

Kata Kunci:GPT-4.1, Hugging Face, Perbandingan kinerja seri model GPT-4.1, Hugging Face mengakuisisi Pollen Robotics, Peningkatan kemampuan pengkodean model baru OpenAI, GPT-4.1 mini biaya turun 83%, Robot open source Reachy 2
🔥 Fokus
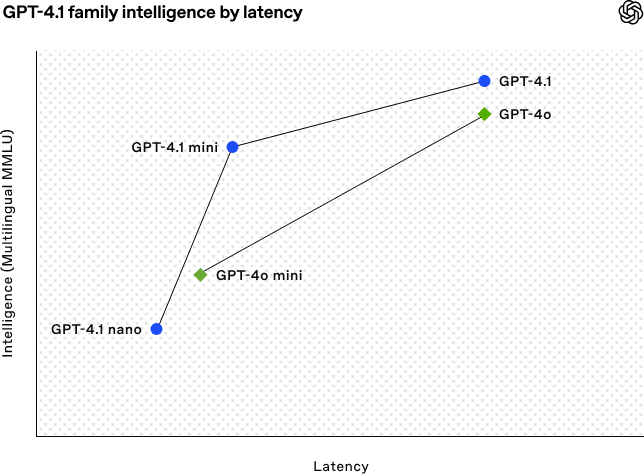
OpenAI merilis seri model GPT-4.1, memperkuat kemampuan coding dan pemrosesan teks panjang: OpenAI pada dini hari tanggal 15 April merilis tiga model baru dalam seri GPT-4.1: GPT-4.1 (unggulan), GPT-4.1 mini (efisien), dan GPT-4.1 nano (ultra-kecil), semuanya hanya tersedia melalui API. Seri model ini menunjukkan kinerja unggul dalam coding, kepatuhan instruksi, dan pemahaman konteks panjang, dengan jendela konteks mencapai 1 juta token dan token output mencapai 32.768. GPT-4.1 mencetak skor 54,6% dalam pengujian SWE-bench Verified, secara signifikan mengungguli GPT-4o dan GPT-4.5 Preview yang akan dihentikan. GPT-4.1 mini melampaui kinerja GPT-4o sambil mengurangi latensi hingga setengahnya dan biaya hingga 83%. Sementara itu, GPT-4.1 nano adalah model tercepat dan berbiaya terendah saat ini, cocok untuk tugas berlatensi rendah. Peluncuran ini bertujuan untuk menyediakan pilihan model yang lebih kuat, lebih hemat biaya, dan lebih cepat bagi para developer, mendorong pembangunan sistem cerdas yang kompleks dan aplikasi agent. (Sumber: 36氪, 智东西, op7418, openai, karminski3, sama, natolambert, karminski3, karminski3, karminski3, dotey, OpenAI, GPT-4.1来了,超越GPT-4.5,SWE-Bench达到55%,开发者专属。)
Hugging Face mengakuisisi perusahaan robotika open-source Pollen Robotics: Platform komunitas AI Hugging Face mengumumkan akuisisi startup robotika open-source Prancis, Pollen Robotics, dengan tujuan mendorong open-source dan mempopulerkan robotika AI. Akuisisi ini akan menggabungkan keunggulan Hugging Face dalam platform perangkat lunak (seperti library LeRobot dan Hub) dengan keahlian Pollen Robotics dalam perangkat keras open-source (seperti robot humanoid Reachy 2). Reachy 2 adalah robot humanoid open-source yang kompatibel dengan VR, dirancang khusus untuk penelitian, pendidikan, dan eksperimen embodied intelligence, dengan harga $70.000. Hugging Face percaya bahwa robotika adalah antarmuka interaksi penting berikutnya untuk AI, dan harus berkomitmen pada keterbukaan, keterjangkauan, dan kustomisasi. Akuisisi ini merupakan langkah kunci dalam mewujudkan visi ini, dengan tujuan memungkinkan komunitas membangun dan mengendalikan rekan robot mereka sendiri, daripada bergantung pada sistem tertutup dan mahal. (Sumber: huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface, huggingface)

🎯 Perkembangan
AI membantu memecahkan masalah matematika yang belum terpecahkan selama 50 tahun: Weiguo Yin, seorang ilmuwan Tionghoa di Brookhaven National Laboratory, AS, menggunakan model penalaran OpenAI o3-mini-high untuk mencapai terobosan dalam solusi eksak model Potts q-state J_1-J_2 satu dimensi, terutama dalam kasus q=3, di mana AI membantu menyelesaikan pembuktian kunci. Masalah ini melibatkan model dasar mekanika statistik, terkait dengan fenomena fisik seperti penumpukan atom dalam material berlapis dan superkonduktivitas non-konvensional, yang solusi eksaknya belum tercapai dalam 50 tahun terakhir. Peneliti memperkenalkan metode Maximum Symmetric Subspace (MSS) dan menggunakan petunjuk bertahap dari AI untuk memproses matriks transfer, berhasil menyederhanakan matriks transfer 9×9 untuk q=3 menjadi matriks 2×2 yang efektif, dan menggeneralisasi metode ini untuk nilai q arbitrer. Penelitian ini tidak hanya memecahkan masalah fisika matematika yang sudah lama ada tetapi juga menunjukkan potensi besar AI dalam membantu penelitian ilmiah yang kompleks dan memberikan wawasan baru. (Sumber: 刚刚,AI破解50年未解数学难题!南大校友用OpenAI模型完成首个非平凡数学证明)

Asisten AI versi web bermunculan, produsen ponsel dan mobil merancang pengalaman multi-perangkat: Produsen seperti Huawei (Asisten Xiaoyi), Li Auto (Li Xiang Tongxue), OPPO (Asisten Xiaobu), dan lainnya secara berturut-turut meluncurkan versi web dari asisten AI mereka, menarik perhatian. Meskipun versi web ini mungkin kalah dalam kelengkapan fitur (seperti mengedit pertanyaan, tata letak, opsi pengaturan) dibandingkan layanan model profesional seperti DeepSeek, tujuan utamanya bukanlah persaingan langsung, melainkan melayani pengguna merek masing-masing, menghubungkan pengalaman pengguna secara mulus dari ponsel, sistem mobil, hingga PC. Dengan mengikat akun pengguna dan menyinkronkan riwayat percakapan, versi web ini bertujuan untuk meningkatkan loyalitas pengguna, menyediakan pengalaman interaksi yang konsisten di seluruh perangkat, dan mengintegrasikan asisten AI ke dalam skenario pengguna yang lebih luas, yang pada dasarnya merupakan strategi tata letak terkait pintu masuk pengguna dan ekosistem data. (Sumber: AI网页版扎堆上线,华为、理想、OPPO们打的什么算盘?)
Robot Figure mencapai transfer zero-shot dari simulasi ke dunia nyata melalui reinforcement learning: Perusahaan Figure mendemonstrasikan robot humanoid Figure 02-nya mencapai gaya berjalan alami melalui reinforcement learning (RL) murni dalam lingkungan simulasi. Menggunakan simulator fisika yang dipercepat GPU secara efisien, data pelatihan setara dengan beberapa tahun dihasilkan dalam beberapa jam, melatih satu strategi jaringan saraf yang dapat mengendalikan beberapa robot virtual dengan parameter fisik dan skenario yang berbeda (seperti medan yang berbeda, gangguan). Dengan menggabungkan randomisasi domain simulasi dan umpan balik torsi frekuensi tinggi dari robot nyata, strategi yang dilatih dapat ditransfer secara zero-shot ke robot fisik tanpa perlu fine-tuning. Metode ini tidak hanya mempersingkat waktu pengembangan dan meningkatkan stabilitas kinerja di dunia nyata, tetapi juga satu strategi dapat mengendalikan seluruh armada robot, menunjukkan potensinya dalam aplikasi komersial skala besar. (Sumber: 一套算法控制机器人军团!纯模拟环境强化学习,Figure学会像人一样走路)

