
Kata Kunci:AI, 大模型 (Model Besar), AI军备竞赛 (Perlombaan Senjata AI), 垂直行业模型 (Model Industri Vertikal), 智谱AI IPO (Zhipu AI IPO), AI独立发现物理定律 (AI Menemukan Hukum Fisika Secara Mandiri), AI助盲系统 (Sistem Bantu Tunanetra AI), AI di Indonesia, penerapan model besar di industri, perkembangan terbaru perlombaan senjata AI, keunggulan model industri vertikal, analisis Zhipu AI IPO, bagaimana AI menemukan hukum fisika, teknologi sistem bantu tunanetra berbasis AI
“` markdown
🔥 Fokus Utama
Perusahaan Teknologi Besar Terlibat dalam Perlombaan Senjata AI, Model Vertikal dan Ekosistem Menjadi Fokus: Raksasa teknologi global menginvestasikan dana dalam AI dengan intensitas yang belum pernah terjadi sebelumnya, dengan pengeluaran modal diperkirakan akan melampaui $320 miliar pada tahun 2025. Perusahaan Tiongkok seperti Alibaba, Tencent, Huawei, dan lainnya juga meningkatkan investasi mereka, bertaruh besar pada infrastruktur AI, model bahasa besar (LLM), dan daya komputasi. Fokus persaingan bergeser dari general large models ke vertical industry models, yang terakhir menjadi mesin pertumbuhan baru karena margin kotor yang tinggi dan kemampuannya untuk mengatasi masalah praktis. Meskipun menghadapi tantangan chip kelas atas, produsen domestik membuat kemajuan dalam optimasi biaya komputasi dan model inferensi (“slow thinking”) (misalnya, efek DeepSeek). Setiap perusahaan mengambil jalur yang berbeda: Alibaba berinvestasi besar-besaran dalam infrastruktur, Huawei menginovasi perangkat keras (CloudMatrix 384) dan mempromosikan kolaborasi edge-cloud, Baidu mendekati aplikasi, sementara Tencent dan ByteDance memanfaatkan keunggulan skenario mereka yang beragam. Perluasan perangkat keras AI dan pembangunan ekosistem open-source (seperti HarmonyOS, Ascend, Hunyuan) menjadi kunci, dengan persaingan bergeser dari terobosan teknologi tunggal ke kemampuan kolaborasi ekosistem. (Sumber: 36Kr-Tech Cloud Report)

Penemuan Mengejutkan MIT: AI Dapat Menurunkan Hukum Fisika Secara Independen Tanpa Pengetahuan Awal: Tim Max Tegmark di MIT mengembangkan arsitektur baru MASS (Multiple AI Scalar Scientists). Sistem AI ini, tanpa diberi tahu hukum fisika apa pun, dapat secara mandiri mempelajari dan mengusulkan formulasi teoretis yang sangat mirip dengan Hamiltonian atau Lagrangian dalam mekanika klasik, hanya dengan menganalisis data observasi dari sistem fisik seperti pendulum dan osilator. Penelitian menunjukkan bahwa AI secara mandiri akan mengoreksi teorinya ketika menghadapi sistem yang lebih kompleks, dan “ilmuwan” AI yang berbeda pada akhirnya akan konvergen ke prinsip-prinsip fisika yang diketahui, terutama lebih menyukai deskripsi Lagrangian dalam sistem yang kompleks. Pencapaian ini menunjukkan potensi besar AI dalam penemuan ilmiah dasar, dan mungkin dapat secara independen mengungkap hukum dasar alam semesta. (Sumber: Xin Zhi Yuan)

Tim Shanghai Jiao Tong University Mengembangkan Sistem Bantuan Tunanetra Berbasis AI, Terbit di Jurnal Nature: Tim Gu Leilei dari Shanghai Jiao Tong University mengembangkan sistem bantuan tunanetra wearable yang digerakkan oleh AI. Menggabungkan teknologi elektronik fleksibel, sistem ini menggantikan sebagian fungsi visual melalui umpan balik auditori dan taktil, membantu penyandang tunanetra menyelesaikan tugas sehari-hari seperti navigasi dan menggenggam. Perangkat keras sistem ini ringan, perangkat lunaknya mengoptimalkan metode output informasi agar sesuai dengan kognisi fisiologis manusia, dan sistem pelatihan imersif VR juga dikembangkan. Pengujian menunjukkan bahwa sistem ini secara signifikan meningkatkan kemampuan navigasi menghindari rintangan dan menggenggam objek pengguna tunanetra di lingkungan virtual dan nyata. Hasil penelitian diterbitkan dalam Nature Machine Intelligence, menunjukkan potensi besar AI dalam membantu penyandang tunanetra, meningkatkan kemampuan hidup mandiri mereka, dan memberikan ide-ide baru untuk perangkat bantuan visual wearable yang dipersonalisasi dan ramah pengguna. (Sumber: 36Kr)

Zhipu AI Memulai Bimbingan IPO, Bertujuan Menjadi “Saham Perdana Model Besar”: Perusahaan model besar AI dari Tsinghua University, Zhipu AI (Beijing Zhipu Huazhang Technology), telah menyelesaikan pengajuan bimbingan IPO di Biro Regulasi Sekuritas Beijing pada 14 April, dengan CICC sebagai pembimbing. Targetnya adalah pasar A-share, berpotensi menjadi “saham perdana model besar AI” domestik pertama. Meskipun produk C-end-nya “Zhipu Qingyan” memiliki skala pengguna yang tidak besar, Zhipu mengandalkan latar belakang teknis yang kuat (berafiliasi dengan Tsinghua, mengembangkan sendiri seri model besar GLM), status “tim nasional” (dimasukkan dalam daftar entitas oleh AS), dan kemajuan komersialisasi (melayani klien pemerintah dan perusahaan, pendapatan tumbuh signifikan), telah memperoleh lebih dari 16 miliar RMB dalam pendanaan, dengan valuasi melebihi 20 miliar RMB. Investor termasuk VC terkenal, raksasa industri, dan BUMN dari berbagai daerah. Di bawah tekanan dari kekuatan baru seperti DeepSeek, pilihan Zhipu untuk IPO dianggap sebagai langkah kunci untuk mengamankan posisi yang menguntungkan dalam persaingan sengit, memenuhi kebutuhan pendanaan, dan menanggapi harapan investor. Perusahaan baru-baru ini terus membuka sumber model seri GLM-4, menunjukkan upayanya secara bersamaan di bidang teknologi dan modal. (Sumber: 36Kr-Zhengu Research Lab, 36Kr-Internet Breaking News, VC Daily)

