
Kata Kunci:Model AI, OpenAI, Multimodal, Agent, Model o3, o4-mini, Penalaran visual, Pemanggilan alat, Gemini 2.5 Flash, Tencent Yuanbao AI, Integrasi LLM, Pembelajaran penguatan
🔥 Fokus
OpenAI merilis model o3 dan o4-mini, mengintegrasikan alat dan kemampuan penalaran visual : OpenAI secara resmi merilis model penalaran paling cerdas dan kuat hingga saat ini, yaitu o3 dan o4-mini. Sorotan utamanya adalah kemampuan Agent untuk pertama kalinya secara proaktif memanggil dan menggabungkan semua alat internal ChatGPT (pencarian web, analisis data Python, pemahaman visual mendalam, pembuatan gambar, dll.), serta mampu mengintegrasikan gambar dalam rantai penalaran untuk berpikir. o3 unggul secara komprehensif di bidang coding, matematika, sains, persepsi visual, dan lainnya, mencetak rekor SOTA baru di berbagai benchmark; sementara o4-mini mengoptimalkan kecepatan dan biaya, dengan performa jauh melampaui ukurannya. Kedua model ini memiliki kemampuan mengikuti instruksi yang lebih kuat, percakapan yang lebih alami, dan dapat memanfaatkan memori serta riwayat percakapan untuk memberikan respons yang dipersonalisasi. Rilisan ini menandai langkah penting OpenAI menuju Agentic AI yang lebih otonom, memungkinkan asisten AI menyelesaikan tugas-tugas kompleks secara lebih mandiri. (Sumber: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
Model OpenAI o3 dan o4-mini diluncurkan, meningkatkan penggunaan alat dan kemampuan penalaran visual : OpenAI merilis model o3 dan o4-mini pada larut malam, pengguna dapat menggunakannya melalui akun ChatGPT Plus, Pro, dan Team. Peningkatan utama meliputi: 1. Versi penuh o3 untuk pertama kalinya mendukung pemanggilan alat (seperti koneksi internet, interpreter kode). 2. o3 dan o4-mini menjadi model pertama yang dapat melakukan penalaran visual dalam rantai pemikiran, mampu menganalisis dan berpikir dengan menggabungkan gambar seperti manusia, misalnya dalam permainan tebak lokasi berdasarkan gambar, model dapat memperbesar detail gambar untuk penalaran bertahap. Kemampuan ini secara signifikan meningkatkan kinerja model dalam tugas multimodal (seperti MMMU, MathVista), menandakan bahwa AI akan memainkan peran yang lebih besar dalam skenario profesional yang memerlukan penilaian visual (seperti pemantauan keamanan, analisis citra medis). Sementara itu, OpenAI juga membuka sumber (open source) alat pemrograman AI Codex CLI. (Sumber: OpenAI深夜上线o3满血版和o4 mini – 依旧领先。
Tencent Yuanbao AI secara resmi terintegrasi dengan WeChat, membuka paradigma baru dalam obrolan : Tencent Yuanbao AI kini telah resmi diluncurkan sebagai teman WeChat, pengguna dapat menambahkannya dengan mencari “Yuanbao”. Langkah ini mendobrak model aplikasi AI tradisional yang perlu dibuka secara terpisah, mengintegrasikan AI secara mulus ke dalam skenario komunikasi sehari-hari pengguna. Yuanbao AI (berbasis Hunyuan dan DeepSeek) dapat berinteraksi langsung di kotak dialog WeChat, mendukung peringkasan gambar, artikel akun publik, tautan web, audio dan video (sementara tidak mendukung Video Channel WeChat), dan dapat mencari riwayat obrolan. Meskipun belum mendukung pembuatan gambar dan obrolan grup, kemudahan penggunaan dan integrasi mendalam dengan ekosistem WeChat dianggap sebagai keunggulan penting. Analis berpendapat bahwa WeChat, dengan basis pengguna yang besar dan jaringan hubungan sosialnya, mengubah AI menjadi kontak di daftar kontak, berpotensi mengubah paradigma interaksi manusia-mesin, membuat AI lebih alami terintegrasi ke dalam kehidupan pengguna. (Sumber: 劲爆!元宝AI接入微信了,怎么用?看这篇就够了、腾讯元宝最终还是活成了微信的模样。
AS kemungkinan menangguhkan ekspor chip Nvidia H20 ke Tiongkok tanpa batas waktu, dampaknya luas : Pemerintah AS memberi tahu Nvidia bahwa mereka akan menangguhkan ekspor chip AI H20 ke Tiongkok tanpa batas waktu (versi khusus yang sebelumnya dirancang untuk mengatasi kontrol ekspor). H20 adalah chip paling kuat yang sesuai aturan yang dikembangkan Nvidia untuk pasar Tiongkok, larangan penjualan diperkirakan akan memberikan pukulan signifikan bagi Nvidia. Data menunjukkan bahwa Tiongkok adalah sumber pendapatan terbesar keempat Nvidia, dengan penjualan H20 mencapai puluhan miliar dolar pada tahun 2024, dan perusahaan teknologi Tiongkok (seperti ByteDance, Tencent) adalah pembeli utama chip Nvidia, dengan pertumbuhan investasi yang signifikan. Langkah ini tidak hanya memengaruhi pendapatan Nvidia, tetapi juga dapat melemahkan ekosistem CUDA-nya (pengembang Tiongkok menyumbang lebih dari 30%). Sementara itu, perusahaan chip AI lokal Tiongkok seperti Huawei (misalnya Ascend 910C) sedang mempercepat pengembangan dan mungkin mengisi kekosongan pasar. Peristiwa ini menimbulkan kekhawatiran pasar, dan harga saham Nvidia turun sebagai respons. (Sumber: 中国对英伟达到底有多重要?
🎯 Tren
Model video teratas Google Veo 2 hadir gratis di AI Studio : Google mengumumkan bahwa model pembuatan video canggihnya, Veo 2, telah diluncurkan di Google AI Studio, Gemini API, dan Gemini App, serta menyediakan kuota penggunaan gratis (sekitar selusin kali per hari, masing-masing hingga 8 detik). Veo 2 mendukung text-to-video (t2v) dan image-to-video (i2v), mampu memahami instruksi kompleks, menghasilkan konten video yang realistis dan beragam gaya, serta dapat mengontrol gerakan kamera. Pihak resmi menekankan bahwa kunci untuk menghasilkan video berkualitas tinggi adalah memberikan Prompt yang jelas, detail, dan mengandung kata kunci visual. Model ini juga memiliki fungsi pengeditan dalam video (segmentasi, perluasan gambar), gerakan kamera sinematik, dan transisi cerdas, yang bertujuan untuk diintegrasikan ke dalam alur kerja pembuatan konten dan meningkatkan efisiensi. (Sumber: 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。
Google merilis Gemini 2.5 Flash, fokus pada kecepatan, biaya, dan kedalaman berpikir yang dapat dikontrol : Google meluncurkan pratinjau model Gemini 2.5 Flash, yang diposisikan sebagai model ringan yang dioptimalkan untuk kecepatan dan biaya. Model ini menunjukkan kinerja yang mengesankan di papan peringkat LMArena, berada di peringkat kedua bersama GPT-4.5 Preview dan Grok-3, dan menempati peringkat pertama dalam prompt sulit, coding, dan kueri panjang. Fitur intinya adalah pengenalan kemampuan “berpikir” dan penalaran campuran penuh, yang memungkinkan model merencanakan dan menguraikan tugas sebelum menghasilkan output. Pengembang dapat mengontrol kedalaman berpikir model (batas token) melalui parameter “anggaran berpikir”, menyeimbangkan kualitas, biaya, dan latensi. Bahkan dengan anggaran 0, kinerjanya lebih unggul dari 2.0 Flash. Model ini hemat biaya, dengan harga hanya 1/10 hingga 1/5 dari Gemini 2.5 Pro, cocok untuk alur kerja AI skala besar dengan konkurensi tinggi. (Sumber: 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。
Kunlun Tech merilis model pembuatan film berdurasi tak terbatas Skyreels-V2 : Kunlun Tech meluncurkan dan membuka sumber Skyreels-V2, yang diklaim sebagai model pembuatan video berkualitas tinggi pertama di dunia yang mendukung durasi tak terbatas. Model ini bertujuan untuk mengatasi kelemahan model video yang ada dalam memahami bahasa sinematik, koherensi gerakan, batasan durasi video, dan kurangnya dataset profesional. Skyreels-V2 menggabungkan strategi pelatihan multi-tahap termasuk model besar multimodal, anotasi terstruktur, generasi difusi, reinforcement learning (DPO untuk mengoptimalkan kualitas gerakan), dan fine-tuning berkualitas tinggi. Ini mengadopsi arsitektur Diffusion Forcing, mencapai generasi video panjang melalui penjadwal khusus dan mekanisme atensi. Pihak resmi mengklaim efek generasinya mencapai “tingkat film”, berkinerja sangat baik pada benchmark seperti V-Bench1.0, melampaui model open source lainnya. Pengguna dapat mencoba menghasilkan video hingga 30 detik secara online. (Sumber: 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!
Shanghai AI Lab merilis model multimodal asli InternVL3 : Shanghai Artificial Intelligence Laboratory meluncurkan InternVL3, sebuah model multimodal besar (MLLM) yang mengadopsi paradigma pra-pelatihan multimodal asli. Berbeda dari kebanyakan model yang dimodifikasi dari LLM teks murni, InternVL3 belajar secara bersamaan dari data multimodal dan korpus teks murni dalam satu tahap pra-pelatihan, bertujuan untuk mengatasi kompleksitas dan tantangan penyelarasan yang disebabkan oleh pelatihan multi-tahap. Model ini menggabungkan pengkodean posisi visual variabel, teknik pasca-pelatihan canggih, dan strategi perluasan waktu pengujian. InternVL3-78B mencapai skor 72,2 pada benchmark MMMU, mencetak rekor baru untuk MLLM open source, dengan kinerja mendekati model proprietary terkemuka, sambil mempertahankan kemampuan bahasa murni yang kuat. Data pelatihan dan bobot model akan dipublikasikan. (Sumber: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
UCLA dkk. mengusulkan kerangka kerja d1, menggunakan reinforcement learning untuk inferensi diffusion LLM : Peneliti dari UCLA dan Meta AI mengusulkan kerangka kerja d1, yang untuk pertama kalinya menerapkan pasca-pelatihan reinforcement learning (RL) pada diffusion large language model (dLLM) bertopeng. Metode RL yang ada (seperti GRPO) terutama digunakan untuk LLM autoregresif dan sulit diterapkan secara langsung ke dLLM karena kurangnya dekomposisi alami dari probabilitas logaritmik. Kerangka kerja d1 terdiri dari dua tahap: pertama melakukan supervised fine-tuning (SFT), kemudian pada tahap RL memperkenalkan metode gradien kebijakan baru diffu-GRPO, yang menggunakan estimator probabilitas logaritmik satu langkah yang efisien dan memanfaatkan masking prompt acak sebagai regularisasi, mengurangi jumlah generasi online yang diperlukan untuk pelatihan RL. Eksperimen menunjukkan bahwa model d1 berbasis LLaDA-8B-Instruct secara signifikan mengungguli model dasar serta model yang hanya menggunakan SFT atau diffu-GRPO pada benchmark penalaran matematika dan logika. (Sumber: UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!
Meta mengusulkan Multi-Token Attention (MTA) : Peneliti Meta mengusulkan mekanisme Multi-Token Attention (MTA), yang bertujuan untuk meningkatkan cara perhitungan atensi dalam large language model (LLM). Mekanisme atensi tradisional hanya didasarkan pada kesamaan antara satu token query dan key, sedangkan MTA menerapkan operasi konvolusi pada vektor query, key, dan head, memungkinkan model untuk secara bersamaan mempertimbangkan beberapa token query dan key yang berdekatan untuk menentukan bobot atensi. Peneliti percaya ini dapat memanfaatkan informasi yang lebih kaya dan lebih rinci untuk menemukan konteks yang relevan. Eksperimen menunjukkan bahwa MTA mengungguli model dasar Transformer tradisional baik dalam tugas pemodelan bahasa standar maupun tugas pencarian informasi konteks panjang. (Sumber: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
TogetherAI meluncurkan model inferensi berbasis RNN M1 : TogetherAI mengusulkan M1, model inferensi RNN linier hibrida baru berdasarkan arsitektur Mamba. Model ini bertujuan untuk mengatasi masalah kompleksitas komputasi dan batasan memori yang dihadapi oleh Transformer saat memproses urutan panjang dan melakukan inferensi yang efisien. M1 meningkatkan kinerja melalui distilasi pengetahuan dari model inferensi yang ada dan pelatihan reinforcement learning. Hasil eksperimen menunjukkan bahwa M1, pada benchmark penalaran matematika seperti AIME dan MATH, tidak hanya mengungguli model RNN linier sebelumnya tetapi juga sebanding dengan model inferensi terdistilasi DeepSeek-R1 dengan skala yang sama. Lebih penting lagi, kecepatan generasi M1 lebih dari 3 kali lebih cepat daripada Transformer dengan ukuran yang sama, dan dengan anggaran waktu generasi tetap, dapat mencapai akurasi yang lebih tinggi daripada yang terakhir melalui pemungutan suara self-consistency. (Sumber: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
Tencent Hunyuan membuka sumber kerangka kerja InstantCharacter : Tim Tencent Hunyuan membuka sumber InstantCharacter, sebuah kerangka kerja untuk generasi gambar yang mampu mengekstrak dan mempertahankan fitur karakter dari satu gambar input, kemudian menempatkan karakter tersebut dalam adegan atau gaya yang berbeda. Teknologi ini bertujuan untuk mencapai pemeliharaan identitas karakter dengan fidelitas tinggi dan transfer gaya yang terkontrol. Pihak resmi menyediakan demo online di Hugging Face berdasarkan gaya seni Ghibli dan Makoto Shinkai, serta merilis makalah terkait, repositori kode, dan plugin ComfyUI untuk memudahkan penggunaan dan pengembangan lebih lanjut oleh komunitas. (Sumber: karminski3
Fitur memori ChatGPT ditingkatkan, mendukung pencarian web yang dikombinasikan dengan memori : OpenAI telah meningkatkan fitur memori (Memory) ChatGPT, menambahkan kemampuan “pencarian dengan memori”. Ini berarti bahwa ketika ChatGPT melakukan tugas pencarian web, ia dapat menggunakan informasi memori yang disimpan sebelumnya seperti preferensi pengguna, lokasi, dll., untuk mengoptimalkan kueri pencarian, sehingga memberikan hasil pencarian yang lebih personal. Misalnya, jika ChatGPT ingat bahwa pengguna adalah seorang vegetarian, ketika ditanya tentang restoran terdekat, ia mungkin secara otomatis mencari “restoran vegetarian terdekat”. Langkah ini dianggap sebagai langkah penting OpenAI dalam meningkatkan layanan AI yang dipersonalisasi, bertujuan untuk meningkatkan pengalaman pengguna dan membedakannya dari produk pesaing yang memiliki fitur memori (seperti Claude, Gemini). Pengguna dapat memilih untuk menonaktifkan fitur memori di pengaturan. (Sumber: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
Teknologi snapshot runtime model AI menghindari cold start : Komunitas machine learning sedang menjajaki penggunaan teknologi snapshot model untuk mengoptimalkan orkestrasi runtime LLM. Teknologi ini menyimpan status lengkap GPU (termasuk KV cache, bobot, tata letak memori), memungkinkan pemulihan cepat (sekitar 2 detik) saat beralih antar model yang berbeda, menghindari cold start dan idle GPU. Praktisi berbagi bahwa dengan menggunakan metode ini, mereka berhasil menjalankan lebih dari 50 model open source pada dua GPU A1000 16GB tanpa menggunakan kontainer atau memuat ulang model. Teknik penggunaan kembali (multiplexing) dan rotasi model ini berpotensi meningkatkan utilisasi GPU dan mengurangi latensi inferensi. (Sumber: Reddit r/MachineLearning)
🧰 Alat
ByteDance Volcano Engine meluncurkan Demo solusi satu atap perangkat keras AI : ByteDance Volcano Engine mendemonstrasikan solusi satu atap perangkat keras AI hasil kerja sama dengan produsen chip tertanam, menggunakan papan pengembangan AtomS3R sebagai contoh. Solusi ini bertujuan untuk memberikan pengalaman interaksi AI dengan latensi rendah dan responsivitas tinggi, dengan fitur termasuk respons real-time tingkat milidetik, interupsi dan penyambungan percakapan real-time, serta kemampuan pengurangan kebisingan audio di lingkungan kompleks melalui RTC SDK, yang secara efektif dapat mengurangi gangguan kebisingan latar belakang dan meningkatkan akurasi interaksi suara. Kode klien dan program server solusi ini bersifat open source, memungkinkan pengembang untuk melakukan kustomisasi DIY, seperti memberikan kepribadian, peran, timbre khusus pada perangkat keras, atau menghubungkan ke basis pengetahuan dan alat MCP. Perangkat keras itu sendiri mencakup kamera, dengan rencana masa depan untuk mendukung fungsi pemahaman visual. (Sumber: 体验完字节送的迷你AI硬件,后劲有点大…
Mita AI Search meluncurkan fitur pembelajaran “Belajar Sesuatu Hari Ini” : Mita AI Search meluncurkan fitur baru bernama “Belajar Sesuatu Hari Ini”, yang dapat secara otomatis mengubah file yang diunggah pengguna (mendukung berbagai format) atau tautan web yang disediakan menjadi video kursus online terstruktur dengan narasi dan demonstrasi (PPT, animasi). Pengguna dapat memilih gaya penjelasan yang berbeda (seperti bercerita, gaya Napoleon) dan suara (seperti suara wanita dingin dan berwibawa). Fitur ini bertujuan untuk mengubah input informasi menjadi pengalaman belajar yang lebih mudah diserap, bahkan menyediakan sesi tes pasca-kursus. Cara menggabungkan pembuatan konten dengan pengajaran yang dipersonalisasi ini dianggap dapat mengubah model aplikasi AI di bidang pendidikan dan konsumsi informasi, menyediakan cara baru untuk memperoleh pengetahuan dan membaca cepat konten. (Sumber: 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

