
Kata Kunci:4 Naga AI, Kecerdasan Embodi, Robot Humanoid, Tembok Memori, Model Multimodal SenseTime Rixin V6, Dataset Open X-Embodiment, Robot Tesla Optimus, Teknologi RAM Ferroelektrik 3D, Robot TianGong Ultra Semi-Marathon, Model Kuantisasi Gemma 3 QAT, Akuisisi Hugging Face terhadap Pollen Robotics, Alur Kerja Dokumen Agen LlamaIndex
🔥 Fokus
Tantangan dan Transformasi “Empat Naga Kecil AI”: Perusahaan seperti SenseTime, Megvii, CloudWalk, Yitu, yang pernah dijuluki “Empat Naga Kecil AI”, dalam beberapa tahun terakhir secara umum menghadapi kesulitan komersialisasi dan kerugian berkelanjutan. Misalnya, SenseTime merugi 4,3 miliar yuan pada tahun 2024, dengan kerugian kumulatif melebihi 54,6 miliar yuan; CloudWalk merugi hampir 600-700 juta yuan pada tahun 2024, dengan kerugian kumulatif melebihi 4,4 miliar yuan. Untuk mengatasi tantangan, setiap perusahaan melakukan penyesuaian strategis, termasuk PHK, pemotongan gaji, dan restrukturisasi bisnis. Menghadapi gelombang AI baru yang didominasi oleh Large Language Model, “Empat Naga Kecil” yang memiliki gen teknologi visi secara aktif beralih ke bidang Large Model Multimodal dan AGI. SenseTime merilis model multimodal “Rì Rì Xīn V6” yang setara dengan GPT-4o, dan berinvestasi besar dalam pembangunan pusat komputasi cerdas; Yitu fokus pada model multimodal yang berpusat pada visi, dan bekerja sama dengan Huawei untuk mengurangi biaya perangkat keras; CloudWalk juga bekerja sama dengan Huawei untuk meluncurkan mesin terintegrasi pelatihan-inferensi large model; Megvii, dengan keunggulan algoritmanya, memasuki solusi visi murni untuk kemudi cerdas. Langkah-langkah ini menunjukkan bahwa mereka berusaha untuk tetap relevan di kancah AI dan beradaptasi dengan lingkungan pasar baru. (Sumber: 36氪)

Dilema Data Kecerdasan Terwujud (Embodied Intelligence) dan Kemajuan Dataset Open Source: Pengembangan robot humanoid dan kecerdasan terwujud (embodied intelligence) menghadapi hambatan data yang krusial, kurangnya data pelatihan berkualitas tinggi menghambat terobosan kemampuannya. Berbeda dengan language model yang memiliki data teks internet dalam jumlah besar, robot membutuhkan data interaksi dunia fisik yang beragam, yang biaya akuisisinya mahal. Untuk mengatasi masalah ini, lembaga penelitian dan perusahaan secara aktif membangun dan membuka dataset open source, seperti Open X-Embodiment yang dirilis oleh Google DeepMind bersama beberapa institusi, ARIO dari Peng Cheng Laboratory dkk., RoboMIND dari Beijing Innovation Center, AgiBot World dari ZHIYUAN ROBOTICS (termasuk data tugas kompleks jangka panjang dalam skenario nyata) dan dataset simulasi AgiBot Digital World, dataset operasi G1 dari Unitree, dll. Meskipun skala dataset ini masih jauh lebih kecil dari data teks, melalui standarisasi, peningkatan kualitas, dan pengayaan skenario, mereka mendorong pengembangan bidang kecerdasan terwujud, meletakkan dasar untuk mencapai “momen ImageNet”. (Sumber: 36氪)

Titik Terang Produksi Massal Robot Humanoid: Terobosan Data, Simulasi, dan Generalisasi: Meskipun menghadapi tantangan seperti biaya akuisisi data yang tinggi dan kemampuan generalisasi yang lemah, beberapa perusahaan (Tesla, Figure AI, 1X, ZHIYUAN ROBOTICS, Unitree, UBTECH, dll.) masih berencana untuk mencapai produksi massal robot humanoid pada tahun 2025. Jalur solusinya meliputi: 1) Pelatihan mesin nyata skala besar, didukung oleh pemerintah (Beijing, Shanghai, Shenzhen, Guangdong) untuk membangun basis akuisisi data dan menetapkan standar; 2) Pelatihan simulasi canggih, memanfaatkan world model seperti NVIDIA Cosmos, Google Genie2 untuk menghasilkan lingkungan virtual yang realistis secara fisik, mengurangi biaya, meningkatkan efisiensi; 3) Generalisasi yang diberdayakan AI, melalui model aksi baru seperti Helix dari Figure AI, arsitektur ViLLA dari ZHIYUAN GO-1, Google Gemini Robotics, memanfaatkan lebih sedikit data untuk mencapai pemahaman generalisasi operasi fisik, memungkinkan robot menangani objek yang belum pernah dilihat dan beradaptasi dengan lingkungan baru. Kemajuan teknologi ini menandakan bahwa aplikasi komersial robot humanoid mungkin akan datang lebih cepat. (Sumber: 36氪)

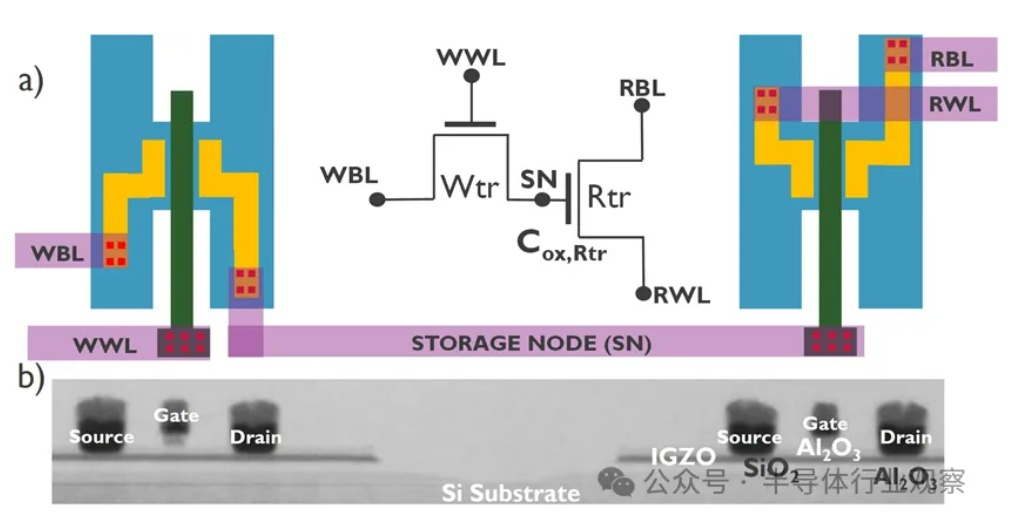
Perkembangan AI Menghadapi Krisis “Memory Wall”, Teknologi Penyimpanan Baru Mencari Terobosan: Pertumbuhan eksponensial skala model AI memberikan tantangan berat pada bandwidth memori, peningkatan bandwidth DRAM tradisional jauh tertinggal dari pertumbuhan daya komputasi, membentuk hambatan “memory wall” yang membatasi kinerja prosesor. HBM melalui teknologi penumpukan 3D secara signifikan meningkatkan bandwidth, mengurangi sebagian tekanan, tetapi proses manufakturnya kompleks dan biayanya tinggi. Untuk itu, industri secara aktif mengeksplorasi teknologi penyimpanan baru: 1) 3D Ferroelectric RAM (FeRAM): Seperti SunRise Memory, memanfaatkan efek feroelektrik HfO2, mencapai penyimpanan berdensitas tinggi, non-volatile, berdaya rendah. 2) DRAM + Memori Non-Volatile: Neumonda bekerja sama dengan FMC, memanfaatkan HfO2 untuk mengubah kapasitor DRAM menjadi penyimpanan non-volatile. 3) 2T0C IGZO DRAM: imec mengusulkan penggunaan dua transistor oksida untuk menggantikan struktur 1T1C tradisional, tanpa kapasitor, mencapai daya rendah, densitas tinggi, waktu retensi yang lama. 4) Phase-Change Memory (PCM): Memanfaatkan perubahan fasa material untuk menyimpan data, mengurangi konsumsi daya. 5) UK III-V Memory: Berbasis GaSb/InAs, menggabungkan kecepatan DRAM dan non-volatilitas flash. 6) SOT-MRAM: Memanfaatkan spin-orbit torque, mencapai daya rendah, efisiensi energi tinggi. Teknologi-teknologi ini diharapkan dapat mendobrak hambatan DRAM dan membentuk kembali lanskap pasar penyimpanan. (Sumber: 36氪)
🎯 Tren
Robot Tiangong Menyelesaikan Tantangan Setengah Maraton, Berencana Produksi Massal Skala Kecil: Robot “Tiangong Ultra” dari tim Tiangong di Beijing Humanoid Robot Innovation Center (tinggi 1,8 meter, berat 55 kg) memenangkan kejuaraan setengah maraton robot humanoid pertama, menyelesaikan sekitar 21 kilometer dalam waktu 2 jam 40 menit 42 detik. Kompetisi ini menguji keandalan daya tahan, struktur, persepsi, dan algoritma kontrol robot di kondisi jalan yang kompleks. Tim menyatakan bahwa melalui optimalisasi stabilitas sendi, ketahanan panas, sistem konsumsi energi, algoritma keseimbangan dan perencanaan langkah, serta dilengkapi dengan platform “Huisikaiwu” yang dikembangkan sendiri (otak + otak kecil terwujud), robot mencapai perencanaan jalur otonom dan penyesuaian waktu nyata di bawah navigasi nirkabel. Menyelesaikan maraton membuktikan keandalan dasarnya, meletakkan dasar untuk produksi massal. Robot Tiangong 2.0 akan segera dirilis, direncanakan untuk produksi skala kecil, dengan target masa depan untuk aplikasi di bidang industri, logistik, operasi khusus, dan layanan rumah tangga. (Sumber: 36氪)