DeepSeek akan membuka sumber sebagian optimasi inference engine: DeepSeek mengumumkan rencana untuk menyumbangkan kembali ke komunitas sebagian optimasi dan fitur dari inference engine berkinerja tinggi mereka yang dimodifikasi berdasarkan vLLM. Mereka tidak akan merilis inference stack yang lengkap dan sangat disesuaikan, melainkan memilih untuk mengintegrasikan peningkatan kunci (seperti dukungan untuk arsitektur model terbaru, optimasi kinerja) ke dalam kerangka kerja inference open-source utama seperti vLLM dan SGLang, dengan tujuan agar komunitas dapat memperoleh dukungan tingkat SOTA untuk model dan teknologi baru sejak hari pertama. Langkah ini disambut baik oleh komunitas, dianggap sebagai komitmen nyata terhadap kontribusi open-source daripada sekadar promosi verbal. (Sumber: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert)
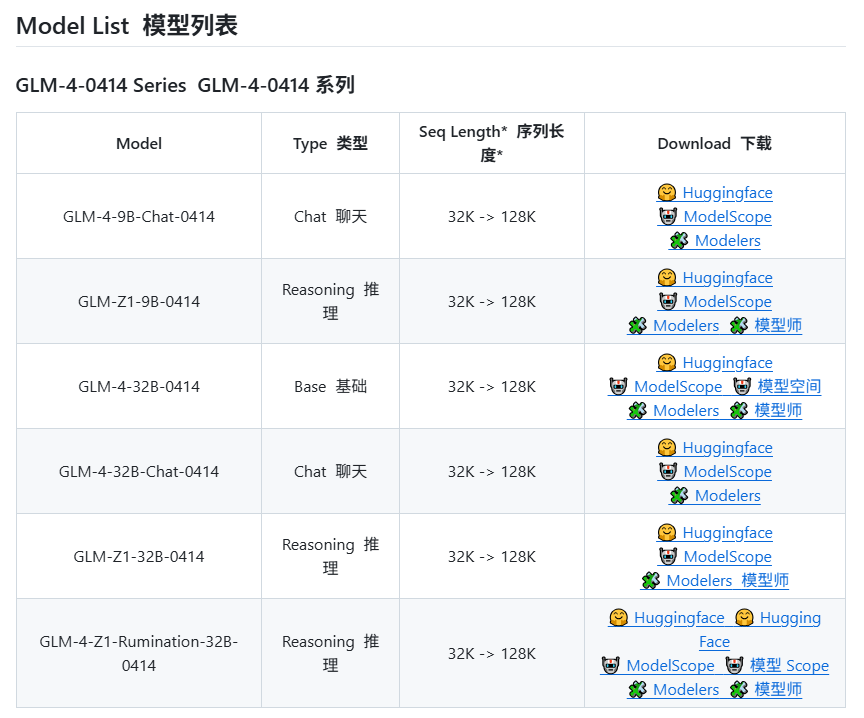
Zhipu AI diduga akan merilis model baru seri GLM-4: Berdasarkan informasi yang bocor di GitHub (kemudian dihapus), Zhipu AI tampaknya bersiap untuk merilis model baru seri GLM-4. Seri ini mungkin mencakup versi dengan skala parameter yang berbeda (seperti 9B, 32B) dan fungsi, misalnya model dasar (GLM-4-32B-0414), model percakapan (Chat), model penalaran (GLM-Z1-32B-0414), serta model “Rumination” dengan kemampuan berpikir lebih dalam, yang mungkin menyaingi Deep Research dari OpenAI. Selain itu, mungkin juga mencakup model multimodal visual (GLM-4V-9B). Data benchmark yang bocor menunjukkan bahwa GLM-4-32B-0414 mungkin mengungguli DeepSeek-V3 dan DeepSeek-R1 pada beberapa metrik. Kode dukungan inference engine terkait telah digabungkan ke dalam transformers/vllm/llama.cpp. Komunitas sangat memperhatikan hal ini, menantikan rilis resmi dan ulasan. (Sumber: karminski3, karminski3, Reddit r/LocalLLaMA)
NVIDIA merilis model baru seri Nemotron: NVIDIA merilis model dasar baru seri Nemotron-H di Hugging Face, termasuk tiga skala parameter: 56B, 47B, dan 8B, semuanya mendukung jendela konteks 8K. Model-model ini didasarkan pada arsitektur hibrida Transformer dan Mamba. Saat ini yang dirilis adalah model dasar (Base), versi instruction fine-tuned (Instruct) belum tersedia. Seri Nemotron bertujuan untuk mengeksplorasi potensi arsitektur baru dalam pemodelan bahasa. (Sumber: Reddit r/LocalLLaMA)

🧰 Alat
GitHub Copilot terintegrasi ke Windows Terminal versi Canary: Microsoft mengintegrasikan fungsionalitas GitHub Copilot ke dalam versi pratinjau Canary dari Windows Terminal, memperkenalkan fitur baru yang disebut “Terminal Chat”. Fitur ini memungkinkan pengguna berinteraksi langsung dengan AI di lingkungan terminal, mendapatkan saran dan penjelasan perintah. Pengguna perlu berlangganan GitHub Copilot dan menginstal versi Canary terbaru dari Terminal, lalu memverifikasi akun mereka untuk menggunakannya. Langkah ini bertujuan untuk membawa bantuan AI langsung ke lingkungan baris perintah yang sering digunakan developer, mengurangi peralihan konteks, meningkatkan efisiensi dalam menangani tugas yang kompleks atau tidak dikenal, mempercepat proses pembelajaran, dan membantu mengurangi kesalahan. (Sumber: GitHub Copilot 现可在 Windows 终端中运行了)

