
Kata Kunci:ChatBot Arena, Phi-4-reasoning, Claude Integrations, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, Agen Cerdas Buatan, Halusinasi Peringkat, Kemampuan Penalaran Model Kecil, Integrasi Aplikasi Pihak Ketiga, Agen Pemrograman AI, Pembuktian Teorema Matematika
🔥 Fokus
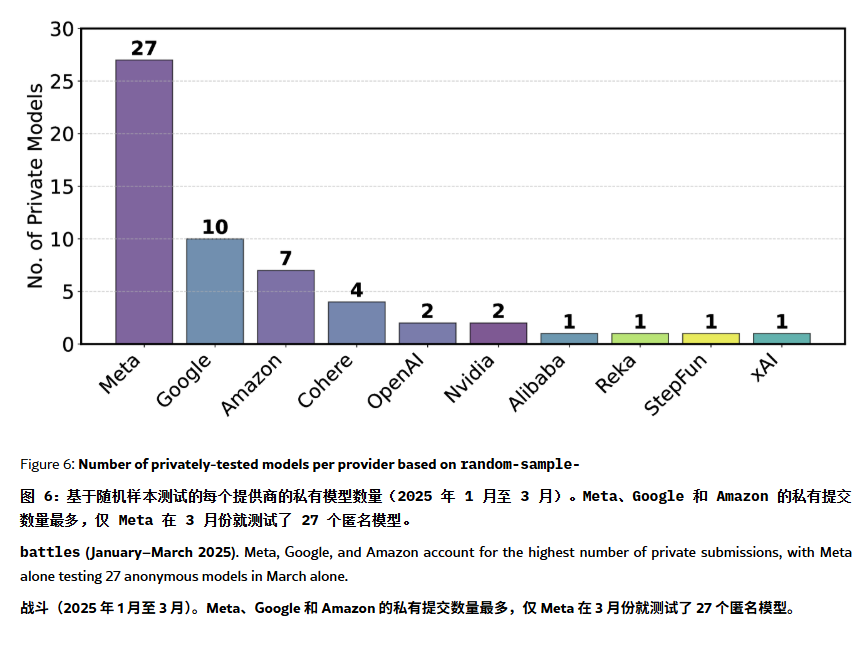
Peringkat ChatBot Arena Dituduh Mengandung “Halusinasi” dan Manipulasi: Sebuah makalah ArXiv [2504.20879] mempertanyakan peringkat model ChatBot Arena yang banyak dikutip, menganggapnya memiliki “halusinasi peringkat”. Makalah tersebut menunjukkan bahwa perusahaan teknologi besar (seperti Meta) mungkin memanipulasi peringkat dengan mengirimkan banyak varian model fine-tuned (misalnya Llama-4 diuji 27 kali) dan hanya mempublikasikan hasil terbaik; frekuensi tampilan model juga mungkin condong ke model perusahaan besar, menekan peluang eksposur model open-source; mekanisme eliminasi model kurang transparan, dengan banyak model open-source dihapus karena data pengujian yang tidak mencukupi; selain itu, kesamaan pertanyaan yang sering diajukan pengguna dapat menyebabkan model melakukan overfitting secara spesifik untuk meningkatkan skor. Hal ini menimbulkan kekhawatiran tentang keandalan dan keadilan benchmark LLM mainstream saat ini, menyarankan pengembang dan pengguna untuk melihat peringkat dengan hati-hati dan mempertimbangkan membangun sistem evaluasi yang sesuai dengan kebutuhan mereka sendiri. (Sumber: karminski3, op7418, TheRundownAI)
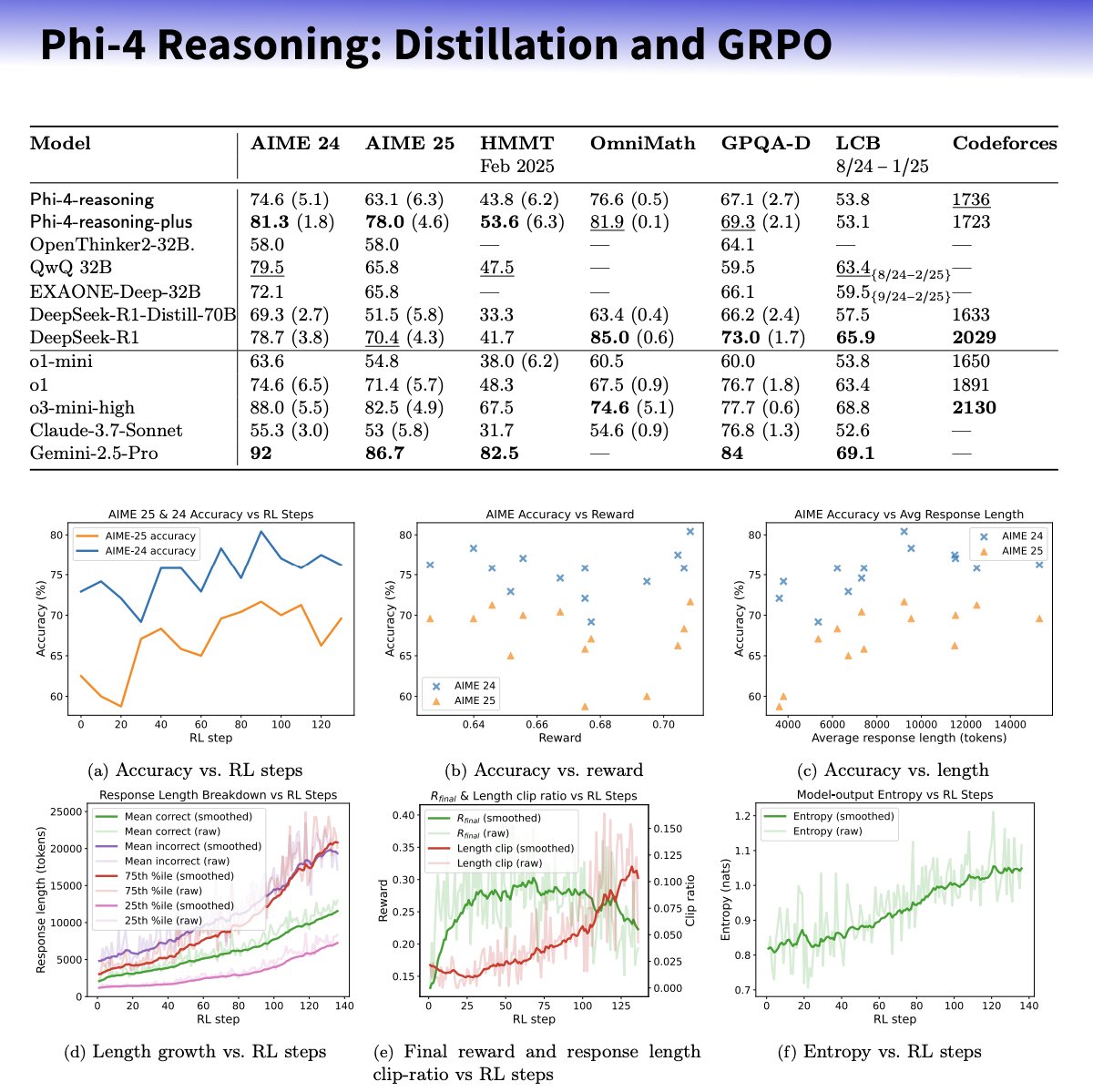
Microsoft Merilis Seri Model Kecil Phi-4-reasoning, Fokus pada Peningkatan Kemampuan Penalaran: Microsoft meluncurkan model Phi-4-reasoning dan Phi-4-reasoning-plus berdasarkan arsitektur Phi-4, yang bertujuan untuk meningkatkan kemampuan penalaran model bahasa kecil melalui dataset yang dikurasi dengan cermat, supervised fine-tuning (SFT), dan targeted reinforcement learning (RL). Dilaporkan, model-model ini menggunakan OpenAI o3-mini sebagai “guru” untuk menghasilkan lintasan penalaran Chain-of-Thought (CoT) berkualitas tinggi dan dioptimalkan melalui algoritma GRPO untuk reinforcement learning. Peneliti Microsoft Sebastien Bubeck mengklaim Phi-4-reasoning mengungguli DeepSeek R1 dalam kemampuan matematika, meskipun ukuran modelnya hanya 2% darinya. Seri model ini menggunakan token penalaran khusus dan panjang konteks 32K yang diperluas. Langkah ini dianggap sebagai eksplorasi ke arah model yang lebih kecil dan terspesialisasi, yang berpotensi memberikan solusi penalaran yang lebih kuat untuk skenario dengan sumber daya terbatas, tetapi juga menimbulkan diskusi tentang apakah ia memanfaatkan teknologi OpenAI dan dirilis di bawah lisensi MIT. (Sumber: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic Meluncurkan Fitur Integrations dan Memperluas Kemampuan Riset: Anthropic mengumumkan peluncuran Claude Integrations, yang memungkinkan pengguna menghubungkan Claude dengan 10 aplikasi dan layanan pihak ketiga seperti Jira, Confluence, Zapier, Cloudflare, Asana, dan lainnya, dengan dukungan untuk Stripe, GitLab, dll. di masa mendatang. Dukungan MCP (Model Context Protocol) yang sebelumnya terbatas pada server lokal diperluas ke server jarak jauh, memungkinkan pengembang membuat integrasi mereka sendiri dalam waktu sekitar 30 menit melalui dokumentasi atau solusi seperti Cloudflare. Sementara itu, fungsi Riset (Research) Claude ditingkatkan dengan mode lanjutan baru, yang dapat mencari web, Google Workspace, dan Integrations yang terhubung, memecah permintaan kompleks untuk diselidiki, menghasilkan laporan komprehensif dengan kutipan, dengan waktu pemrosesan hingga 45 menit. Fungsi pencarian web juga dibuka untuk pengguna berbayar global. Pembaruan ini bertujuan untuk meningkatkan integrasi dan kemampuan riset mendalam Claude sebagai asisten kerja. (Sumber: _philschmid, Reddit r/ClaudeAI)