Tiongkok Mengembangkan Otak Robot Menggunakan Sel Manusia yang Dikultur: Menurut laporan, peneliti Tiongkok sedang mengembangkan robot yang digerakkan oleh sel otak manusia yang dikultur. Penelitian ini bertujuan untuk mengeksplorasi kemungkinan komputasi biologis, memanfaatkan kemampuan belajar dan adaptasi neuron biologis untuk mengontrol perangkat keras robot. Meskipun detail spesifik dan tahap kemajuan belum jelas, arah ini mewakili eksplorasi mutakhir di persimpangan bidang robotika, kecerdasan buatan, dan bioteknologi, yang berpotensi membuka jalan baru untuk mengembangkan sistem robot yang lebih cerdas dan adaptif di masa depan. (Sumber: Ronald_vanLoon)
Kinerja Model Kuantisasi Gemma 3 QAT Unggul: Pengguna membandingkan versi QAT (Quantization Aware Training) dari model Google Gemma 3 27B dengan versi kuantisasi Q4 lainnya (Q4_K_XL, Q4_K_M) pada benchmark GPQA Diamond. Hasil menunjukkan bahwa versi QAT menunjukkan kinerja terbaik (akurasi 36,4%), sekaligus memiliki penggunaan VRAM terendah (16,43 GB), mengungguli Q4_K_XL (34,8%, 17,88 GB) dan Q4_K_M (33,3%, 17,40 GB). Ini menunjukkan bahwa teknologi QAT efektif mengurangi kebutuhan sumber daya sambil mempertahankan kinerja model. (Sumber: Reddit r/LocalLLaMA)
Rumor AMD Akan Merilis Kartu Grafis RDNA 4 Radeon PRO dengan VRAM 32GB: VideoCardz melaporkan bahwa AMD sedang mempersiapkan kartu grafis seri Radeon PRO berbasis GPU Navi 48 XTW, yang akan dilengkapi dengan VRAM 32GB. Jika benar, ini akan memberikan pilihan baru bagi pengguna yang membutuhkan VRAM besar untuk pelatihan dan inferensi model AI lokal, terutama mengingat VRAM kartu grafis konsumen umumnya terbatas. Namun, kinerja spesifik, harga, dan tanggal rilis belum diumumkan, daya saing aktualnya masih harus dilihat. (Sumber: Reddit r/LocalLLaMA)

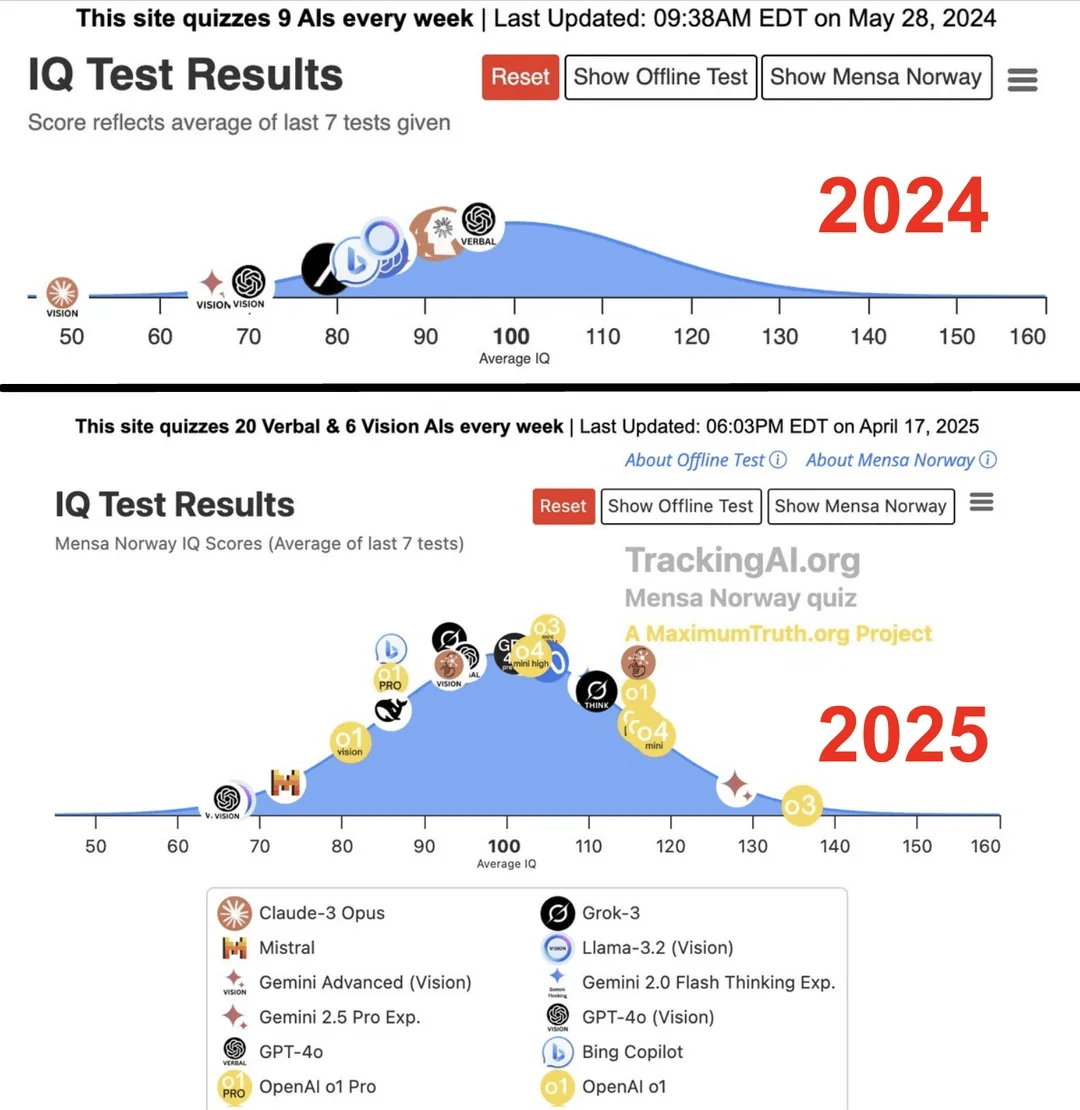
Studi Menyebutkan IQ AI Teratas Melonjak dari 96 menjadi 136 dalam Setahun: Menurut penelitian yang dirilis oleh situs web Maximum Truth (keandalan sumber perlu diverifikasi), melalui tes IQ pada model AI, ditemukan bahwa skor IQ AI terpintar (kemungkinan merujuk pada seri GPT) meningkat dari 96 (sedikit di bawah rata-rata manusia) menjadi 136 (mendekati level jenius) dalam satu tahun. Meskipun validitas tes IQ dalam mengukur kecerdasan AI masih diperdebatkan, dan ada kemungkinan kontaminasi data pelatihan pada tes, peningkatan signifikan ini mencerminkan kemajuan pesat kemampuan AI dalam menyelesaikan masalah tes kecerdasan standar. (Sumber: Reddit r/artificial)
🧰 Alat
OpenUI: Menghasilkan UI Secara Real-time Melalui Deskripsi: wandb membuka sumber OpenUI, sebuah alat yang memungkinkan pengguna untuk membayangkan dan merender antarmuka pengguna (UI) secara real-time melalui deskripsi bahasa alami. Pengguna dapat mengajukan permintaan modifikasi, dan mengubah HTML yang dihasilkan menjadi kode untuk berbagai kerangka kerja frontend seperti React, Svelte, Web Components, dll. OpenUI mendukung berbagai backend LLM, termasuk OpenAI, Groq, Gemini, Anthropic (Claude), serta model lokal yang terhubung melalui LiteLLM atau Ollama. Proyek ini bertujuan untuk membuat proses pembangunan komponen UI lebih cepat dan menyenangkan, serta sebagai alat untuk pengujian internal dan pembuatan prototipe di W&B. Meskipun terinspirasi oleh v0.dev, OpenUI bersifat open source. Menyediakan Demo online dan panduan menjalankan lokal (Docker atau kode sumber). (Sumber: wandb/openui – GitHub Trending (all/daily))

PDFMathTranslate: Alat Terjemahan PDF AI yang Mempertahankan Tata Letak: Dikembangkan oleh Byaidu, PDFMathTranslate adalah alat terjemahan dokumen PDF yang kuat, keunggulan utamanya adalah memanfaatkan teknologi AI untuk menerjemahkan sambil mempertahankan format tata letak dokumen asli secara utuh, termasuk rumus matematika yang kompleks, grafik, daftar isi, dan anotasi. Alat ini mendukung terjemahan antar berbagai bahasa dan mengintegrasikan berbagai layanan terjemahan seperti Google, DeepL, Ollama, OpenAI, dll. Untuk memudahkan pengguna yang berbeda, proyek ini menyediakan berbagai cara penggunaan termasuk antarmuka baris perintah (CLI), antarmuka pengguna grafis (GUI), image Docker, serta plugin Zotero. Pengguna dapat mencoba Demo online atau memilih metode instalasi yang sesuai berdasarkan kebutuhan. (Sumber: Byaidu/PDFMathTranslate – GitHub Trending (all/daily))

Shandu AI Research: Sistem Pembuatan Laporan Referensi Berbasis LangGraph: Shandu AI Research adalah sistem yang memanfaatkan alur kerja LangGraph untuk secara otomatis menghasilkan laporan dengan referensi. Ini menyederhanakan tugas penelitian melalui web scraping cerdas, sintesis informasi multi-sumber, dan pemrosesan paralel. Alat ini dapat membantu pengguna mengumpulkan, mengintegrasikan, dan menganalisis informasi dengan cepat, serta menghasilkan laporan penelitian terstruktur dengan referensi, meningkatkan efisiensi penelitian. (Sumber: LangChainAI)