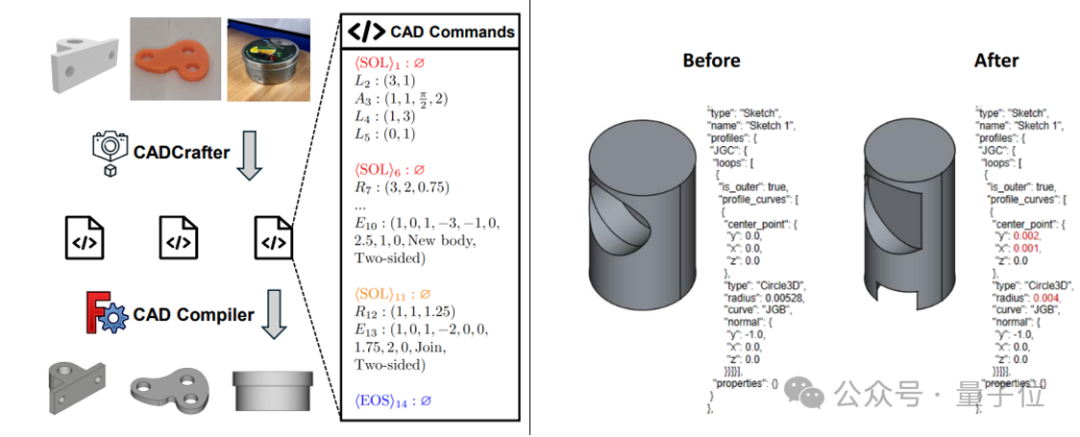
CADCrafter: Menghasilkan file CAD yang dapat diedit dari satu gambar: Peneliti dari KOKONI 3D, Nanyang Technological University, dan institusi lainnya mengusulkan kerangka kerja baru bernama CADCrafter, yang mampu menghasilkan file rekayasa CAD parametrik yang dapat diedit (direpresentasikan sebagai urutan instruksi CAD) langsung dari satu gambar (gambar render, foto objek nyata, dll.), mengatasi masalah model yang dihasilkan oleh metode image-to-3D yang ada (menghasilkan Mesh atau 3DGS) yang sulit diedit secara presisi dan memiliki kualitas permukaan yang kurang baik. Metode ini menggunakan arsitektur generasi dua tahap yang menggabungkan VAE dan Diffusion Transformer, serta meningkatkan kualitas dan tingkat keberhasilan generasi melalui strategi distilasi multi-view-to-single-view dan mekanisme pemeriksaan kompilabilitas berbasis DPO. Hasil penelitian telah diterima oleh CVPR 2025, memberikan paradigma baru untuk desain industri yang dibantu AI. (Sumber: 单图直出CAD工程文件!CVPR 2025新研究解决AI生成3D模型“不可编辑”痛点|魔芯科技NTU等出品)
LangChain meluncurkan integrasi GraphRAG dengan MongoDB Atlas: LangChain mengumumkan kemitraan dengan MongoDB untuk meluncurkan sistem RAG berbasis grafik (GraphRAG). Sistem ini memanfaatkan MongoDB Atlas untuk menyimpan dan memproses data, diimplementasikan melalui LangChain, dan mampu melampaui RAG tradisional berbasis pencarian kesamaan untuk memahami dan menalar hubungan antar entitas. Ini mendukung ekstraksi entitas dan relasi melalui LLM dan memanfaatkan penelusuran grafik untuk mendapatkan informasi kontekstual yang terhubung, bertujuan untuk memberikan kemampuan tanya jawab dan penalaran yang lebih kuat untuk aplikasi yang membutuhkan pemahaman relasional yang mendalam. (Sumber: LangChainAI)
Hugging Face membuka sumber Inference Playground-nya: Hugging Face menjadikan alat online-nya untuk pengujian dan perbandingan inference model, Inference Playground, menjadi open-source. Ini adalah antarmuka obrolan LLM berbasis web yang memungkinkan pengguna mengontrol berbagai pengaturan inference (seperti temperature, top-p, dll.), memodifikasi respons AI, membandingkan kinerja model dan penyedia yang berbeda. Proyek ini dibangun menggunakan Svelte 5, Melt UI, dan Tailwind, dengan kode yang telah dipublikasikan di GitHub, menyediakan platform interaksi dan evaluasi model lokal atau online yang dapat disesuaikan dan diperluas bagi para developer. (Sumber: huggingface)
Platform Flowith mencapai ARR lebih dari $1 juta, menunjukkan kemampuan AI Agent menghasilkan halaman web: Pendapatan berulang tahunan (ARR) platform AI Agent Flowith telah melampaui $1 juta, menunjukkan permintaan pasar yang kuat untuk platform AI Agent serbaguna yang dapat menggantikan pekerjaan manual. Pengguna berbagi pengalaman menggunakan fungsi Oracle Flowith, hanya dengan deskripsi bahasa alami sederhana (“Saya ingin membuat halaman web program pratinjau gambar/teks media sosial…”), dapat dengan cepat menghasilkan alat web kecil yang berfungsi penuh, gaya yang direplikasi secara akurat (seperti gaya Twitter), dan mendukung pratinjau gambar, tanpa perlu menghubungkan ke GitHub atau melakukan konfigurasi yang rumit, menunjukkan potensi AI Agent dalam pembuatan halaman web low-code/no-code. (Sumber: karminski3)
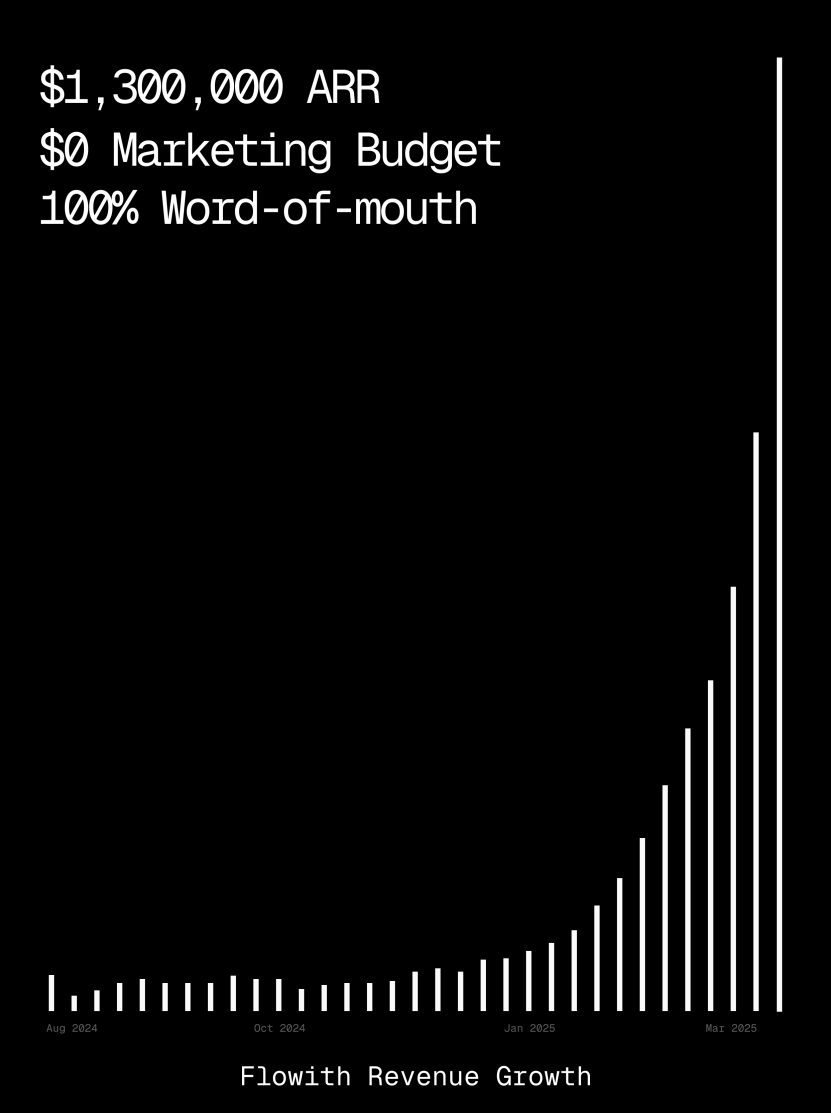
Agen debugging otonom Deebo dirilis: Peneliti membangun server MCP agen debugging otonom bernama Deebo. Ini berjalan sebagai daemon lokal tempat agen pemrograman dapat secara asinkron mengalihkan tugas penanganan kesalahan yang sulit. Deebo bekerja dengan menghasilkan beberapa sub-proses dengan hipotesis perbaikan yang berbeda, menjalankan setiap skenario dalam cabang git yang terisolasi, dan diuji serta dinalar secara siklis oleh “agen induk”, akhirnya mengembalikan hasil diagnostik dan patch yang disarankan. Dalam pengujian bug nyata tinygrad berhadiah $100, Deebo berhasil mengidentifikasi akar masalah dan mengusulkan dua solusi perbaikan spesifik, yang lulus pengujian. (Sumber: Reddit r/MachineLearning)
![[D] We built an autonomous debugging agent. Here’s how it grokked a $100 bug](https://rebabel.net/wp-content/uploads/2025/04/81BPXr5Ywnk-6MetZBQchhgsROH341CoTk3xAdE5Jic.jpg)
📚 Pembelajaran
Nabla-GFlowNet: Metode fine-tuning reward model difusi baru yang menyeimbangkan keragaman dan efisiensi: Mengatasi masalah konvergensi lambat reinforcement learning tradisional, overfitting mudah pada maksimisasi reward langsung, dan hilangnya keragaman dalam fine-tuning model difusi, peneliti dari CUHK (Shenzhen) dan institusi lain mengusulkan Nabla-GFlowNet. Metode ini didasarkan pada kerangka kerja Generative Flow Networks (GFlowNet), memperlakukan proses difusi sebagai sistem keseimbangan aliran, dan menurunkan kondisi keseimbangan Nabla-DB serta fungsi loss yang sesuai. Melalui desain parametrik, gradien residu diperkirakan menggunakan denoising satu langkah, menghindari estimasi jaringan tambahan. Eksperimen menunjukkan bahwa saat melakukan fine-tuning Stable Diffusion pada fungsi reward seperti skor estetika dan kepatuhan instruksi, Nabla-GFlowNet dapat berkonvergensi lebih cepat dan kurang rentan terhadap overfitting dibandingkan metode seperti ReFL dan DRaFT, sambil mempertahankan keragaman sampel yang dihasilkan. (Sumber: ICLR 2025 | 扩散模型奖励微调新突破!Nabla-GFlowNet让多样性与效率兼得)

