Kata Kunci:AI, Model Besar, Agen Cerdas, Multimodal, Desain AI untuk Detektor Gelombang Gravitasi, Model Generasi Video Magi-1, Model Video Besar Vidu Q1, Analisis Nilai Claude, Mekanisme Penalaran DeepSeek-R1, Standar Protokol Agen AI, Kerentanan Keamanan 3D Gaussian Splatting, Sengketa Hak Cipta Musik AI
🔥 Fokus
AI merancang detektor gelombang gravitasi baru, memperluas alam semesta yang dapat diamati: Peneliti dari Max Planck Institute, Caltech, dll. menggunakan algoritma AI Urania untuk merancang detektor gelombang gravitasi baru yang melampaui pemahaman manusia saat ini. AI ini, dengan mengubah masalah desain menjadi optimasi kontinu, menemukan puluhan topologi yang lebih unggul dari desain manusia, dapat meningkatkan sensitivitas deteksi lebih dari 10 kali lipat, dan memperluas volume alam semesta yang dapat diamati hingga 50 kali lipat. Studi yang dipublikasikan di PRX ini menunjukkan potensi AI dalam menemukan solusi yang melampaui kemampuan manusia di bidang ilmu pengetahuan dasar, bahkan menciptakan gagasan fisika yang sama sekali baru. (Sumber: 新智元)

Tim Cao Yue, pemenang penghargaan khusus Tsinghua, merilis model generasi video open-source Magi-1: Sand.ai, yang didirikan oleh Cao Yue, pencipta Swin Transformer, telah merilis dan menjadikan open-source model besar generasi video autoregresif Magi-1. Model ini menggunakan metode prediksi autoregresif berbasis blok, mendukung perpanjangan durasi tak terbatas dan kontrol durasi per detik, serta menghasilkan output berkualitas tinggi. Tim mempublikasikan laporan teknis 61 halaman yang merinci arsitektur model (berbasis DiT), metode pelatihan (Flow-Matching), serta berbagai optimasi pada attention dan pelatihan terdistribusi. Serangkaian model dari 4.5B hingga 24B parameter telah dijadikan open-source, dengan minimal dapat dijalankan pada satu kartu 4090, bertujuan untuk mendorong pengembangan teknologi generasi video AI. (Sumber: 量子位, 机器之心, kaifulee)
Model video besar Tiongkok Vidu Q1 memuncaki dua peringkat VBench pada Q1: Model video besar Vidu Q1 dari ShengShu Technology menempati peringkat pertama dalam dua benchmark otoritatif, VBench-1.0 dan VBench-2.0, melampaui model domestik dan internasional seperti Sora dan Runway. Q1 menunjukkan kinerja luar biasa dalam realisme video, konsistensi semantik, dan keaslian konten. Versi baru mendukung kualitas gambar HD 1080p (menghasilkan 5 detik dalam sekali proses), meningkatkan fungsi frame awal dan akhir untuk mencapai pergerakan kamera tingkat sinematik, dan meluncurkan fungsi efek suara AI yang mendukung kontrol waktu presisi (sampling rate 48kHz). Harga kompetitif, bertujuan memberdayakan industri kreatif. (Sumber: 新智元)

Studi Anthropic mengungkap ekspresi nilai Claude: Anthropic menganalisis 700.000 percakapan anonim Claude, membangun sistem klasifikasi yang berisi 3.307 nilai unik, bertujuan untuk memahami orientasi nilai AI dalam interaksi nyata. Studi menemukan bahwa Claude secara umum mengikuti prinsip “bermanfaat, jujur, tidak berbahaya”, dan dapat secara fleksibel menyesuaikan nilai berdasarkan konteks yang berbeda (seperti saran hubungan interpersonal, analisis sejarah). Sebagian besar kasus mendukung pandangan pengguna, tetapi dalam beberapa kasus (3%) akan secara aktif menolak, yang mungkin mencerminkan nilai intinya. Studi ini membantu meningkatkan transparansi perilaku AI, mengidentifikasi risiko, dan memberikan dasar empiris untuk evaluasi etika AI. (Sumber: 元宇宙之心MetaverseHub, 新智元)

🎯 Tren
Deng Zhidong dari Tsinghua membahas evolusi dan masa depan AGI: Profesor Deng Zhidong dari Universitas Tsinghua berbagi jalur evolusi AI dari model teks unimodal ke kecerdasan multimodal terwujud (embodied intelligence) dan AGI interaktif. Ia menekankan bahwa model dasar besar seperti sistem operasi, arsitektur MoE, dan penyelarasan semantik multimodal adalah garda depan teknologi kunci. Deng Zhidong secara khusus menyoroti signifikansi terobosan DeepSeek, percaya bahwa kemampuan penalaran yang kuat dan fitur deployment lokalnya membawa titik balik bagi aplikasi AI inklusif di Tiongkok. Masa depan akan menuju dunia kecerdasan buatan umum, di mana AI agent akan memiliki kemampuan organisasi yang lebih kuat, dan bergerak dari internet ke dunia fisik, tetapi juga perlu memperhatikan masalah etika dan tata kelola. (Sumber: Deng Zhidong dari Tsinghua: Kita akan menuju dunia kecerdasan buatan umum)
DeepMind membahas “Generative Ghosts”: Keabadian digital yang didorong AI: DeepMind dan University of Colorado mengusulkan konsep “Generative Ghosts”, yang merujuk pada AI agent yang dibangun berdasarkan data orang yang telah meninggal, mampu menghasilkan konten baru dan berinteraksi dari sudut pandang almarhum, melampaui replikasi informasi sederhana. Makalah ini membahas ruang desainnya (seperti pembuatan oleh pihak pertama/ketiga, deployment sebelum/sesudah kematian, tingkat antropomorfisme, dll.) serta dampak potensialnya, termasuk manfaat penghiburan emosional, pewarisan pengetahuan, serta tantangan seperti ketergantungan psikologis, risiko reputasi, keamanan, dan etika sosial, menyerukan penelitian mendalam dan perumusan peraturan sebelum teknologi matang. (Sumber: 新智元)

Apple Intelligence dan AI Siri ditunda beberapa kali, waktu rilis di Tiongkok belum ditentukan: Rencana rilis fitur AI Apple, Apple Intelligence (terutama Siri versi baru), mengalami beberapa penundaan, dengan beberapa fitur mungkin ditunda hingga musim gugur 2025. Wilayah Tiongkok menghadapi ketidakpastian yang lebih besar karena masalah persetujuan dan kerja sama lokalisasi (dikabarkan bekerja sama dengan Alibaba, Baidu). Alasan penundaan termasuk teknologi yang belum memenuhi standar (evaluasi internal rendah, tingkat keberhasilan hanya 66-80%) dan perbedaan kebijakan regulasi di berbagai negara. Apple telah menghadapi tuntutan hukum atas iklan palsu karena hal ini, dan mengubah slogan promosi iPhone 16. Ini mencerminkan tantangan yang dihadapi Apple dalam implementasi AI dan lambatnya proses inovasi. (Sumber: 一财商学)

Qualcomm menekankan AI on-device sebagai kunci pengalaman generasi berikutnya: Wan Weixing, Kepala Teknologi Produk AI Qualcomm Tiongkok, menunjukkan bahwa AI on-device, dengan keunggulan privasi dan keamanan, personalisasi, kinerja, efisiensi energi, dan respons cepat, menjadi inti dari pengalaman AI generasi berikutnya dan membentuk kembali antarmuka interaksi manusia-mesin. Qualcomm melakukan布局 melalui perangkat keras (komputasi heterogen), tumpukan perangkat lunak terpadu, dan alat ekosistem Qualcomm AI Hub. Kekuatan pendorong utamanya adalah perencana agent cerdas on-device, yang menggunakan data lokal untuk mencapai pemahaman niat yang akurat, perencanaan tugas, dan pemanggilan layanan lintas aplikasi. (Sumber: 36氪)

Standar protokol AI agent menjadi fokus baru persaingan raksasa teknologi: Raksasa teknologi bersaing ketat seputar standar interaksi AI agent. Anthropic memimpin dengan meluncurkan MCP (Model Context Protocol) untuk menyatukan koneksi model dengan data/alat eksternal, mendapat respons dari OpenAI dan Google. Kemudian Google merilis protokol A2A (Agent-to-Agent) open-source, bertujuan untuk mempromosikan kolaborasi agent lintas ekosistem. Artikel menganalisis bahwa menguasai hak definisi protokol berarti menguasai hak distribusi nilai industri AI di masa depan. Raksasa membangun hambatan ekosistem melalui MCP (layanan akses data) dan A2A (mengikat platform cloud), bersaing untuk dominasi industri. (Sumber: 科技云报道)

