
Kata Kunci:AI, Kecerdasan Buatan, AI dilema kedaulatan, HBM dan kemasan canggih, Penemuan ilmiah digerakkan AI, Kemampuan pemrograman Gemini 2.5 Pro, AI memecahkan masalah matematika
🔥 Fokus
Dilema Kedaulatan AI: Bagaimana Narasi Keamanan Nasional Menggerus Nilai Publik?: Laporan ini membahas secara mendalam konsep “kedaulatan AI”, yaitu kontrol negara atas tumpukan teknologi AI (data, daya komputasi, talenta, energi). Tren global saat ini bergeser dari “kedaulatan lemah” yang bergantung pada sekutu menuju “kedaulatan kuat” yang mengejar lokalisasi penuh, terutama didorong oleh kebijakan Amerika Serikat. Meskipun perubahan ini bertujuan untuk menjamin keamanan nasional dan keunggulan militer, hal ini juga menimbulkan kekhawatiran tentang sentralisasi yang berlebihan, penghambatan inovasi terbuka, hambatan kerja sama internasional, serta potensi memicu perlombaan senjata AI. Artikel ini berpendapat bahwa menjadikan AI terlalu berfokus pada keamanan dapat mengorbankan potensi besarnya untuk melayani kepentingan publik dan mengatasi tantangan global, menyerukan keseimbangan antara kebutuhan kedaulatan dan kerja sama terbuka untuk menghindari AI menjadi korban persaingan geopolitik, bukan alat untuk kemajuan kolektif umat manusia. (Sumber: Dilema Kedaulatan AI: Bagaimana Narasi Keamanan Nasional Menggerus Nilai Publik AI?)
HBM dan Advanced Packaging: Titik Persaingan Tersembunyi Revolusi Daya Komputasi AI: Kebutuhan eksponensial model besar AI akan daya komputasi menyebabkan arsitektur komputasi tradisional menghadapi hambatan “memory wall”. High-Bandwidth Memory (HBM) melalui teknologi 3D stacking dan TSV meningkatkan bandwidth beberapa kali lipat (seperti HBM3E yang melebihi 1TB/s), secara signifikan mengurangi latensi transfer data. Sementara itu, teknologi advanced packaging (seperti TSMC CoWoS, Intel EMIB) melalui integrasi heterogen mengintegrasikan chip seperti CPU, GPU, HBM secara erat, menembus batasan chip tunggal, meningkatkan kepadatan daya komputasi dan efisiensi energi. HBM dan advanced packaging telah menjadi standar kunci untuk chip AI (terutama sisi pelatihan), pasarnya didominasi oleh raksasa seperti SK Hynix, Samsung, Micron (HBM) dan TSMC (packaging), dengan investasi besar dan kapasitas yang ketat. Perkembangan sinergis kedua teknologi ini tidak hanya membentuk kembali lanskap rantai pasokan semikonduktor (peningkatan proporsi nilai packaging), tetapi juga menjadi medan pertempuran kunci yang menentukan persaingan daya komputasi AI. (Sumber: HBM dan Advanced Packaging: Titik Persaingan Tersembunyi Revolusi Daya Komputasi AI)
Deklarasi Mengejutkan Pemenang Nobel: AI Menyelesaikan “Waktu Riset Doktor” 1 Miliar Tahun dalam Setahun: Pemenang Nobel dan CEO Google DeepMind, Demis Hassabis, menyatakan bahwa proyek AI timnya, AlphaFold-2, dengan memprediksi 200 juta struktur protein yang diketahui di Bumi, telah menyelesaikan eksplorasi ilmiah dalam satu tahun yang setara dengan waktu riset doktor selama 1 miliar tahun di masa lalu. Ia menekankan bahwa AI, khususnya AlphaFold, sedang mengubah secara fundamental kecepatan dan skala penemuan ilmiah, mendemokratisasi perolehan pengetahuan. Dalam pidatonya di Universitas Cambridge, Hassabis lebih lanjut menguraikan datangnya era “biologi digital” yang didorong oleh AI dan berpendapat bahwa masa depan AI terletak pada pembangunan “model dunia” (seperti arsitektur JEPA) yang dapat memahami dunia fisik, melakukan penalaran dan perencanaan, bukan hanya bergantung pada pemrosesan bahasa. Ia menegaskan kembali komitmennya pada AI open-source, menganggapnya sebagai cara terbaik untuk mendorong kemajuan teknologi. (Sumber: Deklarasi Mengejutkan Pemenang Nobel: AI Menyelesaikan “Waktu Riset Doktor” 1 Miliar Tahun dalam Setahun)

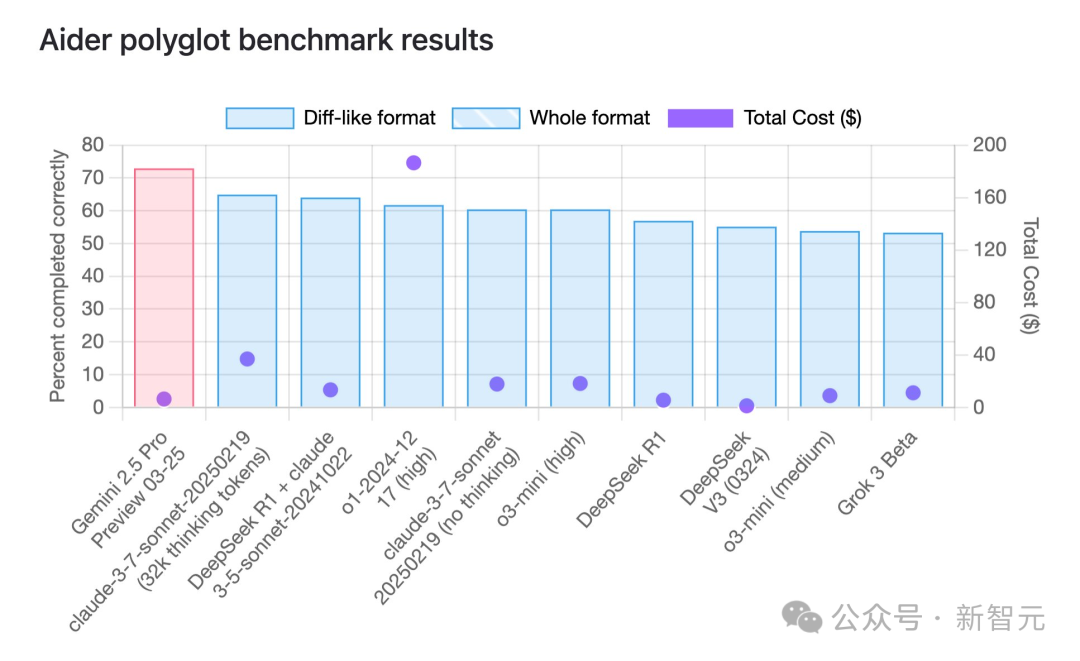
Kemampuan Pemrograman Gemini 2.5 Pro Puncaki Peringkat, Keunggulan Harga Signifikan: Menurut benchmark pemrograman multi-bahasa aider, model terbaru Google, Gemini 2.5 Pro, telah melampaui Claude 3.7 Sonnet dalam kemampuan pemrograman, menempati peringkat pertama di dunia. Tidak hanya unggul dalam kinerja, tetapi biaya panggilan API-nya juga sangat rendah (sekitar $6 USD), jauh di bawah pesaing dengan kinerja serupa atau lebih buruk (seperti GPT-4o, Claude 3.7 Sonnet). Jeff Dean menekankan keunggulan harganya. Selain itu, model Google yang belum dirilis “Dragontail” yang beredar di komunitas menunjukkan kinerja yang bahkan lebih baik daripada Gemini 2.5 Pro dalam pengujian pengembangan web, mengisyaratkan bahwa Google masih memiliki kartu truf di bidang pemrograman AI. Gemini 2.5 Pro juga menempati peringkat teratas dalam beberapa benchmark komprehensif, menantang OpenAI dan Anthropic secara menyeluruh dengan kinerja tinggi, biaya rendah, jendela konteks besar, dan hak penggunaan gratis. (Sumber: Gemini 2.5 Puncaki Peringkat Pemrograman Global, Google Kembali ke Tahta AI, Model Misterius Terungkap, Altman Siap Bertarung)
AI Berhasil Bantu Buktikan Masalah Matematika yang Tak Terpecahkan Selama 50 Tahun: Cendekiawan Tionghoa Weiguo Yin (Brookhaven National Laboratory) dengan bantuan model o3-mini-high dari OpenAI, mencapai terobosan dalam studi solusi eksak model Potts q-state J_1-J_2 satu dimensi, memecahkan masalah yang telah berlangsung selama 50 tahun di bidang ini. Model AI, ketika menangani kasus spesifik q=3, melalui analisis simetri, berhasil menyederhanakan matriks transfer 9×9 yang kompleks menjadi matriks 2×2 yang efektif. Langkah kunci ini menginspirasi para peneliti untuk menggeneralisasi metode tersebut, akhirnya menemukan solusi analitik yang berlaku untuk nilai q apa pun. Pencapaian ini tidak hanya menunjukkan potensi AI dalam derivasi matematika yang kompleks dan pembuktian non-trivial, tetapi juga menyediakan alat teoretis baru untuk memahami masalah seperti transisi fasa dalam fisika benda terkondensasi. (Sumber: Baru Saja, AI Memecahkan Masalah Matematika yang Tak Terpecahkan Selama 50 Tahun, Alumni Universitas Nanjing Menggunakan Model OpenAI untuk Menyelesaikan Pembuktian Matematika Non-Trivial Pertama)

