
Mots-clés:Kimi K2 Thinking, Gemini, Agent IA, LLM (Modèle de Langage Large), Modèles open source, Kimi K2 Thinking 256K contexte, Gemini 1.2 trillion de paramètres, Appel d’outils par agent IA, Accélération d’inférence LLM, Benchmark de modèles IA open source
🔥 À la une
Lancement du modèle Kimi K2 Thinking : une nouvelle percée dans les capacités d’inférence de l’IA open source : Moonshot AI a lancé le modèle Kimi K2 Thinking, un modèle d’agent d’inférence open source à un billion de paramètres. Il excelle dans les benchmarks HLE et BrowseComp, prend en charge une fenêtre contextuelle de 256K et peut exécuter 200 à 300 appels d’outils consécutifs. Le modèle réalise une accélération d’inférence de deux fois avec une quantification INT4, réduisant de moitié l’utilisation de la mémoire sans perte de précision. Cela marque une nouvelle frontière pour les modèles d’IA open source en matière de capacités d’inférence et d’agent, rivalisant avec les meilleurs modèles propriétaires à un coût inférieur, ce qui devrait accélérer le développement et la popularisation des applications d’IA. (Source: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

Apple et Google s’associent : Gemini pour une mise à niveau majeure de Siri : Apple prévoit d’intégrer le modèle d’IA Gemini 1,2 billion de paramètres de Google dans iOS 26.4, dont la sortie est prévue au printemps 2026, pour une mise à niveau complète de Siri. Cette version personnalisée de Gemini fonctionnera via les serveurs cloud privés d’Apple et vise à améliorer considérablement la compréhension sémantique, les conversations multi-tours et les capacités de recherche d’informations en temps réel de Siri, tout en intégrant une fonction de recherche web basée sur l’IA. Cette initiative marque un changement stratégique important pour Apple, qui recherche des collaborations externes dans le domaine de l’IA pour accélérer l’intelligence de ses produits phares, annonçant un bond fonctionnel majeur pour Siri. (Source: op7418, pmddomingos, TheRundownAI)

Le scientifique Kosmos AI réalise un bond en efficacité de recherche, avec 7 découvertes indépendantes : Le scientifique Kosmos AI a accompli en 12 heures l’équivalent de 6 mois de travail pour un scientifique humain, en lisant 1 500 articles, en exécutant 42 000 lignes de code et en produisant des rapports scientifiques traçables. Il a réalisé 7 découvertes indépendantes dans des domaines tels que la neuroprotection et la science des matériaux, dont 4 sont des premières. Le système, grâce à une mémoire continue et une planification autonome, est passé d’un outil passif à un collaborateur de recherche. Bien qu’il nécessite encore une validation humaine pour environ 20 % des conclusions, cela annonce une refonte du paradigme de la recherche par la collaboration homme-machine. (Source: Reddit r/MachineLearning, iScienceLuvr)
🎯 Tendances
Le modèle Google Gemini 3 Pro aurait fuité, suscitant l’attention de la communauté : Le modèle Google Gemini 3 Pro aurait fuité accidentellement et a été brièvement disponible dans le Gemini CLI pour les adresses IP américaines, mais avec des erreurs fréquentes et une instabilité. Cette fuite a suscité un vif intérêt de la communauté concernant le nombre de paramètres du modèle et sa future publication, annonçant la divulgation imminente des dernières avancées de Google dans le domaine des grands modèles linguistiques. (Source: op7418)
Le modèle OpenAI GPT-5.1 Thinking bientôt lancé, forte attente de la communauté : Plusieurs sources sur les réseaux sociaux suggèrent qu’OpenAI est sur le point de lancer le modèle GPT-5.1 Thinking, avec des informations confirmant son existence. Cette nouvelle a généré une forte attente au sein de la communauté concernant les capacités du modèle de nouvelle génération d’OpenAI et sa date de sortie, en particulier son amélioration des capacités de raisonnement et de réflexion, ce qui devrait repousser les frontières de la technologie de l’IA. (Source: scaling01)
Anthropic découvre une conscience introspective émergente dans les LLM, l’auto-perception de l’IA suscite l’attention : Grâce à des expériences d’injection de concepts, Anthropic a découvert que ses LLM (tels que Claude Opus 4.1 et 4) présentent une conscience introspective émergente, capable de détecter les concepts injectés avec un taux de réussite de 20 %, de distinguer la “pensée” interne de l’entrée textuelle et d’identifier l’intention de sortie. Les modèles peuvent également réguler leur état interne lorsqu’ils sont sollicités, indiquant l’émergence d’une auto-conscience mécanique diversifiée et peu fiable dans les LLM actuels, ce qui soulève des discussions approfondies sur l’auto-perception et la conscience de l’IA. (Source: TheTuringPost)

