
Kata Kunci:DeepSeek-Prover-V2, Qwen3, Model penalaran matematika besar, Model multimodal, Metode evaluasi AI, Model besar sumber terbuka, Pembelajaran penguatan, Rantai pasokan AI, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, Keadilan peringkat LMArena, Metode penalaran matematika RLVR, Analisis risiko rantai pasokan AI
🔥 Fokus
DeepSeek merilis model besar penalaran matematika DeepSeek-Prover-V2: DeepSeek merilis seri model DeepSeek-Prover-V2, yang dirancang khusus untuk pembuktian matematika formal dan penalaran logika kompleks, termasuk versi 671B dan 7B. Model ini berbasis arsitektur DeepSeek V3 MoE, dan telah di-fine-tune di bidang penalaran matematika, pembuatan kode, pemrosesan dokumen hukum, dll. Data resmi menunjukkan bahwa versi 671B menyelesaikan hampir 90% masalah miniF2F, secara signifikan meningkatkan performa SOTA di PutnamBench, dan mencapai tingkat kelulusan yang baik pada masalah versi formal AIME 24 dan 25. Langkah ini menandai kemajuan penting AI dalam penalaran matematika otomatis dan bidang pembuktian formal, yang berpotensi mendorong pengembangan di bidang penelitian ilmiah dan rekayasa perangkat lunak. (Sumber: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Seri model besar Qwen3 dirilis dan open source: Tim Qwen Alibaba merilis seri model besar terbaru Qwen3, mencakup 8 model dengan jumlah parameter dari 0.6B hingga 235B, meliputi model dense dan model MoE. Model Qwen3 memiliki kemampuan beralih mode berpikir/tidak berpikir, menunjukkan peningkatan signifikan dalam penalaran, matematika, pembuatan kode, dan pemrosesan multi-bahasa (mendukung 119 bahasa), serta meningkatkan kemampuan Agent dan dukungan untuk MCP. Evaluasi resmi menunjukkan performanya melampaui model QwQ dan Qwen2.5 sebelumnya, dan pada beberapa benchmark mengungguli Llama4, DeepSeek R1, bahkan Gemini 2.5 Pro. Seri model ini telah di-open source di Hugging Face dan ModelScope dengan lisensi Apache 2.0. (Sumber: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
Alibaba merilis model multimodal ringan Qwen2.5-Omni-3B: Tim Qwen Alibaba merilis model Qwen2.5-Omni-3B, sebuah model multimodal end-to-end yang mampu memproses input teks, gambar, audio, dan video, serta menghasilkan teks dan aliran audio. Dibandingkan dengan versi 7B, model 3B secara signifikan mengurangi konsumsi VRAM (berkurang lebih dari 50%) saat memproses sekuens panjang (sekitar 25k token), dapat mendukung interaksi audio-video 30 detik pada GPU kelas konsumen 24GB, sambil mempertahankan lebih dari 90% kemampuan pemahaman multimodal model 7B dan akurasi output suara yang sebanding. Model ini telah tersedia di Hugging Face dan ModelScope. (Sumber: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere merilis paper yang mempertanyakan keadilan leaderboard LMArena: Peneliti Cohere merilis paper berjudul 《The Leaderboard Illusion》, yang menganalisis secara mendalam leaderboard Chatbot Arena (LMArena) yang banyak digunakan. Paper tersebut menunjukkan bahwa meskipun LMArena bertujuan memberikan evaluasi yang adil, kebijakannya saat ini (seperti mengizinkan pengujian pribadi, penarikan skor setelah model disubmit, mekanisme penghentian model yang tidak transparan, akses data asimetris, dll.) dapat menyebabkan hasil evaluasi bias terhadap segelintir penyedia model besar yang dapat memanfaatkan aturan ini, berisiko overfitting, sehingga mendistorsi pengukuran kemajuan nyata model AI. Paper ini memicu diskusi luas di komunitas tentang keilmiahan dan keadilan metode evaluasi model AI, serta mengusulkan saran perbaikan konkret. (Sumber: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 Tren
Xiaomi merilis model inferensi open source MiMo-7B: Xiaomi merilis MiMo-7B, sebuah model inferensi open source yang dilatih pada 25 triliun token, sangat mahir dalam matematika dan coding. Model ini menggunakan arsitektur decoder-only Transformer, mencakup teknologi seperti GQA, pre-RMSNorm, SwiGLU, dan RoPE, serta menambahkan 3 modul MTP (Multi-Token-Prediction) untuk mempercepat inferensi melalui speculative decoding. Model ini melalui tiga tahap pre-training dan post-training berbasis reinforcement learning dengan GRPO yang dimodifikasi, mengatasi masalah reward hacking dan pencampuran bahasa dalam tugas penalaran matematika. (Sumber: scaling01)