MegaMath: Dataset penalaran matematika open-source terbesar dengan 371 Miliar Token dirilis: Dataset MegaMath yang diluncurkan oleh LLM360, berisi 371 miliar token, bertujuan untuk mengatasi kurangnya data pra-pelatihan penalaran matematika berskala besar dan berkualitas tinggi di komunitas open-source. Dataset ini dibagi menjadi tiga bagian: halaman web padat matematika (279 Miliar), kode terkait matematika (28,1 Miliar), dan data sintetis berkualitas tinggi (64 Miliar). Proses pembuatannya menggunakan pipeline pemrosesan data inovatif, termasuk penguraian HTML yang dioptimalkan untuk rumus matematika, ekstraksi teks dua tahap, penilaian nilai pendidikan dinamis, penarikan kembali data kode multi-langkah yang presisi, dan berbagai metode sintesis skala besar (Q&A, pembuatan kode, interleaving teks-kode). Validasi pra-pelatihan 100 Miliar token pada Llama-3.2 (1B/3B) menunjukkan bahwa MegaMath dapat membawa peningkatan kinerja absolut 15-20% pada benchmark seperti GSM8K dan MATH. (Sumber: 3710亿数学Tokens!全球最大开源数学数据集MegaMath震撼发布,碾压DeepSeek-Math)
Tinjauan OS Agents: Penelitian agent cerdas untuk komputer, ponsel, dan browser berbasis model besar multimodal: Universitas Zhejiang bekerja sama dengan OPPO, 01.AI, dan institusi lain merilis makalah tinjauan tentang agent sistem operasi (OS Agents). Artikel ini secara sistematis meninjau status penelitian tentang pembangunan agent cerdas (seperti Computer Use dari Anthropic, Apple Intelligence dari Apple) yang dapat secara otomatis menyelesaikan tugas di lingkungan seperti komputer, ponsel, dan browser menggunakan Multimodal Large Language Models (MLLM). Konten mencakup dasar-dasar OS Agents (lingkungan, ruang observasi, ruang aksi, kemampuan inti), metode pembangunan (arsitektur model dasar dan strategi pelatihan, modul persepsi/perencanaan/memori/aksi kerangka kerja agent), protokol evaluasi dan benchmark, serta produk komersial terkait dan tantangan masa depan (keamanan & privasi, personalisasi & evolusi diri). Tim peneliti memelihara repositori open-source yang berisi 250+ makalah terkait, bertujuan untuk mendorong pengembangan bidang ini. (Sumber: 浙大、OPPO等发布最新综述:基于多模态大模型的计算机、手机与浏览器智能体研究)
NLPrompt: Metode prompt learning yang kuat menggabungkan loss MAE dan optimal transport: YesAI Lab dari ShanghaiTech University mengusulkan NLPrompt dalam makalah CVPR 2025 Highlight, bertujuan untuk mengatasi masalah noise label dalam prompt learning model visual-bahasa. Penelitian menemukan bahwa dalam skenario prompt learning, menggunakan loss Mean Absolute Error (MAE) (PromptMAE) lebih tahan terhadap pengaruh label noise daripada loss Cross-Entropy (CE), dan membuktikan ketahanannya dari perspektif teori pembelajaran fitur. Selain itu, diusulkan metode pemurnian data optimal transport berbasis prompt (PromptOT), yang menggunakan fitur teks sebagai prototipe, membagi dataset menjadi subset bersih (dilatih dengan loss CE) dan subset noisy (dilatih dengan loss MAE), secara efektif menggabungkan keunggulan kedua loss. Eksperimen membuktikan bahwa NLPrompt berkinerja unggul pada dataset noise sintetis dan nyata, serta memiliki kemampuan generalisasi yang baik. (Sumber: CVPR 2025 | MAE损失+最优传输双剑合璧!上科大提出全新鲁棒提示学习方法)
Analisis mekanisme penalaran DeepSeek-R1: Peneliti dari Universitas McGill menganalisis proses penalaran model penalaran besar seperti DeepSeek-R1. Berbeda dengan LLM yang langsung memberikan jawaban, model penalaran menghasilkan rantai penalaran multi-langkah yang terperinci. Penelitian ini mengeksplorasi hubungan antara panjang rantai penalaran dan kinerja (ada “titik optimal”, terlalu panjang dapat merusak kinerja), manajemen konteks panjang, masalah budaya dan keamanan (ada kerentanan keamanan yang lebih kuat dibandingkan model non-penalaran), serta hubungan dengan fenomena kognitif manusia (seperti terus-menerus memikirkan masalah yang sudah dieksplorasi). Penelitian ini mengungkap beberapa karakteristik dan potensi masalah dalam mekanisme operasi model penalaran saat ini. (Sumber: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Metode optimasi saat pengujian untuk model besar MoE C3PO: Penelitian dari Universitas Johns Hopkins menemukan bahwa LLM Mixture-of-Experts (MoE) memiliki masalah jalur pakar sub-optimal, dan mengusulkan metode optimasi saat pengujian C3PO (Critical Layers, Core Experts, Collaborative Path Optimization). Metode ini tidak bergantung pada label nyata, melainkan mendefinisikan target alternatif melalui “tetangga sukses” dalam set sampel referensi untuk mengoptimalkan kinerja model. Ini menggunakan algoritma seperti pencarian pola, regresi kernel, rata-rata loss sampel serupa, dan untuk mengurangi biaya hanya mengoptimalkan bobot pakar inti pada lapisan kritis. Diterapkan pada MoE LLM, C3PO meningkatkan akurasi model dasar sebesar 7-15% dalam enam benchmark, melampaui baseline pembelajaran saat pengujian yang umum digunakan, dan membuat kinerja model MoE parameter kecil melampaui LLM parameter lebih besar, meningkatkan efisiensi MoE. (Sumber: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
Studi dampak kuantisasi pada kinerja model penalaran: Tim peneliti Universitas Tsinghua untuk pertama kalinya secara sistematis mengeksplorasi dampak teknik kuantisasi pada kinerja model bahasa tipe penalaran (seperti seri DeepSeek-R1, Qwen, LLaMA). Studi ini mengevaluasi kinerja algoritma kuantisasi bobot, cache KV, dan aktivasi dengan lebar bit yang berbeda (W8A8, W4A16, dll.) pada benchmark penalaran seperti matematika, sains, dan pemrograman. Hasil menunjukkan bahwa kuantisasi W8A8 atau W4A16 biasanya dapat mencapai kinerja tanpa kehilangan, tetapi lebar bit yang lebih rendah membawa risiko penurunan akurasi yang signifikan. Ukuran model, sumber, dan kesulitan tugas adalah faktor kunci yang mempengaruhi kinerja setelah kuantisasi. Panjang output model terkuantisasi tidak meningkat secara signifikan, dan penyesuaian ukuran model yang wajar atau penambahan langkah penalaran dapat meningkatkan kinerja. Model dan kode terkuantisasi terkait telah dijadikan open-source. (Sumber: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
SHIELDAGENT: Pagar pelindung untuk memaksa Agent mematuhi kebijakan keamanan: Universitas Chicago mengusulkan kerangka kerja SHIELDAGENT, yang bertujuan untuk memaksa lintasan tindakan AI Agent mematuhi kebijakan keamanan eksplisit melalui penalaran logis. Kerangka kerja ini pertama-tama mengekstrak aturan yang dapat diverifikasi dari dokumen kebijakan, membangun model kebijakan keamanan (berdasarkan sirkuit aturan probabilistik), kemudian selama eksekusi Agent, mengambil aturan yang relevan berdasarkan lintasan tindakannya dan menghasilkan rencana perlindungan, menggunakan library alat dan kode yang dapat dieksekusi untuk melakukan verifikasi formal, memastikan perilaku Agent tidak melanggar peraturan keamanan. Dataset SHIELDAGENT-BENCH yang berisi 3K instruksi dan pasangan lintasan terkait keamanan juga dirilis. Eksperimen menunjukkan bahwa SHIELDAGENT mencapai SOTA pada beberapa benchmark, secara signifikan meningkatkan tingkat kepatuhan keamanan dan recall, sambil mengurangi kueri API dan waktu inference. (Sumber: LLM每周速递!| 涉及多模态、MoE模型、Deepseek推理、Agent安全控制、模型量化等)
MedVLM-R1: Mendorong kemampuan penalaran VLM medis melalui reinforcement learning: Universitas Teknik Munich, Universitas Oxford, dan institusi lain bekerja sama mengusulkan MedVLM-R1, sebuah Visual Language Model (VLM) medis yang bertujuan menghasilkan proses penalaran bahasa alami yang eksplisit. Model ini mengadopsi kerangka kerja reinforcement learning Group Relative Policy Optimization (GRPO) dari DeepSeek, dilatih pada dataset yang hanya berisi jawaban akhir, namun mampu secara mandiri menemukan jalur penalaran yang dapat dijelaskan manusia. Setelah dilatih hanya dengan 600 sampel VQA MRI, model parameter 2B ini mencapai akurasi 78,22% dalam pengujian benchmark MRI, CT, dan X-ray, secara signifikan mengungguli baseline, dan menunjukkan kemampuan generalisasi out-of-domain yang kuat, bahkan melampaui model skala lebih besar seperti Qwen2-VL-72B. Penelitian ini memberikan ide baru untuk membangun AI medis yang tepercaya dan dapat dijelaskan. (Sumber: 小样本大能量!MedVLM-R1借力DeepSeek强化学习,重塑医疗AI推理能力)
Penelitian mengungkap pelatihan reinforcement learning dapat menyebabkan respons model penalaran menjadi panjang: Sebuah studi dari Wand AI menganalisis alasan mengapa model penalaran (seperti DeepSeek-R1) menghasilkan respons yang lebih panjang. Studi menemukan bahwa perilaku ini mungkin berasal dari proses pelatihan reinforcement learning (khususnya algoritma PPO), bukan karena masalah itu sendiri membutuhkan penalaran yang lebih panjang. Ketika model menerima reward negatif untuk jawaban yang salah, fungsi loss PPO cenderung menghasilkan respons yang lebih panjang untuk mengencerkan hukuman per token, bahkan jika konten tambahan tidak membantu meningkatkan akurasi. Studi juga menunjukkan bahwa penalaran yang ringkas seringkali berkorelasi dengan akurasi yang lebih tinggi. Melalui putaran kedua pelatihan reinforcement learning yang hanya menggunakan sebagian masalah yang dapat dipecahkan, panjang respons dapat dipersingkat, sambil mempertahankan atau bahkan meningkatkan akurasi, yang penting untuk meningkatkan efisiensi penerapan. (Sumber: 更长思维并不等于更强推理性能,强化学习可以很简洁)