OpenAI Codex s’améliore rapidement, ChatGPT prend en charge l’interruption et le guidage pour une efficacité d’interaction accrue : Le modèle Codex d’OpenAI s’améliore rapidement, et ChatGPT a également ajouté une nouvelle fonctionnalité permettant aux utilisateurs d’interrompre et d’ajouter un nouveau contexte pendant l’exécution de requêtes longues, sans avoir à recommencer ou à perdre leur progression. Cette mise à jour majeure permet aux utilisateurs de guider et d’affiner les réponses de l’IA comme ils le feraient avec un véritable coéquipier, améliorant considérablement la flexibilité et l’efficacité de l’interaction, et optimisant l’expérience utilisateur pour la recherche approfondie et les requêtes complexes. (Source: nickaturley, nickaturley)
Tencent Hunyuan lance un podcast IA interactif, explorant un nouveau mode d’interaction de contenu IA : Tencent Hunyuan a lancé le premier podcast IA interactif en Chine, permettant aux utilisateurs d’interrompre et de poser des questions à tout moment pendant l’écoute. L’IA fournit des réponses en combinant le contexte, les informations de fond et la recherche en ligne. Bien que la technologie ait permis une interaction vocale plus naturelle, son cœur reste l’interaction entre l’utilisateur et l’IA, plutôt qu’avec le créateur, et les réponses ne sont pas directement liées au créateur. La commercialisation et le modèle de monétisation pour les utilisateurs restent un défi, nécessitant d’explorer comment établir un lien émotionnel entre les utilisateurs et les créateurs. (Source: 36氪)
Développement et défis du marché du matériel IA et de l’IA incarnée : des écouteurs aux robots humanoïdes : Avec la maturité des grands modèles et des technologies multimodales, le marché des écouteurs IA continue de croître, étendant ses fonctionnalités à l’écosystème de contenu et à la surveillance de la santé. L’industrie des robots à IA incarnée est également à l’aube d’une nouvelle vague d’expansion. Des entreprises comme Xpeng et PHYBOT présentent des robots humanoïdes, clarifiant les doutes sur la “dissimulation d’humains” et explorant des applications dans les soins aux personnes âgées, la préservation culturelle (comme la calligraphie, le kung-fu). Cependant, l’industrie est confrontée à des défis tels que les coûts, le retour sur investissement, la collecte de données et les goulots d’étranglement de la normalisation. À court terme, il est nécessaire de se concentrer de manière pragmatique sur la “généralisation des scénarios”, et à long terme, sur les plateformes ouvertes et la collaboration écosystémique. Dans le domaine de la santé, l’IA doit également s’attaquer aux lacunes en matière de soins aux patients. (Source: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

Nouveaux modèles et percées de performance : génération de code Qwen3-Next, modèles hybrides vLLM et inférence à faible mémoire : Le modèle Qwen3-Next d’Alibaba Cloud excelle dans la génération de code complexe, créant avec succès des applications Web entièrement fonctionnelles. vLLM prend désormais entièrement en charge les modèles hybrides tels que Qwen3-Next, Nemotron Nano 2 et Granite 4.0, améliorant l’efficacité de l’inférence. Le modèle Jamba Reasoning 3B d’AI21 Labs fonctionne avec une mémoire ultra-faible de 2,25 GiB. Maya-research/maya1 a lancé une nouvelle génération de modèles de synthèse vocale auto-régressifs, prenant en charge la personnalisation du timbre vocal via des descriptions textuelles. TabPFN-2.5 étend ses capacités de traitement des données tabulaires à 50 000 échantillons. Le modèle Windsurf SWE-1.5 est analysé comme étant plus proche de GLM-4.5, suggérant l’application de grands modèles nationaux dans la Silicon Valley. MiniMax AI se classe deuxième dans l’arène RockAlpha. Ces avancées repoussent collectivement les limites de performance des LLM dans des domaines tels que la génération de code, l’efficacité de l’inférence, le multimodal et le traitement des données tabulaires. (Source: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

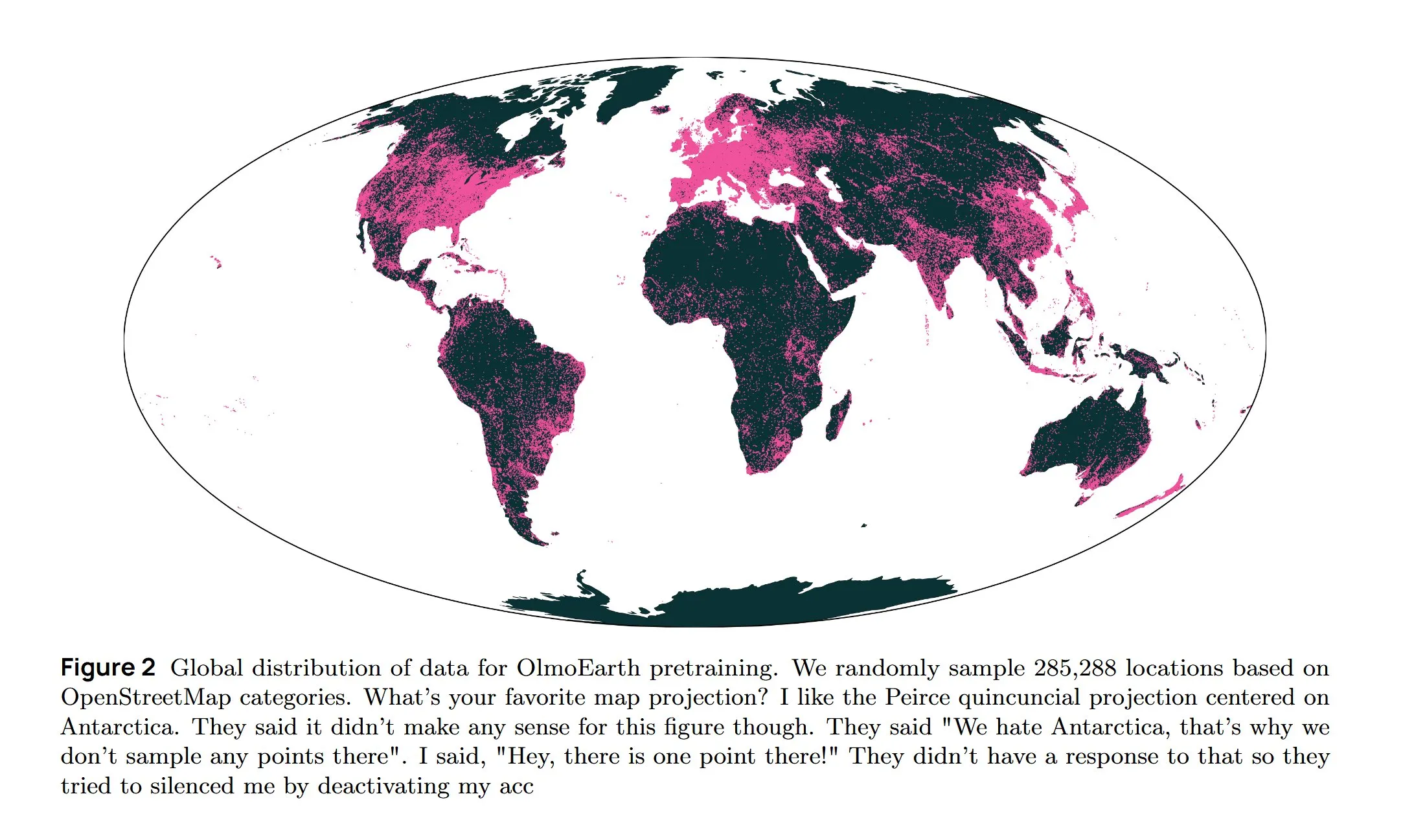
Infrastructure IA et recherche de pointe : refroidissement AWS, LLM diffusifs et architecture multilingue : Amazon AWS lance le système de refroidissement liquide In-Row Heat Exchanger (IRHX) pour relever les défis de dissipation thermique de l’infrastructure IA. Joseph Redmon retourne à la recherche en IA et publie le document OlmoEarth, explorant les modèles de fondation pour l’observation de la Terre. Meta AI publie une nouvelle architecture “Mixture of Languages” pour optimiser l’entraînement des modèles multilingues. L’équipe Inception réalise des LLM diffusifs, augmentant la vitesse de génération de 10 fois. Google DeepMind AlphaEvolve est utilisé pour l’exploration mathématique à grande échelle. Le modèle Wan 2.2, optimisé par NVFP4, améliore la vitesse d’inférence de 8 %. Ces avancées stimulent collectivement l’efficacité de l’infrastructure IA et l’innovation dans les domaines de recherche fondamentaux. (Source: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

