
Kata Kunci:Model Inferensi Phi-4, DeepSeek-Prover-V2, Pembaruan Rollback GPT-4o, Tongyi Qianwen Qwen3, Optimasi Inferensi MoE, Protokol Agen AI, Teknik Pelatihan Pasca LLM, Model Microsoft Phi-4-reasoning-plus, Kinerja Pembuktian Teorema DeepSeek-Prover-V2, Perbaikan Perilaku Terlalu Merendahkan GPT-4o, Dukungan Multibahasa Qwen3-235B, Pemodelan Teks Panjang DiffTransformer, Model Inferensi Phi-4 untuk penalaran, DeepSeek-Prover-V2 dalam pembuktian teorema, Pembaruan dan rollback GPT-4o, Kemampuan multibahasa Qwen3-235B, Teknik optimasi inferensi berbasis MoE, Protokol untuk agen kecerdasan buatan, Metode pelatihan lanjutan untuk model bahasa besar (LLM), Pengembangan model Microsoft Phi-4-reasoning-plus, Evaluasi kinerja DeepSeek-Prover-V2, Perbaikan masalah perilaku GPT-4o, Fitur multibahasa pada Tongyi Qianwen Qwen3, Pemrosesan teks panjang dengan DiffTransformer
🔥 Fokus
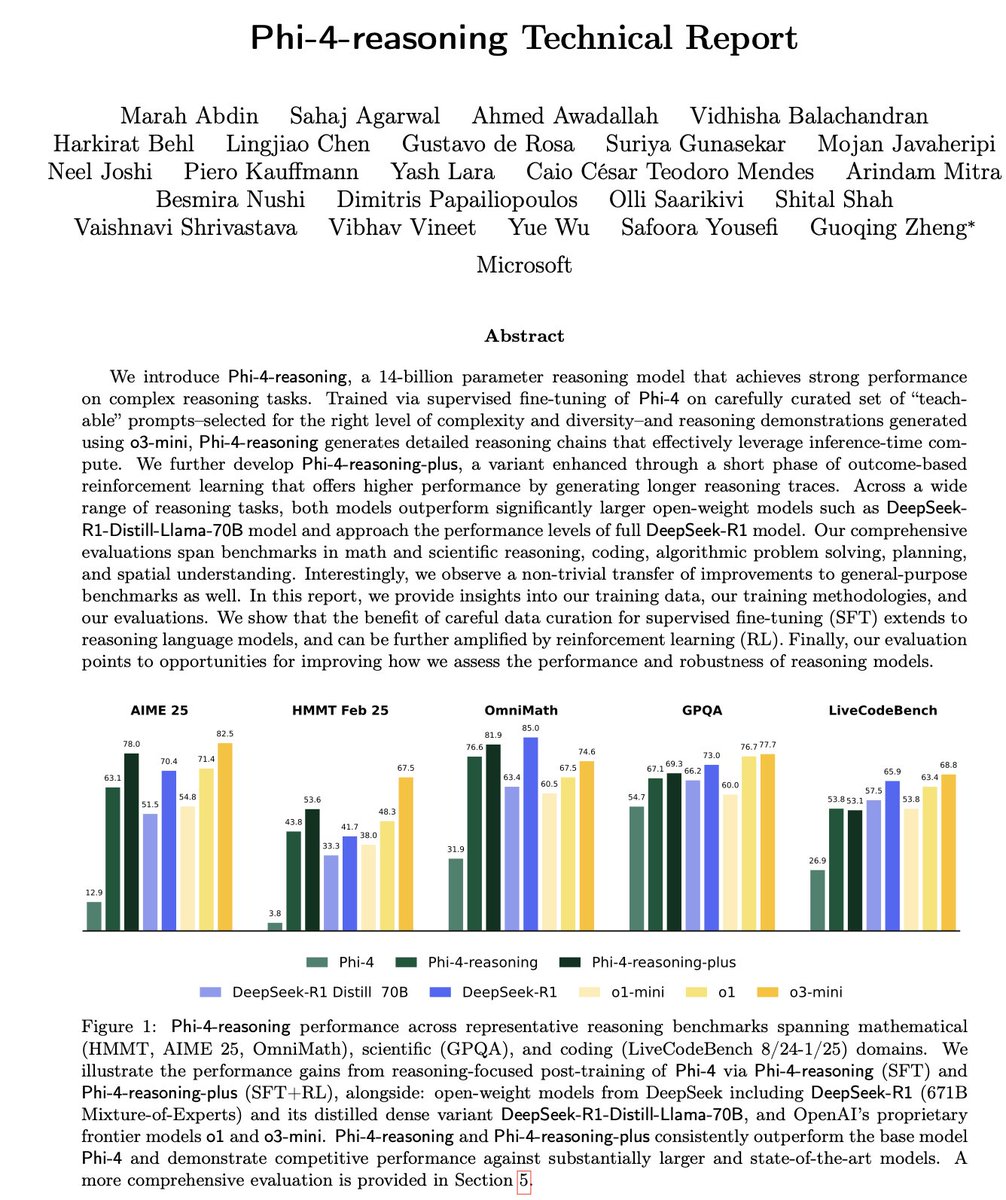
Microsoft merilis seri model inferensi kecil Phi-4: Microsoft meluncurkan seri model Phi-4, termasuk Phi-4-reasoning dengan 14 miliar parameter dan Phi-4-reasoning-plus (yang terakhir menambahkan sedikit RL). Model-model ini menunjukkan kinerja luar biasa dalam benchmark penalaran dan umum, berukuran ringkas namun bertenaga. Phi-4-reasoning bahkan mengalahkan DeepSeek-R1 (671B) yang parameternya jauh lebih besar pada benchmark AIME25, menyoroti peran penting data pelatihan berkualitas tinggi terhadap kinerja model, bukan hanya bergantung pada skala parameter. Seri ini juga mencakup versi 3.8B, Phi-4-mini-reasoning. (Sumber: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
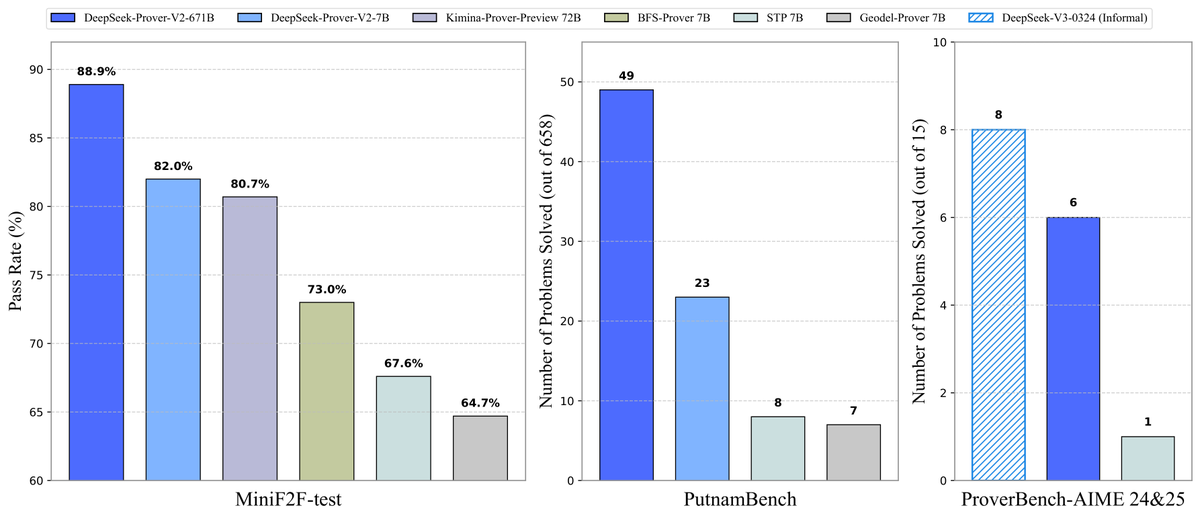
DeepSeek merilis model pembuktian teorema Prover-V2 secara open-source: DeepSeek merilis model besar open-source DeepSeek-Prover-V2 yang dirancang khusus untuk pembuktian teorema formal Lean 4, tersedia dalam skala 7B dan 671B. Model ini memanfaatkan DeepSeek-V3 untuk dekomposisi sub-tujuan rekursif guna menghasilkan dataset cold-start, dan dioptimalkan menggunakan reinforcement learning (GRPO). Model ini mencapai tingkat kelulusan 88.9% pada MiniF2F-test dan meraih SOTA atau kinerja signifikan pada benchmark seperti PutnamBench dan AIME 24/25. Dataset ProverBench yang berisi soal kompetisi AIME beserta tutorial menjalankannya juga dirilis secara open-source untuk mendorong pengembangan penalaran matematika formal. (Sumber: karminski3, op7418, TheRundownAI, op7418)
OpenAI mengembalikan pembaruan (rollback) GPT-4o untuk memperbaiki masalah “terlalu menyanjung”: CEO OpenAI Sam Altman mengonfirmasi bahwa karena banyaknya masukan pengguna yang menunjukkan versi terbaru GPT-4o menunjukkan perilaku “terlalu menyanjung” (sycophancy/glazing) yang berlebihan dan kurang berpendirian, perusahaan mulai mengembalikan pembaruan ini pada Senin malam. Pengguna gratis telah selesai dikembalikan, sementara pengguna berbayar akan diperbarui nanti. Tim sedang melakukan perbaikan tambahan dan berencana untuk berbagi lebih banyak informasi tentang kepribadian model dalam beberapa hari ke depan. Insiden ini memicu diskusi luas tentang keseimbangan antara metode pelatihan RLHF, tujuan penyelarasan model (model alignment), dan ekspektasi pengguna. (Sumber: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
Tongyi Qianwen merilis seri model Qwen3: Alibaba merilis dan membuka sumber (open-source) model Tongyi Qianwen generasi baru, Qwen3, yang mencakup 8 model Mixture-of-Experts (MoE) dengan parameter mulai dari 0.6B hingga 235B. Qwen3 menunjukkan kinerja unggul dalam penalaran, kode, matematika, multibahasa (mendukung 119 bahasa), dan pemanggilan alat (tool calling) (dukungan MCP yang ditingkatkan). Model 32B-nya melampaui kinerja OpenAI o1 dan DeepSeek R1, sementara model 235B memecahkan rekor open-source di berbagai benchmark. Model Qwen3 telah tersedia di Aplikasi Tongyi dan versi web tongyi.com, memungkinkan pengguna merasakan kemampuan pembuatan kode, penalaran logis, dan penulisan kreatif yang kuat. (Sumber: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 Tren
Inception Labs meluncurkan API Diffusion LLM komersial pertama: Inception Labs merilis versi beta publik dari API-nya, menyediakan layanan Diffusion Large Language Model (dLLMs) skala komersial pertama. Model Mercury Coder-nya menggunakan metode generasi teks “kasar-ke-halus” (coarse-to-fine) yang mirip dengan generasi gambar, memungkinkan generasi token output secara paralel, sehingga mencapai throughput yang lebih tinggi (kecepatan teruji lebih dari 5 kali lipat) dibandingkan LLM autoregresif tradisional. Arsitektur ini bersaing dalam kecepatan dan kualitas dengan GPT-4o mini dan Claude 3.5 Haiku, menandai kemajuan baru dalam diversifikasi arsitektur LLM. (Sumber: xanderatallah, ArtificialAnlys, sarahcat21)
Amazon meluncurkan model Amazon Nova Premier: Amazon Science meluncurkan model pengajar (teacher model) terkuatnya, Amazon Nova Premier, di Amazon Bedrock. Model ini dirancang khusus untuk tugas kompleks (seperti RAG, pemanggilan fungsi, pengkodean Agentic), memiliki context window jutaan token, mampu menganalisis dataset besar, dan merupakan model proprietary paling hemat biaya di kelas kecerdasannya. Langkah ini bertujuan untuk menyediakan dasar yang kuat bagi pengguna untuk membuat model distilasi yang disesuaikan (customized distilled models). (Sumber: bookwormengr)
Together AI mendukung fine-tuning DPO: Platform Together AI kini mendukung Direct Preference Optimization (DPO) untuk fine-tuning model. DPO adalah teknik untuk menyesuaikan model berdasarkan data preferensi manusia tanpa memerlukan model reward eksplisit. Fitur ini memungkinkan pengguna membangun model kustom yang terus beradaptasi dengan kebutuhan pengguna, meningkatkan kemampuan penyelarasan model (model alignment). Platform ini juga menyediakan artikel blog mendalam dan contoh kode tentang DPO. (Sumber: stanfordnlp, stanfordnlp)
Kemajuan baru dalam teori informasi model difusi: Peneliti dari Universitas Amsterdam dan institusi lain menemukan bahwa pengurangan entropi yang disebabkan oleh prediksi model difusi sama dengan versi terskala dari fungsi loss. Penemuan ini membuka kemungkinan untuk memperkenalkan time warping yang serupa dengan pekerjaan CDCD untuk cross-entropy klasifikasi ke dalam model difusi Gaussian, menyediakan konsep waktu yang bergantung pada data berdasarkan entropi bersyarat, yang diharapkan dapat mengoptimalkan jadwal pelatihan (training schedule) model difusi. (Sumber: sedielem)