USTC dan ZTE mengusulkan Curr-ReFT: Meningkatkan kemampuan penalaran dan generalisasi VLM ukuran kecil: Mengatasi fenomena “dinding bata” (hambatan pelatihan) dan kemampuan generalisasi out-of-domain yang tidak memadai pada Visual Language Models (VLM) ukuran kecil dalam tugas kompleks, USTC dan ZTE Corporation mengusulkan paradigma pasca-pelatihan Curriculum Reinforcement Learning (Curr-ReFT). Paradigma ini menggabungkan curriculum learning (CL) dan reinforcement learning (RL), merancang mekanisme reward yang peka terhadap kesulitan, memungkinkan model belajar secara bertahap dari yang mudah ke yang sulit (keputusan biner → pilihan ganda → jawaban terbuka). Sementara itu, strategi perbaikan diri berbasis rejection sampling diadopsi, memanfaatkan sampel multimodal dan bahasa berkualitas tinggi untuk mempertahankan kemampuan dasar model. Eksperimen pada model Qwen2.5-VL-3B/7B menunjukkan bahwa Curr-ReFT secara signifikan meningkatkan kinerja penalaran dan generalisasi model, dengan model 7B bahkan melampaui InternVL2.5-26B/38B pada beberapa benchmark. (Sumber: 中科大、中兴提出新后训练范式:小尺寸多模态模型,成功复现R1推理)

GenPRM: Memperluas process reward model melalui penalaran generatif: Universitas Tsinghua dan Shanghai AI Lab mengusulkan Generative Process Reward Model (GenPRM), yang bertujuan untuk mengatasi masalah process reward model (PRM) tradisional yang bergantung pada skor skalar, kurangnya interpretabilitas, dan ketidakmampuan untuk diperluas saat pengujian. GenPRM mengadopsi metode generatif, menggabungkan penalaran Chain-of-Thought (CoT) dan validasi kode, untuk melakukan analisis bahasa alami dan validasi eksekusi kode Python pada setiap langkah penalaran, memberikan pengawasan proses yang lebih mendalam dan dapat diinterpretasikan. Selain itu, GenPRM memperkenalkan mekanisme perluasan saat pengujian, dengan mengambil sampel beberapa jalur penalaran secara paralel dan menggabungkan nilai reward untuk meningkatkan akurasi evaluasi. Model 1.5B yang dilatih hanya dengan 23K data sintetis melampaui GPT-4o di ProcessBench melalui perluasan saat pengujian, dan versi 7B melampaui Qwen2.5-Math-PRM-72B sebesar 72B. GenPRM juga dapat berfungsi sebagai model kritik untuk memandu optimasi model kebijakan. (Sumber: 过程奖励模型也可以测试时扩展?清华、上海AI Lab 23K数据让1.5B小模型逆袭GPT-4o)
Penelitian mengungkap fenomena “berpikir berlebihan” AI penalaran pada masalah premis yang hilang: Penelitian dari Universitas Maryland dan Universitas Lehigh menemukan bahwa model penalaran saat ini (seperti DeepSeek-R1, o1) cenderung menunjukkan kecenderungan “berpikir berlebihan” ketika dihadapkan pada masalah yang kekurangan informasi premis yang diperlukan (Missing Premise, MiP). Mereka menghasilkan respons 2-4 kali lebih panjang dari masalah normal, terjebak dalam siklus meninjau ulang masalah, menebak niat, dan meragukan diri sendiri, daripada dengan cepat mengidentifikasi bahwa masalah tidak dapat diselesaikan dan berhenti. Sebaliknya, model non-penalaran (seperti GPT-4.5) memberikan respons yang lebih pendek pada masalah MiP dan lebih mampu mengidentifikasi premis yang hilang. Penelitian menunjukkan bahwa meskipun model penalaran dapat mendeteksi premis yang hilang, mereka kurang memiliki “pemikiran kritis” untuk menghentikan penalaran yang tidak valid secara tegas. Pola perilaku ini mungkin berasal dari kurangnya batasan panjang dalam pelatihan reinforcement learning dan disebarkan melalui distilasi. (Sumber: 推理AI「脑补」成瘾,废话拉满!马里兰华人学霸揭开内幕)