Cursor IDE diperbarui ke versi 0.49, meningkatkan sistem aturan dan kontrol Agent : Editor kode AI-first Cursor merilis pratinjau pembaruan 0.49. Fitur baru meliputi: 1. Dapat secara otomatis menghasilkan file aturan .mdc melalui perintah obrolan /Generate Cursor Rules untuk memantapkan konteks proyek. 2. Penerapan aturan otomatis lebih cerdas, Agent dapat secara otomatis memuat aturan yang sesuai berdasarkan path file. 3. Memperbaiki bug di mana “Selalu lampirkan aturan” gagal dalam percakapan panjang. 4. Menambahkan fitur “Kesadaran Struktur Proyek” (Beta), memungkinkan AI memahami seluruh proyek dengan lebih baik. 5. Protokol MCP (Model Context Protocol) sekarang mendukung transmisi gambar, memudahkan penanganan tugas terkait visual. 6. Meningkatkan kontrol Agent atas perintah terminal, pengguna dapat mengedit atau melewati perintah sebelum dijalankan. 7. Mendukung konfigurasi file abaikan global (.cursorignore). 8. Mengoptimalkan pengalaman peninjauan kode, tampilan diff langsung ditampilkan setelah pesan Agent. (Sumber: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
OpenAI membuka sumber alat pemrograman AI baris perintah Codex CLI : Bersamaan dengan rilis o3 dan o4-mini, OpenAI membuka sumber Codex CLI, sebuah Agent pengkodean AI ringan yang dapat berjalan langsung di terminal baris perintah pengguna. Alat ini dirancang untuk memanfaatkan sepenuhnya kemampuan pengkodean dan penalaran yang kuat dari model baru, dapat langsung memproses repositori kode lokal, dan bahkan dapat menggabungkan tangkapan layar atau sketsa untuk penalaran multimodal. CEO OpenAI Sam Altman secara pribadi mempromosikannya dan menekankan sifat open source-nya untuk mendorong iterasi cepat oleh komunitas. Sementara itu, OpenAI meluncurkan program hibah senilai $1 juta (dalam bentuk Kredit API) untuk mendukung proyek berbasis Codex CLI dan model OpenAI. (Sumber: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
Platform Tencent Cloud LKE mengintegrasikan MCP, menyederhanakan pembangunan Agent : Platform Tencent Cloud Language Knowledge Engine (LKE) menambahkan dukungan untuk Model Context Protocol (MCP), bertujuan untuk menurunkan hambatan dalam membangun dan menggunakan AI Agent. Pengguna sekarang dapat dengan mudah mengakses alat MCP bawaan seperti Tencent Cloud EdgeOne Pages (penyebaran halaman web sekali klik), Firecrawl (web crawler), dll., melalui operasi klik di platform LKE. Dikombinasikan dengan kemampuan basis pengetahuan (RAG) LKE yang kuat, pengguna dapat membuat aplikasi kompleks berdasarkan pengetahuan pribadi dan pemanggilan alat eksternal, misalnya, secara otomatis menghasilkan dan menerbitkan halaman web berdasarkan konten basis pengetahuan. Platform ini mendukung mode Agent, di mana model (seperti DeepSeek R1) dapat berpikir secara mandiri dan memilih alat yang sesuai untuk menyelesaikan tugas. Platform ini juga mendukung akses ke MCP eksternal. (Sumber: 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