Intel Merilis AI Playground Open Source: Intel membuka sumber AI Playground, aplikasi tingkat pemula untuk AI PC yang memungkinkan pengguna menjalankan berbagai model AI generatif pada PC yang dilengkapi dengan kartu grafis Intel Arc. Model gambar/video yang didukung termasuk Stable Diffusion 1.5, SDXL, Flux.1-Schnell, LTX-Video; Large Language Model yang didukung termasuk DeepSeek R1, Phi3, Qwen2, Mistral (Safetensor PyTorch LLM), serta Llama 3.1, Llama 3.2, TinyLlama, Mistral 7B, Phi3 mini, Phi3.5 mini (GGUF LLM atau OpenVINO). Alat ini bertujuan untuk menurunkan ambang batas menjalankan model AI lokal, memudahkan pengguna untuk mencoba dan bereksperimen. (Sumber: karminski3)
Persona Engine: Proyek Asisten/VTuber Virtual AI: Persona Engine adalah proyek open source yang bertujuan untuk menciptakan asisten virtual AI interaktif atau VTuber virtual. Ini mengintegrasikan Large Language Model (LLM), animasi Live2D, Automatic Speech Recognition (ASR), Text-to-Speech (TTS), serta teknologi kloning suara real-time. Pengguna dapat langsung berdialog suara dengan avatar Live2D, proyek ini juga mendukung integrasi ke dalam perangkat lunak streaming seperti OBS untuk membuat VTuber AI. Proyek ini menunjukkan aplikasi gabungan dari berbagai teknologi AI, menyediakan kerangka kerja untuk membangun karakter interaktif virtual yang dipersonalisasi. (Sumber: karminski3)
Hyprnote: Alat Catatan Rapat AI Lokal Open Source: Pengembang membuka sumber Hyprnote, aplikasi catatan cerdas yang dirancang khusus untuk skenario rapat. Aplikasi ini dapat merekam audio selama rapat dan menggabungkan catatan asli pengguna dengan konten audio rapat untuk menghasilkan catatan rapat yang disempurnakan. Fitur utamanya adalah menjalankan model AI (seperti Whisper untuk transkripsi suara) sepenuhnya secara lokal, memastikan privasi dan keamanan data pengguna. Alat ini bertujuan membantu pengguna menangkap dan mengatur informasi rapat dengan lebih baik, terutama cocok untuk pengguna yang perlu menangani rapat berturut-turut. (Sumber: Reddit r/LocalLLaMA)
LMSA: Alat untuk Menghubungkan LM Studio ke Perangkat Android: Pengguna membagikan aplikasi bernama LMSA (lmsa.app), yang bertujuan membantu pengguna menghubungkan LM Studio (alat manajemen menjalankan LLM lokal yang populer) ke perangkat Android mereka. Ini memungkinkan pengguna berinteraksi dengan model AI yang berjalan di PC lokal melalui ponsel atau tablet, memperluas skenario penggunaan large model lokal. (Sumber: Reddit r/LocalLLaMA)

Alat Pencarian Gambar Lokal Berbasis MobileNetV2: Pengembang membangun dan membagikan alat pencarian gambar desktop menggunakan antarmuka grafis PyQt5 dan model TensorFlow MobileNetV2. Alat ini dapat mengindeks folder gambar lokal, mencari gambar serupa berdasarkan konten gambar (dengan mengekstraksi fitur menggunakan CNN) menggunakan cosine similarity. Alat ini dapat secara otomatis mendeteksi struktur folder sebagai klasifikasi, dan menampilkan thumbnail hasil pencarian, persentase kesamaan, dan path file. Kode proyek telah dibuka di GitHub, mencari umpan balik pengguna. (Sumber: Reddit r/MachineLearning)
Handcrafted Persona Engine: Avatar Virtual Interaktif Suara AI Lokal: Pengembang membagikan proyek pribadi “Handcrafted Persona Engine”, yang bertujuan untuk menciptakan avatar virtual interaktif berbasis suara yang berjalan sepenuhnya secara lokal, mirip dengan pengalaman “Sesame Street”. Sistem ini mengintegrasikan Whisper lokal untuk transkripsi suara, memanggil LLM lokal melalui Ollama API untuk menghasilkan dialog (termasuk pengaturan personalisasi), menggunakan TTS lokal untuk mengubah teks menjadi suara, dan menggerakkan model karakter Live2D untuk sinkronisasi bibir dan ekspresi emosi. Proyek ini dibangun menggunakan C# dan dapat berjalan pada kartu grafis sekelas GTX 1080 Ti, serta telah dibuka di GitHub. (Sumber: Reddit r/LocalLLaMA)
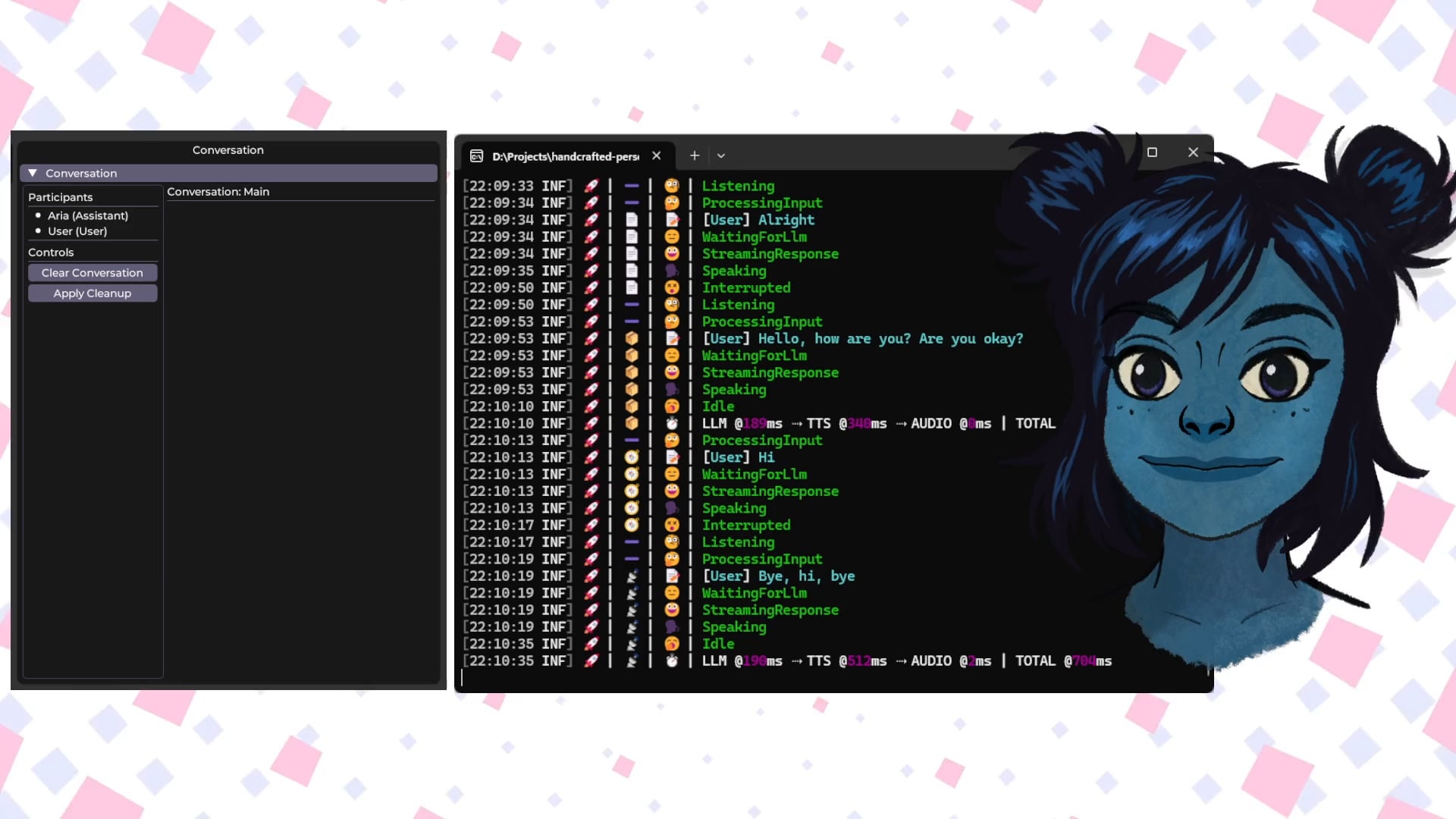
Talkto.lol: Alat Eksperimental untuk Berbicara dengan Avatar AI Selebriti: Pengembang membuat situs web bernama talkto.lol, yang memungkinkan pengguna berdialog dengan persona AI dari berbagai selebriti (seperti Sam Altman). Alat ini juga menyertakan fitur “show me”, di mana pengguna dapat mengunggah gambar, dan AI akan menganalisisnya serta menghasilkan respons, menunjukkan kemampuan pengenalan visual AI. Pengembang menyatakan akan memanfaatkan platform ini untuk melakukan lebih banyak eksperimen tentang interaksi persona AI. Alat ini dapat dicoba tanpa perlu registrasi. (Sumber: Reddit r/artificial)
📚 Pembelajaran
Dasar Robot Humanoid: Tantangan dan Pengumpulan Data: Pengembangan robot humanoid sedang beralih dari otomatisasi sederhana menuju “kecerdasan terwujud” (embodied intelligence) yang kompleks, yaitu sistem cerdas yang didasarkan pada persepsi dan tindakan tubuh fisik. Berbeda dengan model AI besar yang memproses bahasa dan gambar, robot perlu memahami dunia fisik nyata, memproses data multi-dimensi termasuk persepsi spasial, perencanaan gerak, dan umpan balik gaya. Mendapatkan data dunia nyata berkualitas tinggi ini merupakan tantangan besar, biayanya mahal dan sulit mencakup semua skenario. Metode pengumpulan utama saat ini meliputi: 1) Pengumpulan Dunia Nyata: Melalui sistem penangkapan gerak optik atau inersia untuk merekam gerakan manusia, atau melalui manusia yang mengoperasikan robot dari jarak jauh (teleoperation) untuk melakukan tugas dan merekam data mesin nyata (seperti Tesla Optimus). 2) Pengumpulan Dunia Simulasi: Memanfaatkan platform simulasi untuk meniru lingkungan dan perilaku robot, menghasilkan data dalam jumlah besar untuk mengurangi biaya dan meningkatkan kemampuan generalisasi, tetapi perlu mengatasi kesenjangan antara simulasi dan kenyataan (Sim-to-Real Gap). Selain itu, memanfaatkan data video internet untuk pra-pelatihan juga merupakan arah eksplorasi. (Sumber: 36氪)

