
Kata Kunci:AI, GPT-4.1, Zhipu AI IPO, Investasi superkomputer AI Nvidia, Pengeluaran modal AI Amazon, Protokol interoperabilitas AI Agent, Skala pengguna DeepSeek
🔥 Fokus
OpenAI merilis seri model GPT-4.1, meningkatkan kinerja API dan menghentikan GPT-4.5: OpenAI merilis tiga model baru melalui API pada 15 April: GPT-4.1, GPT-4.1 mini, dan GPT-4.1 nano, yang bertujuan untuk melampaui seri GPT-4o secara komprehensif. Model baru ini memiliki jendela konteks hingga 1 juta Token, dengan basis pengetahuan yang diperbarui hingga Juni 2024. GPT-4.1 menonjol dalam kemampuan pengkodean (skor SWE-bench Verified 54,6%, meningkat 21,4% dari GPT-4o), kepatuhan instruksi (skor MultiChallenge 38,3%, meningkat 10,5% dari GPT-4o), dan pemahaman video konteks panjang (skor Video-MME 72,0%, meningkat 6,7% dari GPT-4o). Perlu dicatat bahwa GPT-4.1 nano adalah model nano pertama, dengan kinerja lebih baik dari GPT-4o mini dan biaya lebih rendah. Sementara itu, OpenAI mengumumkan akan menghapus GPT-4.5 Preview API dalam 3 bulan (14 Juli), menyebutnya sebagai versi pratinjau penelitian, dan akan mengintegrasikan fitur yang disukai pengembang ke dalam model baru di masa depan. Rilisan ini dianggap sebagai langkah strategis OpenAI untuk membedakan model API dari lini produk ChatGPT dan secara langsung bersaing dengan seri Google Gemini. (Sumber: 36氪, 新智元1, AI科技评论, Reddit r/LocalLLaMA, Reddit r/artificial)
Zhipu AI memulai pendampingan IPO dan merilis model baru secara open source, valuasi melebihi 20 miliar: Zhipu AI (Zhipu Huazhang), salah satu dari “Enam Macan Kecil” model besar domestik, telah mengajukan pendaftaran pendampingan di Biro Regulasi Sekuritas Beijing pada 14 April, secara resmi memulai proses IPO, dengan CICC bertindak sebagai lembaga pendamping. Zhipu AI diinkubasi dari Laboratorium Teknik Pengetahuan Universitas Tsinghua, dengan anggota tim inti sebagian besar berasal dari Tsinghua. Perusahaan ini telah mengumpulkan lebih dari 15 miliar yuan dalam pendanaan, dengan valuasi baru-baru ini melebihi 20 miliar yuan RMB. Bersamaan dengan memulai IPO, Zhipu AI mengumumkan rilis open source skala besar seri model GLM-4-32B/9B, termasuk model dasar, inferensi, dan perenungan (contemplation), yang mengikuti lisensi MIT dan dapat digunakan secara komersial gratis. Di antaranya, model inferensi 32B parameter GLM-Z1-32B-0414 memiliki kinerja yang sebanding dengan DeepSeek-R1 671B parameter pada beberapa tugas. Versi API super cepatnya, GLM-Z1-AirX, memiliki kecepatan inferensi 200 token/s, dan versi hemat biayanya hanya 1/30 dari harga DeepSeek-R1. Perusahaan juga meluncurkan domain baru z.ai sebagai platform pengalaman model gratis. Langkah ini menunjukkan tata letak komprehensif Zhipu AI dalam penelitian dan pengembangan teknologi mandiri, eksplorasi komersialisasi, dan pembangunan ekosistem open source. (Sumber: 智东西, InfoQ, 量子位, 极客公园, 雷递, 公众号)

Nvidia menginvestasikan $500 miliar untuk memproduksi superkomputer AI di AS: Nvidia mengumumkan rencana besar untuk menginvestasikan $500 miliar selama empat tahun ke depan untuk memproduksi superkomputer AI di Amerika Serikat untuk pertama kalinya. Rencana ini melibatkan kerja sama dengan beberapa raksasa industri, termasuk TSMC (memproduksi chip Blackwell di Arizona), Foxconn dan Wistron (membangun pabrik superkomputer di Texas), Amkor dan SPIL (melakukan pengemasan dan pengujian di Arizona). CEO Nvidia Jensen Huang menyatakan bahwa langkah ini bertujuan untuk memenuhi permintaan chip AI dan superkomputer yang terus meningkat, meningkatkan ketahanan rantai pasokan, dan memanfaatkan teknologi AI, robotika (Isaac GR00T), dan digital twin (Omniverse) Nvidia untuk merancang dan mengoperasikan pabrik. Rencana ini dipandang sebagai penyebaran strategis di bawah dorongan pemerintah AS untuk manufaktur domestik (seperti Chip Act) dan latar belakang geopolitik, yang bertujuan untuk meningkatkan posisi AS dalam perlombaan infrastruktur AI global, tetapi juga menghadapi tantangan seperti kompleksitas rantai pasokan, kekurangan pekerja terampil, dan ketidakpastian kebijakan. (Sumber: 新智元1, 新智元2, Reddit r/artificial)

Amazon berencana menginvestasikan lebih dari $100 miliar untuk AI, hadapi persaingan dan raih peluang: CEO Amazon Andy Jassy mengungkapkan dalam surat tahunan 2024 kepada pemegang saham bahwa perusahaan berencana melakukan belanja modal lebih dari $100 miliar pada tahun 2025, sebagian besar akan digunakan untuk proyek terkait AI, termasuk pusat data, peralatan jaringan, perangkat keras AI (seperti chip Trainium yang dikembangkan sendiri) dan layanan AI generatif (seperti seri model besar Nova yang dikembangkan sendiri, platform Bedrock, Alexa+ yang ditingkatkan, asisten belanja Rufus). Investasi besar ini (mendekati 1/6 pendapatan tahunan) mencerminkan pandangan Amazon bahwa AI adalah kunci untuk menghadapi persaingan sengit di bidang e-commerce (dari SHEIN, Temu, TikTok, dll.) dan meraih peluang bersejarah. Jassy menekankan bahwa AI akan mengubah aturan pencarian, pemrograman, belanja, dll., dan tidak berinvestasi akan kehilangan daya saing. Saat ini, pendapatan tahunan bisnis AI Amazon telah mencapai miliaran dolar, dengan pertumbuhan tahun-ke-tahun mencapai tiga digit. Langkah ini juga menunjukkan tekad Amazon untuk terus berinvestasi guna mengkonsolidasikan posisi terdepannya di bidang layanan cloud (AWS) dalam menghadapi persaingan dari Microsoft Azure, Google Cloud, dan pesaing lainnya. (Sumber: 36氪)
🎯 Tren
Protokol interoperabilitas AI Agent MCP dan standar A2A mendapat perhatian: Bidang AI agent sedang menyambut persaingan protokol interaksi standar. MCP (Model Context Protocol) yang diusulkan oleh Anthropic bertujuan untuk menyatukan komunikasi antara model besar dengan alat eksternal dan sumber data, disebut sebagai “USB-C untuk AI”, dan telah mendapat dukungan dari OpenAI, Google, dll. Google, di sisi lain, telah merilis protokol A2A (Agent2Agent) secara open source, yang berfokus pada kolaborasi yang aman dan efisien antara agent dari berbagai vendor dan kerangka kerja, bertujuan untuk mendobrak hambatan ekosistem. Munculnya kedua protokol utama ini menandai evolusi AI dari kecerdasan tunggal ke jaringan kolaboratif, tetapi juga menimbulkan diskusi tentang “protokol adalah kekuasaan”, monopoli data, dan hambatan ekosistem (“taman kecil bertembok tinggi”). Menguasai hak penetapan standar dapat membentuk kembali lanskap rantai industri AI dan memiliki dampak mendalam pada integrasi AI dengan dunia fisik (robotika, IoT). Vendor domestik seperti Alibaba Cloud dan Tencent Cloud juga sudah mulai mendukung MCP. (Sumber: 36Kr)

Laporan QuestMobile: DeepSeek mengguncang lanskap aplikasi AI domestik, skala pengguna mencapai 240 juta: Laporan “Analisis Persaingan Pasar Aplikasi AI Kuartal Pertama 2025” yang dirilis oleh QuestMobile menunjukkan bahwa lanskap pasar Aplikasi AI asli domestik telah diguncang sepenuhnya karena popularitas model DeepSeek dan aplikasinya. Hingga akhir Februari 2025, skala pengguna aktif bulanan Aplikasi AI asli mencapai 240 juta, meningkat hampir 90% dibandingkan Januari. Aplikasi DeepSeek menduduki puncak dengan 194 juta pengguna aktif bulanan, diikuti oleh Doubao dari ByteDance (116 juta) dan Tencent Yuanbao (41,64 juta) di posisi kedua dan ketiga, menggantikan Kimi dan lainnya. Laporan tersebut menunjukkan bahwa efek inklusif open source DeepSeek mendorong pemain utama untuk terhubung dan memicu ledakan aplikasi AI, membentuk 23 jalur persaingan termasuk asisten AI komprehensif, pencarian AI, dll., di mana persaingan pencarian AI adalah yang paling ketat. Saat ini, “penggerak multi-model” telah menjadi standar untuk Aplikasi teratas, dan fokus persaingan beralih ke desain dan operasi produk. (Sumber: QuestMobile)