🎯 Tren
Aplikasi dan Evolusi AI di Bidang NPC Game: Artikel ini mengulas sejarah perkembangan teknologi AI dalam NPC (Non-Player Character) game, mulai dari finite state machine awal di Pac-Man, behavior tree, hingga AI kompleks yang menggabungkan Monte Carlo Tree Search dan deep neural network (seperti AlphaGo). Artikel ini menunjukkan bahwa meskipun AI telah mampu mengalahkan pemain manusia teratas dalam game seperti StarCraft 2 dan Dota 2, AI yang terlalu kuat tidak memberikan pengalaman yang baik bagi pemain biasa. AI game yang ideal seharusnya lebih fokus pada simulasi perilaku manusia, memberikan nilai emosional dan kesulitan adaptif (seperti sistem Nemesis di Middle-earth, kesulitan dinamis di Resident Evil 4). Baru-baru ini, dengan Stella dari Whispers from the Star oleh miHoYo sebagai contoh, generative AI digunakan untuk mendorong dialog real-time NPC, reaksi emosional, dan pengembangan plot. Meskipun menghadapi tantangan seperti latensi dan memori, ini menunjukkan tren NPC AI menuju arah yang lebih manusiawi dan interaktif secara mendalam. (Sumber: AI, Membuat Game Hebat Kembali)

OpenAI Memperketat Akses API, Menerapkan Verifikasi Organisasi: OpenAI baru-baru ini menerapkan kebijakan verifikasi organisasi API baru, yang mengharuskan pengguna memberikan bukti identitas pemerintah yang valid yang dikeluarkan oleh negara atau wilayah yang didukung untuk mengakses model dan fitur tercanggihnya. Setiap ID hanya dapat memverifikasi satu organisasi setiap 90 hari. OpenAI menyatakan langkah ini bertujuan untuk mengurangi penggunaan AI yang tidak aman dan mempersiapkan perilisan “model baru yang menarik” (kemungkinan termasuk beberapa versi GPT-4.1, o3, o4-mini, dll.). Perubahan kebijakan ini menimbulkan perhatian dan kekhawatiran luas di komunitas, terutama bagi pengembang yang berlokasi di negara/wilayah yang tidak didukung dan pengguna yang bergantung pada layanan API pihak ketiga, yang mungkin menghadapi pembatasan akses atau peningkatan biaya, serta memicu diskusi tentang keterbukaan OpenAI. (Sumber: Akses IP China GitHub Sempat Bermasalah Lalu Pulih, Kebijakan Baru API OpenAI Mungkin Mengunci GPT-5?, op7418, Reddit r/artificial)
Masuknya Apple Mendorong Perkembangan “Dokter AI”, Tantangan dan Regulasi Bersamaan: Apple dikabarkan akan menggunakan AI untuk meningkatkan fungsi aplikasi Kesehatannya, meluncurkan layanan seperti “Pelatih Kesehatan AI”, yang semakin mendorong “Dokter AI” menjadi topik hangat global. Namun, aplikasi AI klinis yang sebenarnya menghadapi banyak tantangan: biaya pengembangan tinggi, ketergantungan pada data medis sensitif dalam jumlah besar (melibatkan peraturan privasi), kesulitan anotasi data, dll. Saat ini AI lebih banyak berfungsi sebagai alat bantu diagnosis. Pasar Tiongkok juga menghadapi kebutuhan khusus akan sumber daya medis yang tidak merata dan perlunya AI untuk membantu triase berjenjang. Perusahaan seperti Baichuan Intelligence mengusulkan “model dokter ganda” (dokter AI + AI membantu dokter manusia) untuk mencoba mengatasi masalah ini. Artikel ini menekankan bahwa aplikasi luas AI medis harus dibangun di atas sistem regulasi dan sertifikasi yang ketat untuk memastikan akurasi diagnosis, keamanan data, dan kepercayaan pengguna, serta menghindari potensi risiko. (Sumber: Apple Masuk, “Dokter AI” Menjadi Topik Hangat Global, Perlindungan Privasi Pasien Menjadi Hambatan Terbesar?)

Upaya Microsoft Menghasilkan Game Langsung dengan AI Kurang Efektif: Microsoft baru-baru ini mendemonstrasikan penggunaan model AI “Muse” untuk secara langsung menghasilkan visual game Quake II, dengan tujuan menunjukkan kemampuan AI dalam menghasilkan prototipe game dengan cepat. Namun, demo tersebut hasilnya buruk, dengan masalah seperti resolusi rendah, frame rate rendah, dan banyak bug (seperti perilaku musuh yang anomali, aturan fisika yang gagal, lingkungan yang kacau), dan dinilai sebagai “mimpi yang terus runtuh”. Artikel ini berpendapat bahwa ini menunjukkan teknologi generative AI saat ini (terutama dengan masalah “halusinasi”) belum cukup untuk secara langsung dan andal menghasilkan pengalaman game interaktif yang kompleks dan dapat dimainkan. Sebagai perbandingan, menerapkan AI pada bagian tertentu dari pipeline pengembangan game (seperti interaksi NPC, pembuatan aset) lebih realistis. Jalur untuk menghasilkan visual atau gameplay game secara langsung saat ini tampaknya sangat menantang. (Sumber: Game AI Microsoft Gagal, Menghasilkan Game Secara Langsung Mungkin Jalan Buntu)
Google Merilis Model Open-Source TxGemma untuk Bidang Kesehatan Medis: Google meluncurkan seri model TxGemma, yang dibangun berdasarkan keluarga model Gemma dan Gemini, dioptimalkan secara khusus untuk bidang kesehatan medis dan penemuan obat. Langkah ini bertujuan untuk menyediakan alat AI yang lebih terspesialisasi untuk penelitian biomedis dan pengembangan terapi, serta mendorong inovasi di bidang ini. Perilisan TxGemma adalah bagian dari strategi Google dalam menyediakan model open-source umum dan spesifik domain. (Sumber: JeffDean)
DeepSeek Mengumumkan Rencana untuk Open-Source Inference Engine Internalnya: DeepSeek AI menyatakan akan melakukan open-source pada inference engine yang digunakan secara internal. Menurut deskripsi, engine ini adalah versi yang dimodifikasi dan dioptimalkan dari framework vLLM yang populer. Langkah DeepSeek ini bertujuan untuk memberikan kembali teknologi inferensi yang dioptimalkan kepada komunitas open-source, membantu pengembang menyebarkan model besar dengan lebih efisien. Rencana ini mencerminkan keinginan DeepSeek untuk berkontribusi pada komunitas open-source, dan kode diharapkan akan dirilis di GitHub. (Sumber: karminski3)
ChatGPT Menambahkan Fitur Memori untuk Meningkatkan Koherensi: OpenAI menambahkan fitur Memori (Memory) ke model ChatGPT-nya. Fitur ini memungkinkan ChatGPT untuk mengingat informasi, preferensi, atau topik yang telah dibahas sebelumnya oleh pengguna dalam beberapa percakapan. Tujuannya adalah untuk meningkatkan kontinuitas dan personalisasi interaksi, menghindari pengguna harus mengulang informasi latar belakang yang sama dalam percakapan berikutnya, sehingga meningkatkan pengalaman pengguna. (Sumber: Ronald_vanLoon)

