
Keywords:GPT-4.5, Model besar, Huawei Pangu Ultra, Detail pelatihan GPT-4.5, Pengaruh RLHF pada kemampuan penalaran, Penelitian batas belajar manusia 4GB, Dataset matematika open source MegaMath, Kinerja Huawei Pangu Ultra
🔥 Fokus
OpenAI Ungkap Detail dan Tantangan Pelatihan GPT-4.5: CEO OpenAI Sam Altman berdiskusi dengan tim inti teknis GPT-4.5, mengungkapkan detail pengembangan model. Proyek dimulai dua tahun lalu, melibatkan hampir seluruh tim, dan memakan waktu lebih lama dari perkiraan. Selama pelatihan, mereka menghadapi “masalah katastropik” seperti kegagalan cluster 100.000 kartu GPU dan bug tersembunyi, yang mengekspos hambatan infrastruktur tetapi juga mendorong peningkatan tumpukan teknologi (tech stack). Kini, hanya dibutuhkan 5-10 orang untuk mereplikasi model sekelas GPT-4. Tim percaya bahwa kunci peningkatan kinerja di masa depan adalah efisiensi data, bukan daya komputasi, sehingga perlu mengembangkan algoritma baru untuk belajar lebih banyak dari jumlah data yang sama. Arsitektur sistem beralih ke multi-cluster, dan di masa depan mungkin melibatkan kolaborasi jutaan GPU, menuntut toleransi kesalahan (fault tolerance) yang lebih tinggi. Diskusi juga mencakup Scaling Law, desain kolaboratif machine learning dan sistem, serta esensi unsupervised learning, menunjukkan pemikiran dan praktik OpenAI dalam mendorong penelitian model besar terdepan (Sumber: 36Kr)

Huawei Rilis Model Besar Dense Ascend Native 135B Pangu Ultra: Tim Pangu Huawei merilis model bahasa umum dense dengan 135 miliar parameter, Pangu Ultra, yang dilatih menggunakan NPU Ascend buatan dalam negeri. Model ini menggunakan struktur Transformer 94 lapis dan memperkenalkan teknologi Depth-scaled sandwich-norm (DSSN) serta inisialisasi TinyInit untuk mengatasi masalah stabilitas pelatihan model yang sangat dalam. Pelatihan stabil tanpa lonjakan loss (loss spike) dicapai pada data berkualitas tinggi sebesar 13,2T. Di tingkat sistem, melalui optimasi seperti hybrid parallelism, operator fusion, dan subsequence splitting, utilisasi daya komputasi (MFU) pada cluster Ascend 8192 kartu ditingkatkan hingga lebih dari 50%. Evaluasi menunjukkan Pangu Ultra melampaui model dense seperti Llama 405B dan Mistral Large 2 pada beberapa benchmark, serta mampu bersaing dengan model MoE skala lebih besar seperti DeepSeek-R1, membuktikan kelayakan pengembangan model besar terdepan berbasis daya komputasi domestik (Sumber: Jiqizhixin)

Penelitian Meragukan Signifikansi Peningkatan Kemampuan Penalaran LLM oleh Reinforcement Learning: Peneliti dari Universitas Tübingen dan Universitas Cambridge mempertanyakan klaim baru-baru ini bahwa Reinforcement Learning (RL) dapat secara signifikan meningkatkan kemampuan penalaran model bahasa. Melalui investigasi ketat pada benchmark penalaran umum (seperti AIME24), penelitian menemukan hasil yang sangat tidak stabil; hanya dengan mengubah random seed dapat menyebabkan skor berfluktuasi secara drastis. Di bawah evaluasi standar, peningkatan kinerja yang dibawa oleh RL jauh lebih kecil dari laporan asli, seringkali tidak signifikan secara statistik, bahkan lebih lemah dari efek Supervised Fine-Tuning (SFT), dan kemampuan generalisasinya juga lebih buruk. Penelitian menunjukkan bahwa perbedaan sampling, konfigurasi decoding, kerangka evaluasi, dan heterogenitas hardware adalah penyebab utama ketidakstabilan, dan menyerukan penggunaan standar evaluasi yang lebih ketat dan dapat direplikasi untuk menilai kemajuan nyata kemampuan penalaran model secara lebih objektif (Sumber: Jiqizhixin)

