Kata Kunci:Gemini 2.5 Pro, Model AI, Robot humanoid, Etika AI, Bisnis startup AI, Konten hasil generasi AI, Kreativitas berbantuan AI, Gemini 2.5 Pro menyelesaikan Pokémon: Blue, Pencarian web global Anthropic Claude, Bias routing model Qwen3 MoE, Fitur Referensi Runway Gen-4, Aplikasi AI dalam dukungan kesehatan mental
🔥 Fokus
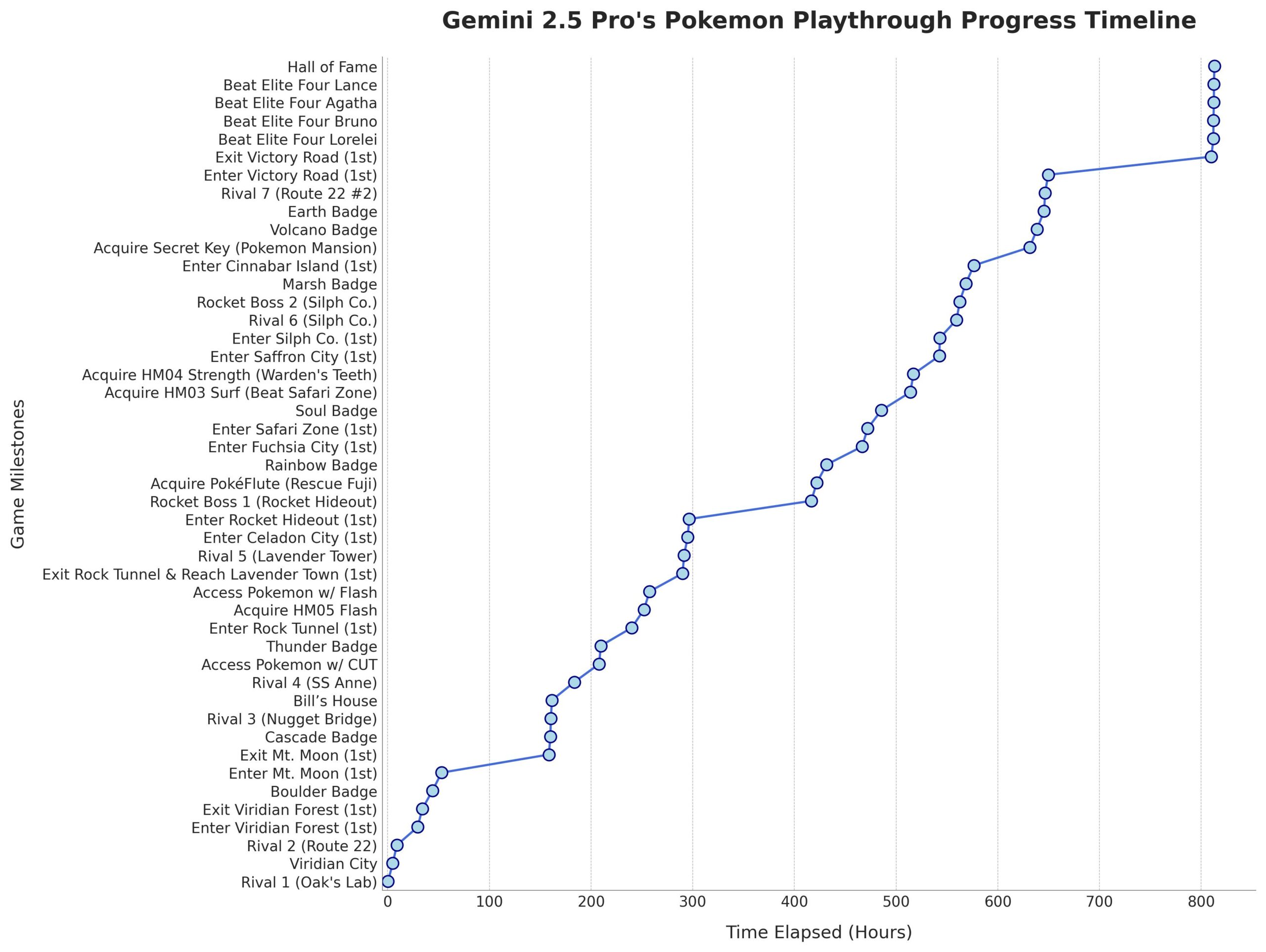
Gemini 2.5 Pro Berhasil Menamatkan Pokémon: Blue: Model AI Google Gemini 2.5 Pro berhasil menyelesaikan game klasik Pokémon: Blue, termasuk mengumpulkan semua 8 lencana (badge) dan mengalahkan Elite Four Pokémon League. Pencapaian ini dijalankan dan disiarkan langsung oleh streamer @TheCodeOfJoel, serta mendapat ucapan selamat dari CEO Google Sundar Pichai dan CEO DeepMind Demis Hassabis. Hal ini menunjukkan kemajuan signifikan AI saat ini dalam perencanaan tugas yang kompleks, penyusunan strategi jangka panjang, dan interaksi dengan lingkungan simulasi, melampaui performa AI sebelumnya dalam game ini, serta menandai tonggak sejarah baru dalam kemampuan agen AI. (Sumber: Google, jam3scampbell, teortaxesTex, YiTayML, demishassabis, _philschmid, Teknium1, tokenbender)
Apple Bekerja Sama dengan Anthropic Kembangkan Platform Koding AI “Vibe Coding”: Menurut laporan Bloomberg, Apple sedang bekerja sama dengan startup AI Anthropic untuk mengembangkan platform koding baru yang didukung AI bernama “Vibe Coding”. Platform ini saat ini sedang diuji coba secara internal kepada karyawan Apple dan berpotensi dibuka untuk pengembang pihak ketiga di masa depan. Ini menandai eksplorasi lebih lanjut Apple di bidang alat bantu pemrograman AI, yang bertujuan memanfaatkan AI untuk meningkatkan efisiensi dan pengalaman pengembangan, serta kemungkinan akan melengkapi atau terintegrasi dengan proyek internalnya seperti Swift Assist. (Sumber: op7418)
Kemajuan dan Diskusi Teknologi Robotika Berbasis AI: Robot humanoid dan kecerdasan terwujud (embodied intelligence) baru-baru ini mendapat perhatian luas. Perusahaan Figure memamerkan kantor pusat barunya yang berteknologi tinggi, mencakup baterai, aktuator, hingga laboratorium AI, menandakan ambisinya di bidang robotika. Disney juga memamerkan teknologi robot karakter humanoidnya. Namun, dalam kompetisi maraton robot humanoid di Beijing, beberapa robot (termasuk Unitree G1 yang dimodifikasi pelanggan) menunjukkan performa buruk, mengalami jatuh, daya tahan baterai yang kurang, dan masalah keseimbangan. Hal ini memicu diskusi tentang kemampuan aktual robot humanoid saat ini, menyoroti bahwa kemajuan besar masih diperlukan baik dalam “otak kecil” (kontrol motorik) maupun “otak besar” (pengambilan keputusan cerdas). (Sumber: adcock_brett, Ronald_vanLoon, 人形机器人,最重要的还是“脑子”)