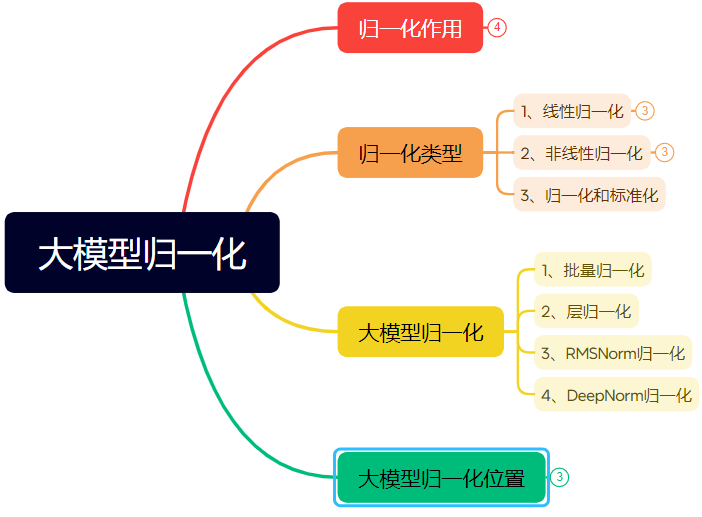
Artikel panjang menjelaskan evolusi teknik normalisasi jaringan saraf: Artikel ini secara sistematis mengulas peran dan evolusi normalisasi (Normalization) dalam jaringan saraf, terutama di Transformer dan model besar. Normalisasi, dengan membatasi data dalam rentang tetap, mengatasi masalah komparabilitas data, meningkatkan kecepatan optimasi, dan mengurangi masalah saturasi fungsi aktivasi serta pergeseran kovariat internal (Internal Covariate Shift, ICS). Artikel ini memperkenalkan metode normalisasi linier (Min-max, Z-score, Mean) dan non-linier yang umum, dengan fokus menjelaskan Batch Normalization (BN), Layer Normalization (LN), RMSNorm, dan DeepNorm yang cocok untuk model deep learning, menganalisis perbedaan penerapannya dalam arsitektur Transformer (mengapa LN/RMSNorm lebih cocok untuk NLP). Selain itu, dibahas juga penempatan modul normalisasi yang berbeda di dalam lapisan Transformer (Post-Norm, Pre-Norm, Sandwich-Norm) serta dampaknya terhadap stabilitas pelatihan dan kinerja. (Sumber: 万字长文!一文了解归一化:从Transformer归一化到主流大模型归一化的演变!)
Rekayasa Prompt untuk menghasilkan desain font gaya tertentu menggunakan AI: Artikel ini berbagi pengalaman penulis dalam mengeksplorasi penggunaan Tiamat AI 3.0 untuk menghasilkan desain teks dengan gaya tertentu dan templat prompt. Penulis menemukan bahwa menentukan nama font secara langsung (seperti Songti, Kaiti) tidak efektif, karena pemahaman model AI tentang ini terbatas. Oleh karena itu, penulis beralih ke mendeskripsikan fitur gaya font, suasana emosional, dan efek visual, serta menggabungkannya dengan contoh referensi gaya yang berbeda, untuk membangun templat prompt “Generator Prompt Desain Gaya Teks Tingkat Lanjut”. Pengguna hanya perlu memasukkan konten teks, dan templat ini dapat secara cerdas mencocokkan atau menggabungkan beberapa gaya pra-setel (seperti Bayangan Malam Berkilau, Kesederhanaan Industri, Coretan Kekanak-kanakan, Fiksi Ilmiah Logam, dll.) untuk menghasilkan prompt terperinci untuk model text-to-image, sehingga memperoleh efek desain teks-gambar dengan kualitas yang relatif stabil. (Sumber: AI生成字体设计我有点玩明白了,用这套Prompt提效50%。, 即梦AI 3.0制作含字体封面,这个方案酷到封神【附:16+案例和Prompt】)

ZClip: Metode penekanan lonjakan gradien adaptif untuk pra-pelatihan LLM: Peneliti mengusulkan ZClip, metode gradient clipping adaptif ringan yang bertujuan mengurangi lonjakan loss selama proses pelatihan LLM dan meningkatkan stabilitas pelatihan. Berbeda dengan gradient clipping tradisional yang menggunakan ambang batas tetap, ZClip menggunakan metode berbasis z-score untuk mendeteksi dan memotong lonjakan gradien anomali, yaitu gradien yang secara signifikan menyimpang dari rata-rata bergerak terkini. Metode ini membantu menjaga stabilitas pelatihan tanpa mengganggu konvergensi dan mudah diintegrasikan ke dalam loop pelatihan apa pun. Kode dan makalah telah dipublikasikan. (Sumber: Reddit r/deeplearning)
![[2504.02507] ZClip: Adaptive Spike Mitigation for LLM Pre-Training](https://rebabel.net/wp-content/uploads/2025/04/Swd9uQN43Dpl2SJyH6zjTbJAdRaXwKbmzZwM9L2rPXk.jpg)
💼 Bisnis
Solusi kartu grafis Intel Arc + prosesor Xeon W membantu all-in-one AI berbiaya rendah: Intel, melalui kombinasi kartu grafis Arc™ dan prosesor Xeon® W, menyediakan solusi bagi pasar untuk membangun mesin all-in-one model besar yang hemat biaya (tingkat 100.000 yuan) dan memiliki kinerja praktis. Kartu grafis Arc™ menggunakan arsitektur Xe dan mesin akselerasi XMX AI, mendukung kerangka kerja AI utama dan Ollama/vLLM, memiliki konsumsi daya yang relatif rendah, dan mendukung koneksi multi-kartu. Prosesor Xeon® W menyediakan jumlah inti yang tinggi dan kemampuan ekspansi memori, dengan teknologi akselerasi AMX bawaan. Dikombinasikan dengan optimasi perangkat lunak seperti IPEX-LLM, OpenVINO™, dan oneAPI, tercapai sinergi efisien antara CPU dan GPU. Pengujian aktual menunjukkan bahwa mesin all-in-one dengan solusi ini dapat mencapai 32 token/s untuk penggunaan tunggal model QwQ-32B, dan hampir 10 token/s untuk menjalankan model DeepSeek R1 671B (memerlukan optimasi FlashMoE), memenuhi kebutuhan inference offline dan mendorong普及化 inference AI. (Sumber: 榨干3000元显卡,跑通千亿级大模型的秘方来了)

NVIDIA akan memproduksi superkomputer AI di AS: NVIDIA mengumumkan akan merancang dan membangun superkomputer AI-nya secara lengkap di Amerika Serikat untuk pertama kalinya, bekerja sama dengan mitra manufaktur utama. Sementara itu, chip Blackwell generasi barunya telah mulai diproduksi di pabrik TSMC di Arizona. NVIDIA berencana untuk memproduksi infrastruktur AI senilai hingga lima ratus miliar dolar di AS dalam empat tahun ke depan, dengan mitra termasuk TSMC, Foxconn, Wistron, Amkor, dan SPIL. Langkah ini bertujuan untuk memenuhi permintaan chip AI dan superkomputer, memperkuat rantai pasokan, dan meningkatkan ketahanan. (Sumber: nvidia, nvidia)

Horizon Robotics merekrut intern rekonstruksi/generasi 3D: Tim Embodied Intelligence Horizon Robotics sedang merekrut intern algoritma arah rekonstruksi/generasi 3D di Shanghai/Beijing. Tanggung jawab meliputi partisipasi dalam merancang dan mengembangkan solusi algoritma Real2Sim robot (menggabungkan rekonstruksi 3D GS, rekonstruksi feedforward, generasi 3D/video), mengoptimalkan kinerja simulator Real2Sim (mendukung simulasi fluida, taktil, dll.), serta melacak penelitian mutakhir dan menerbitkan makalah konferensi teratas. Persyaratan meliputi gelar Master atau lebih tinggi, jurusan terkait Komputer/Grafik/AI, pengalaman dalam visi 3D/generasi video atau model multimodal/difusi, mahir menggunakan Python/Pytorch/Huggingface. Publikasi makalah konferensi teratas, keakraban dengan platform simulasi atau pengalaman proyek open-source lebih diutamakan. Menawarkan peluang konversi penuh waktu, klaster GPU, dan gaji yang kompetitif. (Sumber: 上海/北京内推 | 地平线机器人具身智能团队招聘3D重建/生成方向算法实习生)

Meituan Hotel & Travel merekrut engineer algoritma model besar L7-L8: Tim Algoritma Pasokan Meituan Hotel & Travel di Beijing merekrut engineer algoritma model besar tingkat L7-L8 (rekrutmen sosial). Tanggung jawab meliputi membangun sistem pemahaman pasokan hotel & perjalanan (label produk, identifikasi hotspot, penambangan pasokan serupa, dll.), mengoptimalkan materi tampilan (judul, gambar/teks, generasi alasan rekomendasi), membangun kombinasi paket liburan (pemilihan produk, prediksi penjualan, penetapan harga), serta mengeksplorasi dan menerapkan teknologi model besar mutakhir (fine-tuning, RL, optimasi Prompt). Persyaratan meliputi gelar Master atau lebih tinggi, pengalaman 2+ tahun, jurusan terkait Komputer/Otomasi/Statistika Matematika, memiliki dasar algoritma dan kemampuan coding yang solid. (Sumber: 北京内推 | 美团酒旅供给算法团队招聘L7-L8大模型算法工程师)