Pidato TED Altman: Akan Rilis Model Open-Source Kuat, Anggap ChatGPT Bukan AGI: CEO OpenAI Sam Altman menyatakan di konferensi TED bahwa mereka sedang mengembangkan model open-source yang kuat, yang kinerjanya akan melampaui semua model open-source yang ada saat ini, sebagai respons langsung terhadap pesaing seperti DeepSeek. Dia menekankan bahwa jumlah pengguna ChatGPT terus meningkat pesat, dan fungsi memori baru akan meningkatkan pengalaman personalisasi. Dia percaya AI akan membawa terobosan dalam penemuan ilmiah dan pengembangan perangkat lunak (peningkatan efisiensi sangat besar), tetapi model saat ini seperti ChatGPT belum memiliki kemampuan belajar mandiri berkelanjutan dan generalisasi lintas domain, sehingga bukan AGI. Dia juga membahas masalah hak cipta dan “hak gaya” yang ditimbulkan oleh kemampuan kreatif GPT-4o, serta menegaskan kembali keyakinan OpenAI pada keamanan model dan mekanisme kontrol risiko (Sumber: Xinzhiyuan)

Studi Sebut Batas Belajar Manusia Seumur Hidup Sekitar 4GB, Picu Diskusi BCI dan AI: Jurnal Neuron di bawah Cell menerbitkan penelitian Caltech yang memperkirakan kecepatan pemrosesan informasi otak manusia sekitar 10 bit per detik, jauh di bawah tingkat pengumpulan data sistem sensorik sebesar 1 miliar bit per detik. Berdasarkan ini, penelitian menyimpulkan batas atas akumulasi pengetahuan manusia seumur hidup (dengan asumsi 100 tahun belajar terus menerus tanpa lupa) adalah sekitar 4GB, jauh lebih kecil dari kapasitas penyimpanan parameter model besar (misalnya, model 7B dapat menyimpan 14 miliar bit). Studi berpendapat bahwa hambatan ini berasal dari mekanisme pemrosesan serial sistem saraf pusat dan memprediksi bahwa kecerdasan mesin melampaui manusia hanyalah masalah waktu. Penelitian ini juga mempertanyakan Neuralink milik Musk, berpendapat bahwa itu tidak dapat menembus batasan struktural dasar otak dan lebih baik mengoptimalkan metode komunikasi yang ada. Studi ini memicu diskusi luas tentang batas kognitif manusia, potensi pengembangan AI, dan arah antarmuka otak-komputer (brain-computer interface) (Sumber: QubitAI)

🎯 Tren
GPT-4 Segera Pensiun, GPT-4.1 dan Model Baru Misterius Mungkin Akan Muncul: OpenAI mengumumkan akan sepenuhnya menggantikan GPT-4 yang dirilis dua tahun lalu dengan GPT-4o di ChatGPT mulai 30 April; GPT-4 masih akan tersedia melalui API. Sementara itu, bocoran dari komunitas dan kode menunjukkan bahwa OpenAI mungkin akan segera merilis serangkaian model baru, termasuk GPT-4.1 (dan versi mini/nano-nya), model inferensi o3 versi penuh, serta seri o4 baru (seperti o4-mini). Sebuah model misterius bernama Optimus Alpha telah muncul di OpenRouter, menunjukkan kinerja yang sangat baik (terutama dalam pemrograman), mendukung konteks jutaan token, dan banyak diduga sebagai salah satu model baru yang akan dirilis OpenAI (mungkin GPT-4.1 atau o4-mini), yang memiliki banyak kesamaan (seperti bug spesifik) dengan model OpenAI. Ini menandakan percepatan iterasi model OpenAI, yang secara aktif mengkonsolidasikan posisi kepemimpinan teknologinya (Sumber: source, source)