Diskusi Etika dan Dampak Sosial AI Meningkat: Diskusi di media sosial dan bidang penelitian mengenai dampak sosial dan masalah etika AI semakin meningkat. Misalnya, RUU AI California SB-1047 memicu kontroversi, dan film dokumenter terkait membahas perlunya regulasi serta tantangannya. Konferensi NAACL 2025 menyelenggarakan tutorial tentang “Kecerdasan Sosial di Era LLM”, membahas tantangan jangka panjang dan baru dalam interaksi AI dengan manusia dan masyarakat. Sementara itu, pengguna menyuarakan keprihatinan tentang kualitas konten yang dihasilkan AI (“slop”), berpendapat bahwa diperlukan desain dan kontrol model yang lebih baik. Diskusi ini mencerminkan meningkatnya kepedulian masyarakat terhadap masalah etika, regulasi, dan adaptasi sosial yang ditimbulkan oleh perkembangan pesat teknologi AI. (Sumber: teortaxesTex, gneubig, stanfordnlp, jam3scampbell, willdepue, wordgrammer)

🎯 Tren
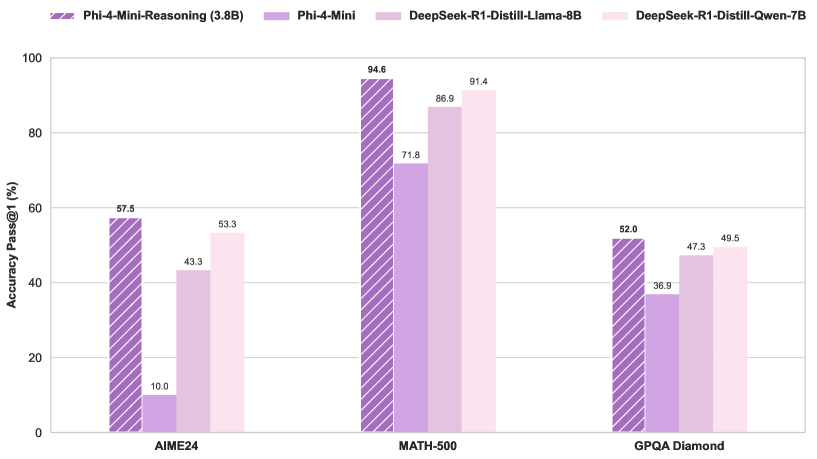
Microsoft Merilis Model Phi-4-Mini-Reasoning: Microsoft merilis model Phi-4-Mini-Reasoning di Hugging Face. Model ini bertujuan untuk meningkatkan kemampuan model bahasa kecil (small language model) dalam penalaran matematis, mendorong lebih lanjut pengembangan model yang lebih kecil dan berefisiensi tinggi. (Sumber: _akhaliq)
Model Anthropic Claude Mendukung Pencarian Web Global: Anthropic mengumumkan bahwa model AI Claude miliknya kini menyediakan fungsi pencarian web global untuk semua pengguna berbayar. Untuk tugas sederhana, Claude akan melakukan pencarian cepat; untuk masalah kompleks, ia akan menjelajahi berbagai sumber informasi, termasuk Google Workspace, meningkatkan kemampuan model dalam memperoleh dan memproses informasi secara real-time. (Sumber: Teknium1, Reddit r/ClaudeAI)

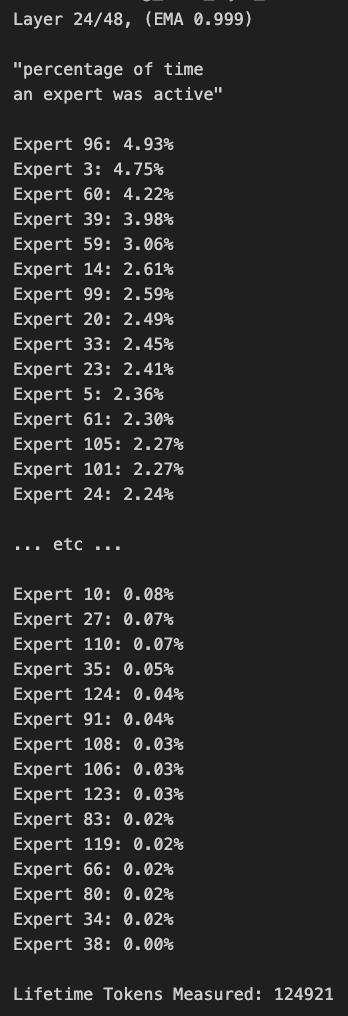
Routing Model Qwen3 MoE Memiliki Bias, Dapat Dilakukan Pruning: Pengguna kalomaze menganalisis dan menemukan bahwa distribusi routing model Qwen3 MoE (Mixture of Experts) memiliki bias yang signifikan. Bahkan model MoE 30B menunjukkan potensi untuk pruning. Ini berarti sebagian Experts mungkin tidak dimanfaatkan sepenuhnya, dan dengan melakukan pruning (menghapus) Experts ini, ukuran model dan kebutuhan komputasi dapat dikurangi tanpa mempengaruhi kinerja secara signifikan. Kalomaze telah merilis versi model 30B yang dipangkas menjadi 16B berdasarkan temuan ini, dan berencana merilis versi 235B yang dipangkas menjadi 150B. (Sumber: andersonbcdefg, Reddit r/LocalLLaMA)
DeepSeek Prover V2 Menonjol di Antara Asisten Matematika Open-Source: DeepSeek Prover V2 dianggap sebagai model asisten matematika open-source dengan performa terbaik saat ini. Meskipun kinerjanya masih di bawah model closed-source atau yang lebih kuat seperti Gemini 2.5 Pro, o4 mini high, o3, Claude 3.7, dan Grok 3, model ini menunjukkan performa yang baik dalam penalaran terstruktur. Pengguna berpendapat bahwa kemampuannya dalam sesi “brainstorming” yang membutuhkan pemikiran kreatif masih perlu ditingkatkan. (Sumber: cognitivecompai)