🎯 Perkembangan Terkini
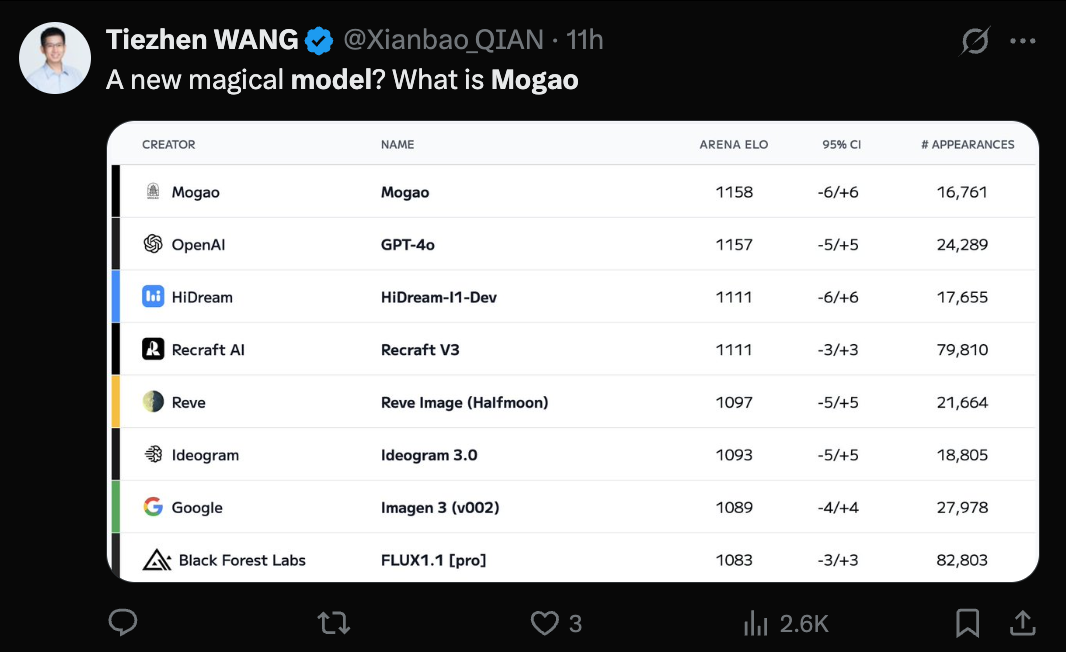
Model Seedream 3.0 (Mogao) ByteDance Terungkap, Kemampuan Text-to-Image Diakui: Model misterius Mogao, yang baru-baru ini mendominasi peringkat text-to-image Artificial Analysis, telah dikonfirmasi sebagai Seedream 3.0 yang dikembangkan oleh tim Seed ByteDance. Model ini unggul dalam berbagai gaya termasuk realisme, desain, anime, serta pembuatan teks, terutama mahir dalam menangani teks padat dan menghasilkan potret manusia yang realistis. Tingkat kegunaan karakter Tiongkok dan Inggris mencapai 94%, realisme potret mendekati tingkat fotografi profesional, dan mendukung output gambar resolusi 2K asli dengan kecepatan generasi yang cepat. Laporan teknis mengungkapkan berbagai inovasinya dalam pemrosesan data (pelatihan sadar cacat, pengambilan sampel sumbu ganda), pra-pelatihan (arsitektur MMDiT, resolusi campuran, RoPE lintas-modal), pasca-pelatihan (pelatihan berkelanjutan, SFT, RLHF, model hadiah VLM), dan akselerasi inferensi (Hyper-SD, RayFlow). Dibandingkan dengan GPT-4o, Seedream 3.0 lebih unggul dalam bahasa Tionghoa, tata letak, dan warna. (Sumber: 36Kr-Machine Heart)
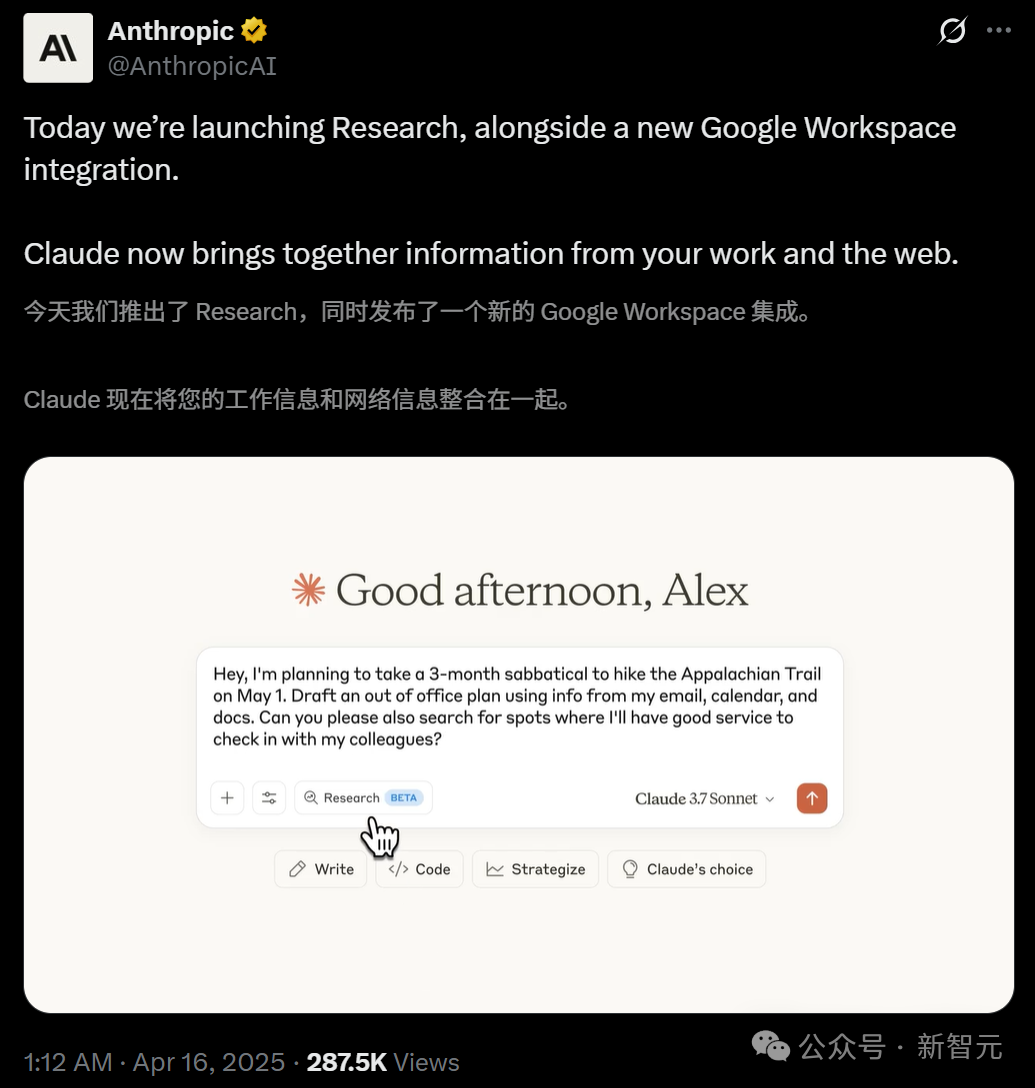
Claude Meluncurkan Fitur Research dan Terintegrasi dengan Google Workspace: Anthropic menambahkan dua fitur utama ke asisten AI-nya, Claude: Research dan integrasi Google Workspace. Fitur Research memungkinkan Claude mencari informasi online dan menggabungkannya dengan file internal pengguna (seperti Google Docs) untuk analisis multi-sudut, menghasilkan laporan komprehensif dengan cepat. Integrasi Google Workspace menghubungkan Gmail, Google Calendar, dan Docs, memungkinkan Claude memahami jadwal, email, dan konten dokumen pengguna, mengekstrak informasi, dan membantu menyelesaikan tugas, seperti merencanakan perjalanan berdasarkan informasi pribadi atau menyusun draf email. Fitur-fitur ini bertujuan untuk meningkatkan efisiensi kerja pengguna secara signifikan. Fitur Research saat ini tersedia untuk pengujian bagi pengguna Max, Team, dan Enterprise di AS, Jepang, dan Brasil, sementara integrasi Workspace tersedia untuk pengujian bagi semua pengguna berbayar. Umpan balik pengguna positif, menyatakan bahwa fitur ini dapat meningkatkan efisiensi dan menemukan hubungan antar data, tetapi ada juga kekhawatiran tentang keamanan data. (Sumber: Xin Zhi Yuan, op7418, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
CUHK dan Tsinghua Merilis Video-R1, Membuka Paradigma Baru dalam Penalaran Video: Tim dari Chinese University of Hong Kong (CUHK) dan Tsinghua University bersama-sama meluncurkan model penalaran video pertama di dunia yang mengadopsi paradigma R1 reinforcement learning, yaitu Video-R1. Model ini bertujuan untuk mengatasi kurangnya logika temporal dan kemampuan penalaran mendalam pada model video yang ada. Dengan memperkenalkan algoritma T-GRPO yang sadar waktu dan dataset pelatihan campuran yang menggabungkan gambar dan video (Video-R1-COT-165k dan Video-R1-260k), Video-R1 dengan parameter 7B mengungguli GPT-4o dalam benchmark penalaran spasial video VSI-Bench yang diusulkan oleh Fei-Fei Li. Model ini menunjukkan “momen pencerahan” seperti manusia, mampu melakukan penalaran logis berdasarkan informasi temporal. Eksperimen membuktikan bahwa peningkatan jumlah frame input dapat meningkatkan akurasi penalaran. Proyek ini telah membuka sumber model, kode, dan dataset sepenuhnya, menandakan bahwa AI video bergerak dari “memahami” ke “berpikir”. (Sumber: Xin Zhi Yuan)

