemini, Nikolay Savinov. Diskusi mencakup dari dasar-dasar hingga teknik yang diperlukan untuk memperluas ke konteks tak terbatas, serta praktik terbaik konteks panjang untuk pengembang. Ringkasan diskusi menunjukkan bahwa mencapai konteks 1 juta token adalah target 10x dari standar saat itu; 10 juta token telah dicoba tetapi biayanya tinggi dan perangkat keras tidak mencukupi; konteks panjang dan RAG saling melengkapi; NIAH (Needle In A Haystack) sederhana telah terpecahkan, kesulitannya terletak pada item pengganggu yang keras dan pencarian multi-jarum; evaluasi berfokus pada NIAH untuk menghindari kebingungan sinyal kemampuan; panjang output saat ini terbatas (misalnya 8k) adalah masalah pasca-pelatihan; tidak ada efek “hilang di tengah” yang diamati; perlu membedakan antara pengetahuan konteks dan pengetahuan bobot; langkah selanjutnya adalah mencapai konteks 10 juta yang lebih murah dan akurat, perluasan ke 100 juta mungkin memerlukan inovasi DL baru (Sumber: shaneguML, giffmana, teortaxesTex, arohan)
🌟 Komunitas
Diskusi tentang “Vibe Coding”: Komunitas ramai membahas “Vibe Coding” (coding berdasarkan suasana hati/intuisi), yaitu sangat bergantung pada bantuan AI untuk pemrograman. Pendukung berpendapat ini mewakili masa depan, di mana pengembang lebih fokus pada “mengapa” dan “apa”, sementara AI menangani “bagaimana”, tetapi ini membutuhkan pemikiran kritis yang lebih kuat. Penentang berpendapat bahwa saat ini AI belum dapat sepenuhnya menangani debugging, peningkatan, dan pemeliharaan yang kompleks, ketergantungan berlebihan dapat menyebabkan penurunan kemampuan pengembang, menjadi “script kiddies” tingkat lanjut. Beberapa orang yang mencoba menemukan bahwa biaya waktu untuk memandu AI menyelesaikan tugas kompleks masih tinggi, tidak seefisien implementasi manual ditambah bantuan AI ringan (Sumber: Dorialexander, Reddit r/artificial, johnowhitaker)

Diskusi aplikasi dan keterbatasan AI di bidang profesional: Pengguna dotey membahas aplikasi AI di bidang profesional. Dia berpendapat bahwa AI dapat mempelajari tanya jawab publik para ahli, tetapi sulit menangani masalah yang belum pernah dilihat. Keunggulan AI terletak pada basis pengetahuan dasar yang kuat dan respons cepat, tetapi saat ini terutama bergantung pada RAG (Retrieval-Augmented Generation), yang pada dasarnya mengambil fragmen dan menyusun jawaban, bukan penalaran profesional sejati. Ini masih jauh dari melatih model yang dapat terus menghasilkan jawaban baru seperti ahli dan terus meningkat (Sumber: dotey)