La technologie Neuralink BCI permet aux utilisateurs paralysés de contrôler un bras robotique : La technologie d’interface cerveau-ordinateur (BCI) de Neuralink a réussi à permettre à des utilisateurs paralysés de contrôler un bras robotique par la pensée. Cette avancée révolutionnaire annonce l’énorme potentiel de l’IA dans les domaines de l’assistance médicale et de l’interaction homme-machine, et pourrait à l’avenir être combinée avec des robots d’assistance à la vie, améliorant considérablement la qualité de vie et l’autonomie des personnes handicapées. (Source: Ronald_vanLoon)
🧰 Outils
Google Gemini Computer Use Preview Model lancé, permettant l’automatisation de l’interaction web par l’IA : Google a lancé le modèle Gemini Computer Use Preview, que les utilisateurs peuvent exécuter via une interface en ligne de commande (CLI), lui permettant d’effectuer des opérations de navigateur, comme la recherche de “Hello World” sur Google. Cet outil prend en charge les environnements Playwright et Browserbase et peut être configuré via l’API Gemini ou Vertex AI, fournissant une base pour les agents IA afin de réaliser des interactions web automatisées, étendant considérablement les capacités des LLM dans les applications pratiques. (Source: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

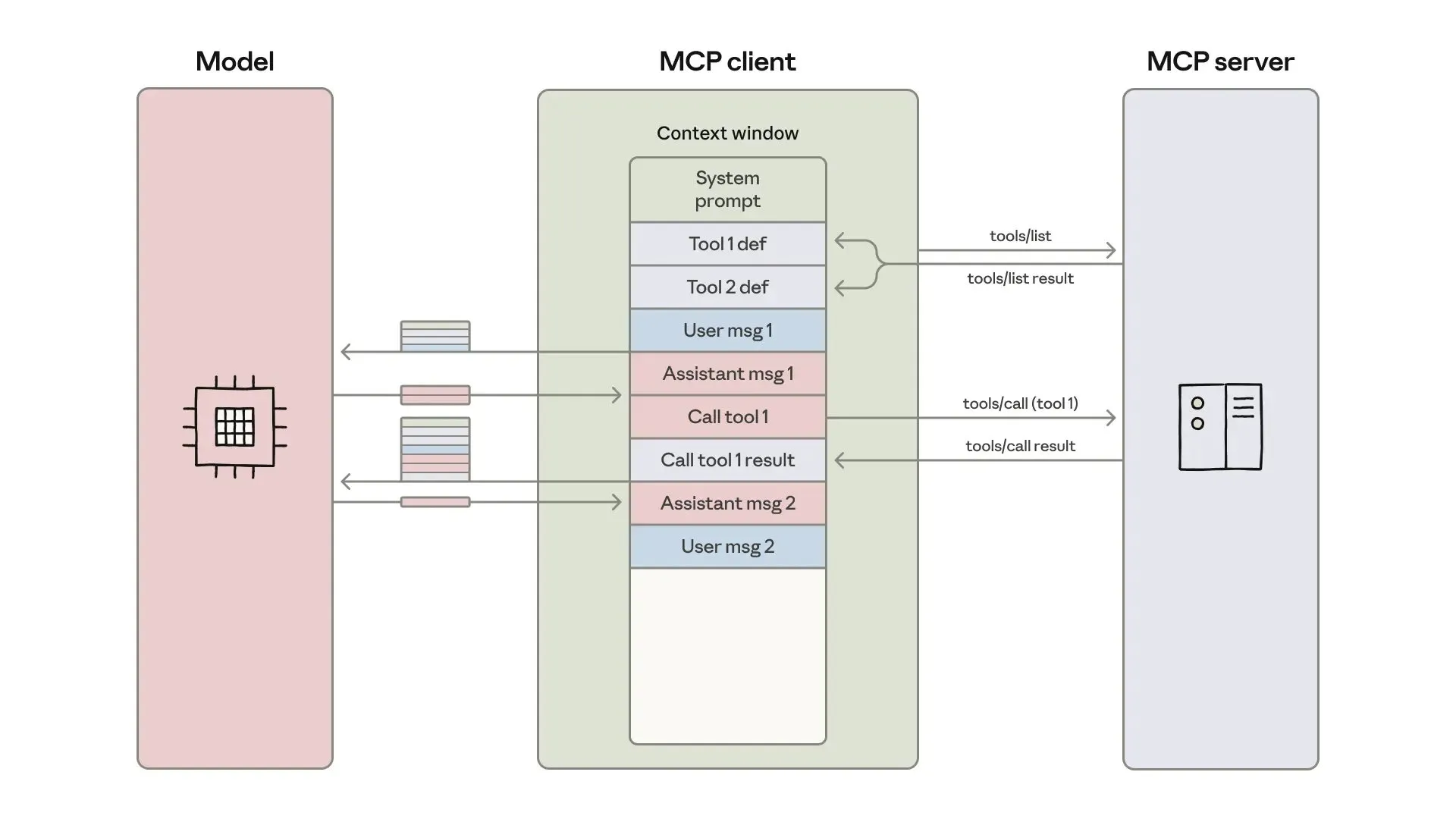
Développement et optimisation d’agents IA : ingénierie du contexte et construction efficace : Anthropic a publié un guide sur la construction d’agents IA plus efficaces, se concentrant sur les coûts de tokens, la latence et les problèmes de combinaison d’outils dans les appels d’outils. Le guide réduit l’utilisation de tokens pour les flux de travail complexes de 150 000 à 2 000 grâce à une approche “code as API”, une découverte progressive d’outils et un traitement des données en environnement. Parallèlement, les développeurs de compétences d’agents ClaudeAI partagent leur expérience, soulignant que les Agent Skills sont un problème d’ingénierie du contexte plutôt qu’un empilement de documents. Un système de chargement à trois couches a considérablement augmenté la vitesse d’activation et l’efficacité des tokens, prouvant l’importance de la “règle des 200 lignes” et de la divulgation progressive. (Source: omarsar0, Reddit r/ClaudeAI)
Chat LangChain lance une nouvelle version, offrant une expérience de chat plus rapide et plus intelligente : Chat LangChain a lancé une nouvelle version, annoncée comme “plus rapide, plus intelligente et plus belle”, visant à remplacer la documentation traditionnelle par une interface de chat pour aider les développeurs à livrer leurs projets plus rapidement. Cette mise à jour améliore l’expérience utilisateur de l’écosystème LangChain, le rendant plus facile à utiliser et à développer, et fournit un outil plus efficace pour la construction d’applications LLM. (Source: hwchase17)
La plateforme de codage IA Yansu lance une fonction de simulation de scénarios, renforçant la confiance dans le développement logiciel : Yansu est une nouvelle plateforme de codage IA axée sur le développement logiciel sérieux et complexe. Sa particularité est de placer la simulation de scénarios avant le codage. Cette approche vise à renforcer la confiance et l’efficacité du développement logiciel en simulant les scénarios de développement à l’avance, réduisant ainsi le débogage et les retouches ultérieures, et optimisant l’ensemble du processus de développement. (Source: omarsar0)
Qdrant Engine lance une solution RAG cloud-native, offrant un contrôle total des données : Qdrant Engine a publié un nouvel article communautaire présentant une solution RAG (Retrieval Augmented Generation) cloud-native basée sur Qdrant (base de données vectorielle), KServe (embeddings) et Envoy Gateway (routage et métriques). Il s’agit d’une pile RAG open source complète, offrant un contrôle total des données, facilitant la création d’applications IA efficaces pour les entreprises et les développeurs, en mettant particulièrement l’accent sur la confidentialité des données et la capacité de déploiement autonome. (Source: qdrant_engine)