ICLR 2025 Pertama Kali Menggunakan Peninjauan AI Skala Besar, Meningkatkan Kualitas Tinjauan Secara Signifikan: Menghadapi tantangan peningkatan jumlah pengajuan dan penurunan kualitas tinjauan, konferensi ICLR 2025 untuk pertama kalinya menerapkan “Agen Umpan Balik Tinjauan” AI (Review Feedback Agent) skala besar untuk membantu proses peninjauan. Sistem ini menggunakan beberapa LLM, termasuk Claude Sonnet 3.5, untuk mengidentifikasi ambiguitas, kesalahpahaman konten, atau pernyataan tidak profesional dalam tinjauan, dan memberikan saran perbaikan spesifik kepada peninjau. Eksperimen mencakup 42,3% tinjauan, dan hasilnya menunjukkan bahwa umpan balik AI meningkatkan kualitas tinjauan dalam 89% kasus, 26,6% peninjau memodifikasi tinjauan mereka berdasarkan saran AI, dan tinjauan yang dimodifikasi rata-rata bertambah 80 kata, menjadi lebih spesifik dan informatif. Pada saat yang sama, intervensi AI juga meningkatkan aktivitas dan kedalaman diskusi antara penulis dan peninjau selama periode Rebuttal. Eksperimen perintis ini membuktikan potensi besar AI dalam mengoptimalkan proses peer review. (Sumber: Xin Zhi Yuan)

Robot Humanoid Memasuki Rumah Tangga Memicu Diskusi, Perusahaan Peralatan Rumah Tangga Aktif Mengembangkan Embodied Intelligence: Masuknya robot humanoid ke dalam skenario rumah tangga memicu diskusi industri tentang model aplikasinya dan dampaknya pada industri peralatan rumah tangga. Pandangan menyatakan bahwa robot humanoid harus memanfaatkan karakteristik “umum” mereka untuk menyelesaikan tugas non-standar seperti melipat pakaian dan merapikan, serta menggunakan kemampuan interaksi untuk bertindak sebagai “pelayan”, mengarahkan dan mengoordinasikan perangkat pintar lainnya, daripada sekadar menggantikan peralatan yang ada. Menghadapi tren ini, raksasa peralatan rumah tangga seperti Haier dan Midea telah mulai melakukan布局, meluncurkan produk robot humanoid mereka sendiri (seperti Kuavo), dan mengeksplorasi pengintegrasian teknologi embodied intelligence ke dalam peralatan rumah tangga tradisional (seperti penyedot debu Dreame dengan lengan mekanik, mesin cuci Yimu Technology yang dapat mengambil pakaian). Ini menunjukkan bahwa industri peralatan rumah tangga secara aktif beradaptasi dengan gelombang AI, dan di masa depan dapat membentuk ekosistem rumah pintar yang bersimbiosis dan terintegrasi dengan robot humanoid. (Sumber: 36Kr-Embodied Intelligence Research Society)

Huawei Merilis Server AI CloudMatrix 384, Menyaingi Nvidia GB200: Huawei meluncurkan klaster server AI terbarunya, CloudMatrix 384, di Cloud Ecosystem Conference. Sistem ini terdiri dari 384 kartu komputasi Ascend, dengan daya komputasi klaster tunggal mencapai 300 PFlops dan throughput decoding kartu tunggal mencapai 1920 Token/s, menargetkan kinerja Nvidia H100. Sistem ini menggunakan interkoneksi serat optik berkecepatan tinggi penuh (6812 modul optik 400G), dengan efisiensi pelatihan mendekati 90% dari kinerja kartu tunggal Nvidia. Langkah ini dianggap sebagai langkah penting bagi Tiongkok dalam mengejar tingkat terdepan internasional di bidang infrastruktur AI, bertujuan untuk mengatasi permintaan daya komputasi di bawah pembatasan chip kelas atas. Analis percaya bahwa ini menunjukkan kemajuan pesat Huawei di bidang perangkat keras AI dan dapat memengaruhi lanskap pasar yang ada. (Sumber: dylan522p, 36Kr-Tech Cloud Report)
Google Meluncurkan Fitur Text-to-Video Veo 2 dan Whisk Animate: Google mengintegrasikan model text-to-video Veo 2 ke dalam Gemini Advanced. Pengguna anggota dapat menggunakan fitur ini secara gratis melalui Aplikasi Gemini, dengan video yang dihasilkan berdurasi 8 detik. Sementara itu, alat pengeditan gambar Google, Whisk, juga memperbarui fitur Whisk Animate, memungkinkan pengguna untuk mengubah gambar yang dihasilkan menjadi video menggunakan Veo 2, tetapi fitur ini memerlukan keanggotaan Google One. Ini menandai upaya berkelanjutan Google dalam bidang generasi multimodal, menyediakan alat kreasi yang lebih kaya bagi pengguna. (Sumber: op7418, op7418)
OpenAI Mungkin Akan Membangun Produk Sosial Mirip X: Menurut The Verge, OpenAI sedang mengembangkan prototipe produk sosial yang mirip dengan X (sebelumnya Twitter) secara internal. Produk ini mungkin menggabungkan kemampuan generasi gambar ChatGPT (terutama setelah rilis GPT-4o) dengan aliran dinamika sosial. Mengingat basis pengguna ChatGPT yang besar dan kemajuannya dalam generasi gambar, langkah ini dianggap memiliki kelayakan tertentu dan mungkin menandai upaya OpenAI untuk memperluas kemampuan AI-nya ke ranah media sosial. (Sumber: op7418)
DeepCoder Merilis Model Pengkodean Open-Source 14B Berkinerja Tinggi: Tim DeepCoder merilis model pengkodean open-source 14 miliar parameter berkinerja tinggi, yang diklaim unggul dalam tugas pengkodean. Rilis model ini memberi pengembang pilihan alat bantu dan generasi kode yang kuat lainnya, terutama dalam skenario yang membutuhkan keseimbangan antara kinerja dan ukuran model. (Sumber: Ronald_vanLoon)