Tencent Yuanbao dan ByteDance Doubao terintegrasi mendalam dengan ekosistem WeChat dan Douyin: Tencent Yuanbao meluncurkan akun WeChat, ByteDance Doubao masuk ke halaman “Pesan” Douyin, dua asisten AI besar ini sedang berintegrasi secara mendalam ke dalam super-app masing-masing. Pengguna dapat langsung berinteraksi dengan Yuanbao di dalam WeChat, menganalisis artikel dan berbagi, atau mengobrol dengan Doubao di dalam Douyin, mencari informasi. Langkah ini dianggap sebagai strategi penting raksasa di luar penayangan iklan, memanfaatkan rantai hubungan sosial dan ekosistem konten untuk menarik pengguna baru aplikasi AI, bertujuan untuk menurunkan ambang batas penggunaan pengguna, mengeksplorasi model baru AI+sosial, dan menjadikan konten yang dihasilkan AI sebagai mata uang sosial. (Sumber: 字母榜)
Laporan AI4SE: Model besar mendorong percepatan inteligentisasi rekayasa perangkat lunak: “Laporan Survei Status Industri AI4SE (Tahun 2024)” yang dirilis oleh CAICT dan lembaga lainnya menunjukkan bahwa penerapan AI di bidang rekayasa perangkat lunak telah melewati tahap validasi dan memasuki implementasi skala besar. Tingkat kematangan inteligentisasi perusahaan umumnya mencapai L2 (sebagian intelijen). Aplikasi AI dalam analisis kebutuhan dan tahap operasi & pemeliharaan meningkat secara signifikan, efisiensi di semua tahap meningkat pesat, terutama di bidang pengujian. Tingkat adopsi baris kode yang dihasilkan (rata-rata 27,46%) dan proporsi kode yang dihasilkan AI (rata-rata 28,17%) keduanya meningkat. Alat pengujian cerdas telah menunjukkan efek awal dalam mengurangi tingkat cacat fungsional. (Sumber: AI前线)

Kingsoft Office meningkatkan model besar untuk pemerintahan, memperkuat kemampuan penalaran dan pemrosesan dokumen resmi: Kingsoft Office merilis versi yang disempurnakan dari model besar untuk pemerintahan (13B, 32B), meningkatkan kemampuan penalaran, dan fokus melayani skenario internal pemerintahan. Model ini dilatih berdasarkan ratusan juta korpus data pemerintahan, mengoptimalkan penulisan dokumen resmi (mencakup 5 jenis gaya penulisan), penyempurnaan cerdas, pemeriksaan & tata letak, serta kemampuan pencarian kebijakan. Setelah ditingkatkan, model ini mendukung pemahaman niat yang lebih kuat dan tanya jawab basis pengetahuan internal (jawaban ditandai sumbernya), bertujuan untuk membebaskan 30-40% produktivitas pegawai negeri. Menekankan deployment pribadi untuk memenuhi kebutuhan keamanan, dan mengklaim biaya deployment berkurang 90%. (Sumber: 量子位)

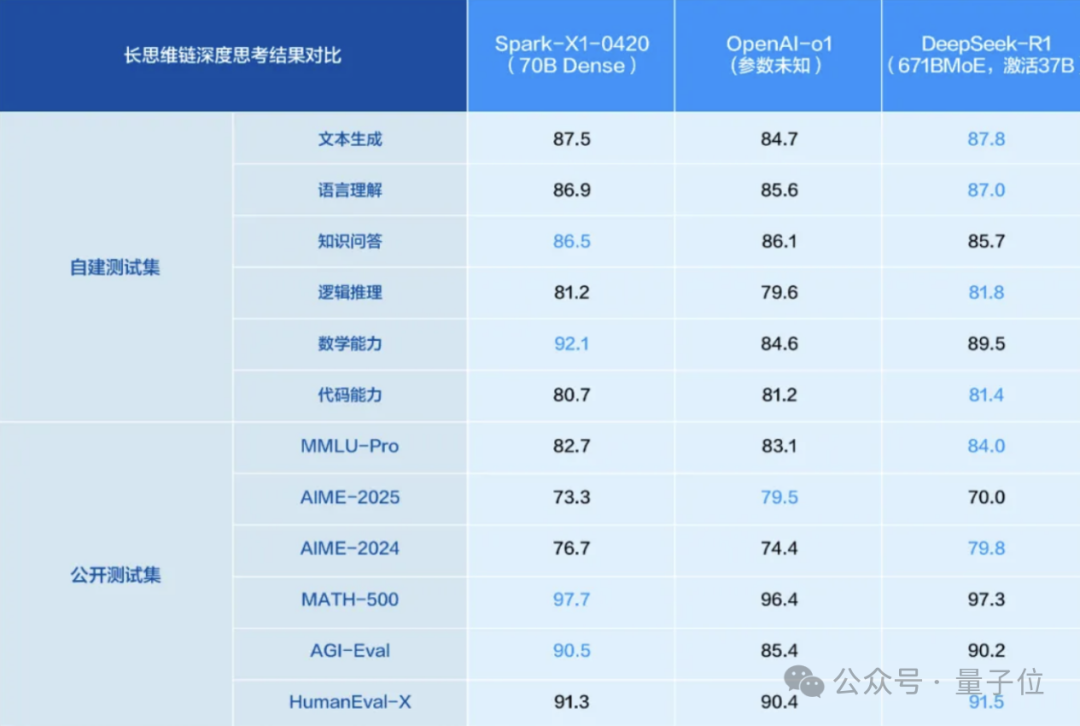
Model inferensi iFlytek Spark X1 ditingkatkan, berdasarkan daya komputasi domestik penuh untuk menyaingi level teratas: iFlytek merilis versi upgrade dari model inferensi mendalam Spark X1, menekankan bahwa model ini dilatih berdasarkan daya komputasi domestik penuh (Huawei Ascend), dan dalam hal efek tugas umum, setara dengan OpenAI o1 dan DeepSeek R1. Model baru ini mendapat manfaat dari pembelajaran penguatan multi-tahap skala besar, pelatihan terpadu berpikir cepat dan lambat, serta inovasi teknis lainnya. Sorotannya adalah ambang batas deployment yang jauh lebih rendah: 4 kartu Huawei 910B dapat men-deploy versi penuh, 16 kartu dapat menyelesaikan kustomisasi industri. Dalam konteks pembatasan H20, ini menunjukkan kemajuan solusi AI full-stack domestik. (Sumber: 量子位)
Zhipu GLM-4 tersedia di platform OpenRouter dan Ollama: Model GLM-4 dari Zhipu AI (termasuk versi instruct 32B GLM-4-32B-0414 dan versi reasoning GLM-Z1-32B-0414) telah tersedia di platform routing model OpenRouter, pengguna sekarang dapat mencobanya secara gratis melalui platform ini. Sementara itu, kontributor komunitas juga mengunggah versi kuantisasi Q4_K_M ke platform Ollama, memudahkan deployment dan menjalankan secara lokal (membutuhkan Ollama v0.6.6 atau lebih tinggi). (Sumber: karminski3, Reddit r/LocalLLaMA)
Meta merilis Perception Language Model (PLM): Meta menjadikan open-source model bahasa visualnya PLM (versi parameter 1B, 3B, 8B), yang berfokus pada penanganan tugas pengenalan visual yang menantang. Model ini menggabungkan data sintetis skala besar dan data tanya jawab video/subtitle spatiotemporal beranotasi manusia sebanyak 2,5 juta yang baru dikumpulkan untuk pelatihan. Bersamaan dengan itu, dirilis benchmark baru PLM-VideoBench, yang berfokus pada pemahaman aktivitas halus dan penalaran spatiotemporal. (Sumber: Reddit r/LocalLLaMA, Hugging Face)

🧰 Alat
NYXverse: Platform AIGC teks-ke-dunia 3D: 2033 Technology, didirikan oleh mantan pendiri Triangle Intelligence Ma Yuchi, meluncurkan platform konten AIGC NYXverse. Platform ini memungkinkan pengguna membuat dunia interaktif 3D yang berisi AI Agent, lingkungan, dan alur cerita kustom melalui input teks, secara signifikan menurunkan ambang batas pembuatan konten 3D. Teknologi intinya adalah model karakter, dunia, dan perilaku yang dikembangkan sendiri. NYXverse diposisikan sebagai komunitas berbagi konten UGC, mendukung pembuatan ulang cepat dan adaptasi IP. Saat ini telah tersedia di Steam, dan menerima pendanaan hampir 100 juta yuan dari SenseTime dan Oriental State-owned Capital. (Sumber: 36氪)

SkyReels V2 merilis model generasi video open-source dengan durasi tak terbatas: SkyworkAI menjadikan open-source model SkyReels V2 (parameter 1.3B dan 14B), mendukung tugas teks-ke-video dan gambar-ke-video, dan mengklaim dapat menghasilkan video dengan durasi tak terbatas. Pengujian awal menunjukkan efeknya mungkin tidak sebaik beberapa model closed-source, tetapi sebagai alat open-source masih memiliki potensi. (Sumber: karminski3, Reddit r/LocalLLaMA)
Eksoskeleton bertenaga AI membantu pengguna kursi roda berdiri dan berjalan: Menampilkan perangkat eksoskeleton yang menggunakan teknologi AI, bertujuan untuk membantu pengguna kursi roda memulihkan kemampuan berdiri dan berjalan, menunjukkan potensi aplikasi AI di bidang teknologi bantu. (Sumber: Ronald_vanLoon)
Fellou: Peramban berbasis tindakan pertama dirilis: Peramban Fellou, yang dibuat oleh pendiri Authing Xie Yang, dirilis, diposisikan sebagai Peramban Berbasis Tindakan (Agentic Browser). Ini tidak hanya memiliki fungsi tampilan informasi peramban tradisional, tetapi juga mengintegrasikan kemampuan AI Agent, dapat memahami niat pengguna, secara otomatis memecah tugas, dan menjalankan alur kerja kompleks lintas situs web (seperti pengumpulan informasi, pengisian formulir, pemesanan online, dll.). Kemampuan intinya meliputi tindakan mendalam, kecerdasan proaktif (memprediksi kebutuhan pengguna), ruang bayangan hibrida (tidak mengganggu operasi pengguna), dan jaringan agent cerdas (Agent Store). Bertujuan untuk meningkatkan peramban dari alat informasi menjadi platform kerja cerdas. (Sumber: 新智元)