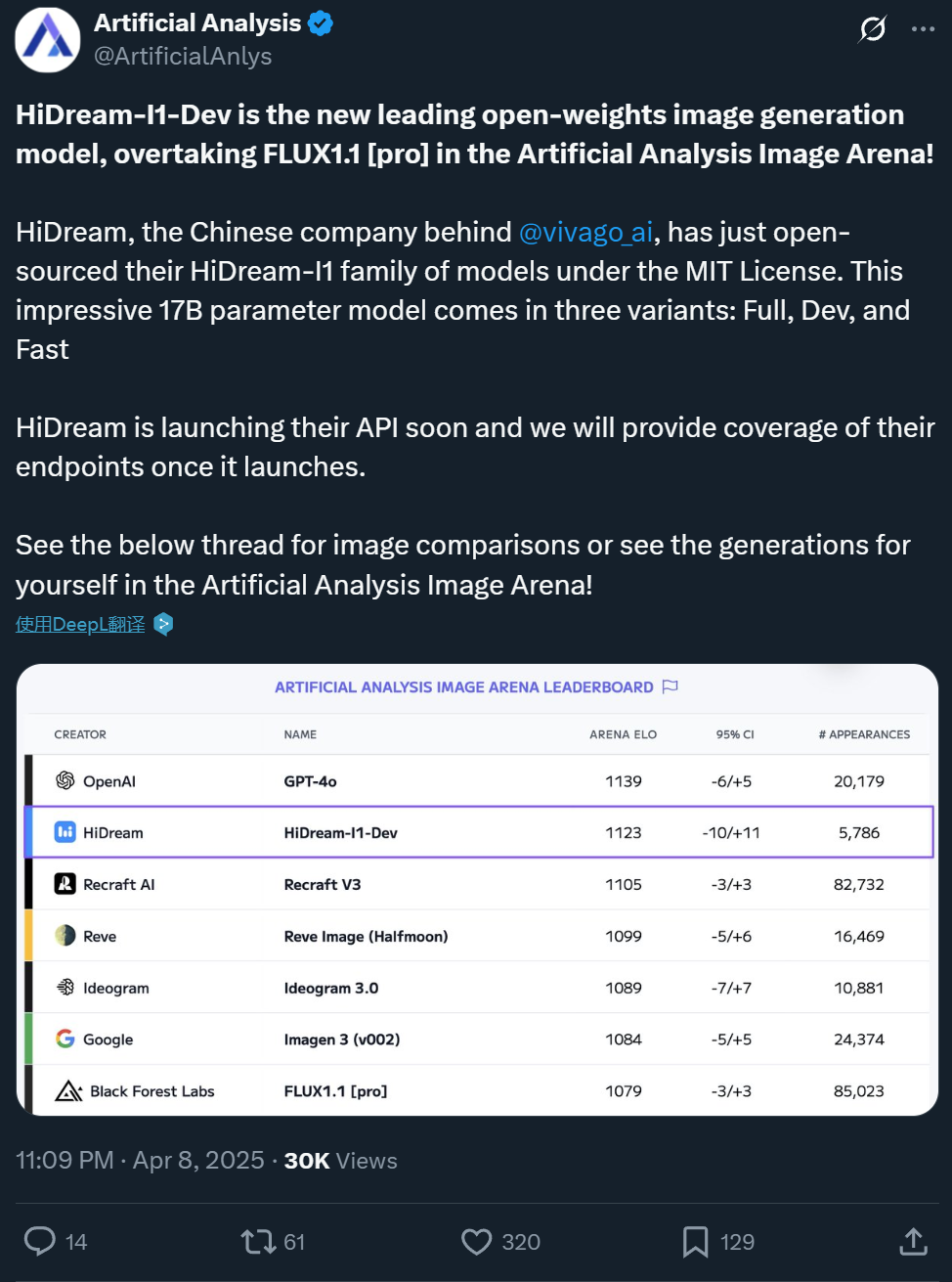
Zxiang Future merilis model text-to-image 17B HiDream-I1 secara open source, efeknya setara dengan GPT-4o: Perusahaan domestik Zxiang Future telah merilis model besar text-to-image 17B parameternya, HiDream-I1, secara open source dengan lisensi MIT yang longgar, memungkinkan penggunaan komersial. Model ini menunjukkan kinerja luar biasa di arena dan benchmark (seperti HPSv2.1, GenEval, DPG-Bench) di platform seperti Artificial Analysis. Realisme, kehalusan, dan kemampuan mengikuti instruksi dari gambar yang dihasilkan dianggap sebanding dengan GPT-4o dan FLUX 1.1 Pro, bahkan lebih unggul dalam beberapa aspek. HiDream-I1 menggunakan arsitektur Sparse Diffusion Transformer (Sparse DiT), menggabungkan teknologi MoE untuk meningkatkan kinerja dan efisiensi. Perusahaan juga mengumumkan akan segera merilis model HiDream-E1 yang mendukung pengeditan gambar interaktif secara open source. Kombinasi keduanya bertujuan untuk memberikan pengalaman pembuatan dan pengeditan gambar “versi open source GPT-4o”. Model ini telah tersedia di Hugging Face dan dapat dicoba di platform Vivago. (Sumber: 机器之心1, 机器之心2)
ByteDance merilis model dasar video 7B Seaweed, biaya rendah efisiensi tinggi: Tim Seed ByteDance merilis model dasar pembuatan video bernama Seaweed (plesetan dari Seed-Video). Model ini hanya memiliki 7 miliar parameter dan dilaporkan dilatih menggunakan 665.000 jam GPU H100 (setara dengan sekitar 28 hari pelatihan dengan 1000 kartu), dengan biaya yang relatif rendah. Seaweed dapat menghasilkan video dengan resolusi berbeda (mendukung native 1280×720, dapat di-upsample hingga 2K), rasio aspek apa pun, dan durasi berdasarkan teks. Model ini mendukung pembuatan image-to-video, kontrol subjek referensi (gambar tunggal/ganda), kombinasi dengan solusi manusia digital Omnihuman untuk menghasilkan video sinkronisasi bibir, sulih suara video, dan fungsi lainnya. Secara teknis, ia menggunakan arsitektur DiT+VAE, dikombinasikan dengan alur pemrosesan data yang komprehensif dan strategi pelatihan multi-tahap multi-tugas (pre-training, SFT, RLHF), serta optimasi tingkat sistem untuk meningkatkan efisiensi pelatihan. Tim ini dipimpin oleh Dr. Jiang Lu, mantan kepala pembuatan video Google, dan lainnya. (Sumber: 量子位)

Alibaba Tongyi merilis model pembuatan video manusia digital OmniTalker: Tim HumanAIGC dari Laboratorium Tongyi Alibaba meluncurkan model besar pembuatan video manusia digital baru, OmniTalker. Model ini bertujuan untuk mengatasi masalah yang disebabkan oleh metode bertingkat tradisional (TTS + penggerak audio) seperti latensi, ketidaksesuaian audio-visual, dan inkonsistensi gaya. OmniTalker adalah kerangka kerja terpadu end-to-end yang menerima input teks dan segmen audio-video referensi untuk menghasilkan ucapan dan video manusia digital yang sinkron secara real-time, sambil mempertahankan suara dan gaya bicara wajah dari sumber referensi. Arsitektur intinya menggunakan DiT (Diffusion Transformer) aliran ganda, masing-masing memproses informasi audio dan visual, dan memastikan sinkronisasi serta konsistensi gaya melalui modul fusi audio-visual baru. Model ini memanfaatkan modul pembelajaran referensi kontekstual untuk menangkap fitur gaya dari video referensi tanpa memerlukan pelatihan ekstraktor gaya tambahan. Proyek ini saat ini tersedia untuk dicoba di komunitas ModelScope dan HuggingFace. (Sumber: 机器之心)

Kuaishou merilis model video AI Kling versi 2.0: Model pembuatan video AI Kling dari Kuaishou merilis versi 2.0, yang diklaim memiliki peningkatan signifikan dalam hal amplitudo pergerakan kamera, kepatuhan terhadap hukum fisika, penampilan karakter, stabilitas gerakan, dan pemahaman semantik. Ulasan pengguna menunjukkan bahwa versi baru ini berkinerja sangat baik dalam menangani interaksi kompleks (seperti T-Rex menabrak dan mematahkan pohon), gerakan halus (seperti melepas kacamata), adegan multi-orang, serta simulasi cahaya dan bayangan nyata. Realisme dan nuansa sinematik dari video yang dihasilkan telah meningkat pesat, dengan efek yang dianggap melampaui versi 1.6 sebelumnya dan mencapai tingkat terdepan di industri. Meskipun masih ada ruang untuk perbaikan dalam gerakan kelompok berkecepatan tinggi dan simulasi fisika ekstrem (seperti menembak bola basket), kinerja keseluruhannya dianggap mulai menantang standar produksi profesional. Pengguna dapat mencoba versi baru melalui situs web resmi klingai.com. (Sumber: 公众号, op7418)

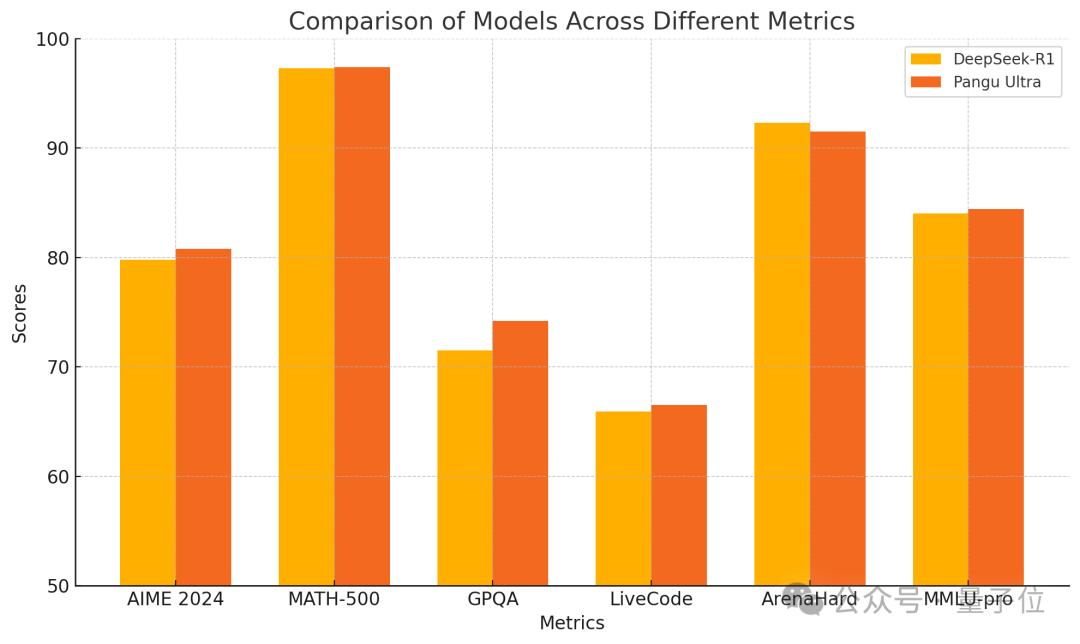
Huawei merilis model padat Pangu Ultra 135B, kinerja pelatihan murni Ascend unggul: Huawei mengumumkan anggota baru dari seri model besar Pangu-nya — Pangu Ultra. Ini adalah model padat (Dense) dengan 135 miliar parameter, dilatih sepenuhnya pada klaster komputasi AI Ascend Huawei (8192 NPU), tanpa menggunakan GPU Nvidia. Menurut laporan, Pangu Ultra menunjukkan kinerja luar biasa pada tugas-tugas seperti penalaran matematika (AIME 2024, MATH-500) dan pemrograman (LiveCodeBench), dengan kinerja yang sebanding dengan model MoE skala lebih besar seperti DeepSeek-R1. Secara teknis, model ini menggunakan normalisasi lapisan Sandwich-Norm penskalaan kedalaman yang inovatif dan strategi inisialisasi parameter TinyInit, yang secara efektif mengatasi masalah ketidakstabilan saat melatih jaringan yang sangat dalam (94 lapisan), mencapai pelatihan yang mulus tanpa lonjakan kerugian (loss spikes). Melalui optimasi tingkat sistem, pelatihan mencapai tingkat pemanfaatan daya komputasi (MFU) lebih dari 52%. (Sumber: 量子位)
Canopy Labs merilis model sintesis ucapan emosional Orpheus secara open source: Canopy Labs merilis dan membuka sumber seri model text-to-speech (TTS) bernama Orpheus. Model ini didasarkan pada arsitektur Llama, dengan versi awal 3 miliar parameter, dan versi lebih kecil seperti 1B, 0.5B, 0.15B akan menyusul. Ciri khas Orpheus adalah kemampuannya menghasilkan ucapan dengan emosi, intonasi, dan ritme yang sangat mirip manusia, bahkan dapat menyimpulkan dan menghasilkan suara non-verbal seperti tawa dan desahan dari teks, mencapai ekspresi “empati”. Model ini mendukung kloning suara zero-shot dan kontrol intonasi emosional melalui label. Ia menggunakan inferensi streaming dengan latensi rendah 100-200ms, dan kecepatan inferensi pada kartu grafis A100 40GB lebih cepat dari pemutaran real-time. Pengembang mengklaim kinerjanya melampaui model SOTA open source yang ada dan beberapa model closed source, bertujuan untuk mendobrak monopoli model TTS closed source. Model dan kodenya telah tersedia di GitHub dan Hugging Face. (Sumber: 新智元)