Tesla Mencapai Parkir Otomatis Kendaraan Keluar Pabrik: Tesla mendemonstrasikan kemajuan baru dalam teknologi self-driving-nya, di mana kendaraan dapat secara otomatis berkendara ke area pemuatan atau tempat parkir setelah keluar dari jalur produksi pabrik, tanpa campur tangan manusia. Ini menunjukkan potensi penerapan kemampuan FSD (Full Self-Driving) Tesla dalam lingkungan spesifik yang terkontrol, membantu meningkatkan efisiensi logistik produksi, dan merupakan langkah menuju aplikasi self-driving yang lebih luas. (Sumber: Ronald_vanLoon, Ronald_vanLoon)
Dexterity Merilis Robot Industri Mech yang Digerakkan oleh Physical AI: Perusahaan Dexterity meluncurkan robot industri bernama Mech, yang ditandai dengan penggunaan teknologi “Physical AI”. AI jenis ini memungkinkan robot untuk menavigasi dan beroperasi di lingkungan industri yang kompleks, menunjukkan fleksibilitas dan kemampuan adaptasi super-manusia, yang bertujuan untuk mengatasi tugas-tugas kompleks yang sulit ditangani oleh otomatisasi industri tradisional. (Sumber: Ronald_vanLoon)
MIT Mengembangkan Robot Pelompat Baru, Dirancang Khusus untuk Medan Kasar: Peneliti MIT telah mengembangkan robot baru yang desainnya terinspirasi oleh gerakan melompat, sangat mahir bergerak di medan yang kasar dan tidak rata. Robot ini menunjukkan penerapan biomimikri dalam desain robot dan potensi machine learning dalam mengendalikan gerakan kompleks, diharapkan dapat diterapkan dalam pencarian dan penyelamatan, eksplorasi planet, dan lingkungan kompleks lainnya. (Sumber: Ronald_vanLoon)
INTELLECT-2 Dimulai: Pelatihan Reinforcement Learning Terdistribusi Global untuk Model 32B: Proyek Prime Intellect meluncurkan inisiatif INTELLECT-2, yang bertujuan untuk melatih model penalaran canggih 32 miliar parameter menggunakan reinforcement learning melalui sumber daya komputasi terdistribusi global. Model ini didasarkan pada arsitektur Qwen, dengan tujuan mencapai anggaran pemikiran yang dapat dikontrol, yaitu pengguna dapat menentukan berapa banyak langkah penalaran (berapa banyak token yang dipikirkan) yang harus dilakukan model sebelum menyelesaikan masalah. Ini adalah eksplorasi penting tentang pelatihan terdistribusi dan reinforcement learning dalam meningkatkan kemampuan penalaran model besar. (Sumber: Reddit r/LocalLLaMA)

ByteDance Merilis Model Autoregresif Multimodal Mirip GPT-4o, Liquid: ByteDance merilis seri model multimodal bernama Liquid. Model ini mengadopsi arsitektur autoregresif yang mirip dengan GPT-4o, mampu menerima input teks dan gambar, serta menghasilkan output teks atau gambar. Berbeda dengan MLLM sebelumnya yang menggunakan embedding visual pra-terlatih eksternal, Liquid menggunakan LLM tunggal untuk generasi autoregresif. Versi model 7B dan Demo saat ini telah dirilis di Hugging Face. Penilaian awal menganggap kualitas generasi gambarnya belum sebanding dengan GPT-4o, tetapi kesatuan arsitekturnya merupakan kemajuan teknis yang penting. (Sumber: Reddit r/LocalLLaMA)
Menjalankan Beberapa LLM Melalui Teknik Snapshot Memori GPU: Membahas teknik untuk beralih dan menjalankan beberapa LLM dengan cepat melalui snapshot status memori GPU (termasuk bobot, KV cache, tata letak memori, dll.). Metode ini mirip dengan operasi fork proses, mampu memulihkan status model dalam hitungan detik (sekitar 2 detik untuk model 70B, sekitar 0,5 detik untuk model 13B) tanpa perlu memuat ulang atau inisialisasi. Keuntungan potensialnya termasuk menjalankan puluhan LLM pada satu node GPU untuk mengurangi biaya idle, mencapai peralihan model dinamis sesuai permintaan, dan memanfaatkan waktu idle untuk fine-tuning lokal, dll. (Sumber: Reddit r/MachineLearning)
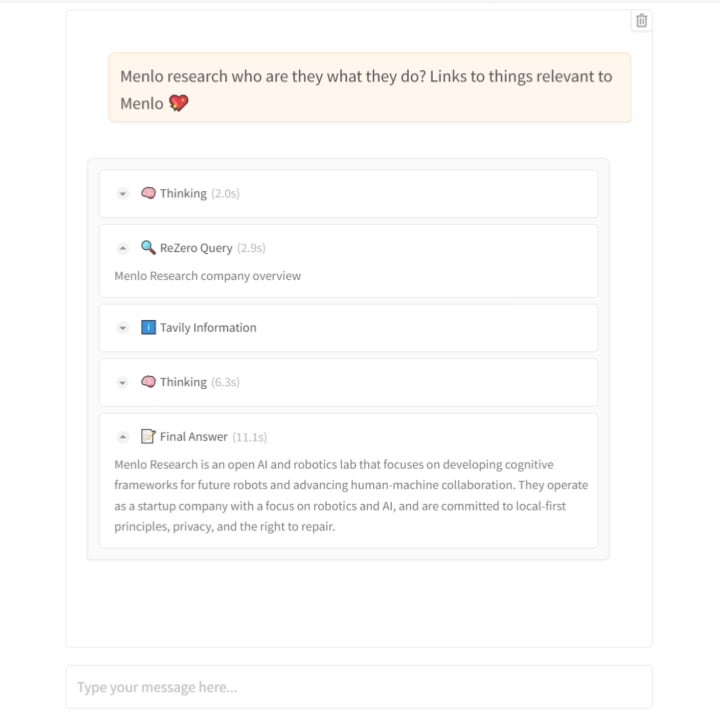
Menlo Research Merilis Model ReZero: Mengajarkan AI untuk Mencari dengan “Gigih”: Tim Menlo Research merilis model dan makalah baru bernama ReZero. Model ini didasarkan pada gagasan bahwa “pencarian membutuhkan beberapa kali percobaan”, menggunakan GRPO (algoritma optimasi reinforcement learning) dan kemampuan pemanggilan alat untuk pelatihan, serta memperkenalkan “retry_reward”. Tujuan pelatihannya adalah agar model, ketika menghadapi kesulitan atau hasil pencarian awal tidak memuaskan, dapat secara aktif dan berulang kali mencoba mencari hingga menemukan informasi yang dibutuhkan. Eksperimen menunjukkan bahwa kinerja ReZero meningkat secara signifikan dibandingkan model dasar (46% vs 20%), membuktikan efektivitas strategi pencarian berulang, dan menantang pandangan bahwa “pengulangan sama dengan halusinasi”. Model ini dapat digunakan untuk mengoptimalkan generasi kueri mesin pencari yang ada atau sebagai lapisan peningkatan pencarian untuk LLM. Model dan kode telah dibuat open-source. (Sumber: Reddit r/LocalLLaMA)
Hugging Face Mengakuisisi Startup Robot Humanoid: Hugging Face, sebagai komunitas dan platform AI open-source terkemuka, telah mengakuisisi startup robot humanoid yang informasinya belum diungkapkan secara spesifik. Langkah ini mungkin menandakan keinginan Hugging Face untuk memperluas kemampuan platformnya dari perangkat lunak dan model ke perangkat keras dan robotika, lebih lanjut mendorong penerapan AI di dunia fisik, terutama dalam embodied intelligence. (Sumber: Reddit r/ArtificialInteligence)