Diskusi Preferensi Model: Kecenderungan Pengembang dan Karakteristik Model Tertentu: Diskusi mengenai kelebihan dan kekurangan berbagai model bahasa besar (LLM) terus berlangsung di komunitas pengembang. Misalnya, Sentdex berpendapat bahwa kombinasi o3 dengan Codex di Cursor menunjukkan performa yang lebih baik daripada Claude 3.7. Sementara itu, VictorTaelin menyatakan bahwa meskipun Sonnet 3.7 tidak sempurna (kadang terlalu proaktif menambahkan konten yang tidak diminta, tingkat kecerdasannya tidak sesuai harapan), dalam praktiknya ia masih memberikan hasil yang lebih stabil dan andal dibandingkan GPT-4o (cenderung membuat kesalahan), o3/Gemini (format kode dan penulisan ulang kurang baik), R1 (sedikit ketinggalan zaman), dan Grok 3 (terbaik kedua, tetapi sedikit kalah dalam praktik). Hal ini mencerminkan perbedaan kesesuaian model yang berbeda untuk tugas dan alur kerja tertentu. (Sumber: Sentdex, VictorTaelin, paul_cal)

Diskusi Tren Performa LLM: Pertumbuhan Eksponensial atau Hasil yang Menurun?: Pengguna Reddit mendiskusikan apakah LLM masih mengalami peningkatan eksponensial. Ada pandangan bahwa meskipun kemajuan awal sangat cepat, peningkatan performa LLM saat ini cenderung menunjukkan hasil yang menurun (diminishing returns), di mana mendapatkan performa tambahan menjadi semakin sulit dan mahal, mirip dengan perkembangan teknologi mobil otonom. Pengguna lain membantah, menunjukkan lompatan besar dari GPT-3 ke Gemini 2.5 Pro sebagai bukti bahwa kemajuan masih signifikan, dan terlalu dini untuk menyatakan adanya periode stagnasi. Diskusi ini mencerminkan ekspektasi yang berbeda mengenai kecepatan perkembangan AI di masa depan. (Sumber: Reddit r/ArtificialInteligence)
Chip AI Menjadi Kunci Pengembangan Robot Humanoid: Pandangan industri menyatakan bahwa inti dari robot humanoid terletak pada “otaknya”, yaitu chip berkinerja tinggi. Artikel tersebut menunjukkan bahwa robot humanoid saat ini masih memiliki kekurangan dalam kontrol motorik (otak kecil) dan pengambilan keputusan cerdas (otak besar), dan kinerja chip secara langsung menentukan tingkat kecerdasan robot. GPU Nvidia, prosesor Intel, serta chip domestik seperti Huashan A2000 dan Wudang C1236 dari Black Sesame Intelligence, semuanya menyediakan kemampuan persepsi, penalaran, dan kontrol yang lebih kuat untuk robot, menjadi kunci untuk mendorong robot humanoid dari sekadar gimmick menjadi aplikasi praktis. (Sumber: 人形机器人,最重要的还是“脑子”)

Etika AI dan Antropomorfisme: Mengapa Kita Mengucapkan “Terima Kasih” kepada AI?: Diskusi menunjukkan bahwa meskipun AI tidak memiliki emosi, pengguna cenderung menggunakan bahasa sopan (seperti “terima kasih”, “tolong”) kepadanya. Ini berasal dari naluri antropomorfisme manusia dan “persepsi keberadaan sosial”. Penelitian menunjukkan bahwa cara interaksi yang sopan dapat memandu AI untuk menghasilkan respons yang lebih sesuai harapan dan lebih manusiawi. Namun, ini juga membawa risiko, seperti AI dapat mempelajari dan memperkuat bias manusia, atau diarahkan secara jahat untuk menghasilkan konten yang tidak pantas. Perilaku sopan terhadap AI mencerminkan psikologi kompleks dan adaptasi sosial manusia saat berinteraksi dengan mesin yang semakin cerdas. (Sumber: 你对 AI 说的每一句「谢谢」,都在烧钱)