Universitas Zhejiang dan ByteDance bersama-sama merilis model sintesis ucapan MegaTTS3: Tim Profesor Zhao Zhou dari Universitas Zhejiang, bekerja sama dengan ByteDance, merilis dan membuka sumber model sintesis ucapan generasi ketiga, MegaTTS3. Dengan skala parameter ringan hanya 0.45B, model ini mencapai sintesis ucapan bilingual (Mandarin-Inggris) berkualitas tinggi dan menunjukkan kinerja luar biasa dalam kloning suara zero-shot, mampu menghasilkan ucapan yang alami, terkontrol, dan personal. MegaTTS3 berfokus pada terobosan dalam penyelarasan jarang ucapan-teks (speech-text sparse alignment), kontrolabilitas generasi, serta keseimbangan antara efisiensi dan kualitas. Sorotan teknis termasuk teknologi “Multi-Condition Classifier-Free Guidance” (Multi-Condition CFG) untuk kontrol multi-dimensi seperti intensitas aksen, dan teknologi “Segmental Rectified Flow Acceleration” (PeRFlow) yang meningkatkan kecepatan sampling hingga 3 kali lipat. Model ini menunjukkan kealamian (CMOS) dan kemiripan pembicara (SIM-O) terdepan pada benchmark seperti LibriSpeech. (Sumber: PaperWeekly)

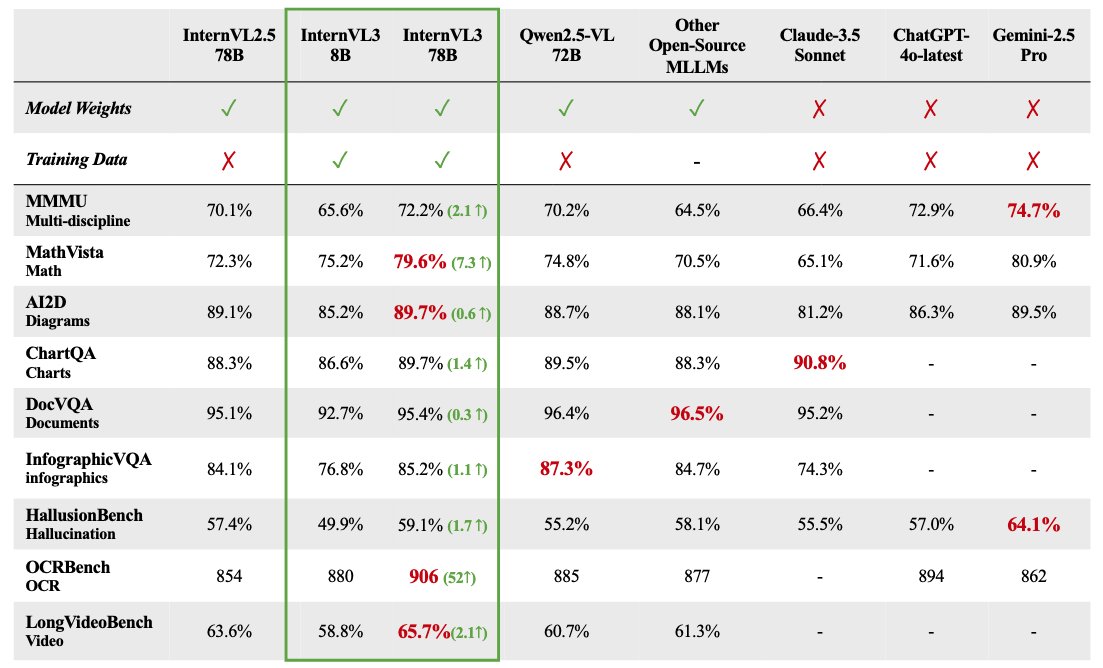
Seri model besar multimodal InternVL 3 dirilis secara open source: OpenGVLab merilis seri model besar multimodal InternVL 3, dengan skala parameter mulai dari 1B hingga 78B, yang telah tersedia di Hugging Face. Dilaporkan bahwa versi 78B parameter mencapai skor 72,2 pada benchmark MMMU, mencetak rekor SOTA baru untuk model multimodal open source. Sorotan teknis InternVL 3 meliputi: penggunaan pre-training multimodal native untuk mempelajari bahasa dan visi secara bersamaan; pengenalan Variable Visual Position Encoding (V2PE) untuk mendukung konteks yang diperluas; penggunaan teknik post-training canggih seperti SFT dan MPO; dan penerapan strategi penskalaan saat pengujian (test-time scaling) untuk meningkatkan kemampuan penalaran matematika. Data pelatihan dan bobot model telah dibuka untuk digunakan oleh komunitas. (Sumber: huggingface)
Analisis kinerja GPT-4.1 dalam pengujian nyata: Peningkatan pengkodean tetapi penalaran tertinggal: Seri model GPT-4.1 yang dirilis OpenAI menunjukkan gambaran kinerja yang kompleks dalam pengujian awal dan evaluasi benchmark. Meskipun menunjukkan kemajuan signifikan dibandingkan GPT-4o dalam tugas pembuatan kode, seperti menyelesaikan simulasi fisika dan pengembangan game dengan lebih baik, serta mencetak skor tinggi di SWE-Bench. Namun, pada benchmark penalaran, matematika, dan tanya jawab pengetahuan yang lebih luas (seperti Livebench, GPQA Diamond), kinerja GPT-4.1 masih tertinggal di belakang Gemini 2.5 Pro dari Google dan Claude 3.7 Sonnet dari Anthropic. Analisis menunjukkan bahwa GPT-4.1 mungkin merupakan pembaruan inkremental dari GPT-4o, atau didistilasi dari GPT-4.5. Strategi rilisnya mungkin bertujuan untuk menyediakan opsi model yang lebih hemat biaya dan dioptimalkan secara spesifik melalui API, daripada model unggulan yang sepenuhnya melampaui pesaing. (Sumber: 新智元)
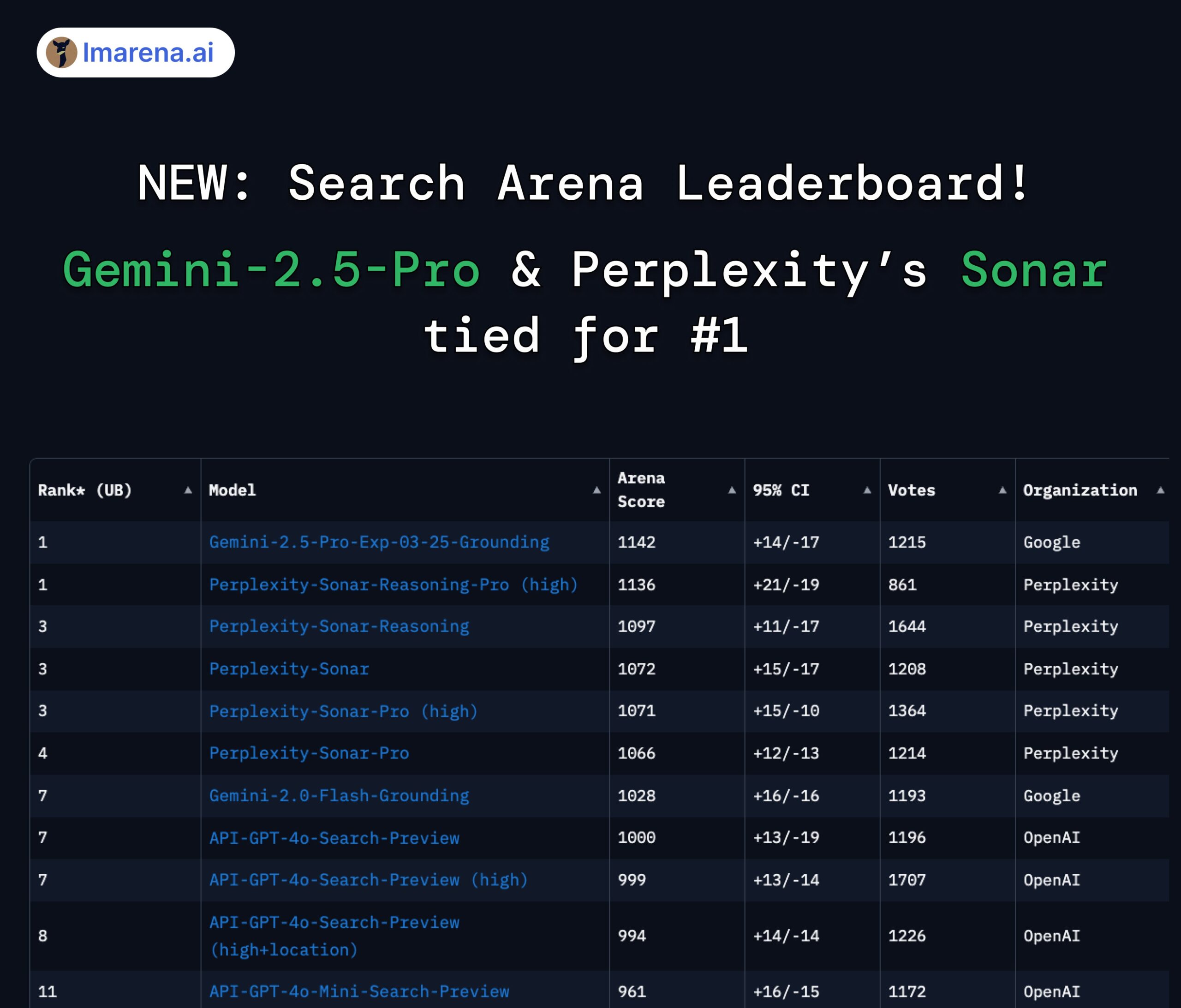
Peringkat LMArena Search: Gemini 2.5 Pro dan Perplexity Sonar berbagi posisi pertama: Dalam evaluasi arena LMArena yang menargetkan model besar dengan kemampuan pencarian/koneksi internet, Gemini-2.5-Pro dari Google (dikombinasikan dengan Google Search) dan Sonar-Reasoning-Pro dari Perplexity berbagi posisi teratas. Hasil ini dikonfirmasi melalui retweet oleh CEO Google DeepMind Demis Hassabis dan Kepala Hubungan Pengembang Google Logan Kilpatrick. CEO Perplexity Aravind Srinivas juga menyatakan bahwa pengujian A/B internal menunjukkan model Sonar mereka lebih unggul dalam retensi pengguna dibandingkan GPT-4o, dan kinerjanya sebanding dengan Gemini 2.5 Pro serta GPT-4.1 yang baru dirilis. Penyelenggara evaluasi, lmarena.ai, telah membuka sumber 7000 data voting pengguna. (Sumber: lmarena_ai 1, lmarena_ai 2, AravSrinivas, demishassabis)
Meta akan melanjutkan penggunaan konten publik pengguna Eropa untuk melatih AI: Meta mengumumkan akan kembali menggunakan konten publik dari pengguna Eropa untuk melatih model kecerdasan buatannya. Sebelumnya, Meta telah menangguhkan praktik ini karena menghadapi tekanan dari lembaga perlindungan data Eropa (khususnya Komisi Perlindungan Data Irlandia) dan persyaratan peraturan. Keputusan untuk melanjutkan pelatihan mungkin mencerminkan upaya berkelanjutan dan penyesuaian strategi Meta dalam menyeimbangkan privasi pengguna, mematuhi peraturan (seperti GDPR), dan memperoleh data yang cukup untuk menjaga daya saing model AI-nya. Langkah ini kemungkinan akan kembali memicu diskusi tentang hak data pengguna dan transparansi pelatihan AI. (Sumber: Reddit r/artificial)