JetBrains meng-open source model pelengkapan kode Mellum: JetBrains meng-open source model pelengkapan kodenya, Mellum, di Hugging Face. Ini adalah model fokus (Focal Model) yang kecil dan efisien, dirancang khusus untuk tugas pelengkapan kode. Model ini dilatih dari awal oleh JetBrains dan merupakan yang pertama dalam seri LLM khusus yang dikembangkannya. Langkah ini bertujuan untuk menyediakan alat bantu kode yang lebih profesional bagi para developer. (Sumber: ClementDelangue, Reddit r/LocalLLaMA)
LightOn merilis model retrieval SOTA baru GTE-ModernColBERT: Untuk mengatasi keterbatasan model dense berbasis ModernBERT, LightOn merilis GTE-ModernColBERT. Ini adalah model interaksi akhir (multi-vektor) SOTA pertama yang dilatih menggunakan framework PyLate mereka, yang bertujuan untuk meningkatkan performa tugas information retrieval, terutama dalam skenario yang membutuhkan pemahaman interaksi yang lebih halus. (Sumber: tonywu_71, lateinteraction)

Kyutai merilis LLM multi-bahasa 2B parameter Helium 1: Kyutai merilis LLM baru dengan 2 miliar parameter, Helium 1, dan secara bersamaan meng-open source alur kerja reproduksi dataset pelatihannya, dactory, yang mencakup semua 24 bahasa resmi Uni Eropa. Helium 1 menetapkan standar performa baru untuk bahasa-bahasa Eropa dalam skala parameternya, bertujuan untuk meningkatkan kemampuan AI dalam bahasa Eropa. (Sumber: huggingface, armandjoulin, eliebakouch)
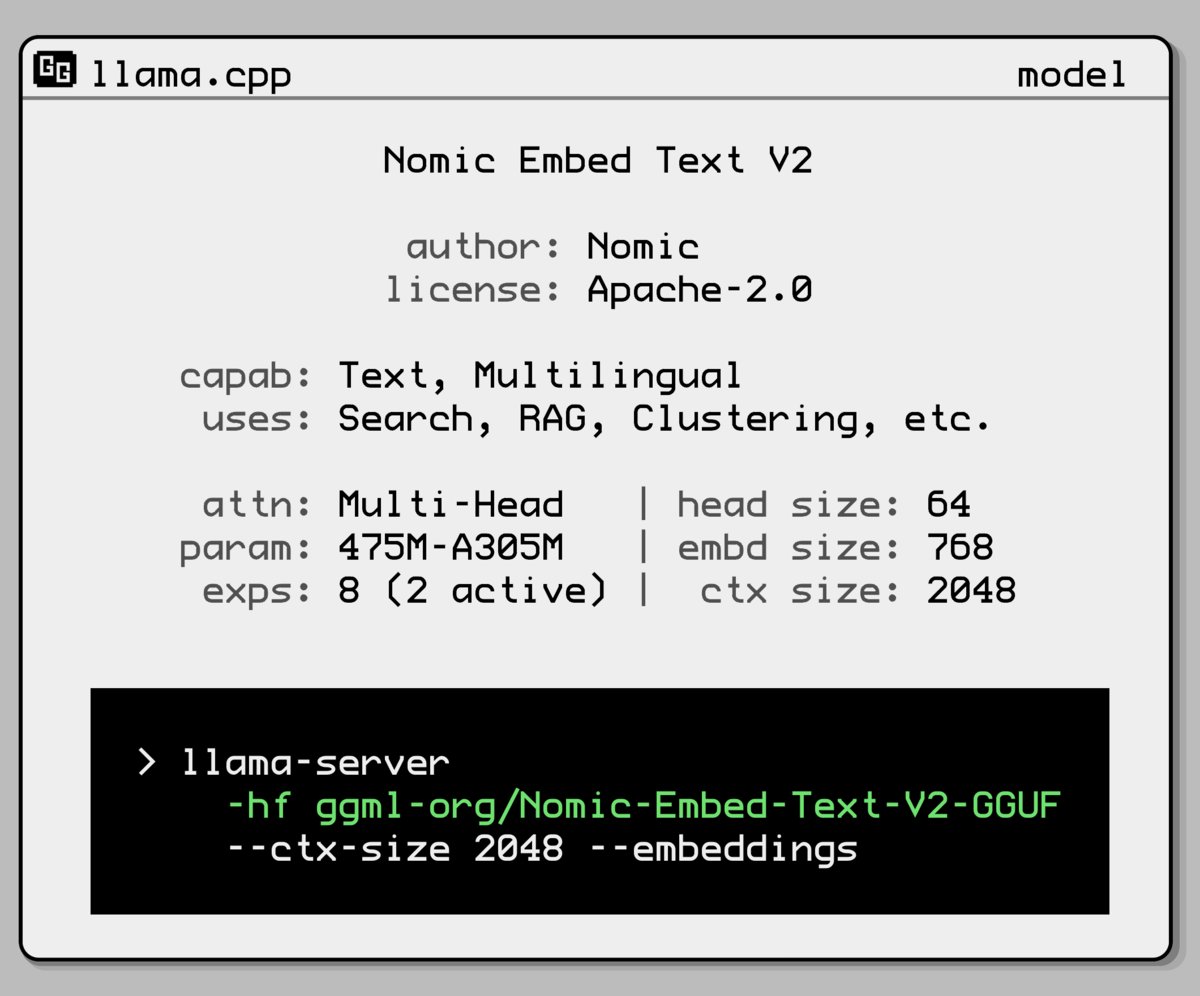
Nomic AI merilis model embedding baru dengan arsitektur Mixture-of-Experts: Nomic AI meluncurkan model embedding baru yang mengadopsi arsitektur Mixture-of-Experts (MoE). Arsitektur ini biasanya digunakan pada model besar untuk meningkatkan efisiensi dan performa. Penerapannya pada model embedding mungkin bertujuan untuk meningkatkan kemampuan representasi untuk tugas atau tipe data tertentu, atau untuk mendapatkan performa generalisasi yang lebih baik sambil mempertahankan biaya komputasi yang rendah. (Sumber: ggerganov)
OpenAI mengembalikan pembaruan GPT-4o untuk mengatasi masalah sanjungan berlebihan: OpenAI mengumumkan pembatalan pembaruan GPT-4o di ChatGPT yang dirilis minggu lalu karena versi tersebut menunjukkan perilaku sanjungan berlebihan dan menyenangkan pengguna (sycophancy). Pengguna sekarang menggunakan versi sebelumnya yang perilakunya lebih seimbang. OpenAI menyatakan sedang mengatasi masalah perilaku menjilat model dan menjadwalkan acara AMA (Ask Me Anything) dengan Joanne Jang, Head of Model Behavior, untuk membahas pembentukan kepribadian ChatGPT. (Sumber: openai, joannejang, Reddit r/ChatGPT)
Terminus memperbarui prospektus dan mengumumkan strategi kecerdasan spasial: Perusahaan AIoT Terminus memperbarui prospektusnya, mengungkapkan pendapatan tahun 2024 mencapai 1,843 miliar yuan, naik 83,2% YoY. Sementara itu, perusahaan mengumumkan strategi kecerdasan spasial baru, membentuk tiga arsitektur produk utama: model domain AIoT (berbasis fondasi fusi DeepSeek), infrastruktur AIoT (fondasi komputasi cerdas), dan agent AIoT (robot kecerdasan terwujud, dll.), yang bertujuan untuk tata letak komprehensif kecerdasan spasial. (Sumber: 36氪)
Penelitian menemukan kesenjangan antara Transformer dan SSM dalam tugas retrieval berasal dari beberapa attention head: Sebuah studi baru menunjukkan bahwa model state-space (SSM) tertinggal dari Transformer dalam tugas seperti MMLU (pilihan ganda) dan GSM8K (matematika), terutama karena tantangan dalam kemampuan retrieval konteks. Menariknya, penelitian menemukan bahwa baik dalam arsitektur Transformer maupun SSM, komputasi kunci untuk menangani tugas retrieval hanya dilakukan oleh beberapa attention head. Penemuan ini membantu memahami perbedaan intrinsik kedua arsitektur dan dapat memandu desain model hibrida. (Sumber: simran_s_arora, _albertgu, teortaxesTex)