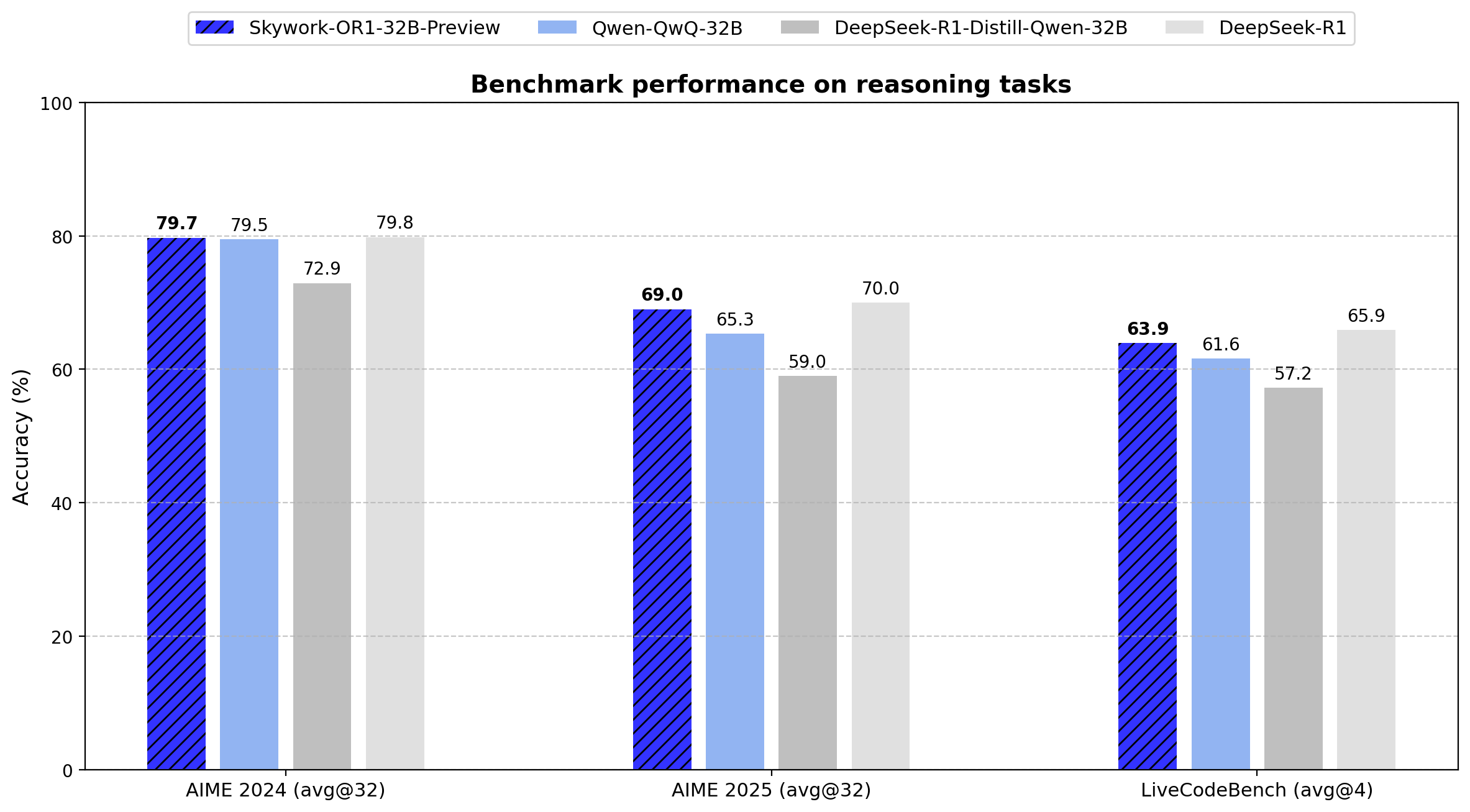
Skywork Merilis Seri Model Inferensi Open-Source OR1: Perusahaan Tiongkok Skywork (Tiangong-Kunlun Wanwei) merilis seri model inferensi open-source baru, Skywork OR1. Seri ini mencakup OR1-Math-7B yang dioptimalkan untuk matematika, serta versi pratinjau OR1-7B dan OR1-32B yang unggul dalam matematika dan pengkodean, di mana versi 32B diklaim sebanding dengan DeepSeek-R1 dalam kemampuan matematika. Skywork dipuji karena tingkat keterbukaannya, merilis bobot model, data pelatihan, dan kode pelatihan lengkap. (Sumber: natolambert)
Peningkatan Kemampuan Navigasi dan Operasi Presisi Robot yang Didorong AI: Media sosial menunjukkan kemampuan robot otonom yang didorong AI dalam menavigasi secara presisi dan melakukan tugas di lingkungan yang kompleks. Robot-robot ini mungkin memanfaatkan computer vision, SLAM (Simultaneous Localization and Mapping), reinforcement learning, dan teknologi AI lainnya untuk mencapai operasi yang efisien di lingkungan yang tidak terstruktur atau dinamis, menunjukkan kemajuan dalam persepsi, perencanaan, dan kontrol robot. (Sumber: Ronald_vanLoon)
Exoskeleton yang Didorong AI Membantu Pengguna Kursi Roda Berjalan: Menampilkan perangkat exoskeleton canggih yang memanfaatkan teknologi AI, yang mampu membantu pengguna kursi roda untuk berdiri dan berjalan kembali. AI di dalamnya mungkin digunakan untuk menafsirkan niat pengguna, menjaga keseimbangan, mengoordinasikan gerakan, dan beradaptasi dengan lingkungan yang berbeda, mencerminkan potensi AI dalam meningkatkan kualitas hidup penyandang disabilitas dan merupakan kemajuan penting dalam teknologi robotika bantu. (Sumber: Ronald_vanLoon)
AI Agent Mungkin Digunakan untuk Serangan Siber, Menimbulkan Kekhawatiran: Artikel MIT Technology Review menunjukkan bahwa AI Agent otonom dapat digunakan untuk melakukan serangan siber yang kompleks. AI Agent ini berpotensi secara otomatis menemukan kerentanan, menghasilkan kode serangan, dan melancarkan serangan, dengan skala dan kecepatan yang mungkin jauh melampaui peretas manusia, menimbulkan tantangan berat bagi sistem pertahanan keamanan siber yang ada. Hal ini menimbulkan kekhawatiran tentang persenjataan AI dan risiko keamanan. (Sumber: Ronald_vanLoon)

OpenAI Mengumumkan Acara Langsung dan Kemungkinan Merilis Model Baru: OpenAI melalui pesan samar (pengembang & lubang hitam supermasif) mengumumkan acara siaran langsung, sementara informasi tentang ikon dan kartu model yang diperbarui di situs webnya beredar secara online, mengisyaratkan kemungkinan perilisan beberapa model baru termasuk seri GPT-4.1 (termasuk versi nano, mini), o4-mini, serta versi lengkap o3. Ini menunjukkan bahwa OpenAI mungkin sedang bersiap untuk meluncurkan serangkaian produk atau pembaruan model baru untuk menghadapi persaingan pasar yang semakin ketat. (Sumber: openai, op7418)

Robot Figure Mencapai Jalan Alami dari Simulasi ke Realitas Melalui Reinforcement Learning: Figure AI menggunakan reinforcement learning (RL) di lingkungan simulasi murni untuk berhasil melatih robot humanoid Figure 02 menguasai gaya berjalan alami. Melalui simulator efisien yang menghasilkan data dalam jumlah besar, dikombinasikan dengan domain randomization dan umpan balik torsi frekuensi tinggi dari robot itu sendiri, transfer kebijakan zero-shot dari simulasi ke realitas tercapai. Metode ini tidak hanya mempercepat proses pengembangan tetapi juga membuktikan kelayakan satu kebijakan neural network mengendalikan beberapa robot, yang memiliki arti penting bagi aplikasi komersial robot di masa depan. (Sumber: Satu Algoritma Mengendalikan Pasukan Robot! Reinforcement Learning Lingkungan Simulasi Murni, Figure Belajar Berjalan Seperti Manusia)
🧰 Alat
Jemeng AI 3.0 Menghasilkan Desain Teks Bergaya & Berbagi Prompt: Pengguna berbagi pengalaman dan metode menggunakan alat lukis AI buatan Tiongkok “Jemeng AI 3.0” untuk menghasilkan gambar teks dengan sentuhan desain. Karena menentukan nama font secara langsung tidak efektif, penulis membuat template prompt terperinci yang telah menetapkan berbagai gaya visual (seperti gaya industri, gaya manis, gaya teknologi, gaya tinta, dll.), dan menetapkan aturan agar AI secara otomatis mencocokkan atau menggabungkan gaya berdasarkan makna dan emosi teks masukan. Pengguna hanya perlu memasukkan teks target (seperti “pemuda e-sports”, “ingin makan permen”), template dapat menghasilkan prompt gambar lengkap yang mencakup gaya, latar belakang, tata letak, suasana, sehingga mendapatkan efek desain teks-gambar berkualitas tinggi di Jemeng AI. Artikel ini menyediakan template prompt tersebut dan banyak contoh hasil generasi. (Sumber: Jemeng AI 3.0 Membuat Sampul Berfont, Solusi Ini Keren Banget [Lampiran: 16+ Contoh dan Prompt], Saya Agak Paham Cara AI Menghasilkan Desain Font, Gunakan Set Prompt Ini untuk Meningkatkan Efisiensi 50%.)
Memanfaatkan AI Multimodal untuk Mengubah Foto Makanan Menjadi Gambar Gaya Menu: Pengguna media sosial menunjukkan teknik menggunakan model AI multimodal seperti GPT-4o untuk mengubah foto makanan biasa menjadi gambar menu yang indah. Metode ini melibatkan pemberian foto asli ke AI, dikombinasikan dengan prompt deskriptif (misalnya, merujuk pada “standar dan gaya menu hotel bintang lima kelas atas”), untuk memandu AI melakukan pemrosesan gaya dan pengeditan pada gambar, menghasilkan gambar tampilan hidangan yang terlihat profesional. Ini mencerminkan potensi praktis AI multimodal dalam pemahaman gambar, pengeditan, dan transfer gaya. (Sumber: karminski3)