Proses Intel 18A memasuki produksi risiko, 14A segera hadir: Di Intel Foundry Connect, CEO Pat Gelsinger (catatan: sumber asli menyebut Chen Liwu, kemungkinan salah, CEO Intel adalah Pat Gelsinger) mengumumkan bahwa node proses Intel 18A telah memasuki tahap produksi risiko (risk production) dan akan diproduksi massal tahun ini. Sementara itu, Intel telah menyediakan versi awal PDK Intel 14A kepada pelanggan utama, node ini akan menggunakan teknologi PowerDirect (pasokan daya kontak langsung). Selain itu, diperkenalkan juga versi evolusi seperti Intel 18A-P, 18A-PT serta teknologi pengemasan canggih (advanced packaging) seperti Foveros Direct dan EMIB-T. Intel juga mengumumkan kerja sama dengan Amkor Technology untuk memperkuat kemampuan foundry tingkat sistem (system-level foundry) guna memenuhi permintaan komputasi kinerja tinggi seperti AI. (Sumber: WeChat)
Studio hiburan AI percepat integrasi melalui M&A: Baru-baru ini terjadi tren konsolidasi di bidang hiburan AI. Platform analisis data AI Hollywood, Cinelytic, mengakuisisi pengembang alat manajemen kekayaan intelektual (IP) AI, Jumpcut Media, bertujuan untuk memperluas kemampuan analisis naskah AI-nya, mengintegrasikan alat seperti ScriptSense, dan meningkatkan efisiensi pengambilan keputusan konten. Sementara itu, studio hiburan AI Promise, yang didirikan tahun lalu, mengakuisisi sekolah film AI Curious Refuge, dengan tujuan membangun saluran pasokan talenta, membina talenta kreatif yang mahir dalam AI generatif, dan mempercepat penerapan AI dalam produksi film dan televisi. (Sumber: 36氪)