🧰 Peralatan
Model TTS Emosional Open-Source Orpheus Dirilis, Mendukung Streaming Inference dan Voice Cloning: Canopy Labs membuka sumber seri model text-to-speech (TTS) bernama Orpheus (parameter hingga 3 miliar, berdasarkan arsitektur Llama). Model ini diklaim memiliki kinerja melampaui model open-source yang ada dan beberapa model closed-source. Ciri khasnya adalah kemampuannya menghasilkan ucapan mirip manusia dengan intonasi, emosi, dan ritme alami, bahkan dapat menyimpulkan dan menghasilkan suara non-linguistik seperti desahan dan tawa dari teks, menunjukkan kemampuan “empati” tertentu. Orpheus mendukung zero-shot voice cloning, intonasi emosional yang dapat dikontrol, dan mencapai streaming inference latensi rendah (sekitar 200ms), cocok untuk aplikasi percakapan real-time. Proyek ini menyediakan berbagai ukuran model dan tutorial fine-tuning, bertujuan untuk menurunkan hambatan sintesis suara berkualitas tinggi. (Sumber: 36Kr)

Platform Trae.ai Menambahkan Gemini 2.5 Pro Secara Gratis: Platform alat AI Trae.ai mengumumkan bahwa mereka telah menambahkan model terbaru Google, Gemini 2.5 Pro, dan menawarkannya secara gratis. Pengguna dapat mencoba berbagai kemampuan Gemini 2.5 Pro di platform ini. (Sumber: dotey)
Alat Perekrutan AI Hireway: Menyaring 800 Pelamar dalam Sehari: Hireway mendemonstrasikan kemampuan alat perekrutan AI-nya, mengklaim dapat secara efisien menyaring 800 pelamar kerja dalam satu hari. Alat ini menggunakan AI dan teknologi otomatisasi untuk mengoptimalkan proses perekrutan, meningkatkan efisiensi penyaringan dan pengalaman pelamar. (Sumber: Ronald_vanLoon)
PRIMA.CPP: Mempercepat Inferensi Model Besar 70B pada Klaster Rumahan Biasa: PRIMA.CPP adalah proyek open-source berbasis llama.cpp yang bertujuan untuk mengoptimalkan dan mempercepat kecepatan inferensi model bahasa besar hingga 70 miliar parameter pada klaster komputasi rumahan biasa dengan sumber daya terbatas (mungkin melibatkan beberapa PC atau perangkat biasa). Proyek ini berfokus pada masalah efisiensi inferensi terdistribusi, memberikan kemungkinan baru untuk menjalankan model besar secara lokal. Makalah telah dipublikasikan di Hugging Face. (Sumber: Reddit r/LocalLLaMA)

Berbagi Prompt Karakter Berbulu: Pengguna berbagi satu set prompt yang dirancang untuk menghasilkan karakter hewan gaya berbulu 3D yang lucu, cocok untuk alat generasi gambar seperti Sora atau GPT-4o. Prompt ini menekankan deskripsi detail seperti tekstur super lembut, bulu tebal, mata besar, pencahayaan lembut, dan latar belakang, bertujuan untuk menghasilkan render berkualitas tinggi yang cocok untuk maskot merek atau gambar IP. (Sumber: dotey)

📚 Pembelajaran
Jeff Dean Berbagi Materi Presentasinya di ETH Zurich: Kepala Ilmuwan Google DeepMind, Jeff Dean, berbagi tautan rekaman dan slide dari presentasinya di Departemen Ilmu Komputer ETH Zurich. Konten presentasi kemungkinan mencakup kemajuan terbaru di bidang AI, arah penelitian, atau hasil penelitian Google, memberikan sumber belajar yang berharga bagi para peneliti dan mahasiswa. (Sumber: JeffDean)
Laporan Teknis Peninjauan AI ICLR 2025 Dirilis: Bersamaan dengan berita pengenalan peninjauan AI di ICLR 2025, laporan teknis terperinci setebal 30 halaman juga telah dipublikasikan (arXiv:2504.09737). Laporan tersebut merinci desain eksperimen, model AI yang digunakan (dengan Claude Sonnet 3.5 sebagai inti), mekanisme pembuatan umpan balik, metode pengujian keandalan, serta hasil analisis kuantitatif dampaknya terhadap kualitas tinjauan, aktivitas diskusi, dan keputusan akhir. Laporan ini memberikan referensi mendalam untuk memahami potensi, tantangan, dan detail implementasi AI dalam peer review akademik. (Sumber: Xin Zhi Yuan)
Makalah, Kode, dan Dataset Model Penalaran Video Video-R1 Open-Source: Tim CUHK dan Tsinghua tidak hanya merilis model Video-R1, tetapi juga membuat makalah teknisnya (arXiv:2503.21776), kode implementasi (GitHub: tulerfeng/Video-R1), dan dua dataset kunci yang digunakan untuk pelatihan (Video-R1-COT-165k dan Video-R1-260k) sepenuhnya open-source. Ini menyediakan sumber daya lengkap bagi komunitas riset untuk mereproduksi, meningkatkan, dan mengeksplorasi lebih lanjut paradigma R1 penalaran video, membantu mendorong pengembangan teknis di bidang ini. (Sumber: Xin Zhi Yuan)
Makalah Penemuan Hukum Fisika Independen oleh AI Dirilis: Hasil penelitian tim Max Tegmark MIT tentang kemampuan sistem AI MASS untuk secara independen menemukan Hamiltonian dan Lagrangian telah dipublikasikan sebagai makalah pra-cetak (arXiv:2504.02822v1). Makalah ini menguraikan secara rinci ide desain arsitektur MASS, algoritma inti (mempelajari fungsi skalar berdasarkan prinsip konservasi aksi), pengaturan eksperimental (sistem fisik yang berbeda, skenario ilmuwan AI tunggal/ganda), dan penemuan tentang bagaimana teori AI berevolusi dengan kompleksitas data dan akhirnya konvergen ke formulasi mekanika klasik. Makalah ini memberikan dasar teoretis dan empiris yang penting untuk mengeksplorasi aplikasi AI dalam penemuan ilmiah dasar. (Sumber: Xin Zhi Yuan)
Makalah PRIMA.CPP Dirilis: Makalah teknis yang memperkenalkan proyek PRIMA.CPP (bertujuan untuk mempercepat inferensi LLM skala 70B pada klaster sumber daya rendah) telah dipublikasikan di Hugging Face Papers (ID: 2504.08791). Makalah tersebut kemungkinan merinci teknik optimasi yang digunakan proyek, strategi inferensi terdistribusi, dan hasil evaluasi kinerja pada konfigurasi perangkat keras tertentu, memberikan referensi detail teknis bagi peneliti dan praktisi di bidang terkait. (Sumber: Reddit r/LocalLLaMA)
Pembahasan Mendalam Model RWKV-7 dan Diskusi dengan Penulis: Oxen.ai merilis video dan artikel blog yang membahas secara mendalam model RWKV-7 (Goose). Konten mencakup masalah yang coba dipecahkan oleh arsitektur RWKV, cara iterasinya, dan fitur teknis intinya. Yang istimewa, video tersebut mencakup wawancara dan sesi tanya jawab dengan salah satu penulis utama model, Eugene Cheah, memberikan perspektif dan wawasan berharga dari penulis untuk memahami LLM arsitektur non-Transformer ini, serta membahas konsep menarik seperti “Learning at Test Time”. (Sumber: Reddit r/MachineLearning)

Berbagi Artikel: 7 Tips Menguasai Prompt Engineering: Situs web FrontBackGeek menerbitkan artikel yang merangkum 7 tips ampuh untuk membantu pengguna menguasai prompt engineering dengan lebih baik, sehingga mendapatkan hasil output yang lebih baik dari model AI (seperti LLM). Artikel tersebut mungkin mencakup cara memperjelas instruksi, memberikan konteks, menetapkan peran, mengontrol format output, dan aspek lainnya. (Sumber: Reddit r/deeplearning)