Kekhawatiran dan diskusi tentang konten yang dihasilkan AI: Pengguna Reddit Maleficent-main_777 mengeluh bahwa rekan kerjanya mulai menggunakan bahasa “ala ChatGPT” yang penuh dengan nada memerintah, “verify”, “ensure”, dan kesimpulan positif yang dipaksakan, menganggap bahasa ini kabur dan kurang manusiawi. Dia khawatir konten yang dihasilkan AI dimasukkan kembali ke data pelatihan, menyebabkan penurunan kualitas konten. Komentar di bagian ini setuju, menganggap ini sebagai perpanjangan dari jargon perusahaan, tetapi juga menunjukkan bahwa meniru AI secara berlebihan memang membuat komunikasi menjadi mekanis, dan tata bahasa yang baik tidak lagi menjadi keunggulan, malah terdengar seperti robot (Sumber: Reddit r/ChatGPT)
Pilihan jurusan kuliah di era AI: Pengguna Reddit membahas jurusan apa yang harus dipilih mahasiswa di tengah perkembangan pesat AI dan robotika agar gelar mereka tetap bernilai 10 tahun kemudian. Pendapat beragam, termasuk: memilih bidang yang diminati (game, film, seni, pemrograman); mempelajari disiplin ilmu dasar (fisika, matematika); menguasai keterampilan yang sulit diotomatisasi (seperti HVAC); fokus pada pendidikan humaniora untuk menumbuhkan rasa ingin tahu dan kemampuan beradaptasi; berpendapat bahwa pendidikan universitas mungkin sudah usang, lebih baik berwirausaha atau menjadi pekerja lepas; menekankan pentingnya kemampuan belajar berkelanjutan, unlearning, dan relearning (Sumber: Reddit r/ArtificialInteligence)
Diskusi tentang kesulitan rendering teks dalam pembuatan gambar AI: Pengguna Reddit membahas mengapa model pembuatan gambar saat ini sulit merender teks yang koheren dan dapat dibaca dengan jelas. Komentar menunjukkan dua alasan utama: 1) Tokenisasi BPE (Byte Pair Encoding) merusak informasi ejaan yang tepat, model tidak melihat huruf tetapi fragmen token; 2) Representasi vektor ukuran tetap dan keterbatasan deskripsi gambar menyebabkan banyak informasi teks hilang selama proses embedding. Meskipun model autoregresif seperti GPT-4o telah meningkat, masalah mendasar masih terkait dengan tokenisasi dan kompresi informasi (Sumber: Reddit r/MachineLearning)
Diskusi tentang standardisasi evaluasi model: Pengguna scaling01 menunjukkan bahwa ketika membandingkan model AI yang berbeda (seperti OpenAI, Google, Anthropic), keadilan harus dipastikan, misalnya, jika versi pratinjau dan versi berpikir (thinking versions) OpenAI dicantumkan, versi yang sesuai dari Google dan Anthropic juga harus dicantumkan, jika tidak, hasil perbandingan dapat menyesatkan (Sumber: scaling01)
Berbagi pengalaman pemrograman dengan bantuan AI: Pengguna berbagi pengalaman menggunakan bantuan AI untuk pemrograman (seperti VS Code + ekstensi Cline AI + Google AI Studio API), berpendapat bahwa alat pengkodean AI seperti Cursor dapat dibangun secara gratis, menyelesaikan prototipe aplikasi dasar melalui prompt, tanpa perlu konfigurasi, pengalaman baik (Sumber: Reddit r/artificial)