Model Besar Alibaba Qwen3 Siap Diluncurkan: Kabar menyebutkan Alibaba diperkirakan akan merilis model besar Qwen3 dalam waktu dekat. Tim R&D mengonfirmasi model tersebut telah memasuki tahap persiapan akhir, tetapi waktu rilis spesifik belum ditentukan. Diketahui, Qwen3 adalah produk model penting Alibaba untuk paruh pertama tahun 2025, pengembangannya dimulai setelah Qwen2.5. Dipengaruhi oleh model pesaing seperti DeepSeek-R1, tim model dasar Alibaba Cloud semakin mengarahkan fokus strategisnya untuk meningkatkan kemampuan penalaran model, menunjukkan fokus strategis pada kemampuan spesifik di tengah lanskap persaingan model besar (Sumber: InfoQ)

Platform Terbuka Kimi Turunkan Harga dan Rilis Model Visual Ringan Open-Source: Platform terbuka Kimi di bawah naungan Moonshot AI mengumumkan penurunan harga untuk layanan inferensi model dan cache konteks, bertujuan untuk mengurangi biaya pengguna melalui optimasi teknis. Sementara itu, Kimi merilis dua model bahasa visual ringan berbasis arsitektur MoE secara open-source, yaitu Kimi-VL dan Kimi-VL-Thinking, yang mendukung konteks 128K dengan parameter aktif hanya sekitar 3 miliar. Model ini diklaim secara signifikan mengungguli model besar dengan parameter 10 kali lipat dalam kemampuan penalaran multimodal, bertujuan untuk mendorong pengembangan dan penerapan model multimodal kecil yang efisien (Sumber: InfoQ)
Google Rilis Protokol Interoperabilitas Agent A2A dan Beberapa Produk AI Baru: Di konferensi Google Cloud Next ’25, Google bersama lebih dari 50 mitra meluncurkan protokol terbuka Agent2Agent (A2A), yang bertujuan untuk memungkinkan interoperabilitas dan kolaborasi antara agent AI yang dikembangkan oleh perusahaan dan platform yang berbeda. Google juga merilis beberapa model dan aplikasi AI baru, termasuk Gemini 2.5 Flash (model flagship versi efisien), Lyria (teks-ke-musik), Veo 2 (pembuatan video), Imagen 3 (pembuatan gambar), Chirp 3 (suara kustom), serta meluncurkan chip TPU generasi ketujuh, Ironwood, yang dioptimalkan khusus untuk inferensi. Rangkaian rilis ini mencerminkan tata letak komprehensif dan strategi terbuka Google dalam infrastruktur AI, model, platform, dan agent (Sumber: InfoQ)
ByteDance Rilis Model Inferensi 200B Parameter Seed-Thinking-v1.5: Tim Doubao ByteDance merilis laporan teknis yang memperkenalkan model inferensi MoE mereka, Seed-Thinking-v1.5, dengan total 200 miliar parameter. Model ini mengaktifkan 20 miliar parameter setiap kali inferensi dan menunjukkan kinerja yang sangat baik di beberapa benchmark, diklaim melampaui DeepSeek-R1 yang memiliki total 671 miliar parameter. Komunitas berspekulasi bahwa ini mungkin model yang digunakan dalam mode “pemikiran mendalam” di aplikasi ByteDance Doubao saat ini, menunjukkan kemajuan ByteDance dalam pengembangan model inferensi yang efisien (Sumber: InfoQ)
Midjourney Rilis Model V7, Tingkatkan Kualitas Gambar dan Efisiensi Generasi: Alat generasi gambar AI Midjourney merilis model barunya, V7 (versi alpha). Versi baru ini meningkatkan koherensi dan konsistensi generasi gambar, terutama pada detail tangan, bagian tubuh, dan objek, serta mampu menghasilkan tekstur yang lebih realistis dan kaya. V7 memperkenalkan Draft Mode, yang mencapai kecepatan render sepuluh kali lipat dengan setengah biaya, cocok untuk eksplorasi iteratif cepat. Tersedia juga mode generasi turbo (lebih cepat tapi lebih mahal) dan relax (lebih lambat tapi lebih murah) untuk memenuhi kebutuhan pengguna yang berbeda (Sumber: InfoQ)