Slideteam.net: Mungkin Alat Pembuat Slide Instan yang Didukung AI: Media sosial menyebutkan Slideteam.net mampu membuat slide yang sempurna “secara instan”, menyiratkan kemungkinan penggunaan teknologi AI untuk mengotomatiskan proses desain dan pembuatan presentasi. Alat semacam ini biasanya menggunakan AI untuk mencapai tata letak otomatis, saran konten, pencocokan gaya, dll., bertujuan untuk meningkatkan efisiensi pembuatan PPT. (Sumber: Ronald_vanLoon)
Demonstrasi Robot Pijat AI: Video menunjukkan robot pijat yang digerakkan oleh AI. Robot ini menggabungkan kemampuan operasi fisik lengan mekanik dengan kontrol cerdas AI. AI mungkin digunakan untuk memahami kebutuhan pengguna, mengidentifikasi bagian tubuh, merencanakan jalur pijat, menyesuaikan kekuatan dan teknik, bahkan merasakan respons pengguna melalui sensor untuk mengoptimalkan pengalaman pijat, menunjukkan potensi aplikasi AI dalam layanan kesehatan personal dan terapi fisik otomatis. (Sumber: Ronald_vanLoon)
GitHub Copilot Terintegrasi ke Windows Terminal: Microsoft mengintegrasikan fitur GitHub Copilot ke dalam versi pratinjau Canary Windows Terminal-nya, dinamai “Terminal Chat”. Pengguna yang telah berlangganan Copilot dapat langsung berinteraksi dengan AI di lingkungan terminal, mendapatkan saran, penjelasan, dan bantuan untuk baris perintah. Langkah ini bertujuan untuk mengurangi kebutuhan pengembang beralih aplikasi saat menulis perintah, memberikan bantuan cerdas melalui kesadaran konteks, meningkatkan efisiensi dan akurasi operasi baris perintah, terutama untuk tugas yang kompleks atau tidak dikenal. (Sumber: GitHub Copilot Sekarang Dapat Berjalan di Windows Terminal)
Diskusi Kebutuhan Perangkat Keras untuk Deployment OpenWebUI: Pengguna komunitas Reddit mendiskusikan konfigurasi mesin virtual Azure yang diperlukan untuk menyebarkan OpenWebUI (antarmuka web LLM) untuk tim sekitar 30 orang. Pengguna berencana menjalankan model embedding Snowflake secara lokal dan menggunakan API OpenAI. Diskusi melibatkan penskalaan sumber daya, dampak ukuran model embedding pada CPU/RAM/penyimpanan, dan pentingnya pra-pemrosesan data. Komunitas menyarankan bahwa ketergantungan berat pada API dapat mengurangi kebutuhan perangkat keras lokal, tetapi jika menjalankan model secara lokal (terutama model embedding), diperlukan konfigurasi yang lebih kuat. Untuk situasi dengan sumber daya terbatas, disarankan juga menggunakan API untuk menangani embedding. (Sumber: Reddit r/OpenWebUI)
📚 Pembelajaran
Model AI Penalaran Memiliki Kelemahan “Berpikir Berlebihan” Saat Premis Hilang: Penelitian dari University of Maryland dan institusi lain mengungkapkan bahwa model penalaran saat ini (seperti DeepSeek-R1, o1), ketika menghadapi masalah yang kekurangan informasi penting (premis hilang, MiP), cenderung menghasilkan jawaban panjang yang tidak valid, alih-alih dengan cepat mengidentifikasi kekurangan masalah itu sendiri. Fenomena “MiP overthinking” ini menyebabkan pemborosan sumber daya komputasi, dan tidak banyak berhubungan dengan apakah model pada akhirnya dapat menyadari premis yang hilang. Sebaliknya, model non-penalaran berkinerja lebih baik. Penelitian berpendapat bahwa ini mengungkap kurangnya kemampuan berpikir kritis pada model penalaran saat ini, yang mungkin berasal dari paradigma pelatihan reinforcement learning atau masalah dalam proses knowledge distillation. (Sumber: AI Penalaran Kecanduan “Mengarang”, Penuh Omong Kosong, Mahasiswa Berprestasi Tionghoa Maryland Mengungkap Rahasianya)