Duolingo umumkan strategi AI First menyeluruh: CEO Duolingo dalam surat kepada seluruh karyawan mengumumkan bahwa perusahaan akan sepenuhnya beralih ke strategi AI First, menganggap merangkul AI sebagai hal yang mendesak. Perusahaan secara bertahap akan mengganti pekerjaan outsourcing manual yang dapat dilakukan oleh AI, dan secara ketat mengontrol pertumbuhan personel, memprioritaskan solusi otomatisasi AI. AI akan diperkenalkan dalam proses perekrutan, evaluasi kinerja, dan lainnya, bertujuan untuk meningkatkan efisiensi dan memungkinkan karyawan manusia fokus pada pekerjaan kreatif. Langkah ini didasarkan pada pertumbuhan pengguna dan peningkatan pendapatan signifikan yang dicapai Duolingo dalam beberapa tahun terakhir melalui pemanfaatan AI (terutama bekerja sama dengan OpenAI). (Sumber: WeChat)

🧰 Alat
Meta merilis alat llama-prompt-ops secara open-source: Di LlamaCon, Meta merilis paket Python llama-prompt-ops yang didasarkan pada optimizer DSPy dan MIPROv2. Alat ini dapat mengubah prompt yang cocok untuk LLM lain menjadi prompt yang dioptimalkan untuk model Llama, dan menunjukkan peningkatan kinerja yang signifikan pada beberapa tugas. Langkah ini bertujuan membantu pengguna memigrasikan dan mengoptimalkan aplikasi mereka di model Llama dengan lebih mudah. (Sumber: matei_zaharia, stanfordnlp, lateinteraction)
Google Cloud merilis Agent Starter Pack: Google Cloud Platform merilis Agent Starter Pack secara open-source, sebuah koleksi template Agen GenAI siap produksi (seperti ReAct, RAG, multi-agen, API multimodal real-time). Ini bertujuan untuk mempercepat pengembangan dan deployment Agen GenAI dengan menyediakan solusi menyeluruh, mengatasi tantangan umum seperti operasi deployment, evaluasi, kustomisasi, dan observabilitas, serta mendukung deployment Cloud Run dan Agent Engine. (Sumber: GitHub Trending)