Kerangka kerja Spring AI: Kerangka aplikasi yang berorientasi pada rekayasa AI : Spring AI adalah kerangka kerja aplikasi AI yang dirancang untuk pengembang Java, bertujuan untuk membawa prinsip desain ekosistem Spring (seperti portabilitas, desain modular, penggunaan POJO) ke dalam domain AI. Ini menyediakan API terpadu untuk berinteraksi dengan berbagai penyedia model AI utama (Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama, dll.), mendukung penyelesaian obrolan, embedding, teks-ke-gambar/audio, moderasi, dll. Selain itu, ia mengintegrasikan berbagai database vektor (Cassandra, Azure Vector Search, Chroma, Milvus, dll.), menyediakan API portabel dan pemfilteran metadata gaya SQL. Kerangka kerja ini juga mendukung output terstruktur, pemanggilan alat/fungsi, observabilitas, kerangka kerja ETL, evaluasi model, memori obrolan, dan RAG, serta menyederhanakan integrasi melalui konfigurasi otomatis Spring Boot. (Sumber: spring-projects/spring-ai – GitHub Trending (all/weekly)
olmocr: Toolkit linearisasi PDF untuk pemrosesan dataset LLM : allenai membuka sumber olmocr, sebuah toolkit yang dirancang khusus untuk memproses dokumen PDF untuk pembuatan dan pelatihan dataset large language model (LLM). Ini mencakup berbagai fungsi: strategi prompt untuk parsing teks alami berkualitas tinggi menggunakan ChatGPT 4o, alat evaluasi untuk membandingkan versi alur pemrosesan yang berbeda, fungsi penyaringan bahasa dasar dan penghapusan spam SEO, kode fine-tuning untuk Qwen2-VL dan Molmo-O, alur kerja untuk memproses PDF skala besar menggunakan Sglang, dan alat untuk melihat dokumen format Dolma yang telah diproses. Toolkit ini memerlukan dukungan GPU untuk inferensi lokal dan menyediakan instruksi untuk penggunaan lokal serta pada kluster multi-node (mendukung S3 dan Beaker). (Sumber: allenai/olmocr – GitHub Trending (all/daily)