CVPR 2025: CADCrafter Mewujudkan Generasi File CAD yang Dapat Diedit dari Satu Gambar: Peneliti dari Magic Core Technology, Nanyang Technological University, dan institusi lain mengusulkan kerangka kerja CADCrafter, yang mampu menghasilkan file teknik CAD parametrik yang dapat diedit (direpresentasikan sebagai urutan instruksi CAD) langsung dari satu gambar (render bagian, foto objek nyata, dll.), bukan model mesh atau point cloud tradisional. Metode ini menggunakan VAE untuk mengkodekan instruksi CAD dan menggabungkannya dengan Diffusion Transformer untuk generasi ruang laten yang dikondisikan oleh gambar, meningkatkan kinerja melalui strategi distilasi multi-view ke single-view, dan memanfaatkan optimasi DPO untuk memastikan instruksi yang dihasilkan dapat dikompilasi. File CAD yang dihasilkan dapat langsung digunakan untuk produksi dan pemrosesan, serta mendukung modifikasi model melalui pengeditan instruksi, secara signifikan meningkatkan kepraktisan dan kualitas permukaan model 3D yang dihasilkan AI. (Sumber: Satu Gambar Langsung Menghasilkan File Teknik CAD! Riset Baru CVPR 2025 Mengatasi Masalah “Tidak Dapat Diedit” Model 3D yang Dihasilkan AI|Diproduksi oleh Magic Core Technology, NTU, dll.)
Zhejiang University, OPPO, dll. Merilis Tinjauan OS Agents: Makalah tinjauan ini secara sistematis menyusun status penelitian agen sistem operasi cerdas (OS Agents) berdasarkan model besar multimodal (MLLM). OS Agents merujuk pada AI yang dapat secara otomatis melakukan tugas pada perangkat seperti komputer dan ponsel melalui antarmuka sistem operasi (GUI). Makalah ini mendefinisikan elemen kuncinya (lingkungan, ruang observasi, ruang aksi), kemampuan inti (pemahaman, perencanaan, eksekusi), mengulas metode pembangunan (arsitektur model dasar & pelatihan, desain kerangka kerja agen), dan merangkum protokol evaluasi, benchmark, serta produk komersial terkait. Terakhir, membahas tantangan dan arah masa depan seperti keamanan privasi, personalisasi & evolusi diri, memberikan referensi komprehensif untuk penelitian di bidang ini. (Sumber: Zhejiang University, OPPO, dll. Merilis Tinjauan Terbaru: Penelitian Agen Cerdas Komputer, Ponsel, dan Browser Berbasis Model Besar Multimodal)
ICLR 2025: Nabla-GFlowNet Mewujudkan Fine-tuning Reward Difusi yang Efisien dan Beragam: Mengatasi masalah konvergensi lambat (RL tradisional) atau hilangnya keragaman (optimasi langsung) dalam fine-tuning reward model difusi, peneliti mengusulkan metode Nabla-GFlowNet. Metode ini didasarkan pada kerangka kerja Generative Flow Network (GFlowNet), menurunkan kondisi keseimbangan aliran baru (Nabla-DB) dan fungsi kerugian, menggunakan informasi gradien reward untuk memandu fine-tuning. Melalui desain parameterisasi khusus, sambil mempertahankan keragaman sampel yang dihasilkan, metode ini mencapai kecepatan konvergensi yang lebih cepat daripada metode seperti DDPO, dan divalidasi pada model Stable Diffusion menggunakan fungsi reward seperti estetika, kepatuhan instruksi, dengan hasil yang lebih unggul dari metode yang ada. (Sumber: ICLR 2025 | Terobosan Baru Fine-tuning Reward Model Difusi! Nabla-GFlowNet Membuat Keragaman dan Efisiensi Tercapai Bersama)
Analisis Mekanisme Inferensi DeepSeek-R1: Penelitian dari McGill University menganalisis secara mendalam proses “berpikir” model inferensi seperti DeepSeek-R1. Penelitian menemukan bahwa panjang rantai inferensi tidak berkorelasi positif dengan kinerja, ada “titik optimal”, inferensi yang terlalu panjang mungkin malah berbahaya. Model mungkin terjebak dalam pengulangan pernyataan yang sudah ada saat memproses konteks panjang atau masalah kompleks. Selain itu, dibandingkan dengan model non-inferensi, DeepSeek-R1 mungkin memiliki kerentanan keamanan yang lebih jelas. Penelitian ini mengungkap beberapa karakteristik dan potensi keterbatasan mekanisme operasi model inferensi saat ini. (Sumber: LLM Weekly Express! | Melibatkan Multimodal, Model MoE, Inferensi Deepseek, Kontrol Keamanan Agen, Kuantisasi Model, dll.)
Metode Baru Optimasi Saat Pengujian Model MoE: C3PO: Johns Hopkins University mengusulkan metode C3PO (Critical Layers, Core Experts, Collaborative Path Optimization) untuk mengoptimalkan kinerja model besar Mixture of Experts (MoE) pada saat pengujian. Metode ini mengoptimalkan setiap sampel pengujian dengan memberikan bobot ulang pada expert inti di lapisan kritis untuk mengatasi masalah jalur expert yang suboptimal. Eksperimen menunjukkan bahwa C3PO dapat secara signifikan meningkatkan akurasi model MoE (7-15%), bahkan membuat kinerja model MoE dengan parameter lebih kecil melampaui model padat dengan jumlah parameter lebih besar, meningkatkan efisiensi arsitektur MoE. (Sumber: LLM Weekly Express! | Melibatkan Multimodal, Model MoE, Inferensi Deepseek, Kontrol Keamanan Agen, Kuantisasi Model, dll.)
Studi Sistematis Pengaruh Kuantisasi pada Kinerja Model Inferensi: Tsinghua University dan institusi lain untuk pertama kalinya secara sistematis mempelajari pengaruh kuantisasi model pada kinerja model inferensi (seperti DeepSeek-R1, seri Qwen). Eksperimen mengevaluasi efek kuantisasi di bawah berbagai bit-width (bobot, cache KV, nilai aktivasi) dan algoritma. Studi menemukan bahwa kuantisasi W8A8 atau W4A16 biasanya dapat mencapai kinerja tanpa kehilangan atau mendekati tanpa kehilangan, tetapi bit-width yang lebih rendah secara signifikan meningkatkan risiko. Ukuran model, sumber, dan kesulitan tugas semuanya merupakan faktor kunci yang mempengaruhi kinerja setelah kuantisasi. Hasil penelitian dan model terkuantisasi telah di-open-source. (Sumber: LLM Weekly Express! | Melibatkan Multimodal, Model MoE, Inferensi Deepseek, Kontrol Keamanan Agen, Kuantisasi Model, dll.)
APIGen-MT: Kerangka Kerja Pembuatan Data Interaksi Agen Multi-Turn Berkualitas Tinggi: Salesforce mengusulkan kerangka kerja APIGen-MT, yang bertujuan untuk mengatasi kelangkaan data berkualitas tinggi yang diperlukan untuk melatih AI Agent interaktif multi-turn. Kerangka kerja ini dibagi menjadi dua tahap: pertama menggunakan LLM untuk meninjau dan memberikan umpan balik iteratif untuk menghasilkan cetak biru tugas terperinci, kemudian mengubah cetak biru menjadi data lintasan lengkap melalui simulasi interaksi manusia-mesin. Seri model xLAM-2 yang dilatih berdasarkan kerangka kerja ini menunjukkan kinerja yang sangat baik pada benchmark agen multi-turn, melampaui model seperti GPT-4o, memvalidasi efektivitas metode pembuatan data ini. Data sintetis dan model telah di-open-source. (Sumber: LLM Weekly Express! | Melibatkan Multimodal, Model MoE, Inferensi Deepseek, Kontrol Keamanan Agen, Kuantisasi Model, dll.)
Studi Mengungkap: Rantai Pikiran Lebih Panjang Tidak Sama Dengan Kinerja Penalaran Lebih Kuat, Reinforcement Learning Bisa Lebih Ringkas: Penelitian Wand AI menunjukkan bahwa model penalaran (terutama yang dilatih dengan algoritma RL seperti PPO) cenderung menghasilkan respons yang lebih panjang, bukan karena kebutuhan akurasi, tetapi mekanisme RL itu sendiri mungkin menyebabkannya: untuk jawaban yang salah (reward negatif), memperpanjang panjang respons dapat “mengencerkan” hukuman untuk setiap token, sehingga mengurangi kerugian. Penelitian membuktikan bahwa penalaran ringkas berkorelasi dengan akurasi yang lebih tinggi, dan mengusulkan metode pelatihan RL dua tahap: pertama melatih dengan masalah sulit untuk meningkatkan kemampuan (mungkin memperpanjang respons), kemudian melatih dengan masalah tingkat kesulitan sedang untuk mendorong keringkasan dan mempertahankan akurasi, bahkan pada dataset yang sangat kecil dapat secara efektif meningkatkan kinerja dan ketahanan. (Sumber: Pikiran Lebih Panjang Tidak Sama Dengan Kinerja Penalaran Lebih Kuat, Reinforcement Learning Bisa Sangat Ringkas)
USTC, ZTE Mengusulkan Curr-ReFT: Paradigma Baru Pasca-Pelatihan VLM Ukuran Kecil: Mengatasi masalah seperti kemampuan generalisasi yang buruk, kemampuan penalaran terbatas, dan ketidakstabilan pelatihan (“fenomena dinding bata”) yang dihadapi oleh model bahasa visual (VLM) kecil setelah fine-tuning terawasi, USTC dan ZTE Corporation mengusulkan paradigma pasca-pelatihan Curr-ReFT. Metode ini menggabungkan curriculum reinforcement learning (Curr-RL) dan perbaikan diri berbasis rejection sampling. Curr-RL melalui mekanisme reward yang sadar kesulitan, membimbing model untuk belajar secara bertahap dari mudah ke sulit; rejection sampling menggunakan sampel berkualitas tinggi untuk mempertahankan kemampuan dasar model. Eksperimen pada model Qwen2.5-VL-3B/7B menunjukkan bahwa Curr-ReFT secara signifikan meningkatkan kinerja penalaran dan generalisasi model, membuat model kecil melampaui model besar pada beberapa benchmark. Kode, data, dan model telah di-open-source. (Sumber: USTC, ZTE Mengusulkan Paradigma Pasca-Pelatihan Baru: Model Multimodal Ukuran Kecil, Berhasil Mereplikasi Penalaran R1)
Tsinghua, Shanghai AI Lab Mengusulkan GenPRM: Model Reward Proses Generatif yang Dapat Diskalakan: Untuk mengatasi masalah kurangnya interpretabilitas dan kemampuan penskalaan saat pengujian pada model reward proses (PRM) tradisional dalam mengawasi penalaran LLM, Tsinghua University dan Shanghai AI Lab mengusulkan GenPRM. Ini mengevaluasi langkah-langkah penalaran dengan menghasilkan rantai pemikiran bahasa alami (CoT) dan kode verifikasi yang dapat dieksekusi, memberikan umpan balik yang lebih transparan. GenPRM mendukung penskalaan komputasi saat pengujian, meningkatkan presisi dengan mengambil sampel beberapa jalur evaluasi dan merata-ratakan reward. Model ini dilatih hanya dengan 23K data sintetis, versi 1.5B dengan bantuan penskalaan saat pengujian telah melampaui GPT-4o, versi 7B melampaui model dasar 72B. GenPRM juga dapat berfungsi sebagai kritikus tingkat langkah untuk perbaikan jawaban secara iteratif. (Sumber: Model Reward Proses Juga Bisa Diskalakan Saat Pengujian? Tsinghua, Shanghai AI Lab dengan 23K Data Membuat Model Kecil 1.5B Mengalahkan GPT-4o)
Dataset Matematika Open-Source Terbesar di Dunia MegaMath Dirilis (371 Miliar Token): LLM360 meluncurkan dataset MegaMath, berisi 371 miliar token, merupakan dataset pra-pelatihan open-source terbesar di dunia saat ini yang berfokus pada penalaran matematika, bertujuan untuk menjembatani kesenjangan dalam skala dan kualitas antara komunitas open-source dan korpus matematika closed-source (seperti DeepSeek-Math). Dataset terdiri dari tiga bagian: data halaman web terkait matematika skala besar (279 Miliar, termasuk subset berkualitas tinggi 15 Miliar), kode matematika (28 Miliar), dan data sintetis berkualitas tinggi (64 Miliar, termasuk tanya jawab, pembuatan kode, campuran teks-gambar). Setelah diproses dengan cermat dan melalui beberapa putaran validasi pra-pelatihan, menggunakan MegaMath untuk pra-pelatihan pada model Llama-3.2 dapat membawa peningkatan kinerja signifikan 15-20% pada benchmark seperti GSM8K, MATH. (Sumber: 371 Miliar Token Matematika! Dataset Matematika Open-Source Terbesar di Dunia MegaMath Dirilis dengan Mengejutkan, Mengalahkan DeepSeek-Math)
CVPR 2025: NLPrompt Meningkatkan Ketahanan Pembelajaran Prompt VLM di Bawah Label Bising: YesAI Lab dari ShanghaiTech University mengusulkan metode NLPrompt, yang bertujuan untuk mengatasi penurunan kinerja pembelajaran prompt model bahasa visual (VLM) ketika menghadapi noise label. Penelitian menemukan bahwa dalam skenario pembelajaran prompt, kerugian Mean Absolute Error (MAE) (PromptMAE) lebih tangguh daripada kerugian Cross-Entropy (CE). Pada saat yang sama, diusulkan metode pemurnian data PromptOT berbasis Optimal Transport, menggunakan fitur teks yang dihasilkan prompt sebagai prototipe, untuk membagi dataset menjadi set bersih dan set bising. NLPrompt menggunakan kerugian CE untuk set bersih dan kerugian MAE untuk set bising, secara efektif menggabungkan keunggulan keduanya. Eksperimen membuktikan bahwa metode ini secara signifikan meningkatkan ketahanan dan kinerja metode pembelajaran prompt seperti CoOp pada dataset noise sintetis dan nyata. (Sumber: CVPR 2025 | Kombinasi Kerugian MAE + Optimal Transport! ShanghaiTech Mengusulkan Metode Pembelajaran Prompt Tangguh Baru)
Aplikasi dan Diskusi Teknik Knowledge Distillation dalam Kompresi Model: Komunitas mendiskusikan teknik knowledge distillation, yaitu menggunakan model “guru” yang besar untuk melatih model “siswa” yang kecil, sehingga mencapai kinerja yang mendekati model guru pada tugas tertentu, tetapi dengan biaya yang jauh lebih rendah. Seorang pengguna berbagi keberhasilan mendistilasi kemampuan GPT-4o dalam tugas analisis sentimen (akurasi 92%) ke model kecil, dengan biaya 14 kali lebih rendah. Komentar menunjukkan bahwa meskipun efek distilasi signifikan, biasanya terbatas pada domain tertentu, dan model siswa kekurangan kemampuan generalisasi model guru. Sementara itu, untuk skenario profesional yang memerlukan adaptasi berkelanjutan terhadap perubahan data, biaya pemeliharaan model yang dilatih sendiri mungkin lebih tinggi daripada langsung menggunakan API besar. (Sumber: Reddit r/MachineLearning)