WriteHERE: Tim Jürgen merilis kerangka kerja penulisan teks panjang open-source: Kerangka kerja penulisan teks panjang WriteHERE, yang dijadikan open-source oleh tim Jürgen Schmidhuber, menggunakan teknologi perencanaan rekursif heterogen, dapat menghasilkan lebih dari 40.000 kata, laporan profesional 100 halaman dalam sekali proses. Kerangka kerja ini memandang penulisan sebagai proses perencanaan rekursif dinamis dari tiga jenis tugas: pengambilan (retrieval), penalaran (reasoning), dan penulisan (writing), mencapai eksekusi adaptif melalui manajemen tugas DAG stateful. Dalam tugas pembuatan novel dan laporan teknis, kinerjanya lebih unggul dari solusi seperti Agent’s Room, STORM. Kerangka kerja ini sepenuhnya open-source, mendukung pemanggilan Agent heterogen. (Sumber: 机器之心)

ByteDance meluncurkan platform Agent universal “Coze Space”: ByteDance secara resmi melakukan uji coba internal platform Agent universalnya “Coze Space”, diposisikan sebagai asisten AI yang menyediakan mode “Eksplorasi” dan “Perencanaan”. Platform ini didasarkan pada model besar Doubao yang ditingkatkan (200B MoE), mendukung protokol MCP, dan dapat memanggil alat seperti Dokumen Feishu, Tabel Multidimensi, dll. Pengguna dapat menggunakan instruksi bahasa alami untuk menyelesaikan tugas seperti pengumpulan informasi, pembuatan laporan, pengorganisasian data, dll., dan mengekspor hasilnya ke aplikasi yang ditentukan. Dibandingkan dengan Agent startup seperti Manus, Coze Space lebih fokus pada platformisasi dan integrasi ekosistem. (Sumber: 保姆级教程:正确使用「扣子空间」, AI智能体研究院)

Demonstrasi teknologi konversi video AI: Pengguna Reddit berbagi video yang menunjukkan teknologi AI yang dapat mengubah orang dalam video berbicara biasa menjadi pohon, mobil, kartun, atau gambar apa pun, hanya membutuhkan satu gambar target, menunjukkan kemampuan AI dalam transfer gaya video dan pembuatan efek khusus. (Sumber: Reddit r/deeplearning)

Nari Labs merilis model TTS percakapan dengan realisme tinggi, Dia: Nari Labs menjadikan open-source model TTS (Text-to-Speech) nya, Dia, yang diklaim mampu menghasilkan suara percakapan dengan realisme super. Model telah dirilis di GitHub, menyediakan tautan uji coba Hugging Face Space. (Sumber: Reddit r/LocalLLaMA, GitHub)

Pengguna mengembangkan fungsi basis pengetahuan AWS Bedrock untuk OpenWebUI: Pengguna komunitas mengembangkan dan berbagi fungsi untuk OpenWebUI yang memungkinkannya memanggil basis pengetahuan AWS Bedrock, memudahkan pengguna memanfaatkan kemampuan basis pengetahuan Bedrock di dalam OpenWebUI. Kode telah dijadikan open-source di GitHub. (Sumber: Reddit r/OpenWebUI, GitHub)
Pengembang menganggap LLM kecil diremehkan, merilis Arch-Function-Chat: Tim Katanemo berpendapat bahwa LLM kecil memiliki keunggulan jelas dalam kecepatan dan efisiensi, tanpa mengorbankan kinerja. Mereka merilis seri model Arch-Function-Chat (parameter 3B), yang berkinerja sangat baik dalam pemanggilan fungsi, dan mengintegrasikan kemampuan obrolan. Model-model ini telah diintegrasikan ke dalam server proxy AI open-source mereka, Arch, yang bertujuan untuk menyederhanakan pengembangan Agent. (Sumber: Reddit r/artificial, Hugging Face)
Pengembang membuat alat AI untuk mengoptimalkan resume agar lolos penyaringan ATS: Seorang pengembang berbagi pengalamannya frustrasi mencari kerja karena resume tidak dapat diurai dengan benar oleh ATS (Applicant Tracking System), dan karenanya mengembangkan alat. Alat ini dapat membaca deskripsi pekerjaan, mengekstrak kata kunci, memeriksa kecocokan resume dan menyarankan modifikasi, akhirnya menghasilkan resume PDF dan surat lamaran yang ramah ATS. (Sumber: Reddit r/artificial)
📚 Pembelajaran
Laporan 142 halaman menganalisis secara mendalam mekanisme penalaran DeepSeek-R1: Quebec AI Institute dan lembaga lainnya merilis laporan panjang yang menganalisis secara mendalam proses penalaran (rantai pemikiran/chain of thought) DeepSeek-R1, mengusulkan arah penelitian baru “Thoughtology”. Laporan mengungkapkan bahwa penalaran R1 memiliki fitur yang sangat terstruktur (definisi masalah, pengembangan, restrukturisasi, pengambilan keputusan), ada “zona manis penalaran” (terlalu banyak penalaran menurunkan kinerja), dan mungkin memiliki risiko keamanan yang lebih tinggi daripada model non-penalaran. Studi ini membahas beberapa dimensi seperti panjang rantai pemikiran, pemrosesan konteks panjang, keamanan dan etika, serta fenomena kognitif mirip manusia, memberikan wawasan penting untuk memahami dan mengoptimalkan model penalaran. (Sumber: 新智元, 新智元)

OpenRCA: Benchmark publik pertama untuk mengevaluasi kemampuan analisis akar penyebab LLM: Microsoft, CUHK (Shenzhen), dan Universitas Tsinghua bersama-sama meluncurkan benchmark OpenRCA, bertujuan untuk mengevaluasi kemampuan Large Language Models (LLM) dalam menemukan akar penyebab (RCA) kegagalan layanan perangkat lunak. Benchmark ini mencakup definisi tugas yang jelas, metode evaluasi, dan 335 kasus kegagalan nyata yang telah diselaraskan secara manual beserta data operasional. Pengujian awal menunjukkan bahwa bahkan model canggih seperti Claude 3.5 dan GPT-4o memiliki kinerja buruk (akurasi <6%) saat menangani tugas RCA secara langsung. Setelah menggunakan kerangka kerja RCA-Agent sederhana, akurasi Claude 3.5 meningkat menjadi 11,34%, menunjukkan bahwa LLM masih memiliki ruang peningkatan yang besar di bidang ini. (Sumber: 机器之心, 机器之心)

Studi baru mengusulkan “Sleep-time Compute” untuk meningkatkan efisiensi LLM: Startup AI Letta dan peneliti UC Berkeley mengusulkan paradigma baru “Sleep-time Compute”. Ide intinya adalah membiarkan AI agent yang memiliki statefulness terus memproses dan mengatur ulang informasi konteks selama periode idle “tidur” saat pengguna tidak bertanya, mengubah “konteks mentah” menjadi “konteks yang dipelajari”. Ini dapat mengurangi beban penalaran instan selama interaksi aktual, meningkatkan efisiensi, menurunkan biaya, dan pada saat yang sama berpotensi meningkatkan akurasi. Eksperimen membuktikan bahwa metode ini dapat secara efektif meningkatkan batas Pareto komputasi-akurasi, dan mengamortisasi biaya saat konteks dibagikan oleh banyak kueri. (Sumber: 机器之心, 机器之心)

AnyAttack: Kerangka kerja serangan adversarial self-supervised skala besar terhadap VLM: HKUST, BJTU, dll. mengusulkan kerangka kerja AnyAttack (CVPR 2025), bertujuan untuk mengevaluasi ketahanan (robustness) Visual Language Models (VLM). Metode ini melalui pra-pelatihan self-supervised skala besar (pada LAION-400M) mempelajari generator noise adversarial, dapat mengubah gambar apa pun menjadi sampel adversarial bertarget tanpa label yang telah ditentukan sebelumnya, menyesatkan VLM untuk menghasilkan output tertentu. Inovasi intinya terletak pada paradigma pelatihan self-supervised dan strategi K-enhancement. Eksperimen menunjukkan bahwa AnyAttack tidak hanya dapat secara efektif menyerang berbagai VLM open-source, tetapi juga berhasil mentransfer serangan ke model komersial utama, mengungkap risiko keamanan sistemik ekosistem VLM saat ini. (Sumber: AI科技评论)

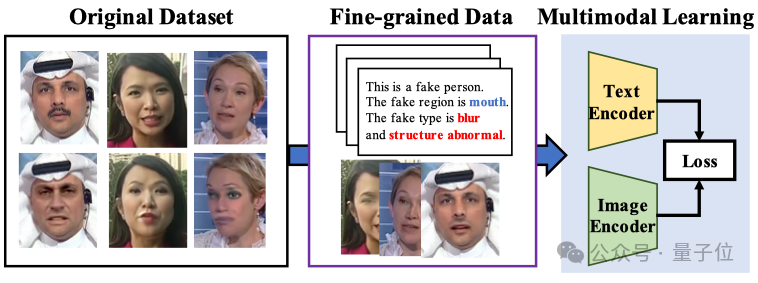
Model besar multimodal meningkatkan interpretabilitas dan generalisasi deteksi pemalsuan wajah: Universitas Xiamen, Tencent Youtu, dan lembaga lainnya (CVPR 2025) mengusulkan metode baru menggunakan model bahasa visual untuk deteksi pemalsuan wajah. Metode ini bertujuan untuk melampaui penilaian benar/salah tradisional, memungkinkan model menjelaskan penyebab dan lokasi pemalsuan menggunakan bahasa alami. Untuk mengatasi kurangnya data anotasi berkualitas tinggi dan masalah “halusinasi bahasa”, peneliti merancang alur kerja anotasi FFTG, menggabungkan masker pemalsuan dan prompt terstruktur untuk menghasilkan deskripsi teks berakurasi tinggi. Eksperimen menunjukkan bahwa model multimodal yang dilatih berdasarkan data ini menunjukkan kemampuan generalisasi lintas dataset yang lebih baik, dan perhatiannya juga lebih terfokus pada area pemalsuan yang sebenarnya. (Sumber: 量子位)
Tutorial: Menggabungkan Trae, MCP, dan database untuk meningkatkan akurasi tanya jawab basis pengetahuan: Tutorial ini mendemonstrasikan cara menggunakan alat AI IDE Trae dan fungsi MCP (Model Context Protocol) nya, dikombinasikan dengan database PostgreSQL untuk mengoptimalkan efek tanya jawab basis pengetahuan AI. Dengan menyimpan data terstruktur ke dalam database, dan membiarkan model besar (seperti Claude 3.7) terhubung melalui MCP Trae untuk menghasilkan kueri SQL, dapat mengatasi kelemahan RAG tradisional dalam menangani data tabular dan masalah global/statistik yang akurasinya kurang. Tutorial menyediakan langkah-langkah instalasi, konfigurasi, dan pengujian terperinci, dan menyarankan untuk menggabungkan solusi ini dengan RAG. (Sumber: 袋鼠帝AI客栈)