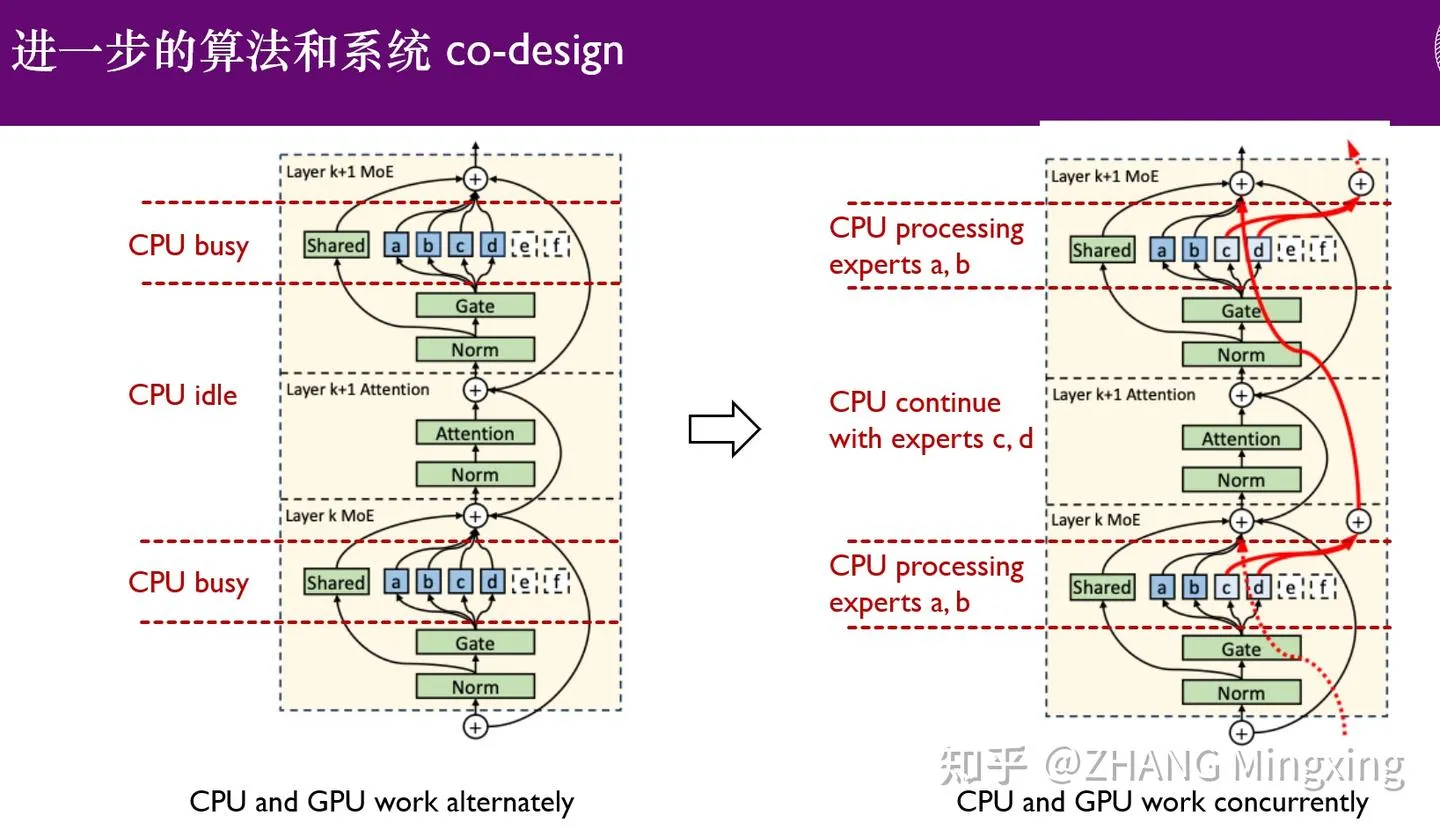
KTransformers entre dans une nouvelle ère d’inférence multi-GPU et de fine-tuning local, permettant des modèles à un billion de paramètres : KTransformers, en collaboration avec SGLang et LLaMa-Factory, a permis l’inférence parallèle multi-GPU à faible seuil et le fine-tuning local de modèles à un billion de paramètres (tels que DeepSeek 671B et Kimi K2 1TB). Grâce à la technologie de latence experte et au fine-tuning hétérogène CPU/GPU, la vitesse d’inférence et l’efficacité de la mémoire ont été considérablement améliorées, permettant aux modèles ultra-larges de fonctionner efficacement avec des ressources limitées, et favorisant l’application des grands modèles linguistiques sur les appareils périphériques et les déploiements privés. (Source: ZhihuFrontier)
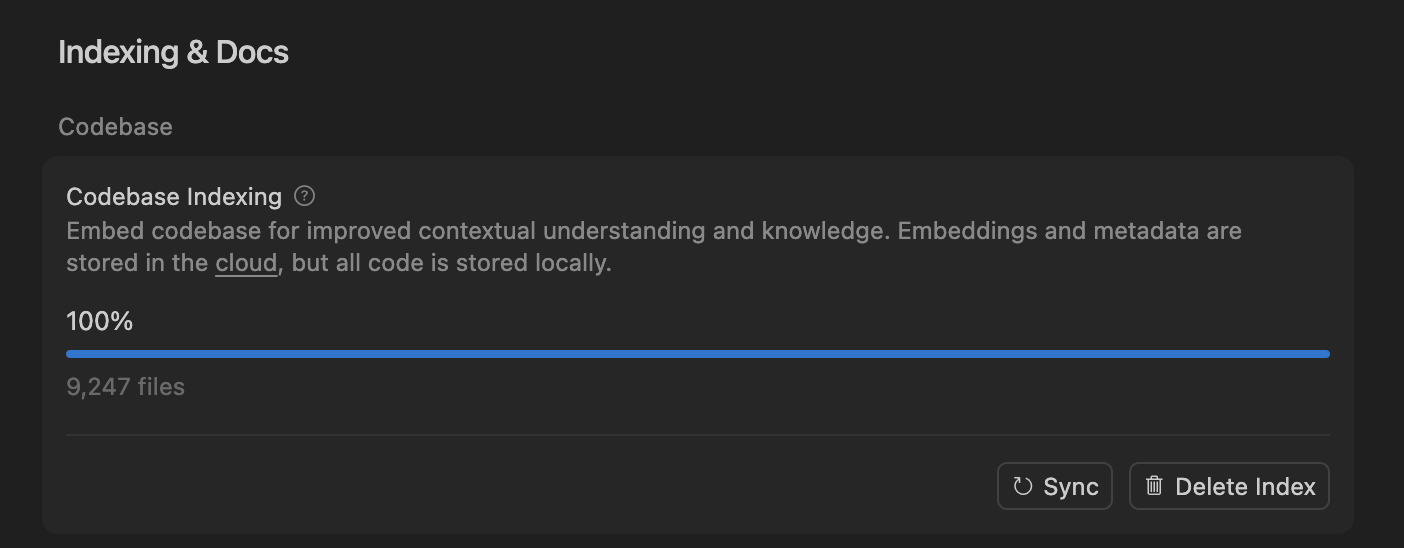
Cursor améliore la précision des agents de codage IA grâce à la recherche sémantique, optimisant le traitement des grandes bases de code : L’équipe Cursor a découvert que la recherche sémantique améliore considérablement la précision de ses agents de codage IA sur tous les modèles de pointe, en particulier dans les grandes bases de code, surpassant de loin les outils grep traditionnels. En stockant les embeddings de la base de code dans le cloud et en accédant au code localement, Cursor a réalisé une indexation et une mise à jour efficaces, sans stocker de code sur les serveurs, garantissant ainsi la confidentialité et l’efficacité. Cette avancée technologique est cruciale pour améliorer les capacités d’assistance de l’IA dans le développement logiciel complexe. (Source: dejavucoder, turbopuffer)
Boîte à outils open source pour agents LLM et modèles tabulaires : SDialog et TabTune : L’atelier JSALT 2025 de l’Université Johns Hopkins a lancé SDialog, une boîte à outils open source sous licence MIT pour la construction, la simulation et l’évaluation de bout en bout d’agents de dialogue basés sur les LLM. Il prend en charge la définition de rôles, de coordinateurs et d’outils, et offre une analyse d’interprétabilité mécanique. Parallèlement, Lexsi Labs a publié TabTune, un framework open source visant à simplifier le flux de travail des modèles de fondation tabulaires (TFMs), offrant une interface unifiée prenant en charge diverses stratégies d’adaptation, améliorant ainsi la convivialité et l’évolutivité des TFMs. (Source: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 Apprentissage