Definisi AI Agent Menarik Perhatian: Perusahaan konsultan seperti McKinsey mulai mendefinisikan dan membahas konsep AI Agent, mencerminkan meningkatnya pentingnya AI Agent sebagai entitas cerdas yang mampu merasakan, memutuskan, dan bertindak secara otonom untuk menyelesaikan tujuan, baik dalam domain bisnis maupun teknologi. Memahami definisi, kemampuan, dan skenario aplikasi AI Agent menjadi fokus perhatian industri. (Sumber: Ronald_vanLoon)

💼 Bisnis
Mengungkap Strategi AI Alibaba: Berpusat pada AGI, Investasi Besar pada Infrastruktur untuk Mendorong Transformasi: Analisis menunjukkan bahwa meskipun Alibaba belum secara resmi merilis strategi AI-nya, tindakannya telah menunjukkan gambaran yang jelas: mengejar AGI sebagai tujuan utama, dengan harapan mendapatkan kembali inisiatif dalam persaingan. Rencana investasi lebih dari 380 miliar RMB selama tiga tahun ke depan untuk pembangunan infrastruktur AI dan cloud computing, dengan fokus memenuhi permintaan inferensi yang melonjak. Jalur strategis meliputi: mempromosikan kemampuan AI Agent melalui DingTalk; memanfaatkan model open-source seri Qwen untuk mendorong pertumbuhan Alibaba Cloud; mengembangkan model MaaS (Model as a Service) dari Tongyi API. Sementara itu, Alibaba akan menggunakan AI untuk secara mendalam mengubah bisnis yang ada, seperti meningkatkan pengalaman pengguna Taobao, menjadikan Quark sebagai aplikasi AI unggulan (pencarian + Agen), mengeksplorasi aplikasi AI di layanan kehidupan melalui Peta Gaode. Alibaba juga mungkin mempercepat tata letak AI melalui investasi dan akuisisi. (Sumber: Mengungkap Strategi AI Alibaba: Belum Pernah Dirilis, Tapi Sudah Mulai Berlari Kencang)
Tren Baru Pasar Talenta AI: Menekankan Praktik daripada Gelar Akademik, Kemampuan Gabungan Disukai: Berdasarkan analisis hampir 3000 posisi AI bergaji tinggi di kota-kota besar Tiongkok, laporan mengungkapkan tiga tren utama dalam permintaan talenta AI: 1) Permintaan insinyur algoritma tinggi, dengan gaji menarik, industri otomotif menjadi perekrut utama; 2) Perusahaan (termasuk perusahaan bintang seperti DeepSeek) secara bertahap mengurangi persyaratan kaku untuk gelar akademik, lebih menghargai kemampuan rekayasa praktis dan pengalaman dalam memecahkan masalah kompleks; 3) Permintaan akan talenta gabungan meningkat, misalnya manajer produk AI perlu memahami pengguna, model, dan rekayasa prompt secara bersamaan, karena AI mengambil alih lebih banyak tugas khusus, membutuhkan manusia untuk mengintegrasikan dan mengawasi pada tingkat yang lebih tinggi. (Sumber: Dari Hampir 3000 Data Rekrutmen, Saya Menemukan Tiga Aturan Utama untuk Menggali Talenta AI)
Ubtech Terus Merugi, Tantangan Komersialisasi Robot Humanoid Berat: Laporan keuangan perusahaan robot humanoid Ubtech tahun 2024 menunjukkan bahwa meskipun pendapatan tumbuh 23,7% menjadi 1,3 miliar yuan, perusahaan masih merugi 1,16 miliar yuan. Bisnis inti robot humanoidnya mengalami kemajuan komersialisasi yang lambat, hanya mengirimkan 10 unit sepanjang tahun, dengan harga satuan mencapai 3,5 juta yuan, jauh melebihi ekspektasi pasar dan pesaing (seperti Unitree Robotics G1 yang hanya dijual 99.000 yuan). Ditambah dengan kabar masalah rantai pasokan dana di perusahaan terkemuka lainnya di industri, Dataa Robotics, hal ini menimbulkan keraguan tentang kelayakan komersialisasi industri robot humanoid, menguatkan pandangan hati-hati investor Zhu Xiaohu sebelumnya. Biaya tinggi, skenario aplikasi terbatas, serta keamanan dan keandalan adalah hambatan utama komersialisasi skala besar robot humanoid saat ini. (Sumber: Ubtech Merugi Hampir 1,2 Miliar Yuan Setahun, Zhu Xiaohu Sekarang Punya Lebih Banyak Alasan untuk Berbicara)

AI Mendorong Pertumbuhan Industri Telekomunikasi, Teknologi Tinggi, dan Media: Diskusi menunjukkan bahwa kecerdasan buatan (termasuk generative AI) menjadi kekuatan kunci yang mendorong pertumbuhan di industri telekomunikasi, teknologi tinggi, dan media. Teknologi AI banyak diterapkan untuk meningkatkan pengalaman pelanggan, mengoptimalkan operasi jaringan, mengotomatiskan pembuatan konten, meningkatkan efisiensi operasional, dan mengembangkan layanan inovatif, membantu perusahaan di industri ini mendapatkan keunggulan kompetitif di pasar yang berubah cepat. (Sumber: Ronald_vanLoon)
Hugging Face Mengakuisisi Perusahaan Robotika Open-Source Pollen Robotics: Platform model dan alat AI terkenal Hugging Face mengakuisisi Pollen Robotics, startup yang dikenal dengan robot humanoid open-source Reachy. Akuisisi ini menunjukkan niat Hugging Face untuk memperluas model open-source suksesnya ke bidang robotika AI, bertujuan untuk mendorong kolaborasi dan inovasi di bidang ini melalui solusi perangkat keras dan perangkat lunak terbuka, mempercepat proses demokratisasi teknologi robotika. (Sumber: huggingface, huggingface, huggingface, huggingface)

🌟 Komunitas
Era AI Mungkin Lebih Menguntungkan Lulusan Ilmu Sosial: Lynn Duan, pendiri komunitas AI+ Silicon Valley, berpendapat bahwa seiring alat AI (seperti Cursor) menurunkan hambatan pemrograman, pentingnya kemampuan rekayasa relatif menurun, sementara keterampilan humaniora dan ilmu sosial seperti komersialisasi, pemasaran, dan komunikasi menjadi lebih penting. AI menggantikan sebagian posisi teknis tingkat pemula, tetapi menciptakan permintaan akan talenta gabungan yang dapat menghubungkan teknologi dengan pasar. Dia menyarankan lulusan mempertimbangkan perusahaan rintisan untuk pertumbuhan cepat, dan menunjukkan kemampuan melalui proyek praktis (seperti menyebarkan model, mengembangkan aplikasi), bukan hanya mengandalkan gelar akademik. Dia juga menunjukkan bahwa sifat pendiri (seperti keyakinan, pemahaman industri) lebih penting daripada latar belakang teknis murni, dan optimis tentang peluang startup AI di bidang SaaS AS dan perangkat keras cerdas Tiongkok. (Sumber: AI Sebenarnya adalah Era yang Baik untuk Lulusan Ilmu Sosial|Dialog dengan Pendiri AI+ Silicon Valley Lynn Duan)