Kemampuan Agen AI Mengikuti Hukum Moore Baru: Berlipat Ganda Setiap 4 Bulan: Riset dari AI Digest menunjukkan bahwa kemampuan agen pemrograman AI untuk menyelesaikan tugas mengalami pertumbuhan eksponensial. Durasi waktu yang dibutuhkan untuk memproses tugas (diukur berdasarkan waktu yang dibutuhkan oleh ahli manusia) antara tahun 2024-2025 kira-kira berlipat ganda setiap 4 bulan, lebih cepat dari periode 2019-2025 di mana ia berlipat ganda setiap 7 bulan. Agen AI teratas saat ini sudah dapat menangani tugas pemrograman yang membutuhkan 1 jam kerja manusia. Jika tren percepatan ini berlanjut, diperkirakan pada tahun 2027 agen AI mungkin dapat menyelesaikan tugas kompleks yang memakan waktu hingga 167 jam (sekitar satu bulan). Peningkatan kemampuan yang pesat ini didorong oleh kemajuan model itu sendiri serta peningkatan efisiensi algoritma, dan mungkin membentuk lingkaran umpan balik positif pertumbuhan super-eksponensial karena AI membantu R&D AI. Hal ini menandakan kemungkinan “ledakan kecerdasan perangkat lunak”, yang akan secara mendalam mengubah bidang seperti pengembangan perangkat lunak dan penelitian ilmiah, sambil juga membawa tantangan sosial seperti dampak otomatisasi pada pasar kerja. (Sumber: 新智元)

🎯 Tren
DeepSeek-Prover-V2 Dirilis, Meningkatkan Kemampuan Pembuktian Teorema Matematika: DeepSeek AI merilis DeepSeek-Prover-V2, tersedia dalam skala 7B dan 671B, yang berfokus pada pembuktian teorema formal Lean 4. Model ini dilatih menggunakan pencarian bukti rekursif dan reinforcement learning (GRPO), memanfaatkan DeepSeek-V3 untuk menguraikan teorema kompleks dan menghasilkan draf bukti, kemudian dikombinasikan dengan iterasi ahli dan data cold-start sintetis untuk fine-tuning dan reinforcement learning. DeepSeek-Prover-V2-671B mencapai tingkat kelulusan 88,9% pada MiniF2F-test dan menyelesaikan 49 masalah di PutnamBench, menunjukkan kinerja SOTA. Bersamaan dengan itu dirilis juga benchmark ProverBench yang mencakup soal AIME dan buku teks. Model ini bertujuan untuk menyatukan penalaran informal dengan pembuktian formal, mendorong pengembangan pembuktian teorema otomatis. (Sumber: 新智元)

Nvidia dan UIUC Mengusulkan Metode Baru Perluasan Konteks 4 Juta Token: Peneliti dari Nvidia dan University of Illinois Urbana-Champaign mengusulkan metode pelatihan efisien yang dapat memperluas jendela konteks Llama 3.1-8B-Instruct dari 128K menjadi 1M, 2M, bahkan 4M token. Metode ini menggunakan strategi dua tahap yaitu pre-training berkelanjutan dan instruction fine-tuning, dengan teknik kunci termasuk penggunaan pemisah dokumen khusus, perluasan pengkodean posisi berbasis YaRN, dan pre-training satu langkah. Model UltraLong-8B yang dilatih menunjukkan kinerja unggul pada benchmark konteks panjang seperti RULER, LV-Eval, InfiniteBench, dan mempertahankan atau bahkan melampaui kinerja baseline Llama 3.1 pada tugas konteks pendek standar seperti MMLU, MATH, mengungguli model konteks panjang lainnya seperti ProLong, Gradient. Penelitian ini menyediakan jalur yang efisien dan dapat diskalakan untuk membangun LLM dengan konteks ultra-panjang. (Sumber: 新智元)

Qwen3 Dirilis, Peningkatan Kinerja Signifikan: Alibaba merilis seri model Qwen3, termasuk Qwen3-30B-A3B, dll. Berdasarkan pengujian awal pengguna Reddit dan data benchmark (seperti AHA Leaderboard), Qwen3 menunjukkan kinerja yang lebih baik dibandingkan versi Qwen2.5 dan QwQ sebelumnya dalam beberapa dimensi (seperti pengetahuan domain spesifik tentang kesehatan, Bitcoin, Nostr, dll.). Umpan balik pengguna menunjukkan bahwa Qwen3 menunjukkan kemampuan yang kuat dalam menangani tugas-tugas spesifik (seperti mensimulasikan dinamika tata surya), mampu menerapkan hukum fisika dengan benar untuk menghasilkan orbit elips dan periode relatif. Namun, beberapa pengguna menunjukkan bahwa kinerja Qwen3 menurun secara signifikan pada konteks panjang (misalnya mendekati 16K), dan konsumsi token saat inferensi tinggi, menyarankan penggunaan bersama dengan alat pencarian. Skema penamaan Qwen3 (seperti Qwen3-30B-A3B) juga dipuji karena kejelasannya. (Sumber: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini Segera Mengintegrasikan Data Akun Google untuk Pengalaman yang Dipersonalisasi: Google berencana memungkinkan asisten AI Gemini mengakses data akun Google pengguna, termasuk Gmail, Photos, riwayat YouTube, dll., bertujuan untuk memberikan pengalaman bantuan yang lebih personal, proaktif, dan kuat. Kepala Produk Google Josh Woodward menyatakan bahwa ini bertujuan agar Gemini lebih memahami pengguna dan menjadi perpanjangan dari pengguna. Fitur ini akan bersifat opsional (opt-in), pengguna dapat memilih apakah akan mengaktifkan izin akses data. Langkah ini memicu diskusi tentang privasi dan keamanan data, mengharuskan pengguna menimbang antara kenyamanan personalisasi dan privasi data. (Sumber: JeffDean, Reddit r/ArtificialInteligence)

