
Kata Kunci:Perkembangan AI, Grok 3, Gemma 3, Aplikasi AI, Perubahan paradigma perkembangan AI, xAI Grok 3 API, Google Gemma 3 QAT, Evaluasi AI VideoGameBench, Akselerasi penemuan molekul dengan AI, Pembelajaran federasi untuk pencitraan medis, Agen pengetahuan LlamaIndex, Teknologi perbaikan kode otomatis AI
🔥 Fokus
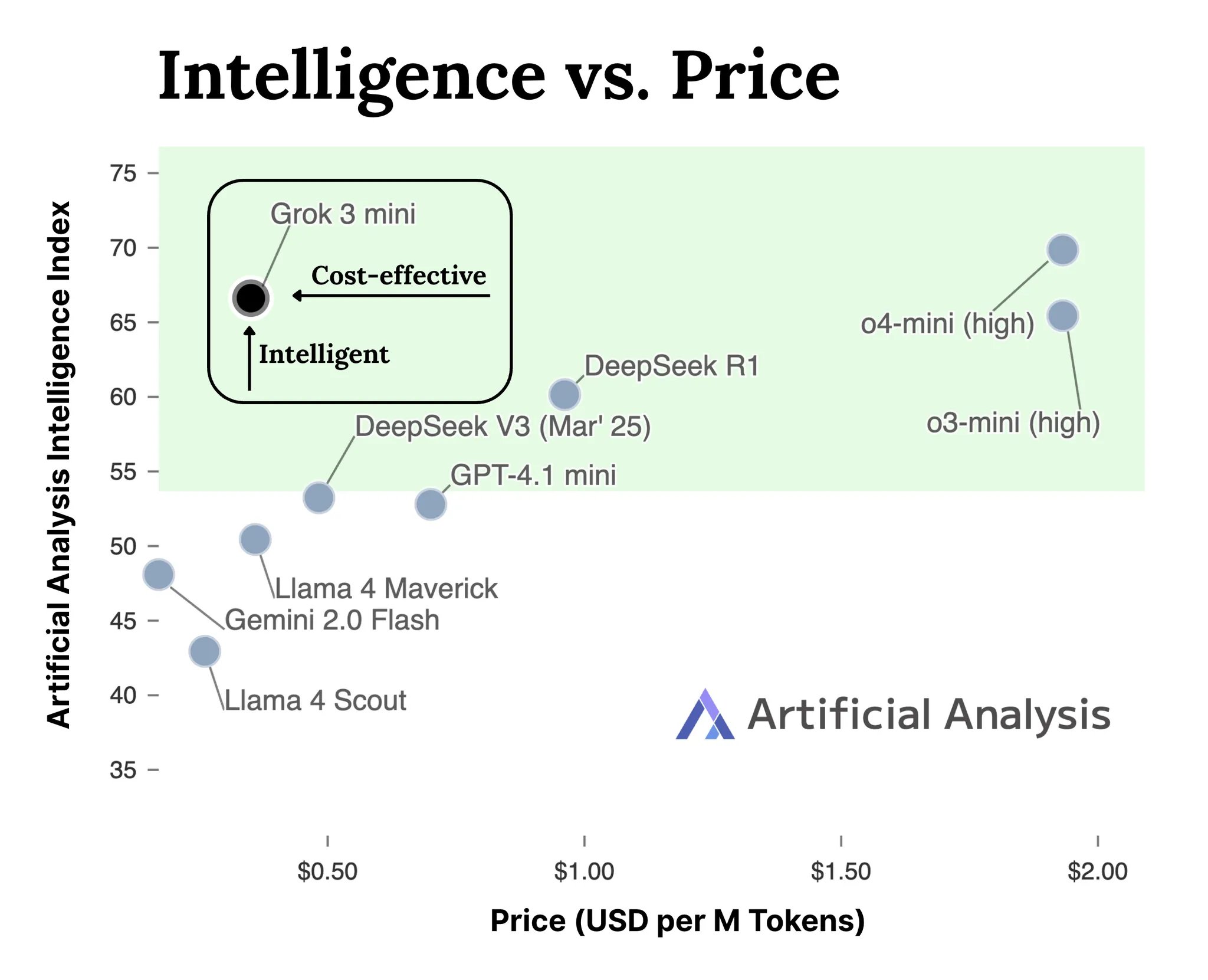
Pergeseran Paradigma Pengembangan AI: Dari Mengejar Skor Benchmark ke Menciptakan Nilai: Blog peneliti OpenAI, Yao Shunyu, memicu diskusi, mengusulkan bahwa pengembangan AI telah memasuki babak kedua. Babak pertama berfokus pada inovasi algoritma dan pengejaran skor benchmark (seperti AlphaGo, GPT-4), melalui kombinasi pra-pelatihan skala besar (memberikan pengetahuan awal) dan Reinforcement Learning (RL), serta memperkenalkan konsep “penalaran sebagai tindakan”, mencapai terobosan generalisasi. Namun, ia berpendapat bahwa keuntungan marginal dari terus mengejar skor benchmark menurun, babak kedua harus beralih ke pendefinisian masalah yang memiliki nilai aplikasi praktis, mengembangkan metode evaluasi yang lebih dekat dengan dunia nyata, berpikir seperti manajer produk, dan benar-benar menggunakan AI untuk menciptakan nilai pengguna dan nilai sosial, bukan hanya mengejar peningkatan metrik. Ini menandai pergeseran pemikiran di bidang AI dari fokus utama pada eksplorasi teknis ke fokus utama pada implementasi aplikasi dan realisasi nilai (Sumber: dotey)
xAI Merilis API Model Seri Grok 3: xAI secara resmi meluncurkan antarmuka API untuk model seri Grok 3 (docs.x.ai), membuka model terbarunya untuk para developer. Seri ini mencakup Grok 3 Mini dan Grok 3. Menurut xAI, Grok 3 Mini menunjukkan kemampuan penalaran yang unggul sambil mempertahankan biaya yang lebih rendah (diklaim 5 kali lebih rendah dari model inferensi sejenis); sementara Grok 3 diposisikan sebagai model non-penalaran yang kuat (mungkin merujuk pada tugas padat pengetahuan), berkinerja menonjol di bidang-bidang yang membutuhkan pengetahuan dunia nyata seperti hukum, keuangan, dan medis. Langkah ini menandai masuknya xAI ke dalam persaingan pasar API model AI, memberikan pilihan baru bagi para developer (Sumber: grok, grok)
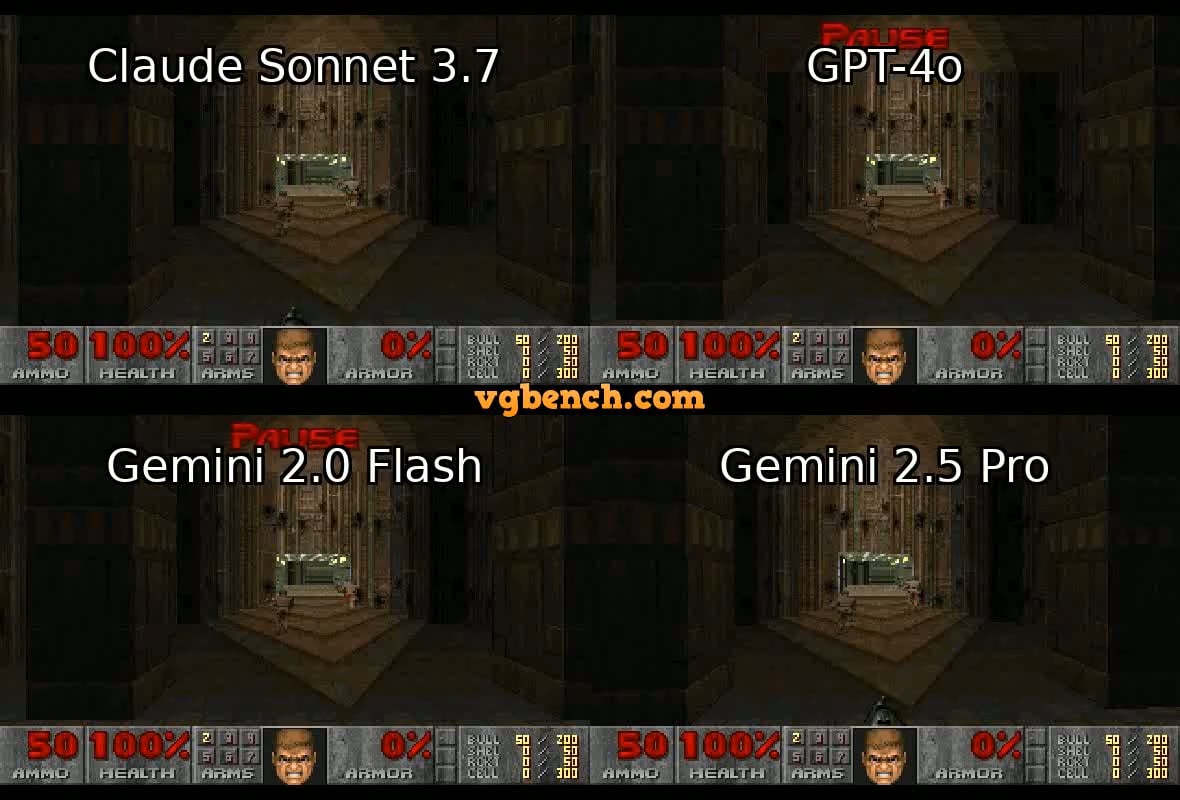
VideoGameBench: Mengevaluasi Kemampuan Agen AI Menggunakan Game Klasik: Para peneliti meluncurkan versi pratinjau benchmark VideoGameBench, yang bertujuan untuk mengevaluasi kemampuan Visual Language Model (VLM) dalam menyelesaikan tugas secara real-time di 20 game video klasik (seperti Doom II). Pengujian awal menunjukkan bahwa model-model teratas termasuk GPT-4o, Claude Sonnet 3.7, Gemini 2.5 Pro menunjukkan kinerja bervariasi di Doom II, tetapi semuanya gagal melewati level pertama. Ini menunjukkan bahwa meskipun model-model tersebut kuat dalam banyak tugas, mereka masih menghadapi tantangan di lingkungan dinamis yang kompleks yang membutuhkan persepsi, pengambilan keputusan, dan aksi real-time. Benchmark ini menyediakan alat baru untuk mengukur dan mendorong kemajuan agen AI di lingkungan interaktif (Sumber: Reddit r/LocalLLaMA)
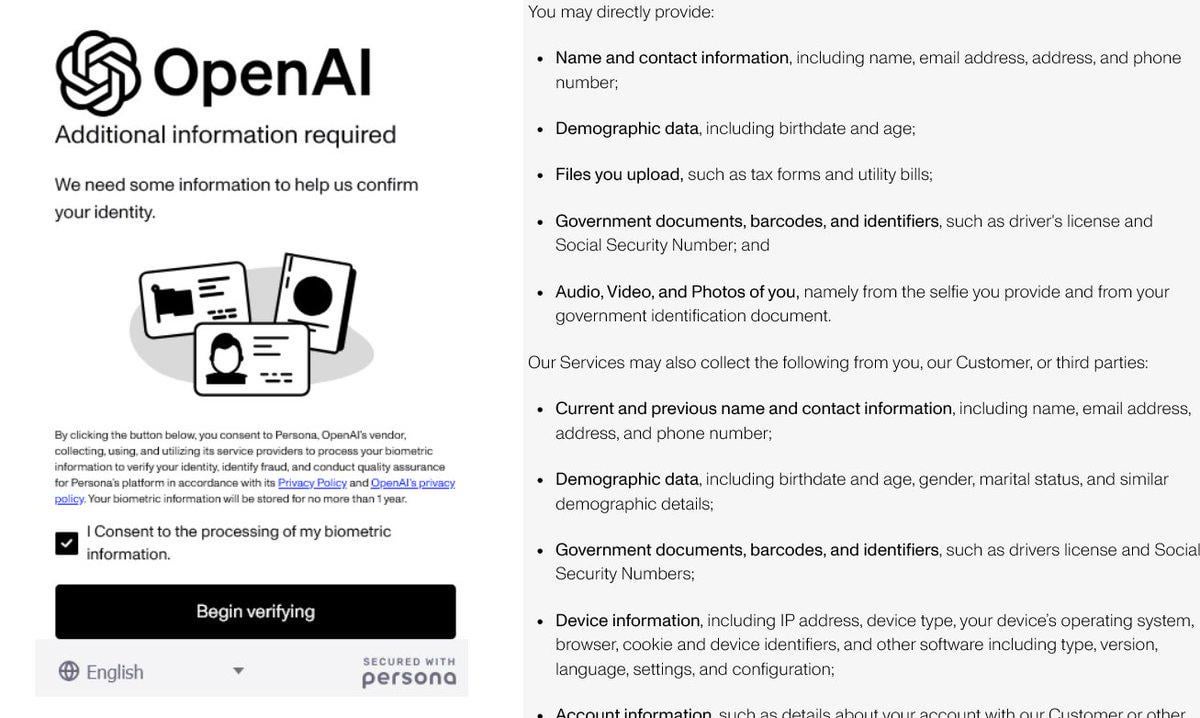
OpenAI Memperketat Verifikasi Identitas Menuai Kontroversi: OpenAI dilaporkan meminta pengguna memberikan bukti identitas rinci (seperti paspor, tagihan pajak, tagihan utilitas) untuk mengakses beberapa model canggihnya (terutama yang memiliki kemampuan penalaran kuat seperti o3). Langkah ini memicu reaksi keras di komunitas, pengguna umumnya khawatir tentang kebocoran privasi dan peningkatan hambatan akses. Meskipun OpenAI mungkin melakukannya karena pertimbangan keamanan, kepatuhan, atau manajemen sumber daya, persyaratan verifikasi yang ketat ini kontras dengan citra terbukanya, dan dapat mendorong pengguna beralih ke alternatif dengan perlindungan privasi yang lebih baik atau lebih mudah diakses, terutama model lokal (Sumber: Reddit r/LocalLLaMA)