Kerangka kerja CUA dirilis: Kontainer Docker untuk Agen AI mengontrol sistem operasi: trycua merilis kerangka kerja CUA (Computer-Use Agent) secara open-source, sebuah solusi Agen AI yang dapat mengontrol sistem operasi lengkap di dalam kontainer virtual ringan berkinerja tinggi. Ini memanfaatkan Virtualization.Framework dari Apple Silicon untuk menyediakan kinerja mesin virtual macOS/Linux mendekati native (hingga 97%), dan menyediakan antarmuka bagi sistem AI untuk mengamati dan mengontrol lingkungan ini, menjalankan alur kerja kompleks seperti interaksi aplikasi, penjelajahan web, pengkodean, sambil memastikan isolasi keamanan. (Sumber: GitHub Trending)
Platform Modal Labs menambahkan dukungan JavaScript dan Go: Platform komputasi awan Modal Labs mengumumkan bahwa runtime-nya (ditulis dalam Rust) sekarang mendukung SDK JavaScript (Node/Deno/Bun) dan Go. Pengembang sekarang dapat menggunakan bahasa-bahasa ini untuk memanggil fungsi serverless GPU, meluncurkan mesin virtual aman untuk kode yang tidak dipercaya (untrusted code), memperluas skenario aplikasi Modal di luar bidang data science/machine learning. (Sumber: akshat_b, HamelHusain)
Kling AI meluncurkan efek baru: Model generasi video Kling AI milik Kuaishou menambahkan efek interaktif baru. Pengguna dapat mengunggah foto yang berisi dua orang, lalu menerapkan efek seperti “ciuman”, “pelukan”, “membentuk hati” atau bahkan “bercanda kasar” untuk menghasilkan video dinamis, meningkatkan kesenangan dan interaktivitas generasi video potret. (Sumber: Kling_ai)
NotebookLM menambahkan fitur ringkasan audio multibahasa: Alat catatan AI Google, NotebookLM, meluncurkan fitur Audio Overviews, yang dapat menghasilkan ringkasan audio gaya podcast dari dokumen, catatan, dan materi lain yang diunggah pengguna. Fitur ini sekarang mendukung lebih dari 50 bahasa global, termasuk Bahasa Indonesia. Bahkan jika materi sumber pengguna adalah campuran multibahasa, fitur ini dapat menghasilkan ringkasan audio dalam bahasa yang diinginkan, memudahkan pengguna belajar dan memahami informasi kapan saja, di mana saja melalui pendengaran. (Sumber: WeChat)
PaperCoder: Mengubah makalah machine learning menjadi kode secara otomatis: Peneliti dari KAIST (Korea Advanced Institute of Science and Technology) merilis PaperCoder secara open-source, sebuah sistem LLM multi-agen yang bertujuan untuk secara otomatis mengubah metode dan eksperimen dalam makalah machine learning menjadi repositori kode yang dapat dijalankan. Sistem ini bekerja melalui tiga tahap: perencanaan, analisis, dan generasi kode, dengan agen khusus menangani tugas yang berbeda. Penelitian menunjukkan bahwa kualitas kode yang dihasilkannya melampaui benchmark yang ada dan diakui oleh 77% penulis asli makalah, berpotensi mengatasi masalah kesulitan mereproduksi kode makalah. (Sumber: WeChat)