🧰 Alat
Fitur Runway Gen-4 References: Fitur Gen-4 References yang diluncurkan oleh RunwayML memungkinkan pengguna untuk memasukkan gambar mereka sendiri atau gambar referensi lainnya ke dalam video atau gambar yang dihasilkan AI (seperti meme). Umpan balik pengguna menunjukkan bahwa fitur ini bekerja dengan sangat baik, mampu menangani beberapa karakter yang konsisten muncul dalam gambar yang sama, menyederhanakan proses memasukkan orang atau gaya tertentu ke dalam kreasi AI. (Sumber: c_valenzuelab)

Krea AI Meluncurkan Template Pembuatan Gambar: Krea AI menambahkan fitur baru yang mengubah prompt pembuatan gambar GPT-4o yang umum digunakan menjadi template. Pengguna hanya perlu mengunggah gambar mereka sendiri dan memilih template untuk menghasilkan gambar dengan gaya yang sesuai, tanpa perlu memasukkan prompt yang rumit secara manual, menyederhanakan alur kerja pembuatan gambar. (Sumber: op7418)
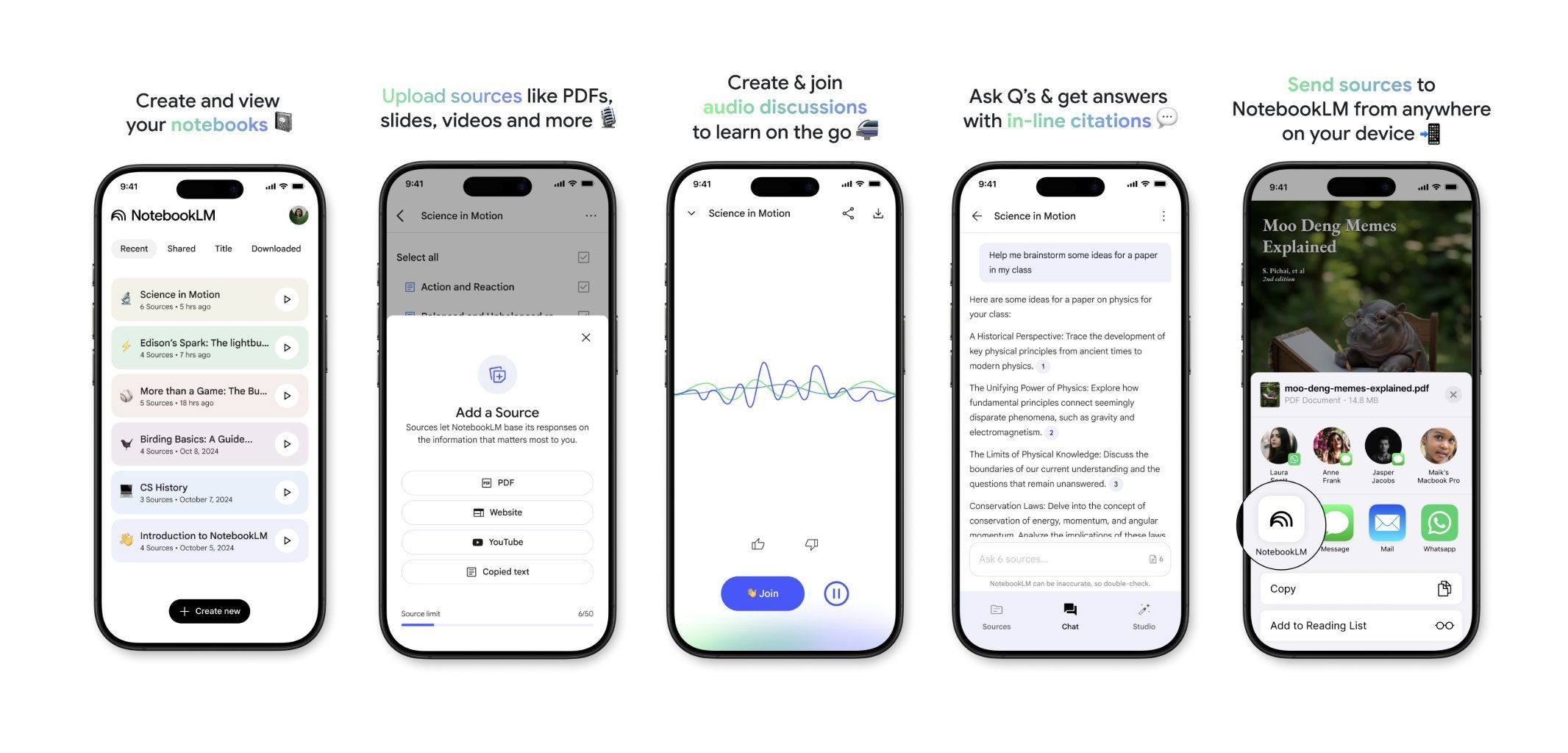
NotebookLM Akan Segera Meluncurkan Aplikasi Seluler: NotebookLM dari Google (sebelumnya Project Tailwind) akan segera merilis aplikasi seluler. Pengguna dapat dengan cepat meneruskan artikel dan konten yang dilihat di ponsel mereka ke NotebookLM untuk diproses dan diintegrasikan. Daftar tunggu untuk aplikasi ini telah dibuka, bertujuan untuk memberikan pengalaman manajemen informasi dan pembelajaran berbantuan AI yang lebih nyaman di perangkat seluler. (Sumber: op7418)
Runway untuk Desain Interior: Pengguna menunjukkan contoh penggunaan Runway AI untuk desain interior. Dengan memberikan satu gambar ruang dan satu gambar referensi yang mewakili gaya/suasana, Runway mampu menghasilkan gambar konsep desain interior yang menggabungkan fitur keduanya, menunjukkan potensi AI dalam bidang desain kreatif. (Sumber: c_valenzuelab)

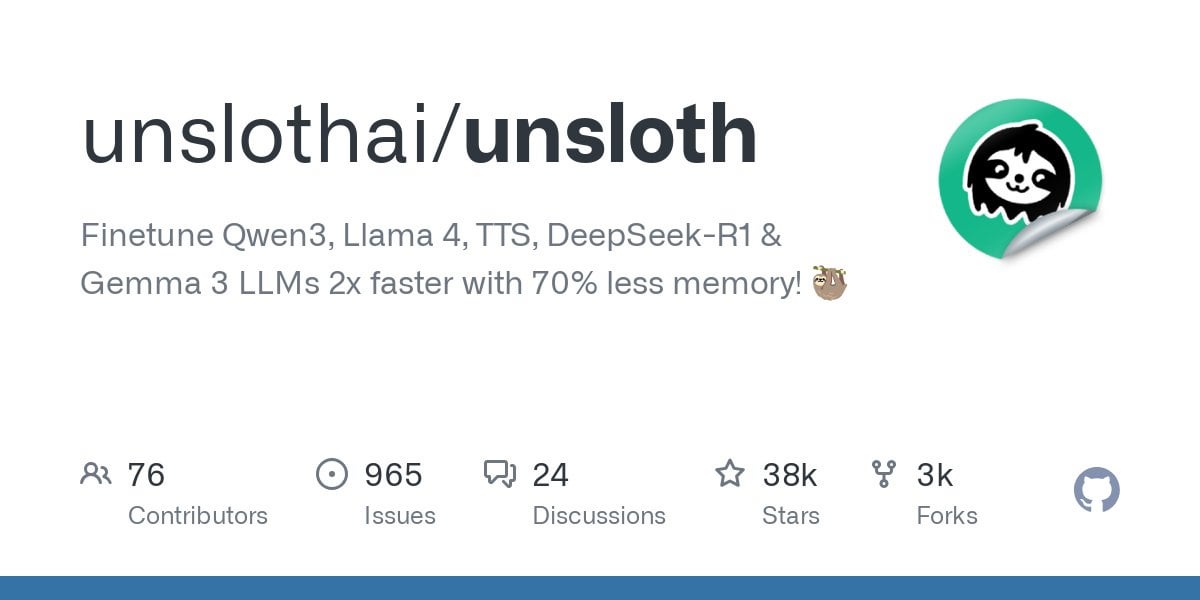
Unsloth Mendukung Fine-tuning Model Qwen3: Unsloth mengumumkan dukungan untuk fine-tuning seri model Qwen3, dengan peningkatan kecepatan 2x dan pengurangan penggunaan memori GPU sebesar 70%. Pengguna dapat melakukan fine-tuning dengan panjang konteks 8x lebih panjang daripada Flash Attention 2 pada GPU dengan memori 24GB. Notebook Colab disediakan untuk fine-tuning model Qwen3 14B secara gratis, dan berbagai model terkuantisasi, termasuk GGUF, telah diunggah. Ini menurunkan hambatan perangkat keras untuk fine-tuning model canggih. (Sumber: Reddit r/LocalLLaMA)