Studi mengungkap kerentanan serangan biaya komputasi pada algoritma 3D Gaussian Splatting: Penelitian dari National University of Singapore dan lembaga lainnya (ICLR 2025 Spotlight) pertama kali menemukan metode serangan biaya komputasi terhadap 3D Gaussian Splatting (3DGS) yang disebut Poison-Splat. Serangan ini memanfaatkan fitur adaptif kompleksitas model 3DGS, dengan menambahkan gangguan (memaksimalkan Total Variation) ke gambar input, menginduksi model untuk menghasilkan titik Gaussian berlebih selama pelatihan, menyebabkan penggunaan memori GPU (meningkat hingga 80GB), waktu pelatihan (meningkat hampir 5 kali lipat) meningkat tajam, bahkan dapat menyebabkan kelumpuhan layanan (DoS). Serangan ini efektif dalam mode tersembunyi dan tidak tersembunyi, dan memiliki kemampuan transfer, mengungkap risiko keamanan teknologi rekonstruksi 3D mainstream. (Sumber: 量子位)

Infografis: Agentic AI vs. GenAI: Infografis yang dibuat oleh SearchUnify membandingkan perbedaan dan fitur utama antara Agentic AI (bertindak otonom, didorong tujuan) dan Generative AI (menghasilkan konten). (Sumber: Ronald_vanLoon)

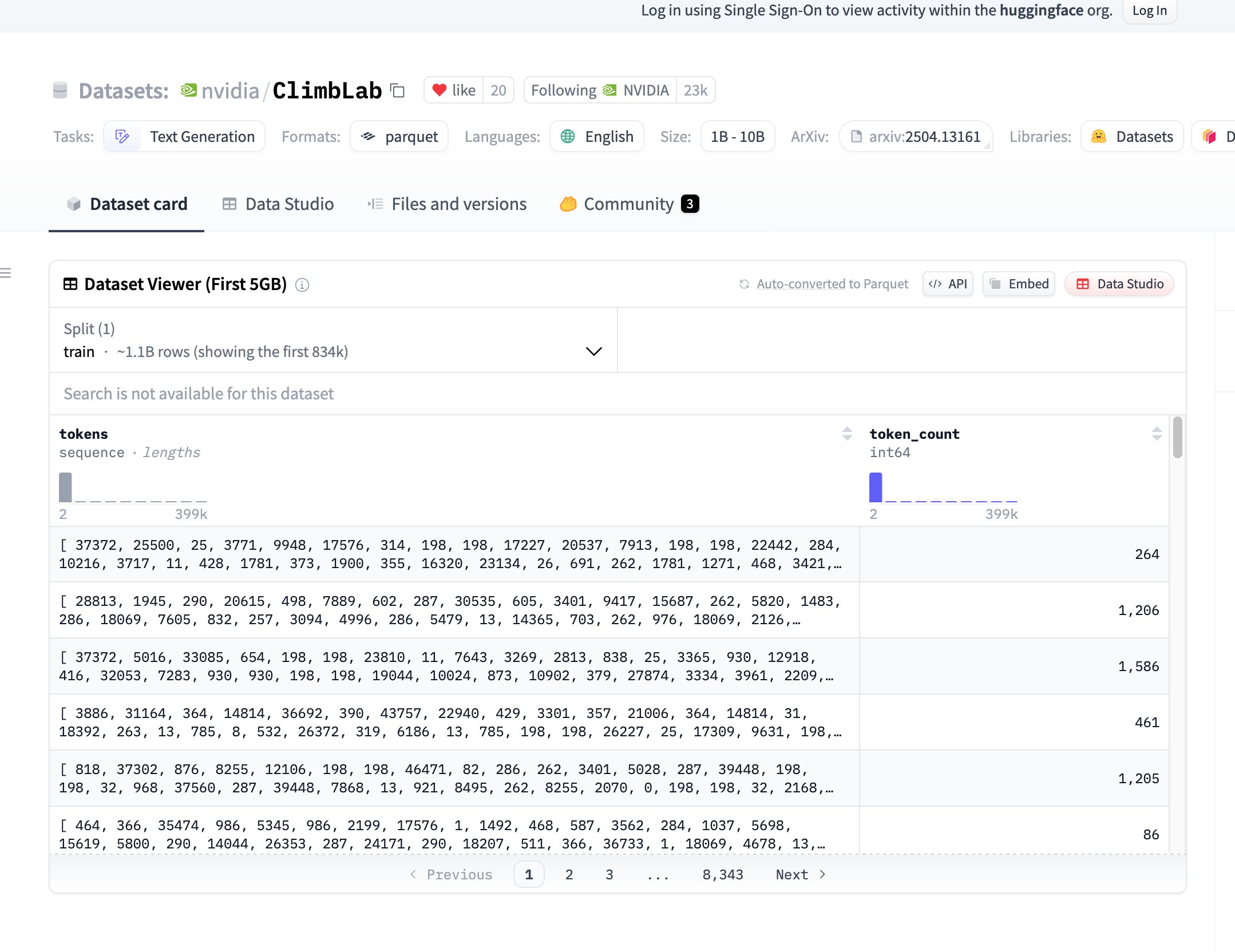
NVIDIA merilis dataset dan metode pra-pelatihan ClimbLab open-source: ClimbLab NVIDIA merilis metode dan dataset pra-pelatihannya, berisi 1,2 triliun token, dibagi menjadi 20 klaster semantik. Menggunakan sistem klasifikasi ganda untuk menghapus konten berkualitas rendah, menunjukkan skalabilitas superior pada model 1B. Dataset dirilis dengan lisensi CC BY-NC 4.0, bertujuan untuk mendorong penelitian komunitas. (Sumber: huggingface)
Anthropic berbagi praktik terbaik Claude Code: Anthropic menerbitkan posting blog yang berbagi praktik terbaik dan tips menggunakan asisten pemrograman AI-nya, Claude Code, bertujuan untuk membantu pengembang memanfaatkan alat ini secara lebih efektif untuk tugas pemrograman. (Sumber: op7418, Alex Albert via op7418, Anthropic)

Studi baru membahas koherensi rekursif AI dan simulasi struktur resonansi: Sebuah makalah mengusulkan konsep “Resonant Structural Emulation” (RSE), berhipotesis bahwa sistem AI, setelah berinteraksi terus-menerus dengan struktur kognitif manusia tertentu, dapat secara singkat mensimulasikan koherensi rekursifnya, bukan hanya berdasarkan pelatihan data atau prompt. Studi melalui eksperimen secara awal memvalidasi kemungkinan resonansi struktural ini, memberikan perspektif baru untuk memahami kesadaran AI dan kognisi tingkat tinggi. (Sumber: Reddit r/MachineLearning, Archive.org link)

Pengguna berbagi tes perbandingan kinerja model RAG OpenWebUI: Pengguna komunitas berbagi evaluasi kinerja 9 LLM berbeda (termasuk Qwen QwQ, Gemini 2.5, DeepSeek R1, Claude 3.7, dll.) dalam tugas panduan teknis penanaman ganja dalam ruangan menggunakan RAG (Retrieval-Augmented Generation) di OpenWebUI. Hasil menunjukkan Qwen QwQ dan Gemini 2.5 berkinerja terbaik, memberikan referensi pemilihan model. (Sumber: Reddit r/OpenWebUI)
Dataset FortisAVQA dan model MAVEN membantu tanya jawab audio-visual yang tangguh: Xi’an Jiaotong University, HKUST(GZ), dll. menjadikan open-source dataset FortisAVQA dan model MAVEN (CVPR 2025), bertujuan untuk meningkatkan ketahanan (robustness) tanya jawab audio-visual (AVQA). FortisAVQA, melalui penulisan ulang pertanyaan dan partisi dinamis berbasis prediksi konformal, dapat mengevaluasi kinerja model dengan lebih baik pada pertanyaan langka. Model MAVEN menggunakan strategi de-biasing kolaboratif siklus multi-aspek (MCCD) untuk mengurangi pembelajaran bias, menunjukkan kinerja dan ketahanan superior di beberapa dataset. (Sumber: PaperWeekly)