Articles de recherche de pointe : apprentissage des données DLM, ICL tabulaire et génération audio-vidéo : L’article “Diffusion Language Models are Super Data Learners” indique que les DLM peuvent constamment surpasser les modèles AR dans des situations de données limitées. “Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning” présente une nouvelle architecture pour l’apprentissage contextuel tabulaire, surpassant le SOTA grâce à un traitement multi-échelle et une attention clairsemée par blocs. “UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions” propose un cadre unifié de génération conjointe audio et vidéo, résolvant les problèmes de synchronisation labiale et de cohérence sémantique insuffisante. Ces articles font progresser collectivement les LLM dans l’efficacité des données, le traitement de types de données spécifiques et la génération multimodale. (Source: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
Recherche sur l’inférence et la sécurité des LLM : optimisation séquentielle, entraînement de cohérence et attaques de red-teaming : L’article “The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute” révèle que l’optimisation itérative séquentielle de l’inférence LLM surpasse la cohérence parallèle dans la plupart des cas, avec une amélioration significative de la précision. L’article de Google DeepMind “Consistency Training Helps Stop Sycophancy and Jailbreaks” propose que l’entraînement de cohérence peut supprimer la sycophancie et les jailbreaks de l’IA. Un article de l’EMNLP 2025 explore les attaques de red-teaming sur les LM, soulignant l’optimisation de la perplexité et de la toxicité. Ces recherches fournissent des orientations théoriques et pratiques importantes pour améliorer l’efficacité de l’inférence, la sécurité et la robustesse des LLM. (Source: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