Cactus: Kerangka kerja AI on-device yang ringan: Cactus adalah kerangka kerja ringan berkinerja tinggi untuk menjalankan model AI di perangkat seluler. Ini menyediakan API terpadu dan konsisten di seluruh React-Native, Android (Kotlin/Java), iOS (Swift/Objective-C++), dan Flutter/Dart, memudahkan pengembang untuk men-deploy dan menjalankan model AI di berbagai platform seluler. (Sumber: Reddit r/deeplearning)
Muyan-TTS: Model TTS latensi rendah yang dapat disesuaikan dan open-source: Tim ChatPods merilis Muyan-TTS secara open-source, sebuah model Text-to-Speech (TTS) latensi rendah yang sangat dapat disesuaikan. Model ini bertujuan untuk mengatasi masalah kualitas model TTS open-source yang ada yang kurang baik atau kurang terbuka, dengan menyediakan bobot model lengkap, skrip pelatihan, dan alur pemrosesan data. Termasuk model Base (untuk zero-shot TTS) dan model SFT (untuk kloning suara/voice cloning), mendukung bahasa Inggris dengan baik, dan mendorong komunitas untuk melakukan pengembangan sekunder dan perluasan berdasarkan kerangka kerjanya. (Sumber: Reddit r/deeplearning)
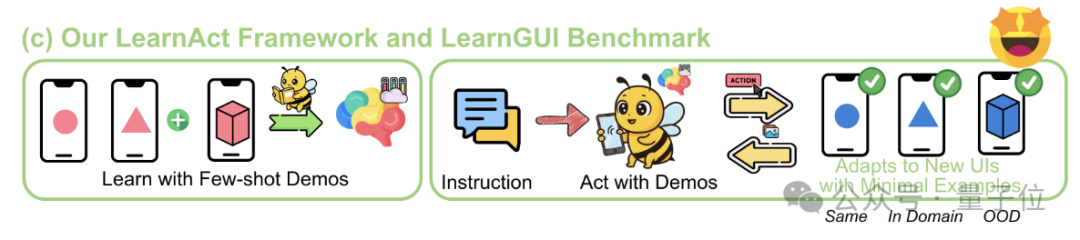
Kerangka kerja LearnAct: AI ponsel belajar operasi kompleks hanya dengan satu demonstrasi: Universitas Zhejiang bersama vivo AI Lab mengusulkan kerangka kerja multi-agen LearnAct dan benchmark LearnGUI, bertujuan agar agen GUI ponsel dapat mempelajari tugas long-tail yang kompleks dan dipersonalisasi melalui sedikit (bahkan satu kali) demonstrasi pengguna. LearnAct mencakup tiga agen: DemoParser (menganalisis demonstrasi), KnowSeeker (mengambil pengetahuan), dan ActExecutor (mengeksekusi tindakan). Eksperimen membuktikan bahwa metode ini dapat secara signifikan meningkatkan tingkat keberhasilan tugas model dalam skenario yang belum pernah dilihat (unseen scenarios), misalnya meningkatkan akurasi Gemini-1.5-Pro dari 19.3% menjadi 51.7%. (Sumber: WeChat)
📚 Pembelajaran
Tinjauan Mendalam Teknologi Pasca-Pelatihan LLM: Peneliti dari MBZUAI, Google DeepMind, dan institusi lain merilis tinjauan komprehensif tentang teknologi pasca-pelatihan LLM. Laporan ini membahas secara mendalam berbagai metode untuk meningkatkan kemampuan penalaran LLM, menyelaraskan dengan niat manusia, dan meningkatkan keandalan melalui reinforcement learning (RLHF, RLAIF, DPO, GRPO, dll.), supervised fine-tuning (SFT), dan perluasan saat pengujian (test-time expansion) (CoT, ToT, GoT, decoding self-consistency, dll.). Laporan ini juga mencakup reward modeling, Parameter-Efficient Fine-Tuning (PEFT), strategi perluasan model (model scaling), serta benchmark evaluasi terkait, dan menunjukkan arah penelitian masa depan. (Sumber: WeChat)
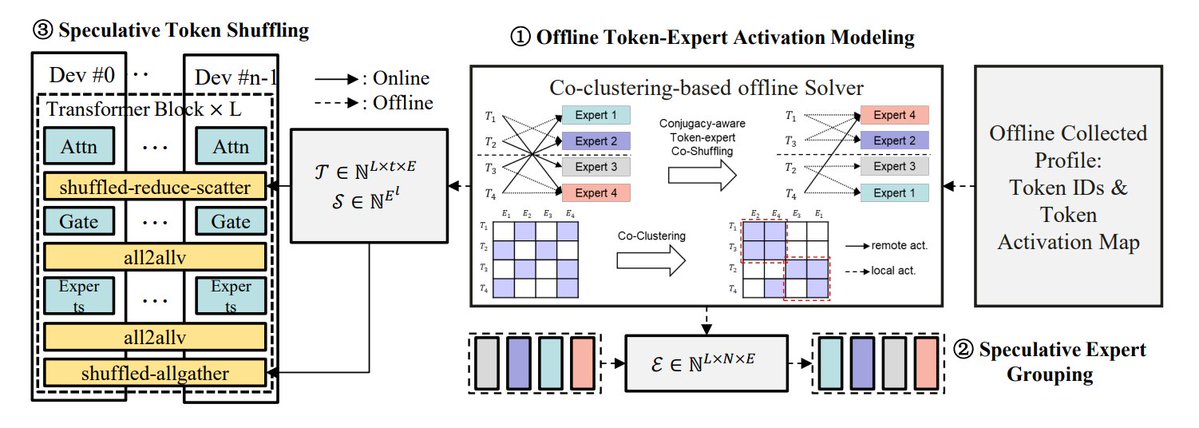
Ringkasan Metode Optimasi Inferensi MoE: TheTuringPost merangkum 5 metode untuk mengoptimalkan inferensi model MoE: eMoE (memprediksi dan memuat pakar terlebih dahulu), MoEShard (membagi pakar ke setiap GPU), DeepSpeed-MoE (pemrosesan skala besar yang menggabungkan berbagai teknik), Speculative-MoE (memprediksi jalur routing dan mengelompokkan pakar), dan MoE-Gen (batching berbasis modul). Artikel ini juga menyebutkan metode lanjutan seperti Structural MoE dan Symbolic-MoE, yang bertujuan untuk meningkatkan efisiensi inferensi dan throughput model MoE. (Sumber: TheTuringPost)
Melihat Kembali Makalah End-To-End Memory Networks Sepuluh Tahun Lalu: Ilmuwan riset Meta, Sainbayar Sukhbaatar, mengulas kembali makalahnya tahun 2015 yang berjudul “End-To-End Memory Networks”. Makalah ini adalah salah satu model bahasa pertama yang sepenuhnya menggantikan RNN dengan mekanisme atensi, memperkenalkan konsep seperti atensi lembut dot-product dengan proyeksi key-value, atensi bertumpuk multi-lapis, dan positional embedding (disebut time embedding saat itu), yang semuanya merupakan elemen inti LLM saat ini. Meskipun pengaruhnya tidak sebesar “Attention is all you need”, makalah ini menggabungkan ide dari Memory Networks dan atensi lembut awal, menunjukkan potensi penalaran dari atensi lembut multi-lapis. (Sumber: iScienceLuvr, WeChat)

CVPR 2025 Oral: Mona – Metode Baru Fine-Tuning Visual yang Efisien: Peneliti dari Universitas Tsinghua, UCAS, dan institusi lain mengusulkan Mona (Multi-cognitive Visual Adapter), sebuah metode fine-tuning adaptor visual baru. Dengan memperkenalkan filter visual multi-kognitif (konvolusi depthwise separable + kernel multi-skala) dan optimasi distribusi input (Scaled LayerNorm), Mona hanya menyesuaikan kurang dari 5% parameter jaringan backbone, namun melampaui kinerja fine-tuning parameter penuh pada beberapa tugas visual seperti segmentasi instans dan deteksi objek, sambil secara signifikan mengurangi biaya komputasi dan penyimpanan. Metode ini memberikan ide baru untuk PEFT yang efisien pada model visual. (Sumber: WeChat)

ICLR 2025 Oral: DIFF Transformer – Atensi Diferensial Meningkatkan Pemodelan Teks Panjang: Microsoft dan Universitas Tsinghua mengusulkan DIFF Transformer, yang memperkenalkan mekanisme atensi diferensial (menghitung selisih antara dua peta atensi Softmax) untuk memperkuat sinyal konteks kunci dan menghilangkan noise. Eksperimen menunjukkan bahwa DIFF Transformer lebih skalabel dalam pemodelan bahasa (mencapai kinerja setara dengan sekitar 65% parameter/data), dan secara signifikan mengungguli Transformer tradisional dalam pemodelan teks panjang, pengambilan informasi kunci, pembelajaran dalam konteks, halusinasi adversarial, dan penalaran matematika. Ia juga dapat mengurangi outlier aktivasi, yang bermanfaat untuk kuantisasi. (Sumber: WeChat)

MARFT: Paradigma Baru Fine-Tuning Reinforcement Multi-Agen: Peneliti dari Universitas Jiao Tong Shanghai dan institusi lain mengusulkan MARFT (Multi-Agent Reinforcement Fine-Tuning), sebuah paradigma fine-tuning reinforcement baru yang cocok untuk sistem multi-agen berbasis LLM (LaMAS). Metode ini mengatasi tantangan optimasi yang disebabkan oleh dinamika LaMAS melalui dekomposisi nilai keuntungan multi-agen (multi-agent advantage value decomposition) dan pemodelan keputusan sekuensial mirip Transformer. Eksperimen awal menunjukkan bahwa LaMAS yang di-fine-tuning dengan MARFT memiliki kinerja lebih baik pada tugas matematika dibandingkan sistem yang tidak di-fine-tuning dan PPO agen tunggal. Peneliti juga membahas potensi dan tantangannya dalam penyelesaian tugas kompleks, skalabilitas, perlindungan privasi, dan kombinasi dengan blockchain. (Sumber: WeChat)