Nvidia Meluncurkan Model ASR Parakeet-TDT-0.6B-v2: Nvidia merilis model Automatic Speech Recognition (ASR) baru, Parakeet-TDT-0.6B-v2, dengan 600 juta parameter. Dilaporkan, model ini mengungguli Whisper3-large (1,6 miliar parameter) di Open ASR Leaderboard, terutama dalam menangani dataset yang beragam (termasuk data dari LibriSpeech, Fisher Corpus, YouTube, dll., sekitar 120 ribu jam data). Model ini mendukung timestamp tingkat karakter, kata, dan paragraf, tetapi saat ini hanya mendukung bahasa Inggris dan memerlukan GPU Nvidia serta framework tertentu untuk dijalankan. Umpan balik awal pengguna menunjukkan akurasi transkripsi dan tanda baca yang tinggi. (Sumber: Reddit r/LocalLLaMA)

Qwen2.5-VL Dirilis, Meningkatkan Pemahaman Bahasa Visual: Alibaba merilis seri model multimodal Qwen2.5-VL (termasuk parameter 3B, 7B, 72B), yang bertujuan untuk meningkatkan pemahaman dan interaksi mesin dengan dunia visual. Model-model ini dapat digunakan untuk tugas-tugas seperti ringkasan gambar, tanya jawab visual, menghasilkan laporan dari informasi visual yang kompleks, dll. Artikel tersebut menjelaskan arsitekturnya, kinerja benchmark, dan detail inferensi, menunjukkan kemajuannya dalam pemahaman bahasa visual. (Sumber: Reddit r/deeplearning)

Dukungan Mistral Small 3.1 Vision Telah Digabungkan ke llama.cpp: Proyek llama.cpp telah menggabungkan dukungan untuk model Mistral Small 3.1 Vision (parameter 24B). Ini berarti pengguna akan dapat menjalankan model multimodal ini dalam framework llama.cpp untuk tugas-tugas seperti pemahaman gambar. Unsloth telah menyediakan file model format GGUF yang sesuai. Ini memberikan kemudahan untuk menjalankan model visual Mistral secara lokal. (Sumber: Reddit r/LocalLLaMA)
Meta Merilis Synthetic Data Kit: Meta merilis sebuah command-line tool open-source bernama Synthetic Data Kit, yang bertujuan untuk menyederhanakan tahap persiapan data yang diperlukan untuk fine-tuning LLM. Alat ini menyediakan empat perintah: ingest (impor data), create (hasilkan pasangan QA, opsional rantai inferensi), curate (gunakan Llama sebagai penilai untuk menyaring sampel berkualitas tinggi), save-as (ekspor ke format yang kompatibel), memanfaatkan LLM lokal (melalui vLLM) untuk menghasilkan data pelatihan sintetis berkualitas tinggi, sangat cocok untuk membuka kemampuan penalaran tugas spesifik untuk model seperti Llama-3. (Sumber: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 Menjadi Model Embedding Populer: Model GTE-ModernColBERT-v1 yang diluncurkan oleh LightOnIO menjadi model pencarian/embedding tren baru yang populer di Hugging Face. Model ini menggunakan metode pencarian multi-vektor (juga dikenal sebagai interaksi akhir atau ColBERT), memberikan pilihan baru bagi pengembang yang tertarik pada teknologi semacam ini. (Sumber: lateinteraction)
Pembaruan Algoritma Rekomendasi X: Platform X (sebelumnya Twitter) melakukan perbaikan pada algoritma rekomendasinya, bertujuan untuk mengatasi masalah lama seperti umpan balik negatif pengguna yang tidak diadopsi, konten yang sama muncul berulang kali, dan algoritma SimCluster yang merekomendasikan konten yang tidak relevan. Dilaporkan bahwa umpan balik awal positif. (Sumber: TheGregYang)
Wikipedia Mengumumkan Strategi AI Baru untuk Membantu Editor Manusia: Wikipedia mengumumkan strategi kecerdasan buatan barunya, yang bertujuan memanfaatkan alat AI untuk mendukung dan meningkatkan pekerjaan editor manusia, bukan menggantikan mereka. Detail spesifik tidak dirinci dalam sumber, tetapi menunjukkan bahwa ensiklopedia online terbesar di dunia ini sedang menjajaki cara mengintegrasikan teknologi AI ke dalam proses pembuatan dan pemeliharaan kontennya. (Sumber: Reddit r/artificial)
🧰 Alat
Midjourney Meluncurkan Fitur Omni-Reference: Midjourney merilis fitur baru Omni-Reference (oref), yang memungkinkan pengguna memberikan URL gambar referensi (menggunakan parameter –oref) untuk memandu generasi gambar, guna mencapai konsistensi karakter, objek, kendaraan, atau makhluk non-manusia. Pengguna dapat mengontrol bobot pengaruh gambar referensi melalui parameter –ow, bobot rendah cocok untuk gaya, bobot tinggi cocok untuk realisme atau pencocokan wajah yang presisi. Fitur ini bertujuan untuk meningkatkan konsistensi dan kontrol elemen spesifik dalam gambar yang dihasilkan. (Sumber: op7418, DavidSHolz)

Runway Gen-4 References Mewujudkan Personalisasi Gambar Tunggal: Model Gen-4 Runway meluncurkan fitur References (Referensi), di mana pengguna hanya perlu memberikan satu gambar referensi untuk menerapkan gaya atau fitur karakter dari gambar tersebut ke konten baru yang dihasilkan. Demonstrasi menunjukkan bahwa fitur ini dapat dengan mudah menciptakan kembali potret orang dengan gaya gambar referensi atau menempatkannya di dunia yang digambarkan oleh gambar referensi, menunjukkan kemampuan model untuk mencapai personalisasi dengan konsistensi dan kualitas estetika yang tinggi hanya dengan satu gambar referensi. (Sumber: c_valenzuelab, c_valenzuelab)