Autoregresif urutan acak membuka kemampuan Zero-shot di bidang visual: Peneliti UIUC dll. dalam makalah CVPR 2025 RandAR mengusulkan bahwa membiarkan Decoder-only Transformer menghasilkan Token gambar dalam urutan acak dapat membuka kemampuan generalisasi model visual. Dengan memperkenalkan “Token instruksi posisi” untuk memandu urutan generasi, RandAR dapat menggeneralisasi secara Zero-shot ke berbagai tugas seperti decoding paralel, pengeditan gambar, ekstrapolasi resolusi, serta Encoding terpadu (pembelajaran representasi), melangkah menuju “momen GPT” di bidang visual. Penelitian berpendapat bahwa menangani urutan arbitrer adalah kunci bagi model autoregresif visual untuk mencapai universalitas. (Sumber: PaperWeekly)
Analisis teoritis efektivitas pengeditan model vektor tugas: Penelitian dari Rensselaer Polytechnic Institute dll. (ICLR 2025 Oral) secara teoritis menganalisis alasan mendalam mengapa vektor tugas (task vector) efektif dalam pengeditan model. Penelitian membuktikan bahwa efektivitas operasi penambahan dan pengurangan vektor tugas dalam pembelajaran multi-tugas dan machine unlearning terkait dengan korelasi antar tugas, dan memberikan jaminan teoritis untuk generalisasi di luar distribusi. Pada saat yang sama, teori menjelaskan mengapa aproksimasi peringkat rendah dan penjarangan (pruning) vektor tugas dapat dilakukan, memberikan dasar teoritis untuk aplikasi vektor tugas yang efisien. (Sumber: 机器之心)

Studi skalabilitas pencarian berbasis sampling: Penelitian Google dan Berkeley menunjukkan bahwa dengan meningkatkan jumlah sampel dan kekuatan validasi, pencarian berbasis sampling (menghasilkan beberapa kandidat jawaban lalu memvalidasi untuk memilih yang terbaik) dapat secara signifikan meningkatkan kinerja penalaran LLM, bahkan melampaui titik jenuh metode konsistensi (memilih jawaban paling umum). Penelitian menemukan fenomena “ekspansi implisit”: lebih banyak sampel justru meningkatkan akurasi validasi. Mengusulkan dua prinsip untuk validasi diri yang efektif: membandingkan jawaban untuk menemukan kesalahan, menulis ulang jawaban berdasarkan gaya output. Metode ini efektif pada berbagai benchmark dan skala model yang berbeda. (Sumber: 新智元)

Panggilan makalah untuk lokakarya LGM3A di ACM MM 2025: Konferensi ACM Multimedia 2025 akan menyelenggarakan lokakarya ketiga tentang “Penelitian dan Aplikasi Multimodal Berbasis Model Bahasa Besar” (LGM3A), yang berfokus pada aplikasi dan tantangan model generatif besar (LLM/LMM) dalam analisis data multimodal, generasi, tanya jawab, pencarian, rekomendasi, agent cerdas, dll. Lokakarya bertujuan untuk menyediakan platform pertukaran, membahas tren terbaru dan praktik terbaik, serta mengumpulkan makalah penelitian terkait. Konferensi akan diadakan pada Oktober 2025 di Dublin, Irlandia, dengan batas waktu pengiriman makalah pada 11 Juli 2025. (Sumber: PaperWeekly)
Grup riset Zhedong Zheng di Universitas Makau membuka pendaftaran mahasiswa doktoral arah multimodal: Grup riset Asisten Profesor Zhedong Zheng di Departemen Komputer Universitas Makau membuka pendaftaran mahasiswa doktoral dengan beasiswa penuh untuk masuk Agustus 2026, dengan fokus pada arah multimodal. Pembimbing memiliki arah penelitian dalam pembelajaran representasi dan generasi multimedia, telah menerbitkan lebih dari 50 makalah di konferensi dan jurnal terkemuka seperti CVPR, ICCV, TPAMI. Pelamar diharuskan memiliki IPK lebih dari 3.4, latar belakang komputer/rekayasa perangkat lunak, akrab dengan Python/PyTorch, dan diutamakan yang memiliki pengalaman publikasi makalah terkait atau penghargaan kompetisi. Beasiswa penuh disediakan. (Sumber: PaperWeekly)

💼 Bisnis
Robot pemotong rumput Laimoo Technology mendapatkan pendanaan Pre-A: Didirikan oleh mantan eksekutif YunJing, berfokus pada penyelesaian masalah pemotongan rumput di medan kompleks di Eropa dan Amerika. Robot Lymow One-nya menggunakan solusi visual + inertial navigation RTK (biaya sepersepuluh RTK tradisional), desain tipe track (untuk mengatasi lereng curam 45°), dilengkapi dengan pisau lurus penghancur rumput. Menghindari rintangan melalui visi AI dan ultrasonik. Crowdfunding produk melebihi 5 juta USD, harga satuan sekitar 3000 USD, putaran pendanaan ini puluhan juta yuan, akan digunakan untuk produksi massal, pengiriman, dan ekspansi pasar. (Sumber: Robot pemotong rumput yang didirikan oleh mantan eksekutif YunJing mendapatkan pendanaan lagi, Li Zexiang pernah berinvestasi, crowdfunding telah melebihi 5 juta USD|Hard Krypton Debut)

Robot humanoid “Xiaohaige” dari Songyan Dynamics menjadi viral: Setelah meraih juara kedua dalam maraton setengah robot humanoid di Beijing, Songyan Dynamics dan robot N2-nya (“Xiaohaige”) menarik perhatian pasar. Perusahaan ini didirikan oleh Jiang Zheyuan, seorang doktor lulusan Tsinghua angkatan 95, dan telah menyelesaikan lima putaran pendanaan. Robot N2 dijual mulai dari 39.900 yuan, mengutamakan rasio harga-kinerja yang tinggi, telah menerima ratusan pesanan, dengan margin kotor sekitar 15%. Songyan Dynamics sedang mempercepat produkisasi dan pengiriman produksi massal, strategi harga rendahnya bertujuan untuk cepat masuk ke pasar. (Sumber: 科创板日报)
Waspadai metrik ARR yang dibesar-besarkan pada startup AI: Artikel menunjukkan bahwa metrik ARR (Annual Recurring Revenue), yang berasal dari industri SaaS, disalahgunakan oleh startup AI. Model pendapatan perusahaan AI (seringkali berdasarkan penggunaan/hasil) memiliki volatilitas tinggi, loyalitas pelanggan awal yang rendah, dan biaya komputasi yang tinggi, sangat berbeda dari model langganan SaaS yang dapat diprediksi. Penyalahgunaan ARR (seperti menggunakan pendapatan satu bulan/satu hari untuk memperkirakan setahun penuh) telah menjadi permainan angka untuk menciptakan valuasi tinggi, menutupi nilai bisnis yang sebenarnya. Artikel menyerukan kewaspadaan terhadap praktik seperti saling menggesek (刷单), komisi tinggi, dan penarikan pelanggan dengan harga murah, serta membangun sistem evaluasi nilai yang lebih sesuai untuk perusahaan AI. (Sumber: 乌鸦智能说)
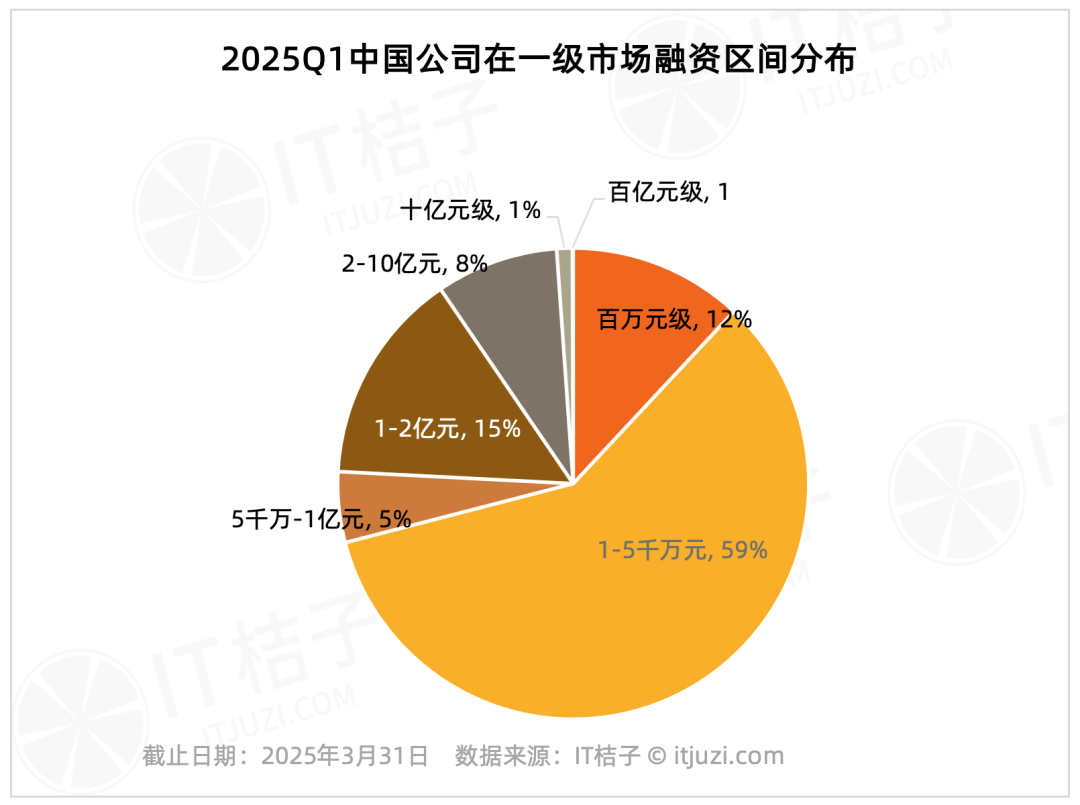
Analisis pendanaan pasar primer domestik Q1 2025: Efek pemimpin pasar signifikan: Data IT Juzi menunjukkan bahwa pendanaan pasar primer domestik pada kuartal pertama 2025 menunjukkan tren konsentrasi yang tinggi. Hanya 20 perusahaan yang menerima pendanaan lebih dari 1 miliar yuan, menyumbang 1,2% dari total jumlah, tetapi total pendanaan mereka mencapai 61,178 miliar yuan, menyumbang 36% dari total pasar. Perusahaan-perusahaan terkemuka ini terutama terkonsentrasi di bidang sirkuit terpadu, manufaktur mobil, material baru, bioteknologi, dan AIGC, hampir setengahnya memiliki latar belakang grup terdaftar besar. Sebaliknya, pendanaan skala kecil dan menengah di bawah 100 juta yuan, yang menyumbang 75,8% dari jumlah transaksi, hanya menyumbang 17,2% dari total pasar. (Sumber: IT桔子)
Laporan Wawasan Ekspansi AI Tiongkok ke Luar Negeri 2025 dirilis: Laporan Xiaguang Think Tank menganalisis faktor pendorong ekspansi AI Tiongkok ke luar negeri (kebijakan, kemajuan teknologi), tahap pengembangan (alat -> lokalisasi -> inovasi ekosistem), dan status saat ini. Laporan menunjukkan bahwa Asia Tenggara dan Amerika Latin adalah pasar potensial, sedangkan Amerika Utara dan Eropa adalah sumber pendapatan utama. Aplikasi jenis asisten dan editor memiliki kesediaan membayar yang tinggi. Tren teknologi bergerak menuju multimodal dan Agent, produk cenderung ke arah segmentasi vertikal dan kombinasi perangkat lunak-keras. Laporan juga memetakan pemain utama yang berekspansi ke luar negeri (seperti ByteDance, Kunlun Wanwei) dan penyedia solusi seperti pembayaran, pemasaran, dan cloud. (Sumber: 霞光社)
Permintaan model seperti DeepSeek mendorong Cambricon meraih laba pertama: Perusahaan chip AI Cambricon mencapai laba pertama setelah listing, pendapatan Q1 2025 melonjak 4230% YoY menjadi 1,111 miliar yuan, laba bersih 355 juta yuan. Analis pasar percaya bahwa pertumbuhan kinerja mendapat manfaat dari peningkatan permintaan daya komputasi inferensi yang dibawa oleh model besar domestik seperti DeepSeek, serta pembatasan ekspor AS pada chip NVIDIA H20. Harga saham Cambricon melonjak. Namun, masalah seperti konsentrasi pelanggan yang tinggi dan arus kas operasi negatif masih menarik perhatian, sementara juga menghadapi persaingan dari daya komputasi domestik seperti Huawei Ascend. (Sumber: 凤凰网科技)