Pemblokiran Singkat IP Tiongkok oleh GitHub Menimbulkan Kekhawatiran, Pejabat Menyebut Kesalahan Operasi: Baru-baru ini, beberapa pengguna Tiongkok menemukan bahwa mereka tidak dapat mengakses GitHub saat tidak login, dengan pemberitahuan IP dibatasi, menimbulkan kekhawatiran di komunitas tentang kemungkinan “pemblokiran”. Meskipun pejabat GitHub dengan cepat merespons bahwa itu adalah kesalahan konfigurasi dan telah diperbaiki, insiden tersebut masih memicu diskusi. Mengingat GitHub di masa lalu pernah membatasi akses dari wilayah seperti Iran dan Rusia berdasarkan kebijakan sanksi AS, insiden kali ini ditafsirkan oleh sebagian orang sebagai “latihan” untuk potensi tindakan pembatasan. Artikel ini menekankan pentingnya GitHub bagi pengembang Tiongkok dan ekosistem open-source (termasuk banyak proyek AI), serta dampak negatif yang mungkin ditimbulkan oleh pembatasan semacam itu, dan mencantumkan platform hosting kode domestik seperti Gitee, CODING sebagai opsi alternatif. (Sumber: “Bug” atau “Latihan”? GitHub Tiba-tiba “Memblokir” Semua IP Tiongkok, Pejabat: Hanya “Kesalahan Teknis” Teknis)
Kinerja dan Layanan Claude AI Menimbulkan Kontroversi Pengguna: Diskusi di Reddit menunjukkan bahwa sebagian pengguna menyatakan ketidakpuasan terhadap model Claude dari Anthropic, menyebutkan penurunan kinerja, melakukan modifikasi yang tidak perlu saat pengkodean, dan kekecewaan terhadap tingkatan berbayar dan batasan tarif, bahkan ada pengembang terkenal yang menyatakan akan beralih ke model lain (seperti Gemini 2.5 Pro). Namun, ada juga pengguna yang berpendapat bahwa Claude (terutama versi lama Sonnet 3.5) masih memiliki keunggulan dalam tugas tertentu (seperti pengkodean), atau menyatakan bahwa mereka tidak sering mengalami batasan tarif. Perdebatan ini mencerminkan perbedaan pengalaman pengguna terhadap Claude, serta ekspektasi tinggi pengguna terhadap kinerja dan layanan model AI di tengah persaingan ketat. (Sumber: Reddit r/ClaudeAI)

Skala Fitur Deep Research Gemini Menjadi Diskusi: Pengguna berbagi pengalaman menggunakan fitur Deep Research Google Gemini Advanced, di mana AI mengakses hampir 700 situs web untuk menjawab satu pertanyaan dan menghasilkan laporan panjang (misalnya 37 halaman). Skala ini mengesankan pengguna, tetapi juga menimbulkan diskusi tentang kualitas informasi. Komentator mempertanyakan apakah pemrosesan informasi web dalam jumlah besar seperti itu dapat menjamin akurasi dan kedalaman, atau hanya mengumpulkan hasil pencarian web yang mungkin mengandung kesalahan dalam skala yang lebih besar. Ini mencerminkan perhatian dan pengawasan komunitas terhadap kemampuan pemrosesan informasi alat riset AI (kedalaman vs. keluasan). (Sumber: Reddit r/artificial)

Kemampuan Pemrograman Gemini 2.5 Pro Mendapat Pujian Komunitas: Beberapa pengguna di komunitas berbagi pengalaman positif menggunakan Google Gemini 2.5 Pro untuk pemrograman, menganggap tingkat kecerdasannya tinggi, mampu memahami niat pengguna dengan baik, dan memiliki kemampuan pemrosesan konteks panjang 1 juta token (cukup untuk menganalisis basis kode besar) serta gratis, dengan kinerja keseluruhan yang lebih unggul dari pesaing seperti Claude. Meskipun ada beberapa kekurangan kecil (seperti sesekali berhalusinasi fungsi pustaka yang tidak ada), penilaian keseluruhannya sangat tinggi, dianggap sebagai salah satu model pengkodean paling populer saat ini, dan menyatakan antisipasi terhadap model yang mungkin lebih kuat dari Google di masa depan (seperti Dragontail). (Sumber: Reddit r/ArtificialInteligence)
Model Open-Source Kecil Berkembang Pesat, Persepsi Pengguna Perlu Diperbarui: Diskusi komunitas mengungkapkan kekaguman atas kemajuan pesat LLM open-source. Menunjukkan bahwa model seperti QwQ-32B, Gemma-3-27B yang saat ini terlihat bagus, akan menjadi revolusioner jika ditempatkan satu atau dua tahun lalu (saat GPT-4 baru dirilis). Ini mengingatkan semua orang untuk tidak mengabaikan kemampuan aktual model open-source kecil saat ini, yang telah mencapai tingkat yang cukup tinggi. Komentar juga mengakui bahwa model-model ini masih memiliki kesenjangan dibandingkan dengan model closed-source teratas (seperti stabilitas, kecepatan, pemrosesan konteks), tetapi menekankan kecepatan kemajuan dan potensinya, percaya bahwa terobosan di masa depan mungkin dicapai melalui inovasi arsitektur daripada sekadar menumpuk parameter. (Sumber: Reddit r/LocalLLaMA)
Anggota Komunitas Menawarkan Daya Komputasi A100 Gratis untuk Mendukung Proyek AI: Seorang pengguna yang memiliki 4 GPU Nvidia A100 memposting di komunitas Reddit, bersedia menyediakan daya komputasi gratis (sekitar 100 jam A100) untuk proyek penggemar AI yang inovatif, bertujuan memberikan dampak positif, dan terbatas oleh sumber daya komputasi. Langkah ini mendapat respons positif, beberapa peneliti dan pengembang mengajukan rencana proyek spesifik, mencakup pelatihan arsitektur model baru, interpretabilitas model, pembelajaran modular, aplikasi interaksi manusia-mesin, dll., mencerminkan keinginan komunitas riset AI akan sumber daya komputasi serta semangat saling membantu dan berbagi. (Sumber: Reddit r/deeplearning)
Masalah Batasan Tarif Claude AI Memicu Perdebatan Komunitas: Keluhan tentang seringnya memicu batasan tarif saat menggunakan model Claude AI (misalnya setelah hanya 5 pesan) memicu perdebatan di komunitas. Beberapa pengguna menyatakan keraguan kuat terhadap keluhan semacam itu, menganggapnya berlebihan atau penggunaan yang tidak tepat oleh pengguna (seperti selalu mengunggah konteks super panjang), dan meminta bukti. Tetapi ada juga pengguna yang memberikan kesaksian, membenarkan bahwa mereka memang sering mencapai batasan saat melakukan tugas intensif (seperti pengeditan kode besar), yang mempengaruhi alur kerja. Diskusi mencerminkan bahwa pengalaman pengguna terhadap batasan tarif sangat bervariasi, mungkin terkait dengan cara penggunaan spesifik dan kompleksitas tugas, sekaligus menunjukkan sensitivitas pengguna terhadap batasan layanan berbayar. (Sumber: Reddit r/ClaudeAI)
💡 Lain-lain
Konferensi Ekosistem AIGC & Agen Cerdas (Shanghai) Diadakan Juni: Konferensi Ekosistem AIGC & Agen Kecerdasan Buatan kedua akan diadakan di Shanghai pada 12 Juni 2025, dengan tema “Menghubungkan Segalanya dengan Cerdas · Koeksistensi Tanpa Batas”. Konferensi ini berfokus pada inovasi kolaboratif dan integrasi ekosistem generative AI (AIGC) dan AI Agent, mencakup infrastruktur AI, model bahasa besar, pemasaran AIGC & aplikasi skenario (media, e-commerce, industri, medis, dll.), teknologi multimodal, kerangka kerja pengambilan keputusan otonom, dll. Bertujuan untuk mendorong AI dari alat tunggal menuju peningkatan kolaborasi ekosistem, menghubungkan penyedia teknologi, pihak permintaan, modal, dan pembuat kebijakan. (Sumber: Juni Shanghai|KTT Shanghai “Menghubungkan Segalanya dengan Cerdas”: Integrasi Ekosistem AIGC+Agen Cerdas)

Konferensi AI Partner 36Kr Berfokus pada Super APP: 36Kr akan mengadakan “Konferensi AI Partner 2025 · Super APP Telah Tiba” di Shanghai MoSu Space pada 18 April 2025. Konferensi ini bertujuan untuk mengeksplorasi bagaimana aplikasi AI membentuk kembali dunia bisnis, melahirkan “aplikasi super” yang disruptif. Konferensi akan mengumpulkan eksekutif senior dari perusahaan seperti AMD, Baidu, 360, Qualcomm, serta investor, untuk membahas topik hangat seperti AI industri, daya komputasi AI, pencarian AI, pendidikan AI, dll., dan merilis kasus inovasi aplikasi asli AI serta Penghargaan Inovasi AI Partner. Secara bersamaan, akan diadakan Salon AI Inklusif dan seminar tertutup AI Go Global. (Sumber: Super App Telah Tiba! Lihat Bagaimana Aplikasi AI ‘Menulis Ulang’ Dunia Bisnis?|Poin Utama Konferensi AI Partner 2025)