Bot WhatsApp Perplexity Memulihkan Layanan: Bot obrolan WhatsApp dari Perplexity AI, setelah sempat nonaktif karena permintaan yang jauh melebihi perkiraan, kini telah memulihkan layanannya. Pengguna dapat berinteraksi dengannya melalui nomor telepon +1 (833) 436-3285, dapat meneruskan pesan untuk pemeriksaan fakta, bertanya langsung untuk mendapatkan jawaban, melakukan percakapan teks bentuk bebas, dan membuat gambar. (Sumber: AravSrinivas, AravSrinivas)
Krea AI Menggabungkan Model Gambar 4o untuk Kontrol Gambar yang Presisi: Alat kreatif AI Krea AI menambahkan fitur baru yang memungkinkan pengguna menggabungkan kemampuan model gambar 4o dari OpenAI, melalui kolase gambar dan coretan, untuk mengontrol konten dan gaya gambar yang dihasilkan dengan lebih presisi. Ini menunjukkan inovasi berkelanjutan Krea dalam generasi gambar interaktif, memungkinkan pengguna memandu kreasi AI secara lebih intuitif dan detail. (Sumber: op7418)
Mesin All-in-One Xingyun Brown Ant: Menjalankan DeepSeek Penuh dengan Biaya Rendah: Xingyun Integrated Circuit, yang berlatar belakang Tsinghua, meluncurkan mesin AI all-in-one Brown Ant, yang diklaim dapat menjalankan model DeepSeek-R1/V3 671B presisi FP8 tanpa kuantisasi dengan kecepatan lebih dari 20 token/s dan mendukung konteks 128K, dengan harga 149.000 yuan. Solusi ini menggunakan CPU AMD EPYC dual-socket dan memori frekuensi tinggi berkapasitas besar, dikombinasikan dengan sejumlah kecil akselerasi GPU, bertujuan untuk secara signifikan mengurangi biaya perangkat keras penerapan model besar secara privat melalui arsitektur CPU+memori, memberikan pengalaman lokal yang mendekati kinerja resmi, cocok untuk skenario perusahaan yang sensitif terhadap biaya dan membutuhkan presisi tinggi. (Sumber: 新智元)

Aplikasi NotebookLM Segera Dirilis: Aplikasi catatan AI Google, NotebookLM, akan segera meluncurkan aplikasi resmi untuk iOS dan Android, diperkirakan akan上线 pada 20 Mei, saat ini sudah dibuka untuk pre-order. Ini akan membawa fungsi NotebookLM yang berbasis pada catatan dan dokumen pengguna untuk memberikan ringkasan, tanya jawab, dan generasi ide ke platform seluler. (Sumber: zacharynado)
Granola Meluncurkan Aplikasi iOS, Mewujudkan Notulen Rapat AI Real-time: Aplikasi catatan AI Granola merilis versi iOS, memperluas fungsi catatan AI rapat Zoom yang sudah ada ke skenario percakapan tatap muka offline. Pengguna dapat menggunakan Granola di iPhone untuk merekam dan mentranskripsi percakapan, serta memanfaatkan AI untuk menghasilkan ringkasan dan catatan, memudahkan peninjauan dan pengorganisasian selanjutnya. (Sumber: amasad)
Grok Studio Mendukung Pemrosesan PDF: Asisten AI Grok menambahkan kemampuan pemrosesan file PDF ke dalam fitur Studio-nya. Pengguna sekarang dapat memproses dan menganalisis dokumen PDF dengan lebih mudah di Grok Studio. Detail fungsi spesifik tidak dirinci, tetapi ini menandai perluasan kemampuan Grok dalam pemahaman dan interaksi dokumen multi-format. (Sumber: grok, TheGregYang)
Model Baru Suno Menunjukkan Kemampuan Generasi Musik yang Luar Biasa: Platform generasi musik AI Suno meluncurkan model baru, dengan umpan balik pengguna yang menyatakan hasil generasinya “sangat luar biasa”. Seorang pengguna mencoba menggunakannya untuk menghasilkan lagu gaya pertunjukan langsung, meskipun tidak sepenuhnya mencapai efek respons yang diharapkan, musik yang dihasilkan menunjukkan kinerja yang baik dalam hal suasana keramaian, menunjukkan kemajuan model baru dalam kualitas musik dan keragaman gaya. (Sumber: nptacek, nptacek)
Aplikasi Frog Spot: AI Membantu Mengidentifikasi Suara Katak: Seorang pengembang membuat aplikasi gratis bernama Frog Spot, menggunakan model CNN yang dilatih sendiri (TensorFlow Lite) untuk mengidentifikasi berbagai jenis suara katak dengan menganalisis spektogram audio 10 detik. Aplikasi ini bertujuan membantu publik mempelajari spesies lokal, sekaligus menunjukkan potensi penerapan deep learning dalam pemantauan bioakustik dan citizen science. (Sumber: Reddit r/deeplearning)
AI Membantu Otomatisasi Gambar Teknis Industri: Sebuah makalah IAAI 2025 memperkenalkan metode untuk mengotomatiskan perluasan “Instrument Typicals” dalam diagram alir perpipaan dan instrumentasi (P&ID). Metode ini menggabungkan model computer vision (deteksi dan pengenalan teks) dan aturan domain-spesifik untuk secara otomatis mengekstrak informasi dari gambar P&ID dan tabel legenda, memperluas simbol tipikal instrumen yang disederhanakan menjadi daftar instrumen terperinci, menghasilkan indeks instrumen yang akurat. Ini bertujuan untuk meningkatkan efisiensi proyek rekayasa (terutama pada tahap penawaran) dan mengurangi kesalahan manual. (Sumber: aihub.org)

Memanfaatkan Sora untuk Menghasilkan Lanskap Miniatur Bebek Kecap: Pengguna berbagi gambar “bebek kecap lanskap miniatur” yang dihasilkan menggunakan Sora berdasarkan prompt teks yang detail. Prompt tersebut secara rinci mendeskripsikan gaya adegan (fotografi makro, lanskap miniatur), subjek utama (bangunan kios yang terbuat dari bebek kecap), detail (kulit berwarna merah kecap, cabai wijen, koki mengiris, pengunjung), lingkungan (jalan yang terbuat dari saus daging bebek, dinding gaya diasinkan, lentera merah, dll.). Ini menunjukkan kemampuan Sora dalam memahami deskripsi teks yang kompleks dan imajinatif serta menghasilkan gambar berkualitas tinggi yang sesuai. (Sumber: dotey)

Membuat GPTs Prakiraan Cuaca 3D: Pengguna berbagi aplikasi ChatGPTs buatan sendiri bernama “Weather 3D”, yang dapat memanggil API cuaca untuk mendapatkan data cuaca real-time berdasarkan nama kota yang dimasukkan pengguna, dan menghasilkan ilustrasi gaya model miniatur isometrik 3D dari bangunan ikonik kota tersebut, sambil menggabungkan kondisi cuaca saat ini. Bagian atas ilustrasi akan menampilkan nama kota, kondisi cuaca, suhu, dan ikon cuaca. GPTs ini menunjukkan bagaimana menggabungkan pemanggilan API dan kemampuan generasi gambar untuk menciptakan aplikasi AI yang praktis dan menarik secara visual. (Sumber: dotey)

📚 Pembelajaran
AdaRFT: Metode Baru untuk Mengoptimalkan Fine-tuning Reinforcement Learning: Taiwei Shi dkk. mengusulkan metode curriculum learning ringan dan plug-and-play bernama AdaRFT, yang bertujuan untuk mengoptimalkan proses pelatihan algoritma reinforcement learning from human feedback (RFT) (seperti PPO, GRPO, REINFORCE). Dilaporkan, AdaRFT dapat mempersingkat waktu pelatihan RFT hingga 2 kali lipat dan meningkatkan kinerja model, dengan mengatur urutan data pelatihan secara lebih cerdas untuk meningkatkan efisiensi dan efektivitas pembelajaran. (Sumber: menhguin)

Kelas Master Online Evaluasi AI (Evals): Hamel Husain dan Shreya Shankar membuka kelas master online selama 4 minggu tentang evaluasi aplikasi AI (Evals). Kursus ini bertujuan membantu pengembang membawa aplikasi AI dari tahap prototipe ke kondisi siap produksi, mencakup metode evaluasi selama pengembangan dan pasca-peluncuran, perbedaan antara benchmark dan evaluasi praktis, pemeriksaan data, PromptEvals, dll. Menekankan pentingnya evaluasi dalam memastikan keandalan dan kinerja aplikasi AI. (Sumber: HamelHusain, HamelHusain)