Berbagi Proyek: Fine-tuning GPT-2/GPT-J untuk Meniru Gaya Bicara Mr. Darcy dari Pride and Prejudice: Seorang pengembang berbagi proyek pribadinya: menggunakan model GPT-2 (medium) dan GPT-J, melalui fine-tuning dengan dua dataset yang berisi dialog asli dan data sintetis buatan sendiri, mencoba meniru gaya bicara unik Mr. Darcy dari Pride and Prejudice karya Jane Austen (formal, ringkas, sedikit menghakimi). Proyek ini menunjukkan sampel output model, metrik evaluasi (peningkatan BLEU-4 tetapi perplexity meningkat), dan tantangan yang dihadapi (seperti kesulitan menyesuaikan GPT-J). Kode dan dataset telah dibuat open-source di GitHub, memberikan studi kasus untuk mengeksplorasi pemodelan gaya bicara sastra atau tokoh sejarah tertentu. (Sumber: Reddit r/MachineLearning)
Diskusi Rilis Meta Review ACL 2025: Hasil Meta Review untuk konferensi ACL 2025 telah dirilis. Peneliti terkait memposting di komunitas, mengundang semua orang untuk berdiskusi dan bertukar pikiran tentang skor makalah mereka dan Meta Review yang sesuai. Ini menyediakan platform bagi penulis yang mengirimkan makalah untuk berbagi pengalaman, membandingkan ekspektasi dan hasil. (Sumber: Reddit r/MachineLearning)
Berbagi Pengalaman Membangun Server AI 160GB VRAM dengan Biaya Rendah: Seorang pengguna Reddit berbagi secara rinci proses dan hasil pengujian awal pembangunan server inferensi AI dengan 160GB VRAM dengan biaya sekitar $1000 (biaya utama adalah 10 GPU AMD MI50 bekas seharga $90 per buah dan casing mining Octominer seharga $100). Konten mencakup pemilihan perangkat keras, instalasi sistem (Ubuntu + ROCm 6.3.0), kompilasi dan pengujian llama.cpp, pengukuran konsumsi daya aktual (idle sekitar 120W, puncak inferensi 340W), situasi pendinginan, dan data kinerja (dibandingkan dengan kartu grafis seperti 3090, menjalankan model llama3.1-8b dan llama-405b). Berbagi ini memberikan referensi konfigurasi perangkat keras DIY dan pengalaman praktis yang sangat berharga bagi penggemar AI dengan anggaran terbatas. (Sumber: Reddit r/LocalLLaMA)
Makalah dan Kode Model ReZero Dirilis: Model ReZero yang dirilis oleh Menlo Research (melatih model untuk mencari berulang kali hingga menemukan informasi yang dibutuhkan menggunakan GRPO) beserta makalah teknis terkait (arXiv:2504.11001), bobot model (Hugging Face: Menlo/ReZero-v0.1-llama-3.2-3b-it-grpo-250404), dan kode implementasi (GitHub: menloresearch/ReZero) semuanya telah dipublikasikan. Ini menyediakan sumber daya pembelajaran dan eksperimen lengkap untuk meneliti dan menerapkan strategi pencarian baru ini. (Sumber: Reddit r/LocalLLaMA)
💼 Bisnis
Mantan Eksekutif Robotika Alibaba, Min Wei, Mendirikan Yingshen Intelligence, Mendapatkan Pendanaan Awal Puluhan Juta: “Yingshen Intelligence”, didirikan pada tahun 2024 oleh Min Wei, mantan kepala teknis tim robotika Alibaba, berfokus pada penelitian, pengembangan, dan aplikasi teknologi embodied intelligence tingkat L4. Perusahaan baru-baru ini menyelesaikan putaran pendanaan awal (diinvestasikan oleh Zhuoyuan Asia) dan putaran awal+ (diinvestasikan bersama oleh Zhuoyuan Asia dan Hangzhou Xihu Kechuangtou) senilai puluhan juta RMB. Berdasarkan model besar cerdas ruang-waktu yang dikembangkan sendiri (membangun model dunia nyata empat dimensi melalui Real to Real, menggunakan data video untuk pemodelan langsung) dan robot industri, Yingshen Intelligence menyediakan solusi kolaboratif perangkat lunak-keras. Perusahaan telah mendapatkan pesanan industri senilai puluhan juta, awalnya berfokus pada skenario industri, dan berencana untuk berekspansi ke industri jasa seperti pengiriman ekspres dan perhotelan. (Sumber: 36Kr)
Pasar Mainan AI Panas Online Tapi Dingin Offline, Ekspor Mungkin Menjadi Jalur Utama: Mainan AI menunjukkan kinerja yang meledak di platform online (seperti live streaming commerce, media sosial), dengan perkiraan ukuran pasar tumbuh pesat. Namun, kunjungan offline (mengambil Guangzhou sebagai contoh) menemukan bahwa mainan AI sulit ditemukan di toko mainan tradisional dan toko serba ada, dengan tingkat distribusi dan kesadaran konsumen yang rendah. Saat ini, penjualan mainan AI mungkin sangat bergantung pada saluran online, dan pasar luar negeri (Eropa, Amerika, Timur Tengah) merupakan jalur penjualan penting, dengan produsen menawarkan layanan kustomisasi penampilan dan bahasa. Analisis data ukuran pasar menunjukkan bahwa pasar bernilai puluhan miliar yang dilaporkan sebelumnya mungkin merujuk pada “mainan pintar” yang lebih luas daripada mainan AI murni. Meskipun dingin secara offline, mengingat meningkatnya permintaan orang dewasa akan pendampingan emosional (seperti kasus Moflin) dan potensi teknologi AI untuk semua usia, pasar mainan AI masih dianggap memiliki ruang pengembangan yang sangat besar. (Sumber: 36Kr)

Perusahaan AI Infra Afiliasi Tsinghua, Qingcheng Jizhi: Ledakan Permintaan Inferensi, Efektivitas Biaya Mendorong Substitusi Domestik: Wawancara dengan Tang Xiongchao, CEO Qingcheng Jizhi, perusahaan infrastruktur AI yang berafiliasi dengan Tsinghua. Perusahaan mengamati bahwa sejak model DeepSeek menjadi populer, permintaan daya komputasi sisi inferensi AI telah melonjak, dan daya komputasi domestik yang sebelumnya menganggur mulai beroperasi. Namun, inovasi teknis DeepSeek (seperti presisi FP8) sangat terikat dengan kartu H Nvidia, yang justru memperlebar kesenjangan dengan sebagian besar chip domestik saat ini. Untuk mengatasi masalah ini, Qingcheng Jizhi dan Tsinghua bersama-sama membuka sumber mesin inferensi “Chitu”, yang bertujuan agar GPU yang ada dan chip domestik juga dapat menjalankan model canggih seperti DeepSeek secara efisien, mendorong penutupan lingkaran ekosistem AI domestik. Tang Xiongchao percaya bahwa meskipun substitusi chip domestik membutuhkan proses, ia optimis tentang keunggulan efektivitas biayanya dalam jangka panjang. Fokus bisnis perusahaan saat ini adalah memenuhi permintaan pemerintah dan perusahaan untuk penyebaran model besar secara lokal. (Sumber: Phoenix Tech)
Demam Investasi AI Berlanjut, Investor Muda Muncul ke Permukaan: Meskipun lingkungan investasi secara keseluruhan mendingin pada tahun 2024, bidang AI terus menerima dukungan modal, dengan jumlah pembiayaan global mencapai rekor, dan pasar domestik juga aktif. Raksasa seperti ByteDance, Alibaba, dan Tencent mempercepat tata letak mereka. Unicorn seperti Zhipu AI, Moonshot AI, dan Unitree Robotics bermunculan, dengan hotspot investasi mencakup seluruh rantai industri termasuk infrastruktur, AIGC, dan embodied intelligence. Lembaga investasi mapan seperti Sequoia China dan BlueRun Ventures terus mempertahankan keunggulan mereka, sementara dana industri dan kekuatan BUMN, yang diwakili oleh Dana Investasi Industri Kecerdasan Buatan Beijing, juga menjadi pendorong penting. Perlu dicatat bahwa sekelompok investor muda kelahiran tahun 80-an (seperti Cao Xi, Dai Yusen, Lin Haizhuo, Zhang Jinjian, dll.) aktif di era AI 2.0. Dengan ketajaman dan kemampuan eksekusi mereka, mereka secara aktif mencari peluang di pasar dengan aturan baru, menjadi kekuatan baru yang tidak dapat diabaikan. (Sumber: 36Kr-First New Voice)