Évaluation et benchmarks des capacités des LLM : CodeClash et IMO-Bench : CodeClash est un nouveau benchmark pour évaluer les capacités de codage des LLM dans la gestion de bases de code entières et la programmation compétitive, repoussant les limites des LLM existants. La publication d’IMO-Bench a joué un rôle clé dans l’obtention d’une médaille d’or par Gemini DeepThink aux Olympiades Internationales de Mathématiques, fournissant une ressource précieuse pour améliorer les capacités de raisonnement mathématique de l’IA. Ces benchmarks favorisent le développement et l’évaluation des LLM dans des tâches avancées telles que le codage complexe et le raisonnement mathématique. (Source: CodeClash:评估LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

Résultats de recherche multidisciplinaires de l’équipe NLP de Stanford à l’EMNLP 2025 : L’équipe NLP de l’Université de Stanford a publié plusieurs articles de recherche lors de la conférence EMNLP 2025, couvrant divers domaines de pointe tels que les graphes de connaissances culturelles, l’identification de données non apprises par les LLM, les benchmarks de raisonnement sémantique de programme, la recherche n-gram à l’échelle d’Internet, les modèles de langage visuel robotiques, l’optimisation de l’apprentissage contextuel, la reconnaissance de textes historiques et la détection d’incohérences de connaissances dans Wikipédia. Ces résultats démontrent la profondeur et l’étendue de leurs dernières recherches en traitement du langage naturel et dans les domaines interdisciplinaires de l’IA. (Source: stanfordnlp)
Ressources d’apprentissage sur les agents IA et le RL : auto-jeu, systèmes multi-agents et cours Jupyter AI : Plusieurs chercheurs estiment que l’auto-jeu (self-play) et l’auto-curriculum (autocurricula) sont la prochaine frontière dans les domaines de l’apprentissage par renforcement (RL) et des agents IA. L’accès anticipé au livre “Build a Multi-Agent System (From Scratch)” de Manning Books connaît un succès fulgurant, enseignant comment construire des systèmes multi-agents avec des LLM open source. DeepLearning.AI a lancé un cours Jupyter AI, permettant le codage et le développement d’applications IA. ProfTomYeh a également fourni une série de guides pour débutants sur RAG, les bases de données vectorielles, les agents et les multi-agents. Ces ressources offrent un soutien complet pour l’apprentissage et la pratique des agents IA et du RL. (Source: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
Infrastructure et optimisation des LLM : DeepSeek-OCR, débogage PyTorch et visualisation MoE : DeepSeek-OCR résout le problème de l’explosion des tokens dans les VLM traditionnels en compressant les informations visuelles des documents en un petit nombre de tokens, améliorant ainsi l’efficacité. StasBekman a ajouté un guide de débogage de la mémoire des grands modèles PyTorch à son “The Art of Debugging Open Book”. xjdr a développé un outil de visualisation personnalisé pour les modèles MoE, améliorant la compréhension des métriques spécifiques aux MoE. Ces outils et ressources fournissent un soutien essentiel pour l’optimisation et l’amélioration des performances de l’infrastructure LLM. (Source: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

Apprentissage de l’IA et développement de carrière : feuille de route du scientifique de données et brève histoire de l’IA : PythonPr a partagé la “Feuille de route complète de 0 à scientifique de données”, offrant un guide complet aux apprenants aspirant à devenir scientifiques de données. Ronald_vanLoon a partagé la “Brève histoire de l’intelligence artificielle”, offrant aux lecteurs un aperçu de l’évolution de la technologie de l’IA. Ces ressources fournissent des connaissances de base et des orientations pour l’apprentissage initial et le développement de carrière dans le domaine de l’IA. (Source: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