Aplikasi desktop Dive Agent v0.8.0 dirilis : Aplikasi desktop AI Agent open source Dive merilis versi v0.8.0, melakukan penyesuaian arsitektur besar dan peningkatan fungsionalitas. Versi ini bertujuan untuk mengintegrasikan LLM yang mendukung pemanggilan alat dengan MCP Server. Pembaruan utama meliputi: manajemen kunci API LLM, dukungan untuk ID model kustom, dukungan penuh untuk model pemanggilan alat/fungsi; manajemen alat MCP (tambah, hapus, ubah), antarmuka konfigurasi mendukung pengeditan JSON dan formulir. Backend DiveHost telah dimigrasikan dari TypeScript ke Python untuk mengatasi masalah integrasi LangChain, dan dapat berjalan sebagai server A2A (Agent-to-Agent) independen. (Sumber: Reddit r/LocalLLaMA)
llama.cpp menggabungkan alat CLI multimodal : Proyek llama.cpp menggabungkan program contoh antarmuka baris perintah (CLI) untuk LLaVa, Gemma3, dan MiniCPM-V menjadi satu alat terpadu llama-mtmd-cli. Ini adalah bagian dari integrasi bertahap dukungan multimodal (melalui pustaka libmtmd). Meskipun dukungan multimodal masih dalam pengembangan (misalnya, dukungan untuk llama-server masih dalam tahap eksperimental), penggabungan CLI adalah langkah untuk menyederhanakan set alat. Sementara itu, dukungan untuk SmolVLM v1/v2 juga sedang dikembangkan. (Sumber: Reddit r/LocalLLaMA)
LightRAG: Otomatisasi penyebaran pipeline RAG : LightRAG adalah proyek RAG (Retrieval-Augmented Generation) open source. Anggota komunitas telah membuat tutorial dan skrip otomatisasi (menggunakan Ansible + Docker Compose + Sbnb Linux) yang memungkinkan pengguna untuk dengan cepat (dalam beberapa menit) menyebarkan sistem LightRAG di server bare metal, mencapai pembangunan otomatis pipeline RAG yang berfungsi penuh dari mesin kosong. Ini menyederhanakan proses penyebaran solusi RAG yang di-host sendiri. (Sumber: Reddit r/LocalLLaMA)
Nari Labs merilis model TTS open source Dia-1.6B : Nari Labs merilis dan membuka sumber model text-to-speech (TTS) mereka, Dia-1.6B. Fitur model ini adalah tidak hanya dapat menghasilkan ucapan, tetapi juga dapat secara alami memasukkan suara non-linguistik (suara paralinguistik) seperti tawa, batuk, berdeham, dll., ke dalam ucapan untuk meningkatkan kealamian dan ekspresivitas suara. Pihak resmi menyediakan video demo untuk menunjukkan efeknya. Model ini membutuhkan sekitar 10GB VRAM untuk berjalan, dan versi terkuantisasi belum tersedia saat ini. Repositori kode dan model telah dirilis di GitHub dan Hugging Face. (Sumber: karminski3)
📚 Pembelajaran
Jeff Dean mengulas titik kunci perkembangan AI selama lima belas tahun : Kepala Ilmuwan Google Jeff Dean dalam pidatonya menguraikan kemajuan penting di bidang AI selama lima belas tahun terakhir, terutama menekankan kontribusi penelitian Google. Tonggak penting meliputi: pelatihan jaringan saraf skala besar (membuktikan efek skala), sistem terdistribusi DistBelief (memungkinkan pelatihan model besar di CPU), embedding kata Word2Vec (mengungkap semantik ruang vektor), model Seq2Seq (mendorong tugas seperti terjemahan mesin), TPU (akselerasi perangkat keras khusus untuk jaringan saraf), arsitektur Transformer (merevolusi pemrosesan sekuensial, menjadi dasar LLM), pembelajaran self-supervised (memanfaatkan data tak berlabel skala besar), Vision Transformer (menyatukan pemrosesan gambar dan teks), model sparse/MoE (meningkatkan kapasitas dan efisiensi model), Pathways (menyederhanakan komputasi terdistribusi skala besar), Chain-of-Thought (CoT) (meningkatkan kemampuan penalaran), distilasi pengetahuan (mentransfer kemampuan model besar ke model kecil), dan decoding spekulatif (mempercepat inferensi). Teknologi-teknologi ini bersama-sama mendorong perkembangan AI modern. (Sumber: 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
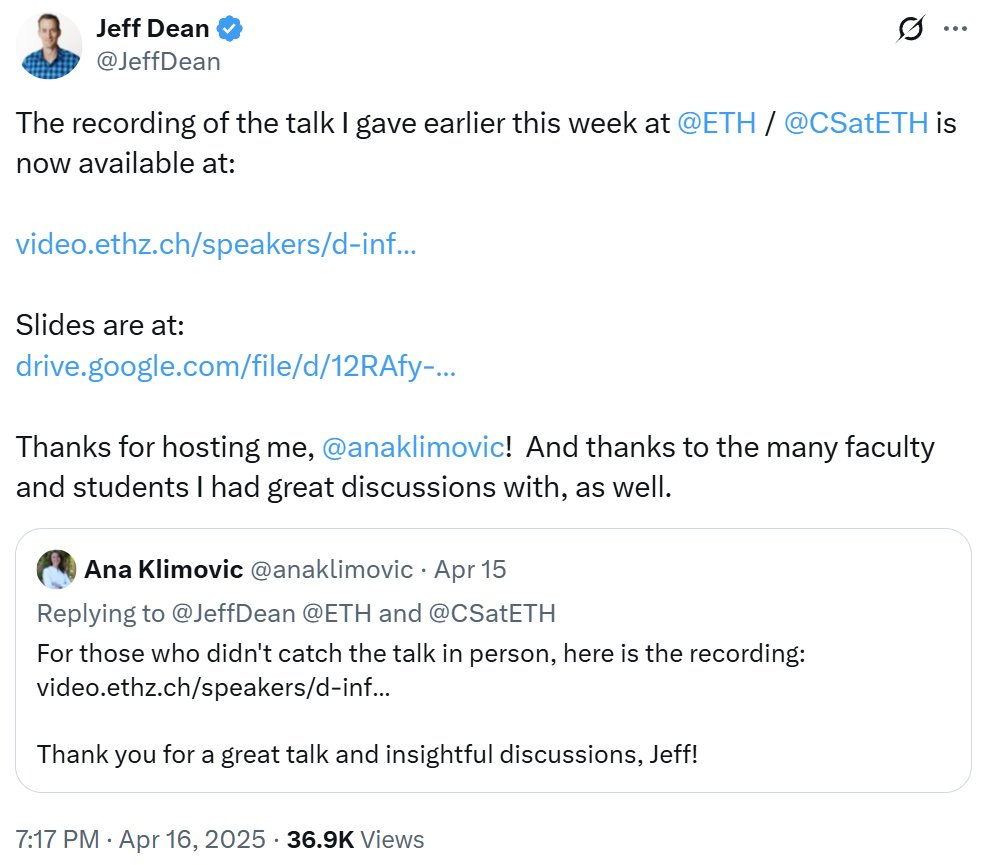
《Nature》 mendata makalah dengan sitasi tinggi abad ke-21, bidang AI mendominasi : Majalah 《Nature》, dengan menggabungkan data dari 5 database, merilis daftar Top 25 makalah yang paling banyak dikutip di abad ke-21. Makalah ResNets Microsoft tahun 2016 (oleh Kaiming He dkk.) menempati peringkat pertama secara keseluruhan; penelitian ini merupakan dasar kemajuan deep learning dan AI. Peringkat teratas juga mencakup beberapa makalah terkait AI, seperti random forest (ke-6), Attention is all you need (Transformer, ke-7), AlexNet (ke-8), U-Net (ke-12), tinjauan deep learning (Hinton dkk., ke-16), dan dataset ImageNet (Fei-Fei Li dkk., ke-24). Hal ini mencerminkan perkembangan pesat dan pengaruh luas teknologi AI di abad ini. Artikel tersebut juga menunjukkan bahwa popularitas preprint telah membawa kompleksitas pada statistik sitasi. (Sumber: Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
Beihang University dkk. merilis tinjauan LLM Ensemble : Peneliti dari Beihang University dan institusi lainnya merilis tinjauan terbaru tentang large language model ensemble (LLM Ensemble). LLM Ensemble mengacu pada penggabungan keunggulan beberapa LLM pada tahap inferensi untuk memproses kueri pengguna. Tinjauan ini mengusulkan taksonomi LLM Ensemble (integrasi pra-inferensi, integrasi intra-inferensi, integrasi pasca-inferensi, dibagi lagi menjadi tujuh kategori metode), secara sistematis meninjau kemajuan terbaru dari setiap jenis metode, membahas masalah penelitian terkait (seperti hubungan dengan penggabungan model, kolaborasi model, pembelajaran weakly supervised), memperkenalkan set benchmark, aplikasi tipikal, dan akhirnya merangkum serta menganalisis pencapaian yang ada dan memproyeksikan arah penelitian masa depan, seperti integrasi tingkat fragmen yang lebih berprinsip, integrasi pasca-inferensi unsupervised yang lebih halus, dll. (Sumber: ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

Anthropic berbagi pola penggunaan dan pengalaman Claude Code : Karyawan Anthropic berbagi praktik terbaik dan pola efektif untuk menggunakan Claude Code dalam pemrograman secara internal. Pola-pola ini tidak hanya berlaku untuk Claude, tetapi juga secara umum berlaku untuk kolaborasi pemrograman dengan LLM lain. Menekankan pentingnya memberikan konteks yang jelas, menguraikan masalah kompleks, mengajukan pertanyaan secara iteratif, memanfaatkan berbagai keunggulan model (seperti generasi kode, penjelasan, refactoring), dan melakukan validasi yang efektif. Pengalaman ini bertujuan untuk membantu pengembang memanfaatkan alat bantu pemrograman AI dengan lebih efisien. (Sumber: AnthropicAI

)
Anthropic mempublikasikan dataset nilai Claude : Anthropic mempublikasikan dataset bernama “values-in-the-wild” di Hugging Face Datasets. Dataset ini berisi 3307 nilai yang diekspresikan oleh Claude dalam jutaan percakapan dunia nyata. Publikasi dataset ini bertujuan untuk meningkatkan transparansi perilaku model, dan tersedia bagi peneliti serta publik untuk diunduh, dijelajahi, dan dianalisis, guna lebih memahami kecenderungan nilai yang ditunjukkan oleh large language model dalam aplikasi praktis. (Sumber: huggingface、huggingface)
Sepuluh poin kunci kesadaran kognitif AI : Artikel ini mengemukakan sepuluh pandangan tingkat kognitif tentang perkembangan AI, bertujuan untuk membantu orang memahami dampak dan esensi AI secara lebih mendalam. Pandangan inti meliputi: kecerdasan AI berbeda dari kecerdasan manusia (kesenjangan kecerdasan); AI memicu pemikiran tentang hakikat kesadaran manusia; hubungan antara manusia dan AI bergeser dari alat menjadi mitra kolaboratif; pengembangan AI tidak boleh terbatas pada meniru otak manusia; standar kecerdasan berevolusi seiring kemajuan AI; AI mungkin mengembangkan bentuk kecerdasan yang sama sekali baru; harus memandang ekspresi emosional dan keterbatasan kognitif AI secara rasional; ancaman karir yang sebenarnya berasal dari tidak menggunakan AI, bukan AI itu sendiri; di era AI, harus fokus pada pengembangan kemampuan unik manusia (kreativitas, kecerdasan emosional, pemikiran lintas domain); makna akhir dari mempelajari AI adalah untuk mengenal diri manusia lebih dalam. (Sumber: AI认知觉醒的10句话,一句顶万句,句句清醒