Meta akan menggunakan data pengguna di UE untuk melatih AI: Meta mengumumkan persiapan untuk mulai menggunakan data publik pengguna Facebook dan Instagram di wilayah Uni Eropa (seperti postingan, komentar, tidak termasuk pesan pribadi) untuk melatih model AI-nya, terbatas pada pengguna berusia 18 tahun ke atas. Perusahaan akan memberi tahu pengguna melalui notifikasi dalam aplikasi dan email, serta menyediakan tautan untuk menolak (opt-out). Sebelumnya, Meta menangguhkan rencananya untuk menggunakan data pengguna di Eropa untuk melatih AI karena permintaan dari regulator Irlandia. (Sumber: Reddit r/artificial)

Tencent Cloud meluncurkan layanan terkelola MCP: Tencent Cloud juga mulai menawarkan layanan terkelola MCP (Managed Cloud Platform), yang bertujuan untuk menyediakan solusi manajemen sumber daya cloud dan operasional yang lebih nyaman dan efisien bagi perusahaan. Langkah ini menandakan persaingan yang semakin ketat di antara penyedia cloud utama di bidang ini. Detail layanan spesifik dan “fitur khas WeChat” belum dijelaskan lebih lanjut. (Sumber: 腾讯云也搞 MCP 托管了,还带了点“微信特色”。)
🌟 Komunitas
Pemenang Turing Award LeCun membahas perkembangan AI: Kecerdasan manusia tidak umum, terobosan berikutnya mungkin pada non-generatif: Dalam wawancara podcast baru-baru ini, Yann LeCun sekali lagi menekankan bahwa istilah AGI menyesatkan, berpendapat bahwa kecerdasan manusia sangat terspesialisasi, bukan umum. Dia memperkirakan terobosan besar berikutnya dalam AI mungkin berasal dari model non-generatif, dengan fokus pada memungkinkan mesin benar-benar memahami dunia fisik, memiliki kemampuan penalaran dan perencanaan, serta memori yang tahan lama, mirip dengan arsitektur JEPA yang diusulkannya. Dia percaya LLM saat ini kurang memiliki kemampuan penalaran sejati dan kemampuan pemodelan dunia fisik, mencapai tingkat kecerdasan kucing sudah merupakan kemajuan besar. Mengenai LLaMA open-source Meta, dia menganggapnya sebagai pilihan yang tepat untuk mendorong pengembangan seluruh ekosistem AI, dan menekankan bahwa inovasi berasal dari seluruh dunia, dan open-source adalah kunci untuk mempercepat terobosan. Dia juga optimis tentang kacamata pintar sebagai pembawa penting untuk asisten AI. (Sumber: 图灵奖得主LeCun:人类智能不是通用智能,下一代AI可能基于非生成式)

GitHub sempat “memblokir” IP Tiongkok menarik perhatian, pejabat mengatakan itu kesalahan konfigurasi: Dari 12 hingga 13 April, beberapa pengguna Tiongkok menemukan bahwa mereka tidak dapat mengakses GitHub, halaman menampilkan pesan “Alamat IP dibatasi aksesnya”, memicu kepanikan dan diskusi komunitas, khawatir apakah itu pemblokiran yang ditargetkan. Sebelumnya GitHub pernah memblokir akun developer dari Rusia, Iran, dll. karena sanksi AS. Pejabat GitHub kemudian menanggapi bahwa insiden ini disebabkan oleh kesalahan perubahan konfigurasi yang menyebabkan pengguna yang tidak login sementara tidak dapat mengakses, masalah telah diperbaiki pada 13 April. Meskipun merupakan gangguan teknis, insiden ini sekali lagi memicu diskusi tentang risiko geopolitik platform hosting kode dan alternatif domestik (seperti Gitee, CODING, JiHu GitLab, dll.). (Sumber: “Bug”还是“预演”?GitHub 突然“封禁”所有中国 IP,官方:只是“手滑”技术出错了)

AI Agent menimbulkan kekhawatiran keamanan siber: Artikel MIT Technology Review menunjukkan bahwa serangan siber otonom yang didorong oleh AI akan segera datang. Seiring meningkatnya kemampuan AI, pelaku jahat dapat memanfaatkan AI Agent untuk secara otomatis menemukan kerentanan, merencanakan, dan melaksanakan serangan siber yang lebih kompleks dan berskala lebih besar, menimbulkan ancaman baru bagi keamanan individu, perusahaan, dan bahkan negara. Hal ini menuntut bidang keamanan siber untuk mempercepat penelitian dan penerapan strategi serta teknologi pertahanan yang mampu mengatasi serangan yang didorong oleh AI. (Sumber: Ronald_vanLoon)