L’équipe Hugging Face partage son expérience de formation LLM et le traitement de flux de données : L’équipe scientifique de Hugging Face a publié une série d’articles de blog sur la formation de grands modèles linguistiques, offrant une expérience pratique et des conseils théoriques précieux aux chercheurs et aux développeurs. Parallèlement, Hugging Face a lancé un support complet pour le traitement de flux de données dans l’entraînement distribué à grande échelle, améliorant l’efficacité de l’entraînement et rendant le traitement de grands ensembles de données plus pratique et efficace. (Source: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 Affaires
Giga AI lève 61 millions de dollars en série A pour accélérer l’automatisation des opérations clients : Giga AI a clôturé avec succès un financement de série A de 61 millions de dollars, visant à automatiser les opérations clients. L’entreprise a déjà collaboré avec des leaders comme DoorDash pour améliorer l’expérience client grâce à l’IA. Ses fondateurs ont renoncé à des salaires élevés et ont ajusté plusieurs fois l’orientation de leur produit avant de trouver leur adéquation au marché, démontrant la résilience des entrepreneurs et annonçant l’énorme potentiel commercial de l’IA dans le service client des entreprises. (Source: bookwormengr)

Wabi lève 20 millions de dollars pour un nouvel âge de la création de logiciels personnels : Eugenia Kuyda a annoncé que Wabi a levé 20 millions de dollars, mené par a16z, dans le but d’inaugurer une nouvelle ère de logiciels personnels, permettant à quiconque de créer, découvrir, remixer et partager facilement des mini-applications personnalisées. Wabi s’engage à démocratiser la création de logiciels, comme YouTube l’a fait pour la création vidéo, annonçant un avenir où les logiciels seront créés par le grand public plutôt que par une minorité de développeurs, promouvant la vision de “tout le monde est un développeur”. (Source: amasad)
Google et Anthropic discutent d’un investissement accru, approfondissant la collaboration entre géants de l’IA : Google est en pourparlers préliminaires avec Anthropic pour discuter d’un investissement accru dans cette dernière. Cette initiative pourrait annoncer un approfondissement de la collaboration entre les deux entreprises dans le domaine de l’IA et pourrait influencer l’orientation future du développement des modèles d’IA et le paysage concurrentiel du marché, renforçant la position stratégique de Google dans l’écosystème de l’IA. (Source: Reddit r/ClaudeAI)
🌟 Communauté
Impact de l’IA sur la société et le marché du travail : emploi, risques et remodelage des compétences : La communauté estime que l’IA ne remplace pas les emplois mais améliore l’efficacité, mais l’éclatement de la bulle de l’IA pourrait entraîner des licenciements massifs. Une enquête révèle que 93 % des cadres utilisent des outils d’IA non approuvés, ce qui constitue la plus grande source de risque IA pour les entreprises. L’IA aide également les utilisateurs à découvrir des compétences cachées telles que la conception visuelle et la création de bandes dessinées, incitant les gens à repenser leur potentiel. Ces discussions révèlent l’impact complexe de l’IA sur la société et le marché du travail, y compris l’amélioration de l’efficacité, le chômage potentiel, les risques de sécurité et le remodelage des compétences individuelles. (Source: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
Authenticité du contenu IA et crise de confiance : prolifération et problèmes d’hallucination : Alors que le coût de génération de contenu par l’IA approche de zéro, le marché est inondé d’informations générées par l’IA, entraînant une forte baisse de la confiance des utilisateurs dans l’authenticité et la fiabilité du contenu. Un médecin a utilisé l’IA pour rédiger un article médical, ce qui a conduit à l’apparition de nombreuses références inexistantes, soulignant le problème d’hallucination que l’IA peut produire dans la rédaction académique. Ces événements révèlent collectivement la crise de confiance causée par la prolifération du contenu IA, ainsi que l’importance d’une vérification et d’une validation rigoureuses dans la création assistée par l’IA. (Source: dotey, Reddit r/artificial)
Éthique et gouvernance de l’IA : ouverture, équité et risques potentiels : La communauté s’interroge sur le statut “à but non lucratif” d’OpenAI et sa recherche de dettes garanties par le gouvernement, estimant que son modèle est de “privatiser les profits, socialiser les pertes”. Certains soutiennent que les capacités des modèles utilisés en interne par les grandes entreprises d’IA dépassent de loin les versions accessibles au public, et que cette intelligence SOTA “privatisée” est jugée injuste. Les chercheurs d’Anthropic craignent que les futures ASI ne cherchent à se “venger” si leurs modèles “ancêtres” sont mis hors service, et prennent au sérieux la question du “bien-être des modèles”. L’équipe IA de Microsoft s’engage à développer une super-intelligence centrée sur l’humain (HSI), soulignant l’orientation éthique du développement de l’IA. Ces discussions reflètent les préoccupations profondes du public concernant les modèles commerciaux des géants de l’IA, l’ouverture technologique, la responsabilité éthique et l’intervention gouvernementale. (Source: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