Panduan Penyetelan Model Google: Google Research menyediakan repositori sumber daya bernama “tuning_playbook”, yang bertujuan untuk memberikan panduan dan praktik terbaik untuk penyetelan model. Ini adalah sumber belajar yang berharga bagi pengembang dan peneliti yang perlu melakukan fine-tuning pada model bahasa besar atau model machine learning lainnya agar sesuai dengan tugas atau dataset tertentu. (Sumber: zacharynado)

EnronQA: Dataset Benchmark RAG yang Dipersonalisasi: Peneliti meluncurkan dataset EnronQA, yang berisi 103.638 email dari 150 pengguna dan 528.304 pasangan tanya jawab berkualitas tinggi. Dataset ini bertujuan sebagai benchmark untuk mengevaluasi kinerja sistem Retrieval-Augmented Generation (RAG) yang dipersonalisasi dalam memproses dokumen pribadi. Dataset ini mencakup jawaban referensi emas, jawaban salah, alasan inferensi, dan jawaban alternatif, membantu analisis yang lebih rinci tentang kinerja sistem RAG. (Sumber: tokenbender)
ReXGradient-160K: Dataset Rontgen Dada dan Laporan Skala Besar: Dirilis sebuah dataset rontgen dada publik berskala besar bernama ReXGradient-160K, yang berisi 60.000 studi rontgen dada dari 109.487 pasien unik dari 3 sistem kesehatan AS (79 titik medis) beserta laporan radiologi (teks bebas) pasangannya. Dilaporkan ini adalah dataset rontgen dada dengan jumlah pasien terbanyak yang tersedia untuk umum saat ini, menyediakan sumber daya berharga untuk melatih dan mengevaluasi model AI pencitraan medis. (Sumber: iScienceLuvr)

Artikel Blog Membahas Pertumbuhan Kemampuan Agen AI: Peneliti Shunyu Yao menerbitkan artikel blog berjudul “The Second Half”, mengemukakan bahwa perkembangan AI saat ini berada pada momen “jeda paruh waktu”. Sebelumnya, pelatihan lebih penting daripada evaluasi; setelah ini, evaluasi akan lebih penting daripada pelatihan, alasannya adalah reinforcement learning (RL) akhirnya mulai berfungsi secara efektif. Artikel tersebut membahas pentingnya pergeseran metodologi evaluasi dalam konteks peningkatan kemampuan AI yang berkelanjutan. (Sumber: andersonbcdefg)
Berbagi Riset OpenAI tentang Privasi dan Memorisasi: Peneliti OpenAI Pratyush Maini dan Zhili Feng akan memberikan presentasi tentang riset privasi dan memorisasi, membahas cara mendeteksi, mengukur, dan menghilangkan fenomena memorisasi dalam model bahasa besar, serta aplikasi praktisnya dalam LLM lingkungan produksi. Ini berkaitan dengan cara menyeimbangkan kemampuan model dengan perlindungan privasi data pengguna. (Sumber: code_star)