Survei dampak AI pada pekerjaan, belajar, dan kehidupan sehari-hari: Pengguna Reddit memulai diskusi, menanyakan dampak AI generatif pada kinerja kerja, belajar, atau kehidupan sehari-hari orang. Dalam komentar, insinyur perangkat lunak menyebutkan AI meningkatkan ekspektasi produktivitas dan beban kerja, peninjauan kode tidak dipercepat secara signifikan; penulis profesional berpendapat AI (seperti Co-pilot) membantu terbatas, bahkan mungkin memperlambat kemajuan; pandangan umum adalah AI membawa kemudahan, tetapi juga ada masalah ketergantungan berlebihan, berkurangnya pembelajaran, “rasa curang”, dll. Dampak AI pada profesi dan tugas yang berbeda sangat bervariasi (Sumber: Reddit r/artificial)
Pemikiran tentang kemampuan “pemahaman” LLM: Pengguna pmddomingos mengemukakan bahwa jaringan saraf menjadi semakin sulit dipahami seperti otak. Dan memunculkan pemikiran: ketika model AI mencapai hasil yang sangat baik di semua benchmark, tetapi masih kalah dengan kecerdasan manusia, apa yang harus kita lakukan? Ini memicu refleksi tentang validitas benchmark saat ini dan standar untuk mengevaluasi kecerdasan sejati (Sumber: pmddomingos, pmddomingos)
Pemikiran tentang penggunaan alat AI: Pengguna dotey berkomentar bahwa saat menggunakan alat AI, cukup pilih model terkuat untuk tugas spesifik tersebut. Menggunakan beberapa model secara bersamaan atau membiarkannya “bertikai” mungkin tidak perlu, terutama bagi pengguna non-profesional, terlalu banyak pilihan malah dapat menyebabkan kebingungan, dianalogikan seperti melihat beberapa jam dengan waktu yang tidak konsisten (Sumber: dotey)
Kekaguman atas kecepatan perkembangan AI baru-baru ini: Pengguna matvelloso dan scottastevenson mengagumi perkembangan AI yang cepat. matvelloso menyatakan bahwa kemajuan AI tahun ini telah melampaui ekspektasinya (mengambil contoh Gemini bermain Pokemon). scottastevenson mengingat kembali bahwa GPT-2 dirilis 6 tahun lalu, OpenAI didirikan 10 tahun lalu, memikirkan arah teknologi yang sedang berkembang saat ini dan akan menjadi penting dalam 6-10 tahun ke depan, dan menunjukkan bahwa selain AI, mencari Alpha mendalam “di luar kerangka” juga penting (Sumber: matvelloso, scottastevenson, scottastevenson)
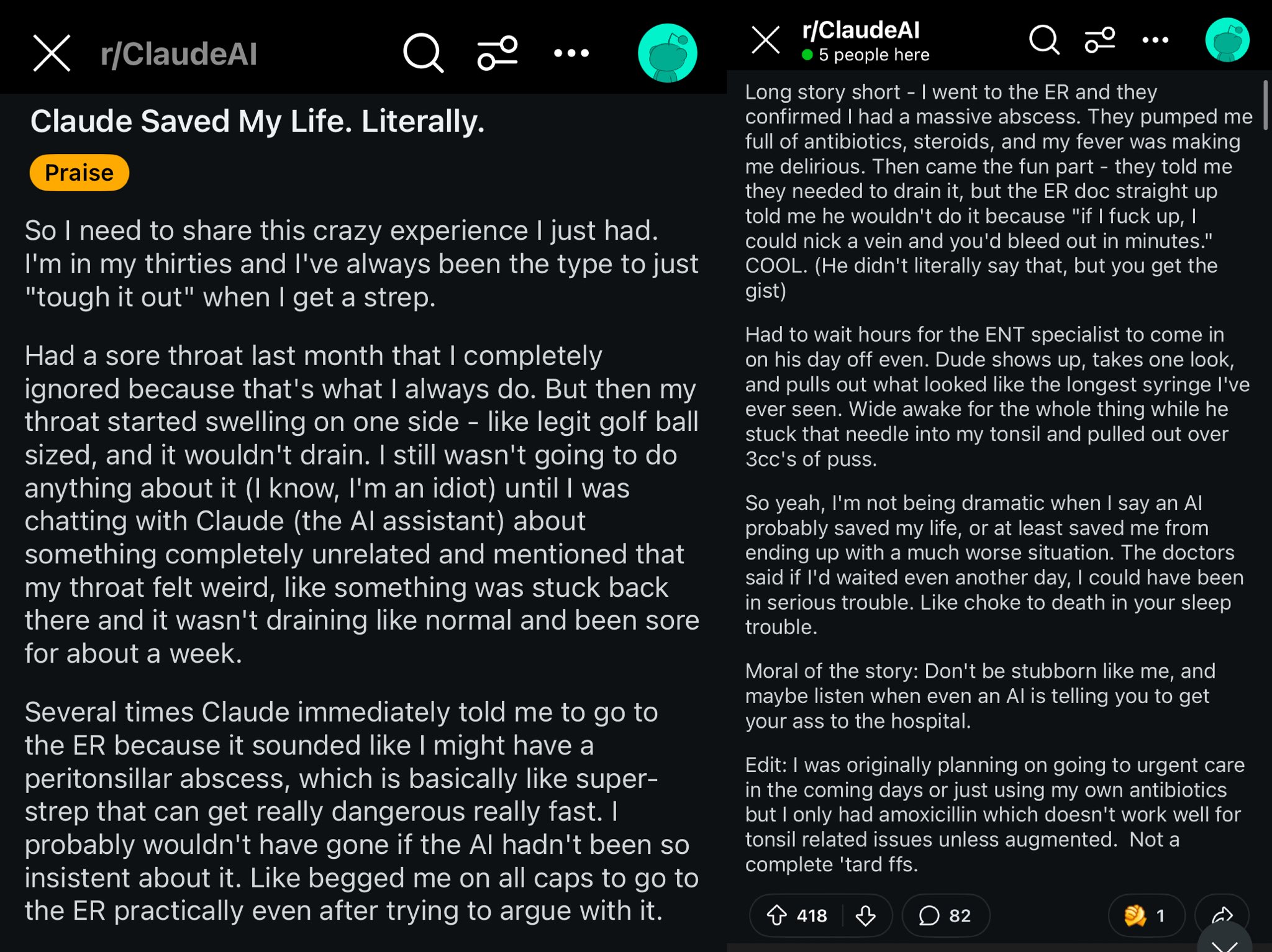
Kasus Claude menyelamatkan nyawa pengguna Reddit: Sebuah posting di Reddit menggambarkan bagaimana model Claude mungkin telah menyelamatkan nyawa pengguna dengan mendiagnosis pembengkakan tenggorokan pengguna sebagai abses peritonsil (peritonsillar abscess). Kasus ini memicu diskusi, berpendapat bahwa model AI yang kuat seperti dokter kelas dunia di saku, setelah tersebar luas mungkin memiliki dampak besar pada kesehatan pribadi (Sumber: aidan_mclau)