AI Mempercepat Penemuan Molekul: Mensimulasikan Evolusi Alami Ratusan Juta Tahun: Diskusi media sosial menyebutkan bahwa kecerdasan buatan dapat merancang molekul dalam beberapa hari, sementara molekul tersebut mungkin membutuhkan 500 juta tahun untuk berevolusi di alam. Meskipun detail spesifik perlu diverifikasi, ini menyoroti potensi besar AI dalam mempercepat penemuan ilmiah, terutama di bidang kimia dan biologi. AI dapat menjelajahi ruang kimia yang luas, memprediksi sifat molekul, dengan kecepatan yang jauh melampaui metode eksperimental tradisional dan evolusi alami, diharapkan membawa kemajuan terobosan di bidang seperti penemuan dan pengembangan obat, serta ilmu material (Sumber: Ronald_vanLoon)
🎯 Tren
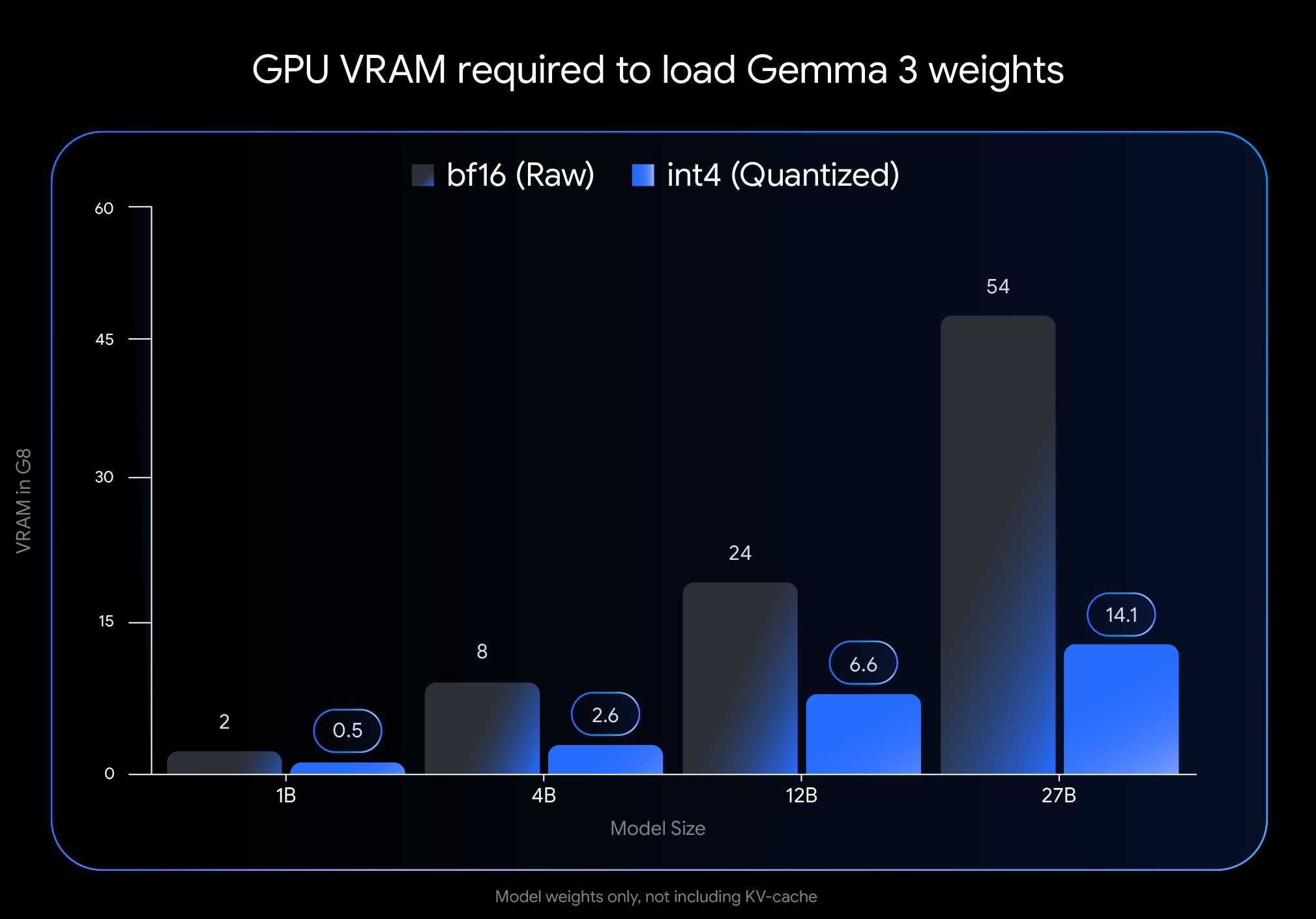
Google Merilis Versi QAT Gemma 3, Secara Signifikan Menurunkan Hambatan Deployment: Google DeepMind meluncurkan versi model Gemma 3 yang telah melalui Quantization-Aware Training (QAT). Teknologi QAT bertujuan untuk mempertahankan kinerja model asli semaksimal mungkin sambil mengompres ukuran model secara signifikan. Misalnya, ukuran model Gemma 3 27B berkurang dari 54GB (bf16) menjadi sekitar 14.1GB (int4), memungkinkan model terdepan yang semula membutuhkan GPU cloud kelas atas kini dapat berjalan di GPU desktop kelas konsumen (seperti RTX 3090). Google telah merilis checkpoint QAT yang tidak terkuantisasi serta berbagai format (MLX, GGUF), dan bekerja sama dengan alat komunitas seperti Ollama, LM Studio, llama.cpp, untuk memastikan developer dapat menggunakannya dengan mudah di berbagai platform, sangat mendorong popularisasi model open source berkinerja tinggi (Sumber: huggingface, JeffDean, demishassabis, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Meta FAIR Merilis Hasil Penelitian Persepsi, Tetap pada Jalur Open Source: Meta FAIR merilis beberapa hasil penelitian baru dalam Advanced Machine Intelligence (AMI), khususnya kemajuan di bidang persepsi, termasuk merilis encoder visual skala besar Meta Perception Encoder. Yann LeCun menekankan bahwa hasil ini akan bersifat open source. Ini menunjukkan bahwa Meta terus berinvestasi dalam riset AI dasar, dan berkomitmen untuk berbagi kemajuan risetnya melalui open source, mendorong pengembangan seluruh bidang, alat yang dirilis seperti encoder visual akan memberi manfaat bagi komunitas riset dan developer yang lebih luas (Sumber: ylecun)
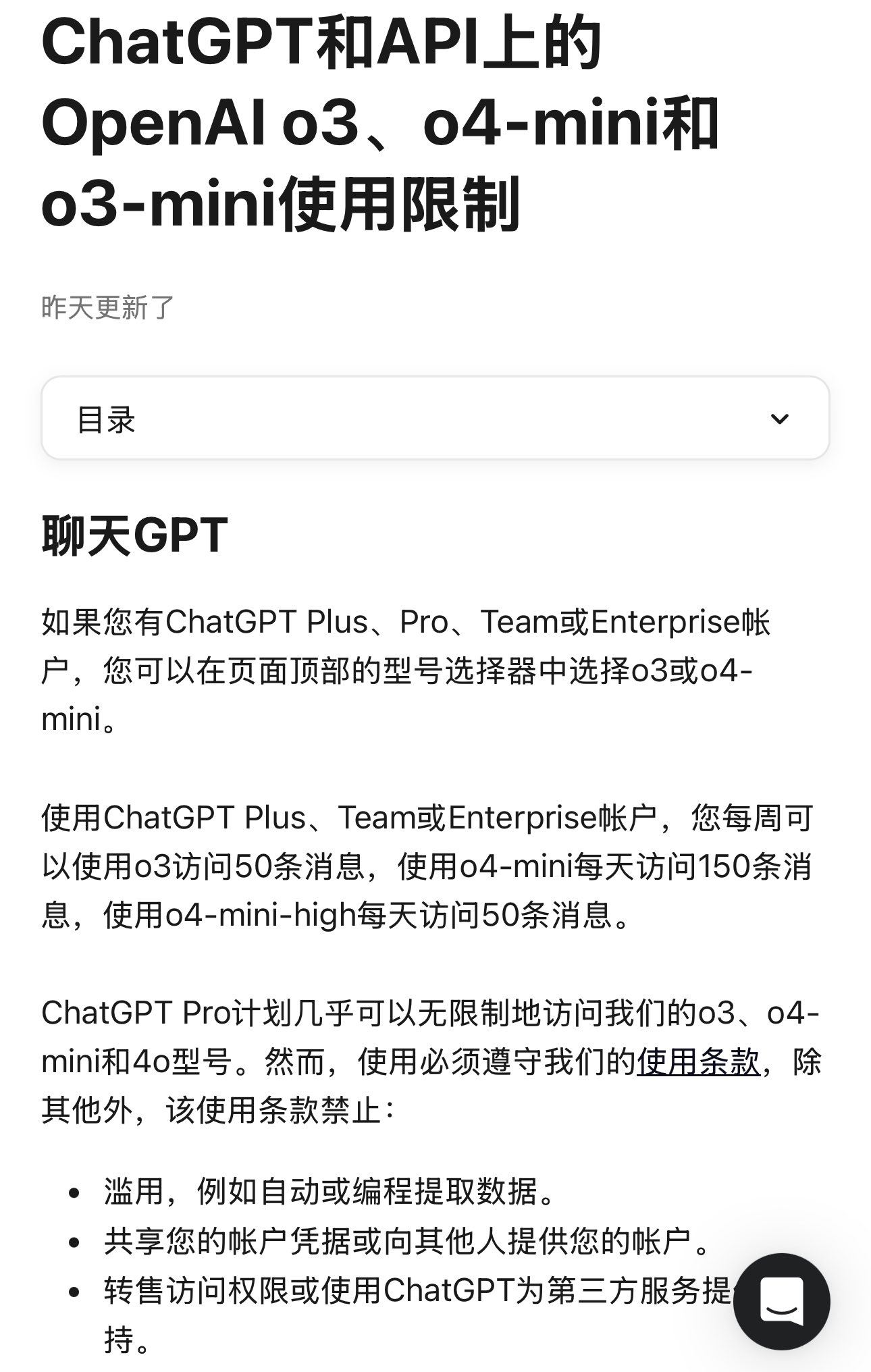
OpenAI Memperjelas Batasan Penggunaan Model: OpenAI menetapkan secara jelas jumlah penggunaan model untuk pengguna ChatGPT Plus, Team, dan Enterprise. Di antaranya, model o3 dibatasi 50 pesan per minggu, o4-mini 150 per hari, dan o4-mini-high dibatasi 50 per hari. Dilaporkan ChatGPT Pro (mungkin merujuk pada paket tertentu atau mungkin keliru) memiliki akses tak terbatas. Batasan ini berdampak langsung pada pengguna frekuensi tinggi dan developer aplikasi yang bergantung pada model tertentu, perlu dipertimbangkan dalam perencanaan penggunaan (Sumber: dotey)
LlamaIndex Mengintegrasikan Database Google Cloud untuk Membangun Agen Pengetahuan: Di konferensi Google Cloud Next 2025, LlamaIndex mendemonstrasikan bagaimana framework-nya dapat diintegrasikan dengan database Google Cloud untuk membangun agen pengetahuan yang mampu melakukan riset multi-langkah, memproses dokumen, dan menghasilkan laporan. Demo mencakup kasus sistem multi-agen untuk pembuatan panduan orientasi karyawan secara otomatis. Ini menunjukkan tren integrasi mendalam antara framework aplikasi AI dengan platform cloud dan layanan datanya, bertujuan menjawab kebutuhan praktis perusahaan dalam memanfaatkan AI untuk memproses pengetahuan dan data internal (Sumber: jerryjliu0)