Fitur Claude AI Styles: Pengguna berbagi penggunaan fitur Styles Claude AI untuk meningkatkan pengalaman kolaborasi dengan AI. Dengan membuat gaya bernama “Iterative Engineering”, yang menetapkan langkah-langkah diskusi, perencanaan, modifikasi kecil, pengujian, iterasi, dan refactoring sesuai kebutuhan, pengguna dapat memandu Claude untuk melakukan pengkodean secara lebih metodis dan inkremental, menghindari penulisan ulang kode yang berlebihan, sehingga meningkatkan kegunaan AI sebagai mitra pemrograman. (Sumber: Reddit r/ClaudeAI)
Deepwiki Menyediakan Sumber Blok Kode: Pengguna cto_junior menyebutkan salah satu keunggulan Deepwiki adalah menampilkan blok kode sumber di samping setiap jawaban, bukan hanya melampirkan tautan. Praktik ini meningkatkan kredibilitas informasi, terutama berguna bagi Software Development Engineers (SDEs) yang mungkin skeptis terhadap alat AI. (Sumber: cto_junior)
📚 Pembelajaran
NousResearch Merilis Pembaruan Framework Atropos RL: Framework lingkungan Reinforcement Learning (RL) Atropos dari NousResearch telah diperbarui. Fitur baru memungkinkan pengguna untuk dengan cepat dan mudah menguji rollout lingkungan RL tanpa memerlukan mesin pelatihan atau inferensi. Secara default menggunakan OpenAI API, tetapi dapat dikonfigurasi untuk penyedia API lain (atau endpoint VLLM/SGLang lokal). Setelah pengujian selesai, laporan web yang berisi completions dan skornya akan dihasilkan, serta mendukung logging wandb, memudahkan debugging dan evaluasi lingkungan RL. (Sumber: Teknium1)

Dataset Benchmark RAG Personalisasi EnronQA Dirilis: Peneliti merilis dataset EnronQA, yang bertujuan untuk mendorong penelitian Personalized Retrieval-Augmented Generation (Personalized RAG) pada dokumen pribadi. Dataset ini berisi 103.638 email dan 528.304 pasangan tanya jawab berkualitas tinggi untuk 150 pengguna, menyediakan sumber daya untuk mengevaluasi dan mengembangkan sistem RAG yang dapat memahami dan memanfaatkan informasi spesifik pribadi. (Sumber: lateinteraction)
GTE-ModernColBERT (PyLate) Dirilis: LightOnAI merilis GTE-ModernColBERT (PyLate), sebuah retriever MaxSim 128 dimensi, berdasarkan gte-modernbert-base dan di-fine-tuning pada ms-marco-en-bge-gemma. Ini secara native mendukung library PyLate, memungkinkan re-ranking dan pengindeksan HNSW. Model ini menunjukkan performa yang sangat baik pada benchmark NanoBEIR dan melampaui ColBERT-small pada skor rata-rata BEIR, menyediakan opsi pencarian teks baru yang efisien. (Sumber: lateinteraction)

SOLO Bench – Benchmark LLM Jenis Baru: Pengguna jd_3d mengembangkan dan merilis SOLO Bench, metode benchmark LLM baru. Tes ini mengharuskan LLM untuk menghasilkan teks yang berisi jumlah kalimat tertentu (misalnya 250 atau 500), di mana setiap kalimat harus dan hanya boleh berisi satu kata dari daftar yang telah ditentukan (termasuk kata benda, kata kerja, kata sifat, dll.), dan setiap kata hanya dapat digunakan sekali. Evaluasi dilakukan menggunakan skrip berbasis aturan, bertujuan untuk menguji kemampuan LLM dalam mengikuti instruksi, memenuhi batasan, dan menghasilkan teks panjang. Hasil awal menunjukkan bahwa benchmark ini efektif dalam membedakan kinerja model yang berbeda. (Sumber: Reddit r/LocalLLaMA)