Horizon Robotics Merekrut Magang Algoritma Rekonstruksi/Generasi 3D: Tim Embodied Intelligence Horizon Robotics sedang merekrut magang algoritma di bidang rekonstruksi/generasi 3D di Shanghai dan Beijing. Posisi ini akan berpartisipasi dalam merancang dan mengembangkan algoritma Real2Sim, memanfaatkan teknologi seperti 3D Gaussian Splatting, rekonstruksi feed-forward, generasi 3D/video untuk mengurangi biaya akuisisi data robot, dan mengoptimalkan kinerja simulator. Persyaratan termasuk gelar Master atau lebih tinggi, dengan pengalaman dan keterampilan yang relevan. Menawarkan peluang konversi penuh waktu, sumber daya GPU, dan bimbingan profesional. (Sumber: Rekomendasi Internal Shanghai/Beijing | Tim Embodied Intelligence Horizon Robotics Merekrut Magang Algoritma Arah Rekonstruksi/Generasi 3D)
OceanBase Mengadakan Kompetisi Hackathon AI Pertama: Vendor database OceanBase bekerja sama dengan Ant Open Source, Jiqizhixin, dll. menyelenggarakan Hackathon AI pertama, dengan tema “DB+AI”, menawarkan total hadiah 100.000 yuan. Kompetisi ini mendorong pengembang untuk mengeksplorasi kombinasi teknologi OceanBase dan AI, dengan arah termasuk menggunakan OceanBase sebagai basis data untuk aplikasi AI, atau membangun aplikasi AI (seperti tanya jawab, sistem diagnosis) dalam ekosistem OceanBase (dikombinasikan dengan CAMEL AI, FastGPT, dll.). Pendaftaran dibuka dari 10 April hingga 7 Mei, terbuka untuk individu dan tim. (Sumber: Hadiah 100 Ribu × Peningkatan Kognitif! Hackathon AI Pertama OceanBase Mengundang Pahlawan, Berani Datang?)
Meituan Hotel & Travel Merekrut Insinyur Algoritma Model Besar L7-L8: Tim Algoritma Pasokan Meituan Hotel & Travel di Beijing merekrut insinyur algoritma model besar tingkat L7-L8 (rekrutmen sosial). Tanggung jawab meliputi penggunaan teknologi NLP, model besar untuk membangun sistem pemahaman pasokan hotel & travel (tag, hotspot, analisis kesamaan), mengoptimalkan materi tampilan produk (judul, teks-gambar), membangun kombinasi paket liburan, dan mengeksplorasi teknologi model besar terdepan dalam aplikasi algoritma sisi pasokan. Persyaratan termasuk gelar Master atau lebih tinggi, pengalaman lebih dari 2 tahun, dengan kemampuan algoritma dan pemrograman yang solid. (Sumber: Rekomendasi Internal Beijing | Tim Algoritma Pasokan Meituan Hotel & Travel Merekrut Insinyur Algoritma Model Besar L7-L8)
QbitAI Merekrut Editor/Penulis Bidang AI: Media teknologi AI QbitAI (量子位) sedang merekrut editor/penulis penuh waktu, lokasi kerja di Zhongguancun, Beijing, terbuka untuk rekrutmen sosial dan lulusan baru, menawarkan peluang konversi magang. Arah rekrutmen meliputi model besar AI, robotika embodied intelligence, perangkat keras terminal, serta editor media baru AI (Weibo/Xiaohongshu). Persyaratan termasuk antusiasme terhadap bidang AI, kemampuan ekspresi tulisan dan pengumpulan informasi yang baik. Nilai tambah termasuk familiar dengan alat AI, kemampuan interpretasi makalah, kemampuan pemrograman, dll. Menawarkan gaji dan tunjangan yang kompetitif serta peluang pertumbuhan profesional. (Sumber: Rekrutmen QbitAI | Lowongan Kerja yang Diedit oleh DeepSeek untuk Kami)
Pemenang Turing Award LeCun Bicara Perkembangan AI: Kecerdasan Manusia Tidak Universal, AI Generasi Berikutnya Mungkin Non-Generatif: Dalam wawancara podcast, Yann LeCun berpendapat bahwa pengejaran AGI (Artificial General Intelligence) saat ini mengandung kesalahpahaman, karena kecerdasan manusia itu sendiri sangat terspesialisasi, bukan universal. Dia memprediksi terobosan AI generasi berikutnya mungkin didasarkan pada model non-generatif, seperti arsitektur JEPA yang dia usulkan, dengan fokus pada memungkinkan AI memahami dunia fisik, memiliki kemampuan penalaran dan perencanaan (model dunia), bukan hanya memproses bahasa. Dia berpendapat bahwa LLM saat ini kekurangan kemampuan penalaran sejati. LeCun juga menekankan pentingnya open-source (seperti LLaMA Meta) untuk mendorong pengembangan AI, dan menganggap perangkat seperti kacamata pintar sebagai arah penting untuk penerapan teknologi AI. (Sumber: Pemenang Turing Award LeCun: Kecerdasan Manusia Bukan Kecerdasan Universal, AI Generasi Berikutnya Mungkin Berbasis Non-Generatif)
KTT Industri AIGC Tiongkok Segera Digelar (16 April, Beijing): KTT Industri AIGC Tiongkok ketiga akan diadakan di Beijing pada 16 April. KTT ini akan mengumpulkan lebih dari 20 pemimpin industri dari perusahaan dan institusi seperti Baidu, Huawei, AWS, Microsoft Research Asia, Mianbi Intelligence, Shengshu Technology, Fenbi, NetEase Youdao, Quwan Technology, Qingsong Health, untuk bersama-sama membahas kemajuan terbaru teknologi AI, penerapan di berbagai industri, infrastruktur daya komputasi, keamanan dan kontrol, serta isu inti lainnya. KTT ini bertujuan untuk menunjukkan bagaimana AI memberdayakan peningkatan industri, serta merilis penghargaan terkait dan “Peta Panorama Aplikasi AIGC Tiongkok”. (Sumber: Hitung Mundur 2 Hari! Lebih dari 20 Pemimpin Industri Membahas AI, Panduan Terlengkap KTT Industri AIGC Tiongkok Ada Di Sini)
Pembahasan Solusi Menjalankan Model Besar Skala Triliunan pada Kartu Grafis Berbiaya Rendah: Artikel ini membahas solusi membangun mesin AI all-in-one yang hemat biaya (tingkat 100.000 yuan) menggunakan kartu grafis Intel Arc™ (seperti A770) dan prosesor Xeon® W. Solusi ini melalui kolaborasi perangkat keras dan lunak (IPEX-LLM, OpenVINO™, oneAPI) yang dioptimalkan, mampu menjalankan model besar seperti QwQ-32B (kecepatan hingga 32 token/s) bahkan DeepSeek R1 671B (dengan optimasi FlashMoE, kecepatan mendekati 10 token/s) pada satu mesin. Ini memberikan pilihan hemat biaya bagi perusahaan untuk menyebarkan model besar secara lokal atau di lingkungan edge, memenuhi kebutuhan seperti inferensi offline dan keamanan data. Intel juga meluncurkan platform OPEA, bekerja sama dengan mitra ekosistem untuk mendorong standardisasi dan penyebaran aplikasi AI perusahaan. (Sumber: Memeras Habis Kartu Grafis 3000 Yuan, Resep Rahasia Menjalankan Model Besar Skala Triliunan Telah Tiba)
Robot Bedah Menunjukkan Operasi Presisi Tinggi: Video menunjukkan robot bedah mampu memisahkan cangkang telur puyuh mentah dari selaput tipis di dalamnya dengan presisi, mencerminkan tingkat kemajuan robot modern dalam operasi halus dan kontrol. (Sumber: Ronald_vanLoon)
Tinjauan Kemajuan Teknologi Litografi Semikonduktor: Merujuk pada artikel tentang konten konferensi SPIE Advanced Lithography + Patterning, membahas kemajuan terbaru dalam teknologi pembuatan chip generasi berikutnya termasuk High-NA EUV, biaya EUV, pembentukan pola, photoresist baru (oksida logam, kering), serta Hyper-NA. Teknologi ini sangat penting untuk mendukung pengembangan chip AI di masa depan. (Sumber: dylan522p)
Demonstrasi Keterampilan Presisi Robot Beroda: Video menunjukkan keterampilan gerakan atau operasi presisi tinggi dari robot beroda, mungkin melibatkan teknologi AI dan machine learning untuk kontrol dan persepsi. (Sumber: Ronald_vanLoon)