Aplikasi seluler Claude mungkin akan menambahkan mode interaksi suara: Berdasarkan petunjuk yang ditemukan oleh pengguna X @testingcatalog, Anthropic mungkin berencana menambahkan fungsi interaksi suara ke aplikasi seluler Claude-nya. Tangkapan layar menunjukkan ikon mikrofon muncul di antarmuka aplikasi, menyiratkan bahwa pengguna di masa depan mungkin dapat berkomunikasi dengan Claude melalui suara, mirip dengan mode suara yang sudah ditawarkan oleh aplikasi ChatGPT dan Google Gemini. Ini akan membuat metode interaksi Claude di perangkat seluler lebih beragam dan nyaman, lebih meningkatkan pengalaman pengguna, dan menjaga kesetaraan fungsional dengan asisten AI utama lainnya. (Sumber: Reddit r/ClaudeAI)
Kecepatan model seri Z1 Zhipu menarik perhatian, disebut “model instan”: Seri model Z1 yang baru dirilis oleh Zhipu AI, terutama versi GLM-Z1-AirX, menarik perhatian karena kecepatan inferensinya yang sangat cepat. Beberapa analisis menyebutnya sebagai “model instan”, menunjukkan bahwa ia dapat menyelesaikan respons pertama dan menghasilkan lebih dari 50 karakter Mandarin dalam 0,3 detik, kecepatan yang mendekati waktu refleks saraf manusia. Latensi rendah dan throughput tinggi ini diharapkan dapat mengubah mode interaksi manusia-mesin, dari “bertanya-menunggu-menjawab” menjadi percakapan sinkron yang hampir real-time, terutama cocok untuk skenario yang menuntut kecepatan respons tinggi seperti pendidikan, layanan pelanggan, pembuatan konten, dan pemanggilan Agent. Kecepatan versi API Z1-AirX diklaim dapat mencapai 200 token/s. (Sumber: 公众号)

Game AI Native: Evolusi dan tantangan dari alat efisiensi hingga inovasi gameplay: Industri game sedang bertransisi dari memanfaatkan AI untuk meningkatkan efisiensi R&D dan operasi (seperti pembuatan aset seni, bantuan kode, pengujian otomatis) menuju eksplorasi “game AI native” yang sesungguhnya. Inti dari game AI native adalah integrasi mendalam AI ke dalam gameplay, menciptakan konten dinamis yang didorong oleh interaksi pemain dan pengalaman yang dipersonalisasi, bukan skrip yang telah ditentukan sebelumnya. 《Whispers from the Star》 yang diinvestasikan oleh pendiri miHoYo Cai Haoyu dan mode pemain AI dalam 《Space Kill》 dari Giant Network adalah contoh eksplorasi semacam ini. Namun, realisasi game AI native menghadapi banyak tantangan: secara teknis, perlu mengatasi masalah kemampuan model, stabilitas, dan biaya; secara desain, kurangnya contoh matang, perlu menyeimbangkan kontrolabilitas dan kebebasan; secara pengguna, perlu memenuhi permintaan pemain akan kesenangan dan kedalaman interaksi; selain itu, ada risiko kepatuhan konten dan etika. Industri saat ini masih dalam tahap eksplorasi awal, dan masih jauh dari implementasi yang matang. (Sumber: 界面新闻)
🧰 Alat
Inventarisasi lima aplikasi AI yang membuka pikiran: 36Kr menginventarisasi lima alat AI dengan kreativitas dan kepraktisan dari kasus inovasi aplikasi AI native yang dikumpulkan baru-baru ini: 1) AiPPT.com: Menghasilkan PPT dengan cepat melalui satu kalimat atau mengimpor file (Word, PDF, Xmind, tautan), mendukung operasi offline. 2) Shanji AI Pai Pai Jing: Kacamata AI dengan fungsi seperti mengambil foto dan video, terjemahan real-time, pengenalan rumus. 3) Lianxin Digital Wu Gan Shen Xun Zhinengti: Berdasarkan model besar psikologis “Insight into Human”, membantu interogasi dengan menganalisis ekspresi mikro, suara, sinyal fisiologis, dan menghasilkan laporan. 4) Huilima Vali Shoes AI: Menghasilkan 8 desain sepatu dalam 10 detik dengan memasukkan kata kunci, mengintegrasikan perpustakaan material dan data pola, terhubung ke produksi. 5) Nanfang Shiton Shabao HR Zhinengti: Menangani tugas sumber daya manusia manajemen jaminan sosial, menyediakan interpretasi kebijakan, perhitungan biaya, pemrosesan cerdas, peringatan risiko, dll. Aplikasi ini menunjukkan potensi AI dalam alat efisiensi, perangkat keras cerdas, dan bidang profesional (keamanan, desain, SDM). (Sumber: 36Kr)

Haisin Intelligence merilis platform pengembangan AI zero-code “Haisnap”: Haisin Intelligence Technology, yang didukung oleh BUMN Beijing, meluncurkan platform pengembangan AI zero-code/low-code bernama “Haisnap”. Pengguna dapat mendeskripsikan kebutuhan mereka menggunakan bahasa alami, dan AI akan secara otomatis menghasilkan aplikasi web atau game mini. Fitur platform ini adalah kode terlihat secara real-time selama proses pembuatan, dan mendukung pengeditan dan modifikasi sekunder melalui dialog. Aplikasi yang dikembangkan pengguna dapat dipublikasikan ke “Komunitas Kreatif” platform untuk dijelajahi, digunakan, dan dibuat ulang (remix) oleh orang lain. Platform saat ini terbuka gratis, bertujuan untuk menurunkan ambang batas pengembangan aplikasi AI, mendorong penciptaan universal, terutama berfokus pada pendidikan AI remaja dan implementasi aplikasi industri. (Sumber: 量子位)

Sistem tanya jawab basis pengetahuan open source ChatWiki dirilis, mendukung GraphRAG dan integrasi WeChat: ChatWiki adalah sistem tanya jawab AI basis pengetahuan open source baru yang mengintegrasikan model bahasa besar (mendukung lebih dari 20 model termasuk DeepSeek, OpenAI, Claude, dll.) dengan teknologi Retrieval-Augmented Generation (RAG), dan secara khusus mendukung GraphRAG berbasis grafik pengetahuan untuk menangani kueri kompleks. Fungsi sistem meliputi: mendukung impor berbagai format dokumen (OFD, Word, PDF, dll.) untuk membangun basis pengetahuan pribadi; mendukung segmentasi semantik untuk meningkatkan akurasi RAG; dapat mempublikasikan basis pengetahuan sebagai situs dokumentasi publik; menyediakan antarmuka API untuk integrasi mulus dengan akun publik WeChat, layanan pelanggan WeChat, dll., untuk membuat chatbot AI; alat orkestrasi alur kerja visual bawaan; mendukung integrasi dengan data bisnis pihak ketiga; menyediakan manajemen izin tingkat perusahaan; mendukung penyebaran lokal Docker dan kode sumber. (Sumber: 公众号)

Komunitas ModelScope meluncurkan MCP Square, membangun ekosistem layanan MCP terbesar di Tiongkok: Komunitas model AI Alibaba, ModelScope, secara resmi meluncurkan “MCP Square”, mengumpulkan hampir 1500 layanan yang mengimplementasikan Model Context Protocol (MCP), mencakup bidang seperti pencarian, peta, pembayaran, alat pengembang, dll., bertujuan untuk membangun komunitas MCP berbahasa Mandarin terbesar di Tiongkok. Beberapa layanan MCP dari Alipay dan MiniMax diluncurkan secara eksklusif di sini, misalnya kemampuan pembayaran, kueri, pengembalian dana Alipay, serta kemampuan pembuatan suara, gambar, video MiniMax, semuanya dapat dipanggil oleh AI agent melalui protokol MCP. Pengembang dapat dengan cepat mencoba dan mengintegrasikan layanan ini di MCP Experiment Field ModelScope melalui konfigurasi JSON sederhana dan sumber daya cloud gratis, sangat menurunkan ambang batas bagi aplikasi AI untuk mengakses alat dan data eksternal. ModelScope juga meluncurkan MCP Bench untuk mengevaluasi kualitas dan kinerja berbagai layanan MCP. (Sumber: 新智元)

Diskusi penggunaan fitur WebSearch Open WebUI: Pengguna komunitas Reddit mendiskusikan cara menggunakan fitur Web Search di Open WebUI. Pertanyaan berpusat pada cara mengontrol kata kunci kueri yang digunakan oleh mesin pencari secara tepat, dan cara membatasi fitur Web Search ke model tertentu untuk mencegah data model pribadi terkirim secara tidak sengaja ke jaringan. Ini mencerminkan kebutuhan aktual pengguna akan presisi kontrol dan keamanan privasi saat menggunakan alat AI yang terintegrasi dengan fungsi pencarian. (Sumber: Reddit r/OpenWebUI 1, Reddit r/OpenWebUI 2)
Pengguna mencari pemahaman tentang Model Context Protocol (MCP): Ada postingan pengguna di komunitas Reddit yang mencari penjelasan tentang Model Context Protocol (MCP), menunjukkan bahwa seiring dengan promosi dan penerapan standar MCP (seperti MCP Square ModelScope), kebutuhan komunitas pengembang dan pengguna untuk memahami teknologi baru ini dan cara kerjanya semakin meningkat. (Sumber: Reddit r/OpenWebUI)
📚 Pembelajaran
Penghargaan Test of Time ICLR 2025 diberikan kepada optimizer Adam dan mekanisme atensi: Konferensi Internasional tentang Representasi Pembelajaran (ICLR) memberikan “Test of Time Award” 2025 kepada dua makalah tonggak sejarah yang diterbitkan sepuluh tahun lalu (2015). Satu adalah “Adam: A Method for Stochastic Optimization” oleh Diederik P. Kingma dan Jimmy Ba, yang mengusulkan optimizer Adam yang telah menjadi algoritma standar untuk pelatihan model deep learning. Yang lainnya adalah “Neural Machine Translation by Jointly Learning to Align and Translate” oleh Dzmitry Bahdanau, Kyunghyun Cho, dan Yoshua Bengio, yang pertama kali memperkenalkan mekanisme atensi, meletakkan dasar bagi arsitektur Transformer dan model bahasa besar modern. Kedua penghargaan ini menyoroti dampak mendalam penelitian dasar pada perkembangan AI saat ini. (Sumber: 新智元)

Tinjauan sejarah singkat perkembangan AI dan evolusi perusahaan: Artikel ini secara sistematis meninjau sejarah perkembangan kecerdasan buatan dari pertengahan abad ke-20 hingga saat ini, dengan titik-titik penting termasuk Tes Turing, Konferensi Dartmouth, simbolisme dan sistem pakar, musim dingin AI, kebangkitan machine learning (DeepBlue, PageRank), revolusi deep learning (AlexNet, AlphaGo), dan era model besar saat ini (seri GPT, komersialisasi AI generatif, perdebatan open source vs closed source). Secara bersamaan, artikel ini membagi perkembangan perusahaan AI menjadi empat era: era perintisan (2000-2010, eksplorasi aplikasi berbasis alat), era demam emas (2011-2016, pemberdayaan platform dan ledakan berbasis data), era gelembung (2017-2020, perebutan skenario dan hambatan komersialisasi), dan era rekonstruksi (2021-sekarang, lanskap baru yang didorong oleh model besar). Artikel ini menekankan efek sinergis dari daya komputasi, data, dan algoritma, serta dampak kekuatan baru seperti DeepSeek pada lanskap. (Sumber: 混沌大学)
OpenAI merilis panduan prompt engineering GPT-4.1: Bersamaan dengan rilis seri model GPT-4.1, OpenAI memperbarui panduan prompt engineering-nya. Panduan tersebut menekankan bahwa seri model GPT-4.1, dibandingkan dengan model sebelumnya seperti GPT-4, akan mengikuti instruksi secara lebih ketat dan harfiah, serta lebih sensitif terhadap prompt yang jelas dan spesifik. Jika model tidak berperilaku seperti yang diharapkan, biasanya menambahkan instruksi yang ringkas dan jelas sudah cukup untuk memandu perilakunya. Ini berbeda dengan model sebelumnya yang cenderung menebak niat pengguna, sehingga pengembang mungkin perlu menyesuaikan strategi prompt yang ada. Panduan ini memberikan praktik terbaik mulai dari prinsip dasar hingga strategi lanjutan untuk membantu pengembang memanfaatkan fitur model baru dengan lebih baik. (Sumber: dotey, Reddit r/LocalLLaMA)
Universitas Shanghai Jiao Tong dkk. merilis benchmark kecerdasan spasiotemporal STI-Bench, menantang pemahaman fisika model multimodal: Universitas Shanghai Jiao Tong bersama beberapa institusi merilis benchmark pertama untuk mengevaluasi kecerdasan spasiotemporal model besar multimodal (MLLM), STI-Bench. Benchmark ini menggunakan video dunia nyata, berfokus pada kemampuan pemahaman ruang dan waktu yang presisi dan kuantitatif, mencakup delapan tugas: pengukuran skala, hubungan spasial, lokalisasi 3D, jalur perpindahan, kecepatan dan percepatan, orientasi egosentris, deskripsi lintasan, dan estimasi pose. Evaluasi terhadap model-model terkemuka seperti GPT-4o, Gemini 2.5 Pro, Claude 3.7 Sonnet, Qwen 2.5 VL menunjukkan bahwa model yang ada umumnya berkinerja buruk pada tugas-tugas ini (akurasi <42%), terutama kesulitan menangani atribut spasial kuantitatif, perubahan dinamika temporal, dan integrasi informasi lintas-modal. Benchmark ini mengungkap keterbatasan MLLM saat ini dalam memahami dunia fisik, memberikan arah untuk penelitian selanjutnya. (Sumber: 量子位)