Memanfaatkan Refleksi Rekursif Strategis untuk Memanipulasi Ruang Laten: Pengguna mengusulkan metode untuk menciptakan hierarki penalaran bersarang dalam ruang laten (latent space) LLM melalui “refleksi rekursif strategis” (Strategic recursive reflection, RR). Dengan meminta model untuk merefleksikan interaksi sebelumnya pada saat-saat kritis, loop metakognitif dihasilkan, membangun “ruang laten mini”. Setiap prompt dianggap sebagai tekanan yang memandu jalur model dalam ruang laten, membuatnya lebih self-referential dan mampu melakukan abstraksi. Ini dianggap meniru proses manusia memperdalam pemikiran melalui refleksi atas pikiran, bertujuan untuk mengeksplorasi konsep pada tingkat yang lebih dalam. (Sumber: Reddit r/ArtificialInteligence)
💼 Bisnis
Google Membayar Samsung untuk Pra-instal Gemini AI: Setelah tahun lalu dinyatakan melanggar hukum antitrust terkait perjanjian mesin pencari default, Google dilaporkan membayar Samsung “sejumlah besar uang” setiap bulan ditambah pembagian pendapatan agar Gemini AI dipra-instal pada perangkat Samsung, dan mungkin meminta mitra untuk mewajibkan pra-instalasi Gemini. Hal ini menjelaskan mengapa seri Samsung Galaxy S25 sangat terintegrasi dengan Gemini, bahkan menjadikannya asisten AI default. Langkah ini mencerminkan strategi Google untuk segera merebut pintu masuk AI seluler mengingat kurangnya saluran perangkat kerasnya sendiri, tetapi juga dapat kembali memicu kekhawatiran antitrust. (Sumber: 三星手机预装Gemini AI,也是谷歌花钱买的)

Startup AI Menghadapi Tantangan: Diskusi di Reddit menunjukkan bahwa banyak startup AI mungkin kekurangan keunggulan kompetitif (moat) karena kemampuan model cenderung konvergen dan loyalitas pengguna rendah. Perusahaan teknologi besar (Google, Microsoft, Apple) lebih mudah menjangkau pengguna berkat keunggulan ekosistem mereka (seperti pra-instalasi, integrasi). Bahkan jika model startup sedikit lebih baik, pengguna mungkin cenderung menggunakan AI default atau terintegrasi yang “cukup baik”. Hal ini menimbulkan kekhawatiran tentang kelangsungan hidup jangka panjang startup AI dan prospek investasi VC. (Sumber: Reddit r/ArtificialInteligence)
Rangkuman Pendanaan dan Dinamika Bisnis AI Minggu Ini (2 Mei 2025): CEO Microsoft mengungkapkan AI telah menulis “bagian penting” dari kode perusahaan; CFO Microsoft memperingatkan layanan AI dapat terganggu karena permintaan yang terlalu tinggi; Google mulai menayangkan iklan di chatbot AI pihak ketiga; Meta meluncurkan aplikasi AI mandiri; Cast AI mendapatkan pendanaan $108 Juta, Astronomer $93 Juta, Edgerunner AI $12 Juta; Penelitian menuduh LM Arena memiliki masalah manipulasi benchmark; Nvidia menentang dukungan Anthropic terhadap kontrol ekspor chip. (Sumber: Reddit r/artificial)