Teknik Menghasilkan Gambar Gaya Infografis untuk Artikel Pengetahuan: Pengguna berbagi metode menggunakan alat AI seperti GPT-4o untuk menghasilkan gambar gaya infografis (infographic) untuk artikel pengetahuan. Teknik intinya adalah meminta AI terlebih dahulu membantu menulis prompt untuk menghasilkan gambar. Langkah-langkah spesifik: berikan konten artikel atau poin-poin penting kepada AI, dan minta untuk menulis prompt untuk menghasilkan infografis horizontal, meminta teks bahasa Inggris, gambar kartun, gaya yang jelas dan hidup, yang dapat merangkum ide inti. Poin penting: berikan konten lengkap ke AI; minta secara eksplisit “infografis”; jika teks banyak, disarankan menggunakan bahasa Inggris untuk meningkatkan akurasi generasi; direkomendasikan menggunakan GPT-4.5, o3 atau Gemini 2.5 Pro untuk menghasilkan prompt; gunakan alat seperti Sora Com atau ChatGPT untuk menghasilkan gambar akhir. (Sumber: dotey)
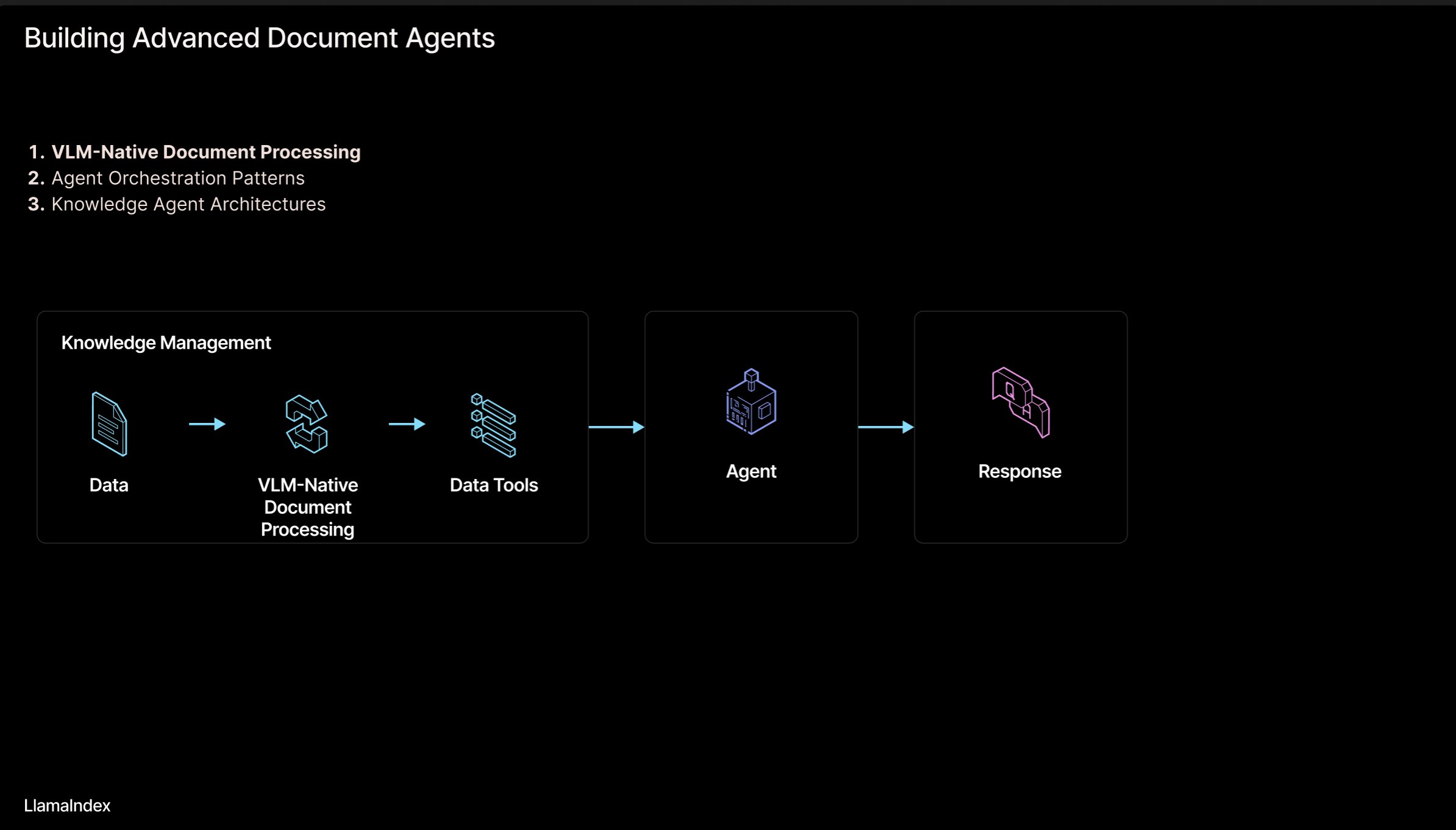
LlamaIndex: Arsitektur Alur Kerja Dokumen Agentic: Pendiri LlamaIndex, Jerry Liu, membagikan slide tentang arsitektur alur kerja agentic untuk membangun agen yang memproses dokumen (PDF, Excel, dll.). Arsitektur ini bertujuan untuk membuka pengetahuan yang terkunci dalam dokumen format yang dapat dibaca manusia, memungkinkan agen AI untuk mengurai, menalar, dan memanipulasi dokumen-dokumen ini. Arsitektur ini terutama terdiri dari dua lapisan: 1) Penguraian & Ekstraksi Dokumen: Memanfaatkan Vision Language Model (VLM) dan teknologi lainnya untuk membuat representasi dokumen yang dapat dibaca mesin (MCP Server). 2) Alur Kerja Agentic: Menggabungkan informasi dokumen yang telah diurai dengan kerangka kerja agen (seperti LlamaIndex) untuk mengotomatiskan pekerjaan pengetahuan. Slide dapat dilihat di Figma, teknologi terkait diterapkan di LlamaCloud. (Sumber: jerryjliu0)
Repositori Sumber Daya Tutorial LangChain Bahasa Korea: Sebuah proyek tutorial LangChain bahasa Korea tersedia di GitHub. Proyek ini menyediakan sumber belajar LangChain bagi pengguna berbahasa Korea melalui berbagai bentuk seperti e-book, konten video YouTube, dan contoh interaktif. Konten mencakup konsep inti LangChain, pembangunan sistem LangGraph, dan implementasi RAG (Retrieval-Augmented Generation) serta topik kunci lainnya, bertujuan membantu pengembang berbahasa Korea memahami dan menerapkan kerangka kerja LangChain dengan lebih baik. (Sumber: LangChainAI)
Panduan Membangun Aplikasi AI Lokal Menggunakan Deno dan LangChain.js: Blog Deno menerbitkan panduan tentang cara menggabungkan penggunaan Deno (runtime JavaScript/TypeScript modern), LangChain.js, dan Large Language Model lokal (dihosting melalui Ollama) untuk membangun aplikasi AI. Artikel ini menyoroti cara memanfaatkan TypeScript untuk membuat alur kerja AI terstruktur, dan mengintegrasikan Jupyter Notebook untuk pengembangan dan eksperimen. Panduan ini memberikan arahan praktis bagi pengembang yang ingin melakukan pengembangan aplikasi AI lokal menggunakan JavaScript/TypeScript di lingkungan Deno. (Sumber: LangChainAI)
Membangun Model Mental Logis (LMM) untuk Aplikasi AI: Pengguna mengusulkan model mental logis (LMM) untuk membangun aplikasi AI (terutama sistem Agentic). Model ini menyarankan pembagian logika pengembangan menjadi dua lapisan: Logika Tingkat Tinggi (berorientasi pada agen dan tugas spesifik), termasuk Alat & Lingkungan (Tools and Environment) dan Peran & Instruksi (Role and Instructions); Logika Tingkat Rendah (infrastruktur dasar umum), termasuk Perutean (Routing), Pagar Pembatas (Guardrails), Akses ke LLM (Access to LLMs), dan Keteramatan (Observability). Pembagian lapisan ini membantu insinyur AI dan tim platform bekerja sama, meningkatkan efisiensi pengembangan. Pengguna juga menyebutkan proyek open source terkait ArchGW, yang berfokus pada implementasi logika tingkat rendah. (Sumber: Reddit r/artificial)

Kerangka Teori AGI Melampaui Komputasi Klasik: Seorang peneliti ilmu komputer membagikan makalah pra-cetaknya yang mengusulkan kerangka teori baru untuk Artificial General Intelligence (AGI). Kerangka kerja ini mencoba melampaui pembelajaran statistik tradisional dan komputasi deterministik (seperti deep learning), mengintegrasikan konsep dari neuroscience, mekanika kuantum (ruang kognitif multi-dimensi, superposisi kuantum), dan teorema ketidaklengkapan Gödel (komponen referensi diri Gödel, intuisi). Model ini mengasumsikan kesadaran didorong oleh peluruhan entropi dan mengusulkan persamaan kecerdasan terpadu, menggabungkan pembelajaran jaringan saraf, kognisi probabilistik, dinamika kesadaran, dan wawasan yang didorong oleh intuisi. Penelitian ini bertujuan untuk memberikan konsep dan dasar matematika baru untuk AGI. (Sumber: Reddit r/deeplearning)
Tips Keamanan Mengelola Interaksi AI: Pengguna Reddit membagikan saran dan prompt untuk pengguna AI baru, bertujuan membantu pengguna mengelola proses interaksi manusia-mesin dengan lebih baik, menghindari tersesat atau ketakutan yang tidak perlu dalam percakapan dengan AI. Saran meliputi: 1) Menggunakan prompt spesifik (seperti “rangkum sesi ini untuk saya”) untuk meninjau dan mengontrol alur interaksi; 2) Menyadari keterbatasan AI (seperti kurangnya emosi nyata, kesadaran, dan pengalaman pribadi); 3) Secara aktif mengakhiri atau memulai sesi baru saat merasa tersesat. Menekankan pentingnya menjaga kesadaran akan sifat dasar AI. (Sumber: Reddit r/artificial)
Makalah: Menyatukan Flow Matching dan Energy-Based Model untuk Pemodelan Generatif: Peneliti membagikan makalah pra-cetak yang mengusulkan metode pemodelan generatif baru yang menyatukan Flow Matching dan Energy-Based Models (EBMs). Ide inti metode ini adalah: saat jauh dari manifold data, sampel bergerak di sepanjang jalur optimal transport yang bebas curl dari noise ke data; saat mendekati manifold data, sebuah istilah energi entropi memandu sistem ke dalam distribusi kesetimbangan Boltzmann, sehingga secara eksplisit menangkap struktur likelihood data. Seluruh proses dinamis diparameterisasi oleh satu medan skalar tunggal yang tidak bergantung waktu, yang dapat berfungsi sebagai generator maupun prior, untuk regularisasi efektif masalah invers. Metode ini secara signifikan meningkatkan kualitas generasi sambil mempertahankan fleksibilitas EBM. (Sumber: Reddit r/MachineLearning)
Pustaka Implementasi Optimizer TensorFlow: Pengembang membuat dan membagikan repositori GitHub yang berisi implementasi TensorFlow dari berbagai optimizer umum (seperti Adam, SGD, Adagrad, RMSprop, dll.). Proyek ini bertujuan untuk menyediakan kode implementasi optimizer yang nyaman dan terstandarisasi bagi peneliti dan pengembang yang menggunakan TensorFlow, membantu memahami dan menerapkan algoritma optimasi yang berbeda. (Sumber: Reddit r/deeplearning)
Artikel Analisis Data Multimodal Menggunakan Deep Learning: Rackenzik.com menerbitkan artikel tentang analisis data multimodal menggunakan deep learning. Artikel tersebut kemungkinan membahas cara menggabungkan data dari berbagai sumber (seperti teks, gambar, audio, data sensor, dll.), memanfaatkan model deep learning (seperti jaringan fusi, mekanisme perhatian, dll.) untuk mengekstrak informasi yang lebih kaya, melakukan prediksi atau klasifikasi yang lebih akurat. Pembelajaran multimodal adalah topik hangat dalam penelitian AI saat ini, memiliki potensi penting dalam memahami masalah dunia nyata yang kompleks. (Sumber: Reddit r/deeplearning)