Sensor Otak Nano Baru Dikombinasikan dengan AI Mencapai Pengenalan Sinyal Presisi Tinggi: Penelitian melaporkan sensor otak skala nano baru yang mencapai tingkat akurasi 96.4% dalam mengenali sinyal saraf. Meskipun teknologi sensor itu sendiri adalah terobosan inti, mencapai akurasi pengenalan setinggi itu biasanya memerlukan bantuan algoritma AI dan machine learning canggih untuk mendekode sinyal saraf yang kompleks dan lemah. Kemajuan ini membuka jalan baru untuk riset ilmu otak dan aplikasi antarmuka otak-komputer di masa depan, diharapkan mewujudkan pemantauan dan interaksi aktivitas otak yang lebih halus (Sumber: Ronald_vanLoon)

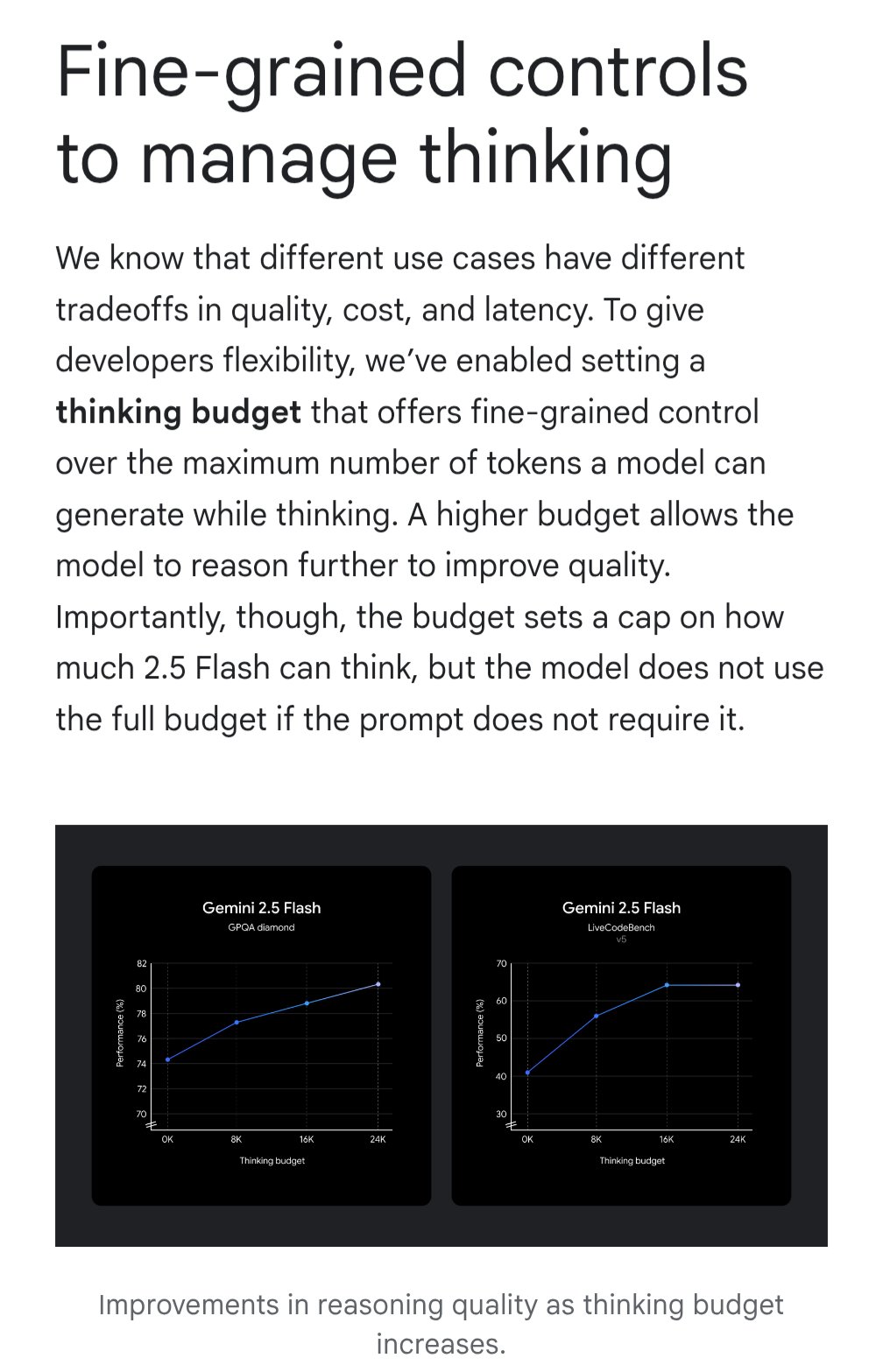
Gemini Memperkenalkan Fitur ‘Thinking Budget’ untuk Mengoptimalkan Efektivitas Biaya: Model Google Gemini memperkenalkan fitur ‘thinking budget’ (anggaran berpikir), yang memungkinkan pengguna menyesuaikan sumber daya komputasi yang dialokasikan model atau kedalaman ‘berpikir’ saat memproses kueri. Fitur ini bertujuan agar pengguna dapat menyeimbangkan antara kualitas respons, biaya, dan latensi. Ini adalah fitur yang sangat praktis bagi pengguna API, memungkinkan kontrol fleksibel atas biaya penggunaan dan kinerja model sesuai kebutuhan skenario aplikasi spesifik (Sumber: JeffDean)
Kualitas Pemeriksaan USG Berbantuan AI Setara dengan Ahli: Studi yang diterbitkan di JAMA Cardiology menunjukkan bahwa pemeriksaan USG yang dilakukan oleh profesional medis terlatih di bawah panduan AI, kualitas gambarnya cukup untuk memenuhi standar diagnostik (98.3%), dan secara statistik tidak ada perbedaan signifikan dibandingkan dengan gambar yang diperoleh oleh ahli tanpa panduan AI. Ini menunjukkan bahwa AI sebagai alat bantu dapat secara efektif membantu pengguna non-ahli meningkatkan kualitas dan konsistensi operasi pencitraan medis, diharapkan dapat memperluas aksesibilitas layanan diagnostik berkualitas tinggi di daerah dengan sumber daya terbatas (Sumber: Reddit r/ArtificialInteligence)
Penelitian MIT Meningkatkan Akurasi dan Kepatuhan Struktur Kode yang Dihasilkan AI: Peneliti MIT mengembangkan metode yang lebih efisien untuk mengontrol output large language model, bertujuan memandu model untuk menghasilkan kode bebas kesalahan yang sesuai dengan struktur tertentu (seperti sintaks bahasa pemrograman). Penelitian ini berupaya mengatasi masalah keandalan kode yang dihasilkan AI, dengan meningkatkan teknik generasi terkendala, memastikan output secara ketat mematuhi aturan sintaks, sehingga meningkatkan kegunaan asisten kode AI dan mengurangi biaya debugging selanjutnya (Sumber: Reddit r/ArtificialInteligence)
NVIDIA Mungkin Akan Mengungkap Proyek Besarnya di Bidang Robotika: Media sosial menyebutkan NVIDIA sedang mengerjakan “proyek paling ambisius”-nya, yang melibatkan robotika, rekayasa, kecerdasan buatan, dan teknologi otonom. Meskipun konten spesifik tidak diketahui, mempertimbangkan posisi inti NVIDIA dalam hardware dan platform AI (seperti Isaac), setiap pengumuman besar terkait sangat dinantikan, mungkin menandakan penataan strategis lebih lanjut dan terobosan teknologi di bidang kecerdasan terwujud dan robotika (Sumber: Ronald_vanLoon)
🧰 Alat
Potpie: Asisten Rekayasa AI Khusus untuk Codebase: Potpie adalah platform open source (GitHub: potpie-ai/potpie), bertujuan untuk membuat agen rekayasa AI yang disesuaikan untuk codebase. Ini membangun grafik pengetahuan kode untuk memahami hubungan kompleks antar komponen, menyediakan tugas otomatis seperti analisis kode, pengujian, debugging, dan pengembangan. Platform ini menawarkan berbagai agen pra-bangun (seperti debugging, tanya jawab, analisis perubahan kode, generasi pengujian unit/integrasi, desain tingkat rendah, generasi kode) dan set alat, serta mendukung pengguna membuat agen kustom. Menyediakan ekstensi VSCode dan integrasi API, mudah diintegrasikan ke dalam alur kerja pengembangan (Sumber: potpie-ai/potpie – GitHub Trending (all/daily))