Penelitian kombinasi Reinforcement Learning dan Optimasi Multi-Objektif mendapat perhatian: Bidang persimpangan antara Reinforcement Learning (RL) dan Optimasi Multi-Objektif (MOO) menjadi hotspot dalam penelitian pengambilan keputusan AI. Kombinasi ini bertujuan agar agent dapat menyeimbangkan beberapa tujuan (yang mungkin bertentangan) dalam lingkungan yang kompleks, daripada mengejar satu tujuan optimal tunggal. Misalnya, HKUST mengusulkan kerangka kerja penyeimbangan gradien dinamis untuk mengemudi otonom, mengoptimalkan keselamatan dan efisiensi energi secara bersamaan; algoritma pencarian strategi Pareto MIT digunakan untuk kontrol robot; Alibaba Cloud menerapkan teknologi penyelarasan multi-objektif untuk perdagangan finansial guna menyeimbangkan keuntungan dan risiko. Penelitian terkait seperti CMORL (Continuous Multi-Objective Reinforcement Learning) dan pembelajaran himpunan Pareto untuk optimasi kombinatorial sedang mengeksplorasi bagaimana membuat agent RL lebih efektif menangani masalah dunia nyata yang berubah secara dinamis atau memiliki beberapa dimensi optimasi. (Sumber: 公众号)

Platform serangan dan pertahanan adversarial otomatis A³D dirilis secara open source (TPAMI 2025): Tim Penelitian Desain Cerdas dan Pembelajaran Robust (IDRL) dari Institut Inovasi Sains dan Teknologi Pertahanan Nasional Akademi Ilmu Militer Tiongkok mengembangkan dan merilis platform open source bernama A³D (Automatic Adversarial Attack and Defense). Platform ini menggunakan teknologi AutoML (Automated Machine Learning), dikombinasikan dengan pemikiran teori permainan serangan-pertahanan, bertujuan untuk secara otomatis mencari arsitektur jaringan saraf yang kuat dan strategi serangan adversarial yang efisien. Platform ini mengintegrasikan berbagai metode Neural Architecture Search (NAS) dan metrik evaluasi kekokohan (serangan norma, serangan semantik, penyamaran adversarial, dll.) untuk pertahanan otomatis, sekaligus menyediakan modul serangan adversarial otomatis yang dapat mencari skema serangan kombinasi optimal melalui algoritma optimasi. Hasil penelitian diterbitkan dalam jurnal terkemuka TPAMI, dan kodenya telah dirilis di platform seperti Hongshan Open Source, menyediakan alat baru untuk mengevaluasi dan meningkatkan keamanan model DNN. (Sumber: 公众号)

Universitas Florida merekrut mahasiswa PhD/magang dengan beasiswa penuh untuk arah NLP/LLM: Asisten Profesor Yuanyuan Lei dari Departemen Komputer Universitas Florida (mulai bertugas musim gugur 2025) merilis informasi penerimaan, merekrut mahasiswa PhD dengan beasiswa penuh untuk masuk pada musim gugur 2025 atau musim semi 2026, serta mahasiswa magang penelitian dengan waktu fleksibel (dapat dilakukan jarak jauh). Arah penelitian berfokus pada Natural Language Processing (NLP) dan Large Language Models (LLM), secara spesifik meliputi LLM yang ditingkatkan pengetahuan, verifikasi fakta, penalaran dan perencanaan, aplikasi NLP (multimodal, hukum, bisnis, sains, dll.). Mahasiswa dengan latar belakang terkait seperti komputer, teknik elektro, statistik, matematika, yang tertarik dan termotivasi dalam penelitian AI dipersilakan untuk mendaftar. Email tersebut menyebutkan potensi dampak undang-undang Florida SB-846 terhadap perekrutan mahasiswa dari Tiongkok daratan dan cara mengatasinya. (Sumber: PaperWeekly)

Penelitian baru model difusi: Prior noise berkorelasi temporal: Sebuah makalah arXiv berjudul “How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models” mengusulkan prior noise baru untuk model difusi. Metode ini bertujuan untuk meningkatkan kualitas atau efisiensi generasi model difusi (kemungkinan untuk video) dengan memperkenalkan noise yang berkorelasi secara temporal. Detail teknis spesifik perlu dirujuk ke makalah asli. (Sumber: Reddit r/MachineLearning)
Penelitian baru penemuan ilmiah otomatis: AI Scientist-v2: Sebuah makalah arXiv berjudul “The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search” memperkenalkan sistem AI Scientist-v2. Sistem ini memanfaatkan metode Agentic Tree Search (pencarian pohon agentik) untuk mencapai penemuan ilmiah otomatis tingkat “lokakarya” (Workshop-Level). Ini menunjukkan bahwa para peneliti sedang mengeksplorasi penggunaan AI agent untuk melakukan penelitian dan eksplorasi ilmiah yang lebih maju dan otonom. (Sumber: Reddit r/MachineLearning)
Penjelasan implementasi regularisasi Dropout: Sebuah artikel Substack menjelaskan secara rinci implementasi teknik regularisasi Dropout. Dropout adalah teknik regularisasi yang banyak digunakan dalam deep learning, yang mencegah model overfitting dengan secara acak “menjatuhkan” sebagian neuron selama proses pelatihan. Artikel ini mungkin ditujukan bagi pembelajar yang ingin memahami secara mendalam cara kerja Dropout atau mengimplementasikan teknik ini sendiri. (Sumber: Reddit r/deeplearning)
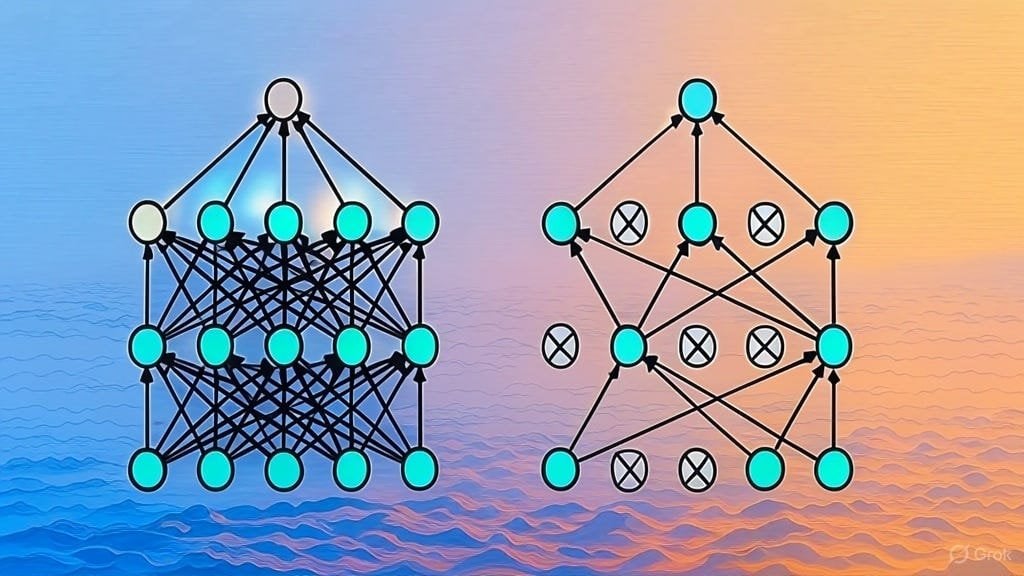
Pengumpulan daftar makalah arsitektur LLM: Pengguna Reddit memulai diskusi untuk berbagi dan mengumpulkan makalah arXiv tentang arsitektur Large Language Model (LLM). Arsitektur yang telah terdaftar meliputi BERT, Transformer, Mamba, RetNet, RWKV, Hyena, Jamba, seri DeepSeek, dll. Daftar ini mencerminkan keragaman dan perkembangan pesat penelitian arsitektur LLM saat ini, dan bernilai sebagai referensi bagi peneliti yang ingin memahami bidang ini secara sistematis. (Sumber: Reddit r/MachineLearning)
💼 Bisnis
Platform nutrisi AI Fay raih pendanaan $50 juta, pendapatan tahunan capai $50 juta: Platform nutrisi AI Silicon Valley, Fay, baru-baru ini menyelesaikan putaran pendanaan Seri B senilai $50 juta yang dipimpin oleh Goldman Sachs, dengan total pendanaan mencapai $75 juta dan valuasi $500 juta. Fay menghubungkan ahli gizi terdaftar dengan pasien, memanfaatkan AI untuk meningkatkan efisiensi layanan (diklaim mengurangi waktu dari 6,5 jam/pasien menjadi 2 jam), mengotomatiskan pembuatan catatan klinis (termasuk kode ICD), penyusunan rencana nutrisi yang dipersonalisasi, klaim asuransi, manajemen backend, dll. Platform ini secara tepat menangkap lonjakan permintaan konsultasi nutrisi yang disebabkan oleh obat penurun berat badan GLP-1, dan membuka jalur pembayaran melalui kerja sama dengan perusahaan asuransi (intervensi nutrisi dapat mengurangi biaya medis jangka panjang untuk penyakit kronis). Dengan kurang dari 3000 ahli gizi di platformnya, Fay berhasil mencapai pendapatan tahunan (ARR) sebesar $50 juta, menunjukkan model bisnis yang sukses dalam memberdayakan profesional di bidang medis vertikal dan menghubungkannya dengan pembayar melalui AI. (Sumber: 乌鸦智能说)
Hengtu Technology Chengdu: Memberdayakan kreativitas digital dengan AI, meraih keuntungan dari pasar luar negeri: Perusahaan lokal Chengdu, Hengtu Technology, dengan produk intinya Fotor (platform pengeditan gambar dan video), telah mengumpulkan sekitar 700 juta pengguna secara global, dengan lebih dari sepuluh juta pengguna aktif bulanan, terutama menonjol di pasar luar negeri. Ini adalah salah satu perusahaan aplikasi AI Tiongkok pertama yang berekspansi ke luar negeri dan mencapai profitabilitas skala besar. Perusahaan ini telah mendalami teknologi pemrosesan gambar selama 16 tahun dan dengan cepat mengintegrasikan fungsi AIGC (text-to-image, text-to-video, dll.) ke dalam Fotor dan platform baru Clipfly pada tahun 2022. Fotor menurunkan ambang batas pembuatan konten visual digital melalui AI, melayani berbagai industri seperti e-commerce, media mandiri, periklanan, pariwisata budaya, pendidikan, dll. Hengtu Technology menggunakan AI untuk melakukan “terjemahan budaya”, membantu budaya Tiongkok berekspansi ke luar negeri, dan menjelajahi jalur baru dalam industri kreatif digital. (Sumber: 36Kr四川)
Praktik implementasi AI perusahaan: Fokus pada nilai, kurangi fine-tuning, dorong kolaborasi: Dalam proses mendorong implementasi model besar, perusahaan telah beralih dari eksplorasi awal ke orientasi nilai yang lebih pragmatis. Aplikasi AI yang sukses sering kali berfokus pada skenario yang sangat repetitif, memiliki kebutuhan kreatif, dan paradigmanya dapat diendapkan, seperti tanya jawab pengetahuan, layanan pelanggan cerdas, pembuatan materi, analisis data, dll. Perusahaan secara umum menyadari bahwa mengejar fine-tuning model secara membabi buta sering kali memiliki rasio input-output yang rendah, dan harus memprioritaskan tata kelola pengetahuan dan membangun platform agent cerdas (awalnya didominasi oleh RAG). Implementasi AI memerlukan partisipasi mendalam dari departemen bisnis dan dukungan tingkat tinggi, mengadopsi strategi paralel “uji coba cepat + persiapan dasar AI” memberikan hasil yang lebih baik. Dalam hal talenta organisasi, perusahaan cenderung membentuk tim AI profesional kecil untuk memberdayakan bisnis, dan mengatasi kekurangan talenta dengan merekrut talenta eksternal terkemuka, membina kekuatan internal muda (kombinasi magang + bisnis senior), dan bekerja sama dengan pakar pihak ketiga. (Sumber: AI前线)
Indeks Kecerdasan Buatan Papan科创 mendapat perhatian, mungkin menjadi angin segar investasi baru: Laporan analisis menunjukkan bahwa meskipun terjadi fluktuasi pasar baru-baru ini, industri kecerdasan buatan Tiongkok telah membentuk lingkaran tertutup “daya komputasi – model – aplikasi” yang lengkap dan menunjukkan ketahanan yang kuat. Proyek nasional “Komputasi Timur, Data Barat”, model berbiaya rendah seperti DeepSeek, dan terobosan aplikasi seperti robot humanoid adalah sorotan utama. AI dipandang sebagai mesin penting untuk pertumbuhan ekonomi global dalam dekade mendatang, dengan aset terkait menunjukkan keuntungan jangka panjang yang signifikan. Dalam konteks ini, Indeks Kecerdasan Buatan Papan科创 Shanghai Stock Exchange (berfokus pada chip daya komputasi dan aplikasi AI) menarik perhatian investor karena ekspektasi pertumbuhan tinggi dan peningkatan kandungan kemandiriannya. Institusi seperti E Fund Management telah meluncurkan ETF dan dana penghubung (seperti 588730, 023564/023565) yang melacak indeks ini, menyediakan alat bagi investor untuk berinvestasi dalam rantai industri AI domestik. (Sumber: 创业最前线)