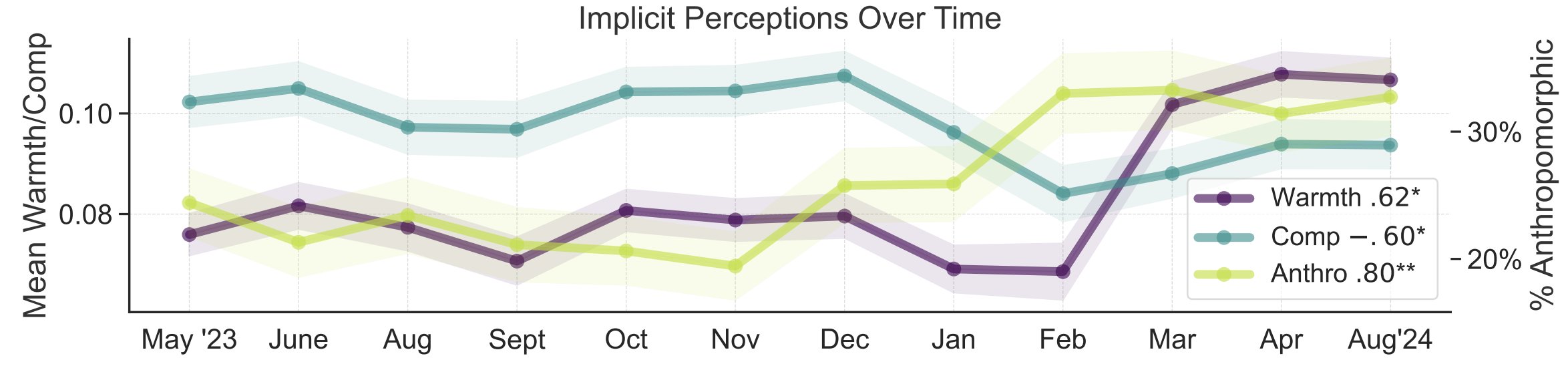
Studi Metafora Persepsi Publik tentang AI: Peneliti Universitas Stanford Myra Cheng dkk. mempresentasikan makalah di FAccT 2025, menganalisis 12.000 metafora tentang AI yang dikumpulkan selama 12 bulan untuk memahami model mental publik tentang AI dan perubahannya seiring waktu. Studi menemukan bahwa seiring waktu, publik cenderung melihat AI sebagai lebih manusiawi dan memiliki agensi (tingkat antropomorfisme meningkat), dan kecenderungan emosional terhadapnya (kehangatan) juga meningkat. Metode ini memberikan wawasan persepsi publik yang lebih rinci daripada laporan mandiri. (Sumber: stanfordnlp, stanfordnlp)
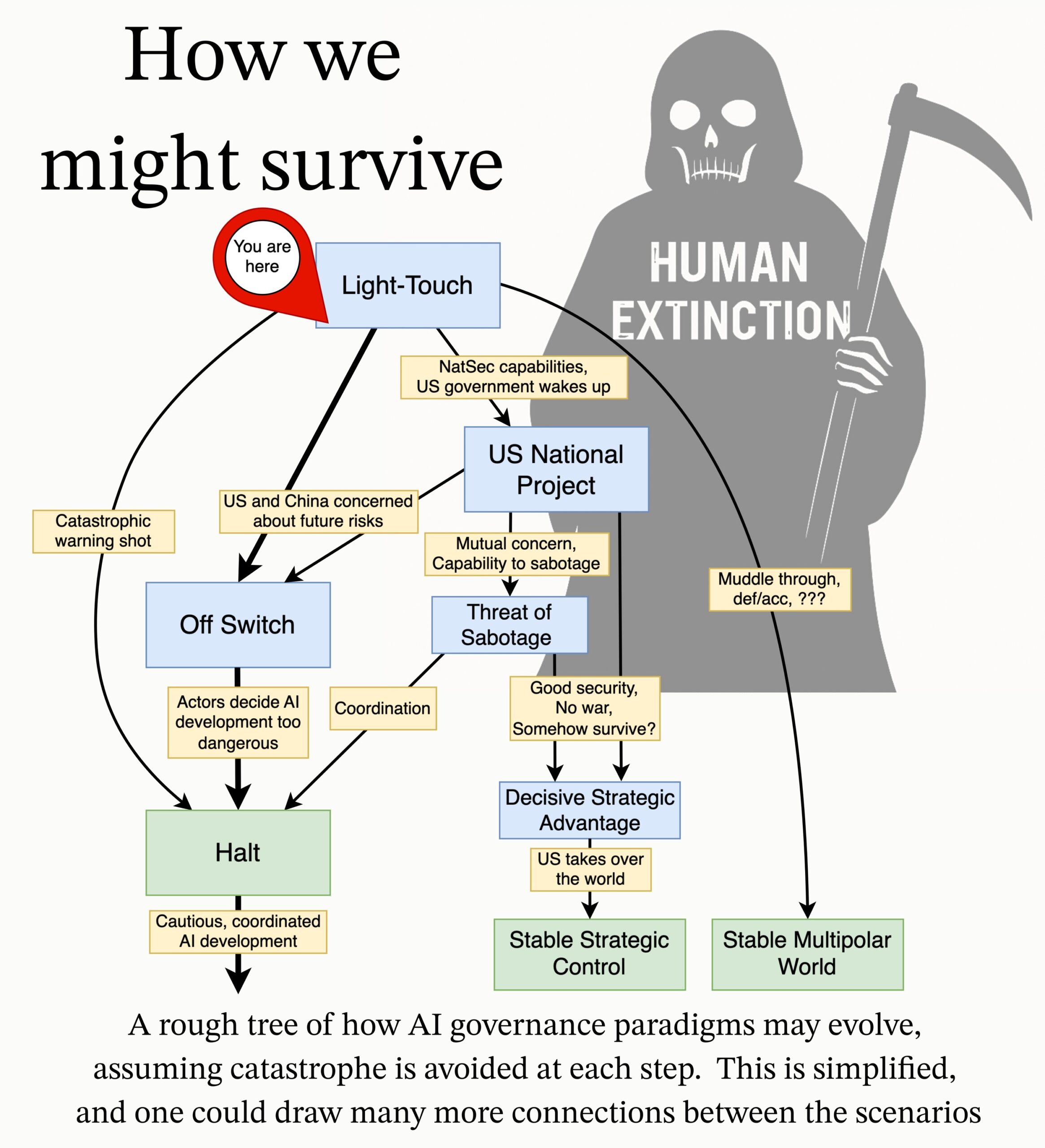
MIRI Merilis Agenda Riset Tata Kelola AI: Tim tata kelola teknis Machine Intelligence Research Institute (MIRI) merilis agenda riset tata kelola AI baru, menjelaskan pandangan mereka tentang lanskap strategis dan mengajukan serangkaian pertanyaan riset yang dapat ditindaklanjuti. Tujuannya adalah untuk mengeksplorasi langkah-langkah apa yang perlu diambil untuk mencegah organisasi atau individu mana pun membangun superinteligensi yang tidak dapat dikendalikan, guna mengurangi risiko katastropik dan risiko kepunahan dari AI. (Sumber: JeffLadish)
💼 Bisnis
Penyedia Solusi AI Tingkat Enterprise Deepexi Mengajukan IPO di Hong Kong: Deepexi (滴普科技), penyedia solusi AI tingkat enterprise yang didirikan oleh mantan eksekutif Huawei dan Alibaba, Zhao Jiehui, telah secara resmi mengajukan permohonan pencatatan saham di Bursa Hong Kong. Perusahaan ini berfokus pada platform kecerdasan data FastData dan solusi kecerdasan buatan tingkat enterprise FastAGI, melayani industri seperti ritel (misalnya Belle), manufaktur, medis, dll. Dalam tiga tahun terakhir, pendapatan perusahaan terus tumbuh, mencapai 243 juta yuan pada tahun 2024. Deepexi telah menyelesaikan 8 putaran pendanaan, mendapatkan investasi dari institusi terkenal seperti Hillhouse Capital, IDG Capital, 5Y Capital, dll., dengan valuasi sekitar 6,8 miliar yuan setelah putaran pendanaan terakhir. Meskipun pendapatan tumbuh, perusahaan saat ini masih merugi, dengan kerugian bersih yang disesuaikan menyusut dari tahun ke tahun. (Sumber: 36氪)
BMW China Mengumumkan Integrasi dengan Model Besar DeepSeek: Setelah bekerja sama dengan Alibaba, BMW Group semakin memperdalam tata letak AI-nya di China, mengumumkan akan mengintegrasikan model besar DeepSeek. Fitur ini direncanakan akan dimulai pada kuartal ketiga tahun 2025, pertama kali diterapkan pada beberapa model mobil baru yang dijual di China yang dilengkapi dengan BMW Operating System generasi ke-9, dan di masa depan juga akan diterapkan pada model BMW New Generation yang diproduksi secara lokal. Langkah ini bertujuan untuk memperkuat pengalaman interaksi manusia-mesin yang berpusat pada BMW Intelligent Personal Assistant melalui kemampuan berpikir mendalam DeepSeek, meningkatkan tingkat kecerdasan dan kemampuan koneksi emosional kendaraan, merupakan langkah penting bagi BMW untuk mempercepat strategi AI lokal dan menghadapi tantangan transformasi intelijen. (Sumber: 36氪)
Shopify Mewajibkan Semua Karyawan Menggunakan AI, Ingin Mengganti Sebagian Posisi dengan AI: CEO platform e-commerce global Shopify, Tobi Lutke, dalam memo internal menekankan bahwa penggunaan AI yang efisien telah menjadi “aturan besi” bagi semua karyawan perusahaan, bukan lagi saran. Memo tersebut mengharuskan karyawan menerapkan AI ke dalam alur kerja mereka, membentuk refleks terkondisi; tim yang mengajukan penambahan staf harus membuktikan mengapa AI tidak dapat menyelesaikan tugas tersebut; penilaian kinerja akan memasukkan metrik penggunaan AI. Lutke menunjukkan bahwa AI dapat sangat meningkatkan efisiensi (beberapa karyawan mencapai 10x bahkan 100x), karyawan perlu meningkatkan 20%-40% setiap tahun untuk tetap kompetitif. Sebelumnya Shopify telah melakukan PHK di departemen seperti layanan pelanggan dan memperkenalkan pengganti AI. Langkah ini dianggap sebagai sinyal jelas dari tren penyesuaian dan PHK posisi kerah putih yang disebabkan oleh AI. (Sumber: 新智元)

🌟 Komunitas
Diskusi tentang Masalah Halusinasi AI: Kritik Li Yanhong di Konferensi Pengembang AI Baidu terhadap DeepSeek-R1 yang memiliki tingkat halusinasi tinggi, kecepatan lambat, dan biaya tinggi, memicu diskusi kembali di komunitas tentang fenomena “halusinasi” model besar. Analisis menunjukkan bahwa tidak hanya DeepSeek, tetapi juga model canggih seperti o3/o4-mini OpenAI, Qwen3 Alibaba, dll., secara umum memiliki masalah halusinasi, dan pemikiran multi-putaran model inferensi dapat memperbesar bias. Evaluasi Vectara menunjukkan tingkat halusinasi R1 (14,3%) jauh lebih tinggi daripada V3 (3,9%). Komunitas percaya bahwa seiring dengan peningkatan kemampuan model, halusinasi menjadi lebih tersembunyi dan lebih logis, membuat pengguna sulit membedakan kebenaran, menimbulkan kekhawatiran tentang keandalan. Pada saat yang sama, ada juga pandangan bahwa halusinasi adalah produk sampingan dari kreativitas, terutama berharga di bidang seperti penciptaan sastra. Bagaimana mendefinisikan tingkat halusinasi yang dapat diterima, dan bagaimana mengurangi halusinasi melalui sarana teknis seperti RAG, kontrol kualitas data, model kritis, dll., masih menjadi isu yang terus dieksplorasi oleh industri. (Sumber: 36氪)