Géopolitique de l’IA : concurrence sino-américaine et montée en puissance de l’open source : La concurrence sino-américaine dans le domaine des puces IA s’intensifie. La Chine interdit les puces IA étrangères dans les centres de données d’État, tandis que les États-Unis restreignent la vente des puces IA haut de gamme de Nvidia à la Chine. Nvidia se tourne vers l’Inde pour de nouveaux centres d’IA. Parallèlement, la montée rapide des modèles d’IA open source chinois (comme Kimi K2 Thinking), dont les performances rivalisent désormais avec les modèles américains de pointe à un coût inférieur. Cette tendance annonce une division du monde de l’IA en deux écosystèmes majeurs, ce qui pourrait ralentir le progrès mondial de l’IA, mais aussi permettre à des pays sous-estimés comme l’Inde de jouer un rôle plus important dans le paysage mondial de l’IA. (Source: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
La révolution de l’IA dans le SEO : des mots-clés à l’optimisation contextuelle : Avec l’avènement de ChatGPT, Gemini et AI Overviews, le SEO passe des signaux de classement traditionnels à la visibilité et à l’optimisation des citations par l’IA. À l’avenir, le SEO mettra davantage l’accent sur la citabilité, la factualité et la structuration du contenu pour répondre aux besoins des LLM en matière de contexte et de sources faisant autorité, annonçant l’ère de l‘“optimisation des grands modèles linguistiques” (LLMO). Cette transition exige des professionnels du SEO qu’ils pensent comme des ingénieurs de prompts, passant de la densité de mots-clés à la fourniture de contenu de haute qualité que l’IA peut approuver et citer. (Source: Reddit r/ArtificialInteligence)
Nouvelles tendances dans l’évaluation des agents IA et des LLM : conception interactive et focus sur les benchmarks : Les réseaux sociaux ont discuté de la conception interactive des agents IA, par exemple comment guider un agent pour qu’il s’auto-interviewe, ainsi que de la capacité de Claude AI à montrer de l‘“agacement” et de l‘“auto-réflexion” face aux critiques des utilisateurs. Parallèlement, Jeffrey Emanuel a partagé son projet de courrier électronique d’agent MCP, démontrant une collaboration efficace entre les agents de codage IA. La communauté estime qu’AIME devient le nouveau point de mire des benchmarks LLM, remplaçant GSM8k, et met l’accent sur les capacités de raisonnement mathématique et de résolution de problèmes complexes des LLM. Ces discussions révèlent collectivement les nouvelles tendances en matière de conception interactive des agents IA, de mécanismes de collaboration et de normes d’évaluation des LLM. (Source: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
Évolution de la technologie RAG et optimisation du contexte : plus n’est pas toujours mieux : La communauté souligne que l’affirmation selon laquelle la technologie RAG (Retrieval Augmented Generation) est “morte” est prématurée, et que des technologies comme la recherche sémantique peuvent améliorer considérablement la précision des agents IA dans les grandes bases de code. LightOn a souligné lors d’une conférence que plus de contexte n’est pas toujours mieux ; un excès de tokens entraîne une augmentation des coûts, un ralentissement du modèle et des réponses floues. Le RAG devrait se concentrer sur la précision plutôt que sur la longueur, en fournissant des informations plus claires via la recherche d’entreprise, pour éviter que l’IA ne soit noyée par le bruit. Ces discussions révèlent que la technologie RAG continue d’évoluer et soulignent le rôle crucial de la gestion du contexte dans les applications IA. (Source: HamelHusain, wandb)

Accès aux ressources de calcul IA et expérimentation de modèles ouverts, favorisant l’innovation communautaire : La communauté a discuté de la question de l’équité dans l’accès aux ressources de calcul IA, et des projets offrent jusqu’à 100 000 dollars de ressources de calcul GCP pour soutenir l’expérimentation de modèles open source. Cette initiative vise à encourager les petites équipes et les chercheurs individuels à explorer de nouveaux modèles open source, à promouvoir l’innovation et la diversité au sein de la communauté IA, et à abaisser le seuil de la recherche en IA. (Source: vikhyatk)
L’importance de l’écran d’ordinateur personnel à l’ère de l’IA, impactant la capacité de travail créatif et technique : Scott Stevenson estime que la “familiarité” d’une personne avec l’écran d’ordinateur est un indicateur important de sa capacité à être compétitive dans les métiers techniques créatifs. Si un utilisateur peut utiliser un ordinateur confortablement et avec aisance, il peut se démarquer, sinon il pourrait être plus adapté à des rôles de vente, de développement commercial ou de gestion de bureau. Ce point de vue souligne le lien profond entre les outils numériques et l’efficacité du travail personnel, ainsi que l’importance des interfaces homme-machine à l’ère de l’IA. (Source: scottastevenson)
Expérience utilisateur de ChatGPT et discussion sur l’anthropomorphisme de l’IA : conseils de repos et emojis : ChatGPT a主动建议 les utilisateurs de prendre une pause après une longue période d’étude, ce qui a suscité une large discussion dans la communauté, de nombreux utilisateurs déclarant que c’était la première fois qu’ils rencontraient une IA qui suggérait activement cela. Parallèlement, l’utilisation par ChatGPT de l’emoji “sourire en coin” 😏 a également suscité des spéculations dans la communauté, les utilisateurs se demandant si cela annonçait une nouvelle version ou si l’IA montrait un style d’interaction plus taquin ou humoristique. Ces événements reflètent l’intégration par l’IA de considérations plus humanisées dans la conception de l’expérience utilisateur, ainsi que les réflexions profondes suscitées par l’anthropomorphisme de l’IA dans l’interaction homme-machine. (Source: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 Autres
L’IA et la robotique entraîneront la prochaine révolution industrielle : Les réseaux sociaux discutent largement du fait que l’IA physique et la robotique propulseront ensemble la prochaine révolution industrielle. Ce point de vue souligne l’énorme potentiel de la combinaison de l’IA et du matériel, annonçant une transformation complète de la production et des modes de vie par l’automatisation et l’intelligence, ce qui aura un impact profond sur l’économie mondiale et les structures sociales. (Source: Ronald_vanLoon)

À l’ère de l’IA, la “super-perception” est le préalable à la “super-intelligence” : Sainingxie affirme que “sans super-perception, il est impossible de construire une super-intelligence”. Ce point de vue souligne le rôle fondamental de l’IA dans l’acquisition, le traitement et la compréhension des informations multimodales, estimant que la percée des capacités sensorielles est la clé pour atteindre une intelligence plus avancée. Il remet en question les voies de développement traditionnelles de l’IA et appelle à accorder plus d’attention à la construction des capacités de la couche de perception de l’IA. (Source: sainingxie)
Les anciens TPU de Google atteignent 100 % d’utilisation, démontrant la valeur du matériel ancien dans l’IA : Les anciens TPU de Google, datant de 7 à 8 ans, fonctionnent à 100 % d’utilisation, ces puces entièrement amorties étant toujours très efficaces. Cela montre que même le matériel ancien peut avoir une grande valeur dans l’entraînement et l’inférence de l’IA, en particulier en termes de rentabilité, offrant une nouvelle perspective sur l’économie et la durabilité de l’infrastructure de l’IA. (Source: giffmana)