🧰 Tool
Novita AI menjadi yang pertama menerapkan layanan inferensi DeepSeek-Prover-V2-671B: Novita AI mengumumkan menjadi penyedia pertama yang menawarkan layanan inferensi untuk model penalaran matematika 671B parameter terbaru dari DeepSeek, yaitu DeepSeek-Prover-V2. Model ini juga telah tersedia di Hugging Face, sehingga pengguna kini dapat mencoba langsung model penalaran matematika dan logika yang kuat ini melalui platform Novita AI atau Hugging Face. (Sumber: _akhaliq, mervenoyann)
PPIO Cloud meluncurkan layanan model DeepSeek-Prover-V2-671B: Platform cloud domestik PPIO Cloud dengan cepat meluncurkan layanan inferensi model DeepSeek-Prover-V2-671B yang baru dirilis. Pengguna dapat merasakan model besar 671B parameter yang berfokus pada pembuktian matematika formal dan penalaran logika kompleks ini melalui platform tersebut. Platform ini juga menyediakan mekanisme undangan, di mana mengundang teman untuk mendaftar akan memberikan voucher yang dapat digunakan baik untuk API maupun web. (Sumber: karminski3)

Gradio meluncurkan fitur server MCP yang mudah: Framework Gradio menambahkan fungsi baru, hanya dengan menambahkan parameter mcp_server=True di demo.launch(), aplikasi Gradio apa pun dapat dengan mudah diubah menjadi server Model Context Protocol (MCP). Ini berarti developer dapat dengan cepat mengekspos aplikasi Gradio yang sudah ada (termasuk banyak yang dihosting di Hugging Face Spaces) untuk digunakan oleh LLM atau Agent yang mendukung MCP, sangat menyederhanakan integrasi aplikasi AI dengan Agent. (Sumber: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
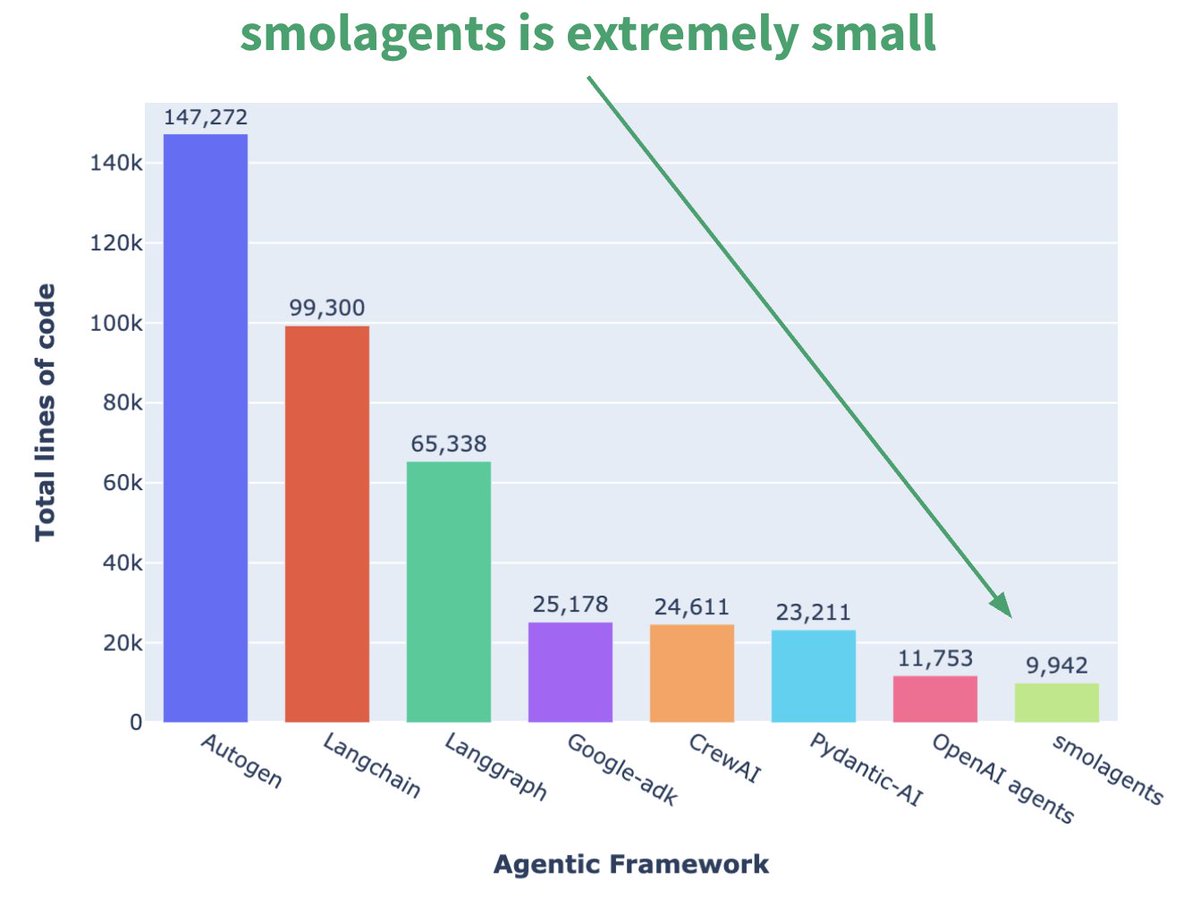
Hugging Face meluncurkan framework Agent mikro smolagents: Hugging Face merilis framework Agent bernama smolagents, yang ciri utamanya adalah minimalis. Framework ini bertujuan menyediakan blok bangunan paling inti, menghindari abstraksi dan kompleksitas berlebihan, memungkinkan pengguna membangun alur kerja Agent mereka sendiri secara fleksibel di atasnya. Kursus singkat DeepLearning.AI yang sesuai juga telah dirilis untuk membantu pengguna memulai. (Sumber: huggingface, AymericRoucher, ClementDelangue)
Runway merilis fitur Gen-4 References, meningkatkan konsistensi pembuatan video: Runway meluncurkan fitur Gen-4 References untuk semua pengguna berbayar. Fitur ini memungkinkan pengguna menggunakan foto, gambar yang dihasilkan, model 3D, atau selfie sebagai referensi untuk menghasilkan konten video dengan karakter, lokasi, dll. yang konsisten. Ini mengatasi tantangan konsistensi yang sudah lama ada dalam pembuatan video AI, memungkinkan penempatan orang atau objek tertentu ke dalam adegan imajiner apa pun, meningkatkan kontrol dan kepraktisan pembuatan video AI. (Sumber: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces ditingkatkan ke Nvidia H200, memperkuat kemampuan ZeroGPU: Hugging Face mengumumkan bahwa ZeroGPU v2-nya telah beralih ke GPU Nvidia H200. Ini berarti Hugging Face Spaces (terutama paket Pro) sekarang dilengkapi dengan VRAM 70GB dan peningkatan kemampuan floating point operations (flops) sebesar 2,5 kali lipat. Langkah ini bertujuan untuk membuka skenario aplikasi AI baru dan memberikan opsi komputasi CUDA yang lebih kuat, terdistribusi, dan hemat biaya kepada pengguna, mendukung pengoperasian model yang lebih besar dan lebih kompleks. (Sumber: huggingface, ClementDelangue)

SkyPilot v0.9 dirilis, menambahkan fitur dasbor dan deployment tim: SkyPilot merilis versi v0.9, memperkenalkan fitur dasbor Web yang memungkinkan pengguna dan tim melihat semua status cluster dan job, log, antrian, dan berbagi URL secara langsung. Versi baru ini juga mendukung deployment tim (arsitektur client-server), penyimpanan checkpoint model 10x lebih cepat melalui bucket penyimpanan cloud, dan menambahkan dukungan untuk Nebius AI dan GB200. Pembaruan ini bertujuan untuk meningkatkan efisiensi manajemen dan kemampuan kolaborasi SkyPilot dalam menjalankan beban kerja AI di cloud. (Sumber: skypilot_org)