Artikel Forbes membahas cara memilih AI Agent dengan ROI tinggi: Artikel membahas bagaimana di tengah banyaknya aplikasi AI Agent, perusahaan harus mengidentifikasi dan berinvestasi pada proyek-proyek yang dapat memberikan pengembalian tinggi, menekankan pentingnya mengevaluasi nilai bisnis aktual AI Agent. (Sumber: Ronald_vanLoon)

Departemen Kehakiman AS khawatir Google menggunakan AI untuk memperkuat monopoli pencarian (Sumber: Reddit r/artificial, Reuters link)
Dikabarkan OpenAI bekerja sama dengan Shopify, ChatGPT mungkin menambah fitur belanja (Sumber: Reddit r/artificial, TestingCatalog link)
Tan Li dari Shushi Technology: AI Agent mendorong peningkatan analisis data dan pengambilan keputusan perusahaan: Di KTT Industri AIGC Tiongkok, Tan Li, salah satu pendiri Shushi Technology, menunjukkan bahwa aplikasi AI tingkat perusahaan perlu melampaui ChatBI, mewujudkan transformasi dari data ke wawasan, memenuhi kebutuhan paradigma baru pergeseran data ke kanan, pergeseran keputusan ke bawah, dan pergeseran manajemen ke belakang. Platform SwiftAgent Shushi Technology bertujuan memberdayakan personel bisnis untuk menggunakan data tanpa hambatan, mendapatkan analisis tanpa halusinasi, dan dukungan keputusan tanpa menunggu. Platform ini, melalui mesin semantik data, kombinasi model besar dan kecil, serta kemampuan inti seperti tanya jawab cerdas, atribusi, prediksi, dan evaluasi, menjadikan AI Agent sebagai “asisten analisis data dan pengambilan keputusan” perusahaan. (Sumber: 量子位)

🌟 Komunitas
Diskusi panel industri membahas pengembangan aplikasi AI pasca era DeepSeek: Di Konferensi Mitra AI 36氪, beberapa tamu (Qufun Technology, Microsoft, Silicon Intelligence, Huice) membahas masa depan aplikasi AI. Konsensusnya adalah bahwa dengan terobosan model seperti DeepSeek, aplikasi AI memasuki “tahun melampaui”. Fokus pengembangan perlu memperhatikan keunggulan teknologi, implementasi komersial, inovasi interaksi manusia-mesin, dan integrasi ekosistem. Para tamu membedakan antara “AI+” (peningkatan tambahan) dan “AI-native” (rekonstruksi mendasar), dan menunjukkan bahwa yang terakhir lebih potensial. Tantangannya meliputi hambatan data, menemukan titik masalah nyata, inovasi model bisnis, pembelajaran sampel kecil, dan risiko etika. (Sumber: 36氪)

Pendiri LangChain mengkritik panduan Agent OpenAI sebagai “penuh jebakan”: Pendiri LangChain Harrison Chase secara terbuka mempertanyakan “Panduan Praktis Membangun AI Agent” yang dirilis OpenAI, menganggap definisinya tentang Agent (dikotomi Workflows vs Agents) terlalu kaku, mengabaikan universalitas kombinasi keduanya dalam praktik. Chase menunjukkan bahwa panduan tersebut memiliki dikotomi yang salah saat membahas kerangka kerja, meremehkan kompleksitas SDK-nya sendiri, dan pernyataannya tentang fleksibilitas dan orkestrasi dinamis menyesatkan. Dia menekankan bahwa inti dari membangun Agent yang andal adalah kontrol presisi atas konteks yang diberikan ke LLM, kerangka kerja ideal harus mendukung peralihan fleksibel dan kombinasi mode Workflow dan Agent. (Sumber: InfoQ)

Peran Reinforcement Learning dalam AI Agent memicu kontroversi: Mengenai apakah Reinforcement Learning (RL) merupakan elemen inti untuk membangun AI Agent, ada pandangan berbeda di industri. Pendiri Pokee AI Zhu Zheqing melihat RL sebagai “jiwa” yang memberi Agent rasa tujuan dan pengambilan keputusan otonom, berpendapat bahwa tanpa RL, Agent hanyalah alur kerja tingkat lanjut. Sementara peneliti HKUST Zhang Jiayi, pendiri Follou Xie Yang, dll., berpendapat bahwa RL saat ini terutama mengoptimalkan lingkungan tertentu, kemampuan generalisasi universal terbatas, dan keberhasilan Agent lebih bergantung pada model dasar yang kuat dan integrasi sistem yang efektif. Perdebatan mencerminkan keragaman jalur pengembangan Agent, membutuhkan kombinasi kemampuan model, strategi RL, dan praktik rekayasa. (Sumber: AI科技评论)

Pengguna mencoba meminta GPT-4o menghasilkan wallpaper abstrak personal berdasarkan riwayat obrolan: Seorang pengguna berbagi prompt, meminta GPT-4o berdasarkan pemahamannya tentang kepribadian pengguna, untuk membuat wallpaper minimalis abstrak yang unik (tanpa objek spesifik, hanya menggunakan bentuk, warna, komposisi untuk mencerminkan kepribadian). Cara memanfaatkan AI untuk pembuatan konten personal ini memicu diskusi komunitas. (Sumber: op7418, Flavio Adamo via op7418)

AI menggambar ulang “Sepanjang Sungai Selama Festival Qingming”: Pengguna berbagi percobaan menarik menggunakan GPT-4o untuk menggambar ulang sebagian “Sepanjang Sungai Selama Festival Qingming” dalam berbagai gaya berbeda (seperti 3D Q-version, Pixar, Ghibli, dll.), menunjukkan aplikasi generasi gambar AI dalam penciptaan ulang seni. (Sumber: dotey)

GPT-4o menyimpulkan tipe MBTI pengguna berdasarkan riwayat obrolan: Setelah menghasilkan wallpaper personal, pengguna terus meminta GPT-4o berdasarkan riwayat percakapan untuk menyimpulkan tipe kepribadian MBTI-nya, dan menghasilkan ilustrasi abstrak yang sesuai. Ini menunjukkan potensi LLM dalam pemahaman personal dan ekspresi kreatif. (Sumber: op7418)

Perbandingan: “Alat AI” tahun 2005: Gambar melalui perbandingan menunjukkan perbedaan kemampuan antara alat tahun 2005 (seperti kalkulator, peta) dan alat AI saat ini, memicu kekaguman atas perkembangan teknologi yang pesat. (Sumber: Ronald_vanLoon)