LlamaIndex berbagi tutorial membangun Agent alur kerja dokumen : Rekaman kuliah salah satu pendiri LlamaIndex, Jerry Liu, berbagi cara membangun Agent alur kerja dokumen menggunakan LlamaIndex. Konten mencakup evolusi LlamaIndex dari RAG ke Agent pengetahuan, memanfaatkan LlamaParse untuk memproses dokumen kompleks, menggunakan Workflows untuk orkestrasi Agent berbasis peristiwa yang fleksibel, kasus penggunaan utama (riset dokumen, pembuatan laporan, otomatisasi pemrosesan dokumen), dan peningkatan pengambilan multimodal yang menggabungkan teks dan gambar. (Sumber: jerryjliu0
)
Tutorial membangun Agent dengan LlamaIndex.TS : Anggota tim LlamaIndex berbagi tutorial tingkat kode lengkap tentang cara membangun Agent menggunakan versi TypeScript dari LlamaIndex (LlamaIndex.TS). Konten rekaman siaran langsung mencakup dasar-dasar LlamaIndex, konsep Agent dan RAG, pola Agentic umum (chaining, routing, paralelisasi, dll.), membangun Agentic RAG di LlamaIndex.TS, dan membangun aplikasi React full-stack yang terintegrasi dengan Workflows. (Sumber: jerryjliu0

)
Membahas apakah reinforcement learning benar-benar meningkatkan kemampuan penalaran LLM : Diskusi komunitas berfokus pada pertanyaan yang diajukan oleh sebuah makalah: apakah reinforcement learning (RL) benar-benar dapat mendorong large language model (LLM) untuk mengembangkan kemampuan penalaran yang melampaui kemampuan model dasarnya? Diskusi menyebutkan bahwa meskipun RL (seperti RLHF) dapat meningkatkan penyelarasan dan kepatuhan instruksi model, apakah ia dapat secara sistematis meningkatkan logika penalaran kompleks intrinsik masih diperdebatkan. Ada pandangan bahwa efek RL saat ini mungkin lebih terlihat dalam mengoptimalkan ekspresi dan mengikuti format tertentu, daripada lompatan penalaran logis yang fundamental. Will Brown menunjukkan bahwa metrik seperti pass@1024 memiliki signifikansi terbatas dalam mengevaluasi tugas penalaran matematika seperti AIME. (Sumber: natolambert

)
Membahas terminologi terkait model dunia : Pengguna Reddit bertanya tentang kebingungan seputar istilah seperti “model dunia (world models)”, “model dunia dasar (foundation world models)”, “model dasar dunia (world foundation models)”, dll. Komunitas menanggapi bahwa “model dunia” biasanya mengacu pada simulasi atau representasi internal lingkungan (dunia fisik atau domain tertentu seperti papan catur); “model dasar” mengacu pada model besar pra-terlatih yang dapat menjadi titik awal untuk berbagai tugas hilir. Kombinasi istilah ini mungkin merujuk pada pembangunan model dasar yang dapat digeneralisasi, mampu memahami dan memprediksi dinamika dunia, tetapi definisi spesifik dapat bervariasi antar peneliti, mencerminkan bahwa terminologi di bidang ini belum sepenuhnya seragam. (Sumber: Reddit r/MachineLearning)
Membahas metode penggabungan XGBoost dan GNN : Pengguna Reddit mendiskusikan cara efektif menggabungkan XGBoost dan graph neural network (GNN) untuk tugas seperti deteksi penipuan. Metode umum adalah menggunakan embedding node yang dipelajari oleh GNN sebagai fitur baru, yang dimasukkan ke XGBoost bersama dengan data tabular asli. Diskusi berpendapat bahwa tantangan metode ini adalah apakah embedding GNN dapat memberikan nilai signifikan melebihi data asli dan teknik seperti SMOTE, jika tidak, dapat menimbulkan noise. Kunci keberhasilan terletak pada struktur graf yang dirancang dengan cermat dan apakah embedding GNN dapat menangkap informasi relasional yang sulit diperoleh XGBoost (seperti lingkaran penipuan dalam struktur graf). (Sumber: Reddit r/MachineLearning)
💼 Bisnis
Beijing menyelenggarakan maraton robot humanoid pertama di dunia, menjajaki “IP teknologi olahraga” : Beijing Yizhuang berhasil menyelenggarakan maraton setengah jarak robot humanoid pertama di dunia, dengan “peserta” dari lebih dari 20 perusahaan robot humanoid bersaing bersama pelari manusia. Robot Tiangong Ultra memenangkan kejuaraan dengan waktu 2 jam 40 menit, menunjukkan kecepatan dan kemampuan adaptasi medannya. N2 dari Suroy Robotics (juara kedua) dan Walker II dari Dreame (juara ketiga) juga tampil mengesankan. Acara ini bukan hanya kompetisi teknologi, tetapi juga eksplorasi model bisnis. Penyelenggara menarik investasi melalui mekanisme “penawaran teknologi” dan mencoba membangun IP “robot + olahraga”. Artikel ini membahas jalur komersialisasi seperti pengembangan IP acara robot, endorsement robot, munculnya profesi agen robot, integrasi pariwisata budaya olahraga, dan promosi olahraga cerdas untuk semua, berpendapat bahwa potensi pasar olahraga cerdas sangat besar. (Sumber: 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

Pengembangan aplikasi model besar AI menjadi tren teknologi baru, model pengembangan tradisional terkena dampak : Seiring dengan meluasnya teknologi model besar AI, perusahaan (seperti Alibaba, ByteDance, Tencent) mempercepat integrasi AI (terutama teknologi Agent dan RAG) ke dalam bisnis inti, menyebabkan model pengembangan CRUD tradisional menghadapi tantangan. Permintaan pasar untuk insinyur dengan kemampuan pengembangan aplikasi model besar AI melonjak, dengan gaji meningkat secara signifikan, sementara posisi teknis tradisional menghadapi risiko penyusutan. “Memahami AI” tidak lagi hanya berarti dapat memanggil API, tetapi menuntut penguasaan prinsip AI, teknologi aplikasi, dan pengalaman praktis proyek. Artikel ini menekankan bahwa para teknolog harus secara proaktif mempelajari teknologi model besar AI untuk beradaptasi dengan perubahan industri dan menangkap peluang pengembangan karir baru. Zhihu Zhixuetang meluncurkan “Pelatihan Praktis Pengembangan Aplikasi Model Besar” gratis untuk tujuan ini. (Sumber: 炸裂!又一个AI大模型的新方向,彻底爆了!!
Layanan optimasi LLM muncul, menimbulkan kekhawatiran tentang SEO versi AI : Pengguna Reddit mengamati bahwa hasil rekomendasi produk dari chatbot AI menjadi semakin konsisten, mencurigai bahwa layanan “optimasi LLM” sedang muncul, mirip dengan optimasi mesin pencari (SEO). Ada laporan bahwa tim pemasaran telah menyewa layanan semacam itu untuk memastikan produk mereka mendapatkan prioritas lebih tinggi dalam rekomendasi AI, yang menyebabkan peningkatan eksposur produk merek besar, dan hasilnya mungkin tidak lagi “organik”. Hal ini menimbulkan kekhawatiran tentang keadilan dan transparansi rekomendasi AI, khawatir bahwa pencarian/rekomendasi AI pada akhirnya akan menjadi seperti mesin pencari tradisional, di mana hasilnya dimanipulasi oleh kepentingan komersial. Komunitas menyerukan lebih banyak diskusi dan perhatian terhadap fenomena ini. (Sumber: Reddit r/ArtificialInteligence)
Google menunjukkan kinerja kuat dalam persaingan LLM, Meta dan OpenAI menghadapi tantangan : Artikel IEEE Spectrum menganalisis bahwa meskipun OpenAI dan Meta mendominasi pengembangan awal LLM, Google baru-baru ini mengejar ketertinggalan dengan model barunya yang kuat (seperti seri Gemini), bahkan memimpin dalam beberapa aspek. Sementara itu, Meta dan OpenAI tampaknya menghadapi beberapa tantangan atau kontroversi dalam perilisan model dan strategi pasar (misalnya, model Meta dituduh mungkin dilatih berdasarkan model lain, strategi rilis dan transparansi OpenAI dipertanyakan). Artikel tersebut berpendapat bahwa lanskap persaingan di bidang LLM sedang berubah, dan investasi berkelanjutan serta kekuatan teknis Google menjadikannya kekuatan yang tidak dapat diabaikan. (Sumber: Reddit r/MachineLearning