Pemikiran dan Diskusi tentang Pendamping/Teman AI: CEO Meta Mark Zuckerberg mengusulkan penggunaan teman AI yang dipersonalisasi untuk memenuhi kebutuhan orang akan lebih banyak koneksi sosial (mengklaim rata-rata orang memiliki 3 teman, tetapi kebutuhannya adalah 15), memicu diskusi komunitas. Sebastien Bubeck percaya bahwa mewujudkan pendamping AI sejati sangat sulit, kuncinya adalah AI perlu dapat menjawab secara bermakna “Apa yang sedang kamu lakukan akhir-akhir ini?”, yaitu memiliki pengalaman dan pengalamannya sendiri, bukan hanya berbagi pengalaman pengguna. Dia percaya bahwa konsepsi pendamping AI saat ini terlalu fokus pada pengalaman bersama, dan mengabaikan bahwa AI itu sendiri juga perlu memiliki pengalaman independen yang dapat dibagikan, bahkan gosip (berbagi pengalaman satu sama lain). Komentator lain mempertanyakan dari sudut pandang Angka Dunbar, percaya bahwa lingkaran sosial besar yang terdiri dari AI mungkin kurang memiliki makna nyata. Ada juga kekhawatiran bahwa teman AI yang disediakan oleh perusahaan komersial pada akhirnya bertujuan untuk konversi pemasaran presisi, bukan pendampingan sejati. (Sumber: jonst0kes, SebastienBubeck, gfodor, gfodor)

Penciptaan Seni AI Memicu Emosi dan Pemikiran: Di komunitas, ada pengguna yang mengungkapkan rasa “sedih” (grieving) karena AI dapat menciptakan karya seni yang “sangat bagus” dalam waktu singkat, percaya bahwa ini menantang keunikan manusia dalam penciptaan seni. Hal ini memicu diskusi tentang seni AI, esensi kreativitas manusia, dan perasaan nilai pribadi di bawah guncangan teknologi. Beberapa komentar percaya bahwa kesenangan penciptaan seni terletak pada proses itu sendiri, bukan bersaing dengan AI; seni AI dapat menjadi sumber inspirasi. Ada juga yang percaya bahwa seni AI kurang memiliki “kesalahan” atau jiwa dari ciptaan manusia, tampak terlalu sempurna atau kaku. Pada saat yang sama, diskusi juga meluas ke pemikiran filosofis yang dibawa oleh AI dalam aspek seperti simulasi emosional, kesadaran, dan struktur sosial masa depan (seperti pekerjaan yang digantikan). (Sumber: Reddit r/ArtificialInteligence)
Etika dan Tanggung Jawab AI: Eksperimen Rahasia dan Pengungkapan Informasi: Komunitas membahas masalah etika dalam penelitian AI. Sebuah berita menyebutkan bahwa ada peneliti AI yang melakukan eksperimen rahasia di Reddit, mencoba mengubah pikiran pengguna, menimbulkan kekhawatiran tentang hak pengguna untuk tahu dan risiko manipulasi AI. Dalam diskusi lain, seorang pengguna melaporkan mengalami kesulitan dengan proses yang rumit dan tanggung jawab yang tidak jelas ketika melaporkan potensi masalah keamanan ke perusahaan AI, menyoroti bahwa bidang AI saat ini belum matang dalam hal pengungkapan yang bertanggung jawab dan mekanisme respons kerentanan. (Sumber: Reddit r/ArtificialInteligence, nptacek)