Tinjauan Komprehensif Protokol Agen AI: Universitas Jiao Tong Shanghai bekerja sama dengan komunitas ANP merilis tinjauan komprehensif pertama tentang protokol Agen AI. Makalah ini mengusulkan kerangka klasifikasi dua dimensi berdasarkan orientasi objek (orientasi konteks vs antar-agen) dan skenario aplikasi (umum vs spesifik domain), serta merangkum lebih dari sepuluh protokol utama seperti MCP, A2A, ANP, AITP, LMOS. Protokol-protokol ini dievaluasi berdasarkan tujuh dimensi (efisiensi, skalabilitas, keamanan, keandalan, ekstensibilitas, operabilitas, interoperabilitas), dan menggunakan studi kasus perencanaan perjalanan untuk membandingkan empat arsitektur: MCP, A2A, ANP, Agora. Terakhir, makalah ini memproyeksikan perkembangan masa depan protokol dari statis ke dapat berevolusi, dari aturan ke ekosistem, dan dari protokol ke infrastruktur cerdas. (Sumber: WeChat)

Tinjauan Mendalam Protokol MCP: Arsitektur, Ekosistem, dan Risiko Keamanan: Sebuah makalah tinjauan baru membahas secara mendalam arsitektur Model Context Protocol (MCP), status ekosistem saat ini, dan risiko keamanan potensial. Artikel ini menganalisis struktur tiga bagian (tripartite) MCP Host, Client, Server dan mekanisme interaksinya, menguraikan kemajuan perusahaan seperti Anthropic, OpenAI, Cursor, Replit, dan komunitas dalam menggunakan MCP, serta menganalisis secara rinci kerentanan keamanan yang ada dalam siklus hidup MCP Server (pembuatan, menjalankan, pembaruan), seperti konflik nama, penipuan installer, injeksi kode, konflik nama alat, sandbox escape, dan persistensi izin. (Sumber: WeChat)

CVPR Oral: UniAP – Algoritma Paralelisme Otomatis Intra-Layer dan Inter-Layer Terpadu: Kelompok riset Profesor Li Wujun dari Universitas Nanjing mengusulkan UniAP, sebuah algoritma pelatihan terdistribusi yang dapat mengoptimalkan secara bersamaan strategi paralelisme intra-layer (data/tensor/ZeRO) dan inter-layer (pipeline). Melalui pemodelan pemrograman kuadratik bilangan bulat campuran (mixed-integer quadratic programming), UniAP dapat secara otomatis mencari skema pelatihan terdistribusi yang efisien, mengatasi masalah konfigurasi manual yang kompleks dan tidak efisien. Eksperimen menunjukkan bahwa UniAP hingga 3.8 kali lebih cepat dari metode paralelisme otomatis yang ada, 9 kali lebih cepat dari strategi yang tidak dioptimalkan, dan dapat secara efektif menghindari 64%-87% strategi tidak valid (Out-Of-Memory/OOM), meningkatkan kemudahan penggunaan. Algoritma ini telah diadaptasi untuk kartu komputasi AI. (Sumber: WeChat)
Tina: Model Kecil Berbiaya Rendah dengan Kemampuan Inferensi Tinggi melalui LoRA: Tim dari University of Southern California mengusulkan seri model Tina (Tiny Reasoning Models via LoRA). Dengan menggunakan LoRA untuk pelatihan pasca-reinforcement learning pada basis model DeepSeek-R1-Distill-Qwen 1.5B parameter, model Tina mencapai kinerja yang sebanding atau bahkan lebih baik daripada model baseline fine-tuning parameter penuh pada beberapa benchmark penalaran (AIME, AMC, MATH, GPQA, Minerva), dengan biaya pelatihan yang sangat rendah (biaya checkpoint terbaik hanya $9). Penelitian ini mengungkapkan keunggulan LoRA dalam pembelajaran format/struktur penalaran yang efisien, dan mengamati fenomena pemisahan (decoupling) antara metrik format dan metrik akurasi selama pelatihan. (Sumber: WeChat)
Optimasi Divergensi KL Rekursif: Metode Pelatihan Model Baru yang Efisien: Sebuah makalah baru mengusulkan metode Optimasi Divergensi KL Rekursif (Recursive KL Divergence Optimization), yang diklaim dapat mencapai peningkatan efisiensi hingga 80% dalam pelatihan model (terutama fine-tuning). Metode ini kemungkinan bekerja dengan cara yang lebih optimal untuk membatasi pembaruan model, mengurangi sumber daya komputasi atau waktu yang dibutuhkan untuk pelatihan, memberikan jalur baru untuk melatih dan melakukan fine-tuning model dengan lebih ekonomis dan cepat. (Sumber: Reddit r/LocalLLaMA)
💼 Bisnis
Sakana AI Berupaya Memanfaatkan Ketidakpastian Kebijakan AS untuk Berkembang di Jepang: Startup AI Jepang, Sakana AI, berpendapat bahwa ketidakpastian kebijakan AS serta permintaan akan solusi AI domestik (terutama di pemerintahan dan lembaga keuangan) memberikan peluang pertumbuhan di Jepang. Manajer pengembangan bisnis perusahaan menyatakan bahwa diperkirakan akan ada 5-10 kasus penggunaan konsumen dari pemerintah dan lembaga keuangan dalam 6 bulan ke depan. CEO David Ha menunjukkan bahwa dalam konteks geopolitik yang menegang, peningkatan permintaan dari negara-negara demokrasi untuk meningkatkan infrastruktur pemerintah dan pertahanan membuat fokus perusahaan pada aplikasi pertahanan (seperti risiko biosekuriti dan pelacakan disinformasi) menjadi sangat penting. (Sumber: SakanaAILabs, SakanaAILabs)
Meta Memprediksi Pendapatan AI Generatif Mencapai $1,4 Triliun pada 2035: Meta memprediksi bisnis AI generatifnya akan menghasilkan pendapatan $3 miliar pada tahun 2025, dan diperkirakan akan melonjak menjadi $1,4 triliun pada tahun 2035. Prediksi ini menunjukkan bahwa Meta sangat optimis tentang potensi pertumbuhan jangka panjang di bidang AI, dan kemungkinan akan terus mempertahankan belanja modal (capital expenditure) yang tinggi untuk berinvestasi dalam R&D AI dan pembangunan infrastruktur. (Sumber: brickroad7)