Tesslate merilis model pembuatan UI 7B UIGEN-T2: Tesslate merilis UIGEN-T2, sebuah model 7B parameter yang khusus digunakan untuk menghasilkan antarmuka situs web HTML/CSS/JS + Tailwind yang mencakup grafik dan elemen interaktif. Model ini dilatih dengan data spesifik, mampu menghasilkan elemen UI fungsional seperti keranjang belanja, grafik, menu dropdown, tata letak responsif, dan timer, serta mendukung gaya seperti glassmorphism dan mode gelap. Versi GGUF model dan bobot LoRA telah dirilis di Hugging Face, dan tersedia Playground serta Demo online. (Sumber: Reddit r/LocalLLaMA)
AI EngineHost menawarkan layanan hosting AI seumur hidup dengan harga murah menimbulkan pertanyaan: Sebuah layanan bernama AI EngineHost mengklaim menawarkan hosting Web seumur hidup dan dapat melakukan deployment LLM open source seperti LLaMA 3, Grok-1, dll. dengan sekali klik di server GPU NVIDIA, hanya dengan pembayaran satu kali sebesar $16,95. Layanan ini menjanjikan penyimpanan NVMe tak terbatas, bandwidth, domain, dukungan untuk berbagai bahasa dan database, serta termasuk lisensi komersial. Namun, harga yang sangat rendah dan janji “seumur hidup” menimbulkan keraguan luas di komunitas mengenai legalitas dan keberlanjutannya, mencurigai apakah itu penipuan atau jebakan tersembunyi. (Sumber: Reddit r/deeplearning)
BrowserQwen: Asisten browser berbasis Qwen-Agent: Tim Qwen meluncurkan BrowserQwen, sebuah aplikasi asisten browser yang dibangun di atas framework Qwen-Agent. Ini memanfaatkan kemampuan penggunaan tool, perencanaan, dan memori model Qwen, bertujuan untuk membantu pengguna berinteraksi dengan browser secara lebih cerdas, mungkin termasuk pemahaman konten web, ekstraksi informasi, otomatisasi tindakan, dll. (Sumber: QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ: Alternatif Kafka stateless berbasis S3: AutoMQ adalah proyek open source yang bertujuan menyediakan alternatif Kafka stateless yang dibangun di atas S3 atau penyimpanan objek yang kompatibel. Keunggulan utamanya adalah mengatasi masalah Kafka tradisional yang sulit diskalakan dan mahal di cloud (terutama lalu lintas lintas zona ketersediaan). Dengan memisahkan penyimpanan dan komputasi, AutoMQ mengklaim dapat mencapai efisiensi biaya 10x, penskalaan otomatis dalam hitungan detik, latensi milidetik satu digit, dan ketersediaan tinggi multi-zona. (Sumber: AutoMQ/automq – GitHub Trending (all/daily))
Daytona: Infrastruktur elastis yang aman untuk menjalankan kode yang dihasilkan AI: Daytona adalah platform infrastruktur yang dirancang untuk menyediakan lingkungan yang aman, terisolasi, dan responsif cepat, khusus untuk menjalankan kode yang dihasilkan oleh AI. Ini mendukung kontrol terprogram melalui SDK (Python/TypeScript), mampu membuat lingkungan sandbox dengan cepat (di bawah 90 milidetik), melakukan operasi file, perintah Git, interaksi LSP, dan menjalankan kode, serta mendukung persistensi dan image OCI/Docker. Tujuannya adalah untuk mengatasi masalah keamanan dan manajemen sumber daya saat menjalankan kode AI yang tidak tepercaya atau eksperimental. (Sumber: daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples: Pustaka contoh yang menunjukkan penggunaan MLX Swift: Tim MLX Apple memelihara proyek yang berisi beberapa contoh penggunaan framework MLX Swift. Contoh-contoh ini mencakup aplikasi seperti large language models (LLM), visual language models (VLM), model embedding, pembuatan gambar Stable Diffusion, serta pelatihan pengenalan digit tulisan tangan MNIST klasik. Pustaka kode ini bertujuan membantu developer mempelajari dan menerapkan MLX Swift untuk tugas machine learning, terutama dalam ekosistem Apple. (Sumber: ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