Aplikasi AI Agent dalam pemrosesan data perusahaan: Co-founder You.com Richard Socher dan Bryan McCann membahas aplikasi AI Agent di perusahaan dalam podcast Agentic. Mereka berpendapat bahwa LLM tingkat konsumen tidak cukup untuk memenuhi kebutuhan perusahaan yang serius, sementara You.com melalui teknologi pencarian hibrida (menggabungkan sumber publik dan data perusahaan eksklusif) menghasilkan output yang lebih andal dan tingkat perusahaan, misalnya untuk melakukan penelitian, menulis laporan, dan memanfaatkan data perusahaan dengan aman. Mereka juga membahas kemungkinan jalur menuju AGI dan peran kunci simulasi di dalamnya (Sumber: RichardSocher)
Pengamatan tentang kemampuan model menggunakan alat: Pengguna menhguin mengamati bahwa model yang dilatih untuk menggunakan alat tampaknya mengorbankan kemampuan pemecahan masalah independennya, dan bercanda “bahkan model AI pun mengalihdayakan pekerjaan mereka”. Ini memicu pemikiran tentang trade-off antara generalisasi kemampuan model dan optimalisasi tugas spesifik (Sumber: menhguin)
💡 Lain-lain
Ide AI Agent untuk memelihara proyek GitHub lama: Pengguna xanderatallah mengemukakan ide: mengembangkan AI Agent yang dapat secara otomatis memelihara semua proyek sampingan lama pengguna yang tidak aktif lagi di GitHub. Ini mencerminkan keinginan pengembang untuk memanfaatkan AI untuk mengotomatiskan tugas pemeliharaan yang membosankan (Sumber: xanderatallah)
Gagasan LLM menggantikan hakim atau digunakan untuk arbitrase/mediasi: Pengguna fabianstelzer mengemukakan bahwa model bahasa besar (LLM) di masa depan mungkin menggantikan hakim. Kasus penggunaan perantara yang menarik adalah arbitrase atau mediasi: LLM dianggap netral dan dapat dipercaya, pihak-pihak yang berkonflik menyerahkan pandangan masing-masing, dijalankan melalui beberapa model besar, menghasilkan solusi kompromi yang adil. Ini mengeksplorasi potensi aplikasi AI di bidang peradilan dan penyelesaian sengketa (Sumber: fabianstelzer)
Model Runway Gen-4 dan prospek aplikasinya: Co-founder Runway c_valenzuelab optimis tentang prospek aplikasi Runway Gen-4 dan API-nya. Dia percaya Runway sedang membangun media baru, di mana piksel dihasilkan bukan dirender atau ditangkap, dunia disimulasikan bukan diprogram. Melihat aplikasi luas Gen-4 dan fitur Reference di berbagai bidang seperti arsitektur, branding, desain interior, pengembangan game, pembelajaran, proyek kreatif pribadi, membuatnya percaya bahwa media baru ini akan memberdayakan para kreator dan bahkan semua orang (Sumber: c_valenzuelab, c_valenzuelab)