Amazon Luncurkan Model Suara AI Nova Sonic: Amazon merilis model AI generatif generasi baru yang memproses suara secara native, Nova Sonic. Diklaim, model ini dapat menandingi model suara teratas dari OpenAI dan Google dalam metrik kunci seperti kecepatan, pengenalan suara, dan kualitas percakapan. Nova Sonic ditawarkan melalui platform pengembang Amazon Bedrock, menggunakan API streaming dua arah baru untuk akses, dan harganya sekitar 80% lebih murah dari GPT-4o, bertujuan untuk menyediakan kemampuan interaksi suara alami yang hemat biaya untuk aplikasi AI tingkat perusahaan (Sumber: InfoQ)
Fitur AI iPhone Versi China Mungkin Hadir Pertengahan Tahun, Integrasikan Teknologi Baidu dan Alibaba: Laporan menyebutkan Apple berencana memperkenalkan layanan Apple Intelligence untuk pasar iPhone di China (kemungkinan di iOS 18.5) sebelum pertengahan 2025. Fitur ini akan memanfaatkan model besar Baidu Ernie Bot untuk menyediakan kemampuan cerdas dan mengintegrasikan mesin sensor Alibaba untuk mematuhi persyaratan regulasi konten. Apple tidak menandatangani perjanjian eksklusif dengan Baidu atau Alibaba, menunjukkan strategi kerja sama lokalnya di pasar utama untuk menerapkan fitur AI dengan cepat (Sumber: InfoQ)
🧰 Alat
Volcano Engine Rilis Data Agent untuk Kecerdasan Data Perusahaan: Volcano Engine meluncurkan Data Agent tingkat perusahaan. Alat ini memanfaatkan kemampuan penalaran, analisis, dan pemanggilan alat dari model besar untuk memahami kebutuhan bisnis perusahaan secara mendalam, mengotomatiskan tugas analisis dan aplikasi data yang kompleks seperti menulis laporan penelitian mendalam dan merancang kampanye pemasaran, serta meningkatkan efisiensi pemanfaatan data dan pengambilan keputusan perusahaan (Sumber: InfoQ)
Gaya Baru Generasi Gambar GPT-4o Menarik Perhatian: Pengguna media sosial menunjukkan gaya baru yang dibuat menggunakan fungsi generasi gambar GPT-4o, misalnya menggabungkan elemen antarmuka retro Windows 2000 dengan gambar karakter untuk menghasilkan efek kolase yang unik. Pengguna berbagi tips prompt, seperti menggunakan gambar referensi (垫图), menggabungkan deskripsi gaya dan konten, memicu minat komunitas untuk mengeksplorasi potensi kreatif GPT-4o (Sumber: source, source)

📚 Pembelajaran
Dataset Pra-Pelatihan Matematika Open-Source Terbesar MegaMath Dirilis: LLM360 meluncurkan MegaMath, sebuah dataset pra-pelatihan penalaran matematika open-source yang berisi 371 miliar token, melampaui skala DeepSeek-Math Corpus. Dataset ini mencakup halaman web padat matematika (279B), kode terkait matematika (28B), dan data sintetis berkualitas tinggi (64B). Tim memastikan skala, kualitas, dan keragaman data melalui alur pemrosesan data yang disempurnakan, termasuk optimasi struktur HTML, ekstraksi dua tahap, penyaringan dan pemurnian yang dibantu LLM. Validasi pra-pelatihan pada model Llama-3.2 menunjukkan bahwa penggunaan MegaMath dapat membawa peningkatan absolut 15-20% pada benchmark seperti GSM8K dan MATH, menyediakan dasar pelatihan kemampuan penalaran matematika yang kuat untuk komunitas open-source (Sumber: Jiqizhixin)