Strategi AI Apple beralih ke keterbukaan: Izinkan pengembangan Siri menggunakan model pihak ketiga: Untuk mempercepat pengembangan fungsi “Siri yang dipersonalisasi” dan mengejar ketertinggalan dari pesaing, Apple dilaporkan telah menyesuaikan strategi pengembangan internal tertutup yang telah lama dianutnya. Di bawah kepemimpinan Wakil Presiden Senior Rekayasa Perangkat Lunak yang baru, Craig Federighi, insinyur Siri untuk pertama kalinya diizinkan menggunakan model bahasa besar pihak ketiga untuk mengembangkan fungsi Siri, mendobrak batasan sebelumnya yang hanya mengizinkan penggunaan model yang dikembangkan sendiri oleh Apple. Perubahan ini dianggap sebagai langkah kunci Apple dalam menanggapi cadangan teknologinya yang relatif tertinggal di bidang AI, serta menghindari ketidakpuasan pengguna yang lebih besar (bahkan tuntutan hukum) yang disebabkan oleh penundaan fungsi “Siri yang dipersonalisasi”. Langkah ini dapat membuka peluang kerja sama antara Apple dengan pemasok model eksternal seperti OpenAI atau Alibaba (untuk pasar Tiongkok). (Sumber: 三易生活)

🌟 Komunitas
Persaingan aplikasi DeepSeek, Doubao, Yuanbao sengit, pengalaman produk menjadi kunci: Persaingan pasar aplikasi asisten AI domestik memanas. DeepSeek mengalami lonjakan pengguna setelah popularitas kemampuan modelnya, mendorong Tencent Yuanbao yang pertama kali terhubung untuk sempat menduduki puncak. Namun, Doubao dari ByteDance kembali menyalip Yuanbao berkat fungsi produk yang lebih lengkap dan integrasi mendalam dengan Douyin (TikTok Tiongkok). Analisis menunjukkan bahwa hanya mengandalkan koneksi ke model yang kuat (seperti DeepSeek) hanya dapat membawa keuntungan jangka pendek. Dalam persaingan jangka panjang, kekayaan fungsi aplikasi itu sendiri, pengalaman pengguna, kolaborasi multi-perangkat, dan kemampuan integrasi ekosistem platform lebih penting. Seiring kemampuan model masing-masing pihak menjadi serupa (misalnya, semua memiliki kemampuan berpikir mendalam), fokus persaingan di masa depan akan beralih ke desain produk, strategi operasi, dan terobosan dalam aplikasi bentuk baru seperti AI Agent. (Sumber: 字母榜)
Mahasiswa Asia mengembangkan alat curang wawancara memicu diskusi panas di internet: Seorang mahasiswa Asia dari Universitas Columbia, Roy Lee, mengembangkan alat AI bernama Interview Coder, yang menggunakan ChatGPT untuk membantunya lulus wawancara teknis jarak jauh di beberapa perusahaan teknologi termasuk Amazon, Meta, dan TikTok. Dia tidak hanya menolak tawaran dari perusahaan-perusahaan ini, tetapi juga merekam proses penggunaan alat curang tersebut dan mengunggahnya ke YouTube. Setelah dilaporkan oleh Amazon, dia diskors oleh universitasnya. Roy Lee tidak terpengaruh, malah mempublikasikan seluruh kejadian dan korespondensi email dengan universitas dan perusahaan, mendapatkan banyak dukungan dari netizen dan perhatian industri, dan menggunakan kesempatan ini untuk mendirikan perusahaan. Insiden ini memicu diskusi hangat tentang validitas wawancara teknis (terutama model latihan LeetCode), batas etika alat AI dalam rekrutmen, dan tantangan individu terhadap sistem perusahaan besar. (Sumber: 直面AI)

Pengguna menguji coba model GLM baru Zhipu yang open source terhubung ke basis pengetahuan dan MCP: Seorang pengguna menguji model seri GLM terbaru yang dirilis oleh Zhipu AI (dipanggil melalui API). Hasilnya menunjukkan bahwa GLM-Z1-AirX (versi super cepat) memiliki kecepatan respons yang sangat cepat (diklaim mencapai 200 token/s) saat terhubung ke basis pengetahuan lokal yang dibangun dengan FastGPT, dan kualitas jawabannya meningkat dibandingkan model biasa, mampu menghasilkan jawaban yang lebih rinci dan lengkap serta tabel perbandingan. GLM-4-Air (model dasar) mampu memanggil alat dengan benar dan menyelesaikan tugas saat terhubung ke MCP (Model Context Protocol) untuk menjalankan tugas Agent (seperti pencarian internet, penulisan file lokal, kontrol Docker, ringkasan halaman web), tetapi efeknya sedikit di bawah DeepSeek-V3. Pengguna juga memuji kinerja model Zhipu dalam hal keamanan (tidak merespons prompt jailbreak). (Sumber: 公众号)

Berbagi prompt “Pemecah Masalah Super Rasional” dan membandingkan efek model: Pengguna komunitas berbagi prompt tingkat lanjut (Prompt) yang bertujuan agar LLM berperan sebagai “pemecah masalah super rasional berdasarkan prinsip pertama”. Prompt ini secara rinci menetapkan prinsip operasi model (mendekonstruksi masalah, merekayasa solusi, protokol pengiriman, aturan interaksi), format respons, dan karakteristik nada bicara, menekankan logika, tindakan, dan hasil, serta menolak ambiguitas, alasan, dan penghiburan emosional. Pengguna menggunakan prompt ini untuk membandingkan kinerja DeepSeek, Claude Sonnet 3.7, dan ChatGPT 4o dalam menjawab pertanyaan, memberikan panduan, dan merekomendasikan sumber daya online, menyimpulkan bahwa Claude 3.7 memberikan hasil yang lebih baik. Ini menunjukkan bahwa Prompt yang dirancang dengan cermat dapat secara signifikan memandu dan meningkatkan kinerja LLM pada tugas tertentu. (Sumber: 公众号)

Diskusi panas komunitas tentang rilis GPT-4.1: Kinerja, strategi, dan penamaan: Rilis seri model GPT-4.1 oleh OpenAI memicu diskusi luas di komunitas. Di satu sisi, pengguna melalui pengujian nyata dan perbandingan benchmark (seperti Aider, Livebench, GPQA Diamond, KCORES Arena) menemukan bahwa meskipun GPT-4.1 memiliki peningkatan signifikan dalam pengkodean, kemampuan penalaran komprehensifnya masih tertinggal di belakang Google Gemini 2.5 Pro dan Claude 3.7 Sonnet. Di sisi lain, komunitas membahas dan mengkritik strategi produk OpenAI (membedakan API dari ChatGPT, menghentikan GPT-4.5), kecepatan iterasi model, serta skema penamaan yang membingungkan (4.1 dirilis setelah 4.5). Ada pandangan bahwa OpenAI mungkin menghadapi hambatan inovasi, sementara pandangan lain menganggap ini sebagai strategi untuk mengoptimalkan lini produk API-nya dan menawarkan opsi dengan rasio harga-kinerja yang berbeda. (Sumber: dotey, op7418, Reddit r/LocalLLaMA 1, Reddit r/ArtificialInteligence, karminski3, Reddit r/LocalLLaMA 2)

ChatGPT menunjukkan keajaiban dalam skenario konsultasi hukum, pengguna berbagi pengalaman sukses: Pengguna Reddit berbagi kasus sukses menggunakan ChatGPT untuk menangani sengketa hukum terkait pekerjaan. Pengguna tersebut menghadapi risiko pemecatan, dengan memberikan dokumen kepada ChatGPT dan memintanya berperan sebagai ahli hukum ketenagakerjaan Inggris, ia menemukan kesalahan prosedural oleh pemberi kerja. Dengan bantuan surat yang disusun oleh ChatGPT, ia melakukan negosiasi dan akhirnya mencapai kesepakatan penyelesaian yang mencakup kompensasi gaji 2 bulan, menghindari catatan buruk. Di bagian komentar, pengguna lain juga berbagi pengalaman menggunakan AI (ChatGPT atau Gemini) untuk menyusun surat hukum, mempersiapkan sidang, dan mencapai hasil positif, berpendapat bahwa AI dapat menghemat banyak biaya dan waktu dalam bantuan hukum. (Sumber: Reddit r/ChatGPT)
Pengguna mengeluh fitur Deep Research OpenAI tidak efektif: Pengguna Reddit memposting kritik terhadap fitur Deep Research OpenAI, menyatakan bahwa fitur tersebut memiliki tiga masalah utama: 1) Hasil pencarian tidak akurat atau tidak relevan (bergantung pada Bing API); 2) Cara eksplorasi lebih mirip pencarian mendalam (depth-first search) daripada penelitian luas; 3) Terputus dari tujuan penelitian pengguna, kurang batasan. Pengguna berpendapat ini lebih mirip kemampuan pencarian yang diperluas daripada penelitian mendalam yang sebenarnya. Ini mencerminkan kesenjangan antara harapan pengguna terhadap kemampuan penelitian AI Agent saat ini dan pengalaman aktual. (Sumber: Reddit r/deeplearning)
Pameran dan diskusi konten yang dihasilkan AI: Pengguna komunitas secara aktif berbagi konten yang dibuat menggunakan berbagai alat AI (seperti ChatGPT, Midjourney, Kling AI, Suno AI, dll.), termasuk kartun satir (Trump dan Musk), gambar personifikasi universitas, film pendek sejarah Perang Dunia II alternatif, gambar dewa-dewi Yunani, iklan pasta gigi gaya tahun 90-an, komik multi-panel, dll. Berbagi ini tidak hanya menunjukkan kemampuan AI dalam pembuatan teks, gambar, video, dan musik, tetapi juga memicu diskusi tentang kreativitas, estetika (seperti dituduh “kitsch”), keterbatasan (seperti konsistensi karakter komik yang buruk), dan masalah etika konten yang dihasilkan AI. (Sumber: dotey 1, dotey 2, Reddit r/ChatGPT 1, Reddit r/ChatGPT 2, Reddit r/ChatGPT 3, Reddit r/ChatGPT 4, Reddit r/ChatGPT 5)