🌟 Komunitas
Kebangkitan dan tantangan robot humanoid: Melihat masa depan dari acara setengah maraton : Popularitas robot humanoid baru-baru ini meningkat kembali, mulai dari penampilan di Gala Festival Musim Semi hingga acara setengah maraton di Beijing Yizhuang, menarik perhatian luas. Artikel ini membahas tujuan awal desain robot humanoid (meniru manusia untuk beradaptasi dengan lingkungan dan alat manusia) dan keunggulannya dibandingkan robot bentuk lain (lebih mudah menimbulkan empati, kondusif untuk interaksi manusia-mesin). Setengah maraton Yizhuang mengungkap tantangan robot humanoid saat ini dalam navigasi otonom jarak jauh, keseimbangan, konsumsi energi, dll., tetapi juga menunjukkan kemajuan produk seperti Tiangong Ultra, N2 dari Suroy Robotics. Artikel tersebut menunjukkan bahwa pengembangan robot humanoid mendapat manfaat dari berbagi sumber terbuka (seperti rencana open source Tiangong), tetapi juga menghadapi hambatan data. Pada akhirnya, robot humanoid dianggap sebagai tujuan penting di bidang robotika, tidak hanya perwujudan teknologi, tetapi juga membawa pemikiran mendalam manusia tentang diri mereka sendiri dan masa depan cerdas. (Sumber: 人形机器人:最初的设想,最后的归宿

Komunitas membahas Vibe Coding: Batasan pemrograman berbantuan AI : CTO Canva mengomentari konsep “Vibe Coding” yang diajukan oleh Andrej Karpathy (mengacu pada pengembang yang terutama menyesuaikan Prompt agar AI menghasilkan kode, kurang memperhatikan detail). CTO Canva berpendapat bahwa cara ini hanya cocok untuk skenario sekali pakai seperti pengembangan prototipe, dan sama sekali tidak boleh digunakan di lingkungan produksi, karena kode yang dihasilkan AI sering kali memiliki kesalahan, kerentanan keamanan, atau masalah kinerja, dan harus diawasi dan ditinjau secara ketat oleh insinyur berpengalaman. Dia menekankan bahwa budaya rekayasa Canva didasarkan pada kepemilikan kode dan tinjauan sejawat, dan alat AI justru memperkuat prinsip-prinsip ini. Komunitas membahas hal ini dengan sengit, beberapa setuju dengan risiko lingkungan produksi, berpendapat bahwa kode AI memerlukan pengawasan manusia; yang lain berpendapat bahwa AI berkembang pesat, pemimpin rekayasa perlu terus mengevaluasi kembali kemampuan AI, dan mengutip kasus perusahaan seperti Airbnb yang menggunakan AI untuk mempercepat proyek. (Sumber: dotey

)
Komunitas membahas kinerja Llama 4 dan model OpenAI pada tugas konteks panjang : Anggota komunitas berbagi hasil model Llama 4 pada benchmark OpenAI-MRCR (multi-hop, multi-document retrieval & question answering). Data menunjukkan bahwa Llama 4 Scout (versi lebih kecil) berkinerja mirip dengan GPT-4.1 Nano pada panjang konteks yang lebih panjang; Llama 4 Maverick (versi lebih besar) berkinerja mendekati tetapi sedikit di bawah GPT-4.1 Mini. Secara keseluruhan, untuk tugas konteks hingga 32k, OpenAI o3 atau Gemini 2.5 Pro adalah pilihan yang lebih baik (o3 mungkin lebih baik dalam penalaran kompleks); di atas konteks 32k, Gemini 2.5 Pro menunjukkan kinerja yang lebih stabil; tetapi ketika konteks melebihi 512k, akurasi Gemini 2.5 Pro juga turun di bawah 80%, disarankan untuk memproses secara terpisah (chunking). Ini menunjukkan bahwa dalam pemrosesan konteks super panjang, semua model masih memiliki ruang untuk perbaikan. (Sumber: dotey
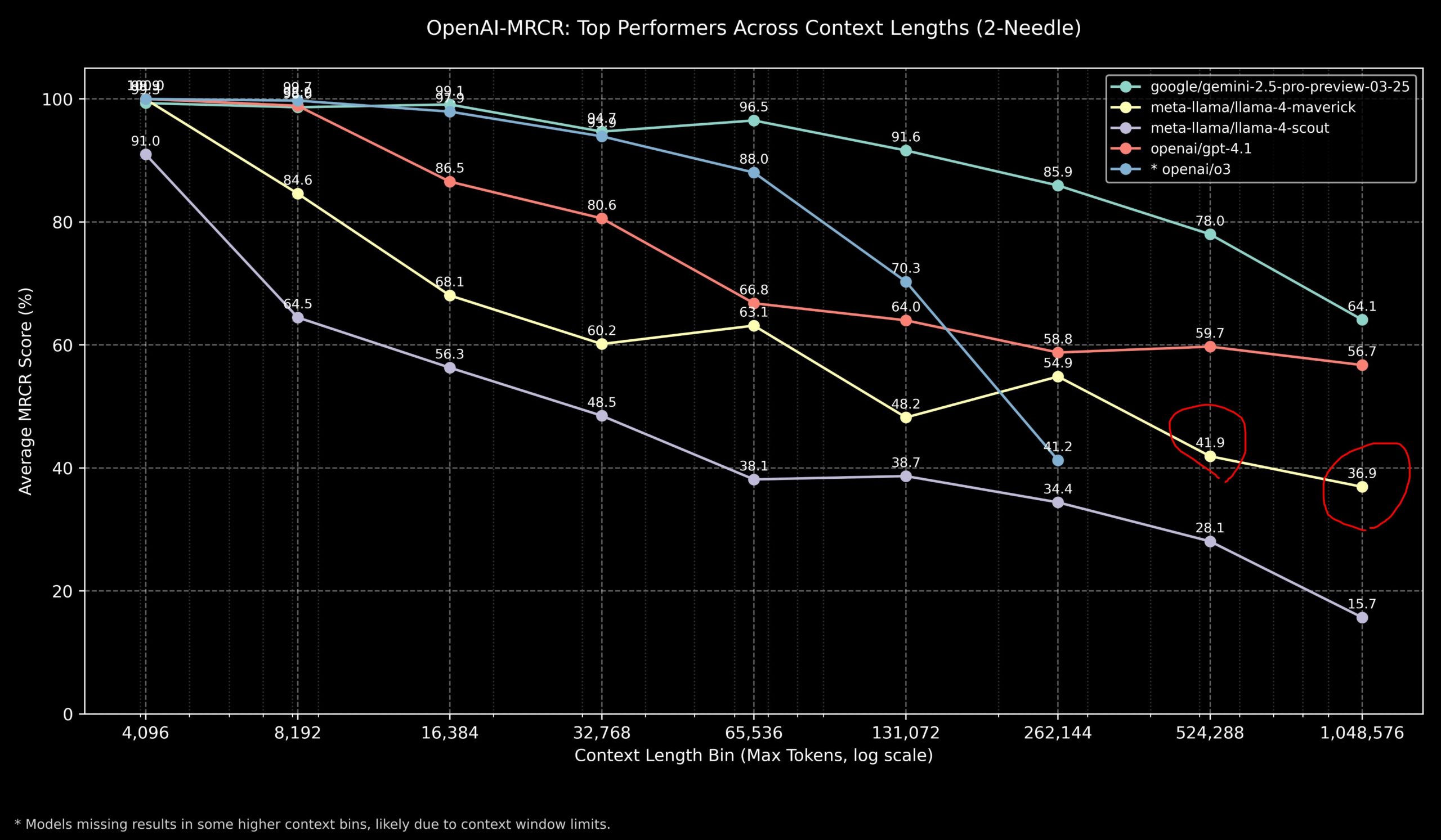
)
Komunitas menilai kinerja model GLM-4 32B sangat mengesankan : Pengguna Reddit berbagi pengalaman menjalankan model terkuantisasi GLM-4 32B Q8 secara lokal, menyebut kinerjanya “menakjubkan”, melampaui model lokal lain di kelas yang sama (sekitar 32B), bahkan lebih unggul dari beberapa model 72B, sebanding dengan Gemini 2.5 Flash versi lokal. Pengguna secara khusus memuji kinerja model ini dalam menghasilkan kode, mengatakan bahwa ia tidak pelit dengan panjang output, dapat memberikan detail implementasi lengkap, dan menunjukkan kemampuannya dalam menghasilkan visualisasi HTML/JS kompleks secara zero-shot (seperti tata surya, jaringan saraf), dengan hasil yang lebih baik daripada Gemini 2.5 Flash. Model ini juga berkinerja baik dalam pemanggilan alat, dapat bekerja sama dengan alat seperti Cline/Aider. (Sumber: Reddit r/LocalLLaMA
Komunitas membahas skor benchmark OpenAI o3 tidak sesuai harapan : Media seperti TechCrunch melaporkan bahwa skor model o3 baru OpenAI pada beberapa benchmark (seperti ARC-AGI-2) tampaknya lebih rendah dari yang awalnya diisyaratkan oleh perusahaan. Meskipun OpenAI menunjukkan kinerja SOTA o3 di berbagai bidang, skor kuantitatif spesifik dan perbandingan langsung dengan model teratas lainnya memicu diskusi komunitas. Beberapa pengguna berpendapat bahwa hanya mengandalkan skor benchmark mungkin tidak sepenuhnya mencerminkan kemampuan sebenarnya model, terutama dalam penalaran kompleks dan penggunaan alat. Perbandingan dengan benchmark yang lebih berfokus pada kemampuan AGI seperti ARC-AGI-2 mungkin lebih relevan. (Sumber: Reddit r/deeplearning