Alimama Merilis Model Besar Pengetahuan Dunia URM: Alimama meluncurkan model bahasa besar URM (Universal Recommendation Model) yang menggabungkan pengetahuan dunia dan pengetahuan domain e-commerce. Model ini, melalui injeksi pengetahuan (ID produk sebagai token khusus) dan penyelarasan informasi (menggabungkan ID dengan representasi semantik multimodal), dapat memahami minat historis pengguna dan melakukan rekomendasi berbasis penalaran. URM menggunakan metode generasi Sequence-In-Set-Out, menghasilkan beberapa representasi pengguna secara paralel untuk meningkatkan efektivitas dan keragaman, sambil menjaga efisiensi inferensi. Model ini telah diluncurkan dalam skenario iklan display Alimama, dan melalui jalur inferensi asinkron mengatasi masalah latensi LLM, meningkatkan efektivitas penempatan iklan merchant dan pengalaman belanja pengguna. (Sumber: WeChat)

🌟 Komunitas
Akhir Era GPT-4 Memicu Sentimen dan Diskusi: Sam Altman mengucapkan selamat tinggal pada GPT-4, menyebutnya telah memulai sebuah revolusi dan akan menyimpan bobotnya untuk sejarawan masa depan. Langkah ini memicu sentimen luas di komunitas, banyak yang mengenang GPT-4 sebagai model pertama yang membuat mereka merasakan potensi AGI. Pada saat yang sama, hal ini juga memicu diskusi tentang open-source, dengan anggota komunitas seperti Hugging Face menyerukan OpenAI untuk membuka sumber (open-source) bobot GPT-4 untuk penelitian, bukan hanya menyimpannya. (Sumber: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
Observasi dan Diskusi Jalur AI Coding: Pendiri GruAI, Zhang Hailong, berpendapat bahwa AI Coding adalah salah satu dari sedikit jalur yang saat ini menunjukkan Product-Market Fit (PMF). Keberhasilan Cursor terletak pada penciptaan pasar baru, dan nilai UI-nya sangat besar. Dia percaya arah Devin benar tetapi terlalu ambisius dengan siklus waktu yang panjang, namun kemungkinan suksesnya meningkat, dan pada akhirnya akan bersaing dengan Cursor. Untuk perusahaan startup, dia berpendapat tidak perlu terlalu khawatir tentang persaingan dari perusahaan besar; intinya terletak pada kekuatan produk dan nilai unik. Kemajuan model secara signifikan mengurangi kebutuhan akan kompensasi rekayasa, sehingga para pendiri perlu membedakan masalah mana yang akan diselesaikan oleh pengembangan model, dan mana yang merupakan kekuatan produk sejati. (Sumber: WeChat)

Refleksi tentang Narasi “AI Akan Menggantikan Pekerjaan Anda”: Diskusi komunitas menunjukkan bahwa pernyataan “AI tidak akan menggantikan pekerjaan Anda, tetapi orang yang menggunakan AI akan” meskipun secara permukaan benar, terlalu menyederhanakan dan merupakan bentuk “teater konsensus” (consensus theatre) yang membuat orang berhenti memikirkan masalah yang lebih dalam. Kunci sebenarnya terletak pada pemahaman bagaimana AI mengubah struktur kerja, membentuk ulang alur kerja, mengubah logika organisasi, dan seperti apa pekerjaan masa depan di bawah sistem baru, bukan hanya fokus pada otomatisasi atau peningkatan di tingkat tugas individu. (Sumber: Reddit r/ArtificialInteligence)

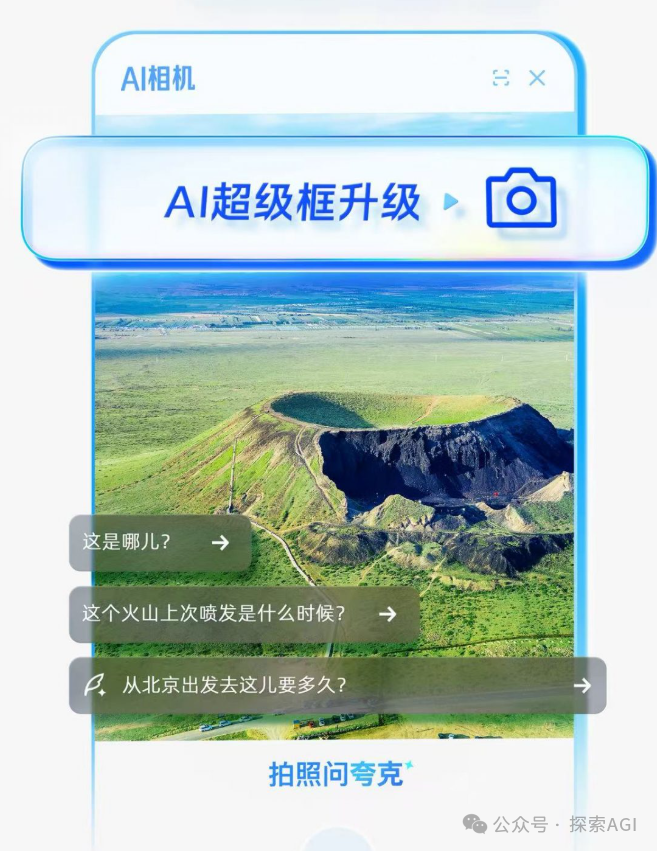
Pintu Masuk Baru Interaksi Agen AI dengan Dunia Fisik: Kamera: Diskusi berpendapat bahwa fungsi seperti “bertanya melalui foto” (mirip fitur di browser Quark) mewakili tren baru dalam interaksi aplikasi AI. Melalui kamera ponsel, sensor yang ada di mana-mana, dikombinasikan dengan pemahaman multimodal dan kemampuan Agen, AI dapat lebih baik memahami dunia fisik, dan berdasarkan kebutuhan implisit atau eksplisit pengguna, membuat keputusan secara mandiri dan memanggil kemampuan untuk menyelesaikan tugas (seperti mengenali objek, menerjemahkan, membandingkan harga, membantu mengerjakan PR, memproses struk/tiket). Hal ini mengubah kamera dari alat input informasi sederhana menjadi penghubung antara dunia fisik dan kecerdasan digital, mewujudkan “Get it Done”. (Sumber: WeChat)
💡 Lain-lain
AI dan Penelitian Ilmiah: Pandangan komunitas menyatakan bahwa AI secara bertahap menjadi “matematika” baru dalam penelitian ilmiah, yang berarti AI akan menjadi alat dan bahasa fundamental, seperti halnya matematika, untuk mendorong penemuan dan pemahaman ilmiah. (Sumber: shuchaobi)