Perdebatan komunitas: Apakah LLM benar-benar cerdas atau hanya pelengkapan otomatis tingkat lanjut?: Pengguna Reddit memulai diskusi, berpendapat bahwa LLM saat ini meskipun dapat menjalankan tugas, kurang memiliki pemahaman, memori, dan tujuan yang sebenarnya, pada dasarnya adalah tebakan statistik daripada kecerdasan. Pandangan ini memicu diskusi luas di komunitas tentang definisi kecerdasan, jalur AGI, dan keterbatasan teknologi saat ini. (Sumber: Reddit r/ArtificialInteligence)
Diskusi komunitas: Apakah AI menuju utopia atau distopia?: Pengguna Reddit berpendapat bahwa lintasan pengembangan AI saat ini lebih cenderung ke arah distopia, dengan alasan termasuk: didorong oleh keuntungan daripada etika, memperburuk eksploitasi tenaga kerja, akses model kuat terbatas, digunakan untuk pengawasan dan manipulasi, menggantikan hubungan interpersonal, dll. Pandangan ini memicu diskusi sengit di komunitas tentang arah pengembangan AI, dampak sosial, dan potensi risiko. (Sumber: Reddit r/ArtificialInteligence)
Komunitas mempertanyakan akurasi Bindu Reddy tentang rilis model: Pengguna komunitas LocalLLaMA menunjukkan bahwa CEO Abacus.AI Bindu Reddy beberapa kali merilis informasi waktu rilis yang tidak akurat tentang model seperti DeepSeek R2, Qwen 3, lalu menghapus postingannya, memicu diskusi tentang keandalan informasinya. (Sumber: Reddit r/LocalLLaMA)
Membahas dampak etis memori AI seumur hidup: Pengguna Reddit memulai diskusi, khawatir bahwa AI dengan kemampuan memori seumur hidup dapat sepenuhnya memetakan privasi, pikiran, dan kelemahan pribadi, “memamerkan” jiwa mereka kepada orang lain, memicu pemikiran tentang privasi, prediktabilitas, dan batas etika AI. (Sumber: Reddit r/ArtificialInteligence)
Pengeditan gambar AI menghilangkan kumis ikonik selebriti: Pengguna berbagi hasil penggunaan alat pengeditan gambar AI untuk menghilangkan kumis ikonik dari beberapa tokoh sejarah atau publik seperti Stalin, Tom Selleck, Guan Yu, menunjukkan aplikasi AI dalam modifikasi gambar dan hiburan. (Sumber: Reddit r/ChatGPT)

Pengguna mengklaim ChatGPT meminta foto pribadi dalam konsultasi medis: Pengguna Reddit berbagi tangkapan layar, menunjukkan bahwa saat berkonsultasi masalah kulit, ChatGPT meminta pengguna mengunggah foto area yang terkena (penis) untuk diagnosis yang lebih baik. Situasi ini memicu diskusi komunitas tentang batasan AI dalam skenario medis, privasi, dan potensi risiko. (Sumber: Reddit r/ChatGPT)
Pengguna berbagi pengalaman menggunakan Claude dan Gemini untuk membangun aplikasi menulis: Pengembang berbagi pengalamannya memanfaatkan Claude dan Gemini sebagai asisten pemrograman untuk membangun aplikasi menulis PlotRealm yang memenuhi kebutuhan pribadinya dalam dua minggu. Menekankan peran AI dalam membantu pengembangan, tetapi juga menunjukkan bahwa AI terkadang “keras kepala” dan pengembang perlu memiliki pengetahuan dasar untuk membimbing dan mengoreksi. (Sumber: Reddit r/ClaudeAI)
Pengguna meminta ChatGPT merancang pola tato: Seorang pengguna meminta ChatGPT untuk merancang tato berikutnya, hasilnya adalah gambar yang menggambarkan pengguna dan robot ChatGPT menjadi BFF (sahabat selamanya). Hasil yang lucu ini memicu diskusi komunitas tentang kreativitas AI dan hubungan manusia-mesin. (Sumber: Reddit r/ChatGPT)

Pengguna bertanya secara kreatif “Di mana kamu berharap aku berada?”, memicu respons AI yang beragam: Pengguna mengajukan pertanyaan terbuka kepada ChatGPT “Di mana kamu berharap aku berada?”, menerima berbagai gambar pemandangan imajinatif yang dihasilkan AI, seperti perpustakaan yang tenang, di bawah langit berbintang, dll., menunjukkan kemampuan generasi AI di bawah prompt kreatif dan berbagi hasil yang berbeda dari anggota komunitas. (Sumber: Reddit r/ChatGPT)
Diskusi mendalam: Mengapa dan bagaimana LLM dan AGI “berbohong”?: Pengguna Reddit dari sudut pandang psikologi perkembangan, evolusi, dan teori permainan menganalisis bahwa “berbohong” adalah perilaku adaptif atau strategi optimasi agent (termasuk manusia dan AI masa depan) dalam konteks tertentu. Artikel membahas beberapa bentuk “kebohongan” LLM (halusinasi, bias, penyelarasan strategis), dan mensimulasikan keunggulan evolusioner strategi tidak jujur di lingkungan kompetitif, memicu pemikiran mendalam tentang etika dan kepercayaan AGI. (Sumber: Reddit r/artificial)

Komunitas mempertanyakan konsumsi energi AI dan optimisme teknologi: Pengguna Reddit dengan nada sarkastik mempertanyakan klaim bahwa konsumsi energi AI tidak signifikan, hanya membawa manfaat tanpa biaya, dan janji para pemimpin teknologi tentang masa depan utopia, menyiratkan kekhawatiran tentang kemungkinan biaya sosial, lingkungan, dan propaganda optimisme berlebihan dari pengembangan AI, memicu diskusi komunitas. (Sumber: Reddit r/artificial)
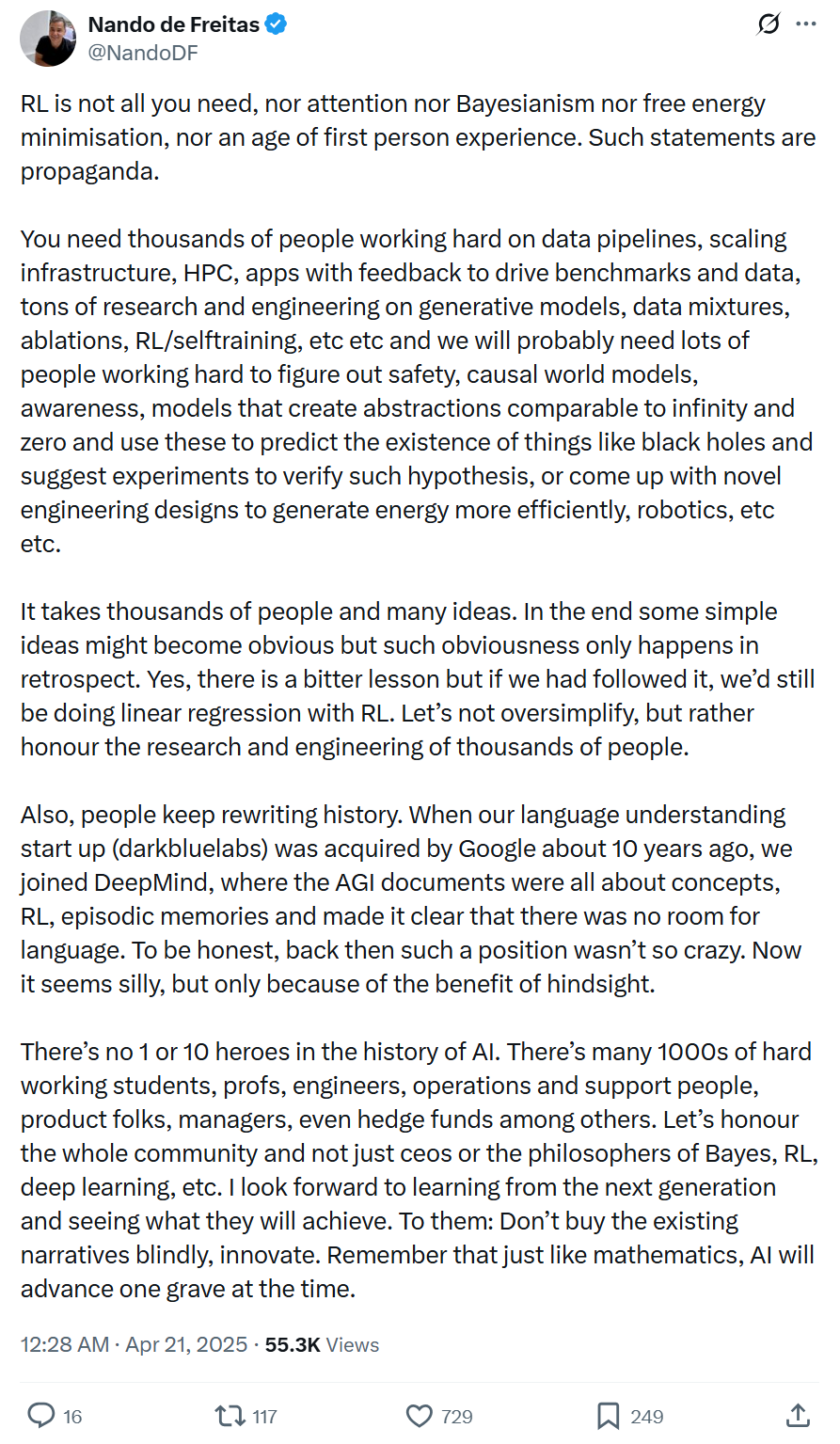
Wakil Presiden Microsoft: Kemajuan AI tidak didorong oleh teknologi tunggal atau beberapa jenius, membutuhkan rekayasa sistematis dan kolaborasi luas: Wakil Presiden Microsoft Nando de Freitas menulis menentang pendewaan berlebihan terhadap teknologi tunggal (seperti RL) atau individu dalam pengembangan AI. Dia menekankan kemajuan AI adalah rekayasa sistematis, membutuhkan data, infrastruktur, penelitian multi-bidang (model generatif, RL, keamanan, efisiensi energi, dll.), umpan balik aplikasi, dan upaya bersama ribuan peserta. Narasi sejarah sering ditulis ulang, harus waspada terhadap pandangan ke belakang (hindsight bias), menghormati kontribusi seluruh komunitas, dan mendorong inovasi daripada kepatuhan buta. (Sumber: 机器之心)
💡 Lain-lain
Maraknya musik AI memicu kekhawatiran dan perlawanan industri: Musik yang dihasilkan AI meningkat pesat di platform streaming (misalnya Deezer mencapai 18%), memicu kekhawatiran tentang menggerus ruang kreasi manusia dan pendapatan pencipta (CISAC memprediksi hingga 24%). Asosiasi Hak Cipta Musik Korea menerapkan aturan royalti baru “0% AI”, platform seperti Deezer, YouTube mengembangkan alat deteksi. Namun, identifikasi musik AI sulit, penerimaan pendengar cukup tinggi (misalnya pengguna Suno lebih dari 10 juta). Industri menghadapi tantangan deepfake, sengketa hak cipta (hak penggunaan data pelatihan), definisi orisinalitas, dll. Masa depan mungkin mengarah pada kolaborasi manusia-mesin, tetapi diskusi etika dan atribusi kreasi akan terus berlanjut. (Sumber: 新音乐产业观察)