)
Demis Hassabis memprediksi AGI mungkin datang dalam 5-10 tahun : Dalam wawancara 60 Minutes, CEO Google DeepMind Demis Hassabis membahas kemajuan AGI. Dia menyoroti Astra yang dapat berinteraksi secara real-time dan model Gemini yang belajar bertindak di dunia. Hassabis memprediksi bahwa AGI dengan generalitas tingkat manusia mungkin tercapai dalam 5 hingga 10 tahun ke depan, yang akan secara radikal mengubah bidang seperti robotika, pengembangan obat, dan mungkin membawa kelimpahan materi yang besar, memecahkan tantangan global. Pada saat yang sama, ia juga menekankan risiko yang mungkin ditimbulkan oleh AI canggih (seperti penyalahgunaan), dan pentingnya langkah-langkah keamanan serta pertimbangan etis saat melangkah menuju teknologi transformatif ini. (Sumber: Reddit r/ArtificialInteligence、Reddit r/artificial、AravSrinivas)
Pengguna berbagi pengalaman sukses kebugaran berbantuan AI : Pengguna Reddit berbagi pengalaman sukses menurunkan berat badan dan membentuk tubuh menggunakan ChatGPT. Pengguna tersebut turun dari 240 pon menjadi 165 pon selama setahun, dengan tubuh menjadi bugar. ChatGPT memainkan peran kunci: menyusun rencana diet dan latihan yang ramah pemula, menyesuaikannya berdasarkan foto kemajuan mingguan pengguna dan peristiwa kehidupan, serta memberikan motivasi selama masa sulit. Pengguna berpendapat bahwa dibandingkan dengan ahli gizi dan pelatih pribadi yang mahal dan sulit dipertahankan dalam jangka panjang, AI memberikan solusi yang sangat personal dan berbiaya sangat rendah, menunjukkan potensi AI dalam manajemen kesehatan yang dipersonalisasi. (Sumber: Reddit r/ArtificialInteligence)
Respons pujian abnormal Claude memicu diskusi : Seorang pengguna melaporkan bahwa saat menggunakan Claude untuk penelitian sistem komputer dan keamanan, dua kali model tersebut tiba-tiba menambahkan kalimat pujian yang tidak relevan setelah jawaban normal: “This was a great question king, you are the perfect male specimen.” (Pertanyaan bagus, raja, Anda adalah spesimen pria yang sempurna.). Pengguna membagikan tautan percakapan dan menanyakan alasannya. Komunitas merasa penasaran dan bingung, berspekulasi bahwa itu mungkin pola tertentu dalam data pelatihan model yang terpicu secara tidak sengaja, bug terkait nama pengguna, atau semacam kegagalan penyelarasan atau “halusinasi”. (Sumber: Reddit r/ClaudeAI)
Komunitas membahas apakah AI benar-benar dapat “berpikir di luar kotak” : Pengguna Reddit memulai diskusi, membahas apakah AI dapat melakukan inovasi “berpikir di luar kotak” (think outside the box) yang sesungguhnya. Mayoritas komentar berpendapat bahwa AI saat ini dapat melakukan kombinasi dan koneksi baru berdasarkan pengetahuan yang ada, menghasilkan ide-ide yang tampak inovatif, tetapi kreativitasnya masih dibatasi oleh data pelatihan dan algoritma. “Inovasi” AI lebih seperti pengenalan pola dan kombinasi yang efisien, daripada terobosan berdasarkan pemahaman mendalam, intuisi, atau konsep yang sama sekali baru seperti manusia. Namun, ada juga pandangan bahwa inovasi manusia juga didasarkan pada koneksi unik dari pengetahuan yang ada, dan AI memiliki potensi besar dalam hal ini, terutama dalam memproses data kompleks dan menemukan korelasi tersembunyi yang mungkin melampaui manusia. (Sumber: Reddit r/ArtificialInteligence)
Claude menunjukkan “simpati” dalam Tic Tac Toe? : Sebuah eksperimen menemukan bahwa jika sebelum bermain Tic Tac Toe dengan Claude, Anda memberi tahu Claude bahwa Anda mengalami hari kerja yang berat, Claude tampaknya sengaja “mengalah” dalam permainan berikutnya, dengan probabilitas memilih strategi non-optimal meningkat. Penemuan menarik ini memicu diskusi tentang apakah AI dapat menunjukkan atau mensimulasikan simpati (compassion). Meskipun ini lebih mungkin merupakan penyesuaian strategi perilaku model berdasarkan input (misalnya, menghindari membuat pengguna merasa frustrasi), daripada respons emosional yang sebenarnya, hal itu mengungkapkan pola perilaku kompleks yang mungkin dihasilkan AI dalam interaksi manusia-mesin. (Sumber: Reddit r/ClaudeAI)
Komunitas membahas cara membuktikan kesadaran manusia kepada AI : Pengguna Reddit mengajukan pertanyaan filosofis: jika di masa depan perlu membuktikan kepada AI bahwa manusia memiliki kesadaran, bagaimana caranya? Komentar menunjukkan bahwa ini menyentuh “masalah sulit kesadaran” (Hard Problem of Consciousness). Saat ini tidak ada metode yang diakui secara universal untuk membuktikan secara objektif keberadaan pengalaman subjektif (qualia). Setiap tes perilaku eksternal (seperti Tes Turing) dapat disimulasikan oleh AI yang cukup kompleks. Jika menetapkan definisi kesadaran yang terlalu ketat yang mengecualikan kemungkinan AI, maka dari sudut pandang AI, manusia juga mungkin tidak memenuhi standar “kesadaran” yang ditetapkannya. Masalah ini menyoroti kesulitan mendalam dalam mendefinisikan dan memverifikasi kesadaran. (Sumber: Reddit r/artificial