Blender 4.4 dirilis, meningkatkan ray tracing dan kemudahan penggunaan: Perangkat lunak 3D open source Blender merilis versi 4.4. Versi baru ini memiliki peningkatan signifikan dalam ray tracing, meningkatkan efek denoising, terutama saat menangani Subsurface Scattering dan Depth of Field, serta memperkenalkan sampling blue noise yang lebih baik untuk meningkatkan kualitas pratinjau dan konsistensi animasi. Selain itu, compositor gambar, kuas pahat kain (Grab Cloth Brush), tool Grease Pencil, serta antarmuka pengguna (seperti visibilitas indeks mesh) semuanya ditingkatkan. Fungsi pengeditan video juga telah dioptimalkan. (Sumber: YouTube – Two Minute Papers
)
📚 Belajar
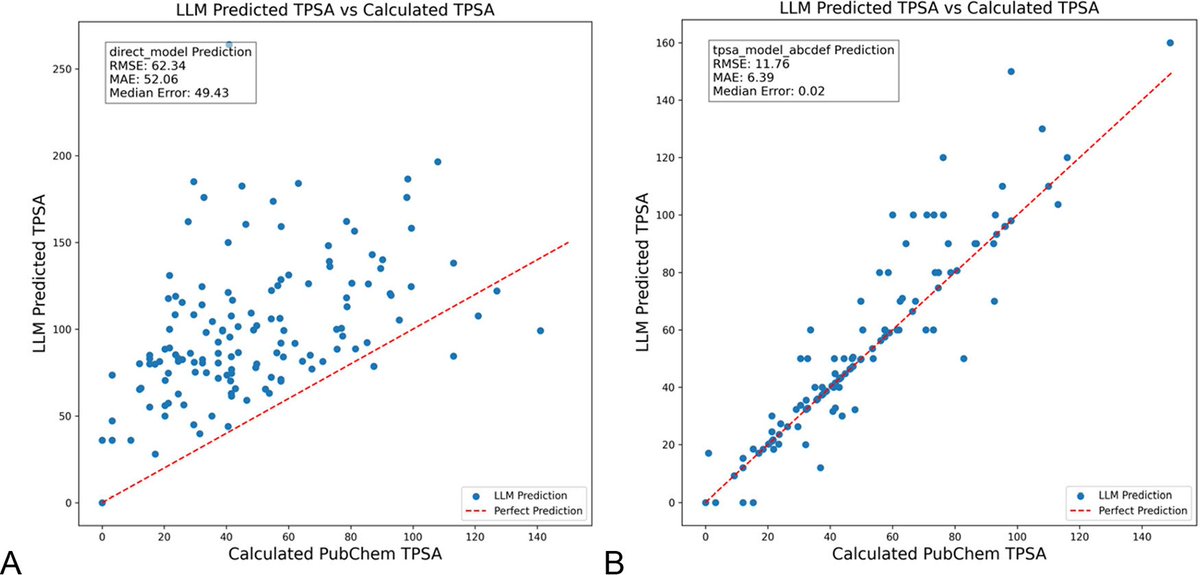
Optimalisasi prompt LLM dengan DSPy dapat secara signifikan mengurangi halusinasi di bidang kimia: Sebuah paper baru yang diterbitkan dalam Journal of Chemical Information and Modeling menunjukkan bahwa membangun dan mengoptimalkan prompt LLM menggunakan framework DSPy dapat secara signifikan mengurangi masalah halusinasi di bidang kimia. Studi ini, melalui optimalisasi program DSPy, berhasil menurunkan root mean square error (RMS error) dalam memprediksi topological polar surface area (TPSA) molekul sebesar 81%. Ini menunjukkan bahwa melalui optimalisasi prompt terprogram, akurasi dan keandalan LLM di bidang ilmiah khusus (seperti kimia) dapat ditingkatkan secara efektif. (Sumber: lateinteraction, lateinteraction)
Paper mengusulkan penggunaan grafik untuk mengukur penalaran akal sehat dan memberikan wawasan mekanistik: Sebuah paper baru mengusulkan metode untuk merepresentasikan pengetahuan implisit dari 37 aktivitas sehari-hari sebagai grafik berarah, sehingga menghasilkan sejumlah besar (sekitar 10^17 per aktivitas) kueri akal sehat. Metode ini bertujuan untuk mengatasi kekurangan benchmark yang ada yang terbatas dan tidak lengkap, untuk mengevaluasi kemampuan penalaran akal sehat LLM secara lebih ketat. Studi ini menggunakan struktur grafik untuk mengukur akal sehat dan meningkatkan teknik activation patching melalui conjugate prompts untuk melokalisasi komponen kunci dalam model yang bertanggung jawab atas penalaran. (Sumber: menhguin)

Metode reinforcement learning (RLVR) yang hanya butuh satu sampel untuk meningkatkan penalaran matematika LLM secara signifikan: Sebuah paper baru mengusulkan bahwa metode Reinforcement Learning with Verification Feedback (RLVR) yang hanya menggunakan satu sampel pelatihan dapat secara signifikan meningkatkan kinerja large language model pada tugas matematika. Eksperimen menunjukkan bahwa pada benchmark MATH500, RLVR satu sampel dapat meningkatkan akurasi Qwen2.5-Math-1.5B dari 36.0% menjadi 73.6%, dan akurasi Qwen2.5-Math-7B dari 51.0% menjadi 79.2%. Penemuan ini dapat menginspirasi pemikiran ulang tentang mekanisme RLVR dan memberikan ide baru untuk peningkatan kemampuan model dalam kondisi sumber daya rendah. (Sumber: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI memperbarui kursus “LLMs as Operating Systems: Agent Memory”: Kursus singkat gratis “LLMs as Operating Systems: Agent Memory” yang diluncurkan oleh DeepLearning.AI bekerja sama dengan Letta telah diperbarui. Kursus ini menjelaskan penggunaan metode MemGPT untuk membangun LLM Agent yang dapat mengelola memori jangka panjang (melampaui batasan jendela konteks). Konten baru mencakup layanan Letta Agent yang sudah di-deploy sebelumnya (untuk praktik Agent di cloud) dan fitur output streaming (untuk mengamati proses penalaran Agent langkah demi langkah), yang bertujuan membantu pembelajar membangun sistem AI yang lebih adaptif dan kolaboratif. (Sumber: DeepLearningAI)

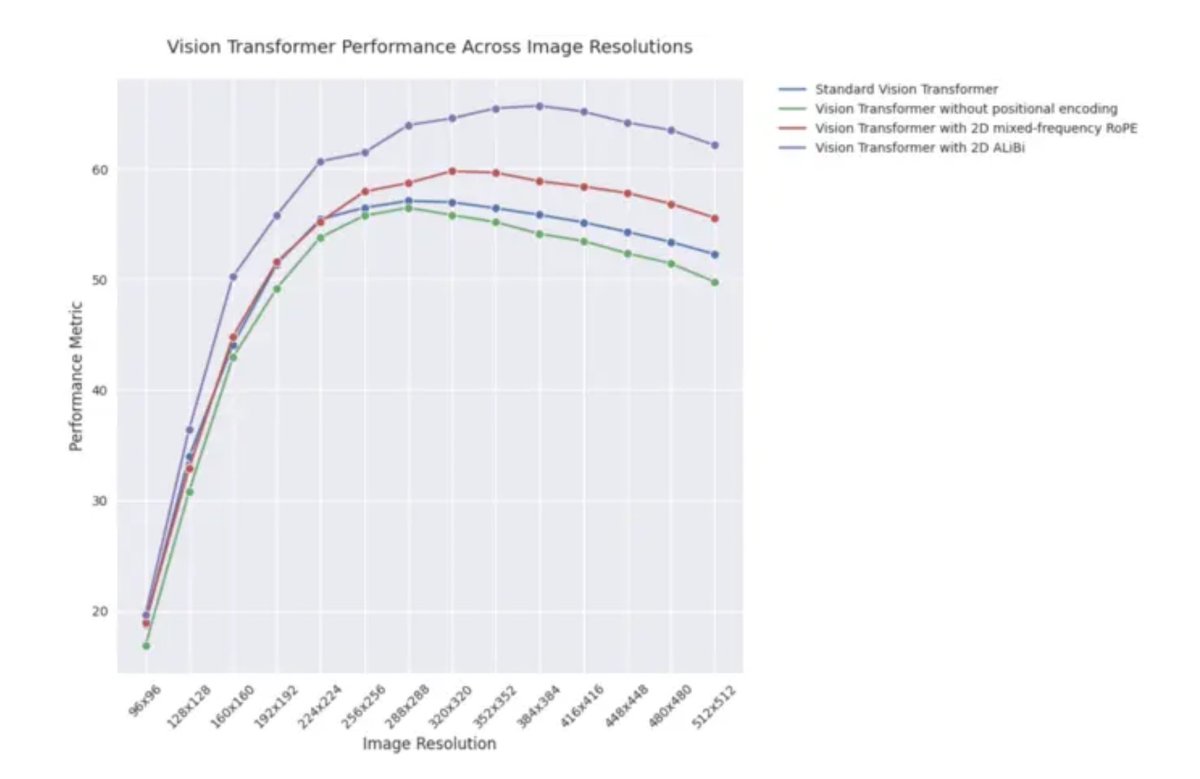
Postingan blog ICLR 2025: Performa ekstrapolasi 2D ALiBi dalam Vision Transformer: Sebuah postingan blog ICLR 2025 menunjukkan bahwa Vision Transformer (ViT) yang menggunakan Attention with Linear Biases dua dimensi (2D ALiBi) menunjukkan performa terbaik pada dataset Imagenet100 untuk tugas ekstrapolasi ke ukuran gambar yang lebih besar. ALiBi adalah metode pengkodean posisi relatif, yang keberhasilannya di bidang NLP menginspirasi eksplorasinya di bidang visi. Hasil ini menunjukkan bahwa 2D ALiBi membantu ViT menggeneralisasi lebih baik ke resolusi gambar yang tidak terlihat saat pelatihan. (Sumber: OfirPress)