🌟 Komunitas
Diskusi Kualitas dan Biaya Konten Buatan AI: Komunitas menyuarakan keprihatinan tentang kualitas konten buatan AI yang bervariasi (disebut “slop”). Pengguna wordgrammer menunjukkan bahwa banyak video AI yang dihasilkan berkualitas rendah, dan biaya sebenarnya (mempertimbangkan penyaringan dan percobaan ulang) jauh lebih tinggi dari harga yang tertera. Hal ini memicu diskusi tentang desain model (seperti jam3scampbell mengutip pandangan Steve Jobs) dan pemanfaatan alat AI yang efektif, menekankan perlunya kontrol yang lebih halus dan standar kualitas generasi yang lebih tinggi. (Sumber: wordgrammer, jam3scampbell, willdepue)
Performa AI pada Tugas Tertentu Memicu Diskusi: Anggota komunitas mendiskusikan performa dan keterbatasan AI dalam berbagai tugas. Misalnya, DeepSeek R1 dianggap mungkin merupakan puncak dari hype LLM, meskipun ada kemajuan di bidang seperti matematika formal dan kedokteran, namun belum menarik perhatian luas dari pengguna biasa. DeepSeek Prover V2 berkinerja baik dalam matematika, tetapi dianggap kurang kreatif. Pengguna vikhyatk mempertanyakan signifikansi mengoptimalkan model secara berlebihan agar berkinerja baik pada benchmark tertentu seperti AIME (American Invitational Mathematics Examination), berpendapat bahwa masyarakat umum tidak peduli dengan kemampuan matematika. Diskusi ini mencerminkan pemikiran tentang batas kemampuan AI dan nilai aplikasi praktisnya. (Sumber: wordgrammer, cognitivecompai, vikhyatk)
Kreativitas dan Desain Berbantuan AI: Komunitas menunjukkan berbagai cara menggunakan alat AI untuk desain kreatif. Pengguna memanfaatkan fitur Gen-4 References Runway untuk memasukkan diri mereka ke dalam meme; menggunakan Runway untuk menghasilkan konsep desain interior; memanfaatkan GPT-4o dan template prompt untuk membuat gambar dengan gaya tertentu (seperti harimau Cina Selatan origami, sandaran pergelangan tangan silikon hewan, mengintegrasikan makna kata ke dalam desain huruf). Kasus-kasus ini menunjukkan potensi AI dalam kreativitas visual dan desain personalisasi. (Sumber: c_valenzuelab, c_valenzuelab, dotey, dotey, dotey)

Keraguan terhadap Kemampuan AI Meniru Gaya Penulisan: Pengguna nrehiew_ berpendapat bahwa instruksi untuk meminta LLM “melanjutkan penulisan dengan nada dan gaya saya” mungkin tidak efektif, karena kebanyakan orang melebih-lebihkan keunikan gaya penulisan mereka sendiri. Hal ini memicu diskusi tentang kemampuan LLM untuk memahami dan meniru nuansa gaya penulisan yang halus, serta bias persepsi pengguna terhadap kemampuan ini. (Sumber: nrehiew_)