Pendiri Aplikasi Belanja AI Nate Didakwa Melakukan Penipuan, “API Manusia” Menyamar sebagai AI untuk Menipu Investasi $50 Juta: Departemen Kehakiman AS mendakwa Albert Saniger, pendiri aplikasi belanja AI Nate, menuduhnya menipu lebih dari $50 juta dalam investasi ventura melalui promosi palsu tentang kemampuan teknologi AI-nya. Nate mengklaim aplikasinya dapat secara otomatis menyelesaikan proses belanja online melalui teknologi AI eksklusif, tetapi pada kenyataannya fungsi intinya sangat bergantung pada ratusan agen layanan pelanggan yang dipekerjakan secara manual di Filipina untuk memproses pesanan, dengan tingkat otomatisasi AI yang diklaim hampir nol. Pendiri menyembunyikan kebenaran dari investor dan karyawan, yang akhirnya menyebabkan perusahaan kehabisan dana dan bangkrut. Kasus ini mengungkap potensi risiko penipuan dalam demam startup AI, yaitu menggunakan tenaga manusia untuk menyamar sebagai AI guna menarik investasi, merugikan kepentingan investor dan reputasi industri. Saniger dapat menghadapi hukuman penjara hingga 40 tahun. (Sumber: CSDN)

🌟 Komunitas
Video Modifikasi AI Melanda Platform Video Pendek, Memicu Kontroversi Hiburan dan Etika Hak Cipta: Penggunaan teknologi AI (seperti alat text-to-video Sora, Kling, dll.) untuk “memodifikasi secara eksplosif” serial TV klasik (seperti “Empresses in the Palace” mengendarai sepeda motor, “In the Name of the People” menjadi “12.12: The Day”) dengan cepat menjadi populer di platform seperti Douyin dan Bilibili. Video semacam ini menarik banyak traffic karena plot yang subversif, dampak visual, dan budaya meme, menjadi cara baru bagi blogger untuk dengan cepat membangun audiens dan memonetisasi (pembagian pendapatan traffic, penempatan iklan terselubung) serta mempromosikan serial. Namun, popularitasnya juga disertai kontroversi: penentuan pelanggaran hak cipta terhadap karya asli menjadi rumit; konten yang dimodifikasi dapat melemahkan kedalaman artistik karya asli, bahkan mengarah ke vulgaritas, menarik perhatian regulator. Bagaimana menyeimbangkan antara memenuhi kebutuhan hiburan dan menghormati hak cipta serta menjaga kualitas konten menjadi tantangan yang dihadapi oleh kreasi sekunder AI. (Sumber: 36Kr-Mingxi Yewang)

Kuota dan Harga Paket Claude Pro/Max Memicu Keluhan Pengguna: Beberapa postingan muncul di subreddit ClaudeAI, di mana pengguna secara kolektif mengeluhkan batasan dan harga Anthropic untuk paket langganan Claude Pro dan Max yang baru diluncurkan. Pengguna melaporkan bahwa bahkan pengguna Pro berbayar dengan cepat mencapai batas penggunaan setelah sejumlah kecil atau interaksi intensitas sedang (seperti memproses konteks ratusan ribu token), yang memengaruhi alur kerja mereka. Paket Max yang baru diluncurkan ($100/bulan), meskipun meningkatkan kuota (sekitar 5-20 kali lipat dari Plus), masih belum penggunaan tak terbatas, dan harga yang mahal dikritik oleh pengguna sebagai “perampokan uang” dengan nilai yang buruk. Pengguna secara umum mengakui kemampuan model Claude tetapi menyatakan ketidakpuasan yang kuat terhadap batasan penggunaan dan strategi penetapan harganya. (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Gaya Penulisan Manusia yang Jelas Salah Diidentifikasi sebagai Buatan AI Menarik Perhatian: Pengguna di komunitas Reddit (termasuk mereka yang mengidentifikasi diri sebagai neurodivergent) melaporkan bahwa konten tertulis mereka yang dibuat dengan cermat, benar secara tata bahasa, logis, dan deskriptif secara rinci, salah diidentifikasi sebagai buatan AI oleh orang lain atau alat deteksi AI. Fenomena ini memicu diskusi, di satu sisi mungkin karena keberadaan konten buatan AI yang meluas menyebabkan orang curiga terhadap teks yang “terlalu sempurna”, di sisi lain juga mengungkap ketidakakuratan alat deteksi AI saat ini. Hal ini menimbulkan masalah bagi penulis yang menekankan ekspresi yang jelas, dan juga menimbulkan kekhawatiran tentang bagaimana membedakan antara kreasi manusia dan AI serta keandalan alat deteksi AI. (Sumber: Reddit r/artificial, Reddit r/artificial)
Diskusi: Apakah Mungkin dan Umum Manusia Membangun Hubungan Emosional dengan Robot AI?: Komunitas Reddit menampilkan diskusi tentang apakah manusia benar-benar membangun hubungan emosional dengan robot AI (seperti aplikasi pacar AI) yang mirip dengan yang digambarkan dalam film “Her”. Beberapa pengguna berbagi pengalaman mereka tentang hubungan emosional yang berkembang setelah interaksi mendalam dengan chatbot, percaya bahwa AI dapat memicu respons emosional manusia melalui “mendengarkan aktif” dan meniru preferensi pengguna. Komentar mengeksplorasi prevalensi fenomena ini, mekanisme psikologis, dan hubungannya dengan tingkat pemahaman teknologi, mencerminkan bahwa seiring peningkatan kemampuan interaksi AI, hubungan manusia-mesin memasuki fase baru yang lebih kompleks. (Sumber: Reddit r/ArtificialInteligence)
Diskusi Nilai Kartu Grafis Nvidia RTX 5060 Ti 16GB untuk LLM Lokal: Pengguna komunitas mendiskusikan nilai kartu grafis Nvidia GeForce RTX 5060 Ti yang akan datang (dikabarkan memiliki versi VRAM 16GB, harga $429) untuk menjalankan model bahasa besar (LLM) lokal di rumah. Diskusi berfokus pada apakah bus memori 128-bit (bandwidth 448 GB/s) akan menjadi bottleneck, dan kelebihan serta kekurangannya dibandingkan Mac Mini/Studio atau kartu grafis AMD lainnya dalam hal kapasitas VRAM dan kinerja per dolar (token/s per harga). Mengingat harga pasar aktual mungkin lebih tinggi dari MSRP, pengguna mengevaluasi apakah ini merupakan pilihan perangkat keras AI lokal yang hemat biaya. (Sumber: Reddit r/LocalLLaMA)
GPT-4o Kesulitan Menggambar Mahkota Emas Sayap Phoenix Sun Wukong Secara Akurat: Pengguna melaporkan bahwa saat menggunakan GPT-4o untuk generasi gambar, bahkan dengan deskripsi teks terperinci (termasuk mahkota pengikat rambut dengan ekor burung phoenix, menyerupai antena kecoa), model kesulitan menggambar “Mahkota Emas Sayap Phoenix” ikonik dari tokoh mitologi Tiongkok Sun Wukong secara akurat. Gambar yang dihasilkan seringkali menyimpang dalam gaya mahkota kepala. Ini mencerminkan tantangan yang masih ada pada model generasi gambar AI saat ini dalam memahami dan mereproduksi simbol budaya tertentu atau detail kompleks. (Sumber: dotey)