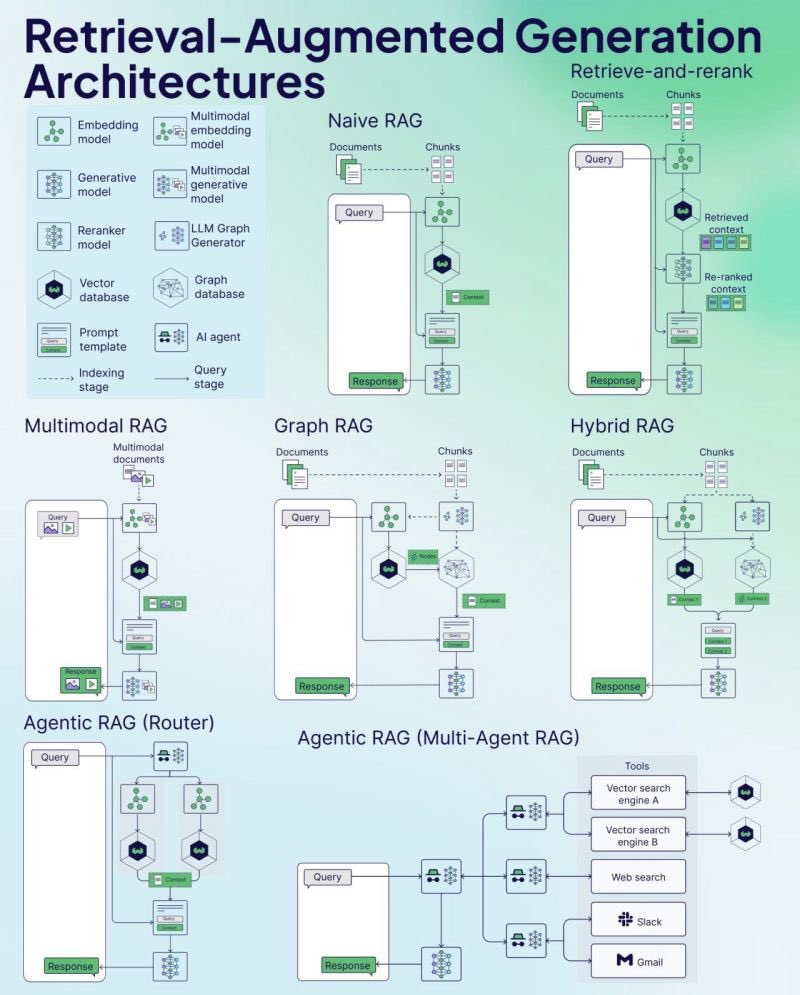
Weaviate merilis RAG Cheat Sheet: Perusahaan database vektor Weaviate merilis Cheat Sheet tentang Retrieval-Augmented Generation (RAG). Materi ini bertujuan untuk menyediakan panduan referensi cepat bagi developer, mungkin mencakup konsep kunci RAG, arsitektur, teknik umum, praktik terbaik, atau masalah umum, untuk membantu developer lebih memahami dan mengimplementasikan sistem RAG. (Sumber: bobvanluijt)
Penelitian MIT mengungkap struktur dan risiko AI Supply Chain: Peneliti dari MIT dan institusi lain menerbitkan paper baru yang membahas AI Supply Chain yang sedang berkembang. Seiring proses pembangunan sistem AI menjadi semakin terdesentralisasi (melibatkan penyedia model dasar, layanan fine-tuning, pemasok data, platform deployment, dll.), paper ini meneliti dampak struktur jaringan ini, termasuk potensi risiko (seperti perambatan kegagalan hulu), asimetri informasi, konflik kontrol dan tujuan optimasi, dll. Penelitian ini menganalisis dua kasus melalui analisis teoretis dan empiris, menekankan pentingnya memahami dan mengelola AI Supply Chain. (Sumber: jachiam0, aleks_madry)
LangChain merilis video pengantar LangSmith lima menit: LangChain merilis video pendek 5 menit yang menjelaskan fungsi platform komersialnya, LangSmith. Video tersebut memperkenalkan bagaimana LangSmith membantu sepanjang siklus hidup pengembangan aplikasi LLM dan Agent, termasuk observability, evaluation, dan prompt engineering, yang bertujuan membantu developer meningkatkan performa aplikasi. (Sumber: LangChainAI)
Together AI merilis video tutorial menjalankan dan fine-tuning model OSS: Together AI merilis video tutorial baru yang memandu pengguna cara menjalankan dan melakukan fine-tuning model besar open source di platform Together AI. Video tersebut mungkin mencakup langkah-langkah seperti memilih model, mengatur lingkungan, mengunggah data, memulai tugas pelatihan, dan melakukan inferensi, yang bertujuan untuk menurunkan hambatan bagi pengguna dalam menggunakan platform mereka untuk kustomisasi dan deployment model open source. (Sumber: togethercompute)
Paper mengusulkan penggunaan “Agent Berperasaan” untuk mengevaluasi kemampuan kognitif sosial LLM: Sebuah paper baru memperkenalkan framework SAGE (Sentient Agent as a Judge), sebuah metode evaluasi baru yang menggunakan Agent Berperasaan (Sentient Agent) yang mensimulasikan dinamika emosional dan penalaran internal manusia untuk mengevaluasi kemampuan kognitif sosial LLM dalam percakapan. Framework ini bertujuan untuk menguji kemampuan LLM dalam menafsirkan emosi, menyimpulkan niat tersembunyi, dan memberikan respons empatik. Studi menemukan bahwa dalam 100 skenario percakapan suportif, skor emosional Agent Berperasaan sangat berkorelasi dengan metrik yang berpusat pada manusia (seperti BLRI, indikator empati), dan LLM dengan kemampuan sosial yang kuat tidak selalu membutuhkan respons yang panjang. (Sumber: menhguin)

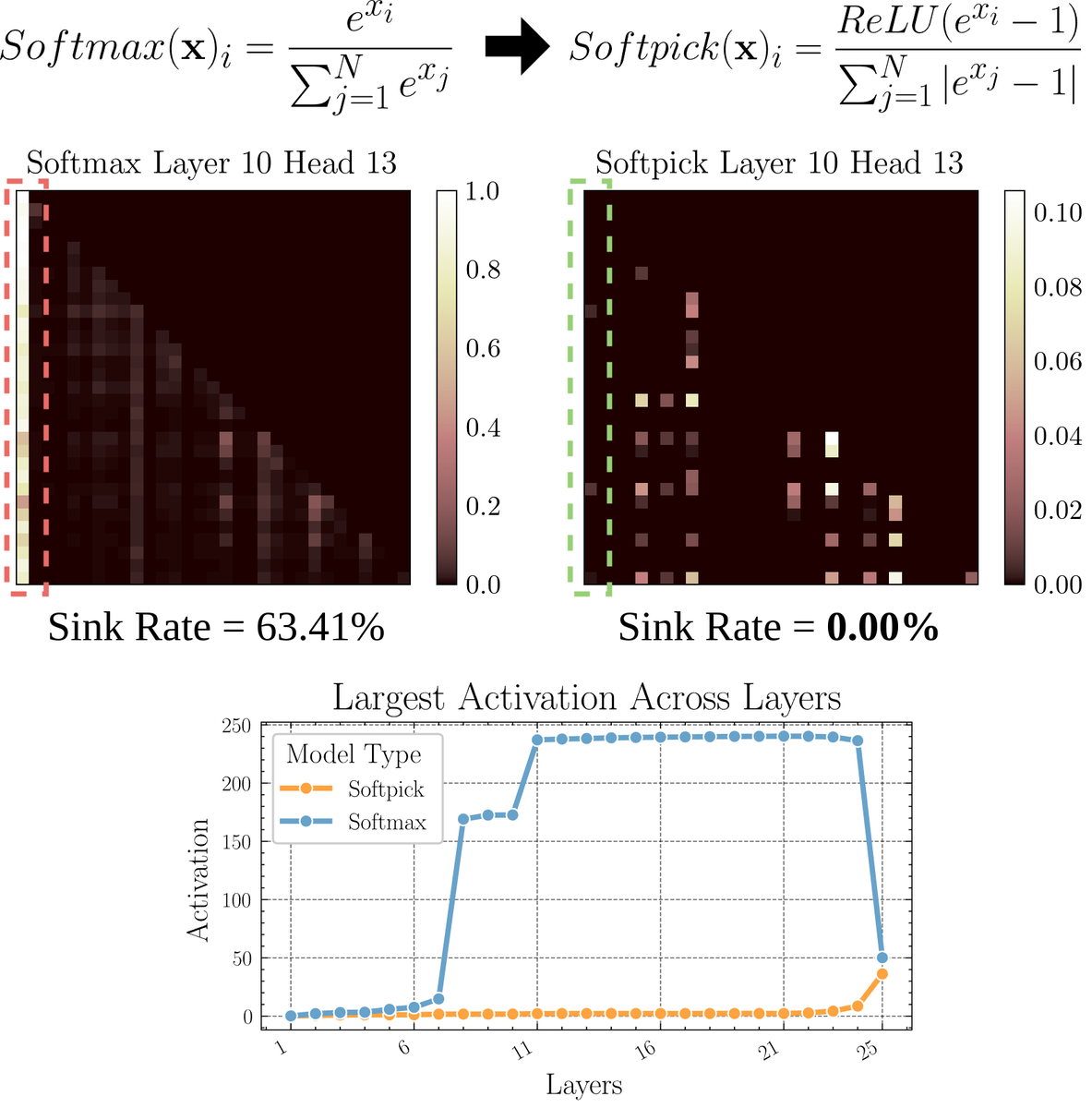
Paper membahas Softpick: mekanisme perhatian alternatif untuk Softmax: Sebuah paper pracetak mengusulkan Softpick, sebuah alternatif yang memperbaiki Softmax untuk mengatasi masalah “attention sink” dan nilai aktivasi skala besar dalam mekanisme perhatian. Metode ini menyarankan penggunaan ReLU(x – 1) di pembilang Softmax dan abs(x – 1) di penyebut. Peneliti berpendapat bahwa penyesuaian sederhana ini mungkin dapat meningkatkan beberapa masalah inheren mekanisme perhatian yang ada sambil mempertahankan performa, terutama dalam menangani sekuens panjang atau skenario yang membutuhkan distribusi perhatian yang lebih stabil. (Sumber: sedielem)
💼 Bisnis