Nabla-GFlowNet: Menyeimbangkan Keanekaragaman dan Efisiensi dalam Fine-Tuning Model Difusi: Peneliti dari CUHK (Shenzhen) dan institusi lain mengusulkan Nabla-GFlowNet, metode baru untuk fine-tuning berbasis reward pada model difusi menggunakan Generative Flow Networks (GFlowNet). Metode ini bertujuan untuk mengatasi masalah konvergensi lambat pada fine-tuning RL tradisional dan masalah overfitting serta hilangnya keanekaragaman pada optimasi reward langsung. Dengan menurunkan kondisi keseimbangan aliran baru (Nabla-DB) dan merancang fungsi loss spesifik serta parameterisasi gradien aliran logaritmik, Nabla-GFlowNet dapat secara efisien menyelaraskan model dengan fungsi reward (seperti skor estetika, kepatuhan instruksi) sambil mempertahankan keanekaragaman sampel yang dihasilkan. Eksperimen pada Stable Diffusion menunjukkan keunggulannya dibandingkan metode seperti DDPO, ReFL, dan DRaFT (Sumber: Jiqizhixin)
Llama.cpp Memperbaiki Masalah Terkait Llama 4: Proyek llama.cpp menggabungkan dua perbaikan untuk model Llama 4, yang melibatkan Rotary Position Embedding (RoPE) dan perhitungan norma (norms) yang salah. Perbaikan ini bertujuan untuk meningkatkan kualitas output model, tetapi pengguna mungkin perlu mengunduh ulang file model GGUF yang dihasilkan oleh alat konversi setelah perbaikan agar efektif (Sumber: source)
💼 Bisnis
Nvidia Selesaikan Akuisisi Lepton AI: Dilaporkan bahwa Nvidia telah mengakuisisi Lepton AI, sebuah startup infrastruktur AI yang didirikan oleh mantan Wakil Presiden Alibaba, Jia Yangqing, dengan nilai transaksi yang mungkin mencapai ratusan juta dolar. Bisnis utama Lepton AI adalah menyewakan server GPU Nvidia dan menyediakan perangkat lunak untuk membantu perusahaan membangun dan mengelola aplikasi AI. Jia Yangqing dan salah satu pendirinya, Bai Junjie, bersama sekitar 20 karyawan lainnya telah bergabung dengan Nvidia. Langkah ini dipandang sebagai penyebaran strategis Nvidia untuk memperluas pasar layanan cloud dan perangkat lunak perusahaan, serta menghadapi persaingan dari chip yang dikembangkan sendiri oleh AWS, Google Cloud, dan lainnya (Sumber: InfoQ)
Kecemasan Melanda Industri Teknologi AS, AI Mengguncang Pasar Kerja: Laporan menunjukkan bahwa industri teknologi AS sedang mengalami kesulitan dengan pengurangan posisi, penurunan gaji, dan perpanjangan siklus pencarian kerja. PHK massal, perusahaan (seperti Salesforce, Meta, Google) yang menggunakan AI untuk menggantikan tenaga manusia atau menangguhkan perekrutan (terutama untuk posisi teknik dan entry-level) memperburuk kecemasan karir para profesional. Data menunjukkan peningkatan proporsi orang yang melaporkan penurunan gaji dan beralih dari posisi manajerial ke posisi kontributor individu. AI sedang membentuk kembali pasar kerja, memaksa pencari kerja untuk memperluas wawasan ke industri non-teknologi atau beralih ke kewirausahaan. Para ahli menyarankan untuk memperhatikan peluang kerja di luar “Tujuh Raksasa” dan menguasai alat AI untuk meningkatkan daya saing (Sumber: InfoQ)

Rumor OpenAI Akan Akuisisi Perusahaan Hardware AI Hasil Kolaborasi Altman & Jony Ive: Kabar menyebutkan OpenAI sedang mendiskusikan akuisisi senilai tidak kurang dari $500 juta terhadap io Products, perusahaan AI yang didirikan oleh CEO-nya, Sam Altman, bekerja sama dengan mantan Direktur Desain Apple, Jony Ive. Perusahaan ini bertujuan mengembangkan perangkat pribadi yang digerakkan oleh AI, dengan kemungkinan bentuk berupa “ponsel” tanpa layar atau perangkat rumah tangga. Tim insinyur io Products membangun perangkat, OpenAI menyediakan teknologi, studio Ive bertanggung jawab atas desain, dan Altman terlibat secara mendalam. Jika akuisisi selesai, tim hardware ini akan diintegrasikan ke dalam OpenAI, mempercepat ekspansinya di bidang hardware AI (Sumber: InfoQ)