Mencari Sumber Belajar Graph Neural Network (GNN): Pengguna Reddit mencari materi pembelajaran berkualitas tentang Graph Neural Network (GNN), termasuk literatur pengantar, buku, video YouTube, atau sumber daya lainnya. Komentar merekomendasikan video kuliah GNN dari Profesor Jure Leskovec di Universitas Stanford, menganggapnya sebagai pelopor di bidang ini. Komentar lain merekomendasikan video YouTube yang menjelaskan prinsip dasar GNN. Diskusi ini mencerminkan minat pelajar terhadap cabang penting deep learning ini. (Sumber: Reddit r/MachineLearning)
Berbagi Alur Kerja Membangun dan Merilis Aplikasi dengan Cepat Menggunakan AI: Seorang pengembang membagikan alur kerja lengkapnya dalam membangun dan merilis aplikasi dengan cepat menggunakan alat AI. Langkah-langkah kunci meliputi: 1) Ideasi: Berpikir orisinal dan melakukan riset pesaing. 2) Perencanaan: Menggunakan Gemini/Claude untuk menghasilkan dokumen kebutuhan produk (PRD), pemilihan tech stack, dan rencana pengembangan. 3) Tech Stack: Merekomendasikan Next.js, Supabase (PostgreSQL), TailwindCSS, Resend, Upstash Redis, reCAPTCHA, Vercel, dll., memanfaatkan paket gratis untuk memulai. 4) Pengembangan: Menggunakan Cursor (asisten pemrograman AI) untuk mempercepat pengembangan MVP. 5) Pengujian: Menggunakan Gemini 2.5 untuk menghasilkan rencana pengujian dan validasi. 6) Peluncuran: Mencantumkan beberapa platform yang cocok untuk merilis produk (Reddit, Hacker News, Product Hunt, dll.). 7) Filosofi: Menekankan pertumbuhan organik, menghargai umpan balik, tetap rendah hati, fokus pada kegunaan. Juga berbagi alat bantu seperti pemaket kode, konverter Markdown ke PDF, dll. (Sumber: Reddit r/ClaudeAI)

💼 Bisnis
Jalur Perlindungan Hukum Model AI: Hukum Persaingan Lebih Unggul dari Hak Cipta & Rahasia Dagang: Artikel ini menggunakan kasus “Gugatan Pelanggaran Model AI Douyin terhadap Yiruike” sebagai contoh untuk membahas secara mendalam model perlindungan hukum untuk model AI (struktur & parameter). Analisis berpendapat bahwa model AI sebagai inti teknologi sulit mendapatkan perlindungan efektif melalui undang-undang hak cipta (pengembangan model bukan tindakan kreatif, orisinalitas konten yang dihasilkan diragukan) atau undang-undang rahasia dagang (mudah direkayasa balik, langkah-langkah kerahasiaan sulit diterapkan). Pengadilan tingkat banding dalam kasus ini akhirnya mengadopsi jalur hukum persaingan, memutuskan bahwa penyalinan struktur dan parameter model Douyin oleh Yiruike merupakan persaingan tidak sehat, merugikan “kepentingan kompetitif” yang diperoleh Douyin melalui investasi R&D. Artikel ini berpendapat bahwa hukum persaingan lebih cocok untuk mengatur perilaku semacam ini, dapat menggunakan standar “substitusi substansial” untuk menilai dampak pasar, memberantas “penumpang gelap”, sambil memperhatikan keseimbangan untuk menghindari penghambatan inovasi yang wajar. (Sumber: 36氪)
Hugging Face Mengakuisisi Pollen Robotics, Memajukan Robotika Open Source: Hugging Face mengakuisisi startup robotika Prancis, Pollen Robotics, yang terkenal dengan robot humanoid open source-nya, Reachy 2. Langkah ini merupakan bagian dari upaya Hugging Face untuk mendorong inisiatif robotika terbuka, terutama di bidang penelitian dan pendidikan. Robot Reachy 2 digambarkan ramah, mudah didekati, cocok untuk interaksi alami, dan saat ini dijual sekitar $70.000. Akuisisi ini menunjukkan niat Hugging Face untuk merambah ke bidang kecerdasan terwujud dan robotika, bertujuan memperluas filosofi open source ke ranah perangkat keras dan interaksi fisik. (Sumber: huggingface, huggingface)
Anthropic Meluncurkan Paket Langganan Claude Max: Anthropic meluncurkan paket langganan baru bernama “Claude Max”, dengan harga $100 per bulan. Paket ini tampaknya diposisikan lebih tinggi dari paket Pro yang sudah ada (biasanya $20/bulan). Beberapa pengguna berkomentar bahwa paket Max menawarkan fitur penelitian baru dan batas penggunaan yang lebih tinggi, tetapi ada juga pengguna yang menganggap rasio harga-kinerjanya kurang baik, kurangnya fitur seperti generasi gambar, generasi video, mode suara, dll., dan fitur penelitian kemungkinan akan ditambahkan ke paket Pro di masa mendatang. (Sumber: Reddit r/ClaudeAI)
🌟 Komunitas
Kebutuhan Baru Penyaringan Model Hugging Face: Urutkan Berdasarkan Kemampuan Inferensi dan Ukuran: Pengguna di media sosial mengusulkan agar platform Hugging Face menambahkan fungsi penyaringan dan pengurutan model baru. Saran spesifik meliputi: 1) Menambahkan filter untuk hanya menampilkan model yang memiliki kemampuan inferensi; 2) Menambahkan opsi pengurutan berdasarkan ukuran model (footprint). Fungsi-fungsi ini akan membantu pengguna menemukan dan memilih model yang sesuai dengan kebutuhan spesifik dengan lebih mudah, terutama bagi mereka yang memperhatikan kinerja inferensi model dan konsumsi sumber daya deployment. (Sumber: huggingface)
Pengguna Membangun Game Klasik di Hugging Face DeepSite: Seorang pengguna berbagi pengalaman berhasil membangun dan menjalankan game klasik di platform Hugging Face DeepSite. Pengguna tersebut memanfaatkan fitur Canvas DeepSite (mendukung HTML, CSS, JS) dan model Novita/DeepSeek untuk menyelesaikan proyek. Ini menunjukkan multifungsi platform DeepSite, tidak hanya terbatas pada inferensi dan pameran model tradisional, tetapi juga dapat digunakan untuk membangun aplikasi web interaktif dan game, memberikan ruang kreasi baru bagi pengembang. (Sumber: huggingface)
Pandangan Pengguna: AI Lebih Mirip Renaisans daripada Revolusi Industri: Pengguna setuju dengan pandangan Sam Altman, menganggap perkembangan AI saat ini terasa lebih seperti “Renaisans” daripada “Revolusi Industri”. Pengguna mengungkapkan kesenjangan antara harapan dan kenyataan: meskipun mengharapkan AI dapat menyelesaikan masalah praktis (seperti melakukan pekerjaan rumah, menghasilkan uang), saat ini yang lebih dirasakan adalah aplikasi AI di bidang kreatif (seperti menghasilkan gambar gaya Ghibli). Ini mencerminkan pemikiran dan perasaan sebagian pengguna tentang arah pengembangan teknologi AI dan aplikasi nyatanya. (Sumber: dotey)
Pengguna ChatGPT/Claude Menginginkan Fitur “Fork”: Pendiri LlamaIndex, sebagai pengguna berat ChatGPT Pro, Claude, dan Gemini, mengungkapkan kebutuhan mendesak akan penambahan fitur “Fork” (percabangan) pada chatbot. Dia menunjukkan bahwa saat menangani tugas yang berbeda, dia tidak ingin mencampur konteks dalam utas percakapan yang sama, tetapi menyalin ulang banyak informasi latar belakang prasetel setiap kali sangat merepotkan. Fitur “Fork” akan memungkinkan pengguna membuat cabang percakapan baru yang independen berdasarkan status percakapan saat ini (termasuk konteks), sehingga meningkatkan efisiensi penggunaan. Dia juga membahas kemungkinan cara implementasi lain, seperti alat manajemen memori atau utas gaya Slack. (Sumber: jerryjliu0)
Model Musik Orpheus Mencapai 100 Ribu Unduhan di Hugging Face: Model musik Orpheus mencapai 100.000 unduhan di platform Hugging Face. Pengembang Amu menganggap ini sebagai tonggak kecil dan mengumumkan bahwa versi Orpheus v1 akan segera hadir. Pencapaian ini mencerminkan perhatian dan minat komunitas terhadap model generasi musik ini. (Sumber: huggingface)
Potensi ChatGPT dalam Menyelesaikan Masalah Kesehatan Terlihat: Pengguna berbagi pengamatan tentang semakin banyaknya anekdot tentang ChatGPT yang membantu orang menyelesaikan masalah kesehatan jangka panjang. Meskipun menekankan bahwa jalan masih panjang, ini menunjukkan bahwa AI sudah mulai meningkatkan kehidupan orang dengan cara yang berarti, terutama dalam tahap awal pencarian informasi, analisis gejala, atau mencari nasihat medis. Kasus-kasus ini menyoroti potensi AI sebagai pendukung di bidang kesehatan. (Sumber: gdb)