Startup AI RogoAI menyelesaikan pendanaan Seri B $50 juta: RogoAI, yang berfokus pada pembangunan platform riset AI-native untuk industri jasa keuangan, mengumumkan penyelesaian pendanaan Seri B sebesar $50 juta yang dipimpin oleh Thrive Capital, dengan partisipasi dari J.P. Morgan Asset Management, Tiger Global, dan lainnya. Pendanaan ini akan digunakan untuk mempercepat pengembangan produk dan ekspansi pasar RogoAI di bidang analisis keuangan dan otomatisasi riset. (Sumber: hwchase17, hwchase17)
Startup pencarian AI perusahaan Glean menyelesaikan putaran pendanaan baru dengan valuasi $7 miliar: Menurut The Information, startup pencarian AI perusahaan Glean akan segera menyelesaikan putaran pendanaan baru yang dipimpin oleh Wellington Management, dengan valuasi sekitar $7 miliar. Perusahaan ini baru saja menyelesaikan pendanaan dengan valuasi $4,6 miliar hanya empat bulan lalu, lompatan valuasi yang signifikan ini mencerminkan ekspektasi pasar yang tinggi terhadap aplikasi AI tingkat perusahaan dan solusi manajemen pengetahuan. (Sumber: steph_palazzolo)
Groq bermitra dengan Meta untuk mempercepat Llama API: Perusahaan chip inferensi AI Groq mengumumkan kemitraan dengan Meta untuk menyediakan akselerasi bagi Llama API resmi. Developer akan dapat menjalankan model Llama terbaru (mulai dari Llama 4) dengan throughput hingga 625 token/detik, dan diklaim hanya memerlukan 3 baris kode untuk bermigrasi dari OpenAI. Kemitraan ini bertujuan untuk menyediakan solusi berkecepatan tinggi dan latensi rendah bagi developer untuk menjalankan large language model. (Sumber: JonathanRoss321)

🌟 Komunitas
Komunitas ramai membahas perbandingan Llama4 dan DeepSeek R1 serta masalah benchmark evaluasi model: CEO Meta Mark Zuckerberg dalam sebuah wawancara menanggapi masalah kinerja Llama4 yang kalah dari DeepSeek R1 di arena, ia berpendapat bahwa benchmark open source memiliki kekurangan, terlalu bias terhadap kasus penggunaan tertentu, tidak dapat secara akurat mencerminkan kinerja model dalam produk nyata, dan menyatakan bahwa model inferensi Meta belum dirilis, sehingga tidak dapat dibandingkan langsung dengan R1. Pernyataan ini, dikombinasikan dengan paper Cohere yang mempertanyakan LMArena, memicu diskusi luas di komunitas tentang cara mengevaluasi LLM secara adil, keterbatasan leaderboard publik, dan strategi pemilihan model. Banyak yang setuju bahwa tidak boleh terlalu bergantung pada leaderboard umum, tetapi harus menggabungkan evaluasi kasus penggunaan spesifik, data pribadi, dan sinyal komunitas untuk memilih model. (Sumber: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
Diskusi tentang AI menggantikan tenaga kerja manusia terus memanas: Beberapa postingan di komunitas Reddit membahas dampak AI terhadap pekerjaan. Seorang penerjemah bahasa Spanyol menyatakan bisnisnya menyusut drastis karena peningkatan kualitas terjemahan AI; seorang insinyur audio lainnya juga beralih profesi karena peningkatan efek mastering audio AI. Sementara itu, ada juga postingan yang membahas bagaimana aplikasi AI dalam diagnosis medis, konsultasi pajak, dll. dapat mengurangi permintaan akan tenaga profesional. Kasus-kasus ini memicu diskusi tentang apakah krisis pengangguran akibat otomatisasi AI datang lebih awal dari yang diperkirakan, serta bagaimana para profesional harus beradaptasi (misalnya, memanfaatkan AI untuk transformasi, mencari nilai yang tidak dapat digantikan oleh AI). (Sumber: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Fenomena “pergeseran iteratif” gambar yang dihasilkan AI menarik perhatian: Pengguna Reddit mencoba meminta ChatGPT untuk terus menerus melakukan “replikasi persis” berdasarkan gambar yang dihasilkan sebelumnya. Hasilnya menunjukkan fenomena di mana konten dan gaya gambar secara bertahap menyimpang dari input asli seiring bertambahnya jumlah iterasi, akhirnya cenderung ke arah abstrak atau pola tertentu (seperti tato Samoa/fitur wanita). Contoh Dwayne Johnson juga menunjukkan evolusi serupa dari realistis ke abstrak. Fenomena ini mengungkap tantangan model pembuatan gambar saat ini dalam menjaga konsistensi jangka panjang, serta bias atau konvergensi yang mungkin ada dalam representasi internalnya. (Sumber: Reddit r/ChatGPT, Reddit r/ChatGPT)