Startup Mantan CTO OpenAI Kembali Merekrut dari Perusahaan Lama: Perusahaan AI “思维机器实验室” (Laboratorium Mesin Berpikir) yang didirikan oleh mantan CTO OpenAI, Mira Murati, menarik dua tokoh kunci mantan OpenAI untuk bergabung dengan tim penasihatnya: mantan Chief Research Officer Bob McGrew dan mantan peneliti Alec Radford. Radford adalah penulis utama makalah teknis inti seri GPT. Perekrutan ini semakin memperkuat kekuatan teknis startup tersebut dan juga mencerminkan persaingan talenta yang ketat di bidang AI (Sumber: InfoQ)
Baichuan Intelligent Sesuaikan Fokus Bisnis, Fokus pada Bidang Medis: Pendiri Baichuan Intelligent, Wang Xiaochuan, dalam surat internal pada ulang tahun kedua perusahaan, menegaskan kembali bahwa perusahaan akan fokus pada bidang medis, mengembangkan layanan aplikasi seperti Baixiaoying, AI Pediatri, AI Dokter Umum, dan Pengobatan Presisi. Dia menekankan perlunya mengurangi tindakan yang tidak perlu dan struktur organisasi akan dibuat lebih datar. Sebelumnya, perusahaan dilaporkan membubarkan tim B2B industri keuangan, mitra bisnis Deng Jiang mengundurkan diri, dan beberapa co-founder lainnya telah atau akan segera mengundurkan diri, menunjukkan bahwa perusahaan sedang mengalami fokus strategis dan penyesuaian organisasi (Sumber: InfoQ)
Alibaba Cloud Luncurkan Program Mitra Ekosistem AI “Fan Hua”: Alibaba Cloud merilis program “Fan Hua” (繁花), yang bertujuan untuk mendukung mitra ekosistem AI. Program ini akan menyediakan sumber daya cloud, dukungan daya komputasi, bundling produk, perencanaan komersialisasi, dan layanan siklus hidup penuh berdasarkan tingkat kematangan produk mitra. Sementara itu, Alibaba Cloud meluncurkan pasar aplikasi dan layanan AI, bertujuan untuk membangun ekosistem AI yang berkembang pesat dan mempercepat penerapan teknologi dan aplikasi AI (Sumber: InfoQ)
Kugou Music Jalin Kerjasama Mendalam dengan DeepSeek: Kugou Music mengumumkan kerjasama dengan perusahaan AI DeepSeek untuk meluncurkan serangkaian fitur inovatif berbasis AI. Ini termasuk penggunaan analisis multimodal untuk menghasilkan laporan mendengarkan yang dipersonalisasi, rekomendasi harian AI, pencarian cerdas, manajemen playlist AI, pembuatan sampul dinamis AI, serta “AI Commentator” dengan pengaturan peran, yang bertujuan untuk meningkatkan pengalaman musik pengguna dan interaksi komunitas melalui teknologi AI (Sumber: InfoQ)
Rumor Google Gunakan Perjanjian Non-Kompetisi “Agresif” untuk Pertahankan Talenta AI: Laporan menyebutkan bahwa DeepMind milik Google menerapkan perjanjian non-kompetisi selama satu tahun pada beberapa karyawan di Inggris untuk mencegah talenta pindah ke pesaing. Selama periode ini, karyawan tidak perlu bekerja tetapi tetap menerima gaji (cuti berbayar), tetapi hal ini membuat beberapa peneliti merasa terpinggirkan dan tidak dapat berpartisipasi dalam kemajuan industri yang cepat. Langkah ini mungkin dilarang oleh FTC di AS, tetapi berlaku di kantor pusat London, memicu diskusi tentang persaingan talenta dan pembatasan inovasi (Sumber: InfoQ)