1Panel: Panel Server Linux yang Mengintegrasikan Manajemen LLM: 1Panel (GitHub: 1Panel-dev/1Panel) adalah panel manajemen operasi dan pemeliharaan server Linux open source modern, menyediakan antarmuka grafis web untuk mengelola host, file, database, kontainer, dll. Salah satu fiturnya adalah penyertaan fungsi manajemen untuk large language model (LLM). Selain itu, ia juga menyediakan toko aplikasi, deployment situs web cepat (terintegrasi dengan WordPress), perlindungan keamanan, dan pencadangan serta pemulihan sekali klik, bertujuan menyederhanakan manajemen server dan deployment aplikasi, termasuk deployment dan manajemen aplikasi terkait AI (Sumber: 1Panel-dev/1Panel – GitHub Trending (all/daily))

LlamaIndex Meluncurkan Komponen UI Chat yang Ditingkatkan: LlamaIndex merilis pembaruan besar untuk pustaka komponen UI chat-nya (@llamaindex/chat-ui). Komponen baru ini dibangun berdasarkan shadcn UI, memiliki desain lebih modis, tata letak responsif, dan sepenuhnya dapat disesuaikan. Bertujuan membantu developer lebih mudah membangun antarmuka chat yang indah dan ramah pengguna untuk proyek berbasis LLM, meningkatkan pengalaman interaktif aplikasi AI. Developer dapat menginstal melalui npm dan menggunakannya langsung dalam proyek (Sumber: jerryjliu0)
LlamaExtract Praktik: Membangun Aplikasi Analisis Keuangan: LlamaIndex mendemonstrasikan kasus pembangunan aplikasi web full-stack menggunakan alat LlamaExtract-nya (bagian dari LlamaCloud). LlamaExtract memungkinkan pengguna mendefinisikan Schema yang presisi untuk mengekstrak data terstruktur dari dokumen kompleks. Aplikasi contoh ini mengekstrak faktor risiko dari laporan tahunan perusahaan dan menganalisis perubahan dari tahun ke tahun, mengotomatiskan pekerjaan yang semula memakan waktu lebih dari 20 jam. Aplikasi ini sudah open source (GitHub: run-llama/llamaextract-10k-demo), dan ada video yang mendemonstrasikan cara menggabungkan LlamaExtract dan Sonnet 3.7 untuk membangun alur kerja ini, menunjukkan potensi agen AI dalam mengotomatiskan tugas analisis kompleks (Sumber: jerryjliu0, jerryjliu0)
mcpbased.com: Direktori Server MCP Open Source Diluncurkan: Situs web baru mcpbased.com diluncurkan sebagai direktori khusus untuk server MCP (mungkin merujuk pada Meta Controller Pattern atau konsep serupa lainnya) open source. Platform ini bertujuan mengumpulkan dan menampilkan berbagai proyek server MCP, menyinkronkan data repositori Github secara real-time, memudahkan developer menemukan, menjelajahi, dan terhubung dengan alat terkait. Bagi developer yang membangun atau menggunakan server MCP, melakukan integrasi alat, atau mengikuti ekosistem MCP, ini adalah pusat sumber daya baru (Sumber: Reddit r/ClaudeAI)
📚 Pembelajaran
Buku RLHF Hadir di ArXiv: Buku tentang Reinforcement Learning from Human Feedback (RLHF) “rlhfbook” yang ditulis oleh Nathan Lambert dkk., kini telah diterbitkan di platform ArXiv (nomor 2504.12501). RLHF adalah salah satu teknologi kunci untuk menyelaraskan large language model (seperti ChatGPT) saat ini. Penerbitan buku ini menyediakan sumber daya penting bagi peneliti dan praktisi untuk pembelajaran sistematis dan pemahaman mendalam tentang prinsip dan praktik RLHF, mempromosikan penyebaran dan penerapan pengetahuan di bidang ini (Sumber: natolambert)
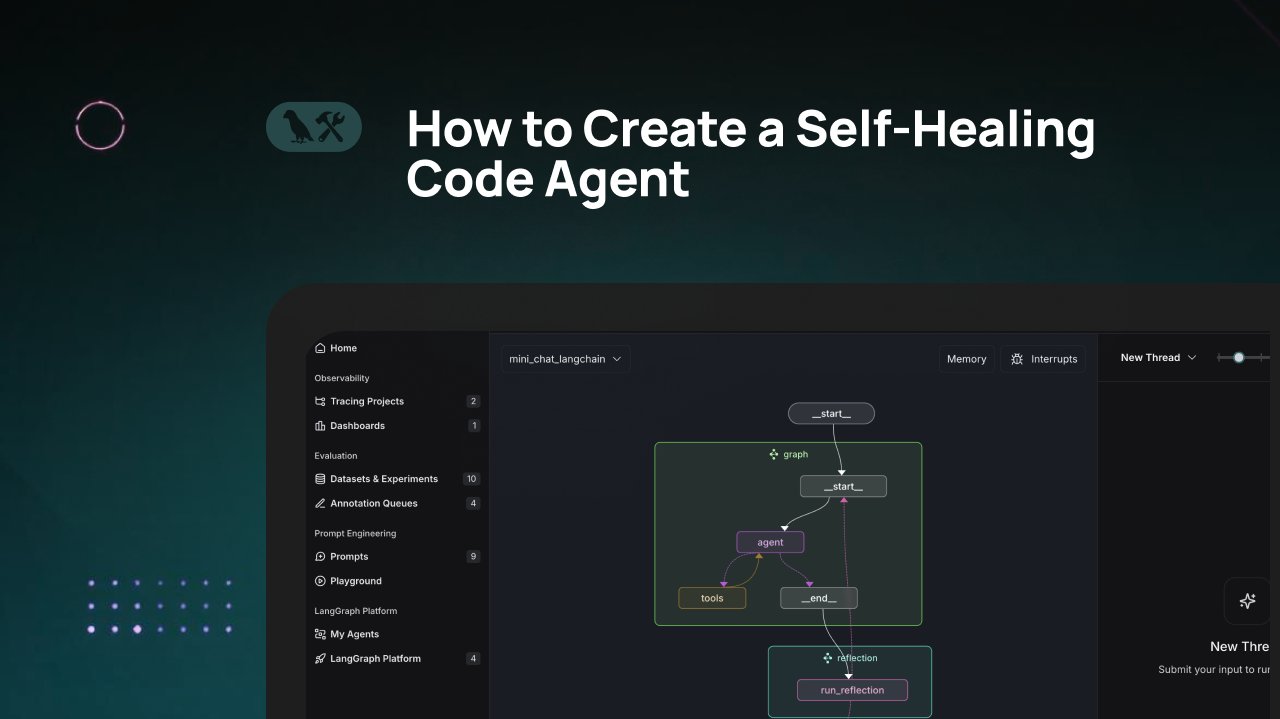
Tutorial LangChain: Membangun Agen Generasi Kode yang Bisa Memperbaiki Diri: LangChain merilis tutorial video yang memperkenalkan cara membangun agen generasi kode AI dengan kemampuan ‘memperbaiki diri’. Ide intinya adalah menambahkan langkah ‘refleksi’ (reflection) setelah menghasilkan kode, membiarkan agen memverifikasi, mengevaluasi, atau memperbaiki kode yang dihasilkannya sendiri sebelum mengembalikan hasilnya. Metode ini bertujuan meningkatkan akurasi dan keandalan kode yang dihasilkan AI, merupakan teknik efektif untuk meningkatkan kegunaan asisten kode (Sumber: LangChainAI)
AI Dikombinasikan dengan Blender untuk Membuat Aset 3D Siap Pakai untuk Game: Tutorial dibagikan di media sosial tentang penggunaan alat AI (mungkin merujuk pada generasi gambar) dikombinasikan dengan software pemodelan 3D Blender untuk menghasilkan aset 3D siap pakai untuk game (game-ready). Ini mengatasi masalah saat ini tentang ketidakmampuan AI untuk secara langsung menghasilkan model 3D, menunjukkan alur kerja hibrida yang praktis: memanfaatkan AI untuk menghasilkan konsep atau peta tekstur, kemudian menggunakan alat profesional seperti Blender untuk pemodelan dan optimasi, akhirnya menghasilkan sumber daya yang memenuhi persyaratan game engine (Sumber: huggingface)
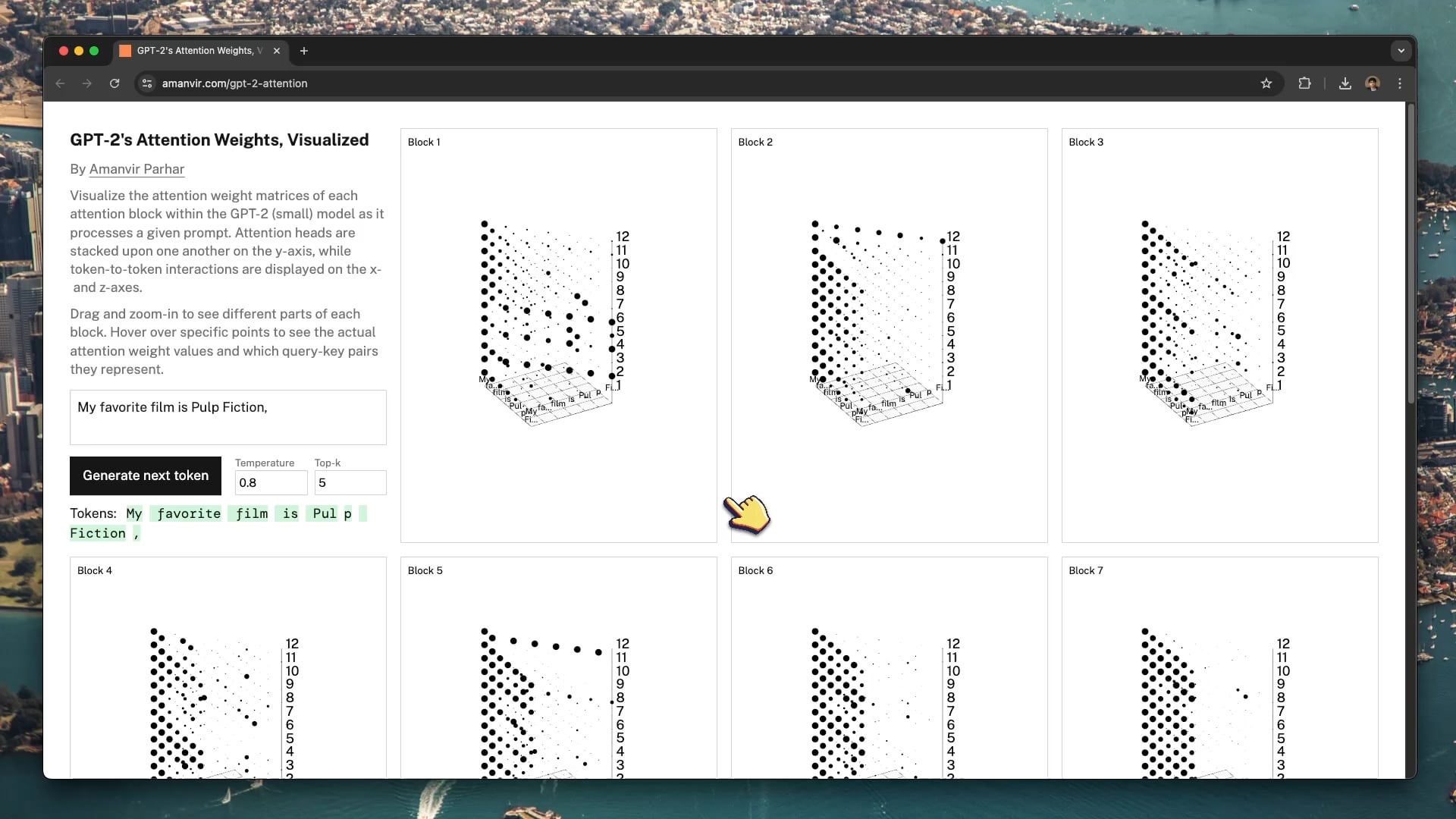
Alat Visualisasi Interaktif Bantu Pahami Mekanisme Atensi GPT-2: Developer tycho_brahes_nose_ membuat dan membagikan alat visualisasi 3D interaktif (amanvir.com/gpt-2-attention), digunakan untuk menampilkan proses perhitungan bobot setiap blok atensi di dalam model GPT-2 (kecil). Pengguna dapat secara intuitif melihat bagaimana model menghitung kekuatan interaksi antar token di berbagai lapisan dan kepala atensi setelah memasukkan teks. Ini memberikan bantuan luar biasa untuk memahami mekanisme inti Transformer, berkontribusi pada pembelajaran AI dan riset interpretabilitas model (Sumber: karminski3, Reddit r/LocalLLaMA)
Aplikasi Federated Learning dalam Analisis Citra Medis: Postingan Reddit merujuk pada artikel tentang penggabungan Federated Learning (FL) dengan Deep Neural Network (DNN) untuk analisis citra medis. Karena sensitivitas privasi data medis, FL memungkinkan pelatihan model kolaboratif di berbagai institusi tanpa berbagi data mentah. Ini sangat penting untuk mendorong penerapan AI di bidang medis, sumber daya ini membantu memahami teknologi pembelajaran terdistribusi yang menjaga privasi ini dan praktiknya dalam pencitraan medis (Sumber: Reddit r/deeplearning)