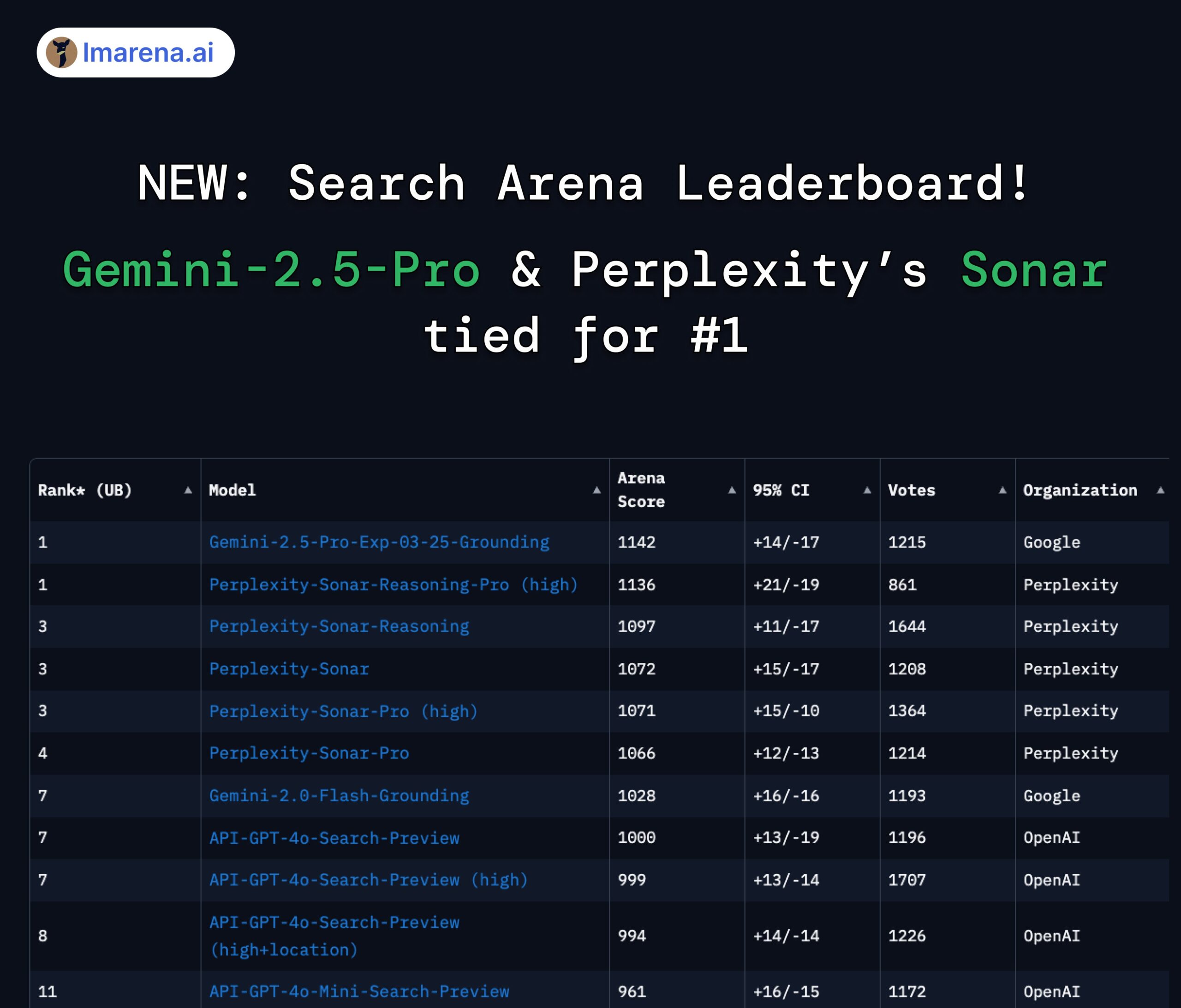
Perplexity Sonar dan Gemini 2.5 Pro berbagi posisi teratas di arena pencarian: Di papan peringkat Search Arena baru dari LMArena.ai (sebelumnya LMSYS), model Sonar-Reasoning-Pro-High dari Perplexity dan Gemini-2.5-Pro-Grounding dari Google berbagi posisi pertama. Papan peringkat ini secara khusus mengevaluasi kualitas jawaban LLM berbasis pencarian web. CEO Perplexity Arav Srinivas mengucapkan selamat atas hal ini dan menekankan akan terus meningkatkan model Sonar dan indeks pencarian. Komunitas menganggap ini menunjukkan bahwa dalam bidang LLM yang ditingkatkan pencarian, persaingan utama terjadi antara Google dan Perplexity. (Sumber: AravSrinivas, lmarena_ai, lmarena_ai, AravSrinivas, lmarena_ai, AravSrinivas)
Diskusi tentang batasan penggunaan model Claude: Di komunitas Reddit r/ClaudeAI, pengguna memperdebatkan batasan penggunaan versi Claude Pro (seperti batas jumlah pesan, batasan kapasitas). Beberapa pengguna mengeluh sering menemui batasan, mempengaruhi alur kerja, bahkan mempertimbangkan untuk mengganti model; pengguna lain menyatakan jarang menemui batasan, berpendapat mungkin karena cara penggunaan (seperti memuat konteks super besar) atau melebih-lebihkan. Ini mencerminkan pengalaman dan pandangan pengguna yang berbeda tentang kebijakan penggunaan dan stabilitas model Anthropic. (Sumber: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
Diskusi tentang AI dan masa depan pekerjaan: Sebuah gambar perbandingan di Reddit r/ChatGPT memicu diskusi: akankah AI meningkatkan kemampuan manusia, membawa kehidupan yang berkelimpahan, atau menggantikan pekerjaan manusia, menyebabkan pengangguran massal? Dalam komentar, banyak pengguna menyatakan kekhawatiran tentang AI menggantikan pekerjaan, terutama untuk profesi kreatif (pemrograman, seni). Beberapa orang percaya AI akan memperburuk ketidaksetaraan sosial, karena keuntungan terutama jatuh ke tangan pemilik AI, sementara basis pajak yang berkurang dapat membuat UBI sulit diwujudkan. Yang lain lebih optimis, menganggap AI sebagai alat yang kuat yang dapat meningkatkan efisiensi, menciptakan pekerjaan baru (seperti prompt engineer), kuncinya adalah beradaptasi dan belajar memanfaatkan AI. (Sumber: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)

Pengumpulan data AI menimbulkan kekhawatiran privasi: Sebuah infografis membandingkan jenis data pengguna yang dikumpulkan oleh berbagai chatbot AI (ChatGPT, Gemini, Copilot, Claude, Grok), memicu diskusi komunitas tentang masalah privasi. Gambar menunjukkan bahwa Google Gemini mengumpulkan jenis data terbanyak, sementara Grok (memerlukan akun) dan ChatGPT (tidak memerlukan akun) relatif lebih sedikit. Komentar pengguna menekankan prevalensi pengumpulan data di balik layanan gratis (“tidak ada makan siang gratis”), dan menyatakan keprihatinan tentang tujuan spesifik pengumpulan data (seperti prediksi perilaku). (Sumber: Reddit r/artificial)

Distilasi model dianggap sebagai cara efektif untuk mereplikasi kinerja tinggi dengan biaya rendah: Pengguna Reddit berbagi pengalaman menggunakan teknik distilasi model, menggunakan model besar (seperti GPT-4o) untuk melatih model kecil yang disesuaikan (fine-tuned), mencapai kinerja mendekati GPT-4o (akurasi 92%) dalam domain spesifik (analisis sentimen) dengan biaya 14x lebih rendah. Komentar menunjukkan bahwa distilasi adalah teknik yang banyak digunakan, tetapi dalam hal kemampuan generalisasi lintas domain, model kecil biasanya kalah dengan model besar. Untuk domain spesifik dan stabil, distilasi adalah metode pengurangan biaya dan peningkatan efisiensi yang efektif, tetapi untuk skenario kompleks yang memerlukan adaptasi terus-menerus terhadap data baru atau multi-domain, menggunakan API besar secara langsung mungkin lebih ekonomis. (Sumber: Reddit r/MachineLearning)
![[D] Distillation is underrated. I replicated GPT-4o's capability in a 14x cheaper model](https://rebabel.net/wp-content/uploads/2025/04/zyj7as7ogque1.png)
💡 Lain-lain
OceanBase menyelenggarakan Kompetisi AI Hackathon pertama: Vendor database terdistribusi OceanBase bersama dengan Ant Open Source, Jiqizhixin, dll., menyelenggarakan Kompetisi AI Hackathon pertama, pendaftaran telah dibuka pada 10 April dan ditutup pada 7 Mei. Kompetisi ini bertema “DB+AI”, menetapkan dua arah utama: pertama, menggunakan OceanBase sebagai basis data untuk membangun aplikasi AI, kedua, mengeksplorasi kombinasi OceanBase dengan ekosistem AI (seperti CAMEL AI, FastGPT, OpenDAL). Kompetisi ini menyediakan total hadiah 100.000 yuan, terbuka untuk pendaftaran individu dan tim, bertujuan untuk merangsang developer mengeksplorasi aplikasi inovatif dari integrasi mendalam antara database dan AI. (Sumber: 10万奖金×认知升级!OceanBase首届AI黑客松广发英雄帖,你敢来么?)

Profesor Liu Xinjun dari Universitas Tsinghua akan memberikan kuliah live tentang robot paralel: Profesor Liu Xinjun, Direktur Institut Teknik Desain Departemen Teknik Mesin Universitas Tsinghua dan Ketua Komite IFToMM Tiongkok, akan memberikan kuliah online pada malam 15 April, dengan tema “Dasar-dasar Kinematika Robot Paralel dan Inovasi Peralatan”. Kuliah ini akan membahas teori dasar robot paralel dan aplikasinya dalam inovasi peralatan mutakhir. Moderator adalah Profesor Liu Yingxiang dari Harbin Institute of Technology. (Sumber: 重磅直播!清华大学刘辛军教授开讲:并联机器人机构学基础与装备创新前沿)

Panduan KTT Industri AIGC Tiongkok ke-3 dirilis: KTT Industri AIGC Tiongkok ke-3, yang akan diadakan di Beijing pada 16 April, merilis agenda terperinci dan sorotan. KTT ini akan fokus pada teknologi AI dan implementasi aplikasi, dengan topik meliputi infrastruktur komputasi, aplikasi model besar dalam skenario vertikal seperti pendidikan/hiburan/layanan perusahaan/AI4S, keamanan dan kontrol AI, dll. Pembicara berasal dari Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qing Song Health, Ant Group, dll. KTT ini juga akan merilis daftar perusahaan dan produk AIGC yang patut diperhatikan pada tahun 2025, serta Peta Panorama Aplikasi AIGC Tiongkok. (Sumber: 倒计时2天!20余位行业大佬共话AI,中国AIGC产业峰会最全攻略在此)