Mantan Karyawan OpenAI Ajukan Dokumen Hukum Dukung Gugatan Musk: 12 mantan karyawan OpenAI mengajukan dokumen hukum untuk mendukung gugatan Elon Musk terhadap OpenAI. Mereka berpendapat bahwa rencana restrukturisasi OpenAI (beralih ke struktur for-profit) dapat secara fundamental melanggar misi nirlaba awal perusahaan, yang merupakan faktor kunci yang menarik mereka untuk bergabung. OpenAI menanggapi bahwa meskipun ada perubahan struktur, misinya tidak akan berubah (Sumber: InfoQ)
🌟 Komunitas
Studi Anthropic Ungkap Pola Aplikasi dan Tantangan AI di Pendidikan Tinggi: Anthropic menganalisis jutaan percakapan siswa anonim di platform Claude.ai, menemukan bahwa siswa di bidang STEM (terutama jurusan komputer) adalah pengguna awal AI. Pola interaksi siswa dengan AI mencakup empat jenis: penyelesaian masalah langsung, pembuatan konten langsung, penyelesaian masalah kolaboratif, dan pembuatan konten kolaboratif, dengan proporsi yang seimbang. AI terutama digunakan untuk tugas kognitif tingkat tinggi seperti kreasi (misalnya, pemrograman, menulis soal latihan) dan analisis (misalnya, menjelaskan konsep). Studi ini juga mengungkap potensi pelanggaran akademik (seperti mendapatkan jawaban, menghindari deteksi plagiarisme), menimbulkan kekhawatiran tentang integritas akademik, pengembangan pemikiran kritis, dan metode evaluasi (Sumber: Xinzhiyuan)

Generasi Gambar GPT-4o Pimpin Tren Baru: Dari Gaya Ghibli hingga Kartu Tokoh AI: Kemampuan generasi gambar GPT-4o yang kuat terus memicu gelombang kreativitas di media sosial. Setelah “foto keluarga gaya Ghibli” menjadi viral (didorong oleh mantan insinyur Amazon Grant Slatton), pengguna mulai membuat kartu gaya “Magic: The Gathering” untuk tokoh-tokoh terkenal di bidang AI (seperti Altman yang ditetapkan sebagai “Penguasa AGI”), serta kartu tarot yang dipersonalisasi. Kasus-kasus ini menunjukkan potensi AI dalam imitasi gaya artistik dan generasi kreatif, tetapi juga menimbulkan diskusi tentang orisinalitas, hak cipta, nilai estetika, dan dampak AI pada profesi desainer (Sumber: Xinzhiyuan)

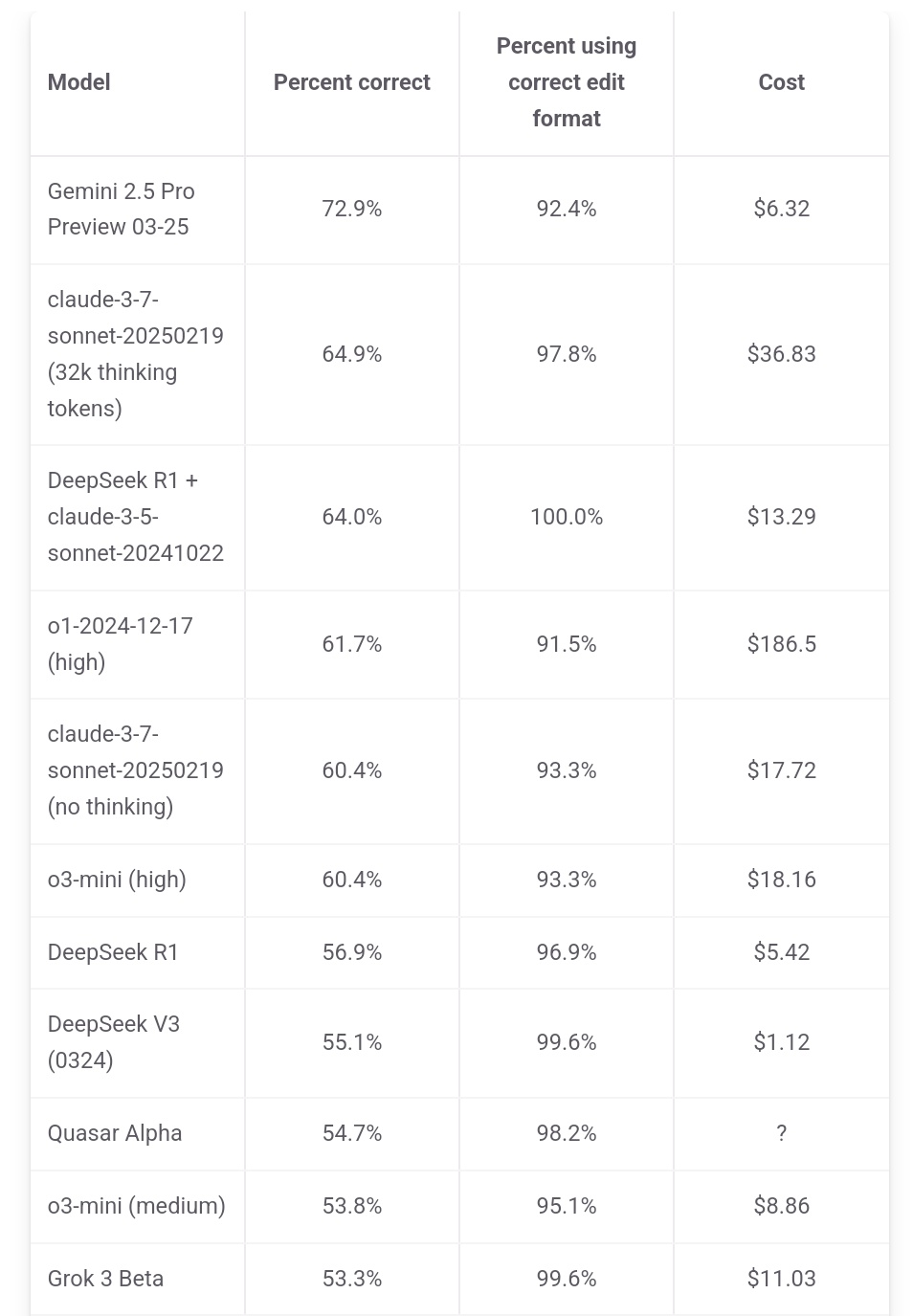
Jeff Dean Tekankan Keunggulan Biaya Gemini 2.5 Pro: Kepala AI Google Jeff Dean membagikan data peringkat dari aider.chat, menunjukkan bahwa Gemini 2.5 Pro tidak hanya unggul dalam kinerja pada benchmark pemrograman Polyglot tetapi juga biayanya ($6) secara signifikan lebih rendah daripada model Top 10 lainnya kecuali DeepSeek, menekankan keunggulan rasio harga-kinerjanya. Biaya beberapa model pesaing mencapai 2x, 3x, bahkan 30x lipat dari Gemini 2.5 Pro (Sumber: JeffDean)
Reddit Ramai Bahas Dampak AI pada Pasar Kerja, Terutama Posisi Entry-Level: Sebuah postingan di forum Reddit memicu diskusi panas. Pembuat postingan (seorang mahasiswa S2 CIS) mengungkapkan keprihatinan mendalam tentang AI yang menggantikan pekerjaan non-fisik entry-level (terutama rekayasa perangkat lunak, analisis data, dukungan IT), berpendapat bahwa narasi “AI tidak akan merebut pekerjaan” mengabaikan kesulitan lulusan baru. Dia menunjukkan bahwa perusahaan besar telah mengurangi perekrutan kampus, dan pasar kerja di masa depan mungkin suram. Komentar terbagi; ada yang setuju dengan krisis tersebut, ada yang menganggapnya sebagai norma perubahan teknologi yang membutuhkan adaptasi ke peran baru (seperti mengelola tim AI), dan ada pula yang meragukan klaim “90% pekerjaan hilang”, berpendapat bahwa siklus ekonomi dan situasi negara yang berbeda sangat bervariasi, dan kemampuan AI saat ini masih terbatas (Sumber: source)