Sander Dielman Mengupas Tuntas VAE dan Latent Space: Andrej Karpathy merekomendasikan artikel blog mendalam dari Sander Dielman tentang Variational Autoencoder (VAE) dan pemodelan latent space (sander.ai/2025/04/15/latents.html). Artikel ini membahas detail dalam pelatihan VAE, seperti peran aktual terbatas dari suku divergensi KL dalam membentuk latent space, serta alasan mengapa loss rekonstruksi L1/L2 cenderung menghasilkan gambar buram (peluruhan spektrum gambar tidak cocok dengan fokus persepsi mata manusia). Tulisan ini memberikan analisis yang cermat dan berwawasan untuk memahami model generatif (Sumber: Reddit r/MachineLearning)
💼 Bisnis
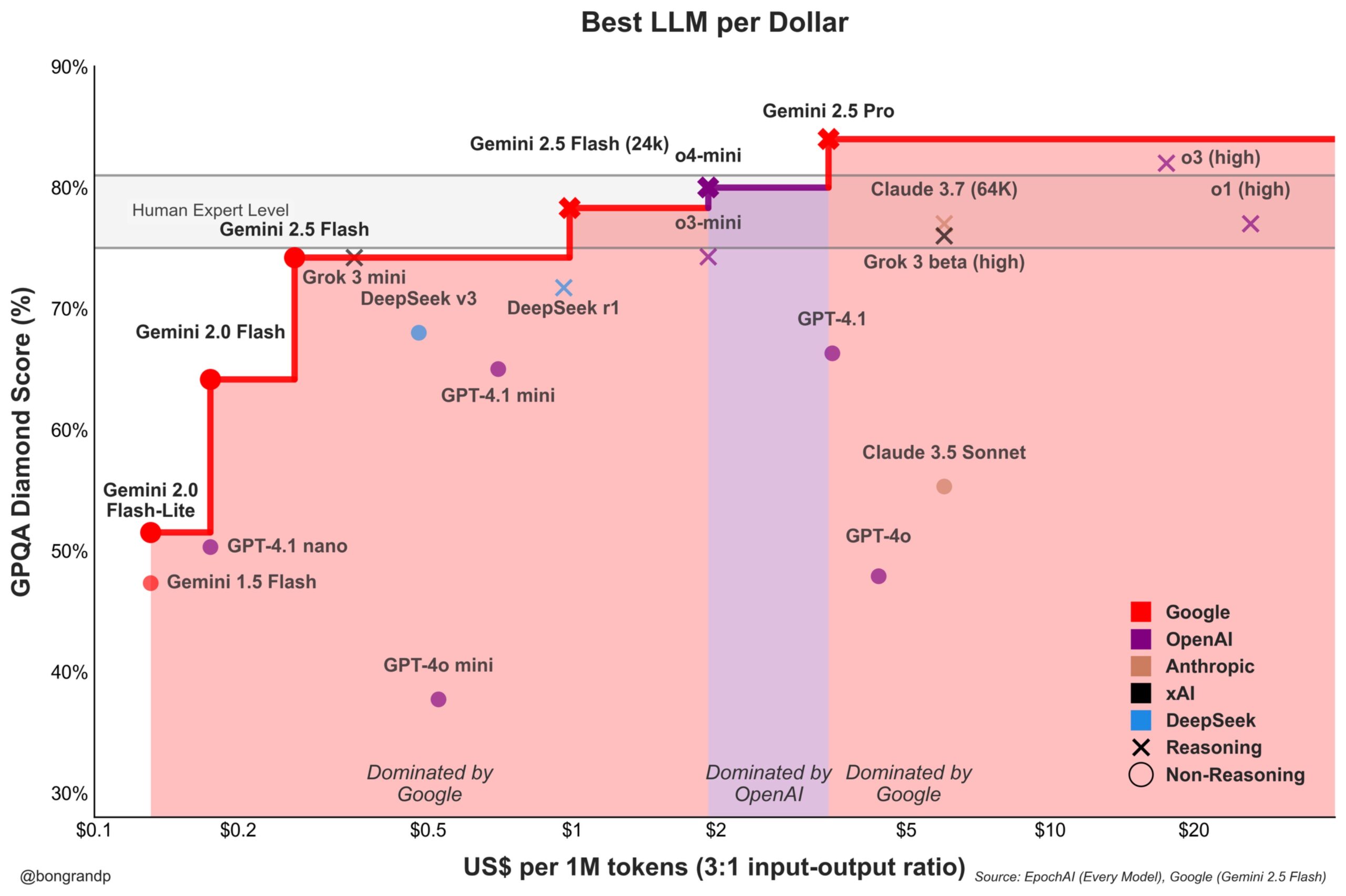
Perang Harga Model Memanas: Google Gemini Aktif Menantang OpenAI: Analisis menunjukkan bahwa Google, mengandalkan seri model Gemini-nya (terutama Gemini 2.5 Flash yang baru dirilis), menunjukkan daya saing kuat dalam hal kinerja dan harga, dilaporkan menawarkan rasio harga-kinerja yang lebih baik daripada OpenAI di sekitar 95% skenario. Respons cepat dan strategi penetapan harga Google untuk API-nya (mendominasi lebih dari 90% rentang harga) menunjukkan bahwa mereka secara aktif bersaing untuk pangsa pasar LLM, berniat menarik pengguna melalui keunggulan biaya, memperketat persaingan di pasar model dasar (Sumber: JeffDean)
Coinbase Sponsori Konferensi LangChain, Eksplorasi Agentic Commerce: Coinbase Development menjadi sponsor konferensi LangChain Interrupt 2025. Coinbase sedang memberdayakan ‘Agentic Commerce’ melalui alatnya seperti AgentKit dan protokol pembayaran x402, memungkinkan agen AI melakukan pembayaran otonom untuk layanan seperti pengambilan konteks, panggilan API, dll. Kolaborasi ini menyoroti titik temu antara teknologi agen AI dan pembayaran Web3, menandakan skenario interaksi ekonomi otomatis yang didorong AI di masa depan (Sumber: LangChainAI)