Refleksi Bidang NLP tentang Kebangkitan ChatGPT: Quanta Magazine menerbitkan artikel, melalui wawancara dengan beberapa ahli di bidang Natural Language Processing (NLP) seperti Chris Potts, Yejin Choi, Emily Bender, meninjau kembali guncangan dan refleksi yang dibawa oleh perilisan ChatGPT ke seluruh bidang. Artikel tersebut membahas bagaimana kebangkitan model bahasa besar menantang dasar teoretis NLP tradisional, memicu perdebatan di dalam bidang, polarisasi faksi, dan penyesuaian arah penelitian. Anggota komunitas memberikan tanggapan antusias terhadap artikel ini, percaya bahwa artikel tersebut dengan baik menguraikan guncangan dan proses adaptasi bidang linguistik setelah GPT-3. (Sumber: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
Munculnya dan Persepsi Iklan yang Dihasilkan AI: Pengguna media sosial melaporkan mulai melihat iklan yang dihasilkan AI di platform seperti YouTube, dan menyatakan merasa “sangat tidak nyaman”. Ini menunjukkan bahwa teknologi generasi konten AI telah mulai diterapkan dalam produksi iklan komersial, sekaligus memicu reaksi awal pengguna mengenai kualitas, keaslian, dan pengalaman emosional konten yang dihasilkan AI. (Sumber: code_star)
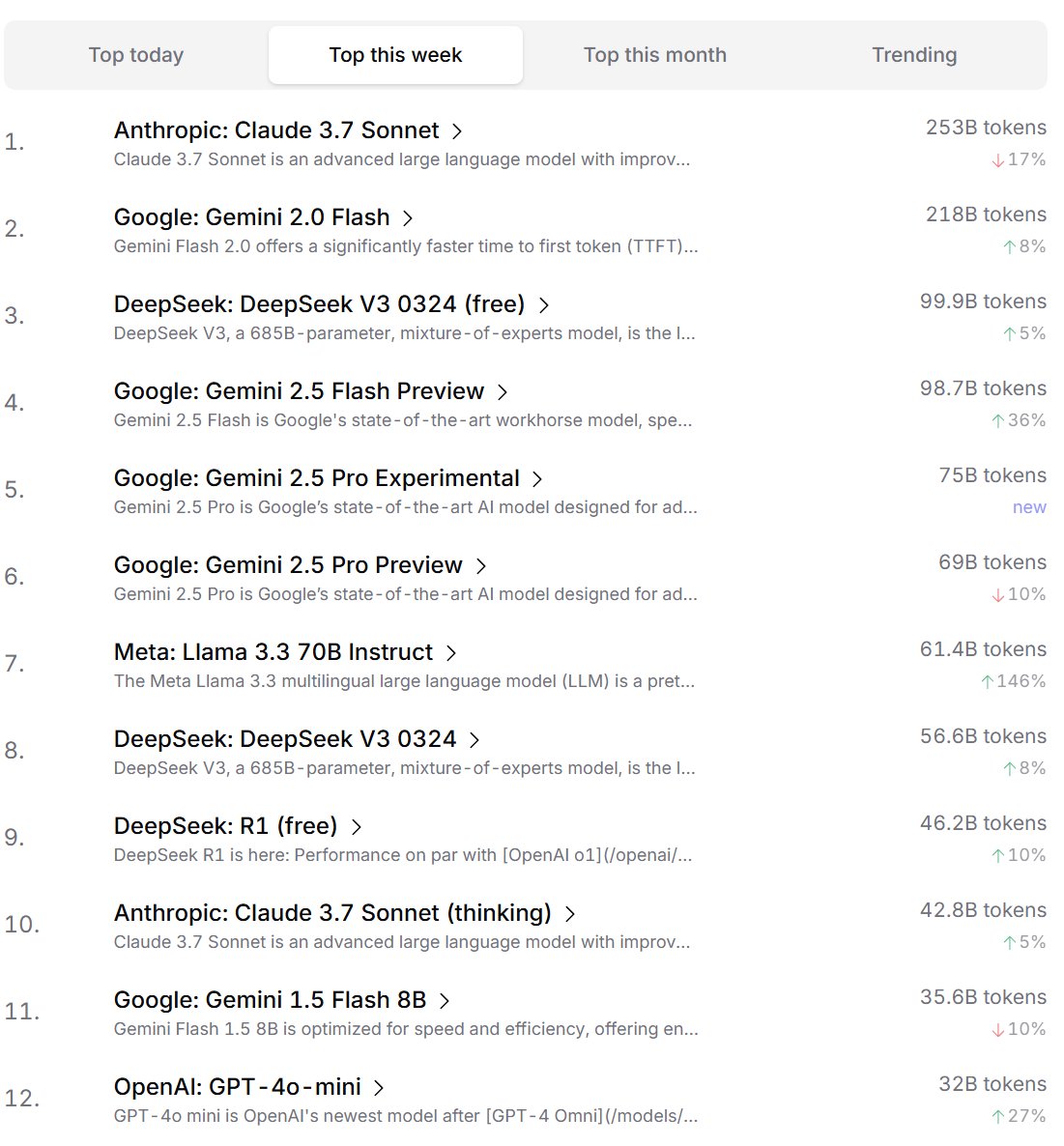
Peringkat Preferensi Model AI oleh Pengembang: Cursor.ai merilis peringkat model AI yang disukai oleh penggunanya (terutama pengembang), sementara Openrouter juga mengumumkan peringkat penggunaan Token model. Peringkat ini, berdasarkan data penggunaan produk aktual, dianggap mungkin lebih mencerminkan preferensi pilihan pengguna dalam skenario pengembangan nyata daripada peringkat gaya arena seperti ChatBot Arena, memberikan perspektif berbeda untuk mengevaluasi kepraktisan model. (Sumber: op7418, Reddit r/LocalLLaMA)
Diskusi tentang Apakah AI Memiliki Kemampuan “Berpikir”: Di komunitas, terdapat diskusi berkelanjutan tentang apakah model bahasa besar (LLMs) benar-benar memiliki kemampuan “berpikir”. Ada pandangan bahwa LLM saat ini sebenarnya tidak berpikir sebelum berbicara, tetapi mensimulasikan proses berpikir dengan menghasilkan lebih banyak teks (seperti chain of thought), yang merupakan kesalahpahaman. Pandangan lain berpendapat bahwa menggunakan metode matematika kontinu (seperti LLM) untuk melakukan penalaran diskrit pada komputer diskrit itu sendiri memiliki masalah mendasar. Diskusi ini mencerminkan pemikiran mendalam tentang sifat teknologi AI saat ini dan arah pengembangan di masa depan. (Sumber: francoisfleuret, pmddomingos)
Pemikiran Dialektis tentang Konsumsi Energi AI dan Dampak Lingkungan: Menanggapi masalah lingkungan yang disebabkan oleh konsumsi energi besar yang dibutuhkan untuk pelatihan dan pengoperasian AI, muncul pemikiran dialektis di komunitas. Satu pandangan berpendapat bahwa permintaan energi besar AI (terutama dari perusahaan komputasi skala besar seperti Google, Amazon, Microsoft) memaksa perusahaan-perusahaan ini untuk berinvestasi dalam membangun energi terbarukan mereka sendiri (surya, angin, baterai), bahkan memulai kembali pembangkit listrik tenaga nuklir (seperti kerja sama Microsoft dengan Constellation untuk memulai kembali PLTN Three Mile Island). Permintaan ini mungkin malah menjadi katalisator untuk mempercepat penyebaran energi bersih dan terobosan teknologi (seperti reaktor nuklir modular kecil SMR). Namun, ada juga pandangan yang menunjukkan masalah diminishing returns dari konsumsi energi AI, serta konsumsi sumber daya air yang dibutuhkan untuk pendinginan yang juga patut diperhatikan. (Sumber: Reddit r/ArtificialInteligence)
Anthropic Dituduh Mencoba Membatasi Persaingan Chip AI: Diskusi komunitas menunjukkan bahwa CEO Anthropic Dario Amodei menganjurkan penguatan kontrol ekspor chip AI ke tempat-tempat seperti China, bahkan mengemukakan klaim bahwa chip mungkin diselundupkan melalui cara-cara seperti menyamar sebagai perut palsu wanita hamil. Kritikus berpendapat bahwa langkah Anthropic ini bertujuan untuk membatasi pesaing (terutama perusahaan China seperti DeepSeek, Qwen) memperoleh sumber daya komputasi canggih, untuk mempertahankan keunggulannya dalam pengembangan model mutakhir. Praktik ini dituduh menggunakan kebijakan untuk menekan persaingan, tidak kondusif bagi pengembangan terbuka teknologi AI global dan komunitas open-source. (Sumber: Reddit r/LocalLLaMA)

💡 Lain-lain
Pemikiran tentang AI dan Batas Kognitif Manusia: Jeff Ladish berkomentar bahwa jendela waktu peran manusia sebagai “asisten copy-paste” AI sangat singkat, menyiratkan bahwa kemampuan otonom AI akan dengan cepat melampaui bantuan sederhana. Sementara itu, pendiri DeepMind Hassabis dalam sebuah wawancara menyatakan bahwa AGI sejati harus dapat secara independen mengajukan hipotesis ilmiah yang berharga (seperti Einstein mengusulkan relativitas umum), bukan hanya menyelesaikan masalah, percaya bahwa AI saat ini masih kurang dalam generasi hipotesis. Liu Cixin berharap AI dapat menembus batas kognitif biologis otak manusia. Pandangan-pandangan ini bersama-sama menunjuk pada pemikiran mendalam tentang batas kemampuan AI, evolusi peran manusia, dan esensi kecerdasan di masa depan. (Sumber: JeffLadish, 新智元)
LiDAR Waymo Menangkap Momen Mengerikan: Sistem LiDAR kendaraan kemudi otonom Waymo, dalam sebuah insiden kecelakaan sepeda motor yang berhasil dihindarinya, dengan jelas menangkap citra point cloud 3D dari pengendara pengantar makanan yang terbalik dalam tabrakan. Ini tidak hanya menunjukkan kemampuan kuat sistem persepsi Waymo (bahkan dalam skenario dinamis yang kompleks), tetapi juga secara tak terduga merekam perspektif unik dari kecelakaan tersebut. Untungnya tidak ada yang terluka parah dalam kecelakaan itu. (Sumber: andrew_n_carr)
Ide Baru untuk Penciptaan Novel AI: Sistem Janji Plot: Pengembang Levi mengusulkan sistem “Janji Plot” (Plot Promise) untuk penciptaan novel AI, sebagai alternatif metode kerangka hierarkis tradisional. Sistem ini terinspirasi oleh teori “janji, kemajuan, imbalan” Brandon Sanderson, memandang cerita sebagai serangkaian alur naratif aktif (janji), setiap janji memiliki skor kepentingan, algoritma menyarankan waktu kemajuan berdasarkan skor dan kemajuan, tetapi AI akan secara logis memilih janji yang paling cocok untuk dimajukan saat ini berdasarkan konteks. Pengguna dapat secara dinamis menambah/menghapus janji. Metode ini bertujuan untuk meningkatkan fleksibilitas cerita, skalabilitas (beradaptasi dengan panjang super), dan kemunculan (emergence) penciptaan, tetapi menghadapi tantangan seperti optimasi keputusan AI, pemeliharaan koherensi jangka panjang, dan batasan panjang prompt input. (Sumber: Reddit r/ArtificialInteligence)