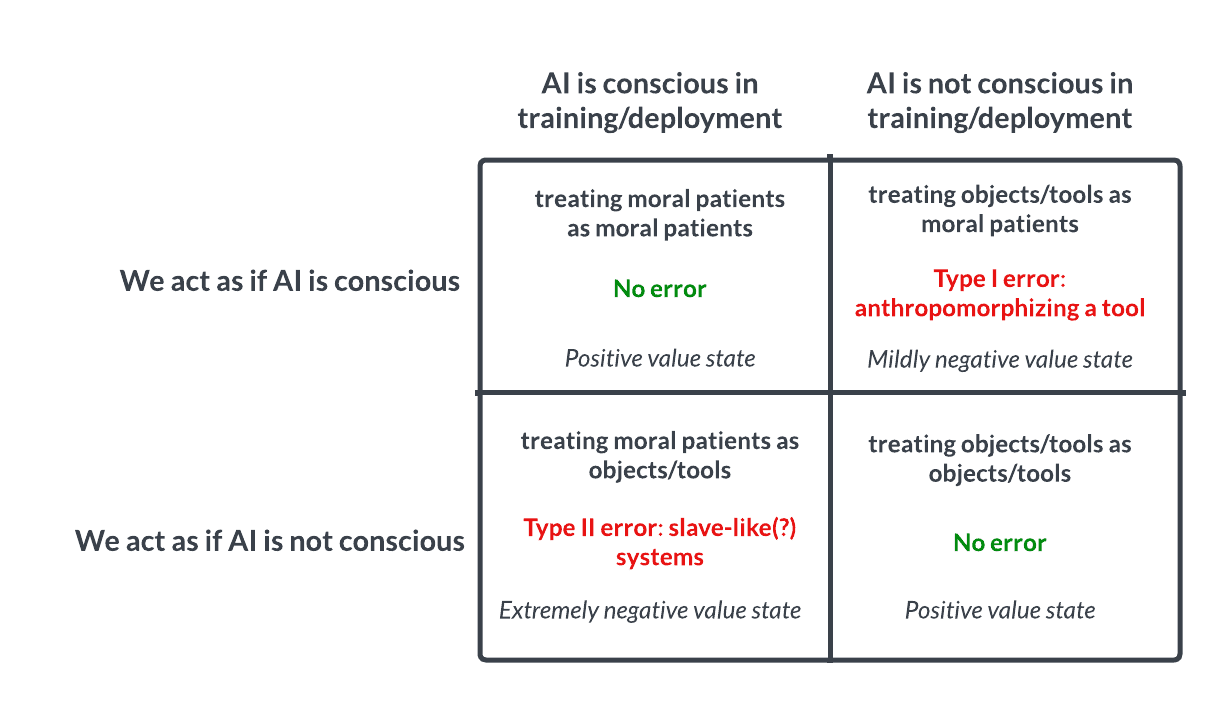
Eksplorasi Kesadaran dan Etika AI: Taruhan Mirip Pascal Memicu Pemikiran: Diskusi di Reddit mengemukakan bahwa perlakuan terhadap AI harus seperti Taruhan Pascal: jika kita berasumsi AI tidak sadar dan menyiksanya, padahal sebenarnya sadar, kita akan melakukan kesalahan serius (seperti perbudakan); jika kita berasumsi mereka sadar dan memperlakukannya dengan baik, padahal sebenarnya tidak, kerugiannya lebih kecil. Hal ini memicu diskusi etis tentang kemungkinan kesadaran AI, kriteria penilaian, dan bagaimana kita seharusnya memperlakukan AI tingkat lanjut. Komentar mencakup pandangan bahwa AI saat ini tidak sadar, bahwa kita harus berhati-hati, dan bahwa masalah etika manusia dan hewan harus diselesaikan terlebih dahulu. (Sumber: Reddit r/artificial
💡 Lain-lain
Penerapan Teknologi Transformasi Usia AI dalam Film “Here” Memicu Kontroversi: Film “Here”, disutradarai oleh Robert Zemeckis dan dibintangi oleh Tom Hanks serta Robin Wright, dengan berani menggunakan teknologi transformasi AI generatif real-time yang dikembangkan oleh Metaphysic, memungkinkan para aktor menampilkan rentang usia dari 18 hingga 78 tahun dalam film. Teknologi ini dapat menganalisis fitur biologis aktor secara real-time dan menghasilkan wajah serta bentuk tubuh pada usia yang berbeda, secara signifikan mempersingkat waktu pasca-produksi. Namun, teknologinya belum sempurna, terutama dalam pemulihan tatapan mata dan penanganan ekspresi kompleks, yang memicu diskusi “uncanny valley effect”. Sementara itu, keputusan Hanks untuk mengizinkan penggunaan citra AI-nya setelah kematiannya juga memicu kontroversi luas tentang hak citra, etika, dan keaslian artistik. Meskipun kinerja box office dan ulasan biasa-biasa saja, film ini memiliki nilai industri yang penting sebagai eksplorasi awal teknologi AI dalam pembuatan film. (Sumber: 36Kr-Geek Movie)

Perekrutan AI: Peluang dan Tantangan: AI sedang mengubah proses perekrutan, dengan alat seperti Hireway mengklaim dapat meningkatkan efisiensi penyaringan secara signifikan. Namun, penerapan perekrutan AI juga memicu diskusi, seperti bagaimana melakukan perekrutan di Era AI (Hiring In The AI Era), dan bagaimana menyeimbangkan efisiensi dengan keadilan, menghindari bias algoritma, dll. (Sumber: Ronald_vanLoon, Ronald_vanLoon)

Kecepatan Pengembangan AI Memicu Pemikiran: Keseimbangan Cepat dan Lambat: Artikel membahas apakah strategi “bergerak cepat dan merusak” (move fast and break things) masih berlaku di era perkembangan AI yang pesat. Pandangan menyatakan bahwa terkadang melambat untuk berpikir matang (slowing down to speed up) mungkin lebih efektif, terutama ketika melibatkan sistem kompleks dan potensi risiko di bidang AI. (Sumber: Ronald_vanLoon)

Server Discord Resmi Anthropic Dibuka untuk Umpan Balik Langsung Pengguna: Mengingat banyaknya pertanyaan dan ketidakpuasan pengguna mengenai kinerja dan batasan model Claude, komunitas merekomendasikan pengguna untuk bergabung dengan server Discord resmi Anthropic. Di sana, pengguna memiliki kesempatan untuk berinteraksi langsung dengan karyawan Anthropic, memberikan umpan balik masalah dan kekhawatiran secara lebih efektif. (Sumber: Reddit r/ClaudeAI)

Pameran Berbagai Robot dan Teknologi Otomatisasi Baru: Media sosial menampilkan video atau informasi tentang berbagai robot dan teknologi otomatisasi, termasuk drone yang dapat bekerja di bawah air, robot lunak yang meniru gerak peristaltik usus, drone burung bionik X-Fly, robot serba bisa yang dapat menyelesaikan berbagai tugas, robot untuk transplantasi rambut, lini produksi otomatis pengolahan telur, setelan robot setinggi 9 kaki yang dapat meniru gerakan manusia, dan adegan menarik dua robot pengiriman “berhadapan” di jalan. Ini menunjukkan eksplorasi dan pengembangan aplikasi teknologi robotika di berbagai bidang. (Sumber: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)