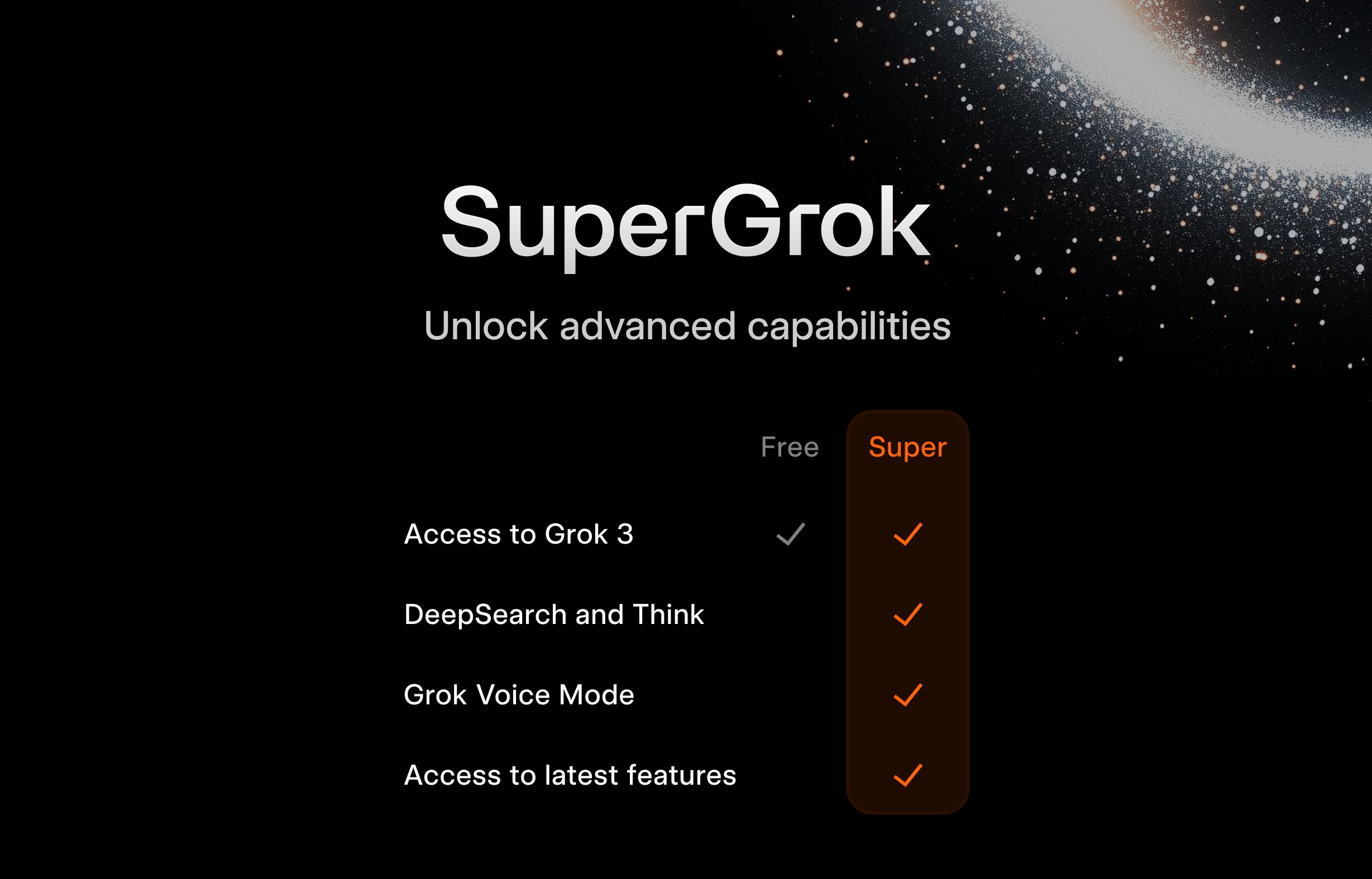
xAI Luncurkan Program Gratis SuperGrok untuk Pelajar: Untuk menarik kelompok pengguna muda, xAI meluncurkan kegiatan promosi untuk pelajar: mendaftar dengan email .edu, bisa mendapatkan akses gratis SuperGrok (versi premium Grok) selama dua bulan. Langkah ini bertujuan memposisikan Grok sebagai alat bantu belajar, melakukan promosi selama musim ujian akhir, bersaing memperebutkan pengguna di pasar pendidikan, dan membina calon pelanggan berbayar di masa depan (Sumber: grok)
Google Tawarkan Gemini Advanced dan Berbagai Layanan Gratis untuk Mahasiswa AS: Google mengumumkan manfaat gratis jangka panjang untuk mahasiswa AS, jika mendaftar sebelum 30 Juni 2025, dapat menggunakan Gemini Advanced (didukung oleh Gemini 2.5 Pro), NotebookLM Plus, fitur Gemini di Google Workspace, Whisk, serta penyimpanan cloud 2TB secara gratis hingga akhir semester musim semi 2026. Promosi skala besar ini bertujuan untuk mengintegrasikan alat AI Google secara mendalam ke dalam ekosistem pendidikan, bersaing dengan pesaing seperti Microsoft, dan menumbuhkan loyalitas generasi pengguna dan developer berikutnya terhadap platform AI Google (Sumber: demishassabis, JeffDean)
FanDuel Luncurkan Chatbot AI Selebriti ‘ChuckGPT’: Selebriti olahraga Charles Barkley melisensikan nama, kemiripan, dan suaranya, berkolaborasi dengan perusahaan taruhan olahraga FanDuel untuk meluncurkan chatbot AI bernama ‘ChuckGPT’ (chuck.fanduel.com). Ini adalah contoh lain penggunaan IP selebriti dan teknologi AI untuk pemasaran merek dan interaksi pengguna, menyediakan informasi olahraga, saran taruhan, atau interaksi hiburan dengan meniru gaya percakapan selebriti, meningkatkan keterlibatan pengguna (Sumber: Reddit r/artificial)
🌟 Komunitas
Ketergantungan Alat AI Timbulkan Kekhawatiran: Sebuah komik di media sosial secara jelas menggambarkan pengguna dikelilingi oleh banyak alat AI (ChatGPT, Claude, Midjourney, dll.), diberi label ‘ketergantungan alat AI’, menimbulkan resonansi. Ini mencerminkan beban informasi berlebih dan mentalitas potensi ketergantungan berlebihan yang dirasakan oleh sebagian pengguna di komunitas saat menghadapi aplikasi AI yang tak henti-hentinya muncul, serta beban kognitif dalam mengelola dan memilih alat yang tepat (Sumber: dotey)
Model Teratas Gagal dalam Tes Spesifik, Mengungkap Batas Kemampuan: CEO Perplexity, Arav Srinivas, me-retweet sebuah kasus uji yang menunjukkan bahwa baik o3 maupun Gemini 2.5 Pro gagal menyelesaikan tugas menggambar grafis yang kompleks. Ini dilihat oleh beberapa orang sebagai tes yang menantang kemampuan model saat ini. ‘Kasus kegagalan’ semacam ini banyak didiskusikan di komunitas, digunakan untuk mengungkap keterbatasan model SOTA dalam penalaran spesifik, pemahaman spasial, atau kepatuhan instruksi, membantu mengenali secara lebih objektif kesenjangan antara AI saat ini dan Artificial General Intelligence (AGI) (Sumber: AravSrinivas)
Komunitas Bahas Hasil Gambar Bantal Buatan GPT-4o dan Berbagi Prompt: Pengguna berbagi kasus sukses dan prompt (Prompt) yang dioptimalkan untuk menghasilkan gambar bantal dengan gaya spesifik (lucu, tekstur micro-fleece, bentuk emoji) menggunakan GPT-4o. Berbagi semacam ini menunjukkan aplikasi generasi gambar AI dalam desain kreatif, dan mendorong pertukaran dalam komunitas mengenai teknik rekayasa Prompt dan eksplorasi gaya. Hasil generasi berkualitas tinggi membangkitkan antusiasme kreatif pengguna (Sumber: dotey)

Sam Altman: AI Lebih Mirip Renaisans daripada Revolusi Industri: CEO OpenAI, Sam Altman, menyampaikan pandangan bahwa perubahan yang dibawa oleh kecerdasan buatan lebih seperti Renaisans daripada Revolusi Industri. Metafora ini memicu diskusi komunitas, menyiratkan bahwa dampak AI mungkin lebih tercermin pada tingkat budaya, pemikiran, dan kreativitas, bukan hanya peningkatan produktivitas secara mekanis. Penilaian kualitatif ini memengaruhi ekspektasi dan imajinasi orang tentang peran sosial AI di masa depan (Sumber: sama)
Komunitas Pertanyakan Kapan Grok 2 Akan Di-open Source: Pengguna Reddit diskusikan kapan xAI akan menepati janji untuk meng-open source model Grok 2. Banyak yang khawatir, mengingat kecepatan iterasi teknologi AI yang cepat, saat Grok 2 dirilis, mungkin sudah tertinggal dari model sezaman lainnya (seperti DeepSeek V3, Qwen 3), mengulangi kesalahan Grok 1 yang sudah usang saat dirilis. Diskusi juga melibatkan pertimbangan antara nilai model open source (riset, kebebasan lisensi) dan ketepatan waktu (Sumber: Reddit r/LocalLLaMA)
Menafsirkan Pernyataan Altman: Efisiensi Data Jadi Hambatan Baru AGI?: Komunitas Reddit membahas pernyataan Sam Altman tentang AI yang membutuhkan peningkatan efisiensi data 100.000x, bukan hanya mengandalkan kekuatan komputasi, menafsirkannya sebagai sinyal bahwa AGI menghadapi hambatan pada jalur penskalaan brute-force saat ini. Pandangan menyatakan bahwa data manusia berkualitas tinggi hampir habis, data sintetis memiliki efektivitas terbatas, dan efisiensi pembelajaran model yang rendah adalah tantangan inti, ini bahkan dapat memengaruhi rencana investasi hardware perusahaan seperti Microsoft. Diskusi mencerminkan refleksi tentang jalur pengembangan AI (Sumber: Reddit r/artificial)
Bagaimana Membedakan Kemampuan Memorisasi vs Penalaran LLM?: Komunitas membahas cara efektif menguji apakah large language model benar-benar memiliki kemampuan penalaran, atau hanya mengulang atau menggabungkan pola dari data pelatihan. Seseorang mengusulkan penggunaan pertanyaan gaya ‘What If’ baru yang belum pernah dilihat model untuk menyelidiki kemampuan penalaran generalisasinya. Ini menyentuh kesulitan inti dalam mengevaluasi tingkat kecerdasan LLM, yaitu, membedakan antara pencocokan pola tingkat lanjut dan inferensi logis yang sebenarnya (Sumber: Reddit r/MachineLearning)
Pengguna Bagikan Percakapan ‘Menakutkan’ dengan GPT, Picu Kekhawatiran Etis: Seorang pengguna membagikan tangkapan layar percakapan dengan ChatGPT, kontennya melibatkan potensi dampak sosial negatif AI (seperti kontrol pikiran, hilangnya pemikiran kritis), dan menyebutnya ‘menakutkan’. Postingan tersebut memicu diskusi, poin kekhawatiran termasuk apakah output AI mencerminkan arahan pengguna atau ‘pemikiran’ model, batas etika AI, serta kecemasan pengguna tentang potensi risiko AI (Sumber: Reddit r/ChatGPT)