Pengguna Claude Keluhkan Penurunan Kinerja dan Pembatasan yang Diperketat: Subreddit ClaudeAI mengalami diskusi terpusat, di mana banyak pengguna (termasuk pengguna Pro) melaporkan menghadapi batasan penggunaan (kuota) yang lebih ketat baru-baru ini, bahkan operasi rutin sering mencapai batas. Beberapa pengguna percaya Anthropic secara diam-diam memperketat kuota dan menyatakan ketidakpuasan, berpendapat ini akan memaksa pengguna beralih ke pesaing. Selain itu, beberapa pengguna melaporkan bahwa “kepribadian” Claude tampaknya berubah, menjadi lebih “dingin”, “mekanis”, kehilangan nuansa filosofis dan puitis dari versi awal, menyebabkan beberapa pengguna membatalkan langganan (Sumber: source, source, source, source)
Generasi Gambar ChatGPT Picu Minat dan Diskusi: Pengguna Reddit berbagi berbagai upaya dan hasil menggunakan ChatGPT untuk generasi gambar. Seseorang meminta untuk “mengubah” anjing menjadi manusia, menghasilkan gambar yang mirip “furry”, memicu diskusi tentang pemahaman prompt dan potensi bias. Pengguna lain meminta untuk digambarkan sebagai jendela kaca patri versi multiverse, dengan hasil yang menakjubkan. Ada juga pengguna yang meminta untuk menghasilkan gambar metaforis tentang AI, atau menanyakan “mimpi buruk” AI, menunjukkan kemampuan dan keterbatasan generasi gambar AI dalam ekspresi kreatif dan visualisasi konsep abstrak (Sumber: source, source, source, source, source)

Komunitas Bahas Pemilihan Model LLM dan Strategi Penggunaan: Subreddit LocalLLaMA mengusulkan diskusi penggunaan model bulanan untuk berbagi model terbaik (open-source dan closed-source) yang digunakan dalam berbagai skenario (coding, menulis, riset, dll.) beserta alasannya. Pengguna di kolom komentar berbagi kombinasi model yang mereka gunakan saat ini, seperti Deepseek V3.1/Gemini 2.5 Pro/4o/R1/Qwen 2.5 Max/Sonnet 3.7/Gemma 3/Claude 3.7/Mistral Nemo, dll., dan menyebutkan penggunaan spesifik (seperti pemanggilan alat, klasifikasi, role-playing), mencerminkan tren pengguna memilih dan menggabungkan model yang berbeda sesuai kebutuhan tugas (Sumber: source)
💡 Lainnya
Konferensi Industri AIGC China Segera Digelar: Konferensi Industri AIGC China ke-3 akan diadakan di Beijing pada 16 April. Konferensi ini akan mengumpulkan lebih dari 20 pemimpin industri dari perusahaan seperti Baidu, Huawei, Microsoft Research Asia, Amazon Web Services, Zhipu AI, ShengShu Technology, untuk membahas terobosan teknologi AI (daya komputasi, model besar), aplikasi industri (pendidikan, hiburan, penelitian, layanan perusahaan), pembangunan ekosistem (keamanan terkendali, tantangan implementasi), dan isu-isu lainnya. Konferensi ini juga akan merilis daftar perusahaan/produk AIGC dan peta lanskap aplikasi AIGC China (Sumber: QubitAI)

Laporan Stanford: Kesenjangan Kinerja Model AI Teratas China-AS Menyempit Jadi 0,3%: Laporan Indeks AI 2025 yang dirilis oleh Universitas Stanford menunjukkan bahwa kesenjangan kinerja antara model AI teratas China dan AS telah menyempit secara signifikan dari 20% pada tahun 2023 menjadi 0,3%. Meskipun AS masih memimpin dalam jumlah model terkenal (40 vs 15) dan perusahaan dominan industri, kecepatan model China dalam mengejar ketertinggalan semakin cepat. Laporan tersebut juga menunjukkan bahwa kesenjangan kinerja antara model-model teratas juga menyempit, turun dari 12% pada tahun 2024 menjadi 5%, menunjukkan fenomena konvergensi yang jelas (Sumber: InfoQ)