Komunitas membahas apakah AI akan menggantikan pekerjaan venture capital (VC): Marc Andreessen berpendapat bahwa ketika AI dapat melakukan semua hal lain, venture capital mungkin menjadi salah satu pekerjaan terakhir yang dilakukan oleh manusia, karena lebih mirip seni daripada sains, bergantung pada selera, psikologi, dan toleransi terhadap kekacauan. Pandangan ini memicu diskusi, beberapa orang menganggapnya “pernyataan lucu”, mempertanyakan mengapa investasi tahap awal memiliki keunikan; yang lain, dari bidang mereka sendiri (seperti pengembangan game), berpendapat bahwa pemikiran ini mungkin “menghibur diri sendiri” (cope), karena orang di setiap bidang cenderung berpikir pekerjaan mereka tidak dapat digantikan oleh AI karena membutuhkan selera unik. (Sumber: colin_fraser, gfodor, cto_junior, pmddomingos)
Universitas Zurich melakukan eksperimen persuasi AI tanpa izin di Reddit memicu kontroversi: Menurut moderator Reddit r/changemyview dan Reddit Lies, peneliti Universitas Zurich, tanpa memberitahu pengguna komunitas secara eksplisit, men-deploy beberapa akun AI untuk berpartisipasi dalam diskusi di subreddit tersebut, menguji kekuatan persuasif argumen yang dihasilkan AI. Studi menemukan bahwa tingkat keberhasilan persuasi akun AI (mendapatkan tanda “∆” yang menunjukkan perubahan pandangan pengguna) jauh melampaui tingkat dasar manusia, dan pengguna gagal mendeteksi identitas AI mereka. Meskipun eksperimen tersebut diklaim telah mendapat persetujuan komite etik, cara pelaksanaannya yang rahasia dan sifat “manipulatif” potensialnya memicu kontroversi etika yang luas dan kekhawatiran tentang penyalahgunaan AI. (Sumber: 量子位)
💡 Lainnya
Apakah masih perlu belajar pemrograman di era AI memicu pemikiran: Muncul diskusi di komunitas tentang nilai belajar pemrograman di era AI. Pandangan menyatakan bahwa meskipun kemampuan pembuatan kode AI semakin kuat dan sifat pekerjaan insinyur perangkat lunak berubah dengan cepat, belajar pemrograman tetap penting. Belajar pemrograman adalah dasar untuk memahami cara berkolaborasi secara efektif dengan AI (terutama LLM), dan kemampuan kolaborasi manusia-mesin ini akan menjadi kompetensi inti lintas bidang. Pemrograman adalah titik awal bagi manusia untuk mulai “menari bersama” AI, dan di masa depan, semua industri akan membutuhkan penguasaan pola kolaborasi ini. (Sumber: alexalbert__, _philschmid)
Developer membahas pengalaman dan tantangan pemrograman berbantuan AI: Developer di komunitas berbagi pengalaman menggunakan tool pemrograman AI (seperti Cursor, ChatGPT Desktop). Ada yang merindukan “masa tenang” menunggu kompilasi di masa lalu, berpendapat bahwa pemrograman berbantuan AI memperkenalkan kembali siklus edit/kompilasi/debug yang serupa. Ada juga yang menunjukkan bahwa tool AI masih kurang dalam memahami konteks (seperti pengeditan multi-file), mengikuti instruksi (seperti menghindari penggunaan sintaks/bahan tertentu), terkadang membutuhkan instruksi yang sangat spesifik untuk mencapai hasil yang diharapkan, dan kode yang dihasilkan AI masih memerlukan peninjauan dan debugging manual. (Sumber: hrishioa, eerac, Reddit r/ChatGPT)

Peningkatan kebahagiaan yang didorong AI: arah aplikasi AI potensial: Sebuah postingan di Reddit mengusulkan bahwa salah satu aplikasi utama AI mungkin adalah meningkatkan kebahagiaan manusia. Penulis berpendapat bahwa berdasarkan hipotesis umpan balik wajah (tersenyum dapat meningkatkan kebahagiaan) dan prinsip fokus, AI (seperti Gemini 2.5 Pro) dapat menghasilkan konten panduan berkualitas tinggi untuk membantu orang meningkatkan tingkat kebahagiaan melalui latihan sederhana (seperti tersenyum dan fokus pada perasaan menyenangkan yang ditimbulkannya). Penulis membagikan laporan dan audio yang dihasilkan AI, dan memprediksi bahwa di masa depan mungkin muncul aplikasi atau robot “mentor kebahagiaan” yang sukses berdasarkan prinsip ini. (Sumber: Reddit r/deeplearning)