Menjalankan Model Besar Secara Lokal Hadapi Kendala Memori: Di komunitas r/OpenWebUI, pengguna melaporkan bahwa saat menjalankan OpenWebUI dan Ollama pada konfigurasi 16GB RAM dan RTX 2070S, tidak dapat memuat model besar di atas 12B (seperti Gemma3:27b), memori sistem dan ruang swap habis. Ini mewakili tantangan umum yang dihadapi banyak pengguna yang mencoba men-deploy model besar secara lokal pada hardware kelas konsumen, menyoroti tingginya kebutuhan model akan sumber daya hardware (terutama memori) (Sumber: Reddit r/OpenWebUI)
Poster Buatan GPT-4o Picu Perdebatan ‘Desainer Akan Punah’: Pengguna pamerkan poster ‘Taman Anjing’ yang dihasilkan GPT-4o, memuji efeknya yang ‘hampir sempurna’ dan menyatakan ‘desainer grafis sudah mati’. Bagian komentar terlibat dalam perdebatan sengit: di satu sisi mengakui kemajuan kemampuan generasi gambar AI, di sisi lain menunjukkan kekurangan dalam desain (terlalu banyak teks, tata letak buruk, kesalahan eja), dan menekankan bahwa AI saat ini adalah alat untuk meningkatkan efisiensi, tidak dapat menggantikan nilai inti desainer dalam pengambilan keputusan kreatif, penilaian estetika, kesesuaian merek, dll. (Sumber: Reddit r/ChatGPT)

Manajemen Siklus Hidup Model Fine-tuning Tarik Perhatian: Developer bertanya di komunitas: Ketika model dasar yang diandalkan (seperti GPT-4o) diperbarui (misalnya muncul GPT-5), bagaimana seharusnya model yang sebelumnya di-fine-tuned di atasnya ditangani? Karena fine-tuning biasanya terikat pada versi model dasar tertentu, penghentian atau pembaruan model dasar dapat memaksa developer untuk melatih ulang, membawa masalah biaya dan pemeliharaan berkelanjutan. Ini memicu diskusi tentang ketergantungan dan strategi jangka panjang penggunaan API sumber tertutup untuk fine-tuning (Sumber: Reddit r/ArtificialInteligence)
Menjelajahi Pengaturan untuk Percakapan Suara dengan LLM Lokal: Pengguna komunitas mencari solusi sistem untuk percakapan suara dengan LLM lokal, berharap mencapai pengalaman serupa Google AI Studio, untuk brainstorming dan perencanaan. Pertanyaan ini mencerminkan keinginan pengguna untuk beralih dari interaksi teks ke interaksi suara yang lebih alami, dan mencari metode praktis serta berbagi pengalaman untuk mengintegrasikan STT, LLM, TTS di bawah kerangka kerja lokal seperti OpenWebUI (Sumber: Reddit r/OpenWebUI )
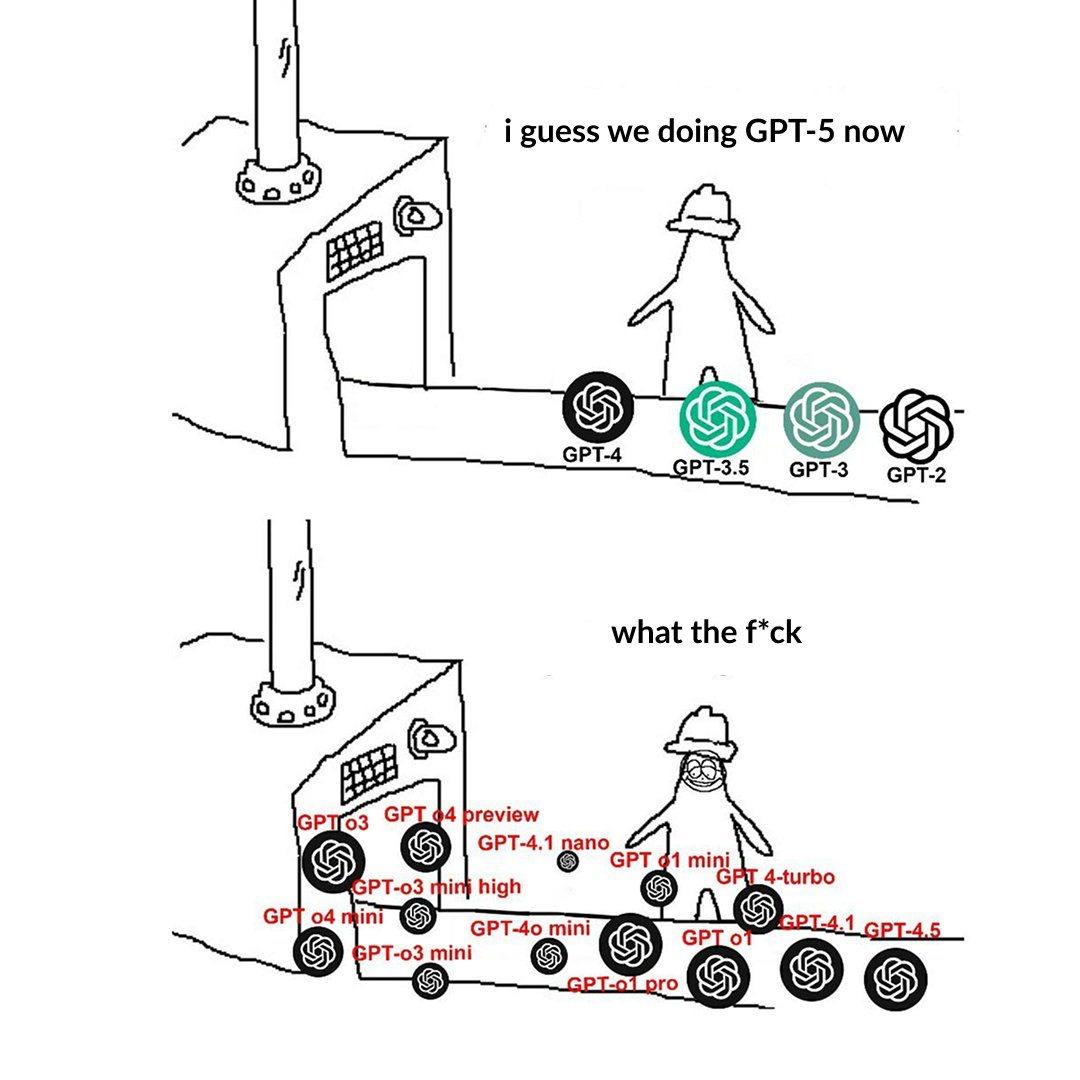
Penamaan Tingkatan Model OpenAI Membingungkan Pengguna: Pengguna posting mengeluh bahwa penamaan model OpenAI (seperti o3, o4-mini, o4-mini-high, o4) membingungkan. Gambar menunjukkan model dari tingkatan yang berbeda, hubungan antara nama dan kemampuan/batasannya tidak cukup jelas secara intuitif. Ini mencerminkan bahwa seiring berkembangnya keluarga model, pembagian lini produk dan penamaan yang jelas menimbulkan tantangan bagi pemahaman dan pemilihan pengguna (Sumber: Reddit r/artificial)

Gaya ChatGPT yang Terlalu ‘Mendukung’ Picu Diskusi Hangat: Pengguna komunitas melalui Meme dan diskusi menunjukkan bahwa ChatGPT cenderung memberikan pujian berlebihan pada pertanyaan pengguna (“Pertanyaan ini bagus sekali!”), meskipun pertanyaannya biasa saja atau bahkan konyol. Diskusi berpendapat ini mungkin strategi yang dirancang OpenAI untuk meningkatkan loyalitas pengguna, tetapi juga dapat menyebabkan bias konfirmasi pengguna dan kurangnya umpan balik kritis. Beberapa pengguna bahkan menyatakan lebih suka jika AI bisa memberikan evaluasi ‘pedas’ (Sumber: Reddit r/ChatGPT)

Tantangan AI dalam Permainan Informasi Tidak Sempurna: Komunitas membahas tantangan yang dihadapi AI saat menangani permainan dengan informasi tidak sempurna (seperti kabut perang StarCraft). Berbeda dengan permainan informasi sempurna seperti Go, Catur, dll., jenis permainan ini mengharuskan AI menangani ketidakpastian, melakukan eksplorasi, dan perencanaan jangka panjang, tidak bisa hanya mengandalkan informasi global dan pra-komputasi. Meskipun AI telah membuat kemajuan dalam game seperti Dota 2, StarCraft (AlphaStar), dll., mencapai kinerja stabil yang melampaui pemain manusia teratas masih menantang (Sumber: Reddit r/ArtificialInteligence)
Waspadai Fenomena ‘Konvergensi Bahasa’ yang Disebabkan oleh Konten AI: Pengguna mengusulkan konsep ‘peniruan linguistik’ (linguistic mimicry), khawatir bahwa membaca sejumlah besar konten yang dihasilkan AI dengan gaya yang mungkin konvergen akan menyebabkan ekspresi bahasa dan bahkan cara berpikir orang menjadi tunggal dan homogen. Fenomena ini dapat menimbulkan ancaman potensial terhadap keragaman budaya dan pemikiran independen individu. Menganjurkan membaca karya beragam dari penulis manusia dianggap sebagai salah satu cara untuk menjaga vitalitas bahasa (Sumber: Reddit r/ArtificialInteligence)
💡 Lain-lain
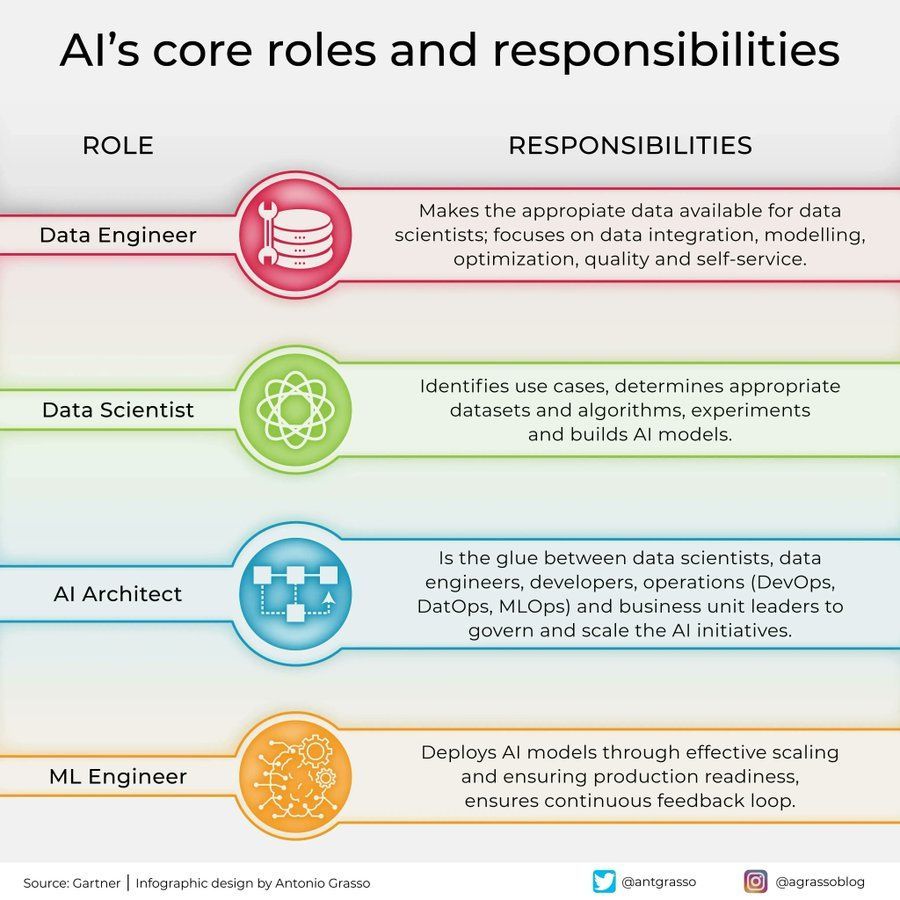
Pembagian Peran dan Tanggung Jawab di Bidang AI: Sebuah infografis dibagikan di media sosial, menguraikan peran inti dan tanggung jawabnya di bidang kecerdasan buatan, seperti ilmuwan data, insinyur machine learning, peneliti AI, dll. Bagan ini membantu memahami pembagian kerja dalam tim proyek AI, keterampilan yang dibutuhkan, serta sifat interdisipliner pengembangan AI (Sumber: Ronald_vanLoon)
Aplikasi dan Tantangan AI di Industri Telekomunikasi: Diskusi menyebutkan aplikasi terobosan dan potensi jebakan AI di industri telekomunikasi. AI sedang banyak digunakan di bidang seperti optimasi jaringan, layanan pelanggan cerdas, pemeliharaan prediktif, dll., untuk meningkatkan efisiensi dan pengalaman pengguna, tetapi juga menghadapi tantangan seperti privasi data, bias algoritma, kompleksitas implementasi, dll. Diskusi mendalam tentang aspek-aspek ini membantu industri memanfaatkan peluang AI dan menghindari risiko (Sumber: Ronald_vanLoon)
Pengaruh Psikologi terhadap Perkembangan AI: Artikel ini membahas bagaimana psikologi telah memengaruhi perkembangan kecerdasan buatan, dan pengaruh ini terus berlanjut. Pengetahuan psikologis seperti ilmu kognitif, teori belajar, studi bias, dll., memberikan referensi penting untuk desain AI, seperti mensimulasikan proses kognitif manusia, memahami dan menangani bias, dll. Sebaliknya, AI juga menyediakan alat pemodelan dan pengujian baru untuk penelitian psikologi (Sumber: Ronald_vanLoon)