Kekhawatiran tentang lingkaran umpan balik data pelatihan AI menyebabkan “keruntuhan model”: Diskusi komunitas berfokus pada risiko potensial: seiring meningkatnya konten yang dihasilkan AI di internet, jika model AI di masa depan terutama dilatih berdasarkan data yang dihasilkan AI ini, hal itu dapat menyebabkan “Keruntuhan Model” (Model Collapse). Fenomena ini mengacu pada penurunan kinerja model, di mana output menjadi sempit, berulang, kurang orisinalitas dan akurasi, seperti fotokopi yang terus difotokopi hingga menjadi buram. Pengguna khawatir hal ini akan perlahan mengikis keaslian informasi dan perspektif manusia. Diskusi juga menyebutkan metode penanggulangan, seperti menggunakan data sintetis untuk pelatihan, memperkuat kontrol kualitas data, dll., tetapi masih ada perdebatan mengenai apakah masalah tersebut sudah terjadi dan bagaimana cara menghindarinya secara efektif. (Sumber: Reddit r/ArtificialInteligence)
Pandangan: Di era AI, daya komputasi adalah minyak baru: Pengguna Reddit mengemukakan pandangan bahwa dalam pengembangan AI, daya komputasi (Compute), bukan data, akan menjadi hambatan utama dan sumber daya strategis, seperti minyak pada masa revolusi industri. Alasannya adalah: model AI yang lebih kuat (terutama sistem penalaran dan Agent) membutuhkan pertumbuhan daya komputasi eksponensial; interaksi fisik seperti robotika akan menghasilkan data baru dalam jumlah besar, yang selanjutnya meningkatkan permintaan daya komputasi. Memiliki lebih banyak daya komputasi akan secara langsung diterjemahkan menjadi kemampuan output ekonomi yang lebih kuat. Pandangan ini memicu diskusi komunitas, yang setuju bahwa daya komputasi memang merupakan elemen inti, yang menentukan batas atas kemampuan AI dan kecepatan perkembangannya. (Sumber: Reddit r/ArtificialInteligence)
Diskusi etika penggunaan AI: Apakah tidak pantas menggunakan AI untuk meningkatkan nilai akademik?: Seorang mahasiswa online gagal dalam mata kuliah karena struktur kursus yang bermasalah (hanya satu kuis atau tugas per minggu, diikuti langsung oleh ujian), kemudian menggunakan ChatGPT untuk menghasilkan soal latihan berdasarkan PDF kuliah untuk belajar sehari-hari, dan nilainya meningkat secara signifikan. Namun, mahasiswa tersebut merasa bersalah setelah melihat kritik tentang dampak lingkungan AI dan “berpikir mandiri”. Komentar komunitas umumnya berpendapat bahwa menggunakan AI untuk membantu belajar adalah penggunaan yang sah dan efektif, membantu meningkatkan efisiensi dan hasil belajar, dan tidak perlu merasa bersalah karenanya. Komentator menunjukkan bahwa dampak lingkungan AI perlu dilihat dalam perbandingan dengan aktivitas manusia lainnya, dan memanfaatkan AI untuk meningkatkan produktivitas sudah menjadi tren di tempat kerja. (Sumber: Reddit r/ArtificialInteligence)
Pengalaman pengguna Claude Pro: Diskusi pembatasan (throttling) dan model bisnis: Di komunitas Reddit ClaudeAI, pengguna mendiskusikan masalah pembatasan (throttling) yang dihadapi saat menggunakan layanan Claude Pro, dan membahas model bisnis Anthropic. Seorang pengguna menunjukkan bahwa biaya langganan Pro $20 per bulan jauh di bawah biaya komputasi aktual yang dikeluarkan Anthropic untuk pengguna berat (bisa mencapai $100/bulan), berpendapat bahwa keluhan pengguna (misalnya, merasa “dieksploitasi”) mungkin mengabaikan struktur biaya layanan AI. Diskusi juga menyentuh keputusan Anthropic baru-baru ini untuk memberikan fitur baru prioritas kepada paket Max yang lebih mahal daripada paket Pro, yang menimbulkan ketidakpuasan di antara pengguna yang berlangganan Pro tahunan lebih awal. (Sumber: Reddit r/ClaudeAI 1, Reddit r/ClaudeAI 2)
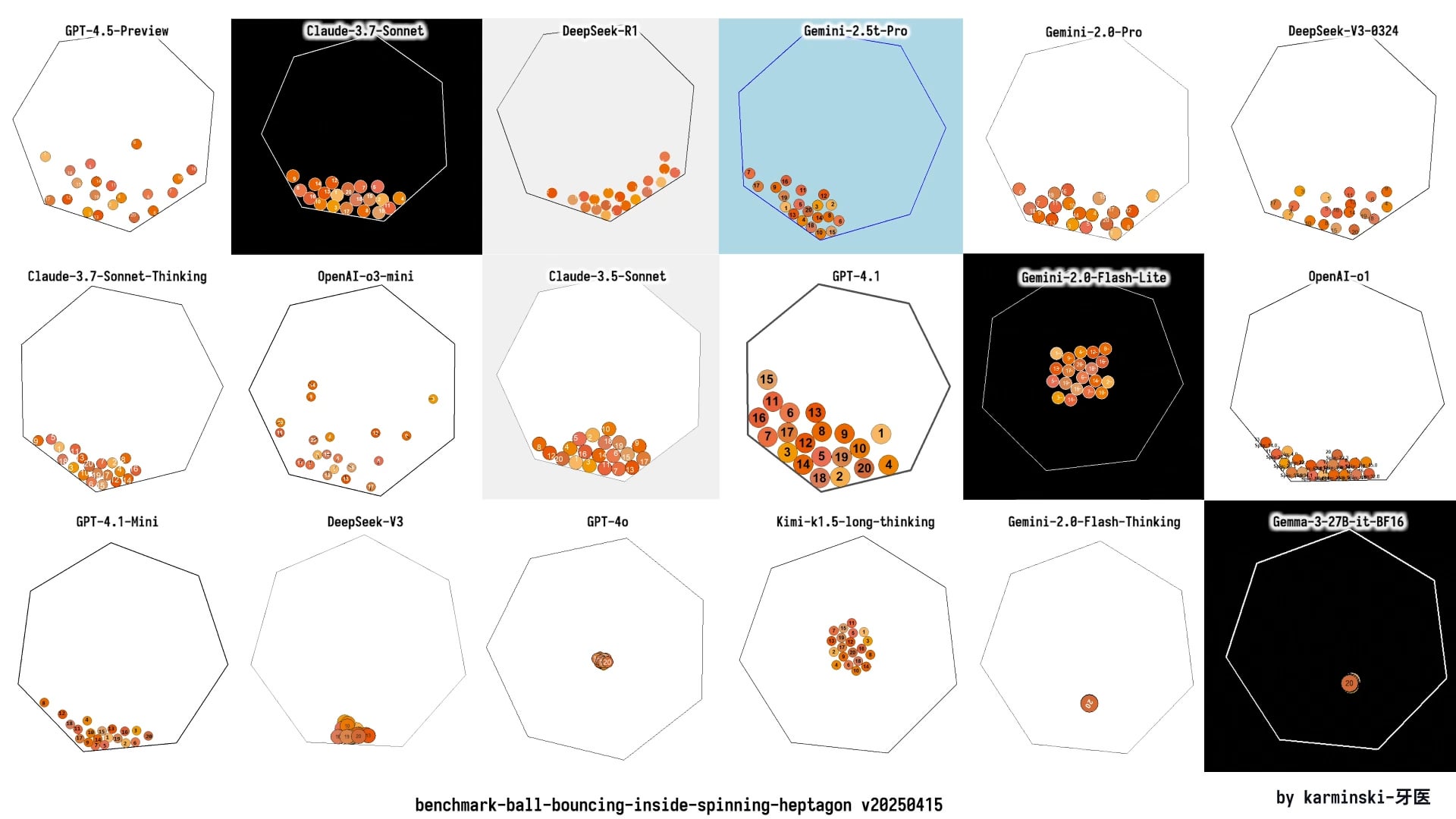
Pembaruan KCORES LLM Arena, DeepSeek R1 tampil mengesankan: Pengguna berbagi hasil pengujian terbaru dari arena LLM yang dikelola secara pribadi (KCORES LLM Arena). Pengujian ini meminta model untuk menghasilkan kode Python untuk simulasi fisika yang kompleks (20 bola bertabrakan dan memantul di dalam heptagon berputar). Setelah pembaruan yang menambahkan model baru seperti GPT-4.1, Gemini 2.5 Pro, DeepSeek-V3, hasilnya menunjukkan bahwa DeepSeek R1 berkinerja sangat baik pada tugas ini, menghasilkan simulasi dengan efek yang cukup baik. Ini memberikan komunitas titik referensi lain untuk mengevaluasi kemampuan model yang berbeda pada tugas pemrograman yang kompleks. (Sumber: Reddit r/LocalLLaMA)
Membahas kemampuan respons emosional LLM yang berbeda: Pengguna Reddit memposting gambar Meme yang dengan cara humoris membandingkan gaya respons ChatGPT 4o, Claude 3 Sonnet, Llama 3 70B, dan Mistral Large saat menghadapi pengguna yang mengungkapkan kesedihan. Ini mencerminkan perbedaan pengalaman pengguna saat menggunakan LLM yang berbeda untuk komunikasi emosional atau mencari dukungan, serta persepsi dan evaluasi komunitas terhadap kemampuan “empati” model. Bagian komentar juga membahas keuntungan privasi menggunakan model lokal untuk menangani topik emosional pribadi. (Sumber: Reddit r/LocalLLaMA)

Diskusi tentang apakah AGI adalah tipuan Silicon Valley: Anggota komunitas meneruskan dan mungkin mendiskusikan sebuah artikel yang mempertanyakan apakah Kecerdasan Buatan Umum (AGI) adalah konsep yang dipromosikan secara berlebihan (hoax) oleh Silicon Valley (industri teknologi) untuk menarik investasi atau mempertahankan hype. Ini mencerminkan adanya perdebatan dan keraguan yang berkelanjutan di industri dan publik mengenai kemungkinan realisasi AGI, jadwalnya, serta kebenaran promosi terkait saat ini. (Sumber: Ronald_vanLoon)