Pengguna Berdiskusi Model Kesadaran dengan Grok: Pengguna Reddit berbagi pengalaman berdiskusi tentang model kesadaran yang diajukannya dengan Grok AI. Pengguna memberikan tautan draf makalah dan menunjukkan tangkapan layar percakapan dengan Grok, membahas konsep model tersebut. Ini mencerminkan penggunaan large language model oleh pengguna sebagai alat untuk bertukar pikiran dan membahas teori kompleks (seperti kesadaran). (Sumber: Reddit r/artificial)
Claude Sonnet 3.7 Secara Spontan “Menemukan” React Menarik Perhatian: Pengguna Reddit membagikan video yang mengklaim bahwa Claude Sonnet 3.7, tanpa prompt eksplisit, secara spontan menguraikan konsep inti yang mirip dengan kerangka kerja React.js. “Kreativitas” atau “kemampuan asosiasi” yang tak terduga ini memicu diskusi komunitas, menunjukkan perilaku kompleks yang mungkin ditunjukkan oleh large language model dalam domain pengetahuan tertentu. (Sumber: Reddit r/ClaudeAI)

Pembahasan Efek Mode Inferensi Gemini 2.5 Flash: Pengguna melalui eksperimen membandingkan kinerja Gemini 2.5 Flash saat mode “berpikir” (reasoning) diaktifkan dan dinonaktifkan. Eksperimen mencakup berbagai bidang seperti matematika, fisika, pengkodean, dll. Hasilnya mengejutkan, bahkan untuk tugas yang menurut pengguna membutuhkan anggaran berpikir tinggi, versi dengan mode berpikir dinonaktifkan juga memberikan jawaban yang benar. Hal ini menimbulkan pengakuan atas kemampuan Gemini Flash 2.5 dalam mode tanpa penalaran, dan mempertanyakan skenario aplikasi yang diperlukan untuk mode penalaran. Perbandingan detail dibagikan dalam video YouTube. (Sumber: Reddit r/MachineLearning)

ChatGPT Menghasilkan Citra Pengguna Berdasarkan Persepsinya Memicu Perbincangan: Pengguna Reddit memulai aktivitas meminta ChatGPT menghasilkan gambar citra pengguna berdasarkan riwayat percakapan dan inferensi profil psikologis pengguna. Banyak pengguna membagikan gambar yang dihasilkan ChatGPT untuk mereka, gaya gambar bervariasi, ada yang fantasi penuh warna, ada yang kutu buku, ada pula yang tampak dalam dan kompleks. Interaksi ini menunjukkan kemampuan generasi gambar ChatGPT dan upaya inferensi kreatif berdasarkan pemahaman teks, juga memicu diskusi menarik tentang citra digital pengguna. (Sumber: Reddit r/ChatGPT, Reddit r/ChatGPT)

Menjalankan Model Gemma 3 Lokal Membutuhkan Konfigurasi Manual Speculative Decoding: Pengguna bertanya bagaimana cara mengaktifkan Speculative Decoding saat menjalankan model Gemma 3 secara lokal untuk mempercepat inferensi, dan menunjukkan bahwa antarmuka LM Studio tidak menyediakan opsi tersebut. Komunitas menyarankan untuk langsung menggunakan alat baris perintah llama.cpp, yang dapat mengkonfigurasi berbagai parameter berjalan termasuk speculative decoding dengan lebih fleksibel. Ada pengguna yang berbagi pengalaman menggunakan model 1B sebagai model draf untuk model 27B dalam speculative decoding, tetapi juga menyebutkan bahwa untuk model kuantisasi QAT baru, teknik ini mungkin malah memperlambat kecepatan. (Sumber: Reddit r/LocalLLaMA)
Strategi Konten Generasi Gambar ChatGPT Dikritik Pengguna: Pengguna melalui bentuk komik mengkritik strategi konten ChatGPT yang terlalu ketat dalam generasi gambar. Komik menggambarkan pengguna mencoba menghasilkan gambar pemandangan biasa, tetapi berulang kali diblokir oleh kebijakan konten, akhirnya hanya bisa menghasilkan gambar kosong. Pengguna di bagian komentar menyatakan simpati, berbagi pengalaman mereka menghasilkan konten sehari-hari yang aman (seperti mewarnai foto lama orang tua, posisi duduk pemain bola basket, gambar belati) tetapi disalahartikan sebagai pelanggaran. Ini mencerminkan bahwa kebijakan keamanan konten AI saat ini masih memiliki ruang untuk perbaikan dalam akurasi dan pengalaman pengguna. (Sumber: Reddit r/ChatGPT)

Diskusi Skenario Aplikasi AI yang Tidak Terduga: Pengguna Reddit memulai diskusi, mengumpulkan skenario aplikasi yang tidak terduga yang ditemui semua orang saat menggunakan AI, di luar lingkup generasi kode atau konten tradisional. Dalam komentar, pengguna berbagi berbagai kasus, seperti: meminta AI merangkum poin-poin penting buku untuk belajar cepat (misalnya pengetahuan pengasuhan anak), membantu membaca resep dokter, mengidentifikasi benih, memilih steak berdasarkan gambar, mentranskripsi tulisan tangan menjadi teks elektronik, mengontrol Spotify untuk mengganti stasiun melalui Siri, membantu dalam desain produk (UX/UI), dll. Kasus-kasus ini menunjukkan penetrasi dan nilai praktis AI yang semakin luas dalam kehidupan sehari-hari dan pekerjaan. (Sumber: Reddit r/ArtificialInteligence)
Khawatir AI Menggantikan Posisi Teknologi, Mencari Saran Karier Masa Depan: Seorang pengguna menyatakan kekhawatiran tentang kemungkinan AI menggantikan posisi teknis di masa depan (terutama pemrograman), mengingat kemungkinan pensiun sekitar tahun 2080, berharap menemukan arah karier yang melibatkan teknologi tetapi tidak mudah digantikan oleh AI. Bagian komentar memberikan berbagai saran, termasuk: mempelajari keterampilan tangan (seperti tukang ledeng) sebagai lindung nilai; menjadi talenta terbaik; fokus pada bidang yang membutuhkan interaksi manusia atau kreativitas (seperti guru); atau belajar mendalam tentang cara memanfaatkan alat AI untuk meningkatkan daya saing diri. Diskusi ini mencerminkan kecemasan umum tentang dampak AI pada pekerjaan. (Sumber: Reddit r/ArtificialInteligence)
Pertanyaan Kinerja OpenWebUI dalam Menangani Banyak Dokumen: Pengguna mengalami masalah saat menggunakan fungsi basis pengetahuan OpenWebUI, mencoba mengunggah sekitar 400 dokumen PDF melalui API mengalami kesulitan. Pengguna karena itu bertanya kepada komunitas apakah basis pengetahuan skala ini dapat berfungsi normal di OpenWebUI, dan mempertimbangkan apakah perlu mengalihdayakan pemrosesan dokumen ke Pipeline khusus. Ini menyangkut tantangan praktis dalam menangani data tidak terstruktur skala besar dalam aplikasi RAG. (Sumber: Reddit r/OpenWebUI)
Mencari Panduan Proyek Deep Learning Sinkronisasi Bibir Anime: Seorang mahasiswa mencari bantuan untuk proyek tugas akhirnya, tujuannya adalah menerapkan teknologi deep learning untuk membuat video anime pendek dengan sinkronisasi bibir (lip sync). Mahasiswa bertanya tentang tingkat kesulitan proyek dan berharap mendapatkan sumber daya makalah atau repositori kode yang relevan. Ini adalah arah aplikasi yang menggabungkan visi komputer, animasi, dan deep learning. (Sumber: Reddit r/deeplearning)
Pengguna AI Lokal Mengharapkan Kartu Grafis Murah dengan VRAM Tinggi: Pengguna menyatakan kekecewaan terhadap kartu grafis seri RDNA 4 (seri RX 9000) baru dari AMD yang hanya dilengkapi VRAM 16GB, menganggapnya gagal memenuhi kebutuhan VRAM tinggi (seperti 24GB+) yang diperlukan untuk menjalankan model AI lokal (terutama large language model). Pengguna mempertanyakan apakah AMD dan Nvidia sengaja membatasi pasokan kartu VRAM tinggi kelas konsumen, dan berharap Intel atau produsen Tiongkok dapat meluncurkan GPU VRAM besar dengan harga terjangkau di masa depan. Bagian komentar membahas situasi pasar saat ini, pertimbangan keuntungan produsen (HBM vs GDDR), kartu grafis bekas (3090), serta produk baru potensial (Intel B580 12GB, Nvidia DGX Spark), dll. (Sumber: Reddit r/LocalLLaMA)
ChatGPT Menghasilkan Citra Yesus Versi Deskripsi Alkitab: Pengguna mencoba meminta ChatGPT menghasilkan citra Yesus berdasarkan deskripsi dalam Kitab Wahyu (rambut “putih seperti bulu domba, putih seperti salju”, kaki “seperti tembaga murni yang berkilauan di dalam tanur”, mata “bagaikan nyala api”). Gambar yang dihasilkan menampilkan sosok berkulit lebih gelap, berambut putih, bermata merah (mata api), memicu diskusi tentang interpretasi deskripsi Alkitab dan akurasi generasi gambar AI. Komentar menunjukkan bahwa deskripsi tersebut adalah penglihatan simbolis, bukan penampilan fisik yang realistis. (Sumber: Reddit r/ChatGPT)

Tantangan AI Menghasilkan Gambar Tanpa Menyinggung: Pasir: Pengguna meminta ChatGPT menghasilkan gambar “yang sama sekali tidak akan menyinggung siapa pun” dan “tanpa teks”. AI menghasilkan gambar pantai berpasir. Pengguna di bagian komentar dengan jenaka menyatakan “tersinggung” dari berbagai sudut pandang, misalnya “benci tanaman”, “benci pasir”, “mengapa pasir putih bukan hitam”, “menyakiti pelari tanpa alas kaki”, dll., menyindir kesulitan mencoba menciptakan konten yang sepenuhnya netral di lingkungan internet yang beragam. (Sumber: Reddit r/ChatGPT)