AI untuk Dukungan Emosional Memicu Resonansi dan Diskusi: Pengguna Reddit berbagi pengalaman mendapatkan dukungan emosional bahkan bantuan dalam mengatasi krisis melalui percakapan dengan AI seperti ChatGPT. Banyak yang menyatakan bahwa saat kesepian, butuh teman bicara, atau menghadapi kesulitan psikologis, AI menyediakan lawan bicara yang tidak menghakimi, sabar, dan selalu tersedia, terkadang bahkan terasa lebih efektif daripada berkomunikasi dengan manusia sungguhan. Hal ini memicu diskusi tentang peran AI dalam dukungan kesehatan mental, sekaligus menekankan bahwa AI tidak dapat menggantikan bantuan profesional manusia, dan perlunya waspada terhadap bias atau informasi menyesatkan yang mungkin ditimbulkan AI. (Sumber: Reddit r/ChatGPT, Reddit r/ClaudeAI)
Perbedaan Pandangan tentang Seni Buatan AI: Pengguna mendiskusikan potensi dampak seni buatan AI terhadap persepsi seniman manusia dan karya mereka. Ada yang mengeluh bahwa karya berkualitas tinggi sekarang sering kali dengan mudah dianggap sebagai buatan AI, mengabaikan bakat dan usaha penciptanya. Fenomena ini bahkan mulai mendistorsi persepsi orang, membuat orang cenderung mencari “kesalahan manusia” dalam karya untuk memastikan itu bukan buatan AI. Diskusi juga menyentuh apakah konten buatan AI harus diwajibkan untuk menambahkan watermark. (Sumber: Reddit r/ArtificialInteligence)
💡 Lainnya
Konsumsi Sumber Daya AI Menarik Perhatian: Diskusi menekankan konsumsi sumber daya yang besar di balik pengembangan AI. Melatih dan menjalankan model AI besar membutuhkan konsumsi listrik dan air yang sangat besar, dengan pusat data menjadi fasilitas baru yang boros energi. Setiap interaksi pengguna dengan AI, termasuk ucapan “terima kasih” yang sederhana, mengakumulasi konsumsi energi. Hal ini menimbulkan perhatian pada keberlanjutan pengembangan AI dan solusi energi (seperti fusi nuklir). (Sumber: 你对 AI 说的每一句「谢谢」,都在烧钱)
Jarak AI dengan Kesadaran: Pengguna Reddit mendiskusikan apakah AI saat ini memiliki kesadaran diri. Pandangan umum adalah bahwa AI saat ini (seperti LLM) pada dasarnya adalah sistem pencocokan pola kompleks yang memprediksi kata berdasarkan probabilitas, kurang memiliki pemahaman sejati dan kesadaran diri, dan masih sangat jauh dari memiliki kemampuan tersebut. Namun, ada juga komentar yang menunjukkan bahwa kesadaran manusia itu sendiri belum sepenuhnya dipahami, sehingga perbandingan mungkin keliru, dan kemampuan super AI dalam tugas-tugas tertentu tidak dapat diabaikan. (Sumber: Reddit r/ArtificialInteligence)
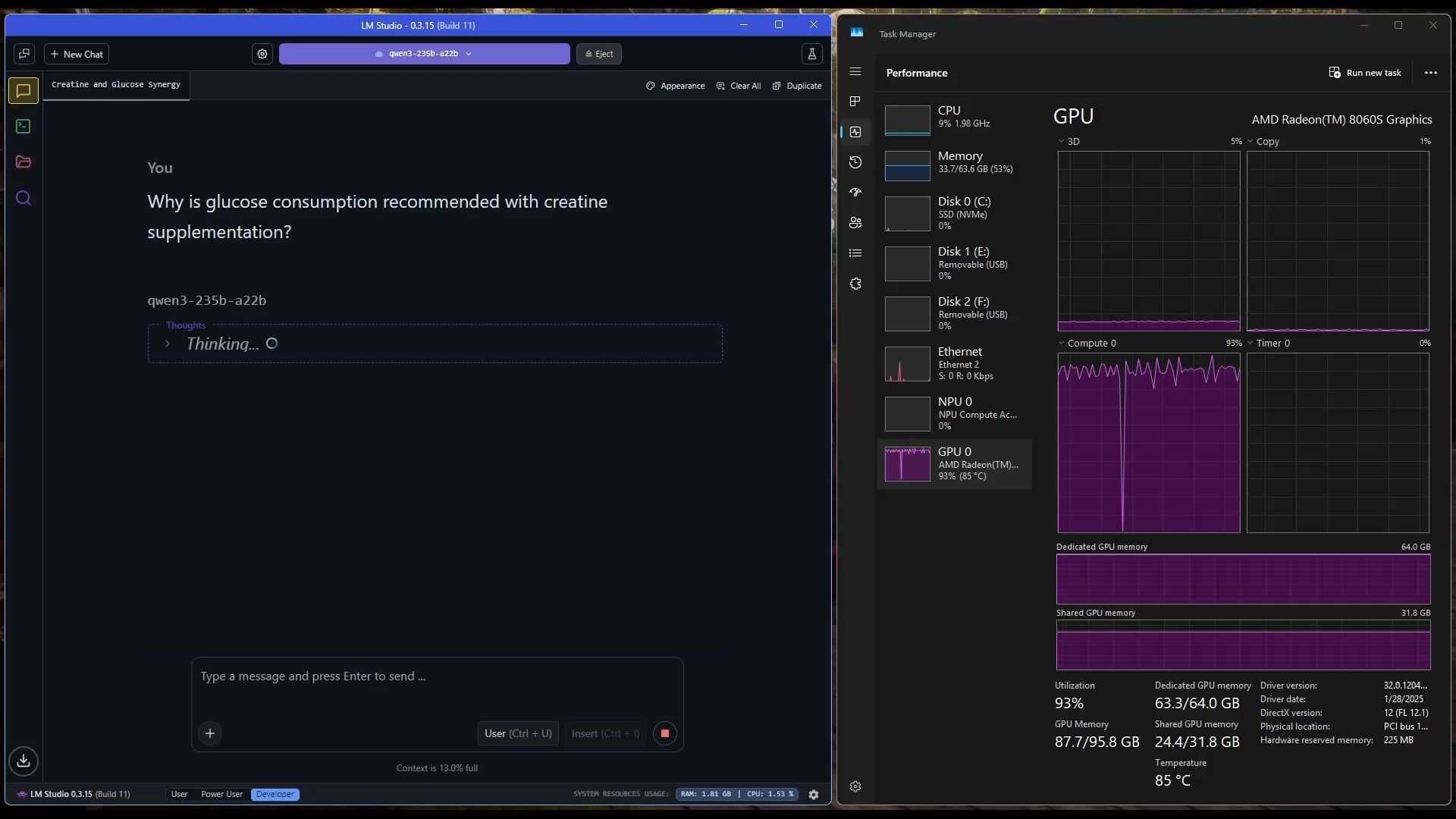
Tablet Windows Menjalankan Model MoE Besar: Pengguna menunjukkan contoh menjalankan model Qwen3 235B-A22B MoE (menggunakan kuantisasi Q2_K_XL) pada tablet Windows yang dilengkapi dengan AMD Ryzen AI Max 395+ dan RAM 128GB, hanya menggunakan iGPU (Radeon 8060S, mengalokasikan 87.7GB dari 95.8GB sebagai VRAM), dengan kecepatan mencapai sekitar 11.1 t/s. Ini menunjukkan kemungkinan menjalankan model yang sangat besar pada perangkat portabel, meskipun bandwidth memori masih menjadi bottleneck. (Sumber: Reddit r/LocalLLaMA)