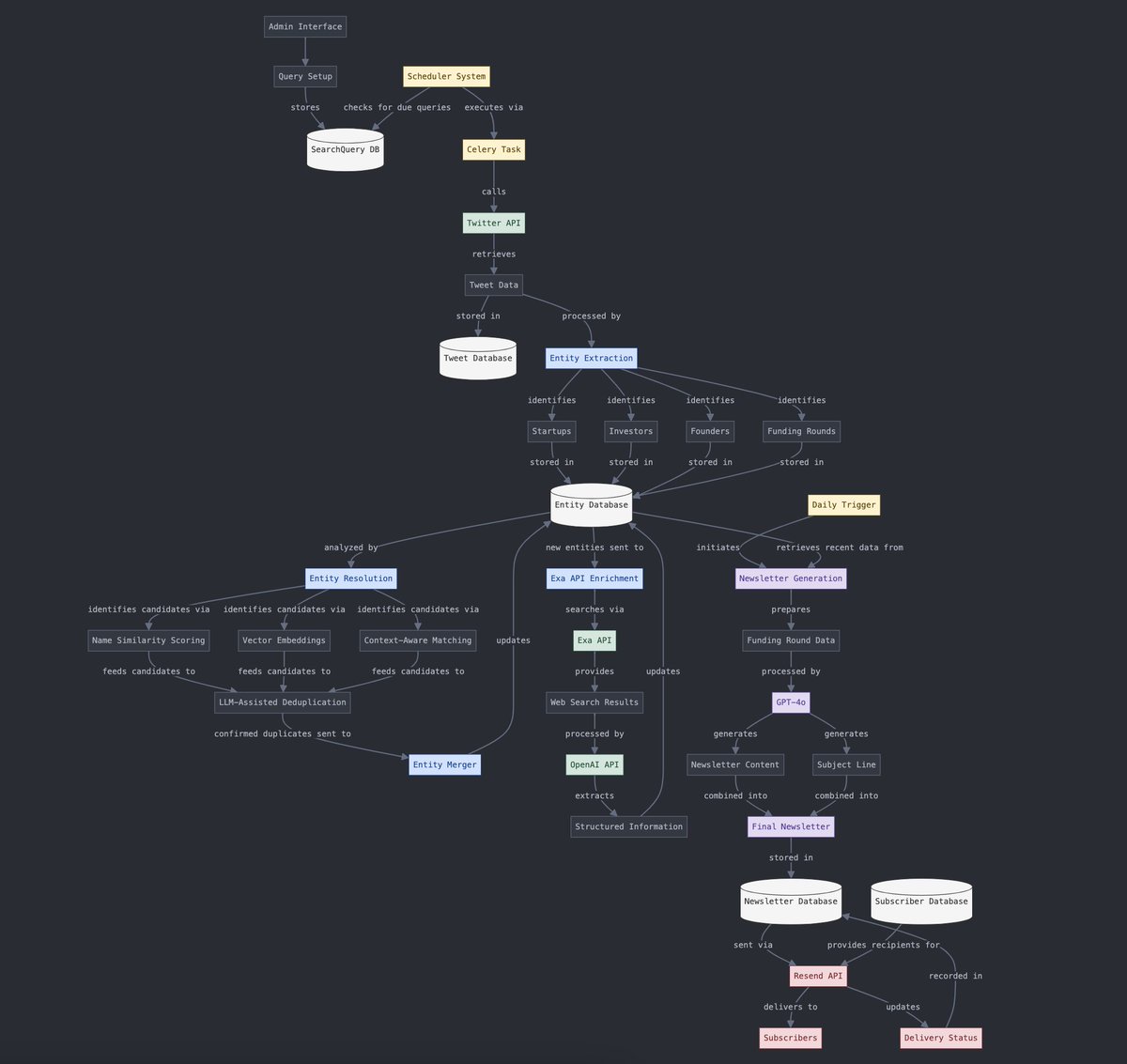
Konversi Data Terstruktur dan Tidak Terstruktur: Yohei Nakajima menunjukkan penggunaan AI untuk mengubah data tweet tidak terstruktur menjadi data terstruktur, yang kemudian dapat diubah kembali menjadi buletin harian tidak terstruktur, menunjukkan aplikasi AI dalam alur pemrosesan informasi dan generasi konten. (Sumber: yoheinakajima)
Masa Depan Kombinasi AI dan VR: Diskusi komunitas melihat potensi kombinasi AI dan VR, membayangkan masa depan di mana mungkin untuk menghasilkan dan memanipulasi objek 3D secara langsung di “ruang papan tulis” VR melalui bahasa alami atau pikiran, mewujudkan kreasi yang didorong oleh kognisi (cognition-driven creation). Meta dianggap sebagai pemain kunci yang mendorong arah ini. (Sumber: Reddit r/ArtificialInteligence)