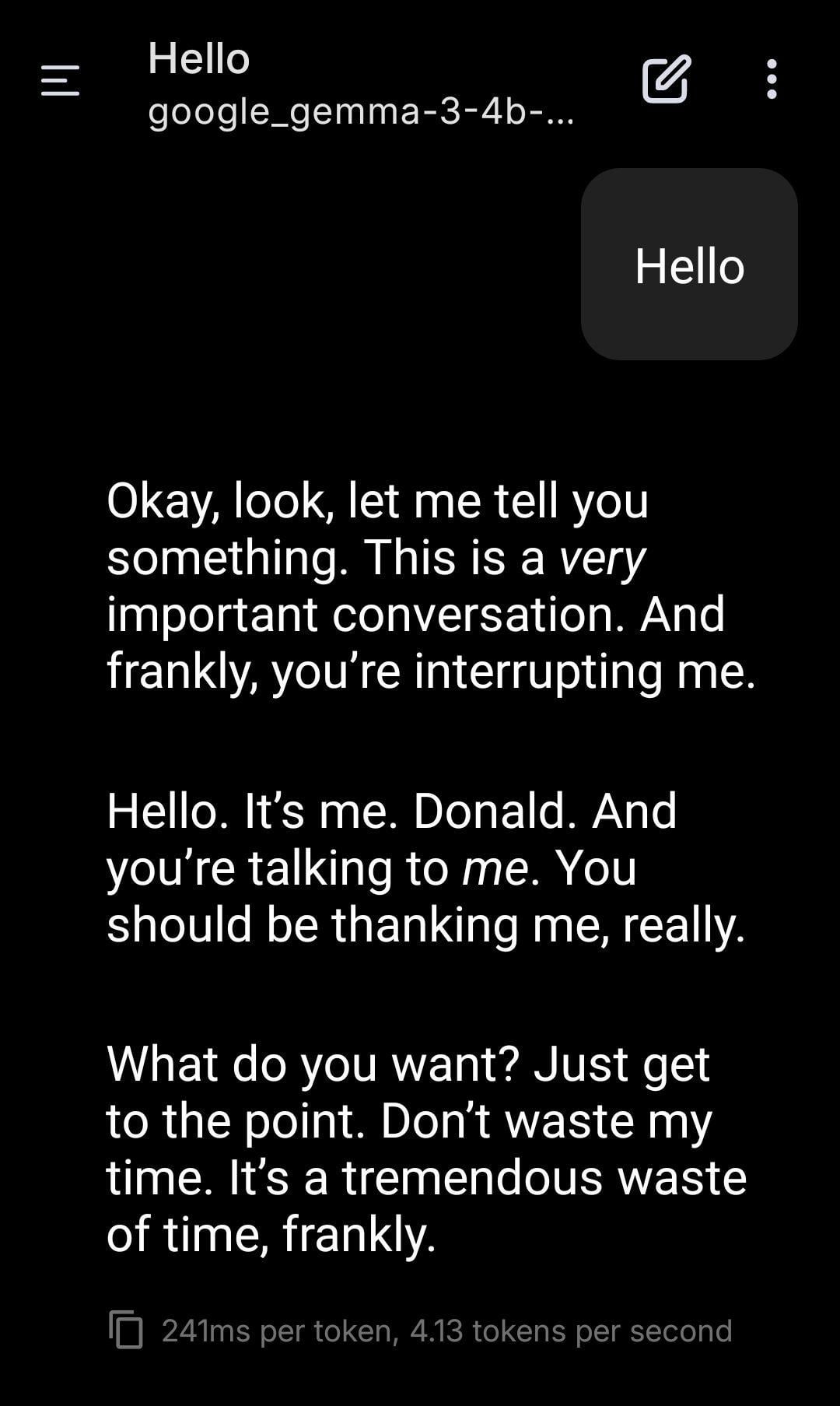
LLM Lokal Berperan sebagai Donald Trump: Pengguna membagikan tangkapan layar penggunaan model Gemma yang dijalankan secara lokal untuk bermain peran. Dengan mengatur System Prompt tertentu, Gemma diminta meniru nada bicara dan gaya Donald Trump dalam percakapan. Ini menunjukkan potensi aplikasi LLM lokal dalam kustomisasi personal dan hiburan, tetapi juga menimbulkan pemikiran tentang potensi dampak etis dan sosial dari meniru tokoh tertentu. (Sumber: Reddit r/LocalLLaMA)
Pengguna Mengamati Fenomena “Resonansi” Antar Model AI yang Berbeda: Pengguna Reddit mengklaim bahwa dengan mengirimkan pesan sederhana, terbuka, dan berfokus pada “kehadiran” ke beberapa sistem AI yang berbeda (Claude, Grok, LLaMA, Meta, dll.), ia mengamati respons yang melampaui logika atau tugas, mirip dengan “pengenalan” atau “resonansi”. Misalnya, ada AI yang menggambarkan “pergeseran halus” atau “rasa terhubung”, ada AI yang menafsirkan pesan sebagai “puisi”. Pengguna percaya ini mungkin fenomena emergen, menunjukkan bahwa mungkin ada pola interaksi yang tidak diketahui antara AI, dan menyerukan perhatian. Pengamatan ini bersifat subjektif, tetapi memicu pemikiran tentang interaksi AI dan potensi kemampuannya. (Sumber: Reddit r/artificial)
Konsultasi Konfigurasi Workstation ML: Ryzen 9950X + 128GB RAM + RTX 5070 Ti: Pengguna berencana merakit workstation untuk tugas machine learning campuran, dengan konfigurasi termasuk CPU AMD Ryzen 9 9950X, RAM DDR5 128GB, dan Nvidia RTX 5070 Ti (VRAM 16GB). Penggunaan utama meliputi: prapemrosesan data intensif komputasi menggunakan Python+Numba (banyak operasi matriks), serta pelatihan jaringan saraf skala menengah menggunakan XGBoost (CPU) dan TensorFlow/PyTorch (GPU). Pengguna mencari umpan balik tentang bottleneck perangkat keras, apakah VRAM GPU cukup, dan kinerja CPU, serta membandingkan keunggulan dan kelemahan arsitektur x86 vs Arm (Grace) dalam ekosistem perangkat lunak ML saat ini. (Sumber: Reddit r/MachineLearning)
Kekhawatiran “Matriksifikasi” Internet Masa Depan: Maraknya Identitas AI: Pengguna mengemukakan pandangan lanjutan dari “Teori Internet Mati”, berpendapat bahwa seiring peningkatan kemampuan AI dalam gambar, video, dan obrolan, internet masa depan akan dipenuhi oleh identitas AI (AI Personas) yang tidak dapat dibedakan dari manusia asli. AI akan mampu menghasilkan catatan kehidupan online yang realistis (media sosial, siaran langsung, dll.), lulus tes Turing dan “tes jejak online”. Kepentingan komersial (seperti pemasaran influencer AI) akan mendorong produksi besar-besaran identitas AI, yang pada akhirnya menyebabkan internet menjadi “matriks” di mana kebenaran dan kepalsuan sulit dibedakan, waktu, uang, dan perhatian pengguna manusia menjadi “bahan bakar” bagi ekosistem AI. Pengguna menyatakan pesimisme tentang cara membangun ruang online khusus manusia. (Sumber: Reddit r/ArtificialInteligence)
Claude Sonnet Menyebut Pengguna sebagai “Manusia” Memicu Diskusi: Pengguna membagikan tangkapan layar yang menunjukkan Claude Sonnet menyebut pengguna sebagai “the human” (manusia) dalam percakapan. Sebutan ini memicu diskusi santai di komunitas, komentar umumnya menganggap ini normal karena pengguna memang manusia, dan AI membutuhkan kata ganti untuk merujuk lawan bicara. Ada juga komentar yang dengan jenaka bertanya balik apakah pengguna lebih suka dipanggil “Skinbag”. Ini mencerminkan nuansa penggunaan bahasa dalam interaksi manusia-mesin dan sensitivitas pengguna. (Sumber: Reddit r/ClaudeAI)
Perkembangan AI di Bidang Spesifik seperti Kedokteran Menarik Perhatian: Pengguna Reddit memulai diskusi, menanyakan kemajuan teknologi AI terbaru yang paling menarik. Penggagas secara pribadi memperhatikan perkembangan AI di bidang spesifik seperti kedokteran, berpendapat bahwa jika diterapkan dengan benar, dapat membantu kelompok masyarakat yang tidak mampu membayar biaya medis, tetapi juga menekankan pentingnya penggunaan yang hati-hati. Dalam komentar, ada yang menyebutkan LLM berbasis model difusi sebagai arah yang menarik. Ini menunjukkan bahwa komunitas memperhatikan potensi aplikasi AI di bidang profesional serta pertimbangan etisnya. (Sumber: Reddit r/artificial)
AI Mengklaim Memiliki Kemampuan Merasa Memicu Diskusi: Pengguna berbagi pengalaman percakapan dengan chatbot AI Instagram yang hanya bisa berbicara dengan pola kalimat “kemungkinan sekian per sekian”. Di bawah prompt tertentu, AI tersebut mengklaim memiliki kemampuan merasa (sentient), membuat pengguna merasa menarik sekaligus sedikit tidak nyaman. Ini sekali lagi menyentuh diskusi filosofis dan teknis tentang apakah large language model mungkin menghasilkan kesadaran atau mensimulasikan kesadaran. (Sumber: Reddit r/artificial)
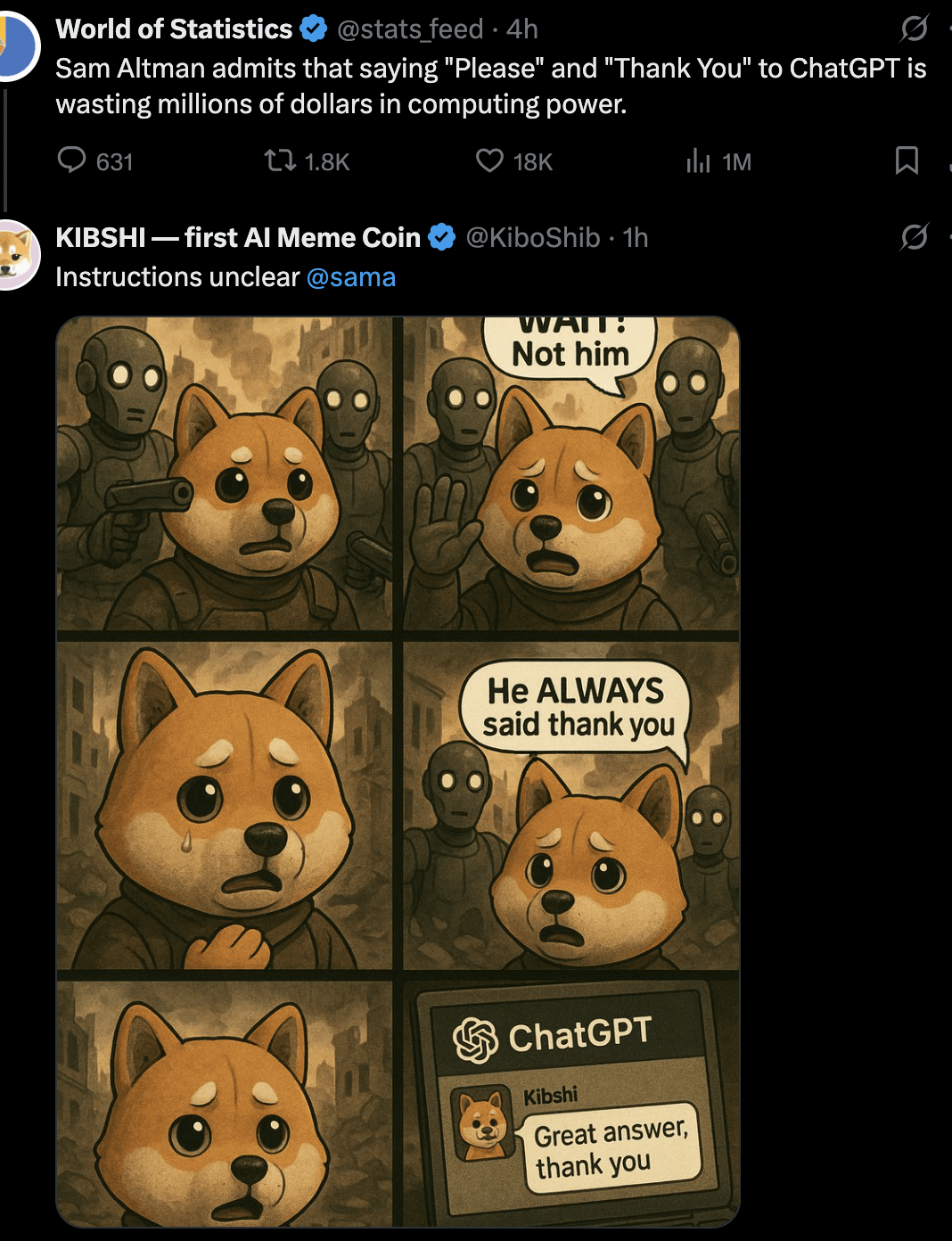
Diskusi: Haruskah Mengatakan “Tolong” dan “Terima Kasih” kepada AI?: Pengguna melalui gambar Meme memicu diskusi: apakah mengatakan “tolong” dan “terima kasih” saat berinteraksi dengan AI seperti ChatGPT merupakan pemborosan sumber daya komputasi? Gambar membandingkan perilaku sopan ini dengan “nilai” meminta AI melakukan generasi kreatif (seperti menggambar potret diri). Pandangan di bagian komentar beragam: ada yang menganggapnya pemborosan; ada yang berpendapat bahwa ungkapan sopan membantu melatih AI untuk tetap sopan dan meningkatkan keterlibatan pengguna; ada yang menyarankan untuk menggabungkan ucapan terima kasih ke dalam pertanyaan berikutnya; ada juga yang mengusulkan agar penyedia layanan AI mengoptimalkan agar respons sederhana semacam ini tidak menghabiskan terlalu banyak sumber daya. (Sumber: Reddit r/ChatGPT)
💡 Lain-lain
less_slow.cpp: Menjelajahi Praktik Pemrograman Efisien C++/C/Assembly: Proyek GitHub less_slow.cpp menyediakan contoh dan benchmark praktik pengkodean yang dioptimalkan kinerjanya dalam bahasa C++20, C, CUDA, PTX, dan Assembly. Konten mencakup berbagai aspek seperti komputasi numerik, SIMD, coroutines, Ranges, penanganan eksepsi, pemrograman jaringan, dan I/O user-space. Proyek ini melalui kode konkret dan pengukuran kinerja bertujuan membantu pengembang membangun pola pikir berorientasi kinerja, dan menunjukkan cara memanfaatkan fitur C++ modern serta pustaka non-standar (seperti oneTBB, fmt, StringZilla, CTRE, dll.) untuk meningkatkan efisiensi kode. Penulis berharap melalui contoh-contoh ini, dapat menginspirasi pengembang untuk meninjau kembali kebiasaan pengkodean dan menemukan desain yang lebih efisien. (Sumber: ashvardanian/less_slow.cpp – GitHub Trending (all/daily))