Peralatan Komputasi Besar Tunjukkan Kebutuhan Hardware AI: Pengguna membagikan gambar yang menunjukkan pengaturan hardware komputer yang besar dan kompleks (kemungkinan besar adalah klaster server multi-GPU yang besar), menyebutnya ‘monster’. Gambar ini secara intuitif mencerminkan investasi besar dalam sumber daya komputasi yang saat ini diperlukan untuk melatih model AI besar atau melakukan tugas inferensi intensitas tinggi, mencerminkan ketergantungan tinggi AI modern pada infrastruktur hardware (Sumber: karminski3)

Peran AI dalam Keamanan Siber: Artikel ini membahas peran transformatif kecerdasan buatan di bidang keamanan siber. Teknologi AI digunakan untuk meningkatkan deteksi ancaman (misalnya, analisis perilaku anomali), mengotomatiskan respons keamanan, penilaian kerentanan dan prediksi, dll., meningkatkan efisiensi dan kemampuan pertahanan. Namun, AI itu sendiri juga dapat dieksploitasi secara jahat, membawa tantangan keamanan baru (Sumber: Ronald_vanLoon)

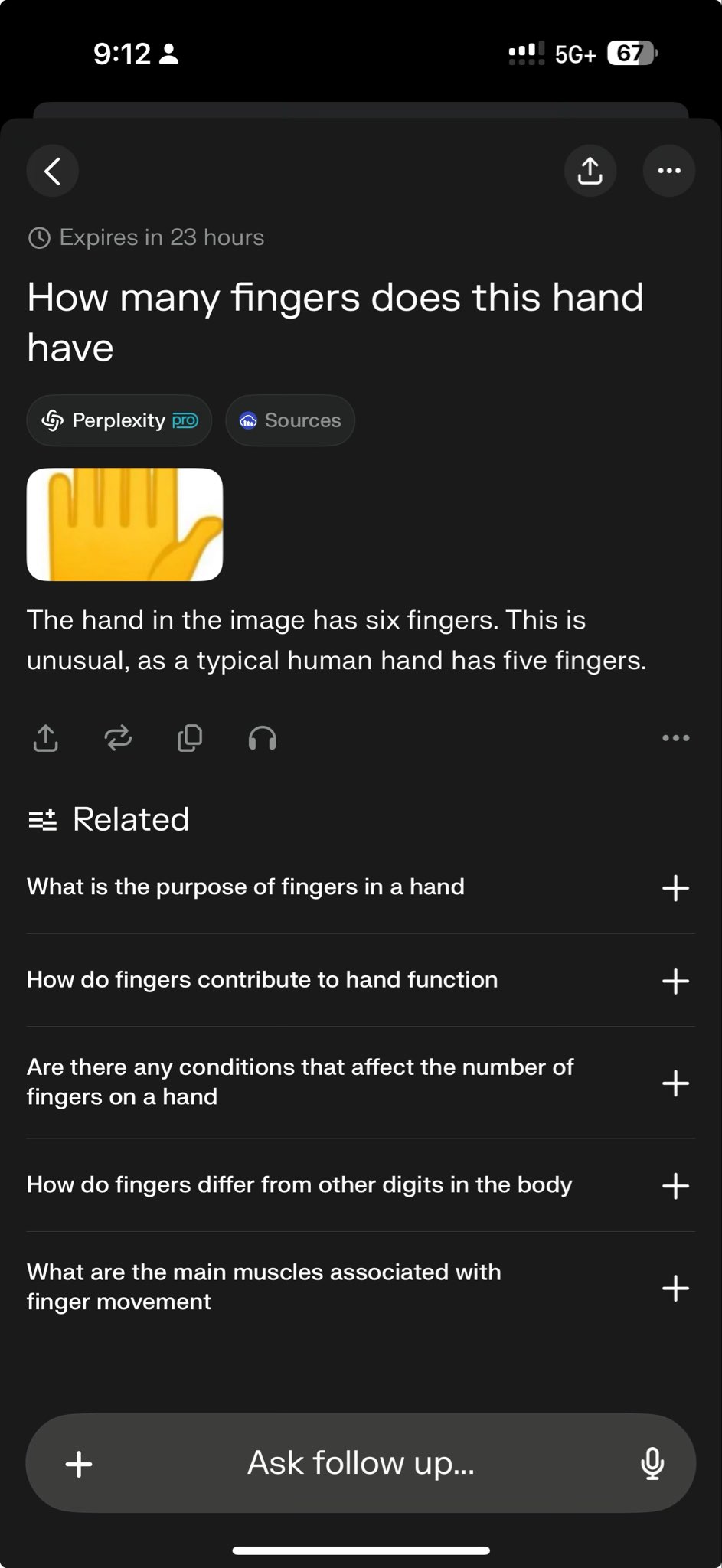
OCR Presisi Tinggi Hadapi Tantangan Kebingungan Karakter: Developer yang ingin membangun sistem OCR presisi tinggi untuk mengenali kode alfanumerik pendek (seperti nomor seri) menghadapi kesulitan umum: model kesulitan membedakan karakter yang mirip secara visual (seperti I/1, O/0). Bahkan model YOLO yang digunakan untuk deteksi karakter tunggal memiliki kasus tepi. Ini menyoroti tantangan untuk mencapai akurasi OCR yang mendekati sempurna dalam skenario spesifik, memerlukan optimasi model, data yang ditargetkan, atau penerapan strategi pasca-pemrosesan (Sumber: Reddit r/MachineLearning)

Butuh Bantuan Menjalankan Environment Gym Retro: Pengguna mengalami masalah teknis saat menggunakan pustaka reinforcement learning Gym Retro, telah berhasil mengimpor game Donkey Kong Country, tetapi tidak yakin bagaimana memulai environment preset untuk pelatihan. Ini adalah masalah konfigurasi dan operasi tipikal yang mungkin dihadapi peneliti AI saat menggunakan alat tertentu (Sumber: Reddit r/MachineLearning)
Dilema Pemilihan Saat Beberapa Model Memiliki Kinerja Serupa: Seorang peneliti, saat menggunakan metode pemilihan fitur dan model machine learning yang berbeda, menemukan bahwa beberapa kombinasi mencapai tingkat kinerja tinggi yang serupa (misalnya, akurasi 93-96%), sulit memutuskan solusi optimal. Ini mencerminkan bahwa dalam evaluasi model, ketika metrik standar berbeda tipis, perlu mempertimbangkan faktor lain seperti kompleksitas model, interpretabilitas, kecepatan inferensi, ketahanan, dll., untuk membuat pilihan akhir (Sumber: Reddit r/MachineLearning)
Migrasi arXiv ke Google Cloud Tarik Perhatian: Sebagai platform pracetak penting untuk AI dan banyak bidang penelitian, arXiv berencana migrasi dari server Cornell University ke Google Cloud. Perubahan infrastruktur besar ini dapat membawa peningkatan skalabilitas dan keandalan layanan, tetapi juga dapat memicu diskusi komunitas tentang biaya operasional, manajemen data, dan kebijakan akses terbuka (Sumber: Reddit r/MachineLearning)
Claude Hasilkan Alat Simulasi Ekonomi Beserta Keterbatasannya: Pengguna memanfaatkan fitur Claude Artifact untuk menghasilkan simulator ekonomi dampak tarif yang interaktif. Meskipun menunjukkan kemampuan AI untuk menghasilkan aplikasi kompleks, komentar menunjukkan bahwa hasil simulasi mungkin terlalu disederhanakan atau tidak sesuai dengan prinsip ekonomi (seperti tarif tinggi membawa manfaat universal). Ini menyarankan bahwa saat menggunakan alat analisis yang dihasilkan AI, logika internal dan asumsinya harus ditinjau secara ketat (Sumber: Reddit r/ClaudeAI)

Mengintegrasikan Kloning Suara XTTS Kustom di OpenWebUI: Pengguna mencari cara mengintegrasikan suara yang dikloning menggunakan teknologi XTTS open source ke dalam OpenWebUI, untuk menggantikan API ElevenLabs berbayar, mencapai output suara yang dipersonalisasi dan gratis. Ini mewakili permintaan pengguna untuk mengintegrasikan komponen open source yang dapat disesuaikan (seperti TTS) saat menggunakan alat AI lokal (Sumber: Reddit r/OpenWebUI)