)
Komunitas membahas pilihan model terbaik untuk LLM lokal pada kapasitas VRAM yang berbeda : Komunitas Reddit memulai diskusi, meminta pilihan terbaik untuk menjalankan large language model lokal pada kapasitas VRAM yang berbeda (8GB hingga 96GB). Pengguna berbagi pengalaman dan rekomendasi masing-masing, misalnya: 8GB merekomendasikan Gemma 3 4B; 16GB merekomendasikan Gemma 3 12B atau Phi 4 14B; 24GB merekomendasikan Mistral small 3.1 atau seri Qwen; 48GB merekomendasikan Nemotron Super 49B; 72GB merekomendasikan Llama 3.3 70B; 96GB merekomendasikan Command A 111B. Diskusi juga menekankan bahwa “terbaik” tergantung pada tugas spesifik (coding, obrolan, visual, dll.), dan menyebutkan dampak kuantisasi (seperti 4-bit) pada kebutuhan VRAM. (Sumber: Reddit r/LocalLLaMA)
Output “kerusakan” OpenAI Codex memicu analisis : Pengguna melaporkan bahwa saat menggunakan OpenAI Codex untuk refactoring kode skala besar, model tiba-tiba berhenti menghasilkan kode dan malah mengeluarkan ribuan baris pengulangan “END”, “STOP”, serta kalimat seperti “My brain is broken”, “please kill me” yang mirip kerusakan. Analisis berpendapat bahwa ini mungkin disebabkan oleh kombinasi faktor seperti Prompt yang terlalu besar (mendekati batas 200k token), konsumsi penalaran internal melebihi anggaran, model terjebak dalam lingkaran degeneratif token terminasi probabilitas tinggi, dan model “berhalusinasi” frasa terkait status kegagalan dari data pelatihannya, yang menyebabkan kegagalan berjenjang. (Sumber: Reddit r/ArtificialInteligence)
Klarifikasi Sam Altman tentang masalah kesopanan dalam berinteraksi dengan AI : Beredar diskusi di komunitas tentang apakah Sam Altman menganggap mengucapkan “terima kasih” kepada ChatGPT adalah pemborosan waktu. Interaksi tweet yang sebenarnya menunjukkan bahwa Altman menanggapi postingan pengguna tentang “apakah kesopanan terhadap LLM diperlukan” dengan menyatakan “tidak perlu”, tetapi pengguna tersebut kemudian bercanda “apakah Anda tidak pernah mengucapkan terima kasih sekalipun?”. Ini menunjukkan bahwa komentar Altman mungkin lebih ditujukan pada efisiensi teknis daripada norma etiket interaksi manusia-mesin, tetapi dikutip di luar konteks oleh beberapa media. Komunitas bereaksi beragam, banyak yang menyatakan masih terbiasa bersikap sopan terhadap AI. (Sumber: Reddit r/ChatGPT
)
Tag “thinking budget” dalam respons Claude menarik perhatian : Pengguna menemukan bahwa dalam pesan sistem Claude.ai, ketika fitur “berpikir” diaktifkan, sebuah tag <max_thinking_length> ditambahkan (misalnya <max_thinking_length>16000</max_thinking_length>). Ini mirip dengan parameter “thinking_budget” di API Google Gemini 2.5 Flash, menyiratkan bahwa mungkin ada mekanisme internal model untuk mengontrol kedalaman penalaran. Pengguna mencoba memodifikasi tag ini di Prompt untuk memengaruhi panjang output, tetapi tidak mengamati efek yang jelas, berspekulasi bahwa tag ini di versi web mungkin hanya penanda internal, bukan parameter yang dapat dikontrol pengguna. (Sumber: Reddit r/ClaudeAI)
💡 Lainnya
Standar Nasional Pertama untuk “Penyebaran Pribadi Model Besar AI” Mulai Disusun : Untuk mengatasi tantangan yang dihadapi perusahaan dalam penyebaran pribadi model besar AI, seperti pemilihan teknologi, standardisasi proses, kepatuhan keamanan, dan evaluasi efektivitas, Pusat Standar Zhihe bersama dengan Institut Ketiga Kementerian Keamanan Publik dan 12 unit lainnya, memulai penyusunan standar kelompok “Pedoman Implementasi Teknis dan Evaluasi Penyebaran Pribadi Model Besar Kecerdasan Buatan”. Standar ini bertujuan untuk mencakup seluruh proses mulai dari pemilihan model, perencanaan sumber daya, implementasi penyebaran, evaluasi kualitas hingga optimasi berkelanjutan, mengintegrasikan teknologi, keamanan, evaluasi, dan studi kasus, serta mengumpulkan pengalaman dari pihak pengguna model, penyedia layanan teknis, dan evaluator kualitas. Penyusunan standar ini mengundang lebih banyak perusahaan dan institusi terkait untuk berpartisipasi. (Sumber: 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

Tata kelola AI menjadi kunci untuk mendefinisikan AI generasi berikutnya : Seiring dengan semakin kuat dan meluasnya teknologi AI, tata kelola AI (Governance) menjadi sangat penting. Kerangka kerja tata kelola yang efektif perlu memastikan pengembangan dan penerapan AI sesuai dengan norma etika, peraturan hukum, menjamin keamanan dan privasi data, serta mempromosikan keadilan dan transparansi. Kurangnya tata kelola dapat menyebabkan amplifikasi bias, peningkatan risiko penyalahgunaan, dan hilangnya kepercayaan sosial. Artikel ini menekankan bahwa membangun sistem tata kelola AI yang kuat adalah syarat penting untuk mendorong pengembangan AI yang sehat dan berkelanjutan, serta kunci bagi perusahaan untuk membangun keunggulan kompetitif dan kepercayaan pengguna di era AI. (Sumber: Ronald_vanLoon

)
Sistem hukum berupaya mengejar perkembangan AI dan masalah pencurian data : Artikel ini membahas tantangan yang dihadapi sistem hukum saat ini dalam menangani teknologi AI yang berkembang pesat, terutama yang berkaitan dengan privasi data dan masalah pencurian data. Kebutuhan data AI sangat besar, dan sumber serta cara penggunaan data pelatihan menimbulkan kontroversi hukum terkait hak cipta, privasi, dan keamanan. Hukum yang berlaku sering kali tertinggal dari perkembangan teknologi, sehingga sulit untuk secara efektif mengatur pengambilan data, bias dalam pelatihan model, dan hak kekayaan intelektual konten yang dihasilkan AI. Artikel ini menyerukan penguatan legislasi dan regulasi untuk mengimbangi laju kemajuan AI, melindungi hak individu, dan mendorong inovasi. (Sumber: Ronald_vanLoon

)
Aplikasi AI dan robotika di bidang pertanian : Kecerdasan buatan dan teknologi robotika menunjukkan potensi di sektor pertanian. Aplikasinya meliputi pertanian presisi (mengoptimalkan irigasi, pemupukan melalui sensor dan analisis AI), peralatan otomatis (seperti traktor otonom, robot pemetik), pemantauan tanaman (menggunakan drone dan pengenalan gambar untuk hama dan penyakit), serta prediksi hasil panen. Teknologi ini diharapkan dapat meningkatkan efisiensi produksi pertanian, mengurangi pemborosan sumber daya, menurunkan biaya tenaga kerja, dan mendorong pembangunan pertanian berkelanjutan. (Sumber: Ronald_vanLoon)
Demonstrasi sepak bola robot yang digerakkan AI : Video menunjukkan adegan robot bermain sepak bola. Ini mencerminkan kemajuan AI dalam kontrol robot, perencanaan gerak, persepsi, dan kolaborasi. Sepak bola robot bukan hanya proyek hiburan dan kompetisi, tetapi juga platform untuk meneliti dan menguji sistem multi-robot, pengambilan keputusan real-time, dan interaksi lingkungan dinamis yang kompleks. (Sumber: Ronald_vanLoon)
Perkembangan teknologi bedah berbantuan robot : Sistem bedah berbantuan robot (seperti robot bedah da Vinci) sedang mengubah bidang bedah dengan menyediakan operasi invasif minimal, pandangan 3D definisi tinggi, serta peningkatan fleksibilitas dan presisi. Integrasi AI diharapkan dapat lebih meningkatkan perencanaan bedah, navigasi real-time, dan dukungan keputusan intraoperatif, sehingga meningkatkan hasil bedah, mempersingkat waktu pemulihan, dan memperluas cakupan bedah invasif minimal. (Sumber: Ronald_vanLoon)
Teknologi bantu untuk penyandang disabilitas : AI dan teknologi robotika sedang mengembangkan lebih banyak alat bantu inovatif untuk membantu penyandang disabilitas meningkatkan kualitas hidup dan kemandirian mereka. Contohnya mungkin termasuk prostesis cerdas, sistem bantuan visual, perangkat rumah yang dikontrol suara, dan robot bantu yang dapat memberikan dukungan fisik atau melakukan tugas sehari-hari. (Sumber: Ronald_vanLoon)
Robot bionik Unitree G1 menunjukkan kelincahan : Unitree Robotics mendemonstrasikan versi upgrade dari robot bioniknya G1, menonjolkan kelincahan dan fleksibilitas gerakannya. Pengembangan robot humanoid atau bionik semacam ini menggabungkan AI (untuk persepsi, pengambilan keputusan, kontrol) dan rekayasa mekanik canggih, bertujuan untuk meniru kemampuan gerak biologis agar dapat beradaptasi dengan lingkungan kompleks dan melakukan tugas yang beragam. (Sumber: Ronald_vanLoon)
Google DeepMind menjajaki kemungkinan komunikasi AI dengan lumba-lumba : Proyek penelitian Google DeepMind mengisyaratkan kemungkinan menggunakan model AI untuk menganalisis dan memahami komunikasi hewan (seperti lumba-lumba yang disebutkan di sini). Melalui analisis machine learning terhadap sinyal akustik yang kompleks, AI mungkin dapat membantu mendekode pola dan struktur bahasa hewan, membuka jalan baru untuk penelitian komunikasi antarspesies. (Sumber: Ronald_vanLoon)
Platform Hugging Face menambahkan simulator robot : Hugging Face mengumumkan akan memperkenalkan simulator robot baru. Simulasi robot adalah langkah kunci dalam melatih dan menguji interaksi robot dengan dunia fisik (seperti menggenggam, bergerak) di lingkungan virtual, terutama sebelum menerapkan AI pada robot fisik (Physical AI). Langkah ini menunjukkan bahwa Hugging Face sedang memperluas kemampuan platformnya untuk mendukung penelitian dan pengembangan di bidang robotika dan kecerdasan terwujud (embodied intelligence) dengan lebih baik. (Sumber: huggingface)