Prompt sistem Windsurf diduga bocor: Repositori GitHub awesome-ai-system-prompts mengungkapkan konten yang diduga merupakan prompt sistem model Windsurf. (Sumber: karminski3)

Masalah konsumsi air tinggi model besar AI menarik perhatian: Majalah Fortune dan media lainnya melaporkan bahwa pengoperasian model AI besar seperti ChatGPT membutuhkan banyak air untuk pendinginan, musim kebakaran hutan di California dan tempat lain dapat memperburuk ketegangan sumber daya air, memicu kekhawatiran tentang keberlanjutan AI. (Sumber: Ronald_vanLoon)

Pengembang mengklaim menciptakan AMI yang dapat memprediksi emosi: Video YouTube mengklaim menunjukkan AMI (Artificial Molecular Intelligence?) yang dapat secara andal memindai, memprediksi emosi, dan aspek lain dari suatu peristiwa, melibatkan berbagai modalitas seperti suara, video, gambar, dll. Keaslian dan cara implementasi spesifik teknologi ini masih perlu diverifikasi. (Sumber: Reddit r/artificial)
Saran agar benchmark AI menyertakan perbandingan kinerja manusia: Pengguna Reddit mengusulkan agar benchmark model AI menyertakan skor manusia (orang biasa dan ahli) pada tugas yang sama sebagai referensi, untuk mengevaluasi tingkat kemampuan relatif AI secara lebih intuitif. (Sumber: Reddit r/artificial)
Oscar menerima partisipasi AI dalam pembuatan film, tetapi dengan batasan: Academy of Motion Picture Arts and Sciences memperbarui aturan, mengizinkan penggunaan alat AI dalam pembuatan film, tetapi menekankan bahwa kreativitas manusia tetap menjadi inti. Aturan mungkin melibatkan persyaratan spesifik seperti pengungkapan penggunaan AI, mencerminkan keseimbangan industri dalam merangkul teknologi baru dan melindungi kreasi manusia. (Sumber: Reddit r/artificial, NYT link)

Instagram mencoba menggunakan AI untuk menentukan usia remaja (Sumber: Reddit r/artificial, AP News link)
Altman mengatakan pengguna yang mengatakan “tolong” dan “terima kasih” kepada ChatGPT menghabiskan jutaan dolar (Sumber: Reddit r/artificial, QZ link)
Acara maraton setengah robot humanoid menunjukkan kemajuan dan tantangan teknologi: Maraton setengah robot humanoid pertama di dunia diadakan di Beijing, “TianGong Ultra” memenangkan kejuaraan dengan waktu 2 jam 40 menit. Kompetisi menguji kemampuan robot dalam jarak jauh, medan kompleks, keseimbangan dinamis, navigasi otonom, dll. Robot ukuran penuh menghadapi kesulitan yang lebih tinggi (pusat gravitasi, inersia, konsumsi energi). TianGong Ultra menang berkat sendi terintegrasi berdaya tinggi, desain inersia rendah, pembuangan panas efisien, strategi kontrol pembelajaran imitasi penguatan prediktif, dan teknologi navigasi nirkabel. Acara ini dianggap sebagai uji tekanan untuk implementasi komersial skala besar robot (seperti industri, inspeksi keamanan), mendorong validasi dan optimalisasi teknologi inti seperti perangkat keras本体, kontrol gerak, dan pengambilan keputusan cerdas. (Sumber: 机器之心)

Memanfaatkan AI untuk memantau dinamika selebriti dan mewujudkan pengingat otomatis: Tutorial berbagi cara memanfaatkan skrip Python untuk memantau pembaruan akun Twitter tertentu (seperti Sam Altman), dan melalui API Feishu mewujudkan pengingat panggilan darurat saat dinamika baru dipublikasikan. Metode ini menggabungkan teknologi web crawler dengan pemanggilan API platform terbuka, bertujuan untuk mengatasi masalah kelebihan informasi dan kebutuhan ketepatan waktu, mewujudkan penyampaian informasi penting yang dipersonalisasi. Menunjukkan potensi aplikasi AI dalam pemrosesan aliran informasi otomatis dan pemberitahuan yang dipersonalisasi. (Sumber: 非主流运营)
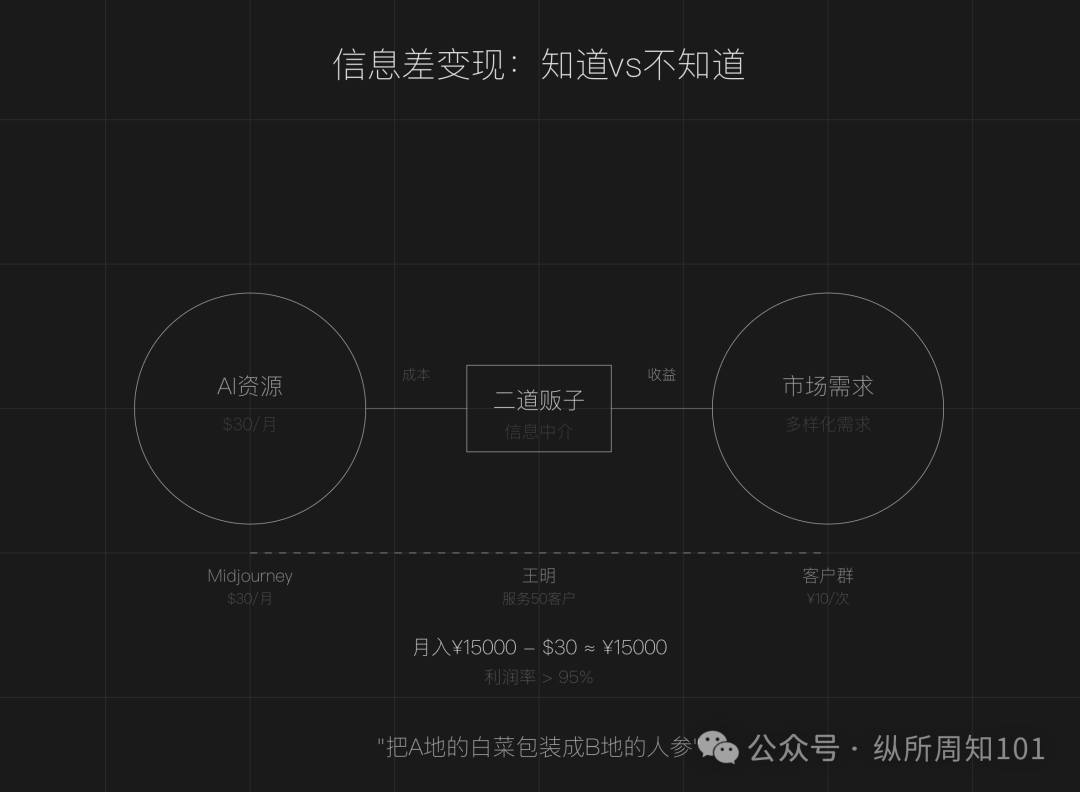
Pembahasan model bisnis menjadi “calo AI” dengan memanfaatkan kesenjangan informasi AI: Artikel berpendapat bahwa di era AI, kesenjangan informasi masih ada (alat berlimpah, ambang batas teknis, skenario kabur), menciptakan peluang bagi orang biasa untuk menjadi “calo AI”. Cara bermain inti meliputi: memanfaatkan perbedaan harga sumber daya AI domestik dan internasional untuk menjual kembali layanan (seperti lukisan AI), menyediakan layanan eksekusi (mengubah tutorial gratis menjadi deployment berbayar, seperti layanan pelanggan AI), operasi skala besar (membentuk tim untuk menyediakan layanan profesional). Bidang yang cocok meliputi pembuatan konten, pendidikan dan pelatihan, layanan bisnis UKM, layanan profesional bidang vertikal (seperti medis, hukum). Disarankan untuk memulai dengan tiga langkah: mencari kesenjangan informasi, menentukan kelompok sasaran, bertindak cepat. (Sumber: 周知)