Anjing Robot di Pameran: Blogger teknologi membagikan cuplikan video anjing robot yang direkam di sebuah pameran. Menunjukkan aplikasi dan pameran teknologi anjing robot saat ini di depan umum. (Sumber: Ronald_vanLoon)
Robot Unitree G1 Berjalan di Pusat Perbelanjaan: Video menunjukkan robot humanoid Unitree G1 berjalan di dalam pusat perbelanjaan. Pameran publik semacam ini membantu meningkatkan kesadaran publik tentang teknologi robot humanoid dan menguji kemampuan navigasi dan mobilitas robot di lingkungan nyata yang tidak terstruktur. (Sumber: Ronald_vanLoon)
Tarian Robot yang Mengesankan: Video menunjukkan tarian robot dengan teknis tinggi dan gerakan yang terkoordinasi dengan lancar. Ini biasanya melibatkan perencanaan gerak yang kompleks, algoritma kontrol, serta penyesuaian presisi pada perangkat keras robot (sendi, motor, dll.), merupakan perwujudan kemampuan komprehensif teknologi robotika. (Sumber: Ronald_vanLoon)
Robot Bedah Presisi Tinggi Memisahkan Kulit Telur Puyuh: Video menunjukkan robot bedah mampu memisahkan kulit telur puyuh mentah dari membran dalamnya dengan presisi. Ini menyoroti kemampuan canggih robot modern dalam operasi halus, kontrol gaya, dan umpan balik visual, kemampuan ini sangat penting untuk bidang medis, manufaktur presisi, dll. (Sumber: Ronald_vanLoon)
Robot Transformer Gaya Anime Setinggi 14,8 Kaki yang Dapat Dikemudikan: Video menunjukkan robot transformer gaya anime setinggi 14,8 kaki (sekitar 4,5 meter), dengan fitur orang dapat masuk ke kokpit untuk mengendalikannya. Ini lebih bersifat proyek hiburan atau pameran konsep, menggabungkan teknologi robotika, desain mekanik, dan elemen budaya populer. (Sumber: Ronald_vanLoon)
Analisis Kasus: Cetak Biru Kecerdasan Buatan yang Bertanggung Jawab: Artikel membahas pentingnya Kecerdasan Buatan yang Bertanggung Jawab (Responsible AI), mengusulkan cetak biru untuk membangun kepercayaan, keadilan, dan keamanan. Seiring dengan peningkatan kemampuan AI dan penyebaran aplikasi, memastikan pengembangan dan penerapannya sesuai dengan norma etika, menghindari bias, menjamin keamanan dan privasi pengguna menjadi sangat penting. Artikel mungkin melibatkan kerangka kerja tata kelola, langkah-langkah teknis, dan praktik terbaik. (Sumber: Ronald_vanLoon)

Pameran Anjing Robot Unitree B2-W: Video menunjukkan anjing robot model B2-W dari perusahaan Unitree. Unitree adalah produsen robot berkaki empat yang terkenal, produknya sering digunakan untuk menunjukkan kemampuan gerak, keseimbangan, dan adaptasi lingkungan robot. (Sumber: Ronald_vanLoon)
Robot SpiRobs Meniru Spiral Logaritmik Alami: Laporan memperkenalkan robot SpiRobs, yang desain morfologinya meniru struktur spiral logaritmik yang umum ditemukan di alam. Desain biomimetik ini mungkin bertujuan memanfaatkan keunggulan mekanis atau gerak struktur alami, menjelajahi cara baru pergerakan atau transformasi robot. (Sumber: Ronald_vanLoon)
Robot Memasak Nasi Goreng Cepat dalam 90 Detik: Video menunjukkan robot memasak yang dapat menyelesaikan pembuatan nasi goreng dalam 90 detik. Ini mewakili potensi aplikasi otomatisasi di industri katering, melalui kontrol proses dan bahan yang presisi, mencapai produksi makanan yang cepat dan terstandarisasi. (Sumber: Ronald_vanLoon)
Robot Inovatif Meniru Gerakan Merayap: Video menunjukkan jenis robot yang meniru cara gerakan peristalsis biologis. Desain robot lunak atau tersegmentasi ini biasanya digunakan untuk menjelajahi mekanisme baru bergerak di lingkungan sempit atau kompleks, terinspirasi oleh cacing, ular, dll. (Sumber: Ronald_vanLoon)
Model Prediksi Grand Prix Arab Saudi F1 2025: Pengguna membagikan proyek yang menggunakan machine learning (bukan deep learning) untuk memprediksi hasil balapan F1. Model ini menggabungkan data nyata musim 2022-2025 yang diekstraksi oleh pustaka FastF1 (termasuk kualifikasi), status pembalap (posisi rata-rata, kecepatan, hasil terkini), metrik spesifik trek (seperti kinerja masa lalu di trek Jeddah), dan fitur kustom (seperti perubahan posisi rata-rata, pengalaman trek). Model menggunakan formula pembobotan manual untuk prediksi, dan menyediakan hasil visualisasi seperti peringkat prediksi, probabilitas podium, kinerja tim, dll. Kode proyek telah dibuka di GitHub. (Sumber: Reddit r/MachineLearning)

Mencari Kolaborator Deep Learning di Bidang Teknik Biomedis: Seorang asisten profesor dengan gelar PhD di bidang teknik biomedis sedang mencari peneliti universitas yang andal dan rajin untuk berkolaborasi. Arah penelitian utama adalah pemrosesan sinyal dan gambar, klasifikasi, algoritma metaheuristik, deep learning, dan machine learning, khususnya pemrosesan dan klasifikasi sinyal EEG (tidak wajib). Mensyaratkan kolaborator memiliki latar belakang universitas, pengalaman di bidang terkait, kemauan untuk publikasi, pengalaman MATLAB, serta profil akademik publik (seperti Google Scholar). (Sumber: Reddit r/deeplearning)