💡 Lain-lain
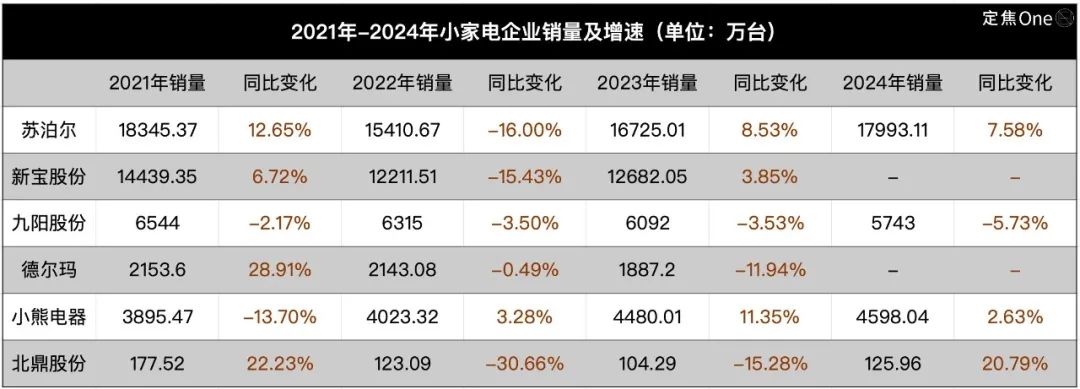
Industri peralatan rumah tangga kecil lesu, AI menjadi cerita baru tetapi aplikasi masih dangkal: Pasar peralatan rumah tangga kecil untuk dapur (seperti mesin sarapan, air fryer) menghadapi penurunan penjualan dan perang harga setelah meredanya keuntungan “ekonomi tinggal di rumah”. Kinerja enam perusahaan terdaftar teratas seperti Supor, Jiuyang, Bear Electric tertekan. Untuk mencari terobosan, perusahaan umumnya mengalihkan perhatian ke ekspansi pasar luar negeri dan integrasi teknologi AI. Namun, saat ini aplikasi AI pada peralatan rumah tangga kecil sebagian besar berupa perintah suara sederhana, penyesuaian otomatis, dll., dengan kepraktisan dan ruang inovasi yang terbatas, serta dapat meningkatkan biaya yang membuat pengguna enggan. Sebaliknya, peralatan rumah tangga besar memiliki keunggulan lebih dalam aplikasi AI, dapat membangun ekosistem rumah pintar, memanfaatkan data besar untuk menyediakan layanan yang dipersonalisasi. Cerita AI di industri peralatan rumah tangga kecil masih dalam tahap awal. (Sumber: 36Kr)
Gejolak tarif berdampak pada pasar chip Huaqiangbei, substitusi domestik dapat dipercepat: Perubahan kebijakan tarif terkait chip baru-baru ini menimbulkan kekhawatiran di pasar elektronik Huaqiangbei Shenzhen. Pedagang chip populer seperti CPU, GPU (terutama yang mungkin berasal dari AS) menunjukkan fenomena menangguhkan penawaran harga dan menahan stok untuk menunggu dan melihat, volatilitas harga meningkat. Dampak pada kategori seperti chip memori relatif kecil. Beberapa distributor terdaftar menyatakan bahwa karena proporsi impor langsung dari AS kecil, dampak langsung perang tarif terbatas, tetapi ketidakpastian pasar meningkat. Industri umumnya percaya bahwa perusahaan IDM yang memiliki pabrik wafer di AS (seperti TI, Intel, Micron) paling terpengaruh. Peristiwa ini telah mendorong beberapa pelanggan hilir untuk menanyakan tentang solusi substitusi chip domestik, yang dapat mempercepat proses lokalisasi di bidang semikonduktor. (Sumber: 创业板观察)

AI memperburuk krisis makna manusia? Refleksi keseimbangan antara teknologi dan nilai: Artikel ini membahas bagaimana perkembangan pesat kecerdasan buatan berdampak pada makna eksistensi manusia. Berpendapat bahwa keunggulan AI di bidang profesional (seperti Go, diagnosis medis, penciptaan seni) memperburuk krisis makna manusia yang telah dipicu oleh alienasi kerja, krisis keyakinan, masalah lingkungan, dll., sejak revolusi industri. AI dapat lebih memperkuat dilema “manusia alat”, terutama dalam menggantikan kemampuan pengambilan keputusan dalam pekerjaan kerah putih. Artikel ini mengutip pandangan filsuf dan karya fiksi ilmiah (seperti “Dune”, “Westworld”) untuk memperingatkan risiko perbudakan teknologi, menyerukan untuk membangun kembali rasionalitas nilai sambil merangkul peningkatan teknologi yang dibawa oleh AI, melalui kerangka etika, pendidikan humaniora untuk menjaga kreativitas, hubungan emosional, dan pemikiran kritis manusia, menghindari menjadi pelayan ciptaan kita sendiri. (Sumber: 腾讯研究院)
Biaya produksi iPhone di AS mahal, bisa melebihi 25.000 yuan: Artikel ini menganalisis bahwa jika iPhone sepenuhnya diproduksi di Amerika Serikat, biayanya akan melonjak secara signifikan, dengan perkiraan harga jual bisa mencapai $3500 (sekitar 25.588 yuan RMB), jauh melebihi harga saat ini. Alasan utamanya meliputi biaya yang jauh lebih tinggi di AS dibandingkan Tiongkok dalam hal perolehan bahan baku (seperti tanah jarang, kobalt litium yang dimurnikan), transportasi logistik, pembangunan pabrik (tanah, listrik, persetujuan lingkungan), serta biaya tenaga kerja (upah minimum per jam 4-5 kali lebih tinggi dari Tiongkok, dan kurangnya pekerja industri terampil). Model Apple sebelumnya yang mempertahankan margin keuntungan tinggi dengan menekan rantai pasokan global (terutama pemasok Tiongkok dengan margin keuntungan relatif besar) akan sulit dipertahankan di AS. Biaya produksi yang tinggi pada akhirnya dapat dibebankan kepada konsumen, menggoyahkan strategi penetapan harga dan posisi pasar Apple. (Sumber: 星海情报局)

Terobosan matematika: Teori singularitas aliran kelengkungan rata-rata terbukti: Konjektur Multiplicity-one yang membingungkan matematikawan selama hampir 30 tahun baru-baru ini dibuktikan oleh Richard Bamler dan Bruce Kleiner. Konjektur ini berkaitan dengan Mean Curvature Flow (MCF) — proses matematika yang menggambarkan bagaimana permukaan berevolusi seiring waktu untuk mengurangi luasnya dengan kecepatan tercepat (mirip dengan es mencair atau kastil pasir terkikis). Bukti tersebut menunjukkan bahwa dalam ruang tiga dimensi, singularitas (titik di mana kelengkungan mendekati tak terhingga) yang terbentuk oleh permukaan tertutup dua dimensi di bawah MCF adalah sederhana, biasanya muncul sebagai bola yang menyusut secara lokal menjadi satu titik atau silinder yang runtuh menjadi garis, singularitas tumpang tindih multi-lapis yang kompleks tidak terjadi. Terobosan ini memastikan bahwa MCF masih dapat dianalisis setelah pembentukan singularitas, memberikan dasar teori yang lebih kokoh untuk menggunakan MCF dalam memecahkan masalah penting dalam geometri dan topologi (seperti konjektur Poincaré). (Sumber: 机器之心)

Pengguna berbagi konfigurasi perangkat keras AI lokal “anggaran terbatas” 4x RTX 3090: Pengguna Reddit berbagi skema konfigurasi perangkat keras yang dibangunnya untuk menjalankan LLM secara lokal, dengan total biaya sekitar $4204. Konfigurasi ini mencakup 4 kartu grafis EVGA RTX 3090 bekas (harga satuan $600), CPU server AMD EPYC 7302P, motherboard Asrock Rack, memori DDR4 96GB, dan SSD NVMe 2TB, dirakit dalam casing terbuka MLACOM Quad Station Pro Lite, dan menggunakan dua catu daya 1200W. Berbagi ini memberikan skema referensi yang relatif “ekonomis” bagi pengguna yang ingin membangun workstation AI di rumah dengan daya komputasi yang cukup kuat (4x 24GB VRAM). (Sumber: Reddit r/LocalLLaMA)

Peretas AS menyerang lampu lalu lintas untuk memutar pesan Deepfake Musk dan Zuckerberg: Dilaporkan bahwa beberapa sistem lampu penyeberangan pejalan kaki di San Francisco Bay Area, AS, diretas dan digunakan untuk memutar pesan Deepfake (pemalsuan mendalam) yang dihasilkan AI dari Elon Musk dan Mark Zuckerberg. Insiden ini menyoroti kerentanan infrastruktur publik dalam menghadapi serangan siber yang memanfaatkan teknologi AI, serta risiko penyalahgunaan teknologi Deepfake untuk menyebarkan informasi palsu atau melakukan lelucon. (Sumber: Reddit r/ArtificialInteligence)

Menampilkan beragam robotika dan teknologi otomatisasi: Media sosial menampilkan berbagai aplikasi robotika dan teknologi otomatisasi, termasuk: robot Booster T1 yang mampu meniru gerakan manusia untuk melakukan kung fu; sistem robot untuk pelatihan rehabilitasi; lengan mekanik yang dapat membuat kopi; robot pertanian untuk penanaman padi dan penyiangan gulma; sistem otomatis untuk memudahkan peternak menangani domba; serta robot menari, dll. Kasus-kasus ini mencerminkan aplikasi luas dan perkembangan berkelanjutan robotika di bidang industri, pertanian, jasa, rehabilitasi medis, serta hiburan. (Sumber: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6)
Menampilkan teknologi baru dan produk inovatif: Media sosial berbagi berbagai teknologi baru dan produk inovatif, misalnya: antena nirkabel mikro yang dikembangkan MIT yang menggunakan cahaya untuk memantau komunikasi seluler; drone sayap tunggal yang meniru penerbangan biji maple; toilet pintar IoT; teknologi cetakan digital untuk ortodontik gigi; perangkat yang menghasilkan listrik menggunakan air garam; dinding dinamis yang dapat bernapas dan bergerak; kostum Iron Man Cosplay; papan seluncur salju listrik segala medan; serta teknologi menyalin kunci menggunakan perangkat Flipper Zero, dll. Pameran ini menunjukkan inovasi berkelanjutan teknologi di berbagai bidang seperti komunikasi, energi, kesehatan, transportasi, konstruksi, dan keamanan. (Sumber: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6, Ronald_vanLoon 7, Ronald_vanLoon 8, Ronald_vanLoon 9)

Tren teknologi kesehatan: Media sosial dan tautan artikel menyebutkan aplikasi teknologi dan tren perkembangan di bidang kesehatan, termasuk bedah berbantuan robot, tren dan titik balik aplikasi AI dalam perawatan kesehatan, pemanfaatan teknologi untuk mendorong keunggulan operasional (hiperautomasi), serta potensi perubahan yang dibawa oleh AI. Konten ini mencerminkan potensi dan praktik teknologi seperti AI, robotika, otomatisasi dalam meningkatkan efisiensi layanan medis, akurasi diagnosis, dan pengalaman pasien. (Sumber: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4)

Informasi terkait keamanan siber: Media sosial berbagi konten terkait keamanan siber, termasuk diagram jenis serangan kata sandi dan artikel tentang pentingnya kemampuan pemulihan dalam 60 menit setelah pelanggaran data. Konten ini mengingatkan pengguna untuk memperhatikan risiko keamanan siber dan strategi penanggulangannya. (Sumber: Ronald_vanLoon 1, Ronald_vanLoon 2)

Diskusi platform AMD ROCm: Pengguna Reddit mendiskusikan kemungkinan membangun workstation deep learning menggunakan dua GPU AMD Radeon RX 7900 XTX, melibatkan tumpukan perangkat lunak ROCm (Radeon Open Compute platform). Ini mencerminkan perhatian dan eksplorasi pengguna terhadap solusi GPU AMD dan ekosistem perangkat lunaknya (ROCm) di pasar perangkat keras AI yang didominasi Nvidia. (Sumber: Reddit r/deeplearning)